This section summarizes related work on SSL for image and audio data, data augmentation for audio, and finally work on Transfer Learning using pre-trained audio embeddings.
2.1. Semi-Supervised Learning
The main idea behind SSL is to include unlabeled data into the training process and take advantage of large unlabeled datasets that can add variety to the training to build more robust classifiers, similar to using larger labeled datasets. The biggest challenge of SSL is that there is no guarantee that introducing unlabeled data into the training process will improve performance, and in some cases, it might even turn out to be detrimental [
3,
10,
11]. One possible reason for this performance drop is the so-called confirmation bias, where incorrect predictions on the unlabeled data are amplified as the model overfits on these mistakes [
7,
12]. To provide some context on SSL, we briefly describe the SSL techniques that are most relevant for this work. For a detailed overview of previous SSL techniques, we refer the reader to [
11].
Current SSL methods for classification tasks can be clustered into two main approaches: consistency regularization and entropy minimization. Consistency regularization is built upon the idea that realistic perturbations of the input data should not change predictions of the model [
13]. An example for this approach is the Mean Teacher (MT) technique [
7], where two separate models with the same architecture are trained: a teacher and a student model. The weights of the teacher model are an exponential moving average of the weights of the student model in previous iterations. The weights of the student model are updated using a combined loss term. The first term of the loss is obtained with the categorical cross-entropy (CCE) loss from classifying the augmented labeled data. The second term of the loss is a consistency term for the unlabeled data. The teacher model outputs predictions on weakly augmented data. The student is then forced to predict the same label distribution on the non-augmented version of the data. Mean squared error showed the best performance for this consistency loss. The final loss is a weighted sum of the CCE and the consistency loss.
In contrast, models using entropy minimization are pushed to output more confident predictions for unlabeled data. A commonly used entropy minimization method is the Pseudo-Label (PL) approach, where a given model predicts labels for the unlabeled data [
8]. The class with the highest probability is taken as the true label and treated like ground truth. The CCE loss of the labeled data is combined with the weighted CCE loss of the unlabeled data. The selection and scheduling of the weighting factor (e.g., slowly increasing it over time) for the unlabeled loss is critical to avoid noisy pseudo labels from disturbing the training.
MixMatch (MM) combines entropy minimization with consistency regularization and resulted in improved performance in image classification tasks [
1]. In MM, unlabeled examples are augmented several times and the output distributions are averaged and used as the target. To encourage high confidence predictions, the entropy of the output distribution is minimized by emphasizing the highest confidence prediction and lowering the others accordingly in a process called “sharpening”. For further details on the “sharpening” process, we refer the reader to the original publication [
1]. The labeled images are also augmented and used in the combined loss. The input images and labels for both labeled and artificially labeled data are additionally augmented using Mixup. Mixup creates new data points by linearly interpolating the inputs features and labels of existing data points. Results have shown that by applying Mixup, decision boundaries between classes can be improved [
14]. MM obtained these results with versions of the “Wide ResNet-28” Convolutional Neural Network (CNN) [
15]. Images were normalized to zero mean and standard deviation of 1 for each color channel before being input to the network. On the CIFAR-10 image dataset [
6], MM improved accuracy from 62% to 89% using only 25 examples for each of the 10 classes and from 90.8% to 93.7% for 400 images per class. As reference, training a model with the complete training dataset in a fully supervised manner achieves 95.8% when all annotations are used.
MM was later extended in ReMixMatch (RMM) [
2] by including distribution alignment and augmentation anchoring. For augmentation anchoring, augmentation methods are categorized as either weak (e.g., horizontal flip) or strong (e.g., changing the color balance), and the label distribution from weakly augmented images is used as target for several strongly augmented versions of the same images. Distribution alignment encourages the model to bring the distribution of the artificial labels closer to that of the labeled dataset. This is achieved by scaling the prediction of the model on an unlabeled example by the ratio between the class distribution of the labeled dataset and the running average of the model’s prediction on unlabeled data. These additions improved the accuracy from 89% to 94.5% on CIFAR-10 with 25 examples per class using the same model architecture as MM.
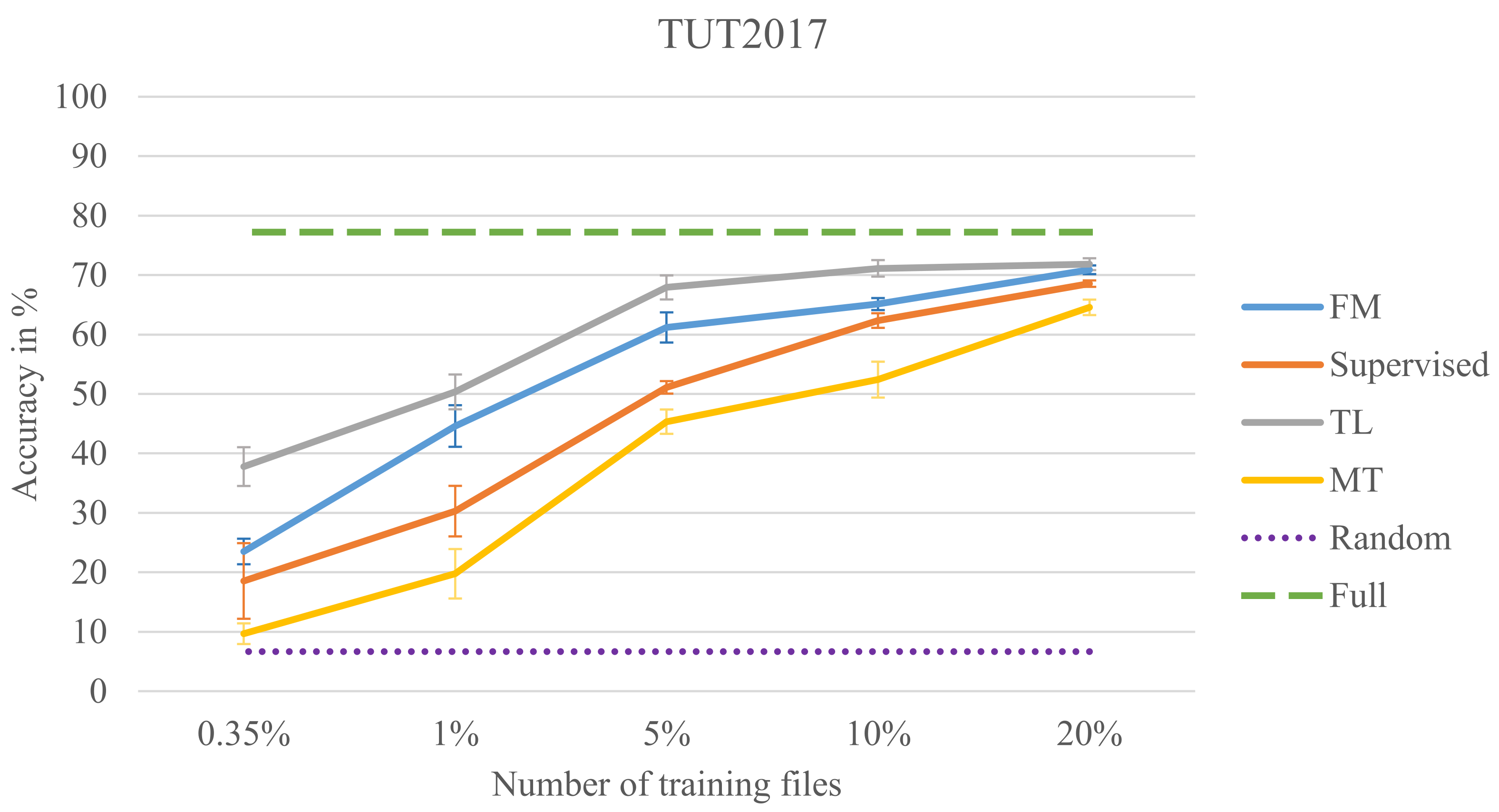
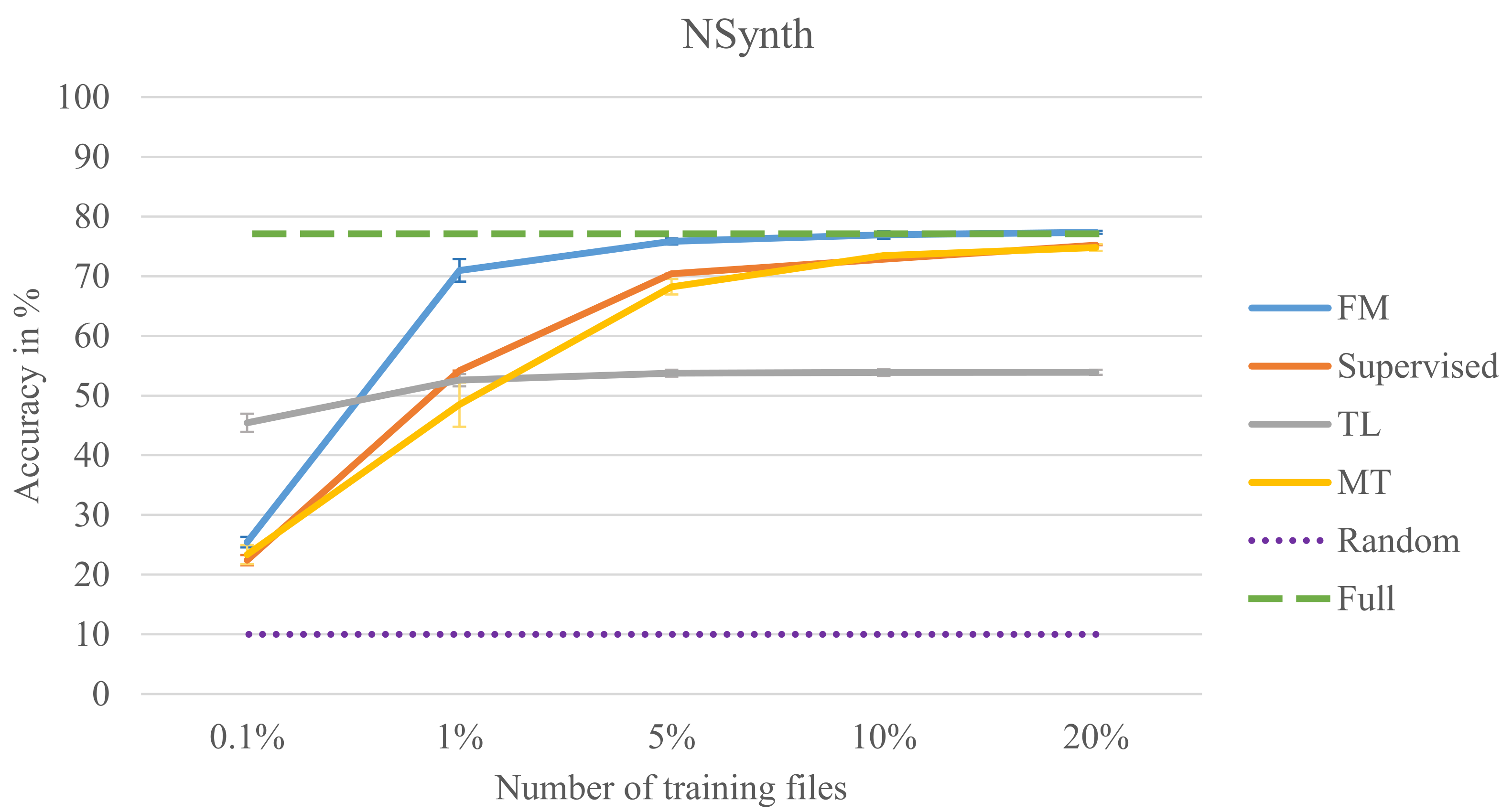
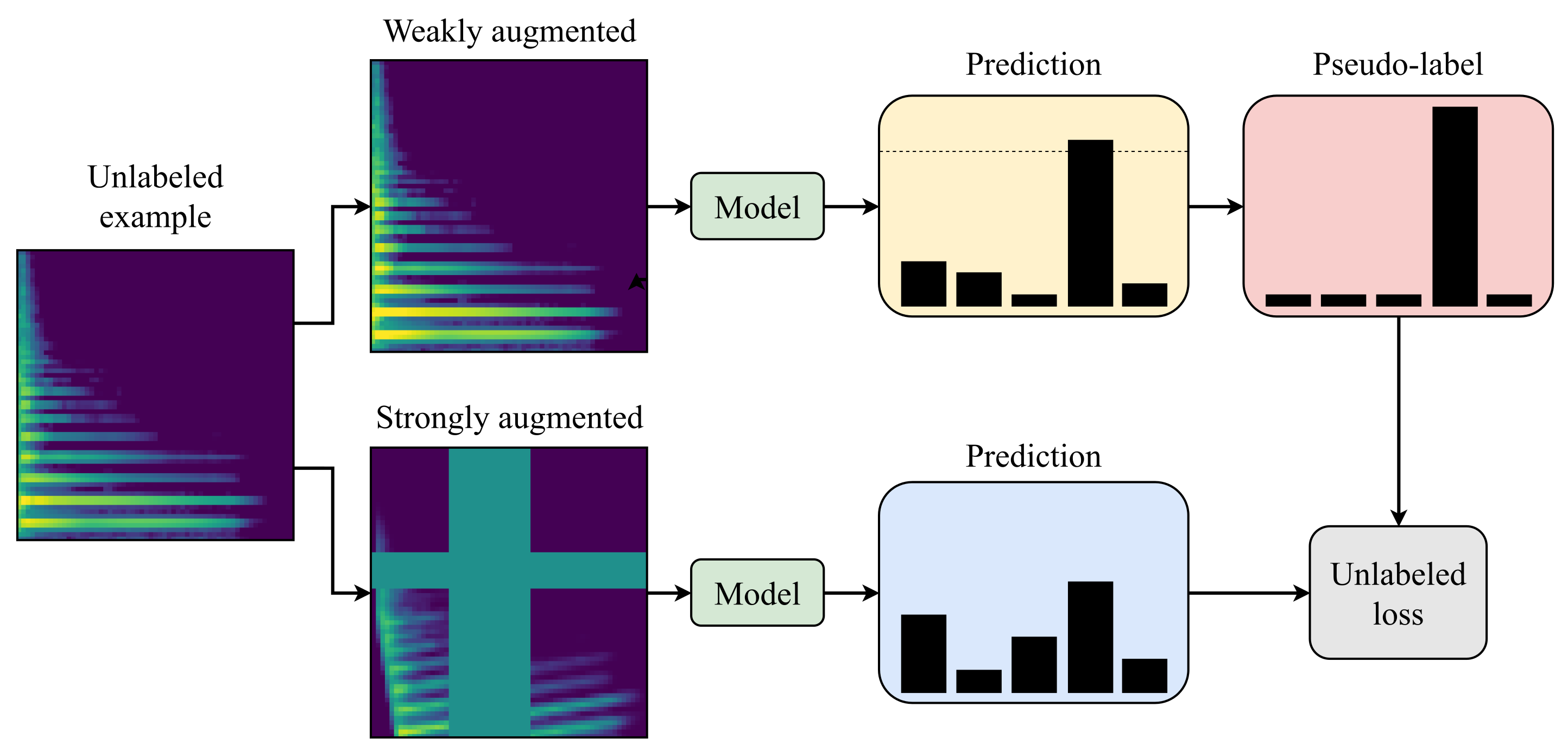
Recently, FixMatch [
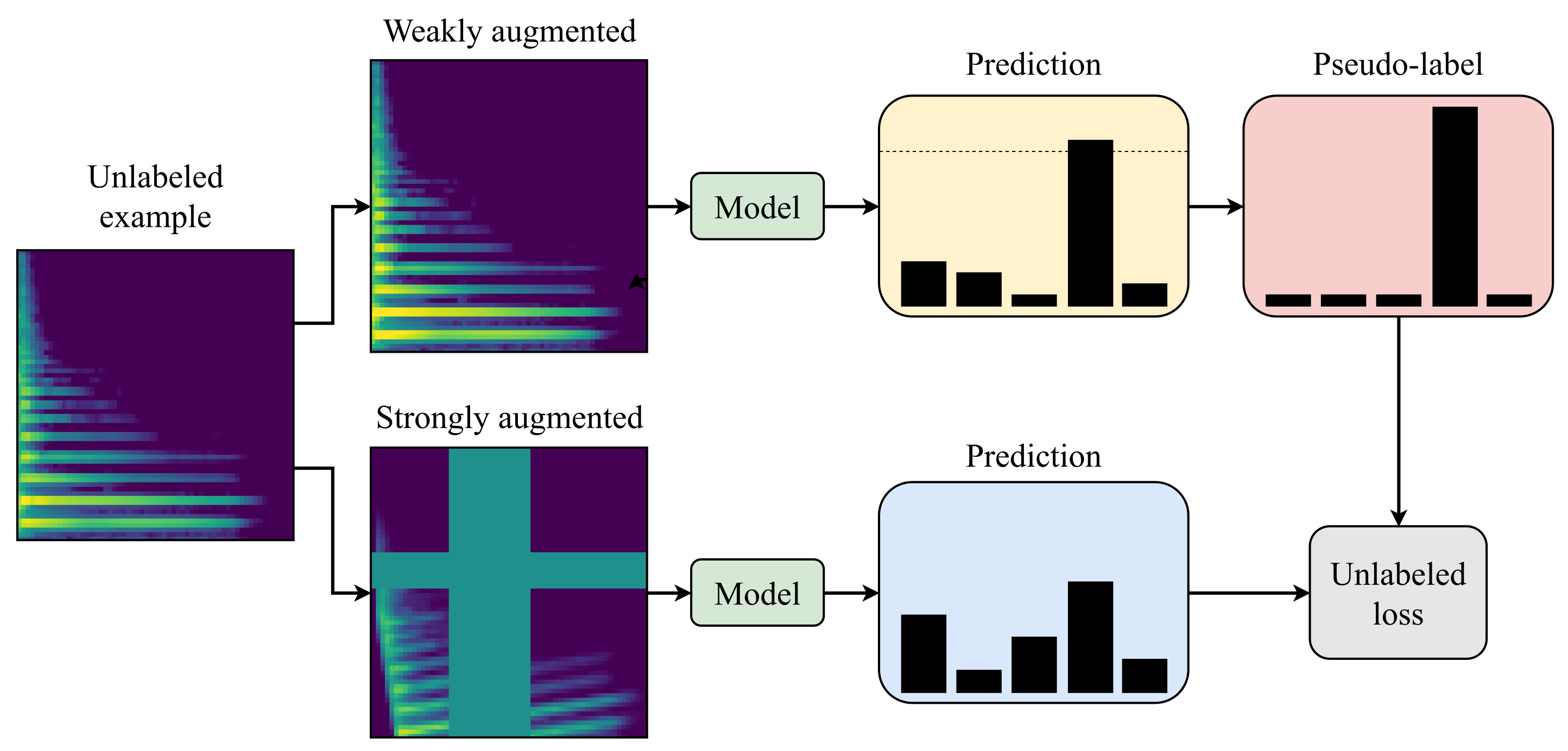
3] was proposed as a simplified version of MM and RMM. Only predictions from weakly augmented data with high confidence are kept as targets. Instead of sharpening the predicted distributions, the class with the highest confidence is used as the target label, comparable to the PL method. The pseudo labels are filtered with a confidence threshold (95% suggested by the authors), and only high confidence predictions are used for training. This excludes uncertain predictions in the early training phases. It also iteratively increases the amount of unlabeled data being included in the training process as the model becomes more confident in its predictions. The filtered instances are then transformed by randomly picking two strong augmentation methods from a predefined set, using a magnitude (strength of the transformation) randomly sampled for each training step. One goal for this approach is to systematically produce the same predictions for the weakly and strongly augmented unlabeled data using the CCE loss as displayed in
Figure 1. The second part of the loss function, similar to PL, is the supervised performance on the weakly augmented version of the labeled dataset using CCE loss as well. In contrast to the PL approach, an additional weighting factor in the loss function is not critical to achieve good performance since the number of unlabeled examples used for training increases over time as more of them pass the threshold. FM achieved 95.7% accuracy on CIFAR-10 using 400 examples per class with the same model architecture as MM. Reducing the amount of labels per class to 25 only slightly reduced performance to 94.9%, while the performance of MT dropped to 67.7%. Using only four examples per class FM still obtained 88.6% while the performance of RMM (80.9%) and MM (52.5%) decreased considerably more, demonstrating the potential of this method in the few label domain. FM also simplified the training process by using only one strong augmentation compared to RMM. Furthermore, it was shown that randomly picking the magnitude for strong augmentations in each training step performed comparable to CTAugment (introduced for RMM) in which the best magnitude for each augmentation is learned over the course of the training.
The Meta Pseudo Labels approach by Pham et al. [
4] slightly improved the upper baseline set by FM to 96.1% using 400 examples per class for CIFAR-10, but no results were reported for fewer labels. Instead of a single model, separate student and teacher models are used. First, the student learns from the pseudo labels generated by the teacher. Next, the teacher is modified depending on how well the updated student performs on the labeled part of the dataset. This should lead to an improved teacher model that generates more accurate pseudo labels for the student in every iteration. To achieve the best performance, the teacher is additionally trained with auxiliary supervised and semi-supervised objectives. Although Meta Pseudo Labels achieves a slightly higher accuracy than FM, we do not include it in this work since it requires a more complicated training procedure and no performance was reported in the low-label domain.
The SSL techniques mentioned so far were mainly developed using image classification tasks and datasets. In the following, we present a brief description of SSL methods applied to audio tasks. Consistency regularization in the form of MT was applied to SED and SCR improving the supervised model trained from scratch with few data. However, this approach did not reach the fully supervised baseline which included all annotated data [
16]. Recently, Cances et al. [
10] applied several SSL methods on one additional SED and the same SCR datasets as [
16]. The study included the SSL methods MT, MM, and FM. When the amount of labeled examples was reduced to 10%, FM and MM outperformed MT and the supervised CNN trained from scratch. This is inline with the findings from the image domain. In contrast to [
16], MT did not perform as well as the supervised baseline on all datasets. On 10% of the dataset size, FM and MM reached the fully supervised baseline which includes the complete labeled dataset (100%) on two of the three datasets confirming the potential of SSL. Further data reduction steps were not conducted. Cances et al. additionally integrated Mixup into FM in a similar way as it was used in MM. This improved results slightly on two datasets. It must be noted that the results of Lu et al. [
16] and Cances et al. [
10] are difficult to compare since different amounts of training data were used, and the similarity of the test set could not be confirmed. For UrbanSound8k [
17] Cances et al. tested on the provided 10-fold split with only 10% reduction of training data, while Lu et al. “split the labeled data into training and test sets” with varying reduction sizes without covering the 10% reduction step.
2.2. Augmentation Methods Applied to Audio Data
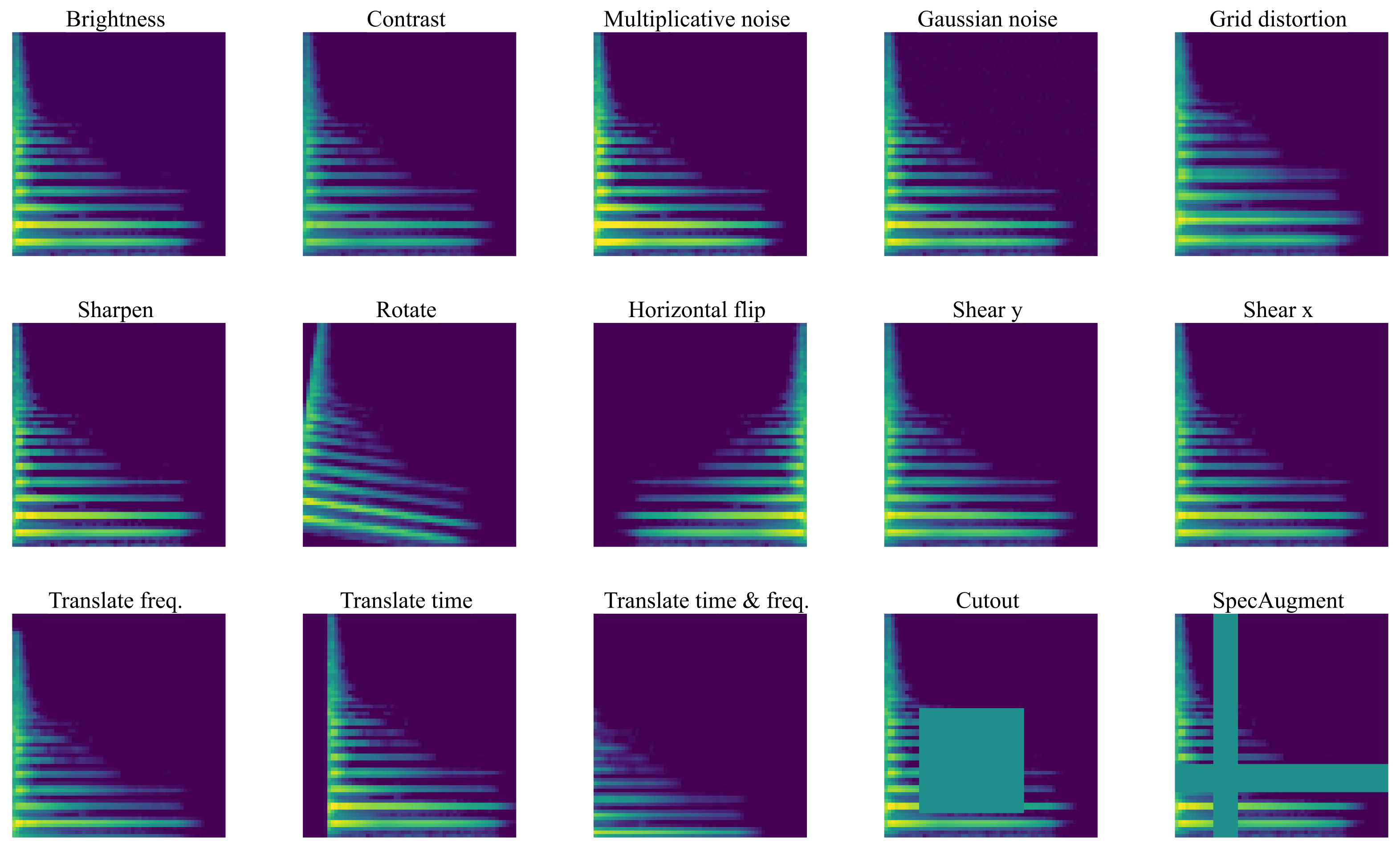
Augmentation methods for audio data can be clustered into two main classes: the ones applied directly on the raw audio signal (e.g., time stretching) and methods applied after the data has been transformed to a time-frequency representation. Since FM was originally proposed to work with 2D input images, we focus on methods that can be applied during run-time to the 2D time-frequency representation of the audio signal. Augmentations applied to the raw audio signal are left for future work.
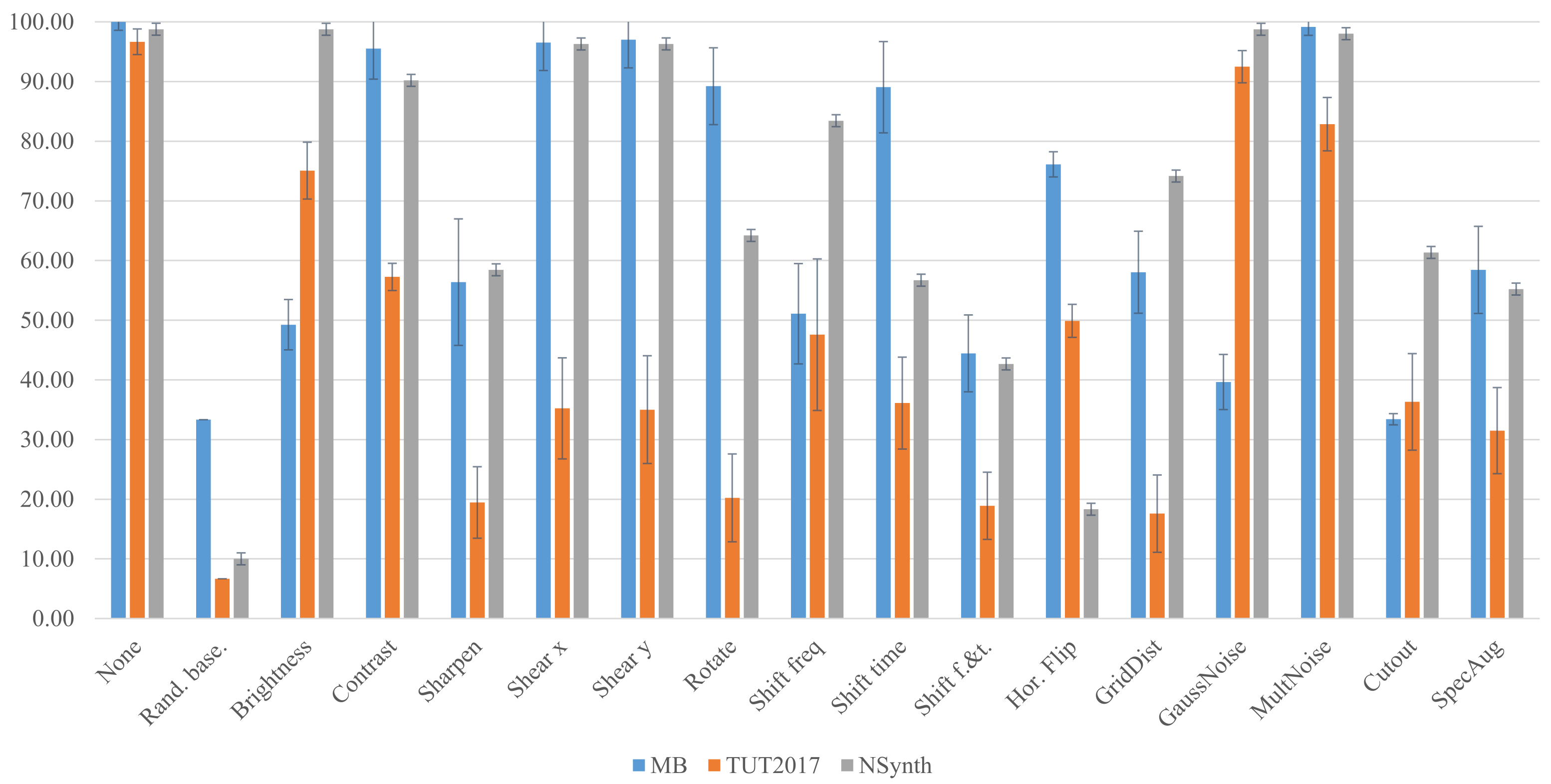
For urban sound tagging, Adapa [
18] applied image augmentation techniques such as random erasing, random rotate, and grid distortion to input audio spectrograms. Color jitter and stretching of the time and frequency axes were applied, amongst others, to bird audio detection using CNNs [
19]. Another successfully used augmentation technique for spectral images is SpecAugment [
20], where one or more contiguous time frames and frequency bins are set to a fixed value. This is comparable to the Cutout technique [
21] used in FM, as well as random erasing where one rectangular region is masked. Johnson et al. [
22] applied image augmentation methods (grid distortion, random brightness, random erasing, random rotating, and SpecAugment) to ISA datasets and increased robustness of CNNs to domain shift between train and test sets. Such augmentation methods have also been successfully used for MIR tasks such as classifying the size of musical ensembles [
23]. These examples demonstrate the general applicability of the proposed image augmentation methods for spectral audio data from various domains.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}