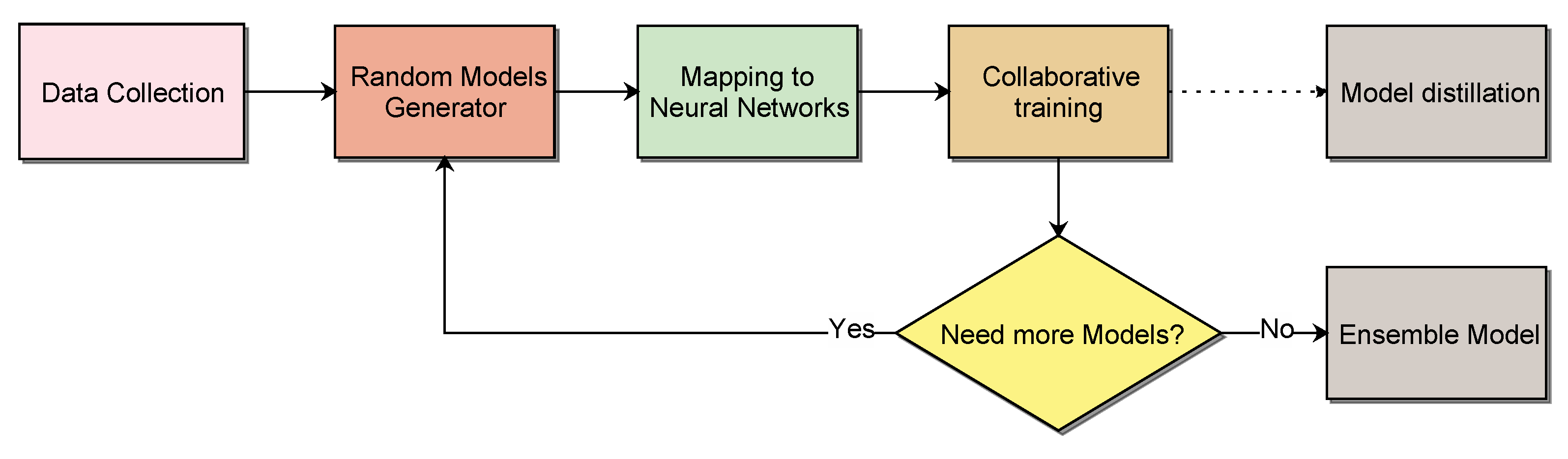
4.2. Results on CIFAR-10, CIFAR-100, and TinyImageNet
We conducted several experiments to compare between training the generated chain of models with and without deep collaborative learning. We evaluated the proposed method as a knowledge distillation model and compared it with the state-of-the-art-methods. We also compared our collaborative learning method with the MotherNets method [
16], and finally, the proposed method was assessed as an ensemble model.
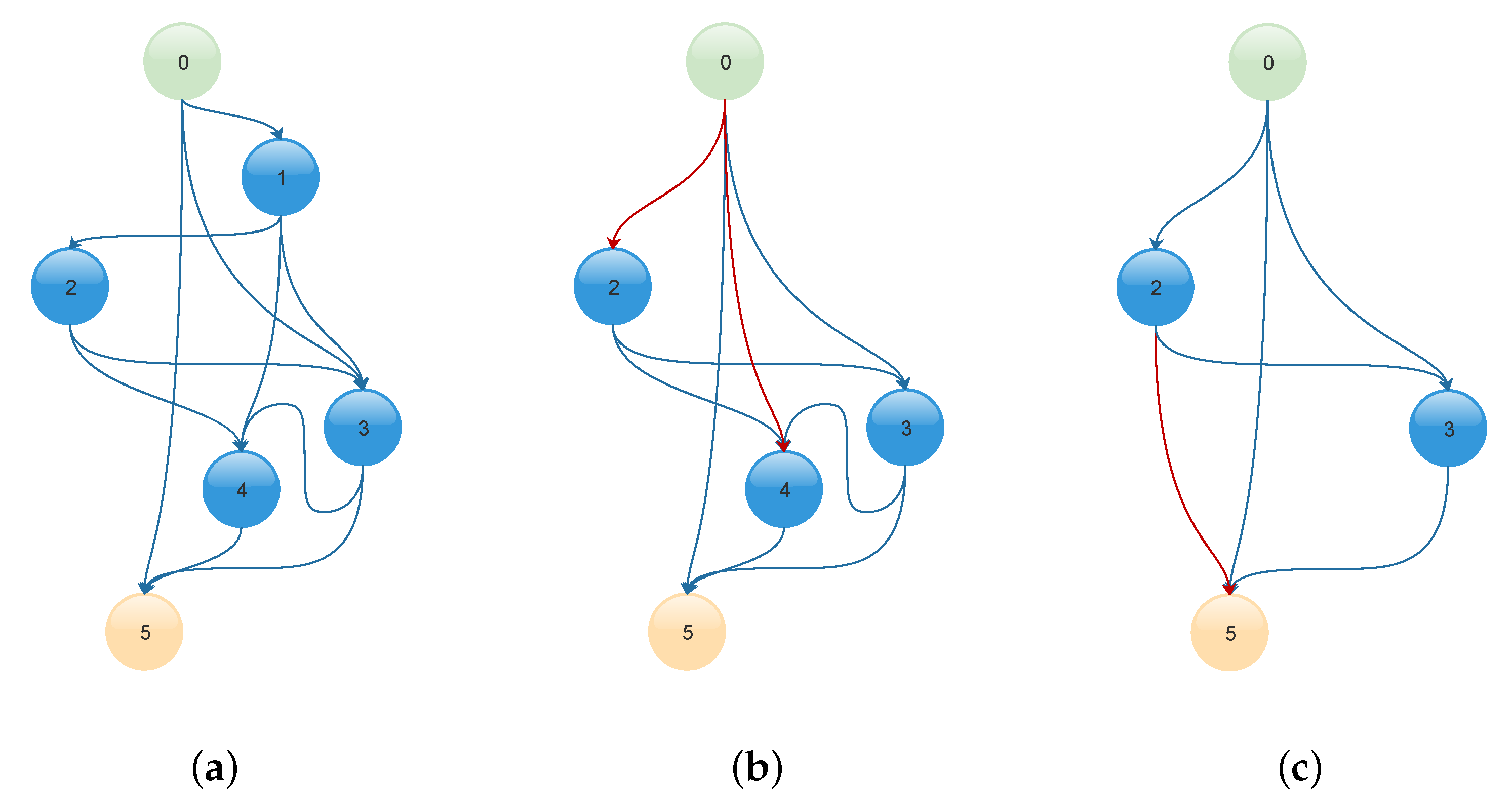
In the first experiment, a chain of three models was defined by iteratively pruning one node from each stage of the initial generated random graphs as described in Algorithm 1. Each model had two stages with 16 initial nodes, and the number of filters was increased by a factor of 3. The first and the second row in
Table 1 report the results when the chain of models trained independently and with the DCL. The first model (i.e., number 1) in the chain refers to the smallest model and the last model (i.e., number 3) refers to the largest model in terms of the number of nodes.
The proposed collaborative learning significantly improved the performance of each model in the chain compared to the individual training of each model. DCL improved the average accuracy of each model by 1.35%, 1.31%, and 3.16% on CIFAR-10, CIFAR-100, and TinyImageNet, respectively. For example, the third model in the chain had an accuracy of , , and on CIFAR-10, CIFAR-100, and TinyImageNet, respectively, compared to , , and for the independent training.
Next, we compared between the DCL and the MotherNets [
16] as shown in
Table 1 rows 2 and 3. In MotherNets, the first model was fully trained and considered as the mother model so that it transfered its learning to the rest of the models. The DCL had a significant improvement over MotherNets. For example, the accuracy of the second model in that chain was
,
, and
on CIFAR-10, CIFAR-100, and TinyImageNet, respectively, compared to
,
, and
using MotherNets. The MotherNets models had a limited improvement compared with the independent training.
To show the advantage of the proposed method as a model distillation, we trained a chain of six models based on two random graphs (i.e., one per stage) of 16 nodes on CIFAR-10 and CIFAR-100 as shown in
Table 2. The smallest model (i.e., model no. 1) had
fewer parameters and approximated floating-point operations (FLOPS) compared with the largest model (i.e., model no. 6).
The DCL demonstrated significant improvement in the accuracy of each model. For CIFAR-10, The accuracy of models 1, 2, and 6 using the DCL was , , and compared to , , and for the independent training models. The accuracy difference between the first and the last model in the DCL trained chain was only with less in the number of parameters of the first model compared to the last model. While the accuracy difference between the second and the last model was , and the second model had less in the number of parameters.
DCL showed a significant advantage as a model distillation by transferring the knowledge between models with different sizes of parameters. For CIFAR-100, The DCL models 1, 2, and 6 had an accuracy of , , and compared to , , and using the independent training of each model. The accuracy difference between the first and the last model and between the second and the last model was and , respectively.
The proposed method was compared to three knowledge distillation methods; DML [
12], AvgMKD [
27], and AMTML-KD [
14] as shown in
Table 3. Each method was used to train three student models on the CIFAR-10, CIFAR-100, and TinyImageNet datasets. DML trained three student networked collaboratively to learn with each other and without using any teacher models. AvgMKD and AMTML-KD used three teacher models based on ResNet, VGG-19, and DenseNet.
Table 3 reports the accuracy difference before and after using the knowledge distillation method.
The performance of the proposed method outperformed other state-of-the-art methods. On CIFAR-10, the proposed DCL method increased the accuracy of student model 1, 2 and 3 by , , and , respectively, compared to , , and for DML, , , and for AvgMKD, and , , and for AMTML-KD. On CIFAR-100, The DCL method achieved an average improvement of compared to , , and for DML, AvgMKD, and AMTML-KD, respectively. The AMTML-KD was slightly better than the DCL for the first student model only. On TinyImageNet, The DCL method significantly improved the performance of all student models. The average accuracy difference of DCL was compared to , , and for DML, AvgMKD, and AMTML-KD, respectively.
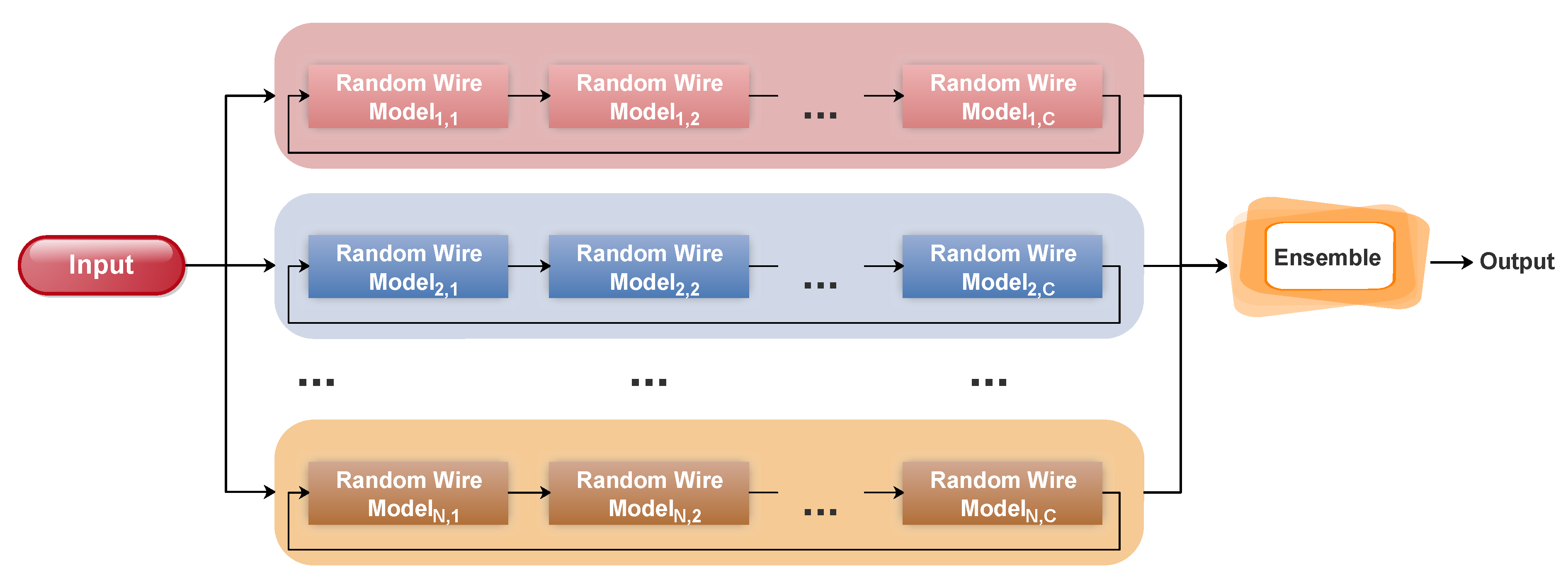
The ensemble model was tested using different combination techniques: sum rule (SR), product rule (PR), and majority voting (MV), as shown in
Table 4. Two chains of random models were trained independently and using DCL. These chains were based on a random graph of eight nodes and contained two stages. The increasing factor of filters was set to 2 for the first chain and 3 for the second one. The PR and SR showed better performance compared to MV.
For example, the results of the ensemble using PR of DCL models were , , and on CIFAR-10, CIFAR-100, and TinyImageNet, respectively, compared to , , and for using SR and , , and for using MV. Here, we used PR to report the results of the ensemble model. The accuracy of the ensemble of models trained independently (, , and on CIFAR-10, CIFAR-100, and TinyImageNet, respectively) was much higher than each model in the chain (the best results were , , and ).
These results indicate that a small change in the model architecture improved the diversity between the models and, therefore, the ensemble accuracy. The ensemble of DCL models demonstrated better performance compared with the ensemble of independent models. The results of the DCL ensemble on CIFAR-10, CIFAR-100, and TinyImageNet were
,
, and
compared to
,
, and
for the ensemble of independent training models.
Table 4 also shows the accuracy of each individual model with and without DCL. The collaborative learning of a small set of models significantly enhanced the accuracy of each model over the independent training.
In the next experiment, we examined a different number of models to form an ensemble on CIFAR-10, CIFAR-100, and TinyImageNet, and we report the ensemble accuracy of the independent training and DCL in
Table 5. The ensemble of DCL models was significantly higher than the independent training of models on the CIFAR-10, and TinyImageNet datasets. The models in the ensemble were created by changing the number of nodes, the number of filters, and/or the number of stages.
We started with a simple configuration of the ensemble by setting the number of stages to 2, the number of nodes to 8, and the increasing factor of filters to 2. Then, we gradually changed these parameters to increase the number of models in the ensemble. The increasing factor of filters was altered between 2 and 3. The number of nodes was increased to 16 and 32, and later the number of stages was set to 3. Note, each configuration resulted in three models that were trained collaboratively using DCL.
On CIFAR-10, the best result of DCL was reached with an ensemble of 18 models () compared to the independent training (). On CIFAR-100, the accuracy of an ensemble of 15, 18, and 21 DCL models was , , and , respectively. For the independent training, the ensemble accuracy was , , and , respectively.
On TinyImageNet, the DCL significantly improved the accuracy of the ensemble. The accuracy of an ensemble of 9, 15, and 21 DCL models was
,
, and
compared to
,
, and
for the independent training, respectively.
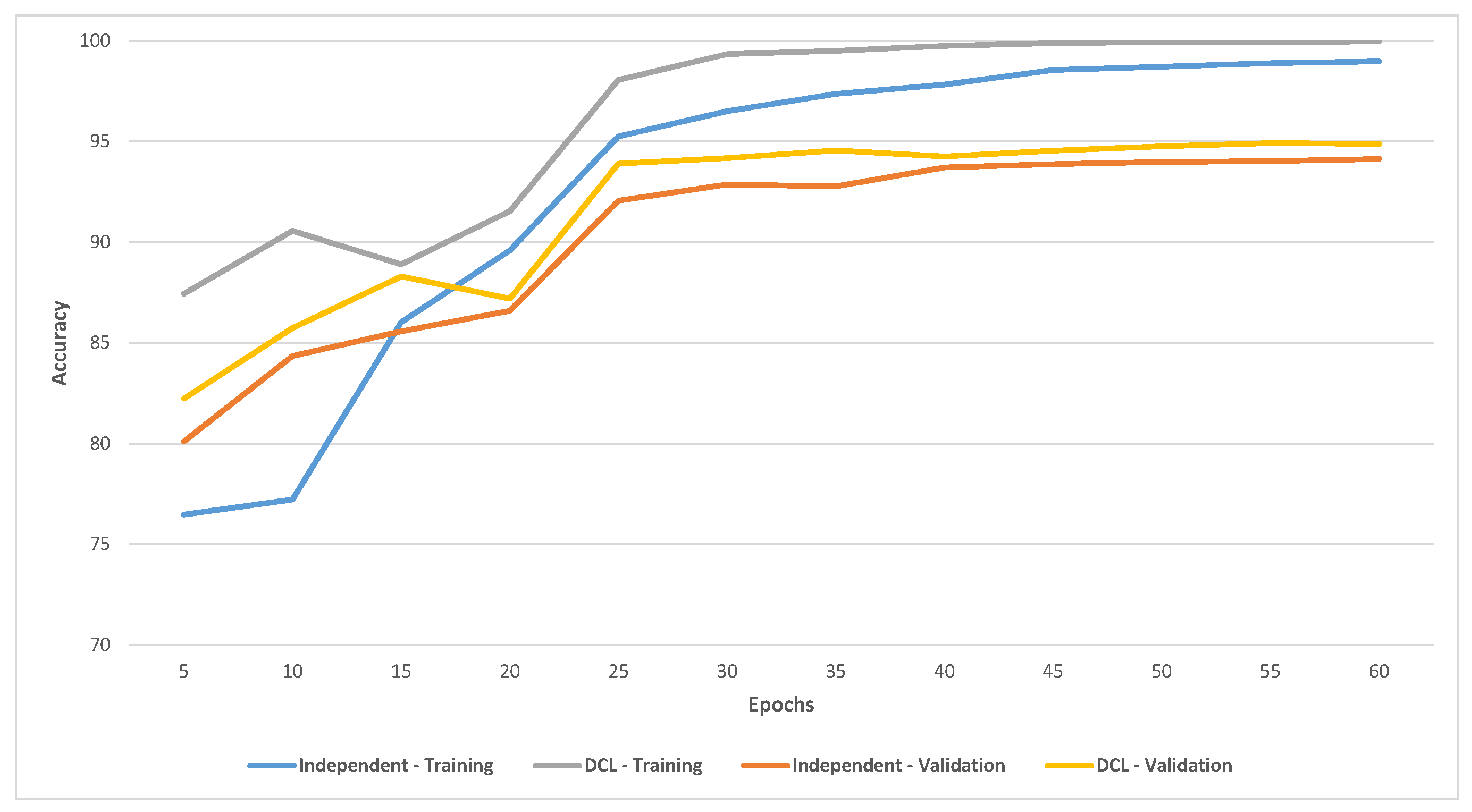
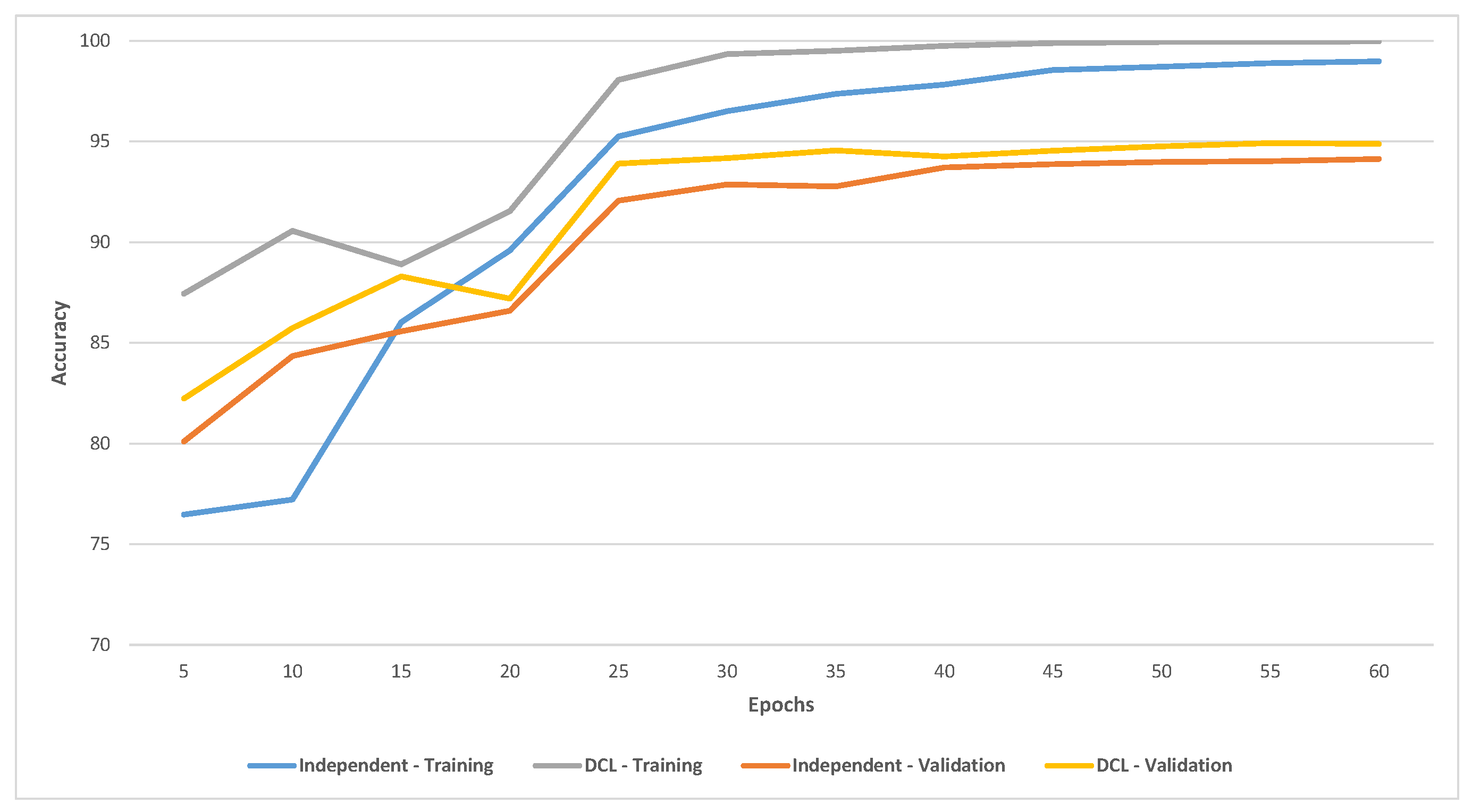
Figure 5 shows the training and validation accuracy on CIFAR-10 of the ensemble of six independent training and DCL models (using 32 nodes). DCL had significantly better accuracy for training and validation and converged faster than independent training.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}