
Spatial Mapping of Distributed Sensors Biomimicking the Human Vision System



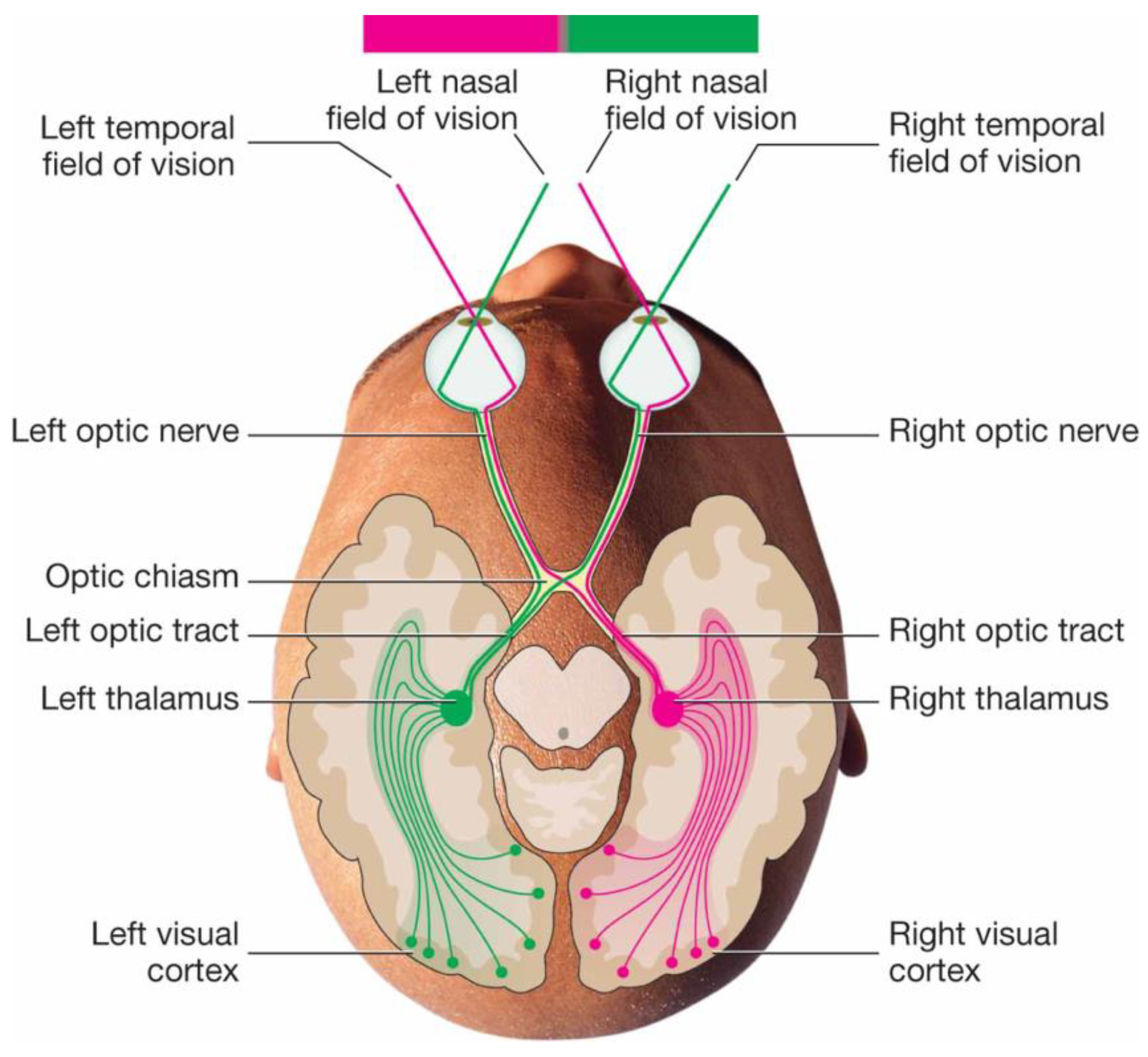{kind=link}
{kind=link}
{kind=link}
{kind=link}
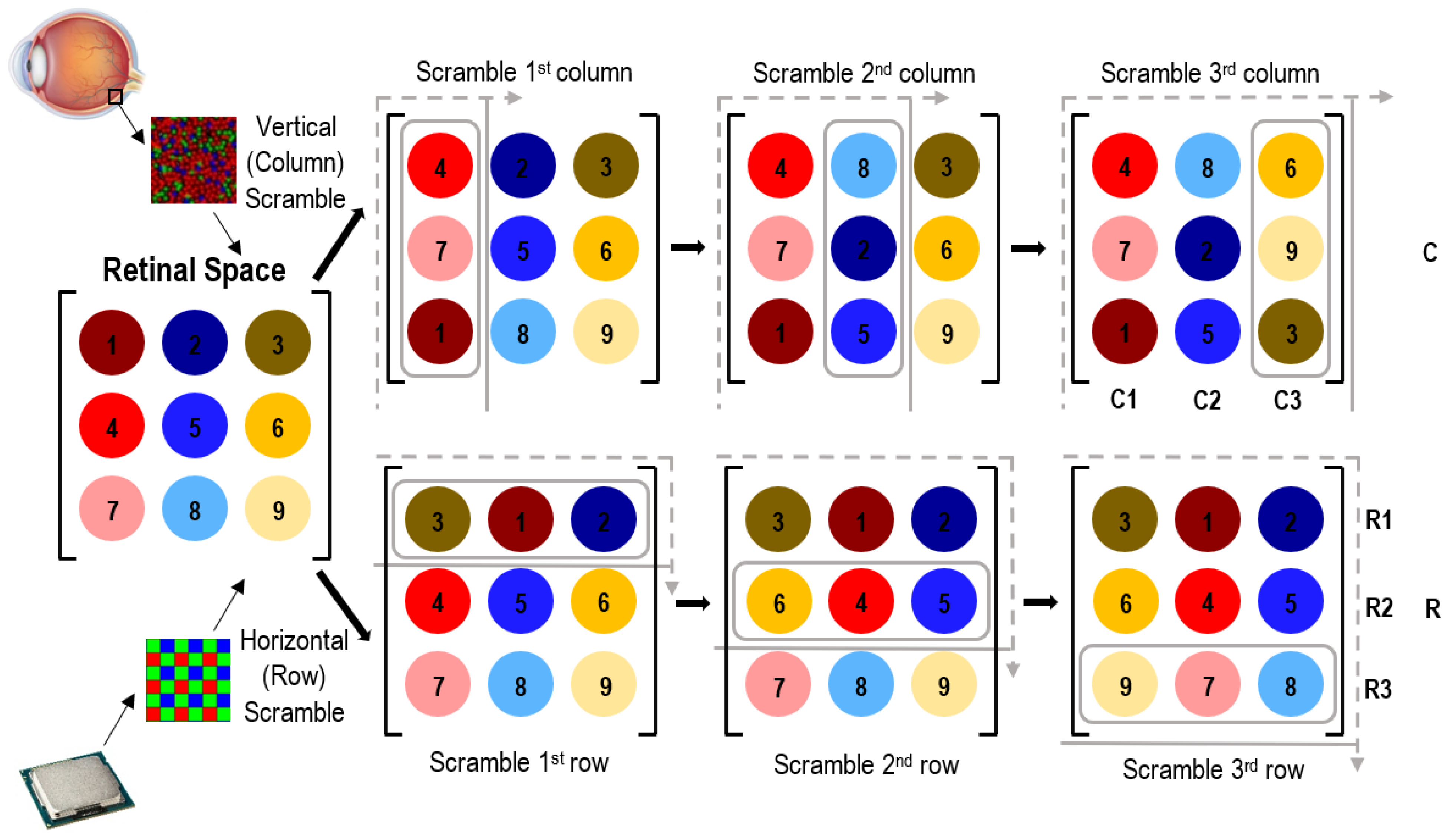{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Previous Work
2.1. Evolution and Functionality of the Visual System
2.2. Visual Learning, Movement, and Memory
2.3. Optical Illusion and Visual Learning
2.4. Modeling and Analysis of the Human Vision System
2.5. Machine Learning
3. Methodology
3.1. Finding the Neural Connections
3.2. Finding the Neural Node Neighbors
4. Results and Discussion
4.1. Failure of Spatial Reconstruction with Static Images
4.2. Spatial Reconstruction with Moving Dynamic Images
4.3. Intercept Method for Sensor ID Location
4.4. Statistical Learning by the Brain Based on Photosensor Response
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Montgomery, N.; Young, P. Baby Sensory Development: Sight. 2019. Available online: https://www.babycenter.com/baby/baby-development/baby-sensory-development-sight_6508#:~:text=world%20around%20her.-,When%20it%20develops,as%20well%20as%20you%20do (accessed on 3 June 2021).
- Churchland, P.S. Is the Visual System as Smart as It Looks? Proceedings of the Biennial Meeting of the Philosophy of Science Association 1982, 2, 541–552. Available online: http://www.jstor.com/stable/192442 (accessed on 3 June 2021).
- Biology Forums Gallery Optic Nerve, Optic Chiasm, Thalamus, and Visual Cortex. Biology Forums. Available online: https://biology-forums.com/index.php?action=gallery;sa=view;id=13954 (accessed on 3 June 2021).
- Lin, J.; Tsai, J. The Optic Nerve and Its Visual Link to the Brain. Discovery Eye Foundation. 2015. Available online: https://discoveryeye.org/optic-nerve-visual-link-brain/#:~:text=In%20the%20brain%2C%20the%20optic,into%20objects%20that%20we%20see (accessed on 3 June 2021).
- Varadarajan, S.G.; Huberman, A.D. Assembly and Repair of Eye-to-Brain Connections. Curr. Opin. Neurobiol. 2018, 53, 198–209. [Google Scholar] [CrossRef]
- Goldman, B. Long-Distance Eye-Brain Connections, Partial Vision Restored for First Time Ever in a Mammal 2016. Stanford Medicine. Available online: https://scopeblog.stanford.edu/2016/07/11/long-distance-eye-brain-connections-partial-vision-restored-for-first-time-ever-in-a-mammal/ (accessed on 11 June 2021).
- Fritzsch, B.; Elliott, K.L.; Pavlinkova, G. Primary Sensory Map Formations Reflect Unique Needs and Molecular Cues Specific to Each Sensory System. F1000 Res. 2019, 8. [Google Scholar] [CrossRef] [PubMed]
- Morgan, J.L.; Berger, D.R.; Wetzel, A.W.; Lichtman, J.W. The Fuzzy Logic of Network Connectivity in Mouse Visual Thalamas. Cell 2016, 165, 192–206. [Google Scholar] [CrossRef]
- Walinga, J. Chapter 5.2 Seeing. In Introduction to Psychology; BC Campus: Vancouver, BC, Canada, 2014; ISBN 978-1-77420-005-6. Available online: https://opentextbc.ca/introductiontopsychology/ (accessed on 3 June 2021).
- Erclik, T.; Hartenstein, V.; McInnes, R.R.; Lipshitz, H.D. Eye Evolution at High Resolution: The Neuron as a Unit of Homology. Dev. Biol. 2009, 332, 70–79. [Google Scholar] [CrossRef]
- Kolb, H.; Fernandez, E.; Nelson, R. Webvision: The Organization of the Retina and Visual System. 2020. Available online: https://webvision.med.utah.edu/ (accessed on 3 June 2021).
- Kolb, H. Cone Pathways through the Retina. 2011. Available online: https://webvision.med.utah.edu/book/part-iii-retinal-circuits/cone-pathways-through-the-retina/#:~:text=Cone%20photoreceptors%20are%20the%20sensors,of%20light%20in%20the%20retina.&text=The%20circuitry%20whereby%20cone%20signals,at%20the%20outer%20plexiform%20layer (accessed on 3 June 2021).
- Emmerton, J.; Delius, J.D. Wavelength Discrimination in the “Visible” and Ultraviolet Spectrum by Pigeons. J. Comp. Physiol. A 1980, 141, 47–52. [Google Scholar] [CrossRef]
- Davies, W.L.; Cowing, J.A.; Carvalho, L.S.; Potter, I.C.; Trezise, A.E.O.; Hunt, D.M.; Collin, S.P. Functional Characterization, Tuning, and Regulation of Visual Pigment Gene Expression in an Anadromous Lamprey. FASEB J. 2007, 21, 2713–2724. [Google Scholar] [CrossRef]
- Rossi, E.A.; Roorda, A. The Relationship between Visual Resolution and Cone Spacing in the Human Fovea. Nat. Neurosci. 2010, 13, 156–157. [Google Scholar] [CrossRef]
- Hall, J.R.; Cuthill, I.C.; Baddeley, R.; Shohet, A.J.; Scott-Samuel, N.E. Camouflage, Detection and Identification of Moving Targets. Proc. Biol. Sci. 2013, 280, 1–7. [Google Scholar] [CrossRef]
- Randel, N.; Asadulina, A.; Bezares-Calderon, L.A.; Veraszto, C.; Williams, E.A.; Conzelmann, M.; Shahidi, R.; Jekely, G. Neuronal Connectome of a Sensory-Motor Circuit for Visual Navigation. eLife 2014, 3. [Google Scholar] [CrossRef]
- Marr, D.; Poggio, T. A Computational Theory of Human Stereo Vision. Proc. R. Soc. Lond. B. 1979, 204, 301–328. [Google Scholar] [CrossRef]
- Armson, M.J.; Diamond, N.B.; Levesque, L.; Ryan, J.D. Vividness of Recollection Is Supported by Eye Movements in Individuals with High, but Not Low Trait Autobiographical Memory. Cognition 2021, 206. [Google Scholar] [CrossRef]
- Ryan, J.D.; Shen, K.; Liu, Z.-X. The Intersection between the Oculomotor and Hippocampal Memory Systems: Empirical Developments and Clinical Implications. Ann. N. Y. Acad. Sci. 2020, 1464, 115–141. [Google Scholar] [CrossRef] [PubMed]
- Sakai, J. How Synaptic Pruning Shapes Neural Wiring During Development and, Possibly, in Disease. Proc. Nat. Acad. Sci. USA 2020, 117. [Google Scholar] [CrossRef] [PubMed]
- Office of Communications and Public Liaison Brain Basics: The Life and Death of a Neuron. 2019. Available online: https://www.ninds.nih.gov/Disorders/Patient-Caregiver-Education/life-and-death-neuron (accessed on 3 June 2021).
- Barnea, A.; Pravosudov, V. Birds as a Model to Study Adult Neurogenesis: Bridging Evolutionary, Comparative and Neuroethological Approches. Eur. J. Neurosci. 2011, 34, 884–907. [Google Scholar] [CrossRef]
- Nottebohm, F. Why Are Some Neurons Replaced in Adult Brain? J. Neurosci. 2002, 22, 624–628. [Google Scholar] [CrossRef] [PubMed]
- Michelon, P. Brain Plasticity: How Learning Changes Your Brain. Sharp Brains. 2008. Available online: https://sharpbrains.com/blog/2008/02/26/brain-plasticity-how-learning-changes-your-brain/ (accessed on 3 June 2021).
- Maguire, E.A.; Woollett, K.; Spiers, H.J. London Taxi Drivers and Bus Drivers: A Structural MRI and Neuropsy-chological Analysis. Hippocampus 2006, 16, 1091–1101. [Google Scholar] [CrossRef]
- Polat, U.; Schor, C.; Tong, J.-L.; Zomet, A.; Lev, M.; Yehezkel, O.; Sterkin, A.; Levi, D.M. Training the Brain to Overcome the Effect of Aging on the Human Eye. Sci. Rep. 2012, 278. [Google Scholar] [CrossRef] [PubMed]
- Thibos, L.N. Image Processing by the Human Eye. In Proceedings of the SPIE 1989 Symposium on Visual Communications, Image Processing, and Intelligent Robotics Systems, Philadelphia, PA, USA, 1 November 1989. [Google Scholar] [CrossRef]
- Rizzi, A.; Bonanomi, C. The Human Visual System Described through Visual Illusions. In Colour Design; Woodhead Publishing: Sawston, UK, 2017; pp. 23–41. [Google Scholar] [CrossRef]
- Heller, M.A.; Brackett, D.D.; Wilson, K.; Yoneyama, K.; Boyer, A.; Steffen, H. The Haptic Muller-Lyer Illusion in Sighted and Blind People. Perception 2002, 31, 1263–1274. [Google Scholar] [CrossRef] [PubMed]
- Williams, R.M.; Yampolskiy, R.V. Optical Illusions Images Dataset. 2018. Available online: https://arxiv.org/abs/1810.00415 (accessed on 3 June 2021).
- Robinson, A.E.; Hammon, P.S.; de Sa, V.R. Explaining Brightness Illusions Using Spatial Filtering and Local Response Normalization. Vis. Res. 2007, 47, 1631–1644. [Google Scholar] [CrossRef] [PubMed]
- Watanabe, S.; Nakamura, N.; Fujita, K. Pigeons Perceive a Reversed Zollner Illusion. Cognition 2011, 119, 137–141. [Google Scholar] [CrossRef]
- Coren, S.; Girgus, J.S. A Comparison of Five Methods of Illusion Measurement. Behav. Res. Methods Instrum. 1972, 4, 240–244. [Google Scholar] [CrossRef]
- Franz, V.H. Manual Size Estimation: A Neuropsychological Measure of Perception? Exp. Brain Res. 2003, 151, 471–477. [Google Scholar] [CrossRef] [PubMed]
- Campbell, F.W.; Marr, D. The Physics of Visual Perception and Discussion. Philos. Trans. R. Soc. Lond. Ser. B Biol. Sci. 1980, 290, 5–9. Available online: www.jstor.org/stable/2395412 (accessed on 3 June 2021).
- McIlhagga, W.; Mullen, K.T. Evidence for Chromatic Edge Detectors in Human Vision Using Classification Images. J. Vis. 2018, 18, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Marr, D.; Hildreth, E. Theory of Edge Detection. Proc. R. Soc. Lond. B. Biol. Sci. 1980, 207, 187–217. [Google Scholar] [CrossRef] [PubMed]
- Georgeson, M.A. Human Vision Combines Oriented Filters to Compute Edges. Proc. Biol. Sci. 1992, 249, 235–245. [Google Scholar] [CrossRef]
- Garcia-Garibay, O.B.; de Lafuente, V. The Muller-Lyer Illusion as Seen by an Artificial Neural Network. Front. Comput. Neurosci. 2015. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks; University of Toronto: Toronto, ON, Canada, 2012; Available online: https://www.cs.toronto.edu/~kriz/imagenet_classification_with_deep_convolutional.pdf (accessed on 3 June 2021).
- Zeman, A.; Obst, O.; Brooks, K.R. Complex Cells Decrease Errors for the Muller-Lyer Illusion in a Model of the Visual Ventral Stream. Front. Comput. Neurosci. 2014. [Google Scholar] [CrossRef] [PubMed]
- Watanabe, E.; Kitaoka, A.; Sakamoto, K.; Yasugi, M.; Tanaka, K. Illusory Motion Reproduced by Deep Neural Networks Trained for Prediction. Front. Psychol. 2018. [Google Scholar] [CrossRef]
- Lades, M.; Vorbruggen, J.C.; Buhmann, J.; Lange, J.; Malsburg, C.; Wurtz, R.P.; Konen, W. Distortion Invariant Object Recognition in the Dynamic Link Architecture. IEEE Trans. Comput. 1993, 42. [Google Scholar] [CrossRef]
- Talbi., H.; Draa, A.; Batouche, M.C. A Genetic Quantum Algorithm for Image Registration. In Proceedings of the 2004 International Conference on Information and Communication Technologies, Damascus, Syria, 23 April 2004. [Google Scholar] [CrossRef]
- Forcen, J.I.; Pagola, M.; Barrenechea, E.; Bustince, H. Learning Ordered Pooling Weights in Image Classification. Neorocomputing 2020, 411, 45–53. [Google Scholar] [CrossRef]
- Grimson, W.E.L. A Computational Theory of Visual Surface Interpolation. Philos. Trans. R. Soc. Lond. Ser. B Biol. Sci. 1982, 298, 395–427. [Google Scholar] [CrossRef]
- Grimson, W.E.L. A Computer Implementation of a Theory of Human Stereo Vision. Philos. Trans. R. Soc. Lond. Ser. B Biol. Sci. 1981, 292, 217–253. [Google Scholar] [CrossRef]
- Bergstra, J.; Yamins, D.; Cox, D.D. Making a Science of Model Search: Hyperparameter Optimization in Hundreds of Dimensions for Vision Architectures. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Available online: http://proceedings.mlr.press/v28/bergstra13.pdf (accessed on 3 June 2021).
- Tsuda, K.; Ratsch, G. Image Reconstruction by Linear Programming. IEEE Trans. Image Process. 2005, 14, 737–744. [Google Scholar] [CrossRef]
- Bhusnurmath, A. Applying Convex Optimization Techniques to Energy Minimization Problems in Computer Vision. Ph.D. Thesis, University of Pennsylvania, Philadelphia, PA, USA, 2008. Available online: https://www.cis.upenn.edu/~cjtaylor/PUBLICATIONS/pdfs/BhusnurmathPHD08.pdf (accessed on 3 June 2021).
- Tefi Shutter Stock Human Eye Diagram. Available online: https://www.shutterstock.com/image-illustration/human-eye-anatomy-detailed-illustration-isolated-174265226 (accessed on 3 June 2021).
- Vaiciulaityte, G. You’ll Be Amazed How People with Color Blindness See the World. Bored Panda. Available online: https://www.boredpanda.com/different-types-color-blindness-photos/?utm_source=google&utm_medium=organic&utm_campaign=organic (accessed on 3 June 2021).
- Kwan, C.; Chou, B. Further Improvement of Debayering Perfromance of RGBW Color Filter Arrays Using Deep Learning and Pansharpening Techniques. J. Imaging 2019, 5, 68. [Google Scholar] [CrossRef]
- Zhang, F.; Kurokawa, K.; Lassoued, A.; Crowell, J.A.; Miller, D.T. Cone Photoreceptor Classification in the Living Human Eye from Photostimulation-Induced Phase Dynamics. Proc. Natl. Acad. Sci. USA 2019, 116, 7951–7956. [Google Scholar] [CrossRef]
- Chulovskyi, Y. Shutterstock Wonderful Autumn Landscape. Available online: https://www.shutterstock.com/image-photo/wonderful-autumn-landscape-beautiful-romantic-alley-1911646903 (accessed on 3 June 2021).
- 7th Son Studio Shutterstock Close up CPU Upside Isolated on White. Available online: https://www.shutterstock.com/image-photo/close-cpu-upside-isolated-on-white-121109950 (accessed on 3 June 2021).
- Chua, L.O. Memristor- The Missing Circuit Element. IEEE Trans. Circuit Theory 1971, 18, 507–519. [Google Scholar] [CrossRef]
- Abraham, I. The Case for Rejecting the Memristor as a Fundamental Circuit Element. Nat. Sci. Rep. 2018. [Google Scholar] [CrossRef] [PubMed]
- Strukov, D.B.; Snider, G.S.; Stewart, D.R.; Williams, R.S. The Missing Memristor Found. Nature 2008, 453. [Google Scholar] [CrossRef] [PubMed]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dutta, S.; Wilson, M. Spatial Mapping of Distributed Sensors Biomimicking the Human Vision System. Electronics 2021, 10, 1443. https://doi.org/10.3390/electronics10121443
Dutta S, Wilson M. Spatial Mapping of Distributed Sensors Biomimicking the Human Vision System. Electronics. 2021; 10(12):1443. https://doi.org/10.3390/electronics10121443
Chicago/Turabian StyleDutta, Sandip, and Martha Wilson. 2021. "Spatial Mapping of Distributed Sensors Biomimicking the Human Vision System" Electronics 10, no. 12: 1443. https://doi.org/10.3390/electronics10121443
APA StyleDutta, S., & Wilson, M. (2021). Spatial Mapping of Distributed Sensors Biomimicking the Human Vision System. Electronics, 10(12), 1443. https://doi.org/10.3390/electronics10121443