
A Novel Bottom-Up/Top-Down Hybrid Strategy-Based Fast Sequential Fault Diagnosis Method





Abstract
1. Introduction
2. Description of the Multi-Signal Flow Graph Combination Problem
- is a set of statically independent failure associated with system, where means the ith fault state and m is the number of failure states;
- is denoted as the priori probability vector according to the failure set ;
- represents a finite set of n reliable binary outcome tests, where checks a subset of ;
- is a set of tests cost based on time, manpower requirements or other economic factors;
- represents a binary matrix with , dimension to depict the relationship between the failure set and the test set, where means the test is able to monitor failure state otherwise, .
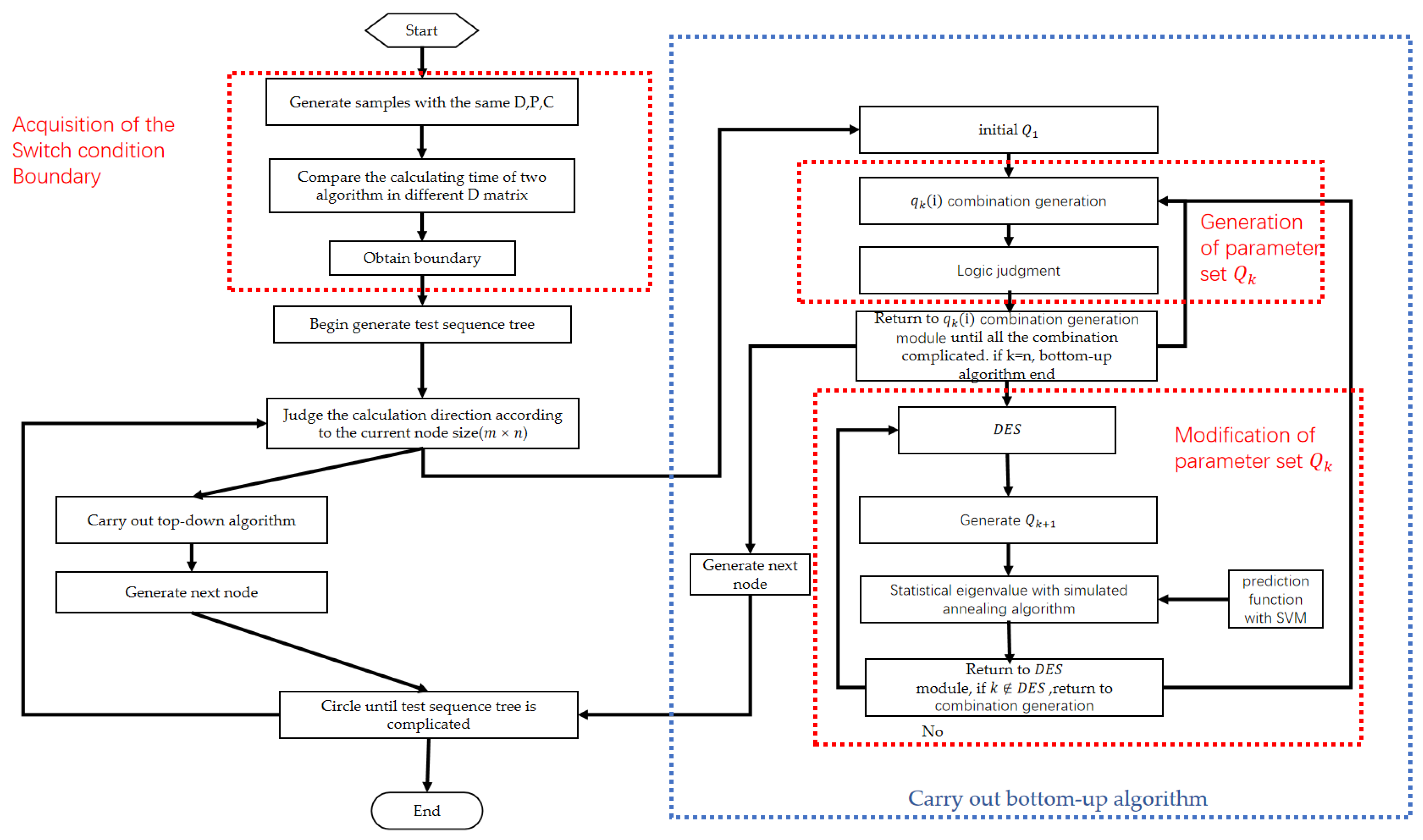
3. Proposed Sequential Fault Diagnosis Approach
3.1. Generation of Parameter Set
- : Any fault subset with size k of the fault complete set , it contains three parts, k faults, k1 and k2 storage location information, and a series of Karnaugh map logic values, the length of which is n;
- : The set of all . is used to denote the ith element in ;
- : If there are only k failures that belong to in the system, the minimum cost of testing is required;
- : The sum of the failure rate of k failures in .
3.1.1. Combination Generation Module
3.1.2. Logic Judgement Module
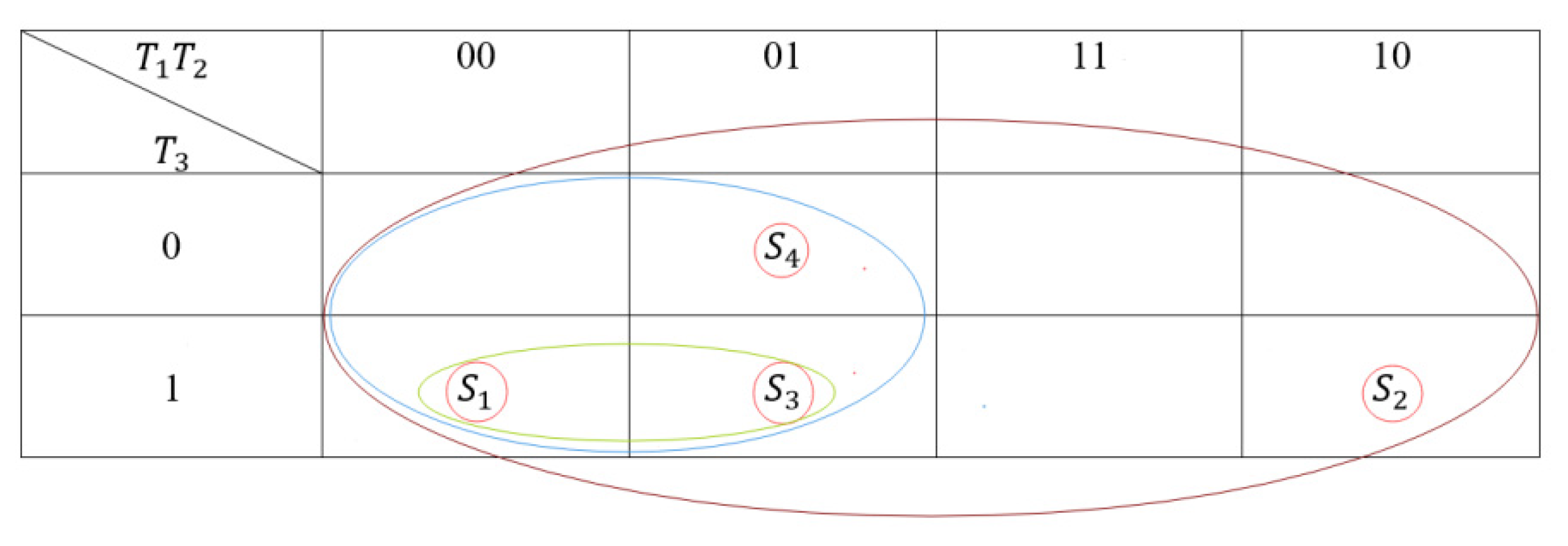
- Each circle conforms to the Karnaugh map circle rule, and its size is ;
- A large circle containing two smaller circles is treated as one circle;
- each have a circle of size one;
- There are only two disjoint circles in a large circle;
- The maximum circle size is , and it must exist.
- The circles of the Karnaugh map corresponding to and have no overlap;
- The circle of the Karnaugh map corresponding to does not contain , and .
3.1.3. Entire Process of Generation of the Parameter Set
| Algorithm 1 production |
| 1: ; 2: , take out one element in and combine it with one element in in turn; 3: Judge the logic of the combination result. If is a non-logic item, return to step 2. Otherwise, go to step 4; 4: Judge whether there is the same in . If not, it will be included, and . Otherwise, compare the of the two and retain the smaller one; |
| 5: Return to step 2, if all elements in step 2 have been combined, then if , the calculation is completed; otherwise return to step 2. |
3.2. Modification of Parameter Set
- If and can be combined into , then and are a pair of couples in ;
- If can be composed of many pairs of couples, then the least cost pair of couples is called a pair of spouses.
- : the number of couples generates in ;
- : the number of spouses generates in ;
- ;
- : The number of d (irrelevant items) in the logic values of the Karnaugh map corresponding to .
3.2.1. Condition Judgement Module
3.2.2. Prediction Function
- : The proportion of 0 and 1 of D array,
- : the average of .
| Algorithm 2 Prediction function |
| 1: According to the test objects D, P and C, generate several similar samples; 2: Take a sample, and calculate in turn; 3: Take an element k in the . Statistics . Take as the first set of eigenvalues. Take as the second set of eigenvalues Take as the th set of eigenvalues. Statistics each and , and calculate the average value: , ; 4: If and are lower than and , the is marked as 0; otherwise, it is marked as 1 ( and are coefficient parameters, which are taken as 1 in this experiment); 5: Delete this element k in , and return to step 3 until ; 6: The eigenvalues obtained in step 2 and the tag values obtained in step 4 are used as the training matrix. Return to step 2 until all samples are calculated, and use all of the training matrix to train the prediction function. |
3.2.3. Statistical Eigenvalue Module
| Algorithm 3 Statistical eigenvalue |
| 1: Through , the eigenvalues are obtained, and the with classification value 0 is included in the set ; 2: If , then go to step 5. Create an array: to record the eigenvalues. Randomly take the subsets of as (The size of the subset is of the total set; in this paper, is 10), use to calculate ; 3: Record all the couples and spouses in each , and add the couples and spouses not included in the into it; 4: Return to step 2; if the eigenvalue is not updated in multiple circles, it shows that the statistics of couples and spouses are completed, the eigenvalues and are obtained, and the elements in take as the eigenvalue to obtain the classification values. Delete the element in with classification value of 1, , empty the, and return to step 2; 5: Finally, the remaining elements in are the elements to be eliminated. |
3.2.4. Entire Process of Modification of the Parameter Set
| Algorithm 4 Modification |
| 1: Judge whether ; if yes, go to step 2, and otherwise, go to step 4; 2: Calculate in the same way as the production part; 3: Enter the statistical eigenvalue module, use the prediction function to obtain the classification value of , and eliminate the with the classification value of 0; 4: |
3.3. Acquisition of the Switch Condition Boundary
- In the top-down algorithm. is not affected by P and C when ; i.e., the calculation time is unchanged. After adding the prediction function, is less affected by P and C, and the calculation time is stable. When the cost of each test point and the probability of each fault are similar, the time of top-down search is short. When the cost of each test point and the probability of each fault are much different, the time of top-down search is long;
- The bottom-up algorithm has an advantage when the number of test points is much larger than the number of faults because the bottom-up algorithm takes fault s as the core and calculates the combination of its subsets. The upper limit of calculation times is
- The core of bottom-up algorithm is comparing the characteristic of each test point. When the number of test points is large, the calculation time is long. In contrast, when the number of test points is much less than the number of faults , top-down search has more advantages.
4. Experiment
4.1. Large-Scale Fault-Test Dependency Matrix
4.2. Superheterodyne Receiver Example
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yang, G.; Zhong, Y.; Yang, L.; Du, R. Fault Detection of Harmonic Drive Using Multiscale Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2020, 70, 1–11. [Google Scholar] [CrossRef]
- Gao, S.; Zhang, W.; He, X.; Zou, Y.; Li, W. Spacecraft Fault Diagnosis Based on Improved A* Algorithm. In Proceedings of the 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 4097–4100. [Google Scholar] [CrossRef]
- Raghavan, V.; Shakeri, M.; Pattipati, K. Optimal and near-optimal test sequencing algorithms with realistic test models. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 1999, 29, 11–26. [Google Scholar] [CrossRef]
- Yang, L.; Yu, P.; Tang, H. Real-Time Failure Diagnosis Technology for Satellites Based on Multi-signal Model. In Proceedings of the 2014 Seventh International Symposium on Computational Intelligence and Design, Hangzhou, China, 13–14 December 2014; pp. 360–364. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A new convolutional neural network-based data-driven fault diagnosis method. IEEE Trans. Ind. Electron. 2017, 65, 5990–5998. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Deb, S.; Pattipati, K.R.; Raghavan, V.; Shakeri, M.; Shrestha, R. Multi-signal flow graphs: A novel approach for system testability analysis and fault diagnosis. In Proceedings of the AUTOTESTCON’94, Anaheim, CA, USA, 20–22 September 1994; pp. 361–373. [Google Scholar]
- Wang, G.; Zhang, H. A Software Based on Multi-Signal Flow Graph Model for PHM-Oriented Design for Testability. In Proceedings of the 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018; pp. 370–373. [Google Scholar]
- Yan, P.; Chen, F.; Sun, S.; Li, X. Testability Modeling of Guided Projectile Based on Multi-Signal Flow Graphs. In Proceedings of the 2018 IEEE 4th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 14–16 December 2018; pp. 1219–1225. [Google Scholar]
- Tian, H.; Duan, F.; Fan, L.; Sang, Y. Novel solution for sequential fault diagnosis based on a growing algorithm. Reliab. Eng. Syst. Saf. 2019, 192, 106174. [Google Scholar] [CrossRef]
- Marteli, A.; Montanari, U. Optimizing decision trees through heuristically guided search. Commum. ACM 1978, 21, 1025–1039. [Google Scholar] [CrossRef]
- Wang, G.; Li, Q. Research on Test Point Allocation Method Based on Multi-signal Flow Graph Using Genetic Algorithm. In Proceedings of the 2013 Third International Conference on Instrumentation, Measurement, Computer, Communication and Control, Shenyang, China, 21–23 September 2013; pp. 1418–1422. [Google Scholar]
- Tu, F.; Pattipati, K.R. Rollout strategies for sequential fault diagnosis. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2003, 33, 86–99. [Google Scholar]
- Zhang, L. Research on fault diagnosis test sequence algorithm based on multi-signal flow graph model. In Proceedings of the 2017 Second International Conference on Reliability Systems Engineering (ICRSE), Beijing, China, 10–12 July 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Shahmoradi, Z.; Ünlüyurt, T. Failure detection for series systems when tests are unreliable. Comput. Indust. Eng. 2018, 118, 309–318. [Google Scholar] [CrossRef]
- Pan, J.; Ye, X.; Xue, Q. A New Method for Sequential Fault Diagnosis Based on Ant Algorithm. In Proceedings of the 2009 Second International Symposium on Computational Intelligence and Design, Changsha, China, 12–14 December 2009; pp. 44–48. [Google Scholar] [CrossRef]
- Srivastava, P.R.; Sravya, C.; Ashima; Kamisetti, S.; Lakshmi, M. Test sequence optimisation: An intelligent approach via cuckoo search. Int. J. Bio-Inspired Comput. 2012, 4, 139–148. [Google Scholar] [CrossRef]
- Lu, B.; Mei, W.; Zhou, J.; Zhou, H.; Du, L.; Liu, Z. An Novel Testing Sequence Optimization Method under Dynamic Environments. In Proceedings of the 2018 10th International Conference on Communications, Circuits and Systems (ICCCAS), Chengdu, China, 22–24 December 2018; pp. 479–483. [Google Scholar] [CrossRef]
- Zhang, Y.S.; Qiao, Z.T.; Jing, J.H. Diagnostic Strategy Optimization Based on Particle Swarm Algorithm. Appl. Mech. Mater. 2012, 215–216, 555–560. [Google Scholar] [CrossRef]
- Georgieva, A.; Jordanov, I. Global optimization based on novel heuristics, low-discrepancy sequences and genetic algorithms. Eur. J. Oper. Res. 2009, 196, 413–422. [Google Scholar] [CrossRef]
- Kundakcioglu, O.E.; Unluyurt, T. Bottom-up construction of minimum-cost and/or trees for sequential fault diagnosis. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2007, 37, 621–629. [Google Scholar] [CrossRef]
- Baoran, A.; Huai, W.; Yahui, S. Fault Diagnosis and Fault-Tolerant Control for Large-Scale Safety-Critical Facilities. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 6371–6375. [Google Scholar] [CrossRef]
- Wei, H.; Yueke, W.; Kefei, X.; Zelong, Z. Modeling of SEE soft error propagation based on multi-signal flow graph. In Proceedings of the 2016 IEEE International Conference on Mechatronics and Automation, Harbin, China, 7–10 August 2016; pp. 1916–1920. [Google Scholar] [CrossRef]
- Sun, Y.; Li, Z.; Zhang, Z. Open-Circuit Fault Diagnosis and Fault-Tolerant Control with Sequential Indirect Model Predictive Control for Modular Multilevel Converters. In Proceedings of the 2019 4th IEEE Workshop on the Electronic Grid (eGRID), Xiamen, China, 11–14 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Kato, Y.; Saito, H.; Ejima, T. An application of SVM: Alphanumeric character recognition. In Proceedings of the International 1989 Joint Conference on Neural Networks, Washington, DC, USA, 18–22 June 1989; p. 576. [Google Scholar] [CrossRef]
- Yu, L.; Lu, L. Research on test data generation based on Modified Genetic and Simulated Annealing Algorithm. In Proceedings of the 2010 8th International Conference on Supply Chain Management and Information, Hong Kong, China, 6–9 October 2010; pp. 1–3. [Google Scholar]
- Huffman, D.A. A Method for the Construction of Minimum-Redundancy Codes. Proc. IRE 1952, 40, 1098–1101. [Google Scholar] [CrossRef]
- Karnaugh, M. The map method for synthesis of combinational logic circuits. Trans. Am. Inst. Electr. Eng. Part I Commun. Electron. 1953, 72, 593–599. [Google Scholar] [CrossRef]
- Yu, J.; Xu, B.; Li, X. Generation of test strategy for sequential fault diagnosis based on genetic algorithms. Acta Simulata Syst. Sin. 2004, 16, 833–836. [Google Scholar]
- Pattipati, K.R.; Alexandridis, M.G. Application of heuristic search and information theory to sequential fault diagnosis. IEEE Trans. Syst. Man Cybern. 1990, 20, 872–887. [Google Scholar] [CrossRef]
- Furth, E.; Grant, G.; Smithline, H. Data Conditioning Display for Apolo Prelaunch Checkout: Test Matrix Technique; Dunlap Associates, Inc.: Darien, CT, USA, 1967. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0 | 1 | 0 | |
| 1 | 1 | 0 | |
| 0 | 0 | 1 | |
| 1 | 0 | 0 |
| 0 | 0 | 0 | |
| 0 | 0 | 1 | |
| 0 | 1 | 0 | |
| 0 | 1 | 1 | |
| 1 | 0 | 0 | |
| 1 | 0 | 1 | |
| 1 | 1 | 0 | |
| 1 | 1 | 1 |
| P | ||||
|---|---|---|---|---|
| 0 | 0 | 1 | 0.1 | |
| 1 | 0 | 1 | 0.2 | |
| 0 | 1 | 1 | 0.3 | |
| 0 | 1 | 0 | 0.4 | |
| C | 1 | 1.5 | 2 | - |
| |T| | 79 | 80 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |S| | |||||||||||||||||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| 5 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 6 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 7 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 8 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | |
| 9 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | |
| 10 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | |
| 11 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 12 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| T | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | p | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S | ||||||||||||||||||||||||||||||||||||||
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.00185 | ||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0.00923 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.185 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.00185 | ||
| 5 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0.00185 | |
| 6 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0.00923 | |
| 7 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0.00185 | |
| 8 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0.00923 | |
| 9 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0.185 | |
| 10 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0.185 | |
| 11 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0.185 | |
| 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.00185 | |
| 13 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0.00923 | |
| 14 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0.185 | |
| 15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.00923 | |
| 16 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.00185 | |
| 17 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0.00923 | |
| 18 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0.00185 | |
| 19 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0.00185 | |
| 20 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0.00185 | |
| 21 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0.00185 | |
| 22 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0.00185 | |
| Algorithm | Rollout and Information Heuristic Algorithm | ||
|---|---|---|---|
| Time | More than 15 min | 88.45 s | 60.97 s |
| Sequence | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||
|---|---|---|---|---|---|---|---|---|---|
| S | |||||||||
| - | |||||||||
| - | - | - | - | ||||||
| - | - | - | - | - | |||||
| 5 | - | ||||||||
| 6 | - | - | - | - | |||||
| 7 | - | - | |||||||
| 8 | - | - | - | - | |||||
| 9 | - | - | - | - | - | ||||
| 10 | - | - | - | - | |||||
| 11 | - | - | - | - | - | ||||
| 12 | - | ||||||||
| 13 | - | - | |||||||
| 14 | - | - | - | - | - | ||||
| 15 | - | - | |||||||
| 16 | |||||||||
| 17 | - | - | - | - | |||||
| 18 | - | - | |||||||
| 19 | - | - | - | ||||||
| 20 | - | - | |||||||
| 21 | - | - | |||||||
| 22 | - | - | - | ||||||
| Algorithm | Genetic Algorithm | Information Gain Algorithm | Rollout and Information Heuristic Algorithm | Hybrid Algorithm |
|---|---|---|---|---|
| Cost | 3.9526 | 6.9124 | 3.3473 | 3.3473 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Liu, Z.; Chen, X.; Long, B.; Yang, C.; Zhou, X. A Novel Bottom-Up/Top-Down Hybrid Strategy-Based Fast Sequential Fault Diagnosis Method. Electronics 2021, 10, 1441. https://doi.org/10.3390/electronics10121441
Wang J, Liu Z, Chen X, Long B, Yang C, Zhou X. A Novel Bottom-Up/Top-Down Hybrid Strategy-Based Fast Sequential Fault Diagnosis Method. Electronics. 2021; 10(12):1441. https://doi.org/10.3390/electronics10121441
Chicago/Turabian StyleWang, Jingyuan, Zhen Liu, Xiaowu Chen, Bing Long, Chenglin Yang, and Xiuyun Zhou. 2021. "A Novel Bottom-Up/Top-Down Hybrid Strategy-Based Fast Sequential Fault Diagnosis Method" Electronics 10, no. 12: 1441. https://doi.org/10.3390/electronics10121441
APA StyleWang, J., Liu, Z., Chen, X., Long, B., Yang, C., & Zhou, X. (2021). A Novel Bottom-Up/Top-Down Hybrid Strategy-Based Fast Sequential Fault Diagnosis Method. Electronics, 10(12), 1441. https://doi.org/10.3390/electronics10121441