Forwarding Path Limitation and Instruction Allocation for In-Order Processor with ALU Cascading

Abstract
1. Introduction
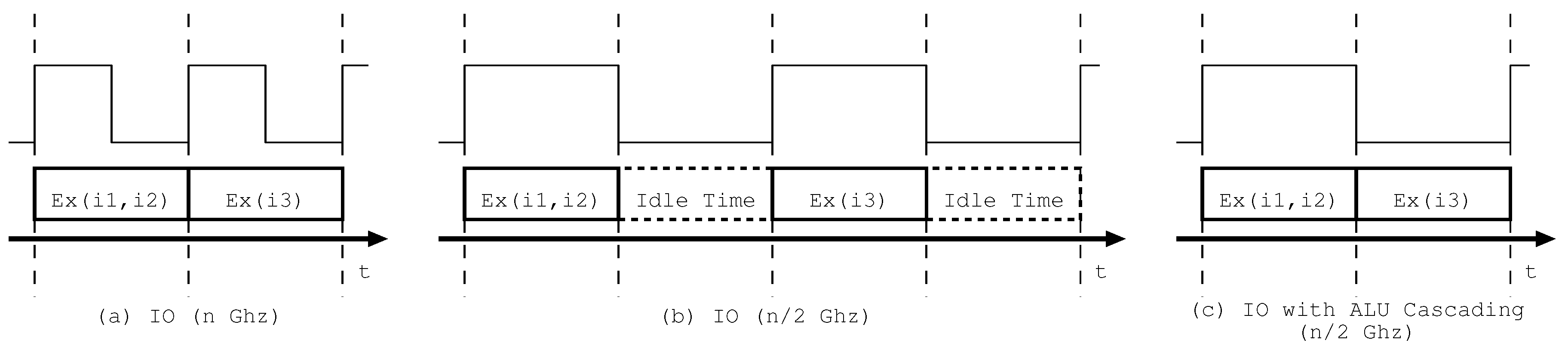
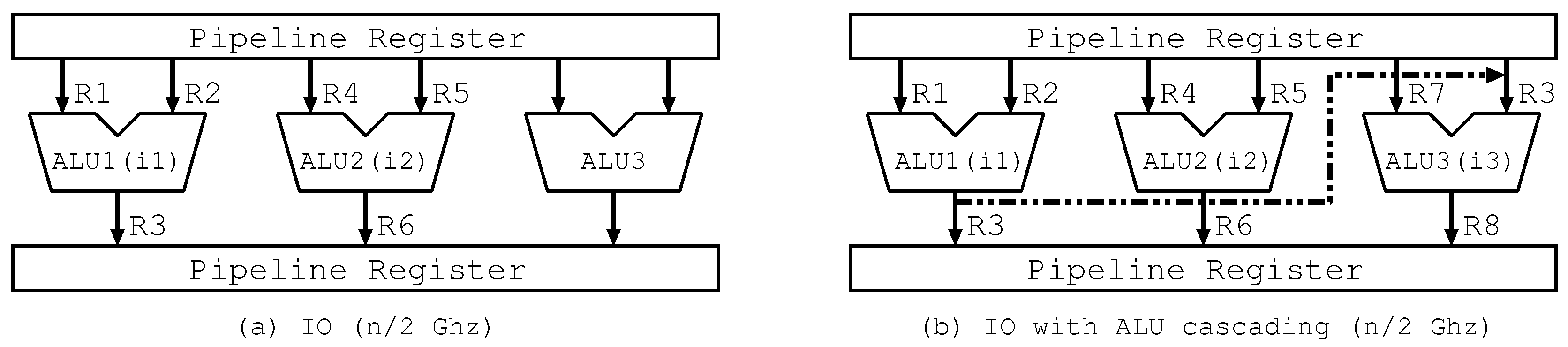
2. ALU Cascading
3. Related Work
4. Our Proposed Approach
4.1. Principle
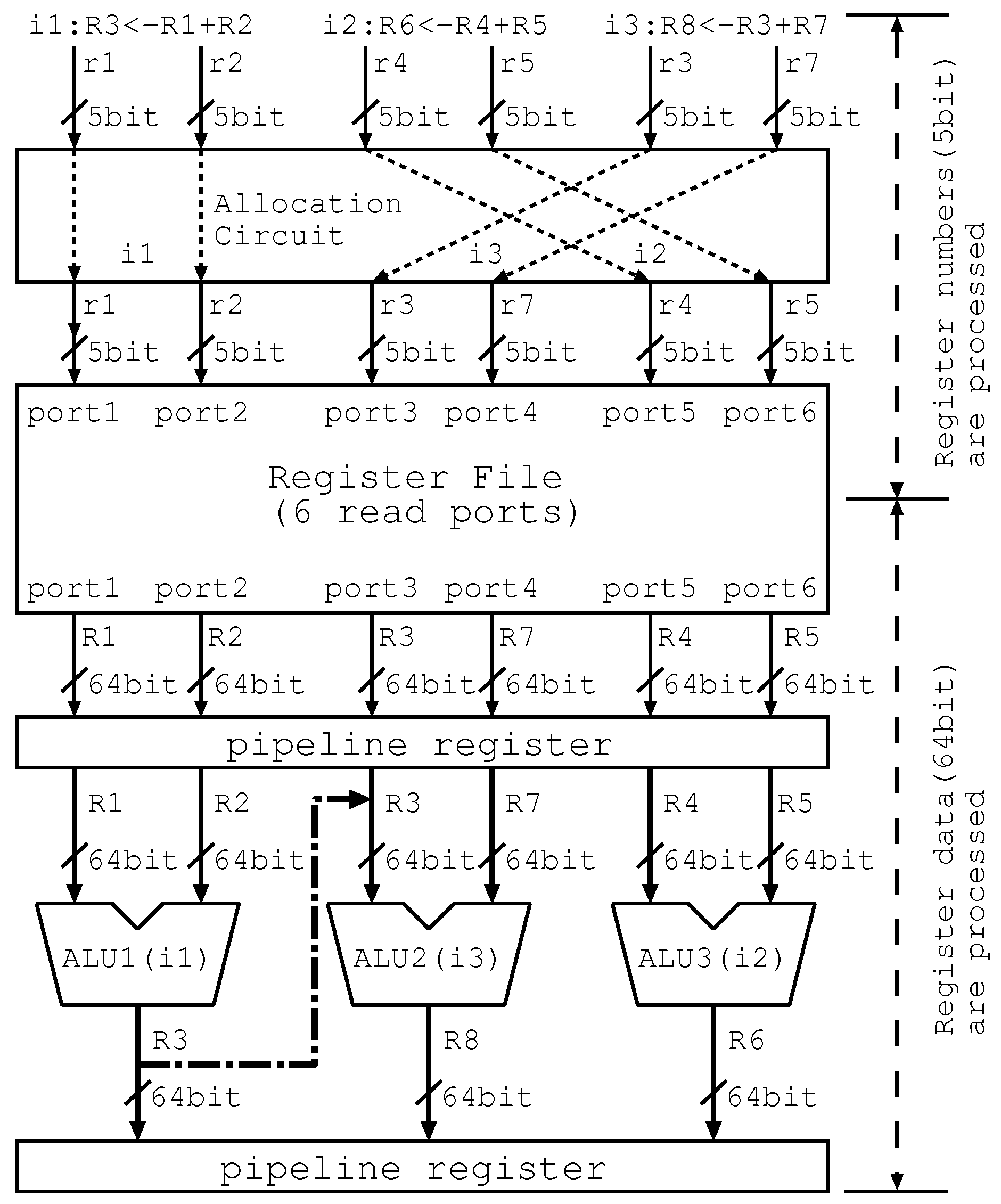
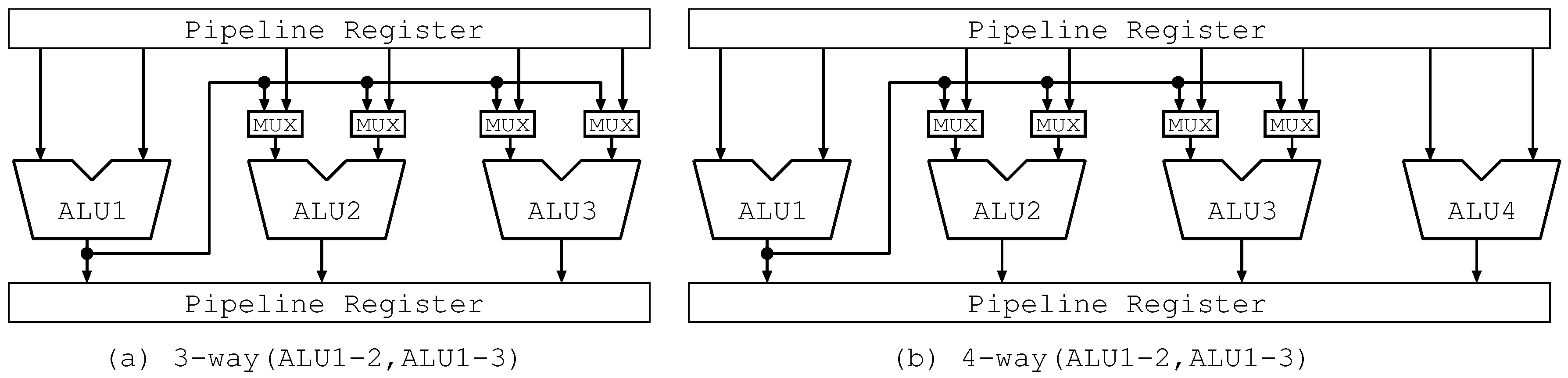
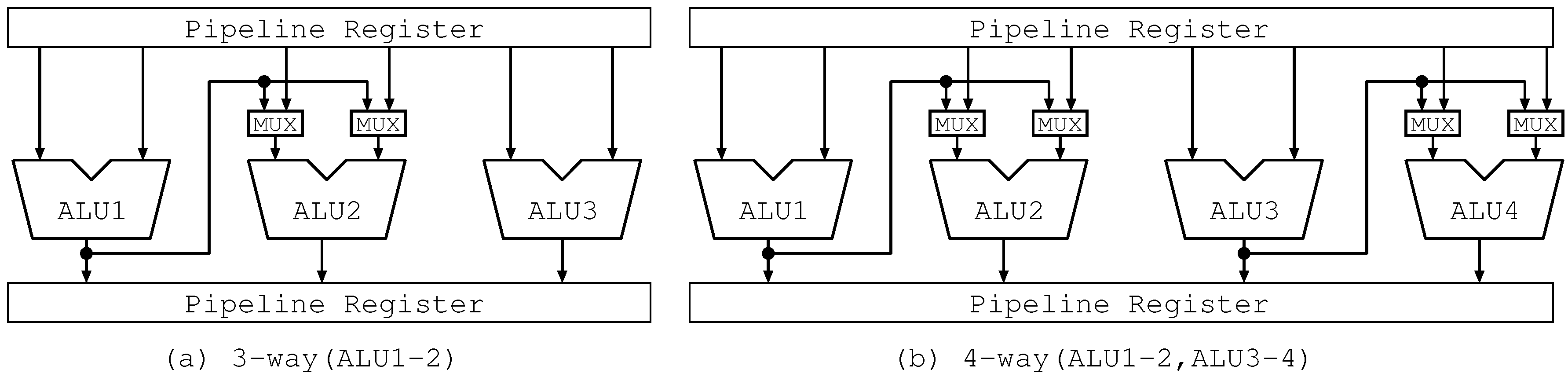
4.2. Hardware Mechanism
4.2.1. Allocation Circuit
- i2 depends on i1The placement is not changed: {i1, i2, and i3}.
- i3 depends on i1It is changed to {i1, i3, and i2}.
- i3 depends on i2It is changed to {i2, i3, and i1}.
- both i2 and i3 depend on i1The replacement is not changed. However, i3 is not issued since there is only one forwarding path.
- i3 depend on both i1 and i2The replacement is not changed. However, i3 is not issued because of the same reason as the above.
- i3 depend on i2 and i2 depends on i1The replacement is not changed. However, i3 is not issued because of the same reason as the above.
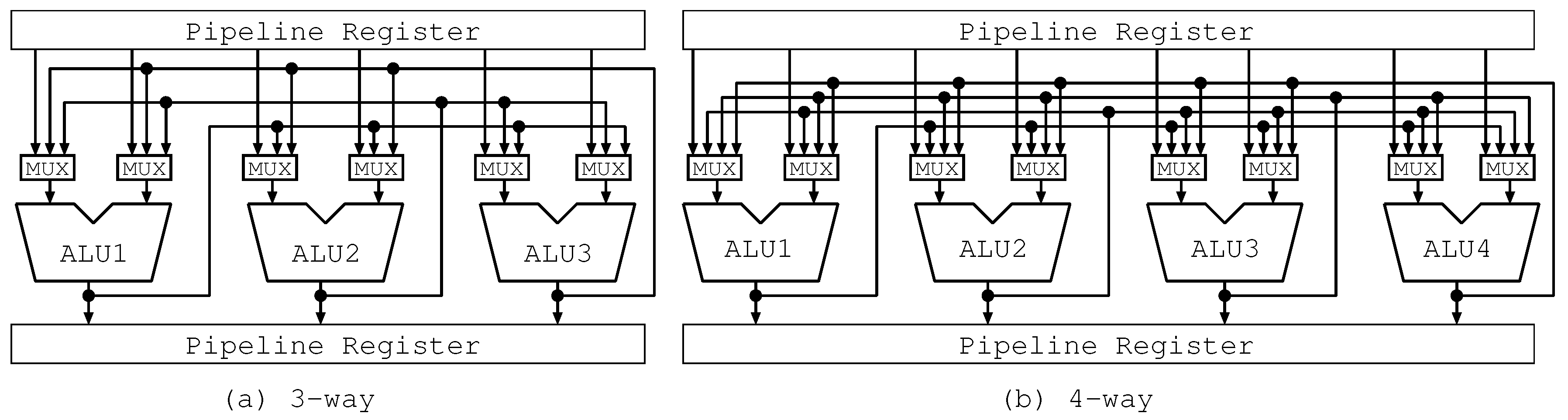
4.2.2. Bypass Circuits
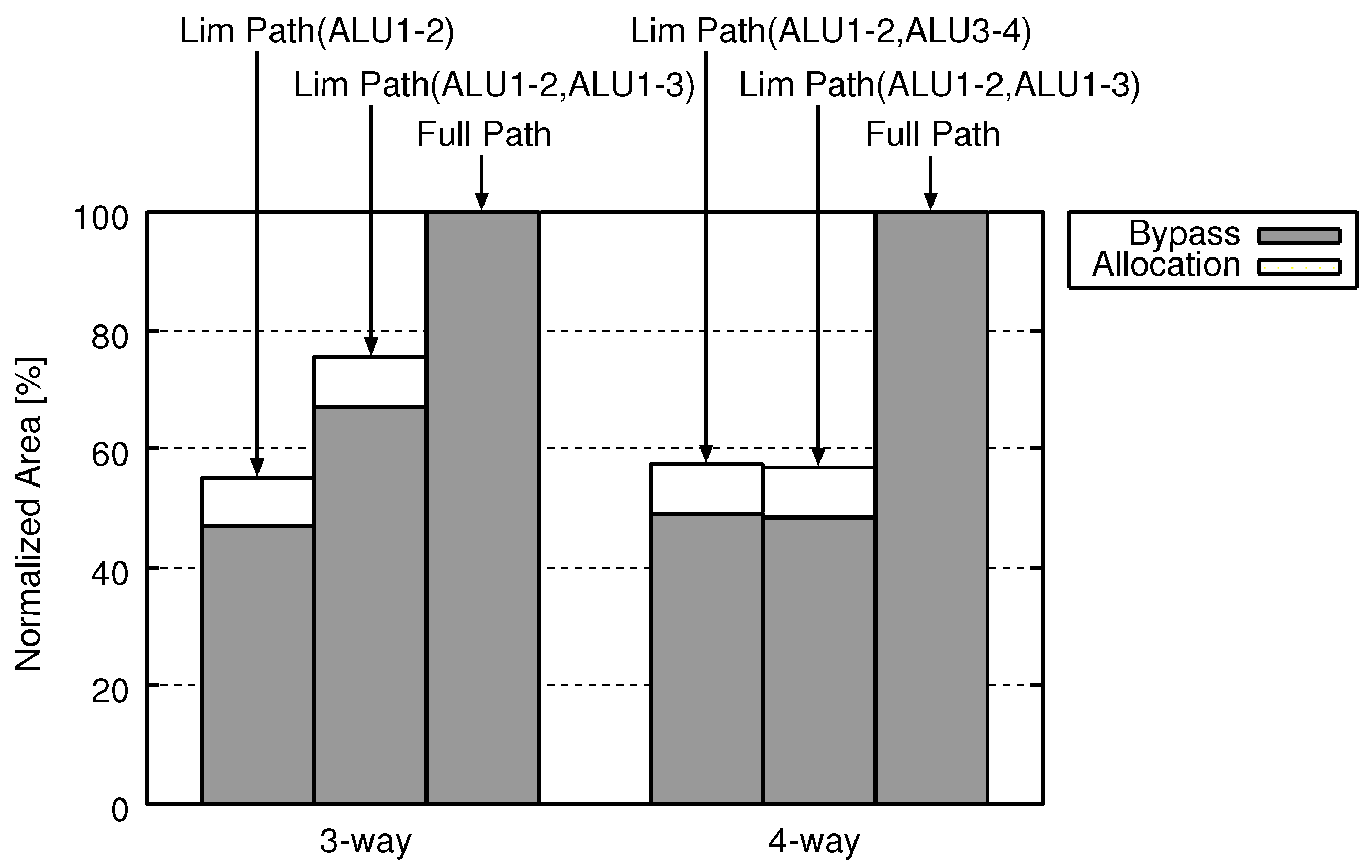
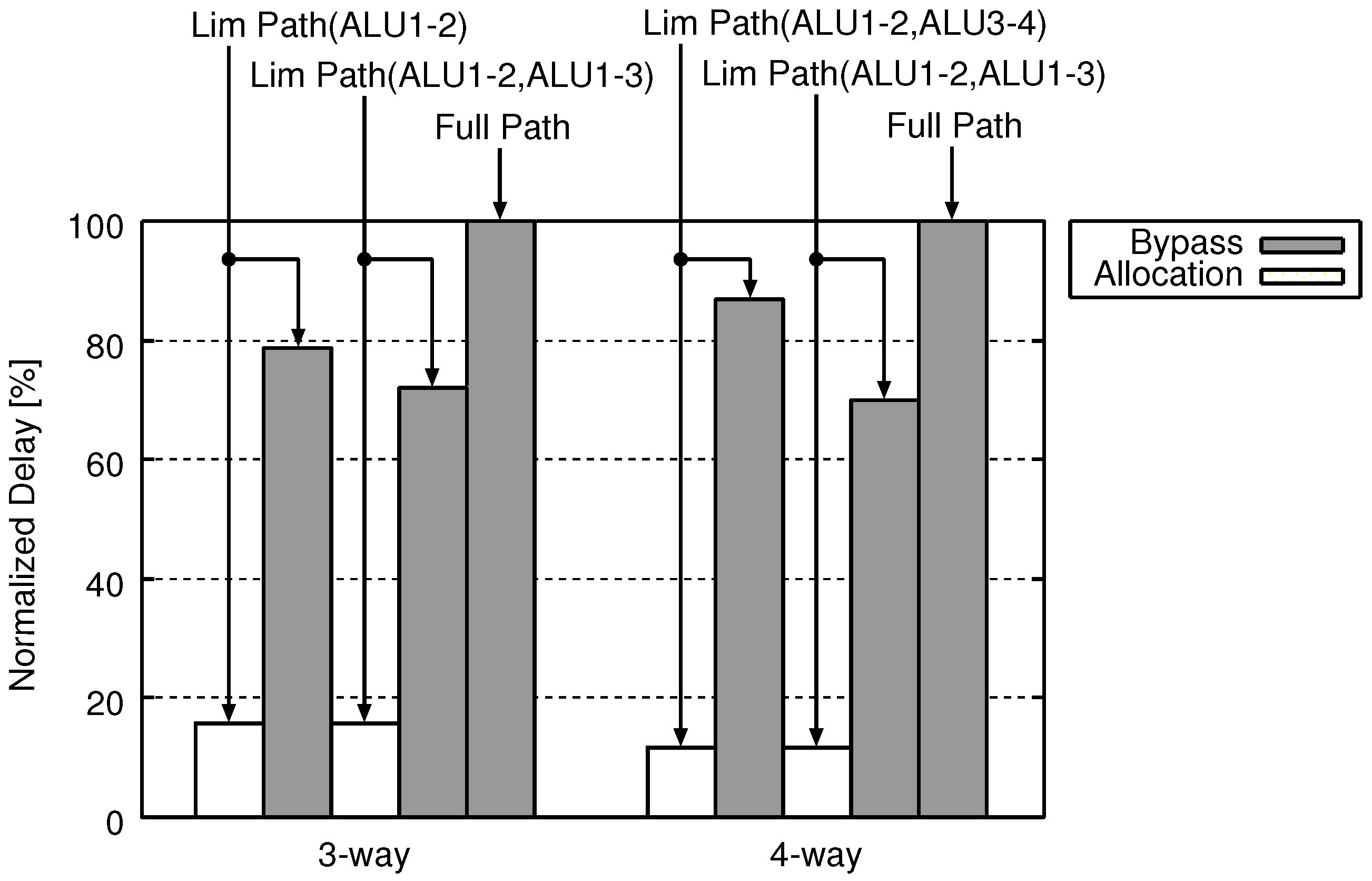
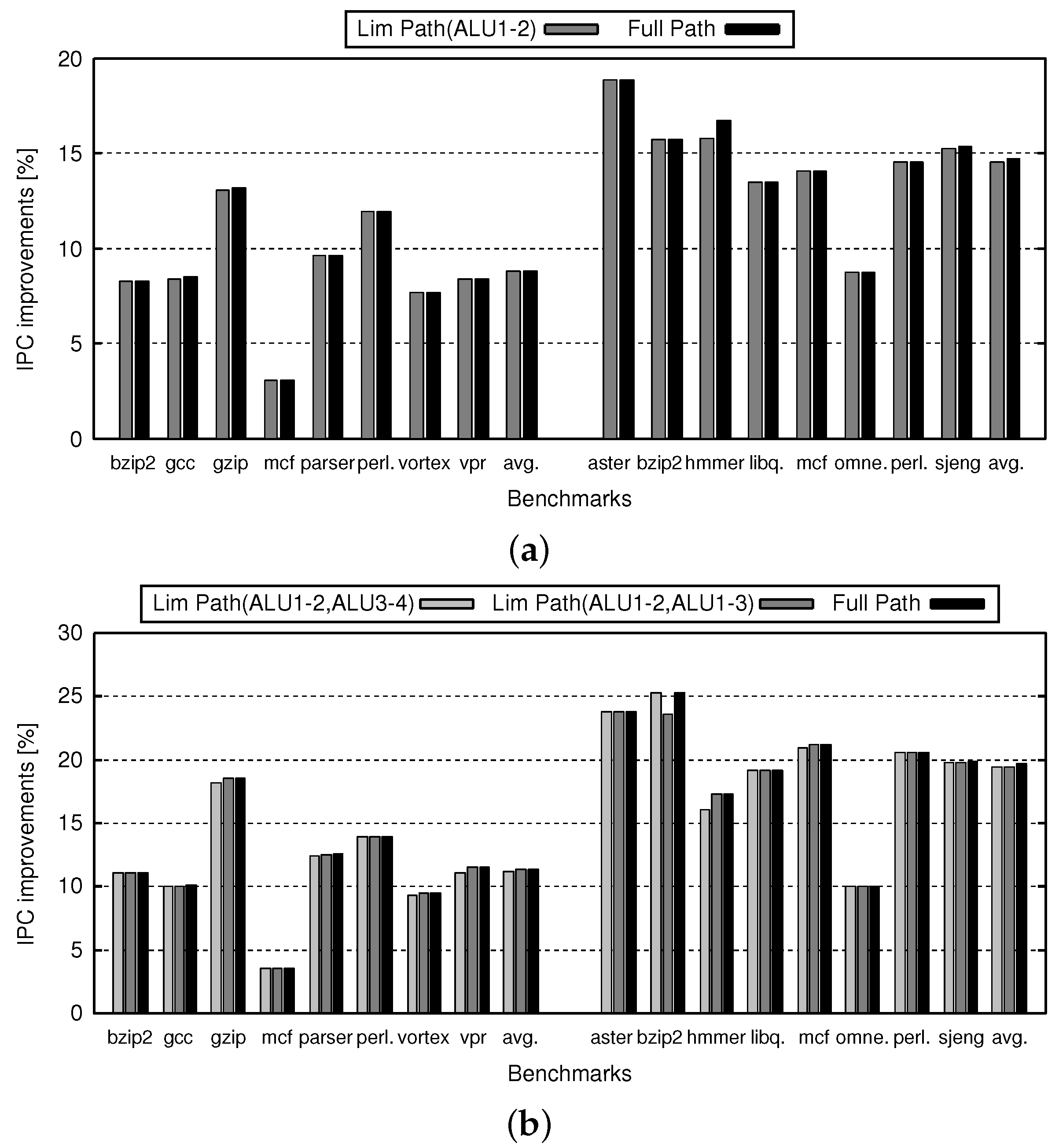
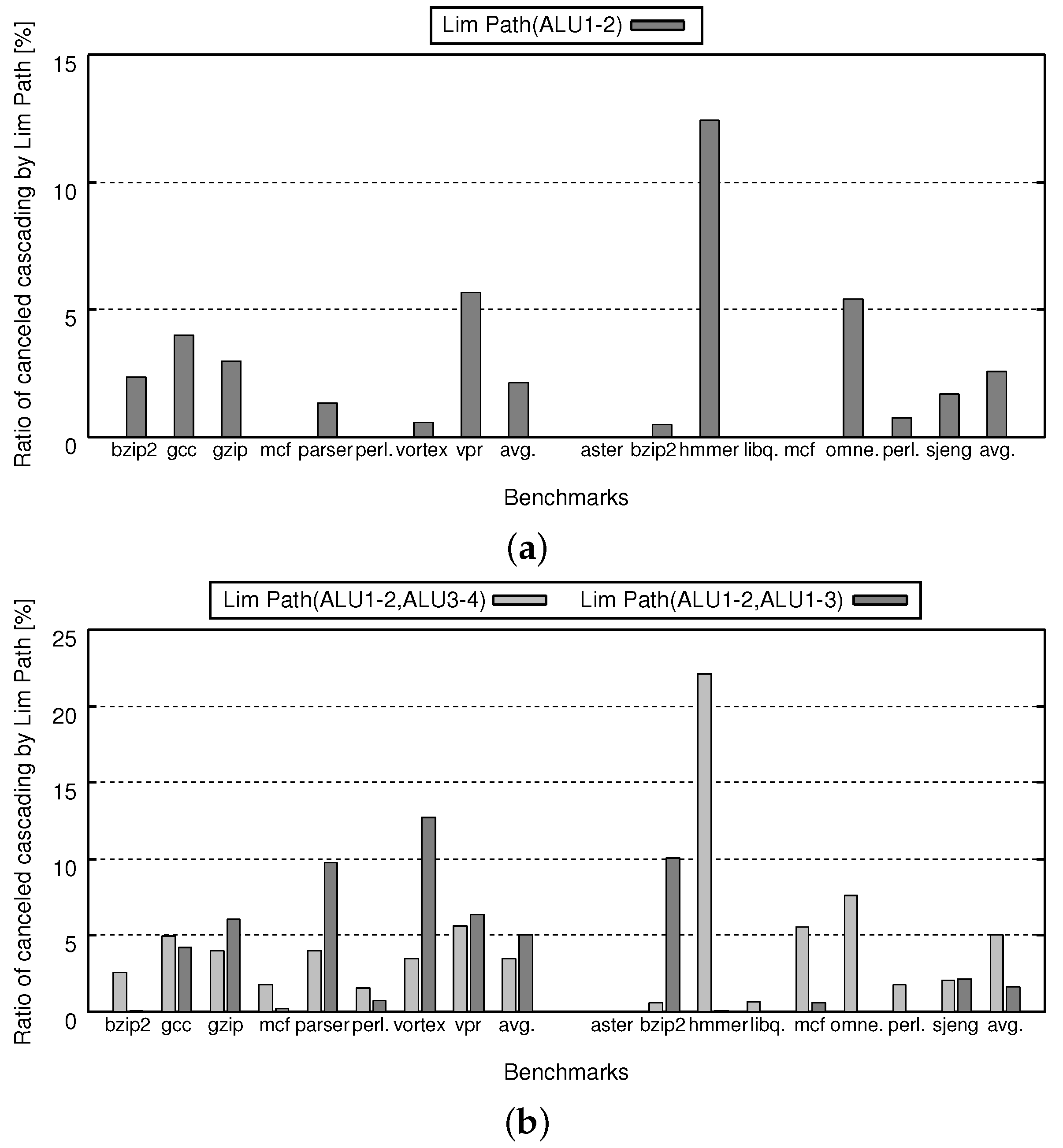
5. Evaluation
5.1. Evaluation Environment
- Area
- Energy
- Delay
- Instructions Per Cycle (IPC) of the core
5.2. Area, Energy, and Delay
- Operating Conditions: typical323
- Wire Load Model Mode: top324
- Global Operating Voltage: 1.8325
- Load for all outputs: 0.02315043326
5.3. IPC
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Intel Corporation. Intel Atom Processor Z3600 and Z3700 Series Datasheet Revision 002; Intel Corporation: Santa Clara, CA, USA, 2014. [Google Scholar]
- ARM Inc. ARM Cortex-A15 MPCore Processor Revision r4p0; ARM Inc.: Cambridge, UK, 2013. [Google Scholar]
- Shimada, H.; Kobayashi, R. Study of Processor Core for Many-core Architecture Combining ALU Cascading and 3-way In-order Execution. IEICE Tech. Rep. 2014, 114, 37–42. (In Japanese) [Google Scholar]
- Suzuki, A.; Kobayashi, R.; Shimada, H. Instruction Rearrangement and Path Limitation for ALU Cascading. In Proceedings of the 2016 International Conference on Advanced Informatics: Concepts, Theory and Application, Computational Science & Engineering, George Town, Malaysia, 16–19 August 2016. [Google Scholar]
- Burger, D.; Austin, T.M. The SimpleScalar Tool Set, Version 2.0; Technical Report CS-TR-97-1342; University of Wisconsin-Madison: Madison, WI, USA, 1997. [Google Scholar]
- Sazeides, Y.; Vassiliadis, S.; Smith, J.E. The Performance Potential of Data Dependence Speculation & Collapsing. In Proceedings of the 29th Annual IEEE/ACM International Symposium on Microarchitecture, Paris, France, 2–4 December 1996; pp. 238–477. [Google Scholar]
- Kise, K.; Katagiri, T.; Honda, H.; Yuba, T. A Super Instruction-Flow Architecture for High Performance and Low-Power Processors. In Proceedings of the Innovative Architecture for Future Generation High-Performance Processors and Systems (IWIA’04), Maui, HI, USA, 12–14 January 2004; pp. 10–19. [Google Scholar]
- Meng, L.; Oyanagi, S. Dynamic RENAME Technique and CHAIN Technique in a Superscalar Processor (Japanese). In Proceedings of the H18 IPSJ Kansai Chapter Convention, Ankleshwar, India, 23–24 September 2006; pp. 207–210. [Google Scholar]
- Watanabe, S.; Hashimoto, M.; Sato, T. ALU Cascading for Improving Timing Yield (Japanese). In Proceedings of the the Annual Symposium on Advanced Computing Systems and Infrastructures SACSIS 2008, Tsukuba, Japan, 11–13 June 2008; pp. 115–122. [Google Scholar]
- Ozawa, M.; Imai, M.; Ueno, Y.; Nakamura, H.; Nanya, T. Performance Evaluation of Cascade ALU Architecture for Asynchronous Super-Scalar Processors. In Proceedings of the Seventh International Symposium on Asynchronous Circuits and Systems, Salt Lake City, UT, USA, 11–14 March 2001; pp. 162–172. [Google Scholar]
- Ozawa, M.; Nakamura, H.; Nanya, T. Cascade ALU Architecture: Preserving Performance Scalability with Power Consumption Suppressed. In Proceedings of the Low-Power and High-Speed Chips (COOL Chips V), Tokyo, Japan, 18–20 April 2002; pp. 171–185. [Google Scholar]
- Sasaki, H.; Kondo, M.; Nakamura, H. Instruction Grouping: Providing an Efficient Execution Using Dependence Information (Japanese). In IPSJ SIG Notes; 2006-ARC-170; Information Processing Society of Japan: Tokyo, Japan, 2006; pp. 73–78. [Google Scholar]
- Kim, I.; Lipasti, M.H. Macro-op Scheduling: Relaxing Scheduling Loop Constraints. In Proceedings of the 36th Annual IEEE/ACM International Symposium on Microarchitecture, San Diego, CA, USA, 5 December 2003; pp. 277–290. [Google Scholar]
- Hu, S.; Kim, I.; Lipasti, M.H.; Smith, J.E. An Approach for Implementing Efficient Superscalar CISC Processors. In Proceedings of the The Twelfth International Symposium on High-Performance Computer Architecture, Austin, TX, USA, 11–15 February 2006; pp. 41–42. [Google Scholar]
- Yao, J.; Ogata, K.; Shimada, H.; Miwa, S.; Nakashima, H.; Tomita, S. An Instruction Scheduler for Dynamic ALU Cascading Adoption. IPSJ Trans. Adv. Comput. Syst. 2009, 2, 30–47. [Google Scholar] [CrossRef]
- Amrutur, B.; Mehta, N.; Dwivedi, S.; Gupte, A. A Practical Framework to Study Low-Power Scheduling Algorithms on Real-Time and Embedded Systems. J. Low Power Electron. Appl. 2011, 4, 261–276. [Google Scholar] [CrossRef]
- Lin, J.; Albert, M.K.; Song, W. Performance Evaluation of Cascade ALU Architecture for Asynchronous Super-Scalar Processors. J. Low Power Electron. Appl. 2014, 1, 90–109. [Google Scholar] [CrossRef]
- Patterson, D.A.; Hennessy, J.L. Computer Organization And Design: The Hardware/Software Interface, 4th ed.; Morgan Kaufmann Publishers, Inc.: Burlington, MA, USA, 2008. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Execution Width | 3, 4-way |
| Data Width | 64-bit |
| Chain Depth | 1-chain |
| Chain Width | 1, 2 |
| Fetch Width | n instruction/cycle |
| Decode Width | n instruction/cycle |
| Issue Width | n instruction/cycle |
| Commit Width | n instruction/cycle |
| Functional Unit | n iALU, 2 iMULT/DIV, n fpALU, |
| 2 fpMULT/DIV/SQRT | |
| L1 I-cache | 32KB, 8 way, 32 byte cache line, |
| 2 cycle hit latency, | |
| L1 D-cache | 32KB, 8 way, 32 byte cache line, |
| 2 cycle hit latency | |
| L2 cache | 1MB, 16 way, 64 byte cache line, |
| 12 cycle hit latency | |
| Main memory | 8 byte/cycle band width, |
| 72 cycle first hit latency, | |
| 1 cycle burst interval | |
| L1 I-TLB | 32 entry, 4 way, 4KB page, |
| 80 cycle first hit latency | |
| L1 D-TLB | 64 entry, 4 way, 4KB page, |
| 80 cycle first hit latency | |
| Branch predictor | gshare (13 bit history, 32K entry PHT), |
| 4096 entry BTB, 32 entry RAS, | |
| 7 cycle miss penalty |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kobayashi, R.; Suzuki, A.; Shimada, H. Forwarding Path Limitation and Instruction Allocation for In-Order Processor with ALU Cascading. J. Low Power Electron. Appl. 2017, 7, 32. https://doi.org/10.3390/jlpea7040032
Kobayashi R, Suzuki A, Shimada H. Forwarding Path Limitation and Instruction Allocation for In-Order Processor with ALU Cascading. Journal of Low Power Electronics and Applications. 2017; 7(4):32. https://doi.org/10.3390/jlpea7040032
Chicago/Turabian StyleKobayashi, Ryotaro, Anri Suzuki, and Hajime Shimada. 2017. "Forwarding Path Limitation and Instruction Allocation for In-Order Processor with ALU Cascading" Journal of Low Power Electronics and Applications 7, no. 4: 32. https://doi.org/10.3390/jlpea7040032
APA StyleKobayashi, R., Suzuki, A., & Shimada, H. (2017). Forwarding Path Limitation and Instruction Allocation for In-Order Processor with ALU Cascading. Journal of Low Power Electronics and Applications, 7(4), 32. https://doi.org/10.3390/jlpea7040032