In this section, we present several experiments to study the effect of vectorization on data reuse transformations. We implement ten different variants of the ME kernel following the data reuse transformation techniques illustrated in
Figure 6. The experiment names reflect the different copy-candidates (
through
) in
Figure 6. The kernels are implemented in C++ using SSE, AVX2 and AVX512 intrinsics. The ten variants are:
Scalar_E0: Implementation of the ME kernel (Algorithm 1) without any of the optimization techniques covered in this study (i.e., no data reuse transformations or vectorization). This sequential implementation is the baseline to which we make a comparative study of different kernel implementations.
Scalar_E1: Non-vectorized ME kernel with data reuse transformation using the n × n copy-candidate.
Scalar_E2: Non-vectorized ME kernel with data reuse transformation using the × copy-candidate.
Scalar_E3: Non-vectorized ME kernel with data reuse transformation using the × and n × n copy-candidates.
SSE_E0: SSE-vectorized ME kernel without any data reuse transformations.
SSE_E2: SSE-vectorized ME kernel with data reuse transformation using the × copy-candidate.
AVX2_E0: AVX2-vectorized ME kernel without any data reuse transformations.
AVX2_E2: AVX2-vectorized ME kernel with data reuse transformation using the × copy-candidate.
AVX512_E0: AVX512-vectorized ME kernel without any data reuse transformations.
AVX512_E2: AVX512-vectorized ME kernel with data reuse transformation using the ( × copy-candidate.
5.1. Test System Architecture
This subsection describes the platforms used in our evaluation. It is important to note that since we conduct our experiment on multi- and many-core systems with a memory hierarchy of fixed sized cache-blocks, the copy-candidates are mapped into system caches according to their sizes (
Table 2).
5.1.1. Intel® CoreTM CPUs
In our experiments, we have used the Intel
® Core
TM i7-4700K (Haswell) and i7-2600K (Sandy Bridge) processors consisting of four physical cores. Both support Hyper-Threading (HT), which allows the CPU to simultaneously process up to eight threads (i.e., two threads per core). The memory hierarchy consists of a 32-KB Level-1 cache, a 256-KB Level-2 cache and a 8192-KB Level-3 cache. Level-1 and Level-2 caches are private to each core, while the Level-3 cache is shared among the cores. Note that this is a memory hierarchy with a fixed number of levels and sizes, typical for a standard processor. This is different from the assumption in [
6], where an application-specific memory hierarchy is assumed. The base clock speeds of the processors are 3.5 GHz and 3.4 GHz, respectively, but it can go as high as 3.9 GHz when Turbo Boost is enabled [
27]. However, we disabled dynamic frequency scaling (SpeedStep and Turbo Boost) to get more stable results from the experiments. The systems run under Ubuntu 14.04.3 LTS. All of the kernels are compiled using Intel C++ compiler (ICC Version 14.0.1) with the -O2 option.
5.1.2. Intel Xeon Phi Processor
Xeon Phi: Knights Landing (KNL) is the second revision of Intel’s Many Integrated Core Architecture (MIC). Many-core architectures offer a high number of cores (68 in our evaluation platform) with up to four threads per core and a potential peak performance close to 6 Tflops for single precision floating point. These cores are based on the Silvermont Atom architecture. Cores are out of order and tiled in pairs. Each core contains two Vector Processing Units (VPUs), which work with vector registers up to 512 bits wide. The VPUs are compatible with SSE, AVX/AVX2 and AVX512.
Each tile in the processor shares 1 MB of L2 memory, using a 2D mesh interconnect (or NOC (Network On Chip)) for communication. This interconnect also links the tiles to two DDR4 memory controllers, with a capacity of up to 384 GB and a bandwidth of 90 GB/s. In addition, some KNL models feature a High Bandwidth Memory Multi-Channel DRAM (HBM-MCDRAM), which is accessed using the NOC. This memory is divided into eight stacks, adding up to 16 GB of capacity, and has a bandwidth close to 400 GB/s. The HBM memory can work in different modes, as a scratchpad memory, as an additional cache level or in hybrid mode (combination of the previous two modes).
Our evaluated Xeon Phi platform is based on the Xeon Phi 7250 processor. This processor features 68 cores running at 1.40 GHz. The system runs SUSE Linux Enterprise Server 12 SP1, and the binaries are generated using Intel C++ compiler (Version 17.0.035) with the -O2 optimization level and the -xMIC-AVX512 flag to generate AVX512 code. The devices are configured to work in cache mode, where the HBM acts as an L3.
5.2. Metrics Used for Analysis
We use execution time (in micro-seconds) as the metric for performance evaluation. To estimate on-chip energy consumption, we read the Model-Specific Registers (MSRs) that provide energy measurements for the cores in Haswell and Sandy Bridge [
27], since package measurements include the integrated GPU power, and we are not interested in that. For KNL, we measure the whole package energy (including core power and DRAM controller traffic), since the core energy counter is not available in our pre-production system. In addition, we have not found any accurate description of what the DRAM controller actually measures as the measurements might include memory controller and caches, or the accesses to the DDR modules (it should not, since manufacturers can have any brand/technology attached to the system and dissipate different power). We decided to go for the isolated core energy (PP0 i.e. Power-Plane 0) and Package energy (PKG) since both are properly defined. These counters can be accessed either by the RAPL (Running Average Power Limit ) interface (root-level) or the powercap interface (user-level). We report both core/package-energy consumption and Energy Delay Product (EDP:
Joule × Second) [
30,
31] to perform energy efficiency analysis. For both, lower values corresponds to better energy efficiency. Speedup, relative on-chip energy and relative EDP at a certain frequency are all computed with respect to the baseline kernel (
Scalar_E0). The PAPI (Performance Application Programming Interface) [
32] is used to track cache- and memory-related events.
5.3. Performance Analysis on the Haswell and Sandy Bridge Platforms
In the first set of experiments, our goal is to gain insight into the effects of vectorization on data reuse transformations.
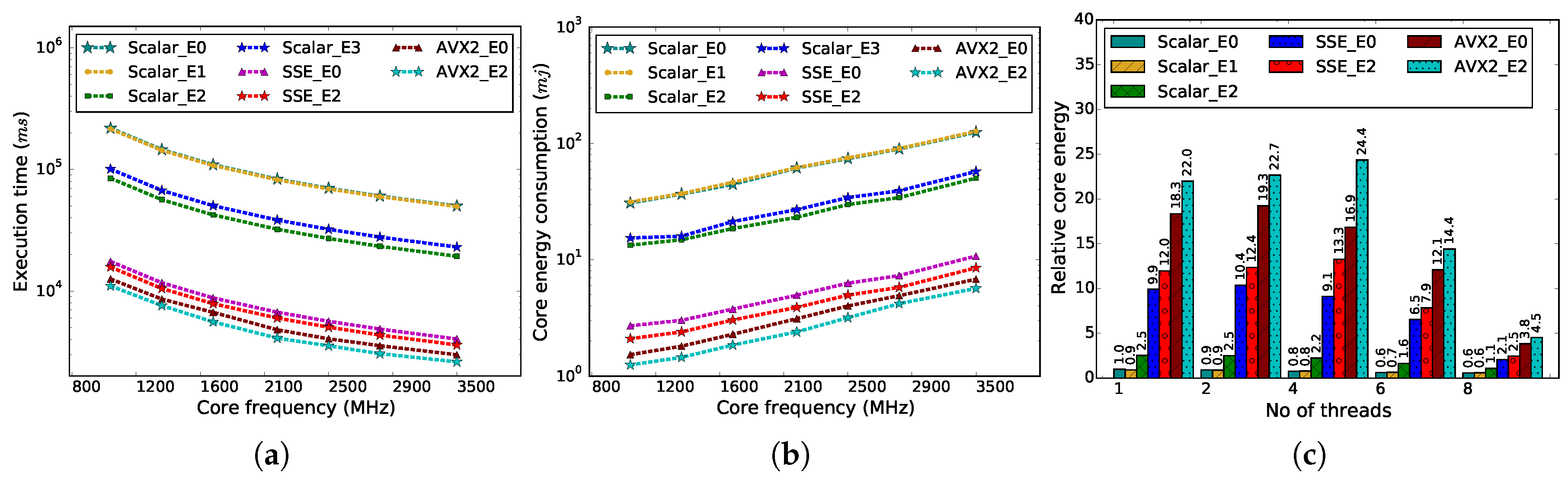
Figure 3a compares the performance of different kernel implementations at different core frequencies on the Haswell platform.
In
Figure 3a, we observe a linear impact of core frequency on the performance of the implemented kernels. The kernel execution time decreases with increasing core frequency. The figure also confirms that the performance of the kernel can be improved by using data reuse transformation techniques despite the overhead of copying the copy-candidates into the buffers. Among the three different data reuse transformation techniques (E1, E2 and E3), E2 appeared to be more effective than the other two transformations, and it (i.e., Scalar_E2) provides more than a two-fold performance gain over the unoptimized (i.e., Scalar_E0) solution when integrated with the scalar ME kernel in a single core on the Haswell system. This improvement is attributed to the use of a smaller block size, since a block of
×
unsigned-characters corresponds to 2209 (47 × 47 ×1) bytes, which is less than the Level-1 cache size in our system. Therefore, a full block is brought into the Level-1 cache during computation, which significantly reduces the cost of expensive memory accesses. This cost reduction is evident in the data presented in
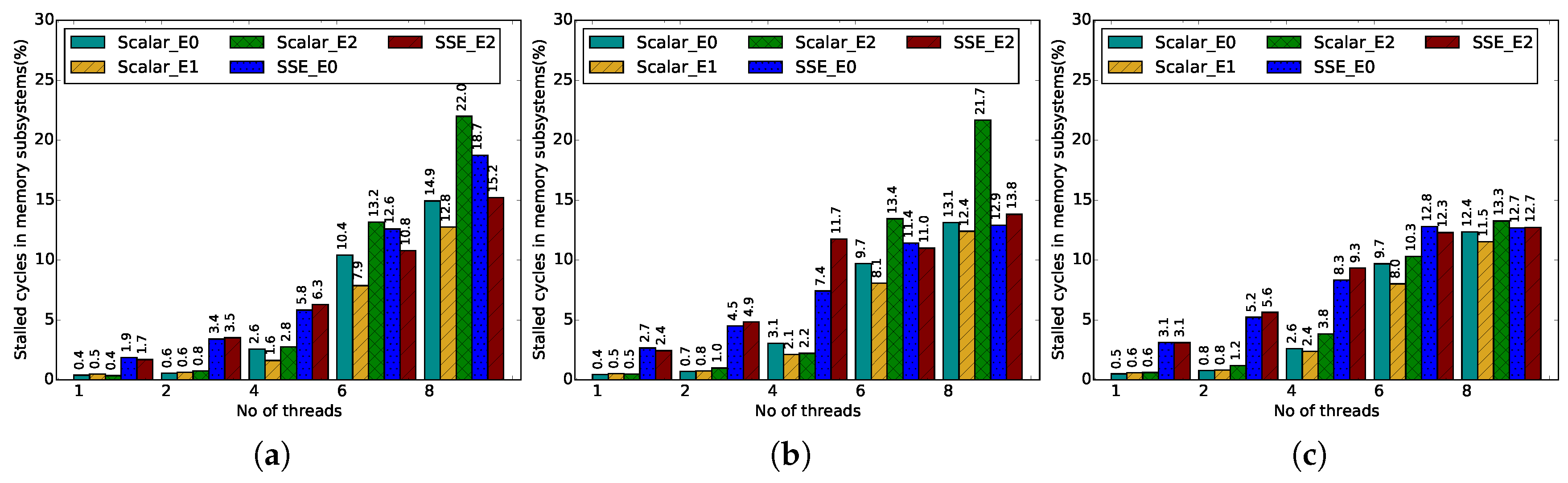
Table 3, as the total number of stalled CPU cycles on memory subsystems is reduced to one third of the stalled cycles for Scalar_E0. It is also interesting to note that the L1D/L2 cache miss rate for SIMD computations is much higher than the scalar computations, and the cache miss rates increase as the width of SIMD register increases. This observation leaves us room for further optimization, particularly for the systems with wider SIMD registers, such as Scalable Vector Extensions (SVE) [
33], which are designed to support up to 2048-bit registers.
Now, comparing the performance of the vectorized kernels with the scalar kernels, the vectorized kernels clearly outperform the scalar kernels by a significant margin (≈10× and ≈17× for SSE and AVX2, respectively). This performance improvement is expected as SIMD computation provides two-fold benefits in this circumstance. First, it reduces the number of instructions needed to be executed for completing the task by simultaneously processing multiple data points using the vector registers. Since the SSE registers are 128-bit wide, SSE-based SIMD computations can process up to 16 unsigned characters (8-bit) at a time. Therefore, we can potentially achieve 16× performance speedup using SSE-based vectorization in the ME kernel. However, due to the inherent complexity of the algorithm (e.g., 8-bit values need to be converted into 32-bit values to continue further computations), we ended up with ≈10× speedup for
SSE_E0 over
Scalar_E0. Similarly, using 256-bit SIMD registers for AVX2-based computations, we have achieved speedup ≈17× for
AVX2_E0 over
Scalar_E0. This speedup is shown in
Figure 4, and the reduction of instruction counts are presented in
Table 3. Second, the SIMD computation also reduces the required number of cache/memory accesses by simultaneously loading/storing multiple data points using a single load/store operation. This can eventually reduce the CPU waiting time for the memory subsystems and improve the overall system’s performance. On the other hand, for bandwidth-bound applications, the increased bandwidth demand caused by the SIMD computations can limit the potential performance improvements if the memory subsystem cannot sustain such demand. Indeed, the data presented in
Table 3 shows that the absolute number of stalled CPU cycles on the memory system for the vectorized ME kernels is reduced, but represents a higher percentage of the overall execution (estimated to be
Figure 5).
Another important observation is the fact that the impact of data reuse transformation is greater for the performance of the scalar ME than for the vectorized ME. As shown in
Figure 4, the data reuse transformations provide two-fold performance gain as we move from E0 to E2 optimizations for the scalar ME kernel. However, with the vectorized ME, the performance is improved by only 10% to 15% on the Haswell system. Three factors can contribute to this limited improvement. First, the total number of memory accesses is greatly reduced by the vectorized computations (e.g., ≈10× less number of memory accesses for SSE). Second, the copy-candidate sizes can also be affected by the length of the vector register and may increase the overhead of copying the data into the buffer. Finally, the relative stalled CPU cycles on the memory subsystems are increased due to the increased bandwidth demands of SIMD computations, which can be clearly seen in
Figure 5.
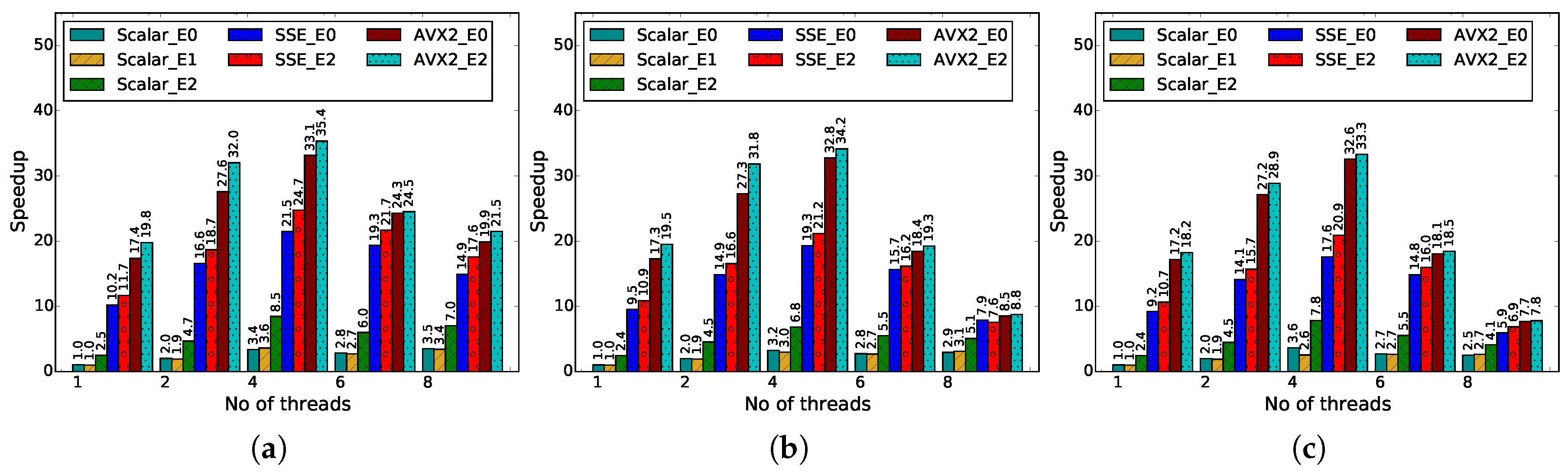
Figure 4 and
Table 4 present the multithreaded performance of different kernel implementations at different core frequencies. From the figure, we can observe that the performance of all of the kernels increases with the increasing number of threads as long as only one thread runs on a given physical-core.
AVX2_E2 provides the best performance in all cases and can provide speedup up to 34× on the Haswell system over the unoptimized scalar kernel (
SSE_E0) when four threads are used. However, beyond four threads, when hyper-threading is used, the performance is degraded. This performance is less than what we could potentially achieve with the combination of multithreading (≈4×), vectorization (≈16× using SSE and ≈32× using AVX2 for an 8-bit value) and data reuse transformations.
In summary, based on our observation, we can conclude that vectorization accelerates the performance of the motion estimation kernel by reducing the total number of instructions and memory accesses through data parallelization. On top of that, data reuse transformations reduce expensive memory accesses to upper cache levels, by improving locality on lower levels. When combined with vectorization, data reuse transformation helps to keep the amount of stalled cycles due to memory accesses low, despite the extra pressure on the memory system. Finally, thread-level parallelism provides further performance improvements on multi-core platforms regardless of the frequency, as long as physical cores are used.
5.4. Energy Efficiency Analysis on the Haswell and Sandy Bridge Platforms
In this section, we present the implications of different strategies on improving the energy efficiency.
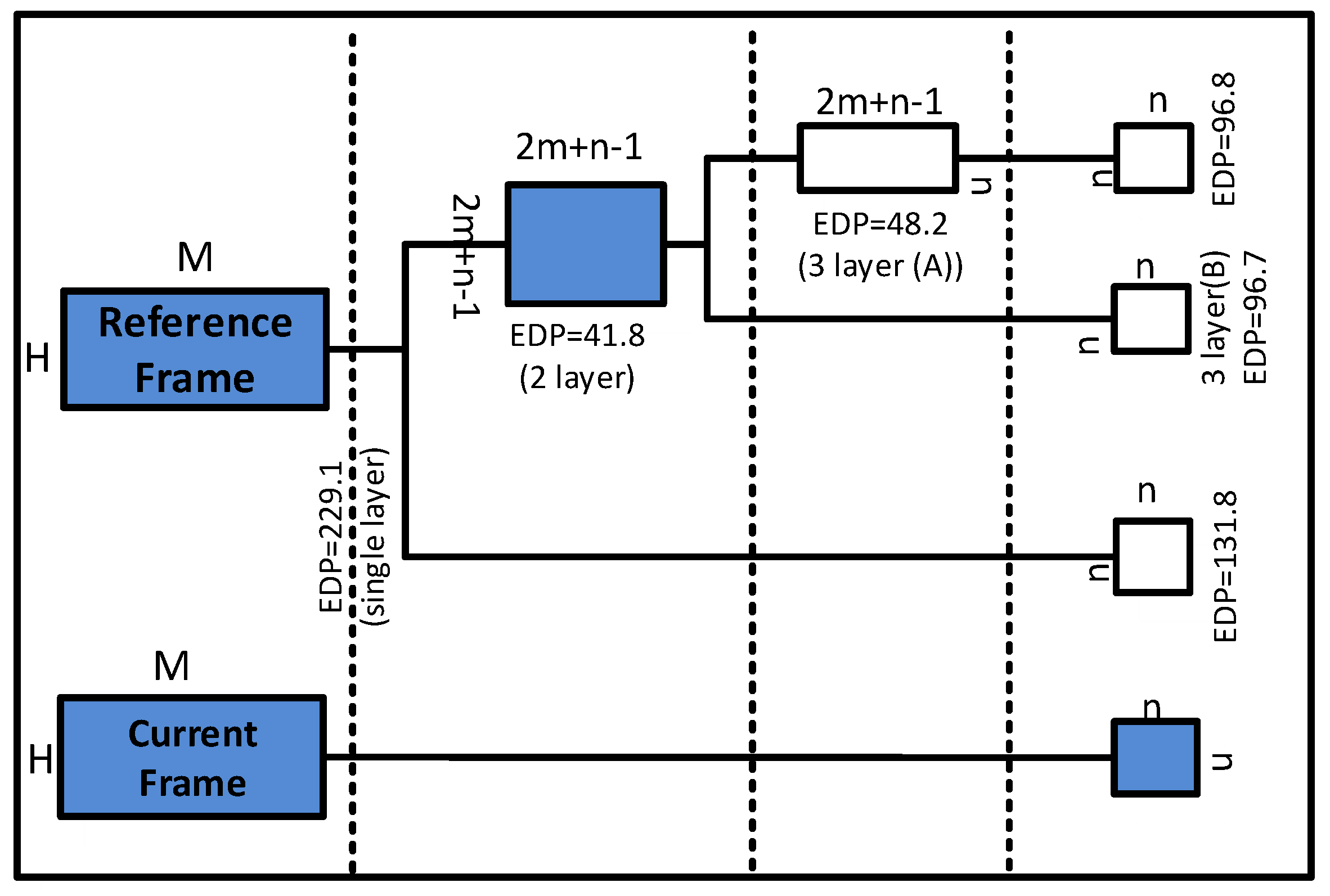
Figure 6 presents the EDP measurements on the Sandy Bridge system for the different data reuse transformation options presented in
Figure 2 for a sequential ME kernel.
Figure 6.
Energy-efficiency optimization using different possible data-reuse transformations on the Sandy Bridge system.
Figure 6.
Energy-efficiency optimization using different possible data-reuse transformations on the Sandy Bridge system.
The use of data reuse transformations in the motion estimation kernel reduces the accesses to the larger memories in the memory hierarchy. Therefore, it is expected that the kernels with data reuse transformations consume less energy than the unoptimized kernels. Indeed,
Figure 6 shows a significant improvement in energy efficiency due to the data-reuse transformation techniques. The core energy consumption of the sequential motion estimation kernel is reduced to one-third of its original energy consumption by the deployment of data reuse transformations (in
Table 5). In terms of the energy-delay product, the EDP of
Scalar_E0 is 5224.4 Js
, whereas the EDP of the
Scalar_E2 kernel that uses an additional memory hierarchy of block size
×
is 608.8 Js
, which is an ≈9× improvement in energy efficiency in terms of EDP.
An important observation from
Figure 6 is that the efficiency peaks with a two-layer memory hierarchy of
×
block memory and degrades with the introduction of any additional layers of smaller memory blocks. Two factors that can contribute to this result are: (i) data-reuse transformations generally make the code more complex and increase the code size; (ii) due to fixed-size caches, smaller data blocks are mapped to relatively larger cache blocks, which negate the advantage of using additional memory layers.
On the Haswell system, we also see that relative EDP measurements are improved by the data-reuse transformations techniques.
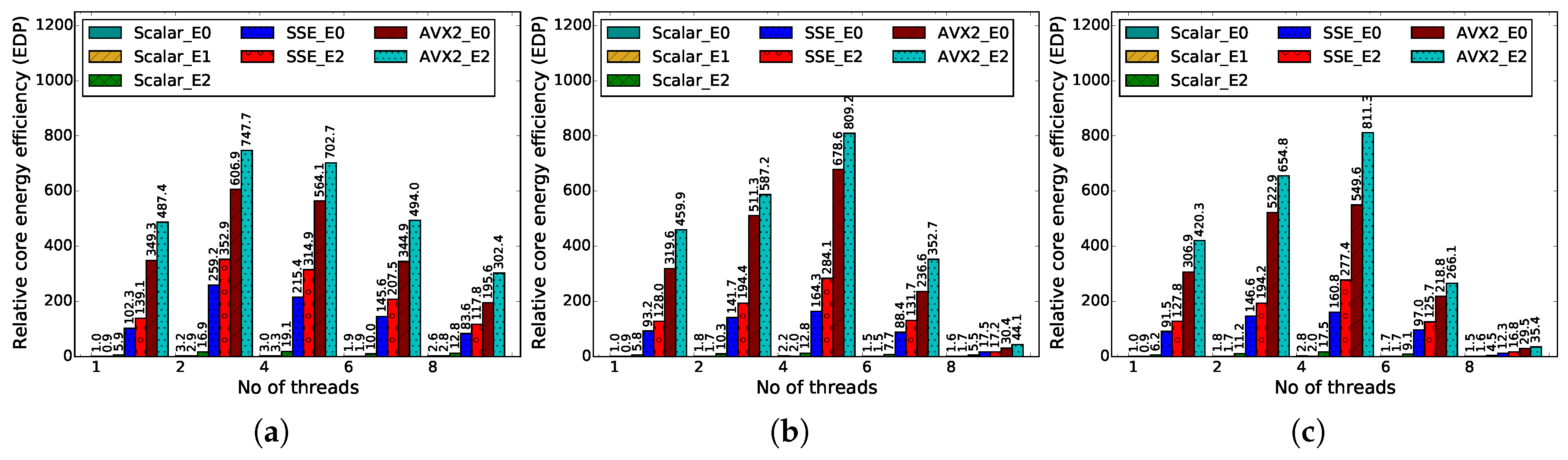
Figure 7 illustrates that both parallelization and vectorization improve the energy efficiency in terms of EDP for the optimized (that exploits the data-reuse transformation methodology), as well as the unoptimized ME kernels (that does not use data-reuse transformations). Among the different possible ME kernels,
AVX2_E2 consumes the least amount of core energy (shown in
Figure 3b), and the relative EDP values are improved rapidly with increasing number of threads and reach the maximum value when the total number of threads is four (in
Figure 7). However, once the number of threads exceeds four, relative EDP begins to decline.
It is also interesting to note that the multithreaded parallelization of the motion estimation kernel does not lead to core-energy savings despite the reduction in execution time due to parallelization at a peak core frequency on the Haswell system. This is an expected behavior if proper power saving mechanisms are in place, meaning that idle cores go into low power mode and do not contribute significantly to the total energy consumed during the application run. This is illustrated in
Figure 3c. In contrast, vectorization results in quite a significant amount of core energy savings for the motion estimation kernel. This is due to several reasons. First, Intel processors do not have a separate vector unit or separate vector registers. This translates into a small increase in the power dissipated by the ALUs/register bank working with SIMD instructions instead of scalar. In fact, GCC/ICC compilers no longer generate the scalar assembly, but rather SIMD instructions working only with the lowest vector lane. In addition, when working with vectors, the system spends more idle waiting time for memory, and therefore, cores can go into low power mode more often. This demonstrates that vectorization can lead to significant core energy savings if they can be applied effectively.
Table 5 gives a summary of our results for the Sandy Bridge platform. They show that data reuse transformations significantly improve the energy efficiency of the ME algorithm. The Relative EDP column in the table presents EDP values of different approaches normalized with respect to the EDP value of optimized parallel ME kernel. Relative EDP values indicate that the best energy efficiency can be achieved by using the parallel-optimized solution. Compared to the optimized serial solution (
Scalar_E2), the parallel optimized solution (
Parallel_E2) gives 3× better EDP, and the serial unoptimized solution (
Scalar_E0) provides 28× higher EDP.
5.5. Performance and Energy Efficiency Analysis on the KNL Coprocessor
In our last set of experiments, we study the same problem in the many-core context. To this end, the best performing transformation options (
E2 kernels) are chosen along with the baseline (
E0) to carry out scalability tests on the Intel Xeop Phi Co-processor (KNL). However, unlike the experiments done on the multi-core platforms, experiments on the KNL platform deal with full HD frames (1920 × 1080) as an input rather than the QCIF format.
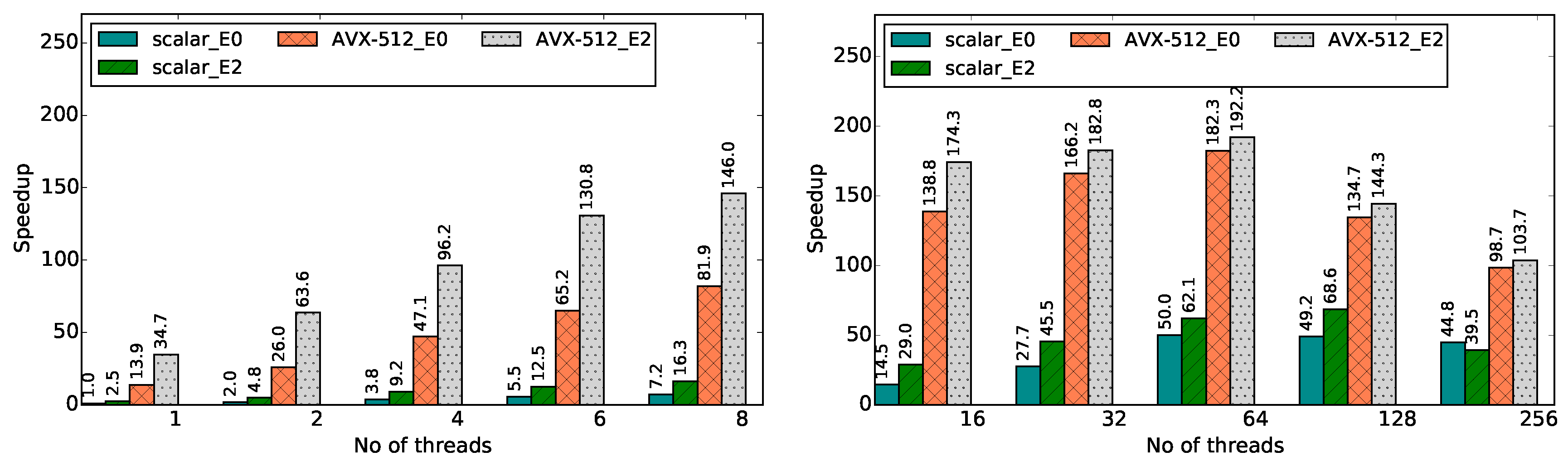
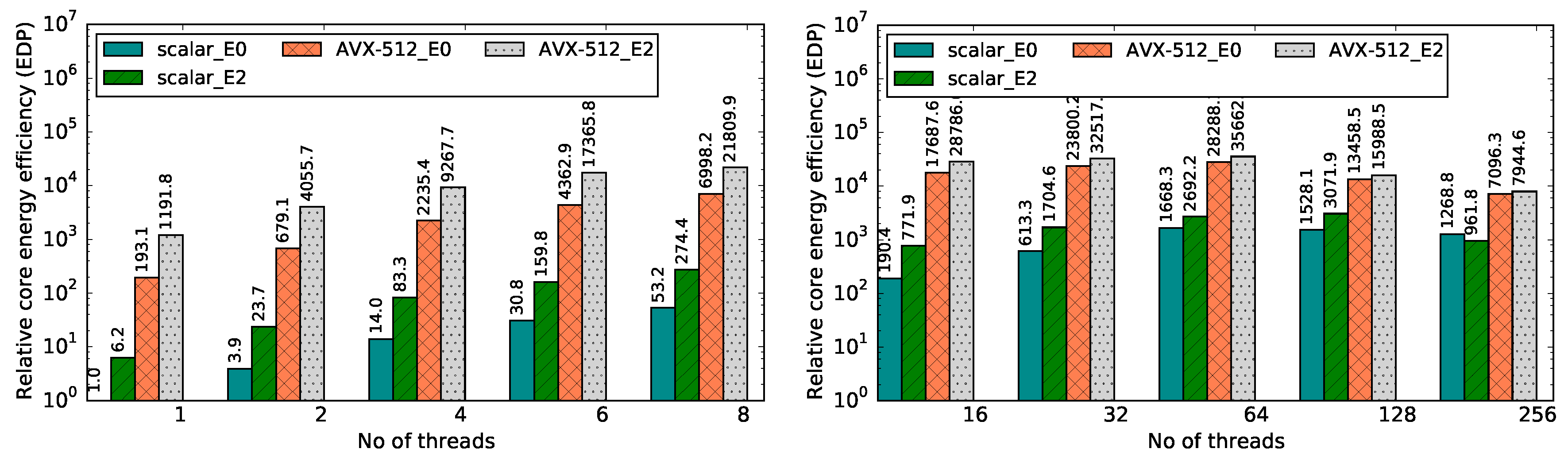
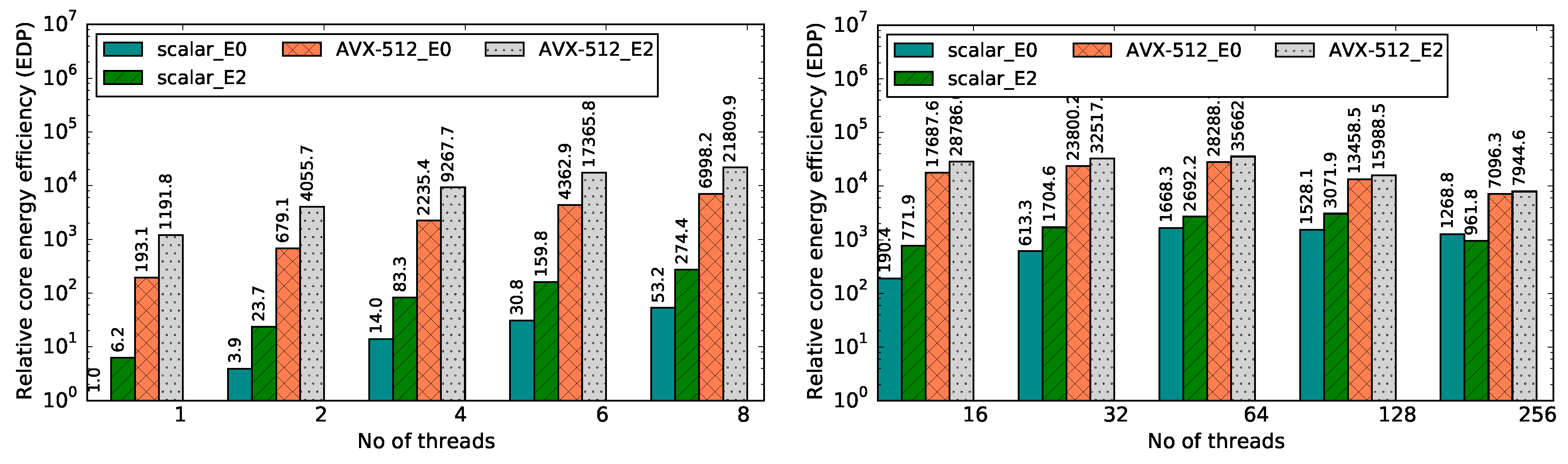
Figure 8 and
Figure 9 present improvements for the speedup and energy efficiency metrics that can be achieved through the optimized kernels when run on up to 256 threads on KNL (64 cores running four threads each; the rest of the cores are reserved to manage the operating system). In
Figure 8, observations on the single core performance highlight two interesting aspects of the kernels being investigated. First,
Scalar_E0 (i.e., unoptimized) and
Scalar_E2 (i.e., optimized using data reuse transformations) kernels exhibit ≈3× performance increase, which is similar to what was observed on the Haswell system. Therefore, we can conclude that the data reuse transformations on a single core in a KNL coprocessor are as effective as the transformations on a single core in the Haswell system. Second, once again, the performance difference between a non-vectorized and vectorized kernel is quite significant; for example, the single-threaded
AVX512_E2) kernel is ≈35× faster than the single-threaded (
Scalar_E0) kernel on the Haswell system (
Figure 4c). Third, a significant amount of performance improvement can be observed by the deployment of data reuse transformations in conjunction with the AVX512 vectorization technique. Particularly for lower number of threads (i.e., <8),
AVX512_E2 provides ≈2× better performance than
AVX512_E0. Furthermore, we can also observe that the performance is increased with the increasing number of threads until it passes 64 threads and simultaneous multithreading takes place.
In terms of energy efficiency, we have also achieved improved results as shown in
Figure 9. This metric is also scalable across multiple threads as long as only one thread runs per core. The energy efficiency improvements on the KNL platform are much larger than for the Haswell platform, which may seem surprising. The governor for our KNL system is set to performance, and it will therefore never throttle the core frequency down. In addition, there is probably not enough time to disable cores. According to Intel, it takes around one minute for an idle KNL core to go completely offline. On low core count, the OS may be jumping/sending system processes to different cores, so none will ever go offline. At best, the OS could use DVFS (Dynamic voltage and frequency scaling) to reduce core frequency, but our governor prevents this. Since we do not have root access, we cannot test shield cores (prevent scheduling of OS processes into specific cores), nor bind all OS processes into a single core, nor change the governor. Nevertheless, this would be the common case for most end users.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}