
Stochastic-Based Spin-Programmable Gate Array with Emerging MTJ Device Technology

Abstract
:
1. Introduction
- We invented a new curve-based method to reinterpret and redefine Boolean logic functions, therefore can efficiently implement multiple-input-multiple-output logic block without noticeable hardware usage overheads. This technique compounds the overall performance benefits resulting from the MTJ devices.
- Taylor expansion, although mathematically elegant and powerful, has never been considered in hardware-assisted functional evaluation due to its excessive hardware cost. Our stochastic-based approach natively exploits the inherent Gaussian-like stochastic switching behavior of the emerging spintronic devices, therefore bypassing the excessive hardware overhead of Boolean-based methodology.
- Due to the SPGA’s unconventional architectural features, we have made several modifications to the existing academic-grade software flow of logic synthesis, technology mapping, placement, and routing. In particular, given the freedom of configuring the output number of SLBs, we developed a variant of the conventional technology mapping algorithm based on computing (k, l)-feasible cuts.
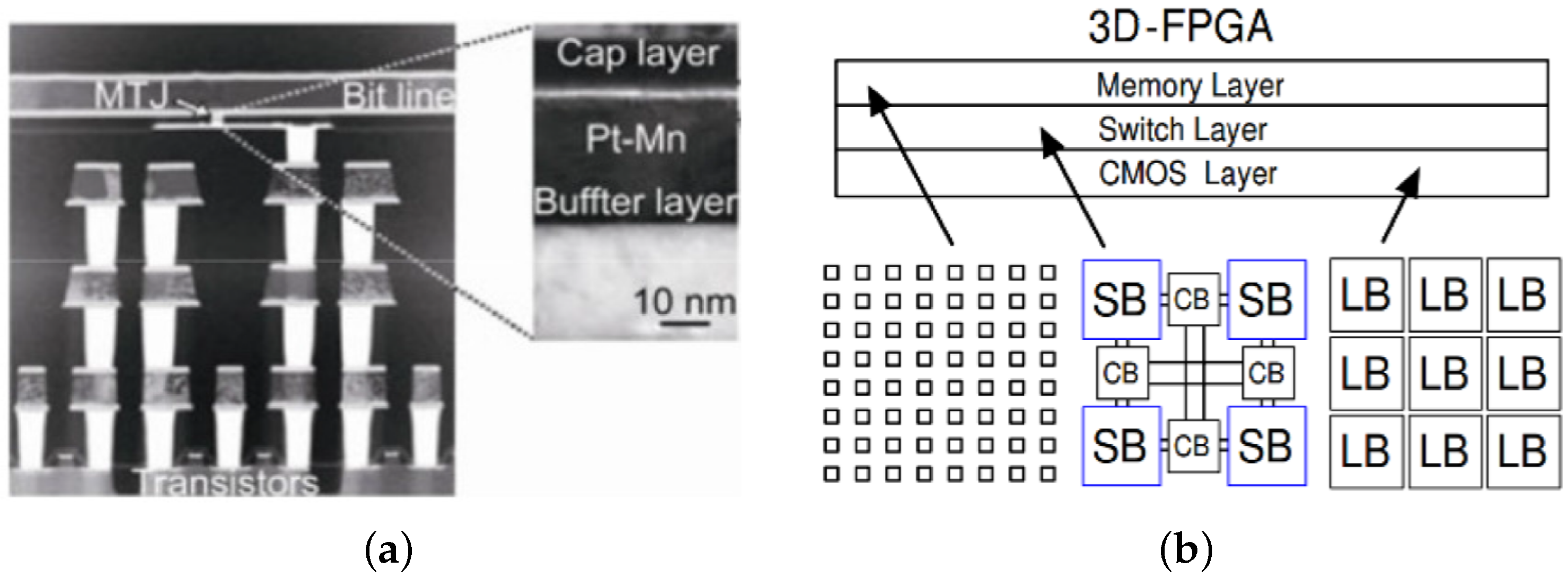
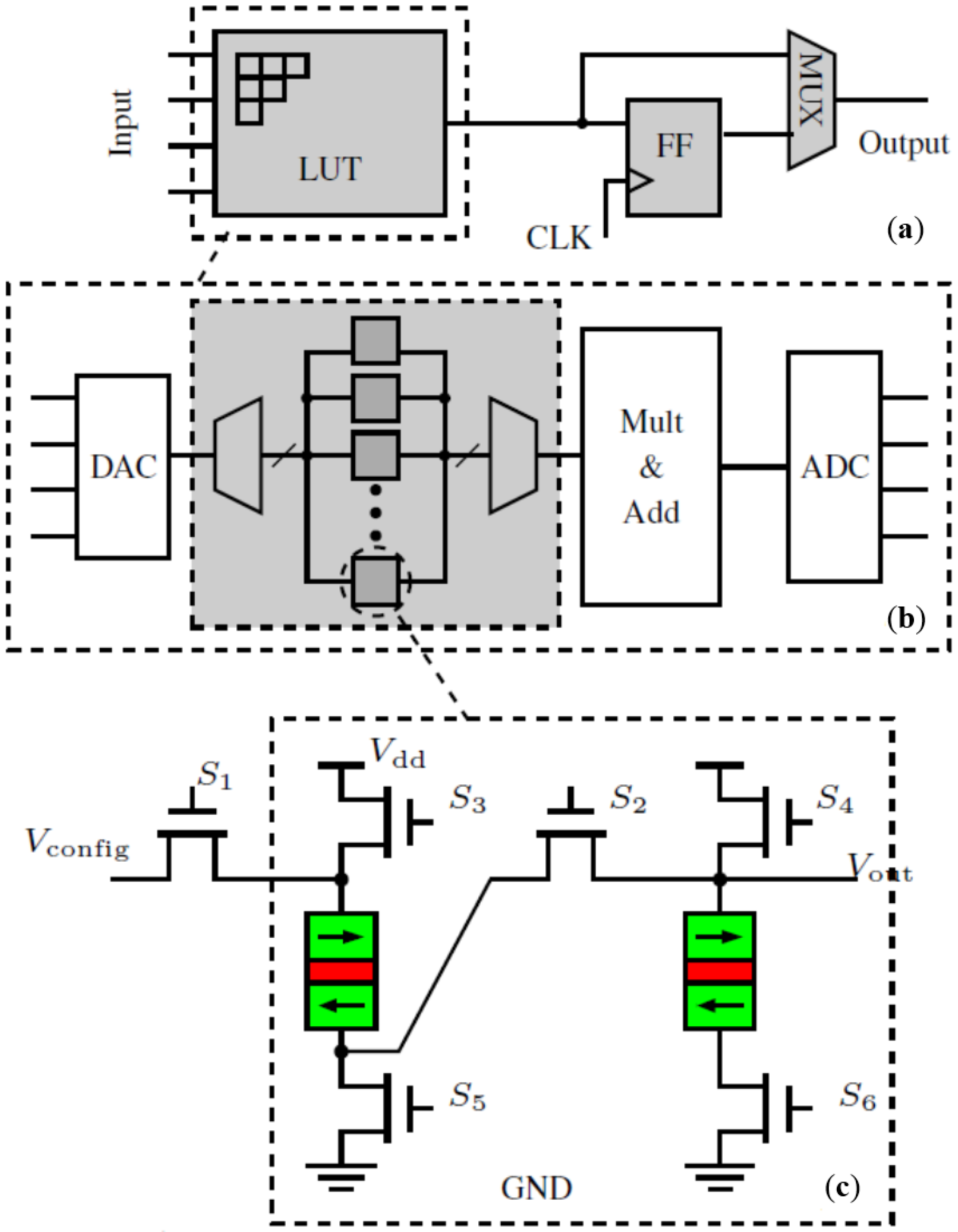
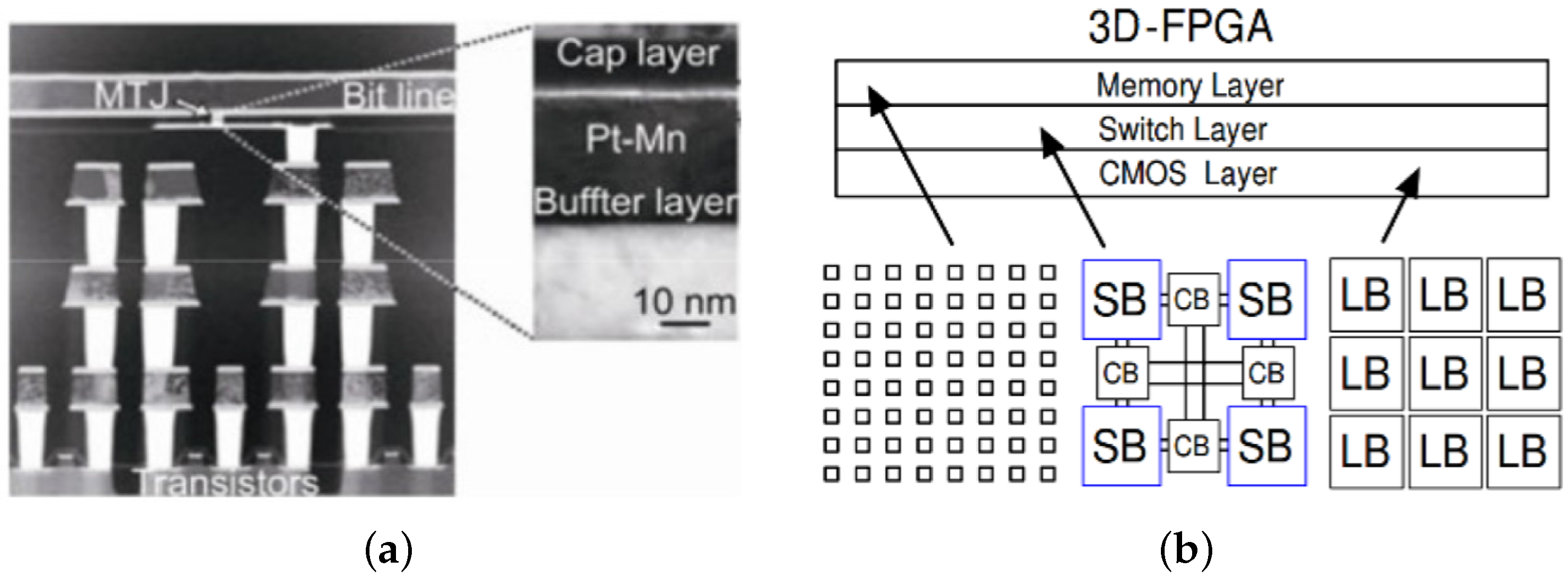
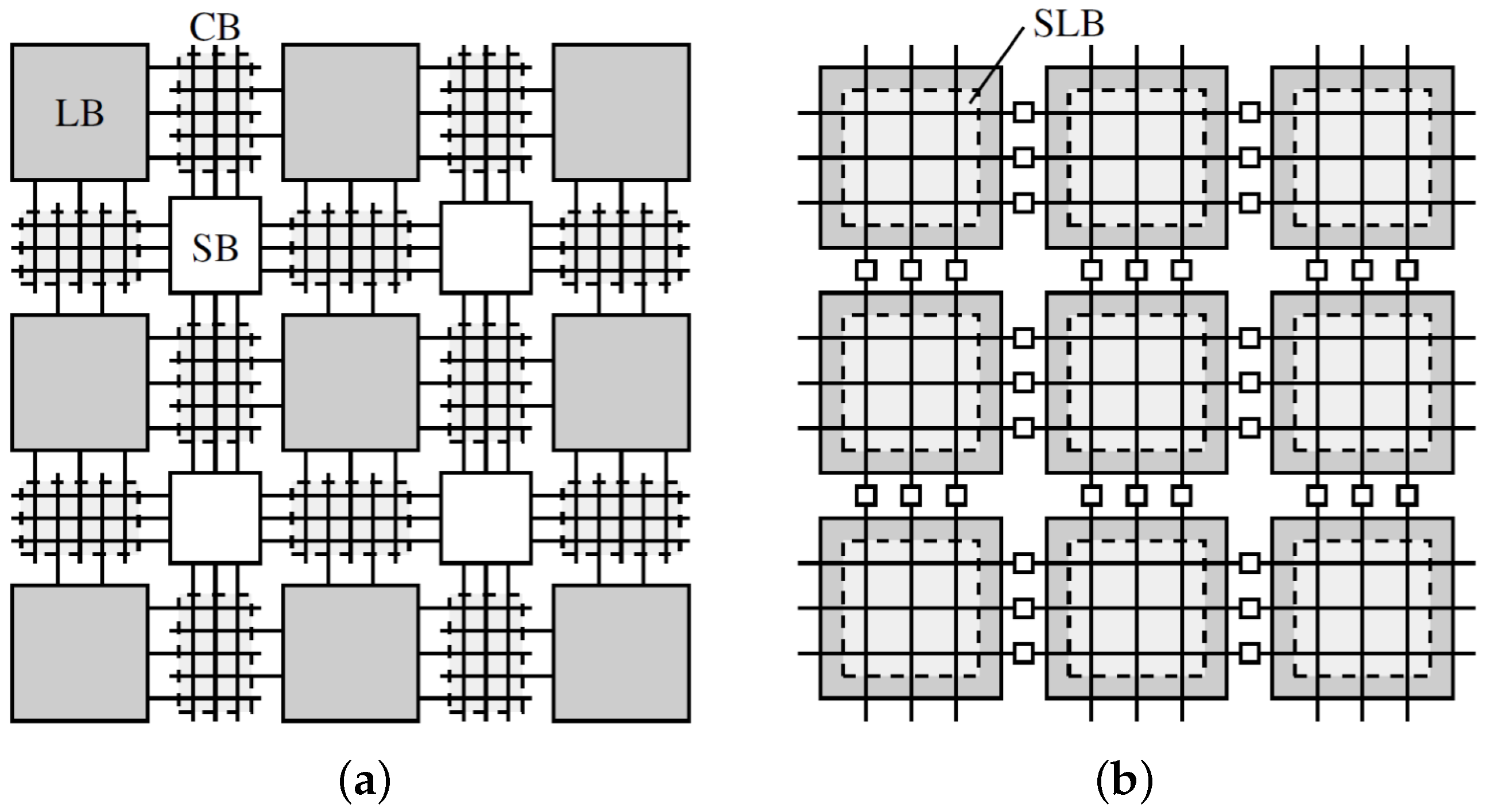
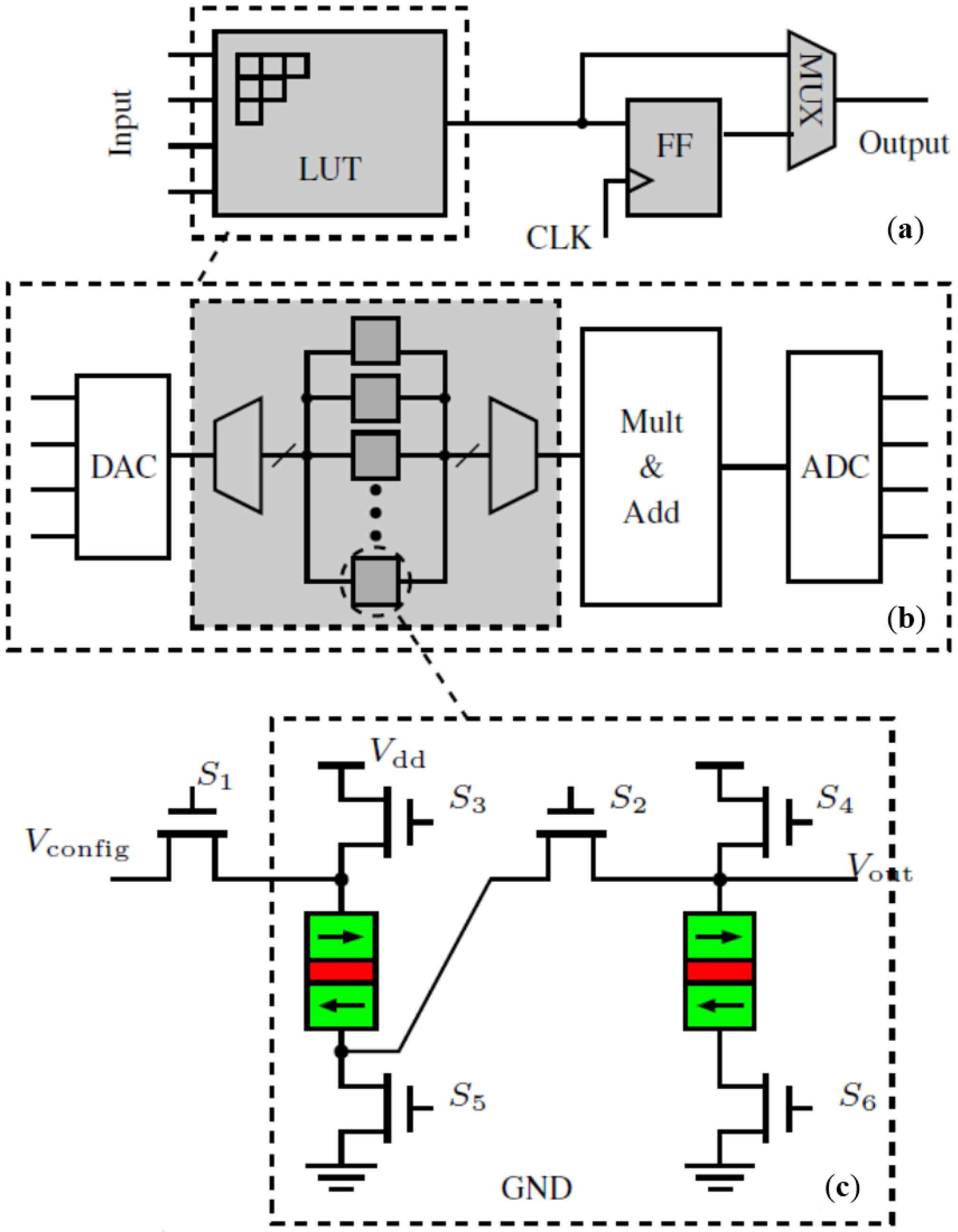
2. Architecture Overview
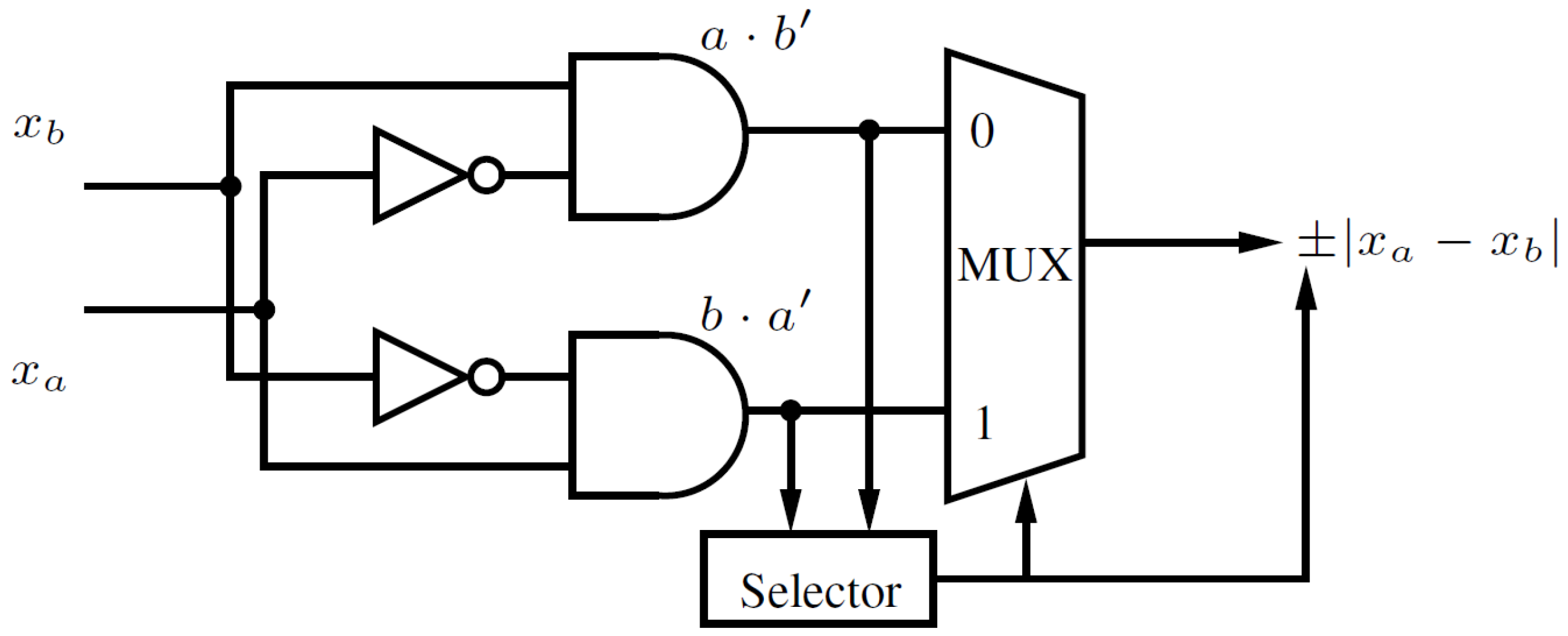
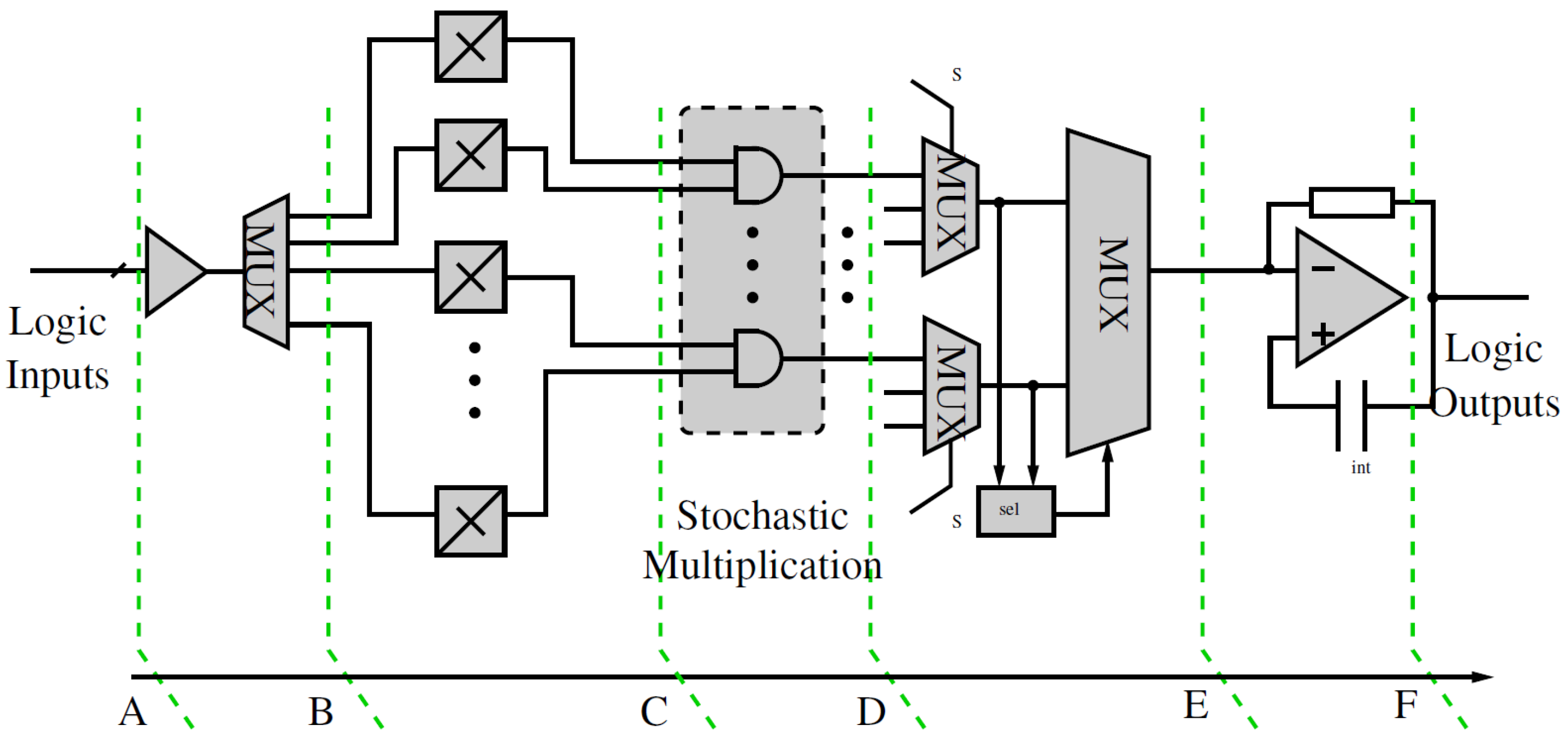
3. Stochastic-Based Logic Block (SLB)
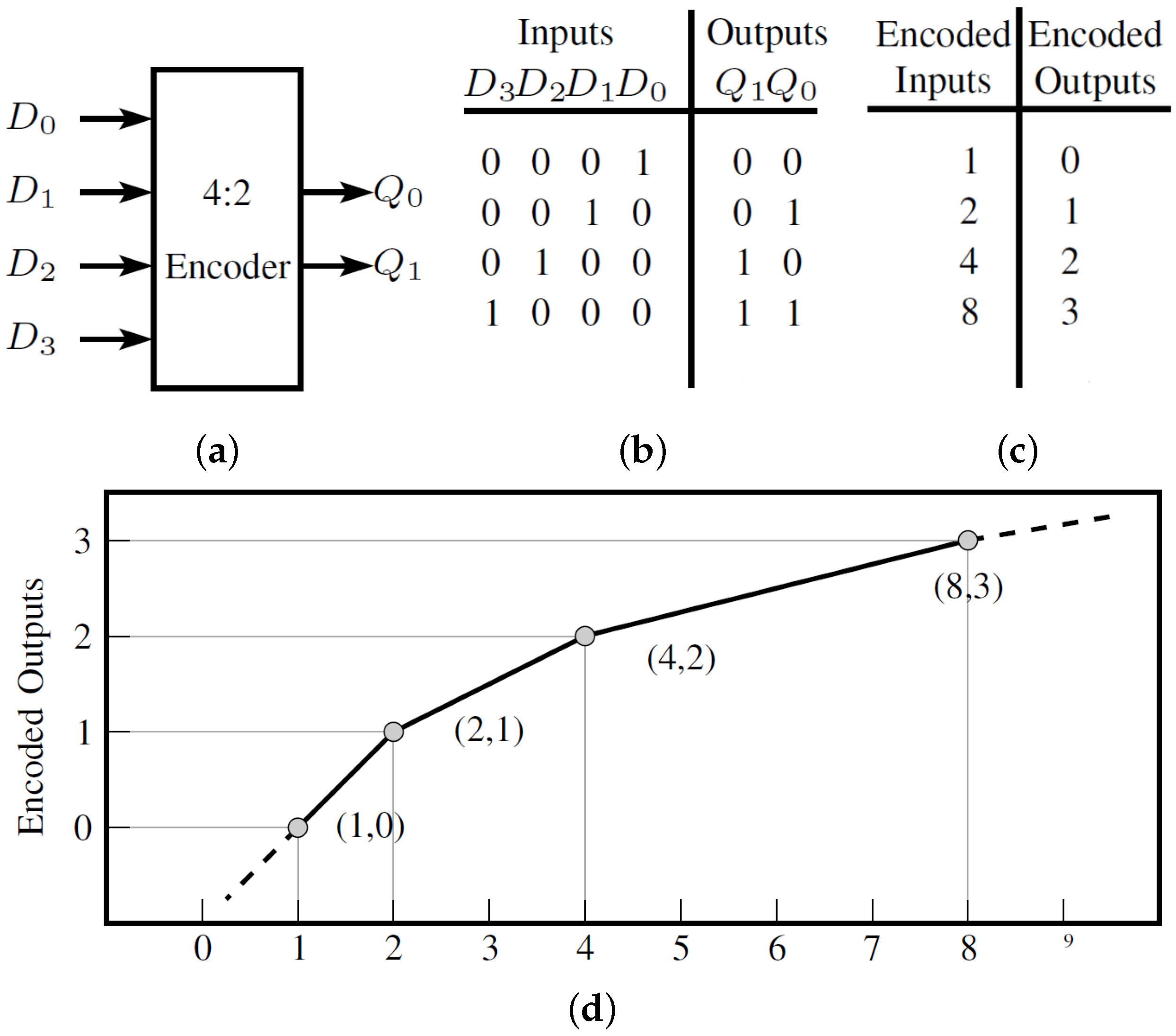
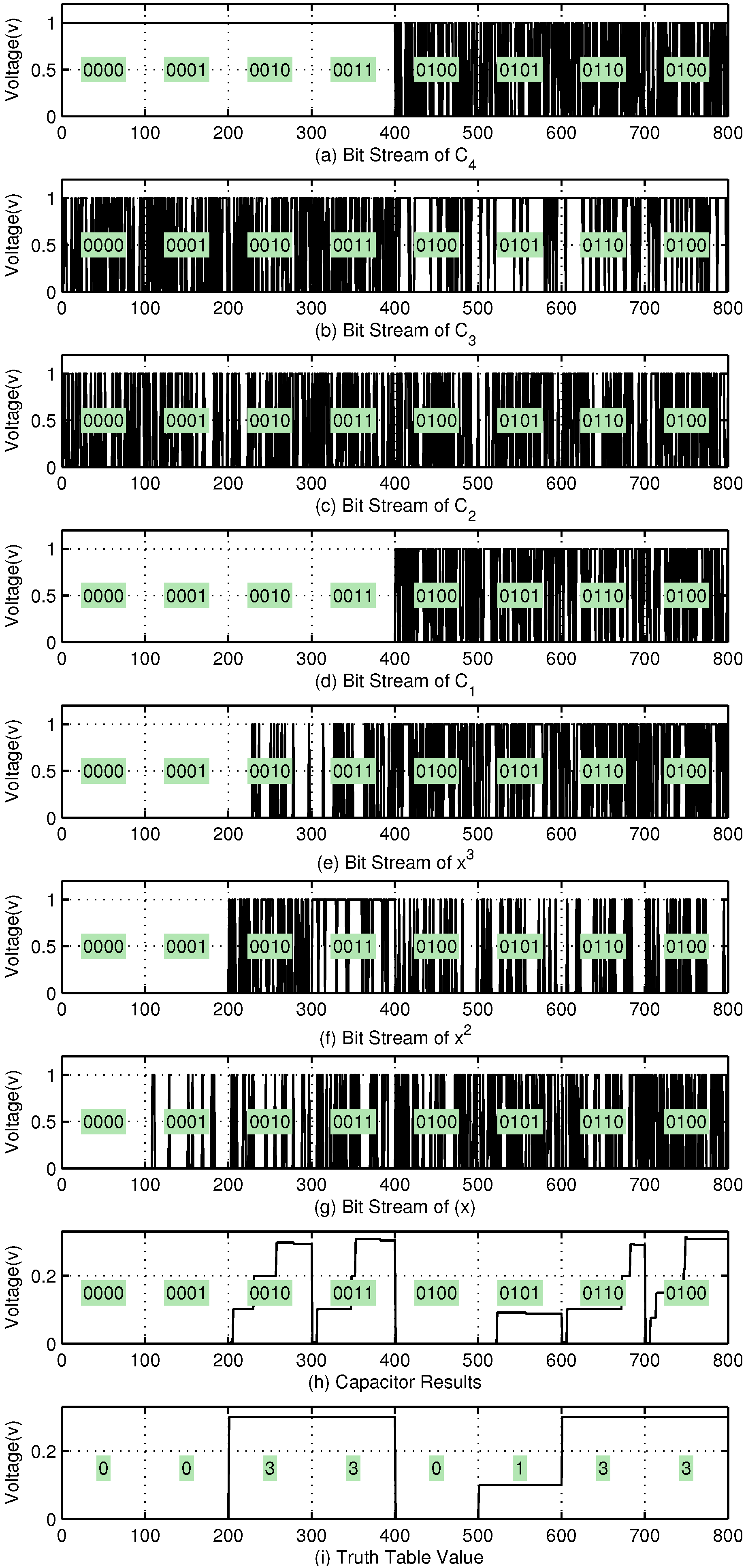
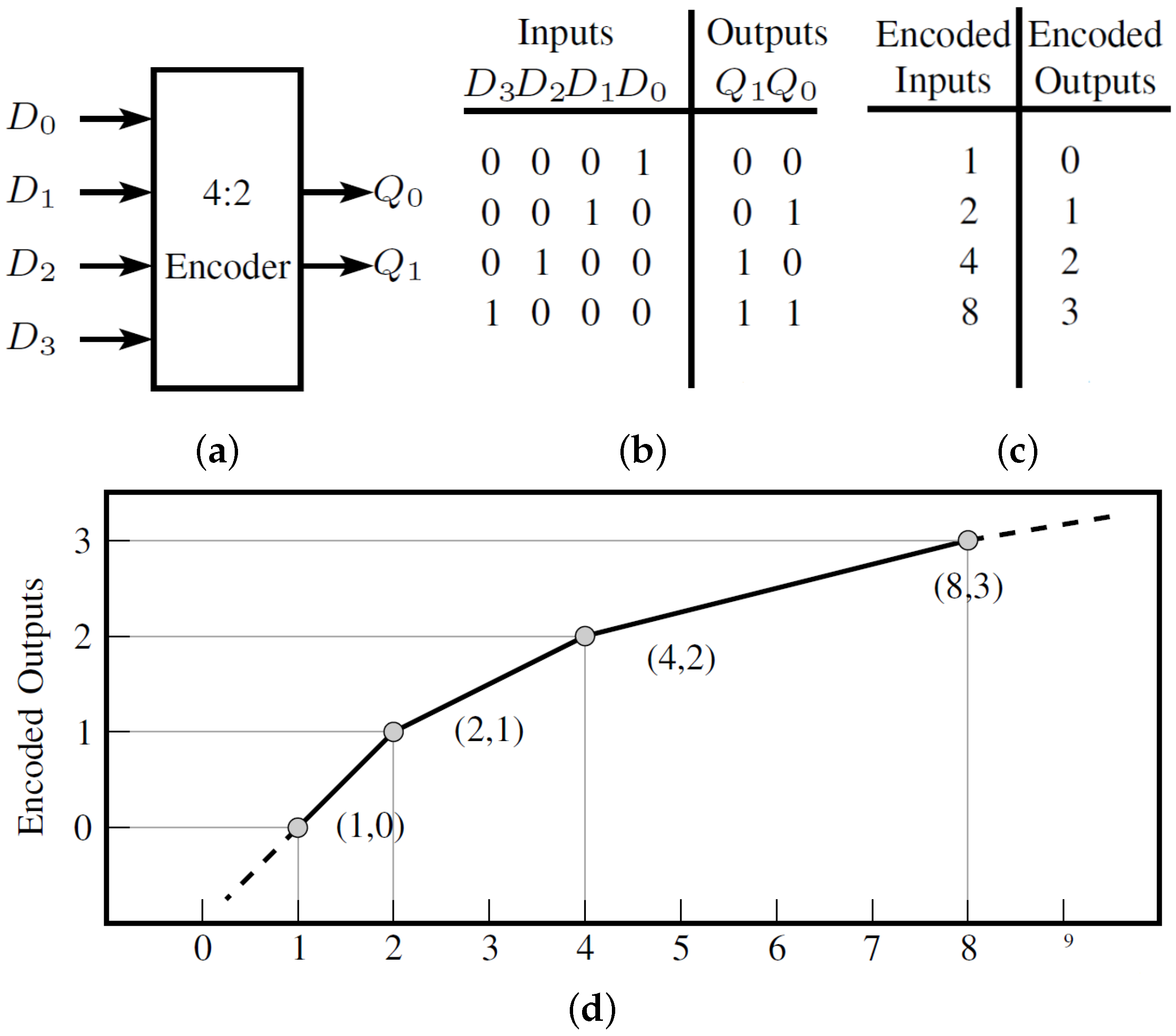
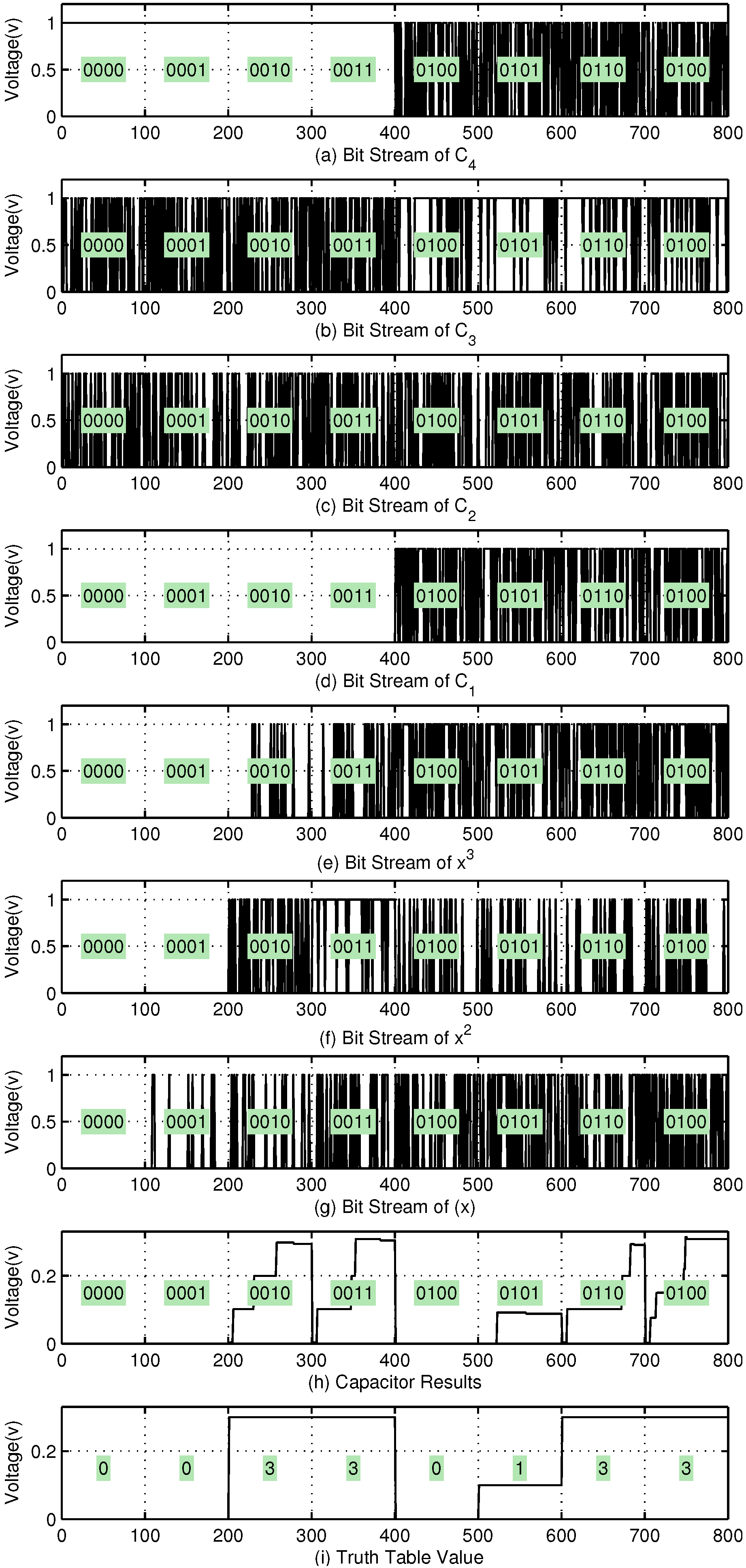
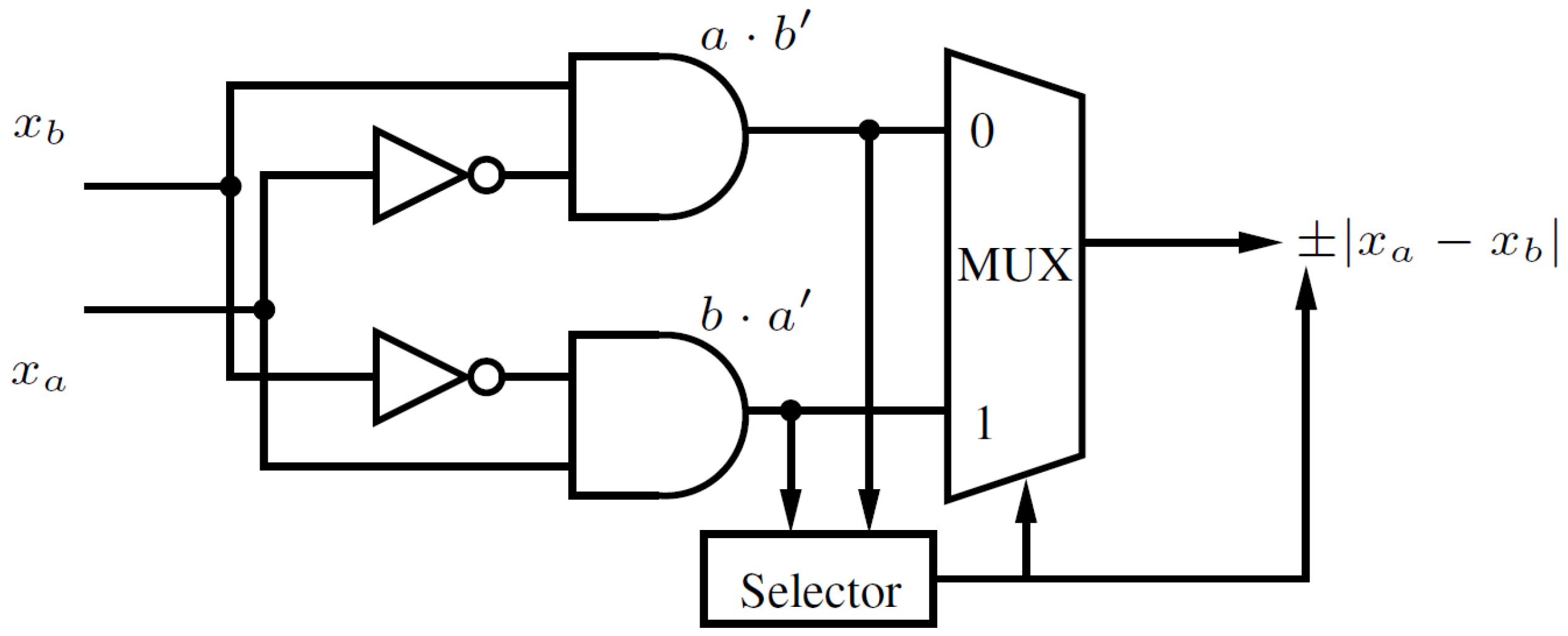
3.1. Algebraically Reinterpreting K-Map
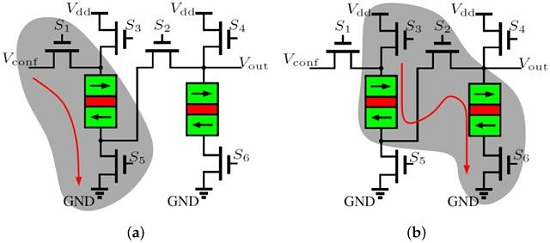
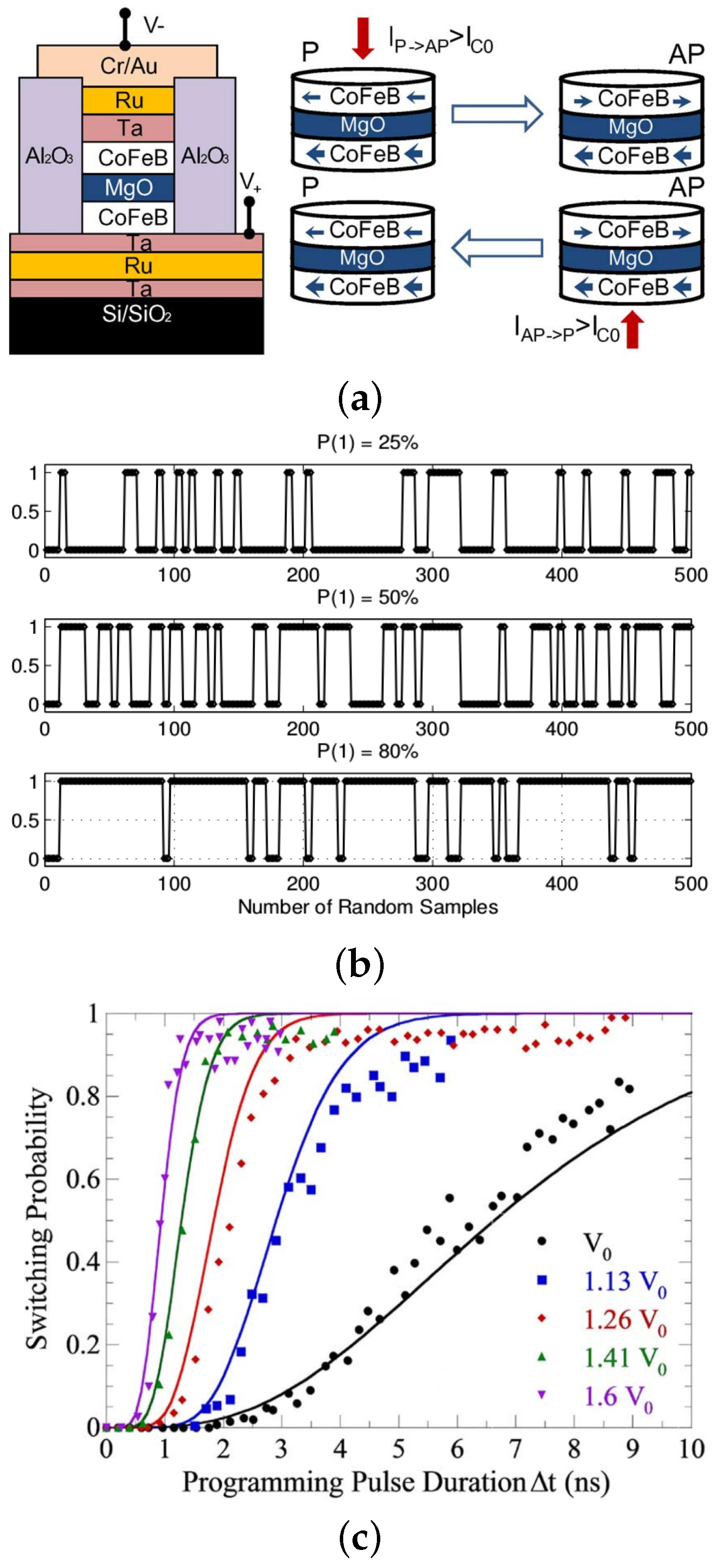
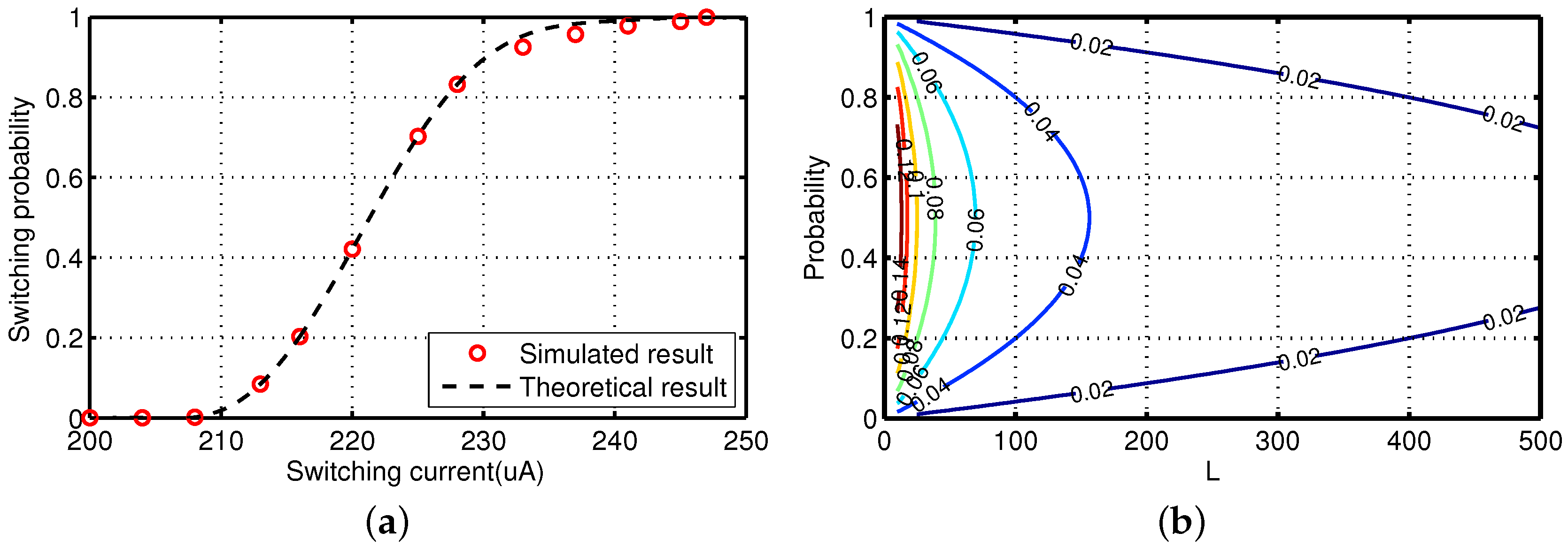
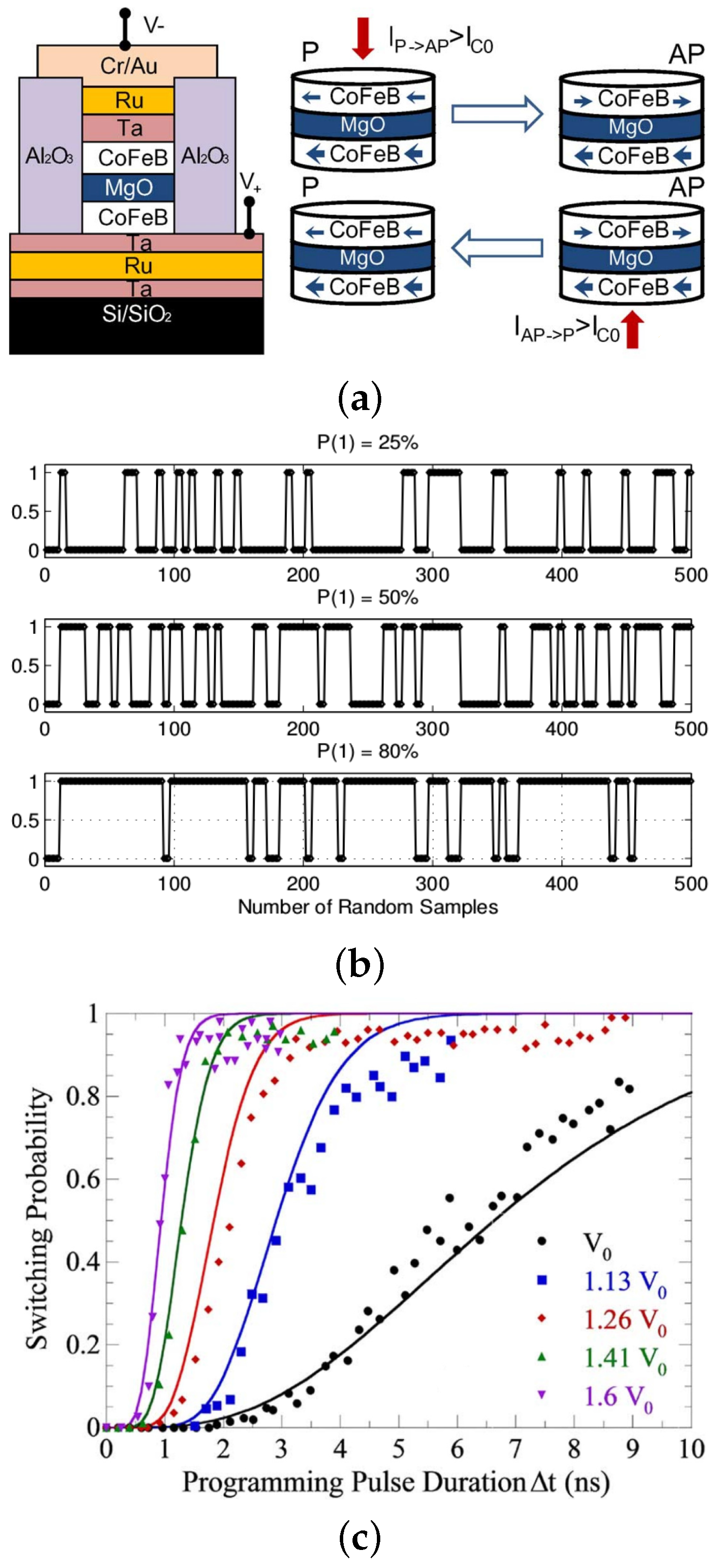
3.2. Stochastic Switching with MTJ Devices
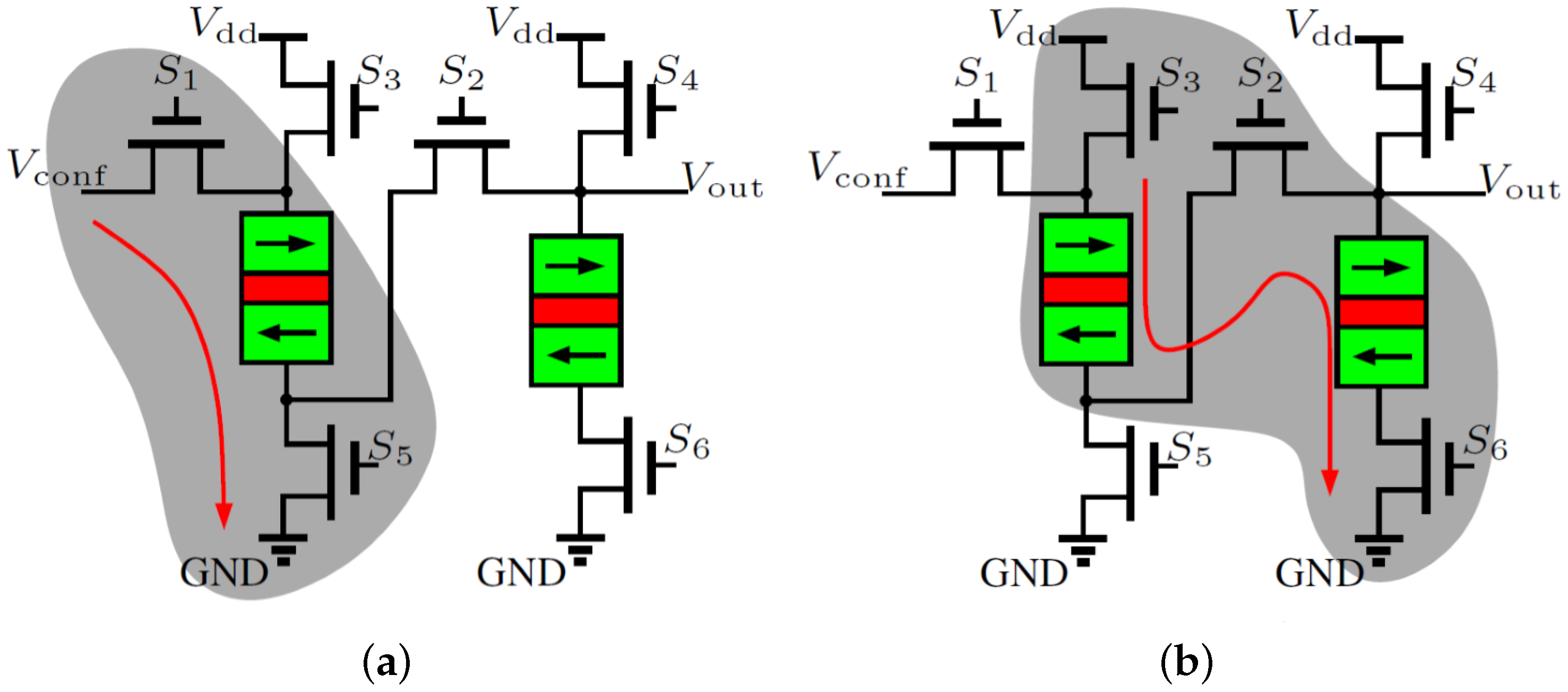
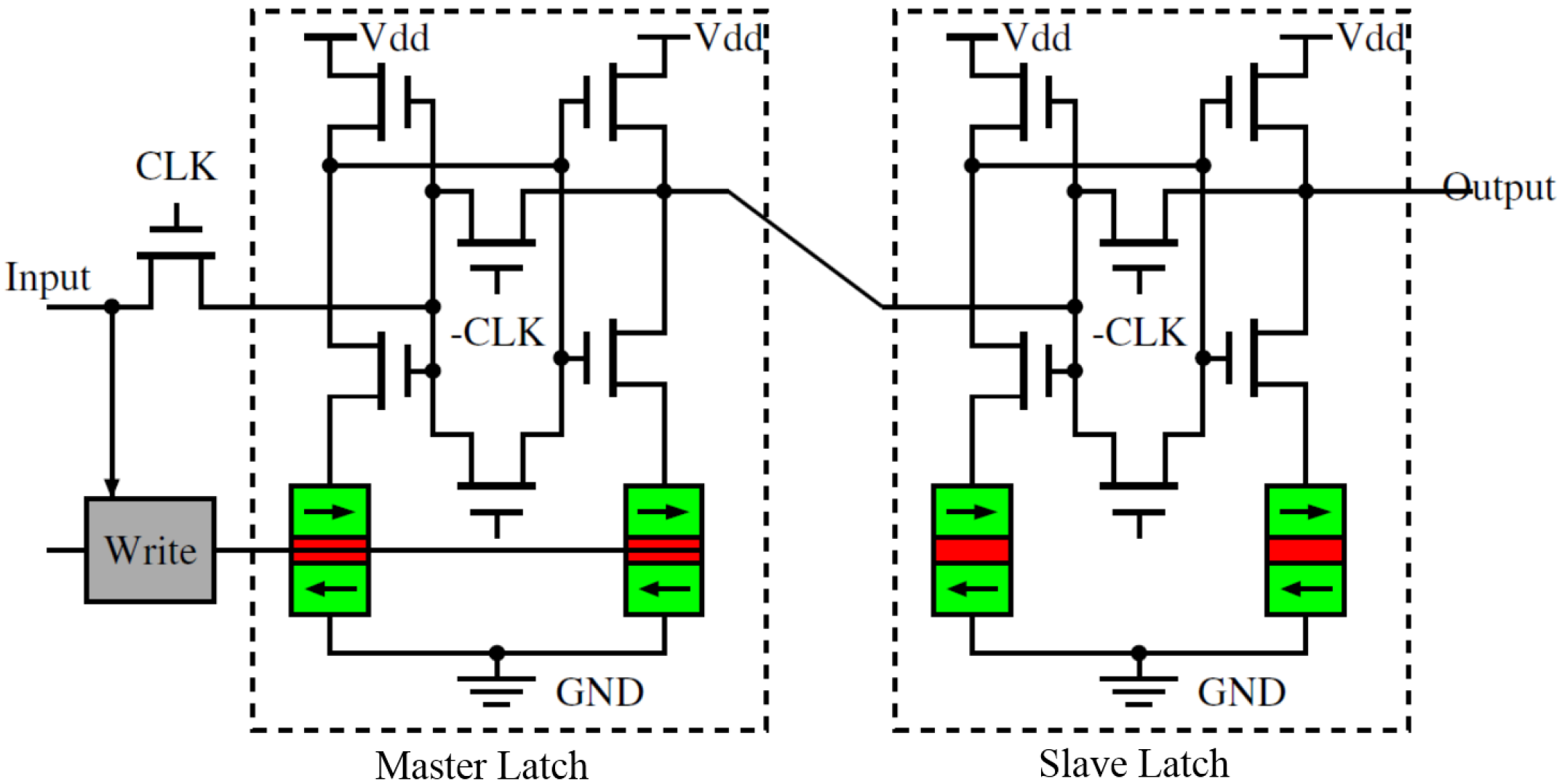
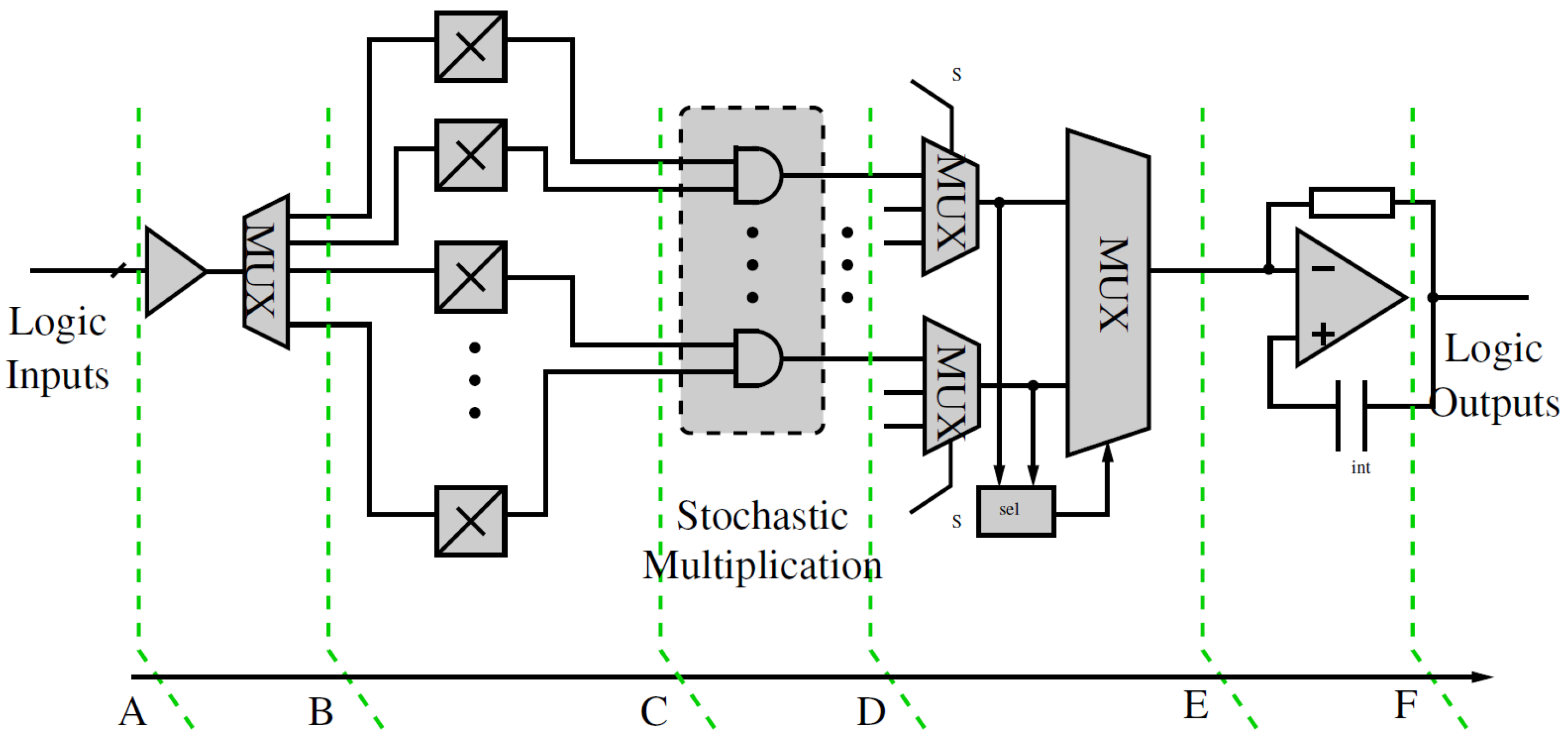
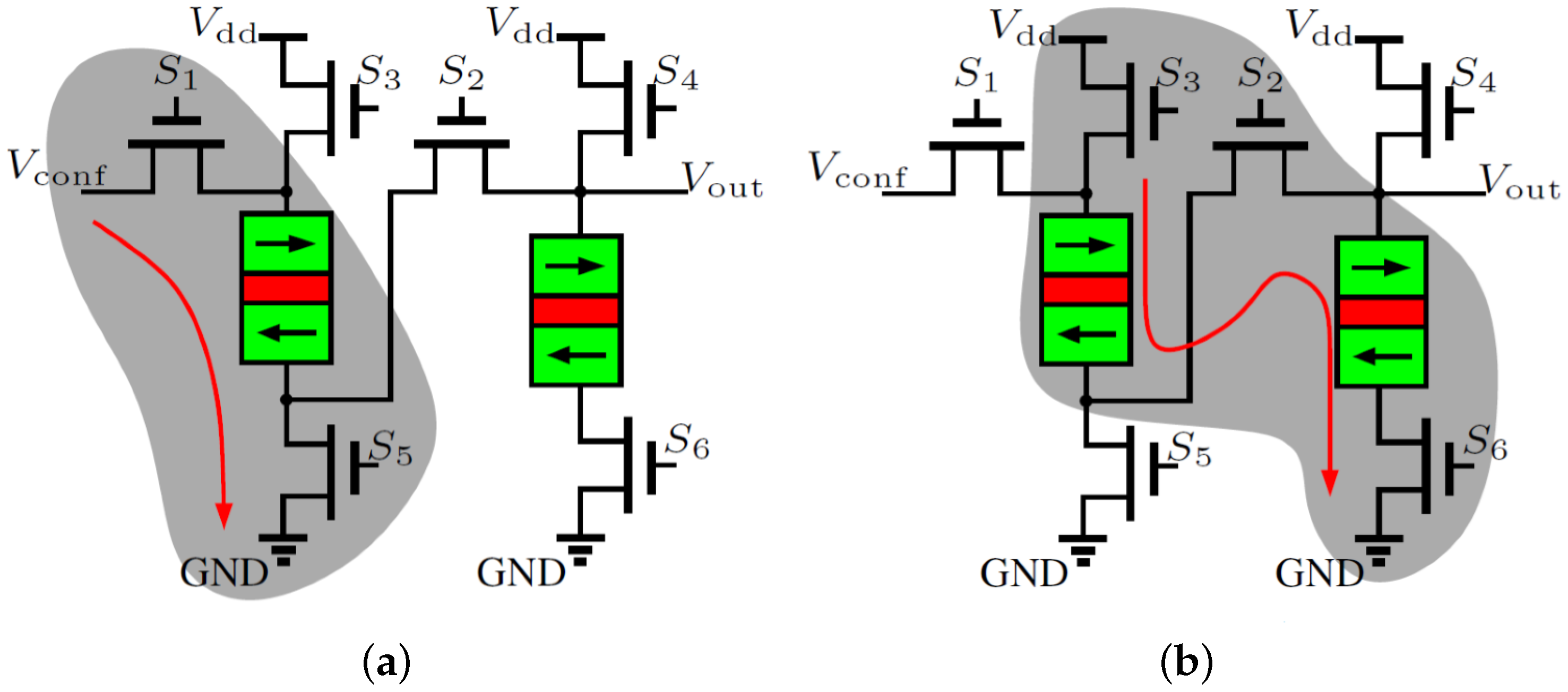
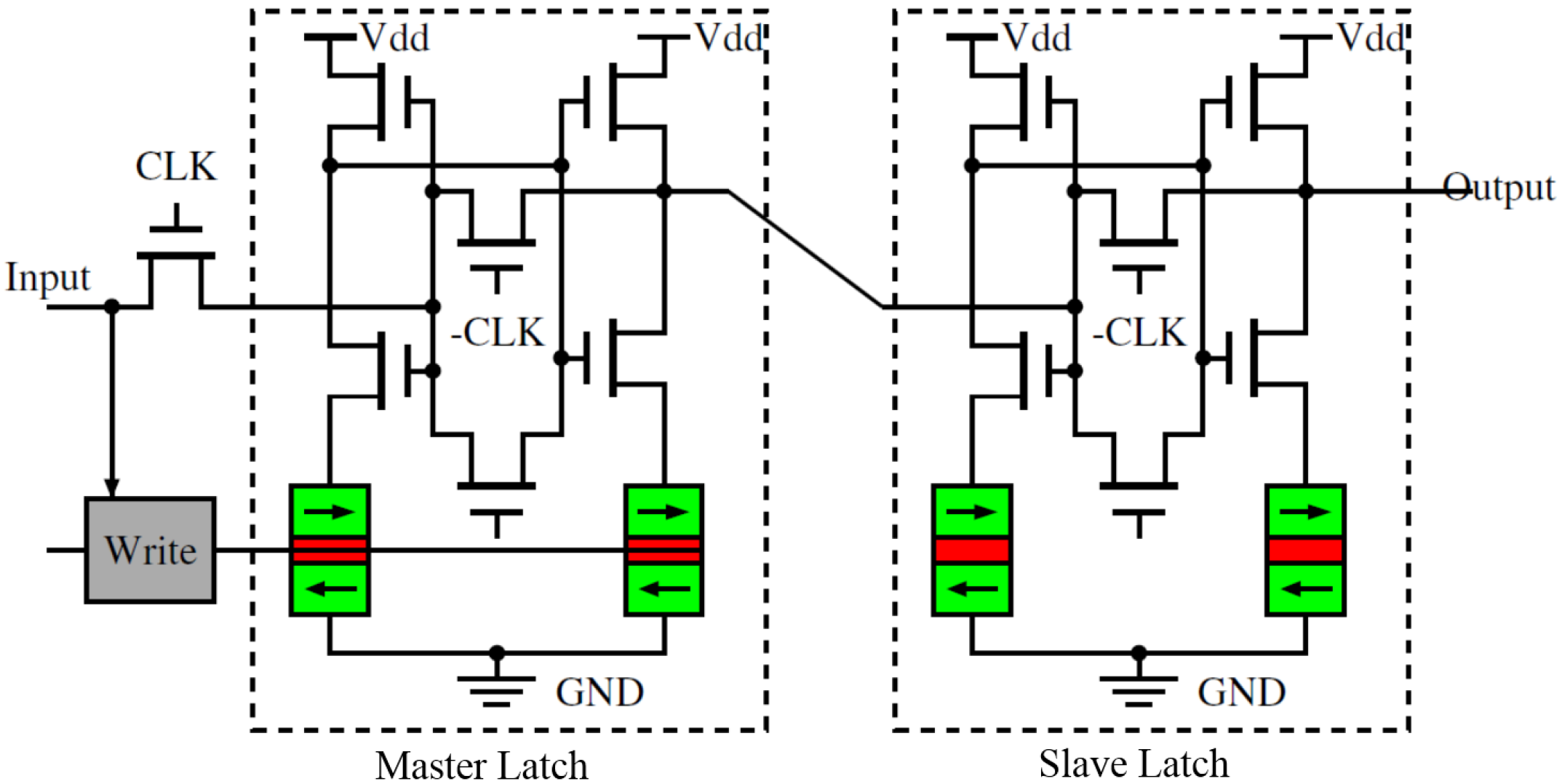
3.3. Detailed Circuit Design of SLB
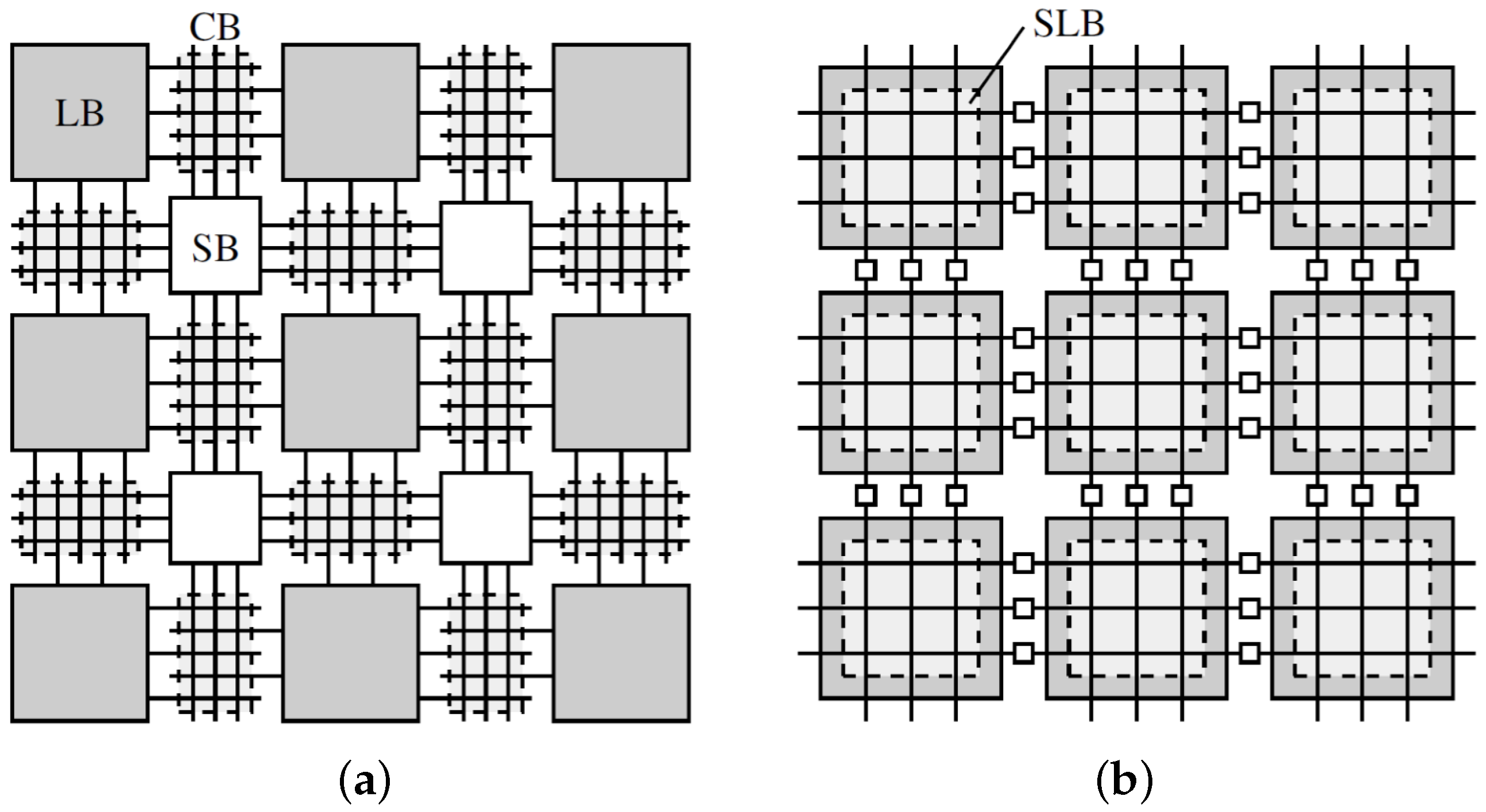
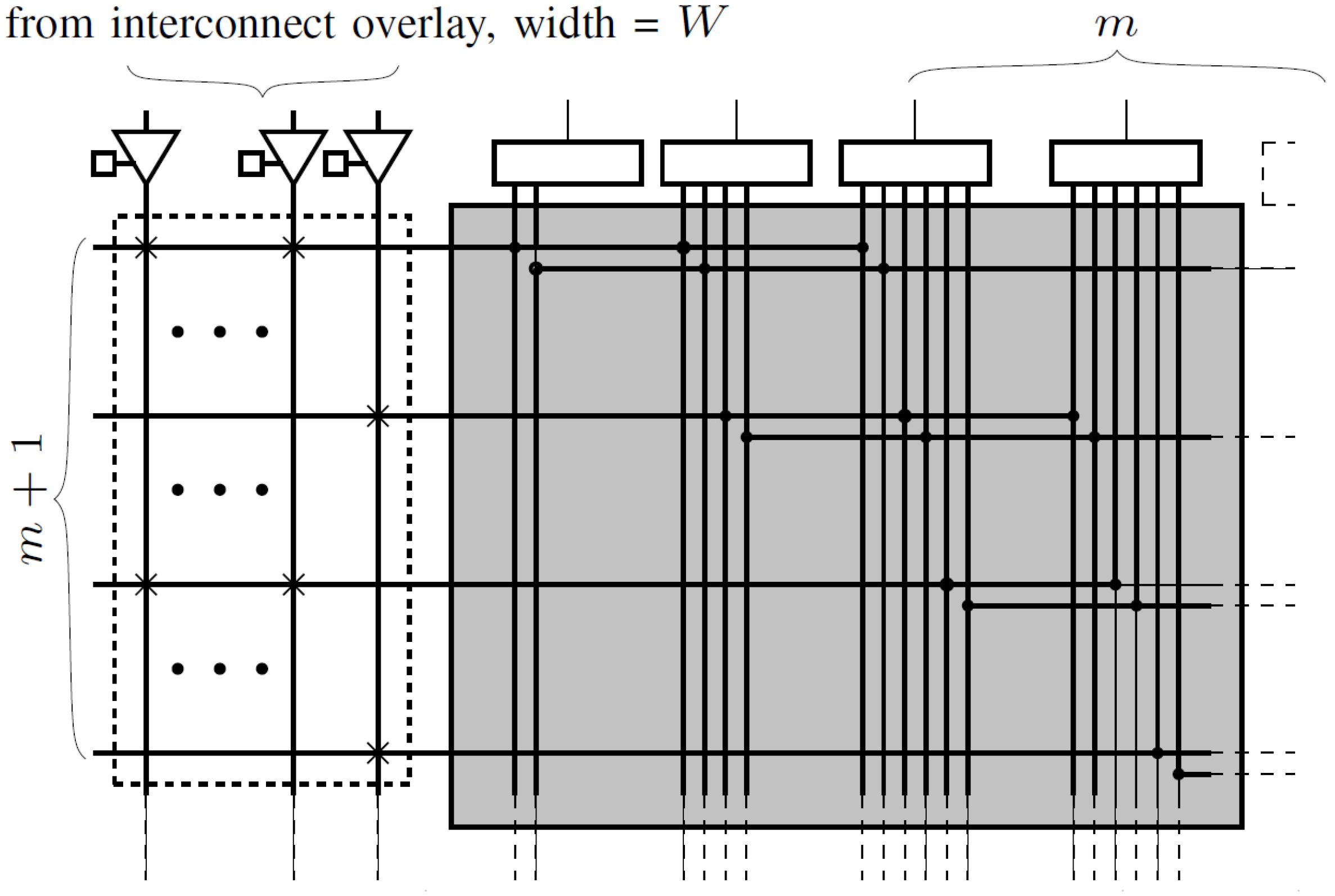
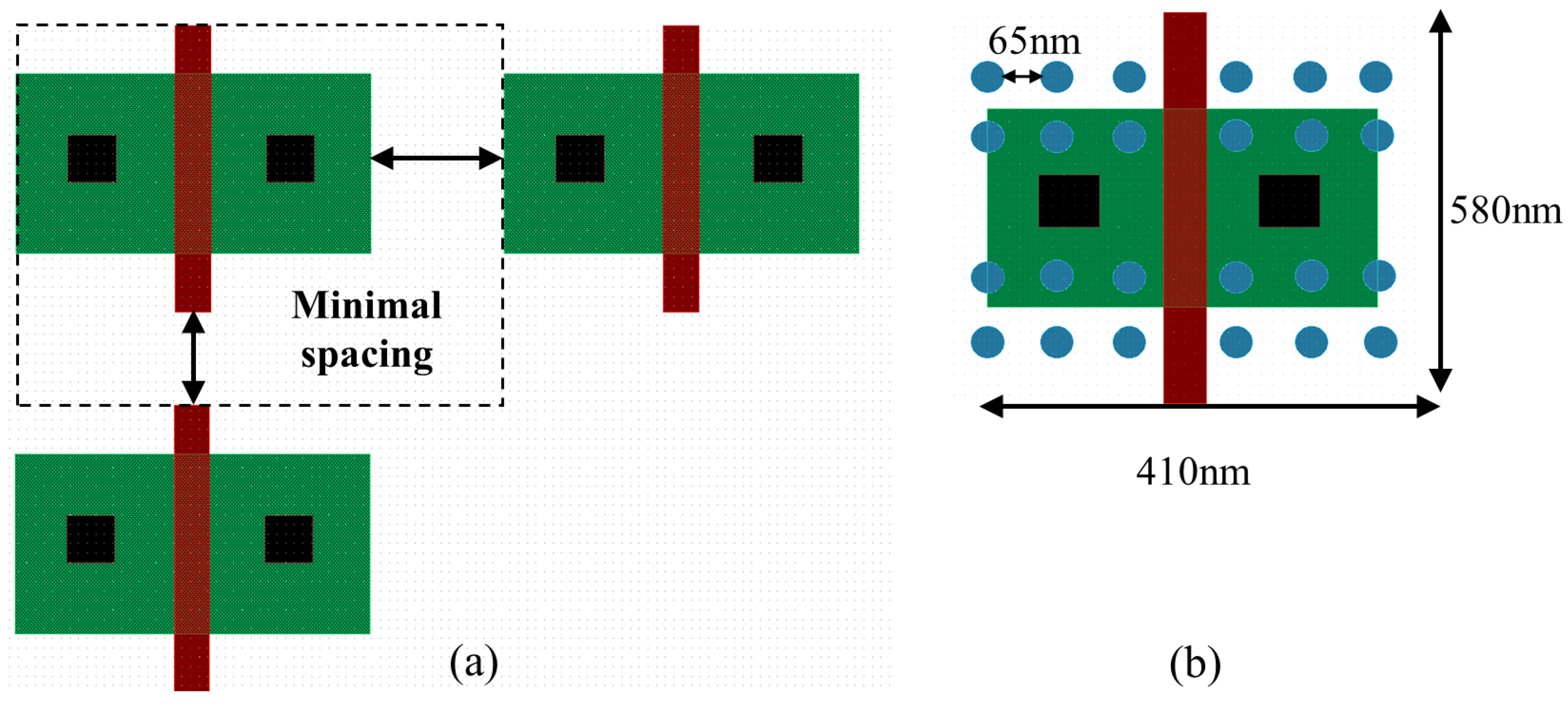
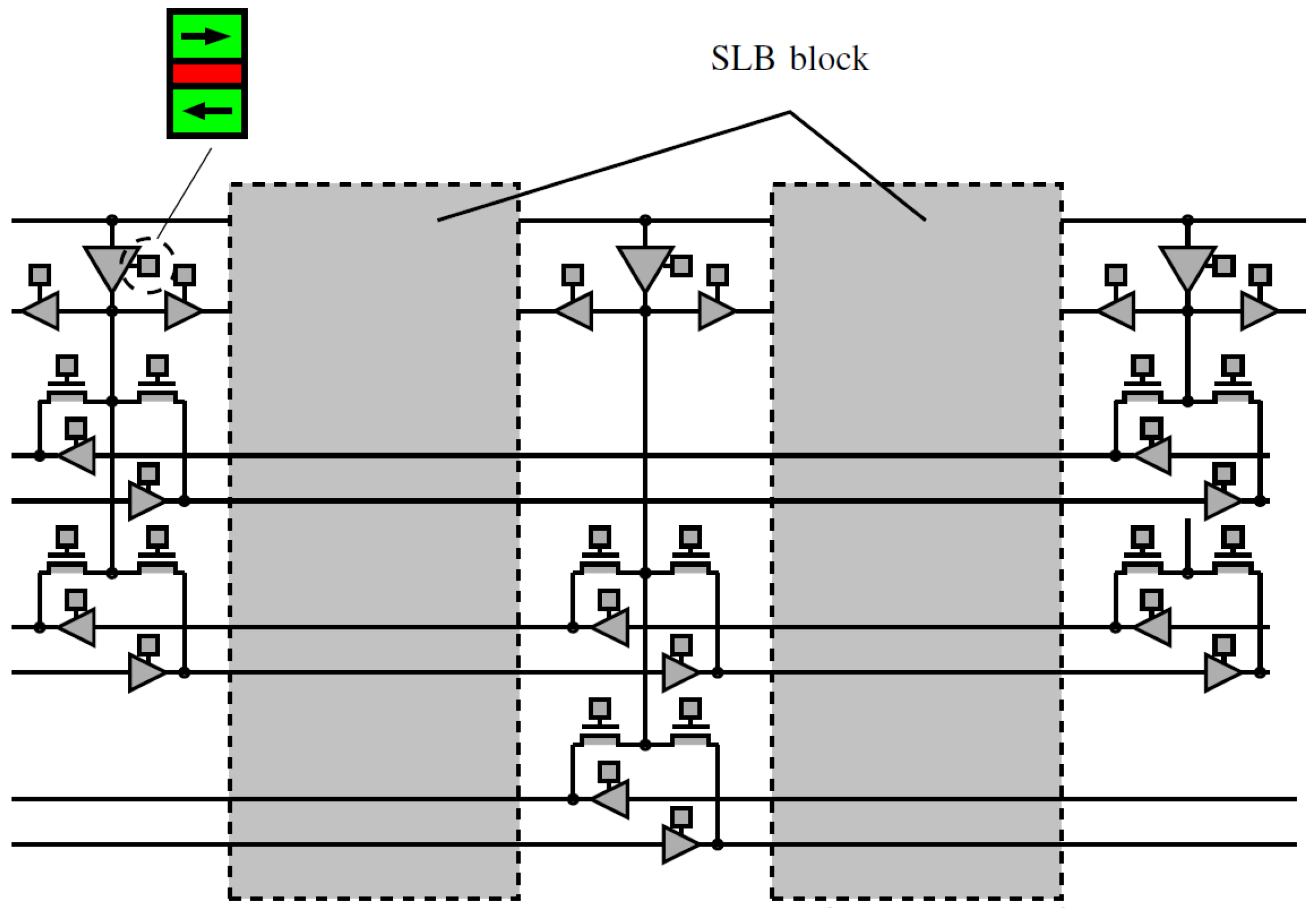
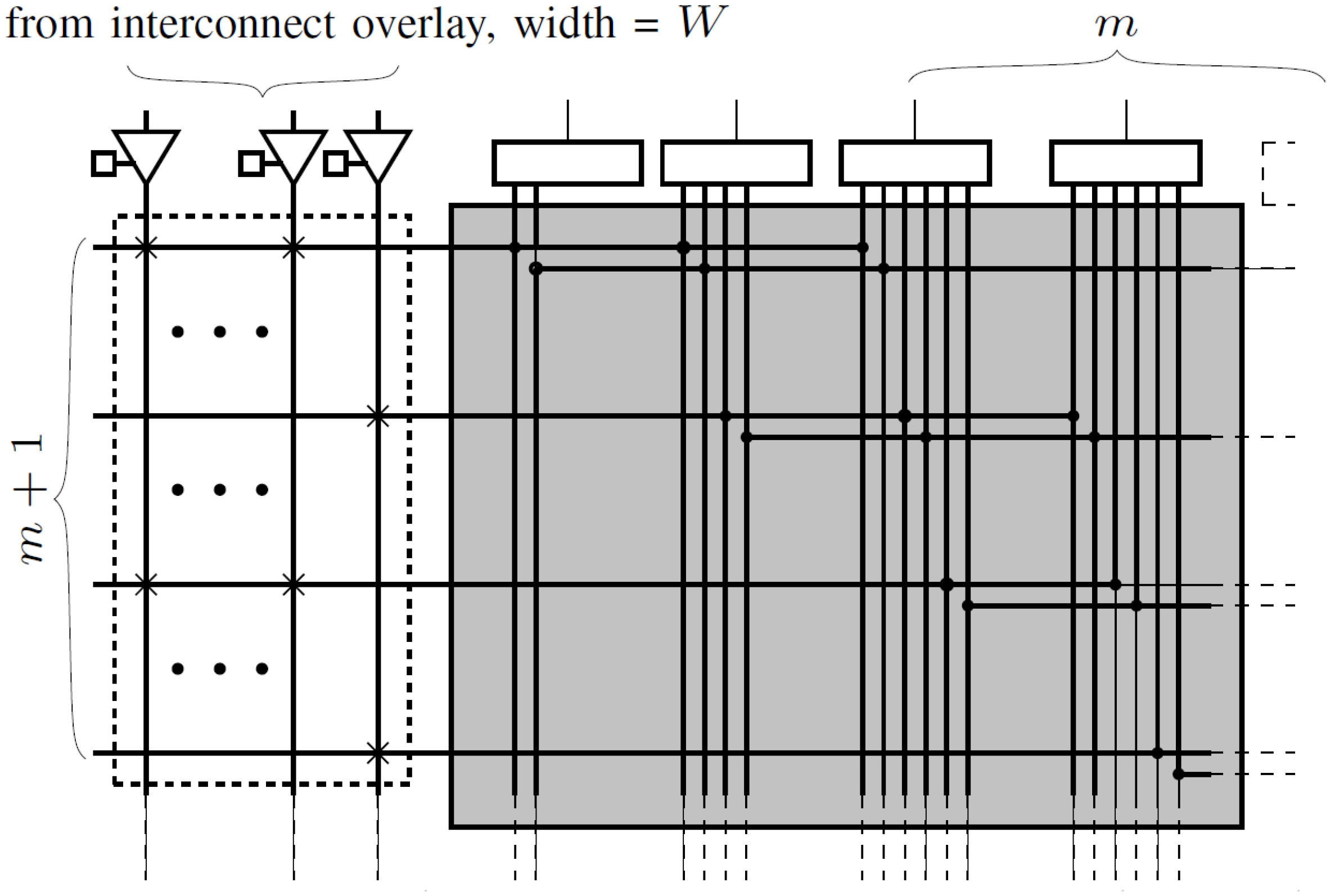
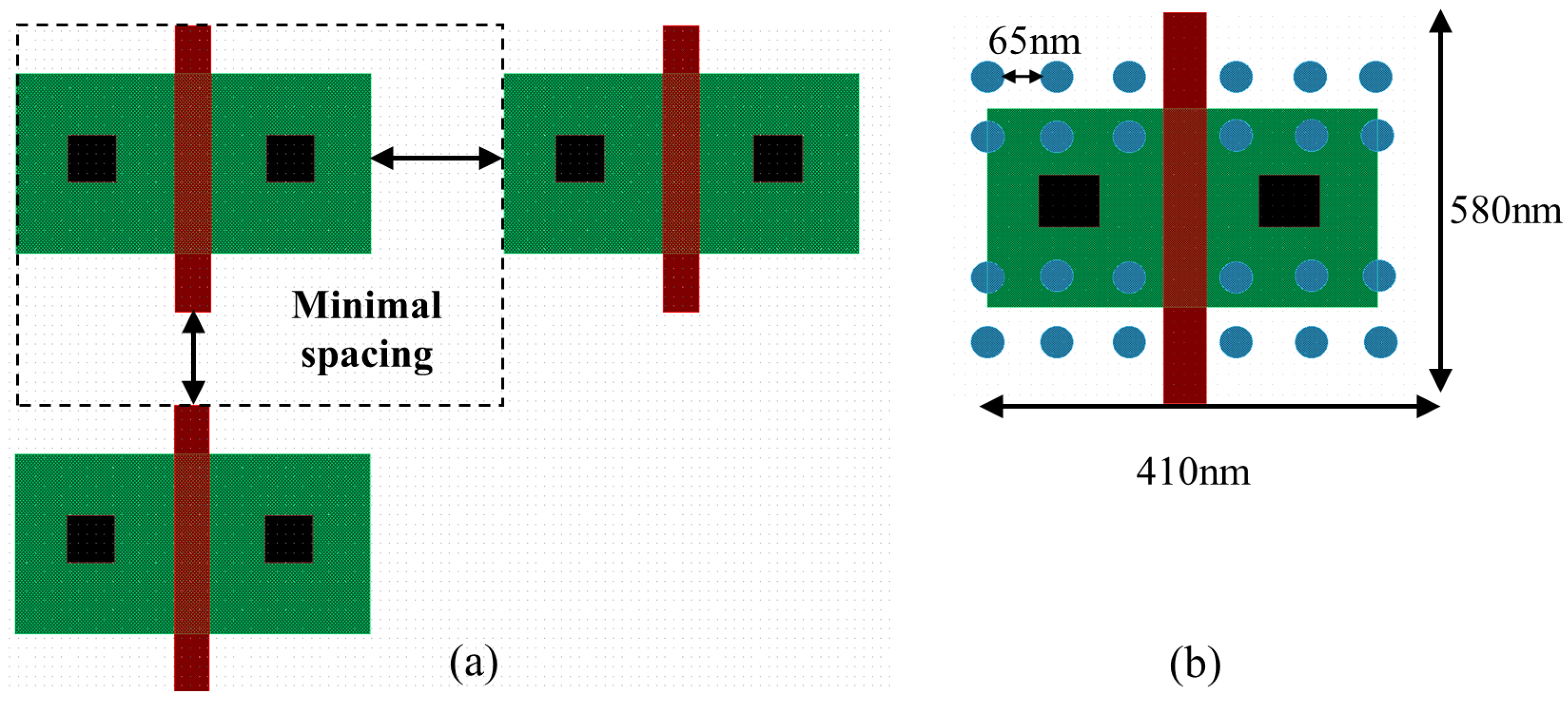
4. Interconnect Architecture
5. CAD Algorithms
5.1. Logic Synthesis and Technology Mapping Algorithm
| Algorithm 1 Algorithm of computing (k, l)-feasible cuts. | |
| 1: | kcuts ← (AIG, k) |
| 2: | lcuts ← (AIG, l) |
| 3: | for each lcut ∈ lcuts do |
| 4: | P ← (lcuts) |
| 5: | for each π∈P do |
| 6: | klcut ← (π, lcut) |
| 7: | if (klcut) then |
| 8: | klcuts.add(klcut) |
| 9: | end if |
| 10: | end for |
| 11: | end for |
| 12: | return klcut |
5.2. Placement Algorithm
| Algorithm 2 The placement algorithm of SPGA. | |
| 1: | RandomPlacement() |
| 2: | InitialTemperature() |
| 3: | g(,p) |
| 4: | freeze_count < 50 |
| 5: | while (ExitCriterion() is FALSE) do |
| 6: | changes ← 0 |
| 7: | trials ← 0 |
| 8: | EvaluateCost(g,b) |
| 9: | while (InnerLoopCriterion() is FALSE) do |
| 10: | trials ← trials + 1 |
| 11: | RandomSwap(p) |
| 12: | IncrementalRoute(g(,), b) |
| 13: | EvaluateCost(g(, )) −c |
| 14: | if /*downhill move*/ then |
| 15: | changes ← changes + 1 |
| 16: | |
| 17: | g(, p) |
| 18: | EvaluateCost(g(, )) |
| 19: | end if |
| 20: | if /*uphill move*/ then |
| 21: | Random(0,1) |
| 22: | if then |
| 23: | |
| 24: | g(, p) |
| 25: | end if |
| 26: | end if |
| 27: | end while |
| 28: | UpdateTemperature() |
| 29: | if changes then |
| 30: | freeze_count ← 0 |
| 31: | end if |
| 32: | if then |
| 33: | freeze_count ← freeze_count + 1 |
| 34: | end if |
| 35: | end while |
5.3. Routing Algorithm
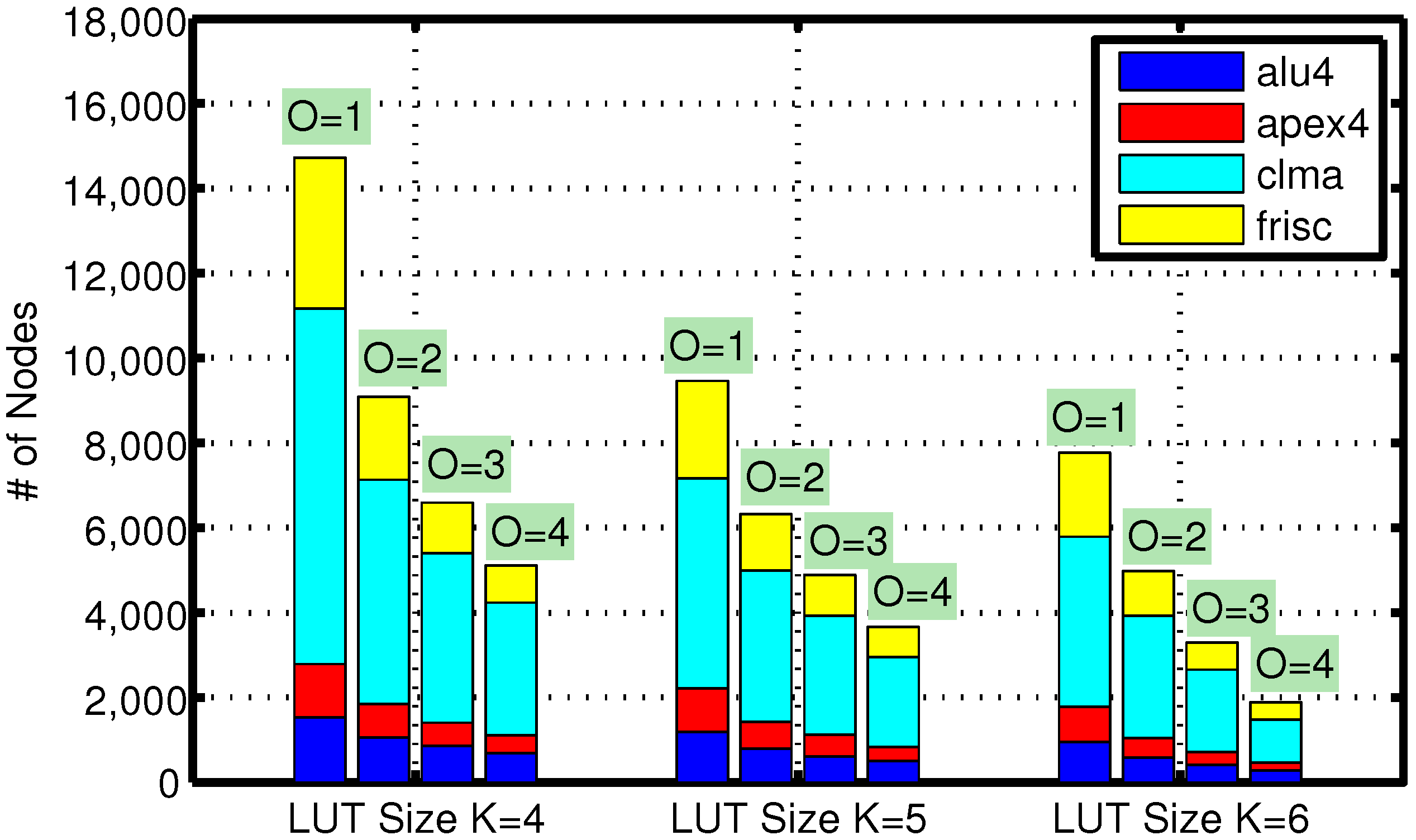
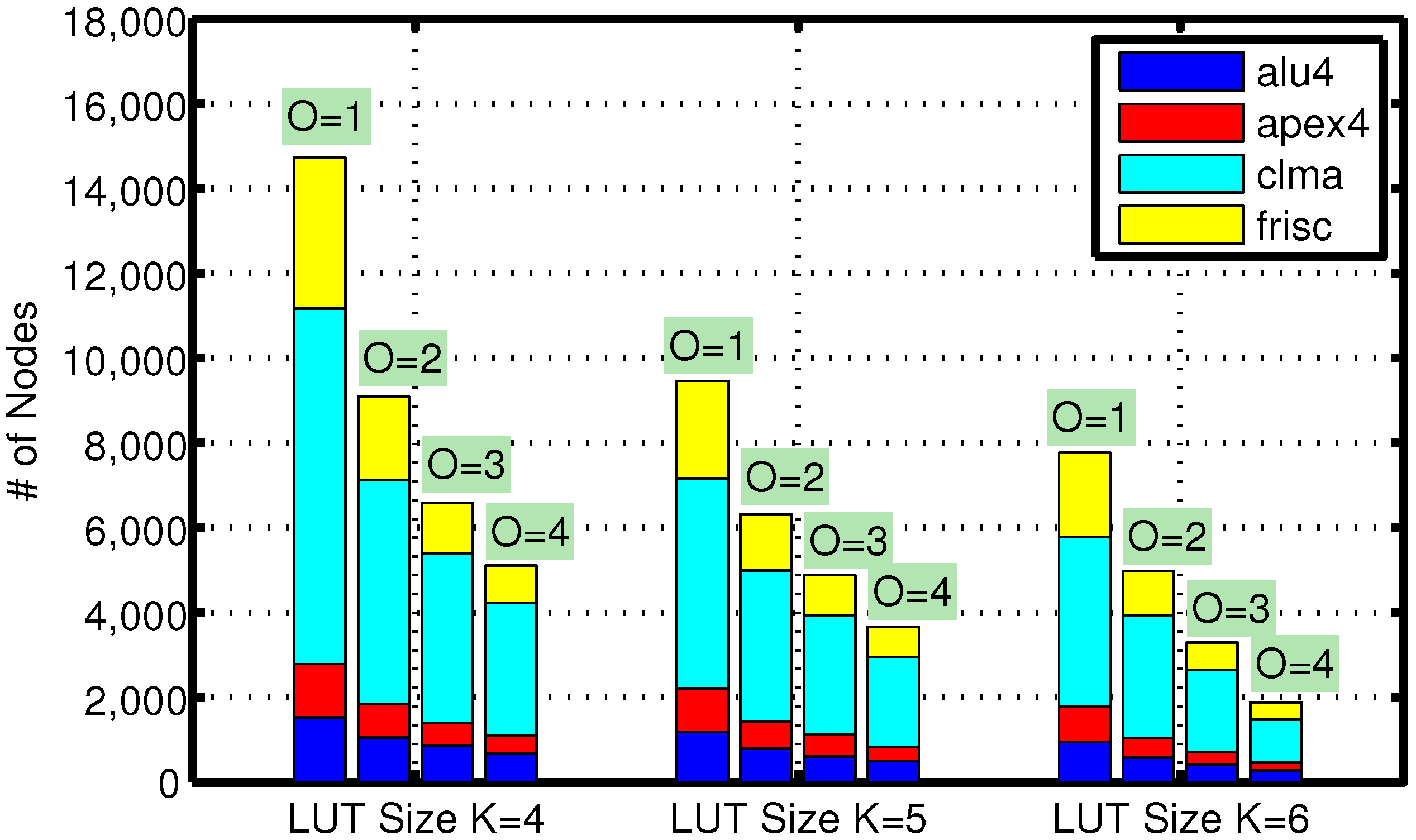
6. Performance Analysis and Comparison
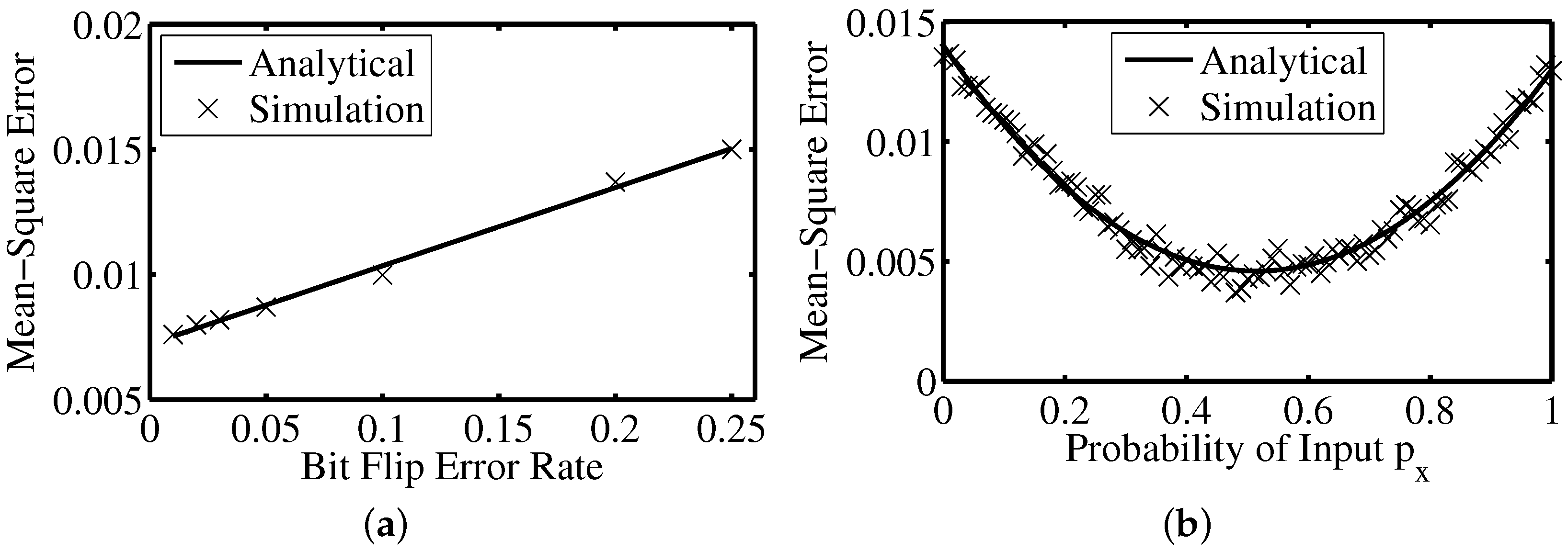
7. Error Analysis
8. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Shin, S.; Kim, K.; Kang, S.M. Memristor applications for programmable analog ICs. IEEE Trans. Nanotechnol. 2011, 10, 266–274. [Google Scholar] [CrossRef]
- Jo, S.H.; Chang, T.; Ebong, I.; Bhadviya, B.B.; Mazumder, P.; Lu, W. Nanoscale memristor device as synapse in neuromorphic systems. Nano Lett. 2010, 10, 1297–1301. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Lin, M. Universal Random Number Generation with Field-Programmable Analog Array and Magnetic Tunneling Junction (MTJ) Devices. In Proceedings of the 2015 IEEE International Conference on Computer and Information Technology; Ubiquitous Computing and Communications; Dependable, Autonomic and Secure Computing; Pervasive Intelligence and Computing (CIT/IUCC/DASC/PICOM), Liverpool, UK, 26–28 October 2015; pp. 1338–1343.
- Bai, Y.; Hu, B.; Kuang, W.; Lin, M. Ultra-robust null convention logic circuit with emerging domain wall devices. In Proceedings of the ACM 26th Edition on Great Lakes Symposium on VLSI, Boston, MA, USA, 18–20 May 2016; pp. 251–256.
- Wang, P.; Zhang, W.; Joshi, R.; Kanj, R.; Chen, Y. A thermal and process variation aware MTJ switching model and its applications in soft error analysis. In Proceedings of the 2012 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, 5–8 November 2012; pp. 720–727.
- Onizawa, N.; Katagiri, D.; Gross, W.; Hanyu, T. Analog-to-stochastic converter using magnetic-tunnel junction devices. In Proceedings of the 2014 IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH), Paris, France, 8–10 July 2014; pp. 59–64.
- Lin, M.; El Gamal, A.; Lu, Y.C.; Wong, S. Performance benefits of monolithically stacked 3D-FPGA. In Proceedings of the 2006 ACM/SIGDA Tenth International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 24–26 February 2006; pp. 113–122.
- Chen, A. Accessibility of nano-crossbar arrays of resistive switching devices. In Proceedings of the 2011 11th IEEE Conference on Nanotechnology (IEEE-NANO), Portland, OR, USA, 15–18 August 2011; pp. 1767–1771.
- Cong, J.; Xiao, B. mrFPGA: A novel FPGA architecture with memristor-based reconfiguration. In Proceedings of the 2011 IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH), San Diego, CA, USA, 8–9 June 2011; pp. 1–8.
- Tanachutiwat, S.; Liu, M.; Wang, W. FPGA Based on Integration of CMOS and RRAM. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2011, 19, 2023–2032. [Google Scholar] [CrossRef]
- Ebong, I.; Mazumder, P. Self-controlled writing and erasing in a memristor crossbar memory. IEEE Trans. Nanotechnol. 2011, 10, 1454–1463. [Google Scholar] [CrossRef]
- Nandha Kumar, T.; Almurib, H.; Lombardi, F. On the operational features and performance of a memristor-based cell for a LUT of an FPGA. In Proceedings of the 2013 13th IEEE Conference on Nanotechnology (IEEE-NANO), Beijing, China, 5–8 August 2013; pp. 71–76.
- Ho, Y.; Huang, G.; Li, P. Dynamical properties and design analysis for nonvolatile memristor memories. IEEE Trans. Circuits Syst. I Regul. Pap. 2011, 58, 724–736. [Google Scholar] [CrossRef]
- Lin, M.; El Gamal, A. A routing fabric for monolithically stacked 3D-FPGA. In Proceedings of the 2007 ACM/SIGDA 15th International Symposium on Field Programmable Gate Arrays, FPGA ’07, Monterey, CA, USA, 18–20 February 2007; ACM: New York, NY, USA, 2007; pp. 3–12. [Google Scholar]
- Dehon, A. Nanowire-based programmable architectures. J. Emerg. Technol. Comput. Syst. 2005, 1, 109–162. [Google Scholar] [CrossRef]
- Kuon, I.; Rose, J. Measuring the gap between FPGAs and ASICs. In Proceedings of the 2006 ACM/SIGDA Tenth International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 24–26 February 2006; pp. 21–30.
- Actel, Inc. Automotive ProASIC3 Flash Family FPGAs Datasheet; Actel. Inc.: Dover, NJ, USA, 2007. [Google Scholar]
- Xilinx. Virtex-II Pro / Virtex-II Pro X Complete Data Sheet (All Four Modules); PXilinx Inc.: San Jose, CA, USA, 2007. [Google Scholar]
- Lewis, D.; Ahmed, E.; Baeckler, G.; Betz, V.; Bourgeault, M.; Cashman, D.; Galloway, D.; Hutton, M.; Lane, C.; Lee, A.; et al. The Stratix II logic and routing architecture. In Proceedings of the 2005 ACM/SIGDA 13th International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 20–22 February 2005; pp. 14–20.
- Ahmed, E.; Rose, J. The effect of LUT and cluster size on deep-submicron FPGA performance and density. In Proceedings of the 2000 ACM/SIGDA Eighth International Symposium on Field Programmable Gate Arrays, Monterey, CA, USA, 9–11 February 2000.
- Zhang, Y.; Zhao, W.; Lakys, Y.; Klein, J.O.; Kim, J.V.; Ravelosona, D.; Chappert, C. Compact modeling of perpendicular-anisotropy CoFeB/MgO magnetic tunnel junctions. IEEE Trans. Electron Dev. 2012, 59, 819–826. [Google Scholar] [CrossRef]
- Vincent, A.; Locatelli, N.; Klein, J.O.; Zhao, W.; Galdin-Retailleau, S.; Querlioz, D. Analytical macrospin modeling of the stochastic switching time of spin-transfer torque devices. IEEE Trans. Electron Dev. 2015, 62, 164–170. [Google Scholar] [CrossRef]
- Zhu, J.G.J.; Park, C. Magnetic tunnel junctions. Mater. Today 2006, 9, 36–45. [Google Scholar] [CrossRef]
- Yagami, K.; Tulapurkar, A.; Fukushima, A.; Suzuki, Y. Inspection of intrinsic critical currents for spin-transfer magnetization switching. IEEE Trans. Magnet. 2005, 41, 2615–2617. [Google Scholar] [CrossRef]
- Fukushima, A.; Seki, T.; Yakushiji, K.; Kubota, H.; Imamura, H.; Yuasa, S.; Ando, K. Spin dice: A scalable truly random number generator based on spintronics. Appl. Phys. Express 2014, 7, 083001. [Google Scholar] [CrossRef]
- Balatti, S.; Ambrogio, S.; Carboni, R.; Milo, V.; Wang, Z.; Calderoni, A.; Ramaswamy, N.; Ielmini, D. Physical unbiased generation of random numbers with coupled resistive switching devices. IEEE Trans. Electron Dev. 2016, 63, 2029–2035. [Google Scholar] [CrossRef]
- Zhao, W.; Belhaire, E.; Javerliac, V.; Chappert, C.; Dieny, B. A non-volatile flip-flop in magnetic FPGA chip. In Proceedings of the International Conference on Design and Test of Integrated Systems in Nanoscale Technology, DTIS 2006, La Marsa, Tunisia, 5–7 September 2006; pp. 323–326.
- Betz, V.; Rose, J. FPGA routing architecture: Segmentation and buffering to optimize speed and density. In Proceedings of the 1999 ACM/SIGDA Seventh International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 1999; pp. 59–68.
- DeHon, A. Balancing interconnect and computation in a reconfigurable computing array. In Proceedings of the 1999 ACM/SIGDA Seventh International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 1999.
- Ciccarelli, L.; Loparco, D.; Innocenti, M.; Lodi, A.; Mucci, C.; Rolandi, P. A low-power routing architecture optimized for deep sub-micron FPGAs. In Proceedings of the 2006 IEEE Custom Integrated Circuits, San Jose, CA, USA, 10–13 September 2006; pp. 309–312.
- Pedram, M.; Nobandegani, B.; Preas, B. Design and analysis of segmented routing channels for row-based FPGAs. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 1994, 13, 1470–1479. [Google Scholar] [CrossRef]
- Betz, V.; Rose, J. VPR: A new packing, placement and routing tool for FPGA research. In Proceedings of the 7th International Workshop on Field-Programmable Logic and Applications, London, UK, 1–3 September 1997; pp. 213–222.
- Martinello, O., Jr.; Marques, F.S.; Ribas, R.P.; Reis, A.I. KL-cuts: A new approach for logic synthesis targeting multiple output blocks. In Proceedings of the Conference on Design, Automation and Test in Europe, DATE ’10, Dresden, Germany, 8–12 March 2010; European Design and Automation Association: Leuven, Belgium, 2010; pp. 777–782. [Google Scholar]
- Kahng, A.; Robins, G. A new class of iterative Steiner tree heuristics with good performance. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 1992, 11, 893–902. [Google Scholar] [CrossRef]
- Ebeling, C.; McMurchie, L.; Hauck, S.; Burns, S. Placement and routing tools for the Triptych FPGA. IEEE Trans. Very Large Scale Integr. Syst. 1995, 3, 473–482. [Google Scholar] [CrossRef]
- Cao, Y.; Sato, T.; Orshansky, M.; Sylvester, D.; Hu, C. New paradigm of predictive MOSFET and interconnect modeling for early circuit simulation. In Proceedings of the IEEE Custom Integrated Circuits Conference (CICC), Orlando, FL, USA, 21–24 May 2000; pp. 201–204.
- Lemieux, G.; Lewis, D. Circuit design of routing switches. In Proceedings of the 2002 ACM/SIGDA Tenth International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 24–26 February 2002; pp. 19–28.
- Ahmed, E.; Rose, J. The effect of LUT and cluster size on deep-submicron FPGA performance and density. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2004, 12, 288–298. [Google Scholar] [CrossRef]
- Zhao, W.; Belhaire, E.; Chappert, C.; Mazoyer, P. Spin transfer torque (STT)-MRAM-based runtime reconfiguration FPGA circuit. ACM Trans. Embed. Comput. Syst. (TECS) 2009, 14, 2–9. [Google Scholar] [CrossRef]
- Abid, Z.; Liu, M.; Wang, W. 3D integration of CMOL structures for FPGA applications. IEEE Trans. Comput. 2011, 60, 463–471. [Google Scholar] [CrossRef]
- Liu, M.; Wang, W. rFGA: CMOS-nano hybrid FPGA using RRAM components. In Proceedings of the 2013 IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH), Anaheim, CA, USA, 12–13 June 2008; pp. 93–98.
- Li, F.; Lin, Y.; He, L.; Chen, D.; Cong, J. Power modeling and characteristics of field programmable gate arrays. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2005, 24, 1712–1724. [Google Scholar]
- Li, F.; Lin, Y.; He, L.; Chen, D.; Cong, J. Behavior of stochastic circuits under severe error conditions. IT Inf. Technol. 2014, 4, 182–191. [Google Scholar]
- Fukami, S.; Yamanouchi, M.; Koyama, T.; Ueda, K.; Yoshimura, Y.; Kim, K.-J.; Chiba, D.; Honjo, H.; Sakimura, N.; Nebashi, R.; et al. High-speed and reliable domain wall motion device: Material design for embedded memory and logic application. In Proceedings of the 2012 Symposium on VLSI Technology (VLSIT), Honolulu, HI, USA, 12–14 June 2012; Volume 63, pp. 61–62.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 301.3 | 305.1 | 250.2 | 522.4 | 478.1 |
| STT-MRAM | Proposed | |
|---|---|---|
| transistor count | 154 MOS + 32 MTJ | 6 MOS + 32 MTJ |
| active power () | 13.4 | 3.22 |
| standby power () | 0 | 0 |
| Design | Conv. 2D Arch. | RRAM FPGA [39] | 3D CMOS FPGA [10,40] | 3D rFPGA [41] | Proposed SPGA Arch. | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| # of | Area | Delay | Power | # of | Area | Delay | Power | # of | Area | Delay | Power | # of | Area | Delay | Power | # of | Area | Delay | Power | |
| LUTs | ) | (ns) | (mW) | LUTs | ) | (ns) | (mW) | LUTs | ) | (ns) | (mW) | LUTs | ) | (ns) | (mW) | LUTs | ) | (ns) | (mW) | |
| alu4 | 512 | 1.37 | 7.13 | 62 | 512 | 0.87 | 17.5 | 54 | 512 | 6.88 | 3.64 | 56.2 | 512 | 5.86 | 3.64 | 46.6 | 63 | 1.44 | 4.13 | 10.78 |
| apex2 | 706 | 1.66 | 8.6 | 67 | 706 | 0.88 | 18.77 | 55 | 706 | 8.3 | 4.38 | 62.1 | 706 | 6.18 | 4.38 | 53.1 | 109 | 2.11 | 4.34 | 11.22 |
| apex4 | 618 | 4.14 | 7.3 | 42 | 618 | 2.01 | 17.6 | 37 | 618 | 20.73 | 3.74 | 40.3 | 618 | 11.54 | 3.74 | 29.8 | 131 | 3.18 | 4.22 | 12.2 |
| mise3 | 500 | 4.62 | 7.42 | 51.3 | 500 | 2.88 | 17.42 | 47.02 | 500 | 6.2 | 3.37 | 49.9 | 500 | 4.76 | 3.37 | 38.4 | 97 | 1.98 | 4.11 | 10.98 |
| diffeq | 526 | 3.91 | 5.56 | 24 | 526 | 2.05 | 15.77 | 19 | 526 | 5.01 | 3.24 | 25.2 | 526 | 4.38 | 3.24 | 23.2 | 139 | 3.19 | 4.23 | 12.36 |
| elliptic | 133 | 2.30 | 10.7 | 69 | 133 | 1.65 | 21 | 58 | 133 | 10.68 | 5.96 | 70.2 | 133 | 7.19 | 5.96 | 58.7 | 158 | 3.58 | 5.37 | 20.6 |
| ex1010 | 612 | 1.24 | 14.6 | 113 | 612 | 0.75 | 25.6 | 105 | 612 | 19.56 | 5.94 | 116 | 612 | 11.32 | 5.94 | 97.9 | 113 | 2.38 | 4.85 | 11.31 |
| frisc | 1905 | 1.6 | 13.3 | 62.7 | 1905 | 0.8 | 24.5 | 56.5 | 1905 | 11.5 | 6.95 | 67.2 | 1905 | 8.54 | 6.95 | 68.3 | 176 | 4.33 | 4.58 | 30.83 |
| seq | 739 | 2.64 | 8.4 | 65 | 739 | 1.82 | 19.5 | 55 | 739 | 7.5 | 3.74 | 62 | 739 | 5.5 | 3.74 | 50.2 | 118 | 2.41 | 4.15 | 11.86 |
| spla | 449 | 1.37 | 13.3 | 87 | 449 | 16.3 | 5.67 | 95.4 | 449 | 0.74 | 24.3 | 78 | 449 | 9.03 | 5.67 | 55.7 | 116 | 2.39 | 4.51 | 11.45 |
| pdc | 276 | 4.38 | 16.8 | 101 | 276 | 2.77 | 18.8 | 96 | 276 | 18.4 | 7.69 | 107 | 276 | 10.76 | 7.69 | 77.5 | 141 | 3.22 | 5.75 | 15.81 |
| tseng | 539 | 1.66 | 6.96 | 29 | 539 | 0.83 | 3.48 | 25 | 539 | 3.92 | 3.54 | 30.1 | 539 | 3.89 | 3.54 | 29.8 | 108 | 2.05 | 3.88 | 11.12 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, Y.; Lin, M. Stochastic-Based Spin-Programmable Gate Array with Emerging MTJ Device Technology. J. Low Power Electron. Appl. 2016, 6, 15. https://doi.org/10.3390/jlpea6030015
Bai Y, Lin M. Stochastic-Based Spin-Programmable Gate Array with Emerging MTJ Device Technology. Journal of Low Power Electronics and Applications. 2016; 6(3):15. https://doi.org/10.3390/jlpea6030015
Chicago/Turabian StyleBai, Yu, and Mingjie Lin. 2016. "Stochastic-Based Spin-Programmable Gate Array with Emerging MTJ Device Technology" Journal of Low Power Electronics and Applications 6, no. 3: 15. https://doi.org/10.3390/jlpea6030015
APA StyleBai, Y., & Lin, M. (2016). Stochastic-Based Spin-Programmable Gate Array with Emerging MTJ Device Technology. Journal of Low Power Electronics and Applications, 6(3), 15. https://doi.org/10.3390/jlpea6030015