1. Introduction
Transformer architectures have emerged as the cornerstone of modern AI, being used as large foundation models that achieve State-of-the-Art (SoA) accuracy in tasks like natural language processing [
1,
2] computer vision [
3,
4], audio [
5,
6], and even multi-modal applications [
7,
8]. However, SoA Transformer designs often prioritize foundational capabilities vs. computational affordability, resulting in architectures scaling up to billions of learnable parameters [
9]. This scale leads to high computational costs and substantial memory requirements even when targeting deployment on mobile (edge) hardware platforms, preventing deployment on resource-constrained platforms, such as TinyML (extreme edge) devices based on single- or multi-core Microcontroller Units (MCUs).
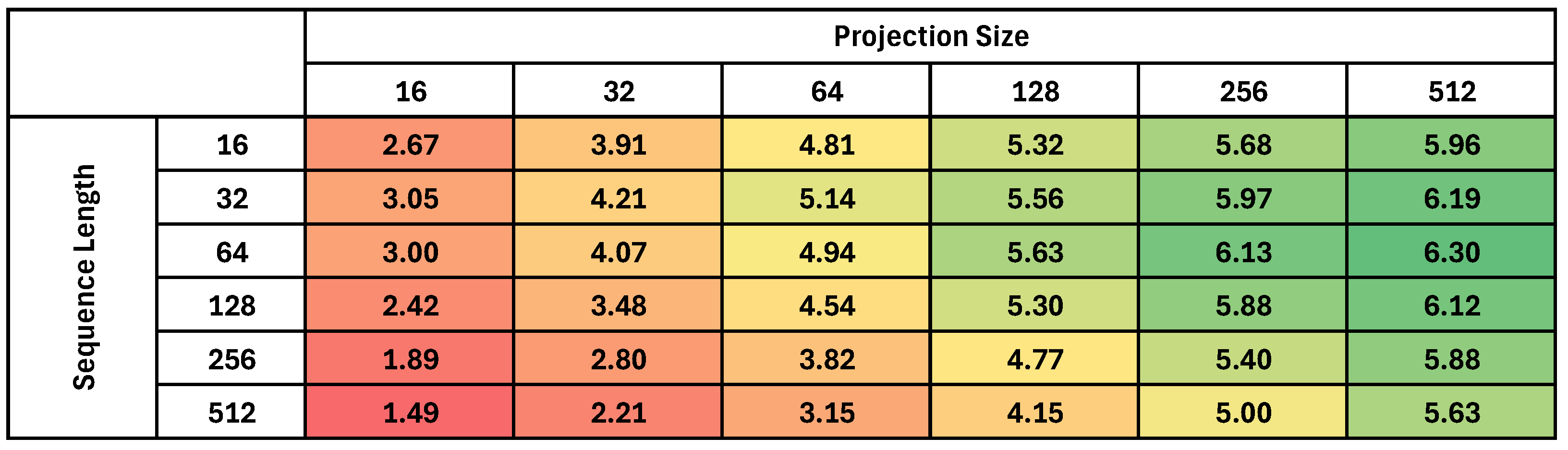
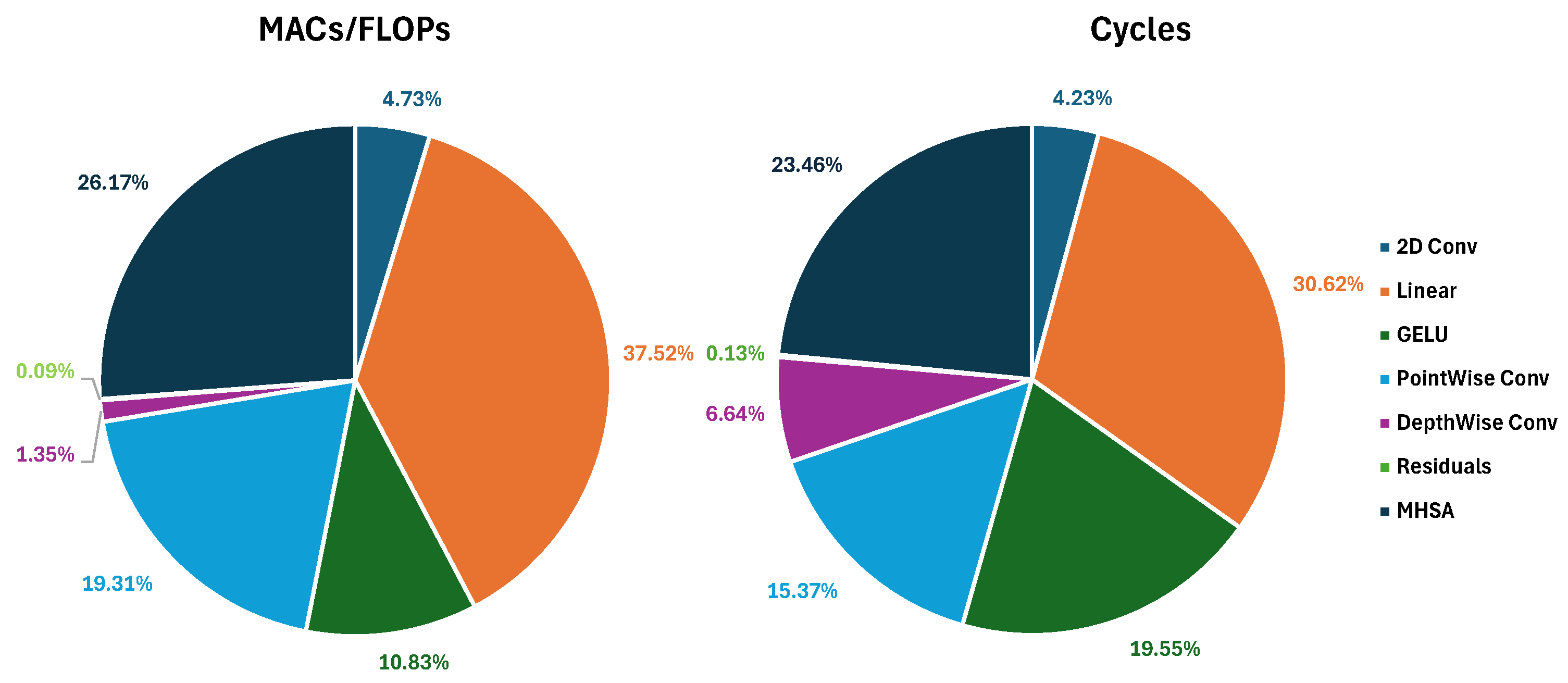
Besides sheer scale, another significant barrier to deploying transformers on TinyML hardware lies in their reliance on computationally expensive operations. For example, the softmax function, integral to the Attention mechanisms, is challenging to optimize for edge devices due to the dependency of each of its outputs on multiple inputs, requiring multiple passes over the Attention matrix to be calculated. Additionally, the quadratic scaling in the number of operations required by Multi-Head Attention layers makes direct deployment infeasible without significant modification or optimization.
In this work, we develop a methodology tailored to overcome these challenges, enabling the deployment of Transformer-based models on battery-powered, ultra-low-power devices. Unlike existing SoA approaches that primarily rely on aggressive quantization to int-8 or int-4 precision [
10], we aim at enabling the usage of Transformers on TinyML devices without requiring any quantization-aware fine-tuning or post-training quantization. These operations typically require a calibration set and significant computational resources for retraining. Instead, we leverage higher-precision formats, such as 32-bit and 16-bit floating-point. Specifically, we analyze the tradeoffs of pruning encoder layers from pre-trained Transformer models. Focusing on task-specific requirements demonstrates that many encoder layers can be removed, leading to drastic reductions in memory usage and energy consumption. Remarkably, this pruning can be achieved with little to no loss in accuracy, making it a viable approach for creating efficient, task-specific models suitable for constrained environments out of general (foundation) pre-trained models. To complement the drastic model complexity reduction, we also present optimizations for the matmul function, the most prominent operation in the Transformer networks targeting state-of-the-art RISC-V multi-core microcontrollers, exploiting the RV32IMFC Instruction Set Architecture (ISA). Lastly, we show that the complexity of the exponential function can be reduced by ∼2× by exploiting Schraudolph’s approximation [
11] while introducing a tolerable error of less than 2%.
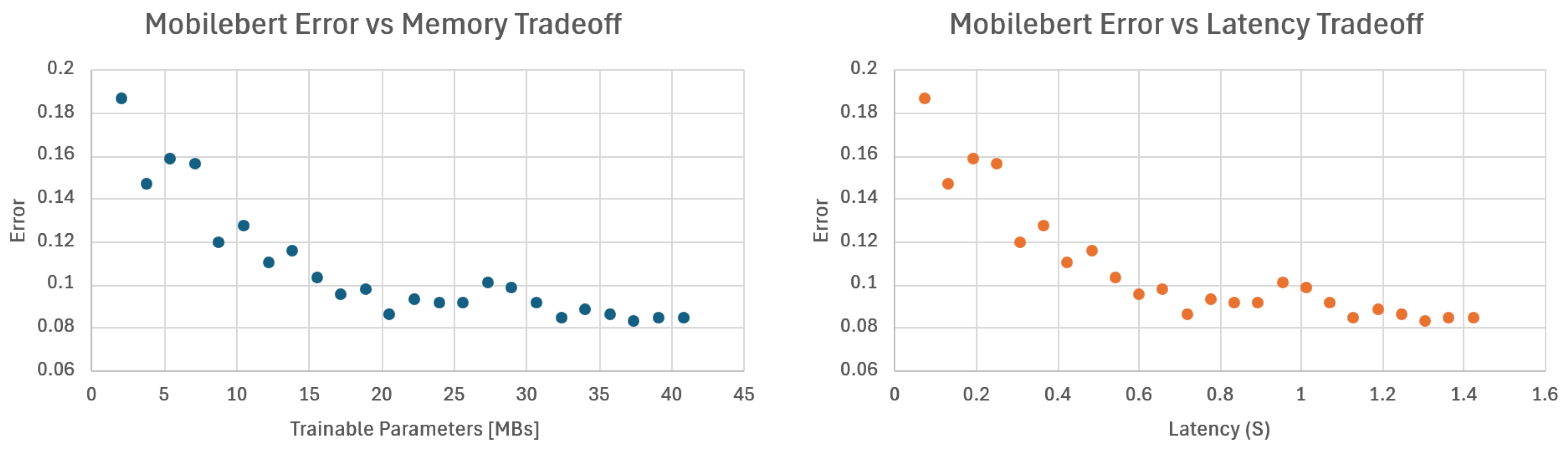
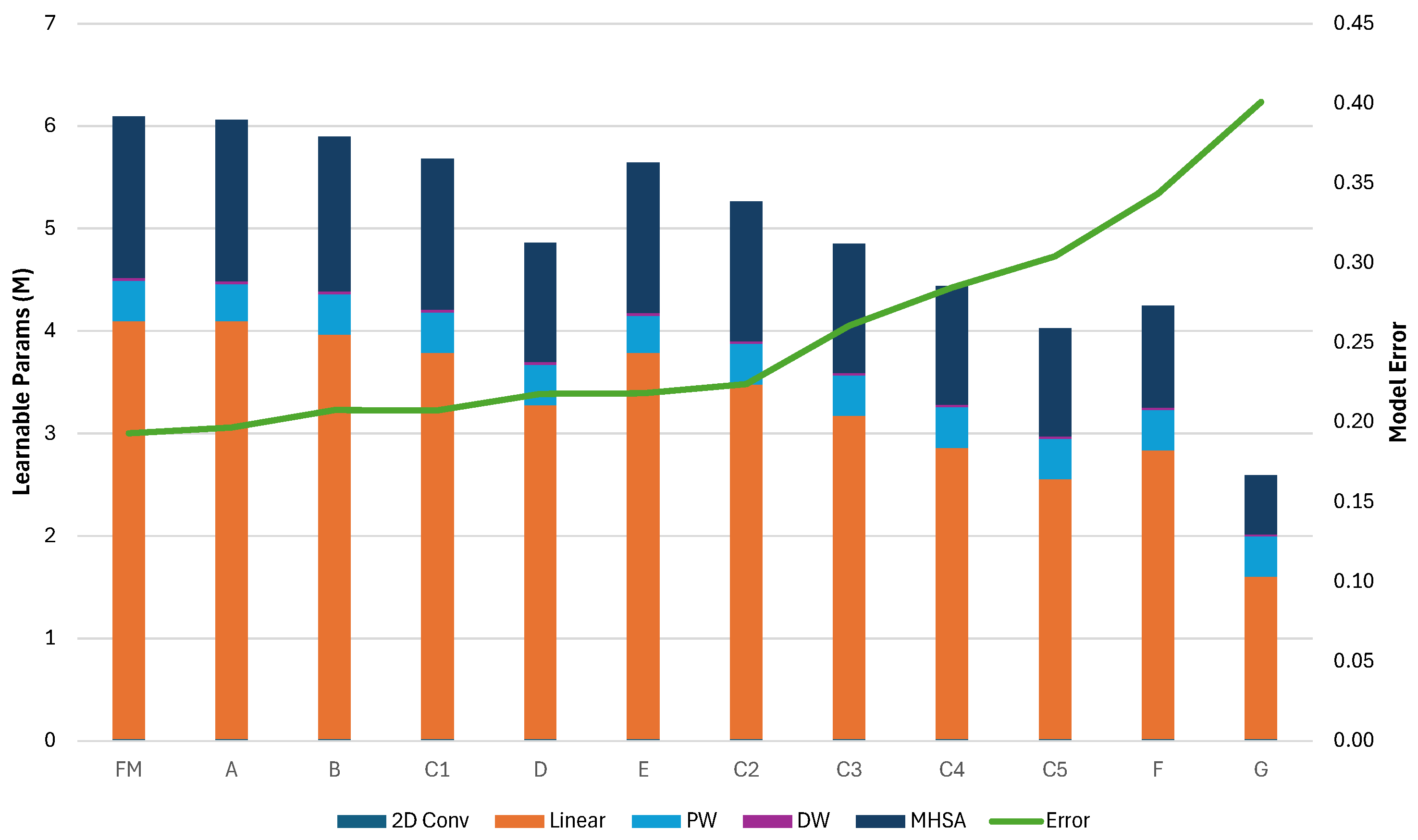
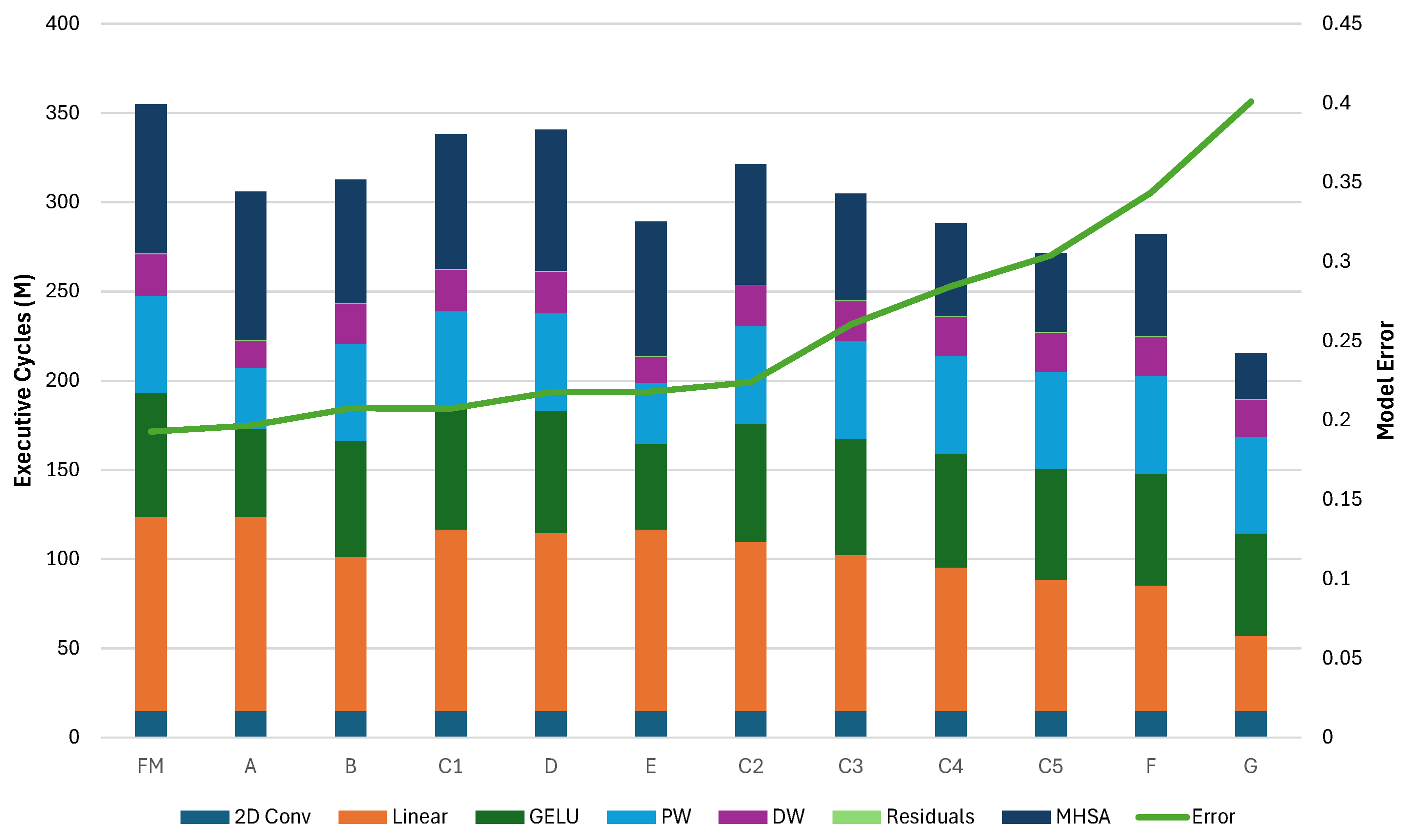
To demonstrate the effectiveness of our methodology, we present the pruning and deployment of three mobile-grade Transformer architectures: MobileBert, tinyViT, and tinyLLAMA2. For the MobileBert architecture, we have removed all but one of the encoder layers, reducing, in this way, the total memory footprint of the model by 94.9% while achieving a 19× speedup from the baseline architecture. Evaluation of the GLUE benchmark sentiment analysis task shows that this aggressively pruned version of the model retains an accuracy error (number of misclassified instances over the total) below 19% (compared to for the full model). We explore accuracy/efficiency tradeoffs for the TinyViT model by removing some of the Attention blocks from varying depths in the architecture. We show that we can reduce the memory footprint for learnable parameters and inference latency up to ∼57% and ∼39%, respectively, by pruning all encoders but with an increase of ∼20% of final accuracy error compared to the original model. A possible tradeoff is pruning only the last encoder, achieving ∼20% memory reduction while limiting the accuracy loss to ∼2.5%.
Lastly, for tinyLLAMA2, we start from a model that is already adequately small [
12], and we focus on inference speed. Our optimizations reduce the total number of cycles required for the generation of 256 tokens from
to only
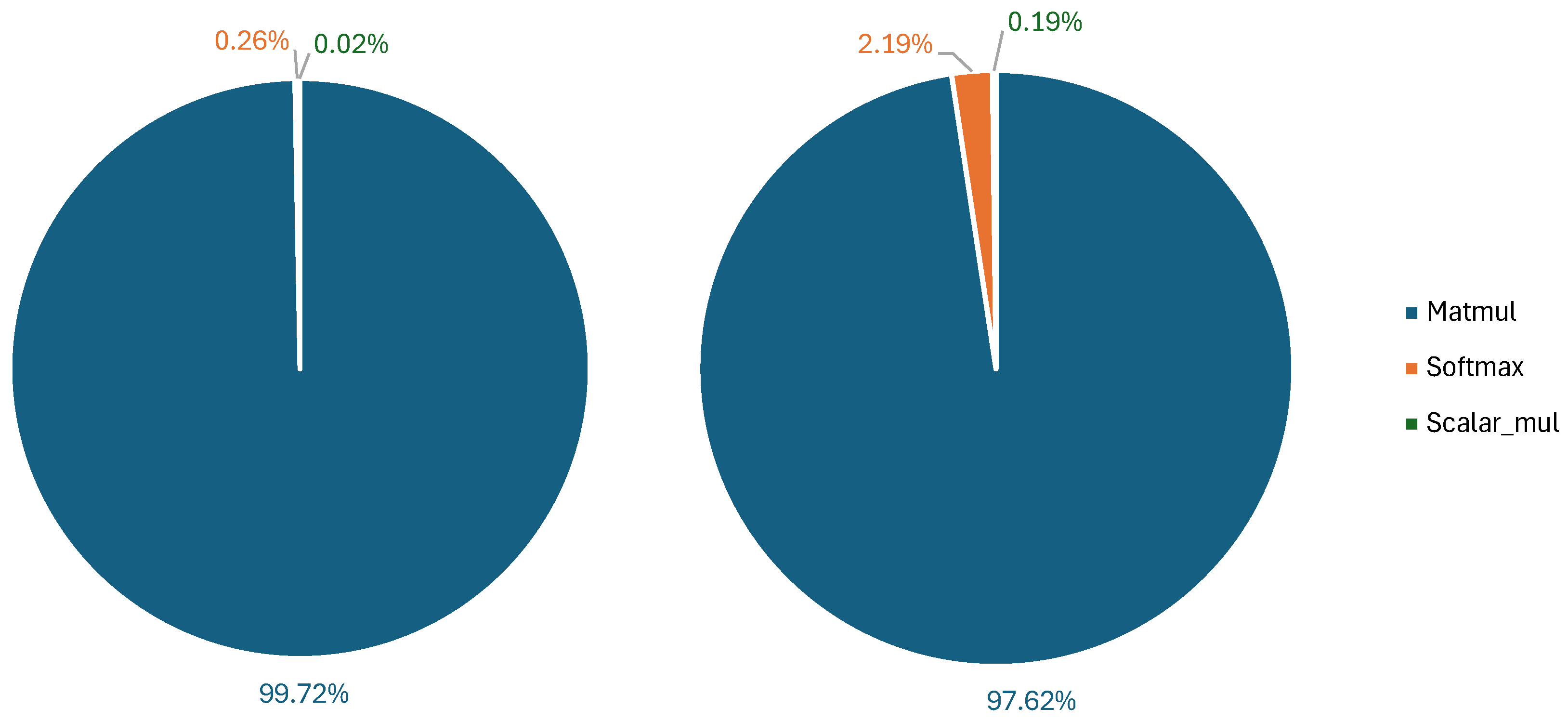
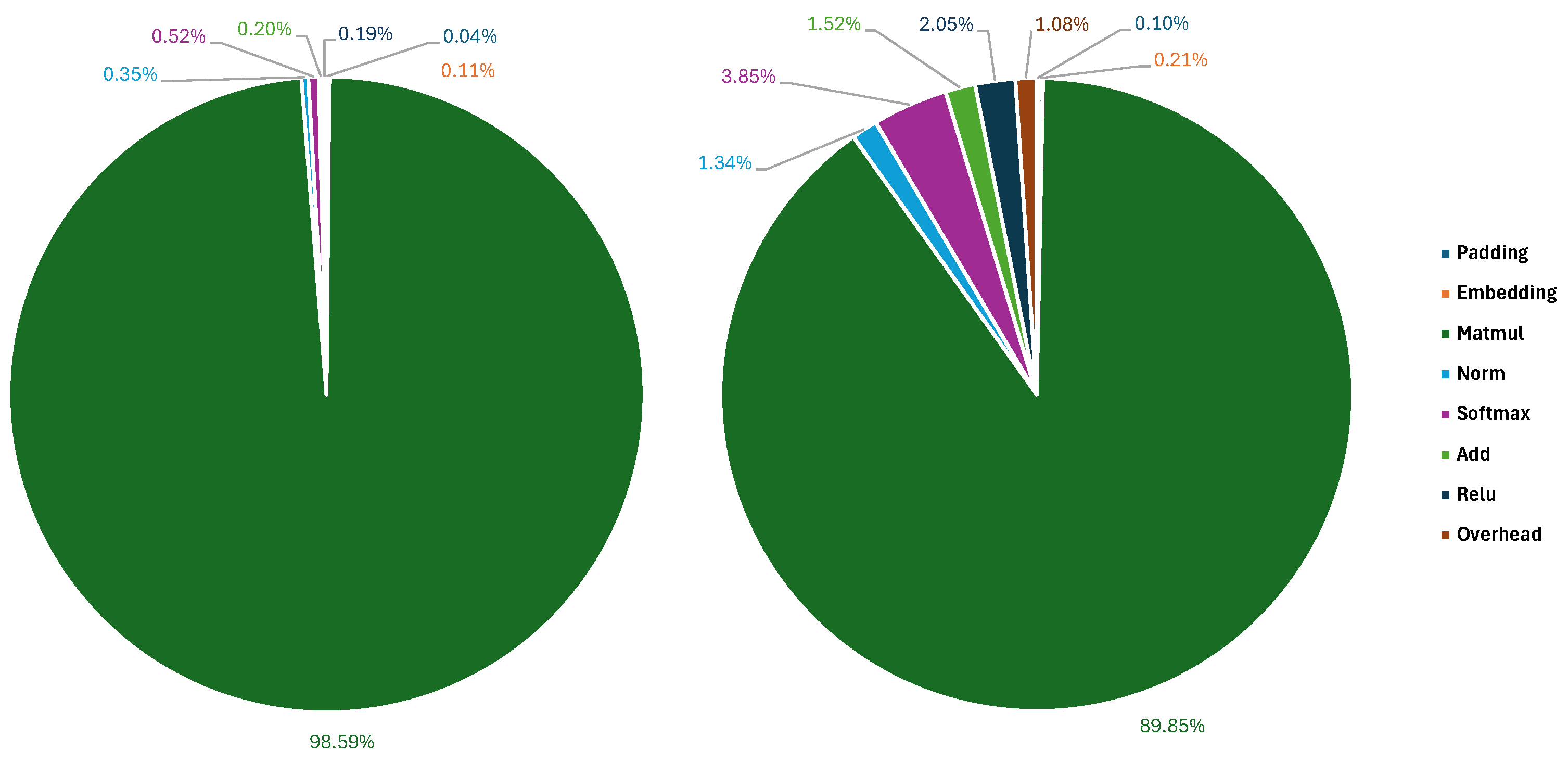
cycles—a ∼10× improvement. In particular, on matrix multiplications, which represent ∼50% of the total amount of operations in the network, we achieve an 18.7× speedup.
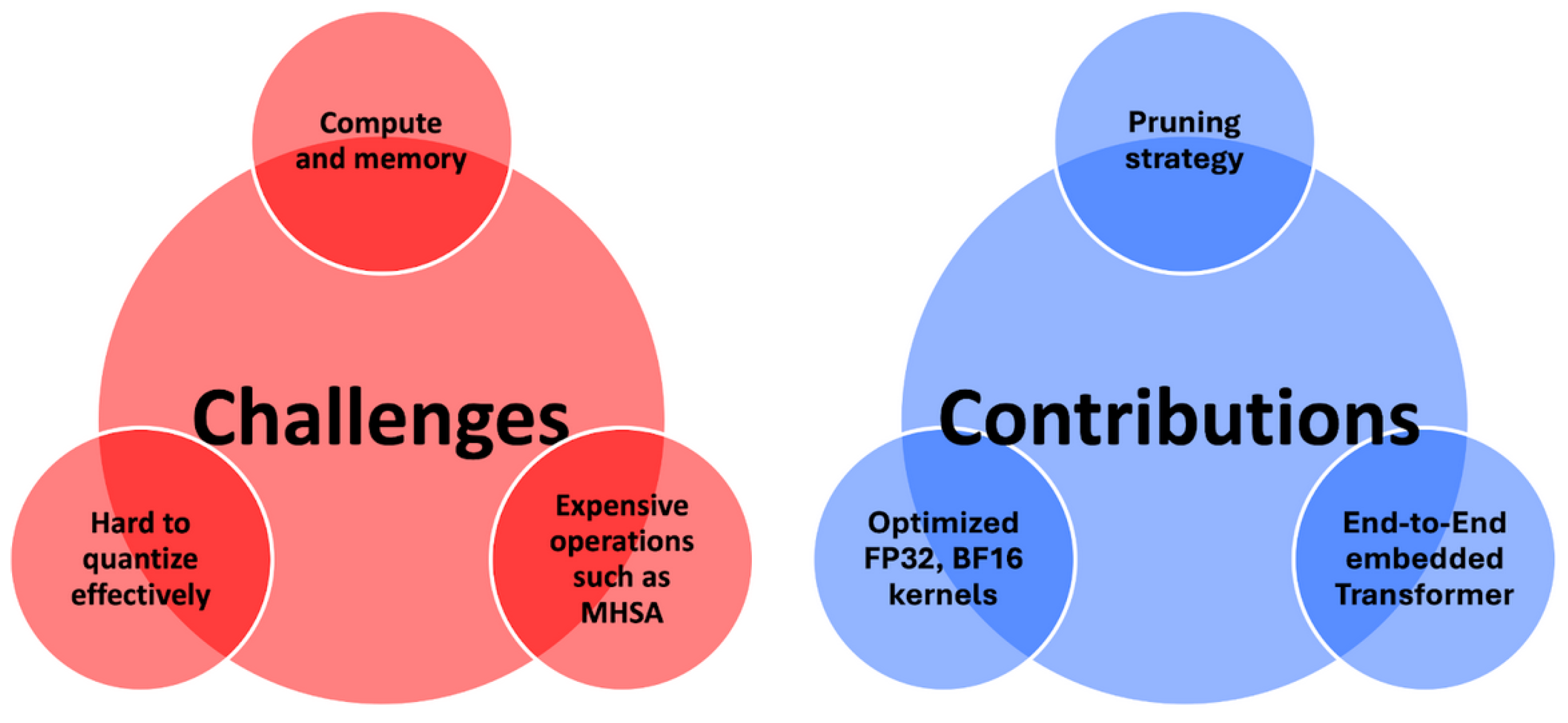
In summary, this work makes the following novel contributions, also summarized in the conceptual diagram in
Figure 1:
A methodology for deploying Transformer-based models on resource-constrained platforms without reliance on aggressive quantization techniques.
An analysis of pruning techniques for encoder layers to reduce memory and energy footprints with controlled accuracy loss.
Experimental results on MobileBert, tinyViT, and tinyLLAMA2, demonstrating the practicality and effectiveness of our approach.
By addressing both architectural inefficiencies and operational bottlenecks, our work lays the foundation for scalable, efficient, and accurate Transformer deployments, bridging the gap between the computational demands of this class of architectures and the limitations of ultra-low-power hardware, enabling Transformer-based applications in scenarios previously deemed impractical due to resource constraints. We release all of our methods and results as open-source code at
https://github.com/Dequino/pulp-trainlib/tree/jlpea (accessed on 1 February 2025).
The rest of this paper is structured as follows: In
Section 2, we discuss current techniques for efficient Transformer deployment, focusing on approaches based on quantization and pruning.
Section 3 provides an overview of the fundamental operations in Transformer architectures. In
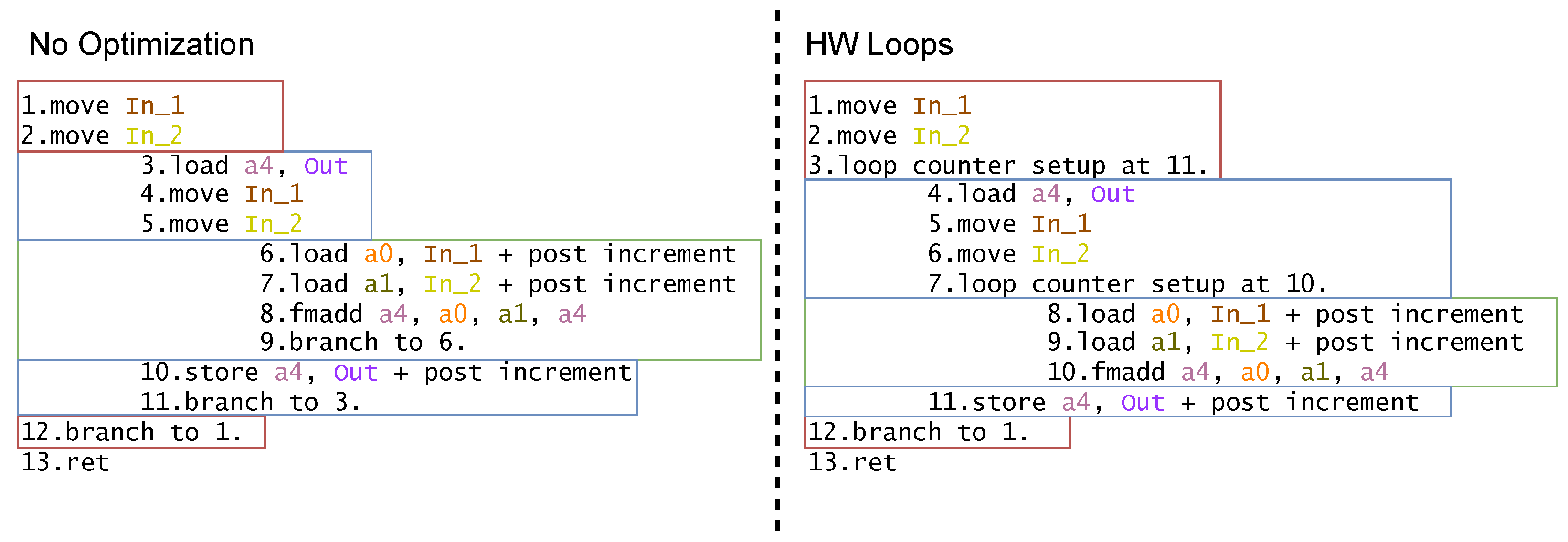
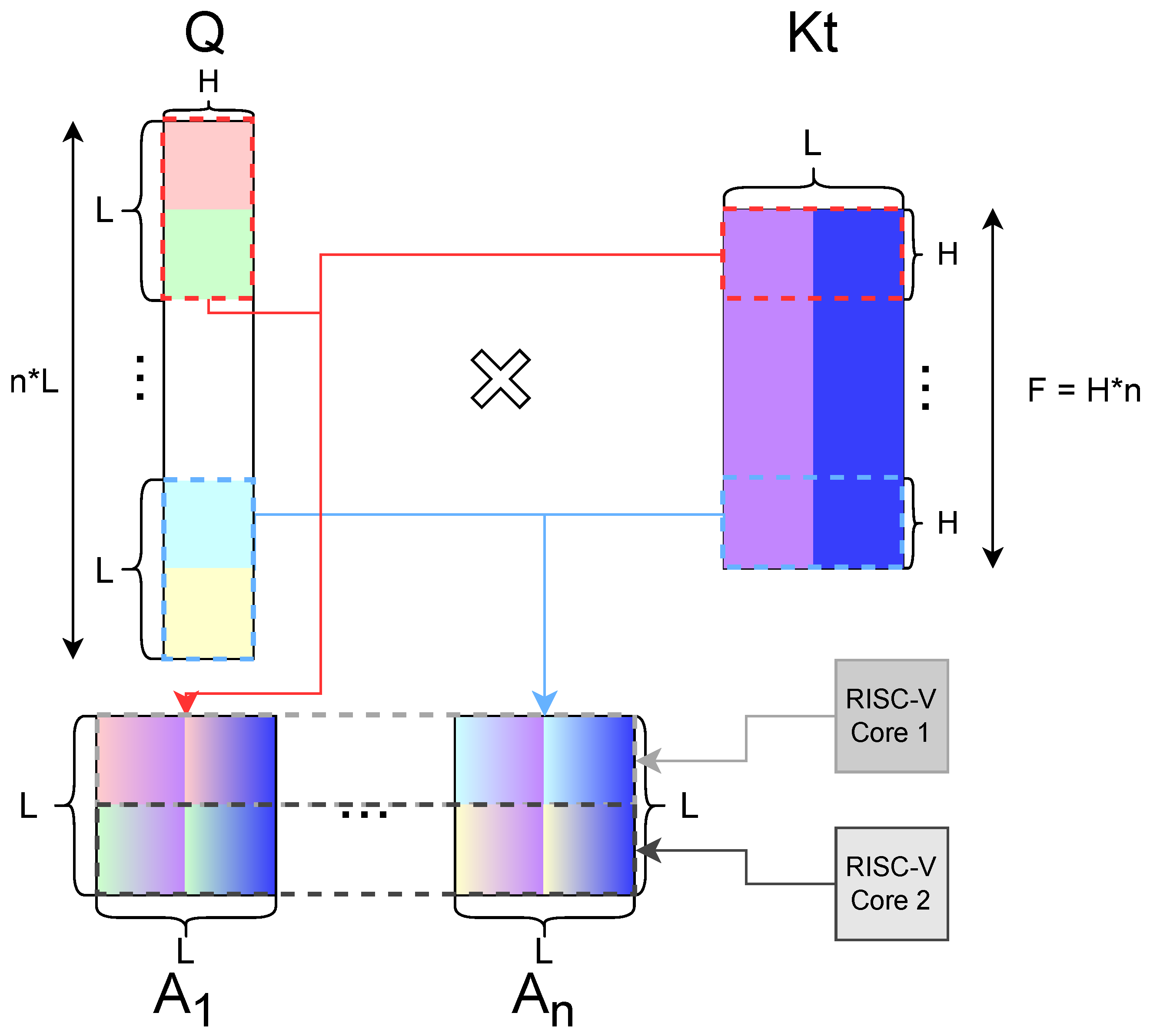
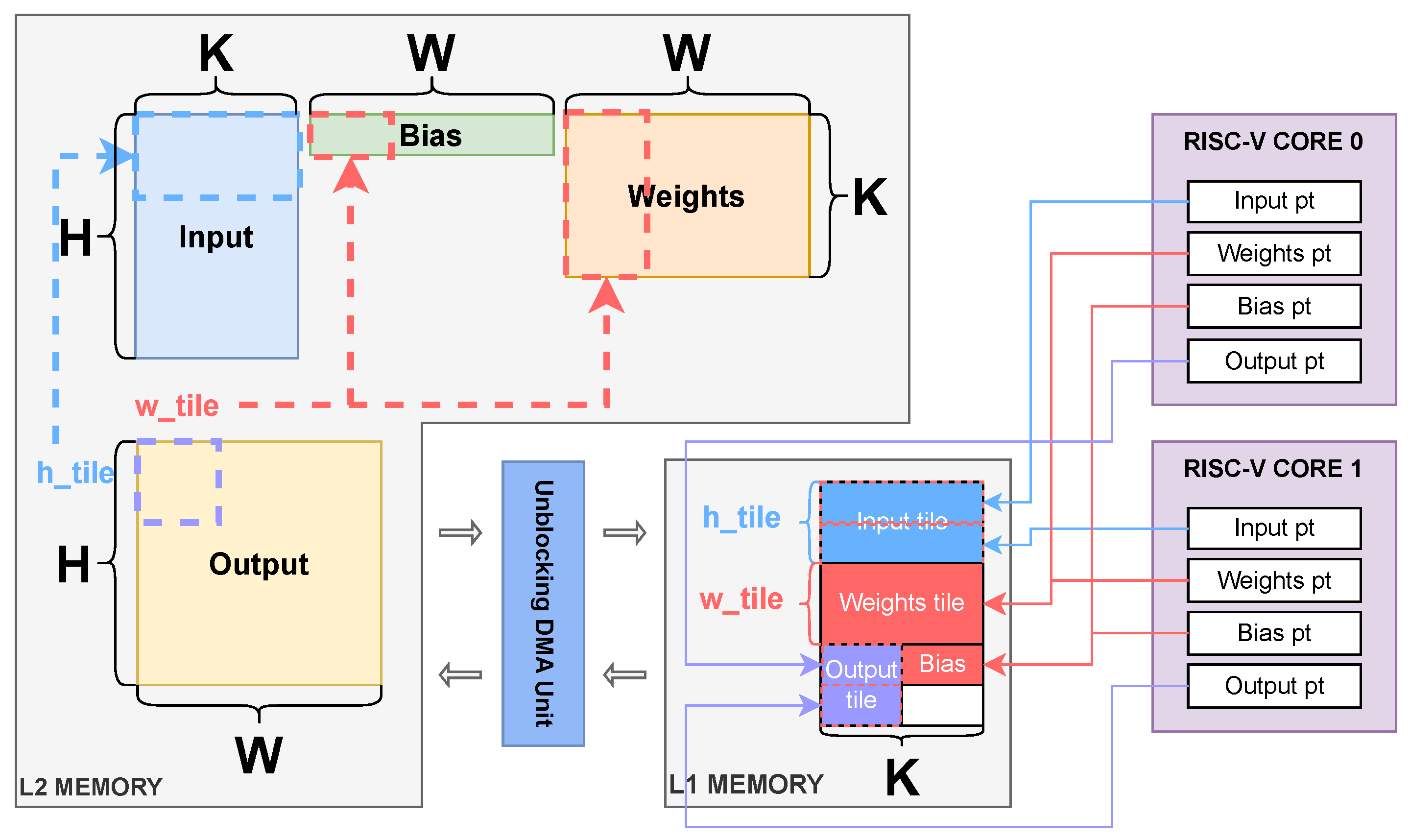
Section 4, we present the optimizations introduced in this work.
Section 5 outlines the results obtained for the selected architectures, demonstrating the effectiveness of our approach. Finally,
Section 6 summarizes our work.
2. Related Work
Deploying Transformer models on low-power devices, such as microcontrollers, necessitates optimizations to address their limited computational resources and stringent energy constraints. One prominent approach is quantizing networks into low-bit integer formats, such as INT8 or INT4. Quantization reduces the memory footprint of the network and eliminates the need for complex hardware capable of floating-point operations, enabling inference on cheaper and more energy-efficient hardware. By quantizing floating-point computations into integer arithmetic, faster execution and lower energy consumption can be achieved. Thus, quantization has become a key strategy for deploying Transformers on resource-constrained devices. An example is I-BERT [
13], which uses a fully integer-based implementation for Transformer operations, approximating the GELU and softmax operations of the BERT architecture with second-order polynomials. A similar quantization scheme is adopted in SwiftTron [
14] to apply to a matrix multiplication accelerator.
Other methods relying on integer-quantization are Sparse-Quantized Representations (SpQRs) [
15], in which weights are quantized mostly to 3–4 bits except for the outliers, which are identified as those weights that cause the highest quantization error, which are kept in the float16 format, allowing the execution of a large language model on consumer-grade GPUs. Other quantization methods are Generative Pre-trained Transformer Quantization (GPTQ) [
16] and Optimal Brain Quantization (OBQ) [
17], which aim to find a quantization scheme that reduces the squared error between the outputs of each layer before and after quantization. GPTQ adopts a block-wise approach, grouping multiple rows of weights and quantizing them to increase computational efficiency. In contrast, OBQ processes the weights row by row, starting with those that have the least impact on the overall quantization error, making it more fine-grained than GPTQ but far less computationally efficient, employing the same amount of time to quantize a model 100× smaller.
For deploying Quantized Neural Networks, Tiny Transformer (TinyFormer) [
18] introduces a comprehensive workflow. It starts with a floating-point PyTorch model, exported as an Open Neural Network Exchange (ONNX) graph. The deployment tool DORY [
19] then processes the ONNX graph to generate optimized C code. This code relies on an extended quantization-aware library to minimize data transfer overhead and maximize data reuse. This approach makes TinyFormer’s deployment workflow the closest point of comparison to our work in the literature.
Another approach to achieving efficiency focuses on pruning the Transformer network architecture. Unlike quantization, which reduces the precision of activations and weights by changing the data type and using fewer bits for representation, pruning focuses on simplifying the model’s topology. It removes less important parts of the model to reduce its size and computational cost, including layers or individual weights, often making it more efficient for inference while retaining the computation in floating-point precision. Despite these differences, both methods aim to improve efficiency while preserving accuracy.
Pruning is mostly divided into two categories: structured and unstructured pruning. In structured pruning, the elements removed from the network follow specific patterns like layers or groups of weights. Some methods include ShearedLLaMa [
20], which applies structured pruning to a pre-existing LLM model by posing the pruning problem as a constrained optimization problem. The method eliminates layers and parameters from the starting model while retaining the original accuracy.When tested on the LLaMa model, the method achieves the best average accuracy on the lm-evaluation-harness [
21] using only 50 Giga tokens from the original 2 Tera tokens training set. Another method, HOMODISTIL [
22], starts from a pre-trained architecture and iteratively removes features from each layer in the network while minimizing the difference between the pruned model and the original output. Applied to the BERT Transformer model, the method reduces the total number of parameters by 35%, losing only 0.8% in average accuracy across six different tasks.
Unstructured pruning, on the other hand, eliminates individual weights within the network. Although it offers finer granularity than structured pruning, it can result in sparse weight matrices, which are more challenging to exploit on general-purpose hardware without specialized libraries. Some examples include Wanda [
23] and SparseGPT [
24]. Both of these methods individuate the weights that impact the output inside the networks less, removing them from the architecture. Both methods allow a reduction of up to 50% of the total weights while causing an accuracy drop that, depending on the original size of the Transformer, can be up to 5% of the original accuracy. Our work focuses on reducing the entire network structure instead of applying quantization. This approach prevents the significant degradation that is often associated with post-training integer quantization in lower-capacity models. By pruning less critical layers in the network architecture, we achieve an efficient design that maintains an accuracy comparable to the baseline model while significantly reducing the total number of parameters and operations without requiring expensive (and often unaffordable) retraining from scratch.
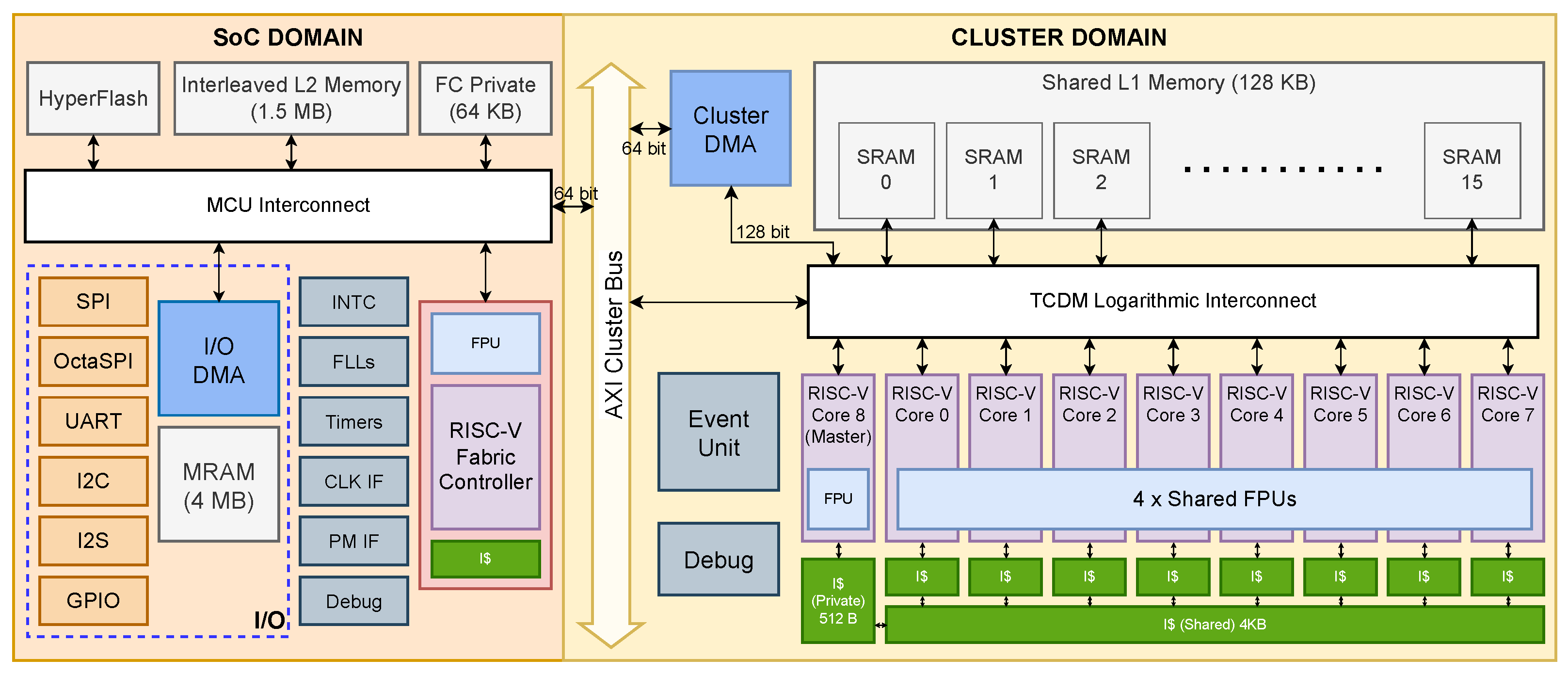
Furthermore, adopting a floating-point format enables our deployed architectures to exploit the existing software infrastructure. Our work extends the PULP-Trainlib [
25], a software open-source framework for high-performance deployment and training of DNNs (Deep Neural Networks) on RISC-V multi-core devices, to support Transformer models.
This library stands out from other frameworks, such as AIfES [
26], which exclusively uses 32-bit floating-point precision. Instead, it is designed to support 32-bit and 16-bit floating-point precision, allowing computational energy and memory reduction with respect to FP32 only, while maintaining high accuracy on IoT (Internet of Things) devices without requiring more fragile integer quantization. In contrast, other libraries such as PULP-NN [
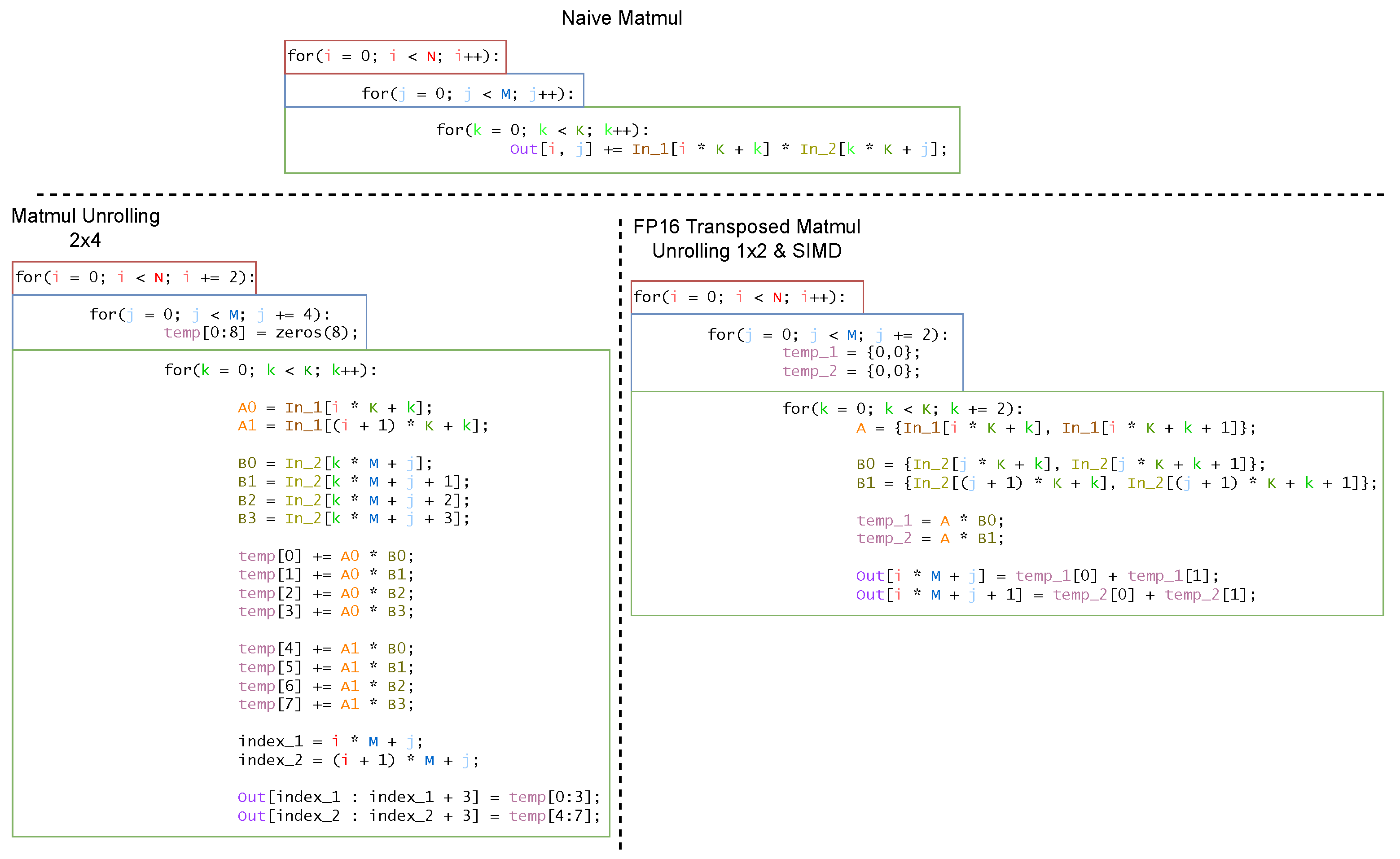
27] are designed exclusively to deploy Quantized Neural Networks in mixed precision, working on 8-bit or lower integer precision. Furthermore, Pulp-Trainlib heavily leverages parallelization and hardware-specific optimization, such as SIMD instructions and non-blocking DMA memory transfers, to enable an almost linear speedup when executing the workload on multiple cores. It also includes a tunable testing environment for profiling and validating singular NN-related kernels and complete ML models.
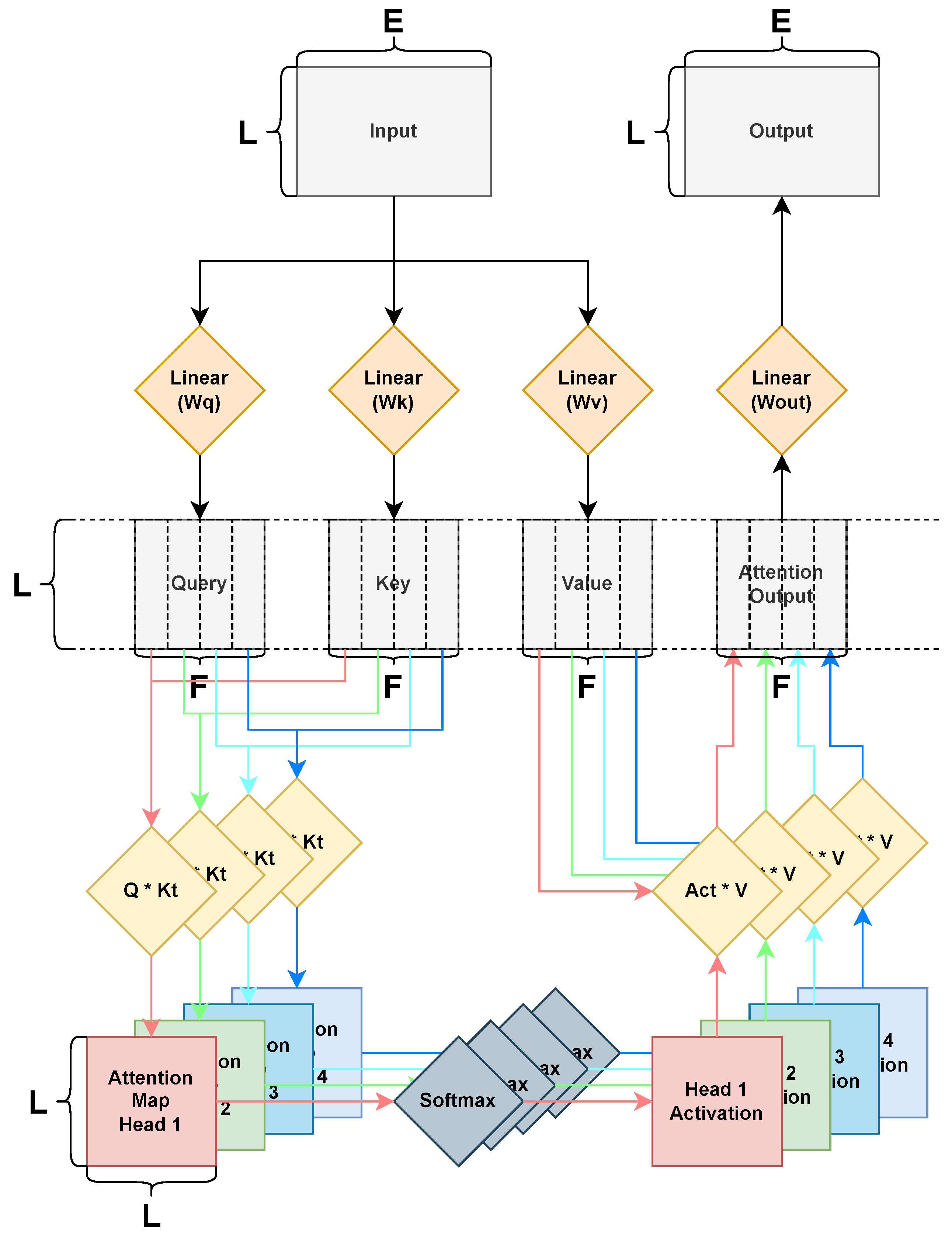
In our work, we extend Pulp-Trainlib to also include Multi-Head Attention, which we leverage for deploying three different Transformer architectures. In the next section, we will provide the necessary background to understand the main building blocks of the Multi-Head Attention kernel, while in
Section 4, we will describe the optimization performed on the Multi-Head Attention kernel and their impact on performance.
6. Conclusions
In this work, we paved the way for the deployment of Tiny Transformers on extreme edge MCUs, without relying on integer quantization schemes, by developing software kernels that achieve up to better performance than naïve C implementations of PyTorch MHSA kernels on BFloat16 accuracy, and by using extensive pruning search, exploiting the intrinsic redundancy of Transformer models. In particular, we demonstrate our deployment methodology on three Transformer-based models: MobileBert, with a memory footprint reduced by and improved latency with an accuracy degradation of ; TinyViT, with memory footprint reduced by up to and reduced latency, but with an accuracy degradation of ; and tinyLLAMA, which did not require model reduction and achieved a throughput of 1219 tokens per second with an energy consumption of 47.5 uJ per token. Our work sets the foundation for deploying high-performance non-quantized Transformer models on commercial off-the-shelf parallel MCUs, showing the possibility of enabling high-accuracy AI capabilities even on cheaper, low-power devices.





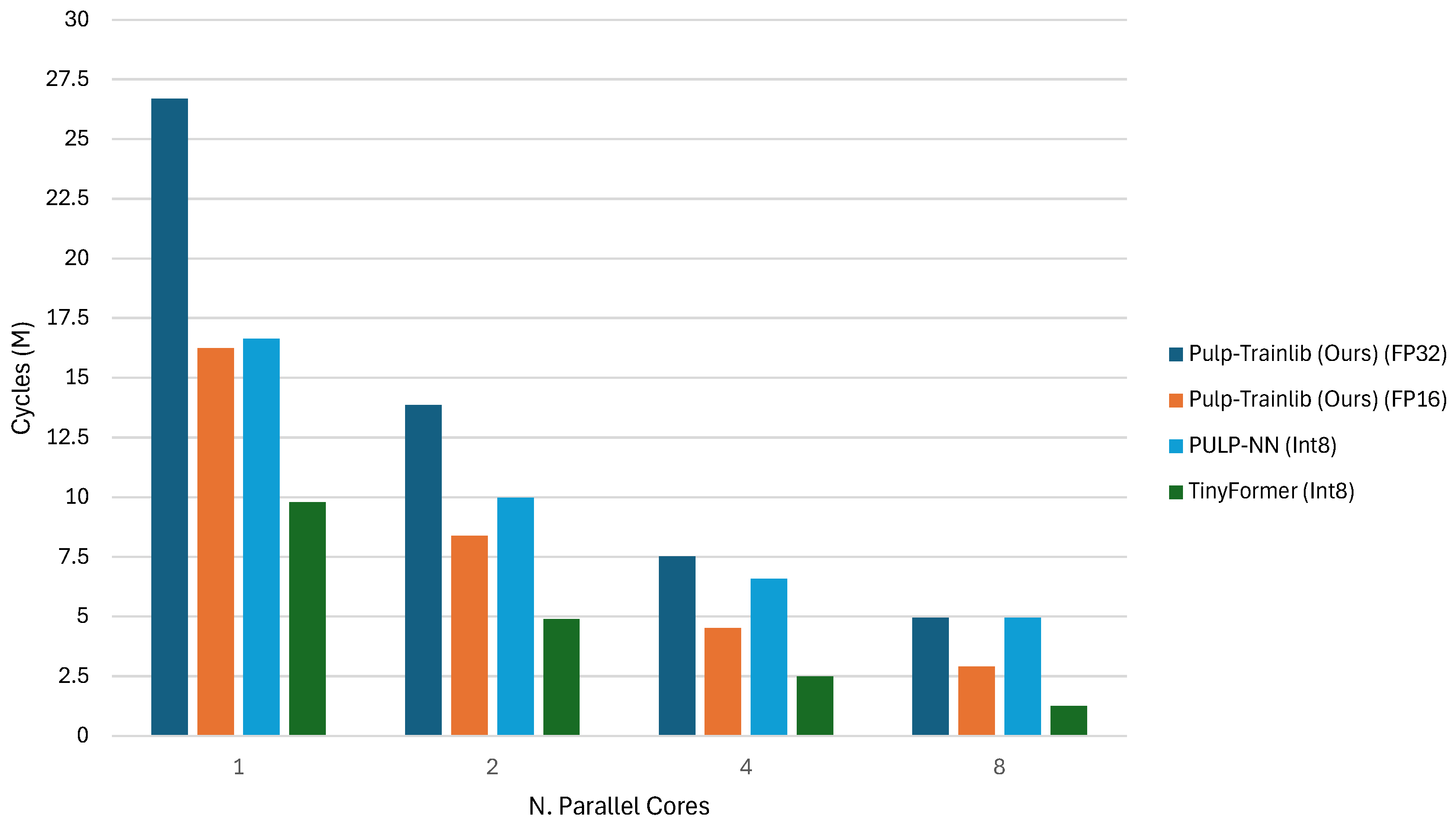



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}