

Optimizing Reservoir Separability in Liquid State Machines for Spatio-Temporal Classification in Neuromorphic Hardware

 , , and
, , and
Abstract
1. Introduction
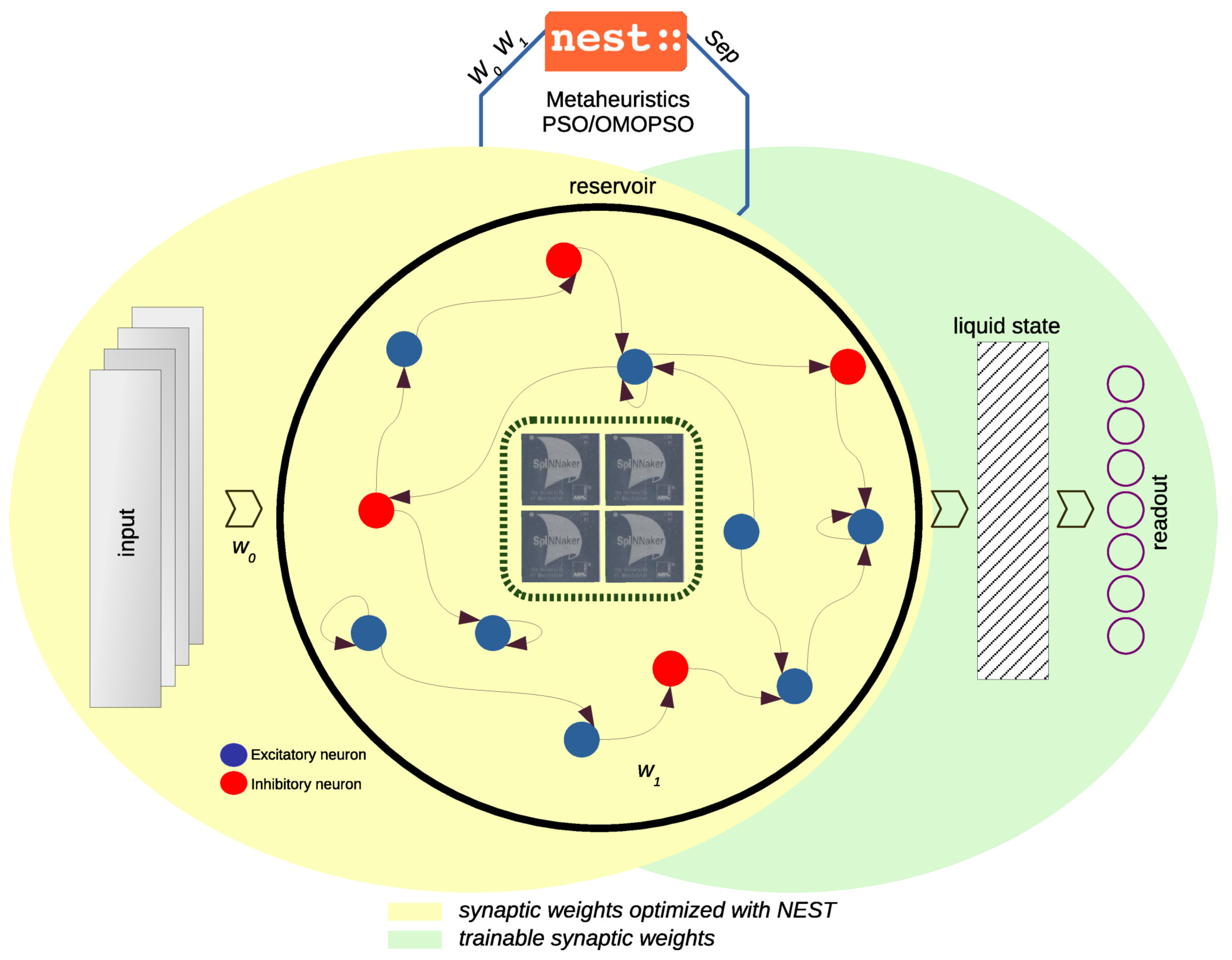
2. Liquid State Machine
- The input layer: The input layer receives external signals or sensory data and encodes them into a form suitable for the spiking neurons in the reservoir. This encoding step often transforms a continuous input into discrete events or “spikes” that can be processed by the spiking neurons. In our case, the data are already encoded as spikes, and the number of channels or neurons depends solely on the characteristics of each problem. For a more detailed description of the datasets, see Section 3.3.
- The reservoir (or liquid): This is a recurrent network of randomly connected spiking neurons. The concept of the “reservoir” is that, similarly to how a liquid responds to a stimulus, this component maps input sequences into a high-dimensional representation of its neural states. Each input to the reservoir generates a “splash” of neural activity that varies over time, transforming it into complex spatial and temporal patterns within the reservoir. This process is nonlinear, enabling the capture of temporal relationships in input data, even in complex, high-frequency signals. In our case, the reservoir consisted of 64 randomly connected neurons, using the Integrate-and-Fire neuron model with exponential synaptic currents, denoted as IF_curr_exp, as defined in Equation (1). In this setup, 80% of the neurons were excitatory (E) and 20% were inhibitory. Here, represents the membrane’s time constant, is the membrane potential, is the membrane’s capacitance, is the resting potential, and is the total synaptic current, which is the sum of both the excitatory and inhibitory currents.The neuron parameters implemented in NEST and on SpiNNaker through PyNN are given in Table 1.To define connectivity within the reservoir, we arranged the 64 neurons in a grid, where each neuron connected to another based on a specified probability. The synaptic connectivity probability, proposed by [22], is defined in Equation (2).where C represents the probability associated with the synaptic connection type (presynaptic–postsynaptic) among neurons; it was set at 0.3 for excitatory–excitatory (EE), 0.2 for excitatory–inhibitory (EI), 0.4 for inhibitory–excitatory (IE), and 0.1 for inhibitory–inhibitory (II) connections. D denotes the Euclidean distance between two neurons, while indicates the average number of connections and distances among neurons, set to a value of 2, thereby reducing synaptic connectivity within the reservoir. Synaptic weights in both the reservoir and the input layer were generated from a normal distribution with a mean of and a standard deviation of , ensuring that they remained representable at lower precisions. Connectivity between the input layer and the reservoir was defined with a probability of 0.3. Additionally, each neuron in the reservoir was subject to noise, drawn from a normal distribution with a standard deviation of nA, and a synaptic delay of 1.0 was incorporated.
- Readout (or output layer): Unlike traditional recurrent neural networks, training in LSMs is only performed on the output layer. In our approach, this output layer was composed of perceptron neurons, which were trained using an Adaptive Moment Estimation (Adam) optimizer with the Softmax activation function using default parameters over 1000 epochs.
3. Materials and Methods
3.1. Separability Metric
3.2. Optimization Methods
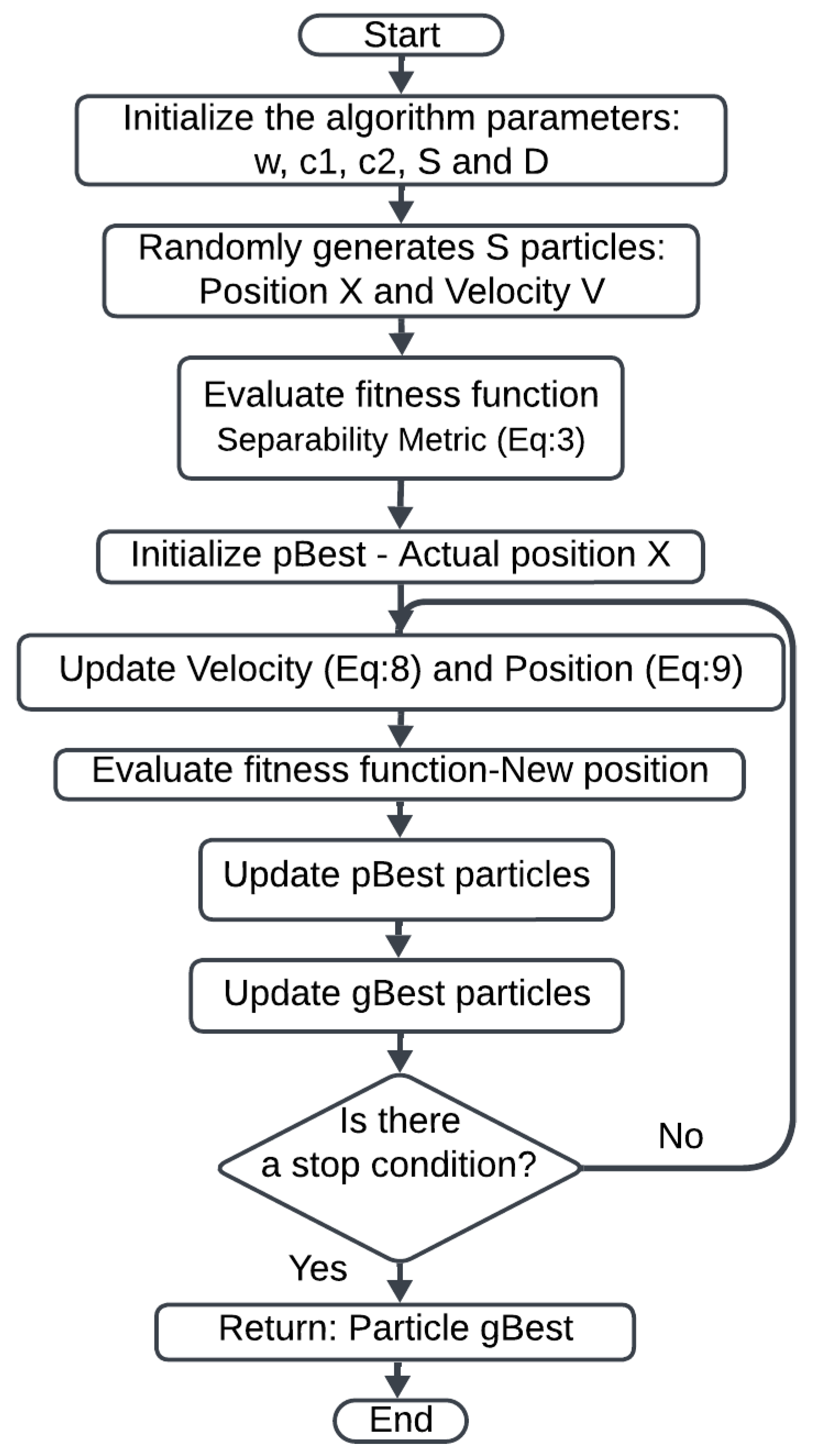
3.2.1. Particle Swarm Optimization
- refers to the best position of each particle.
- represents the best position achieved by the entire swarm of particles.
- is the d-th value of the i-th particle’s velocity.
- is the inertia weight.
- are the cognitive and social acceleration coefficients.
- are two uniform random values generated within the interval.
- is the d-th value of the personal best position.
- is the d-th value of the global best position.
- is the d-th value of the i-th particle’s position.
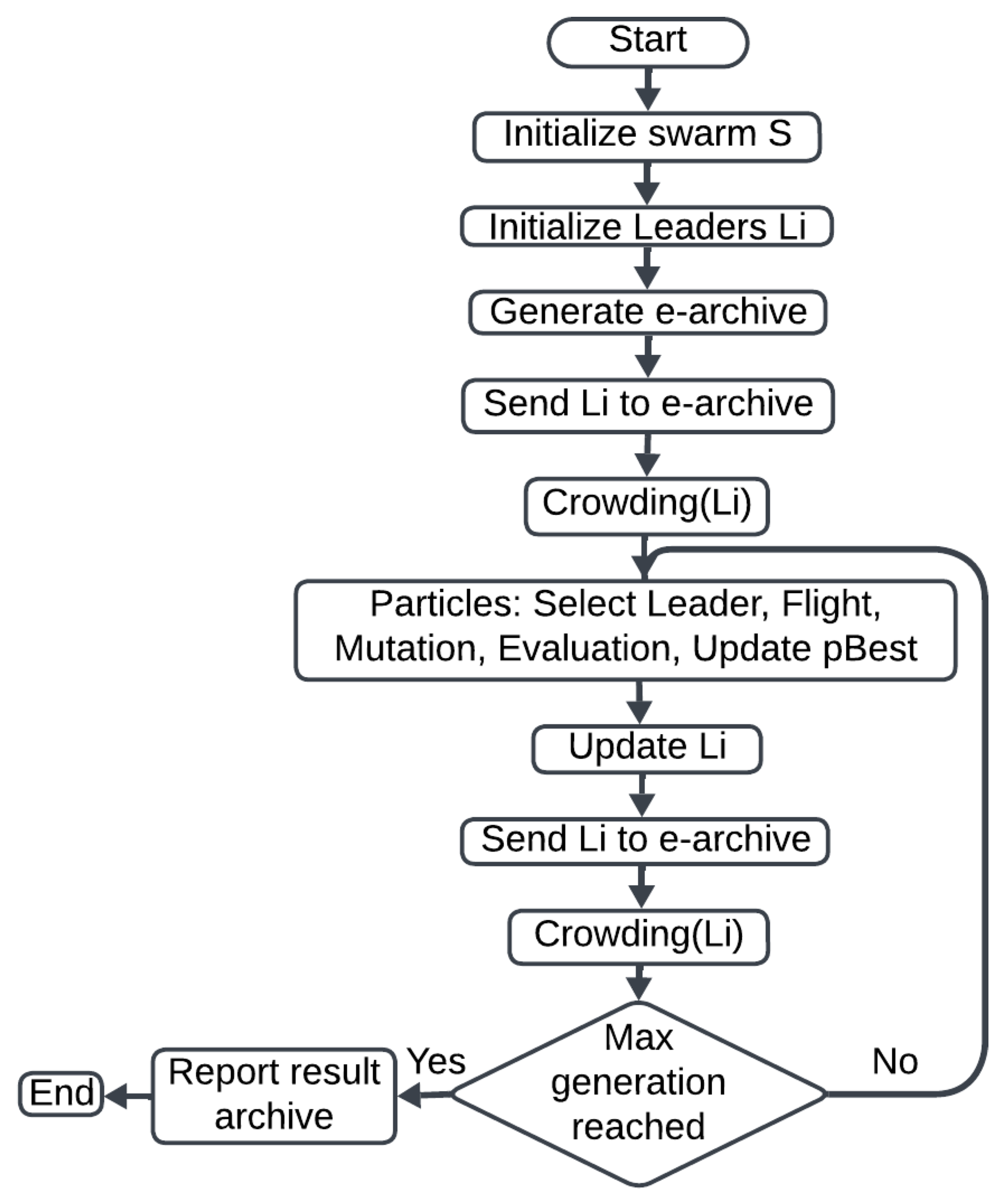
3.2.2. OMOPSO
- Select Leader: the selection of a leader from the e-archive to guide the particle’s movement.
- Flight: updating the particle’s velocity and position based on the previously selected leader.
- Mutation: the implementation of mutation to introduce variability.
- Evaluation: the particle’s updated position is evaluated based on the fitness function.
- Update : updating if a better performance is achieved during the evaluation.
3.3. Dataset
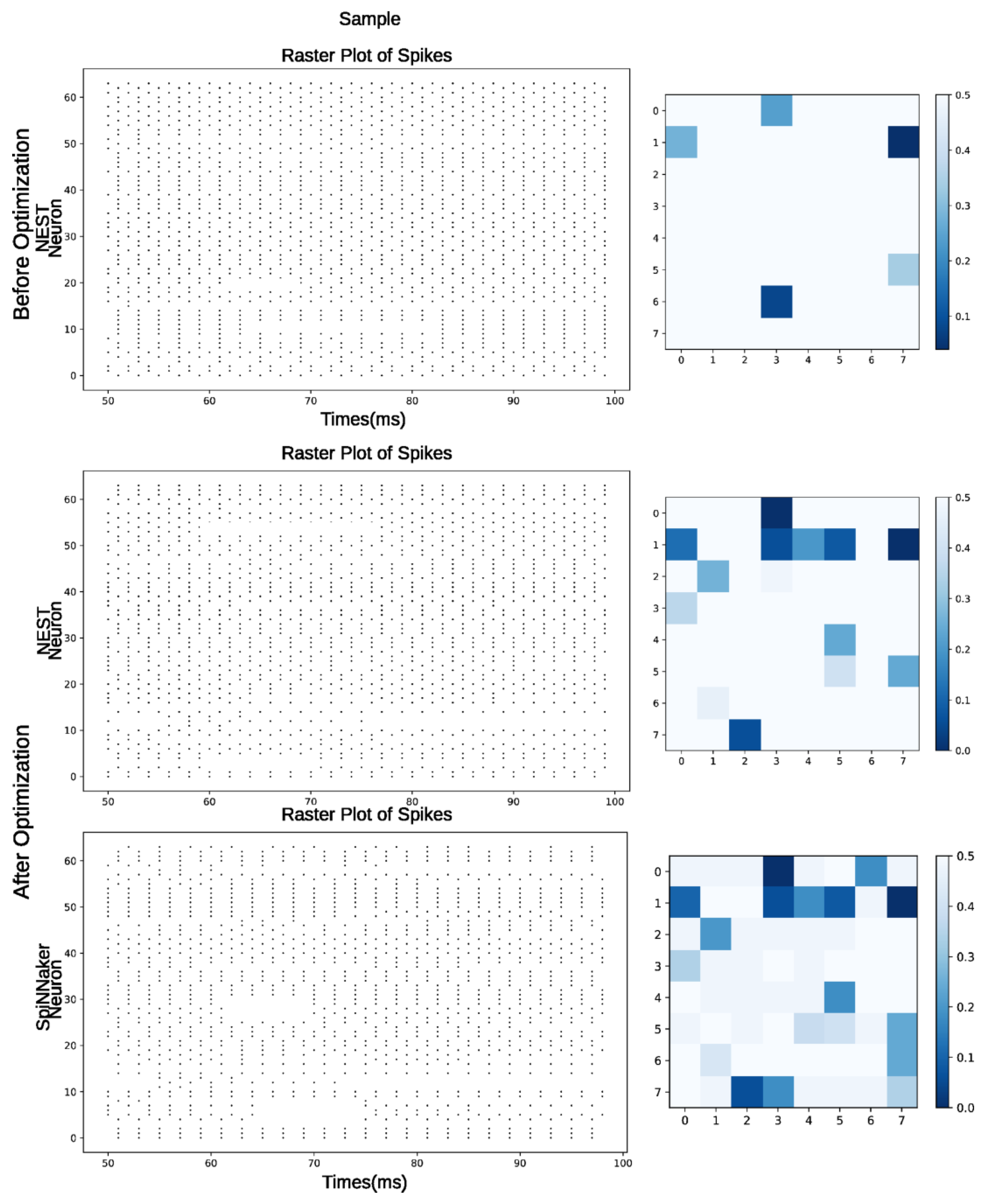
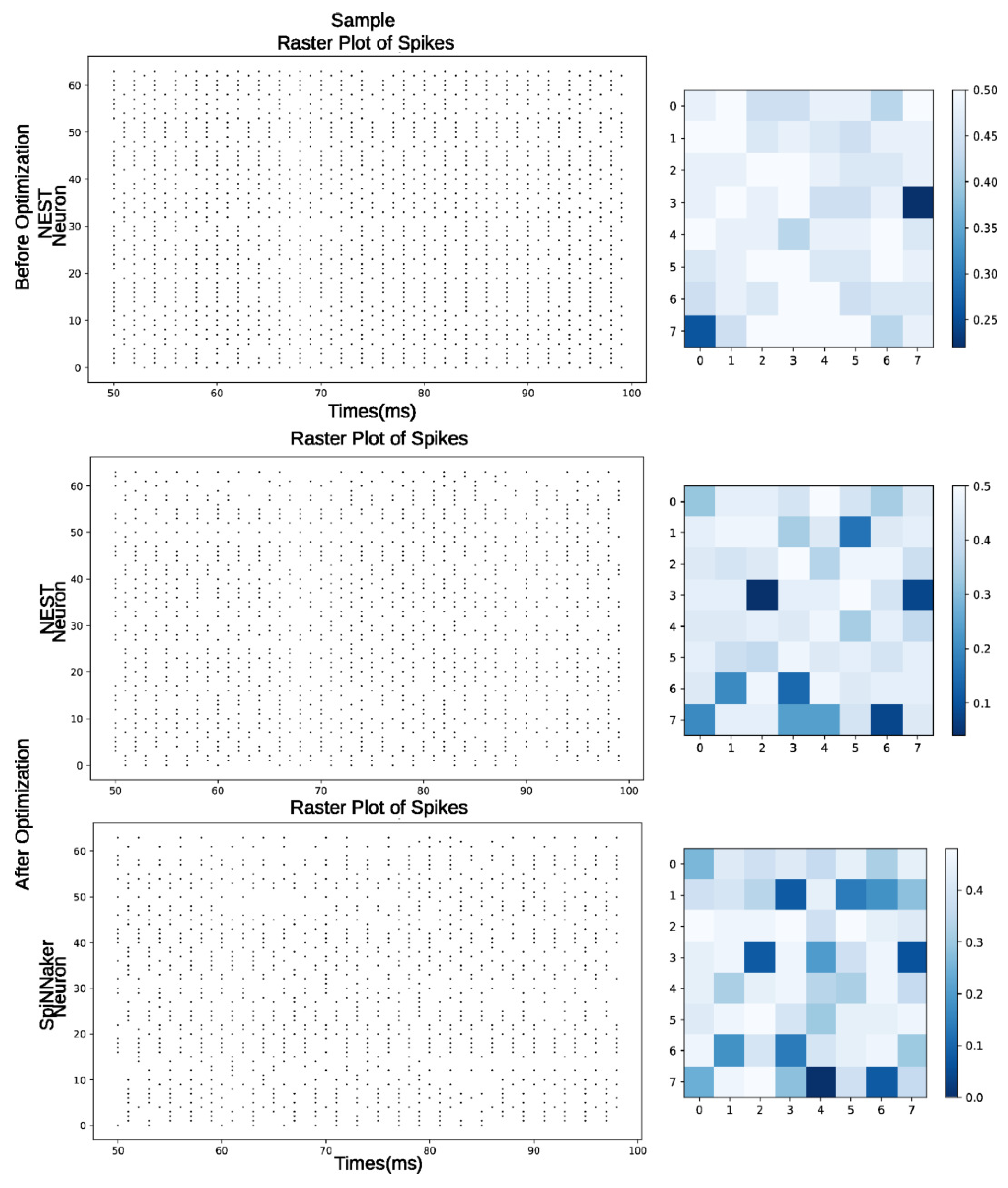
3.4. Offline Training with the NEST Framework
3.5. Implementation on Neuromorphic SpiNNaker Hardware
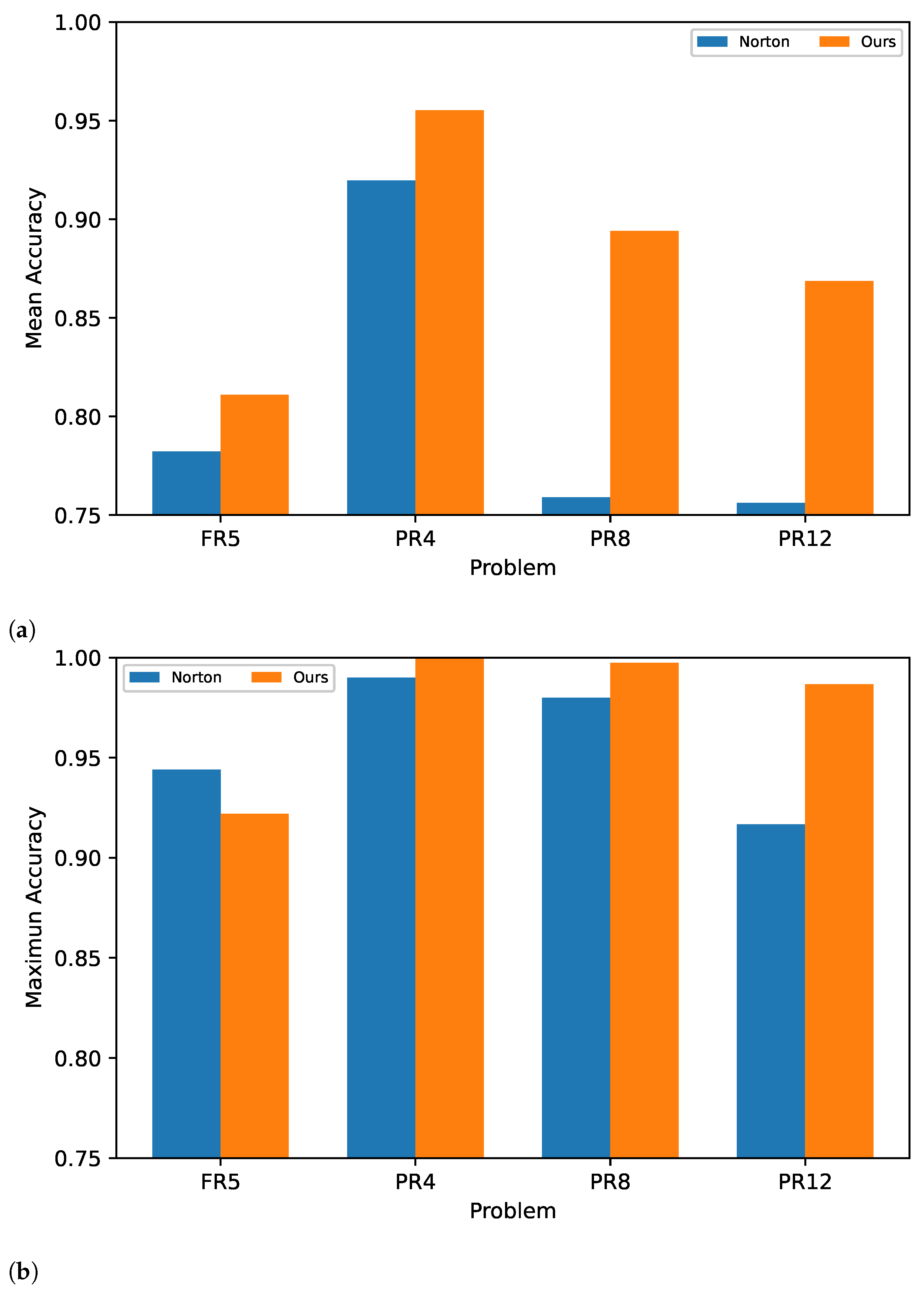
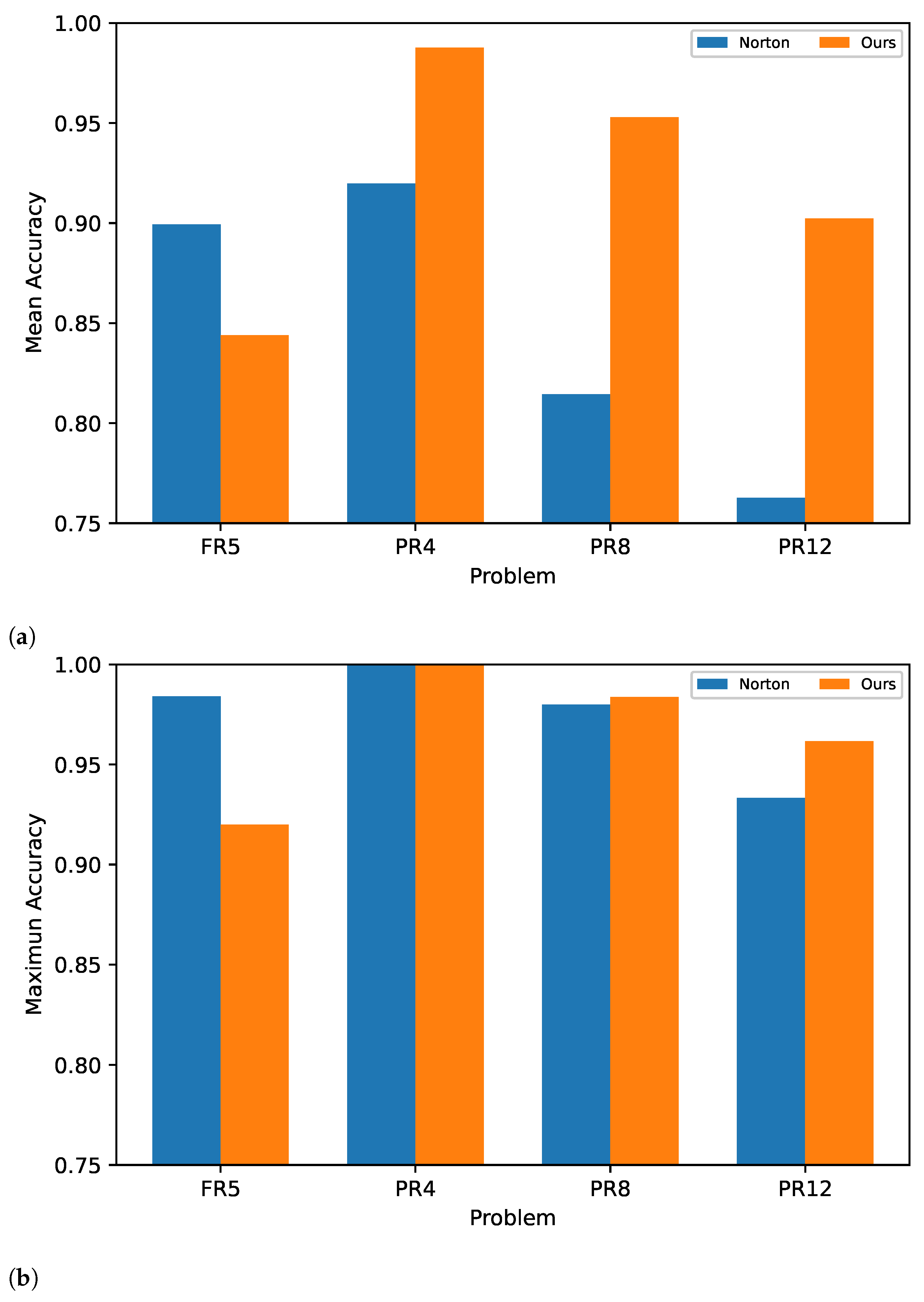
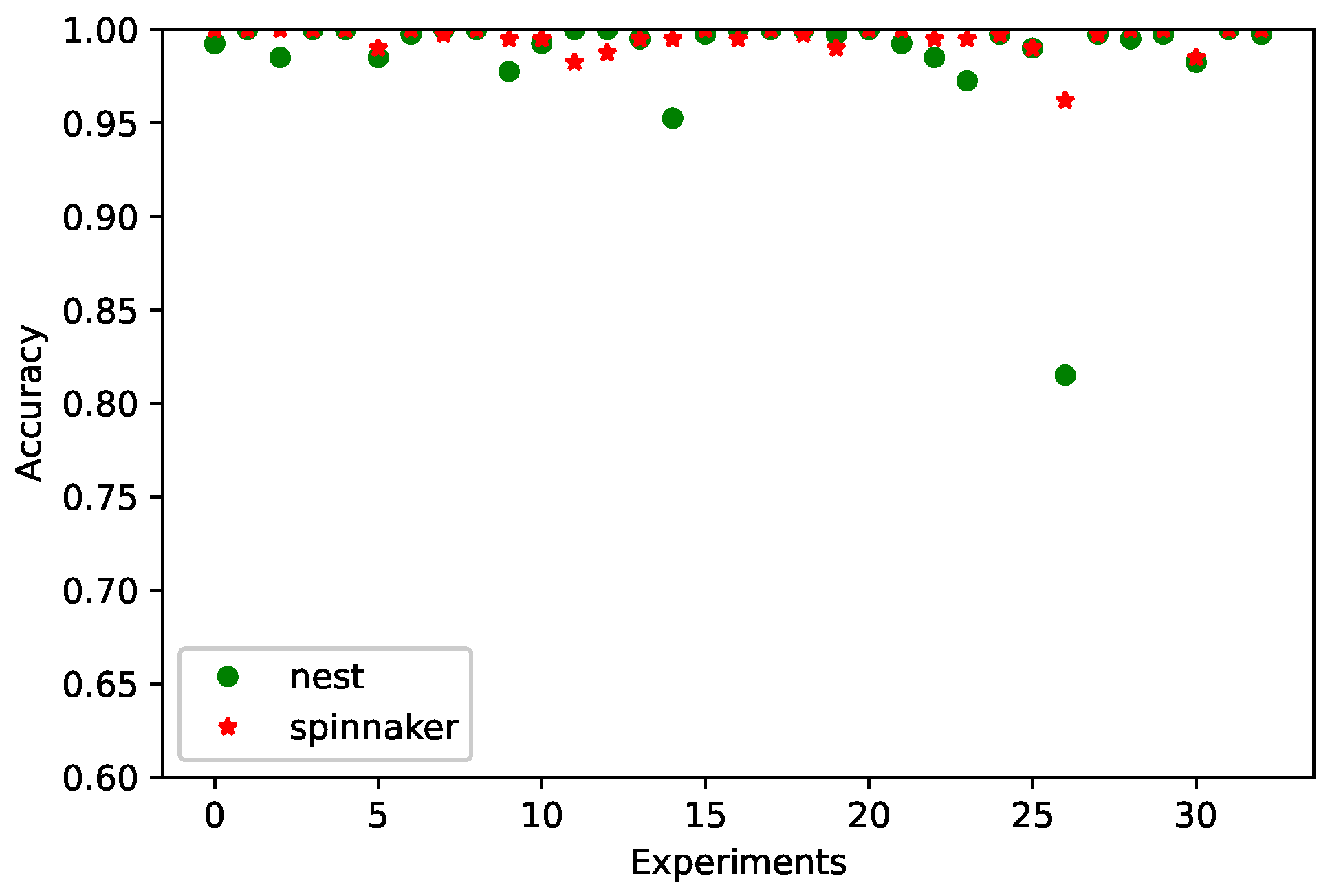
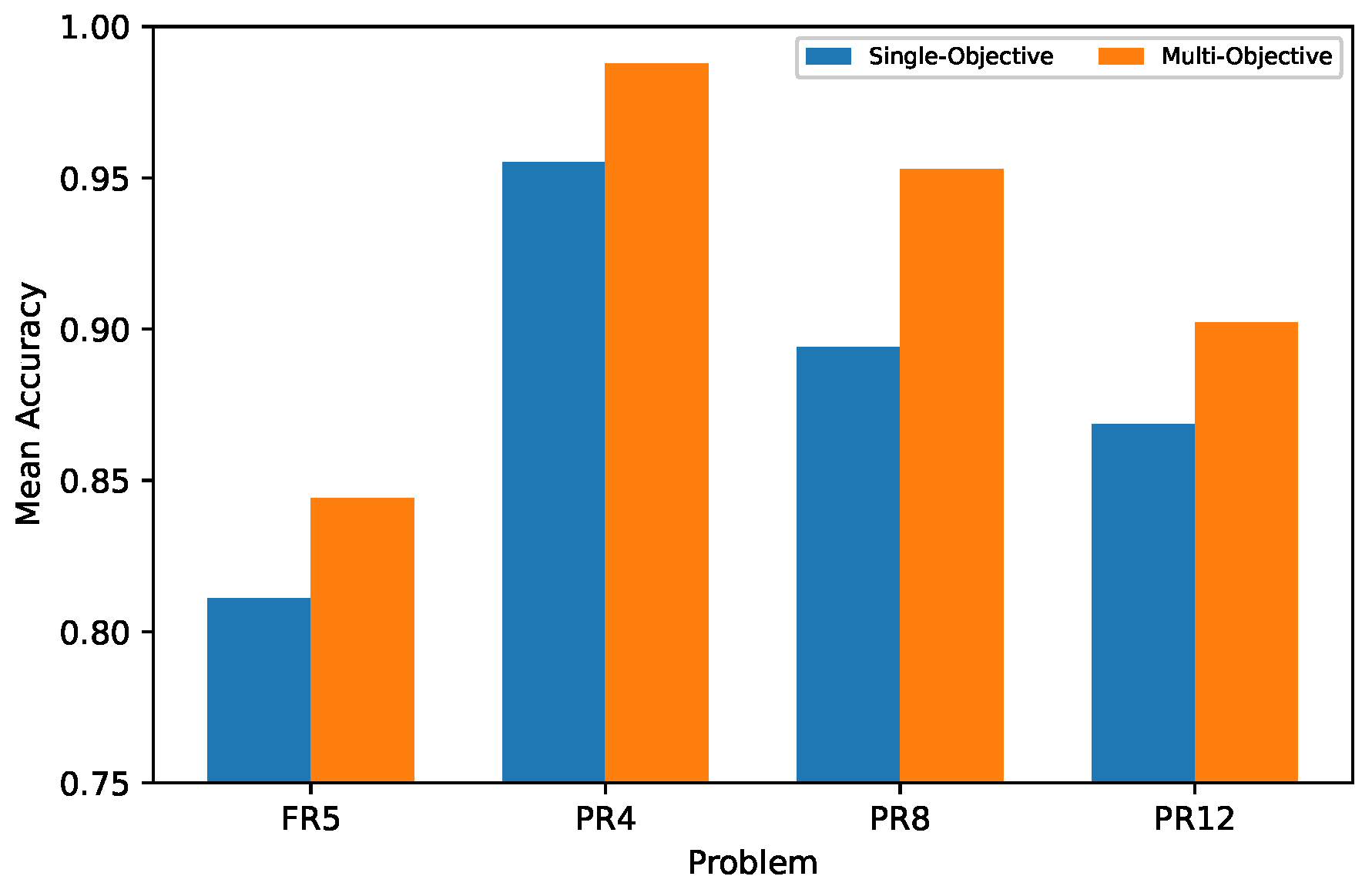
4. Results
- Initial Separability (InitialSP) and Final Separability (FinalSP), which represent how well the liquid states generated by the reservoir could be separated based on the classes, in one or more tasks, before and after optimization, respectively.
- Initial Accuracy (InitialAcc) and Final Accuracy (FinalAcc), which indicate the model’s performance when evaluated using the test datasets in NEST.
- Final Accuracy Hardware (FinalAccHW), which represents the model’s performance when simulated on SpiNNaker.
4.1. PSO Experiments
4.2. OMOPSO Experiments
4.3. Statistical Significance Test
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Budhraja, S.; Singh, B.; Doborjeh, M.; Doborjeh, Z.; Tan, S.; Lai, E.; Goh, W.; Kasabov, N. Mosaic LSM: A Liquid State Machine Approach for Multimodal Longitudinal Data Analysis. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Sai Sree Vaishnavi, V.G.; Bhowmik, B. Evolution of Neuromorphic Computing. In Proceedings of the 2024 Fourth International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 11–12 January 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Schuman, C.D.; Kulkarni, S.R.; Parsa, M.; Mitchell, J.P.; Date, P.; Kay, B. Opportunities for neuromorphic computing algorithms and applications. Nat. Comput. Sci. 2022, 2, 10–19. [Google Scholar] [CrossRef]
- Tian, S.; Qu, L.; Wang, L.; Hu, K.; Li, N.; Xu, W. A neural architecture search based framework for liquid state machine design. Neurocomputing 2021, 443, 174–182. [Google Scholar] [CrossRef]
- Woo, J.; Kim, S.H.; Kim, H.; Han, K. Characterization of the neuronal and network dynamics of liquid state machines. Phys. A Stat. Mech. Its Appl. 2024, 633, 129334. [Google Scholar] [CrossRef]
- Pan, W.; Zhao, F.; Zeng, Y.; Han, B. Adaptive structure evolution and biologically plausible synaptic plasticity for recurrent spiking neural networks. Sci. Rep. 2023, 13, 16924. [Google Scholar] [CrossRef] [PubMed]
- Wijesinghe, P.; Srinivasan, G.; Panda, P.; Roy, K. Analysis of Liquid Ensembles for Enhancing the Performance and Accuracy of Liquid State Machines. Front. Neurosci. 2019, 13, 504. [Google Scholar] [CrossRef] [PubMed]
- Patel, R.; Saraswat, V.; Ganguly, U. Liquid State Machine on Loihi: Memory Metric for Performance Prediction. In Artificial Neural Networks and Machine Learning—ICANN 2022; Pimenidis, E., Angelov, P., Jayne, C., Papaleonidas, A., Aydin, M., Eds.; Springer Nature: Cham, Switzerland, 2022; pp. 692–703. [Google Scholar]
- Patiño-Saucedo, A.; Rostro-González, H.; Serrano-Gotarredona, T.; Linares-Barranco, B. Liquid State Machine on SpiNNaker for Spatio-Temporal Classification Tasks. Front. Neurosci. 2022, 16, 819063. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Yang, Z.; Guo, S.; Qu, L.; Zhang, X.; Kang, Z.; Xu, W. LSMCore: A 69k-Synapse/mm2 Single-Core Digital Neuromorphic Processor for Liquid State Machine. IEEE Trans. Circuits Syst. I Regul. Pap. 2022, 69, 1976–1989. [Google Scholar] [CrossRef]
- Norton, D.; Ventura, D. Improving the separability of a reservoir facilitates learning transfer. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 2288–2293. [Google Scholar] [CrossRef]
- Ortman, R.L.; Venayagamoorthy, K.; Potter, S.M. Input Separability in Living Liquid State Machines. In Adaptive and Natural Computing Algorithms; Dobnikar, A., Lotrič, U., Šter, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 220–229. [Google Scholar]
- Zhou, Y.; Jin, Y.; Ding, J. Evolutionary Optimization of Liquid State Machines for Robust Learning. In Advances in Neural Networks—ISNN 2019; Lu, H., Tang, H., Wang, Z., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 389–398. [Google Scholar]
- Norton, D.; Ventura, D. Improving liquid state machines through iterative refinement of the reservoir. Neurocomputing 2010, 73, 2893–2904. [Google Scholar] [CrossRef]
- Mehonic, A.; Ielmini, D.; Roy, K.; Mutlu, O.; Kvatinsky, S.; Serrano-Gotarredona, T.; Linares-Barranco, B.; Spiga, S.; Savel’ev, S.; Balanov, A.G.; et al. Roadmap to neuromorphic computing with emerging technologies. APL Mater. 2024, 12, 109201. [Google Scholar] [CrossRef]
- Sandamirskaya, Y.; Kaboli, M.; Conradt, J.; Celikel, T. Neuromorphic computing hardware and neural architectures for robotics. Sci. Robot. 2022, 7, eabl8419. [Google Scholar] [CrossRef] [PubMed]
- Cucchi, M.; Abreu, S.; Ciccone, G.; Brunner, D.; Kleemann, H. Hands-on reservoir computing: A tutorial for practical implementation. Neuromorphic Comput. Eng. 2022, 2, 032002. [Google Scholar] [CrossRef]
- Zhou, Y.; Jin, Y.; Sun, Y.; Ding, J. Surrogate-Assisted Cooperative Co-evolutionary Reservoir Architecture Search for Liquid State Machines. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 1484–1498. [Google Scholar] [CrossRef]
- Yan, M.; Huang, C.; Bienstman, P.; Tino, P.; Lin, W.; Sun, J. Emerging opportunities and challenges for the future of reservoir computing. Nat. Commun. 2024, 15, 2056. [Google Scholar] [CrossRef] [PubMed]
- Orchard, G.; Jayawant, A.; Cohen, G.K.; Thakor, N. Converting static image datasets to spiking neuromorphic datasets using saccades. Front. Neurosci. 2015, 9, 437. [Google Scholar] [CrossRef] [PubMed]
- Maass, W. Liquid State Machines: Motivation, Theory, and Applications. In Computability in Context; World Scientific: Singapore, 2011; pp. 275–296. [Google Scholar] [CrossRef]
- Maass, W.; Natschläger, T.; Markram, H. Real-time computing without stable states: A new framework for neural computation based on perturbations. Neural Comput. 2002, 14, 2531–2560. [Google Scholar] [CrossRef]
- Norton, D.; Ventura, D. Preparing more effective liquid state machines using hebbian learning. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, Canada, 16–21 July 2006; pp. 4243–4248. [Google Scholar]
- Zhang, H.; Vargas, D.V. A survey on reservoir computing and its interdisciplinary applications beyond traditional machine learning. IEEE Access 2023, 11, 81033–81070. [Google Scholar] [CrossRef]
- Shen, S.; Zhang, R.; Wang, C.; Huang, R.; Tuerhong, A.; Guo, Q.; Lu, Z.; Zhang, J.; Leng, L. Evolutionary spiking neural networks: A survey. J. Membr. Comput. 2024, 6, 335–346. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Shami, T.M.; El-Saleh, A.A.; Alswaitti, M.; Al-Tashi, Q.; Summakieh, M.A.; Mirjalili, S. Particle swarm optimization: A comprehensive survey. IEEE Access 2022, 10, 10031–10061. [Google Scholar] [CrossRef]
- Sierra, M.R.; Coello Coello, C.A. Improving PSO-based multi-objective optimization using crowding, mutation and ϵ-dominance. In Evolutionary Multi-Criterion Optimization, Proceedings of the Third International Conference, EMO 2005, Guanajuato, Mexico, 9–11 March 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 505–519. [Google Scholar]
- Coello, C.A.C.; Pulido, G.T.; Lechuga, M.S. Handling multiple objectives with particle swarm optimization. IEEE Trans. Evol. Comput. 2004, 8, 256–279. [Google Scholar] [CrossRef]
- Gewaltig, M.O.; Diesmann, M. NEST (NEural Simulation Tool). Scholarpedia 2007, 2, 1430. [Google Scholar] [CrossRef]
- Davison, A.P.; Brüderle, D.; Eppler, J.M.; Kremkow, J.; Muller, E.; Pecevski, D.; Perrinet, L.; Yger, P. PyNN: A common interface for neuronal network simulators. Front. Neuroinform. 2009, 2, 388. [Google Scholar] [CrossRef]
- Trelea, I.C. The particle swarm optimization algorithm: Convergence analysis and parameter selection. Inf. Process. Lett. 2003, 85, 317–325. [Google Scholar] [CrossRef]
- van den Bergh, F.; Engelbrecht, A. A Cooperative approach to particle swarm optimization. IEEE Trans. Evol. Comput. 2004, 8, 225–239. [Google Scholar] [CrossRef]
- Zhang, L.; Yu, H.; Hu, S. Optimal choice of parameters for particle swarm optimization. J. Zhejiang-Univ.-Sci. A 2005, 6, 528–534. [Google Scholar]
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Indiveri, G.; Liu, S.C. Memory and information processing in neuromorphic systems. Proc. IEEE 2015, 103, 1379–1397. [Google Scholar] [CrossRef]
- Furber, S.B.; Galluppi, F.; Temple, S.; Plana, L.A. The spinnaker project. Proc. IEEE 2014, 102, 652–665. [Google Scholar] [CrossRef]
- Temple, S. AppNote 1-SpiNN-3 Development Board; The University of Manchester: Manchester, UK, 2011; Volume 1. [Google Scholar]
- Blank, J.; Deb, K. Pymoo: Multi-objective optimization in python. IEEE Access 2020, 8, 89497–89509. [Google Scholar] [CrossRef]
- Painkras, E.; Plana, L.A.; Garside, J.; Temple, S.; Galluppi, F.; Patterson, C.; Lester, D.R.; Brown, A.D.; Furber, S.B. SpiNNaker: A 1-W 18-Core System-on-Chip for Massively-Parallel Neural Network Simulation. IEEE J.-Solid-State Circuits 2013, 48, 1943–1953. [Google Scholar] [CrossRef]
- Flach, P. Machine Learning: The Art and Science of Algorithms That Make Sense of Data; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Ghasemi, A.; Zahediasl, S. Normality tests for statistical analysis: A guide for non-statisticians. Int. J. Endocrinol. Metab. 2012, 10, 486. [Google Scholar] [CrossRef] [PubMed]
- Grech, V.; Calleja, N. WASP (Write a Scientific Paper): Parametric vs. non-parametric tests. Early Hum. Dev. 2018, 123, 48–49. [Google Scholar] [CrossRef] [PubMed]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- Sharp, T.; Furber, S. Correctness and performance of the SpiNNaker architecture. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar]
- van Albada, S.J.; Rowley, A.G.; Senk, J.; Hopkins, M.; Schmidt, M.; Stokes, A.B.; Lester, D.R.; Diesmann, M.; Furber, S.B. Performance Comparison of the Digital Neuromorphic Hardware SpiNNaker and the Neural Network Simulation Software NEST for a Full-Scale Cortical Microcircuit Model. Front. Neurosci. 2018, 12, 291. [Google Scholar] [CrossRef] [PubMed]
- Akopyan, F.; Sawada, J.; Cassidy, A.; Alvarez-Icaza, R.; Arthur, J.; Merolla, P.; Imam, N.; Nakamura, Y.; Datta, P.; Nam, G.J.; et al. TrueNorth: Design and Tool Flow of a 65 mW 1 Million Neuron Programmable Neurosynaptic Chip. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2015, 34, 1537–1557. [Google Scholar] [CrossRef]
- Davies, M.; Srinivasa, N.; Lin, T.H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A Neuromorphic Manycore Processor with On-Chip Learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Description | Value |
|---|---|---|
| Membrane’s capacitance | 0.05 nF | |
| Membrane’s time constant | 1.0 ms | |
| Threshold | 0.8 mV | |
| Reset potential | −0.06 mV | |
| Resting membrane potential | −0.06 mV |
| Dataset | Statistical | InitialSP | FinalSP | InitialAcc | FinalAcc | FinalAccHW |
|---|---|---|---|---|---|---|
| FR5 | 0.1095 | 0.3524 | 0.4931 | 0.8109 | 0.8620 | |
| 0.1142 | 0.3568 | 0.4820 | 0.8260 | 0.8740 | ||
| 0.0828 | 0.1303 | 0.2056 | 0.0846 | 0.0581 | ||
| PR4 | 0.0772 | 0.3057 | 0.7138 | 0.9552 | 0.9770 | |
| 0.0700 | 0.2859 | 0.7825 | 0.9875 | 0.9925 | ||
| 0.0544 | 0.1086 | 0.2065 | 0.0784 | 0.0358 | ||
| PR8 | 0.0697 | 0.3508 | 0.5263 | 0.8940 | 0.9432 | |
| 0.0729 | 0.3640 | 0.5888 | 0.9425 | 0.9613 | ||
| 0.0442 | 0.1412 | 0.2308 | 0.1199 | 0.0583 | ||
| PR12 | 0.0750 | 0.3079 | 0.4697 | 0.8687 | 0.9177 | |
| 0.0737 | 0.3056 | 0.4975 | 0.9033 | 0.9442 | ||
| 0.0426 | 0.1072 | 0.1829 | 0.0905 | 0.0662 |
| Dataset | Statistical | Initial SP | Final SP | Initial Acc | Final Acc | Final Acc HW |
|---|---|---|---|---|---|---|
| FR5 | 0.1199 | 0.3557 | 0.5555 | 0.8440 | 0.8853 | |
| 0.1136 | 0.3658 | 0.5740 | 0.8880 | 0.9000 | ||
| 0.0712 | 0.0863 | 0.1948 | 0.0886 | 0.0392 | ||
| PR4 | 0.0764 | 0.2325 | 0.7796 | 0.9877 | 0.9952 | |
| 0.0686 | 0.2255 | 0.7989 | 0.9975 | 0.9975 | ||
| 0.0475 | 0.0502 | 0.1895 | 0.0327 | 0.0077 | ||
| PR8 | 0.0859 | 0.2311 | 0.6179 | 0.9529 | 0.9706 | |
| 0.0807 | 0.2234 | 0.6405 | 0.9712 | 0.9750 | ||
| 0.0479 | 0.0439 | 0.2057 | 0.0411 | 0.0158 | ||
| PR12 | 0.0883 | 0.2414 | 0.5165 | 0.9023 | 0.9442 | |
| 0.0895 | 0.2342 | 0.5358 | 0.9200 | 0.9520 | ||
| 0.0474 | 0.0472 | 0.2110 | 0.0537 | 0.0257 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alvarez-Canchila, O.I.; Espinal, A.; Patiño-Saucedo, A.; Rostro-Gonzalez, H. Optimizing Reservoir Separability in Liquid State Machines for Spatio-Temporal Classification in Neuromorphic Hardware. J. Low Power Electron. Appl. 2025, 15, 4. https://doi.org/10.3390/jlpea15010004
Alvarez-Canchila OI, Espinal A, Patiño-Saucedo A, Rostro-Gonzalez H. Optimizing Reservoir Separability in Liquid State Machines for Spatio-Temporal Classification in Neuromorphic Hardware. Journal of Low Power Electronics and Applications. 2025; 15(1):4. https://doi.org/10.3390/jlpea15010004
Chicago/Turabian StyleAlvarez-Canchila, Oscar I., Andres Espinal, Alberto Patiño-Saucedo, and Horacio Rostro-Gonzalez. 2025. "Optimizing Reservoir Separability in Liquid State Machines for Spatio-Temporal Classification in Neuromorphic Hardware" Journal of Low Power Electronics and Applications 15, no. 1: 4. https://doi.org/10.3390/jlpea15010004
APA StyleAlvarez-Canchila, O. I., Espinal, A., Patiño-Saucedo, A., & Rostro-Gonzalez, H. (2025). Optimizing Reservoir Separability in Liquid State Machines for Spatio-Temporal Classification in Neuromorphic Hardware. Journal of Low Power Electronics and Applications, 15(1), 4. https://doi.org/10.3390/jlpea15010004