
Understanding Timing Error Characteristics from Overclocked Systolic Multiply–Accumulate Arrays in FPGAs

 ,
, 

Abstract
1. Introduction
- We uncover fascinating error characteristics in an SMA building block implemented using an FPGA (Section 2). While intuitively, one may expect that timing errors resulting from overclocked hardware may produce a wide variation in output values, our integrated hardware–software experimental platform reveals a lack of variation in erroneous output values.
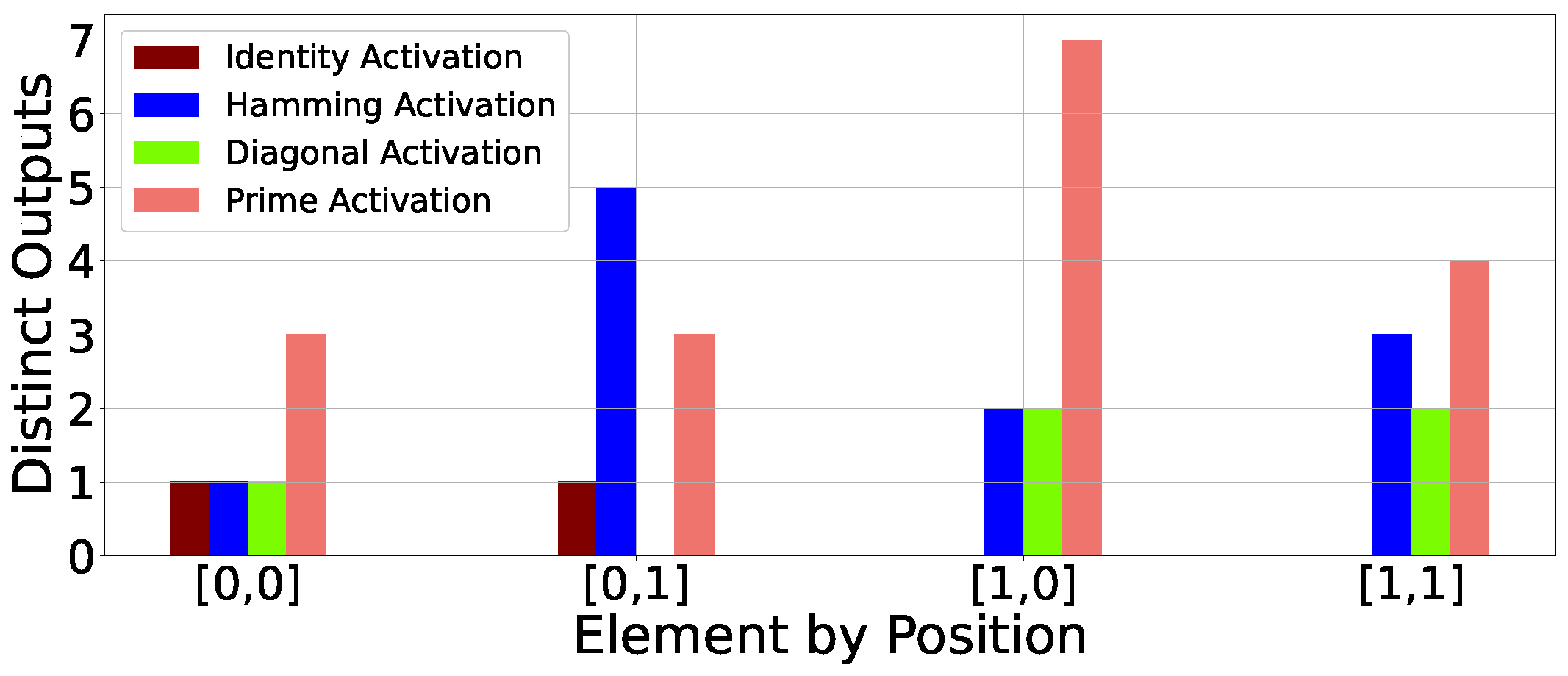
- Based on our intriguing findings, we identify a set of four representative input patterns for an SMA building block. These four patterns are based on their distinct circuit-level activity through the SMA building block and are referred to as Identity Activation, Diagonal Activation, Hamming Activation, and Prime Activation (Section 3).
- We establish a rigorous experimental platform using a software–hardware co-simulation and execution. Our results are obtained in a comprehensive FPGA environment, where an SMA building block is running a specific input pattern under a range of frequencies that rise beyond the rated frequency upper bound of execution of that block (Section 4).
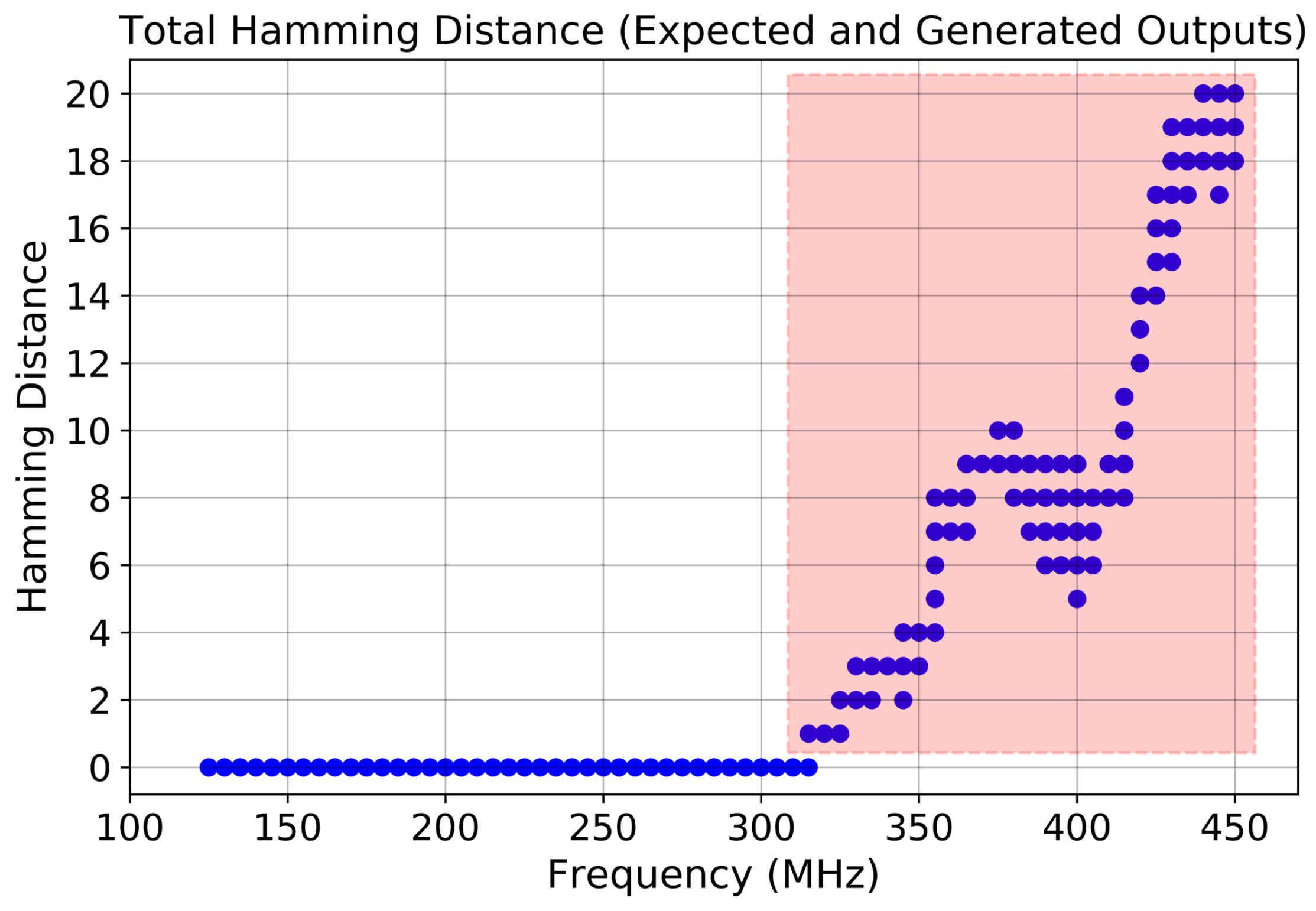
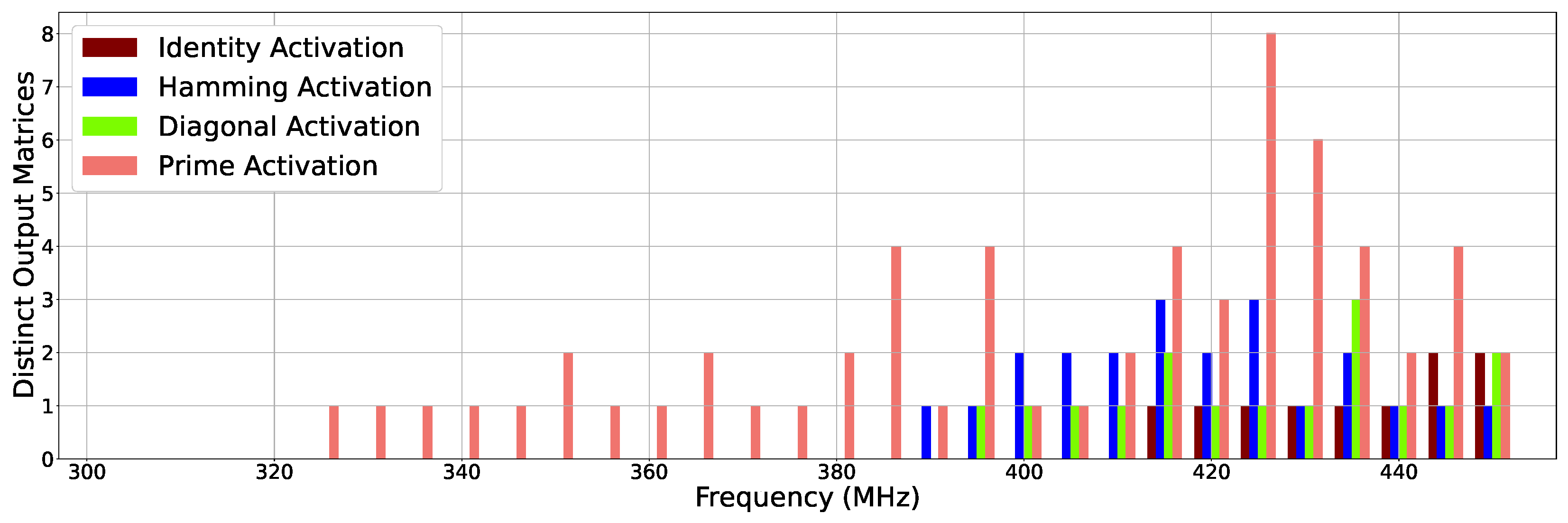
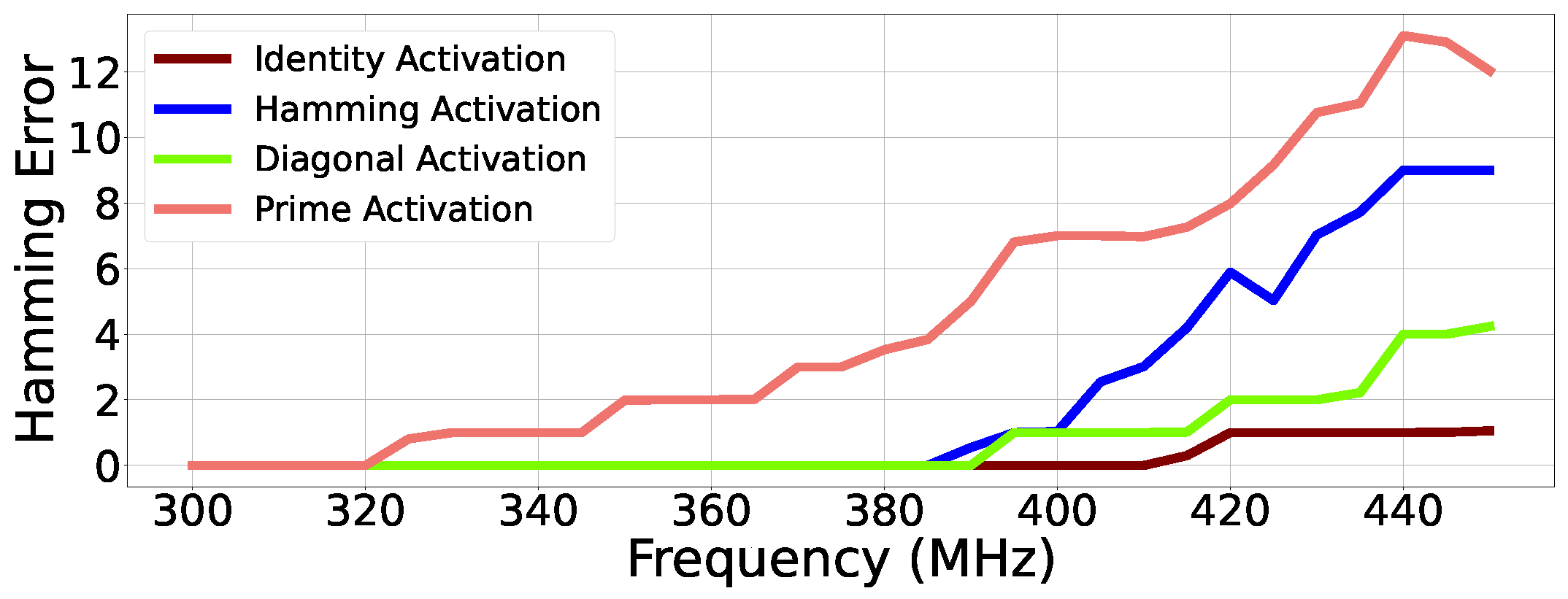
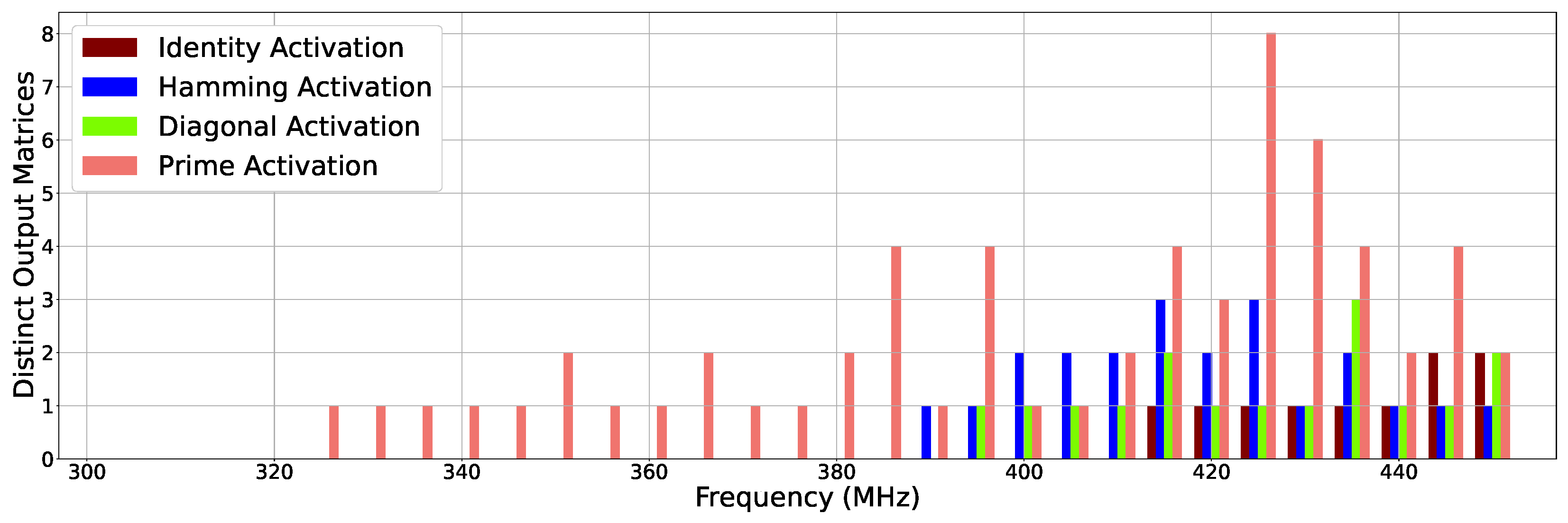
- Our comprehensive experiments and analysis reveal several fascinating characteristics of erroneous outputs produced from the SMA building block under an overclocked environment (Section 5). First, we notice that the hamming distance between the correct output and erroneous output is often stable across input patterns and frequencies. Second, different input patterns show a variation in the total number of distinct erroneous output values seen. For example, Identity Activation shows at most two distinct erroneous output matrices, while Prime Activation shows up to eight different output values across a wide range of frequencies that vary between 1× and 3.5× relative to the rated frequency of the hardware design.
- Our paper presents a methodological pathway to characterize an SMA block implemented in an FPGA platform. It is likely that a different board from the same vendor or competing vendor shows different timing error characteristics. However, we believe that our process of such characterization laid out in this work will still be applicable across various boards and vendors.
2. Motivation
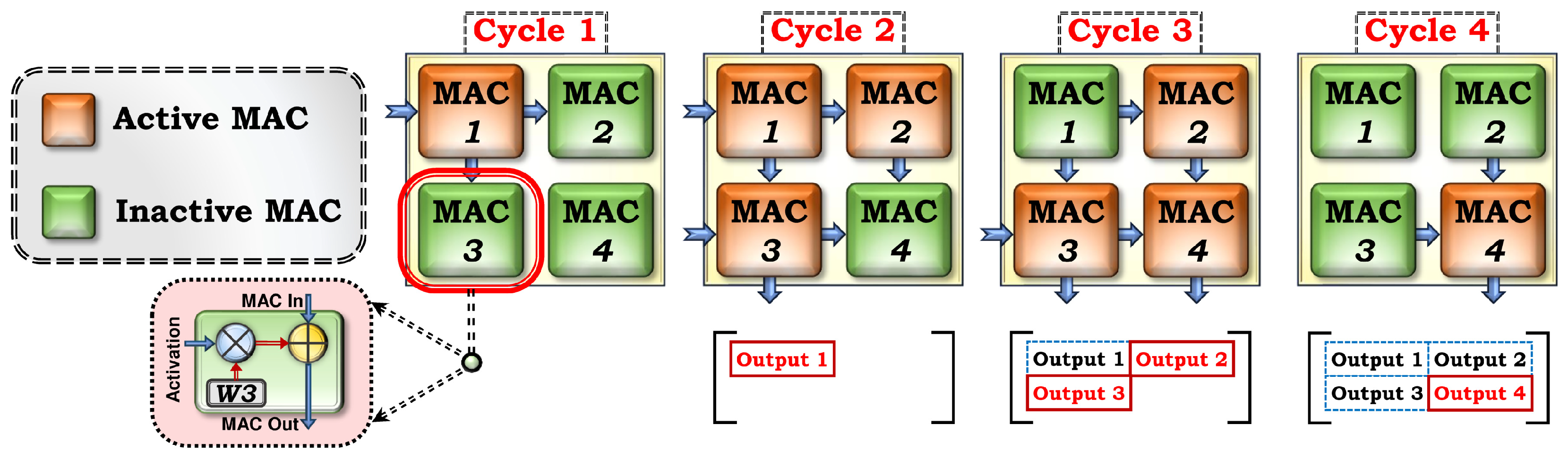
2.1. Dataflow in an SMA Building Block
2.2. Why Overclocking Is Chosen for This Work
2.3. Experimental Design
2.4. Empirical Results
2.4.1. Hamming Distance Analysis
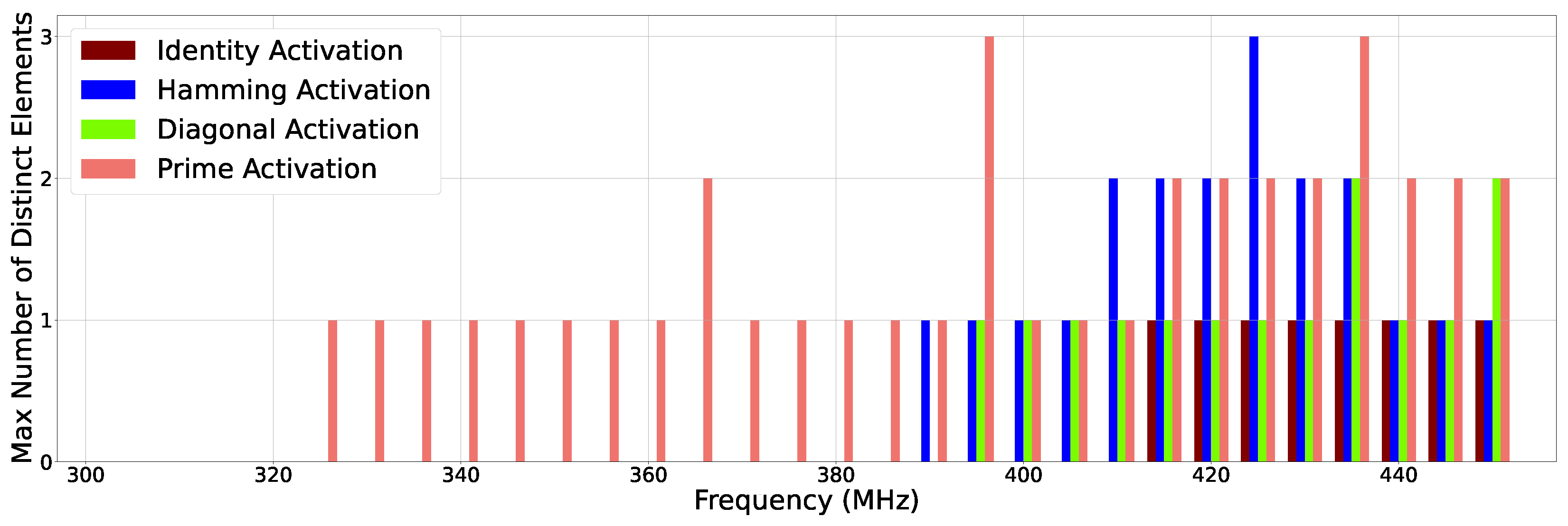
2.4.2. Error Diversity Analysis
2.5. Significance
3. Representative Input Patterns for an SMA Building Block
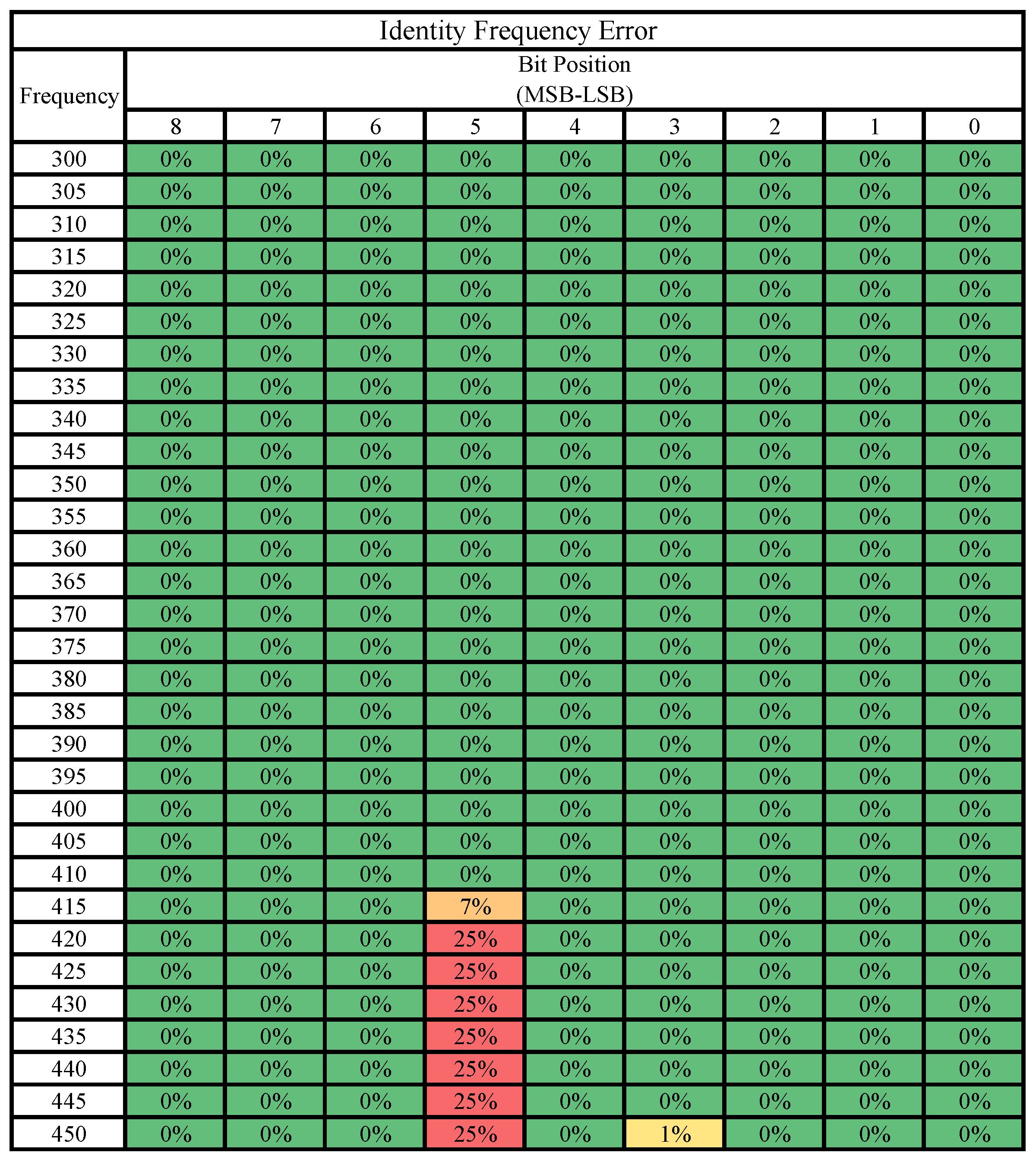
3.1. Case Study 1: Identity Activation
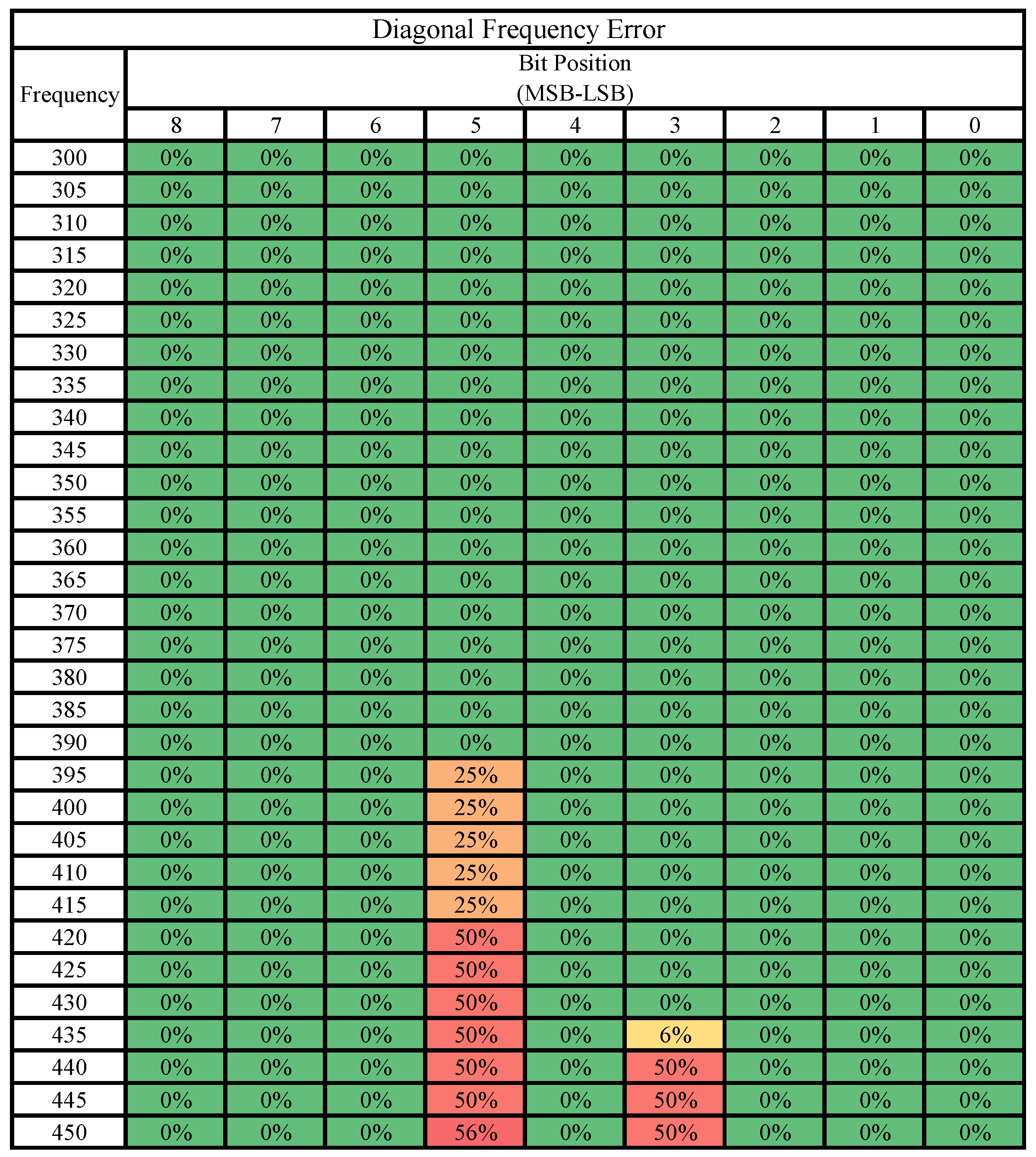
3.2. Case Study 2: Diagonal Activation
3.3. Case Study 3: Hamming Activation
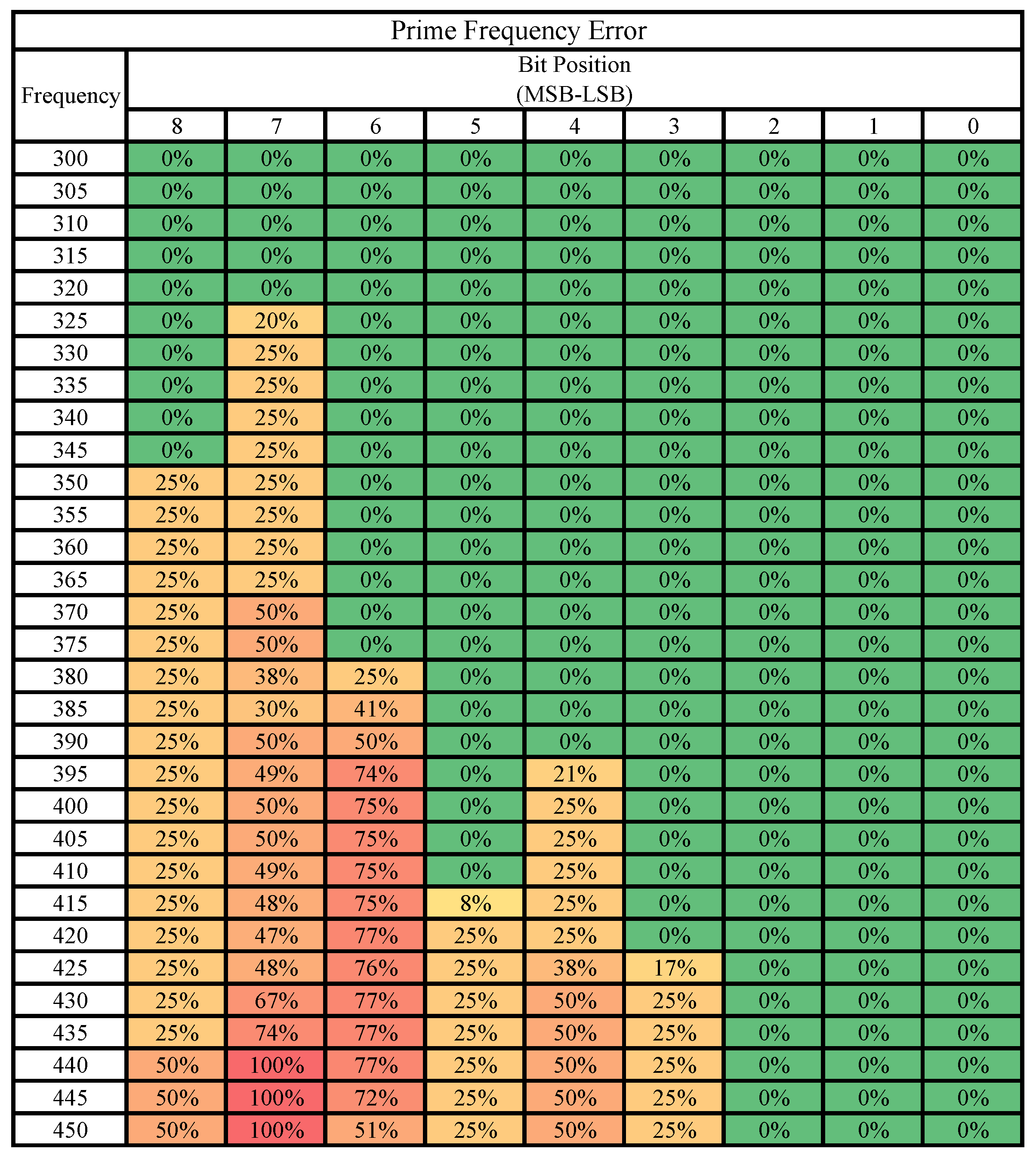
3.4. Case Study 4: Prime Activation
4. Methodology
4.1. Hardware and Software Used
4.2. FPGA Design for the SMA Building Block
4.2.1. MAC Unit
4.2.2. SMA Generator
4.2.3. SMA Wrapper
4.2.4. Critical Path Analysis
4.3. Embedded Software
4.4. Data Capture Challenges
4.5. Methodology Conclusion
5. Experimental Results
5.1. Error Analysis Using Hamming Distance
5.2. Error Diversity Analysis: How Many Erroneous Values Do We Observe?
5.2.1. Case Study 1: Identity Activation
5.2.2. Case Study 2: Diagonal Activation
5.2.3. Case Study 3: Hamming Activation
5.2.4. Case Study 4: Prime Activation
5.3. Bit-Level Error Susceptibility
6. Related Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tian, Y. Artificial Intelligence Image Recognition Method Based on Convolutional Neural Network Algorithm. IEEE Access 2020, 8, 125731–125744. [Google Scholar] [CrossRef]
- Park, S.H.; Han, K. Methodologic Guide for Evaluating Clinical Performance and Effect of Artificial Intelligence Technology for Medical Diagnosis and Prediction. Radiology 2018, 286, 800–809. [Google Scholar] [CrossRef] [PubMed]
- Amberkar, A.; Awasarmol, P.; Deshmukh, G.; Dave, P. Speech Recognition using Recurrent Neural Networks. In Proceedings of the ICCTCT, Coimbatore, India, 1–3 March 2018. [Google Scholar] [CrossRef]
- Roelke, A.; Zhang, R.; Mazumdar, K.; Wang, K.; Skadron, K.; Stan, M.R. Pre-RTL Voltage and Power Optimization for Low-Cost, Thermally Challenged Multicore Chips. In Proceedings of the 2017 IEEE International Conference on Computer Design (ICCD), Boston, MA, USA, 5–8 November 2017; pp. 597–600. [Google Scholar] [CrossRef]
- Swaminathan, K.; Chandramoorthy, N.; Cher, C.Y.; Bertran, R.; Buyuktosunoglu, A.; Bose, P. BRAVO: Balanced Reliability-Aware Voltage Optimization. In Proceedings of the 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA), Austin, TX, USA, 4–8 February 2017; pp. 97–108. [Google Scholar] [CrossRef]
- Tang, Z.; Wang, Y.; Wang, Q.; Chu, X. The impact of GPU DVFS on the energy and performance of deep learning: An empirical study. In Proceedings of the Tenth ACM International Conference on Future Energy Systems, Phoenix, AZ, USA, 25–28 June 2019; pp. 315–325. [Google Scholar]
- Zhang, J.; Rangineni, K.; Ghodsi, Z.; Garg, S. ThunderVolt: Enabling Aggressive Voltage Underscaling and Timing Error Resilience for Energy Efficient Deep Neural Network Accelerators. In Proceedings of the 55th Annual Design Automation Conference, San Francisco, CA, USA, 24–29 June 2018. [Google Scholar]
- Sutter, G.; Boemo, E.I. Experiments in low power FPGA design. Lat. Am. Appl. Res. 2007, 37, 99–104. [Google Scholar]
- Papadimitriou, G.; Kaliorakis, M.; Chatzidimitriou, A.; Gizopoulos, D.; Lawthers, P.; Das, S. Harnessing voltage margins for energy efficiency in multicore CPUs. In Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, Boston, MA, USA, 14–17 October 2017; pp. 503–516. [Google Scholar]
- Zou, A.; Leng, J.; He, X.; Zu, Y.; Gill, C.D.; Reddi, V.J.; Zhang, X. Voltage-stacked GPUs: A control theory driven cross-layer solution for practical voltage stacking in GPUs. In Proceedings of the 2018 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Fukuoka, Japan, 20–24 October 2018; pp. 390–402. [Google Scholar]
- Kim, S.; Howe, P.; Moreau, T.; Alaghi, A.; Ceze, L.; Sathe, V. MATIC: Learning around errors for efficient low-voltage neural network accelerators. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1–6. [Google Scholar]
- Chang, K.K.; Yaglıkçı, A.G.; Ghose, S.; Agrawal, A.; Chatterjee, N.; Kashyap, A.; Lee, D.; O’Connor, M.; Hassan, H.; Mutlu, O. Voltron: Understanding and Exploiting the Voltage-Latency-Reliability Trade-Offs in Modern DRAM Chips to Improve Energy Efficiency. arXiv 2018, arXiv:1805.03175. [Google Scholar]
- Koppula, S.; Orosa, L.; Yağlıkçı, A.G.; Azizi, R.; Shahroodi, T.; Kanellopoulos, K.; Mutlu, O. EDEN: Enabling energy-efficient, high-performance deep neural network inference using approximate DRAM. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, Columbus, OH, USA, 12–16 October 2019; pp. 166–181. [Google Scholar]
- Salami, B.; Onural, E.B.; Yuksel, I.; Koc, F.; Ergin, O.; Cristal, A.; Unsal, O.; Sarbazi-Azad, H.; Mutlu, O. An Experimental Study of Reduced-Voltage Operation in Modern FPGAs for Neural Network Acceleration. In Proceedings of the DSN, Valencia, Spain, 29 June–2 July 2020; pp. 138–149. [Google Scholar]
- Majumdar, S.; Samavatian, M.H.; Barber, K.; Teodorescu, R. Using Undervolting as an on-Device Defense Against Adversarial Machine Learning Attacks. In Proceedings of the 2021 IEEE International Symposium on Hardware Oriented Security and Trust (HOST), Tysons Corner, VA, USA, 12–15 December 2021; pp. 158–169. [Google Scholar]
- Pourreza, M.; Narasimhan, P. A Survey of Faults and Fault-Injection Techniques in Edge Computing Systems. In Proceedings of the IEEE International Conference on Edge Computing and Communications (EDGE), Chicago, IL, USA, 2–8 July 2023; pp. 63–71. [Google Scholar] [CrossRef]
- Zhang, J.J.; Garg, S. FATE: Fast and accurate timing error prediction framework for low power DNN accelerator design. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar]
- Marty, T.; Yuki, T.; Derrien, S. Safe Overclocking for CNN Accelerators Through Algorithm-Level Error Detection. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 4777–4790. [Google Scholar] [CrossRef]
- Deng, J.; Fang, Y.; Du, Z.; Wang, Y.; Li, H.; Temam, O.; Ienne, P.; Novo, D.; Li, X.; Chen, Y.; et al. Retraining-based timing error mitigation for hardware neural networks. In Proceedings of the 2015 Design, Automation and Test in Europe Conference and Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 593–596. [Google Scholar]
- Roy, S.; Chakraborty, K. Predicting Timing Violations Through Instruction Level Path Sensitization Analysis. In Proceedings of the DAC, New York, NY, USA, 3–7 June 2012; pp. 1074–1081. [Google Scholar]
- Pandey, P.; Basu, P.; Chakraborty, K.; Roy, S. GreenTPU: Predictive Design Paradigm for Improving Timing Error Resilience of a Near-Threshold Tensor Processing Unit. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 1557–1566. [Google Scholar] [CrossRef]
- Xilinx. Zynq 7000 SoC. 2020. Available online: https://docs.xilinx.com/v/u/en-US/ds187-XC7Z010-XC7Z020-Data-Sheet (accessed on 29 December 2023).
- Gondimalla, A.; Chesnut, N.; Thottethodi, M.; Vijaykumar, T.N. SparTen: A Sparse Tensor Accelerator for Convolutional Neural Networks. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture. Association for Computing Machinery, Columbus, OH, USA, 12–16 October 2019; pp. 151–165. [Google Scholar] [CrossRef]
- Gundi, N.D.; Mowri, Z.M.; Chamberlin, A.; Roy, S.; Chakraborty, K. STRIVE: Enabling Choke Point Detection and Timing Error Resilience in a Low-Power Tensor Processing Unit. In Proceedings of the of DAC, Tokyo, Japan, 16–19 January 2023. [Google Scholar]
- Shi, K.; Boland, D.; Constantinides, G.A. Accuracy-Performance Tradeoffs on an FPGA through Overclocking. In Proceedings of the 2013 IEEE 21st Annual International Symposium on Field-Programmable Custom Computing Machines, Seattle, WA, USA, 28–30 April 2013; pp. 29–36. [Google Scholar] [CrossRef]
- Wang, X.; Robinson, W.H. Error Estimation and Error Reduction with Input-Vector Profiling for Timing Speculation in Digital Circuits. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2019, 38, 385–389. [Google Scholar] [CrossRef]
- Paim, G.; Amrouch, H.; Rocha, L.M.G.; Abreu, B.; Costa, E.; Bampi, S.; Henkel, J. A Framework for Crossing Temperature-Induced Timing Errors Underlying Hardware Accelerators to the Algorithm and Application Layers. IEEE Trans. Comput. 2022, 71, 349–363. [Google Scholar] [CrossRef]
- Marty, T.; Yuki, T.; Derrien, S. Enabling Overclocking Through Algorithm-Level Error Detection. In Proceedings of the 2018 International Conference on Field-Programmable Technology (FPT), Naha, Japan, 10–14 December 2018; pp. 174–181. [Google Scholar] [CrossRef]
- Jiang, W.; Yu, H.; Chen, F.; Ha, Y. AOS: An Automated Overclocking System for High Performance CNN Accelerator Through Timing Delay Measurement on FPGA. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2023, 42, 1. [Google Scholar] [CrossRef]
- Jiao, X.; Luo, M.; Lin, J.H.; Gupta, R.K. An assessment of vulnerability of hardware neural networks to dynamic voltage and temperature variations. In Proceedings of the 2017 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Irvine, CA, USA, 13–16 November 2017; pp. 945–950. [Google Scholar]
- Gundi, N.D.; Shabanian, T.; Basu, P.; Pandey, P.; Roy, S.; Chakraborty, K.; Zhang, Z. EFFORT: Enhancing Energy Efficiency and Error Resilience of a Near-Threshold Tensor Processing Unit. In Proceedings of the 2020 25th Asia and South Pacific Design Automation Conference (ASP-DAC), Beijing, China, 13–16 January 2020; pp. 241–246. [Google Scholar]
- Pandey, P.; Basu, P.; Chakraborty, K.; Roy, S. GreenTPU: Improving Timing Error Resilience of a Near-Threshold Tensor Processing Unit. In Proceedings of the DAC, Las Vegas, NV, USA, 2–6 June 2019; pp. 173:1–173:6. [Google Scholar]
- Andri, R.; Cavigelli, L.; Rossi, D.; Benini, L. YodaNN: An architecture for ultralow power binary-weight CNN acceleration. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2017, 37, 48–60. [Google Scholar] [CrossRef]
- Salami, B.; Unsal, O.S.; Kestelman, A.C. UnderVolt FNN: An Energy-Efficient and Fault-Resilient Low-Voltage FPGA-based DNN Accelerator. 2018. Available online: https://microarch.org/micro51/SRC/posters/12_salami.pdf (accessed on 15 September 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Temperature Degrees C | |||
|---|---|---|---|
| Study | Min | Avr. | Max |
| Identity | |||
| Hamming | |||
| Diagonal | |||
| Prime | |||
| Error Diversity Analysis | ||||
|---|---|---|---|---|
| Frequency (MHz) | Top Left | Top Right | Bottom Left | Bottom Right |
| 125–310 | 0 | 0 | 0 | 0 |
| 315–320 | 0 | 1 | 0 | 0 |
| 325 | 0 | 2 | 0 | 0 |
| 330–340 | 0 | 1 | 1 | 0 |
| 345 | 0 | 2 | 2 | 0 |
| 350 | 1 | 1 | 1 | 0 |
| 355 | 2 | 1 | 1 | 4 |
| 360 | 1 | 1 | 2 | 2 |
| 365 | 2 | 1 | 1 | 2 |
| 370 | 1 | 0 | 1 | 1 |
| 375 | 3 | 0 | 1 | 1 |
| 380 | 2 | 0 | 1 | 2 |
| 385 | 1 | 0 | 1 | 3 |
| 390 | 2 | 0 | 1 | 4 |
| 395 | 1 | 0 | 2 | 4 |
| 400 | 2 | 1 | 3 | 7 |
| 405 | 1 | 1 | 1 | 2 |
| 410 | 1 | 2 | 1 | 2 |
| 415 | 5 | 3 | 2 | 1 |
| 420 | 3 | 2 | 1 | 2 |
| 425 | 2 | 2 | 3 | 1 |
| 430 | 2 | 2 | 3 | 2 |
| 435 | 1 | 2 | 1 | 2 |
| 440–445 | 2 | 2 | 1 | 4 |
| 450 | 1 | 2 | 1 | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chamberlin, A.; Gerber, A.; Palmer, M.; Goodale, T.; Gundi, N.D.; Chakraborty, K.; Roy, S. Understanding Timing Error Characteristics from Overclocked Systolic Multiply–Accumulate Arrays in FPGAs. J. Low Power Electron. Appl. 2024, 14, 4. https://doi.org/10.3390/jlpea14010004
Chamberlin A, Gerber A, Palmer M, Goodale T, Gundi ND, Chakraborty K, Roy S. Understanding Timing Error Characteristics from Overclocked Systolic Multiply–Accumulate Arrays in FPGAs. Journal of Low Power Electronics and Applications. 2024; 14(1):4. https://doi.org/10.3390/jlpea14010004
Chicago/Turabian StyleChamberlin, Andrew, Andrew Gerber, Mason Palmer, Tim Goodale, Noel Daniel Gundi, Koushik Chakraborty, and Sanghamitra Roy. 2024. "Understanding Timing Error Characteristics from Overclocked Systolic Multiply–Accumulate Arrays in FPGAs" Journal of Low Power Electronics and Applications 14, no. 1: 4. https://doi.org/10.3390/jlpea14010004
APA StyleChamberlin, A., Gerber, A., Palmer, M., Goodale, T., Gundi, N. D., Chakraborty, K., & Roy, S. (2024). Understanding Timing Error Characteristics from Overclocked Systolic Multiply–Accumulate Arrays in FPGAs. Journal of Low Power Electronics and Applications, 14(1), 4. https://doi.org/10.3390/jlpea14010004