
Efficient GEMM Implementation for Vision-Based Object Detection in Autonomous Driving Applications

 ,
,  , ,
, ,  and
and
Abstract
1. Introduction
- Comprehensive analysis: We conduct a thorough investigation of the algorithmic complexity of YOLOv4 on the KITTI and Self Driving Car datasets, considering various input sizes. This analysis provides a detailed understanding of the algorithm’s computational requirements and helps identify potential areas for optimization.
- Performance evaluation: In addition to analyzing the algorithm’s complexity, we evaluate the performance of YOLOv4 on self-driving datasets. This evaluation encompasses accuracy assessment, where we quantify the detection precision and recall rates achieved by YOLOv4 on the autonomous driving datasets.
- FPGA-based GEMM implementation: To optimize the computational efficiency of YOLOv4, we propose a novel FPGA architecture specifically designed for implementing the GEMM operation within the algorithm.
2. Related Work
3. Materials and Methodology
3.1. Vision-Based Object Detection Algorithm
3.2. Datasets
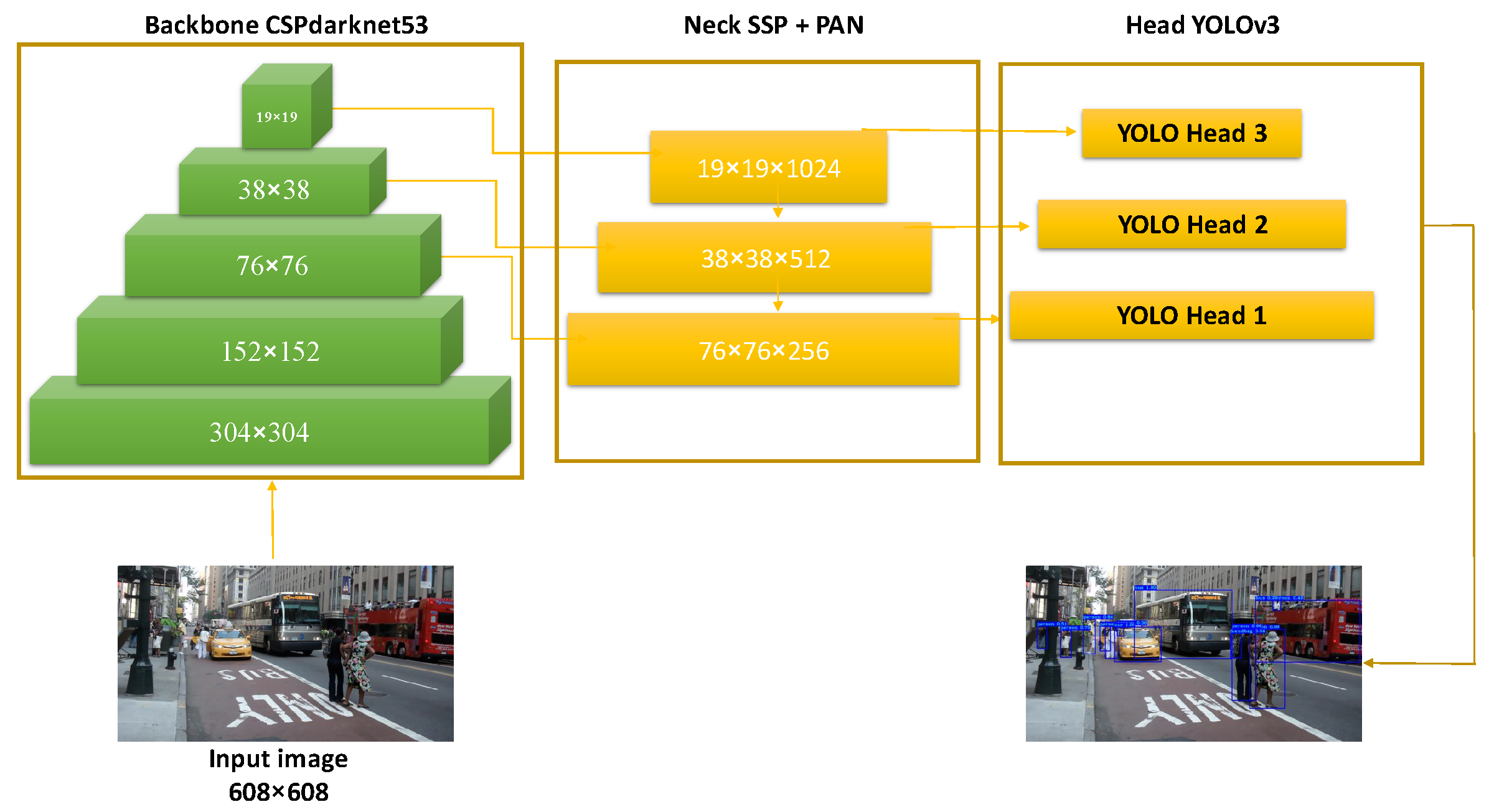
3.3. YOLOv4 Workflow
4. Experiment
4.1. Experimental Settings
4.2. Evaluation Metrics
5. Performance Evaluation
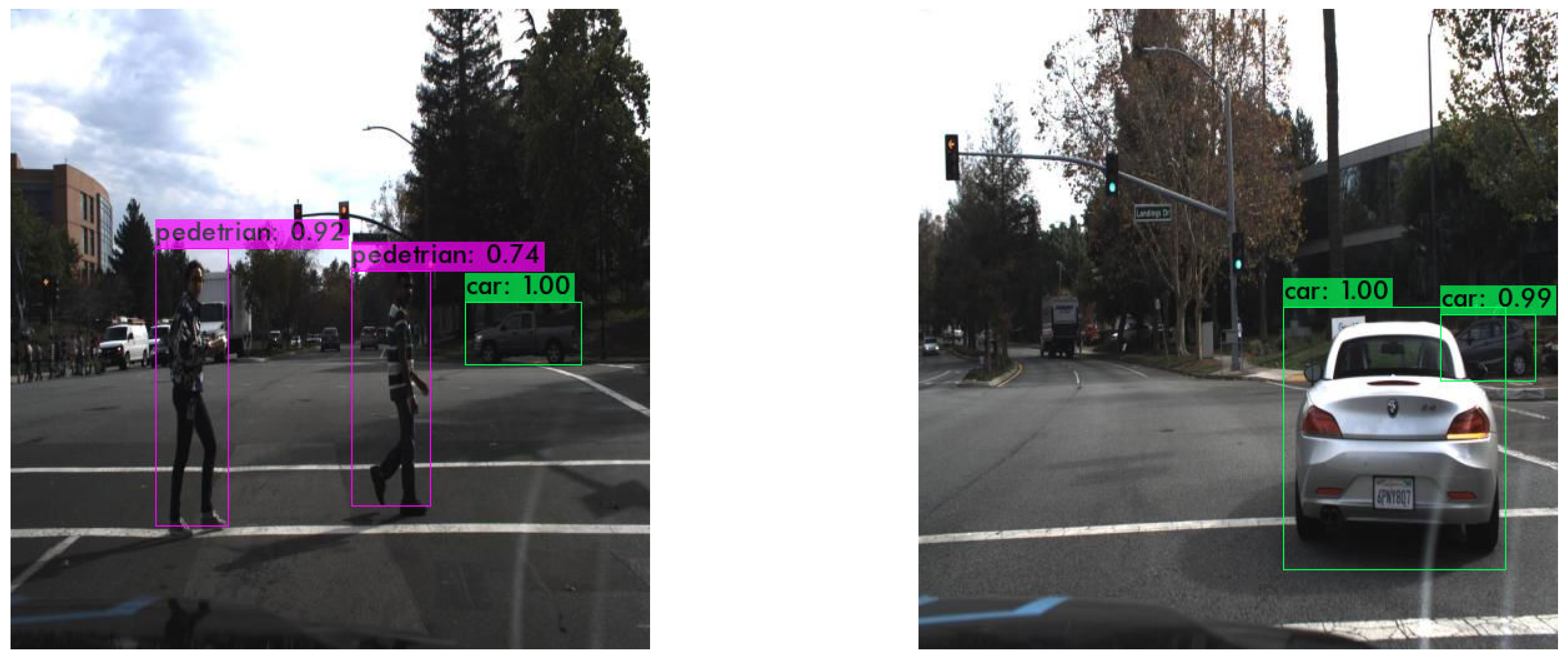
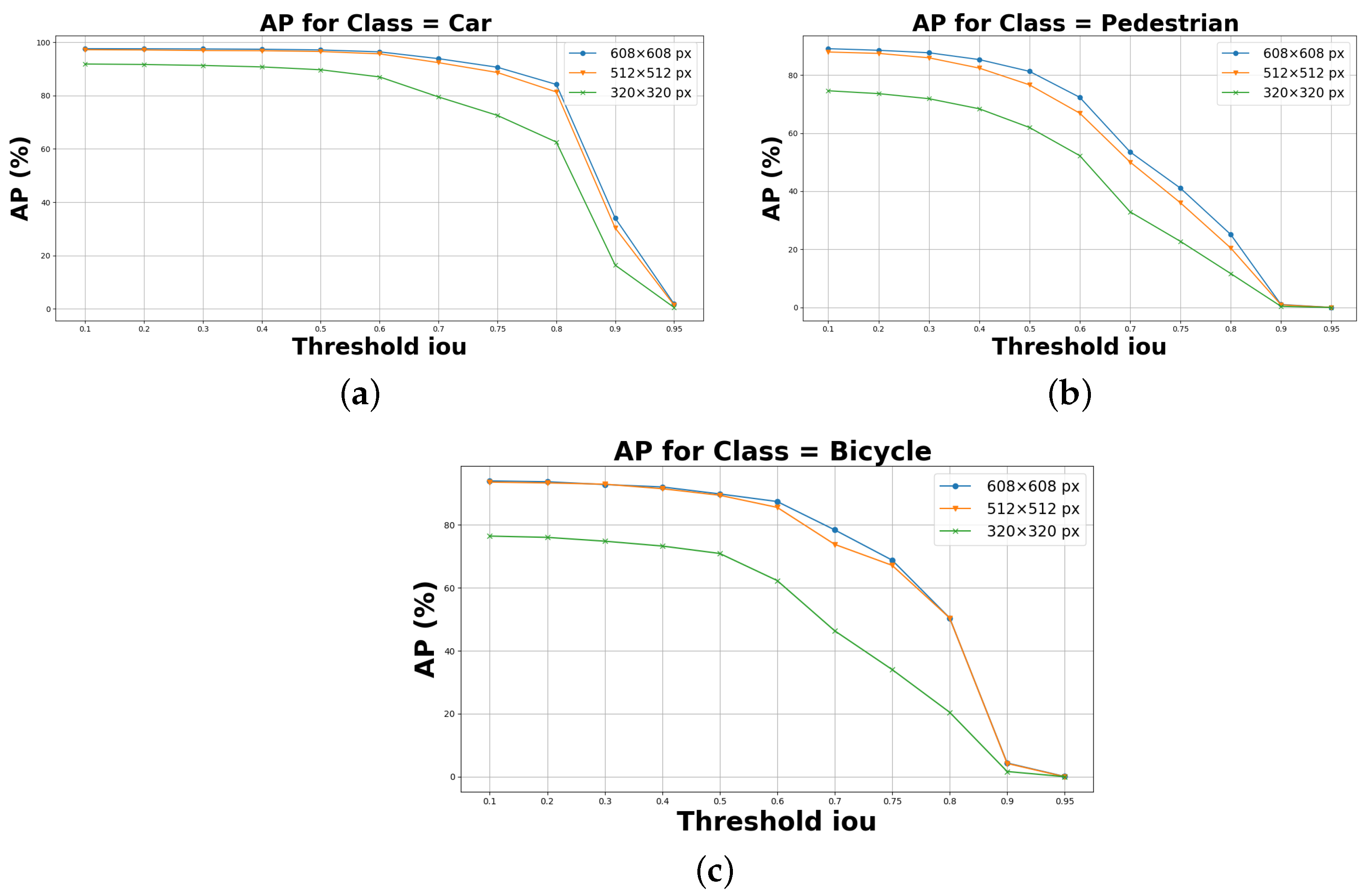
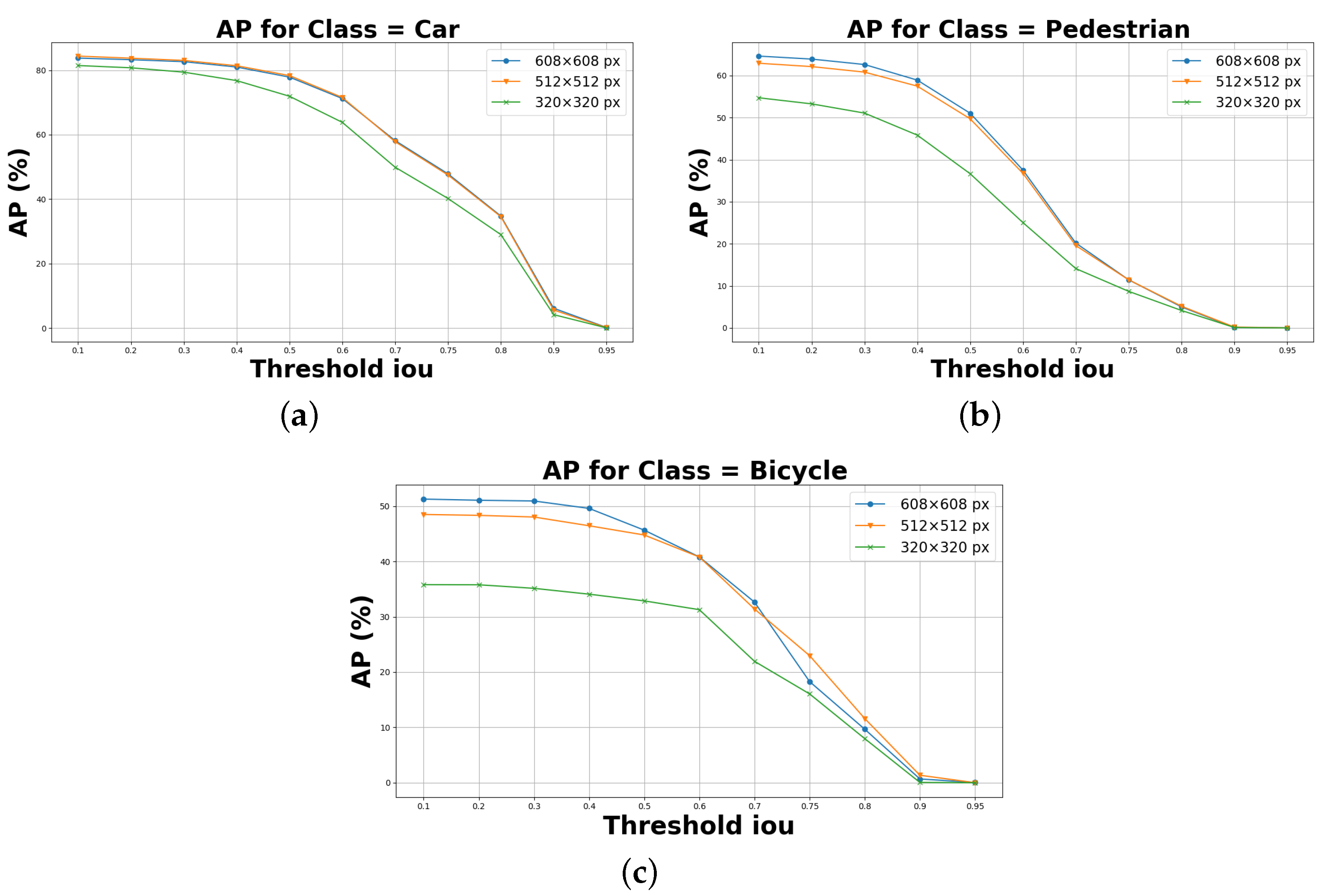
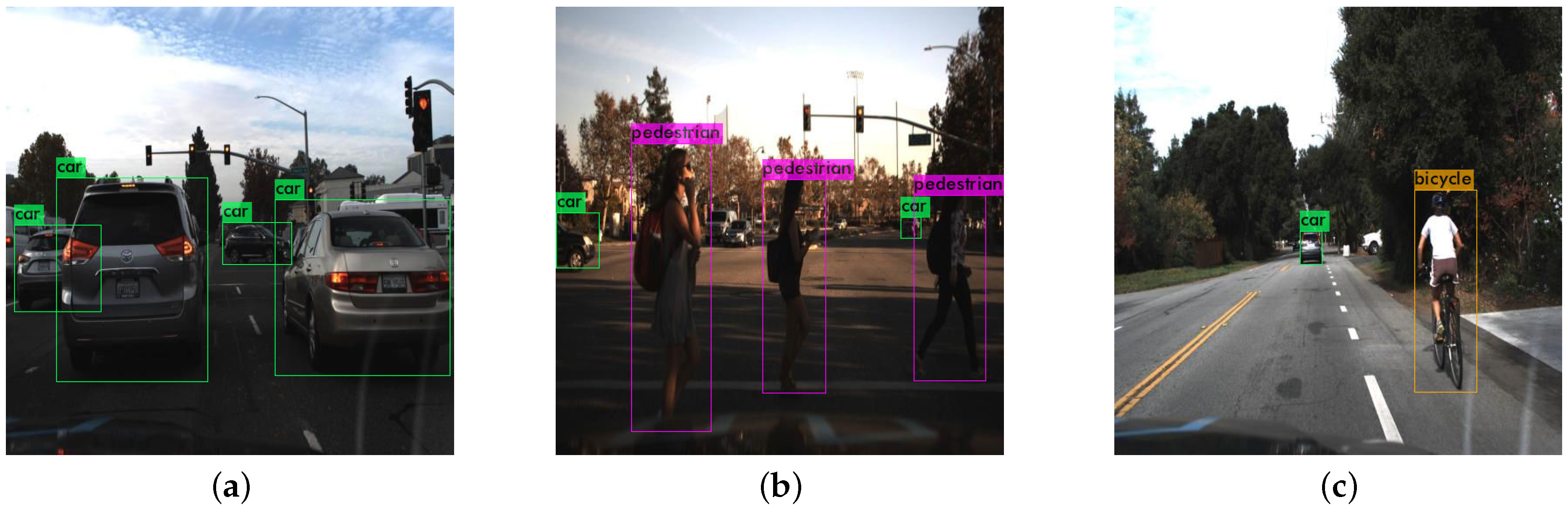
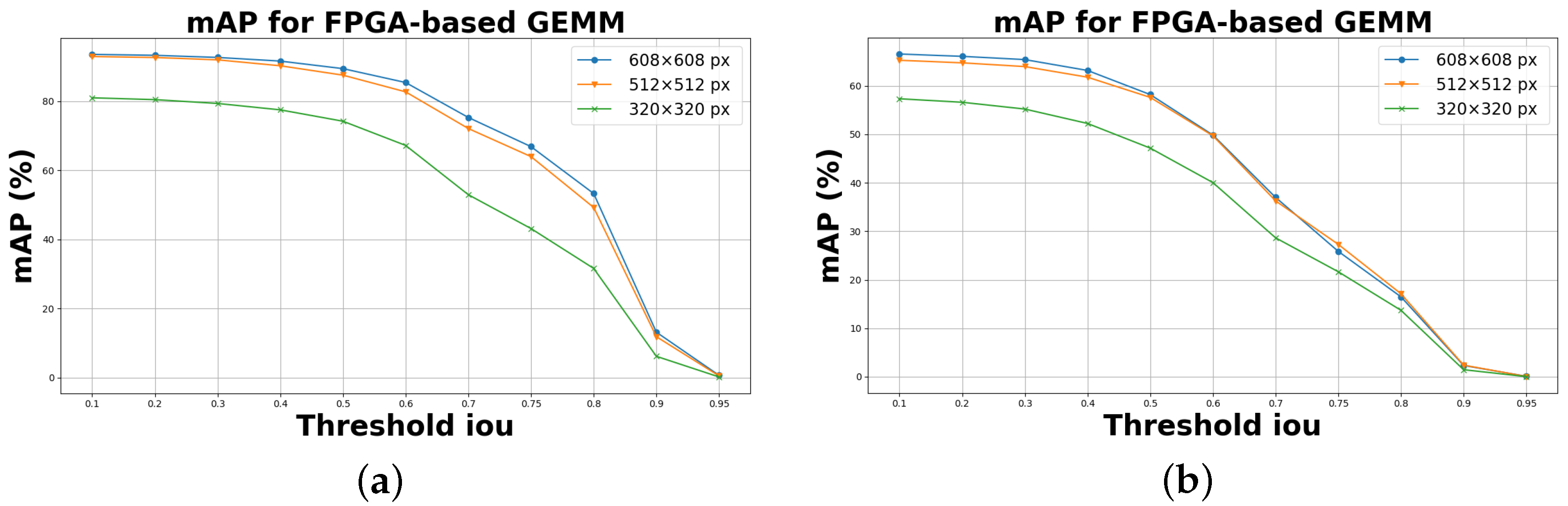
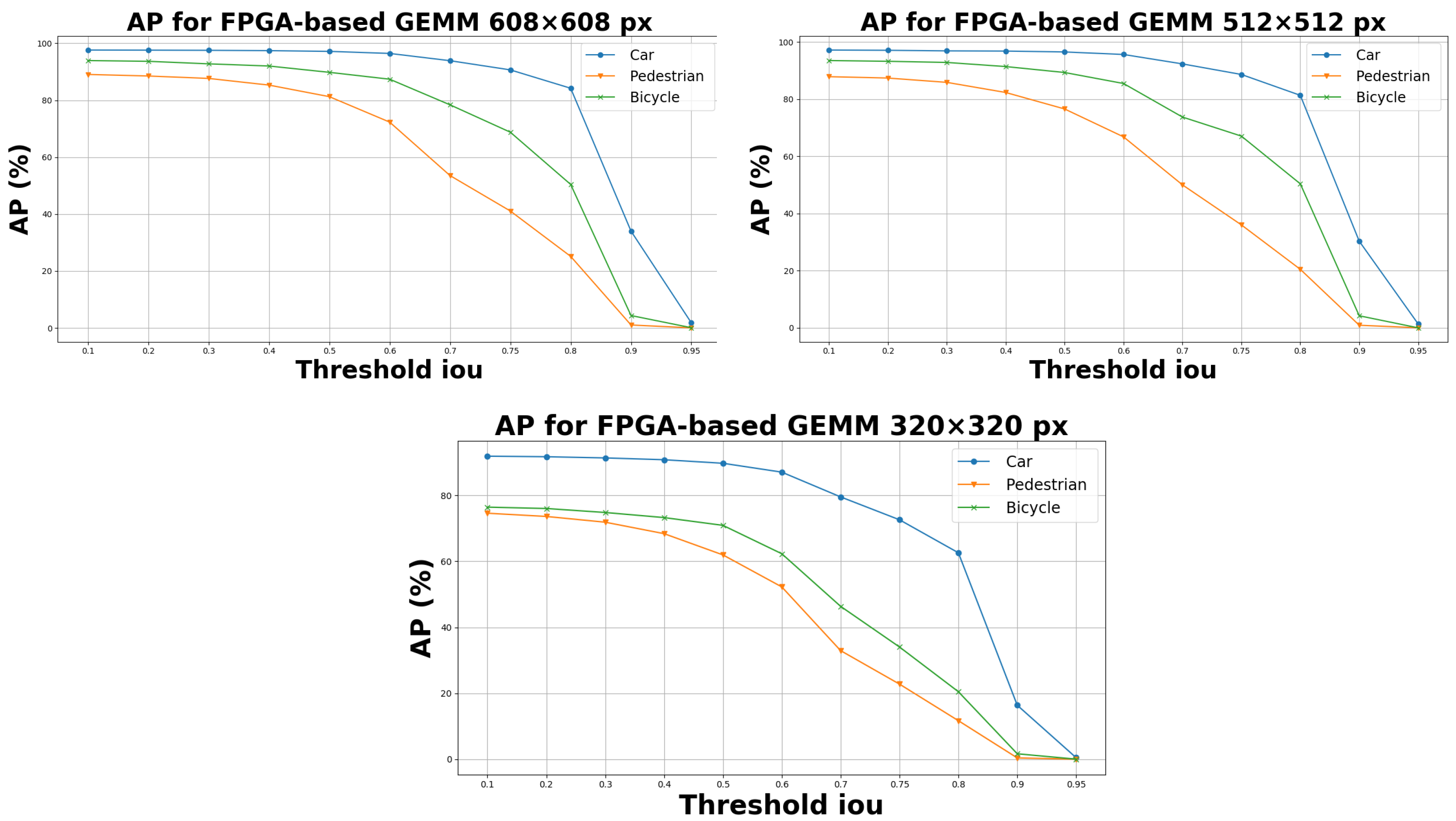
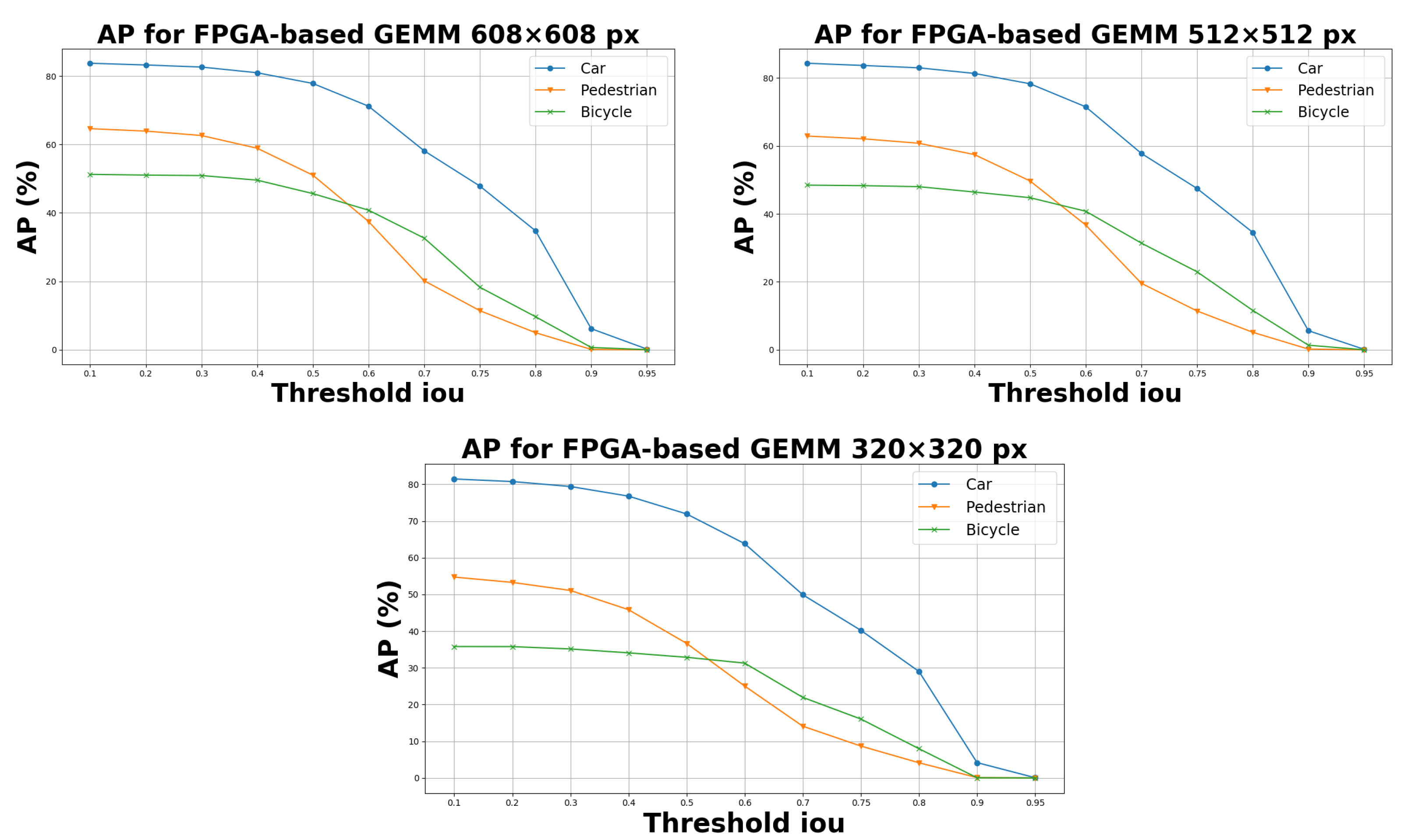
5.1. Experimental Results on KITTI and Self Driving Car Dataset
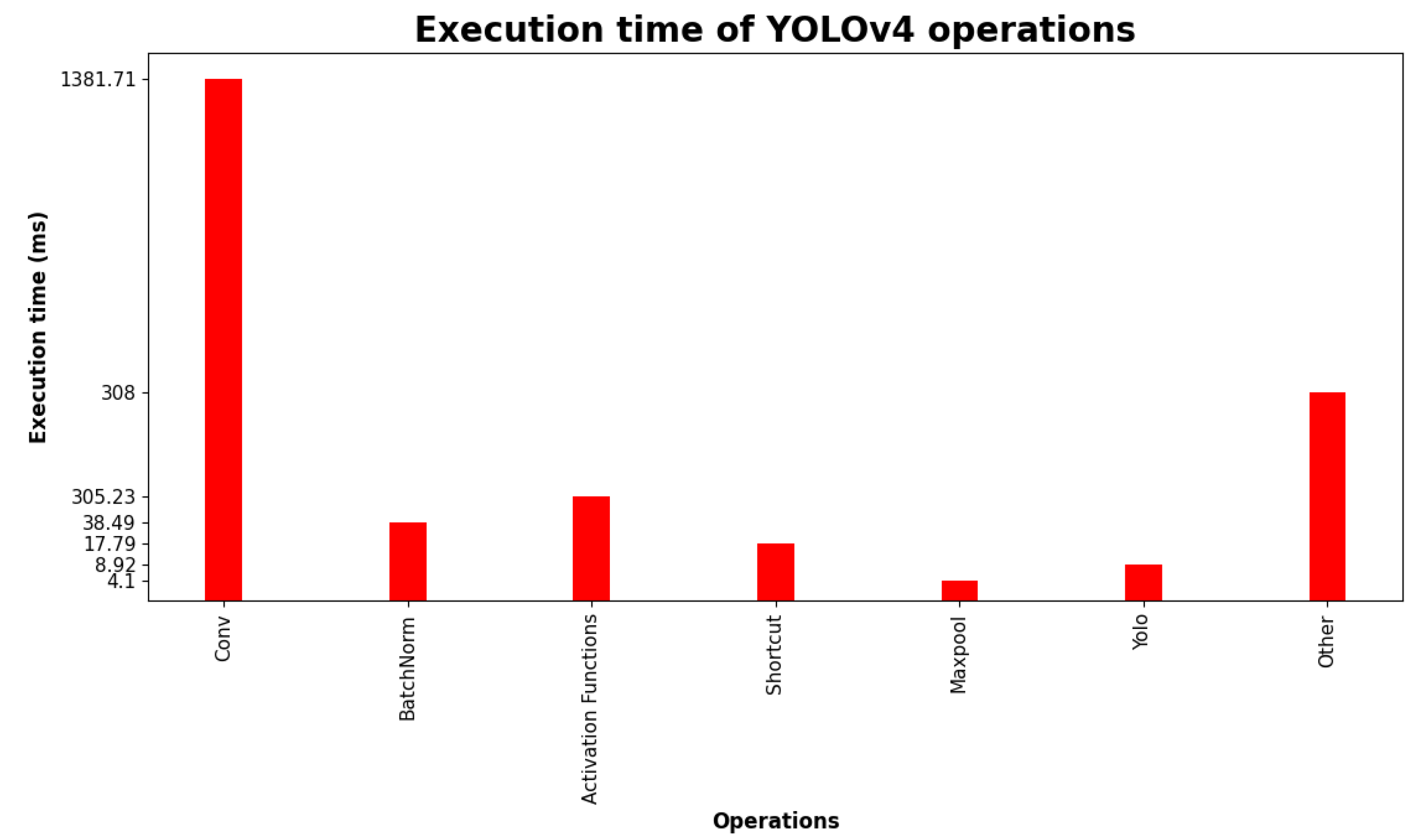
5.2. Processing Time Evaluation
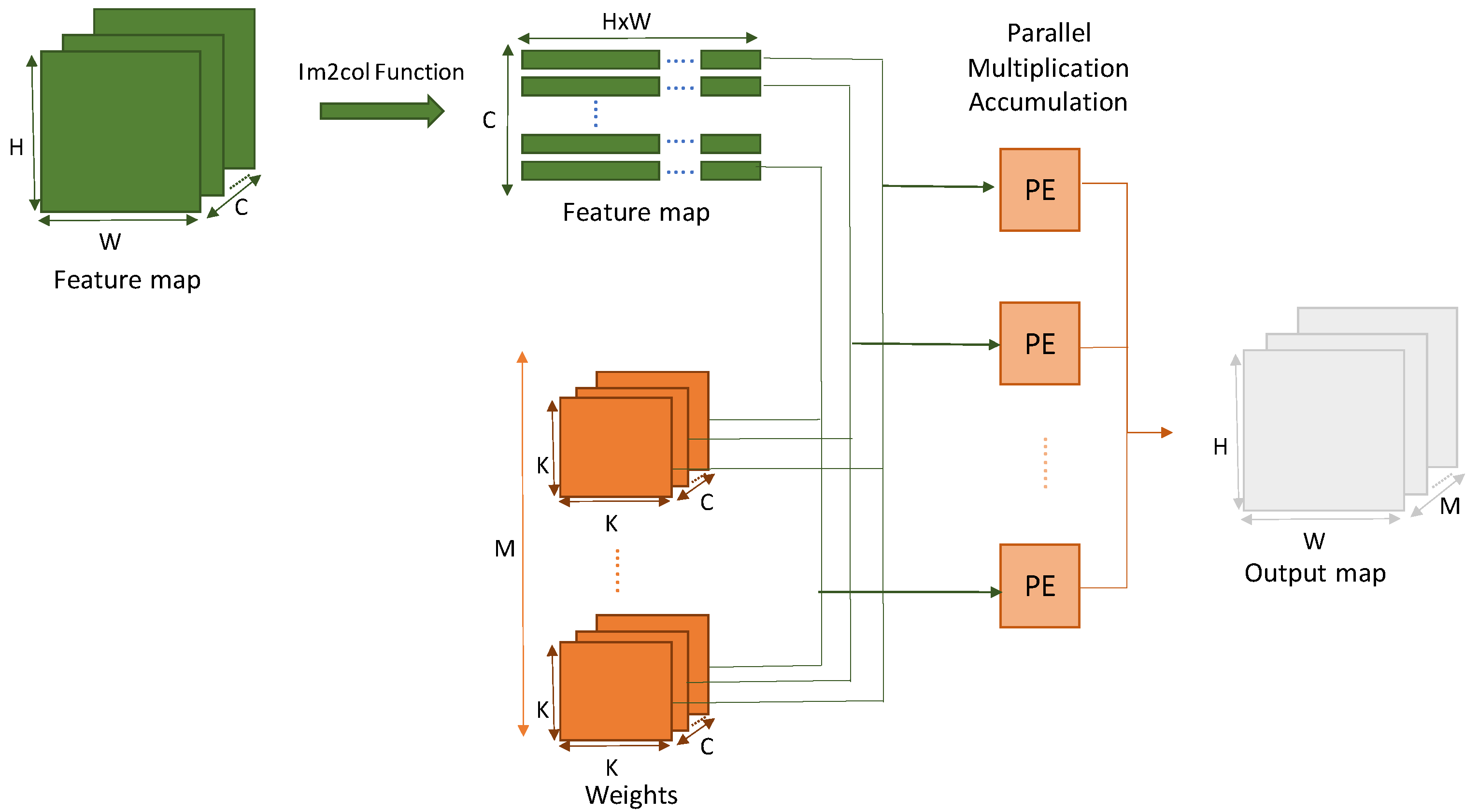
6. Accelerator Design
Results and Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wei, J.; He, J.; Zhou, Y.; Chen, K.; Tang, Z.; Xiong, Z. Enhanced object detection with deep convolutional neural networks for advanced driving assistance. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1572–1583. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Bharati, P.; Pramanik, A. Deep learning techniques—R-CNN to mask R-CNN: A survey. In Computational Intelligence in Pattern Recognition: Proceedings of CIPR 2019; Springer: Singapore, 2020; pp. 657–668. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zeng, K.; Ma, Q.; Wu, J.W.; Chen, Z.; Shen, T.; Yan, C. FPGA-based accelerator for object detection: A comprehensive survey. J. Supercomput. 2022, 78, 14096–14136. [Google Scholar] [CrossRef]
- Minakova, S.; Tang, E.; Stefanov, T. Combining task-and data-level parallelism for high-throughput cnn inference on embedded cpus-gpus mpsocs. In Proceedings of the Embedded Computer Systems: Architectures, Modelling, and Simulation: 20th International Conference, Athens, Greece, 5–9 July 2020; pp. 18–35. [Google Scholar]
- Roszyk, K.; Nowicki, M.R.; Skrzypczyński, P. Adopting the YOLOv4 architecture for low-latency multispectral pedestrian detection in autonomous driving. Sensors 2022, 22, 1082. [Google Scholar] [CrossRef] [PubMed]
- Sim, I.; Lim, J.H.; Jang, Y.W.; You, J.; Oh, S.; Kim, Y.K. Developing a compressed object detection model based on YOLOv4 for deployment on embedded GPU platform of autonomous system. arXiv 2021, arXiv:2108.00392. [Google Scholar]
- Nurvitadhi, E.; Sheffield, D.; Sim, J.; Mishra, A.; Venkatesh, G.; Marr, D. Accelerating binarized neural networks: Comparison of FPGA, CPU, GPU, and ASIC. In Proceedings of the 2016 International Conference on Field-Programmable Technology, Xi’an, China, 7–9 December 2016; pp. 77–84. [Google Scholar]
- Babu, P.; Parthasarathy, E. Hardware acceleration for object detection using YOLOv4 algorithm on Xilinx Zynq platform. J. Real-Time Image Process. 2022, 19, 931–940. [Google Scholar] [CrossRef]
- Pham-Dinh, T.; Bach-Gia, B.; Luu-Trinh, L.; Nguyen-Dinh, M.; Pham-Duc, H.; Bui-Anh, K.; Nguyen, X.Q.; Pham-Quoc, C. An FPGA-Based Solution for Convolution Operation Acceleration. In Intelligence of Things: Technologies and Applications; Nguyen, N.T., Dao, N.N., Pham, Q.D., Le, H.A., Eds.; Springer International Publishing: Cham, Switzerland, 2022. [Google Scholar]
- Sudrajat, M.R.D.; Adiono, T.; Syafalni, I. GEMM-Based Quantized Neural Network FPGA Accelerator Design. In Proceedings of the 2019 International Symposium on Electronics and Smart Devices, Bali, Indonesia, 8–9 October 2019; pp. 1–5. [Google Scholar]
- Zhang, W.; Jiang, M.; Luo, G. Evaluating low-memory GEMMs for convolutional neural network inference on FPGAS. In Proceedings of the 2020 IEEE 28th Annual International Symposium on Field-Programmable Custom Computing Machines, Fayetteville, AR, USA, 3–6 May 2020; pp. 28–32. [Google Scholar]
- Belabed, T.; Coutinho, M.G.F.; Fernandes, M.A.; Sakuyama, C.V.; Souani, C. User driven FPGA-based design automated framework of deep neural networks for low-power low-cost edge computing. IEEE Access 2021, 9, 89162–89180. [Google Scholar] [CrossRef]
- Feng, D.; Harakeh, A.; Waslander, S.L.; Dietmayer, K. A review and comparative study on probabilistic object detection in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2021, 23, 9961–9980. [Google Scholar] [CrossRef]
- Shetty, A.K.; Saha, I.; Sanghvi, R.M.; Save, S.A.; Patel, Y.J. A review: Object detection models. In Proceedings of the 2021 6th International Conference for Convergence in Technology, Pune, India, 2–4 April 2021; pp. 1–8. [Google Scholar]
- Ren, J.; Wang, Y. Overview of object detection algorithms using convolutional neural networks. J. Comput. Commun. 2022, 10, 115–132. [Google Scholar]
- Andriyanov, N.; Papakostas, G. Optimization and Benchmarking of Convolutional Networks with Quantization and OpenVINO in Baggage Image Recognition. In Proceedings of the 2022 VIII International Conference on Information Technology and Nanotechnology, Samara, Russia, 23–27 May 2022; pp. 1–4. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Roboflow Self Driving Car Dataset. Available online: https://public.roboflow.com/object-detection/self-driving-car (accessed on 26 February 2023).
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2020, arXiv:1804.02767. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 136, 103514. [Google Scholar] [CrossRef]
- Lian, X.; Zhang, C.; Zhang, H.; Hsieh, C.J.; Zhang, W.; Liu, J. Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Fränti, P.; Mariescu-Istodor, R. Soft precision and recall. Pattern Recognit. Lett. 2023, 167, 115–121. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Guerrouj, F.Z.; Abouzahir, M.; Ramzi, M.; Abdali, E.M. Analysis of the acceleration of deep learning inference models on a heterogeneous architecture based on OpenVINO. In Proceedings of the 2021 4th International Symposium on Advanced Electrical and Communication Technologies, Alkhobar, Saudi Arabia, 6–8 December 2021; pp. 1–5. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. Available online: https://github.com/ultralytics/ultralytics (accessed on 19 May 2023).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Detection Models | Year | N° of Parameters (×106) | Model Size (MB) | Backbone | mAP % |
|---|---|---|---|---|---|
| RetinaNet | 2017 | 65.13 | 146 | Resnet + FPN 1 | 33.15 |
| Rfcn-resnet-101 | 2016 | 53.46 | 206 | Resnet-101 | 28.40 |
| SSD-mobilenet-v1 | 2017 | 6.80 | 27 | Mobilenet | 23.33 |
| SSD-mobilenet-v1-fpn | 2017 | 36.18 | 119 | Mobilenet + FPN | 35.54 |
| SSD-mobilenet-v2 | 2019 | 16.81 | 65 | Mobilenet | 24.95 |
| SSDlite-mobilenet-v2 | 2018 | 4.47 | 18 | Mobilenet | 24.29 |
| SSD-resnet50-v1-fpn | 2017 | 56.93 | 198 | Resnet-50 + FPN | 35.01 |
| Faster-RCNN-resnet-50 | 2015 | 29.16 | 112 | Resnet-50 | 30 |
| Faster-RCNN-resnet-101 | 2015 | 48.12 | 185 | Resnet-101 | 35.72 |
| Faster-RCNN-inception-v2 | 2015 | 13.30 | 52 | Inception | 26.24 |
| YOLO-v2 | 2016 | 50.95 | 195 | Darknet-19 | 53.15 |
| YOLO-v2-tiny | 2016 | 11.23 | 43 | Darknet-19 | 29.11 |
| YOLO-v3 | 2018 | 61.92 | 237 | Darknet-53 | 67.7 |
| YOLO-v3-tiny | 2018 | 8.84 | 33 | Darknet-19 | 33.1 |
| YOLO-v4 | 2020 | 64.33 | 247 | Cspdarknet-53 | 77.40 |
| YOLO-v4-tiny | 2020 | 6.05 | 24 | Cspdark-53-tiny | 46.3 |
| Dataset | Training Set | Testing Set | Total | Class |
|---|---|---|---|---|
| KITTI [20] | 5237 | 2244 | 7481 | 8 |
| Self Driving Car [21] | 10,500 | 4500 | 15,000 | 11 |
| Datasets | KITTI | Self Driving Car | ||||
|---|---|---|---|---|---|---|
| Resolution | 608 × 608 | 512 × 512 | 320 × 320 | 608 × 608 | 512 × 512 | 320 × 320 |
| mAP (%) | 89.40 | 87.51 | 74.18 | 58.19 | 57.61 | 47.15 |
| Resource | Usage |
|---|---|
| Logic utilization | 24% |
| ALUTs | 12% |
| Dedicated logic registers | 12% |
| Memory blocks | 19% |
| DSP blocks | 6% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guerrouj, F.Z.; Rodríguez Flórez, S.; Abouzahir, M.; El Ouardi, A.; Ramzi, M. Efficient GEMM Implementation for Vision-Based Object Detection in Autonomous Driving Applications. J. Low Power Electron. Appl. 2023, 13, 40. https://doi.org/10.3390/jlpea13020040
Guerrouj FZ, Rodríguez Flórez S, Abouzahir M, El Ouardi A, Ramzi M. Efficient GEMM Implementation for Vision-Based Object Detection in Autonomous Driving Applications. Journal of Low Power Electronics and Applications. 2023; 13(2):40. https://doi.org/10.3390/jlpea13020040
Chicago/Turabian StyleGuerrouj, Fatima Zahra, Sergio Rodríguez Flórez, Mohamed Abouzahir, Abdelhafid El Ouardi, and Mustapha Ramzi. 2023. "Efficient GEMM Implementation for Vision-Based Object Detection in Autonomous Driving Applications" Journal of Low Power Electronics and Applications 13, no. 2: 40. https://doi.org/10.3390/jlpea13020040
APA StyleGuerrouj, F. Z., Rodríguez Flórez, S., Abouzahir, M., El Ouardi, A., & Ramzi, M. (2023). Efficient GEMM Implementation for Vision-Based Object Detection in Autonomous Driving Applications. Journal of Low Power Electronics and Applications, 13(2), 40. https://doi.org/10.3390/jlpea13020040