
Hardware Solutions for Low-Power Smart Edge Computing

 ,
,  , and
, and
Abstract
1. Introduction
- reduced communication bandwidth and power costs as a result of reduced data transfers to centralized cloud servers;
- physical proximity of data and devices facilitates real-time data processing, such as for self-driving cars;
- in-situ processing at the edge devices ensures privacy regarding sensitive data, and prevents their offloading to remote locations;
- as the system is distributed, failure of some nodes can be easily overcome with a minimal impact on the global system and new devices can be added in a modular fashion to increase computing power.
1.1. Machine Learning at the Edge
1.2. Motivation and Contribution of This Study
1.3. Outline of the Paper
2. A Quick Journey in the Landscape of Energy-Efficient Compute Systems for ML Tasks
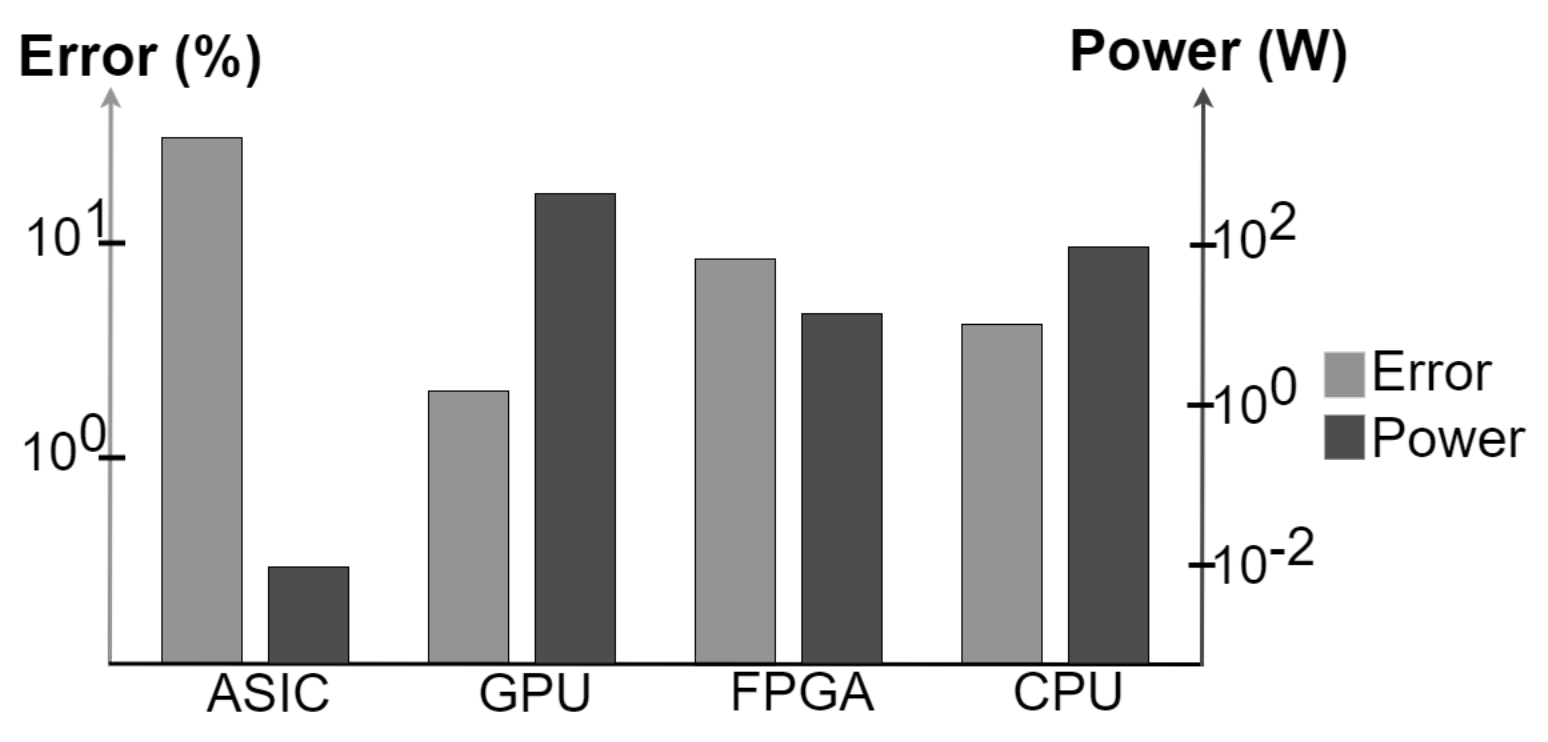
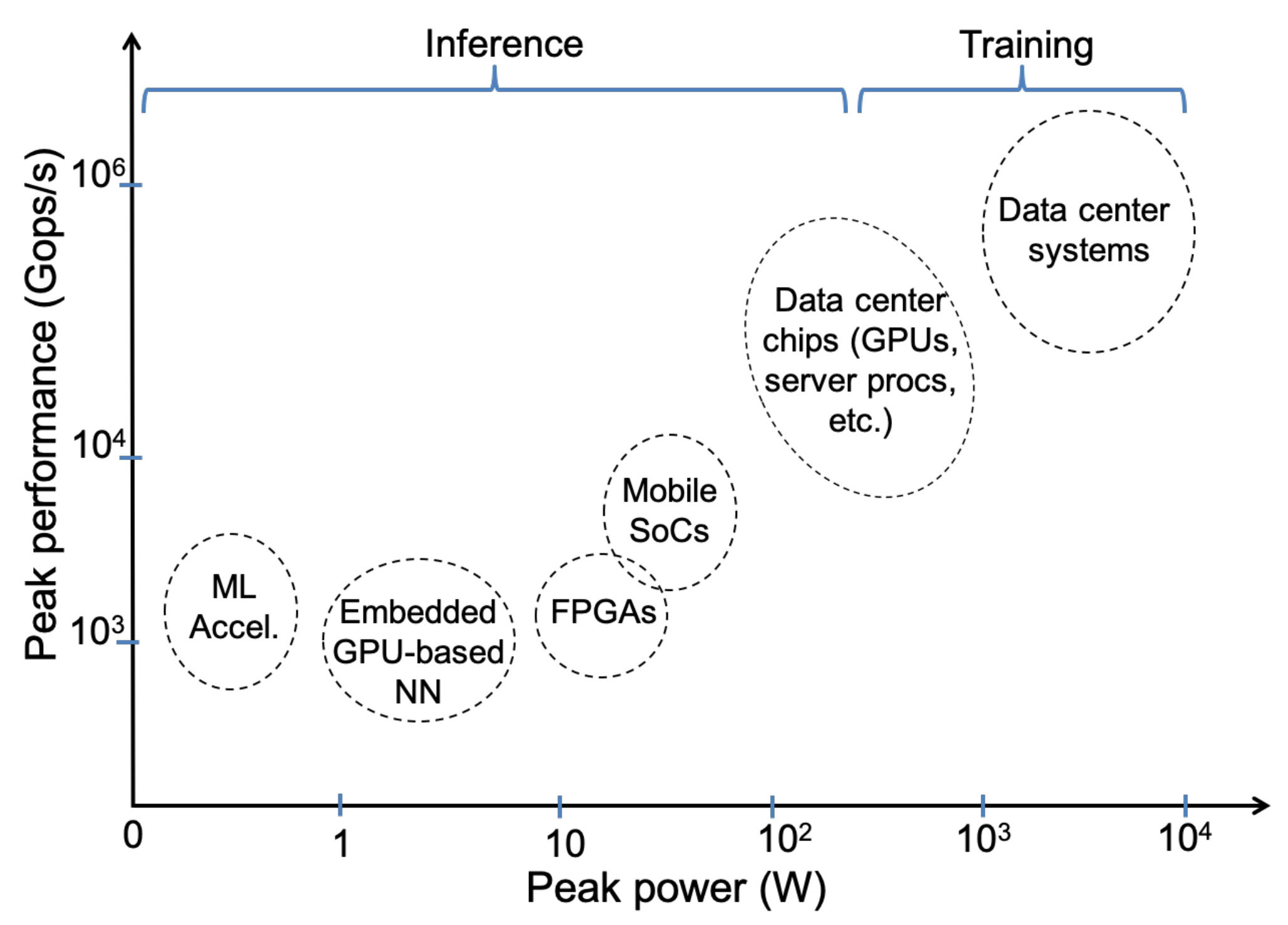
2.1. Focus on ML Accelerators, GPUs and FPGAs
2.2. From Software-Hardware Codesign to Emerging Computing Paradigms
3. Classification of Low-Power Devices for IoT and Smart Edge Computing
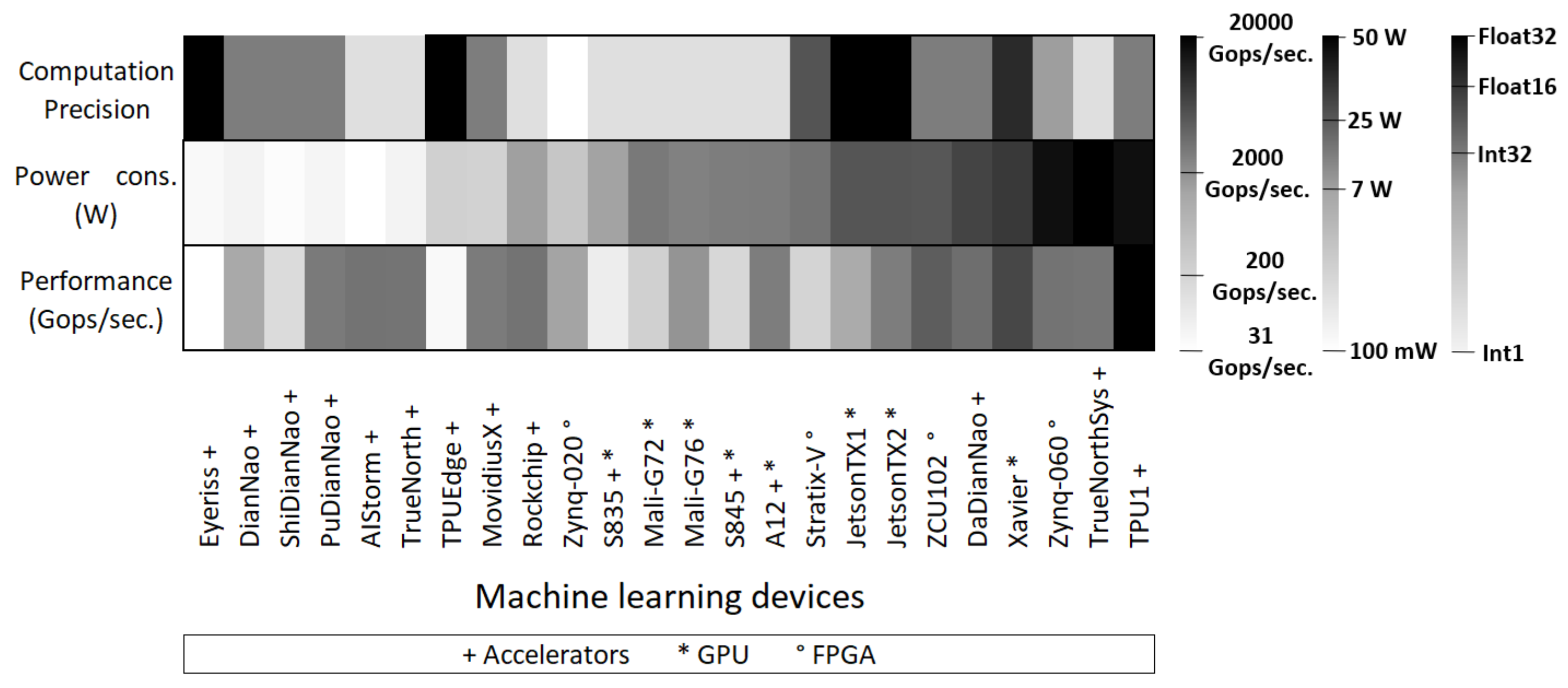
Quick Survey of Typical Embedded Devices
- the first application family includes ultra-low-power devices with limited resources suitable for lightweight IoT and edge applications. This applies to all class 0 and class 1 devices;
- the second application family consists of the most popular devices encountered in average edge computing and IoT applications. All devices in class 2 and part of devices in class 3 are included in this class;
- the third application family includes devices with the most powerful hardware resources for performing machine learning and inference tasks. It covers a significant portion of devices in classes 3 and 4 and 5.
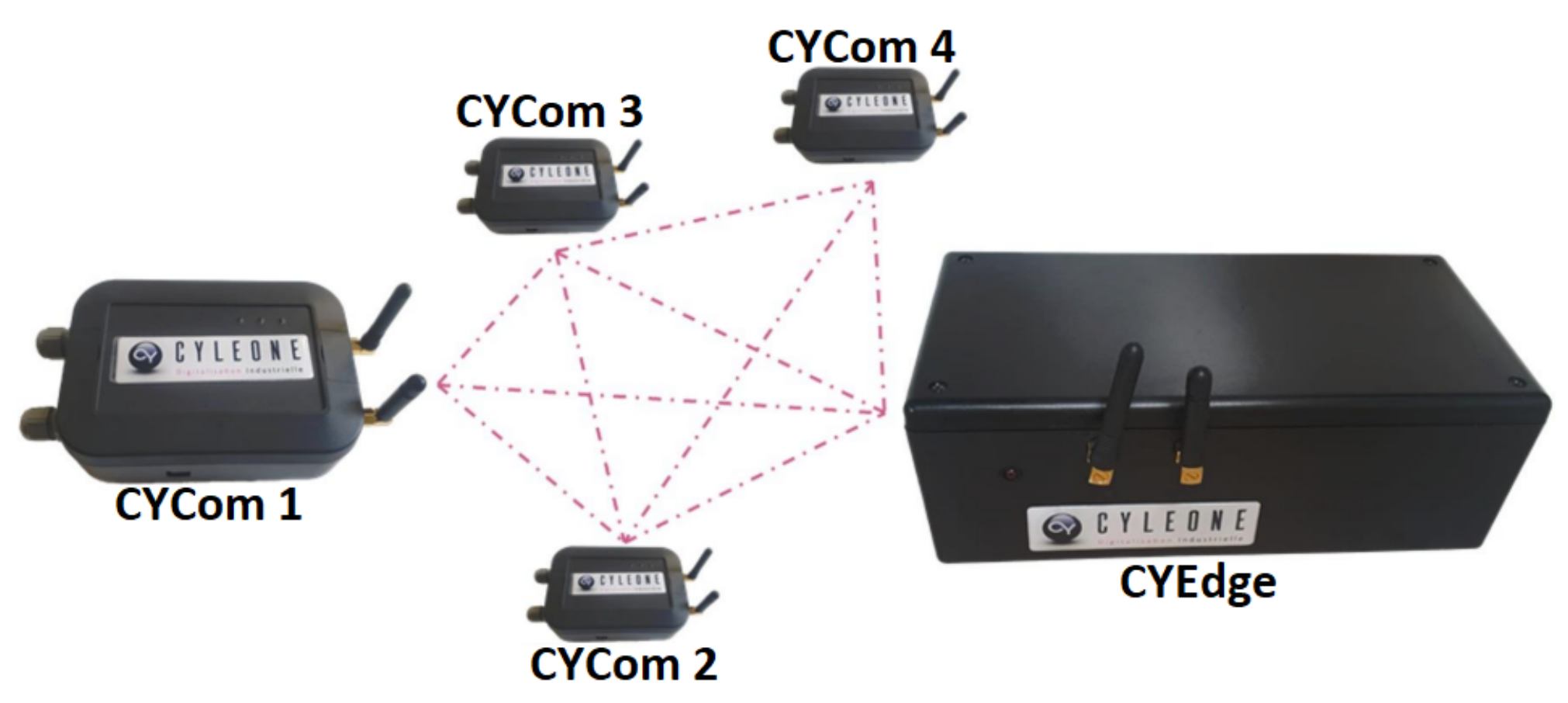
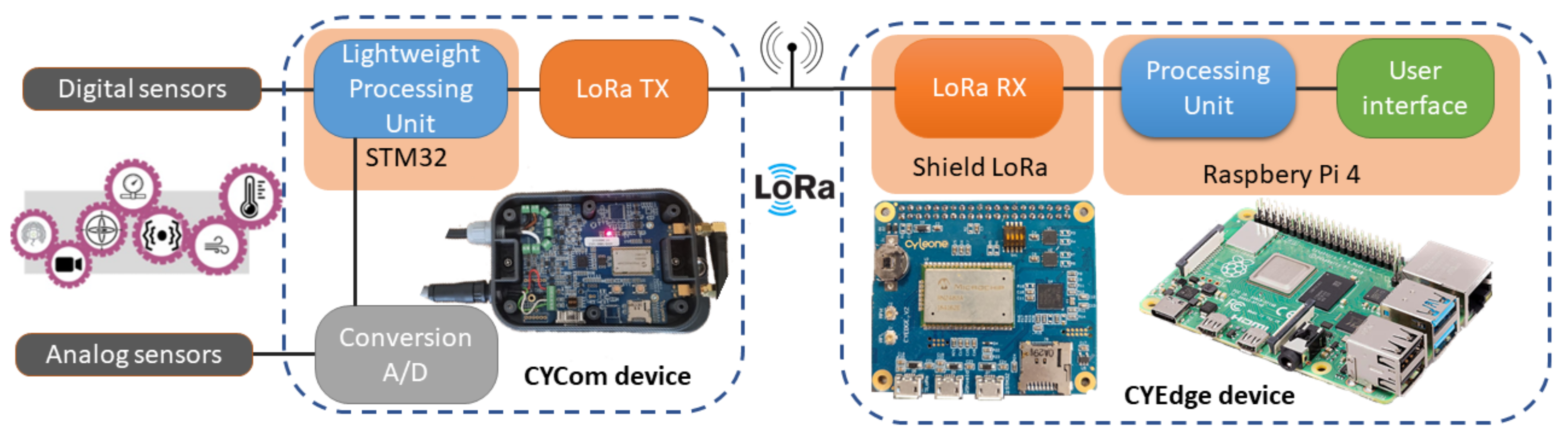
4. Low-Power Smart Edge Computing with CYSmart Solution
- Measurement identifier and name of the point of interest
- Type of measurement performed
- Unit of measurement used
- Range of measurement desired
- Operating mode of the module (continuous measurement, on demand, sleep…)
- Time range of system activity
- Battery level of CYComs
- Limit ranges of expected values
- Alert generation
- Transmission signal strength
- a visualization tool that displays the measurement curves versus time;
- a download of all the information stored on a USB flash drive, computer, or server. Depending on the needs of the customer or the third party software used, the file type and format are adapted.
4.1. Data Acquisition Device: CYCom
4.2. Centralized Early Data Processing: CYEdge
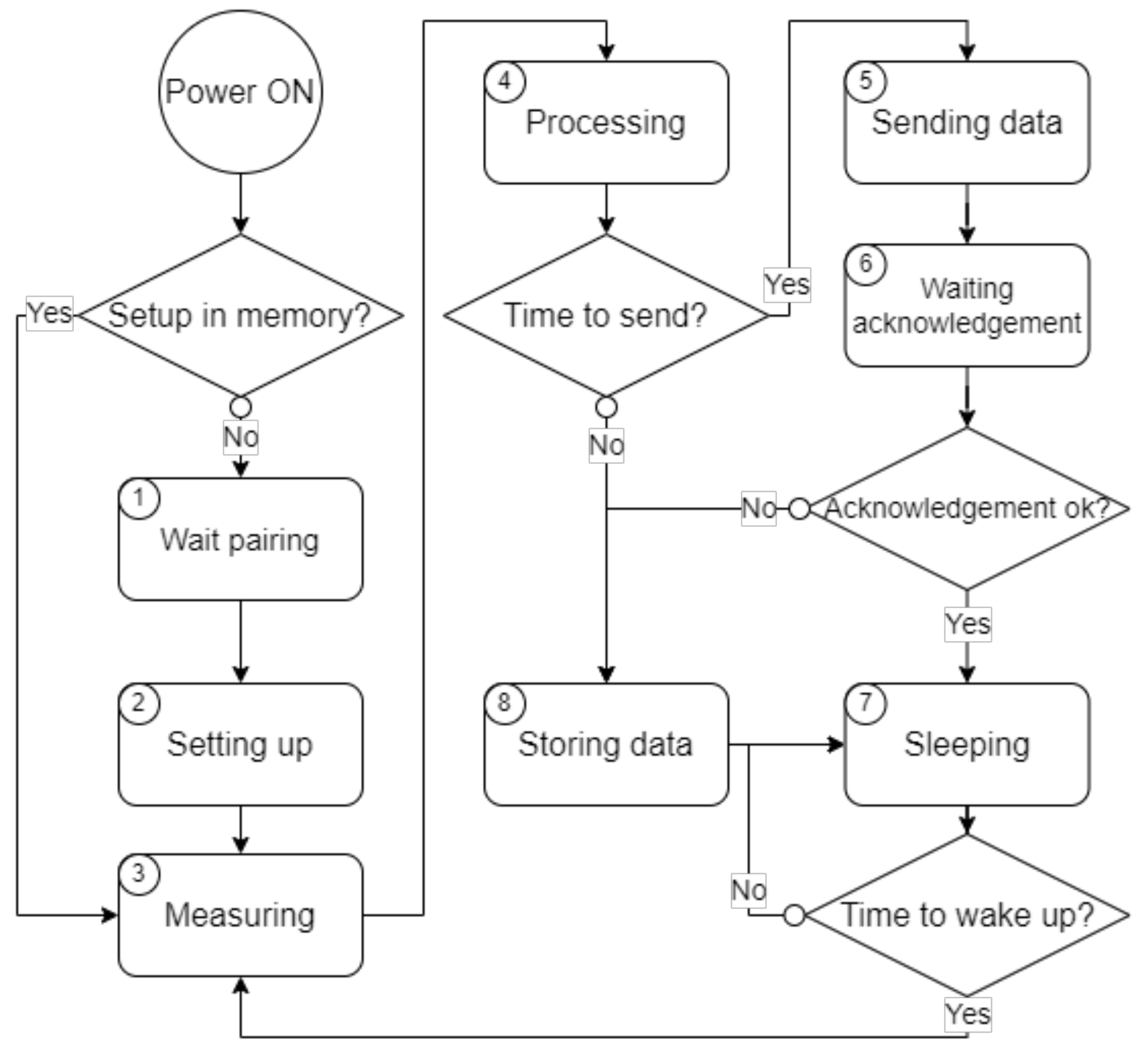
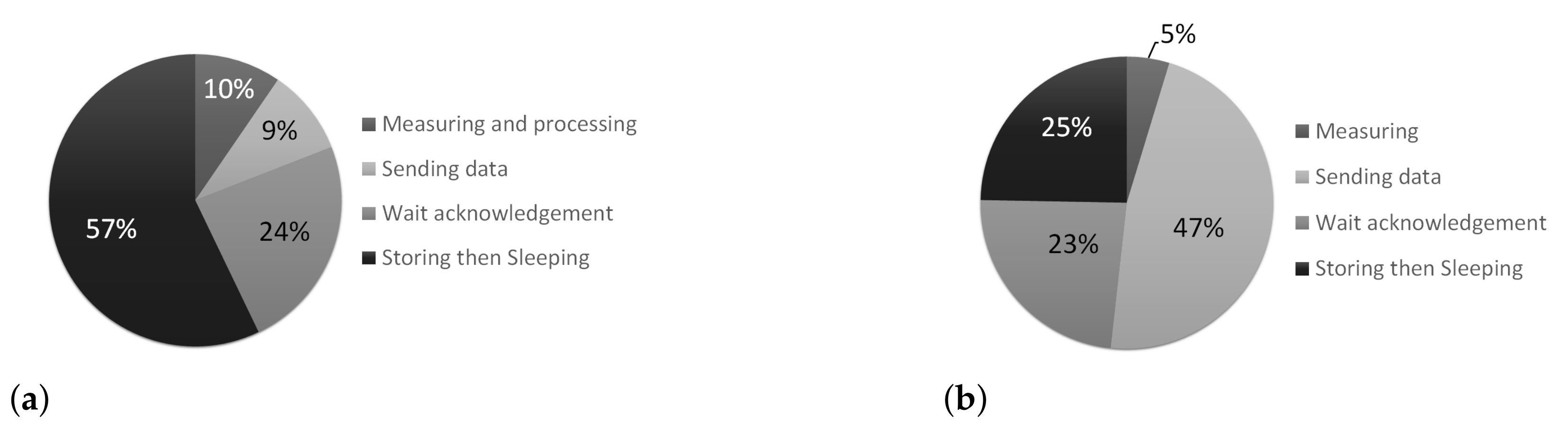
4.3. Use Case Evaluation of CYSmart
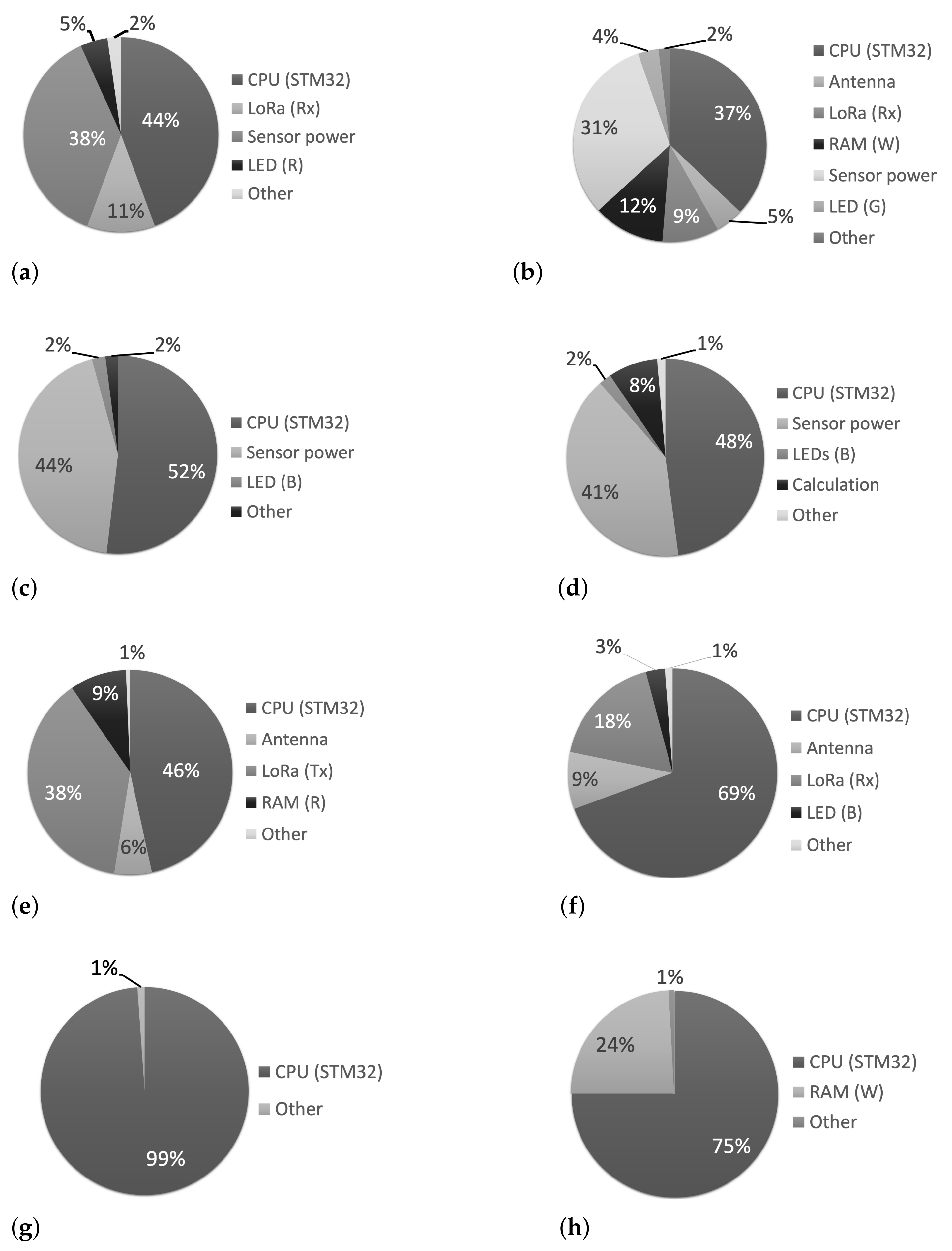
4.4. Gained Insights and Discussion
- Device classes: supported device classes as defined in Table 1. This criterion implicitly suggests a range of power consumption;
- Sensor diversity: diversity of sensor types supported by a technology, such as digital versus analog sensors, as well as sensor voltage ranges. The criterion is qualitative in nature and can be rated on three levels: high, average, and low.
- Transmission speed: the speed of data transmission between the sensors at the edge frontier and the gateway or centralized system that is responsible for pre-processing the data. Generally, it is measured in terms of the number of samples per second (S/sec) or bits per second (b/sec);
- Communication distance: the distance over which a technology communicates wirelessly. It is essential in critical environments, such as basements, bunkers, and nuclear power plants;
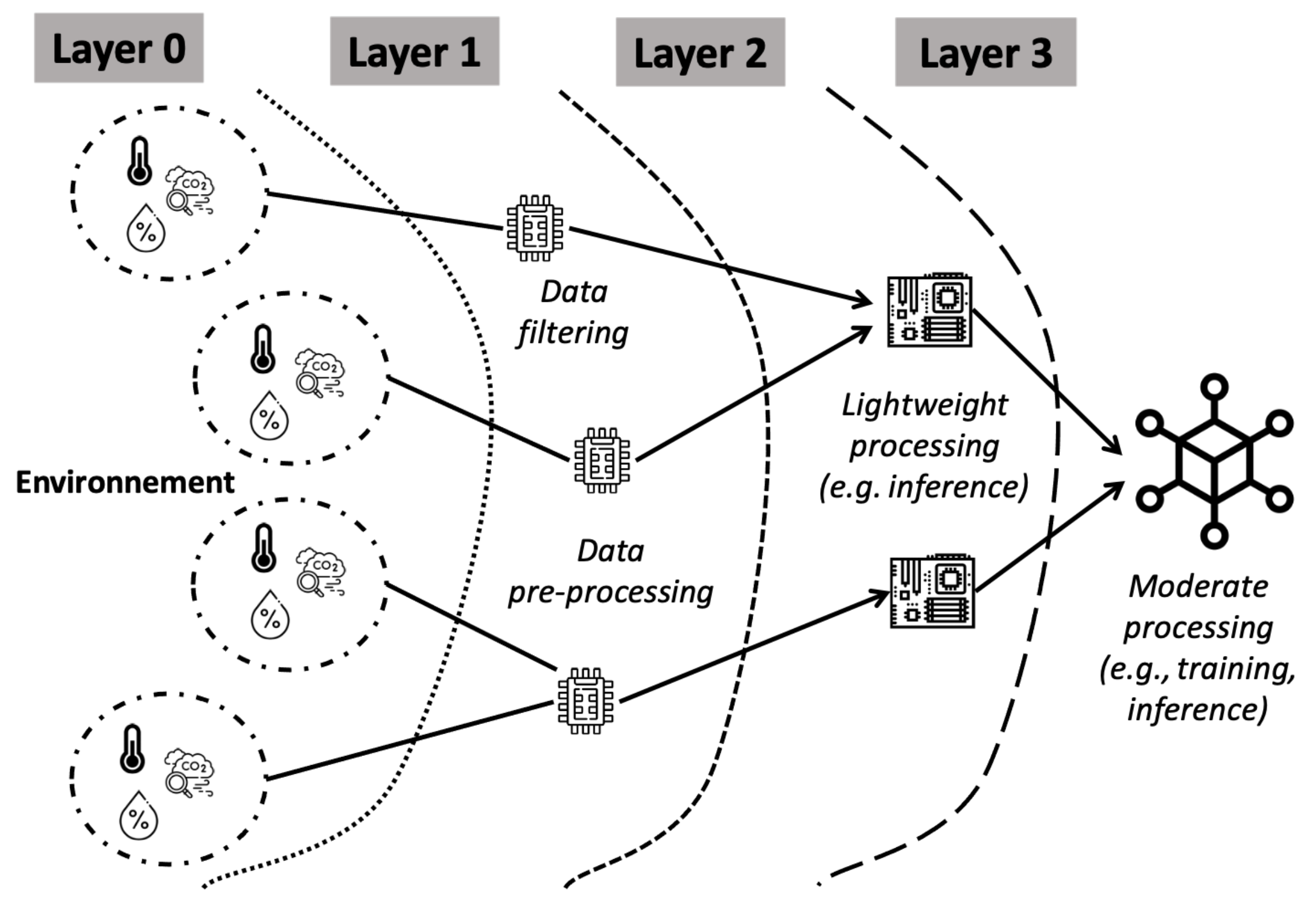
- Number of edge layers: the number of layers considered in the hierarchical edge computing implementation, as shown in Figure 1;
- Measurement points: the number of data measurement points (i.e., sensors) managed by a single gateway or centralized system;
- Dimension of measurement device: the form factor of a device that incorporates sensors to collect data during the deployment of a technology;
- Dimension of gateway/central device: the form factor of a gateway or centralized system that manages sensor data;
- Easy deployment: the effort required for an easy deployment of a technology. This is a qualitative criterion;
- Application diversity: it refers to the variety of applications that can be leveraged by a technology, such as smart-home, smart-industry, and smart-city. The criterion is also qualitative in nature.
5. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| ASIC | Application-Specific Integrated Circuit |
| CNN | Convolution Neural Network |
| COTS | Commercial-Of-The-Shelf |
| CPU | Central Processing Unit |
| DRAM | Dynamic Random Access Memory |
| FPGA | Field-Programmable Gate Array |
| GPU | Graphics Processing Unit |
| HBM | High-Bandwidth Memory |
| HMC | Hybrid Memory Cube |
| I/O | Input/Output |
| IMU | Inertial Measurement Unit |
| IoT | Internet of Thing |
| ISA | Instruction Set Architecture |
| LoRa | Long Range |
| ML | Machine Learning |
| NVM | Non-Volatile Memory |
| RAM | Random Access Memory |
| ReRAM | Resistive RAM |
| ROS | Robot Operating System |
| SoC | System-on-Chip |
| STT-RAM | Spin Transfer Torque RAM |
| SVM | Support Vector Machines |
| TPU | Tensor Processing Unit |
| TSV | Through-Silicon-Vias |
References
- Satyanarayanan, M. The Emergence of Edge Computing. Computer 2017, 50, 30–39. [Google Scholar] [CrossRef]
- Qiu, J.; Wu, Q.; Ding, G.; Xu, Y.; Feng, S. A survey of machine learning for big data processing. EURASIP J. Adv. Signal Process. 2016, 2016, 67. [Google Scholar] [CrossRef]
- Kukreja, N.; Shilova, A.; Beaumont, O.; Huckelheim, J.; Ferrier, N.; Hovland, P.; Gorman, G. Training on the Edge: The why and the how. In Proceedings of the IEEE IPDPS Workshops, Rio de Janeiro, Brazil, 20–24 May 2019; pp. 899–903. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G.E. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Neto, A.R.; Soares, B.; Barbalho, F.; Santos, L.; Batista, T.; Delicato, F.C.; Pires, P.F. Classifying Smart IoT Devices for Running Machine Learning Algorithms. In Proceedings of the XLV Integrated SW and HW Seminar, Natal, Brazil, 14–19 July 2018. [Google Scholar]
- Murshed, M.G.S.; Murphy, C.; Hou, D.; Khan, N.; Ananthanarayanan, G.; Hussain, F. Machine Learning at the Network Edge: A Survey. ACM Comput. Surv. 2022, 54, 1–37. [Google Scholar] [CrossRef]
- Reuther, A.; Michaleas, P.; Jones, M.; Gadepally, V.; Samsi, S.; Kepner, J. Survey and Benchmarking of Machine Learning Accelerators. In Proceedings of the 2019 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 24–26 September 2019. [Google Scholar]
- Andrade, L.; Prost-Boucle, A.; Pétrot, F. Overview of the state of the art in embedded machine learning. In Proceedings of the DATE Conference, Dresden, Germany, 19–23 March 2018; pp. 1033–1038. [Google Scholar]
- Gamatié, A.; Devic, G.; Sassatelli, G.; Bernabovi, S.; Naudin, P.; Chapman, M. Towards Energy-Efficient Heterogeneous Multicore Architectures for Edge Computing. IEEE Access 2019, 7, 49474–49491. [Google Scholar] [CrossRef]
- Deng, Y. Deep Learning on Mobile Devices—A Review. Proc. SPIE 2019, 109930A. [Google Scholar] [CrossRef]
- Chen, T.; Du, Z.; Sun, N.; Wang, J.; Wu, C.; Chen, Y.; Temam, O. DianNao: A Small-footprint High-throughput Accelerator for Ubiquitous Machine-learning. In Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’14), Salt Lake City, UT, USA, 1–5 March 2014; pp. 269–284. [Google Scholar] [CrossRef]
- Shafiee, A.; Nag, A.; Muralimanohar, N.; Balasubramonian, R.; Strachan, J.P.; Hu, M.; Williams, R.S.; Srikumar, V. ISAAC: A Convolutional Neural Network Accelerator with In-Situ Analog Arithmetic in Crossbars. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Republic of Korea, 18–22 June 2016; pp. 14–26. [Google Scholar] [CrossRef]
- Nurvitadhi, E.; Venkatesh, G.; Sim, J.; Marr, D.; Huang, R.; Ong Gee Hock, J.; Liew, Y.T.; Srivatsan, K.; Moss, D.; Subhaschandra, S.; et al. Can FPGAs Beat GPUs in Accelerating Next-Generation Deep Neural Networks? In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA’17), Monterey, CA, USA, 22–24 February 2017; pp. 5–14. [Google Scholar] [CrossRef]
- Lacey, G.; Taylor, G.W.; Areibi, S. Deep Learning on FPGAs: Past, Present, and Future. arXiv 2016, arXiv:1602.04283. [Google Scholar] [CrossRef]
- Google. Edge TPU. Available online: https://coral.ai/products (accessed on 27 October 2022).
- Marantos, C.; Karavalakis, N.; Leon, V.; Tsoutsouras, V.; Pekmestzi, K.; Soudris, D. Efficient support vector machines implementation on Intel/Movidius Myriad 2. In Proceedings of the International Conference on Modern Circuits and Systems Technologies (MOCAST), Thessaloniki, Greece, 7–9 May 2018; pp. 1–4. [Google Scholar]
- Peng, T. AI Chip Duel: Apple A12 Bionic vs Huawei Kirin 980. Available online: https://syncedreview.com/2018/09/13/ai-chip-duel-apple-a12-bionic-vs-huawei-kirin-980 (accessed on 27 October 2022).
- HiSilicon. Kirin. 2019. Available online: https://www.hisilicon.com/en/SearchResult?keywords=Kirin (accessed on 27 October 2022).
- Guo, K.; Sui, L.; Qiu, J.; Yu, J.; Wang, J.; Yao, S.; Han, S.; Wang, Y.; Yang, H. Angel-Eye: A Complete Design Flow for Mapping CNN Onto Embedded FPGA. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 35–47. [Google Scholar] [CrossRef]
- Podili, A.; Zhang, C.; Prasanna, V. Fast and efficient implementation of Convolutional Neural Networks on FPGA. In Proceedings of the IEEE 28th International Conference on Application-specific Systems, Architectures and Processors (ASAP), Seattle, WA, USA, 10–12 July 2017; pp. 11–18. [Google Scholar] [CrossRef]
- NVIDIA. Jetson TX2. 2019. Available online: https://www.nvidia.com/fr-fr/autonomous-machines/embedded-systems/jetson-tx2 (accessed on 27 October 2022).
- Hruska, J. Nvidia’s Jetson Xavier Stuffs Volta Performance Into Tiny Form Factor. 2018. Available online: https://www.extremetech.com/computing/270681-nvidias-jetson-xavier-stuffs-volta-performance-into-tiny-form-factor (accessed on 27 October 2022).
- Teich, P. Tearing Apart Google’s TPU 3.0 AI Coprocessor. 2018. Available online: https://www.nextplatform.com/2018/05/10/tearing-apart-googles-tpu-3-0-ai-coprocessor/ (accessed on 27 October 2022).
- Rao, N. Beyond the CPU or GPU: Why Enterprise-Scale Artificial Intelligence Requires a More Holistic Approach. 2018. Available online: https://newsroom.intel.com/editorials/artificial-intelligence-requires-holistic-approach/ (accessed on 27 October 2022).
- Cutress, I. NVIDIA’s DGX-2: Sixteen Tesla V100s, 30TB of NVMe, Only $400K. 2018. Available online: https://www.anandtech.com/show/12587/nvidias-dgx2-sixteen-v100-gpus-30-tb-of-nvme-only-400k (accessed on 27 October 2022).
- Ignatov, A.; Timofte, R.; Chou, W.; Wang, K.; Wu, M.; Hartley, T.; Gool, L.V. AI Benchmark: Running Deep Neural Networks on Android Smartphones. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Qualcomm. Neural Processing SDK for AI. 2019. Available online: https://developer.qualcomm.com/software/qualcomm-neural-processing-sdk (accessed on 27 October 2022).
- MediaTek. Helio P60. 2019. Available online: https://www.mediatek.com/products/smartphones/mediatek-helio-p60 (accessed on 27 October 2022).
- Ananthanarayanan, R.; Brandt, P.; Joshi, M.; Sathiamoorthy, M. Opportunities and Challenges Of Machine Learning Accelerators In Production. In Proceedings of the USENIX Conference on Operational Machine Learning, Santa Clara, CA, USA, 20 May 2019; pp. 1–3. [Google Scholar]
- Lavin, A.; Gray, S. Fast Algorithms for Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Chen, Y.H.; Yang, T.J.; Emer, J.; Sze, V. Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices. IEEE J. Emerg. Sel. Top. Circuits Syst. 2018, 9, 292–308. [Google Scholar] [CrossRef]
- Xilinx. Tearing Apart Google’s TPU 3.0 AI Coprocessor. 2019. Available online: https://www.xilinx.com/products/boards-and-kits/ek-u1-zcu102-g.html (accessed on 27 October 2022).
- Peccerillo, B.; Mannino, M.; Mondelli, A.; Bartolini, S. A survey on hardware accelerators: Taxonomy, trends, challenges, and perspectives. J. Syst. Archit. 2022, 129, 102561. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the 4th International Conference on Learning Representations, ICLR, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Marculescu, D.; Stamoulis, D.; Cai, E. Hardware-aware Machine Learning: Modeling and Optimization. In Proceedings of the International Conference on Computer-Aided Design (ICCAD ’18), San Diego, CA, USA, 5–8 November 2018; pp. 137:1–137:8. [Google Scholar]
- Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; Narayanan, P. Deep Learning with Limited Numerical Precision. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar] [CrossRef]
- C4ML organizers. Compilers for ML. 2019. Available online: https://www.c4ml.org/ (accessed on 27 October 2022).
- Balasubramonian, R.; Chang, J.; Manning, T.; Moreno, J.H.; Murphy, R.; Nair, R.; Swanson, S. Near-Data Processing: Insights from a MICRO-46 Workshop. IEEE Micro 2014, 34, 36–42. [Google Scholar] [CrossRef]
- Liu, J.; Zhao, H.; Ogleari, M.A.; Li, D.; Zhao, J. Processing-in-Memory for Energy-Efficient Neural Network Training: A Heterogeneous Approach. In Proceedings of the IEEE/ACM MICRO Symposium, Fukuoka, Japan, 20–24 October 2018; pp. 655–668. [Google Scholar]
- Choe, H.; Lee, S.; Park, S.; Kim, S.J.; Chung, E.; Yoon, S. Near-Data Processing for Machine Learning. 2017. Available online: https://openreview.net/pdf?id=H1_EDpogx (accessed on 27 October 2022).
- Endoh, T.; Koike, H.; Ikeda, S.; Hanyu, T.; Ohno, H. An Overview of Nonvolatile Emerging Memories—Spintronics for Working Memories. IEEE JETCAS 2016, 6, 109–119. [Google Scholar] [CrossRef]
- Senni, S.; Torres, L.; Sassatelli, G.; Gamatié, A.; Mussard, B. Exploring MRAM Technologies for Energy Efficient Systems-On-Chip. IEEE J. Emerg. Sel. Top. Circuits Syst. 2016, 6, 279–292. [Google Scholar] [CrossRef]
- Pawlowski, J.T. Hybrid memory cube (HMC). In Proceedings of the IEEE Hot Chips Symposium (HCS), Stanford, CA, USA, 17–19 August 2011; pp. 1–24. [Google Scholar]
- Kusriyanto, M.; Putra, B.D. Smart home using local area network (LAN) based arduino mega 2560. In Proceedings of the 2nd International Conference on Wireless and Telematics (ICWT), Yogyakarta, Indonesia, 1–2 August 2016; pp. 127–131. [Google Scholar]
- Drgoňa, J.; Picard, D.; Kvasnica, M.; Helsen, L. Approximate model predictive building control via machine learning. Appl. Energy 2018, 218, 199–216. [Google Scholar] [CrossRef]
- Sousa, R.d.S. Remote Monitoring and Control of a Reservation-Based Public Parking. Ph.D. Thesis, Universidade de Coimbra, Coimbra, Portugal, 2021. [Google Scholar]
- Brun, D.; Jordan, P.; Hakkila, J. Demonstrating a Memory Orb—Cylindrical Device Inspired by Science Fiction. In Proceedings of the 20th International Conference on Mobile and Ubiquitous Multimedia, Leuven, Belgium, 5–8 December 2021; pp. 239–241. [Google Scholar]
- Stolovas, I.; Suárez, S.; Pereyra, D.; De Izaguirre, F.; Cabrera, V. Human activity recognition using machine learning techniques in a low-resource embedded system. In Proceedings of the 2021 IEEE URUCON, Montevideo, Uruguay, 24–26 November 2021; pp. 263–267. [Google Scholar]
- Edge Impulse. Detect objects with centroids (Sony’s Spresense). Available online: https://docs.edgeimpulse.com/docs/tutorials/detect-objects-using-fomo (accessed on 27 October 2022).
- SparkFun Electronics. Edge Hookup Guide. 2019. Available online: https://learn.sparkfun.com/tutorials/sparkfun-edge-hookup-guide/all (accessed on 27 October 2022).
- Jin, G.; Bai, K.; Zhang, Y.; He, H. A Smart Water Metering System Based on Image Recognition and Narrowband Internet of Things. Rev. D’Intelligence Artif. 2019, 33, 293–298. [Google Scholar] [CrossRef]
- Alasdair Allan. Deep Learning at the Edge on an Arm Cortex-Powered Camera Board. 2018. Available online: https://aallan.medium.com/deep-learning-at-the-edge-on-an-arm-cortex-powered-camera-board-3ca16eb60ef7 (accessed on 27 October 2022).
- Nyamukuru, M.T.; Odame, K.M. Tiny eats: Eating detection on a microcontroller. In Proceedings of the 2020 IEEE Second Workshop on Machine Learning on Edge in Sensor Systems (SenSys-ML), Sydney, Australia, 21 April 2020; pp. 19–23. [Google Scholar]
- Sharad, S.; Sivakumar, P.B.; Narayanan, V.A. The smart bus for a smart city—A real-time implementation. In Proceedings of the IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), Bangalore, India, 6–9 November 2016; pp. 1–6. [Google Scholar]
- Nayyar, A.; Puri, V. A Review of Beaglebone Smart Board’s-A Linux/Android Powered Low Cost Development Platform Based on ARM Technology. In Proceedings of the 9th International Conference on Future Generation Communication and Networking (FGCN), Jeju Island, South Korea, 25–28 November 2015; pp. 55–63. [Google Scholar]
- Zhang, Y.; Suda, N.; Lai, L.; Chandra, V. Hello Edge: Keyword Spotting on Microcontrollers. arXiv 2017, arXiv:1711.07128. [Google Scholar]
- Wang, G.; Bhat, Z.P.; Jiang, Z.; Chen, Y.W.; Zha, D.; Reyes, A.C.; Niktash, A.; Ulkar, G.; Okman, E.; Hu, X. BED: A Real-Time Object Detection System for Edge Devices. arXiv 2022, arXiv:2202.07503. [Google Scholar]
- Wang, C.; Yu, Q.; Gong, L.; Li, X.; Xie, Y.; Zhou, X. DLAU: A Scalable Deep Learning Accelerator Unit on FPGA. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2016, 36, 513–517. [Google Scholar] [CrossRef]
- RISC-V Foundation. RISC-V: The Free and Open RISC ISA. 2019. Available online: https://riscv.org/ (accessed on 27 October 2022).
- Gonzalez-Huitron, V.; León-Borges, J.A.; Rodriguez-Mata, A.; Amabilis-Sosa, L.E.; Ramírez-Pereda, B.; Rodriguez, H. Disease detection in tomato leaves via CNN with lightweight architectures implemented in Raspberry Pi 4. Comput. Electron. Agric. 2021, 181, 105951. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Rodríguez-Gómez, J.P.; Tapia, R.; Paneque, J.L.; Grau, P.; Eguíluz, A.G.; Martínez-de Dios, J.R.; Ollero, A. The GRIFFIN perception dataset: Bridging the gap between flapping-wing flight and robotic perception. IEEE Robot. Autom. Lett. 2021, 6, 1066–1073. [Google Scholar] [CrossRef]
- Valladares, S.; Toscano, M.; Tufiño, R.; Morillo, P.; Vallejo-Huanga, D. Performance Evaluation of the Nvidia Jetson Nano Through a Real-Time Machine Learning Application. In Proceedings of the Intelligent Human Systems Integration 2021; Russo, D., Ahram, T., Karwowski, W., Di Bucchianico, G., Taiar, R., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 343–349. [Google Scholar]
- Chemel, T.; Duncan, J.; Fisher, S.; Jain, R.; Morgan, R.; Nikiforova, K.; Reich, M.; Schaub, S.; Scherlis, T. Tartan Autonomous Underwater Vehicle Design and Implementation of TAUV-22: Kingfisher. 2020. Available online: https://robonation.org/app/uploads/sites/5/2022/06/RS2022_Carnegie_Mellon_University_TartanAUV_TDR.pdf (accessed on 27 October 2022).
- Long, C. BeagleBone AI Makes a Sneak Preview. 2019. Available online: https://beagleboard.org/blog/2019-05-16-beaglebone-ai-preview (accessed on 27 October 2022).
- Hochstetler, J.; Padidela, R.; Chen, Q.; Yang, Q.; Fu, S. Embedded Deep Learning for Vehicular Edge Computing. In Proceedings of the IEEE/ACM Symposium on Edge Computing (SEC), Bellevue, WA, USA, 25–27 October 2018; pp. 341–343. [Google Scholar]
- Xu, R.; Nikouei, S.Y.; Chen, Y.; Polunchenko, A.; Song, S.; Deng, C.; Faughnan, T. Real-Time Human Objects Tracking for Smart Surveillance at the Edge. In Proceedings of the International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Triwiyanto, T.; Caesarendra, W.; Purnomo, M.H.; Sułowicz, M.; Wisana, I.D.G.H.; Titisari, D.; Lamidi, L.; Rismayani, R. Embedded Machine Learning Using a Multi-Thread Algorithm on a Raspberry Pi Platform to Improve Prosthetic Hand Performance. Micromachines 2022, 13, 191. [Google Scholar] [CrossRef] [PubMed]
- Willems, L. Detect People on a Device that Fits in the Palm of Your Hands. Bachelor’s Thesis, University of Twente, Enschede, The Netherlands, 2020. [Google Scholar]
- Flamand, E.; Rossi, D.; Conti, F.; Loi, I.; Pullini, A.; Rotenberg, F.; Benini, L. GAP-8: A RISC-V SoC for AI at the Edge of the IoT. In Proceedings of the International Conference on Application-Specific Systems, Architectures and Processors (ASAP), Milan, Italy, 10–12 July 2018; pp. 1–4. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Kang, D.; Kang, D.; Kang, J.; Yoo, S.; Ha, S. Joint optimization of speed, accuracy, and energy for embedded image recognition systems. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 715–720. [Google Scholar] [CrossRef]
- Cass, S. Taking AI to the edge: Google’s TPU now comes in a maker-friendly package. IEEE Spectr. 2019, 56, 16–17. [Google Scholar] [CrossRef]
- Campmany, V.; Silva, S.; Espinosa, A.; Moure, J.; Vázquez, D.; López, A. GPU-based Pedestrian Detection for Autonomous Driving. Procedia Comput. Sci. 2016, 80, 2377–2381. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, S.; Han, T. Fast and Accurate Object Analysis at the Edge for Mobile Augmented Reality: Demo. In Proceedings of the 2nd ACM/IEEE Symposium on Edge Computing, SEC’17, San Jose/Fremont, CA, USA, 12–14 October 2017; pp. 33:1–33:2. [Google Scholar]
- Ezra Tsur, E.; Madar, E.; Danan, N. Code Generation of Graph-Based Vision Processing for Multiple CUDA Cores SoC Jetson TX. In Proceedings of the International Symposium on Embedded Multicore/Many-core SoC (MCSoC), Hanoi, Vietnam, 12–14 September 2018; pp. 1–7. [Google Scholar]
- Beckman, P.; Sankaran, R.; Catlett, C.; Ferrier, N.; Jacob, R.; Papka, M. Waggle: An open sensor platform for edge computing. In Proceedings of the 2016 IEEE SENSORS, Orlando, FL, USA, 30 October–3 November 2016; pp. 1–3. [Google Scholar]
- Morishita, F.; Kato, N.; Okubo, S.; Toi, T.; Hiraki, M.; Otani, S.; Abe, H.; Shinohara, Y.; Kondo, H. A CMOS Image Sensor and an AI Accelerator for Realizing Edge-Computing-Based Surveillance Camera Systems. In Proceedings of the 2021 Symposium on VLSI Circuits, Kyoto, Japan, 13–19 June 2021; pp. 1–2. [Google Scholar] [CrossRef]
- Hardkernel. Odroid-M1. 2022. Available online: https://www.hardkernel.com/2022/03/ (accessed on 27 October 2022).
- Liu, S.; Zheng, C.; Lu, K.; Gao, S.; Wang, N.; Wang, B.; Zhang, D.; Zhang, X.; Xu, T. Evsrnet: Efficient video super-resolution with neural architecture search. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; Nashville, TN, USA, 19–25 June 2021, pp. 2480–2485.
- Chinchali, S.; Sharma, A.; Harrison, J.; Elhafsi, A.; Kang, D.; Pergament, E.; Cidon, E.; Katti, S.; Pavone, M. Network Offloading Policies for Cloud Robotics: A Learning-based Approach. Auton. Robot. 2021, 45, 997–1012. [Google Scholar] [CrossRef]
- Pouget, A.; Ramesh, S.; Giang, M.; Chandrapalan, R.; Tanner, T.; Prussing, M.; Timofte, R.; Ignatov, A. Fast and accurate camera scene detection on smartphones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2569–2580. [Google Scholar]
- Dextre, M.; Rosas, O.; Lazo, J.; Gutiérrez, J.C. Gun Detection in Real-Time, using YOLOv5 on Jetson AGX Xavier. In Proceedings of the 2021 XLVII Latin American Computing Conference (CLEI), Cartago, Costa Rica, 25–29 October 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Dally, W.J.; Turakhia, Y.; Han, S. Domain-Specific Hardware Accelerators. Commun. ACM 2020, 63, 48–57. [Google Scholar] [CrossRef]
- Apvrille, L.; Bécoulet, A. Prototyping an Embedded Automotive System from its UML/SysML Models. In Proceedings of the Embedded Real Time Software and Systems (ERTS2012), Toulouse, France, 29 January–1 February 2012. [Google Scholar]
- Dekeyser, J.L.; Gamatié, A.; Etien, A.; Ben Atitallah, R.; Boulet, P. Using the UML Profile for MARTE to MPSoC Co-Design. Available online: https://www.researchgate.net/profile/Pierre-Boulet/publication/47363143_Using_the_UML_Profile_for_MARTE_to_MPSoC_Co-Design/links/09e415083fb08c939b000000/Using-the-UML-Profile-for-MARTE-to-MPSoC-Co-Design.pdf (accessed on 27 October 2022).
- Yu, H.; Gamatié, A.; Rutten, É.; Dekeyser, J. Safe design of high-performance embedded systems in an MDE framework. Innov. Syst. Softw. Eng. 2008, 4, 215–222. [Google Scholar] [CrossRef]
- Parashar, A.; Raina, P.; Shao, Y.S.; Chen, Y.H.; Ying, V.A.; Mukkara, A.; Venkatesan, R.; Khailany, B.; Keckler, S.W.; Emer, J. Timeloop: A Systematic Approach to DNN Accelerator Evaluation. In Proceedings of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Madison, WI, USA, 24–26 March 2019; pp. 304–315. [Google Scholar] [CrossRef]
- An, X.; Boumedien, S.; Gamatié, A.; Rutten, E. CLASSY: A Clock Analysis System for Rapid Prototyping of Embedded Applications on MPSoCs. In Proceedings of the 15th International Workshop on Software and Compilers for Embedded Systems, SCOPES’12; Association for Computing Machinery: New York, NY, USA, 2012; pp. 3–12. [Google Scholar] [CrossRef]
- Caliri, G.V. Introduction to analytical modeling. In Proceedings of the 26th International Computer Measurement Group Conference, Orlando, FL, USA, 10–15 December 2000; pp. 31–36. [Google Scholar]
- Corvino, R.; Gamatié, A.; Geilen, M.; Józwiak, L. Design space exploration in application-specific hardware synthesis for multiple communicating nested loops. In Proceedings of the 2012 International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation, SAMOS XII, Samos, Greece, 16–19 July 2012; pp. 128–135. [Google Scholar] [CrossRef]
- Ghenassia, F. Transaction-Level Modeling with SystemC: TLM Concepts and Applications for Embedded Systems; Springer: New York, NY, USA, 2006. [Google Scholar]
- Mello, A.; Maia, I.; Greiner, A.; Pecheux, F. Parallel simulation of systemC TLM 2.0 compliant MPSoC on SMP workstations. In Proceedings of the Design, Automation Test in Europe Conference Exhibition (DATE’10), Dresden, Germany, 8–12 March 2010; pp. 606–609. [Google Scholar] [CrossRef]
- Schirner, G.; Dömer, R. Quantitative Analysis of the Speed/Accuracy Trade-off in Transaction Level Modeling. ACM Trans. Embed. Comput. Syst. 2009, 8, 1–29. [Google Scholar] [CrossRef]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The Gem5 Simulator. SIGARCH Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Butko, A.; Gamatié, A.; Sassatelli, G.; Torres, L.; Robert, M. Design Exploration for next Generation High-Performance Manycore On-chip Systems: Application to big.LITTLE Architectures. In Proceedings of the ISVLSI: International Symposium on Very Large Scale Integration, Montpellier, France, 8–10 July 2015; pp. 551–556. [Google Scholar] [CrossRef]
- Butko, A.; Garibotti, R.; Ost, L.; Lapotre, V.; Gamatié, A.; Sassatelli, G.; Adeniyi-Jones, C. A trace-driven approach for fast and accurate simulation of manycore architectures. In Proceedings of the 20th Asia and South Pacific Design Automation Conference, Chiba, Japan, 19–22 January 2015; pp. 707–712. [Google Scholar] [CrossRef]
- Breuer, M.; Friedman, A.; Iosupovicz, A. A Survey of the State of the Art of Design Automation. Computer 1981, 14, 58–75. [Google Scholar] [CrossRef]
- TMI Orion nano Vacq FUll Radio. Available online: https://www.tmi-orion.com/medias/pdf/en/NanoVACQ-PT-FullRadio-EN.pdf (accessed on 27 October 2022).
- TMI Orion Transceiver. Available online: https://www.tmi-orion.com/medias/pdf/en/Radio-transceiver-en.pdf (accessed on 27 October 2022).
- Gravio Hub. Available online: https://doc.gravio.com/manuals/gravio4/1/en/topic/gravio-hub (accessed on 27 October 2022).
- Moneo Appliance. Available online: https://www.ifm.com/us/en/us/moneo-us/moneo-appliance (accessed on 27 October 2022).
- Advantech WISE-4060. Available online: https://advdownload.advantech.com/productfile/PIS/WISE-4060/file/WISE-4060-B_DS(122121)20221020155553.pdf (accessed on 27 October 2022).
- Advantech EIS-D150. Available online: https://advdownload.advantech.com/productfile/PIS/EIS-D150/file/EIS-D150_DS(050922)20220509111551.pdf (accessed on 27 October 2022).
- inHand Networks Edge Gateway. Available online: https://inhandnetworks.com/upload/attachment/202210/19/InHand%20Networks_InGateway902%20Edge%20Gateway_Prdt%20Spec_V4.1.pdf (accessed on 27 October 2022).
- Adlink MCM Edge DAQ. Available online: https://www.adlinktech.com/Products/Download.ashx?type=MDownload&isDatasheet=yes&file=1938%5cMCM-210_Series_datasheet_20210412.pdf (accessed on 27 October 2022).
- SmartMesh WirelessHART Network Manager. Available online: https://www.analog.com/media/en/technical-documentation/data-sheets/5903whrf.pdf (accessed on 27 October 2022).
- SmartMesh WirelessHART 5900. Available online: https://www.analog.com/media/en/technical-documentation/data-sheets/5900whmfa.pdf (accessed on 27 October 2022).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Storage | Memory | Compute Unit Types | Power | Typical Algorithms |
|---|---|---|---|---|---|
| 0 | ≤512 MB | ≤512 kB | Microcontrollers | ≤1 W | Basic computations (lightweight inference) |
| 1 | ≤4 GB | ≤512 MB | Microcontrollers/ Application cores | ≤2 W | Basic statistics (inference) |
| 2 | ≥4 GB | ≤2 GB | Application cores | ≤4 W | Classification/Regression (inference) |
| 3 | ≥4 GB | ≤8 GB | Application cores | ≤16 W | Prediction/Decision-making (inference) |
| 4 | ≥4 GB | ≤16 GB | Application cores | ≥16 W | Deep learning, auto-encoders, etc. (inference & training) |
| 5 | ≥4 GB | ≥16 GB | Application cores | ≥16 W |
| Device | Class | GPU/Accel. | CPU | ML Usage | Application Examples |
|---|---|---|---|---|---|
| Arduino Mega | 0 | - | Microcontroller ATmega 8-bit @16 MHz | inference (ANN) | domotic [44], robotics [45] |
| Arduino RP2040 | 0 | - | 2xARM Cortex-M0+ @133 MHz (RP2040) | inference (ANN) | parking traffic [46], virtual reality [47] |
| MSP430G2553 LaunchPad | 0 | - | MSP430 16-Bit RISC Architecture @16 MHz | inference (ANN) | activity recognition [48] |
| Sony Spresense | 0 | - | 6xARM Cortex-M4F @156 MHz | inference (ANN) | object detection [49] |
| SparkFun Edge | 0 | - | 32-bit ARM Cortex-M4F @48 MHz | inference (ANN) | speech recognition [50] |
| STM32F103 | 0 | - | ARM Cortex-M3 @72 MHz | inference (CNN) | image recognition [51] |
| STM32F765VI | 0 | - | ARM Cortex-M7 @216 MHz | inference (CNN) | image recognition [52] |
| Tiny Eats | 0 | - | ARM Cortex-M0+ @48 MHz | inference (DNN) | audio recognition [53] |
| Beaglebone Black | 1 | PowerVR SGX530 GPU | ARM Cortex-A8 single-core @1 GHz | inference (ANN) | robotics [54], camera drones [55] |
| Hello-Edge | 1 | - | ARM Cortex-M7 (STM32F746G) | inference (DNN) | keyword spotting [56] |
| MAX78000 | 1 | Deep CNN Accelerator | ARM Cortex-M4 @100 MHz RISC-V coprocessor @60 MHz | inference (DNN) | object detection [57] |
| ZedBoard Dev. Board | 1 | FPGA accel. | 2x ARM Cortex-A9 @667 MHz | inference (DNN,CNN) | image recognition [58] |
| Device | Class | GPU/Accel. | CPU | ML Usage | Application Examples |
|---|---|---|---|---|---|
| BeagleBone AI | 2 | - | 2x ARM Cortex-A15 @1,5 GHz 2x ARM Cortex-M4 SoC with 4 EVEs | inference (CNN) | computer vision [66] |
| Intel Movidius | 2 | - | Myriad-2 VPU | inference (SVM) | computer vision [67] |
| Raspberry Pi 3 | 2 | 400 MHz VideoCore IV GPU | 4xARM A53 @1.2 GHz | inference (SVM, CNN) | video analysis [68] medical data processing [69] |
| Raspberry Pi Z2 W | 2 | 400 MHz VideoCore IV GPU | 4xARM Cortex-A53 @1 GHz | inference (CNN) | object detection [70] |
| RISC-V GAP8 | 2 | - | 8 RISC-V 32-bit @250 MHz + HW ConvolutionEngine | inference (CNN) | image, audio processing [71] |
| Samsung Galaxy S3 (Exynos 4412 SoC) | 2 | Mali-400 MP GPU | 4xARM Cortex-A9 quad-core @1.4 GHz | inference (CNN) | image classif. [72] |
| Khadas VIM 3 | 2,3 | 4xARM Mali-G52 @800 MHz | 4xARM Cortex-A73 @2.2 GHz 2xARM Cortex-A53 @1.8 GHz | inference (CNN) | robotics [63] |
| Raspberry Pi 4 | 2,3 | 500 MHz VideoCore VI GPU | 4xARM Cortex-A72 @1.5 GHz | inference (SVM, CNN) | image analysis [60] |
| Motorola Z2 Force (Snapdragon 835 SoC) | 2, 3 | Qualcomm Adreno 540 GPU | 4x Kryo 280 @ 2.45 GHz 4x Kryo 280 @ 1.9 GHz | inference (CNN) | image classif. [62] recognition [73] |
| Xiaomi Redmi 4X (Snapdragon 435 SoC) | 2, 3 | Qualcomm Adreno 505 GPU | 8xARM Cortex-A53 @1.4 GHz | inference (CNN) | image super resolution [61] |
| Device | Class | GPU / Accel. | CPU | ML Usage | Application Examples |
|---|---|---|---|---|---|
| Coral Development Board | 3 | GC7000 Lite GPU + TPUEdge accel. | NXP i.MX 8M SoC (4x ARM Cortex-A53 + Cortex-M4F) | inference (CNN) | image processing [74] |
| Google Pixel C (Tegra X1 SoC) | 3 | 256-core Maxwell GPU | 4x ARM Cortex-A57 + 4x ARM Cortex-A53 | inference (SVM) | pedestrian recognition [75] |
| Jetson Nano | 3 | 128-core Maxwell GPU | 4x ARM Cortex-A57 | inference (CNN) | video image recognition [64] |
| Jetson TX1 | 3 | 256-core Maxwell GPU | 4x ARM Cortex-A57 2x MB L2 | inference (CNN) | video, image analysis [76], robotics [77] |
| Odroid-XU4 (Exynos 5422 SoC) | 3 | ARM Mali-T628 MP6 GPU | 4x ARM Cortex-A15 + 4x ARM Cortex-A7 | inference/ training (ANN) | urban flooding, automobile traffic [78] |
| RZ/V2M Evaluation Board | 3 | DRP-AI | 1x ARM Cortex-A53 @996 MHz | inference (CNN) | image processing [79] |
| Samsung Galaxy S8 (Exynos 8895 SoC) | 3 | ARM Mali-G71 GPU | 4x ARM Cortex-A53 @ 1.7 GHz 4x Exynos M2 @2.5 GHz | inference (CNN) | image recognition [73] |
| Odroid-M1 | 3,4 | 4xARM Mali-G52 @ 650 MHz | 4xARM Cortex-A55 @2 GHz | inference (CNN) | video image recognition [80] |
| Huawei P40 PRO (Kirin 990) | 4 | 16xARM Mali-G76 @600 MHz | 2x ARM Cortex-A76 @2.86 GHz 2x ARM Cortex-A76 @2.09 GHz 4x ARM Cortex-A55 @1.86 GHz | inference (CNN) | video super resolution [81] |
| Jetson TX2 | 4 | 256-core Pascal GPU | 2x Denver2, 2 MB L2 + 4x ARM Cortex-A57, 2 MB L2 | inference (CNN, DNN, SVM) | video, image analysis [76], robotics [82] |
| One Plus 9 Pro (Snapdragon 888) | 4 | Adreno 660 GPU | 1x ARM Cortex-X1 @ 2.84 GHz 3x ARM Cortex-A78 @2.42 GHz 4x ARM Cortex-A55 @1.80 GHz | inference (CNN) | image classification [83] |
| Jetson AGX Orin | 5 | 2048xCUDA cores 64xTensor cores @1.3 GHz | 12xARM Cortex-A78 @2.2 GHz | inference (CNN) | robotics [65] |
| Jetson AGX Xavier | 5 | 512xVolta GPU | 8xNVIDIA Carmel | inference (CNN) | real-time object detection [84] |
| Step Labels | Detailed of the Step | Power Consumption | Time Duration |
|---|---|---|---|
| 1 | Wait pairing and synchronizing from the CYEdge | 412.5 mW | 20 s |
| 2 | Setting up measurement parameters from the CYEdge | 468 mW | 7 s |
| 3 | Measuring digital and analog data from sensor | 357 mW | 10 s (Case I) 200 ms (Case II) |
| 4 | Data processing (filtering, conversion) | 387 mW | 50 ms |
| 5 | Sending stored and measured data to the CYEdge (LoRa) | 377.5 mW | 2–10 s |
| 6 | Waiting acknowledgement from the CYEdge | 252 mW | 1–25 s |
| 7 | Sleep until next measuring | 177 mW | 1 s–1 min |
| 8 | Storing not sent data in RAM memory | 256.5 mW | 50 ms |
| CYSmart | TMI Orion [100,101] | Gravio [102] | Moneo Appliance [103] | Advantech [104,105] | InHand Networks [106] | ADLINK [107] | Smartmesh WirelessHART [108,109] | |
|---|---|---|---|---|---|---|---|---|
| Device classes | 0 and 3 | 0 and 2 | 2 | 4 | 0 and 3 | 2 | 2 | 0 and 2 |
| Sensor diversity | high | low | low | average | high | low | high | average |
| Transmission speed | 0.3 S/sec | 10 S/sec | - | 2500 S/sec | - | 1000 Mb/sec | 256 KS/sec | 250 Kb/sec |
| Communication distance (in meters) | 800 | 30 | 100 | wired | 110 | wired | wired | 200 |
| Number of edge layers | 2 | 2 | 2 | 2 | 3 | 2 | 2 | 2 |
| Measurement points | 20 | 4 | 64 | 16 | - | 6 | 20 | 500 |
| Dimension of measurement device (in millimeters) | 170 × 90 × 65 | 31 × 129 × 79 | 36 × 36 × 9 | - | 80 × 98 × 25 | - | - | 39 × 24 × 8 |
| Dimension of gateway/central device (in millimeters) | 245 × 110 × 85 | 127 × 8 × 46 | 97 × 97 × 29 | 35 × 105 × 150 | 260 × 140 × 54 | 180 × 115 × 45 | 110 × 40 × 126 | 103 × 56 × 20 |
| Easy deployment | average | average | high | high | average | low | average | low |
| Application diversity | high | low | average | low | high | average | average | high |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martin Wisniewski, L.; Bec, J.-M.; Boguszewski, G.; Gamatié, A. Hardware Solutions for Low-Power Smart Edge Computing. J. Low Power Electron. Appl. 2022, 12, 61. https://doi.org/10.3390/jlpea12040061
Martin Wisniewski L, Bec J-M, Boguszewski G, Gamatié A. Hardware Solutions for Low-Power Smart Edge Computing. Journal of Low Power Electronics and Applications. 2022; 12(4):61. https://doi.org/10.3390/jlpea12040061
Chicago/Turabian StyleMartin Wisniewski, Lucas, Jean-Michel Bec, Guillaume Boguszewski, and Abdoulaye Gamatié. 2022. "Hardware Solutions for Low-Power Smart Edge Computing" Journal of Low Power Electronics and Applications 12, no. 4: 61. https://doi.org/10.3390/jlpea12040061
APA StyleMartin Wisniewski, L., Bec, J.-M., Boguszewski, G., & Gamatié, A. (2022). Hardware Solutions for Low-Power Smart Edge Computing. Journal of Low Power Electronics and Applications, 12(4), 61. https://doi.org/10.3390/jlpea12040061