
Dynamic SIMD Parallel Execution on GPU from High-Level Dataflow Synthesis †


Abstract
:1. Introduction
- The definition of a new FIFO communication channel to improve the communication performance between two computing elements even on different hardware (i.e., GPU and CPU). This was made possible by exploiting the architecture and programming APIs available with the new GPU implementations;
- A new methodology for GPU partitioning of actors synthesized with the CUDA formalism. This new methodology completely removes the need to use a CPU kernel (actively waiting) to control the execution of GPU-mapped actors;
- The dynamic programming model of actors in a dataflow program is leveraged to exploit intra-kernel parallelization and take full advantage of the SIMD architecture of GPUs;
- A low-level code-synthesizing methodology to leverage dynamic actor reprogramming, where internal actions are implemented leveraging SIMD parallelization.
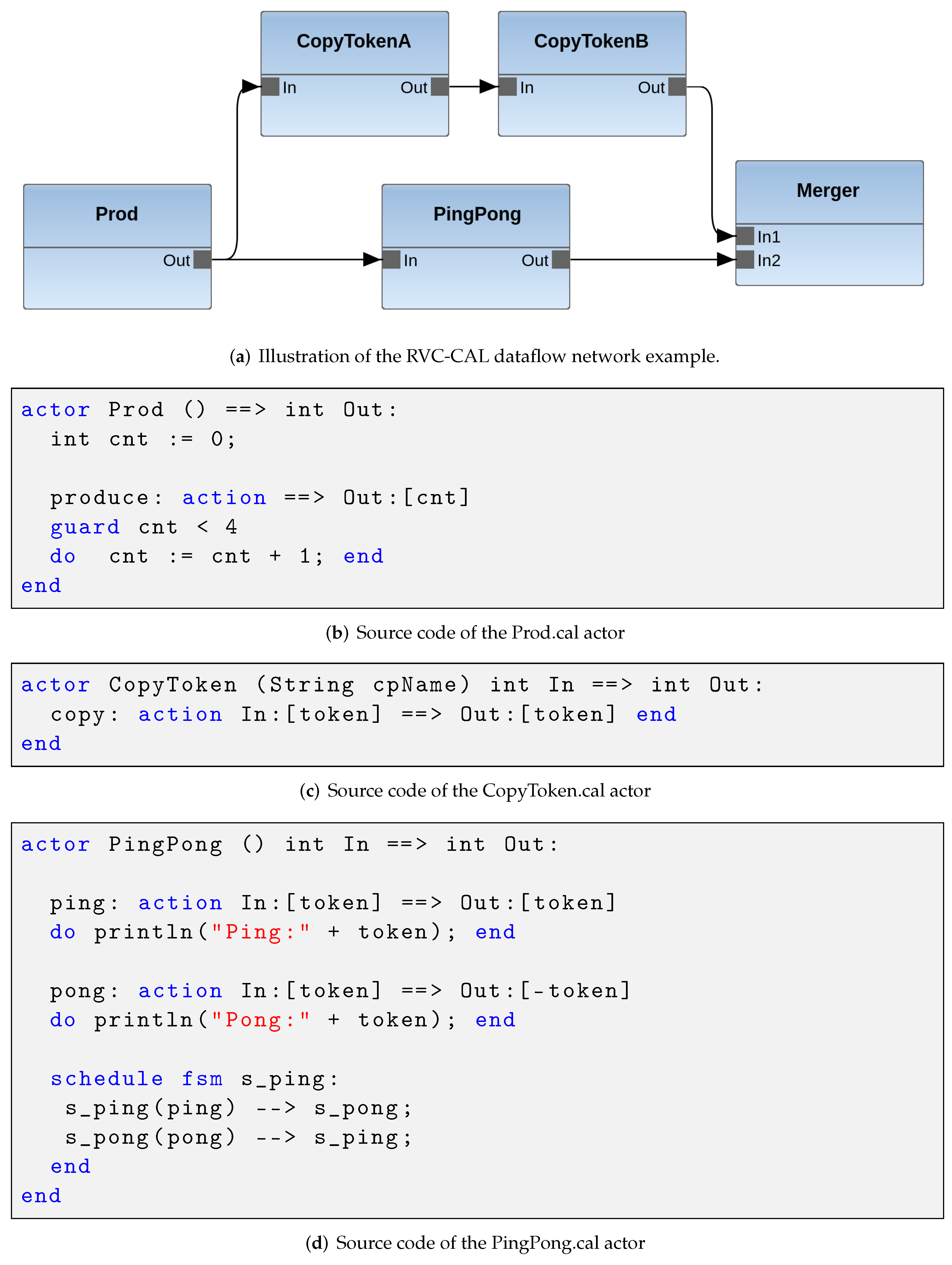
2. Dataflow Model of Computations
3. Related Work
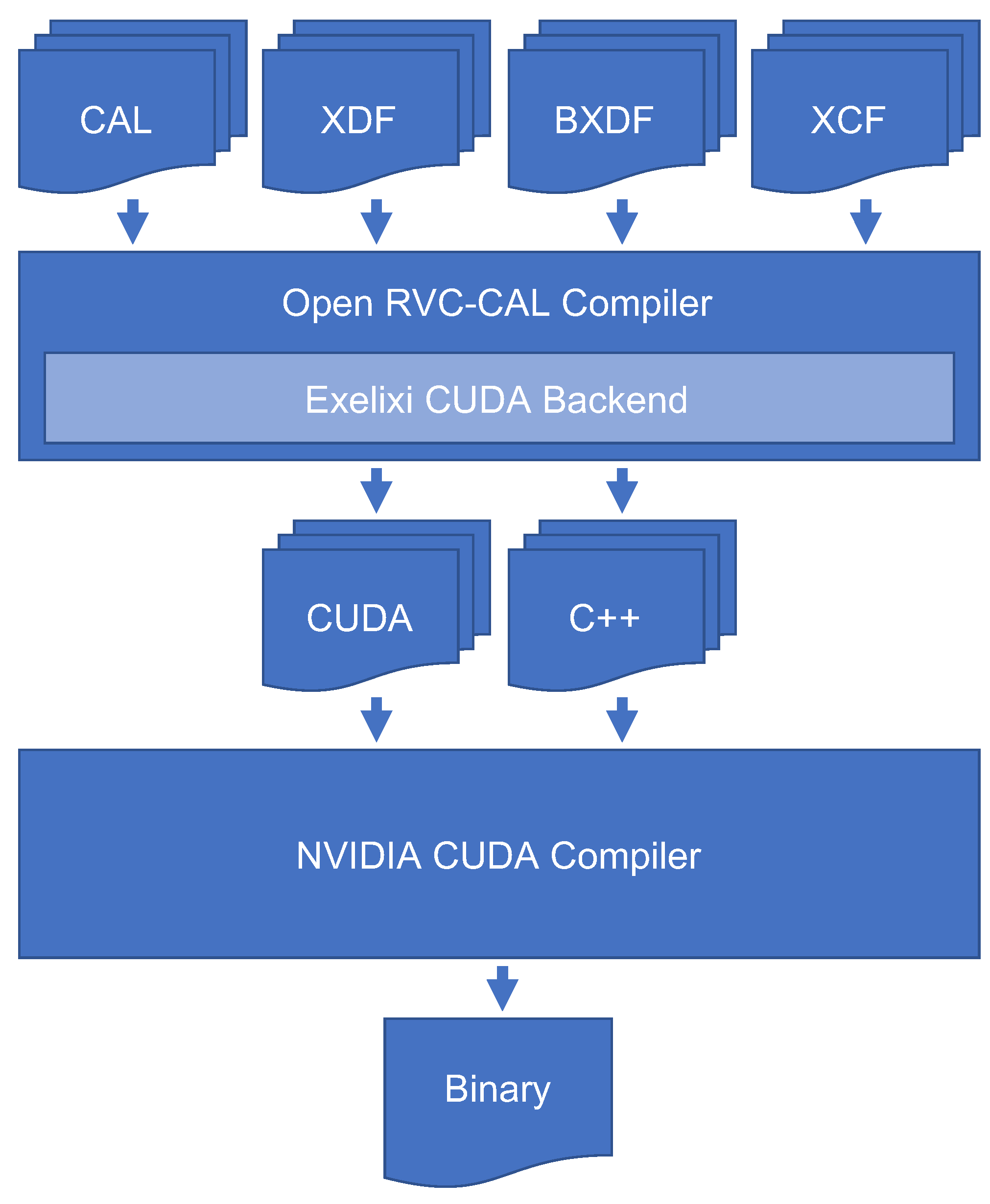
4. Design Process and Development
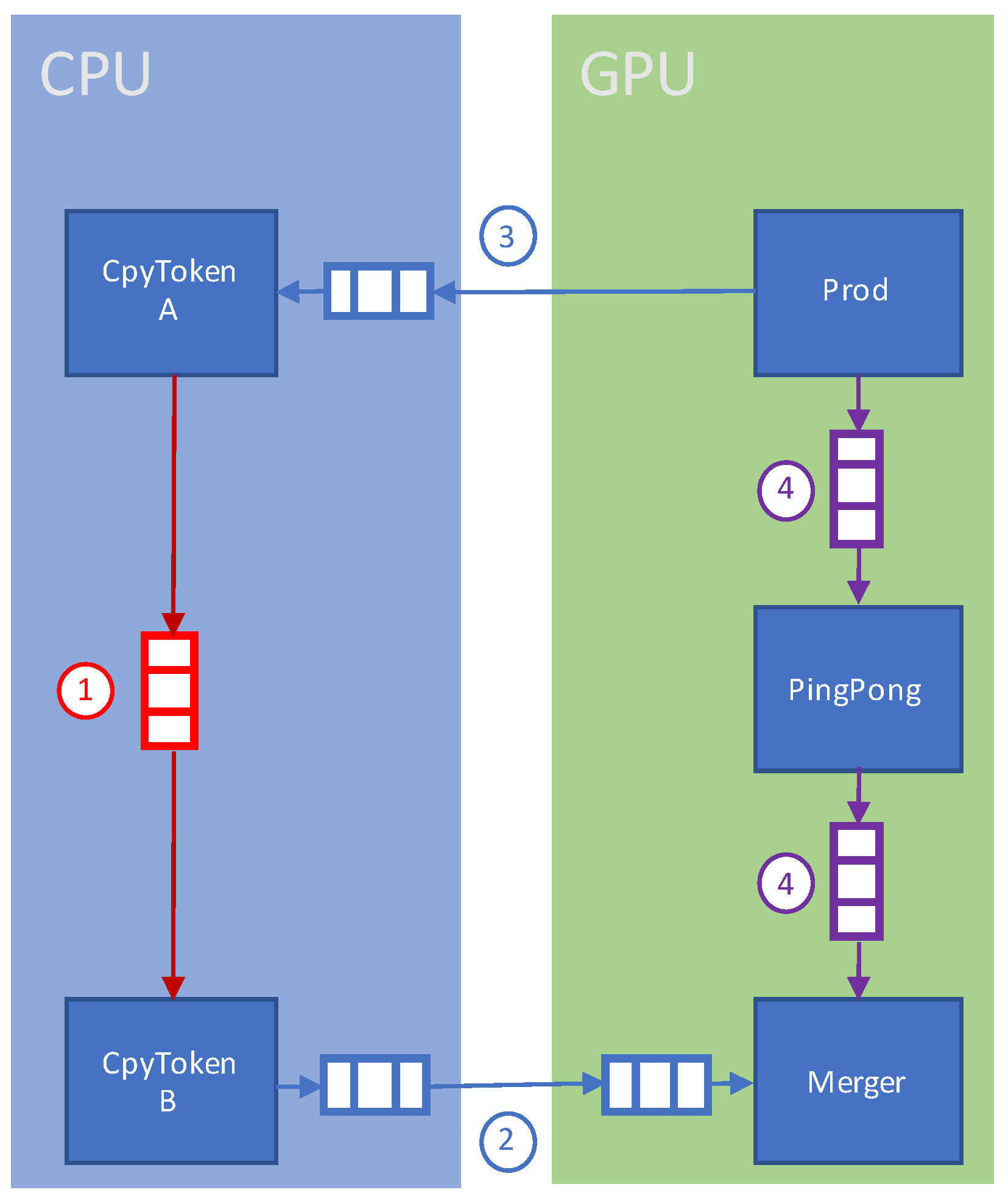
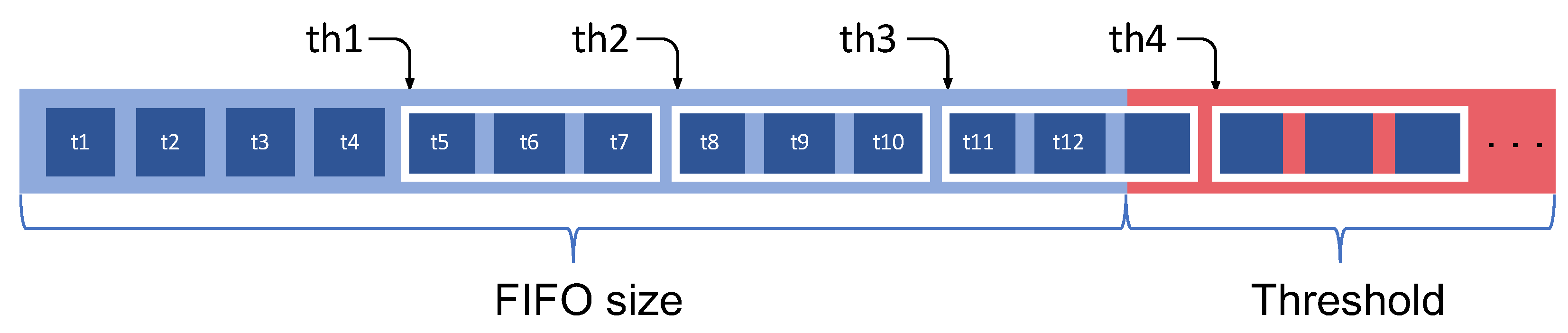
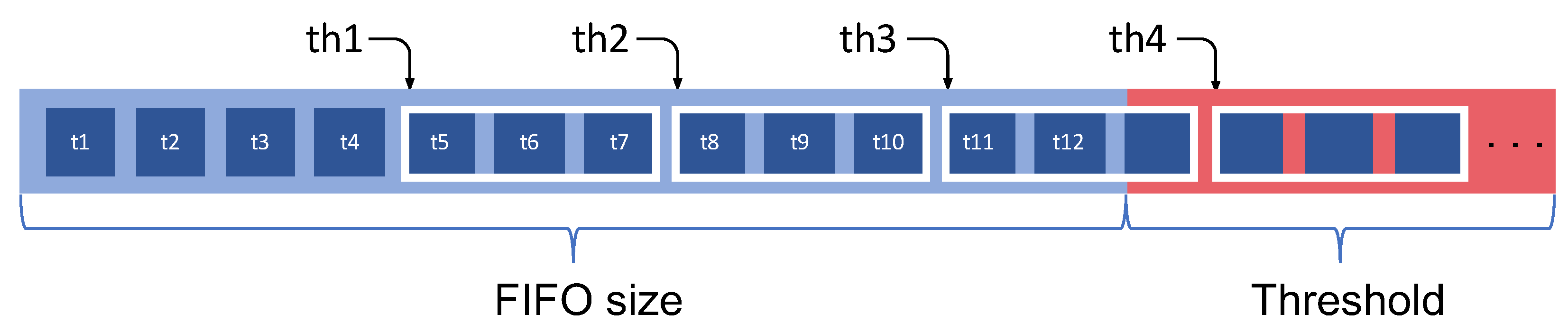
4.1. GPU/CPU Data Communication
4.2. GPU Partitions
4.3. SIMD Parallelization
| Listing 1. Simplified implementation of a CUDA action selection function for an actor of the idct design illustrated in Figure 4. |
 |
4.4. Dynamic SIMD Parallelization
Implementation
5. Experimental Evaluation
5.1. Experimental Hardware and Software Platform
- System 1: GeForce GTX 1660 SUPER Nvidia GPU coupled with an Intel Skylake i5-6600. The GPU graphic co-processor is equipped with 6 GB of memory, whereas the CPU main processing platform is equipped with 16 GBytes of DDR4 RAM.
- System 2: GeForce RTX 3080 Ti Nvidia GPU coupled with an AMD Threadripper 3990X. The GPU graphic co-processor is equipped with 12 GB of memory, whereas the CPU main processing platform is equipped with two 256 GBytes of DDR4 RAM.
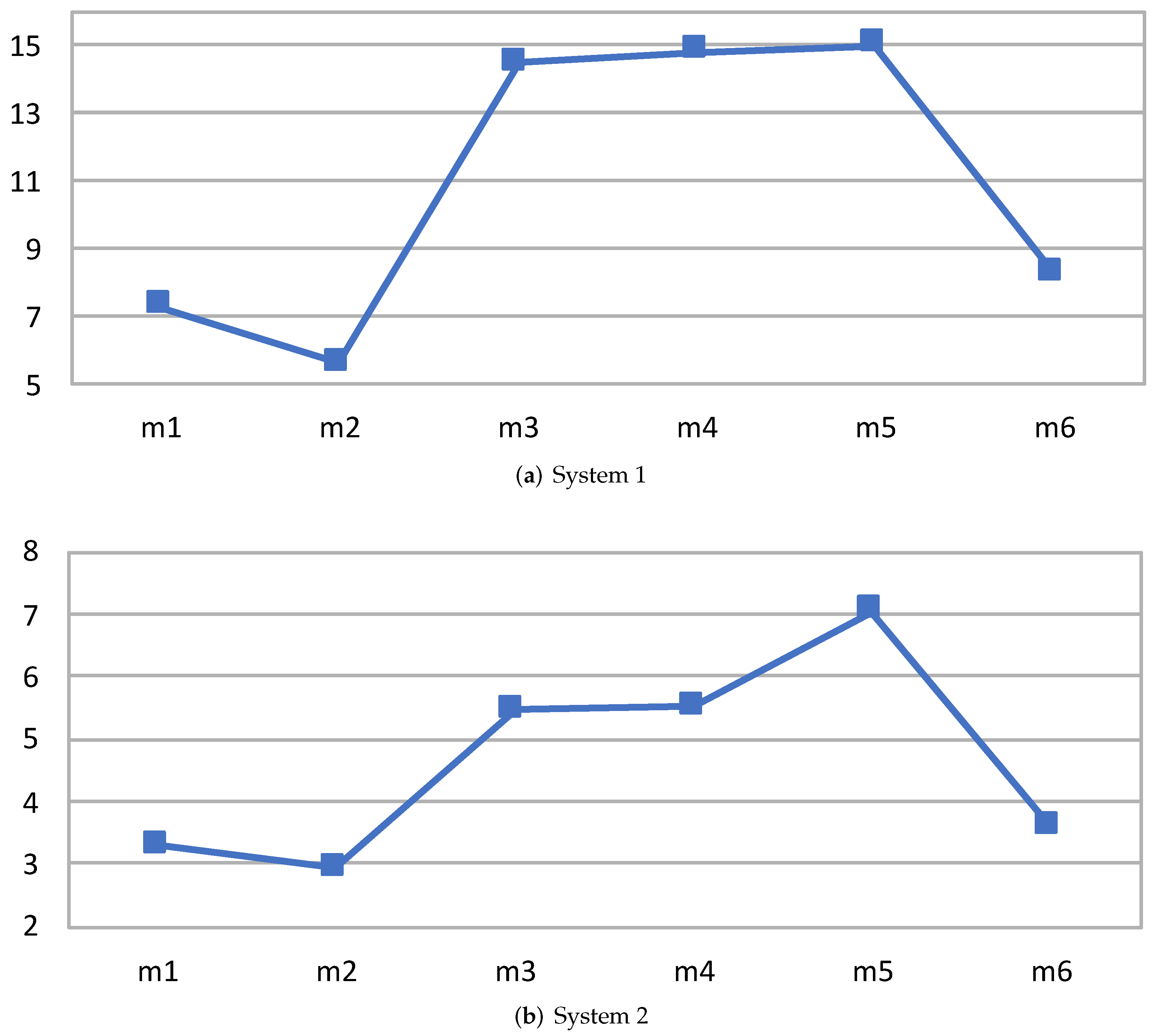
5.2. SIMD Parallelization Capabilities’ Evaluation
5.2.1. Experiments with an IDCT Application
5.2.2. RVC-CAL JPEG Decoder
5.3. CPU/GPU Data Exchange Performance
5.3.1. RVC-CAL FIR Filter
5.3.2. RVC-CAL JPEG Decoder
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Platzer, M.; Sargent, J.; Sutter, K. Semiconductors: U.S. Industry, Global Competition, and Federal Policy (R46581); Technical Report; USA Congressional Research Service: New York, NY, USA, 2020. [Google Scholar]
- Liu, J.; Hegde, N.; Kulkarni, M. Hybrid CPU-GPU Scheduling and Execution of Tree Traversals. SIGPLAN Not. 2016, 51, 2. [Google Scholar] [CrossRef] [Green Version]
- Souravlas, S.; Sifaleras, A.; Katsavounis, S. Hybrid CPU-GPU Community Detection in Weighted Networks. IEEE Access 2020, 8, 57527–57551. [Google Scholar] [CrossRef]
- Antoniadis, N.; Sifaleras, A. A hybrid CPU-GPU parallelization scheme of variable neighborhood search for inventory optimization problems. Electron. Notes Discret. Math. 2017, 58, 47–54. [Google Scholar] [CrossRef] [Green Version]
- Michalska, M.; Casale-Brunet, S.; Bezati, E.; Mattavelli, M. High-precision performance estimation for the design space exploration of dynamic dataflow programs. IEEE Trans. Multi-Scale Comput. Syst. 2017, 4, 127–140. [Google Scholar] [CrossRef]
- Savas, S. Hardware/Software Co-Design of Heterogeneous Manycore Architectures. Ph.D. Thesis, Halmstad University Press, Halmstad, Sweden, 2019. [Google Scholar]
- Goens, A.; Khasanov, R.; Castrillon, J.; Hähnel, M.; Smejkal, T.; Härtig, H. Tetris: A multi-application run-time system for predictable execution of static mappings. In Proceedings of the 20th International Workshop on Software and Compilers for Embedded Systems, St. Goar, Germany, 12–13 June 2017; pp. 11–20. [Google Scholar]
- Bloch, A.; Bezati, E.; Mattavelli, M. Programming Heterogeneous CPU-GPU Systems by High-Level Dataflow Synthesis. In Proceedings of the 2020 IEEE Workshop on Signal Processing Systems (SiPS), Coimbra, Portugal, 20–22 October 2020; pp. 1–6. [Google Scholar]
- Bhattacharyya, S.; Deprettere, E.; Theelen, B. Dynamic Dataflow Graphs. In Handbook of Signal Processing Systems; Springer: Cham, Switzerland, 2013; pp. 905–944. [Google Scholar]
- Johnston, W.; Hanna, J.; Millar, R. Advances in dataflow programming languages. ACM Comput. Surv. 2004, 36, 1–34. [Google Scholar] [CrossRef]
- 23001-4:2011; Information Technology—MPEG Systems Technologies—Part 4: Codec Configuration Representation. ISO: Geneva, Switzerland, 2011.
- Yviquel, H.; Lorence, A.; Jerbi, K.; Cocherel, G.; Sanchez, A.; Raulet, M. Orcc: Multimedia Development Made Easy. In Proceedings of the 21st ACM International Conference on Multimedia, Barcelona, Spain, 21–25 October 2013; pp. 863–866. [Google Scholar]
- Orcc Source Code Repository. Available online: http://github.com/orcc/orcc (accessed on 9 March 2022).
- Cedersjö, G.; Janneck, J.W. Tÿcho: A framework for compiling stream programs. ACM Trans. Embed. Comput. Syst. 2019, 18, 1–25. [Google Scholar] [CrossRef]
- Bezati, E.; Emami, M.; Janneck, J.; Larus, J. StreamBlocks: A compiler for heterogeneous dataflow computing (technical report). arXiv 2021, arXiv:2107.09333. [Google Scholar]
- Siyoum, F.; Geilen, M.; Eker, J.; von Platen, C.; Corporaal, H. Automated extraction of scenario sequences from disciplined dataflow networks. In Proceedings of the 2013 Eleventh ACM/IEEE International Conference on Formal Methods and Models for Codesign (MEMOCODE 2013), Portland, OR, USA, 18–20 October 2013; pp. 47–56. [Google Scholar]
- Boutellier, J.; Nyländen, T. Design flow for GPU and multicore execution of dynamic dataflow programs. J. Signal Process. Syst. 2017, 89, 469–478. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Sbîrlea, A.; Zou, Y.; Budimlíc, Z.; Cong, J.; Sarkar, V. Mapping a data-flow programming model onto heterogeneous platforms. ACM SIGPLAN Not. 2012, 47, 61–70. [Google Scholar] [CrossRef] [Green Version]
- Gautier, T.; Lima, J.V.; Maillard, N.; Raffin, B. Xkaapi: A runtime system for data-flow task programming on heterogeneous architectures. In Proceedings of the 2013 IEEE 27th International Symposium on Parallel and Distributed Processing, Cambridge, MA, USA, 20–24 May 2013; pp. 1299–1308. [Google Scholar]
- Schor, L.; Tretter, A.; Scherer, T.; Thiele, L. Exploiting the parallelism of heterogeneous systems using dataflow graphs on top of OpenCL. In Proceedings of the 11th IEEE Symposium on Embedded Systems for Real-Time Multimedia, Montreal, QC, Canada, 3–4 October 2013; pp. 41–50. [Google Scholar]
- Lin, S.; Liu, Y.; Plishker, W.; Bhattacharyya, S.S. A Design Framework for Mapping Vectorized Synchronous Dataflow Graphs onto CPU-GPU Platforms. In Proceedings of the 19th International Workshop on Software and Compilers for Embedded Systems, Sankt Goar, Germany, 23–25 May 2016; Association for Computing Machinery: New York, NY, USA, 2011; pp. 20–29. [Google Scholar] [CrossRef]
- Lund, W.; Kanur, S.; Ersfolk, J.; Tsiopoulos, L.; Lilius, J.; Haldin, J.; Falk, U. Execution of dataflow process networks on OpenCL platforms. In Proceedings of the 2015 23rd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, Turku, Finland, 4–6 March 2015; pp. 618–625. [Google Scholar]
- Boutellier, J.; Nylanden, T. Programming graphics processing units in the RVC-CAL dataflow language. In Proceedings of the 2015 IEEE Workshop on Signal Processing Systems (SiPS), Hangzhou, China, 14–16 October 2015; pp. 1–6. [Google Scholar]
- Schor, L.; Bacivarov, I.; Rai, D.; Yang, H.; Kang, S.H.; Thiele, L. Scenario-based design flow for mapping streaming applications onto on-chip many-core systems. In Proceedings of the 2012 International Conference on Compilers, Architectures and Synthesis for Embedded Systems, Tempere, Finland, 7–12 October 2012; pp. 71–80. [Google Scholar]
- Lee, E.A.; Messerschmitt, D.G. Synchronous data flow. Proc. IEEE 1987, 75, 1235–1245. [Google Scholar] [CrossRef]
- Rafique, O.; Krebs, F.; Schneider, K. Generating Efficient Parallel Code from the RVC-CAL Dataflow Language. In Proceedings of the 2019 22nd Euromicro Conference on Digital System Design (DSD), Kallithea, Greece, 28–30 August 2019; pp. 182–189. [Google Scholar]
- SYCL. Available online: https://www.khronos.org/sycl/ (accessed on 9 March 2022).
- CAL Exelixi Backends Source Code Repository. Available online: https://bitbucket.org/exelixi/exelixi-backends (accessed on 9 March 2022).
- Bezati, E.; Casale-Brunet, S.; Mosqueron, R.; Mattavelli, M. An Heterogeneous Compiler of Dataflow Programs for Zynq Platforms. In Proceedings of the ICASSP 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1537–1541. [Google Scholar] [CrossRef]
- Orcc-Apps Source Code Repository. Available online: https://github.com/orcc/orc-apps (accessed on 9 March 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| This Work | [23] | [24] | [27] | |
|---|---|---|---|---|
| static | CPU/GPU | CPU/GPU | CPU/GPU | CPU/GPU |
| cyclo-static | CPU/GPU | CPU | CPU | CPU |
| dynamic | CPU/GPU | CPU | CPU | CPU |
| CPU | GPU | Speedup | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Min | Mean | Max | Var | Min | Mean | Max | Var | ||
| System 1 | 9.23 | 9.31 | 9.42 | 2.90 × 10 | 4.36 | 4.60 | 4.77 | 1.40 × 10 | 2.02 |
| System 2 | 8.50 | 12.6 | 18.0 | 1.39 × 10 | 5.72 | 5.73 | 5.74 | 3.22 × 10 | 2.18 |
| Frame Rate (image/s) | Speedup | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Sequential GPU | Parallel GPU | ||||||||
| Min | Mean | Max | Var | Min | Mean | Max | Var | ||
| System 1 | 0.24 | 0.24 | 0.24 | 7.63 × 10 | 2.28 | 2.28 | 2.28 | 4.06 × 10 | 9.44 |
| System 2 | 0.28 | 0.29 | 0.29 | 2.38 × 10 | 5.16 | 5.19 | 5.24 | 8.17 × 10 | 18.20 |
| New FIFO | Old FIFO | Speedup | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Min | Mean | Max | Var | Min | Mean | Max | Var | ||
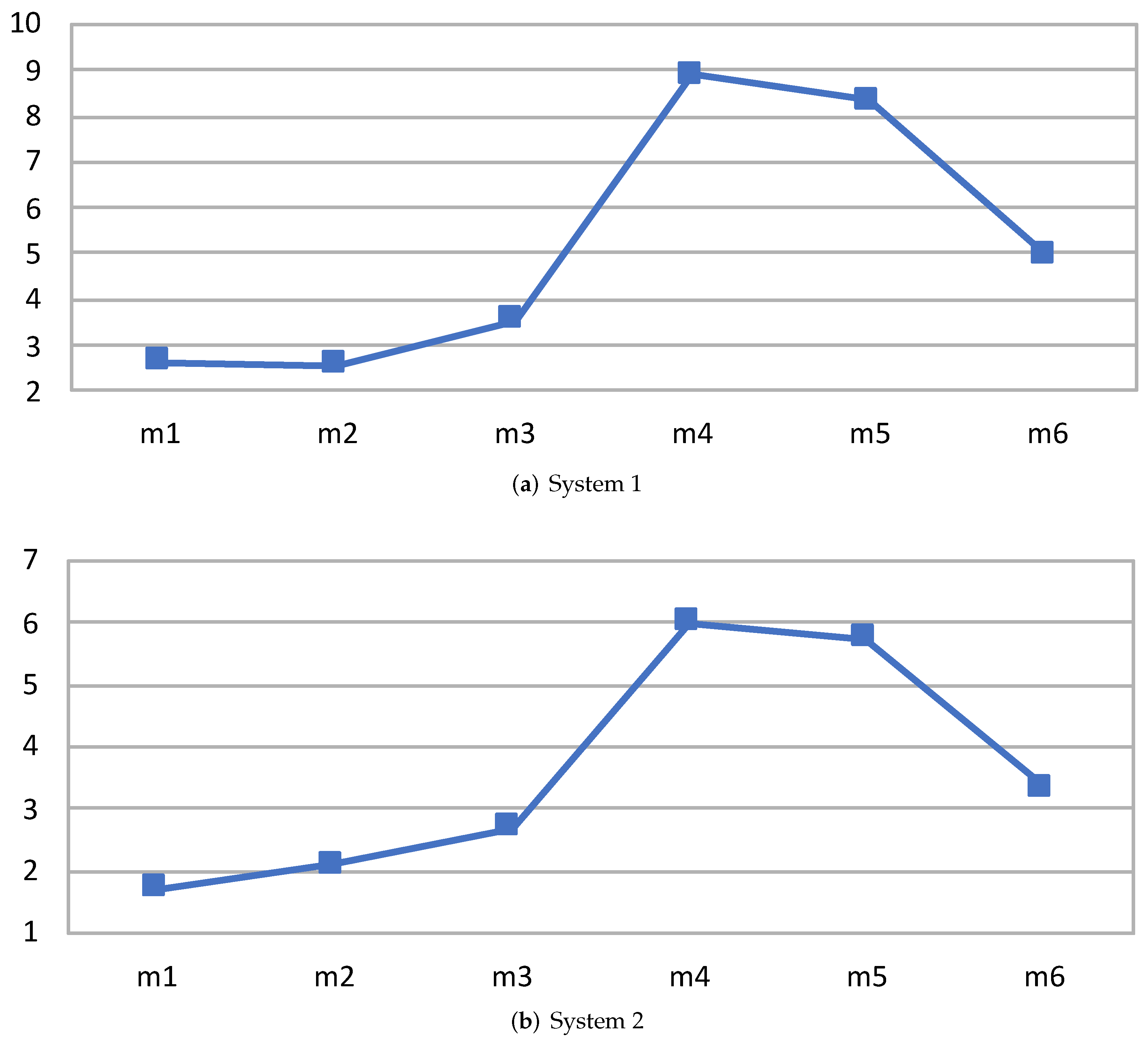
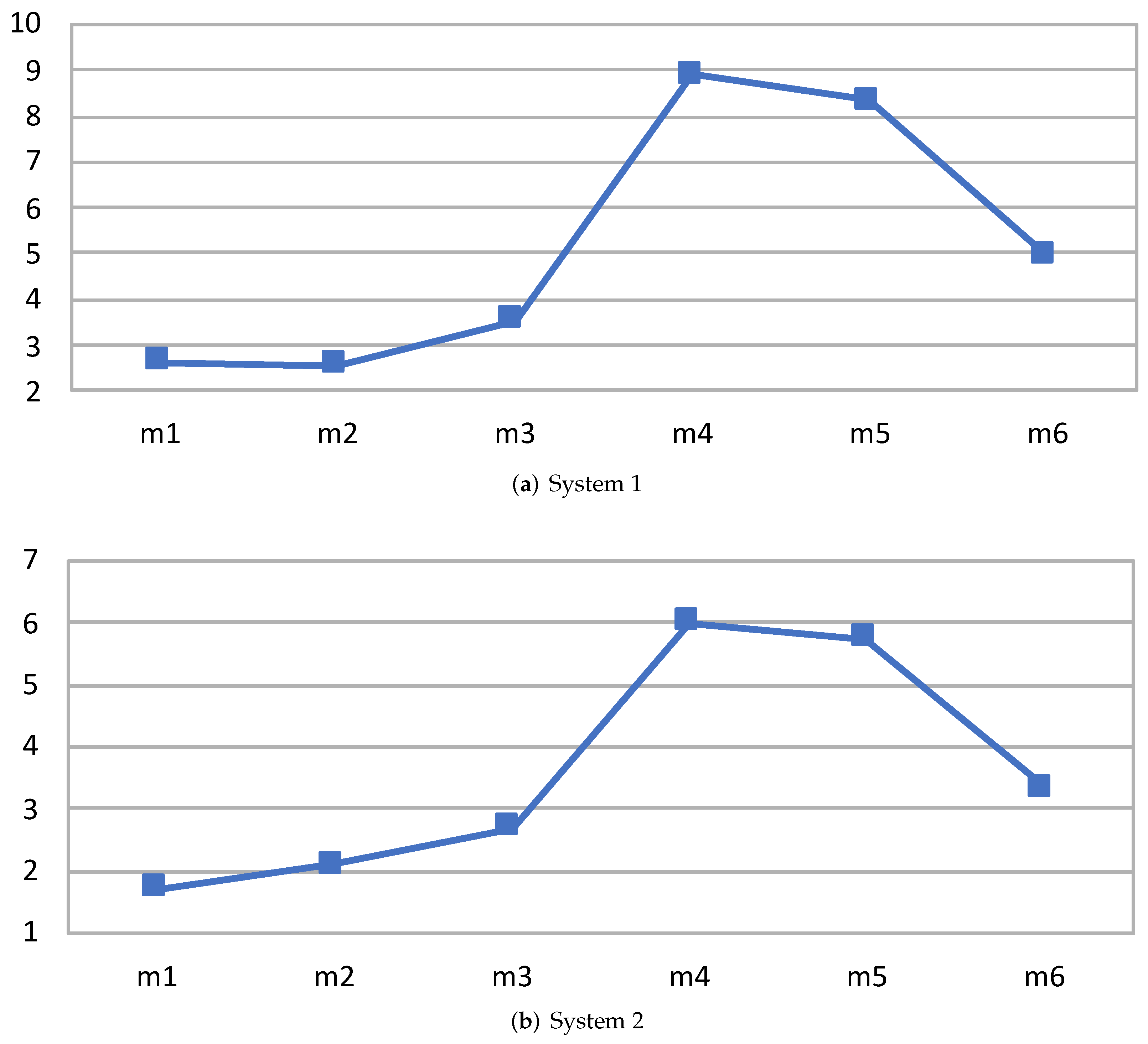
| m1 | 1.36 | 1.37 | 1.38 | 1.00 × 10 | 3.56 | 3.60 | 3.63 | 1.23 × 10 | 2.63 |
| m2 | 1.31 | 1.34 | 1.35 | 4.33 × 10 | 3.40 | 3.42 | 3.45 | 8.33 × 10 | 2.56 |
| m3 | 1.37 | 1.38 | 1.41 | 5.33 × 10 | 4.90 | 4.91 | 4.92 | 1.33 × 10 | 3.55 |
| m4 | 5.73 | 5.76 | 5.80 | 1.43 × 10 | 51.03 | 51.27 | 51.65 | 1.09 × 10 | 8.91 |
| m5 | 5.99 | 6.16 | 6.26 | 2.26 × 10 | 51.23 | 51.30 | 51.37 | 4.90 × 10 | 8.32 |
| m6 | 5.79 | 5.80 | 5.82 | 3.00 × 10 | 28.55 | 28.63 | 28.71 | 6.43 × 10 | 4.94 |
| New FIFO | Old FIFO | Speedup | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Min | Mean | Max | Var | Min | Mean | Max | Var | ||
| m1 | 1.25 | 1.26 | 1.27 | 1.33 × 10 | 2.11 | 2.13 | 2.17 | 1.03 × 10 | 1.70 |
| m2 | 1.25 | 1.28 | 1.31 | 9.33 × 10 | 2.65 | 2.67 | 2.68 | 3.00 × 10 | 2.09 |
| m3 | 1.30 | 1.31 | 1.32 | 1.00 × 10 | 3.48 | 3.52 | 3.56 | 1.63 × 10 | 2.68 |
| m4 | 4.98 | 5.04 | 5.17 | 1.20 × 10 | 30.10 | 30.24 | 30.42 | 2.72 × 10 | 6.00 |
| m5 | 5.23 | 5.26 | 5.31 | 1.73 × 10 | 30.00 | 30.20 | 30.51 | 7.52 × 10 | 5.74 |
| m6 | 5.15 | 5.19 | 5.26 | 3.70 × 10 | 17.16 | 17.31 | 17.53 | 3.72 × 10 | 3.34 |
| CPU | GPU | |
|---|---|---|
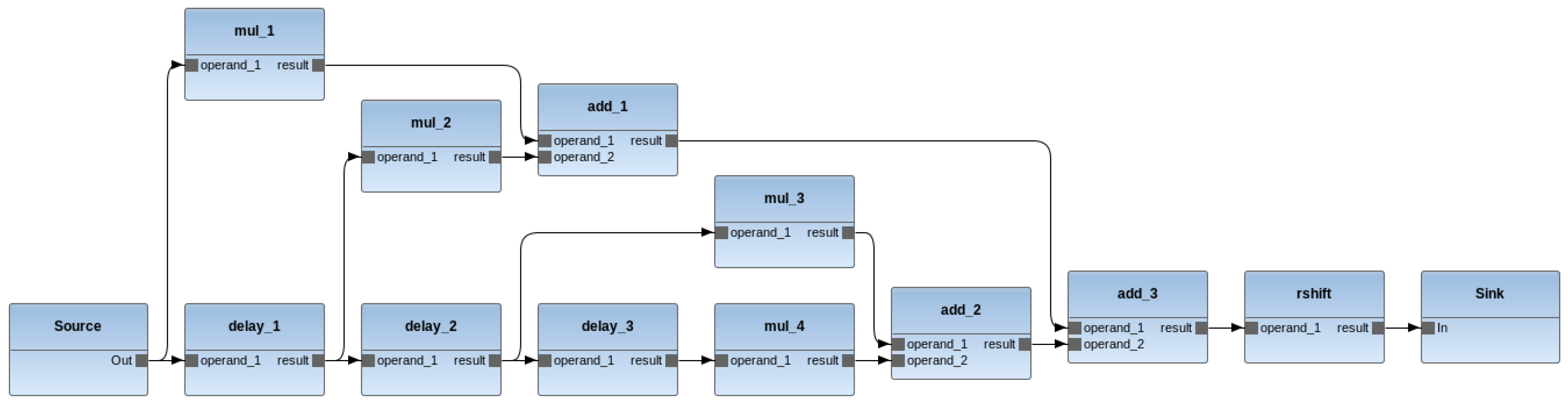
| m1 | Source, Sink | delay_1, delay_2, delay3, mul_1, mul_2, mul_3, mul_4, add_1, add_2, add_3, rshift |
| m2 | Source, Sink, delay_1, mul_1, mul_2, add_1, add_2, rshift | delay_2, delay3, mul_3, mul_4, add_2 |
| m3 | Source, Sink, mul_1, add_3, rshift | delay_1, delay_2, delay3, mul_2, mul_3, mul_4, add_1, add_2 |
| m4 | Source, Sink, delay_1, delay_3, mul_1, mul_3, add_1, add_3 | delay_2, mul_2, mul_4, add_2, rshift |
| m5 | Source, Sink, delay_1, delay_3, mul_1, mul_3, add_1, add_2 | delay_2, mul_2, mul_4, add_3, rshift |
| m6 | Source, Sink, delay_1, delay_2, delay_3, mul_1, mul_2, mul_3, mul_4 | add_1, add_2, add_3, rshift |
| New FIFO | Old FIFO | Speedup | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Min | Mean | Max | Var | Min | Mean | Max | Var | ||
| m1 | 2.07 | 2.07 | 2.07 | 1.33 × 10 | 14.98 | 15.08 | 15.15 | 7.11 × 10 | 7.31 |
| m2 | 1.88 | 1.89 | 1.89 | 5.33 × 10 | 10.47 | 10.58 | 10.65 | 8.14 × 10 | 5.64 |
| m3 | 5.03 | 5.10 | 5.23 | 1.14 × 10 | 73.04 | 73.70 | 74.51 | 5.00 | 14.26 |
| m4 | 5.57 | 5.59 | 5.62 | 5.63 × 10 | 82.61 | 82.72 | 82.81 | 9.31 × 10 | 14.73 |
| m5 | 9.57 | 9.60 | 9.62 | 6.70 × 10 | 143.39 | 143.96 | 144.43 | 2.50 | 15.01 |
| m6 | 7.70 | 7.72 | 7.75 | 7.23 × 10 | 62.96 | 63.36 | 63.64 | 1.14 | 8.21 |
| New FIFO | Old FIFO | Speedup | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Min | Mean | Max | Var | Min | Mean | Max | Var | ||
| m1 | 1.72 | 1.72 | 1.72 | 4.30 × 10 | 5.44 | 5.67 | 5.90 | 4.84 × 10 | 3.29 |
| m2 | 1.31 | 1.31 | 1.32 | 2.52 × 10 | 3.81 | 3.86 | 3.94 | 4.42 × 10 | 2.94 |
| m3 | 4.56 | 4.57 | 4.57 | 2.44 × 10 | 24.93 | 24.95 | 24.99 | 8.83 × 10 | 5.46 |
| m4 | 5.12 | 5.13 | 5.14 | 7.46 × 10 | 27.59 | 28.35 | 29.35 | 7.41 | 5.52 |
| m5 | 8.44 | 8.45 | 8.46 | 5.37 × 10 | 58.56 | 59.51 | 61.25 | 2.03 × 10 | 7.04 |
| m6 | 6.93 | 6.94 | 6.95 | 6.13 × 10 | 23.62 | 24.87 | 25.52 | 1.06 × 10 | 3.58 |
| CPU | GPU | |
|---|---|---|
| m1 | src, parser, huffman, dequant, idct2d, display | dequant |
| m2 | src, parser, huffman, dequant, display | idct2d |
| m3 | src, parser, dequant, idct2d, display | huffman |
| m4 | src, parser, dequant, display | huffman, idct2d |
| m5 | src, huffman, idct2d, display | parser, dequant |
| m6 | src, display | parser, huffman, dequant, idct2d |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bloch, A.; Casale-Brunet, S.; Mattavelli, M. Dynamic SIMD Parallel Execution on GPU from High-Level Dataflow Synthesis. J. Low Power Electron. Appl. 2022, 12, 40. https://doi.org/10.3390/jlpea12030040
Bloch A, Casale-Brunet S, Mattavelli M. Dynamic SIMD Parallel Execution on GPU from High-Level Dataflow Synthesis. Journal of Low Power Electronics and Applications. 2022; 12(3):40. https://doi.org/10.3390/jlpea12030040
Chicago/Turabian StyleBloch, Aurelien, Simone Casale-Brunet, and Marco Mattavelli. 2022. "Dynamic SIMD Parallel Execution on GPU from High-Level Dataflow Synthesis" Journal of Low Power Electronics and Applications 12, no. 3: 40. https://doi.org/10.3390/jlpea12030040
APA StyleBloch, A., Casale-Brunet, S., & Mattavelli, M. (2022). Dynamic SIMD Parallel Execution on GPU from High-Level Dataflow Synthesis. Journal of Low Power Electronics and Applications, 12(3), 40. https://doi.org/10.3390/jlpea12030040