
Performance Estimation of High-Level Dataflow Program on Heterogeneous Platforms by Dynamic Network Execution †


Abstract
:1. Introduction
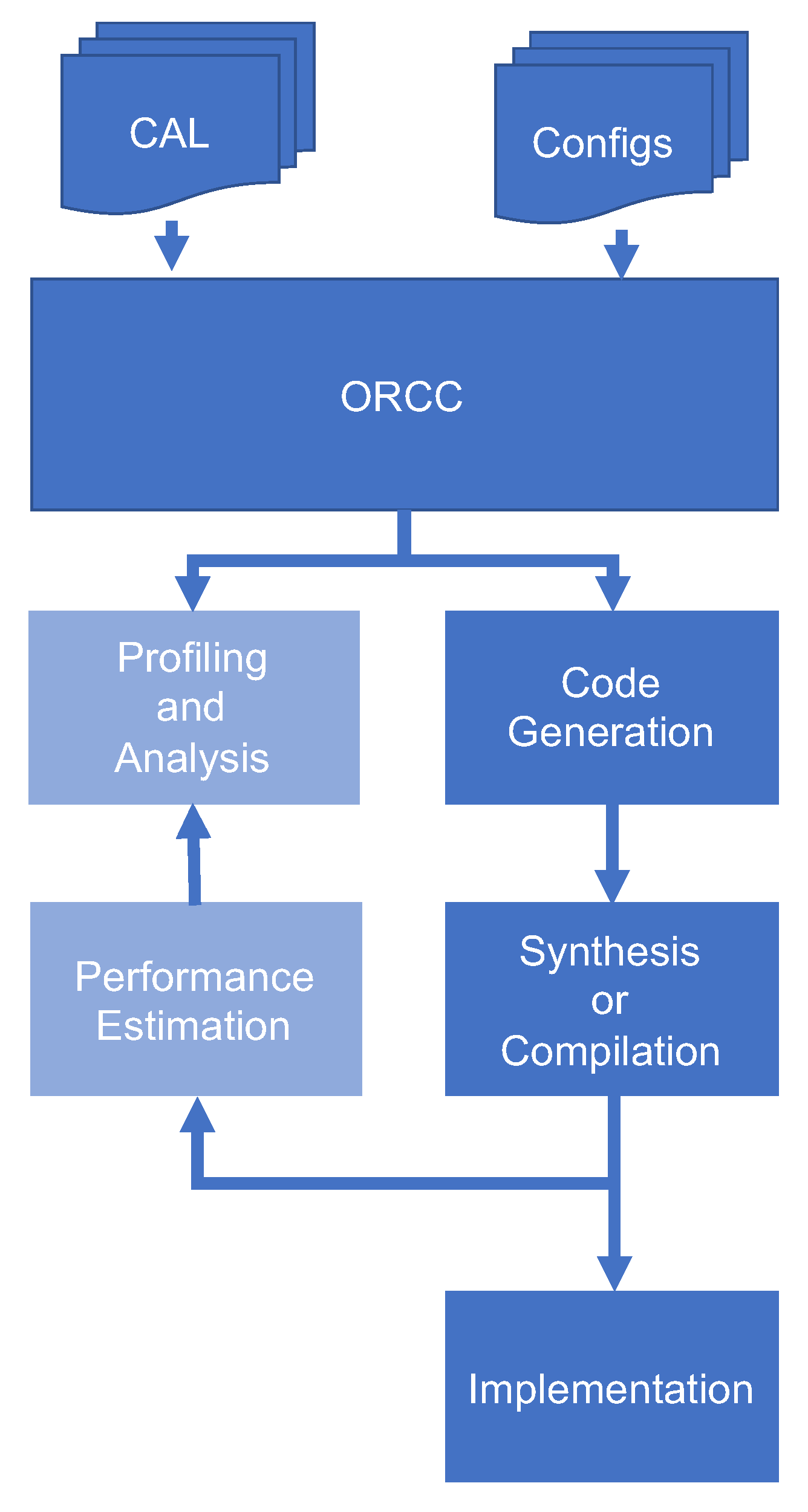
- The development of a method to generate an instrumented code in C++/CUDA from an RVC-CAL actors’ network that, when executed on the appropriate hardware platform, automatically generated the weights (i.e., performance measures) of the actors’ runtime for both platforms, in case it would be executed on the GPU or the CPU system.
- The development of a method for utilizing the performance measures to estimate the overall performance of any configuration of an RVC-CAL dataflow application without the necessity to configure, synthesize, compile, execute, and profile each configuration on a heterogeneous system.
- A methodology for generating code compatible with the creation of an application program for which the network layout could be dynamically configured at runtime.
- An alternative methodology to use the newly introduced dynamic network methodology to generate the runtime profile metrics for use in performance estimation.
2. Related Work
2.1. GPU Profiling
2.2. Heterogeneous Dataflow Profiling
3. Dataflow Programs and Design Space Exploration
3.1. RVC-CAL
3.2. Design Space Exploration
3.3. Performance Estimation
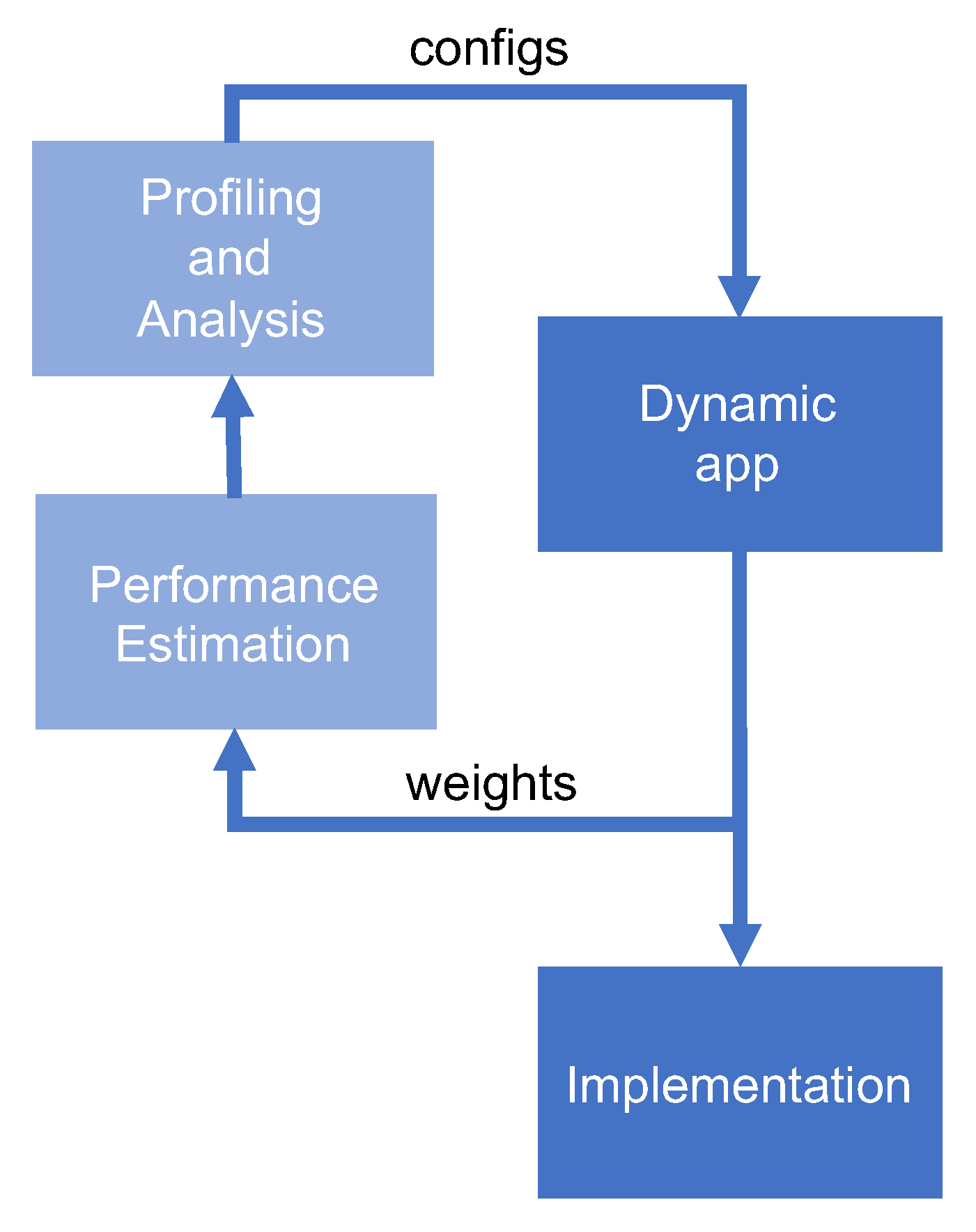
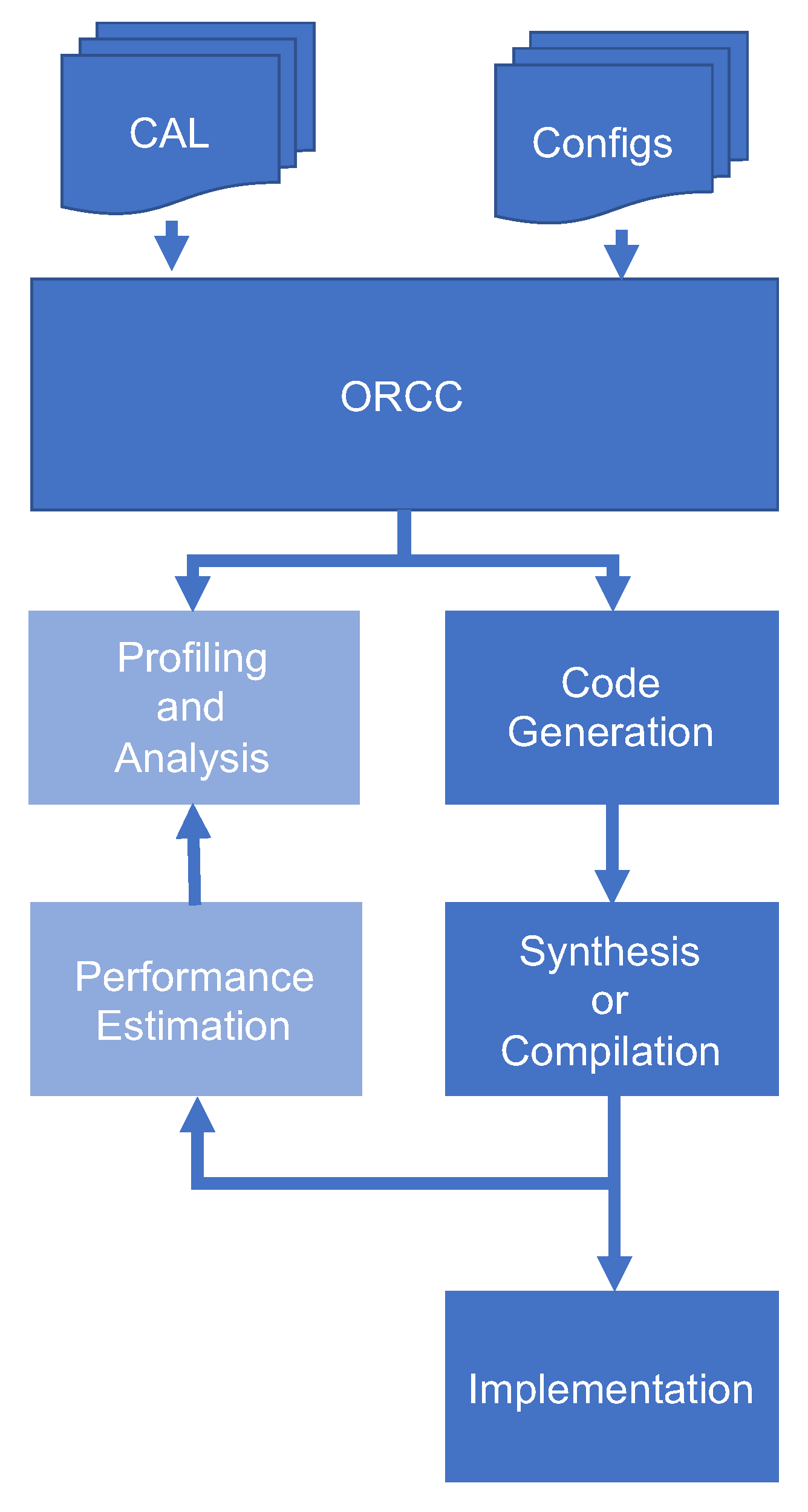
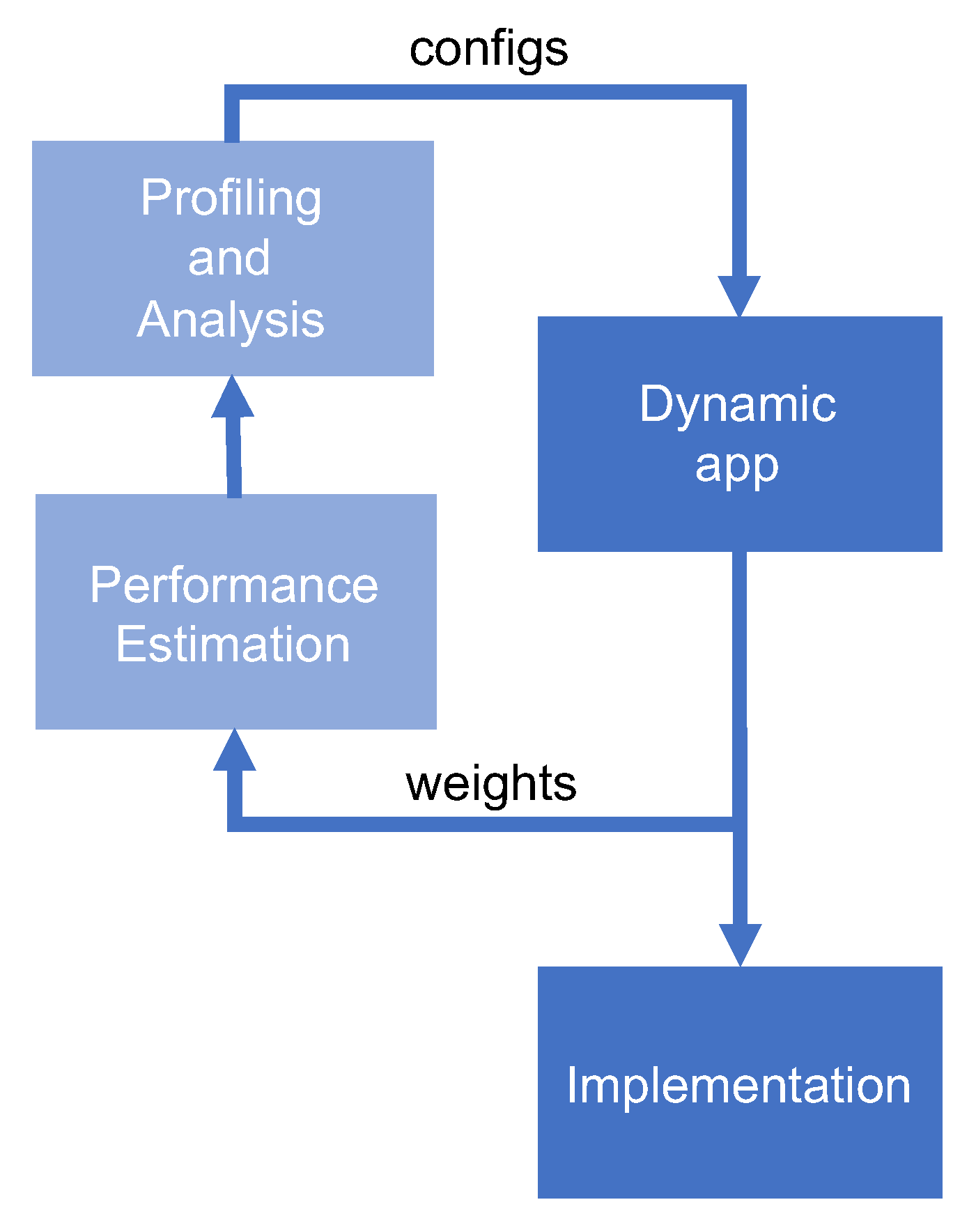
4. Performance Estimation Methodology
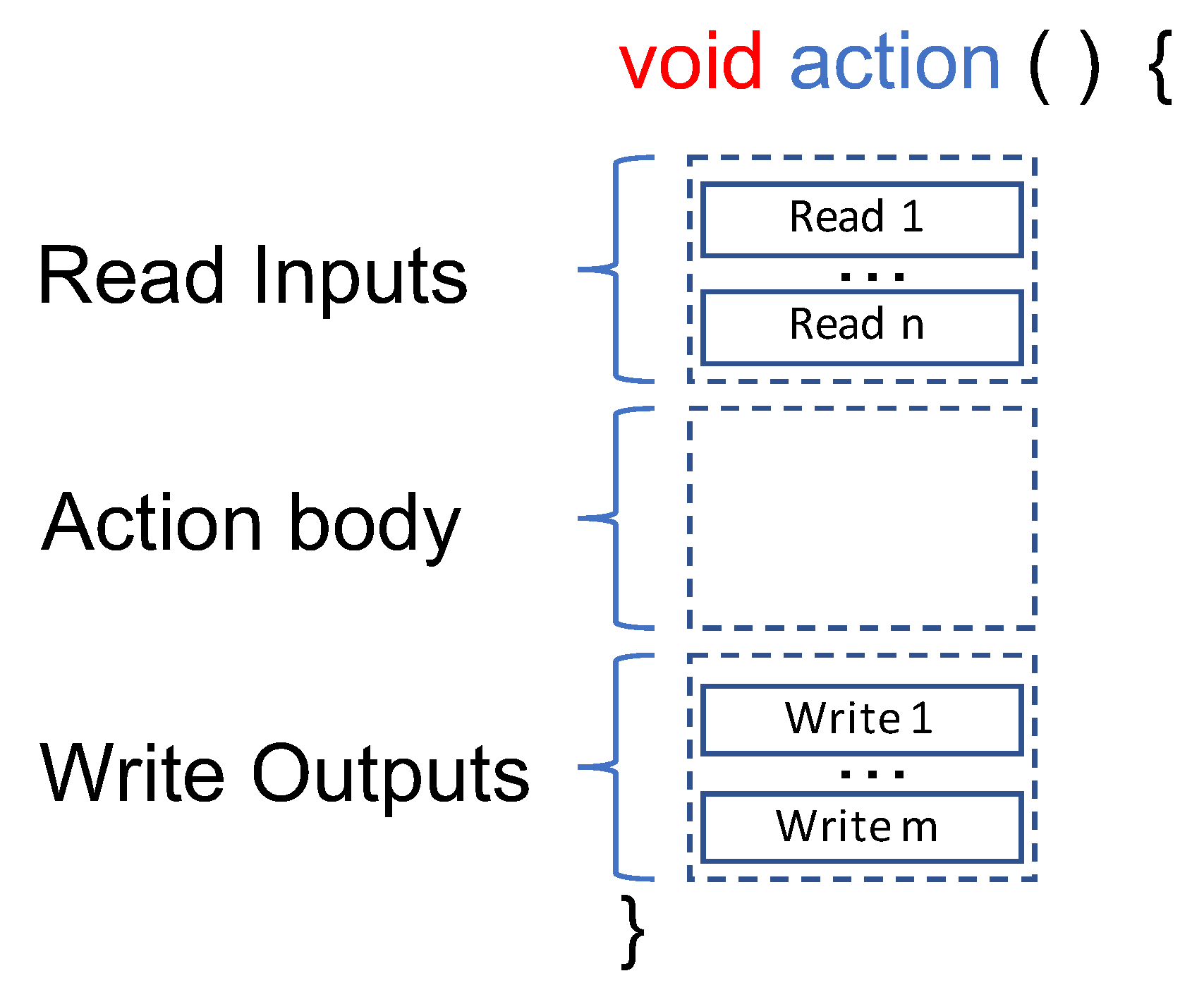
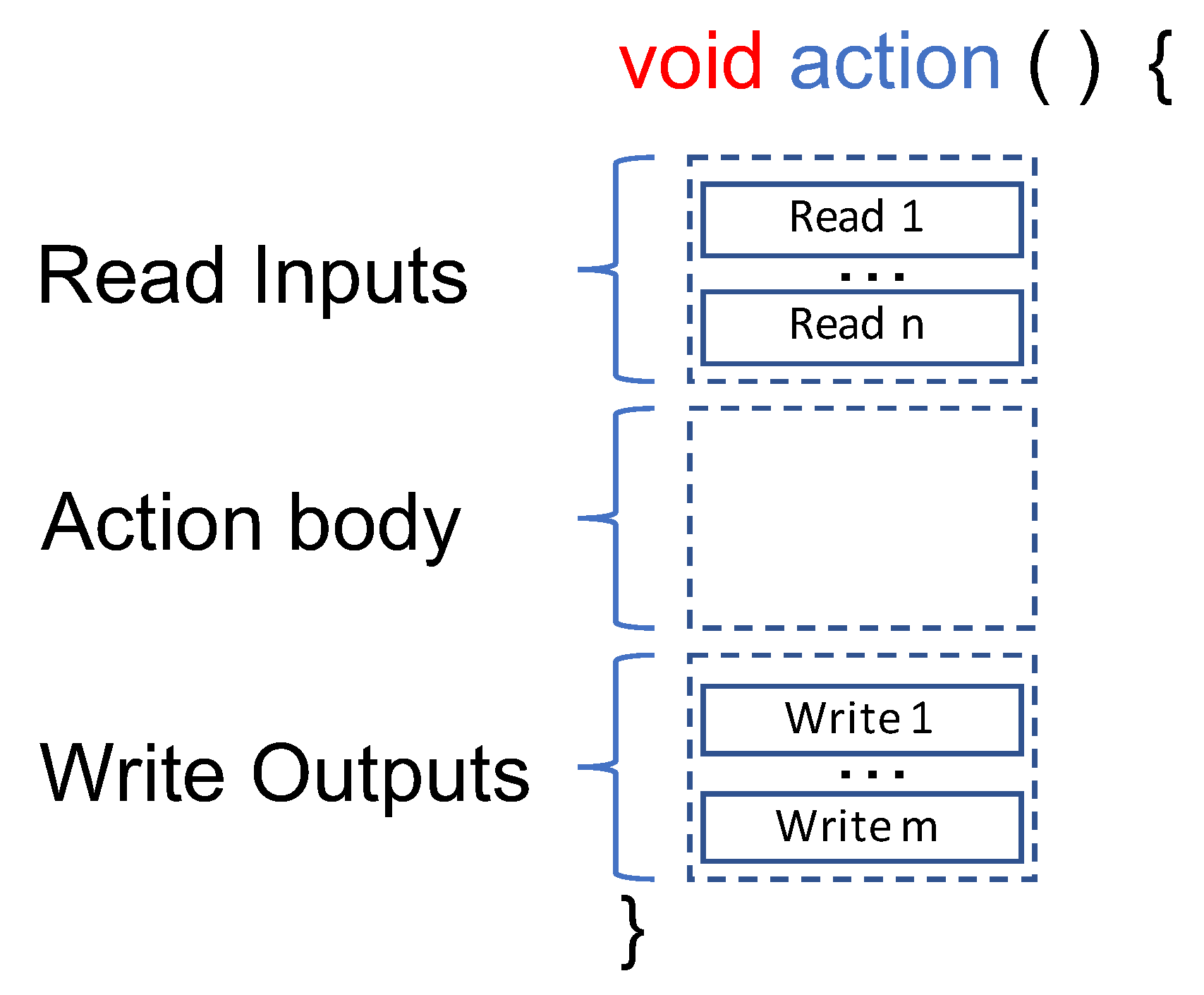
4.1. Clock-Accurate Profiling
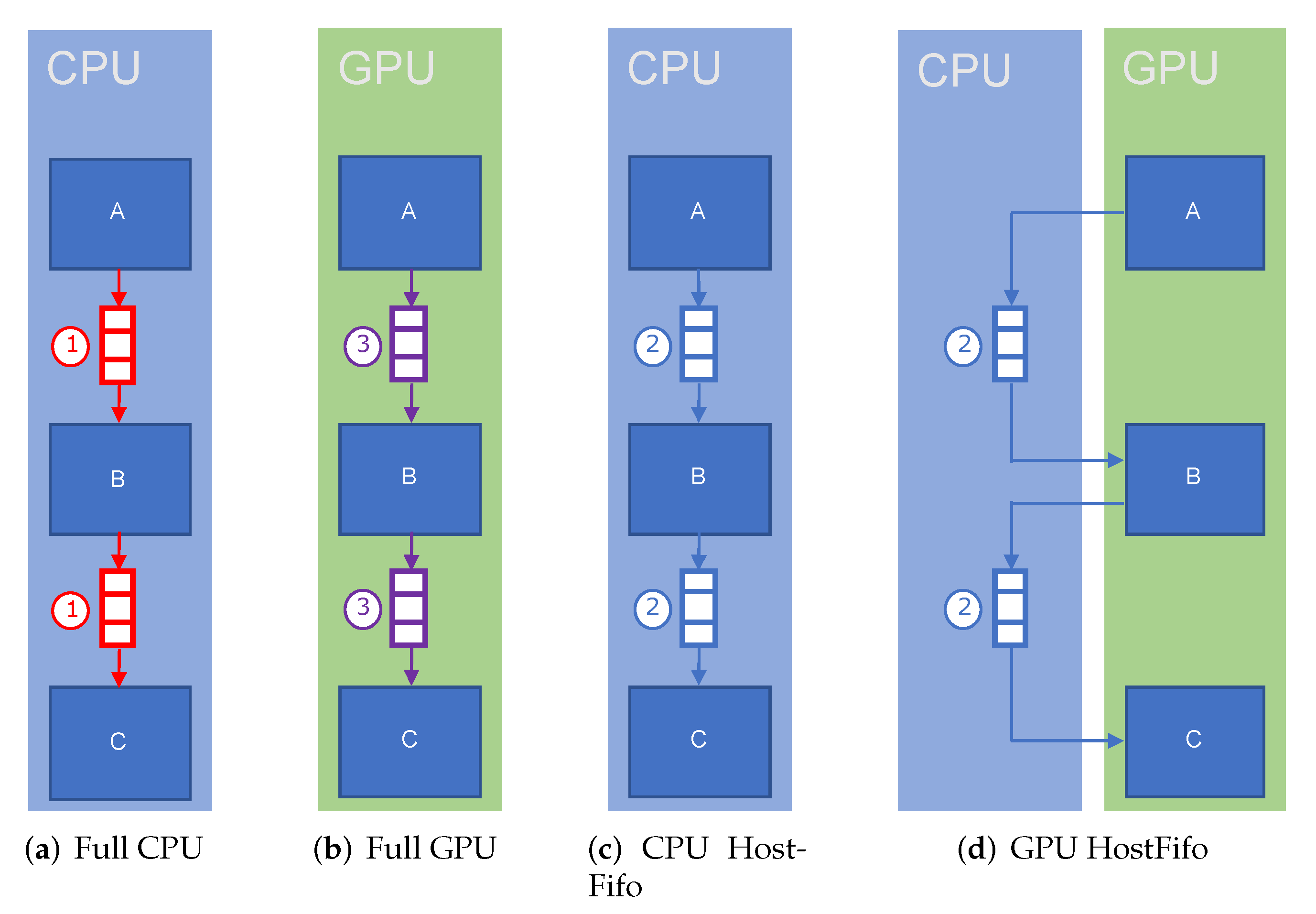
4.2. Static Heterogeneous Estimation
4.3. SIMD Parallel Estimation
4.4. Dynamic Heterogeneous Estimation
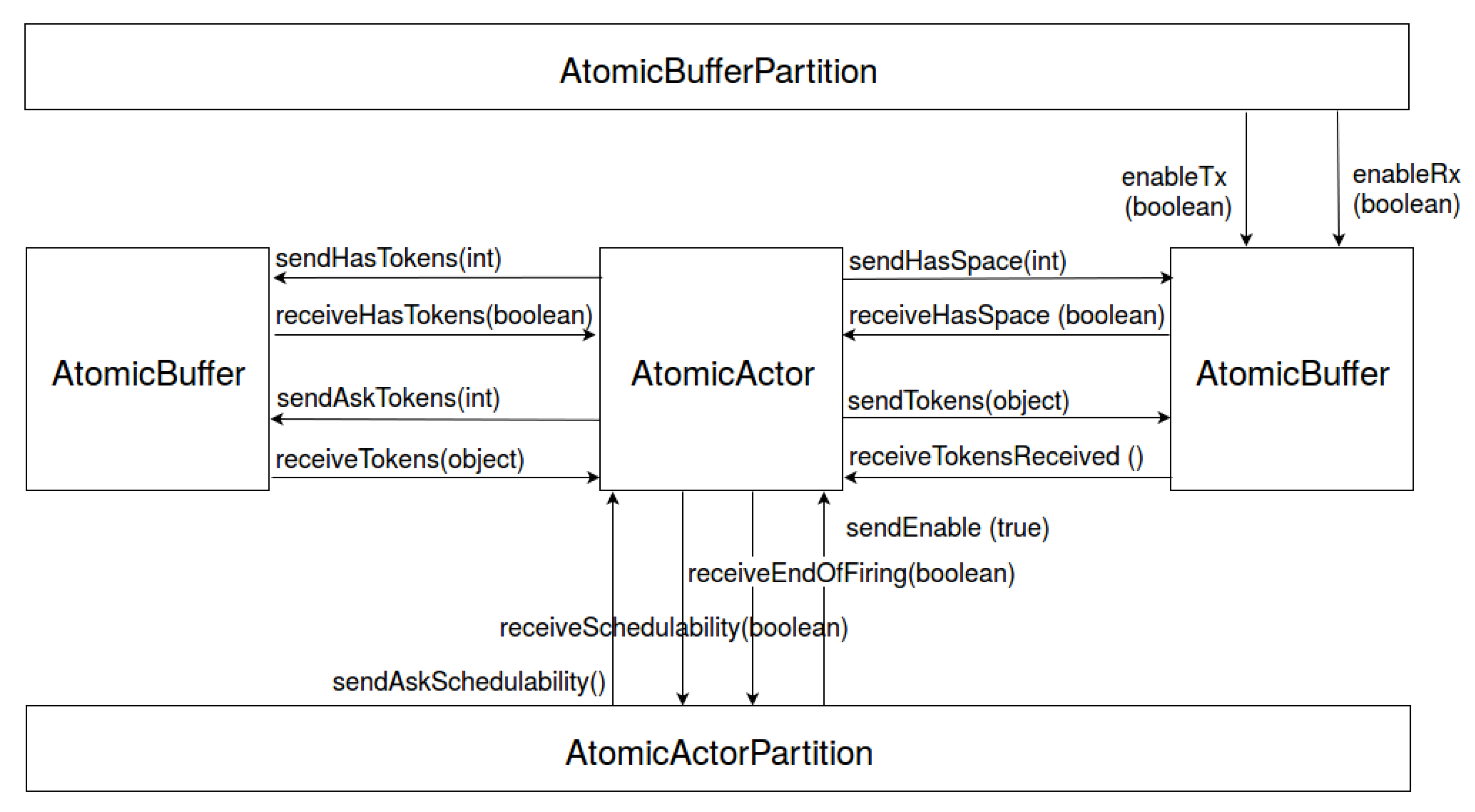
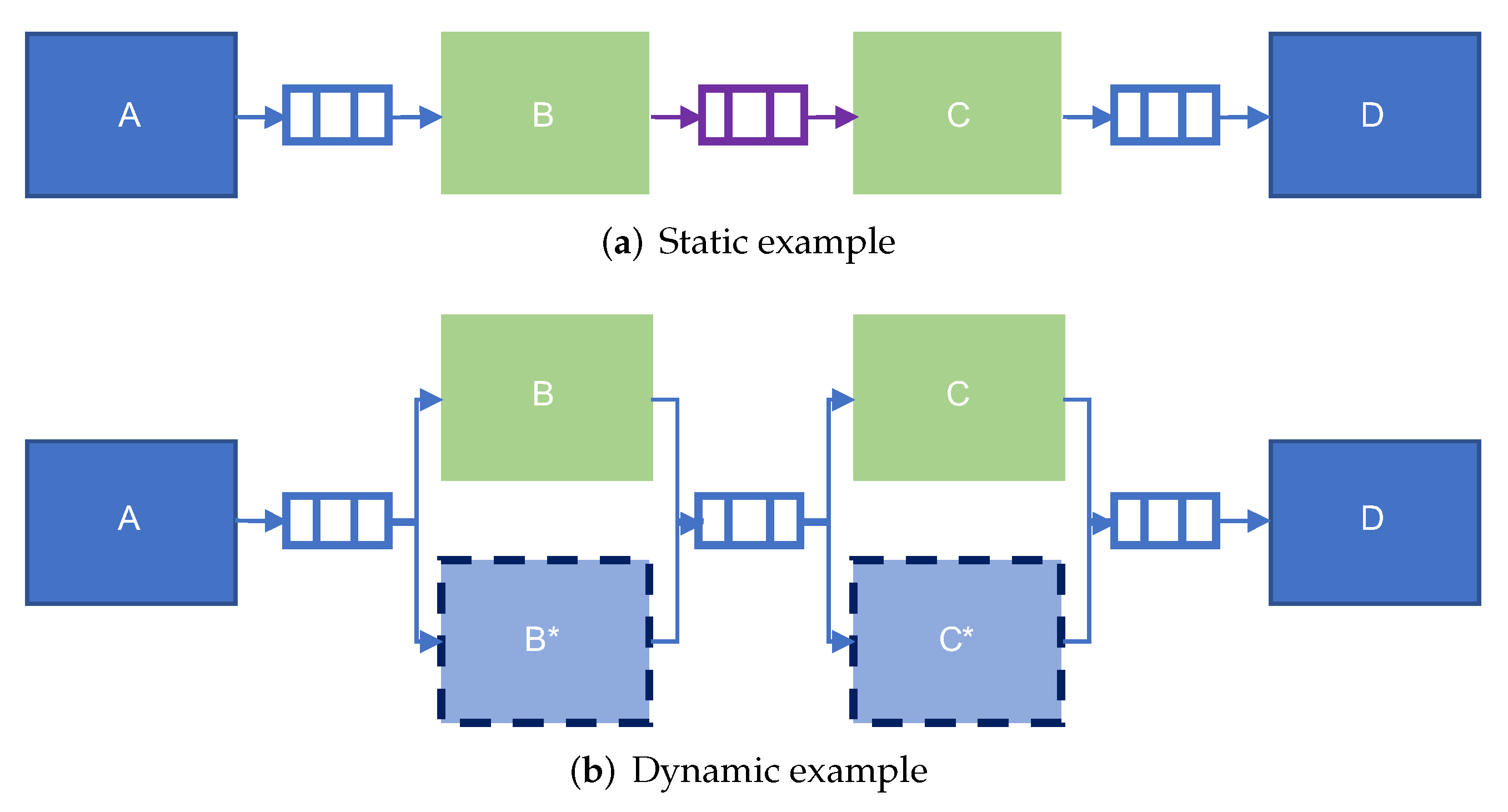
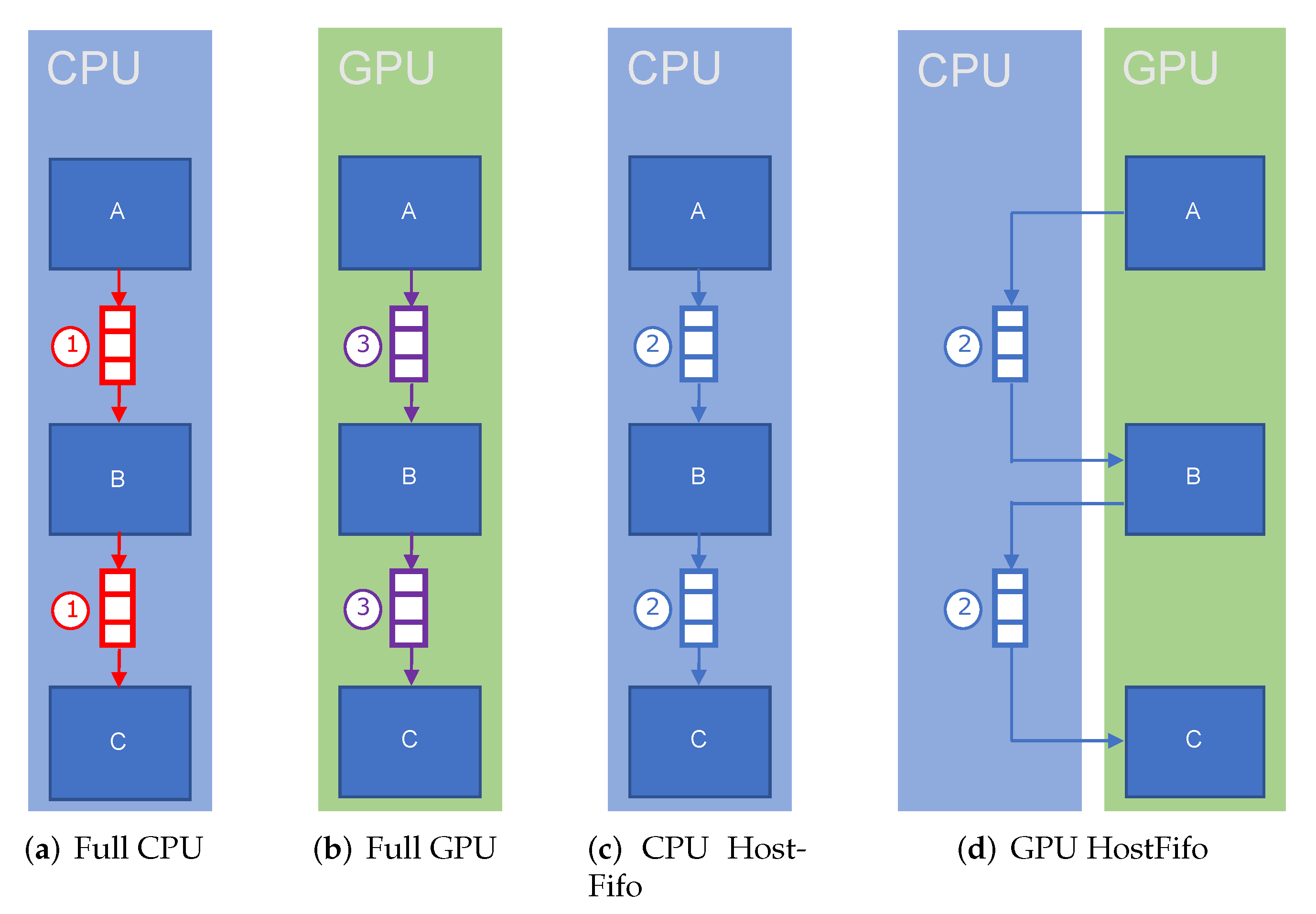
4.4.1. Model for Dynamic Network
- Change the Exelixi CUDA backend parameters configurations files.
- Generates code
- Compile
- Execute
4.4.2. Dynamic Methodology Estimation
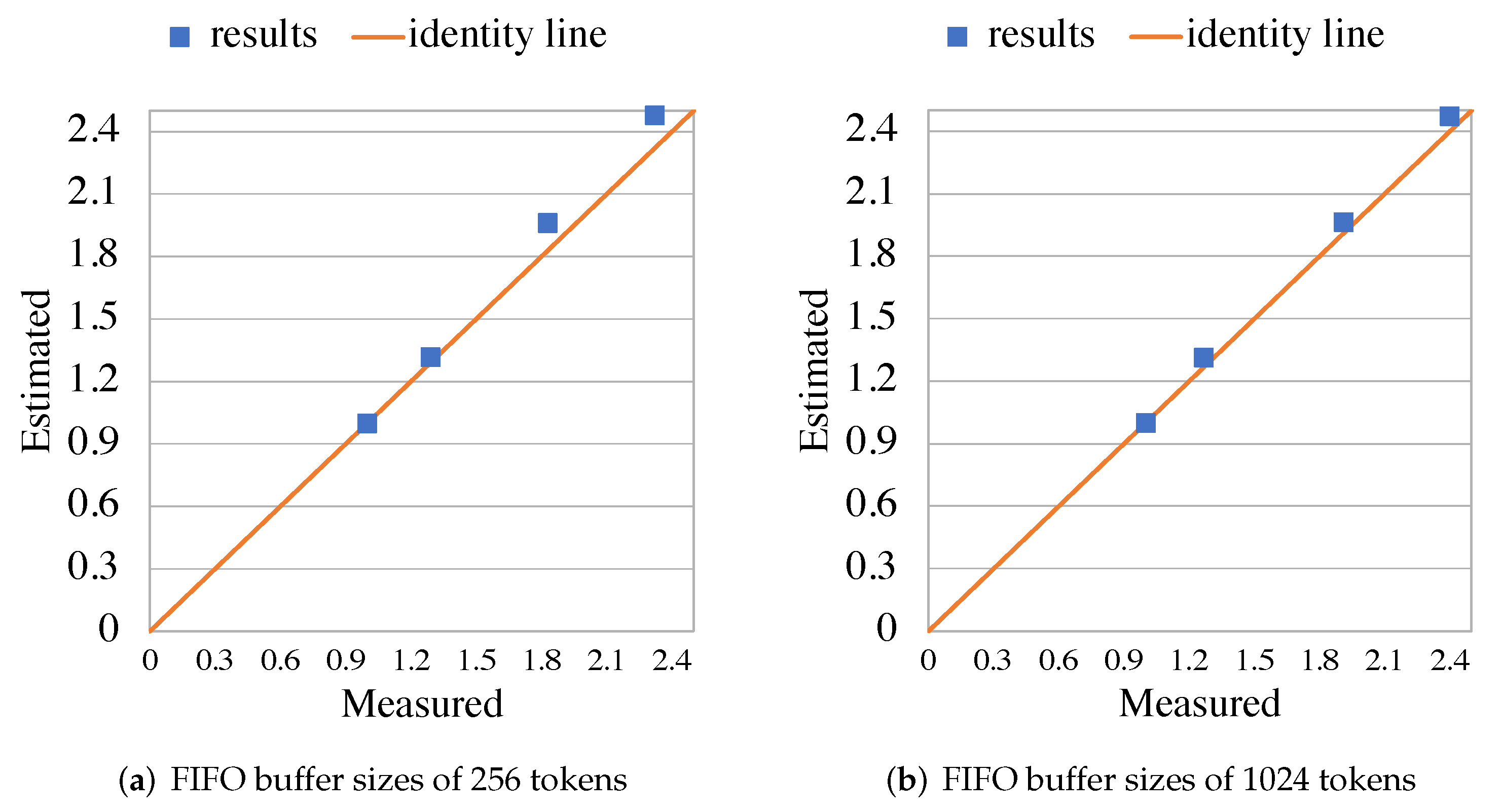
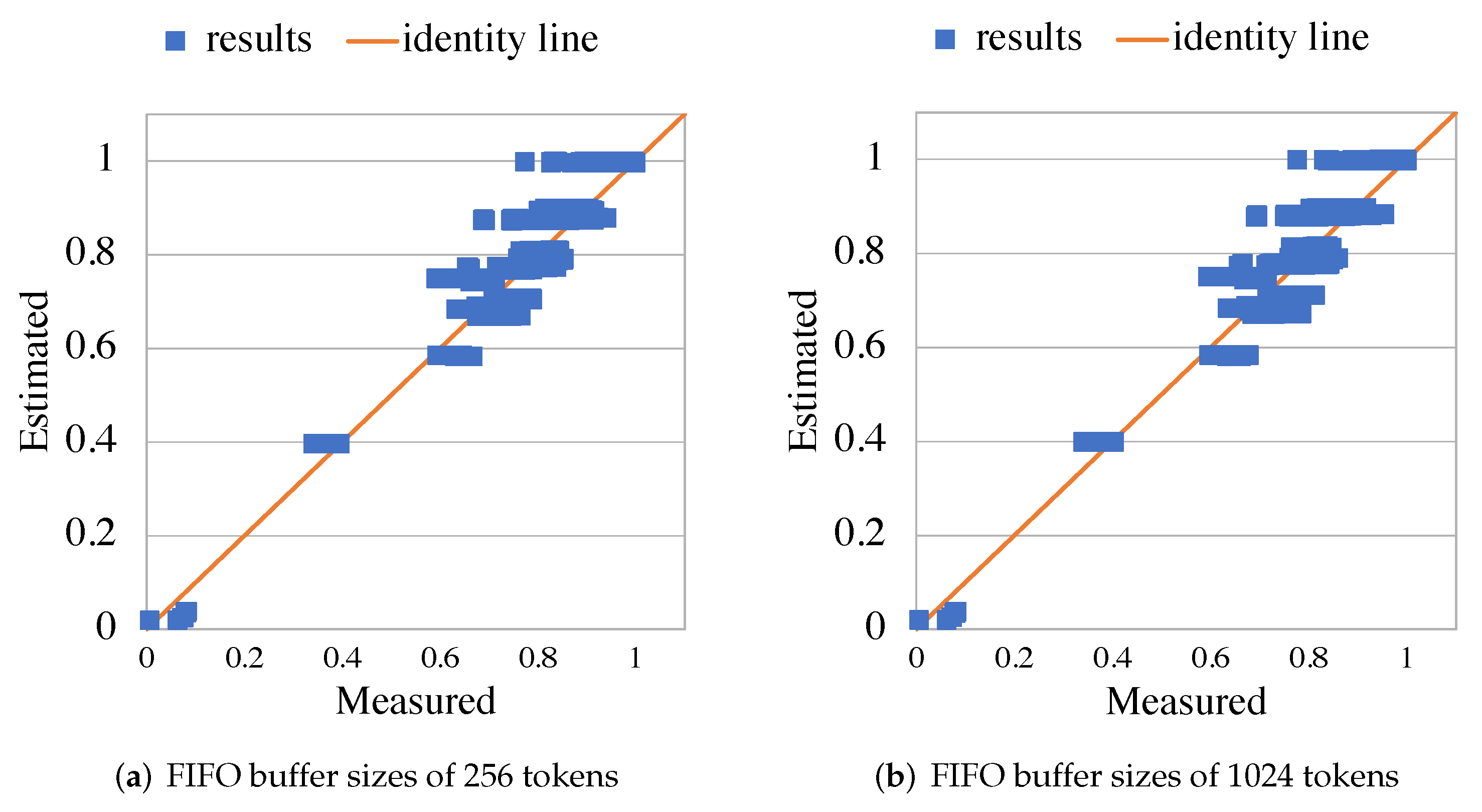
5. Experimental Evaluation
5.1. Experimental Setup
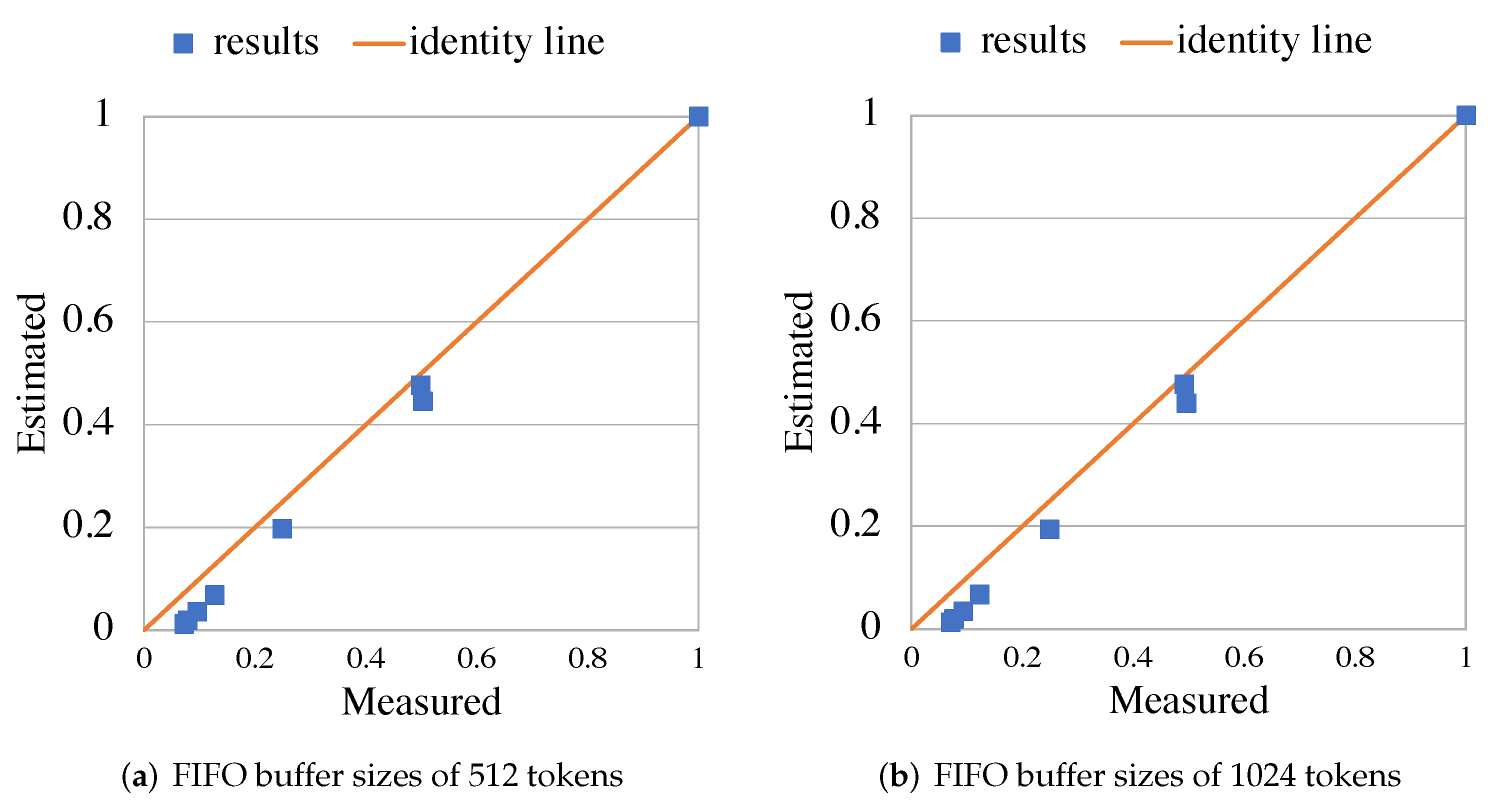
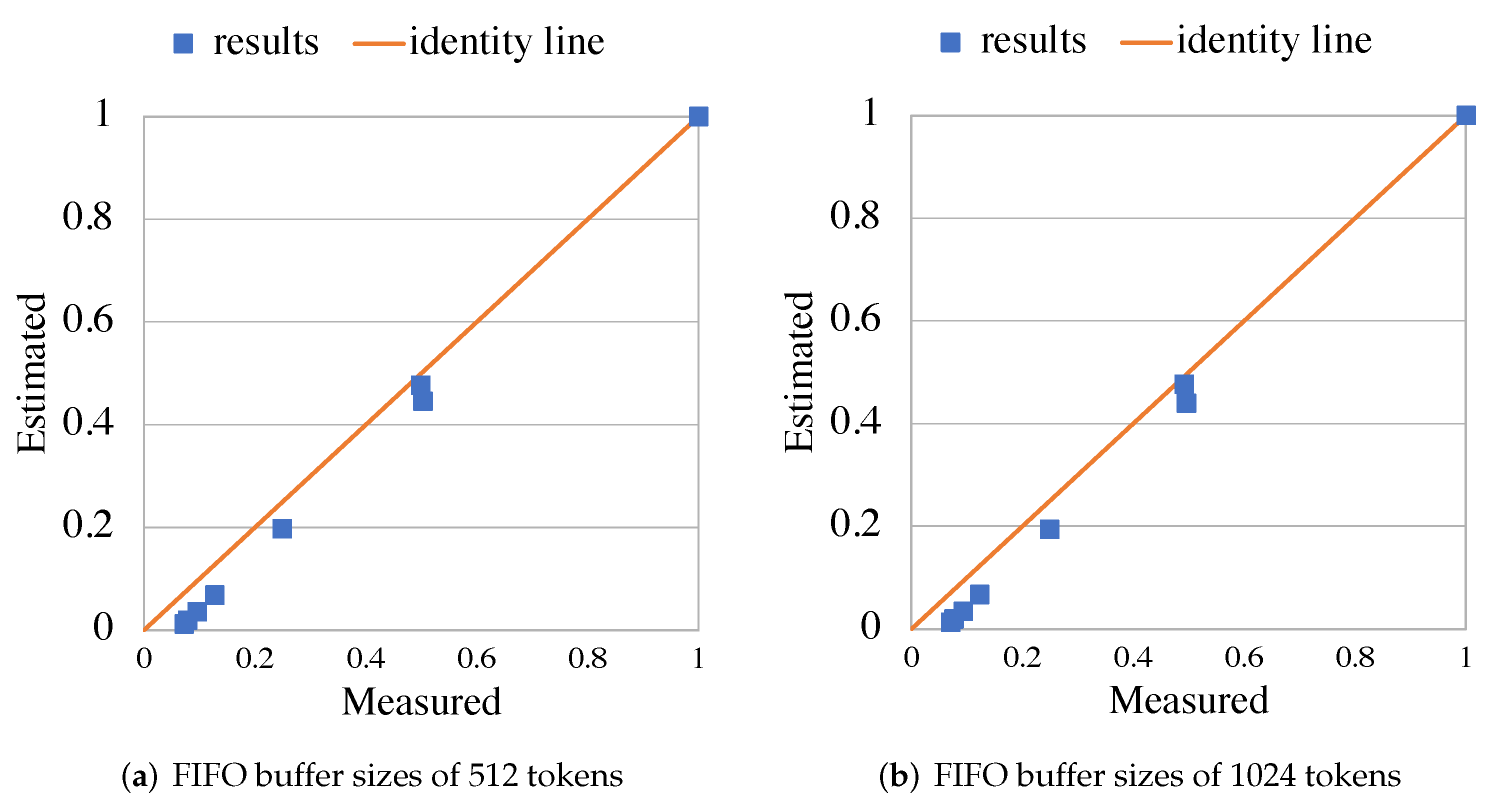
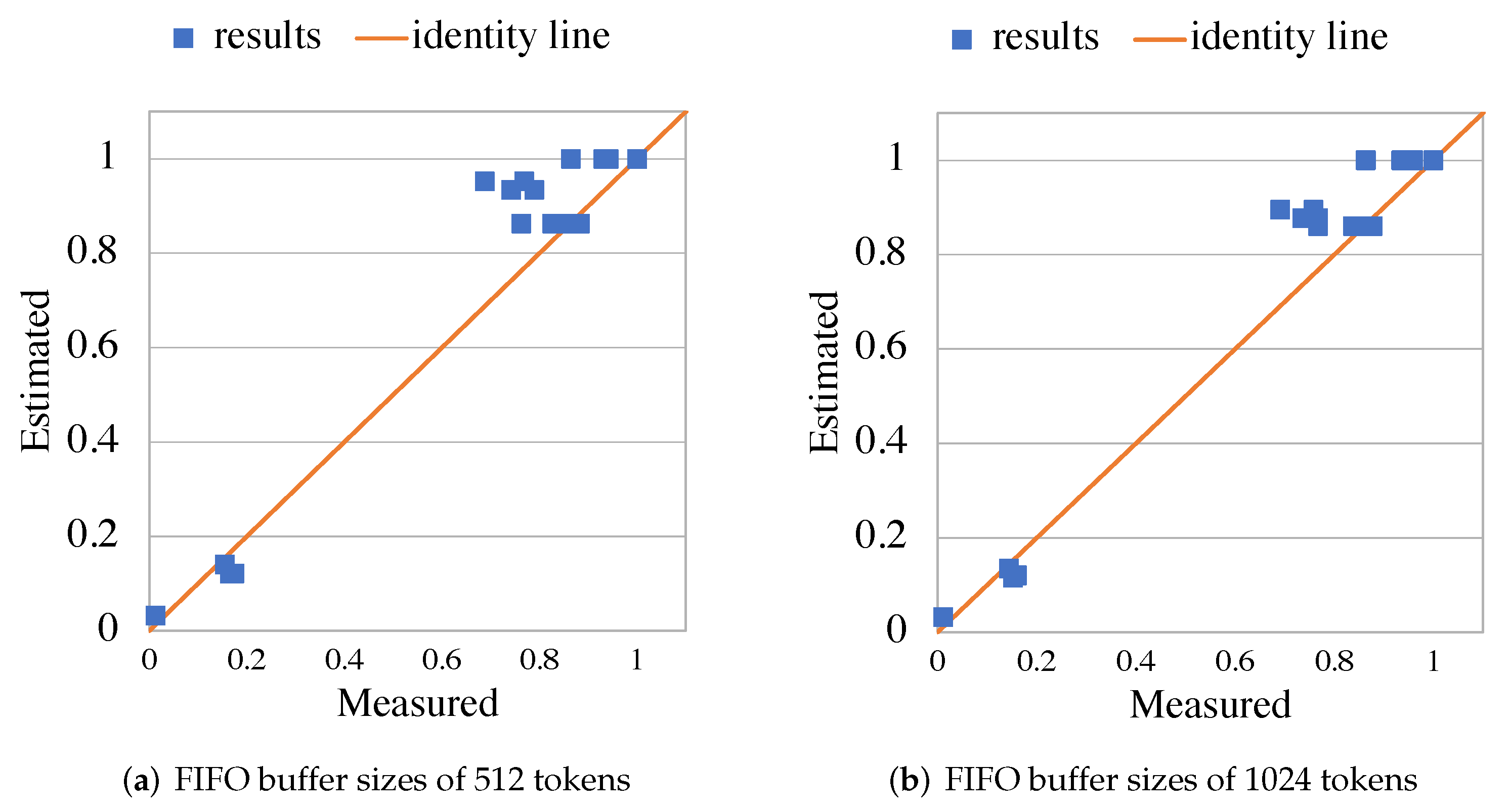
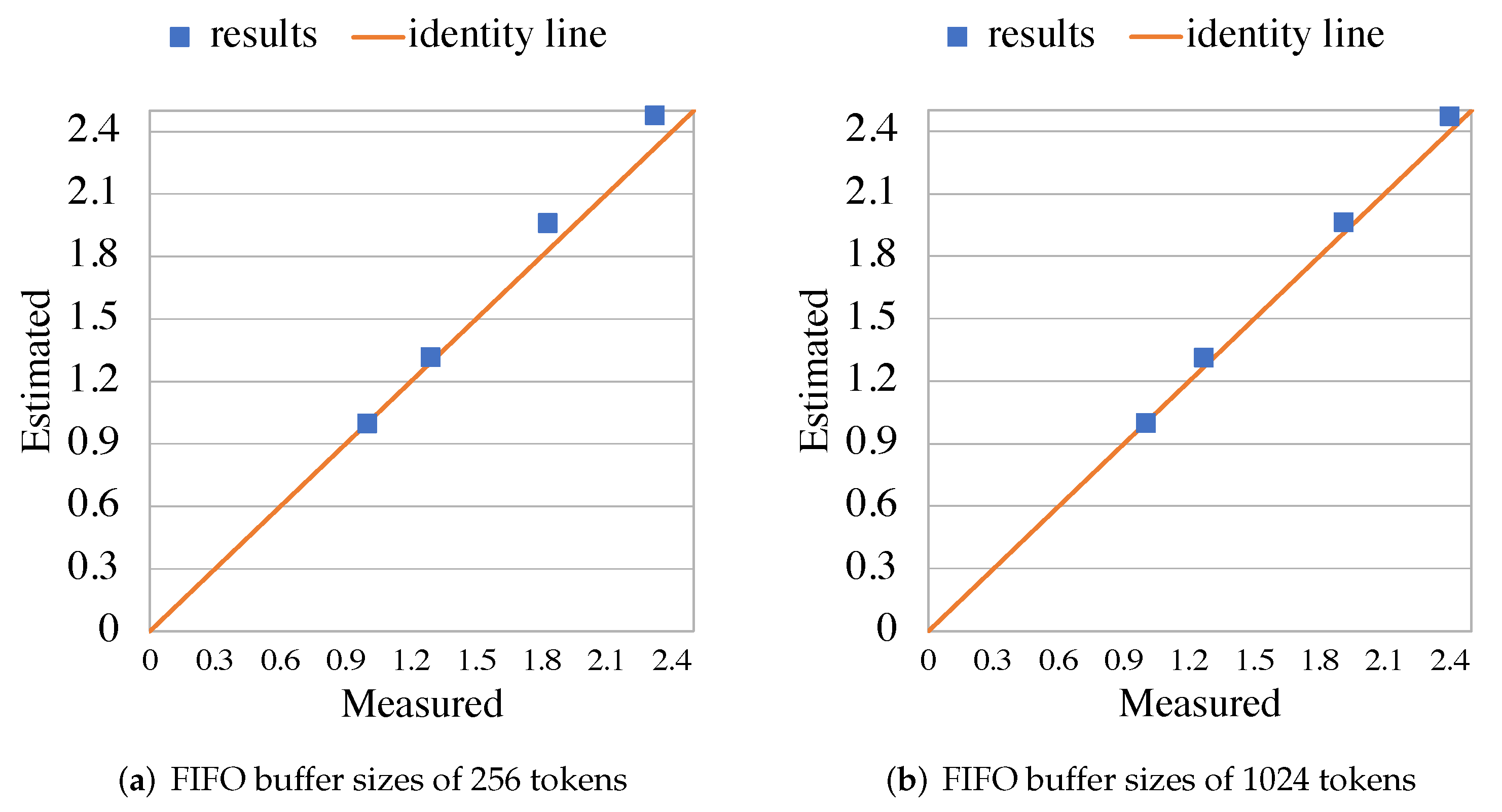
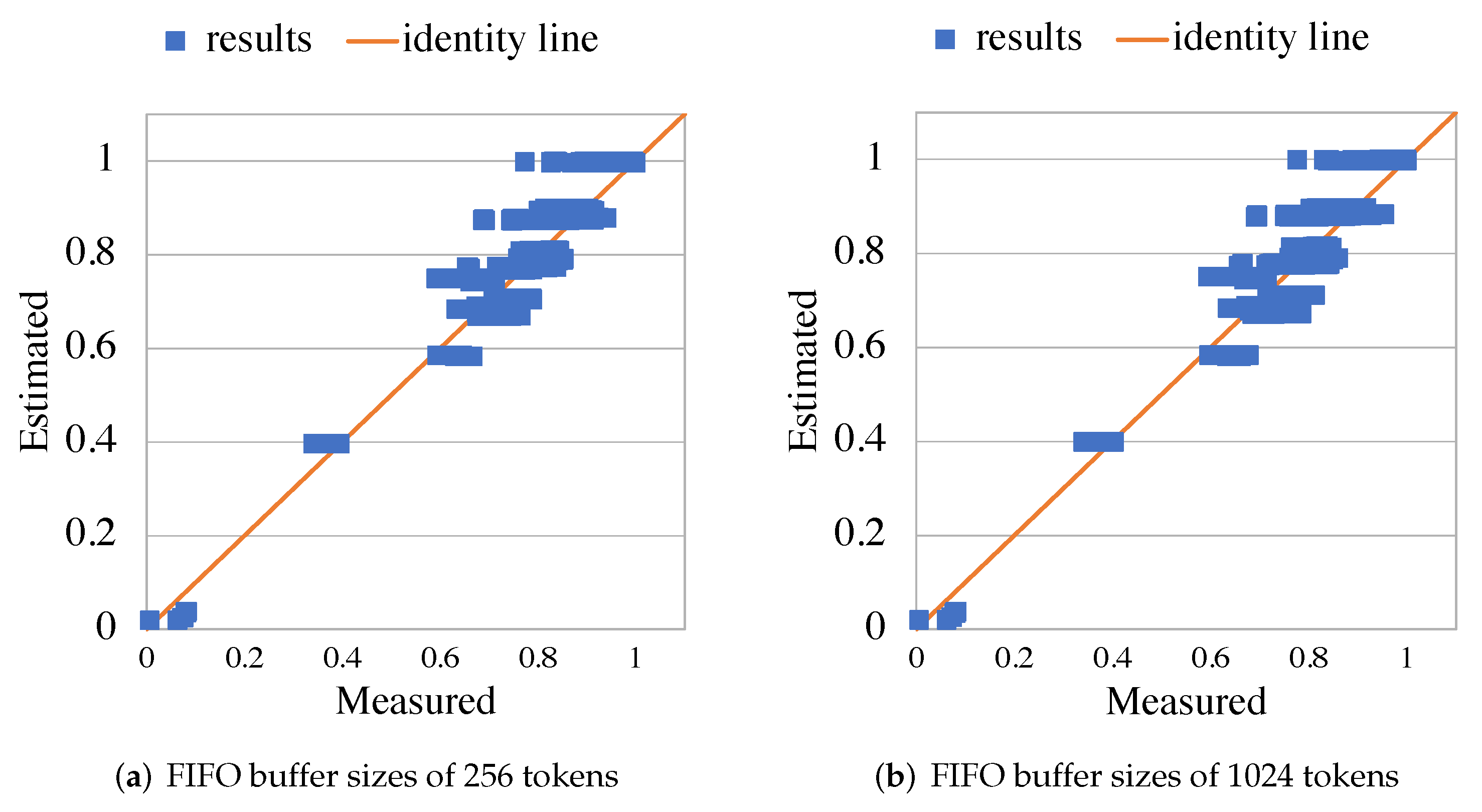
5.2. RVC-CAL JPEG Decoder
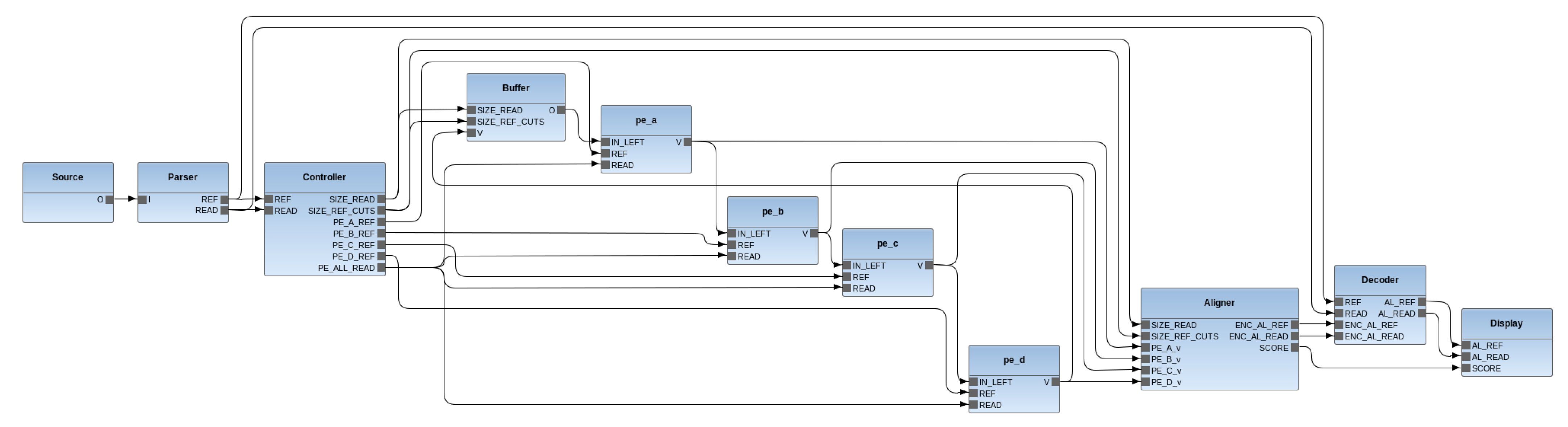
5.3. RVC-CAL Smith-Waterman Aligner
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Microsoft ARM. Available online: https://www.microsoft.com/en-us/surface/business/surface-pro-x/processor (accessed on 9 March 2022).
- NVIDIA Grace. Available online: https://nvidianews.nvidia.com/news/nvidia-introduces-grace-cpu-superchip (accessed on 9 March 2022).
- Apple M1. Available online: https://www.apple.com/newsroom/2020/11/apple-unleashes-m1 (accessed on 9 March 2022).
- Michalska, M.; Casale-Brunet, S.; Bezati, E.; Mattavelli, M. High-precision performance estimation for the design space exploration of dynamic dataflow programs. IEEE Trans. Multi-Scale Comput. Syst. 2017, 4, 127–140. [Google Scholar] [CrossRef]
- Goens, A.; Khasanov, R.; Castrillon, J.; Hähnel, M.; Smejkal, T.; Härtig, H. Tetris: A multi-application run-time system for predictable execution of static mappings. In Proceedings of the 20th International Workshop on Software and Compilers for Embedded Systems, Sankt Goar, Germany, 12–14 June 2017; pp. 11–20. [Google Scholar]
- TURNUS Source Code Repositoy. Available online: http://github.com/turnus (accessed on 9 March 2022).
- Casale-Brunet, S. Analysis and Optimization of Dynamic Dataflow Programs. Ph.D. Thesis, EPFL STI, Lausanne, Switzerland, 2015. [Google Scholar] [CrossRef]
- Bloch, A.; Bezati, E.; Mattavelli, M. Programming Heterogeneous CPU-GPU Systems by High-Level Dataflow Synthesis. In Proceedings of the 2020 IEEE Workshop on Signal Processing Systems (SiPS), Coimbra, Portugal, 20–22 October 2020; pp. 1–6. [Google Scholar]
- CAL Exelixi Backends Source Code Repositoy. Available online: https://bitbucket.org/exelixi/exelixi-backends (accessed on 9 March 2022).
- Bezati, E.; Casale-Brunet, S.; Mosqueron, R.; Mattavelli, M. An Heterogeneous Compiler of Dataflow Programs for Zynq Platforms. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1537–1541. [Google Scholar] [CrossRef]
- NVIDIA CUDA Compute Unified Device Architecture. Available online: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html (accessed on 9 March 2022).
- Brunet, S.C.; Bezati, E.; Bloch, A.; Mattavelli, M. Profiling of dynamic dataflow programs on MPSoC multi-core architectures. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; pp. 504–508. [Google Scholar]
- NVIDIA Visual Profiler. Available online: https://developer.nvidia.com/nvidia-visual-profiler (accessed on 9 March 2022).
- Stephenson, M.; Hari, S.K.S.; Lee, Y.; Ebrahimi, E.; Johnson, D.R.; Nellans, D.; O’Connor, M.; Keckler, S.W. Flexible software profiling of GPU architectures. In Proceedings of the 2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 13–17 June 2015; pp. 185–197. [Google Scholar]
- Matz, A.; Fröning, H. Quantifying the NUMA behavior of partitioned GPGPU applications. In Proceedings of the 12th Workshop on General Purpose Processing Using GPUs, Providence, RI, USA, 13 April 2019; pp. 53–62. [Google Scholar]
- Shen, D.; Song, S.L.; Li, A.; Liu, X. Cudaadvisor: LLVM-based runtime profiling for modern GPUs. In Proceedings of the 2018 International Symposium on Code Generation and Optimization, Vienna, Austria, 24–28 February 2018; pp. 214–227. [Google Scholar]
- Villa, O.; Stephenson, M.; Nellans, D.; Keckler, S.W. NVBit: A Dynamic Binary Instrumentation Framework for NVIDIA GPUs. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, Columbus, OH, USA, 12–16 October 2019; pp. 372–383. [Google Scholar]
- Braun, L.; Fröning, H. CUDA flux: A lightweight instruction profiler for CUDA applications. In Proceedings of the 2019 IEEE/ACM Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS), Denver, CO, USA, 18 November 2019; pp. 73–81. [Google Scholar]
- Pimentel, A.D.; Erbas, C.; Polstra, S. A systematic approach to exploring embedded system architectures at multiple abstraction levels. IEEE Trans. Comput. 2006, 55, 99–112. [Google Scholar] [CrossRef]
- van Stralen, P.; Pimentel, A.D. Signature-based microprocessor power modeling for rapid system-level design space exploration. In Proceedings of the 2007 IEEE/ACM/IFIP Workshop on Embedded Systems for Real-Time Multimedia, Salzburg, Austria, 4–5 October 2007; pp. 33–38. [Google Scholar]
- Keinert, J.; Streubūhr, M.; Schlichter, T.; Falk, J.; Gladigau, J.; Haubelt, C.; Teich, J.; Meredith, M. SystemCoDesigner—An automatic ESL synthesis approach by design space exploration and behavioral synthesis for streaming applications. ACM Trans. Des. Autom. Electron. Syst. (TODAES) 2009, 14, 1–23. [Google Scholar] [CrossRef]
- Eusse, J.F.; Williams, C.; Leupers, R. Coex: A novel profiling-based algorithm/architecture co-exploration for asip design. ACM Trans. Reconfigurable Technol. Syst. (TRETS) 2015, 8, 1–16. [Google Scholar] [CrossRef]
- Chakraborty, S.; Künzli, S.; Thiele, L.; Herkersdorf, A.; Sagmeister, P. Performance evaluation of network processor architectures: Combining simulation with analytical estimation. Comput. Netw. 2003, 41, 641–665. [Google Scholar] [CrossRef]
- Ceng, J.; Castrillón, J.; Sheng, W.; Scharwächter, H.; Leupers, R.; Ascheid, G.; Meyr, H.; Isshiki, T.; Kunieda, H. MAPS: An integrated framework for MPSoC application parallelization. In Proceedings of the 45th annual Design Automation Conference, Anaheim, CA, USA, 8–13 June 2008; pp. 754–759. [Google Scholar]
- Lee, E.; Parks, T. Dataflow Process Networks. Proc. IEEE 1995, 83, 773–801. [Google Scholar] [CrossRef] [Green Version]
- Johnston, W.; Hanna, J.; Millar, R. Advances in dataflow programming languages. ACM Comput. Surv. (CSUR) 2004, 36, 1–34. [Google Scholar] [CrossRef]
- Feo, J.T.; Cann, D.C.; Oldehoeft, R.R. A report on the Sisal language project. J. Parallel Distrib. Comput. 1990, 10, 349–366. [Google Scholar] [CrossRef]
- Eker, J.; Janneck, J.; Lee, E.; Liu, J.; Liu, X.; Ludvig, J.; Neuendorffer, S.; Sachs, S.; Xiong, Y. Taming heterogeneity—The Ptolemy approach. Proc. IEEE 2003, 91, 127–144. [Google Scholar] [CrossRef] [Green Version]
- ISO/IEC 23001-4:2011. Available online: https://www.iso.org/standard/59979.html (accessed on 9 March 2022).
- Yviquel, H.; Lorence, A.; Jerbi, K.; Cocherel, G.; Sanchez, A.; Raulet, M. Orcc: Multimedia Development Made Easy. In Proceedings of the 21st ACM International Conference on Multimedia, MM’13, Barcelona, Spain, 21–25 October 2013; pp. 863–866. [Google Scholar]
- Orcc Source Code Repositoy. Available online: http://github.com/orcc/orcc (accessed on 9 March 2022).
- Siyoum, F.; Geilen, M.; Eker, J.; von Platen, C.; Corporaal, H. Automated extraction of scenario sequences from disciplined dataflow networks. In Proceedings of the 2013 Eleventh ACM/IEEE International Conference on Formal Methods and Models for Codesign (MEMOCODE 2013), Portland, OR, USA, 18–20 October 2013; pp. 47–56. [Google Scholar]
- Caltoopia. Available online: https://github.com/Caltoopia (accessed on 9 March 2022).
- Cedersjö, G.; Janneck, J.W. Tÿcho: A framework for compiling stream programs. ACM Trans. Embed. Comput. Syst. (TECS) 2019, 18, 1–25. [Google Scholar] [CrossRef]
- Gebrewahid, E. Tools to Compile Dataflow Programs for Manycores. Ph.D. Thesis, Halmstad University Press, Halmstad, Sweden, 2017. [Google Scholar]
- Savas, S.; Ul-Abdin, Z.; Nordström, T. A framework to generate domain-specific manycore architectures from dataflow programs. Microprocess. Microsyst. 2020, 72, 102908. [Google Scholar] [CrossRef]
- Boutellier, J.; Ghazi, A. Multicore execution of dynamic dataflow programs on the Distributed Application Layer. In Proceedings of the 2015 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Orlando, FL, USA, 14–16 December 2015; pp. 893–897. [Google Scholar]
- Bezati, E.; Emami, M.; Janneck, J.; Larus, J. StreamBlocks: A compiler for heterogeneous dataflow computing (technical report). arXiv 2021, arXiv:2107.09333. [Google Scholar]
- Michalska, M.; Casale-Brunet, S.; Bezati, E.; Mattavelli, M. High-precision performance estimation of dynamic dataflow programs. In Proceedings of the 2016 IEEE 10th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSOC), Lyon, France, 21–23 September 2016; pp. 101–108. [Google Scholar]
- Bloch, A.; Brunet, S.C.; Mattavelli, M. SIMD Parallel Execution on GPU from High-Level Dataflow Synthesis. In Proceedings of the 2021 IEEE 14th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC), Singapore, 20–23 December 2021; pp. 62–68. [Google Scholar]
- Orcc-Apps Source Code Repositoy. Available online: https://github.com/orcc/orc-apps (accessed on 9 March 2022).
- Bezati, E.; Yviquel, H.; Raulet, M.; Mattavelli, M. A unified hardware/software co-synthesis solution for signal processing systems. In Proceedings of the 2011 Conference on Design & Architectures for Signal & Image Processing (DASIP), Tampere, Finland, 2–4 November 2011; pp. 1–6. [Google Scholar]
- Casale-Brunet, S.; Bezati, E.; Mattavelli, M. High level synthesis of Smith-Waterman dataflow implementations. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 1173–1177. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resolution | 4096 × 2240 | 2048 × 1536 | 4096 × 2240 | 2048 × 1536 |
| QF | 90 | 90 | 50 | 50 |
| Resolution | 1920 × 1080 | 1280 × 720 | 640 × 480 | 512 × 512 |
| QF | 55 | 65 | 80 | 75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bloch, A.; Casale-Brunet, S.; Mattavelli, M. Performance Estimation of High-Level Dataflow Program on Heterogeneous Platforms by Dynamic Network Execution. J. Low Power Electron. Appl. 2022, 12, 36. https://doi.org/10.3390/jlpea12030036
Bloch A, Casale-Brunet S, Mattavelli M. Performance Estimation of High-Level Dataflow Program on Heterogeneous Platforms by Dynamic Network Execution. Journal of Low Power Electronics and Applications. 2022; 12(3):36. https://doi.org/10.3390/jlpea12030036
Chicago/Turabian StyleBloch, Aurelien, Simone Casale-Brunet, and Marco Mattavelli. 2022. "Performance Estimation of High-Level Dataflow Program on Heterogeneous Platforms by Dynamic Network Execution" Journal of Low Power Electronics and Applications 12, no. 3: 36. https://doi.org/10.3390/jlpea12030036
APA StyleBloch, A., Casale-Brunet, S., & Mattavelli, M. (2022). Performance Estimation of High-Level Dataflow Program on Heterogeneous Platforms by Dynamic Network Execution. Journal of Low Power Electronics and Applications, 12(3), 36. https://doi.org/10.3390/jlpea12030036