
Design of In-Memory Parallel-Prefix Adders


Abstract
1. Introduction
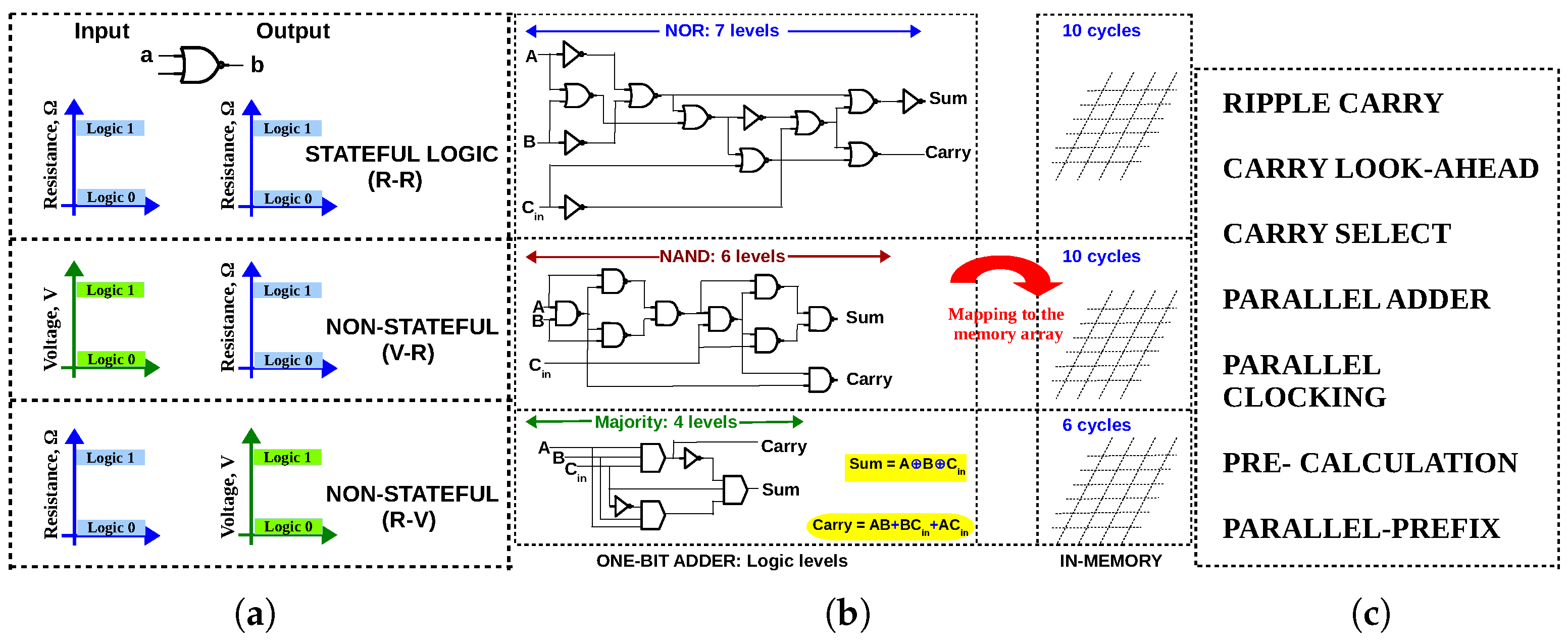
2. In-Memory Adders: A Brief Review
- State variable used for computation—stateful or non-stateful;
- Logic primitive used for computation—NAND or NOR or IMPLY or MAJORITY or XOR or a combination of these;
- Adder architecture—how is the carry propagated?
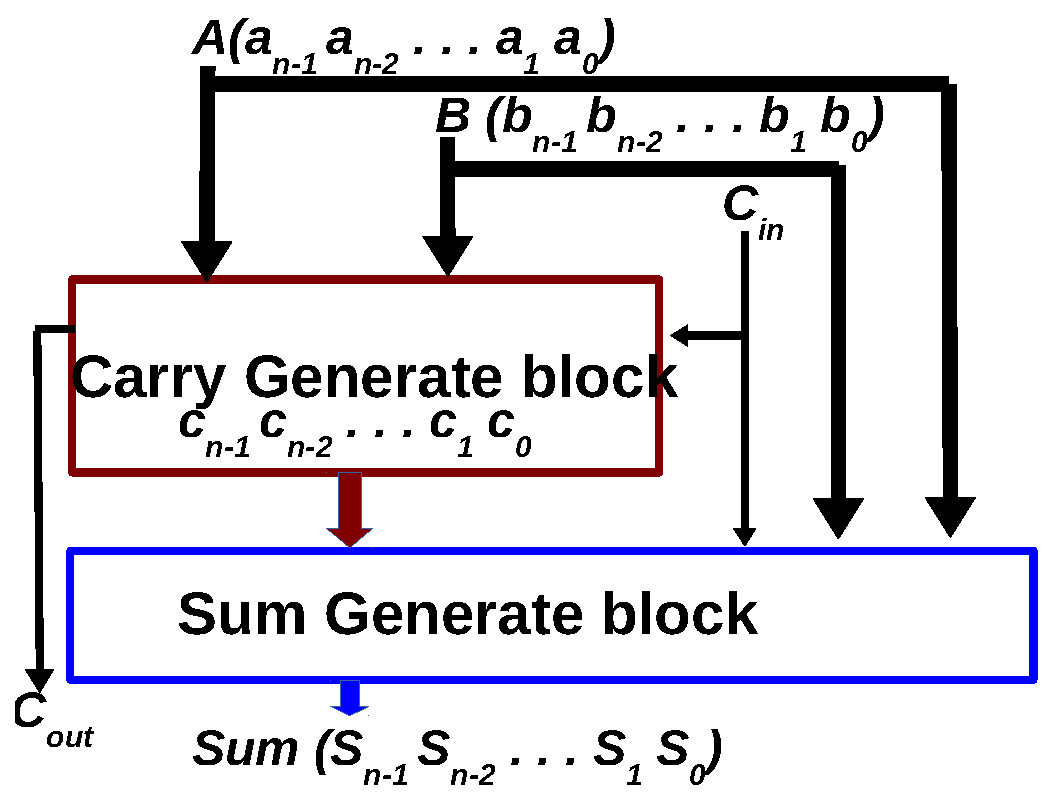
3. Parallel-Prefix Adders: A Solution for the Carry-Propagation Problem
4. In-Memory Implementation of Parallel-Prefix Adders
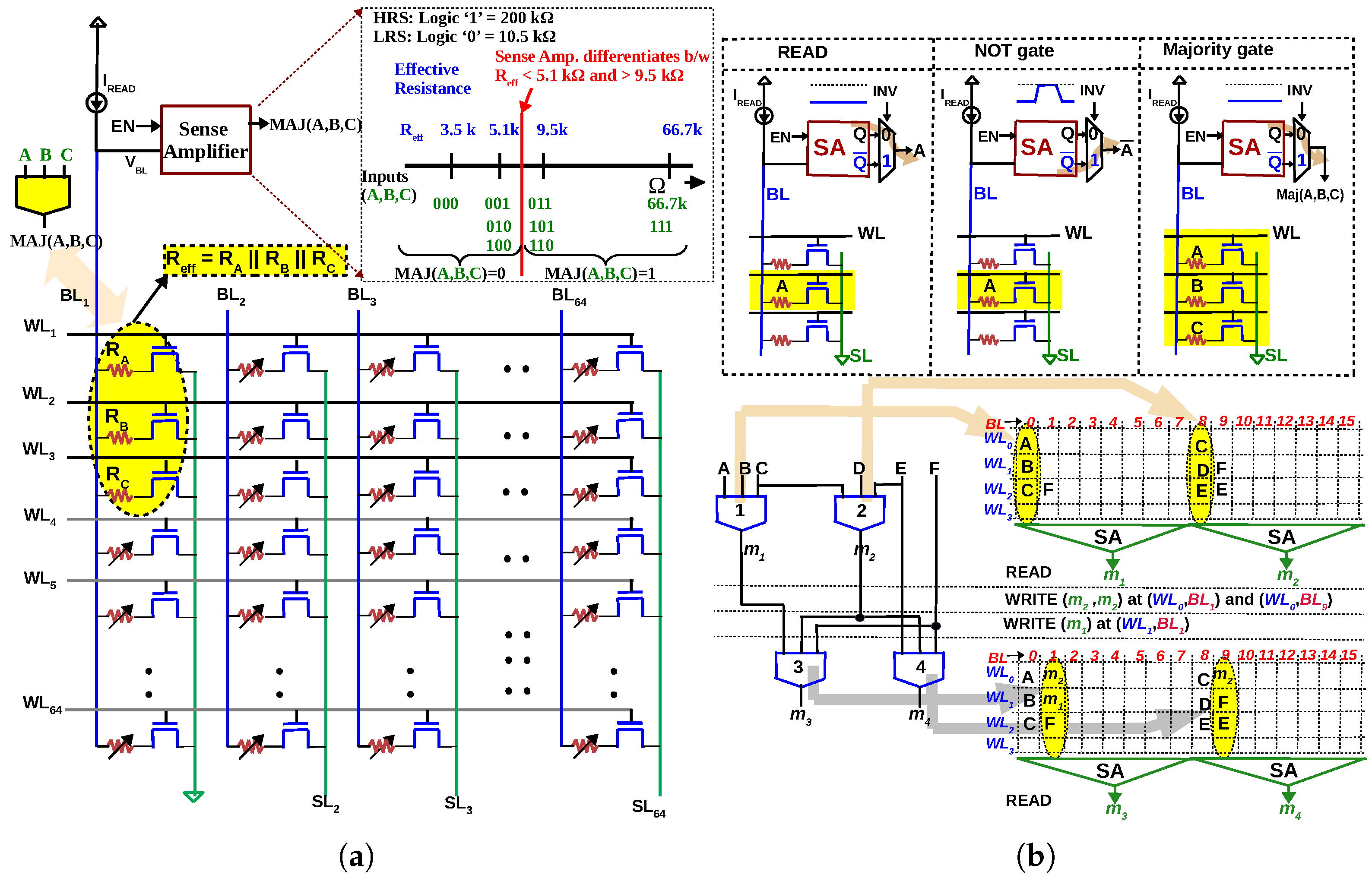
4.1. In-Memory Majority Gate
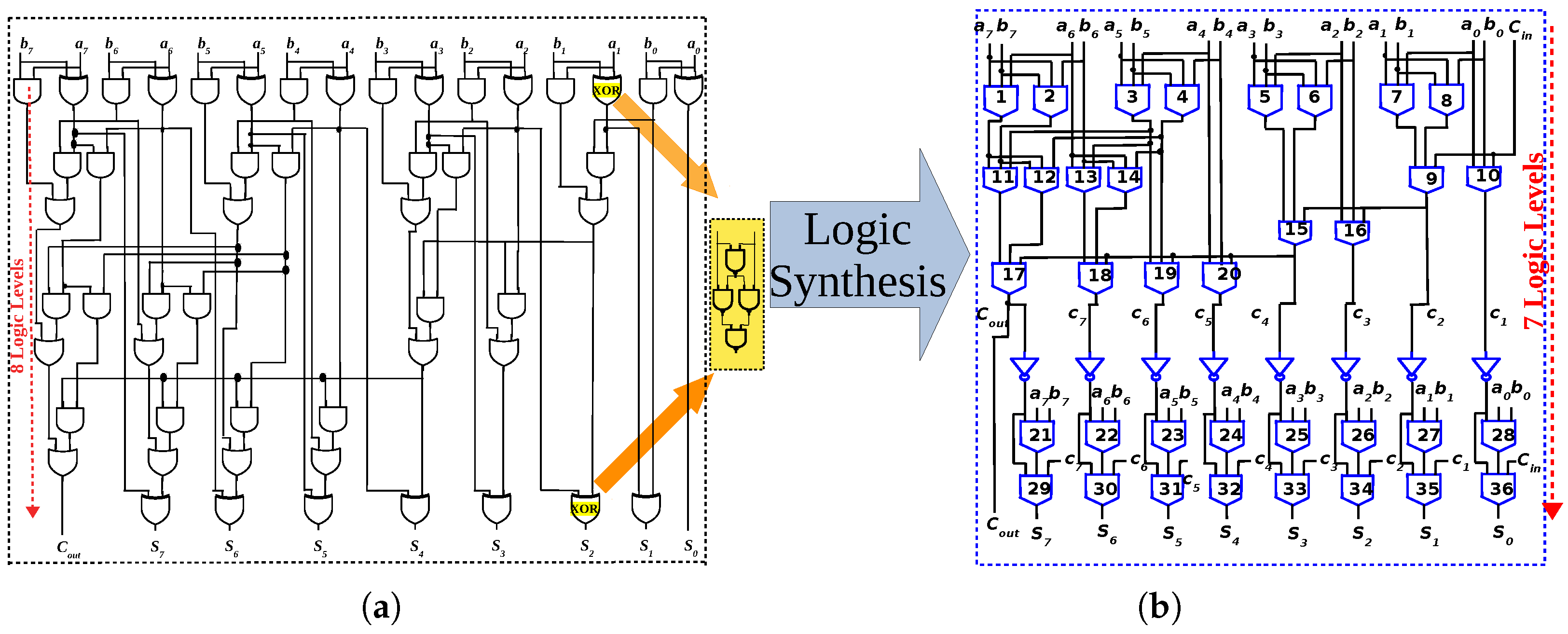
4.2. Homogeneous Synthesis of Parallel-Prefix Adders
4.3. Mapping Methodology
4.3.1. In-Memory Mapping as an Optimization Problem: Objectives
- Latency of in-memory PP adder must be minimized ();
- Energy consumption during addition must be minimized ();
- Area of the array used during computation must be minimized ().
- A conventional adder (in CMOS) is devoted to addition while we re-use the existing memory array in in-memory computation. Hence, the increased array area required during addition is not a disadvantage, as long as computation can be performed in the memory array without an extra array;
- ReRAM memory cell or memristor is a nano-device and does not significantly contribute. For example, a single 1T-1R cell in 130 nm CMOS occupies 0.2 μm2 [40].
4.3.2. In-Memory Mapping as an Optimization Problem: Constraints
- Majority operation must be executed at three consecutive rows ();
- Due to the bounded endurance of ReRAM devices, the number of times a cell is switched must be minimized. ().
4.3.3. Algorithm
- Start with Logic level 1;
- Simultaneously execute all majority gates of a logic level in the columns of the array ();
- Write the outputs of the majority gates to the precise locations where they are needed in the next logic level such that all the majority gates of the following level can be executed simultaneously ();
- During Step 3, write the outputs of the majority gates to a new location and do not overwrite the existing data ();
- During Step 3, write the outputs of the majority gates to contiguous locations in the memory array ();
- Repeat Steps 2–5 for the remaining logic levels.
- Majority at col. (1, 9, 26, 33, 42, 49, 58, 65) rows 4–6 as a READ operation;
- Write () at col. (2, 10, 34, 50, 59), row 4;
- Write () at col. (2, 10, 34, 50, 59), row 5;
- Write () at col. (2, 10, 17, 25), row 6;
- Majority at col. (2, 10, 17, 25, 59, 73) rows 4–6 as a READ operation.
- ………
5. Performance of In-Memory Parallel-Prefix Adders
5.1. Simulation Methodology
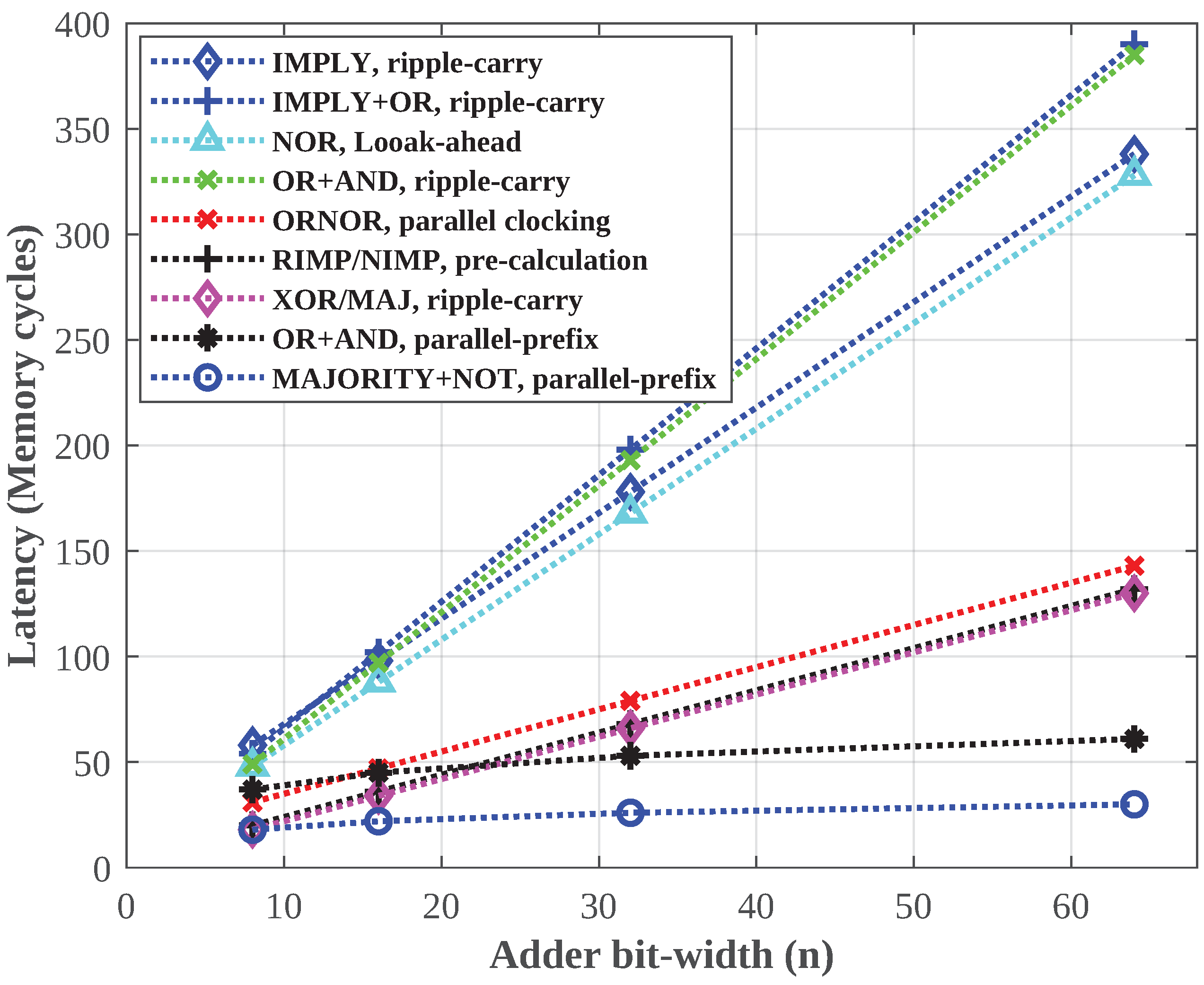
5.2. Latency of In-Memory PP Adders with Increasing Bit-Width
5.3. Energy of In-Memory PP Adders with Increasing Bit-Width
5.4. Area of In-Memory PP Adders with Increasing Bit-Width
5.5. Comparison with Other In-Memory Adders
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
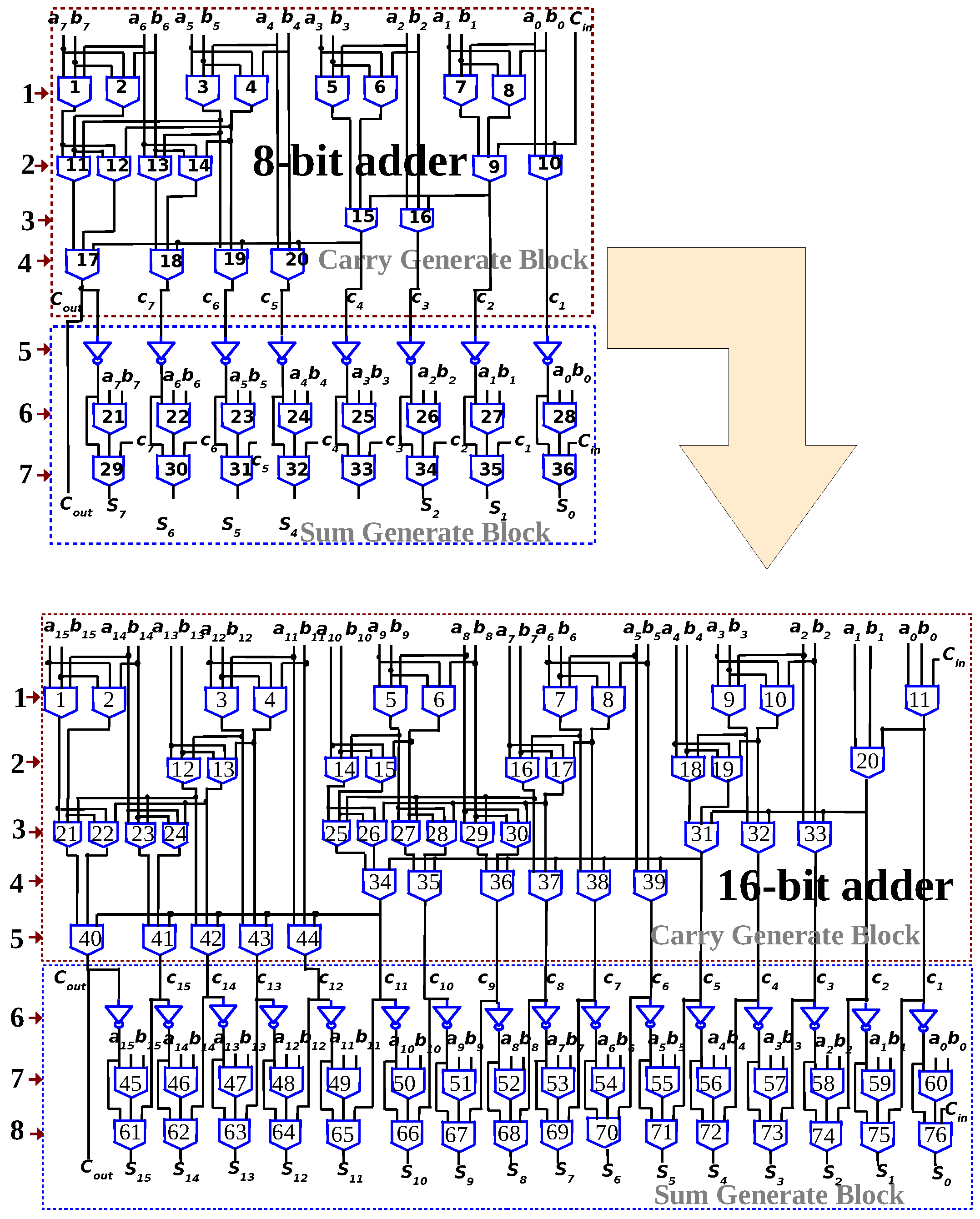
Appendix A. Mapping of 8-Bit Ladner-Fischer Adder to Memory Array

References
- Horowitz, M. Computing’s energy problem (and what we can do about it). In Proceedings of the 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 9–13 February 2014; pp. 10–14. [Google Scholar] [CrossRef]
- Pedram, A.; Richardson, S.; Horowitz, M.; Galal, S.; Kvatinsky, S. Dark Memory and Accelerator-Rich System Optimization in the Dark Silicon Era. IEEE Des. Test 2017, 34, 39–50. [Google Scholar] [CrossRef]
- Singh, G.; Chelini, L.; Corda, S.; Awan, A.J.; Stuijk, S.; Jordans, R.; Corporaal, H.; Boonstra, A. A Review of Near-Memory Computing Architectures: Opportunities and Challenges. In Proceedings of the 2018 21st Euromicro Conference on Digital System Design (DSD), Prague, Czech Republic, 29–31 August 2018; pp. 608–617. [Google Scholar]
- Sebastian, A.; Le Gallo, M.; Khaddam-Aljameh, R.; Eleftheriou, E. Memory devices and applications for in-memory computing. Nat. Nanotechnol. 2020, 15, 529–544. [Google Scholar] [CrossRef] [PubMed]
- Jaberipur, G.; Parhami, B.; Abedi, D. Adapting Computer Arithmetic Structures to Sustainable Supercomputing in Low-Power, Majority-Logic Nanotechnologies. IEEE Trans. Sustain. Comput. 2018, 3, 262–273. [Google Scholar] [CrossRef]
- Ziegler, M.; Stan, M. A unified design space for regular parallel prefix adders. In Proceedings of the Proceedings Design, Automation and Test in Europe Conference and Exhibition, Paris, France, 16–20 February 2004; Volume 2, pp. 1386–1387. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Satat, G.; Wald, N.; Friedman, E.G.; Kolodny, A.; Weiser, U.C. Memristor-Based Material Implication (IMPLY) Logic: Design Principles and Methodologies. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2014, 22, 2054–2066. [Google Scholar] [CrossRef]
- Amarú, L.; Gaillardon, P.E.; Micheli, G.D. Majority-Inverter Graph: A New Paradigm for Logic Optimization. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2016, 35, 806–819. [Google Scholar] [CrossRef]
- Reuben, J.; Pechmann, S. Accelerated Addition in Resistive RAM Array Using Parallel-Friendly Majority Gates. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2021, 29, 1108–1121. [Google Scholar] [CrossRef]
- Shen, W.; Huang, P.; Fan, M.; Han, R.; Zhou, Z.; Gao, B.; Wu, H.; Qian, H.; Liu, L.; Liu, X.; et al. Stateful Logic Operations in One-Transistor-One- Resistor Resistive Random Access Memory Array. IEEE Electron Device Lett. 2019, 40, 1538–1541. [Google Scholar] [CrossRef]
- Ben-Hur, R.; Ronen, R.; Haj-Ali, A.; Bhattacharjee, D.; Eliahu, A.; Peled, N.; Kvatinsky, S. SIMPLER MAGIC: Synthesis and Mapping of In-Memory Logic Executed in a Single Row to Improve Throughput. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2019, 39, 2434–2447. [Google Scholar] [CrossRef]
- Adam, G.C.; Hoskins, B.D.; Prezioso, M.; Strukov, D.B. Optimized stateful material implication logic for three- dimensional data manipulation. Nano Res. 2016, 9, 3914–3923. [Google Scholar] [CrossRef]
- Reuben, J. Rediscovering Majority Logic in the Post-CMOS Era: A Perspective from In-Memory Computing. J. Low Power Electron. Appl. 2020, 10, 28. [Google Scholar] [CrossRef]
- Ali, K.A.; Rizk, M.; Baghdadi, A.; Diguet, J.P.; Jomaah, J.; Onizawa, N.; Hanyu, T. Memristive Computational Memory Using Memristor Overwrite Logic (MOL). IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 2370–2382. [Google Scholar] [CrossRef]
- Siemon, A.; Menzel, S.; Bhattacharjee, D.; Waser, R.; Chattopadhyay, A.; Linn, E. Sklansky tree adder realization in 1S1R resistive switching memory architecture. Eur. Phys. J. Spec. Top. 2019, 228, 2269–2285. [Google Scholar] [CrossRef]
- Karimi, A.; Rezai, A. Novel design for a memristor-based full adder using a new IMPLY logic approach. J. Comput. Electron. 2018, 17, 11303–11314. [Google Scholar] [CrossRef]
- Cheng, L.; Li, Y.; Yin, K.-S.; Hu, S.-Y.; Su, Y.-T.; Jin, M.-M.; Wang, Z.-R.; Chang, T.-C.; Miao, X.-S. Functional Demonstration of a Memristive Arithmetic Logic Unit (MemALU) for In-Memory Computing. Adv. Funct. Mater. 2019, 29, 1905660. [Google Scholar] [CrossRef]
- Ganjeheizadeh Rohani, S.; Taherinejad, N.; Radakovits, D. A Semiparallel Full-Adder in IMPLY Logic. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 297–301. [Google Scholar] [CrossRef]
- Talati, N.; Gupta, S.; Mane, P.; Kvatinsky, S. Logic Design Within Memristive Memories Using Memristor-Aided loGIC (MAGIC). IEEE Trans. Nanotechnol. 2016, 15, 635–650. [Google Scholar] [CrossRef]
- Kim, Y.S.; Son, M.W.; Song, H.; Park, J.; An, J.; Jeon, J.B.; Kim, G.Y.; Son, S.; Kim, K.M. Stateful In-Memory Logic System and Its Practical Implementation in a TaOx-Based Bipolar-Type Memristive Crossbar Array. Adv. Intell. Syst. 2020, 2, 1900156. [Google Scholar] [CrossRef]
- Siemon, A.; Drabinski, R.; Schultis, M.J.; Hu, X.; Linn, E.; Heittmann, A.; Waser, R.; Querlioz, D.; Menzel, S.; Friedman, J.S. Stateful Three-Input Logic with Memristive Switches. Sci. Rep. 2019, 9, 14618. [Google Scholar] [CrossRef] [PubMed]
- Siemon, A.; Menzel, S.; Waser, R.; Linn, E. A Complementary Resistive Switch-Based Crossbar Array Adder. IEEE J. Emerg. Sel. Top. Circuits Syst. 2015, 5, 64–74. [Google Scholar] [CrossRef]
- TaheriNejad, N. SIXOR: Single-Cycle In-Memristor XOR. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2021, 29, 925–935. [Google Scholar] [CrossRef]
- Pinto, F.; Vourkas, I. Robust Circuit and System Design for General-Purpose Computational Resistive Memories. Electronics 2021, 10, 1074. [Google Scholar] [CrossRef]
- Wang, Z.-R.; Li, Y.; Su, Y.-T.; Zhou, Y.-X.; Cheng, L.; Chang, T.-C.; Xue, K.-H.; Sze, S.M.; Miao, X.-S. Efficient Implementation of Boolean and Full-Adder Functions With 1T1R RRAMs for Beyond Von Neumann In-Memory Computing. IEEE Trans. Electron Devices 2018, 65, 4659–4666. [Google Scholar] [CrossRef]
- Dimitrakopoulos, G.; Papachatzopoulos, K.; Paliouras, V. Sum Propagate Adders. IEEE Trans. Emerg. Top. Comput. 2021, 9, 1479–1488. [Google Scholar] [CrossRef]
- Knowles, S. A family of adders. In Proceedings of the 15th IEEE Symposium on Computer Arithmetic. ARITH-15 2001, Vail, CO, USA, 11–13 June 2001; pp. 277–281. [Google Scholar] [CrossRef]
- Dimitrakopoulos, G.; Nikolos, D. High-speed parallel-prefix VLSI Ling adders. IEEE Trans. Comput. 2005, 54, 225–231. [Google Scholar] [CrossRef]
- Harris, D. A taxonomy of parallel prefix networks. In The Thirty-Seventh Asilomar Conference on Signals, Systems Computers; IEEE: Pacific Grove, CA, USA, 2003; pp. 2213–2217. [Google Scholar] [CrossRef]
- Pudi, V.; Sridharan, K.; Lombardi, F. Majority Logic Formulations for Parallel Adder Designs at Reduced Delay and Circuit Complexity. IEEE Trans. Comput. 2017, 66, 1824–1830. [Google Scholar] [CrossRef]
- Reuben, J. Binary Addition in Resistance Switching Memory Array by Sensing Majority. Micromachines 2020, 11, 496. [Google Scholar] [CrossRef]
- Reuben, J.; Pechmann, S. A Parallel-friendly Majority Gate to Accelerate In-memory Computation. In Proceedings of the 2020 IEEE 31st International Conference on Application-Specific Systems, Architectures and Processors (ASAP), Manchester, UK, 6–8 July 2020; pp. 93–100. [Google Scholar]
- Wang, P.; Niamat, M.Y.; Vemuru, S.R.; Alam, M.; Killian, T. Synthesis of Majority/Minority Logic Networks. IEEE Trans. Nanotechnol. 2015, 14, 473–483. [Google Scholar] [CrossRef]
- Chung, C.C.; Chen, Y.C.; Wang, C.Y.; Wu, C.C. Majority logic circuits optimisation by node merging. In Proceedings of the 2017 22nd Asia and South Pacific Design Automation Conference (ASP-DAC), Chiba, Japan, 16–19 January 2017; pp. 714–719. [Google Scholar] [CrossRef]
- Riener, H.; Testa, E.; Amaru, L.; Soeken, M.; Micheli, G.D. Size Optimization of MIGs with an Application to QCA and STMG Technologies. In Proceedings of the 2018 IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH), Athens, Greece, 17–19 July 2018; pp. 1–6. [Google Scholar]
- Devadoss, R.; Paul, K.; Balakrishnan, M. Majority Logic: Prime Implicants and n-Input Majority Term Equivalence. In Proceedings of the 2019 32nd International Conference on VLSI Design and 2019 18th International Conference on Embedded Systems (VLSID), Delhi, India, 5–9 January 2019; pp. 464–469. [Google Scholar] [CrossRef]
- Neutzling, A.; Marranghello, F.S.; Matos, J.M.; Reis, A.; Ribas, R.P. maj-n Logic Synthesis for Emerging Technology. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 747–751. [Google Scholar] [CrossRef]
- Kaneko, M. A Novel Framework for Procedural Construction of Parallel Prefix Adders. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Ayala, C.L.; Takeuchi, N.; Yamanashi, Y.; Ortlepp, T.; Yoshikawa, N. Majority-Logic-Optimized Parallel Prefix Carry Look-Ahead Adder Families Using Adiabatic Quantum-Flux-Parametron Logic. IEEE Trans. Appl. Supercond. 2017, 27, 1–7. [Google Scholar] [CrossRef]
- Levisse, A.; Giraud, B.; Noel, J.; Moreau, M.; Portal, J. RRAM Crossbar Arrays for Storage Class Memory Applications: Throughput and Density Considerations. In Proceedings of the 2018 Conference on Design of Circuits and Integrated Systems (DCIS), Lyon, France, 14–16 November 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Chang, Y.F.; Zhou, F.; Fowler, B.W.; Chen, Y.C.; Hsieh, C.C.; Guckert, L.; Swartzlander, E.E.; Lee, J.C. Memcomputing (Memristor + Computing) in Intrinsic SiOx-Based Resistive Switching Memory: Arithmetic Operations for Logic Applications. IEEE Trans. Electron Devices 2017, 64, 2977–2983. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stateful | Primitive | Architecture | Latency (8 bit) | Latency (n-bit) | Ref. |
|---|---|---|---|---|---|
| Yes | IMPLY | Ripple carry | 58 | 5n + 18 | [7] |
| Yes | IMPLY | Parallel-serial | 56 | 5n + 16 | [16] |
| Yes | IMPLY + OR | Ripple carry | 54 | 6n + 6 | [17] |
| Yes | IMPLY | Semi-parallel | 136 | 17n | [18] |
| Yes | NOR | Ripple carry | 83 | 10n + 3 | [19] |
| Yes | NOR | Look-Ahead | 48 | 5n + 8 | [20] |
| No | OR + AND | Ripple carry | 49 | 6n + 1 | [14] |
| Yes | ORNOR | Parallel-clocking | 31 | 2n + 15 | [21] |
| Yes | RIMP/NIMP* | Pre-calculation | 20 | 2n + 4 | [22] |
| Yes | XOR | Ripple carry | 18 | 2n + 2 | [23] |
| No | XOR + MAJ | Ripple carry | 18 | 2n + 2 | [24] |
| Yes | XNOR/XOR | Carry-Select | 9 | – | [25] |
| No | OR + AND | Parallel-prefix | 37 | 8 + 13 | [15] |
| Logic Primitive | Architecture | Latency (8 bit) | Latency (n-bit) | Ref. |
|---|---|---|---|---|
| IMPLY | Ripple carry | 58 | 5n + 18 | [7] |
| IMPLY | Parallel-serial | 56 | 5n + 16 | [16] |
| IMPLY + OR | Ripple carry | 54 | 6n + 6 | [17] |
| IMPLY | Semi-parallel | 136 | 17n | [18] |
| NOR | Ripple carry | 83 | 10n + 3 | [19] |
| NOR | Look-Ahead | 48 | 5n + 8 | [20] |
| OR + AND | Ripple carry | 49 | 6n + 1 | [14] |
| ORNOR | Parallel-clocking | 31 | 2n + 15 | [21] |
| RIMP/NIMP | Pre-calculation | 20 | 2n + 4 | [22] |
| XOR | Ripple carry | 18 | 2n + 2 | [23] |
| XOR + MAJ | Ripple carry | 18 | 2n + 2 | [24] |
| XNOR/XOR | Carry-Select | 9 | – | [25] |
| OR + AND | Parallel-prefix | 37 | 8 + 13 | [15] |
| Majority + NOT | Parallel-prefix | 18 | 4 + 6 | This work |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reuben, J. Design of In-Memory Parallel-Prefix Adders. J. Low Power Electron. Appl. 2021, 11, 45. https://doi.org/10.3390/jlpea11040045
Reuben J. Design of In-Memory Parallel-Prefix Adders. Journal of Low Power Electronics and Applications. 2021; 11(4):45. https://doi.org/10.3390/jlpea11040045
Chicago/Turabian StyleReuben, John. 2021. "Design of In-Memory Parallel-Prefix Adders" Journal of Low Power Electronics and Applications 11, no. 4: 45. https://doi.org/10.3390/jlpea11040045
APA StyleReuben, J. (2021). Design of In-Memory Parallel-Prefix Adders. Journal of Low Power Electronics and Applications, 11(4), 45. https://doi.org/10.3390/jlpea11040045