
An Approach for Predictive Maintenance Decisions for Components of an Industrial Multistage Machine That Fail before Their MTTF: A Case Study



Abstract
1. Introduction
2. Materials and Methods
- Step One: The multistage thermoforming machine was selected as the case study. This machine was characterized, and all the components were identified and classified by type. See Section 2.1.
- Step Two: Reliable maintenance times were defined for each component. Importantly, an adequate MTTF was established for each component. See Section 2.2.
- Step Three: Possible preventive maintenance strategies were defined, and predictive maintenance strategies adopted. See Section 2.3.
- Step Four: The components that presented a failure before their MTTF after a year of working were studied. See Section 2.4.
- Step Five: For all of the components, the advice shown by the DBT predictive algorithm was presented to ascertain which failures could be identified before occurring unexpectedly. The advice does not entail a change of maintenance strategy. The only purpose of these dates was for use in data logging. See Section 2.5.
- Step Six: The authors proposed a procedure to make decisions for possible maintenance strategy changes in the components studied by looking for the cause of the failure and then by evaluating two key performance indicators (KPIs). See Section 2.6.
2.1. The Case Study: A Multistage Thermoforming Machine
2.2. Maintenance Times for Each Component
- TTRP Time to replace a component
- TTC Time to configure
- TTMA Time to mechanical adjustment
- TTPR Time to provisioning
- MTTR Mean time to repair
- MTTF Mean time to failure
- MTBF Mean time between failure
- TTLR Line restart time, defined by expert knowledge
- TLP Time lost production
2.3. Maintenance Strategies
- Preventive maintenance, based on the MTTF of each component, to avoid unexpected failures during the work process.
- Improved preventive maintenance, based on the above but minimizing the TTPR of each component.
- Digital behavior twin (DBT) for predictive maintenance.
2.3.1. Preventive Programming Maintenance (PPM)
2.3.2. Improved Preventive Programming Maintenance (IPPM)
2.3.3. Digital Behaviour Twin (DBT)
2.4. Recovered Data after a Year of the Machine Working
2.5. DBT Predictive Algorithm Warnings of Failure Recovered
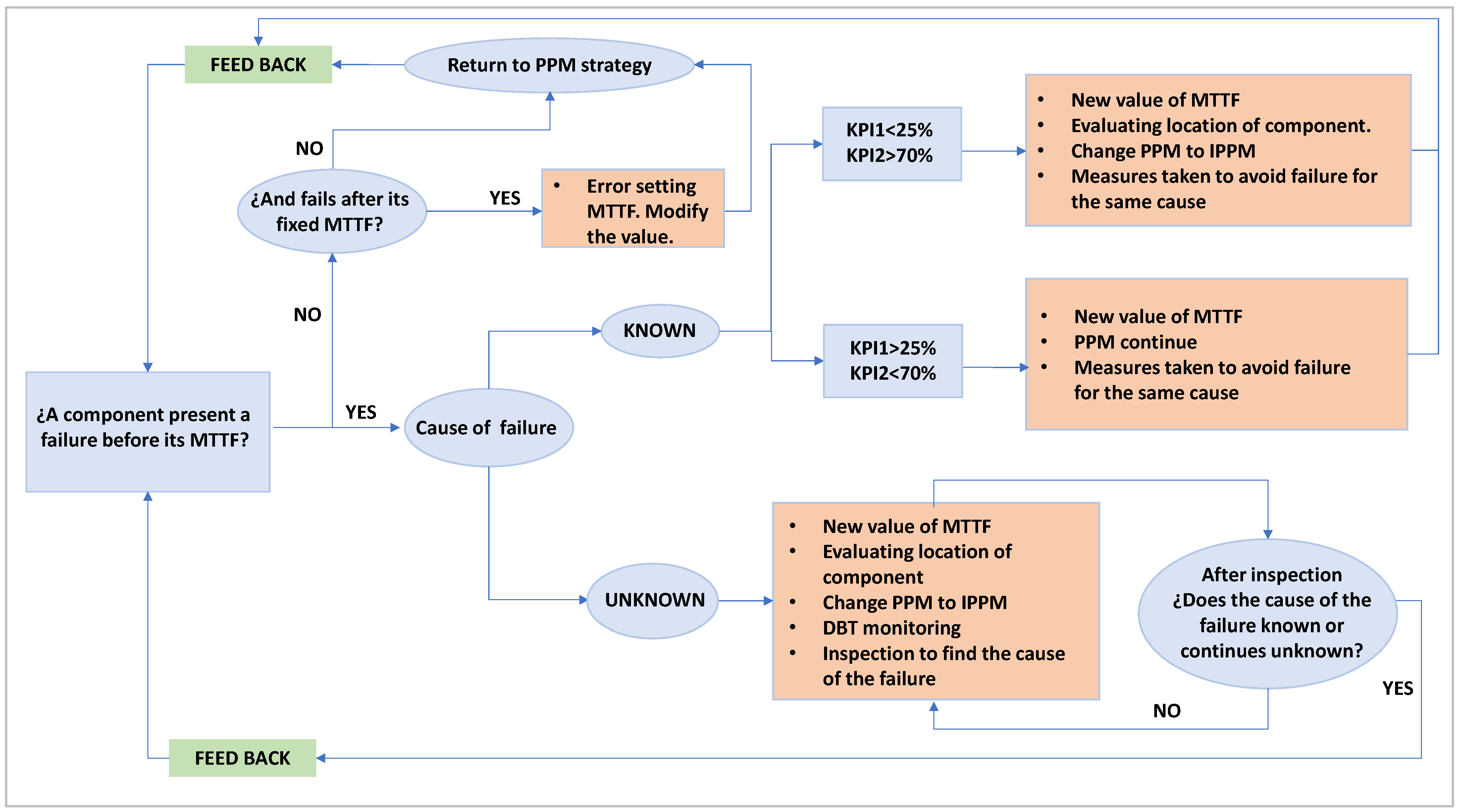
2.6. Method Proposal to Take Decisions for Maintenance Strategy Decisions
- Has the component failed before its MTTF?
- Do we know why it failed?
2.6.1. Procedure to Set KPI1 and KPI2 Values
- Calculate KPI1 interval between PPM and IPPM strategies.
- Calculate KPI2 interval between PPM and IPPM strategies.
- Calculate average value of KPI1 and KPI2, assuming PPM strategy.
- Calculate average value of KPI1 and KPI2, assuming IPPM strategy.
- Calculate average value of TTPR/MTTR ratio assuming PPM strategy.
- If KPI1 < 25% and KPI2 > 70%, the improved preventive maintenance strategy can be proposed, with a previous GOC evaluating the component;
- If KPI1 > 25% and KPI2 < 70%, a preventive maintenance strategy change is unnecessary.
2.6.2. Proposed Method for Maintenance Strategy Adoption
3. Results
4. Discussion
5. Conclusions
- The case study is a multistage thermoforming machine. This machine has an absolute encoder. Its position is constantly sent to the PLC for synchronization and management of all the coordinated steps in the correct order. This encoder allows the use of a digital behavior twin algorithm for predictive maintenance strategy. Not all of the multistage machines have an encoder for this special function, so the normal behavior of the machine must be referred to with a more precise physical analogue.
- Due to the fact that the cycle time is only 4 s, the algorithm for predictive maintenance must be speedy and certain. Other machines with longer cycle times could use predictive maintenance based on the time;
- As Figure 1 indicates, the preventive maintenance strategy depends upon the individual maintenance times. It would be interesting to evaluate the sensibility of the method for an incipient change of TTPR in some components due to global market conditions.
- Providing a method for deciding when to use predictive maintenance strategy and when to stop it in different components of a MSTM.
- Providing a dynamic global method to establish the maintenance strategy of any component of an MSTM.
- Providing a confidence level of a component or type of components in an MSTM that indicates whether the MTTF of said component operating in said machine is reliable.
- Because of the above, obtaining information on the reliability of the components of a MSTM to avoid unexpected failures during its operating time.
- Study the influence of a fixed ATL and cost assessment for possible component manufacturer changes;
- Utilization of DBT monitoring for combined supervision in parallel of the same machine system to use Predictive Maintenance and use the advice for one machine to start DBT monitoring in other machines of the system working in the same operating conditions;
- Global cost analysis of the components, DBT monitoring system, and their influence on possible maintenance strategies for all the components in an industrial multistage machine;
- Mixed method for maintenance strategies using technical parameters and cost terms.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gharbi, A.; Kenne, J.P.; Beit, M. Optimal safety stocks and preventive maintenance periods in unreliable manufacturing systems. Int. J. Prod. Econ. 2007, 107, 422–434. [Google Scholar] [CrossRef]
- Gharbi, A.; Kenne, J.P.; Boulet, J.F.; Berthaut, F. Improved joint preventive maintenance and hedging point policy. Int. J. Prod. Econ. 2010, 127, 60–72. [Google Scholar] [CrossRef][Green Version]
- Jun-Hee, H.; Tae-Sun, Y. Scheduling proportionate flow shops with preventive machine maintenance. Int. J. Prod. Econ. 2021, 231, 107874. [Google Scholar] [CrossRef]
- Zuhua, J.; Jiawen, H.; Haitao, L. Preventive maintenance of a single machine system working under piecewise constant operating condition. Reliab. Eng. Syst. Saf. 2017, 168, 105–115. [Google Scholar] [CrossRef]
- Ruiz-Hernández, D.; Pinar-Pérez, J.M.; Delgado-Gómez, D. Multi-machine preventive maintenance scheduling with imperfect interventions: A restless bandit approach. Comput. Oper. Res. 2020, 119, 104927. [Google Scholar] [CrossRef]
- Chiacchio, F.; D’Urso, D.; Sinatra, A.; Compagno, L. Assesment of the optimal preventive maintenance period using stochastic hybrid modelling. Procedia Comput. Sci. 2022, 200, 1664–1673. [Google Scholar] [CrossRef]
- Fujishima, M.; Mori, M.; Nishimura, K.; Takayama, M.; Kato, Y. Development of sensing interface for preventive maintenance of machine tools. Procedia CIRP 2017, 61, 796–799. [Google Scholar] [CrossRef]
- Irfan, A.; Umar Muhammad, M.; Omer, A.; Mohd, A. Optimization and estimation in system reliability allocation problem. Reliab. Eng. Syst. Saf. 2021, 212, 107620. [Google Scholar] [CrossRef]
- Yang, D.Y.; Frangopol, D.M.; Han, X. Error analysis for approximate structural life-cycle reliability and risk using machine learning methods. Struct. Saf. 2021, 89, 102033. [Google Scholar] [CrossRef]
- Silva, G.; Ferreira, S.; Casais, R.B.; Pereira, M.T.; Ferreira, L.P. KPI development and obsolescence management in industrial maintenance. Procedia Manuf. 2019, 38, 1427–1435. [Google Scholar] [CrossRef]
- Álvarez García, F.J.; Rodríguez Salgado, D. Analysis of the Influence of Component Type and Operating Condition on the Selection of Preventive Maintenance Strategy in Multistage Industrial Machines: A Case Study. Machines 2022, 10, 0385. [Google Scholar] [CrossRef]
- Yuk-Ming, T.; Kai-Leung, Y.; Wai-Hung, I.; Wei-Ting, K.A. Systematic Review of Product Design for Space Instrument Innovation, Reliability, and Manufacturing. Machines 2021, 9, 244. [Google Scholar] [CrossRef]
- Ponce, P.; Meier, A.; Miranda, J.; Molina, A.; Peffer, T. The Next Generation of Social Products Based on Sensing, Smart and Sustainable (S3) Features: A Smart Thermostat as Case Study. Science Direct. IFAC Pap. Line 2019, 52, 2390–2395. [Google Scholar] [CrossRef]
- Hassankhani Dolatabadi, S.; Budinska, I. Systematic Literature Review Predictive Maintenance Solutions for SMEs from the Last Decade. Machines 2021, 9, 191. [Google Scholar] [CrossRef]
- Cavalieri, S.; Salafia, M.G. A Model for Predictive Maintenance Based on Asset Administration Shell. Sensors 2020, 20, 6028. [Google Scholar] [CrossRef]
- Bouabdallaoui, Y.; Lafhaj, Z.; Yim, P.; Ducoulombier, L.; Bennadji, B. Predictive Maintenance in Building Facilities: A Machine Learning-Based Approach. Sensors 2021, 21, 1044. [Google Scholar] [CrossRef]
- Álvarez García, F.J.; Rodríguez Salgado, D. Maintenance Strategies for Industrial Multi-Stage Machines: The Study of a Thermoforming Machine. Sensors 2021, 21, 6809. [Google Scholar] [CrossRef]
- Givnan, S.; Chalmers, C.; Fergus, P.; Ortega-Martorell, S.; Whalley, T. Anomaly Detection Using Autoencoder Reconstruction upon Industrial Motors. Sensors 2022, 22, 3166. [Google Scholar] [CrossRef]
- Pfaff, M.M.L.; Dörrer, F.; Friess, U.; Preedicow, M.; Putz, M. Adaptative Predictive Machine Condition assessment for resilient digital solutions. Procedia CIRP 2021, 104, 821–826. [Google Scholar] [CrossRef]
- Florian, E.; Sgarbossa, F.; Zennaro, I. Machine learning-based predictive maintenance: A cost-oriented model for implementation. Int. J. Prod. Econ. 2021, 236, 108114. [Google Scholar] [CrossRef]
- Arena, S.; Florian, E.; Zennaro, I.; Orrù, P.F.; Sgarboss, F. A novel decision support system for managing predictive maintenance strategies based on machine learning approaches. Saf. Sci. 2022, 146, 105529. [Google Scholar] [CrossRef]
- Stary, C. Digital Twin Generation: Re-Conceptualizing Agent Systems for Behavior-Centered Cyber-Physical System Development. Sensors 2021, 21, 1096. [Google Scholar] [CrossRef] [PubMed]
- O’Sullivan, J.; O’Sullivan, D.; Bruton, K. A case-study in the introduction of a digital twin in a large-scale smart manufacturing facility. Procedia Manuf. 2020, 51, 1523–1530. [Google Scholar] [CrossRef]
- Konstantinidis, F.K.; Kansizoglou, J.; Santavas, N.; Mouroutsos, S.G.; Gasteratos, A. MARMA: A Mobile Augmented Reality Maintenance Assistant for Fast-Track Repair Procedures in the Context of Industry 4.0. Machines 2020, 8, 88. [Google Scholar] [CrossRef]
- Haihua, Z.; Changchun, L.; Tang, D.; Nie, Q.; Zhou, T.; Wang, L.; Song, Y. Probing an intelligent predictive maintenance approach with deep learning and augmented reality for machine tools in IoT-enabled manufacturing. Robot. Comput.-Integr. Manuf. 2022, 77, 102357. [Google Scholar] [CrossRef]
- Hongfeng, W.; Qi, Y.; Fang, W. Digital twin-enabled dynamic scheduling with preventive maintenance using a double-layer Q-learning algorithm. Comput. Oper. Res. 2022, 144, 105823. [Google Scholar] [CrossRef]
- Jiři, D.; Tuhý, T.; Jančíková, Z.K. Method for optimizing maintenance location within the industrial plant. Int. Sci. J. Logist. 2019, 6, 55–62. [Google Scholar] [CrossRef]
- Liberopoulos, G.; Tsarouhas, P. Reliability analysis of an automated pizza production line. J. Food Eng. 2005, 69, 79–96. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Component | Component | Cause of Failure | Failure Event |
|---|---|---|---|
| Electrical | Master power switch | Ambient condition, Power supplier event | Stop |
| Plug-in relay | Ambient condition, Power supplier event, Unexpected hit | Malfunction Stop | |
| Command and signalling | Ambient condition, Power supplier event | Stop | |
| Safety limit switch | Ambient condition, Power supplier event, Unexpected hit | Stop | |
| Electronic | PLC | Ambient condition, Power supplier event | Stop |
| HMI | Ambient condition, Power supplier event | Stop | |
| Chromatic sensor | Ambient condition, Power supplier event | Stop | |
| Safety relay | Ambient condition, Power supplier event | Stop | |
| Temperature controller | Ambient condition, Power supplier event, Unexpected hit | Stop | |
| Solid state relay | Ambient condition, Power supplier event | Stop | |
| Belt drive | Ambient condition, Power supplier event | Malfunction | |
| Pressure sensor | Pressure failure, Global fatigue | Malfunction | |
| Servo drive peristaltic pump | Ambient condition, Power supplier event | Stop | |
| Absolute encoder | Global fatigue, Mechanical hit | Malfunction | |
| Mechanical | Safety button | Ambient condition, Power supplier event | Stop |
| Thermal resistance | Ambient condition, Power supplier event | Malfunction | |
| Thermocouple sensor | Global fatigue | Malfunction | |
| Belt motor | Global fatigue | Stop | |
| Bronze cap | Global fatigue | Malfunction | |
| Linear axis | Global fatigue | Malfunction | |
| Linear bearing | Global fatigue | Malfunction | |
| Peristaltic pump | Ambient condition, Power supplier event, compressed air system failure | Stop | |
| Terrine cutter | Global fatigue | Malfunction | |
| Pneumatic | Pneumatic valve | Global fatigue | Malfunction |
| Pneumatic cylinder | Pressure failure, Failure valve | Malfunction |
| Component | MTTR | TTPR | MTTF | TLP |
|---|---|---|---|---|
| Master power switch | 14,400 | 10,800 | 9,999,999 | 28,800 |
| PLC | 435,600 | 345,600 | 9,999,999 | 450,000 |
| HMI | 435,600 | 345,600 | 9,999,999 | 450,000 |
| Chromatic sensor | 176,520 | 172,800 | 5,000,000 | 190,920 |
| Plug-in relay | 14,400 | 10,800 | 5,000,000 | 28,800 |
| Command and signalling | 14,400 | 10,800 | 5,000,000 | 28,800 |
| Safety limit switch | 14,400 | 10,800 | 9,999,999 | 28,800 |
| Safety relay | 14,400 | 10,800 | 9,999,999 | 28,800 |
| Safety button | 14,400 | 10,800 | 9,999,999 | 28,800 |
| Temperature controller | 435,600 | 345,600 | 9,999,999 | 450,000 |
| Solid state relay | 176,400 | 172,800 | 5,000,000 | 190,800 |
| Thermal resistance | 25,500 | 10,800 | 3,700,800 | 39,900 |
| Thermocouple sensor | 14,700 | 10,800 | 3,700,800 | 29,100 |
| Belt drive | 435,600 | 345,600 | 9,999,999 | 450,000 |
| Belt motor | 187,200 | 172,800 | 5,000,000 | 201,600 |
| Bronze cap | 288,000 | 172,800 | 7,750,000 | 302,400 |
| Linear axis | 288,000 | 172,800 | 7,625,000 | 302,400 |
| Linear bearing | 288,000 | 172,800 | 7,500,000 | 302,400 |
| Pneumatic valve | 176,400 | 172,800 | 9,999,999 | 190,800 |
| Pneumatic cylinder | 176,400 | 172,800 | 9,999,999 | 190,800 |
| Pressure sensor | 176,700 | 172,800 | 5,000,000 | 191,100 |
| Servo drive peristaltic pump | 435,600 | 345,600 | 9,999,999 | 450,000 |
| Peristaltic pump | 547,200 | 518,400 | 5,000,000 | 561,600 |
| Terrine cutter | 288,000 | 172,800 | 9,999,999 | 302,400 |
| Absolute encoder | 360,000 | 172,800 | 5,000,000 | 374,400 |
| Component | Fails before MTTF | Cause of Failure | Corrected MTTF |
|---|---|---|---|
| Chromatic sensor | 1 | Known | 3,998,750 |
| Plug-in relay | 1 | Known | 4,056,010 |
| Temperature controller | 1 | Known | 7,934,710 |
| Solid state relay | 1 | Known | 4,678,034 |
| Thermal resistance | 1 | Unknown | 3,067,090 |
| Thermocouple sensor | 1 | Unknown | 2,890,760 |
| Bronze cap | 1 | Unknown | 6,500,453 |
| Linear bearing | 1 | Unknown | 6,375,010 |
| Pressure sensor | 1 | Unknown | 4,575,102 |
| Peristaltic pump | 1 | Known | 4,434,090 |
| Terrine cutter | 1 | Unknown | 8,750,778 |
| Absolute encoder | 1 | Known | 4,756,002 |
| Component | Situation | Description of the Known Cause of Failure |
|---|---|---|
| Chromatic sensor | Occasional situation | The supplier of the film for the terrine lid changed the color without prior notice and made it darker and more reflective. This caused the sensor to stop seeing the mark correctly. |
| Plug-in relay | Normal situation | The number of commutations exceeded the mechanical endurance. |
| Temperature controller | Occasional situation | Mixed events of voltage RMS and high level of humidity. |
| Solid state relay | Occasional situation | The higher level of humidity and air dust caused a short circuit. |
| Peristaltic pump | Occasional situation | A higher density of fluid dosed in the terrine caused a jam. |
| Absolute encoder | Occasional situation | Accidental mechanical shock. |
| Component | DBT Warning of Failures |
|---|---|
| Chromatic sensor | 1 |
| Plug-in relay | 1 |
| Temperature controller | 1 |
| Solid state relay | 1 |
| Thermal resistance | 1 |
| Thermocouple sensor | 1 |
| Bronze cap | 1 |
| Linear bearing | 1 |
| Pressure sensor | 1 |
| Peristaltic pump | 1 |
| Terrine cutter | 1 |
| Absolute encoder | 1 |
| Strategy | Ratio | Average KPI1 | Average KPI2 | Average TTPR/MTTR |
|---|---|---|---|---|
| PPM | Value | 22.92% | 63.14% | 77.08% |
| Interval | [2.04–57.65%] | [27.07–92.31%] | ||
| IPPM | Value | 96.04% | 0.99% | 3.96% |
| Interval | [92.31–99.84%] | [0.15–1.64%] |
| Component | KPI1 | KPI2 | Maintenance Strategy after a Year of Work |
|---|---|---|---|
| Master power switch | 0.25 | 0.38 | PPM |
| Plug-in relay | 0.25 | 0.38 | PPM |
| Command and signalling | 0.25 | 0.38 | PPM |
| Safety limit switch | 0.25 | 0.38 | PPM |
| PLC | 0.21 | 0.77 | PPM |
| HMI | 0.21 | 0.77 | PPM |
| Chromatic sensor | 0.02 | 0.91 | IPPM |
| Safety relay | 0.25 | 0.38 | PPM |
| Temperature controller | 0.21 | 0.77 | IPPM |
| Solid state relay | 0.02 | 0.91 | IPPM |
| Belt drive | 0.21 | 0.77 | PPM |
| Pressure sensor | 0.02 | 0.90 | IPPM + DBT monitoring |
| Servo drive peristaltic pump | 0.21 | 0.77 | PPM |
| Absolute encoder | 0.52 | 0.46 | PPM |
| Safety button | 0.25 | 0.38 | PPM |
| Thermal resistance | 0.58 | 0.27 | IPPM + DBT monitoring |
| Thermocouple sensor | 0.27 | 0.37 | IPPM + DBT monitoring |
| Belt motor | 0.08 | 0.86 | PPM |
| Bronze cap | 0.40 | 0.57 | IPPM + DBT monitoring |
| Linear axis | 0.40 | 0.57 | PPM |
| Linear bearing | 0.40 | 0.57 | IPPM + DBT monitoring |
| Peristaltic pump | 0.05 | 0.92 | IPPM |
| Terrine cutter | 0.40 | 0.57 | IPPM + DBT monitoring |
| Pneumatic valve | 0.02 | 0.91 | PPM |
| Pneumatic cylinder | 0.91 | 0.91 | PPM |
| Type of Component | Component | Trust Level |
|---|---|---|
| Electronic | Chromatic sensor | 79.98% |
| Electrical | Plug-in relay | 81.12% |
| Electronic | Temperature controller | 79.35% |
| Electronic | Solid state relay | 93.56% |
| Electronic | Thermal resistance | 82.88% |
| Electronic | Thermocouple sensor | 78.11% |
| Mechanical | Bronze cap | 83.88% |
| Mechanical | Linear bearing | 85.00% |
| Electronic | Pressure sensor | 91.50% |
| Mechanical | Peristaltic pump | 88.68% |
| Mechanical | Terrine cutter | 87.51% |
| Electronic | Absolute encoder | 95.12% |
| Item | References | Qualitative Comments after Comparison |
|---|---|---|
| Minimizing security stocks | [1,2] | Correct selection of fixed KPIs allows the optimization of stock and provides the adequate preventive maintenance policy |
| Stops to settings, removal actions. Imperfect maintenance | [3,4] | Settings only at the start time of the machine functioning by the temperature controller, thermal resistance, and thermocouple sensor. The maintenance actions must perform the machine functioning. The system can evaluate if the actions in each component or each type of component are imperfect by trust level or ATL. |
| Mathematical model for Preventive maintenance | [5,6,7,8] | Complex, very theoretical and many variables to manage. Simple, sensitive to variations of individual maintenance times. |
| MTTF reliable Reliability and law degradation | [9,10,11] | Initial MTTF fixed for all components; reliability functions not used. Possibility to change MTTF value if real MTTF lower or upper than initial MTTF fixed. |
| Product design and operation conditions | [12] | If a component exhibits repeated failures, an immediate FMEA analysis procedure is initiated to find design errors or component selection errors. |
| Mathematical model for Predictive maintenance | [13,14,15,16,17,18] | Uses PLC with embedded DBT algorithm. No need training and learning time. Quick response Very useful for a machine with fast cycle time. |
| Location components | [19] | (*) Possible improvement. Can be evaluated for this application |
| Mixed cost and technical analysis | [20,21] | (*) Possible improvement. Also is citated in future research. Coincidence in the use of FMEAS analysis |
| Digital Twin | [22,23] | The behavior of the machine always is the same and does not need a real digital twin since the characterization is special for each MSTM and operation conditions are always are the same. Coincidence in the event failure advises, no training and utilization of FMEAS analysis. |
| Augmented Reality and Computer Vision | [24,25] | (*) Possible improvement. Not used. ATL is used for evaluating the maintenance operator actions required for maintenance policy. But it is used after a maintenance action. |
| Preventive actions in flexible windows time. Predictive maintenance always running Method for decision-making | [26] | (*) Possible improvement to use flexible windows time for preventive maintenance actions. Predictive maintenance only works if a component fails before its MTTF, and the cause of the failure is unknow. Coincidence in the contribution of a method for decision-making |
| Individual preventive maintenance Times | [27,28] | Used in the article and performed by developing KPIS for preventive maintenance decisions |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
García, F.J.Á.; Salgado, D.R. An Approach for Predictive Maintenance Decisions for Components of an Industrial Multistage Machine That Fail before Their MTTF: A Case Study. Systems 2022, 10, 175. https://doi.org/10.3390/systems10050175
García FJÁ, Salgado DR. An Approach for Predictive Maintenance Decisions for Components of an Industrial Multistage Machine That Fail before Their MTTF: A Case Study. Systems. 2022; 10(5):175. https://doi.org/10.3390/systems10050175
Chicago/Turabian StyleGarcía, Francisco Javier Álvarez, and David Rodríguez Salgado. 2022. "An Approach for Predictive Maintenance Decisions for Components of an Industrial Multistage Machine That Fail before Their MTTF: A Case Study" Systems 10, no. 5: 175. https://doi.org/10.3390/systems10050175
APA StyleGarcía, F. J. Á., & Salgado, D. R. (2022). An Approach for Predictive Maintenance Decisions for Components of an Industrial Multistage Machine That Fail before Their MTTF: A Case Study. Systems, 10(5), 175. https://doi.org/10.3390/systems10050175