

Applications of Markov Decision Process Model and Deep Learning in Quantitative Portfolio Management during the COVID-19 Pandemic
Abstract
:1. Introduction
- We suggest a RL model for quantitative portfolio management and propose a multi-level deep learning network that takes into account the instability and temporal correlation of the market.
- We extend the A2C to the stock market, and the experiments show that the proposed model is robust and practical during the COVID-19 pandemic with seven baselines.
- We introduce the omega ratio as our real-time reward function to address the defects in the Sharpe ratio, Sortino ratio, and MDD.
2. Related Works
2.1. Reinforcement Learning Algorithms
2.2. Feature-Augmentation Model
3. Preliminary and Background
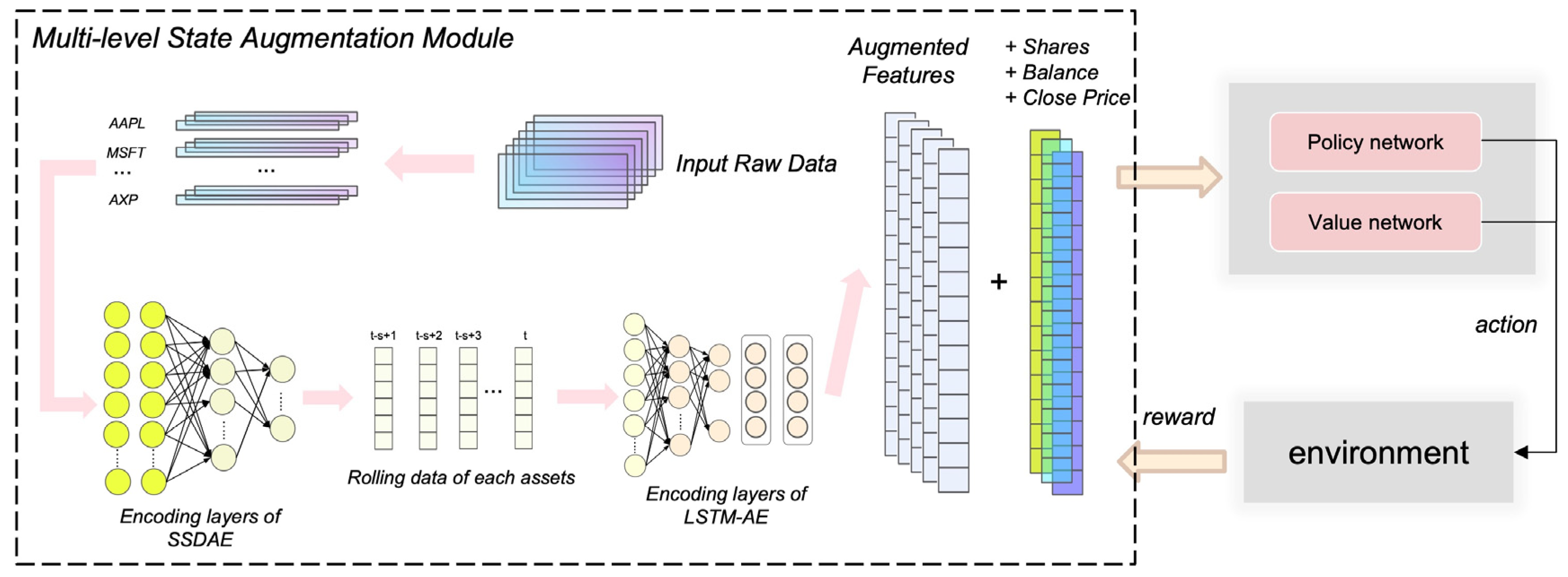
3.1. Markov Decision Process (MDP) Model
- ∈ :available balance at current time-step t;
- ∈ : shares owned of each stock at current time-step t;
- ∈ : close price of each stock at current time-step t;
- ∈ : augmented features at current time-step t.
3.2. Assumption and Constraints
- Adequate liquidity: All market assets are liquid, allowing for the same conditions to be applied to every transaction.
- Minimal slippage: As a result of the high liquidity of the assets under consideration, orders can be executed swiftly at the close price with minimal or no loss in value.
- No market influence: The agent’s trading volume is so negligible relative to the size of the entire market that the agent’s transactions have no effect on the state transition of the market environment.
- In our action space, we prohibit shorting assets; we do not permit investors to borrow assets and return them in the future; and we do not permit investors to borrow assets and return them in the future.
- The transaction cost is a constant proportion of daily trade volume.
- Nonnegative balance b ≥ 0: Permitted acts should not result in a negative balance. The stocks are separated into sets for buy and sell action based on the activity at time t.
4. Data and Methodology
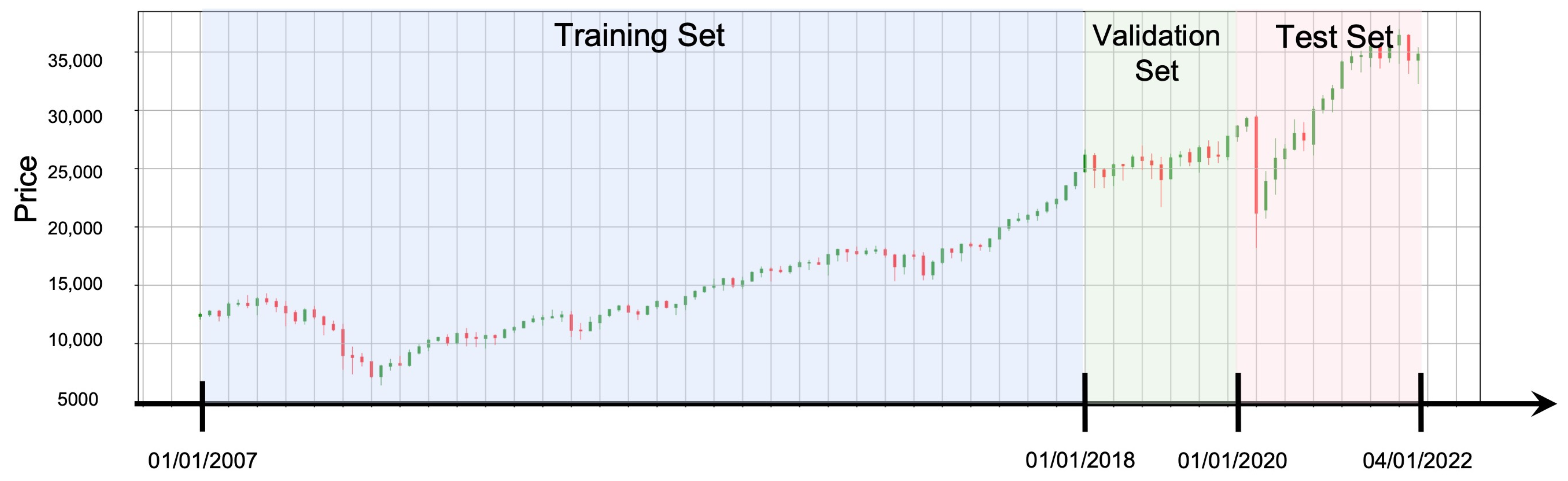
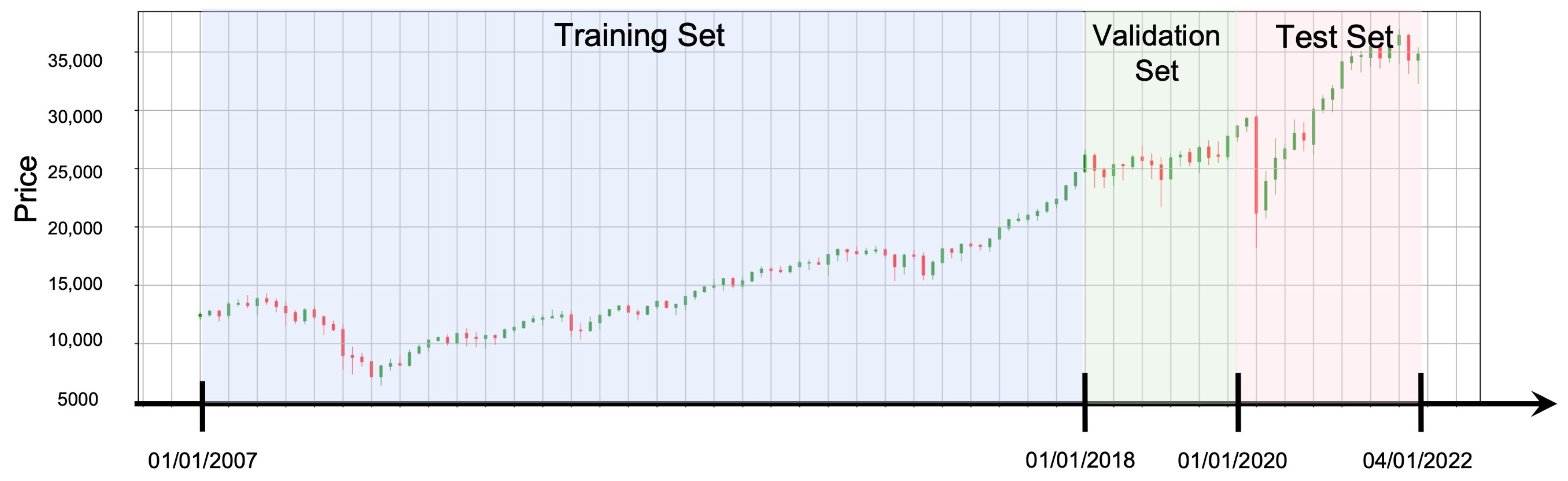
4.1. Data Selection and Preprocessing
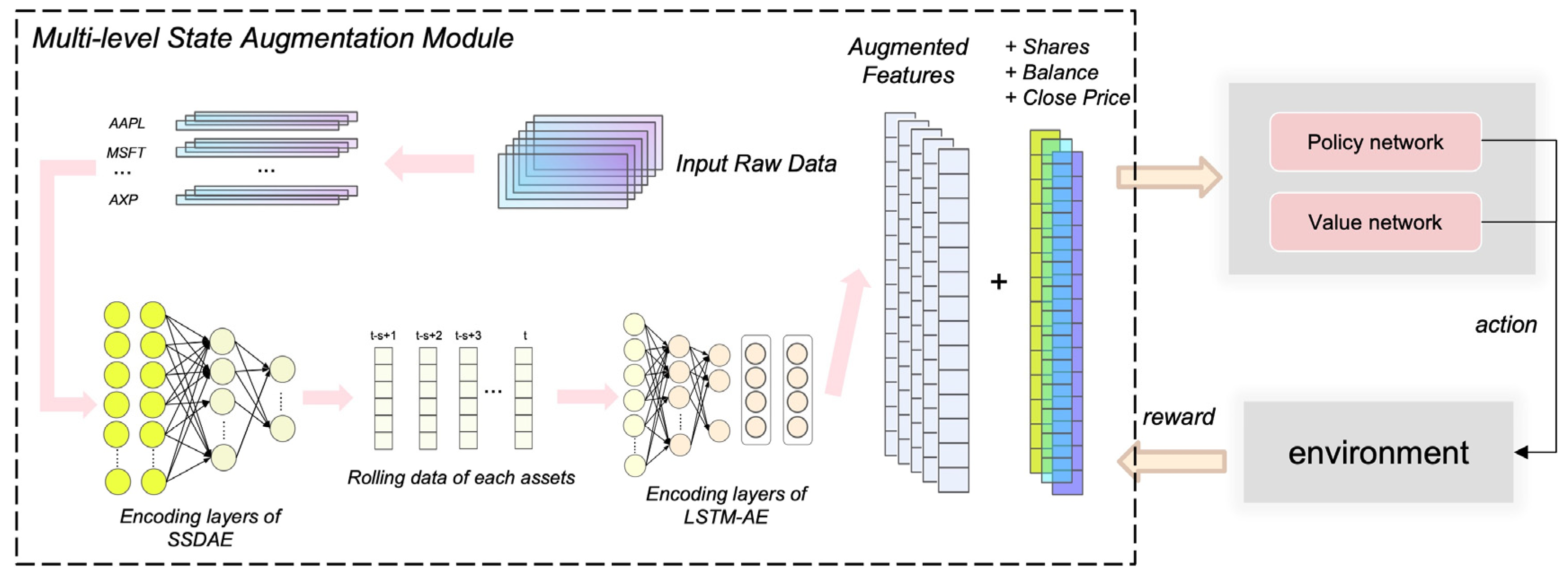
4.2. Multi-Level Augmented Portfolio-Management Model
4.3. Research Models
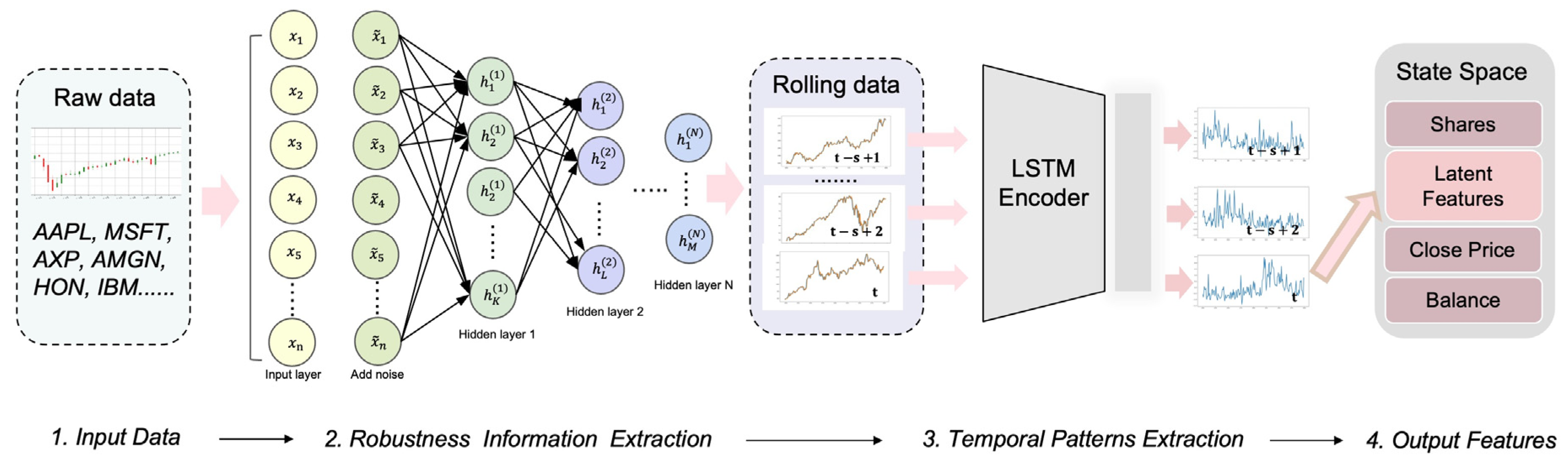
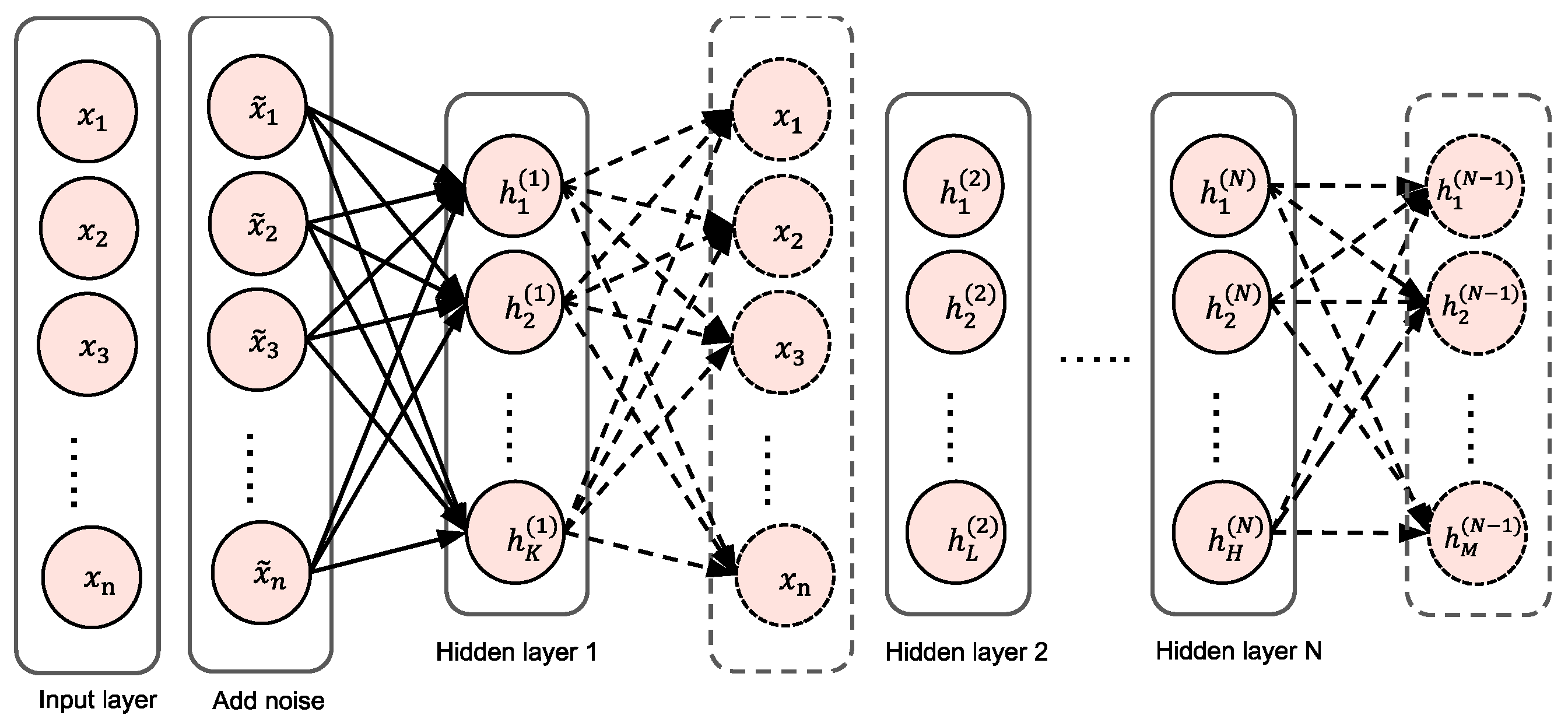
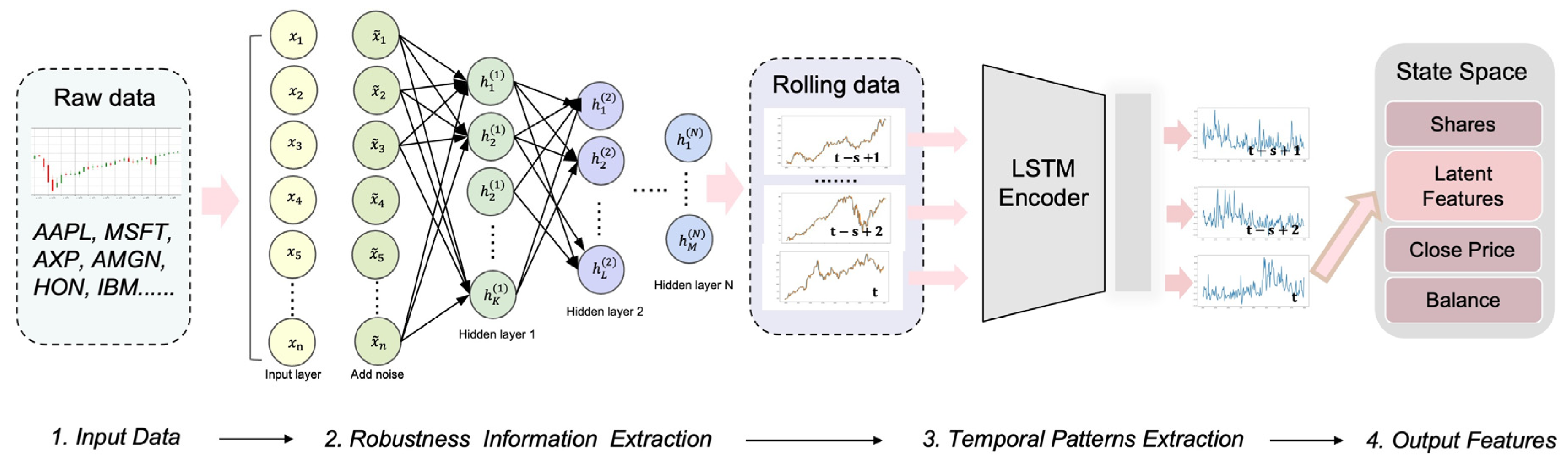
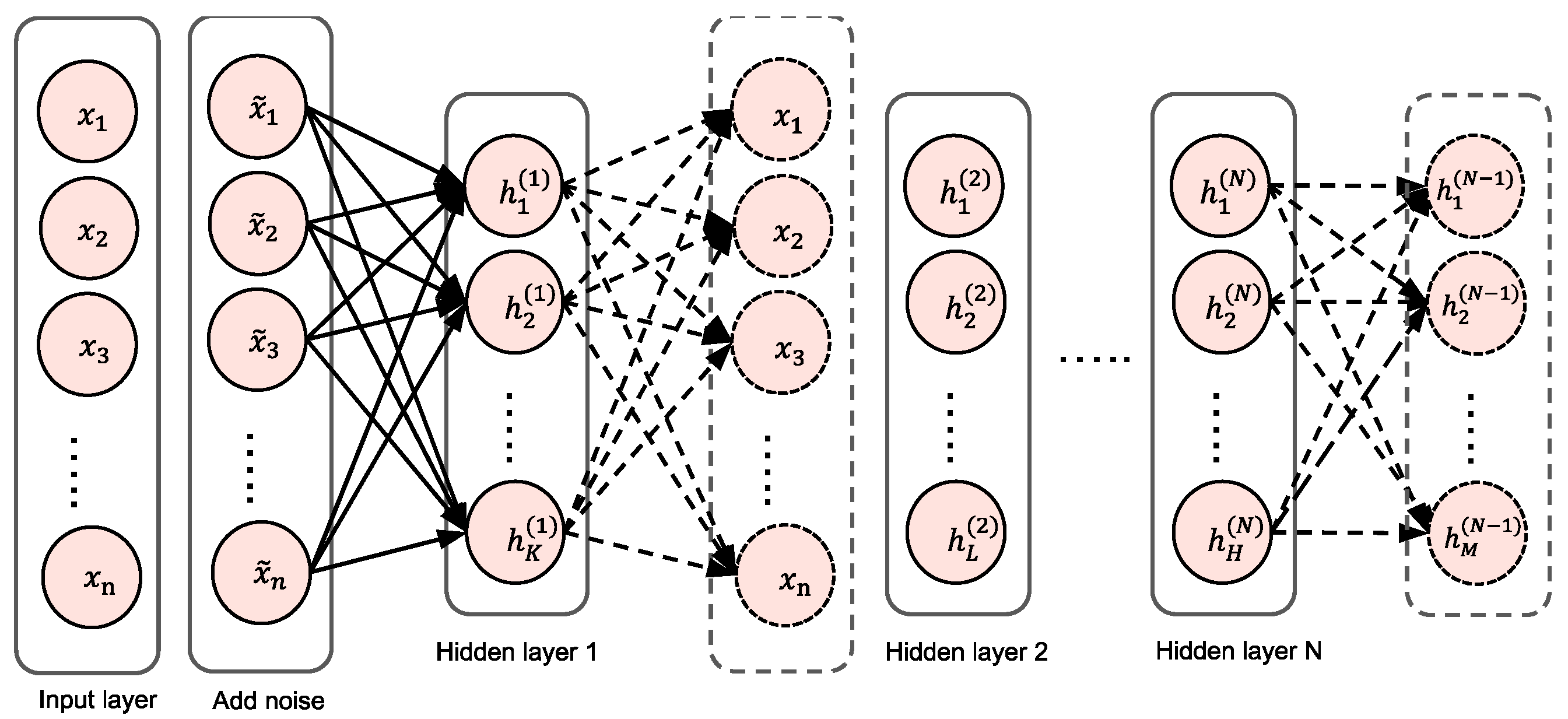
4.3.1. Stacked Sparse Denoising Autoencoder (SSDAE)
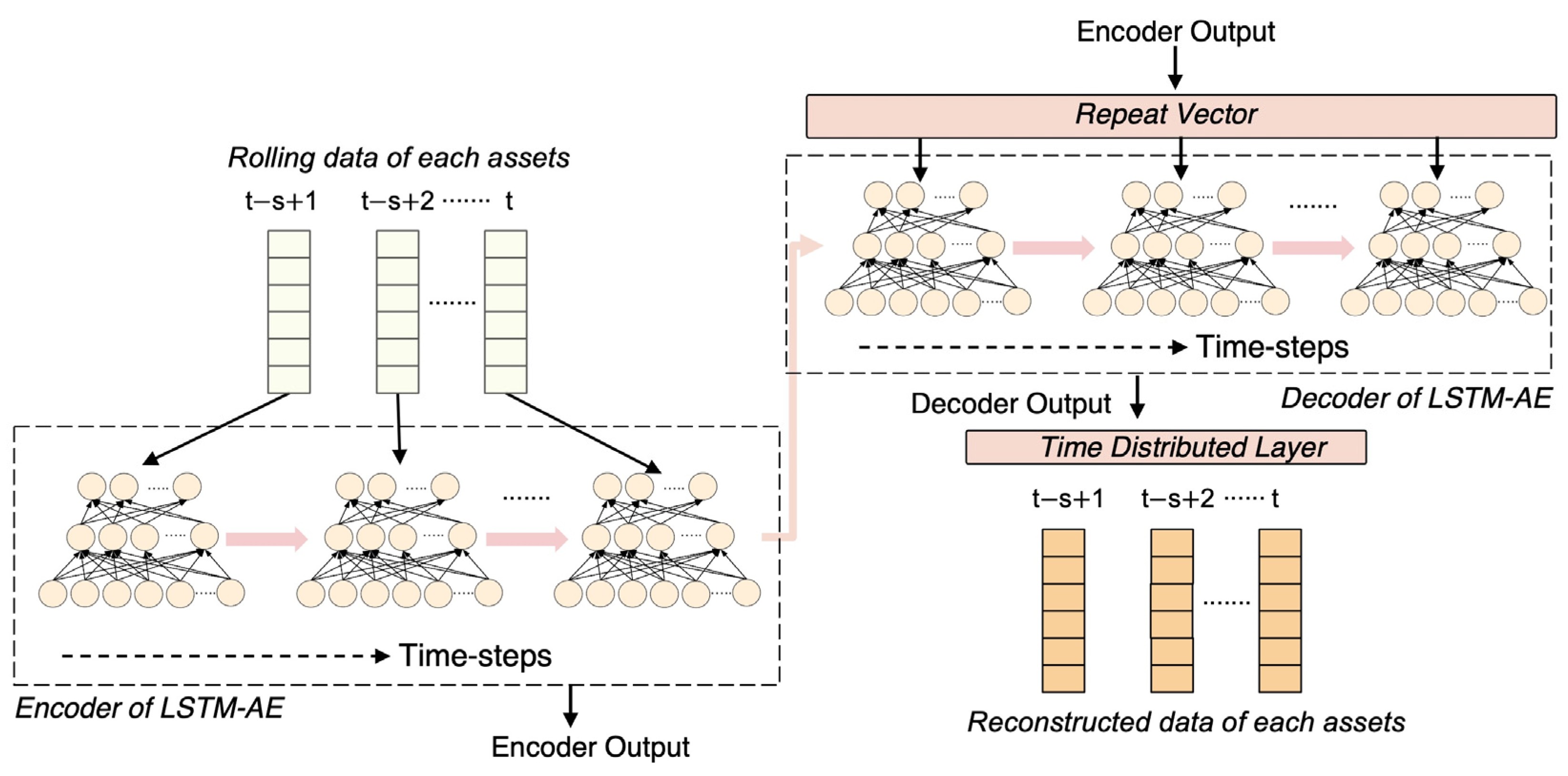
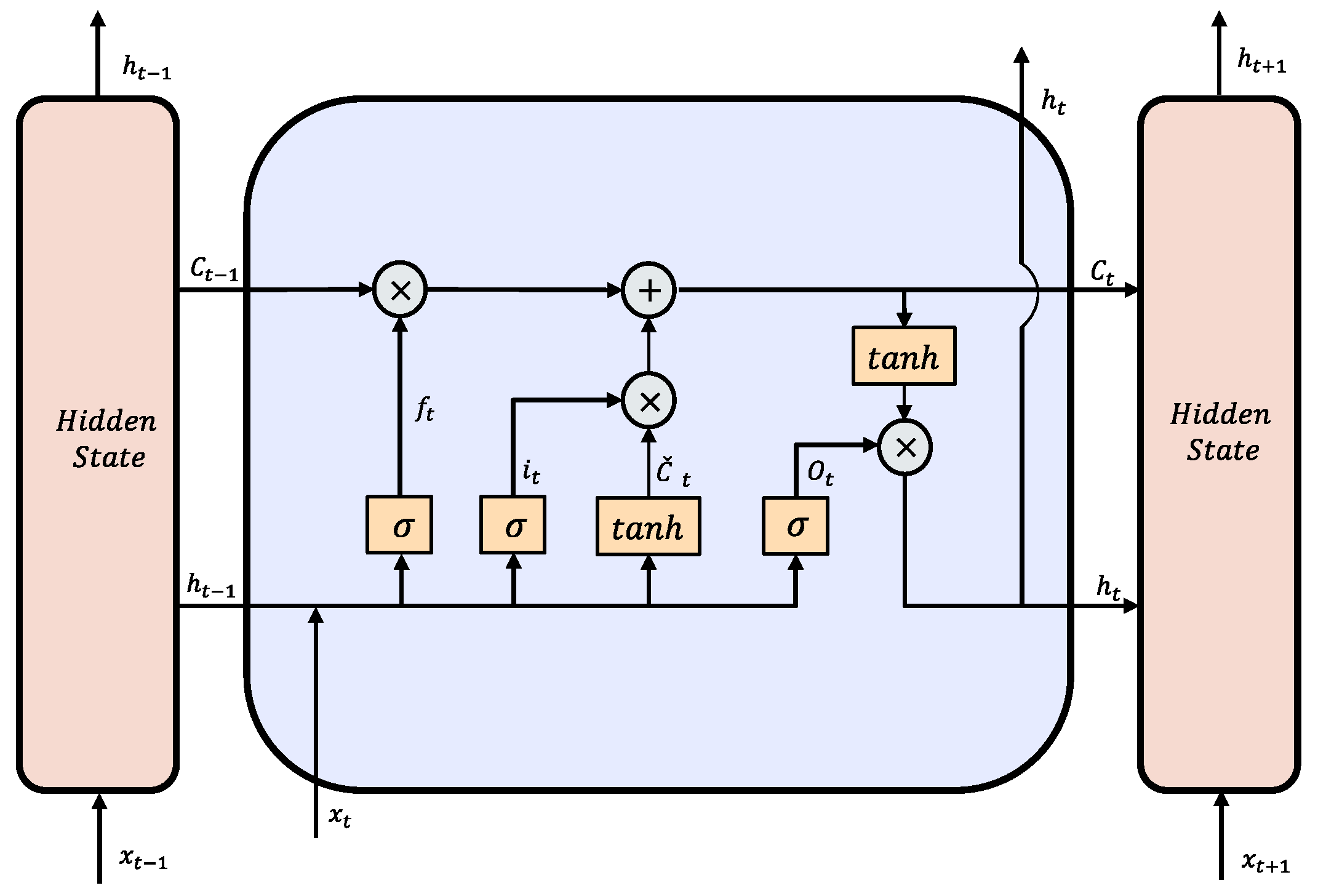
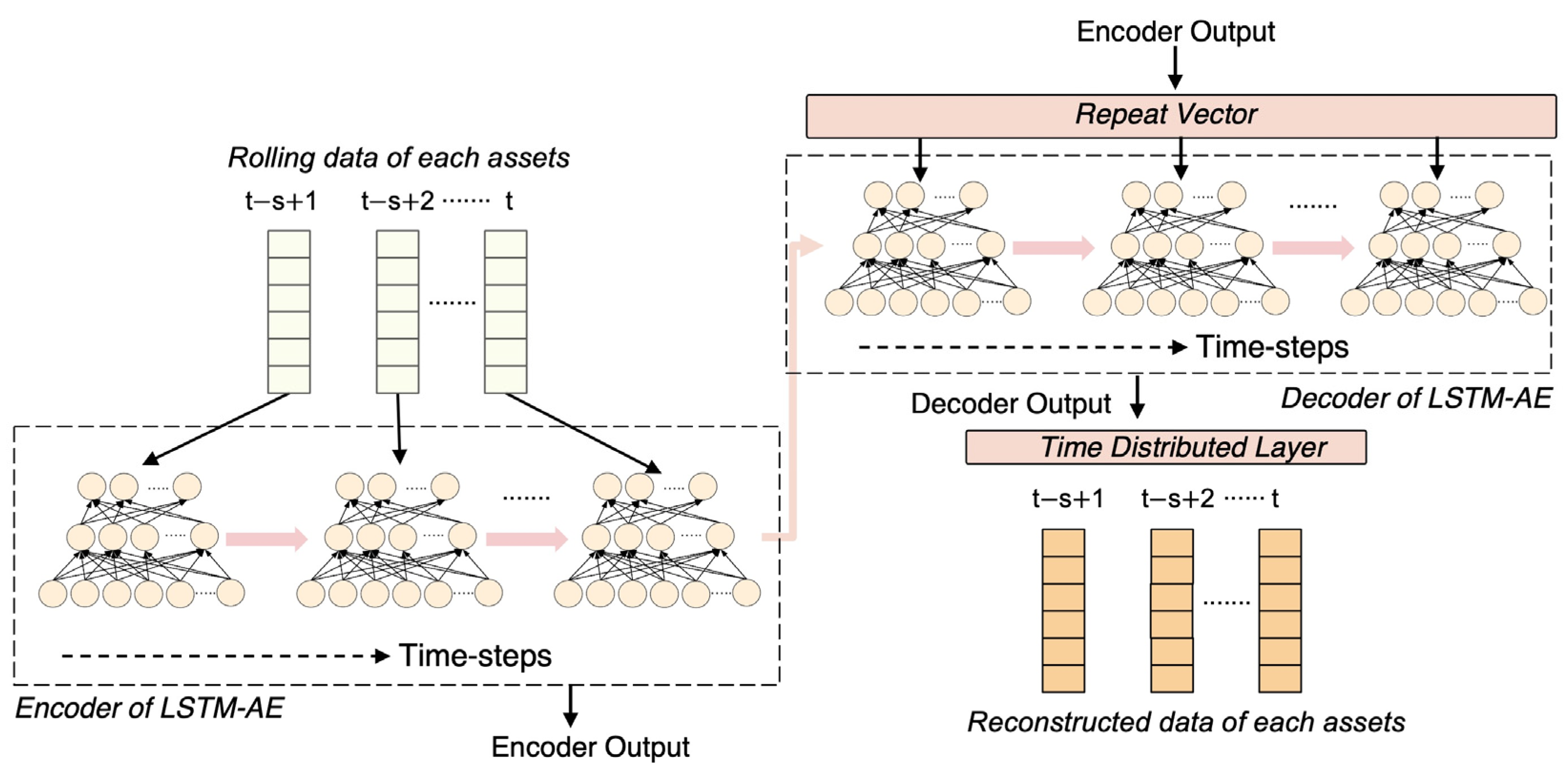
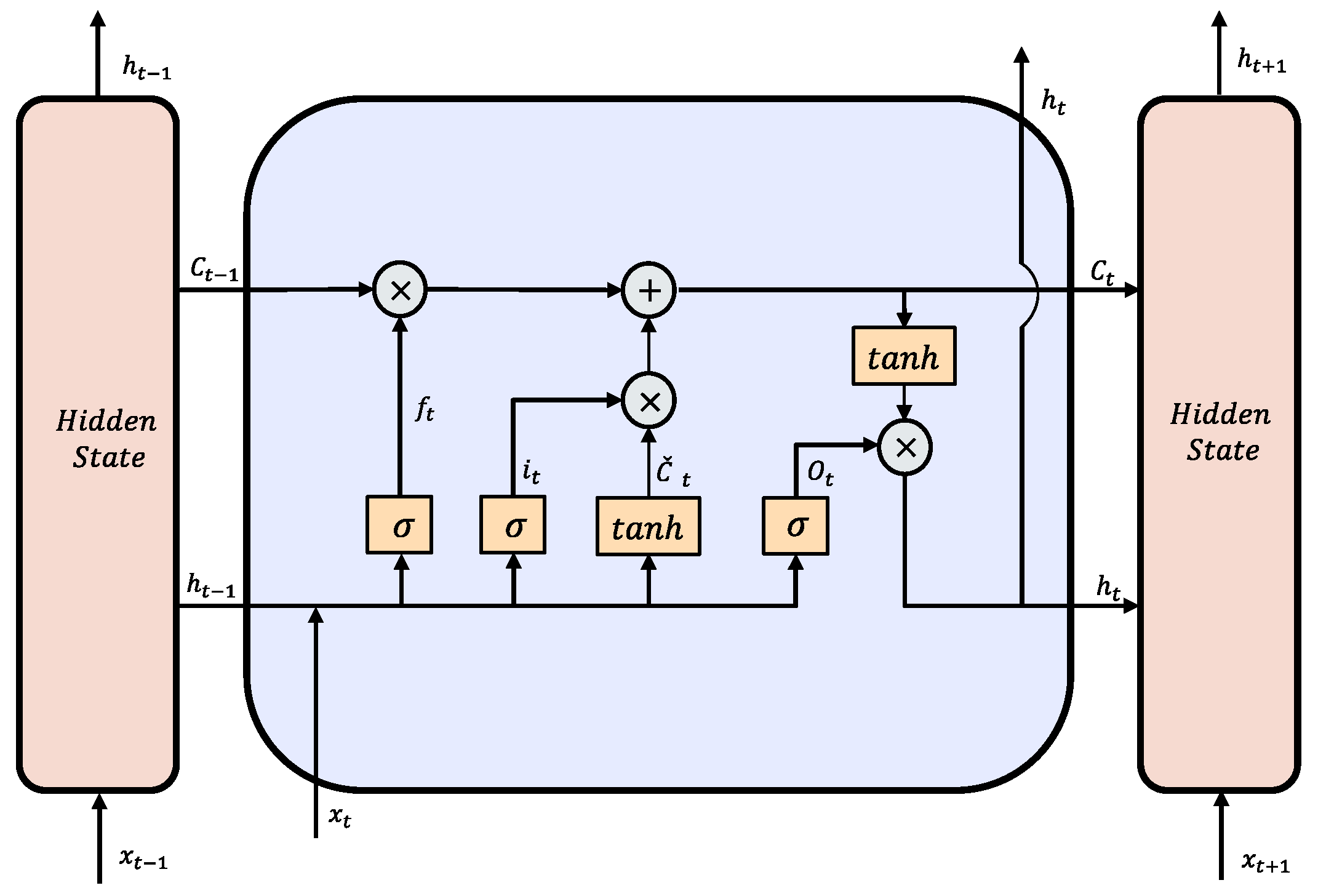
4.3.2. Long–Short-Term-Memory-Based Autoencoder (LSTM-AE)
4.3.3. Optimization Algorithms—Advantage Actor–Critic (A2C)
4.3.4. Setting of Reward Function
5. Experimental Setup and Results
5.1. Parameters of Network
5.2. Metrics
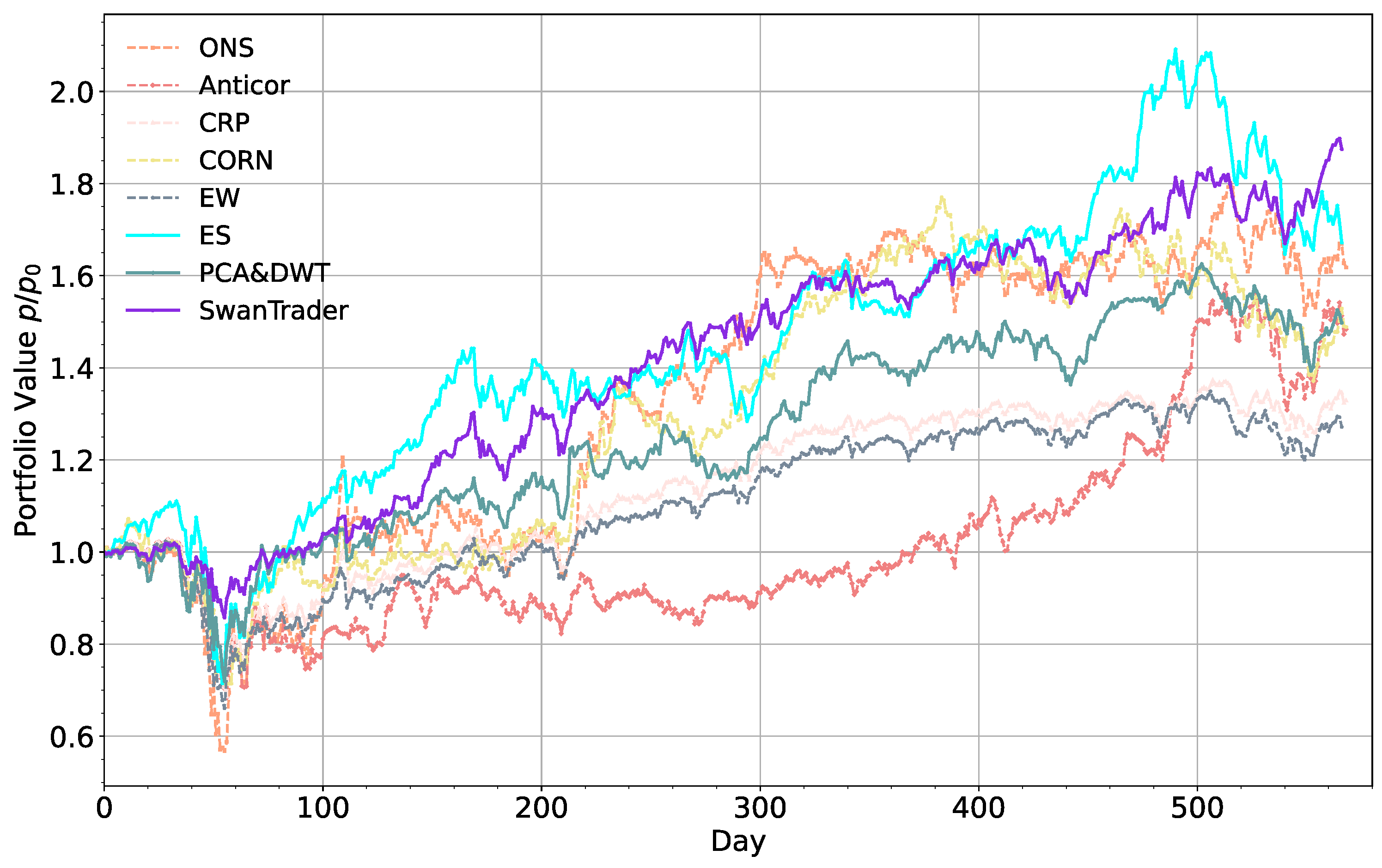
5.3. Baselines
- EW (Equal weight baseline): a simplistic baseline that allocates equal weight to all portfolio assets;
- Anticor (Anti-Correlation) [65]: a heuristic technique for online portfolio selection that uses the consistency of positive lagged cross-correlation and negative autocorrelation to change portfolio weights according to the mean regression principle;
- CRP (Constant rebalanced portfolio) [66]: an investing strategy that maintains the same wealth distribution among a collection of assets on a daily basis, that is, the fraction of total wealth represented by a particular asset remains constant at the start of each day;
- CORN (CORrelation-driven nonparametric learning) [67]: a model for correlation-driven nonparametric learning that combines correlation sample selection with logarithmic optimal utility function;
- ONS (Online newton step algorithm) [68]: an online portfolio selection model based on the newton model which requires relatively weak assumptions;
- ES (Ensemble strategy) [69]: a recently developed RL-based open-source model that improves performance by integrating three actor–critic algorithms without the process of state space augmentation;
- PCA and DWT (Principal Component Analysis and Discrete Wavelet Transform) [23]: by combining PCA and DWT to extract features from financial data, it is found that the profitability is better than the setting without feature processing.
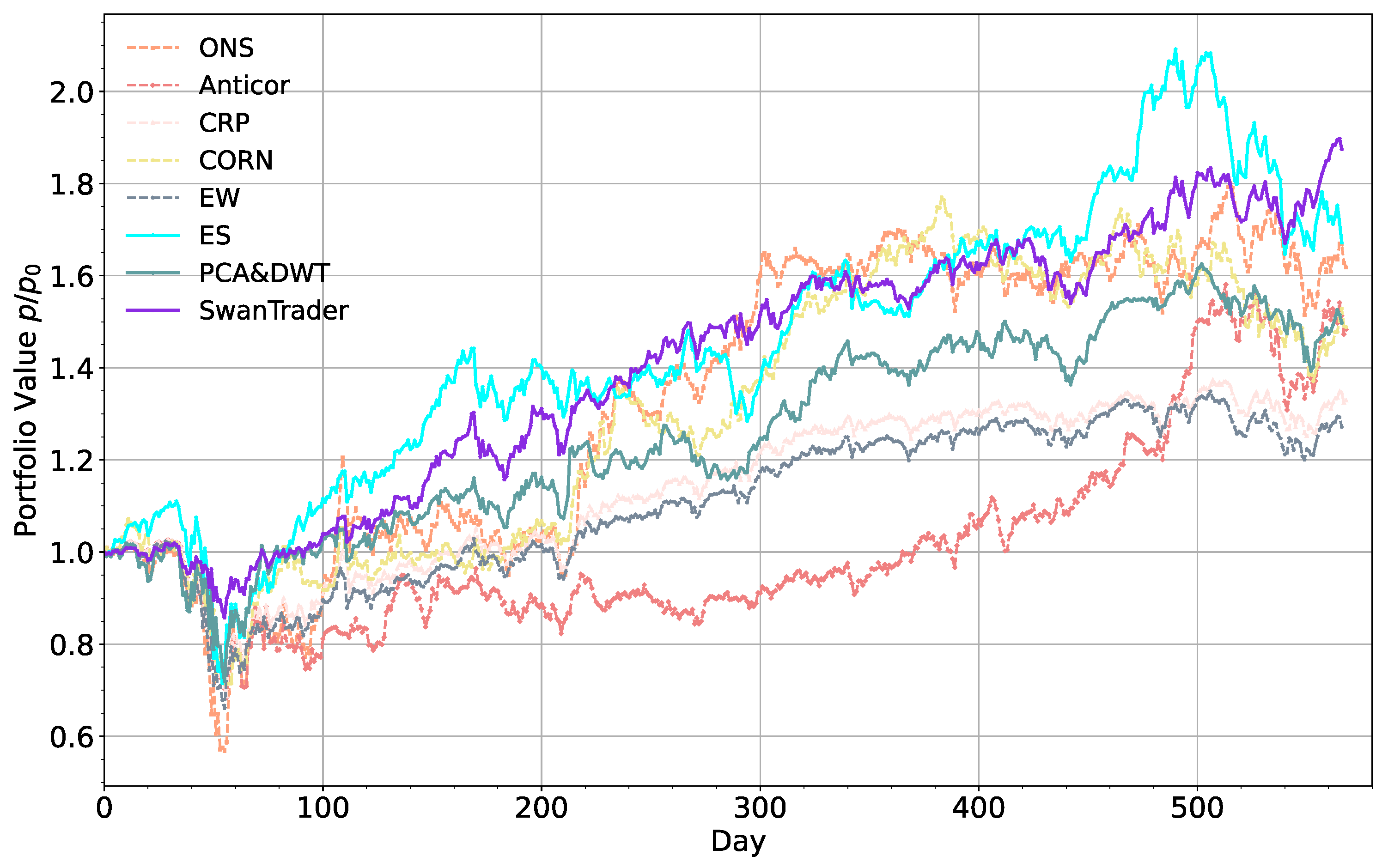
5.4. Result Comparison
6. Analysis and Discussion
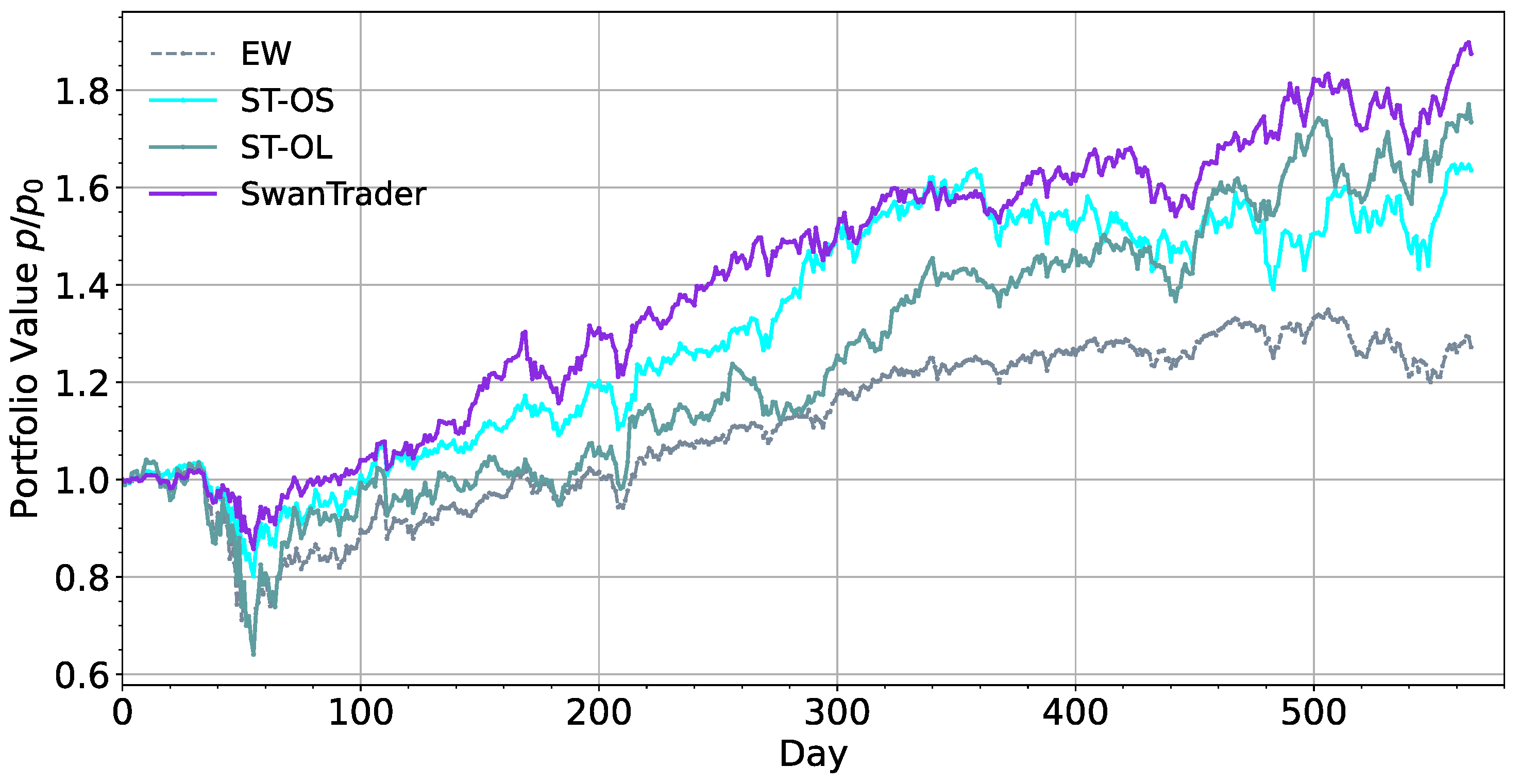
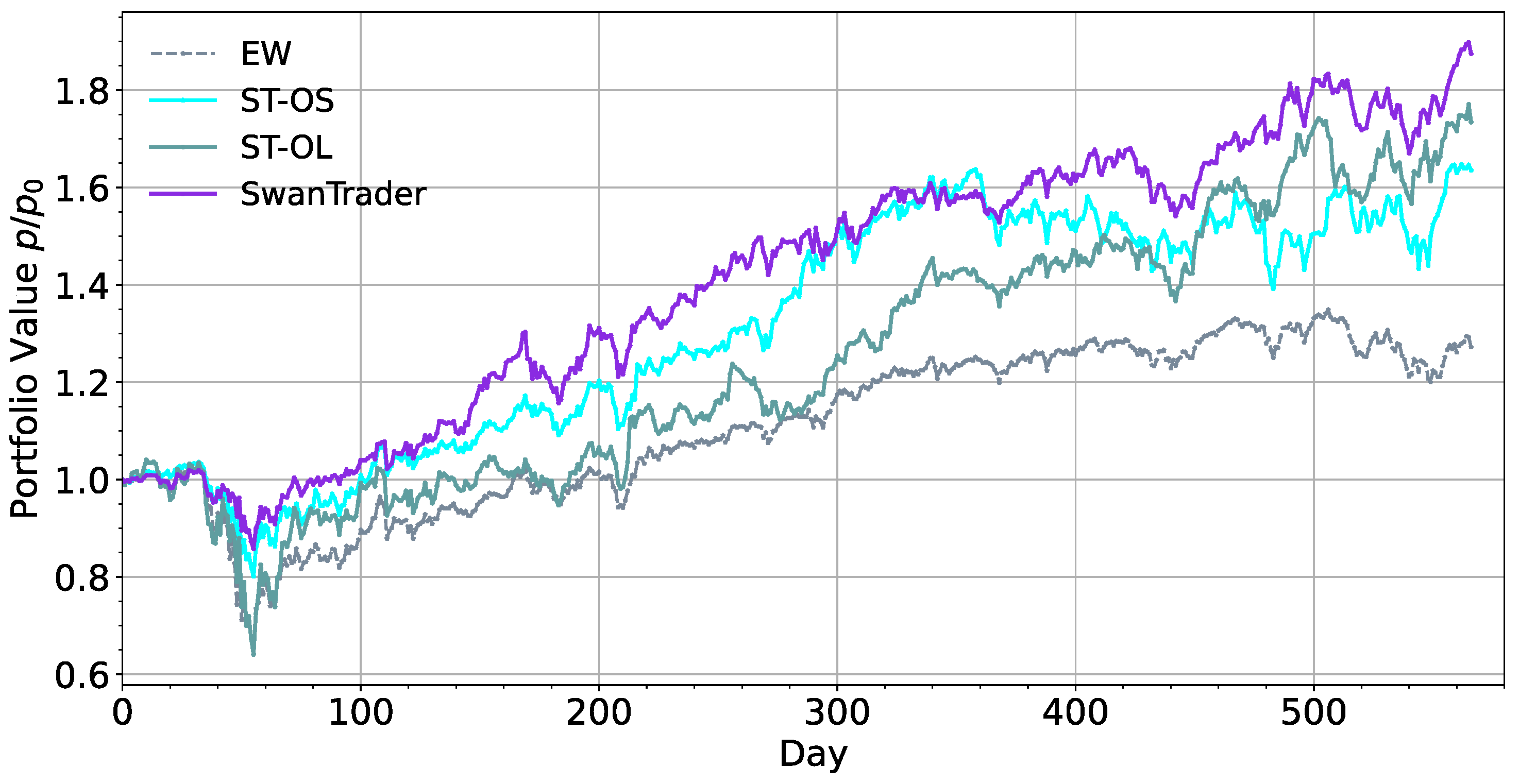
6.1. Effects of Augmentation Network
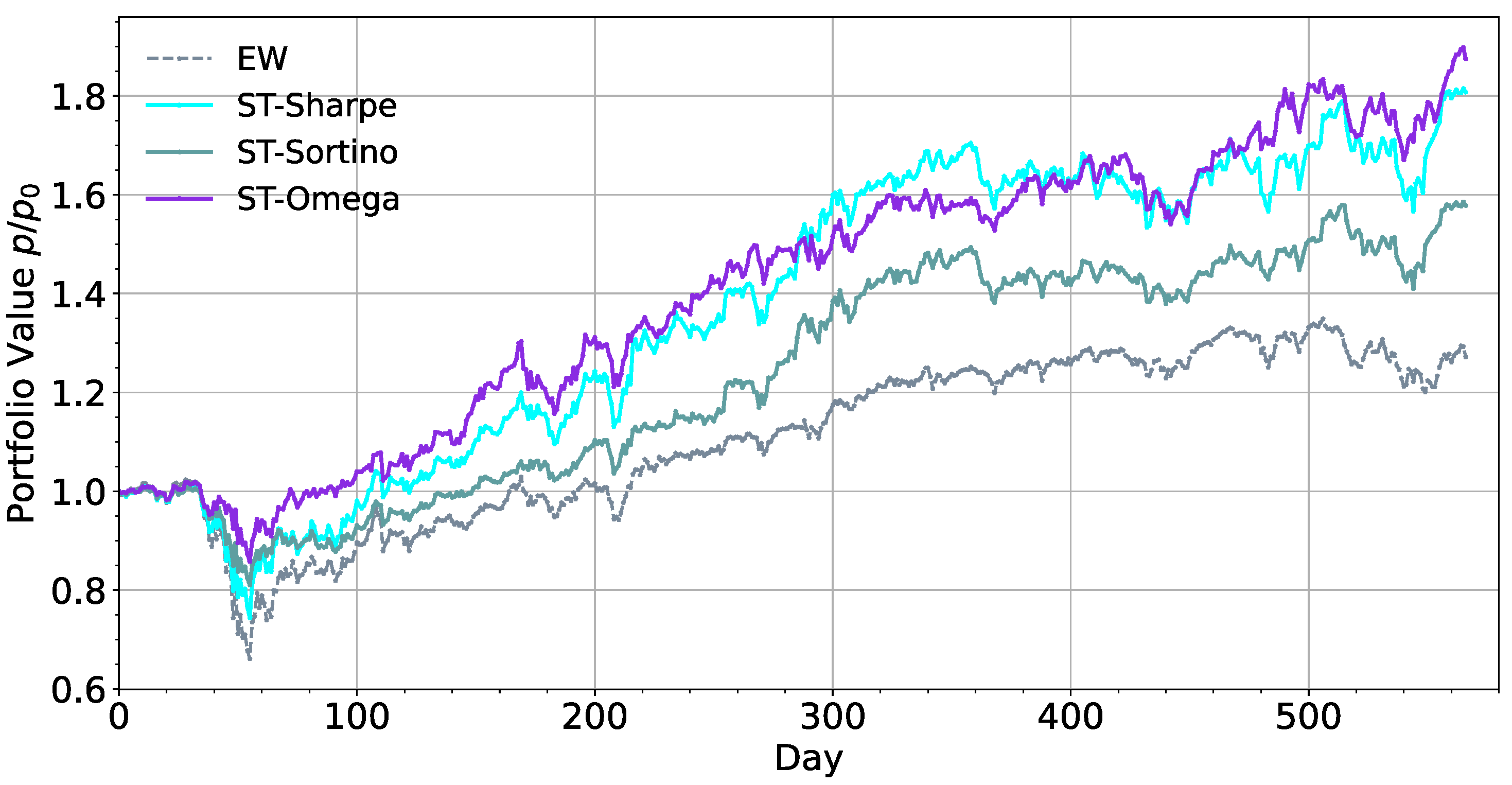
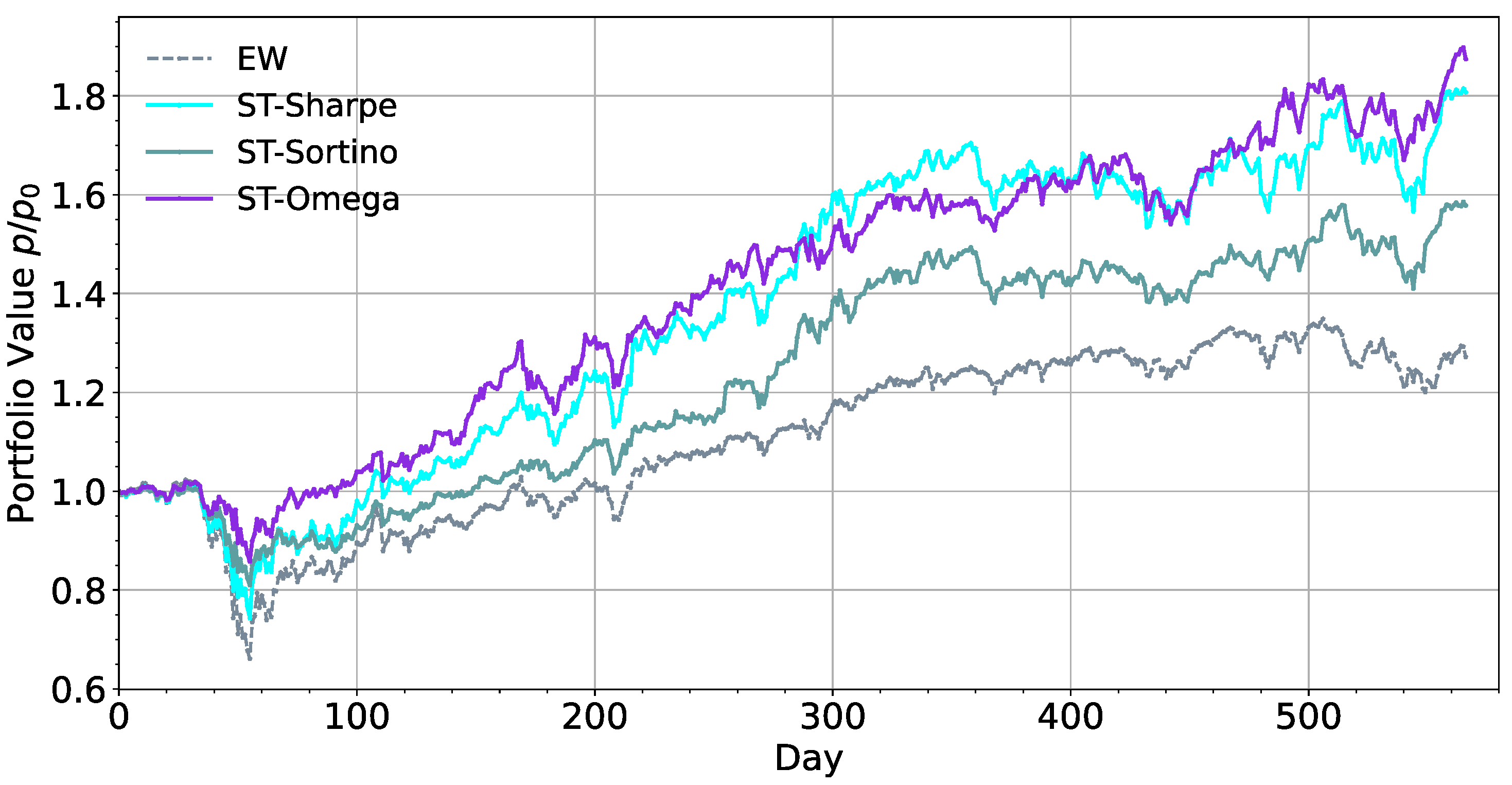
6.2. Effects of Reward Function
7. Conclusions
- (1)
- The DRL-based portfolio-management model outperforms other standard machine learning-based models in terms of Sharpe ratio, Sortino ratio, and MDD, which means that Markov decision process model is more suitable than supervised learning by allowing the tasks of “prediction” and “portfolio construction” to be combined in one integration step.
- (2)
- (3)
- Through the ablation study, it can be seen that SSDAE model has a significant effect on risk control, especially in the volatility and drawdown of model; the LSTM-AE model has a significant effect in capturing market trends, but it will also increase losses while increasing profits. By integrating the two models, we can obtain a better balance between risk and return.
- (4)
- We also found that the choice of reward function will also affect the risk preference of the model. By comparing the trading returns, Sharpe ratio, Sortino ratio, and omega ratio, we found that the more accurate assessment of the value of risk penalty means that the model has a greater tendency to output prudent action.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wolf, P.; Hubschneider, C.; Weber, M.; Bauer, A.; Härtl, J.; Dürr, F.; Zöllner, J.M. Learning How to Drive in a Real World Simulation with Deep Q-Networks. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 244–250. [Google Scholar]
- Ye, D.; Liu, Z.; Sun, M.; Shi, B.; Zhao, P.; Wu, H.; Yu, H.; Yang, S.; Wu, X.; Guo, Q. Mastering Complex Control in Moba Games with Deep Reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6672–6679. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the Game of Go without Human Knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Machado, P.; Zahid, A.; Abdulghani, A.M.; Dashtipour, K.; Heidari, H.; Imran, M.A.; Abbasi, Q.H. Energy and Performance Trade-off Optimization in Heterogeneous Computing via Reinforcement Learning. Electronics 2020, 9, 1812. [Google Scholar] [CrossRef]
- Wang, R.; Wei, H.; An, B.; Feng, Z.; Yao, J. Commission Fee Is Not Enough: A Hierarchical Reinforced Framework for Portfolio Management. arXiv 2020, arXiv:2012.12620. [Google Scholar]
- Jiang, Z.; Liang, J. Cryptocurrency Portfolio Management with Deep Reinforcement Learning. In Proceedings of the 2017 Intelligent Systems Conference (IntelliSys), London, UK, 7–8 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 905–913. [Google Scholar]
- Liang, Q.; Zhu, M.; Zheng, X.; Wang, Y. An Adaptive News-Driven Method for CVaR-Sensitive Online Portfolio Selection in Non-Stationary Financial Markets. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, International Joint Conferences on Artificial Intelligence Organization, Montreal, QC, Canada, 19–26 August 2021; pp. 2708–2715. [Google Scholar]
- Yang, H.; Liu, X.-Y.; Zhong, S.; Walid, A. Deep Reinforcement Learning for Automated Stock Trading: An Ensemble Strategy. In Proceedings of the First ACM International Conference on AI in Finance, New York, NY, USA, 15–16 October 2020; pp. 1–8. [Google Scholar]
- Chen, Y.-F.; Huang, S.-H. Sentiment-Influenced Trading System Based on Multimodal Deep Reinforcement Learning. Appl. Soft Comput. 2021, 112, 107788. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Q.; Zhao, H.; Pan, Z.; Liu, C. Adaptive Quantitative Trading: An Imitative Deep Reinforcement Learning Approach. AAAI 2020, 34, 2128–2135. [Google Scholar] [CrossRef]
- Lu, D.W. Agent Inspired Trading Using Recurrent Reinforcement Learning and LSTM Neural Networks. arXiv 2017, arXiv:1707.07338. [Google Scholar]
- Verleysen, M.; François, D. The Curse of Dimensionality in Data Mining and Time Series Prediction. In Proceedings of the International Work-Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2005; pp. 758–770. [Google Scholar]
- Betancourt, C.; Chen, W.-H. Deep Reinforcement Learning for Portfolio Management of Markets with a Dynamic Number of Assets. Expert Syst. Appl. 2021, 164, 114002. [Google Scholar] [CrossRef]
- Huang, Z.; Tanaka, F. MSPM: A Modularized and Scalable Multi-Agent Reinforcement Learning-Based System for Financial Portfolio Management. PLoS ONE 2022, 17, e0263689. [Google Scholar] [CrossRef]
- Park, H.; Sim, M.K.; Choi, D.G. An Intelligent Financial Portfolio Trading Strategy Using Deep Q-Learning. Expert Syst. Appl. 2020, 158, 113573. [Google Scholar] [CrossRef]
- Théate, T.; Ernst, D. An Application of Deep Reinforcement Learning to Algorithmic Trading. Expert Syst. Appl. 2021, 173, 114632. [Google Scholar] [CrossRef]
- Meng, Q.; Catchpoole, D.; Skillicorn, D.; Kennedy, P.J. Relational Autoencoder for Feature Extraction. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 364–371. [Google Scholar]
- Yashaswi, K. Deep Reinforcement Learning for Portfolio Optimization Using Latent Feature State Space (LFSS) Module. 2021. Available online: https://arxiv.org/abs/2102.06233 (accessed on 7 August 2022).
- Jang, J.-G.; Choi, D.; Jung, J.; Kang, U. Zoom-Svd: Fast and Memory Efficient Method for Extracting Key Patterns in an Arbitrary Time Range. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino Italy, 22–26 October 2018; pp. 1083–1092. [Google Scholar]
- Taylor, G.W.; Hinton, G.E. Factored Conditional Restricted Boltzmann Machines for Modeling Motion Style. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 1025–1032. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Soleymani, F.; Paquet, E. Financial Portfolio Optimization with Online Deep Reinforcement Learning and Restricted Stacked Autoencoder—DeepBreath. Expert Syst. Appl. 2020, 156, 113456. [Google Scholar] [CrossRef]
- Li, L. An Automated Portfolio Trading System with Feature Preprocessing and Recurrent Reinforcement Learning. arXiv 2021, arXiv:2110.05299. [Google Scholar]
- Lee, J.; Koh, H.; Choe, H.J. Learning to Trade in Financial Time Series Using High-Frequency through Wavelet Transformation and Deep Reinforcement Learning. Appl. Intell. 2021, 51, 6202–6223. [Google Scholar] [CrossRef]
- Li, Y.; Zheng, W.; Zheng, Z. Deep Robust Reinforcement Learning for Practical Algorithmic Trading. IEEE Access 2019, 7, 108014–108022. [Google Scholar] [CrossRef]
- Wu, M.-E.; Syu, J.-H.; Lin, J.C.-W.; Ho, J.-M. Portfolio Management System in Equity Market Neutral Using Reinforcement Learning. Appl. Intell. 2021, 51, 8119–8131. [Google Scholar] [CrossRef]
- Sharpe, W.F. Mutual Fund Performance. J. Bus. 1966, 39, 119–138. [Google Scholar] [CrossRef]
- Wu, X.; Chen, H.; Wang, J.; Troiano, L.; Loia, V.; Fujita, H. Adaptive Stock Trading Strategies with Deep Reinforcement Learning Methods. Inf. Sci. 2020, 538, 142–158. [Google Scholar] [CrossRef]
- Almahdi, S.; Yang, S.Y. An Adaptive Portfolio Trading System: A Risk-Return Portfolio Optimization Using Recurrent Reinforcement Learning with Expected Maximum Drawdown. Expert Syst. Appl. 2017, 87, 267–279. [Google Scholar] [CrossRef]
- Grinold, R.C.; Kahn, R.N. Active Portfolio Management: Quantitative Theory and Applications; Probus: Chicago, IL, USA, 1995. [Google Scholar]
- Magdon-Ismail, M.; Atiya, A.F. Maximum Drawdown. Risk Mag. 2004, 17, 99–102. [Google Scholar]
- Benhamou, E.; Guez, B.; Paris, N. Omega and Sharpe Ratio. arXiv 2019, arXiv:1911.10254. [Google Scholar] [CrossRef]
- Bin, L. Goods Tariff vs Digital Services Tax: Transatlantic Financial Market Reactions. Econ. Manag. Financ. Mark. 2022, 17, 9–30. [Google Scholar]
- Vătămănescu, E.-M.; Bratianu, C.; Dabija, D.-C.; Popa, S. Capitalizing Online Knowledge Networks: From Individual Knowledge Acquisition towards Organizational Achievements. J. Knowl. Manag. 2022. [Google Scholar] [CrossRef]
- Priem, R. An Exploratory Study on the Impact of the COVID-19 Confinement on the Financial Behavior of Individual Investors. Econ. Manag. Financ. Mark. 2021, 16, 9–40. [Google Scholar]
- Barbu, C.M.; Florea, D.L.; Dabija, D.-C.; Barbu, M.C.R. Customer Experience in Fintech. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 1415–1433. [Google Scholar] [CrossRef]
- Fischer, T.G. Reinforcement Learning in Financial Markets—A Survey; FAU Discussion Papers in Economics. 2018. Available online: https://www.econstor.eu/handle/10419/183139 (accessed on 7 August 2022).
- Chen, L.; Gao, Q. Application of Deep Reinforcement Learning on Automated Stock Trading. In Proceedings of the 2019 IEEE 10th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 18–20 October 2019; pp. 29–33. [Google Scholar]
- Dang, Q.-V. Reinforcement Learning in Stock Trading. In Proceedings of the International Conference on Computer Science, Applied Mathematics and Applications, Hanoi, Vietnam, 19–20 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 311–322. [Google Scholar]
- Jeong, G.; Kim, H.Y. Improving Financial Trading Decisions Using Deep Q-Learning: Predicting the Number of Shares, Action Strategies, and Transfer Learning. Expert Syst. Appl. 2019, 117, 125–138. [Google Scholar] [CrossRef]
- Deng, Y.; Bao, F.; Kong, Y.; Ren, Z.; Dai, Q. Deep Direct Reinforcement Learning for Financial Signal Representation and Trading. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 653–664. [Google Scholar] [CrossRef]
- Moody, J.; Saffell, M. Learning to Trade via Direct Reinforcement. IEEE Trans. Neural Netw. 2001, 12, 875–889. [Google Scholar] [CrossRef]
- Zhang, Z.; Zohren, S.; Roberts, S. Deep Reinforcement Learning for Trading. arXiv 2019, arXiv:1911.10107. [Google Scholar] [CrossRef]
- Vishal, M.; Satija, Y.; Babu, B.S. Trading Agent for the Indian Stock Market Scenario Using Actor-Critic Based Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Computation System and Information Technology for Sustainable Solutions (CSITSS), Bangalore, India, 16–18 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. Available online: https://ieeexplore.ieee.org/abstract/document/9683467 (accessed on 7 August 2022).
- Pretorius, R.; van Zyl, T. Deep Reinforcement Learning and Convex Mean-Variance Optimisation for Portfolio Management 2022. Available online: https://arxiv.org/abs/2203.11318 (accessed on 5 August 2022).
- Raffin, A.; Hill, A.; Ernestus, M.; Gleave, A.; Kanervisto, A.; Dormann, N. Stable Baselines3. 2019. Available online: https://www.ai4europe.eu/sites/default/files/2021-06/README_5.pdf (accessed on 7 August 2022).
- Bakhti, Y.; Fezza, S.A.; Hamidouche, W.; Déforges, O. DDSA: A Defense against Adversarial Attacks Using Deep Denoising Sparse Autoencoder. IEEE Access 2019, 7, 160397–160407. [Google Scholar] [CrossRef]
- Bao, W.; Yue, J.; Rao, Y. A Deep Learning Framework for Financial Time Series Using Stacked Autoencoders and Long-Short Term Memory. PLoS ONE 2017, 12, e0180944. [Google Scholar] [CrossRef] [PubMed]
- Jung, G.; Choi, S.-Y. Forecasting Foreign Exchange Volatility Using Deep Learning Autoencoder-LSTM Techniques. Complexity 2021, 2021, 6647534. [Google Scholar] [CrossRef]
- Soleymani, F.; Paquet, E. Deep Graph Convolutional Reinforcement Learning for Financial Portfolio Management–DeepPocket. Expert Syst. Appl. 2021, 182, 115127. [Google Scholar] [CrossRef]
- Qiu, Y.; Liu, R.; Lee, R.S.T. The Design and Implementation of Quantum Finance-Based Hybrid Deep Reinforcement Learning Portfolio Investment System. J. Phys. Conf. Ser. 2021, 1828, 012011. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.-A. Extracting and Composing Robust Features with Denoising Autoencoders. In Proceedings of the 25th International Conference on Machine Learning, New York, NY, USA, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Graves, A. Long Short-Term Memory. Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Nelson, D.M.; Pereira, A.C.; De Oliveira, R.A. Stock Market’s Price Movement Prediction with LSTM Neural Networks. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1419–1426. [Google Scholar]
- Yao, S.; Luo, L.; Peng, H. High-Frequency Stock Trend Forecast Using LSTM Model. In Proceedings of the 2018 13th International Conference on Computer Science & Education (ICCSE), Colombo, Sri Lanka, 8–11 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Zhao, Z.; Rao, R.; Tu, S.; Shi, J. Time-Weighted LSTM Model with Redefined Labeling for Stock Trend Prediction. In Proceedings of the 2017 IEEE 29th International Conference on Tools with Artificial Intelligence (ICTAI), Boston, MA, USA, 6–8 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1210–1217. [Google Scholar]
- Liu, X.-Y.; Yang, H.; Gao, J.; Wang, C.D. FinRL: Deep Reinforcement Learning Framework to Automate Trading in Quantitative Finance. In Proceedings of the Second ACM International Conference on AI in Finance, New York, NY, USA, 3 November 2021; pp. 1–9. [Google Scholar]
- Yang, H.; Liu, X.-Y.; Wu, Q. A Practical Machine Learning Approach for Dynamic Stock Recommendation. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1693–1697. [Google Scholar]
- Zhang, Y.; Clavera, I.; Tsai, B.; Abbeel, P. Asynchronous Methods for Model-Based Reinforcement Learning. arXiv 2019, arXiv:1910.12453. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Young, T.W. Calmar Ratio: A Smoother Tool. Futures 1991, 20, 40. [Google Scholar]
- Borodin, A.; El-Yaniv, R.; Gogan, V. Can We Learn to Beat the Best Stock. JAIR 2004, 21, 579–594. [Google Scholar] [CrossRef]
- Cover, T.M. Universal Portfolios. In The Kelly Capital Growth Investment Criterion; World Scientific Handbook in Financial Economics Series; World Scientific: Singapore, 2011; Volume 3, pp. 181–209. ISBN 978-981-4293-49-5. [Google Scholar]
- Li, B.; Hoi, S.C.H.; Gopalkrishnan, V. CORN: Correlation-Driven Nonparametric Learning Approach for Portfolio Selection. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–29. [Google Scholar] [CrossRef]
- Agarwal, A.; Hazan, E.; Kale, S.; Schapire, R.E. Algorithms for Portfolio Management Based on the Newton Method. In Proceedings of the 23rd International Conference on Machine Learning, New York, NY, USA, 25–29 June 2006; pp. 9–16. [Google Scholar]
- Yang, H.; Liu, X.-Y.; Zhong, S.; Walid, A. Deep Reinforcement Learning for Automated Stock Trading: An Ensemble Strategy. SSRN J. 2020. [Google Scholar] [CrossRef]
- Yao, W.; Ren, X.; Su, J. An Inception Network with Bottleneck Attention Module for Deep Reinforcement Learning Framework in Financial Portfolio Management. In Proceedings of the 2022 7th International Conference on Big Data Analytics (ICBDA), Guangzhou, China, 4 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 310–316. [Google Scholar]
- Ye, Y.; Pei, H.; Wang, B.; Chen, P.-Y.; Zhu, Y.; Xiao, J.; Li, B. Reinforcement-Learning Based Portfolio Management with Augmented Asset Movement Prediction States. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1112–1119. [Google Scholar]
- Ren, X.; Jiang, Z.; Su, J. The Use of Features to Enhance the Capability of Deep Reinforcement Learning for Investment Portfolio Management. In Proceedings of the 2021 IEEE 6th International Conference on Big Data Analytics (ICBDA), Xiamen, China, 5 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 44–50. [Google Scholar]
- Jorion, P. Value at Risk. 2000. Available online: http://bear.warrington.ufl.edu/aitsahlia/Financial_Risk_Management.pdf (accessed on 7 August 2022).
- Rockafellar, R.T.; Uryasev, S. Conditional Value-at-Risk for General Loss Distributions. J. Bank. Financ. 2002, 26, 1443–1471. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Name | Number |
|---|---|---|
| Moving averages | Simple Moving Average (SMA), Exponential Moving Average (EMA), Weighted Moving Averages (WMA), Bollinger Bands (BBANDS) | 4 |
| Volatility | Average True Range (ATR), True Range (TRANGE), Ulcer Index (UI) | 3 |
| Trend | Moving Average Convergence Divergence (MACD), Volatility Ratio (VR), Schaff Trend Cycle (STC), Days Payable Outstanding (DPO), Triple Exponential Average (TRIX), Know Sure Thing (KST) | 6 |
| Momentum | Relative Strength Index (RSI), Awesome Oscillator (AO), True Strength Index (TSI), Average Directional Index (ADX), Aroon Oscillator (AROON), Money Flow Index (MFI), Momentum (MOM), Rate of Change (ROC), Williams %R (WILLR), Stochastic (STOCH), Elder Ray Index (ERI) | 11 |
| Volume | On-Balance Volume (OBV), Force Index (FI), Accumulation/Distribution (AD), Ease of Movement (EM), Chaikin Money Flow (CMF), Volume Price Trend (VPT), Negative Volume Index (NVI) | 7 |
| Total | - | 31 |
| Model | ARR (%) | MDD (%) | SR | CMR | Alpha | Beta |
|---|---|---|---|---|---|---|
| EW | 27.2 | −35.4 | 0.54 | 0.32 | −0.02 | 1.01 |
| Anticor | 48.4 | −33.5 | 0.67 | 0.57 | 0.02 | 1.08 |
| CRP | 32.9 | −33.2 | 0.62 | 0.40 | −0.04 | 0.98 |
| CORN | 48.9 | −33.4 | 0.71 | 0.58 | 0.05 | 0.93 |
| ONS | 61.8 | −44.0 | 0.71 | 0.54 | 0.04 | 1.35 |
| ES | 67.2 | −35.6 | 0.88 | 0.72 | 0.07 | 1.10 |
| PCA and DWT | 49.8 | −29.4 | 0.75 | 0.67 | 0.04 | 0.96 |
| SwanTrader | 87.5 | −15.8 | 1.52 | 2.04 | 0.19 | 0.65 |
| Model | ARR (%) | MDD (%) | SR | CMR | Alpha | Beta |
|---|---|---|---|---|---|---|
| ST-OS | 63.6 | −22.7 | 1.03 | 1.08 | 0.10 | 0.77 |
| ST-OL | 73.4 | −38.4 | 0.90 | 0.72 | 0.09 | 1.09 |
| SwanTrader | 87.5 | −15.8 | 1.52 | 2.04 | 0.19 | 0.65 |
| Model | ARR (%) | MDD (%) | SR | CMR | Alpha | Beta |
|---|---|---|---|---|---|---|
| ST-Sharpe | 80.7 | −26.4 | 1.17 | 1.14 | 0.14 | 0.84 |
| ST-Sortino | 57.8 | −19.5 | 1.21 | 1.15 | 0.12 | 0.56 |
| SwanTrader | 87.5 | −15.8 | 1.52 | 2.04 | 0.19 | 0.65 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, H.; Liu, J.; Zhang, Q. Applications of Markov Decision Process Model and Deep Learning in Quantitative Portfolio Management during the COVID-19 Pandemic. Systems 2022, 10, 146. https://doi.org/10.3390/systems10050146
Yue H, Liu J, Zhang Q. Applications of Markov Decision Process Model and Deep Learning in Quantitative Portfolio Management during the COVID-19 Pandemic. Systems. 2022; 10(5):146. https://doi.org/10.3390/systems10050146
Chicago/Turabian StyleYue, Han, Jiapeng Liu, and Qin Zhang. 2022. "Applications of Markov Decision Process Model and Deep Learning in Quantitative Portfolio Management during the COVID-19 Pandemic" Systems 10, no. 5: 146. https://doi.org/10.3390/systems10050146
APA StyleYue, H., Liu, J., & Zhang, Q. (2022). Applications of Markov Decision Process Model and Deep Learning in Quantitative Portfolio Management during the COVID-19 Pandemic. Systems, 10(5), 146. https://doi.org/10.3390/systems10050146