
Effects of Temporal Processing on Speech-in-Noise Perception in Middle-Aged Adults

Abstract
Simple Summary
Abstract
1. Introduction
1.1. Mechanisms of Temporal Processing Investigated
1.2. The Potential Influence of Speech-in-Noise Task Characteristics
2. Materials and Methods
2.1. Participants
2.2. Speech-in-Noise Testing
2.2.1. AzBio Sentence Lists
2.2.2. Spatial Release from Two Talkers
2.3. Psychoacoustic Testing
Dichotic Frequency Modulation (FM) Detection
2.4. Electrophysiology
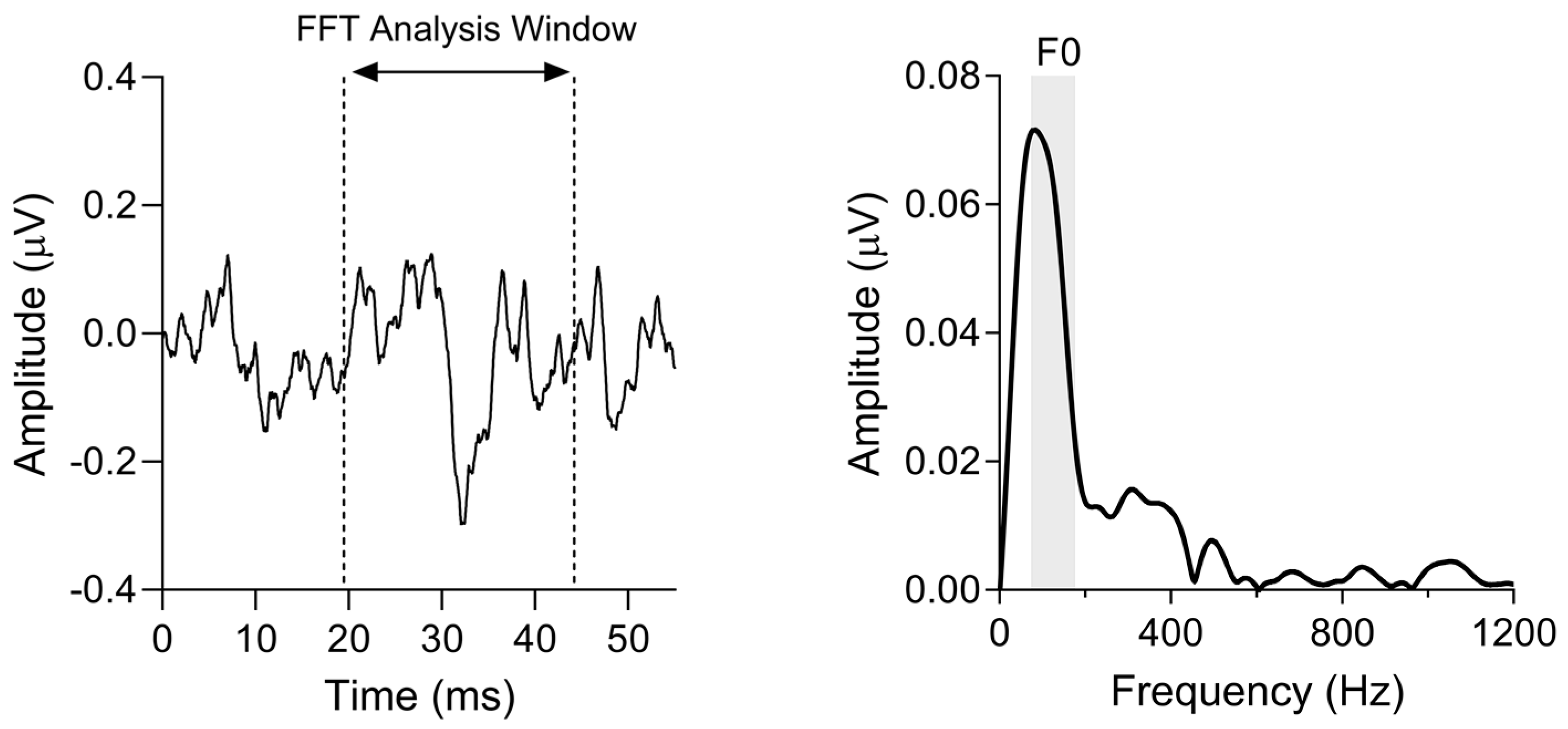
2.4.1. Frequency Following Response (FFR)
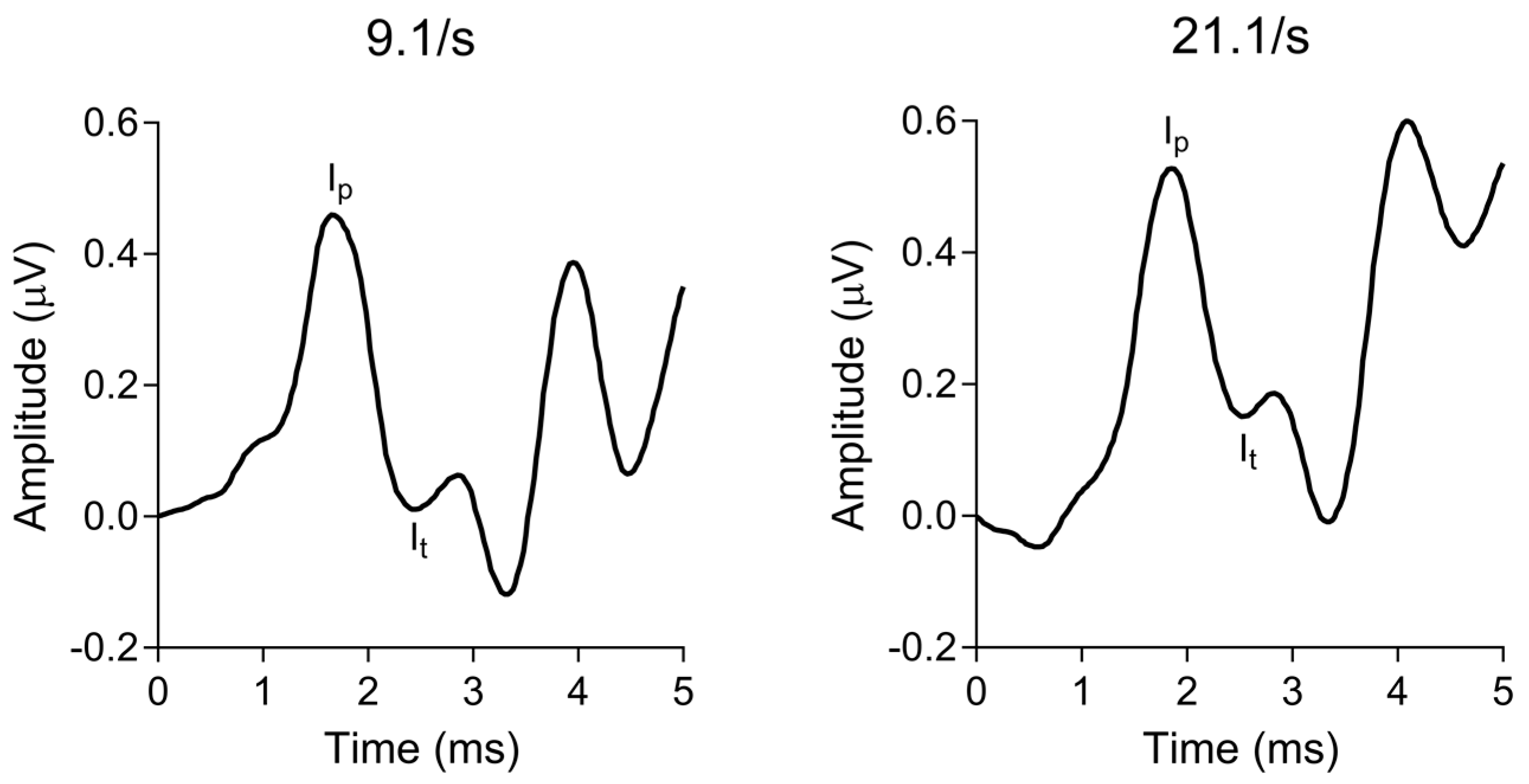
2.4.2. Electrocochleography (ECochG)
2.5. Statistical Analyses
3. Results
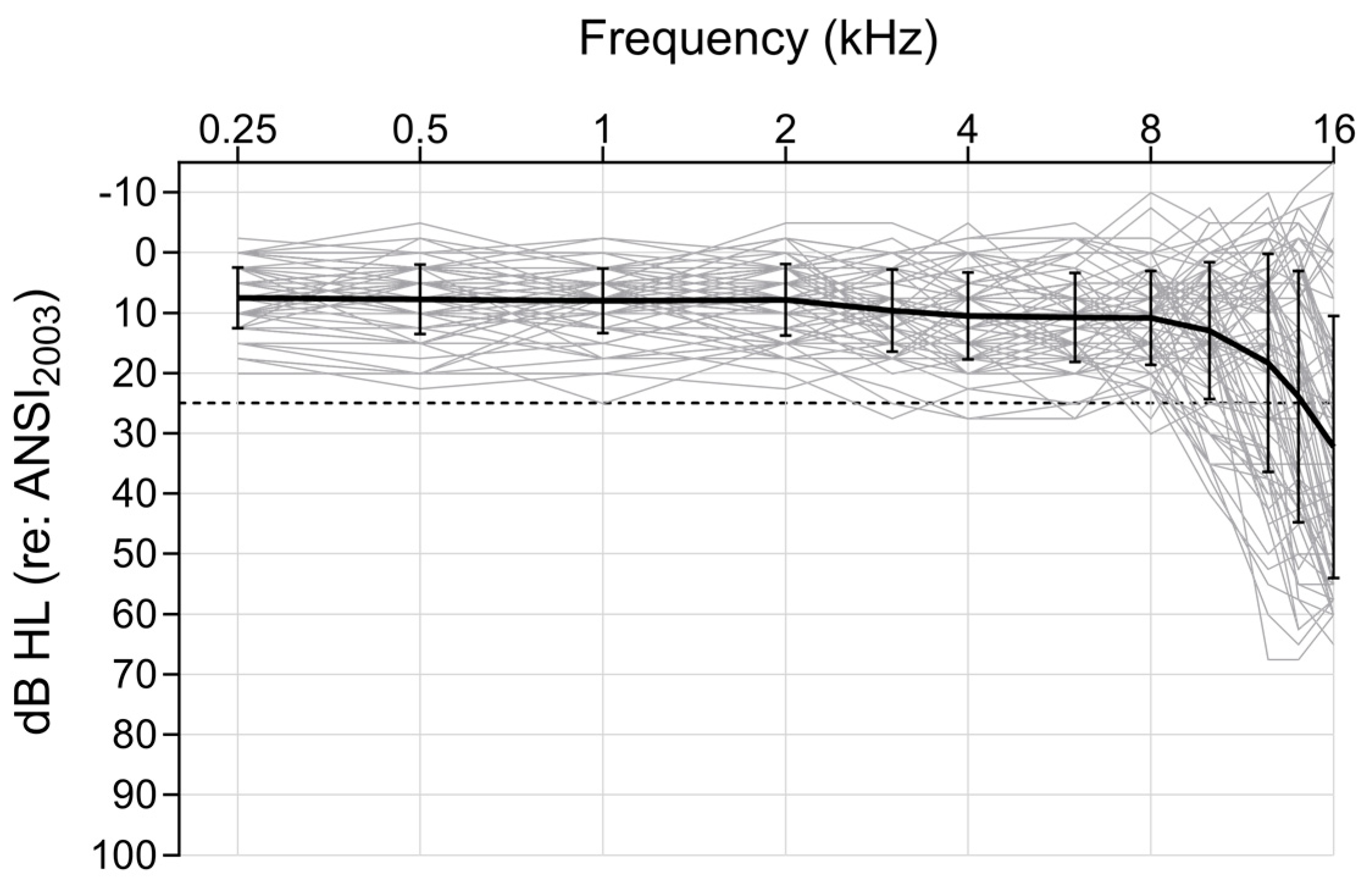
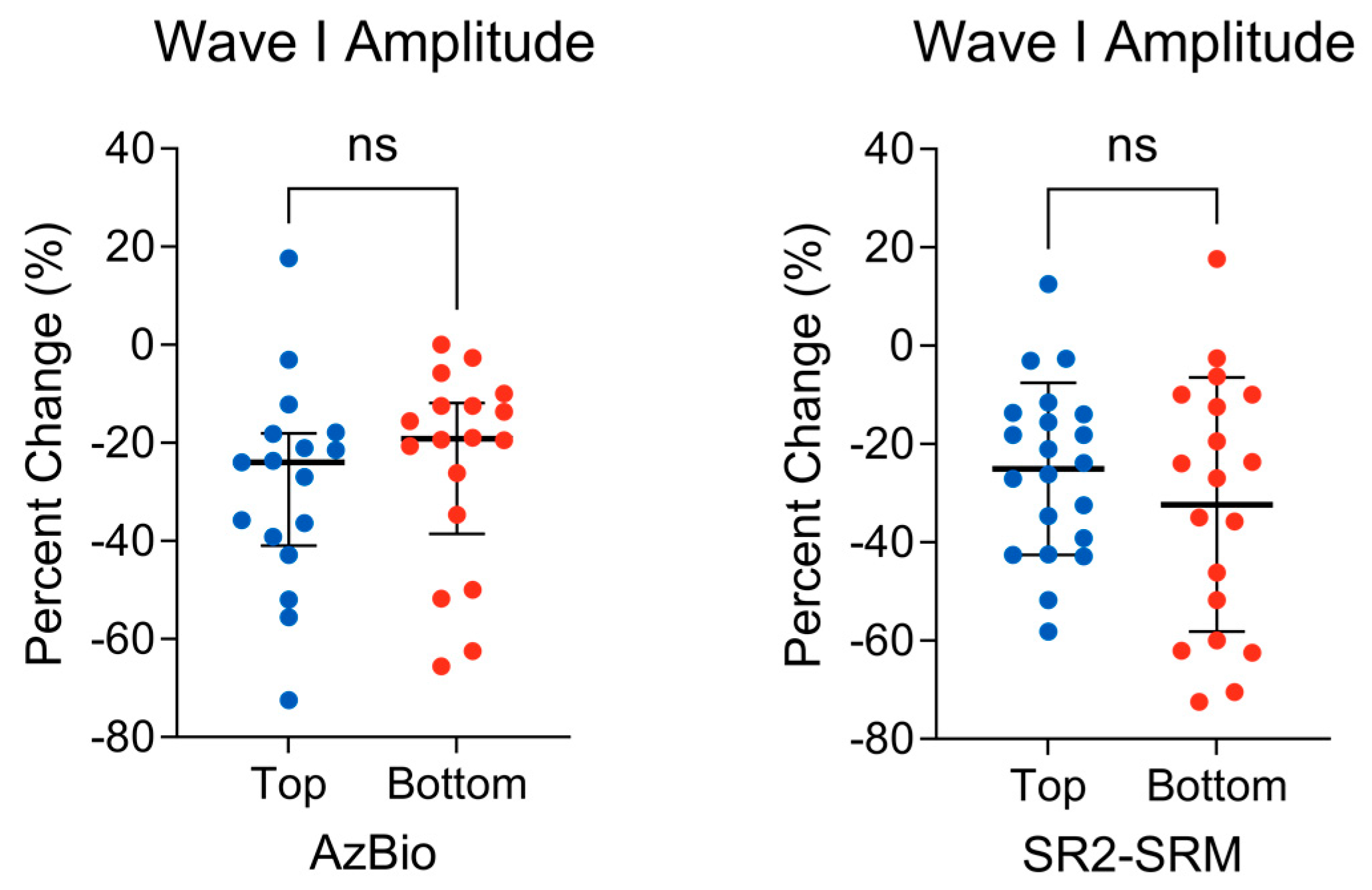
3.1. Peripheral Auditory Nerve Function
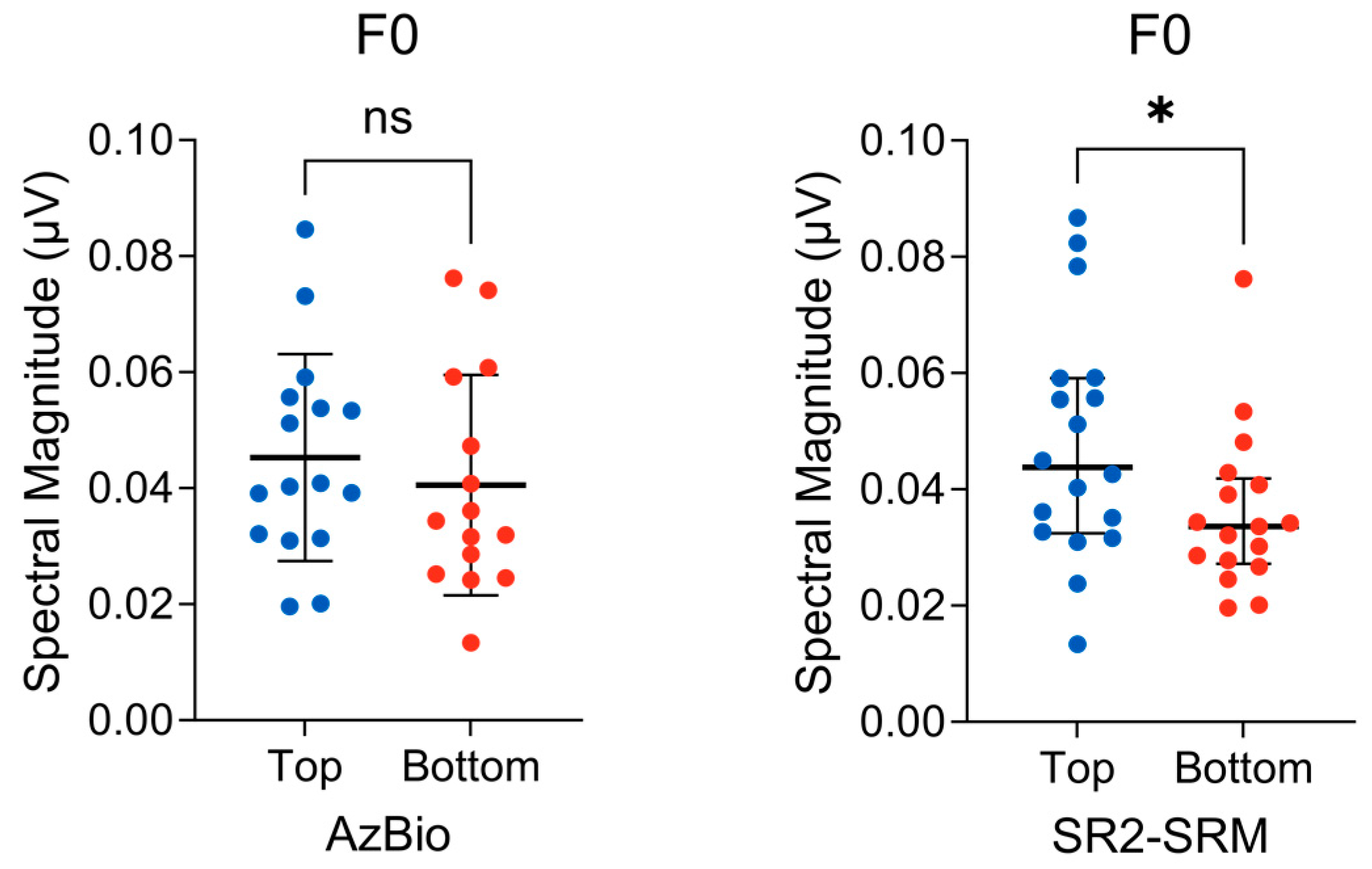
3.2. Subcortical F0 Encoding
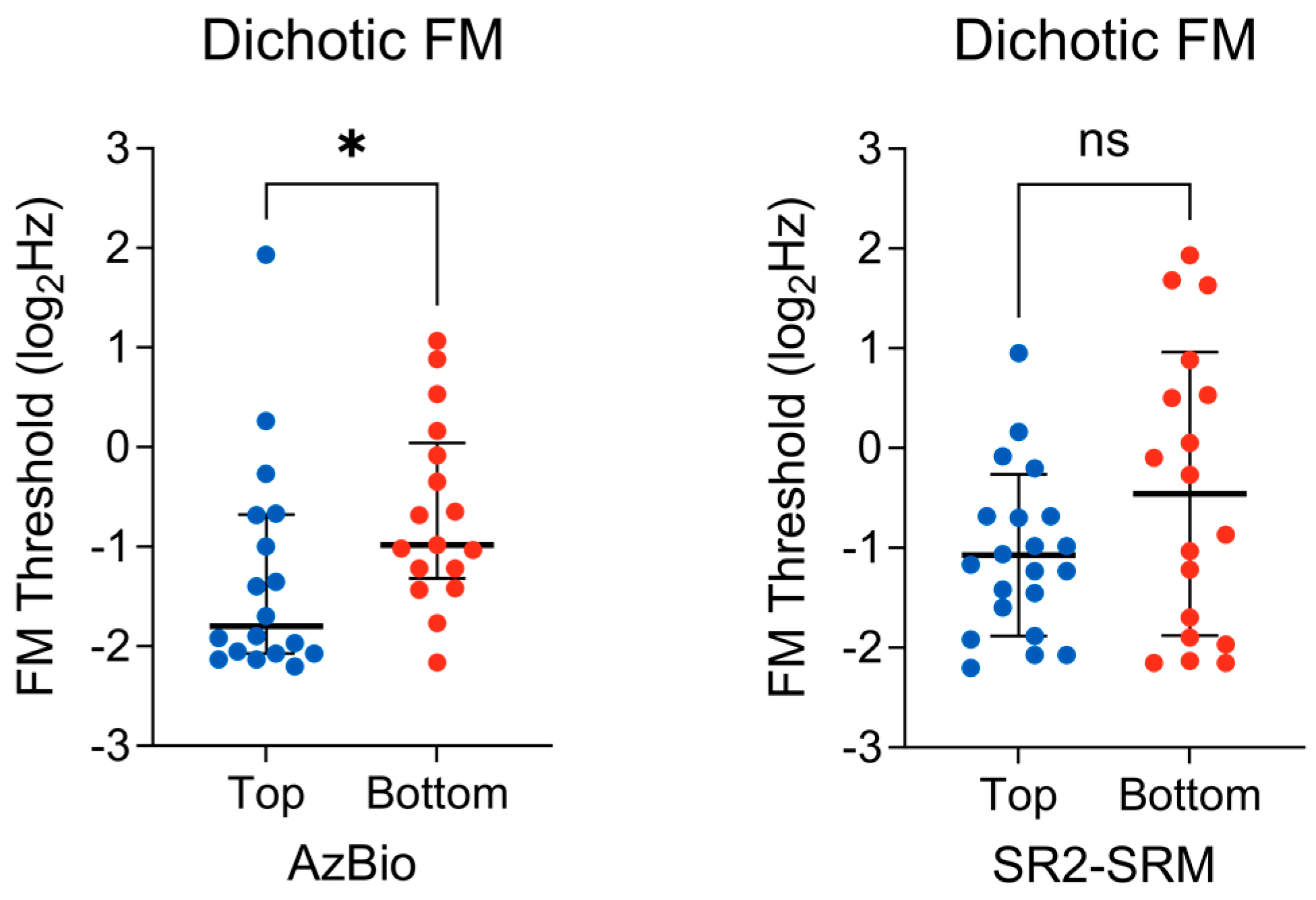
3.3. Binaural TFS Sensitivity
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Beck, D.L.; Danhauer, J.L.; Abrams, H.B.; Atcherson, S.R.; Brown, D.K.; Chasin, M.; Clark, J.G.; de Placido, C.; Edwards, B.; Fabry, D.A.; et al. Audiologic Considerations for People with Normal Hearing Sensitivity Yet Hearing Difficulty and/or Speech-in-Noise Problems: Why do so many people with “normal hearing” report that they have hearing problems? Hear. Rev. 2018, 25, 28. [Google Scholar]
- Parthasarathy, A.; Hancock, K.E.; Bennett, K.; Degruttola, V.; Polley, D.B. Bottom-up and top-down neural signatures of disordered multi-talker speech perception in adults with normal hearing. eLife 2020, 9, e51419. [Google Scholar] [CrossRef] [PubMed]
- Killion, M.C.; Niquette, P.A. What can the pure-tone audiogram tell us about a patient’s SNR loss? Hear. J. 2000, 53, 46–48. [Google Scholar] [CrossRef]
- Arlinger, S. Negative consequences of uncorrected hearing loss—A review. Int. J. Audiol. 2003, 42 (Suppl. S2), 2s17–2s20. [Google Scholar] [CrossRef] [PubMed]
- Musiek, F.E.; Shinn, J.; Chermak, G.D.; Bamiou, D.-E. Perspectives on the Pure-Tone Audiogram. J. Am. Acad. Audiol. 2017, 28, 655–671. [Google Scholar] [CrossRef] [PubMed]
- Eggermont, J.J. Auditory Temporal Processing and Its Disorders; Oxford University Press: Oxford, UK, 2015. [Google Scholar]
- Moore, B.C.J. The Role of Temporal Fine Structure Processing in Pitch Perception, Masking, and Speech Perception for Normal-Hearing and Hearing-Impaired People. J. Assoc. Res. Otolaryngol. 2008, 9, 399–406. [Google Scholar] [CrossRef] [PubMed]
- Anderson, S.; Parbery-Clark, A.; Yi, H.-G.; Kraus, N. A Neural Basis of Speech-in-Noise Perception in Older Adults. Ear Hear. 2011, 32, 750–757. [Google Scholar] [CrossRef] [PubMed]
- Babkoff, H.; Fostick, L. Age-related changes in auditory processing and speech perception: Cross-sectional and longitudinal analyses. Eur. J. Ageing 2017, 14, 269–281. [Google Scholar] [CrossRef] [PubMed]
- Füllgrabe, C.; Moore, B.C.J.; Stone, M.A. Age-group differences in speech identification despite matched audiometrically normal hearing: Contributions from auditory temporal processing and cognition. Front. Aging Neurosci. 2015, 6, 347. [Google Scholar] [CrossRef] [PubMed]
- Gordon-Salant, S.; Fitzgibbons, P.J.; Yeni-Komshian, G.H. Auditory Temporal Processing and Aging: Implications for Speech Understanding of Older People. Audiol. Res. 2011, 1, e4. [Google Scholar] [CrossRef]
- Humes, L.E.; Busey, T.A.; Craig, J.; Kewley-Port, D. Are age-related changes in cognitive function driven by age-related changes in sensory processing? Atten. Percept. Psychophys. 2013, 75, 508–524. [Google Scholar] [CrossRef] [PubMed]
- Tremblay, K.L.; Pinto, A.; Fischer, M.E.; Klein, B.E.K.; Klein, R.; Levy, S.; Tweed, T.S.; Cruickshanks, K.J. Self-Reported Hearing Difficulties Among Adults with Normal Audiograms. Ear Hear. 2015, 36, e290–e299. [Google Scholar] [CrossRef] [PubMed]
- Hoffman, H.J.; Dobie, R.A.; Losonczy, K.G.; Themann, C.L.; Flamme, G.A. Declining Prevalence of Hearing Loss in US Adults Aged 20 to 69 Years. JAMA Otolaryngol. Head Neck Surg. 2017, 143, 274–285. [Google Scholar] [CrossRef] [PubMed]
- Plack, C.J.; Barker, D.; Prendergast, G. Perceptual Consequences of “Hidden” Hearing Loss. Trends Hear. 2014, 18, 233121651455062. [Google Scholar] [CrossRef] [PubMed]
- Kujawa, S.G.; Liberman, M.C. Adding Insult to Injury: Cochlear Nerve Degeneration after “Temporary” Noise-Induced Hearing Loss. J. Neurosci. 2009, 29, 14077–14085. [Google Scholar] [CrossRef] [PubMed]
- Furman, A.C.; Kujawa, S.G.; Liberman, M.C. Noise-induced cochlear neuropathy is selective for fibers with low spontaneous rates. J. Neurophysiol. 2013, 110, 577–586. [Google Scholar] [CrossRef] [PubMed]
- Lobarinas, E.; Spankovich, C.; Le Prell, C.G. Evidence of “hidden hearing loss” following noise exposures that produce robust TTS and ABR wave-I amplitude reductions. Hear. Res. 2017, 349, 155–163. [Google Scholar] [CrossRef] [PubMed]
- Bharadwaj, H.; Verhulst, S.; Shaheen, L.; Liberman, M.C.; Shinn-Cunningham, B. Cochlear neuropathy and the coding of supra-threshold sound. Front. Syst. Neurosci. 2014, 8, 26. [Google Scholar] [CrossRef] [PubMed]
- Brugge, J.F.; Anderson, D.J.; Hind, J.E.; Rose, J.E. Time structure of discharges in single auditory nerve fibers of the squirrel monkey in response to complex periodic sounds. J. Neurophysiol. 1969, 32, 386–401. [Google Scholar] [CrossRef]
- Anderson, S.; Karawani, H. Objective evidence of temporal processing deficits in older adults. Hear. Res. 2020, 397, 108053. [Google Scholar] [CrossRef] [PubMed]
- Sergeyenko, Y.; Lall, K.; Liberman, M.C.; Kujawa, S.G. Age-Related Cochlear Synaptopathy: An Early-Onset Contributor to Auditory Functional Decline. J. Neurosci. 2013, 33, 13686–13694. [Google Scholar] [CrossRef] [PubMed]
- Bramhall, N.; Ong, B.; Ko, J.; Parker, M. Speech Perception Ability in Noise is Correlated with Auditory Brainstem Response Wave I Amplitude. J. Am. Acad. Audiol. 2015, 26, 509–517. [Google Scholar] [CrossRef] [PubMed]
- Liberman, M.C.; Epstein, M.J.; Cleveland, S.S.; Wang, H.; Maison, S.F. Toward a Differential Diagnosis of Hidden Hearing Loss in Humans. PLoS ONE 2016, 11, e0162726. [Google Scholar] [CrossRef] [PubMed]
- Ridley, C.L.; Kopun, J.G.; Neely, S.T.; Gorga, M.P.; Rasetshwane, D.M. Using Thresholds in Noise to Identify Hidden Hearing Loss in Humans. Ear Hear. 2018, 39, 829–844. [Google Scholar] [CrossRef] [PubMed]
- Grant, K.J.; Mepani, A.M.; Wu, P.; Hancock, K.E.; de Gruttola, V.; Liberman, M.C.; Maison, S.F. Electrophysiological markers of cochlear function correlate with hearing-in-noise performance among audiometrically normal subjects. J. Neurophysiol. 2020, 124, 418–431. [Google Scholar] [CrossRef] [PubMed]
- Le Prell, C.G. Effects of noise exposure on auditory brainstem response and speech-in-noise tasks: A review of the literature. Int. J. Audiol. 2019, 58, S3–S32. [Google Scholar] [CrossRef]
- Bramhall, N.F. Use of the auditory brainstem response for assessment of cochlear synaptopathy in humans. J. Acoust. Soc. Am. 2021, 150, 4440–4451. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Kong, L.; Wang, Q.; Wu, X.; Li, L. Auditory frequency-following response: A neurophysiological measure for studying the “cocktail-party problem”. Neurosci. Biobehav. Rev. 2011, 35, 2046–2057. [Google Scholar] [CrossRef]
- Peng, F.; Innes-Brown, H.; McKay, C.M.; Fallon, J.B.; Zhou, Y.; Wang, X.; Hu, N.; Hou, W. Temporal Coding of Voice Pitch Contours in Mandarin Tones. Front. Neural Circuits 2018, 12, 55. [Google Scholar] [CrossRef]
- Song, J.H.; Skoe, E.; Banai, K.; Kraus, N. Perception of Speech in Noise: Neural Correlates. J. Cogn. Neurosci. 2011, 23, 2268–2279. [Google Scholar] [CrossRef]
- Moon, I.J.; Hong, S.H. What Is Temporal Fine Structure and Why Is It Important? Korean J. Audiol. 2014, 18, 1. [Google Scholar] [CrossRef] [PubMed]
- Anderson, S.; Skoe, E.; Chandrasekaran, B.; Kraus, N. Neural Timing Is Linked to Speech Perception in Noise. J. Neurosci. 2010, 30, 4922–4926. [Google Scholar] [CrossRef] [PubMed]
- Chandrasekaran, B.; Kraus, N. The scalp-recorded brainstem response to speech: Neural origins and plasticity. Psychophysiology 2010, 47, 236–246. [Google Scholar] [CrossRef] [PubMed]
- Bidelman, G.M.; Momtaz, S. Subcortical rather than cortical sources of the frequency-following response (FFR) relate to speech-in-noise perception in normal-hearing listeners. Neurosci. Lett. 2021, 746, 135664. [Google Scholar] [CrossRef] [PubMed]
- Lorenzi, C.; Gilbert, G.; Carn, H.; Garnier, S.; Moore, B.C. Speech perception problems of the hearing impaired reflect inability to use temporal fine structure. Proc. Natl. Acad. Sci. USA 2006, 103, 18866–18869. [Google Scholar] [CrossRef] [PubMed]
- Moore, B.C.J. The roles of temporal envelope and fine structure information in auditory perception. Acoust. Sci. Technol. 2019, 40, 61–83. [Google Scholar] [CrossRef]
- Gallun, F.J.; Coco, L.; Koerner, T.K.; Larrea-Mancera, E.S.L.; Molis, M.R.; Eddins, D.A.; Seitz, A.R. Relating Suprathreshold Auditory Processing Abilities to Speech Understanding in Competition. Brain Sci. 2022, 12, 695. [Google Scholar] [CrossRef] [PubMed]
- Hoover, E.C.; Souza, P.E.; Gallun, F.J. Auditory and Cognitive Factors Associated with Speech-in-Noise Complaints following Mild Traumatic Brain Injury. J. Am. Acad. Audiol. 2017, 28, 325–339. [Google Scholar] [CrossRef] [PubMed]
- Füllgrabe, C. Age-dependent changes in temporal-fine-structure processing in the absence of peripheral hearing loss. Am. J. Audiol. 2013, 22, 313–315. [Google Scholar] [CrossRef] [PubMed]
- Grose, J.H.; Mamo, S.K. Frequency modulation detection as a measure of temporal processing: Age-related monaural and binaural effects. Hear. Res. 2012, 294, 49–54. [Google Scholar] [CrossRef] [PubMed]
- Hoover, E.C.; Kinney, B.N.; Bell, K.L.; Gallun, F.J.; Eddins, D.A. A Comparison of Behavioral Methods for Indexing the Auditory Processing of Temporal Fine Structure Cues. J. Speech Lang. Hear. Res. 2019, 62, 2018–2034. [Google Scholar] [CrossRef] [PubMed]
- DiNino, M.; Holt, L.L.; Shinn-Cunningham, B.G. Cutting Through the Noise: Noise-Induced Cochlear Synaptopathy and Individual Differences in Speech Understanding Among Listeners with Normal Audiograms. Ear Hear. 2022, 43, 9–22. [Google Scholar] [CrossRef] [PubMed]
- Brungart, D.S. Informational and energetic masking effects in the perception of two simultaneous talkers. J. Acoust. Soc. Am. 2001, 109, 1101–1109. [Google Scholar] [CrossRef] [PubMed]
- Bregman, A.S. Auditory Scene Analysis: The Perceptual Organization of Sound; MIT Press: Cambridge, MA, USA, 1990. [Google Scholar] [CrossRef]
- Spahr, A.J.; Dorman, M.F.; Litvak, L.M.; Van Wie, S.; Gifford, R.H.; Loizou, P.C.; Loiselle, L.M.; Oakes, T.; Cook, S. Development and Validation of the AzBio Sentence Lists. Ear Hear. 2012, 33, 112–117. [Google Scholar] [CrossRef] [PubMed]
- Gallun, F.J.; Diedesch, A.C.; Kampel, S.D.; Jakien, K.M. Independent impacts of age and hearing loss on spatial release in a complex auditory environment. Front. Neurosci. 2013, 7, 252. [Google Scholar] [CrossRef]
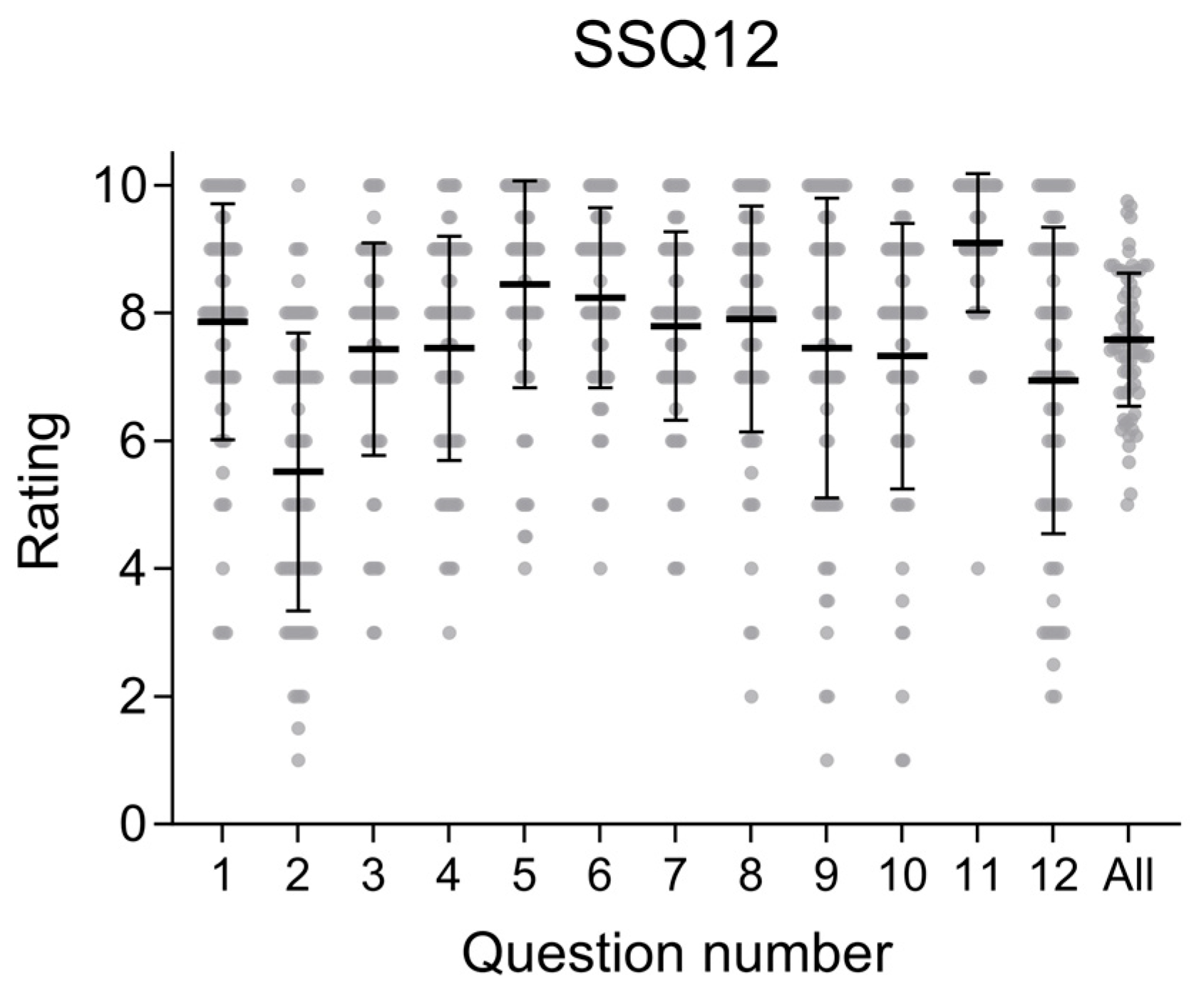
- Noble, W.; Jensen, N.S.; Naylor, G.; Bhullar, N.; Akeroyd, M.A. A short form of the Speech, Spatial and Qualities of Hearing scale suitable for clinical use: The SSQ12. Int. J. Audiol. 2013, 52, 409–412. [Google Scholar] [CrossRef] [PubMed]
- Schafer, E.C.; Pogue, J.; Milrany, T. List equivalency of the AzBio sentence test in noise for listeners with normal-hearing sensitivity or cochlear implants. J. Am. Acad. Audiol. 2012, 23, 501–509. [Google Scholar] [CrossRef] [PubMed]
- Bolia, R.S.; Nelson, W.T.; Ericson, M.A.; Simpson, B.D. A speech corpus for multitalker communications research. J. Acoust. Soc. Am. 2000, 107, 1065–1066. [Google Scholar] [CrossRef] [PubMed]
- Gallun, F.J.; Seitz, A.; Eddins, D.A.; Molis, M.R.; Stavropoulos, T.; Jakien, K.M.; Kampel, S.D.; Diedesch, A.C.; Hoover, E.C.; Bell, K.; et al. Development and validation of Portable Automated Rapid Testing (PART) measures for auditory research. Proc. Mtgs. Acoust. 2018, 33, 050002. [Google Scholar] [CrossRef]
- Lelo de Larrea-Mancera, E.S.; Stavropoulos, T.; Hoover, E.C.; Eddins, D.A.; Gallun, F.J.; Seitz, A.R. Portable Automated Rapid Testing (PART) for auditory assessment: Validation in a young adult normal-hearing population. J. Acoust. Soc. Am. 2020, 148, 1831. [Google Scholar] [CrossRef]
- Skoe, E.; Kraus, N. Auditory brain stem response to complex sounds: A tutorial. Ear Hear. 2010, 31, 302–324. [Google Scholar] [CrossRef] [PubMed]
- Krizman, J.; Kraus, N. Analyzing the FFR: A tutorial for decoding the richness of auditory function. Hear. Res. 2019, 382, 107779. [Google Scholar] [CrossRef] [PubMed]
- Skoe, E.; Krizman, J.; Anderson, S.; Kraus, N. Stability and plasticity of auditory brainstem function across the lifespan. Cereb. Cortex 2015, 25, 1415–1426. [Google Scholar] [CrossRef] [PubMed]
- Meissel, K.; Yao, E.S. Using Cliff’s Delta as a Non-Parametric Effect Size Measure: An Accessible Web App and R Tutorial. Pract. Assess. Res. Eval. 2024, 29, 2. [Google Scholar] [CrossRef]
- Fulbright, A.N.C.; Le Prell, C.G.; Griffiths, S.K.; Lobarinas, E. Effects of Recreational Noise on Threshold and Suprathreshold Measures of Auditory Function. Semin. Hear. 2017, 38, 298–318. [Google Scholar] [CrossRef] [PubMed]
- Guest, H.; Munro, K.J.; Prendergast, G.; Millman, R.E.; Plack, C.J. Impaired speech perception in noise with a normal audiogram: No evidence for cochlear synaptopathy and no relation to lifetime noise exposure. Hear. Res. 2018, 364, 142–151. [Google Scholar] [CrossRef] [PubMed]
- Smith, S.B.; Krizman, J.; Liu, C.; White-Schwoch, T.; Nicol, T.; Kraus, N. Investigating peripheral sources of speech-in-noise variability in listeners with normal audiograms. Hear. Res. 2019, 371, 66–74. [Google Scholar] [CrossRef] [PubMed]
- Harris, K.C.; Bao, J. Optimizing non-invasive functional markers for cochlear deafferentation based on electrocochleography and auditory brainstem responses. J. Acoust. Soc. Am. 2022, 151, 2802–2808. [Google Scholar] [CrossRef]
- Harris, K.C.; Ahlstrom, J.B.; Dias, J.W.; Kerouac, L.B.; McClaskey, C.M.; Dubno, J.R.; Eckert, M.A. Neural Presbyacusis in Humans Inferred from Age-Related Differences in Auditory Nerve Function and Structure. J. Neurosci. 2021, 41, 10293–10304. [Google Scholar] [CrossRef]
- Vasilkov, V.; Liberman, M.C.; Maison, S.F. Isolating auditory-nerve contributions to electrocochleography by high-pass filtering: A better biomarker for cochlear nerve degeneration? JASA Express Lett. 2023, 3, 024401. [Google Scholar] [CrossRef]
- Demeester, K.; Topsakal, V.; Hendrickx, J.J.; Fransen, E.; van Laer, L.; Van Camp, G.; Van de Heyning, P.; van Wieringen, A. Hearing disability measured by the speech, spatial, and qualities of hearing scale in clinically normal-hearing and hearing-impaired middle-aged persons, and disability screening by means of a reduced SSQ (the SSQ5). Ear Hear. 2012, 33, 615–616. [Google Scholar] [CrossRef] [PubMed]
- Killion, M.C.; Niquette, P.A.; Gudmundsen, G.I.; Revit, L.J.; Banerjee, S. Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. J. Acoust. Soc. Am. 2004, 116, 2395–2405. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Units | n | Mean (Std. Dev.) | Median | Range |
|---|---|---|---|---|---|
| 4-PTA | dB HL | 76 | 8.47 (4.68) | 8.12 | 0–20.63 |
| EHF-PTA | dB HL | 75 | 21.84 (16.35) | 21.25 | −6.87–56.88 |
| AzBio | Percent correct | 74 | 66.01 (9.83) | 65.84 | 42.11–84.78 |
| SR2-SRM | dB benefit | 76 | 6.51 (3.64) | 6.19 | −1.04–14.45 |
| Wave I amplitude | Percent change | 74 | −24.84 (21.44) | −23.75 | −72.5–23.81 |
| F0 magnitude | µV | 65 | 0.043 (0.01) | 0.039 | 0.013–0.086 |
| Dichotic FM threshold | Log2 (Hz) | 74 | −0.92 (1.08) | −1.19 | −2.43–1.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
McFarlane, K.A.; Sanchez, J.T. Effects of Temporal Processing on Speech-in-Noise Perception in Middle-Aged Adults. Biology 2024, 13, 371. https://doi.org/10.3390/biology13060371
McFarlane KA, Sanchez JT. Effects of Temporal Processing on Speech-in-Noise Perception in Middle-Aged Adults. Biology. 2024; 13(6):371. https://doi.org/10.3390/biology13060371
Chicago/Turabian StyleMcFarlane, Kailyn A., and Jason Tait Sanchez. 2024. "Effects of Temporal Processing on Speech-in-Noise Perception in Middle-Aged Adults" Biology 13, no. 6: 371. https://doi.org/10.3390/biology13060371
APA StyleMcFarlane, K. A., & Sanchez, J. T. (2024). Effects of Temporal Processing on Speech-in-Noise Perception in Middle-Aged Adults. Biology, 13(6), 371. https://doi.org/10.3390/biology13060371