1. Introduction
Urinary bladder cancer is one of the ten most common cancers worldwide. It is characterized by an cancerous alteration and uncontrollable growth of bladder tissue, typically urothelial cells, which develop into a tumor and can spread into other organs. Patients who suffer from bladder cancer may exhibit various symptoms, such as painful and frequent urination, blood in the urine, and lower back pain. Research indicates that tobacco smoking largely increases the risk of developing bladder cancer [
1]. Other external factors that may increase the risk of bladder cancer are a previous exposure to radiation, frequent bladder infections, obesity, and exposure to certain chemicals, such as aromatic amines [
2,
3].
Multiple different pathohistological subtypes of bladder cancer exist, including urothelial carcinoma (transitional cell carcinoma)—the most common type of bladder cancer [
4]; squamous cell carcinoma—which is rare and associated with chronic irritation of the bladder commonly due to infections or prolonged catheterization [
5]; adenocarcinoma—a very rare subtype of cancer, arising in other, neighboring organs as well [
6]; small cell carcinoma—a highly aggressive type of cancer with a high metastatic potential, commonly diagnosed at advanced stages [
7]; and sarcoma—an extremely rare and aggressive type of bladder cancer [
8].
Diagnosis of bladder cancer is commonly performed using cystoscopy, a procedure in which a fiber-optic instrument is passed through the urethra into the bladder and an optical evaluation is performed by a specialist in vivo [
9]. The process is significantly less invasive than a biopsy but also has a lower success rate in certain cases—such as distinguishing carcinoma in-situ from scarring or inflammatory changes [
10]. As this procedure utilizes a digital camera, previous work [
11,
12] has shown the ability to improve the results of the procedure through the application of Artificial Intelligence (AI) machine learning (ML) algorithms. This indicates that AI methods could be applied in connected, similar diagnostic problems.
Computed tomography (CT) scans are a commonly used medical diagnostic imaging method in which multiple X-ray measurements are taken to produce tomographic images of a patient’s body, allowing the examination of patient’s organs without the need for a more invasive procedure [
13]. Today, multi-detector CT scanners, with 64 to 320 rows of detectors, are used combined with helical image acquisition techniques, as they minimize the exposure to the radiation and can generate sagittal, axial, and frontal images of the body during a single breath-hold [
14]. CT urography and CT of the abdomen and pelvis are contrast-enhanced imaging methods for the detection and staging of bladder cancer that are able to differentiate healthy from cancer-affected regions of the bladder [
15,
16].
Non-ionic monomer iodinated contrast agents are administered intravenously for arterial opacification and parenchymal enhancement, which helps with better delineation of soft tissue [
17]. Acquired images are regularly inspected and interpreted by the radiologist, who provides detailed descriptions of the urinary bladder [
18]. In post-processing, the radiologist can mark and measure the suspected tumor or create a 3D recreation of a urinary system. Detection of urinary bladder cancer by using CT urography has shown high performance, and it can be concluded that CT urography can be used alongside cystoscopy for detecting urinary bladder cancer [
19].
Varghese et al. (2018) [
20] demonstrated the application of semi-supervised learning through denoising autoencoders to detect and segment brain lesions. A limited number of patients was used (20, 40, and 65), but despite this, the method displayed good performance on low-grade glaucoma (LGG) segmentation. Ouyang et al. (2020) [
21] demonstrated a self-supervised approach to medical image segmentation. The researchers applied a novel few-shot semantic segmentation (FSS) framework for general applicability that achieved good performance in three different tasks: abdominal organ segmentation on images collected through both CT and MRI procedures and cardiac segmentation for MRI images.
Renard et al. (2020) [
22] showed the importance of segmentation using deep learning algorithms and proposed three recommendations for addressing possible issues, which are an adequate description of the utilized framework, a suitable analysis of various sources, and an efficient evaluation system for the results achieved with the deep learning segmentation algorithm. Zhang et al. (2020) [
23] discussed the applications of deep-stacked data—an application of multiple stacked image transformations and their influence on the segmentation performance with tests performed on multiple three-dimensional segmentation tasks—the prostate gland, left atrial, and left ventricle.
Zhang et al. (2020) [
24] integrated an Inception-ResNet module and U-Net architecture through a dense-inception block for feature extraction. The proposed model was used for the segmentation of blood vessels from retina images, lung segmentation of CT data, and an MRI scan of the brain for tumor segmentation, on all of which, it achieved extremely high dice scores.
Liu et al. (2020) [
25] demonstrated the application of segmentation for the diagnosis of breast cancer, focusing on the application of Laplacian and Gaussian filters on mammography images available in the MIAS database. The performance was compared to different filters, such as Prewitt, LoG, and Canny, with the tested solutions providing comparable or better performance. Wang et al. (2020) [
26] also demonstrated the application of image segmentation on breast cancer nuclei. The researchers applied the U-Net++ architecture, with Inception-ResNet-V2 used as a backbone, allowing for increased performance compared to previous research.
Hongtao et al. (2020) [
27] demonstrated the application of segmentation and modeling of lung cancer using 3D renderings created from CT images. The segmentation performed using MIMICS17.0 software and demonstrated high precision; however, due to software limitations, the exact coordinates of tumor location cannot yet be exported. Yin et al. (2020) [
28] demonstrated the application of a novel medical image segmentation algorithm—balanced iterative reducing and clustering using hierarchies (BIRCH). The method was applied to brain cancer imagery with the experimental results demonstrating that segmentation accuracy and speed can be applied through the BIRCH application.
Qin et al. (2020) [
29] proposed a novel Match Feature U-Net, a symmetric encoder. The method is compared to U-Net, U-net++, and CE-Net showing improvements in multiple image segmentation tasks: nuclei segmentation in microscopy images, breast cancer cell segmentation, gland segmentation in colon histology images, and disc/cup segmentation. Li et al. (2020) [
30] demonstrated edge detection through image segmentation algorithms on the three dimensional image reconstruction. The proposed method achieved accuracy above 0.95 when applied with a deep learning algorithm.
Kaushal et al. (2020) [
31] showed the application of an algorithm based on the so-called Firefly optimization, with the application on breast cancer images. The proposed method was capable of segmenting images despite their type and modality with effectiveness comparable to or exceeding other state-of-the-art techniques. Alom et al. (2020) [
32] displayed the application of improved deep convolutional networks (DCNN) on skin cancer segmentation and classification. The authors proposed NABLA-N, a novel network architecture that achieved an accuracy of 0.87 on the ISIC2018 dermoscopic skin cancer data set.
Li et al. (2020) [
33] demonstrated the application of a nested attention-aware U-Net on CT images for the goal of liver segmentation. The authors concluded that the proposed novel method achieved competitive performances on the MICCAI 2017 Liver Tumor Segmentation (LiTS) Challenge Dataset. Tiwari et al. (2020) [
34] displayed the application of the fuzzy inference system. The authors applied a pipeline consisting of preprocessing, image segmentation, feature extraction, and the application of fuzzy inference rules, which are capable of identifying lung cancer cells with high accuracy.
Monteiro et al. (2020) [
35] demonstrated the use of CNNs for multiclass semantic segmentation and the quantification of traumatic brain injury lesions on head CT images. The patient data was collected in the period between 2014 and 2017, on which the CNN was trained for the task of voxel-level multiclass segmentation/classification. The authors found that such an approach demonstrated a high quality volumetric lesion estimate and may potentially be applied for personalized treatment strategies and clinical research.
Anthimopoulos et al. (2018) [
36] demonstrated the use of Dilated Fully Convolutional Networks for the task of semantic segmentation on pathological lung tissue. The authors used 172 sparsely annotated CT scans within a cross-validation training scheme with training done in a semi-supervised mode using labeled and unlabeled image regions. The results showed that the proposed methodology achieved significant performance improvement in comparison to previous research in the field.
Another study regarding segmentation on lung CTs was performed by Meraj et al. (2021) [
37] with the goal of performing lung nodule detection. The authors used a publicly available dataset, the Lung Image Database Consortium, upon which filtering and noise removal were applied. The authors used adaptive thresholding and semantic segmentation for unhealthy lung nodule detection, with feature extraction performed via principal component extraction. Such an approach showed results of 99.23% accuracy when the logit boost classifier was applied.
Koitka et al. (2021) proposed an automatic manner of body composition analysis, with the goal of application during routine CT scanning. The authors utilized 3D semantic segmentation CNNs, applying them on a dataset consisting of 50 CTs annotated on every fifth axial slice split into an 80:20 ratio. The authors achieved high results with the average dice scores reaching 0.9553, indicating a successful application of CNNs for the purpose of body composition determination.
To increase the performances of algorithms for the semantic segmentation, we introduce a process of transfer learning. It is important to notice that alongside the performance from the semantic segmentation standpoint, the performance from the generalization standpoint must be evaluated as well. For these reasons, the following questions can be asked:
Is it possible to design a semantic segmentation system separately for each plane?
Is there a possibility to design an automated system for plane recognition?
How does the transfer learning paradigm affect the semantic segmentation and generalization performance of designed U-nets?
Which pre-trained architectures achieve the highest performances if used as a backbone for U-net?
To summarize the novelty of the article, the idea is to utilized multi-objective criteria to evaluate the performances of a transfer learning-based system for the semantic segmentation of urinary bladder cancer masses from CT images. The images are captured in three planes: frontal, axial, and sagittal, and the aim of the research is to maximize semantic segmentation performances by dividing data set according to planes and to introduce the system for automatic plane recognition.
At the beginning of the paper, a brief description of the diagnostic procedure is provided together with the problem description. After the problem description, the used data set is presented, followed by a description of the used algorithms. After algorithm description, a mathematical approach to the transfer learning paradigm is presented together with used backbone architectures. In the end, the research methodology is presented followed by the results and discussion.
2. Problem Description
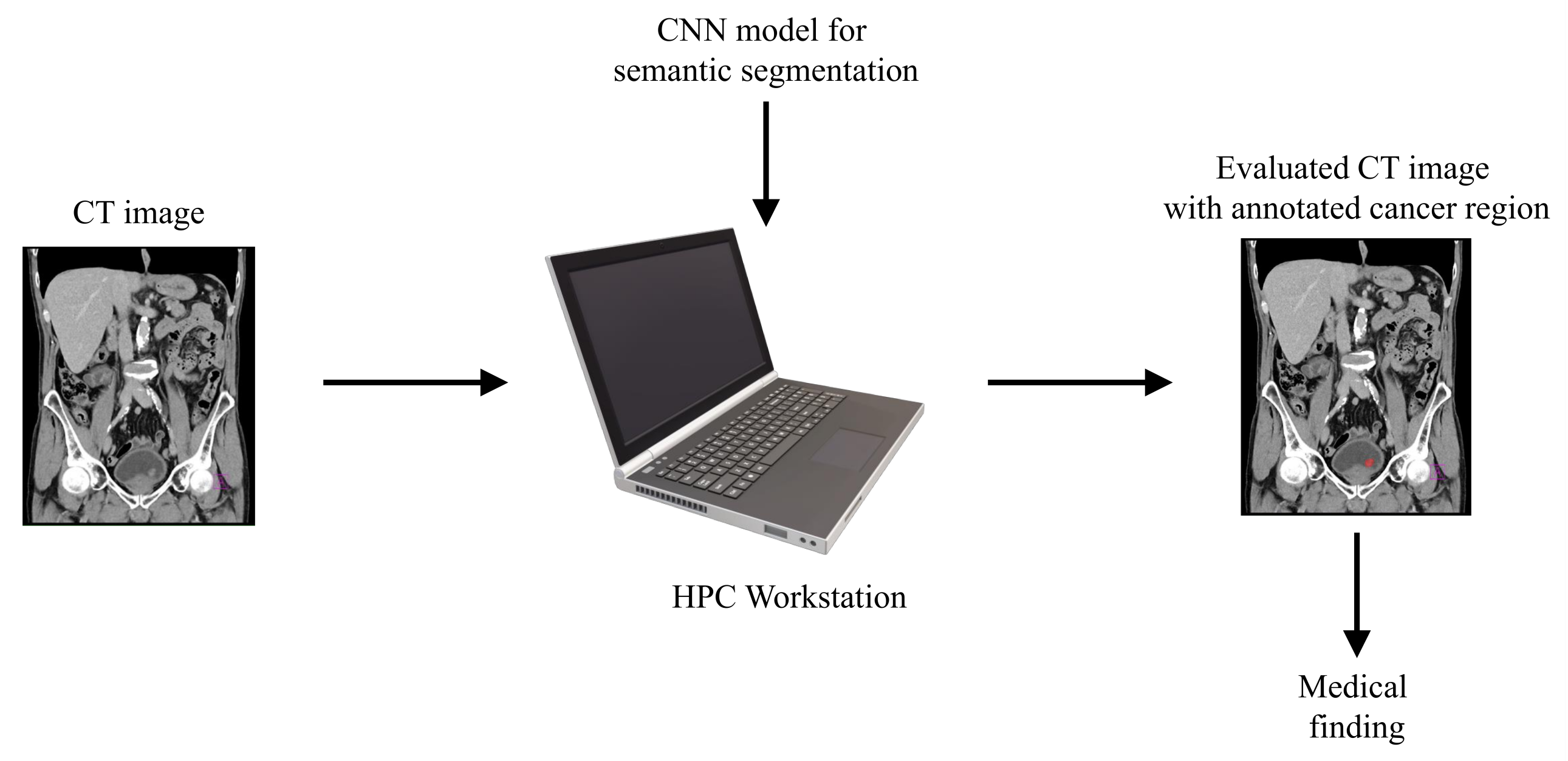
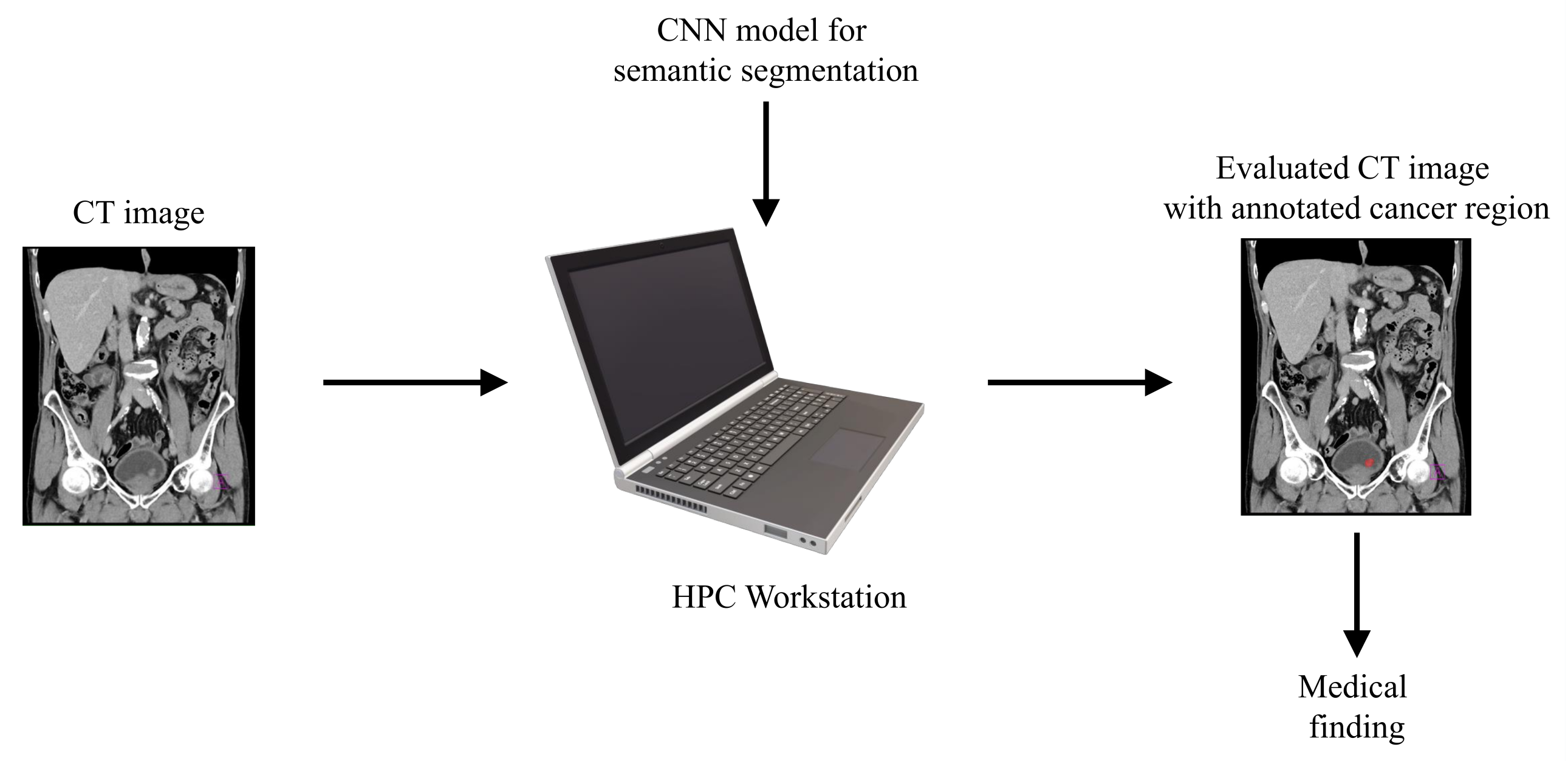
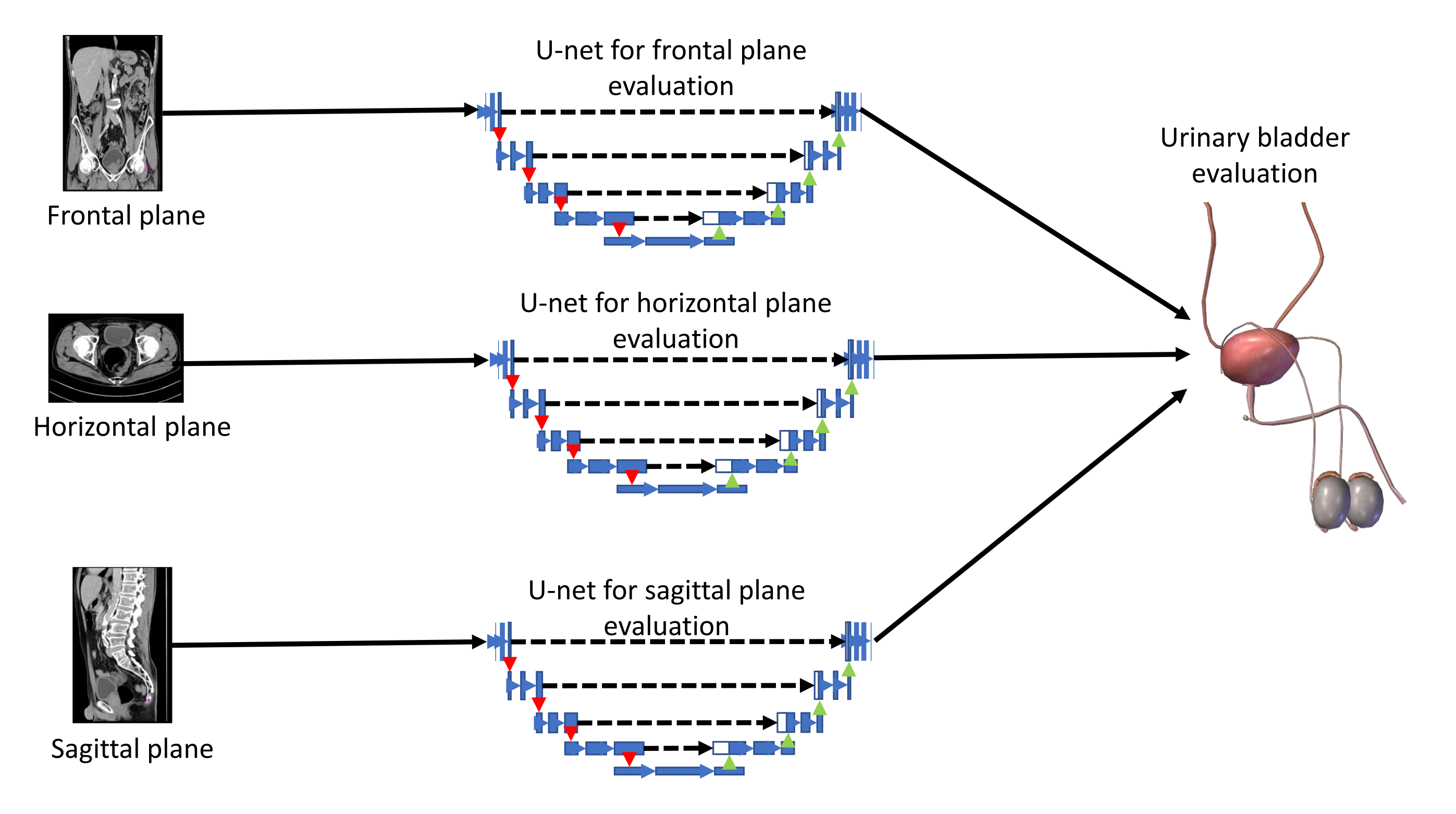
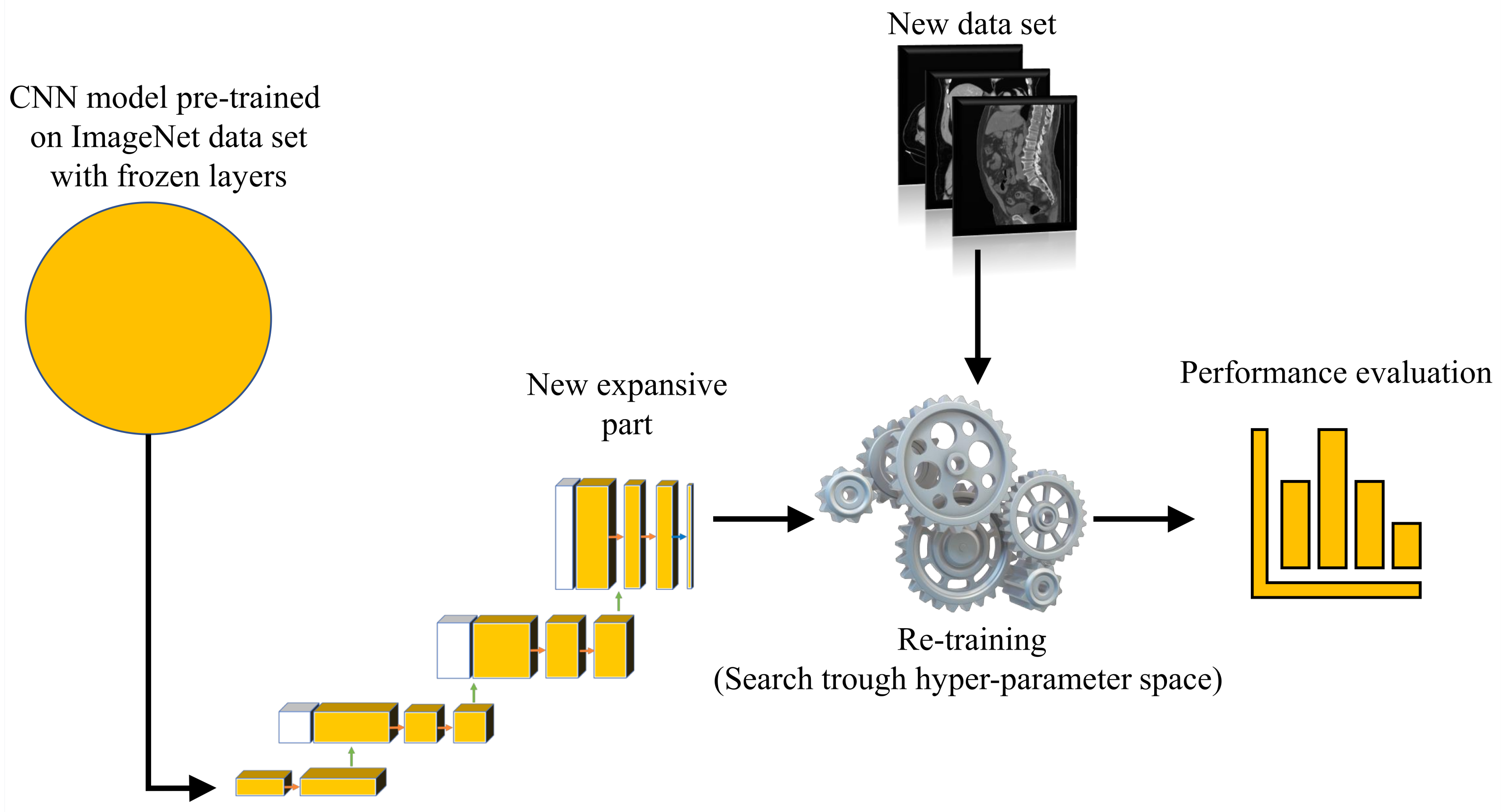
With aim of developing an automated system that could be used in the diagnosis and decision making regarding urinary bladder cancer, a system for the semantic segmentation of urinary bladder cancer from CT images is proposed. The proposed approach is based on the utilization of CNN models that are executed on an HPC workstation. The idea behind the utilization of CNN-based semantic segmentation is to use a data set of images with known annotation to train CNN that will later be used to automatically annotate and evaluate new images. As input data to the semantic segmentation system, images of lower abdomen collected with CT are used.
An input image, captured in three planes. First, the classification is performed, in order to determine the plane in which the image was captured. After the plane is determined, the image is used as an input to U-net architecture for that particular plane. Trained U-net architecture is used to create the output mask. The output mask represents the region of an image where urinary bladder cancer is present. Such an output enables automated evaluation of urinary bladder that results in an annotated image that is used to determine the urinary bladder cancer spread. A graphical overview of such a process is presented in
Figure 1.
The dataset used in this research was created by using CT images collected in the Clinical Hospital Center of Rijeka, and it consists of CT images of the lower abdomen in three planes:
Frontal plane.
Sagittal plane.
Axial plane.
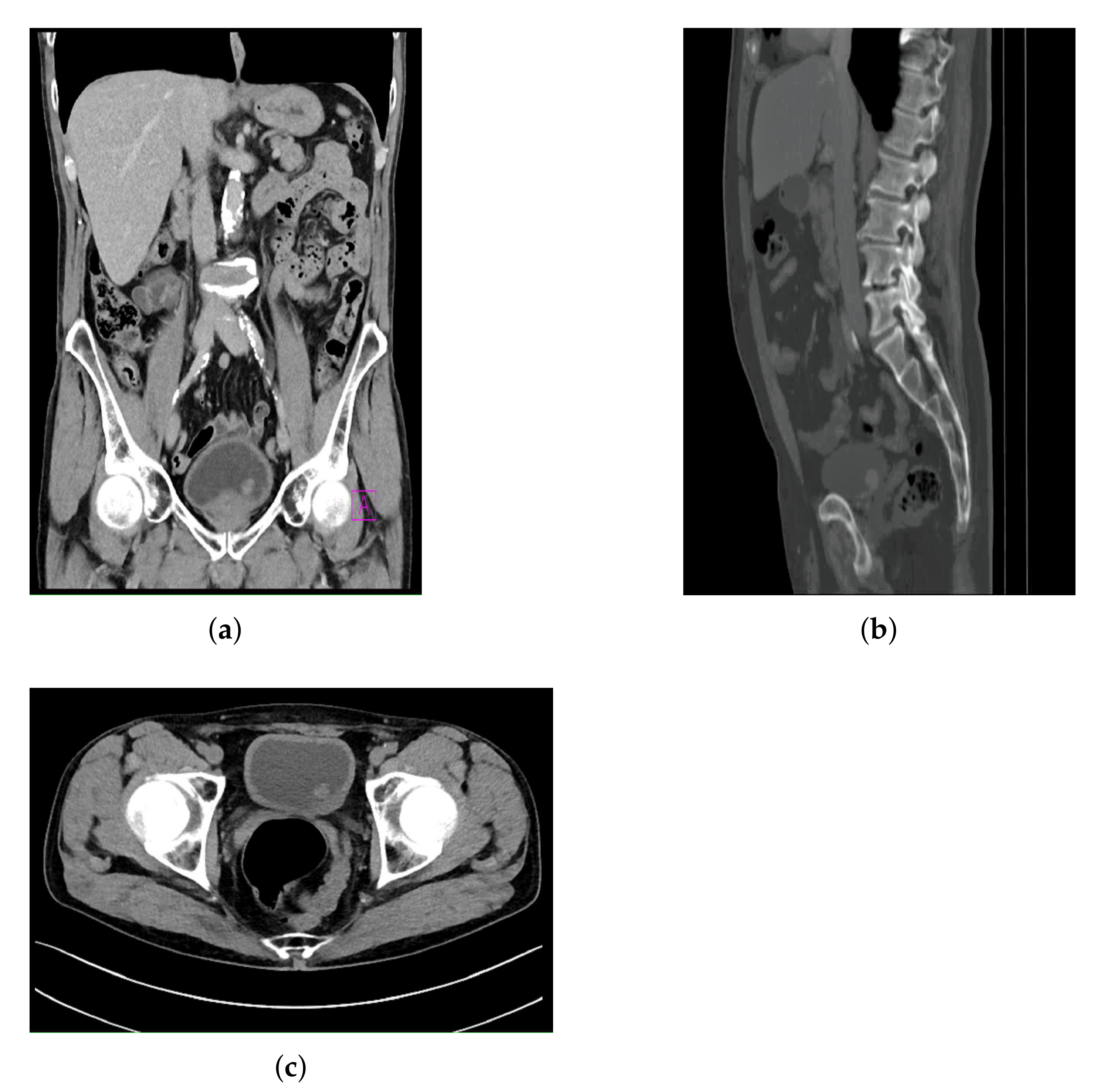
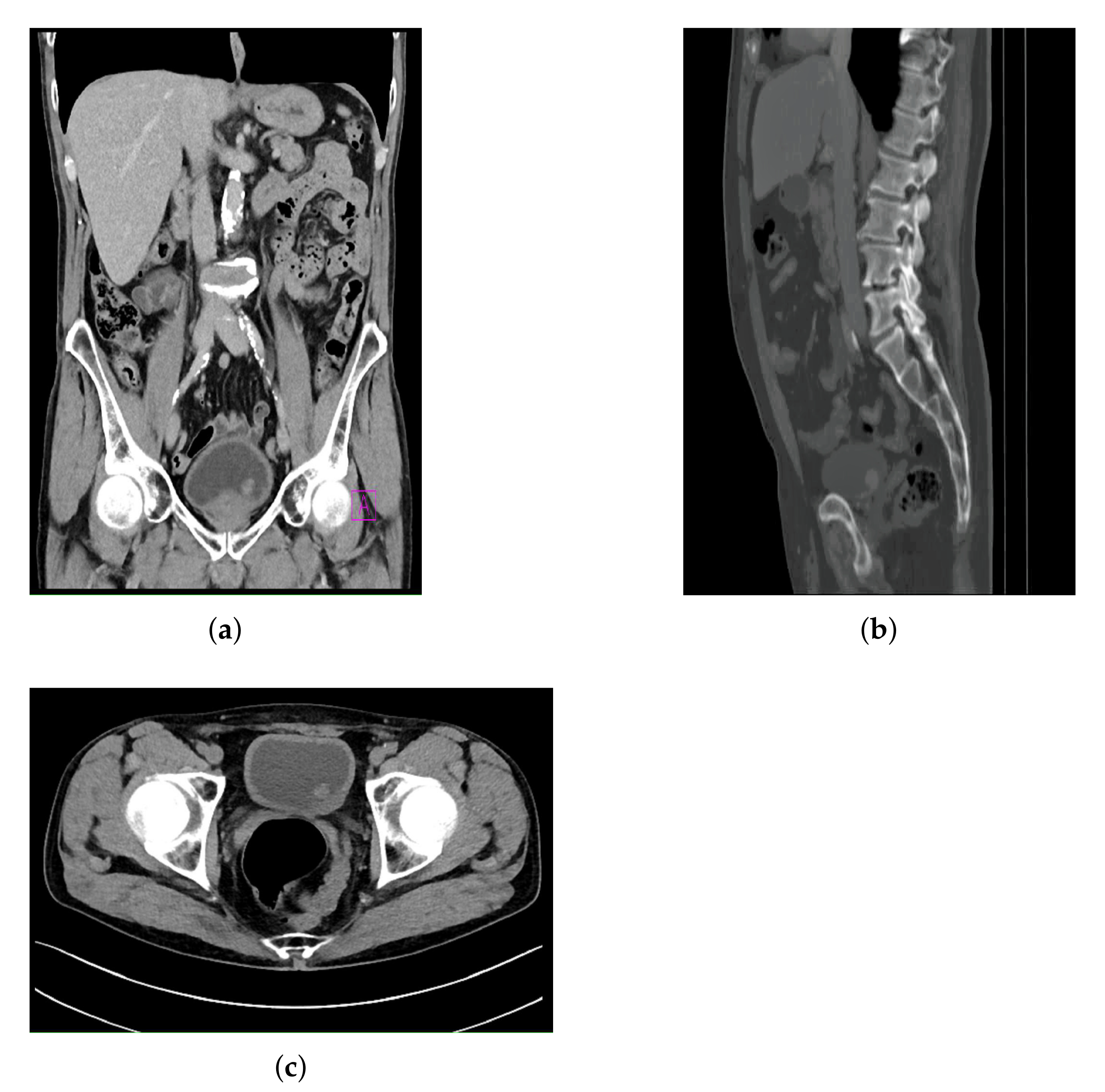
All images contained in the data set are images where a form of bladder cancer is confirmed. The CT images with confirmed bladder cancer are presented in
Figure 2, where
Figure 2a represents a CT image in the frontal plane,
Figure 2b represents a CT image in the sagittal plane, and
Figure 2c represents a CT image in axial plane.
The distribution of the training, validation, and the testing data sets is presented for all three planes in
Table 1.
When the numbers of images in each plane are compared, it can be seen that a significantly lower number of images were captured for the case of the sagittal plane, in comparison with the frontal and axial plane. Such an imbalance is a consequence of the fact that the CT urography procedures are, in the case of this research, dominantly performed in the frontal and axial planes only. Furthermore, images captured in the sagittal plane are captured with lower density, resulting in a lower number of images per patient.
The use of this particular data set was approved by Clinical Hospital Center Rijeka, Ethics Board (Kresimirova 42, 51000 Rijeka); under the number 2170-29-01/1-19-2, on 14 March 2019. In order of creating output data for CNN training, image annotation was performed. Such an approach was utilized for creating output masks that represent the bladder region where a malignant mass is present. The annotation was performed by a specialist urologist according to the obtained medical findings.
It is important to emphasize that all images and corresponding medical findings used during this research are validated with additional medical procedures, such as cystoscopy. Medical findings are evaluated by three independent raters—urologists with the experience in the field of radiography, including CT. As a observer agreement measure, Fless’ kappa (
) coefficient is used [
38]. For the case of this study,
of 0.83 was achieved. This results suggests the conclusion that the agreement of observers is, in this case, of a high degree.
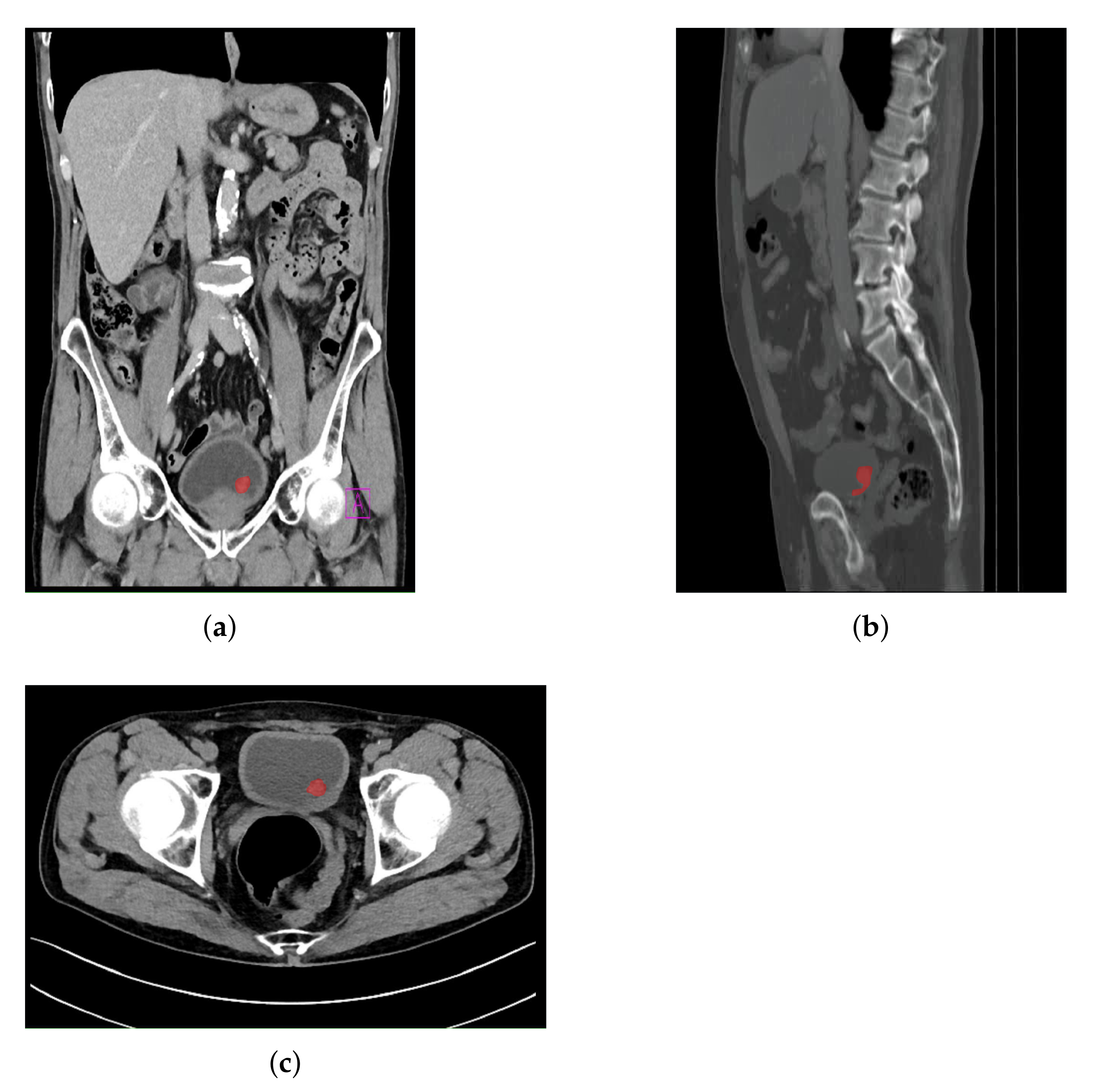
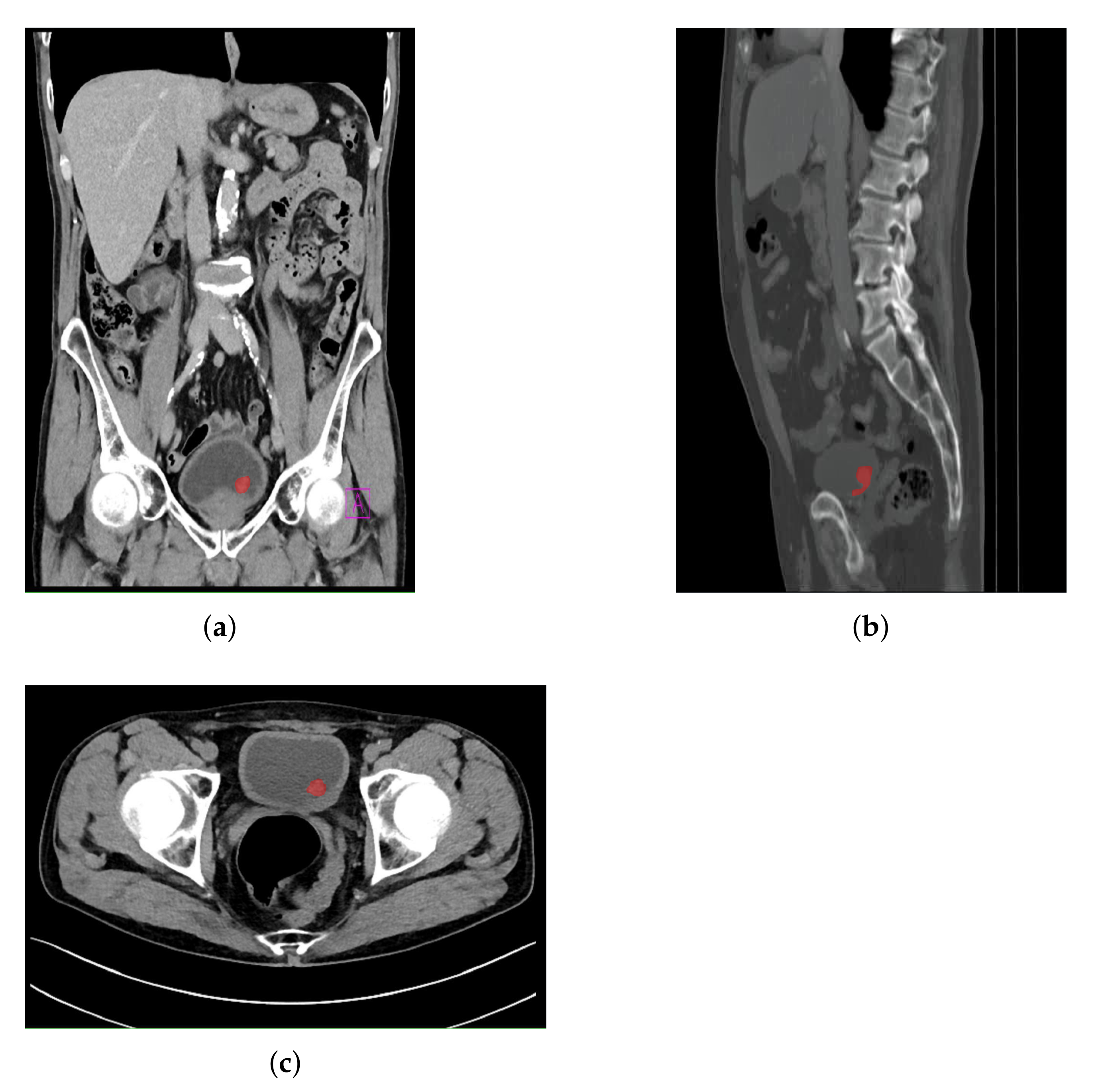
An example of an image annotation procedure is presented in
Figure 3, where
Figure 3a,
Figure 3a,b represent the frontal, sagittal, and axial plane, respectively.
The red areas presented in
Figure 3 are used in the creation of output annotation maps that are used during U-net model development [
39].
4. Transfer Learning Approach
The process of transfer learning can be mathematically defined by using a framework that consists of domain, task, and marginal probabilities definitions. If domain
D is defined as a tuple of two elements [
46]:
where
X represents a sample data point. From the presented rules, a domain can be defined as:
where
X is defined as:
where:
Furthermore, a task
T can also be defined as a tuple that consists of the label space
and objective function
O. The presented objective function can be defined as:
If it is stated that source domain
corresponds with source task
and target domain
corresponds with target task
, it can be stated that the objective of transfer learning process is to enable learning target conditional probability distribution
in
by using knowledge gained from
and
where it is defined that:
and
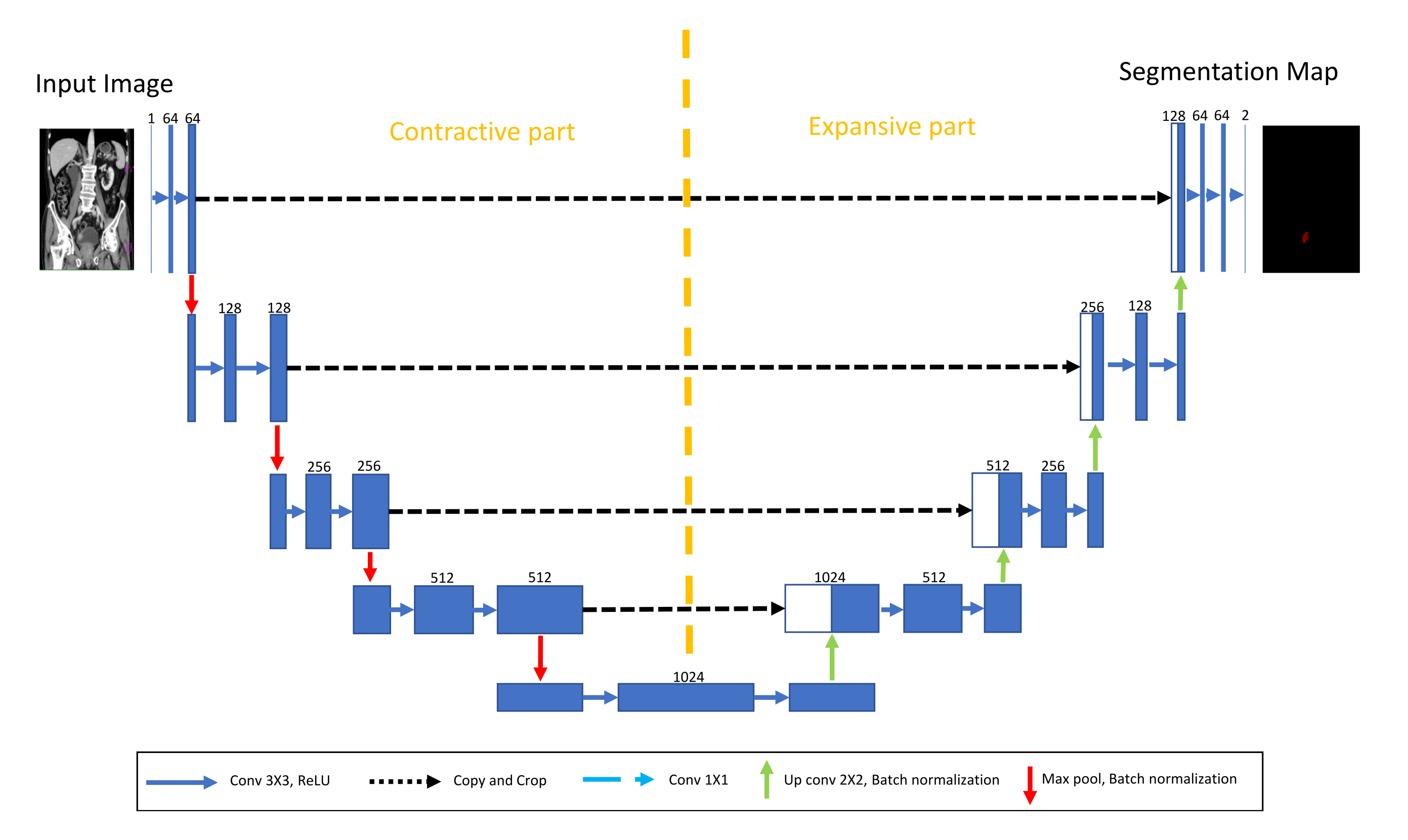
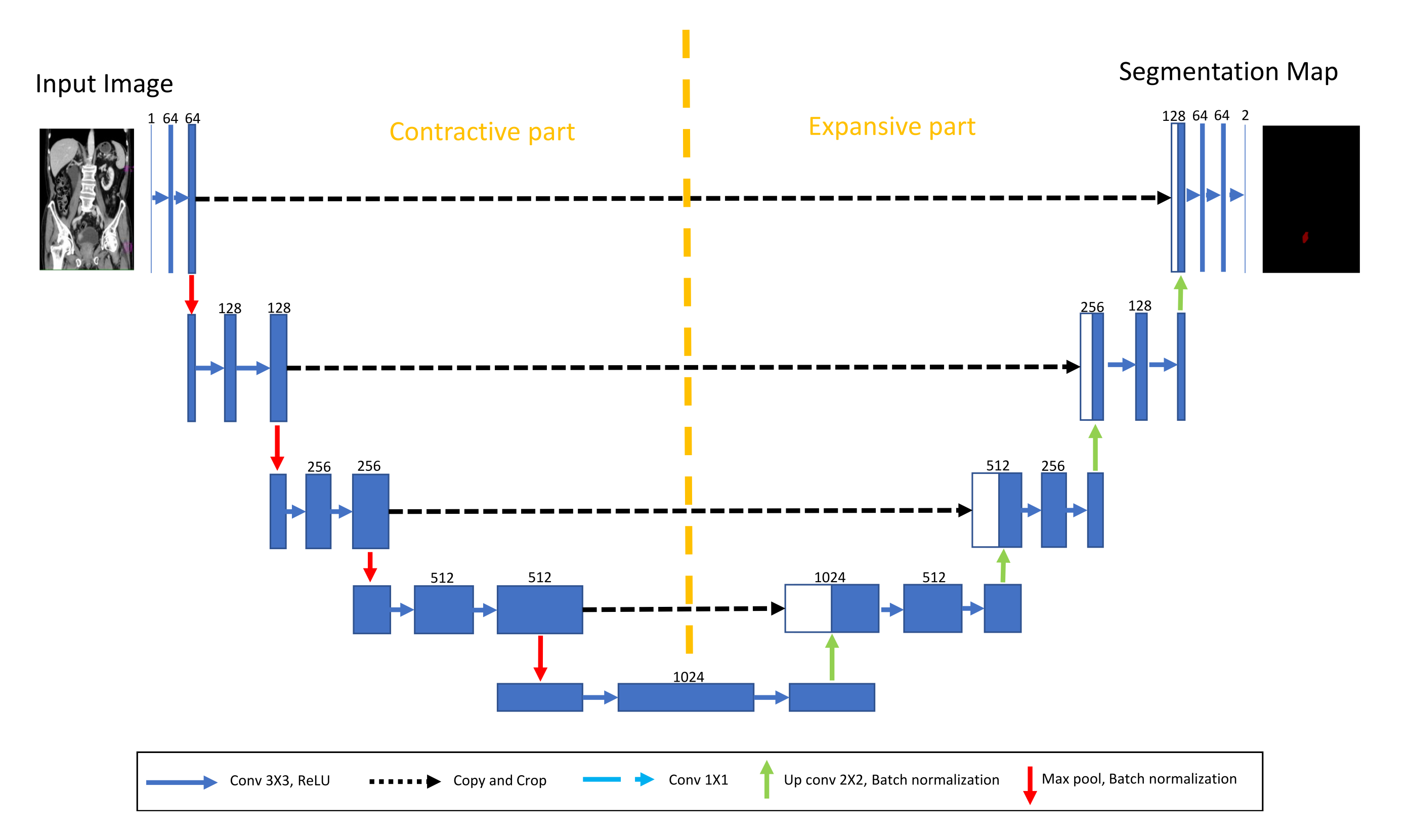
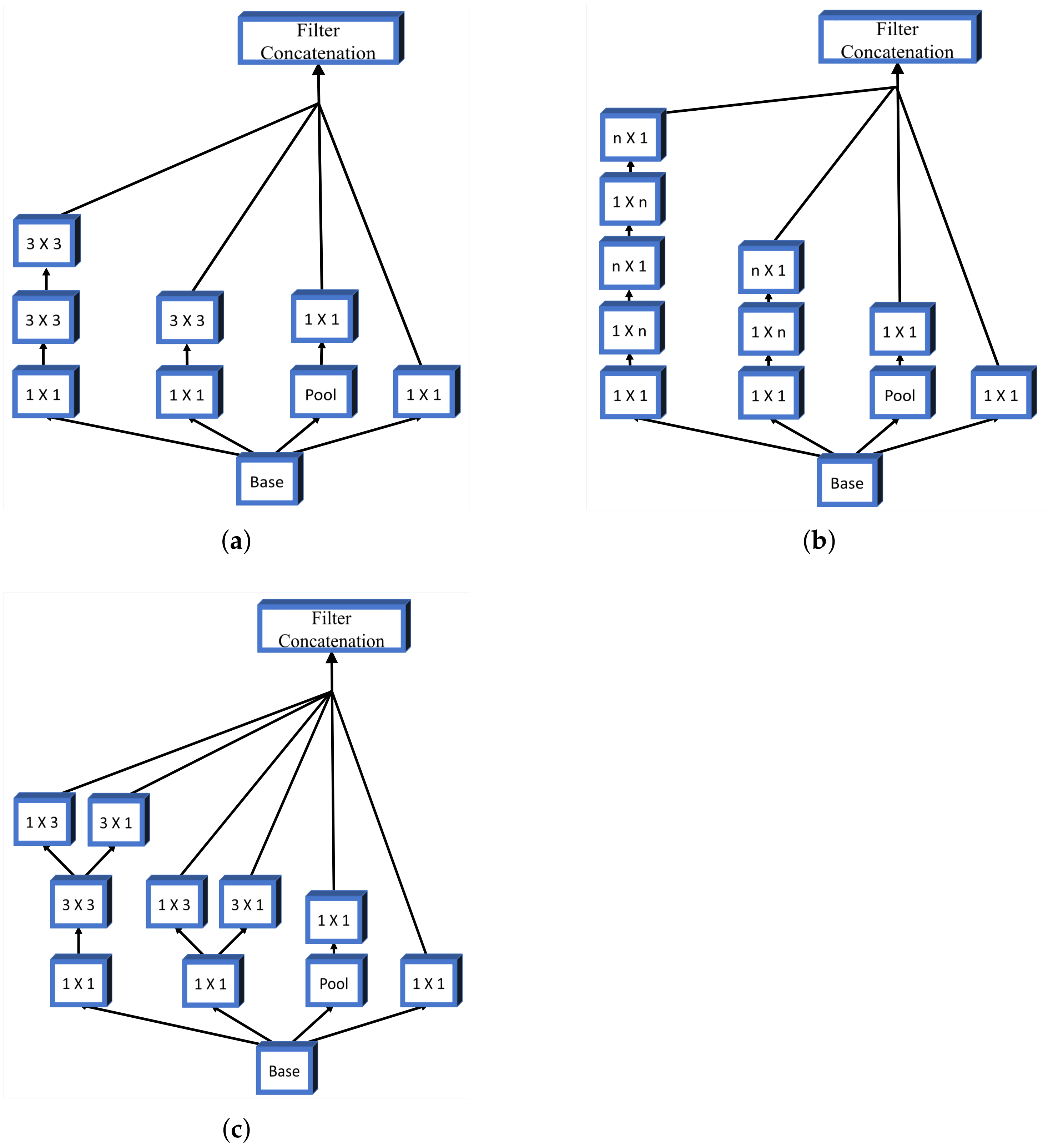
For the purposes of this research, a transfer learning process can be described as utilization of pre-defined and pre-trained CNN architecture as a backbone to U-net. The aforementioned CNNs are pre-trained using one of the standard computer vision data sets.
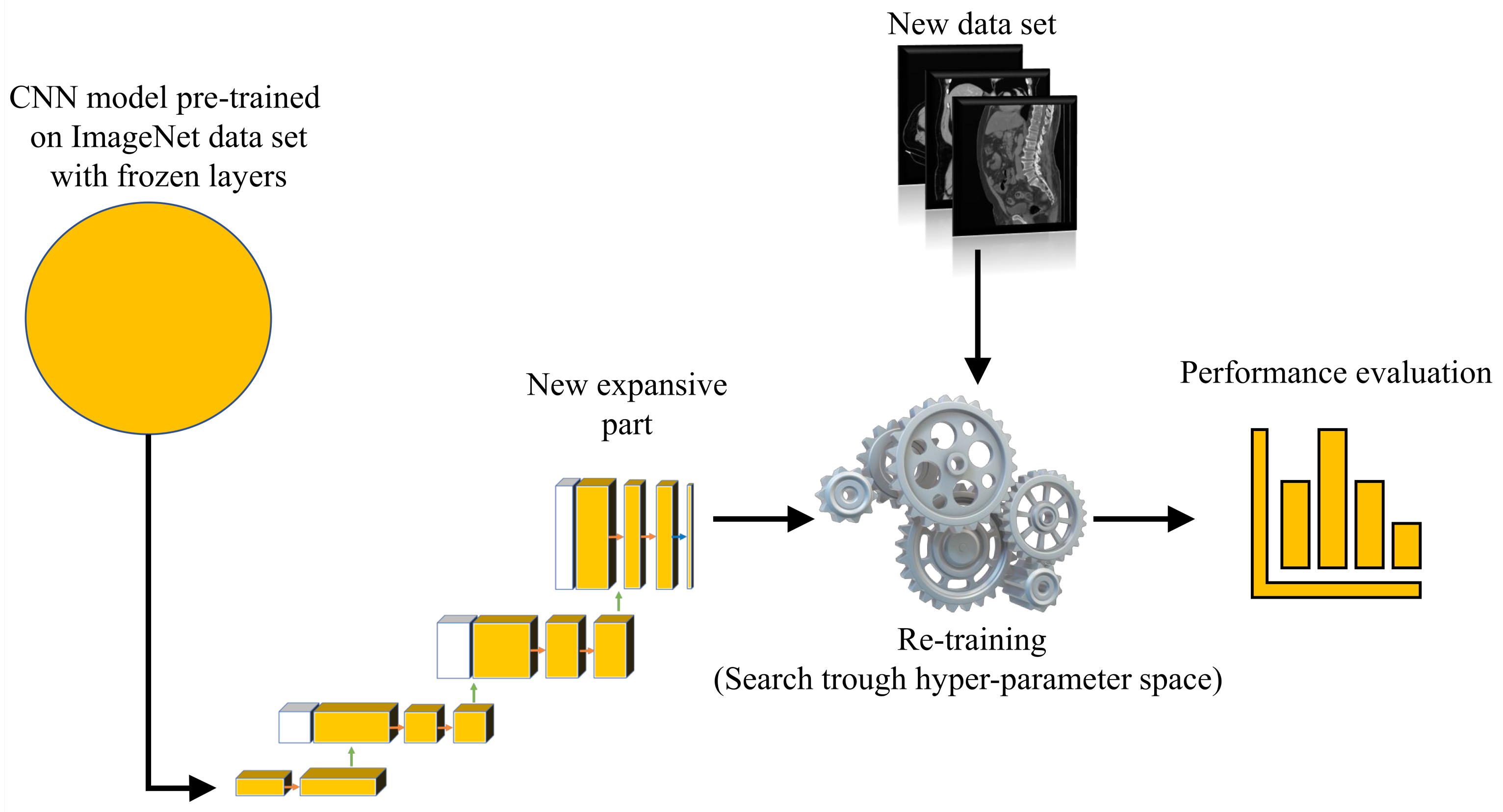
For the purpose of this research, backbone CNNs were pre-trained using the ImageNet data set. Backbone CNNs represent the contractive part of a U-net, while the expansive part is added. As a contractive part of the U-net architecture, only the upper layers of the aforementioned pre-trained CNN architectures are used. On the other hand, the lower, fully connected layers of these CNN architectures are removed from the network in order to achieve the fully convolutional configuration required for achieving the semantic segmentation. During the training of the U-net, the layers in the contractive part of the network are frozen, and there is no change in their parameters.
Such a process is presented in
Figure 6.
7. Results and Discussion
In this section, an overview of the achieved results is presented. In the first subsection, the results achieved with AlexNet CNN architecture for plane recognition are presented. In the second, third, and fourth subsections, the results achieved with U-net architectures are presented for each plane. At the end of the section, a brief discussion about the collected results is provided.
7.1. Plane Recognition
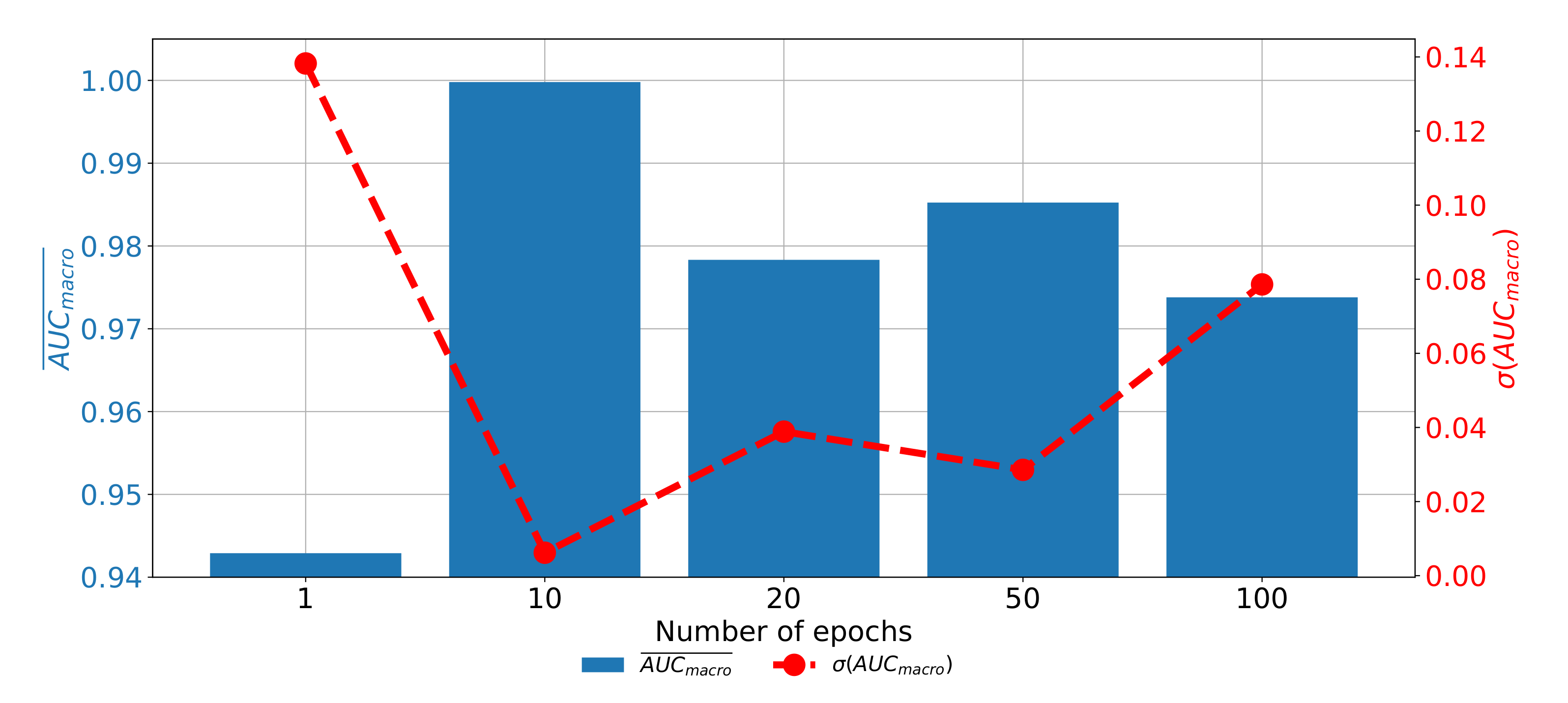
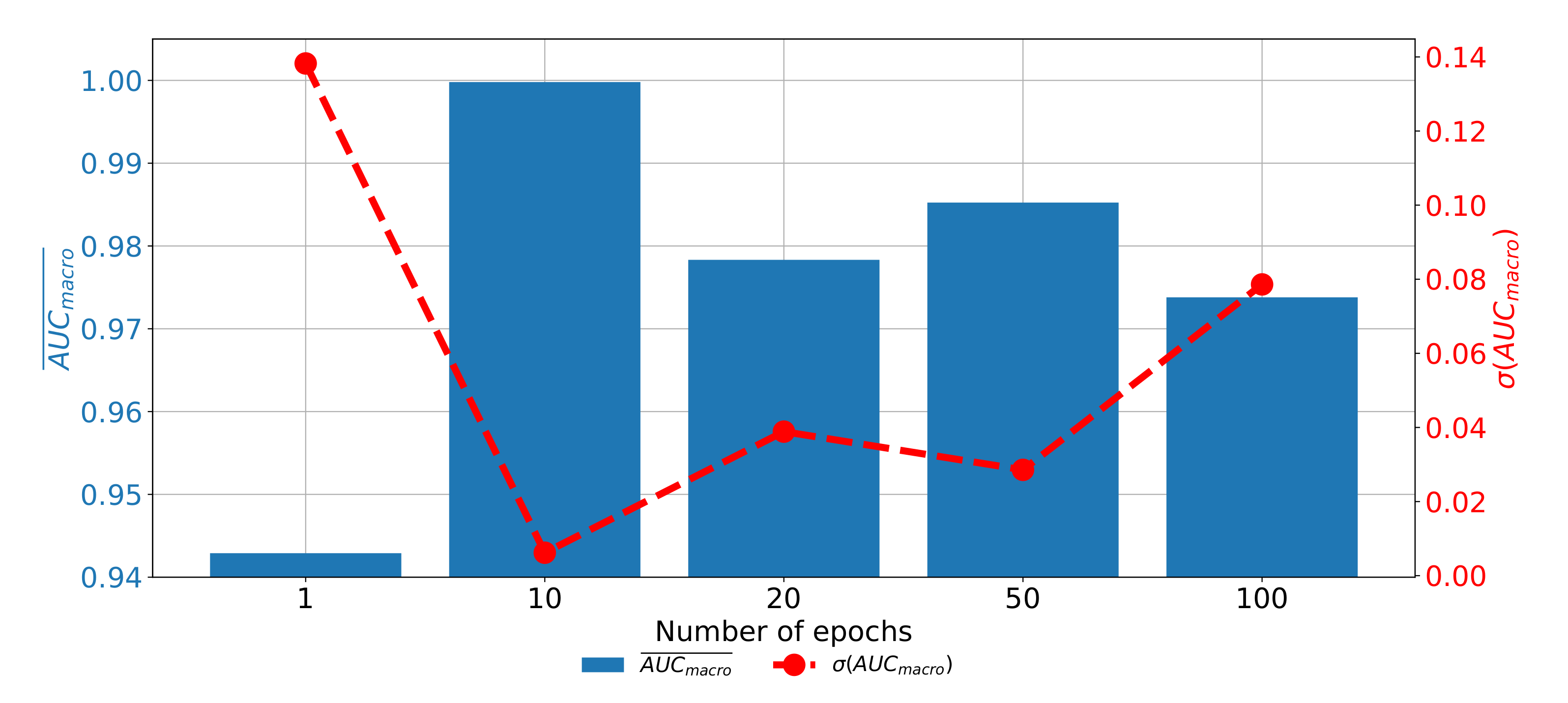
When the results of plane classification achieved by using AlexNet CNN architecture are observed, it can be noticed that the highest classification and generalization performances are achieved if the AlexNet architecture is trained by using RMS-prop optimizer for 10 consecutive epochs with data batches of 16. With the presented architecture
value of 0.9999 and
value of 0.0006 are achieved, as presented in
Table 6.
If the change of classification and generalization performances through epochs are compared, it can be noticed that the highest results are achieved when AlexNet is trained for 10 consecutive epochs. Furthermore, it can be noticed that the performances are significantly lower when AlexNet is trained for higher number of epochs, pointing towards the over-fitting phenomena. If AlexNet is trained for just one epoch, the performances are also significantly lower as presented in
Figure 11.
From the presented result, it can be concluded that AlexNet can be used for CT image plane recognition due the high classification and generalization performances.
7.2. Semantic Segmentation in Frontal Plane
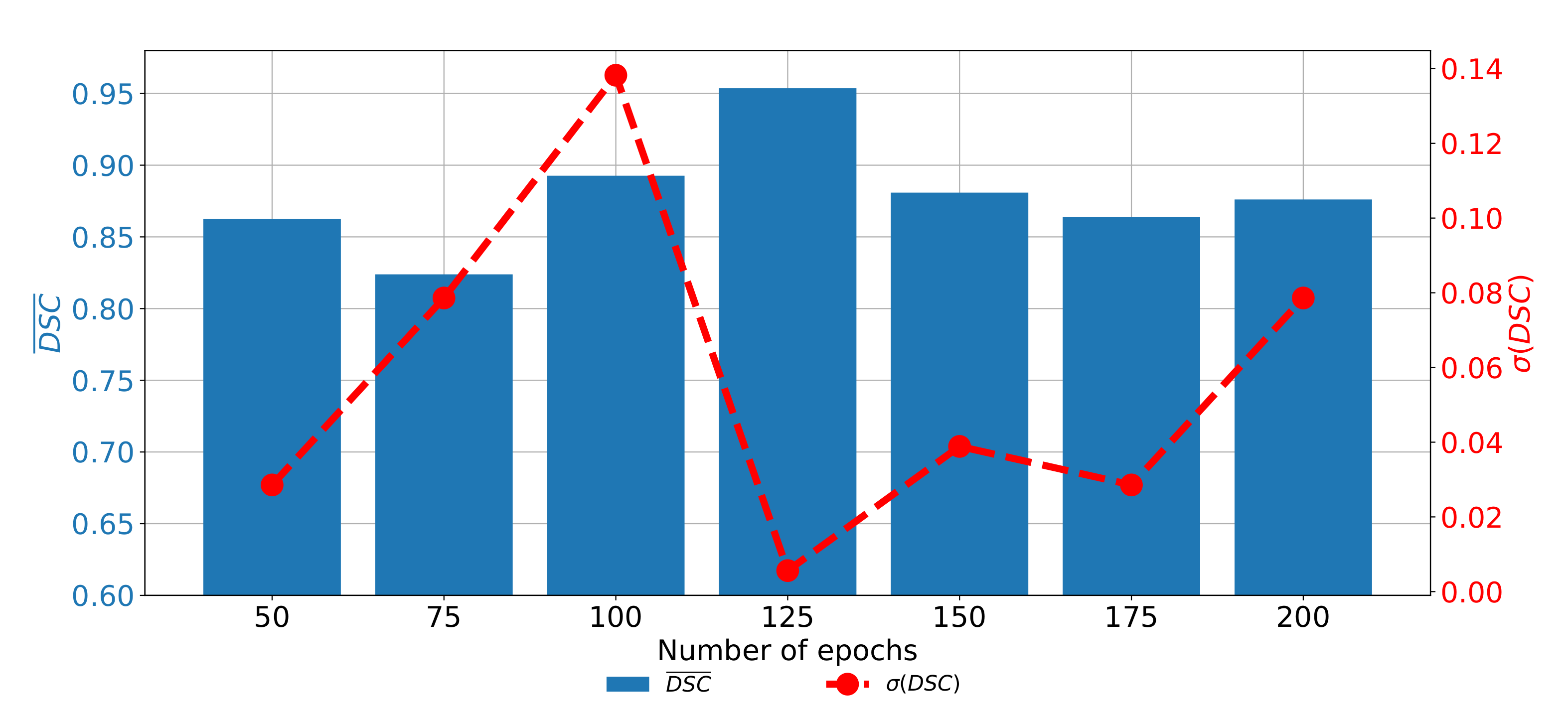
If the results of semantic segmentation in the frontal plane are compared, it can be noticed that by applying the transfer learning paradigm, a significant improvement of semantic segmentation results is achieved. If a standard U-net architecture is utilized, does not exceed 0.79 and value does not exceed 0.77. Such results are pointing toward the conclusion that such a configuration has sufficient performance for practical application. Furthermore, if a transfer learning approach utilized a significant improvement of semantic segmentation and generalization performance is achieved.
The highest performances in both criteria are achieved if a pre-trained ResNet101 CNN architecture is used as a backbone for U-net. In this case,
values up to 0.9587 are achieved. Furthermore,
up to 0.9438 are achieved. When generalization performances are observed, it can be noticed that the lowest standard deviations are achieved when ResNet50 is used, followed by ResNet101. A detailed overview of the results achieved with and without pre-trained backbones is presented in
Table 7, together with the hyper-parameters that achieved the highest results per backbone architecture.
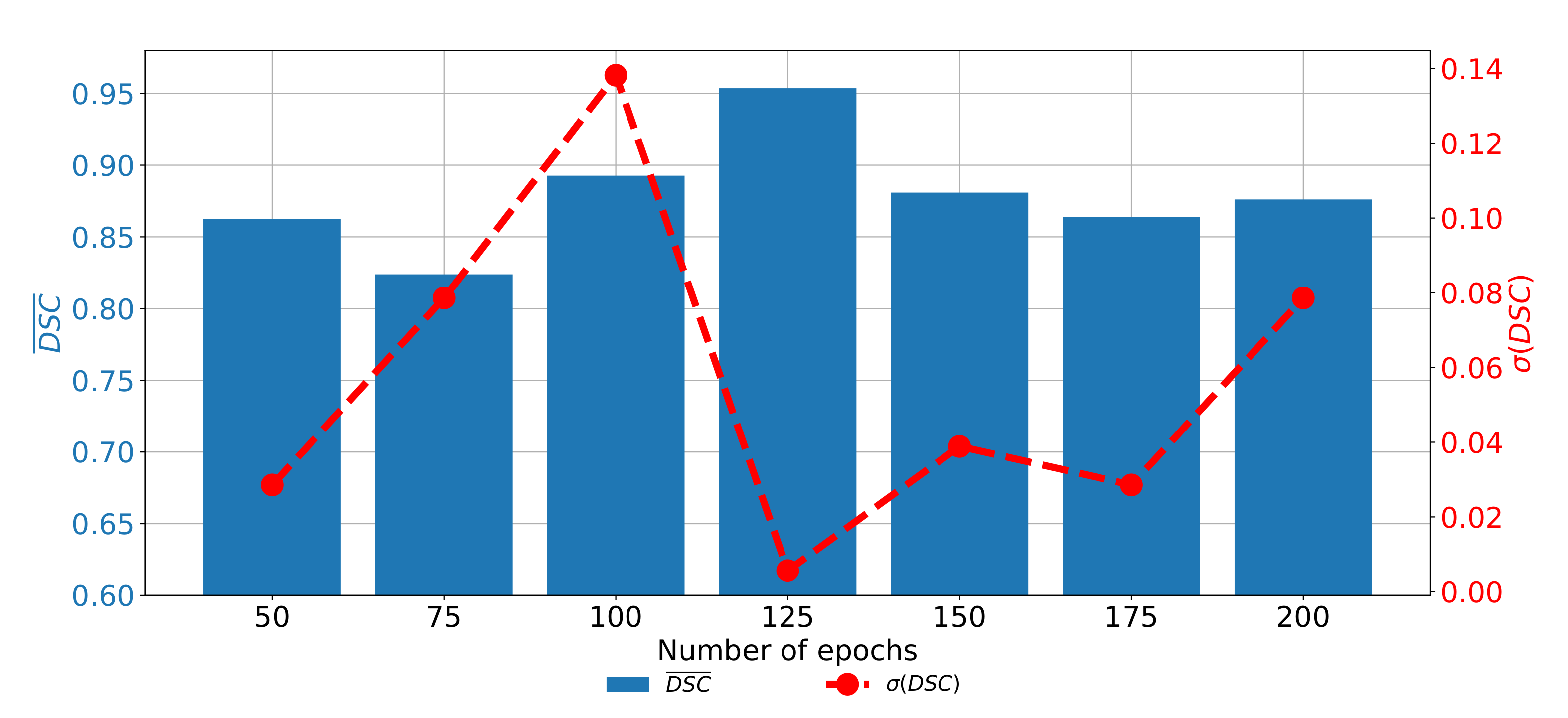
If the change of semantic segmentation and generalization performances through epochs are observed for ResNet101, it can be noticed that the highest semantic segmentation and generalization performances are achieved when the U-net is trained for 125 consecutive epochs. When the network is trained for a higher number of epochs, it can be noticed that significantly poorer performances are achieved. Such a property can be attributed to the occurrence of the over-fitting phenomena. When the network is trained for a lower number of epochs, the results are also poorer, as presented in
Figure 12.
7.3. Semantic Segmentation in Axial Plane
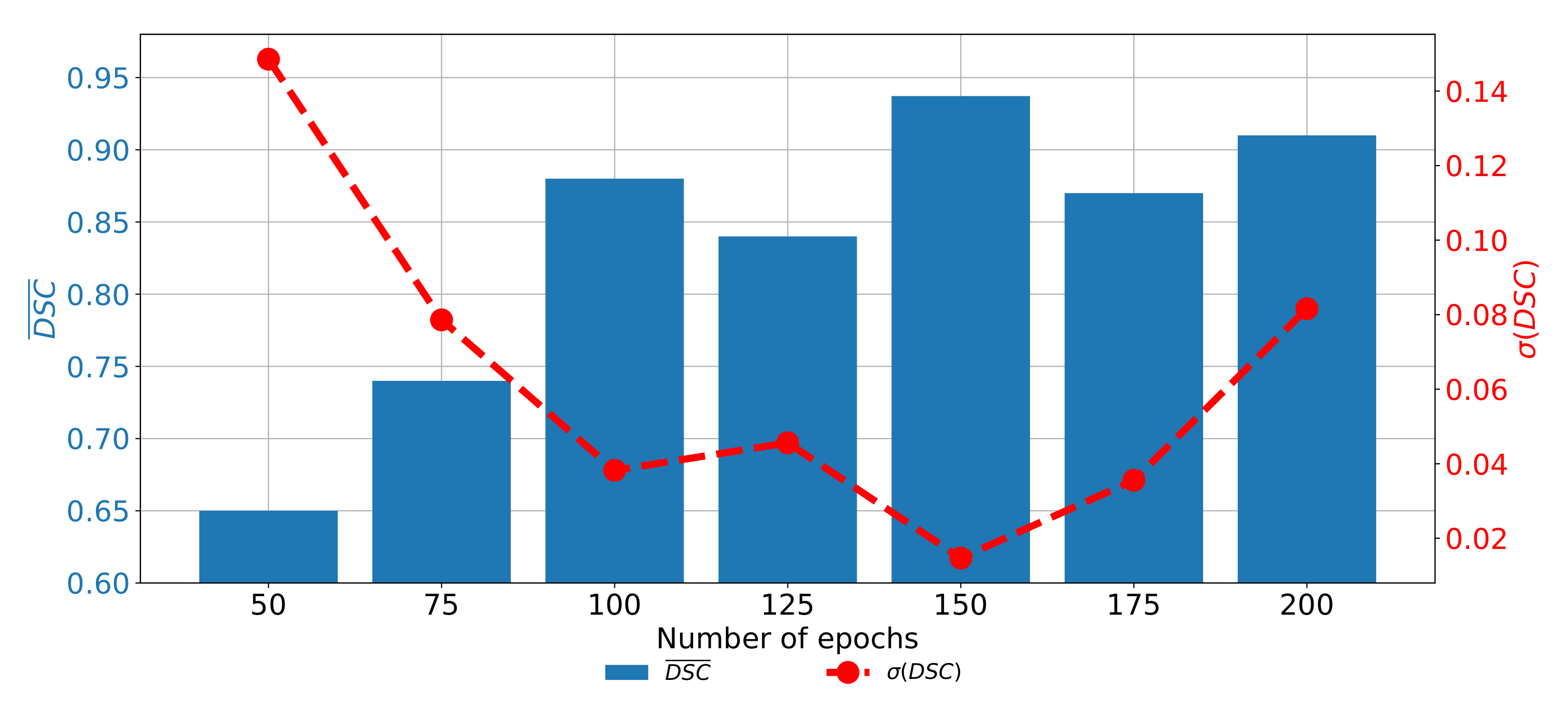
When the performances of semantic segmentation algorithms trained with CT images captured in the axial plane are compared, it can be noticed that by applying the transfer learning approach, significant improvement in both semantic segmentation and generalization performances is achieved. When the isolated learning paradigm is utilized,
and
are not exceeding 0.83 and 0.78, respectively. On the other hand, by utilization of a transfer learning approach,
and
values up to 0.9372 are achieved. From the detailed result presented in
Table 8, it can be noticed that the highest semantic segmentation performances are achieved in a pre-trained ResNet50 architecture used as a backbone for the U-net.
When the change of
and
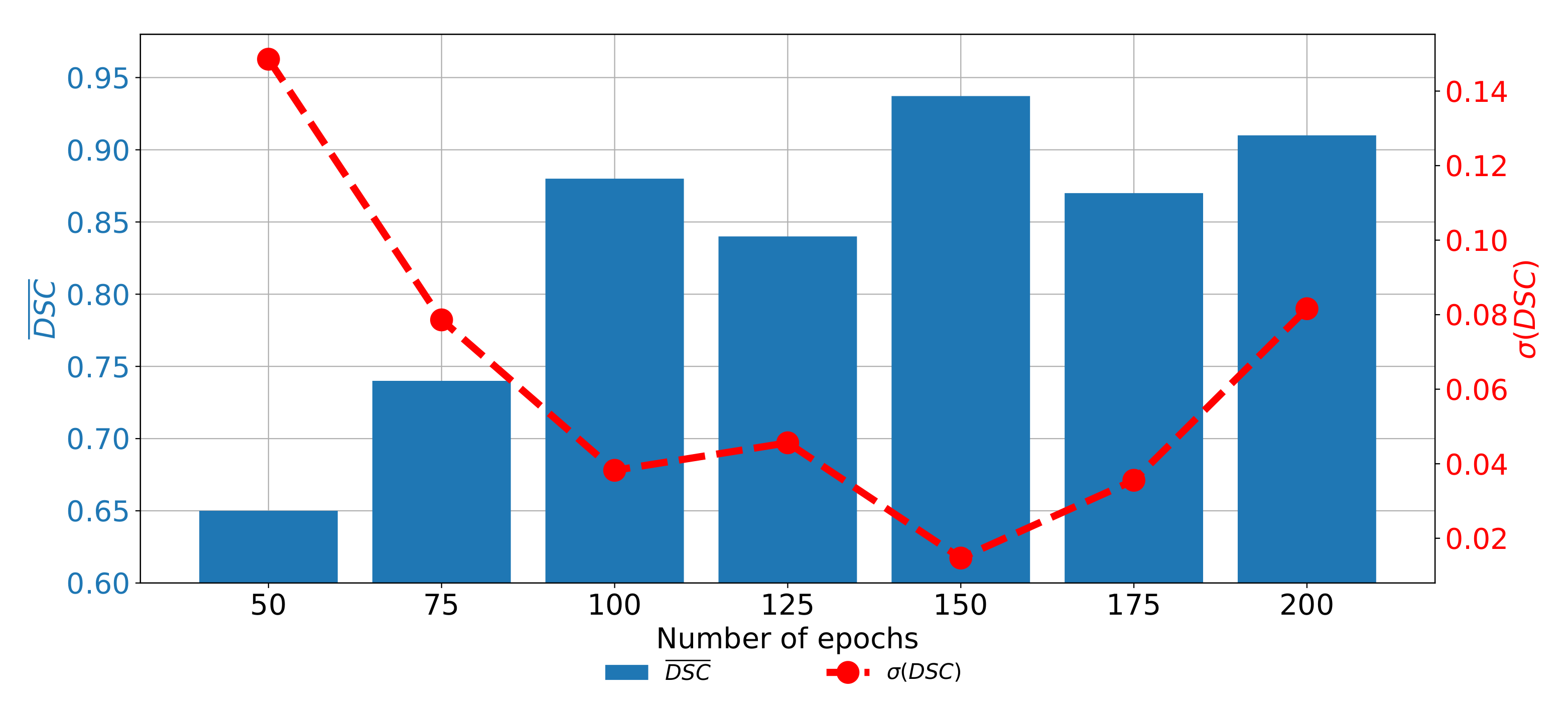
trough epochs is observed for the U-net designed with the pre-trained ResNet50 architecture as a backbone, it can be noticed that the highest semantic segmentation and generalization performances are achieved if the network is trained for 150 consecutive epochs. When the network is trained for a lower number of epochs, significantly lower performances could be noticed. Furthermore, if the network is trained for a higher number of epochs, the trend of decaying performances can be noticed, as presented in
Figure 13. Such a property can be attributed to the over-fitting.
7.4. Semantic Segmentation in Sagittal Plane
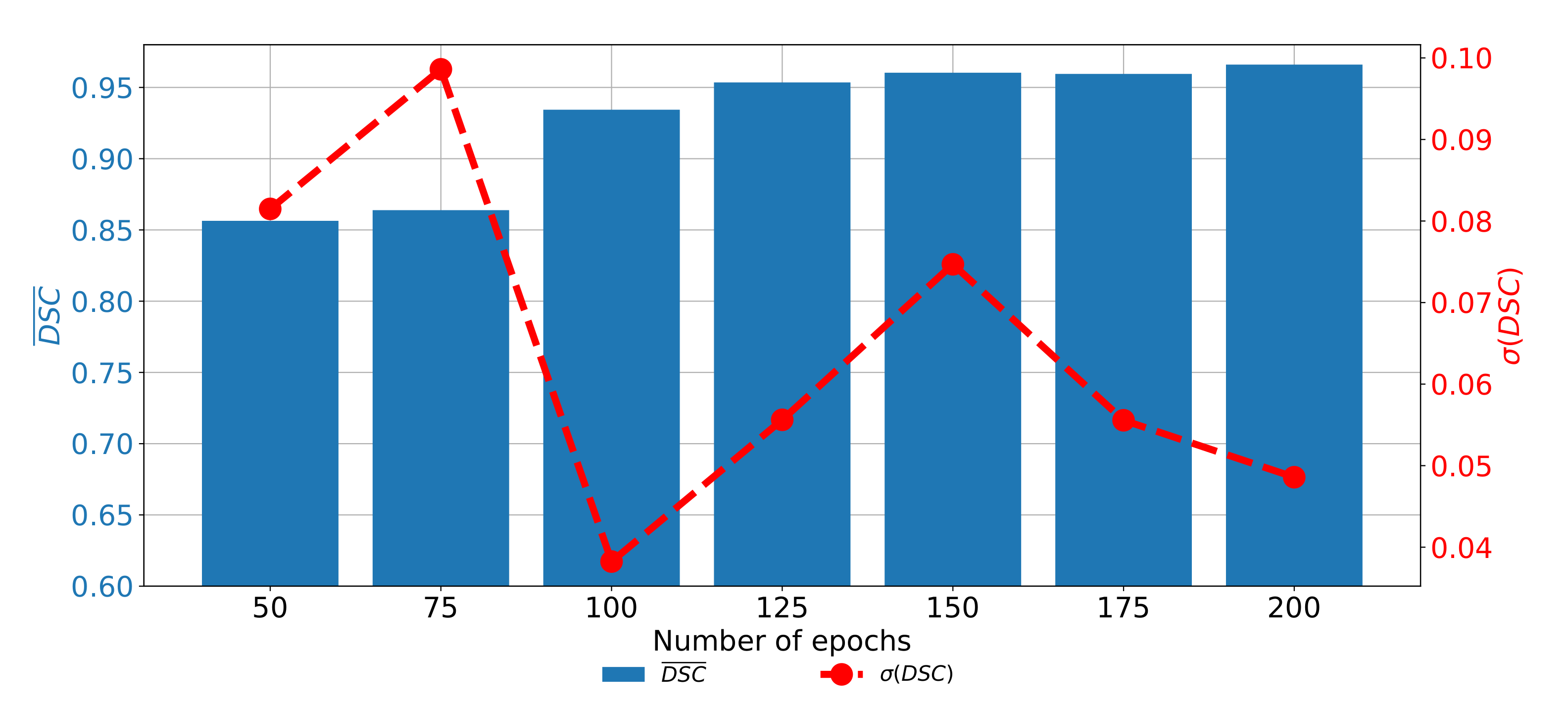
The last data set used in this research is the data set of CT images captured in the sagittal plane. In this case, a significant improvement of semantic segmentation and generalization results can be observed if the transfer learning approach is utilized. In the case of standard U-net architectures,
and
do not exceed 0.86. On the other hand, if the transfer learning paradigm is utilized, significantly higher performances are achieved. By using this approach,
and
values up to 0.96660 are achieved, if a pre-trained VGG-16 architecture is used as a backbone for the U-net. Detailed results and models are presented in
Table 9.
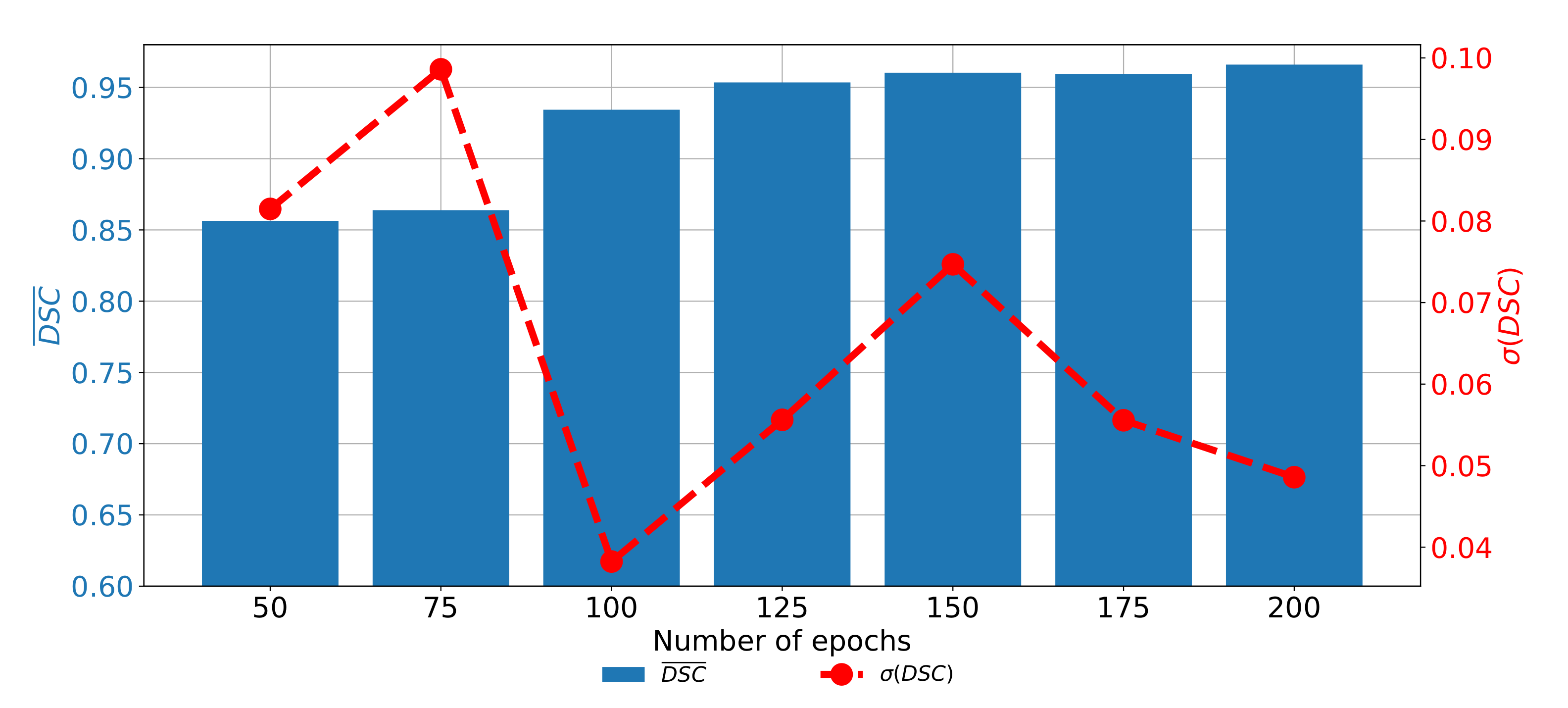
If the change of performances through epochs is observed, it can be noticed that the network with pre-trained VGG-16 architecture as a backbone achieved higher results if it is trained for a higher number of epochs. It is interesting to notice that the network has higher semantic segmentation performances if it is trained for 200 consecutive epochs. On the other hand, generalization performances are higher if the network is trained for 100 consecutive epochs, as presented in
Figure 14.
7.5. Discussion
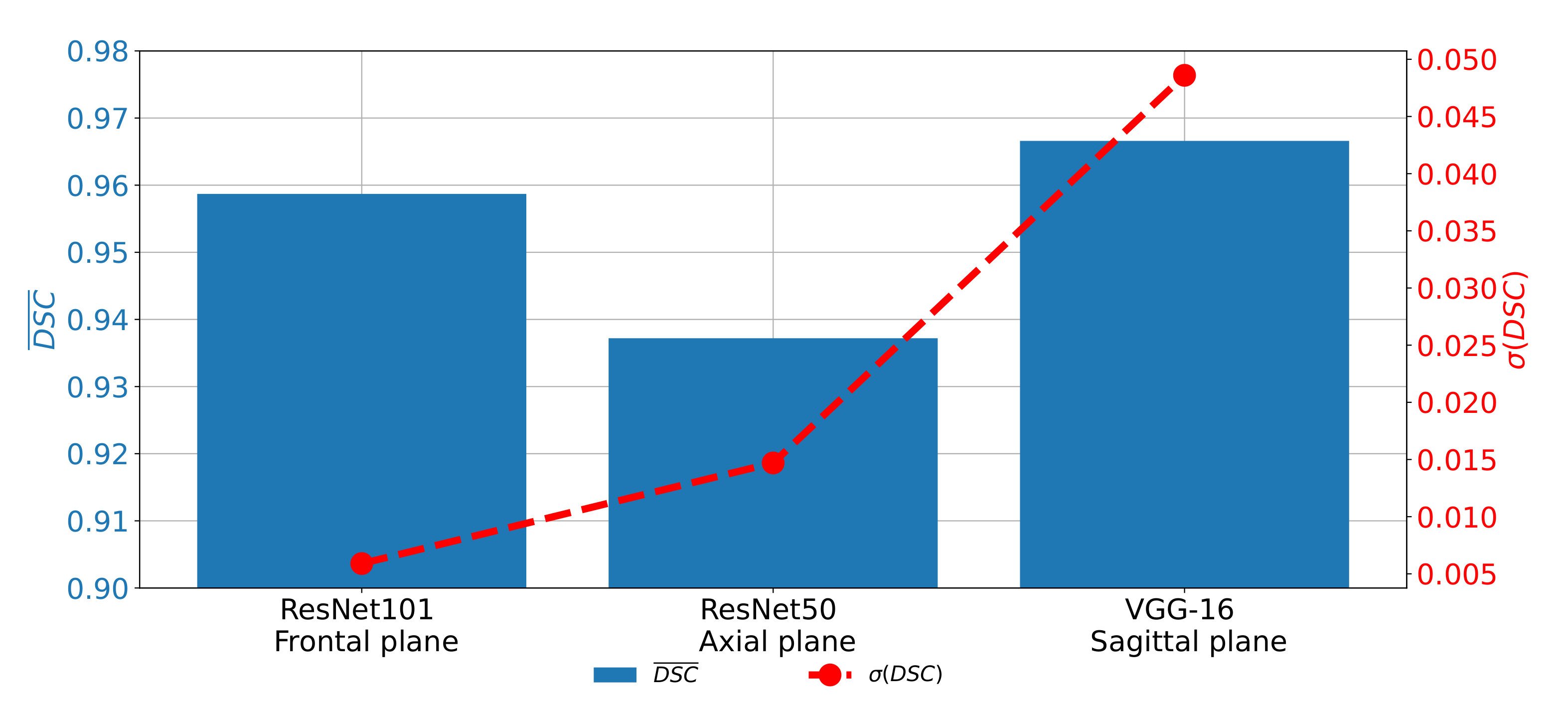
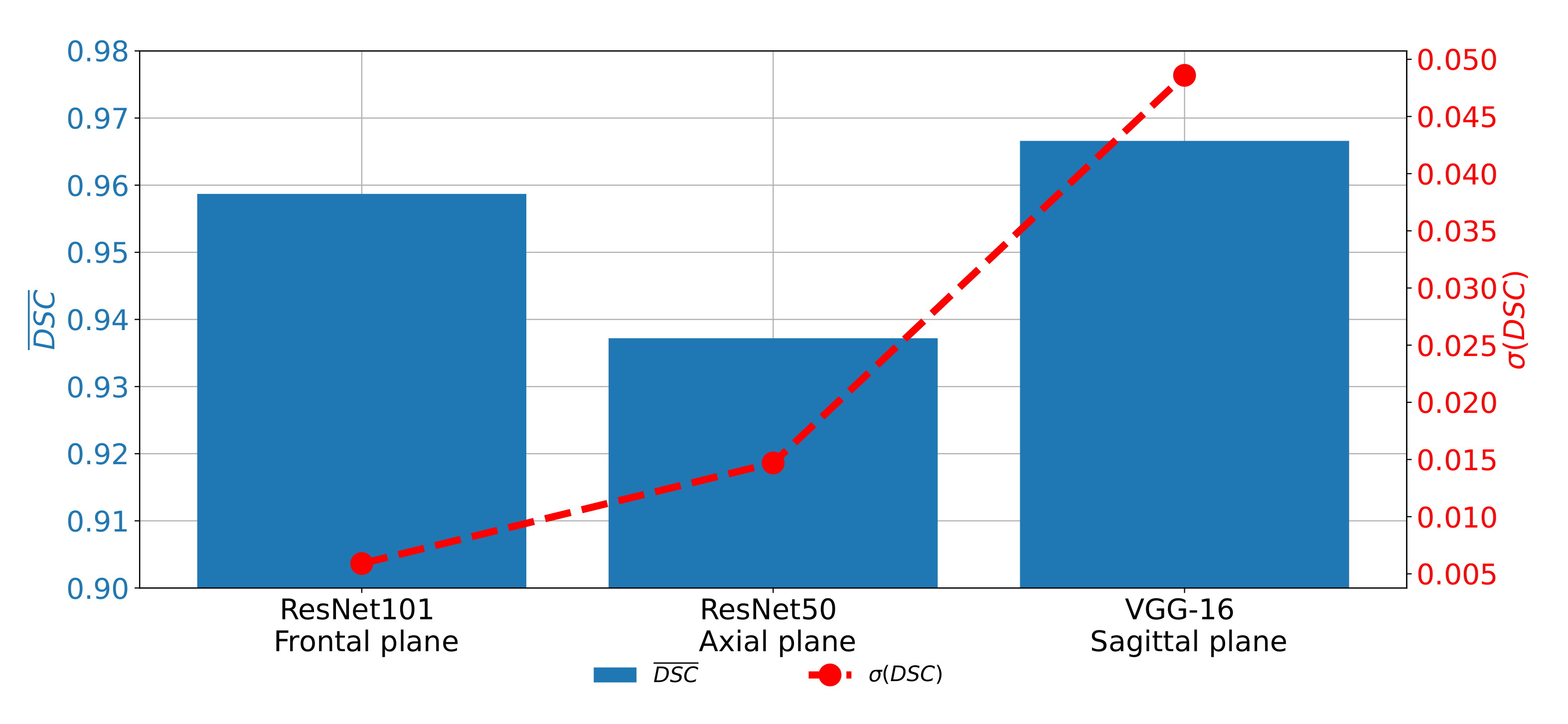
If
and
achieved on all three planes are compared, it can be noticed that the highest semantic segmentation performances are achieved on the sagittal plane, if pre-trained VGG-16 architecture is used as a backbone. For the case of the frontal and axial plane, slightly lover performances are achieved. On the other hand, if generalization performances are compared, it can be noticed that the highest
is achieved for the case of the sagittal plane. The best classification performances are achieved in the case of the frontal plane, as presented in
Figure 15.
From the presented results, it can be seen that U-net for the case of the sagittal plane, although having the highest performance from the point of view of semantic segmentation, has significantly lower results from the point of view of generalization. Such a characteristic can be attributed to the fact that this part of the data set has a significantly lower number of images, in comparison with the other two parts. Such a lower number of images results in a lower number of training images in all five cases of the five-fold cross-validation procedure.
Such a lower number of training images results in lower semantic segmentation performances in some cross-validation cases and, thus, lower generalization performances. For these reasons, it can be concluded that, before the application of the proposed semantic segmentation system, more images captured in the sagittal plane need to be collected in order to increase the generalization performances of U-net for the semantic segmentation of images captured in the sagittal plane.
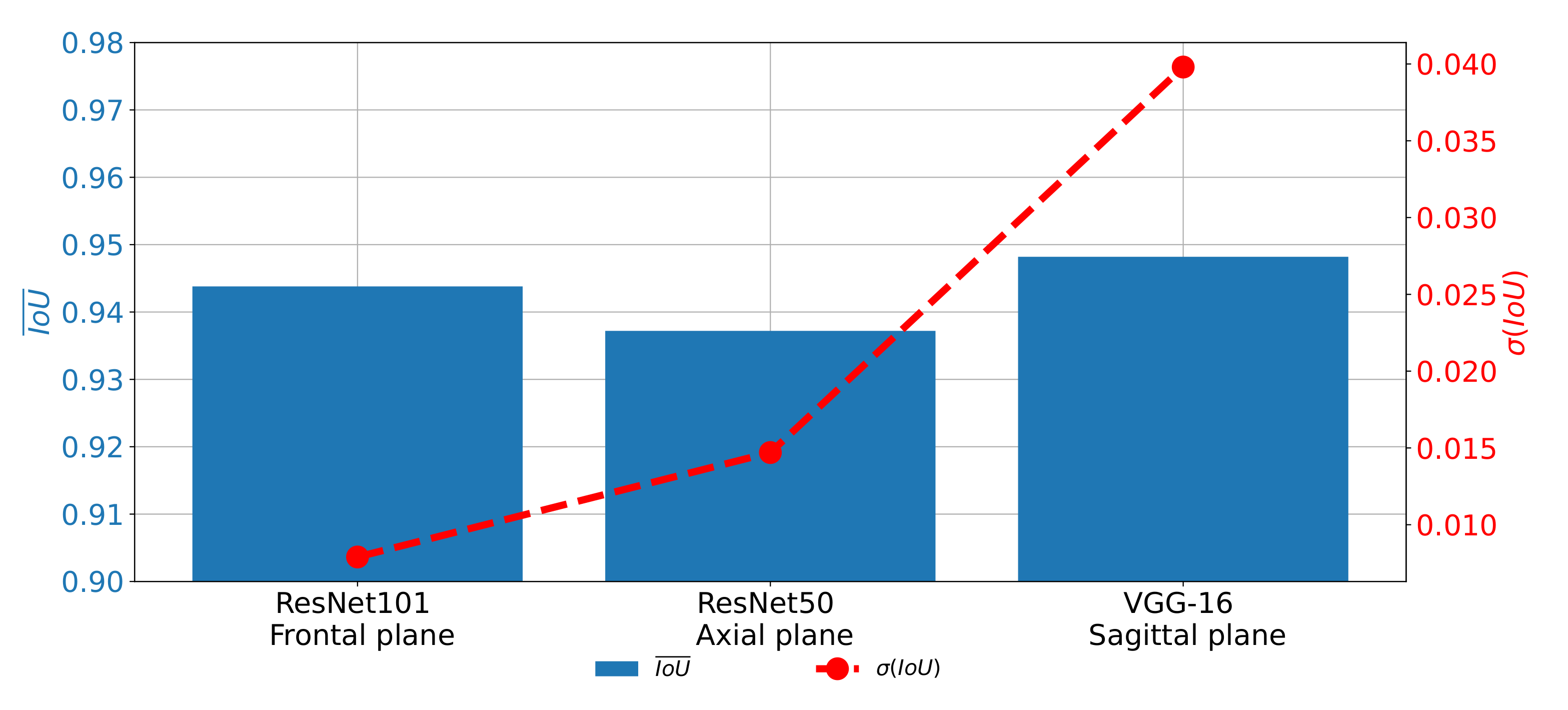
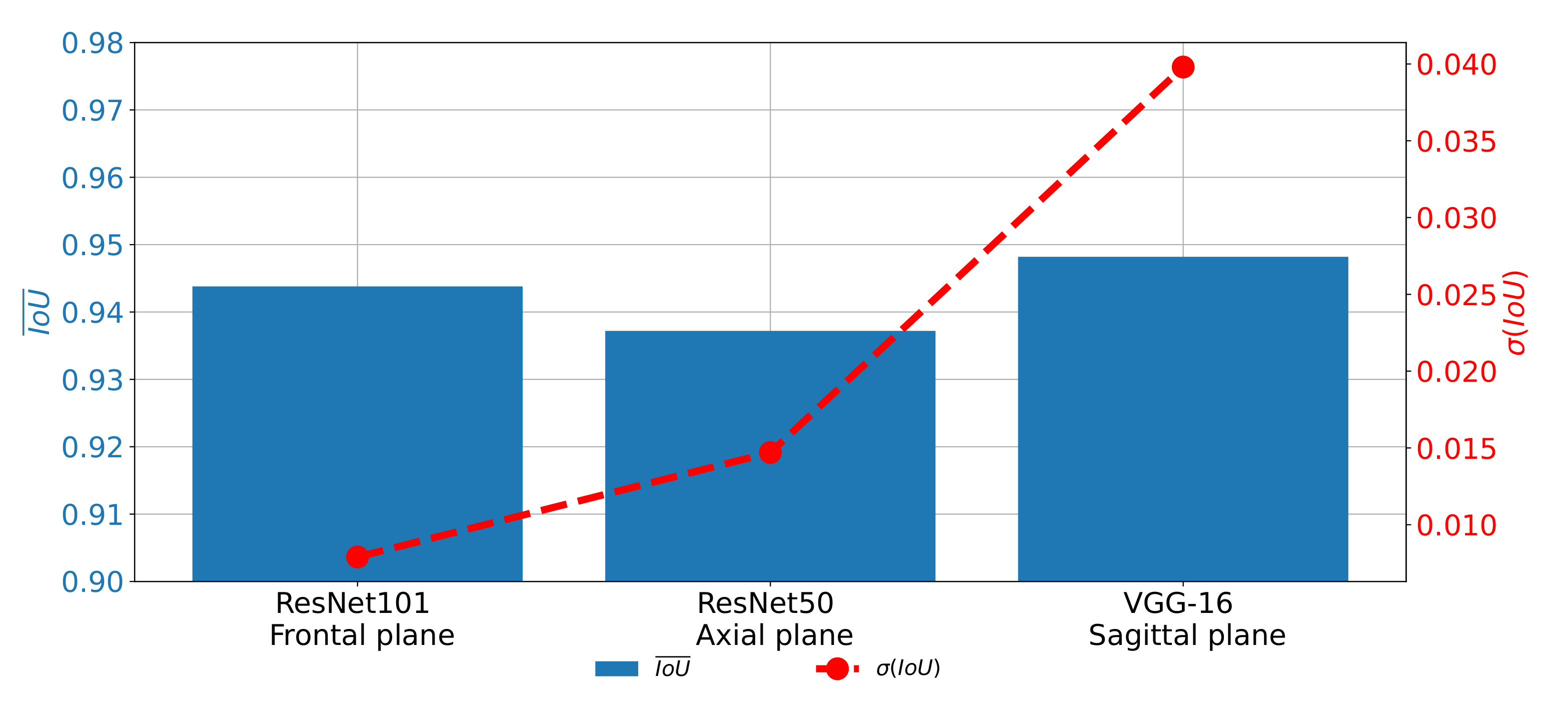
A similar trend can be noticed when the results measured with
are compared as presented in
Figure 16. In this case, the difference between the results achieved on different planes, although lower, is still clearly visible. For these reasons, it can be concluded that the network used for images in the frontal plane has a more stable behavior. On the other hand, it can be concluded that the network used on images taken in the sagittal plane has much less stable behavior. This characteristic can clearly be attributed to the fact that the sagittal part of the data set has a significantly lower number of images.
The presented results are showing that there is a possibility for the application of the proposed system in clinical practice. It is shown that the high semantic segmentation performances enable the automatic evaluation of urinary bladder cancer spread. Furthermore, high generalization performances, especially in the case of the frontal and axial plane, indicate that the semantic segmentation system can be used for the evaluation of the new image data and new patients. The presented system can be used as an assistance system to medical professionals in order to improve clinical decision-making procedures.
8. Conclusions
According to the presented results, we concluded that the utilization of the transfer learning paradigm, in the form of pre-trained CNN architectures used as backbones for U-nets, can significantly improve the performances of semantic segmentation of urinary bladder cancer masses from CT images. Such an improvement can be noticed in both semantic segmentation and generalization performances. If the semantic segmentation performances are compared, values of 0.9587, 0.9587, and 0.9660 are achieved for the case of the frontal, axial, and sagittal planes, respectively.
On the other hand, for the case of generalization performances, of 0.0059, 0.0147, and 0.0486 are achieved for the case of the frontal, axial, and sagittal planes, respectively, suggesting the conclusion that the transfer learning approach opened the possibility for future utilization of such a system in clinical practice. Furthermore, U-nets for the semantic segmentation of urinary bladder cancer masses from images captured in the sagittal plane achieved significantly lower generalization performances. Such a characteristic can be assigned to the fact that the data set of sagittal images consists of the significantly lower number of images in comparison with two other data sets. According to the hypothesis questions, the conclusion can be summarized as:
The design of a semantic segmentation system separately for each plane is possible.
There is a possibility for the design of an automated system for plane recognition.
By utilizing the transfer learning approach, significantly higher semantic segmentation and generalization performances are achieved.
The highest performances are achieved if pre-trained ResNet101, ResNet50, and VGG-16 are used as U-net backbones for the semantic segmentation of images in the frontal, axial, and sagittal planes, respectively.
From the presented results, by utilizing the proposed approach, results in range of the results presented from the state-of-the-art approach were achieved. Furthermore, the proposed redundant approach increased the diagnostic performances and minimized the chance for incorrect diagnoses.
Future work will be based on improvements of the presented combination of classification and semantic segmentation algorithms by the inclusion of multiple classification algorithms before a parallel algorithm for the semantic segmentation. Furthermore, we plan to design a meta-heuristic algorithm for model selection with a fitness function that will be based on the presented multi-objective criteria.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}