Deep Learning-Based Culture-Free Bacteria Detection in Urine Using Large-Volume Microscopy

 , and
, and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Imaging Device Setup and Analysis
2.1.1. LVM
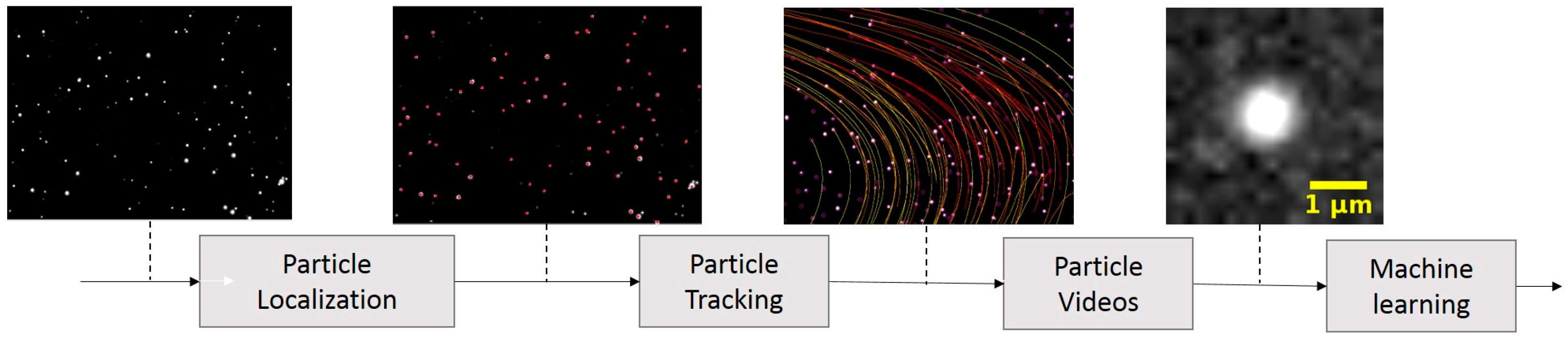
2.1.2. Algorithm
2.1.3. Particle Localization
2.1.4. Tracking
2.1.5. Single-Particle Video Generation
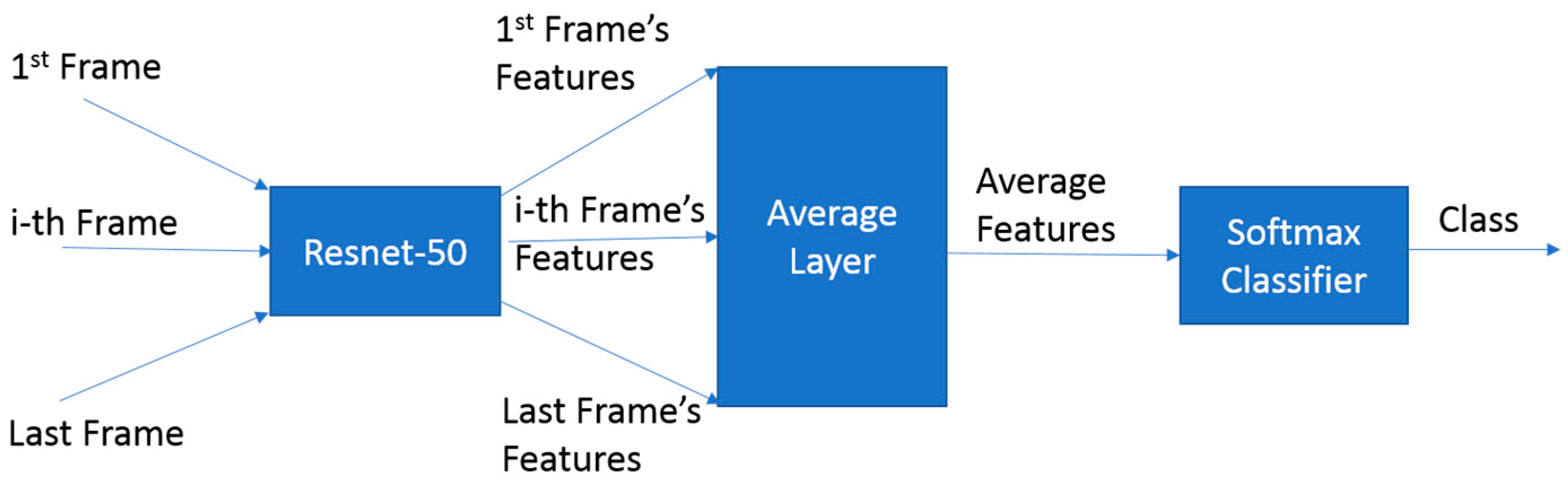
2.1.6. Machine Learning vs. Deep Learning Comparison
- Mean subtraction: implementing mean subtraction, where the mean was calculated as a scalar for each single-particle video by averaging over all pixels and frames, improved accuracy by up to 5%;
- The use of L2-norm regularization and a dropout rate of 0.5, a common practice in deep learning, significantly reduced overfitting. This dropout rate is particularly effective in preventing co-adaptation of neurons during training, thereby enhancing the convergence of validation cross entropy loss;
- Dynamic range adjustment: to improve loss convergence, dynamic range adjustment was performed, capping the maximum intensity value at 1000 and normalizing all values between 0 and 1. We replaced zero values with the smallest non-zero value in each video, which is a critical adjustment considering the original particle pixel range of 0–65,535. This step was necessary to prevent instabilities in the model caused by extreme intensity variations. The highest non-zero value considered as zero is part of this normalization process, ensuring a stable and efficient analysis framework;
- Learning rates: small learning rates, ranging from 10−7 to 10−5, were employed to ensure proper convergence of validation loss;
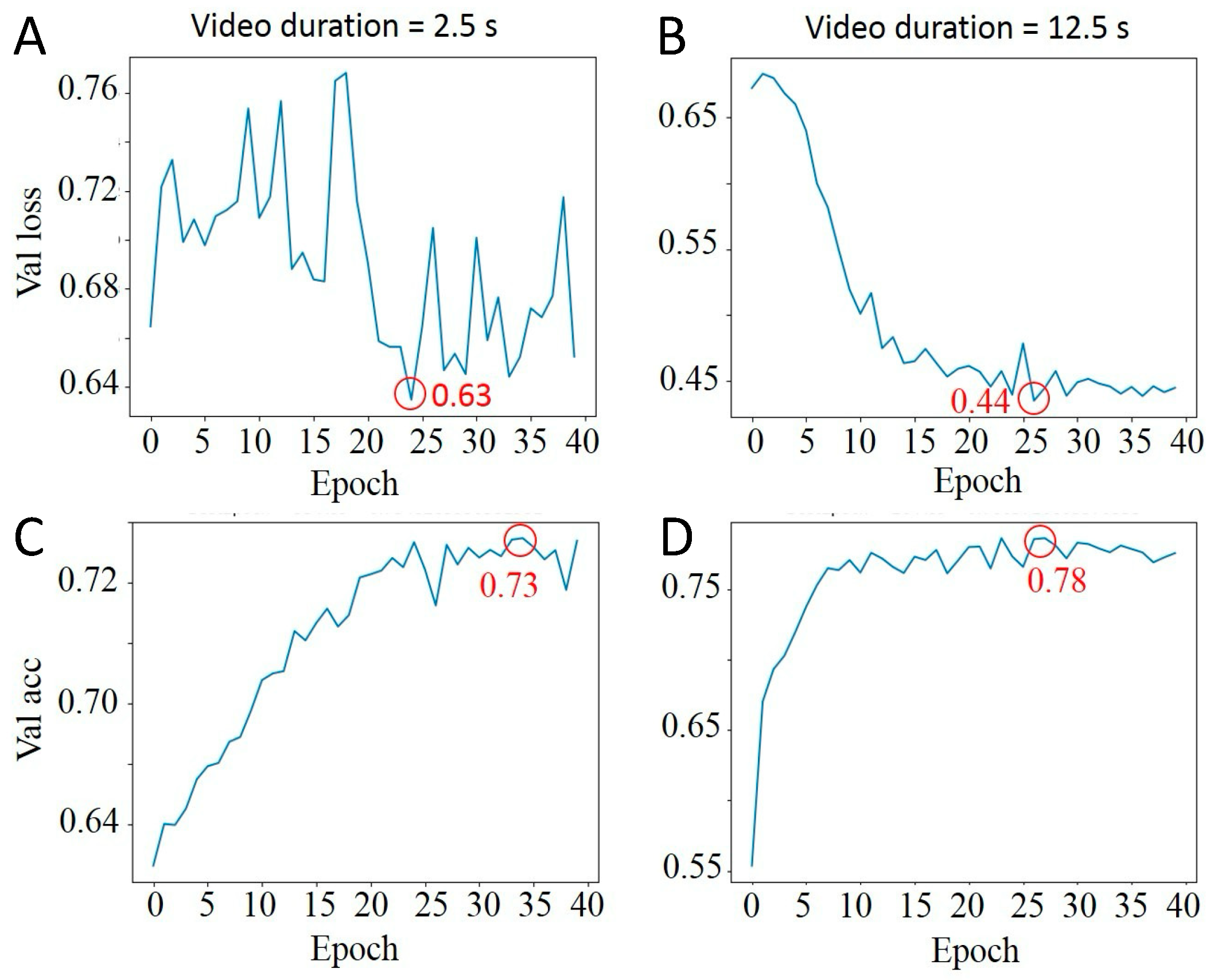
- Video length: the length of videos was critical to provide sufficient particle temporal information for training robust models;
- Class balancing and randomization: to ensure class balance, the number of training samples for each class was equalized in each epoch. Furthermore, samples were randomized in each epoch to maximize the utilization of the dataset for training.
2.1.7. Datasets
- Dataset 1: This dataset included data from a single day, with one E. coli sample and one urine particle sample, each accompanied by four replicates. The first replicate from each category was used for validation, contributing 100–300 videos. For testing, we used a separate day’s data, also consisting of one E. coli and one urine particle sample, along with their replicates, providing an additional 500–1500 videos. The training phase encompassed approximately 400–1200 videos;
- Dataset 2: This dataset featured data from one day, but with four distinct samples (and their respective four replicates) for each particle type. The first sample set was allocated for validation, yielding 500–1500 videos, while the training dataset included 1500–4500 videos. For testing, we used data from a different day, mirroring the sample and replicate structure, resulting in another 500–1500 videos;
- Dataset 3: This dataset encompassed data spanning six days. The first sample (and its replicates) from each day was designated for validation, amounting to a total of 3000–9000 videos. The training phase incorporated data from the remaining samples, tallying up to 12,000–36,000 videos. Testing was conducted with data from a different day, producing an additional 2000–6000 videos.
2.2. Materials and Reagents
2.2.1. LVM Setup
2.2.2. Sample Preparation
2.2.3. Data Processing
2.2.4. Deep Learning
3. Results and Discussion
3.1. Accuracy Performance
3.2. Method Comparison
3.3. Effect of Dynamic Range Adjustment
3.4. Effect of Video Length
3.5. Effect of Setup Configuration
- Laser position in X, Y, Z planes;
- Camera position in X, Y, Z planes;
- Lights turned off;
- Digital controlled field of view (center, top left, and bottom right).
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McLellan, L.K.; Hunstad, D.A. Urinary Tract Infection: Pathogenesis and Outlook. Trends Mol. Med. 2016, 22, 946–957. [Google Scholar] [CrossRef]
- Flores-Mireles, A.L.; Walker, J.N.; Caparon, M.; Hultgren, S.J. Urinary Tract Infections: Epidemiology, Mechanisms of Infection and Treatment Options. Nat. Rev. Microbiol. 2015, 13, 269–284. [Google Scholar] [CrossRef]
- Foxman, B. The Epidemiology of Urinary Tract Infection. Nat. Rev. Urol. 2010, 7, 653–660. [Google Scholar] [CrossRef]
- Kauffman, C.A. Diagnosis and Management of Fungal Urinary Tract Infection. Infect. Dis. Clin. N. Am. 2014, 28, 61–74. [Google Scholar] [CrossRef]
- Simmering, J.E.; Tang, F.; Cavanaugh, J.E.; Polgreen, L.A.; Polgreen, P.M. The Increase in Hospitalizations for Urinary Tract Infections and the Associated Costs in the United States, 1998–2011. Open Forum Infect. Dis. 2017, 4, ofw281. [Google Scholar] [CrossRef]
- Antimicrobial Resistance Collaborators. Global Burden of Bacterial Antimicrobial Resistance in 2019: A Systematic Analysis. Lancet 2022, 399, 629–655. [Google Scholar] [CrossRef]
- Redfield, R.R. Antibiotic Resistance Threats in the United States; Centers for Disease Control and Prevention: Atlanta, GA, USA, 2019; Volume 148.
- Griebling, T.L. Urologic Diseases in America Project: Trends in Resource Use for Urinary Tract Infections in Men. J. Urol. 2005, 173, 1281–1294. [Google Scholar] [CrossRef]
- Van Boeckel, T.P.; Gandra, S.; Ashok, A.; Caudron, Q.; Grenfell, B.T.; Levin, S.A.; Laxminarayan, R. Global Antibiotic Consumption 2000 to 2010: An Analysis of National Pharmaceutical Sales Data. Lancet Infect. Dis. 2014, 14, 742–750. [Google Scholar] [CrossRef]
- Editorials. The Antibiotic Alarm. Nature 2013, 495, 141. [Google Scholar] [CrossRef]
- Hoberman, A.; Wald, E.R.; Reynolds, E.A.; Penchansky, L.; Charron, M. Pyuria and Bacteriuria in Urine Specimens Obtained by Catheter from Young Children with Fever. J. Pediatr. 1994, 124, 513–519. [Google Scholar] [CrossRef]
- Fenwick, E.A.; Briggs, A.H.; Hawke, C.I. Management of Urinary Tract Infection in General Practice: A Cost-Effectiveness Analysis. Br. J. Gen. Pract. 2000, 50, 635–639. [Google Scholar]
- Davenport, M.; Mach, K.; Shortliffe, L.M.D.; Banaei, N.; Wang, T.H.; Liao, J.C. New and Developing Diagnostic Technologies for Urinary Tract Infections. Nat. Rev. Urol. 2017, 14, 296–310. [Google Scholar] [CrossRef]
- Hurlbut, T.A., 3rd; Littenberg, B. The Diagnostic Accuracy of Rapid Dipstick Tests to Predict Urinary Tract Infection. Am. J. Clin. Pathol. 1991, 96, 582–588. [Google Scholar] [CrossRef]
- Devillé, W.L.; Yzermans, J.C.; Van Duijn, N.P.; Bezemer, P.D.; Van Der Windt, D.A.; Bouter, L.M. The Urine Dipstick Test Useful to Rule Out Infections. A Meta-Analysis of the Accuracy. BMC Urol. 2004, 4, 4. [Google Scholar] [CrossRef]
- Lammers, R.L.; Gibson, S.; Kovacs, D.; Sears, W.; Strachan, G. Comparison of Test Characteristics of Urine Dipstick and Urinalysis at Various Test Cutoff Points. Ann. Emerg. Med. 2001, 38, 505–512. [Google Scholar] [CrossRef]
- Fraile Navarro, D.; Sullivan, F.; Azcoaga-Lorenzo, A.; Hernandez Santiago, V. Point-of-Care Tests for Urinary Tract Infections: Protocol for a Systematic Review and Meta-Analysis of Diagnostic Test Accuracy. BMJ Open 2020, 10, e033424. [Google Scholar] [CrossRef]
- Di Toma, A.; Brunetti, G.; Chiriacò, M.S.; Ferrara, F.; Ciminelli, C. A Novel Hybrid Platform for Live/Dead Bacteria Accurate Sorting by On-Chip DEP Device. Int. J. Mol. Sci. 2023, 24, 7077. [Google Scholar] [CrossRef]
- Wang, Y.; Reardon, C.P.; Read, N.; Thorpe, S.; Evans, A.; Todd, N.; Van Der Woude, M.; Krauss, T.F. Attachment and Antibiotic Response of Early-Stage Biofilms Studied Using Resonant Hyperspectral Imaging. NPJ Biofilms Microbiomes. 2020, 6, 57. [Google Scholar] [CrossRef]
- Therisod, R.; Tardif, M.; Marcoux, P.R.; Picard, E.; Jager, J.-B.; Hadji, E.; Peyrade, D.; Houdré, R. Gram-Type Differentiation of Bacteria with 2D Hollow Photonic Crystal Cavities. Appl. Phys. Lett. 2018, 113, 111101. [Google Scholar] [CrossRef]
- Mo, M.; Yang, Y.; Zhang, F.; Jing, W.; Iriya, R.; Popovich, J.; Wang, S.; Grys, T.; Haydel, S.E.; Tao, N. Rapid Antimicrobial Susceptibility Testing of Patient Urine Samples Using Large Volume Free-Solution Light Scattering Microscopy. Anal. Chem. 2019, 91, 10164–10171. [Google Scholar] [CrossRef]
- Zhang, F.; Mo, M.; Jiang, J.; Zhou, X.; McBride, M.; Yang, Y.; Reilly, K.S.; Grys, T.E.; Haydel, S.E.; Tao, N.; et al. Rapid Detection of Urinary Tract Infection in 10 Minutes by Tracking Multiple Phenotypic Features in a 30-Second Large Volume Scattering Video of Urine Microscopy. ACS Sens. 2022, 7, 2262–2272. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Jing, W.; Iriya, R.; Yang, Y.; Syal, K.; Mo, M.; Grys, T.E.; Haydel, S.E.; Wang, S.; Tao, N. Phenotypic antimicrobial susceptibility testing with deep learning video microscopy. Anal. Chem. 2018, 90, 6314–6322. [Google Scholar] [CrossRef]
- Quinn, J.A.; Nakasi, R.; Mugagga, P.K.B.; Byanyima, P.; Lubega, W.; Andama, A. Deep Convolutional Neural Networks for Microscopy-Based Point of Care Diagnostics. arXiv 2016, arXiv:1608.02989. [Google Scholar] [CrossRef]
- Liang, Y.; Kang, R.; Lian, C.; Mao, Y. An End-to-End System for Automatic Urinary Particle Recognition with Convolutional Neural Network. J. Med. Syst. 2018, 42, 10916. [Google Scholar] [CrossRef]
- Hay, E.A.; Parthasarathy, R. Performance of Convolutional Neural Networks for Identification of Bacteria in 3D Microscopy Datasets. PLoS Comput. Biol. 2018, 14, e1006628. [Google Scholar] [CrossRef] [PubMed]
- Iriya, R.; Jing, W.; Syal, K.; Mo, M.; Chen, C.; Yu, H.; Haydel, S.E.; Wang, S.; Tao, N. Rapid Antibiotic Susceptibility Testing Based on Bacterial Motion Patterns with Long Short-Term Memory Neural Networks. IEEE Sens. J. 2020, 20, 4940–4950. [Google Scholar] [CrossRef]
- Abràmoff, M.D.; Magalhães, P.J.; Ram, S.J. Image Processing with ImageJ. Biophotonics Int. 2004, 11, 36–42. [Google Scholar]
- Tinevez, J.Y.; Perry, N.; Schindelin, J.; Hoopes, G.M.; Reynolds, G.D.; Laplantine, E.; Bednarek, S.Y.; Shorte, S.L.; Eliceiri, K.W. TrackMate: An Open and Extensible Platform for Single-Particle Tracking. Methods 2017, 115, 80–90. [Google Scholar] [CrossRef]
- Kong, H.; Akakin, H.C.; Sarma, S.E. A Generalized Laplacian of Gaussian Filter for Blob Detection and Its Applications. IEEE Trans. Cybern. 2013, 43, 1719–1733. [Google Scholar] [CrossRef]
- Kumar, V. Feature Selection: A Literature Review. Smart Comput. Rev. 2014, 4, 211–229. [Google Scholar] [CrossRef]
- Weston, J.; Watkins, C. Support Vector Machines for Multi-Class Pattern Recognition. In Proceedings of the 7th European Symposium on Artificial Neural Networks, Bruges, Belgium, 21–23 April 1999; pp. 219–224. [Google Scholar]
- Donahue, J.; Hendricks, L.A.; Rohrbach, M.; Venugopalan, S.; Guadarrama, S.; Saenko, K.; Darrell, T. Long-Term Recurrent Convolutional Networks for Visual Recognition and Description. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 677–691. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for Aspect-level Sentiment Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; Association for Computational Linguistics. pp. 606–615. [Google Scholar]
- Abu-El-Haija, S.; Kothari, N.; Lee, J.; Natsev, P.; Toderici, G.; Varadarajan, B.; Vijayanarasimhan, S. YouTube-8M: A Large-Scale Video Classification Benchmark. arXiv 2016, arXiv:1609.08675. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Keras: Deep Learning Library for Theano and TensorFlow. 2015. Available online: https://github.com/keras-team/keras-io (accessed on 19 September 2018).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | E. coli Accuracy (%) | Bead/Urine Particle Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| Train | Val | Test | Train | Val | Test | |
| 0 | 97 | 93 | 95 | 94 | 89 | 78 |
| 1 | 100 | 93 | 56 | 98 | 92 | 85 |
| 2 | 89 | 95 | 84 | 62 | 61 | 40 |
| Method | E. coli Accuracy (%) | Bead Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| Train | Val | Test | Train | Val | Test | |
| SVM | 52 | 53 | 93 | 96 | 90 | 75 |
| CNN-LSTM | 97 | 94 | 95 | 95 | 89 | 79 |
| CNNFA | 97 | 93 | 95 | 94 | 89 | 78 |
| Method | E. coli Accuracy (%) | Bead Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| Train | Val | Test | Train | Val | Test | |
| SVM | 78 | 74 | 79 | 62 | 57 | 50 |
| CNN-LSTM | 77 | 89 | 80 | 57 | 46 | 21 |
| CNNFA | 64 | 75 | 63 | 89 | 82 | 60 |
| Configuration | E. coli Accuracy (%) | Urine Particle Accuracy (%) |
|---|---|---|
| Default (training) | 81 | 72 |
| Laser Z (−10) | 79 | 74 |
| Laser Y (+20) | 81 | 72 |
| Laser Y (−10) | 79 | 74 |
| Laser X (+20) | 81 | 72 |
| Laser X (+20) | 79 | 74 |
| Cam Z (+10) | 81 | 72 |
| Cam Z (−10) | 79 | 74 |
| Cam Y (+20) | 81 | 72 |
| Cam Y (−10) | 79 | 74 |
| Cam X (+20) | 81 | 72 |
| Cam X (+10) | 79 | 74 |
| Cam X (−10) | 81 | 72 |
| Lights Off | 81 | 72 |
| Field of view (bottom right) | 79 | 74 |
| Field of view (top left) | 79 | 74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iriya, R.; Braswell, B.; Mo, M.; Zhang, F.; Haydel, S.E.; Wang, S. Deep Learning-Based Culture-Free Bacteria Detection in Urine Using Large-Volume Microscopy. Biosensors 2024, 14, 89. https://doi.org/10.3390/bios14020089
Iriya R, Braswell B, Mo M, Zhang F, Haydel SE, Wang S. Deep Learning-Based Culture-Free Bacteria Detection in Urine Using Large-Volume Microscopy. Biosensors. 2024; 14(2):89. https://doi.org/10.3390/bios14020089
Chicago/Turabian StyleIriya, Rafael, Brandyn Braswell, Manni Mo, Fenni Zhang, Shelley E. Haydel, and Shaopeng Wang. 2024. "Deep Learning-Based Culture-Free Bacteria Detection in Urine Using Large-Volume Microscopy" Biosensors 14, no. 2: 89. https://doi.org/10.3390/bios14020089
APA StyleIriya, R., Braswell, B., Mo, M., Zhang, F., Haydel, S. E., & Wang, S. (2024). Deep Learning-Based Culture-Free Bacteria Detection in Urine Using Large-Volume Microscopy. Biosensors, 14(2), 89. https://doi.org/10.3390/bios14020089