Unity Is Intelligence: A Collective Intelligence Experiment on ECG Reading to Improve Diagnostic Performance in Cardiology



Abstract
1. Introduction
2. Methodology
2.1. Data Collection
2.2. Collective Intelligence Protocols
- Frequency: The responses of the group members were ranked according to their frequency among the members of the group.
- Experience: The responses of each member of the group were weighted proportionally to their experience and then ranked according to their aggregated weight.
- Confidence: The responses of each member of the group were weighted proportionally to the confidence they expressed and then ranked according to their aggregated weight.
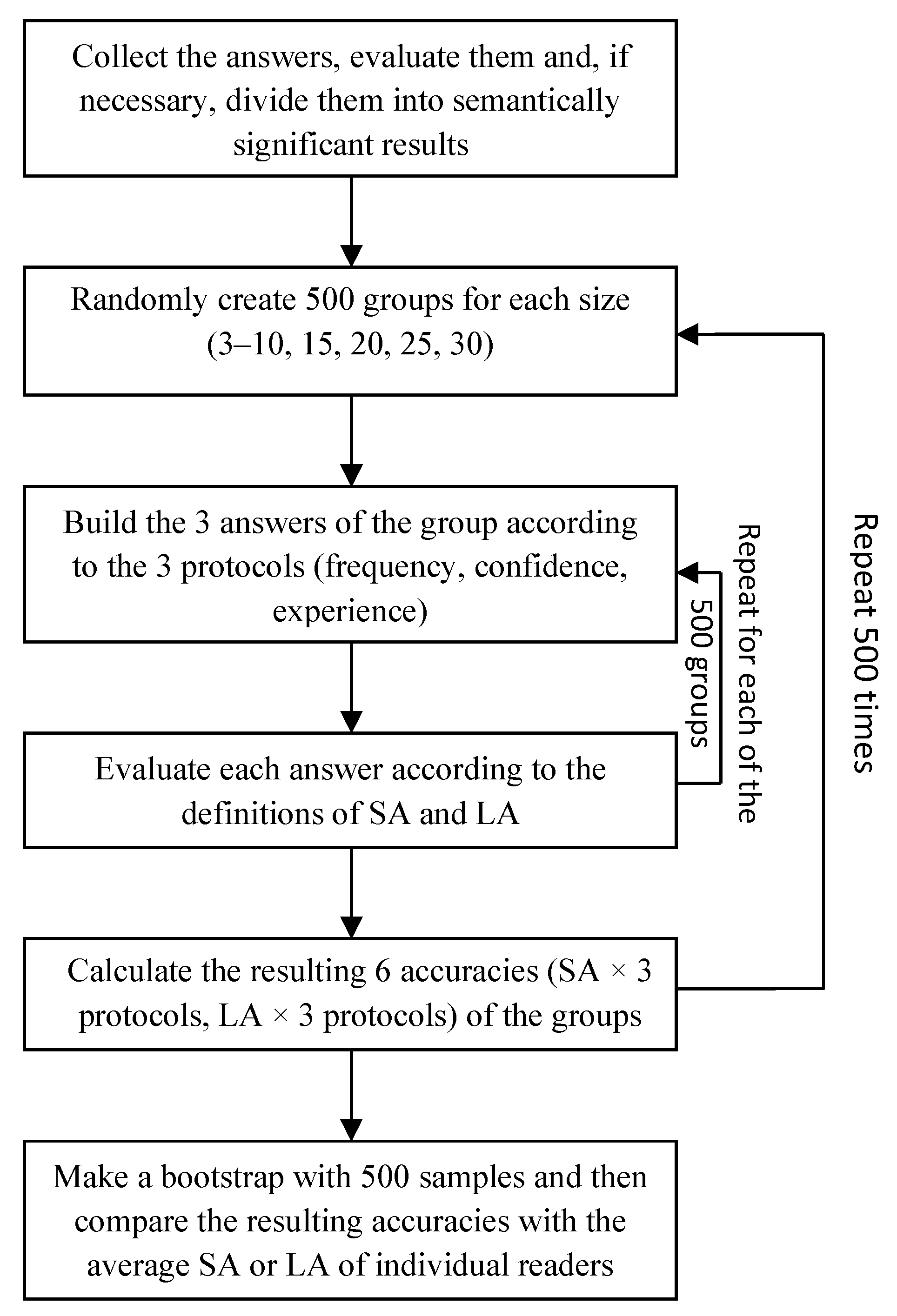
- We sampled groups of size (ranging from three to 30) by extracting (uniformly at random) readers from the set of all respondants;
- For each case and each sampled group, we computed the group answers according to the three considered protocols;
- We evaluated the accuracy (both LA and SA) of each of the sampled groups according to all three protocols;
- We computed the average group accuracy (both LA and SA for each aggregation protocol) by averaging across the sampled groups.
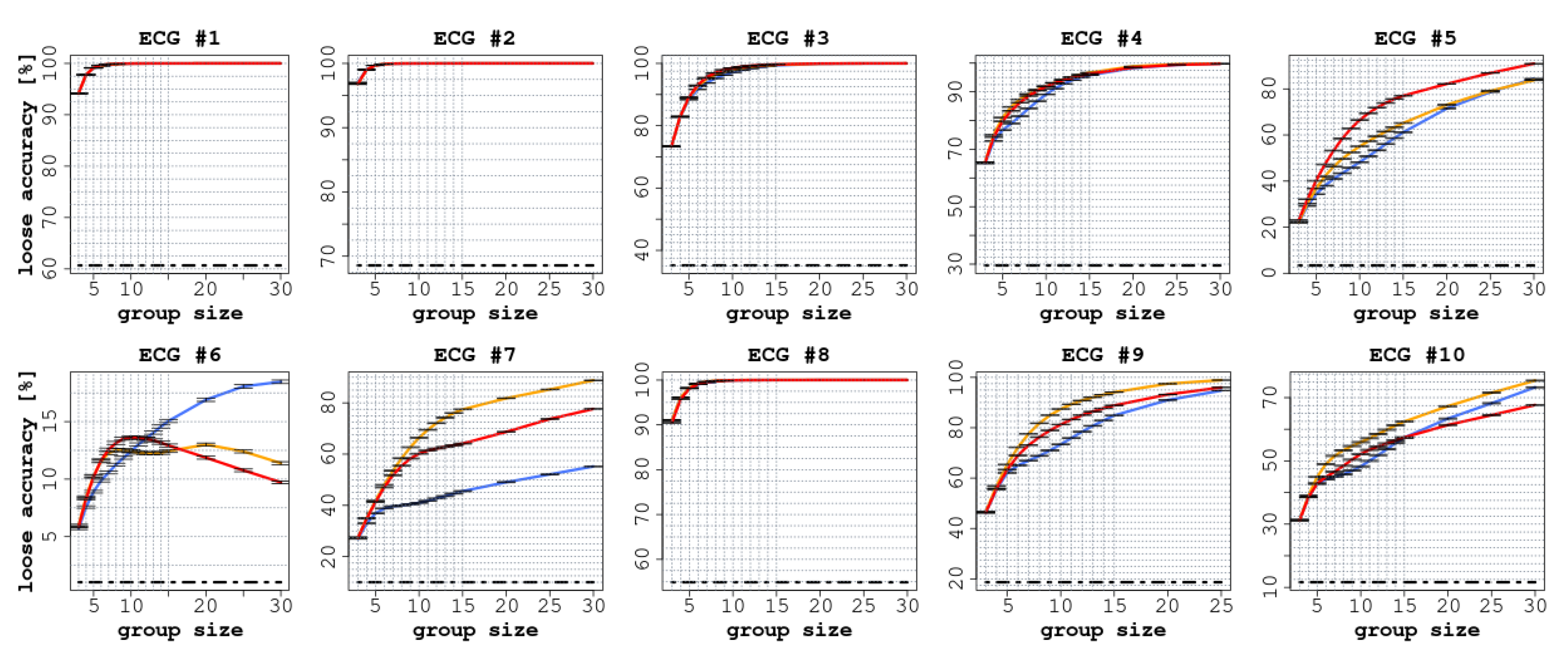
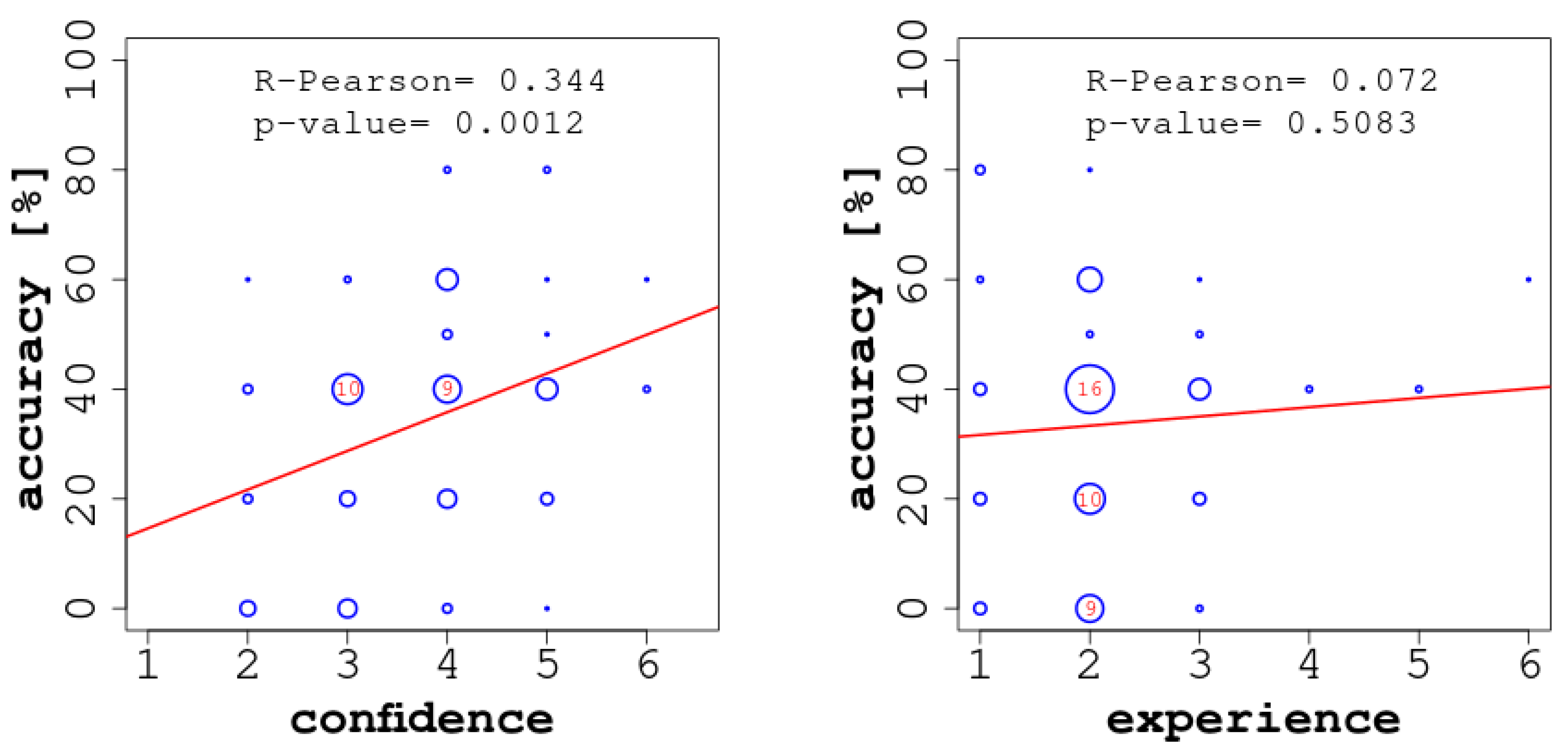
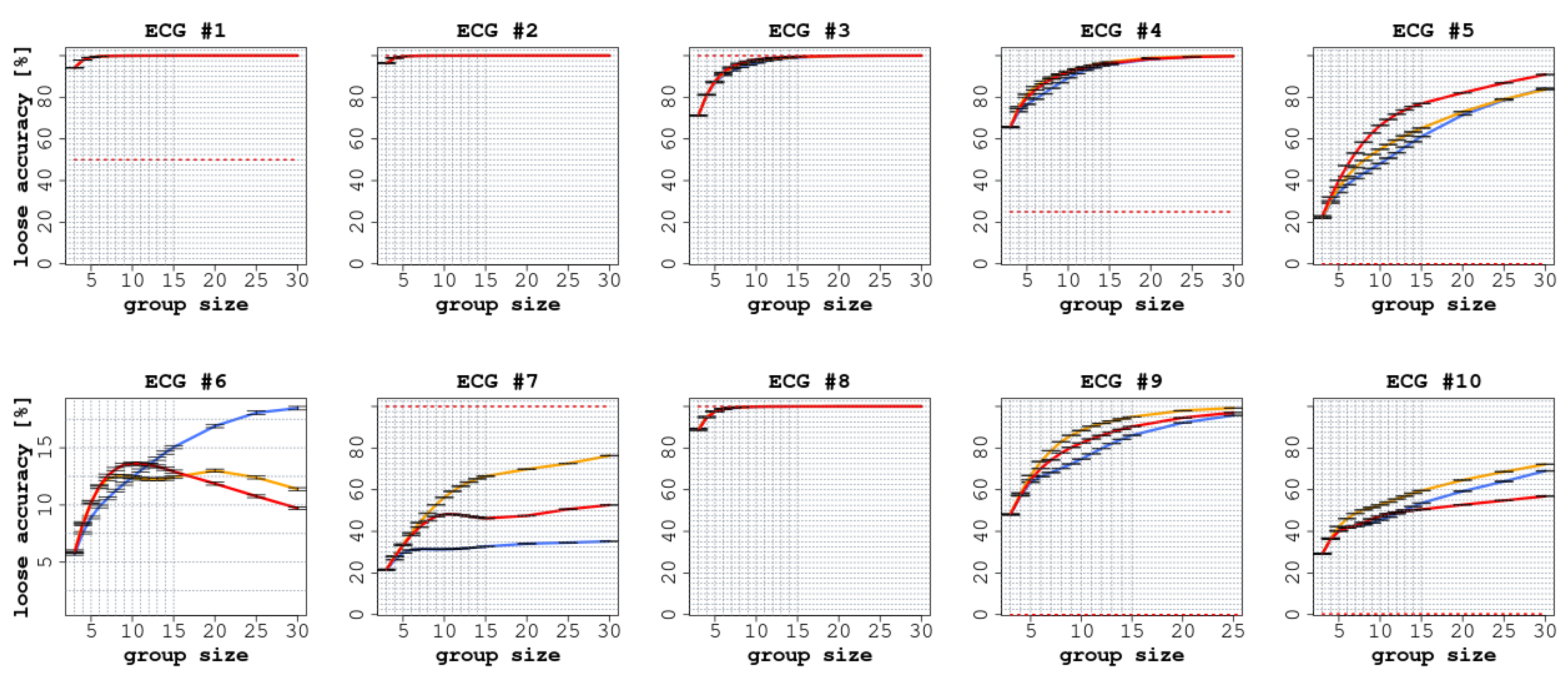
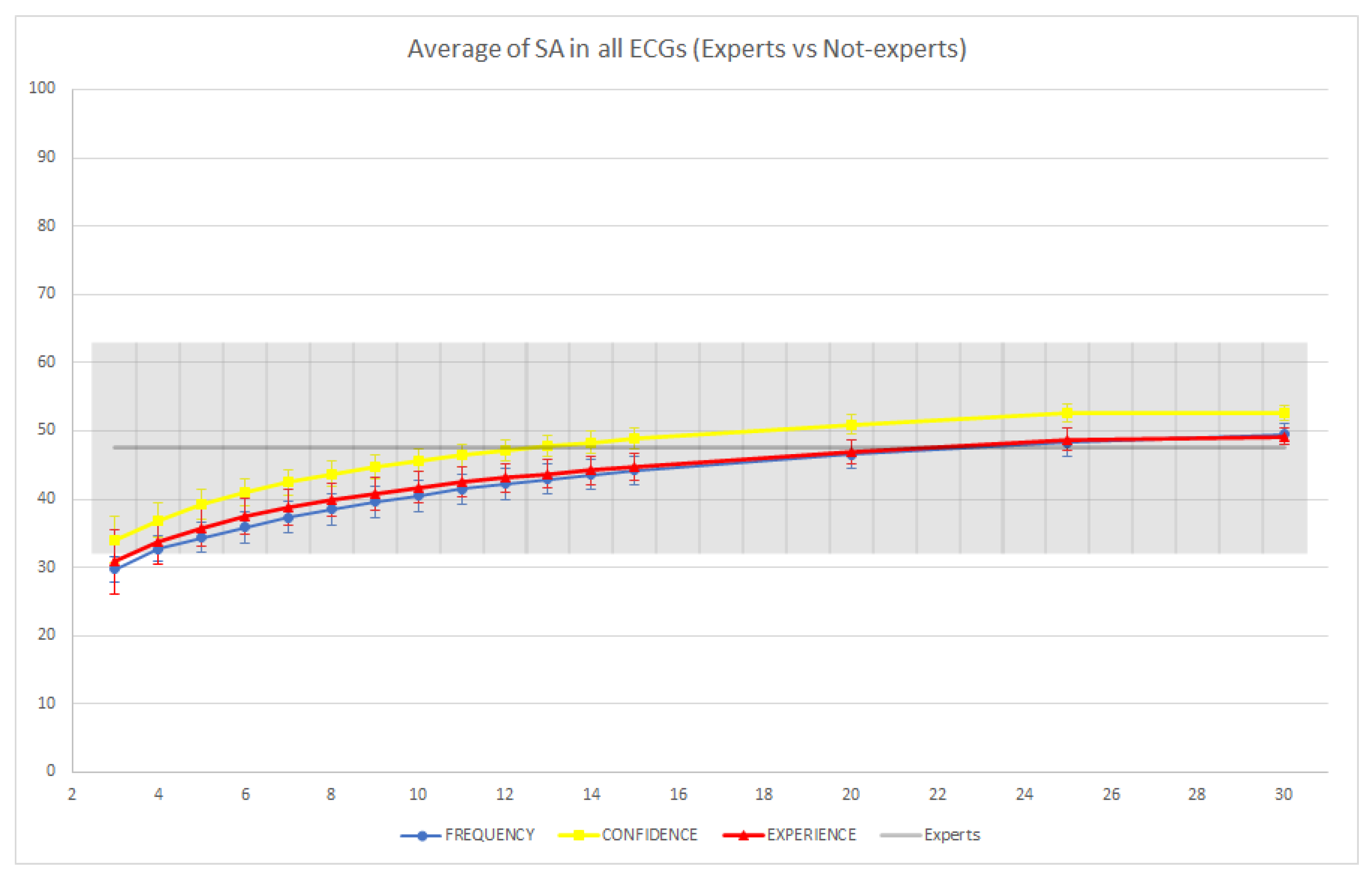
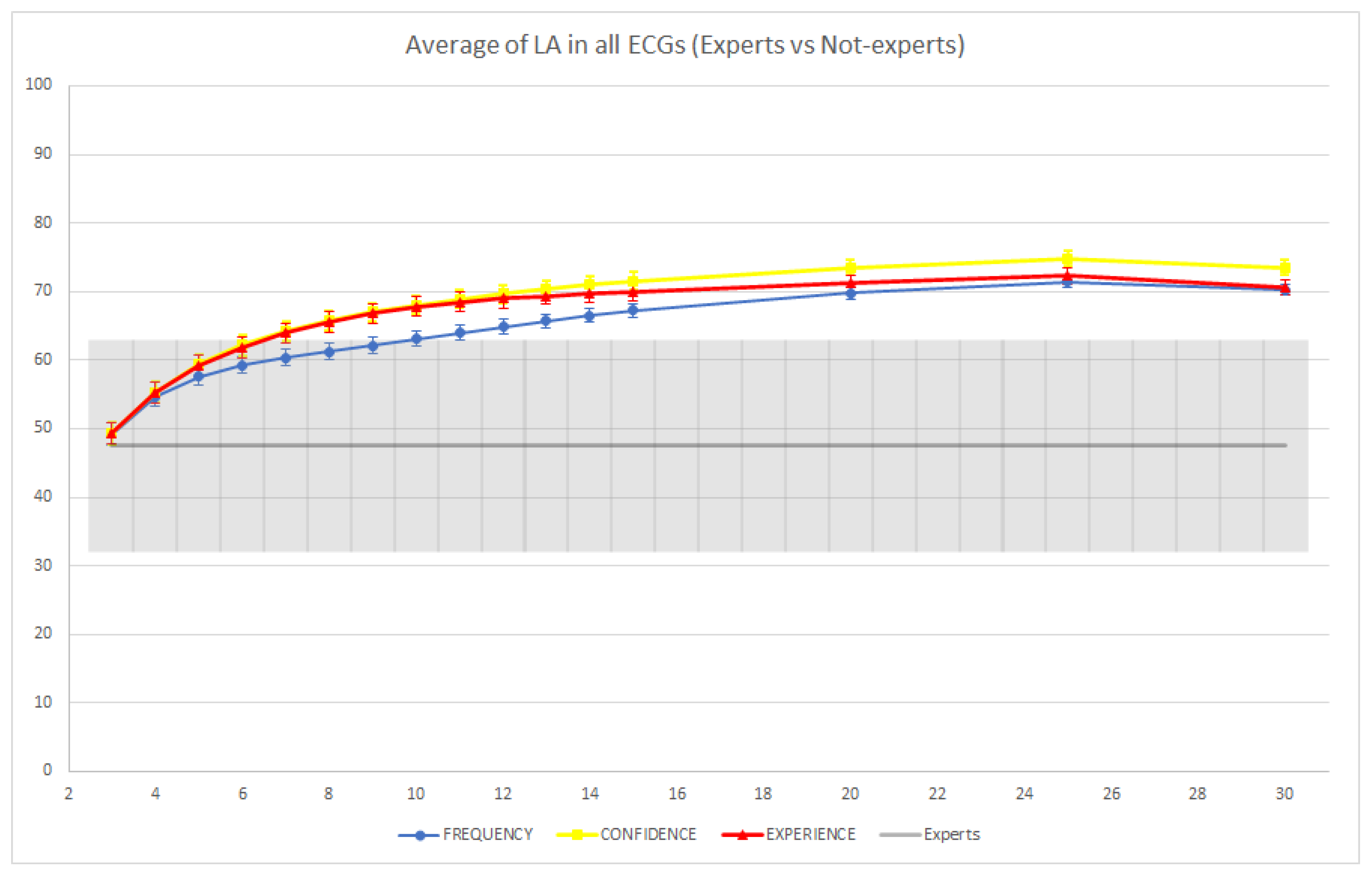
3. Results
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Assale, Michela, Linda Greta Dui, Andrea Cina, Andrea Seveso, and Federico Cabitza. 2019. The revival of the notes field: leveraging the unstructured content in electronic health records. Frontiers in Medicine 6: 66. [Google Scholar] [CrossRef]
- Bahrami, Bahador, Karsten Olsen, Peter E. Latham, Andreas Roepstorff, Geraint Rees, and Chris D. Frith. 2010. Optimally interacting minds. Science 329: 1081–85. [Google Scholar] [CrossRef]
- Balasubramanian, Vineeth, Shen-Shyang Ho, and Vladimir Vovk. 2014. Conformal Prediction for Reliable Machine Learning: Theory, Adaptations and Applications. Burlington: Morgan Kaufmann Publishers Inc. [Google Scholar]
- Barnett, Michael L., Dhruv Boddupalli, Shantanu Nundy, and David W. Bates. 2019. Comparative accuracy of diagnosis by collective intelligence of multiple physicians vs individual physicians. JAMA Network Open 2: e190096. [Google Scholar] [CrossRef]
- Bernstein, Ethan, Jesse Shore, and David Lazer. 2018. How intermittent breaks in interaction improve collective intelligence. Proceedings of the National Academy of Sciences 115: 8734–39. [Google Scholar] [CrossRef]
- Bond, Raymond R., Tomas Novotny, Irena Andrsova, Lumir Koc, Martina Sisakova, Dewar Finlay, Daniel Guldenring, James McLaughlin, Aaron Peace, Victoria McGilligan, and et al. 2018. Automation bias in medicine: The influence of automated diagnoses on interpreter accuracy and uncertainty when reading electrocardiograms. Journal of Electrocardiology 51: S6–S11. [Google Scholar] [CrossRef]
- Cabitza, Federico, Andrea Campagner, and Luca Maria Sconfienza. 2021. Studying human-ai collaboration protocols: the case of the kasparov’s law in radiological double reading. Health Information Science and Systems 9: 1–20. [Google Scholar] [CrossRef] [PubMed]
- Cabitza, Federico, Davide Ciucci, and Raffaele Rasoini. 2019. A giant with feet of clay: On the validity of the data that feed machine learning in medicine. In Organizing for the Digital World. Berlin: Springer, pp. 121–36. [Google Scholar]
- Cabitza, Federico, Raffaele Rasoini, and Gian Franco Gensini. 2017. Unintended consequences of machine learning in medicine. JAMA 318: 517–18. [Google Scholar] [CrossRef] [PubMed]
- Campagner, Andrea, Davide Ciucci, Carl-Magnus Svensson, Marc Thilo Figge, and Federico Cabitza. 2020. Ground truthing from multi-rater labeling with three-way decision and possibility theory. Information Sciences 545: 771–90. [Google Scholar] [CrossRef]
- Campagner, Andrea, Federico Cabitza, and Davide Ciucci. 2020. Three-way decision for handling uncertainty in machine learning: A narrative review. In International Joint Conference on Rough Sets. Berlin: Springer, pp. 137–52. [Google Scholar]
- Davidenko, Jorge Mario, and Lisa Simonettta Snyder. 2007. Causes of errors in the electrocardiographic diagnosis of atrial fibrillation by physicians. Journal of Electrocardiology 40: 450–56. [Google Scholar] [CrossRef] [PubMed]
- De Liddo, Anna, Ágnes Sándor, and Simon Buckingham Shum. 2012. Contested collective intelligence: Rationale, technologies, and a human-machine annotation study. Computer Supported Cooperative Work (CSCW) 21: 417–48. [Google Scholar] [CrossRef]
- Dinh, Julie V., and Eduardo Salas. 2017. Factors that influence teamwork. In The Wiley Blackwell Handbook of the Psychology of Team Working and Collaborative Processes. Hoboken: John Wiley & Sons Ltd., pp. 13–41. [Google Scholar] [CrossRef]
- Efron, Bradley. 1979. Bootstrap methods: Another look at the jackknife. The Annals of Statistics 7: 1–26. [Google Scholar] [CrossRef]
- Efron, Bradley, and Robert J. Tibshirani. 1994. An Introduction to the Bootstrap. Boca Raton: CRC Press. [Google Scholar]
- Fontil, Valy, Elaine C. Khoong, Mekhala Hoskote, Kate Radcliffe, Neda Ratanawongsa, Courtney Rees Lyles, and Urmimala Sarkar. 2019. Evaluation of a health information technology–enabled collective intelligence platform to improve diagnosis in primary care and urgent care settings: protocol for a pragmatic randomized controlled trial. JMIR Research Protocols 8: e13151. [Google Scholar] [CrossRef] [PubMed]
- Fye, W Bruce. 1994. A history of the origin, evolution, and impact of electrocardiography. The American Journal of Cardiology 73: 937–49. [Google Scholar] [CrossRef]
- Gitto, Salvatore, Andrea Campagner, Carmelo Messina, Domenico Albano, Federico Cabitza, and Luca M. Sconfienza. 2020. Collective intelligence has increased diagnostic performance compared with expert radiologists in the evaluation of knee mri. In Seminars in Musculoskeletal Radiology. New York: VThieme Medical Publishers, Inc., vol. 24, p. A011. [Google Scholar]
- Graber, Mark L. 2013. The incidence of diagnostic error in medicine. BMJ Quality & Safety 22 Suppl. 2: ii21–ii27. [Google Scholar]
- Gregg, Dawn G. 2010. Designing for collective intelligence. Communications of the ACM 53: 134–38. [Google Scholar] [CrossRef]
- Gruver, Robert H., and Edward D. Freis. 1957. A study of diagnostic errors. Annals of Internal Medicine 47: 108–20. [Google Scholar] [CrossRef]
- Gur, David, Andriy I. Bandos, Cathy S. Cohen, Christiane M. Hakim, Lara A. Hardesty, Marie A. Ganott, Ronald L. Perrin, William R. Poller, Ratan Shah, Jules H. Sumkin, and et al. 2008. The “laboratory” effect: Comparing radiologists’ performance and variability during prospective clinical and laboratory mammography interpretations. Radiology 249: 47–53. [Google Scholar] [CrossRef] [PubMed]
- Hancock, E. William, Barbara J. Deal, David M. Mirvis, Peter Okin, Paul Kligfield, and Leonard S. Gettes. 2009. Aha/accf/hrs recommendations for the standardization and interpretation of the electrocardiogram: Part V. Journal of the American College of Cardiology 53: 992–1002. [Google Scholar] [CrossRef] [PubMed]
- Hernández-Chan, Gandhi S., Alejandro Rodríguez-González, Giner Alor-Hernández, Juan Miguel Gómez-Berbís, Miguel Angel Mayer-Pujadas, and Ruben Posada-Gómez. 2012. Knowledge acquisition for medical diagnosis using collective intelligence. Journal of Medical Systems 36: 5–9. [Google Scholar] [CrossRef] [PubMed]
- Hernández-Chan, Gandhi S., Edgar Eduardo Ceh-Varela, Jose L. Sanchez-Cervantes, Marisol Villanueva-Escalante, Alejandro Rodríguez-González, and Yuliana Pérez-Gallardo. 2016. Collective intelligence in medical diagnosis systems: A case study. Computers in Biology and Medicine 74: 45–53. [Google Scholar] [CrossRef]
- Hong, Lu, and Scott E. Page. 2012. Some microfoundations of collective wisdom. Collective Wisdom, 56–71. [Google Scholar] [CrossRef]
- Hong, Shenda, Yuxi Zhou, Junyuan Shang, Cao Xiao, and Jimeng Sun. 2020. Opportunities and challenges of deep learning methods for electrocardiogram data: A systematic review. Computers in Biology and Medicine 122: 103801. [Google Scholar] [CrossRef] [PubMed]
- Howard, Jonathan. 2019. Bandwagon effect and authority bias. In Cognitive Errors and Diagnostic Mistakes. Berlin: Springer, pp. 21–56. [Google Scholar]
- Kaba, Alyshah, Ian Wishart, Kristin Fraser, Sylvain Coderre, and Kevin McLaughlin. 2016. Are we at risk of groupthink in our approach to teamwork interventions in health care? Medical Education 50: 400–8. [Google Scholar] [CrossRef] [PubMed]
- Kammer, Juliane E., Wolf Hautz, Stefan M. Herzog, Olga Kunina-Habenicht, and Rhjm Kurvers. 2017. The potential of collective intelligence in emergency medicine: Pooling medical students’ independent decisions improves diagnostic performance. Medical Decision Making 37: 715–24. [Google Scholar] [CrossRef]
- Kattan, Michael W., Colin O’Rourke, Changhong Yu, and Kevin Chagin. 2016. The wisdom of crowds of doctors: Their average predictions outperform their individual ones. Medical Decision Making 36: 536–40. [Google Scholar] [CrossRef] [PubMed]
- Koriat, Asher. 2012. The self-consistency model of subjective confidence. Psychological Review 119: 80–113. [Google Scholar] [CrossRef] [PubMed]
- Koriat, Asher. 2015. When two heads are better than one and when they can be worse: The amplification hypothesis. Journal of Experimental Psychology: General 144: 934. [Google Scholar] [CrossRef]
- Kurvers, Ralf H. J. M., Jens Krause, Giuseppe Argenziano, Iris Zalaudek, and Max Wolf. 2015. Detection accuracy of collective intelligence assessments for skin cancer diagnosis. JAMA Dermatology 151: 1346–53. [Google Scholar] [CrossRef]
- Launer, John. 2016. Clinical case discussion: Using a reflecting team. Postgraduate Medical Journal 92: 245–46. [Google Scholar] [CrossRef][Green Version]
- Liang, Jennifer J., Ching-Huei Tsou, and Murthy V. Devarakonda. 2017. Ground truth creation for complex clinical nlp tasks—An iterative vetting approach and lessons learned. AMIA Summits on Translational Science Proceedings 2017: 203. [Google Scholar]
- LimeSurvey Project Team/Carsten Schmitz. 2012. LimeSurvey: An Open Source Survey Tool. Hamburg: LimeSurvey Project. [Google Scholar]
- Liu, Xiaoxuan, Livia Faes, Aditya U. Kale, Siegfried K. Wagner, Dun Jack Fu, Alice Bruynseels, Thushika Mahendiran, Gabriella Moraes, Mohith Shamdas, Christoph Kern, and et al. 2019. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: A systematic review and meta-analysis. The Lancet DIGITAL Health 1: e271–97. [Google Scholar] [CrossRef]
- Macfarlane, Peter W., Adriaan Van Oosterom, Olle Pahlm, Paul Kligfield, Michiel Janse, and John Camm. 2010. Comprehensive Electrocardiology. London: Springer Science & Business Media. [Google Scholar]
- Maglogiannis, Ilias, Constantinos Delakouridis, and Leonidas Kazatzopoulos. 2006. Enabling collaborative medical diagnosis over the internet via peer-to-peer distribution of electronic health records. Journal of Medical Systems 30: 107–16. [Google Scholar] [CrossRef]
- Meyer, Ashley N.D., Christopher A. Longhurst, and Hardeep Singh. 2016. Crowdsourcing diagnosis for patients with undiagnosed illnesses: An evaluation of crowdmed. Journal of Medical Internet Research 18: e12. [Google Scholar] [CrossRef] [PubMed]
- Murat, Fatma, Ozal Yildirim, Muhammed Talo, Ulas Baran Baloglu, Yakup Demir, and U. Rajendra Acharya. 2020. Application of deep learning techniques for heartbeats detection using ecg signals-analysis and review. Computers in Biology and Medicine 120: 103726. [Google Scholar] [CrossRef] [PubMed]
- Nathanson, Larry A., Charles Safran, Seth McClennen, and Ary L. Goldberger. 2001. Ecg wave-maven: A self-assessment program for students and clinicians. Proceedings of the AMIA Symposium, 488–92. [Google Scholar] [CrossRef]
- Newman-Toker, David E., Zheyu Wang, Yuxin Zhu, Najlla Nassery, Ali S. Saber Tehrani, Adam C. Schaffer, Chihwen Winnie Yu-Moe, Gwendolyn D. Clemens, Mehdi Fanai, and Dana Siegal. 2020. Rate of diagnostic errors and serious misdiagnosis-related harms for major vascular events, infections, and cancers: toward a national incidence estimate using the “big three”. Diagnosis 1. [Google Scholar] [CrossRef]
- O’Connor, Nick, and Scott Clark. 2019. Beware bandwagons! The bandwagon phenomenon in medicine, psychiatry and management. Australasian Psychiatry 27: 603–6. [Google Scholar] [CrossRef] [PubMed]
- Patel, Bhavik N., Louis Rosenberg, Gregg Willcox, David Baltaxe, Mimi Lyons, Jeremy Irvin, Pranav Rajpurkar, Timothy Amrhein, Rajan Gupta, Safwan Halabi, and et al. 2019. Human–machine partnership with artificial intelligence for chest radiograph diagnosis. NPJ Digital Medicine 2: 1–10. [Google Scholar] [CrossRef]
- Peeters, Marieke M.M., Jurriaan van Diggelen, Karel Van Den Bosch, Adelbert Bronkhorst, Mark A Neerincx, Jan Maarten Schraagen, and Stephan Raaijmakers. 2020. Hybrid collective intelligence in a human—AI society. AI & Society 36: 1–22. [Google Scholar]
- Prelec, Dražen, H. Sebastian Seung, and John McCoy. 2017. A solution to the single-question crowd wisdom problem. Nature 541: 532–35. [Google Scholar] [CrossRef]
- Quer, Giorgio, Evan D. Muse, Nima Nikzad, Eric J. Topol, and Steven R. Steinhubl. 2017. Augmenting diagnostic vision with ai. The Lancet 390: 221. [Google Scholar] [CrossRef]
- Radcliffe, Kate, Helena C. Lyson, Jill Barr-Walker, and Urmimala Sarkar. 2019. Collective intelligence in medical decision-making: A systematic scoping review. BMC Medical Informatics and Decision Making 19: 1–11. [Google Scholar] [CrossRef]
- Rautaharju, Pentti M., Borys Surawicz, and Leonard S. Gettes. 2009. Aha/accf/hrs recommendations for the standardization and interpretation of the electrocardiogram: Part IV. Journal of the American College of Cardiology 53: 982–91. [Google Scholar] [CrossRef]
- Rinner, Christoph, Harald Kittler, Cliff Rosendahl, and Philipp Tschandl. 2020. Analysis of collective human intelligence for diagnosis of pigmented skin lesions harnessed by gamification via a web-based training platform: Simulation reader study. Journal of Medical Internet Research 22: e15597. [Google Scholar] [CrossRef]
- Rosenberg, Louis, Matthew Lungren, Safwan Halabi, Gregg Willcox, David Baltaxe, and Mimi Lyons. 2018. Artificial swarm intelligence employed to amplify diagnostic accuracy in radiology. Paper presented at the 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, November 1–3; pp. 1186–91. [Google Scholar]
- Sattar, Yasar, and Lovely Chhabra. 2020. Clinical Electrocardiography, Chapter Electrocardiogram. Treasure Island: StatPearls Publishing. [Google Scholar]
- Scalvini, Simonetta, Francesca Rivadossi, Laura Comini, Maria Lorenza Muiesan, and Fulvio Glisenti. 2011. Telemedicine: The role of specialist second opinion for gps in the care of hypertensive patients. Blood Pressure 20: 158–65. [Google Scholar] [CrossRef] [PubMed]
- Steurer, Johann. 2011. The delphi method: An efficient procedure to generate knowledge. Skeletal Radiology 40: 959–61. [Google Scholar] [CrossRef] [PubMed]
- Strubell, Emma, Ananya Ganesh, and Andrew McCallum. 2020. Energy and policy considerations for modern deep learning research. Paper presented at the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, February 7–12, vol. 34, pp. 13693–96. [Google Scholar]
- Surawicz, Borys, Rory Childers, Barbara J. Deal, and Leonard S. Gettes. 2009. Aha/accf/hrs recommendations for the standardization and interpretation of the electrocardiogram: Part III. Journal of the American College of Cardiology 53: 976–81. [Google Scholar] [CrossRef]
- Surowiecki, James. 2004. The Wisdom of Crowds: Why the Many Are Smarter than the Few and How Collective Wisdom Shapes Business, Economies, Societies, and Nations, 1st ed. New York: Doubleday. [Google Scholar]
- Topol, Eric J. 2019. High-performance medicine: The convergence of human and artificial intelligence. Nature Medicine 25: 44–56. [Google Scholar] [CrossRef] [PubMed]
- Tucker, Joseph D., Suzanne Day, Weiming Tang, and Barry Bayus. 2019. Crowdsourcing in medical research: Concepts and applications. PeerJ 7: e6762. [Google Scholar] [CrossRef]
- Vayena, Effy, Alessandro Blasimme, and I. Glenn Cohen. 2018. Machine learning in medicine: Addressing ethical challenges. PLoS Medicine 15: e1002689. [Google Scholar] [CrossRef]
- Wagner, Galen S., Peter Macfarlane, Hein Wellens, Mark Josephson, Anton Gorgels, David M. Mirvis, Olle Pahlm, Borys Surawicz, Paul Kligfield, Rory Childers, and et al. 2009. Aha/accf/hrs recommendations for the standardization and interpretation of the electrocardiogram: Part VI. Journal of the American College of Cardiology 53: 1003–11. [Google Scholar] [CrossRef]
- Watson, David S., Jenny Krutzinna, Ian N. Bruce, Christopher E.M. Griffiths, Iain B. McInnes, Michael R. Barnes, and Luciano Floridi. 2019. Clinical applications of machine learning algorithms: Beyond the black box. BMJ 364: 1884. [Google Scholar]
- Wiens, Jenna, W. Nicholson Price, and Michael W. Sjoding. 2020. Diagnosing bias in data-driven algorithms for healthcare. Nature Medicine 26: 25–26. [Google Scholar] [CrossRef]
- Wolf, Max, Jens Krause, Patricia A. Carney, Andy Bogart, and Ralf H. J. M. Kurvers. 2015. Collective intelligence meets medical decision-making: The collective outperforms the best radiologist. PLoS ONE 10: e0134269. [Google Scholar] [CrossRef]
- World Health Organization, OECD, and International Bank for Reconstruction and Development. 2018. Delivering Quality Health Services: A Global Imperative for Universal Health Coverage. Geneva: World Health Organization. [Google Scholar]
- Zhu, Tingting, Alistair E.W. Johnson, Joachim Behar, and Gari D. Clifford. 2014. Crowd-sourced annotation of ecg signals using contextual information. Annals of Biomedical Engineering 42: 871–84. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
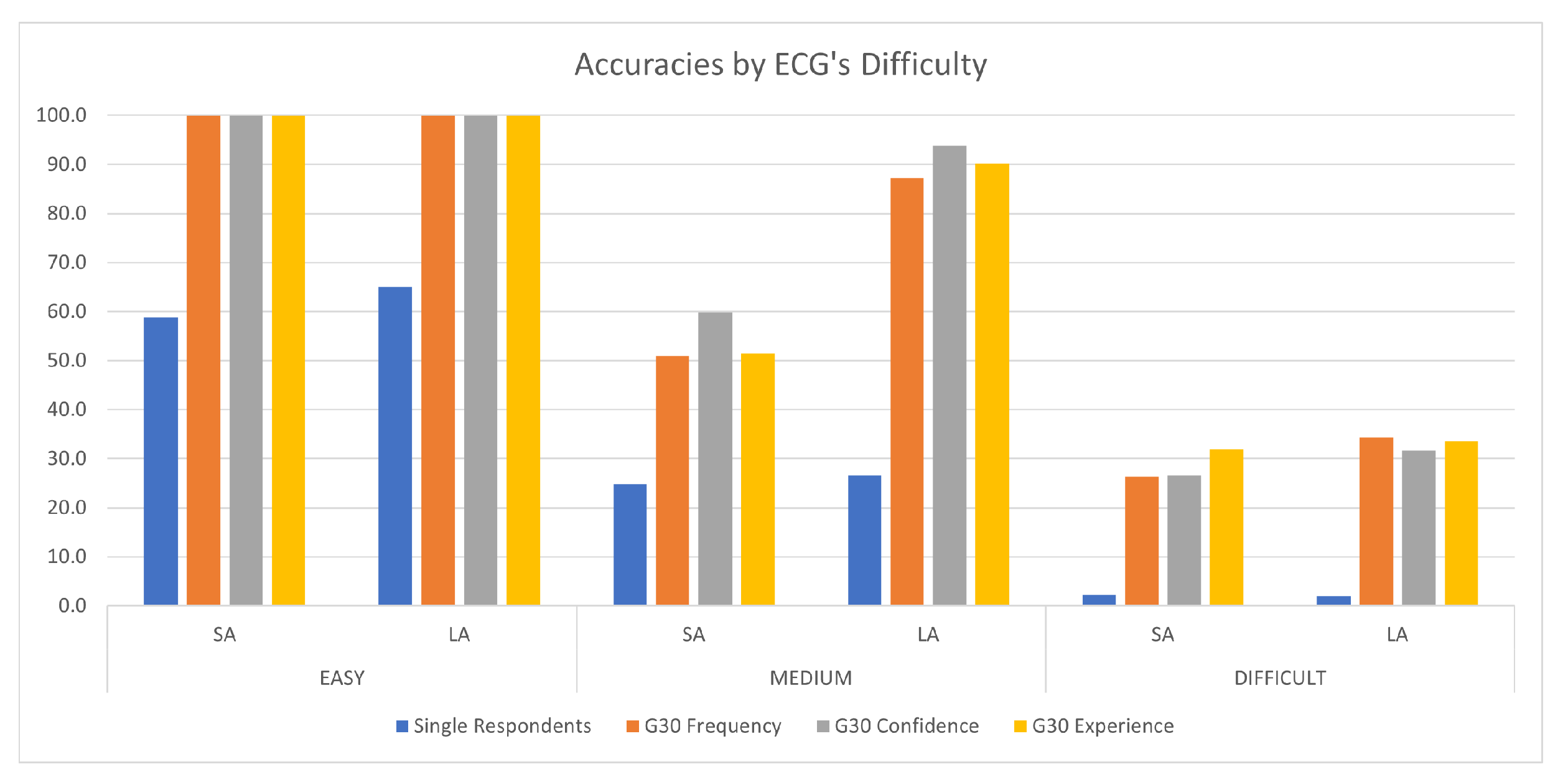{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ECG ID | MW Reference | MW Difficulty | Evaluated Difficulty | Pathology Class |
|---|---|---|---|---|
| 1 | 251 | 1/5 | Easy | Normal |
| 2 | 91 | 1/5 | Easy | STEMI |
| 3 | 3 | 3/5 | Medium | Pericarditis |
| 4 | 32 | 3/5 | Medium | PE |
| 5 | 18 | 4/5 | Difficult | AF + RVH |
| 6 | 6 | 4/5 | Difficult | EAR + AV Block II Mobitz 1 |
| 7 | 285 | 3/5 | Medium | Hypothermia |
| 8 | 323 | 2/5 | Medium | PSVT |
| 9 | 108 | 5/5 | Medium | STEMI |
| 10 | 19 | 4/5 | Medium | Dextrocardia |
| ECG ID | Readers | Senior Students | Recnt Graduates | Residents (Not Cardiology) | Residents (Cardiology) |
|---|---|---|---|---|---|
| 1 | 117 | 32.5% | 48.7% | 17.1% | 1.7% |
| 2 | 140 | 22.1% | 50.7% | 22.1% | 4.3% |
| 3 | 91 | 31.9% | 49.5% | 16.5% | 2.2% |
| 4 | 88 | 20.5% | 55.7% | 19.3% | 3.4% |
| 5 | 88 | 31.8% | 47.7% | 18.2% | 2.3% |
| 6 | 97 | 19.6% | 54.6% | 20.6% | 4.1% |
| 7 | 80 | 32.5% | 46.3% | 18.8% | 2.5% |
| 8 | 102 | 20.6% | 53.9% | 19.6% | 4.9% |
| 9 | 75 | 30.7% | 49.3% | 17.3% | 2.7% |
| 10 | 86 | 19.8% | 55.8% | 20.9% | 2.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ronzio, L.; Campagner, A.; Cabitza, F.; Gensini, G.F. Unity Is Intelligence: A Collective Intelligence Experiment on ECG Reading to Improve Diagnostic Performance in Cardiology. J. Intell. 2021, 9, 17. https://doi.org/10.3390/jintelligence9020017
Ronzio L, Campagner A, Cabitza F, Gensini GF. Unity Is Intelligence: A Collective Intelligence Experiment on ECG Reading to Improve Diagnostic Performance in Cardiology. Journal of Intelligence. 2021; 9(2):17. https://doi.org/10.3390/jintelligence9020017
Chicago/Turabian StyleRonzio, Luca, Andrea Campagner, Federico Cabitza, and Gian Franco Gensini. 2021. "Unity Is Intelligence: A Collective Intelligence Experiment on ECG Reading to Improve Diagnostic Performance in Cardiology" Journal of Intelligence 9, no. 2: 17. https://doi.org/10.3390/jintelligence9020017
APA StyleRonzio, L., Campagner, A., Cabitza, F., & Gensini, G. F. (2021). Unity Is Intelligence: A Collective Intelligence Experiment on ECG Reading to Improve Diagnostic Performance in Cardiology. Journal of Intelligence, 9(2), 17. https://doi.org/10.3390/jintelligence9020017