Simulation of Fire with a Gas Kinetic Scheme on Distributed GPGPU Architectures


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Gas Kinetic Scheme Solver
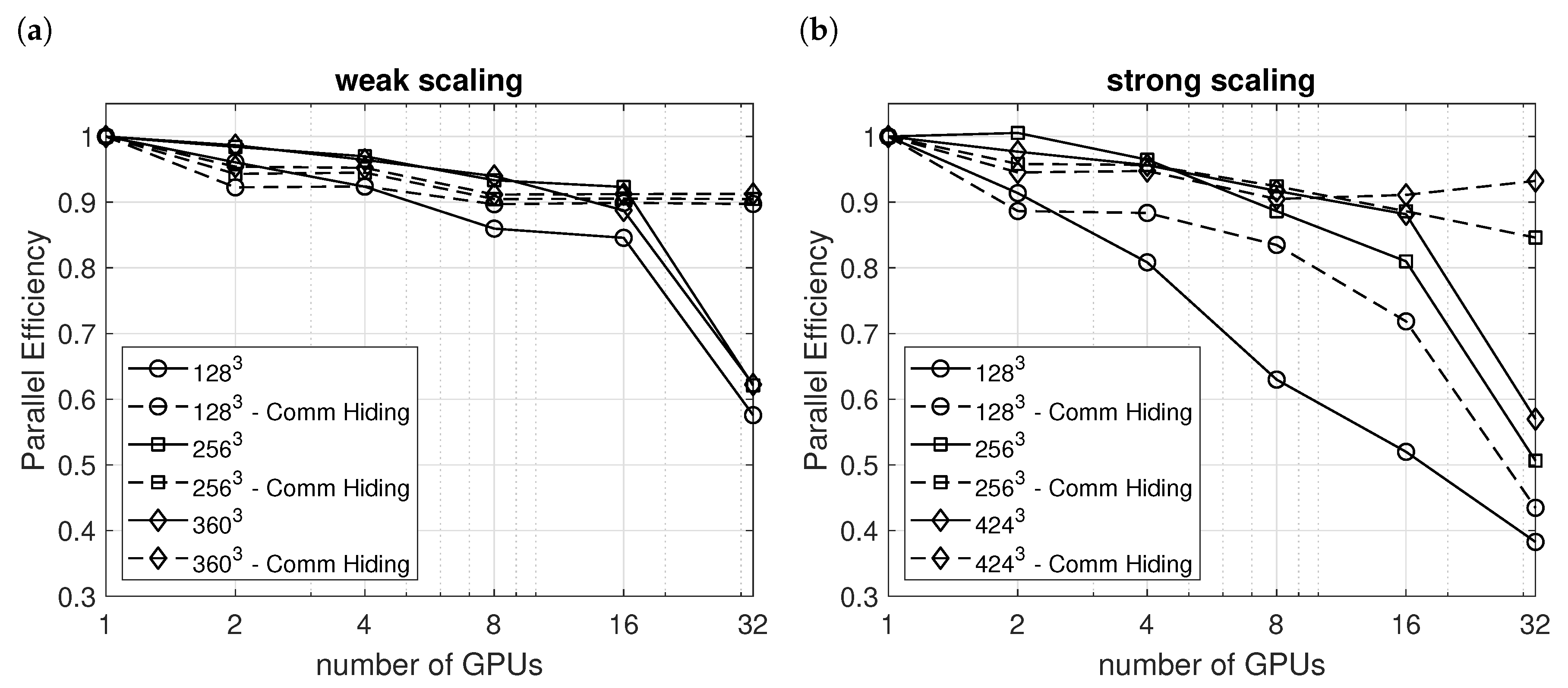
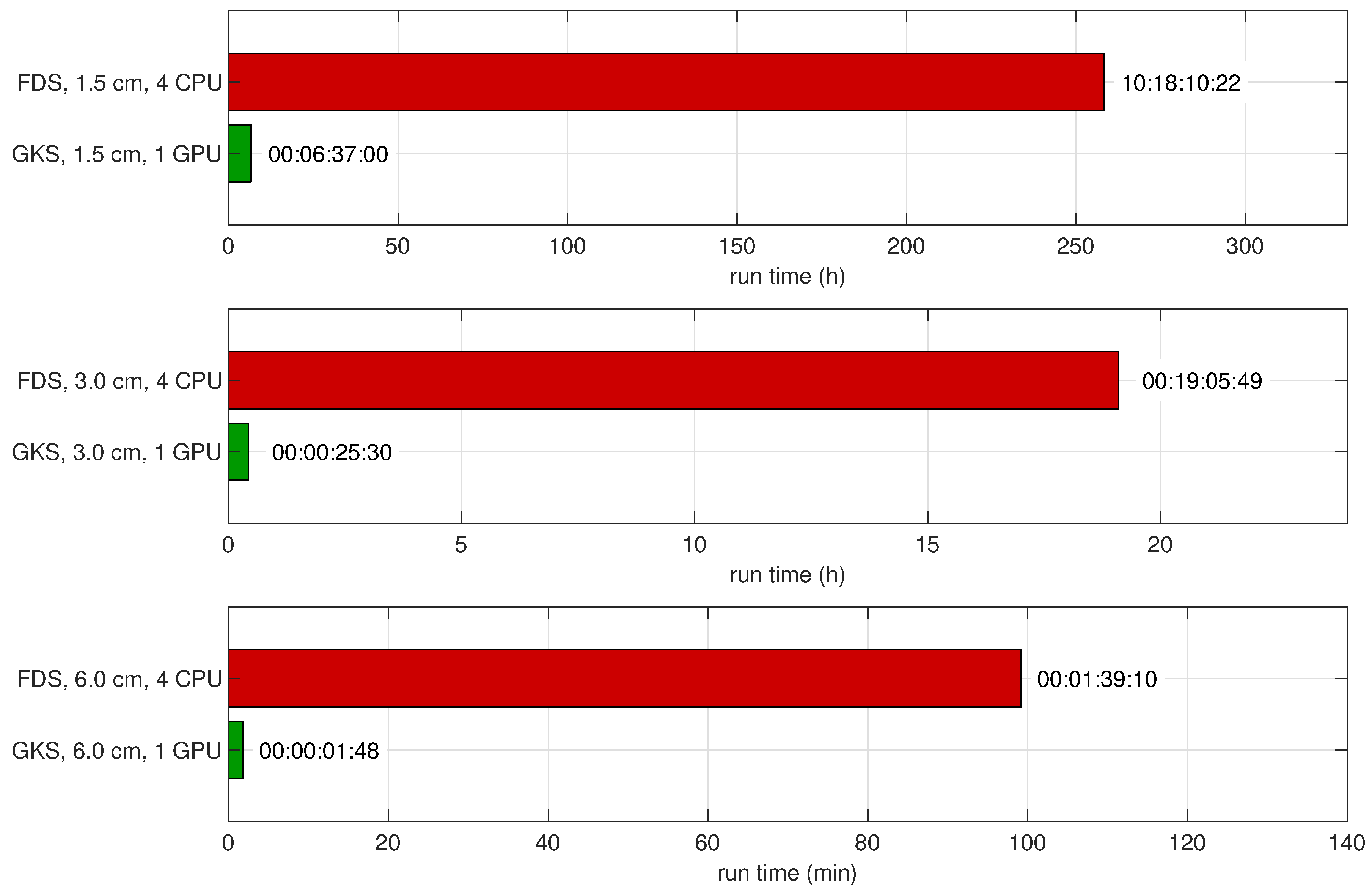
3. Performance of the Single GPGPU Implementation
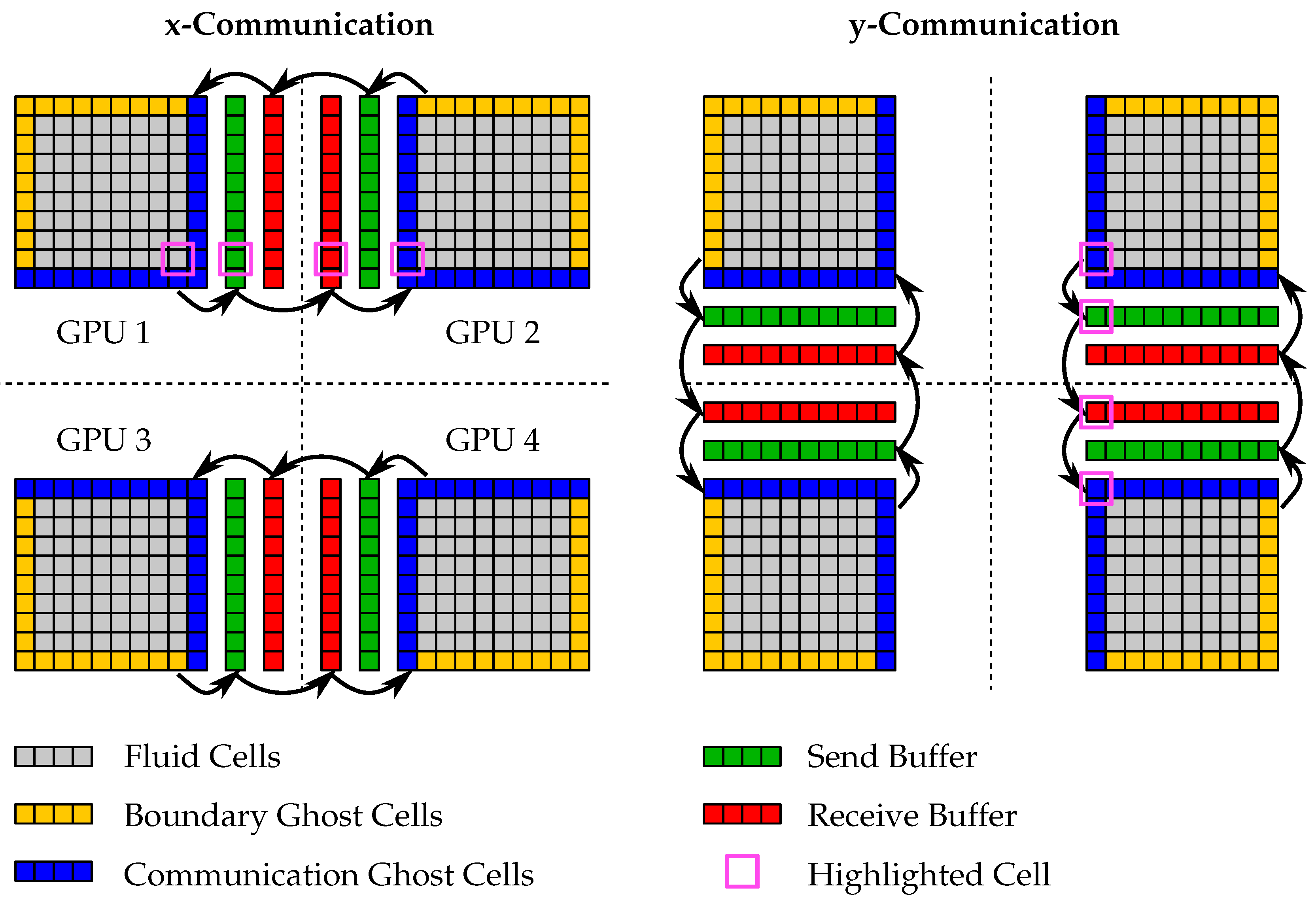
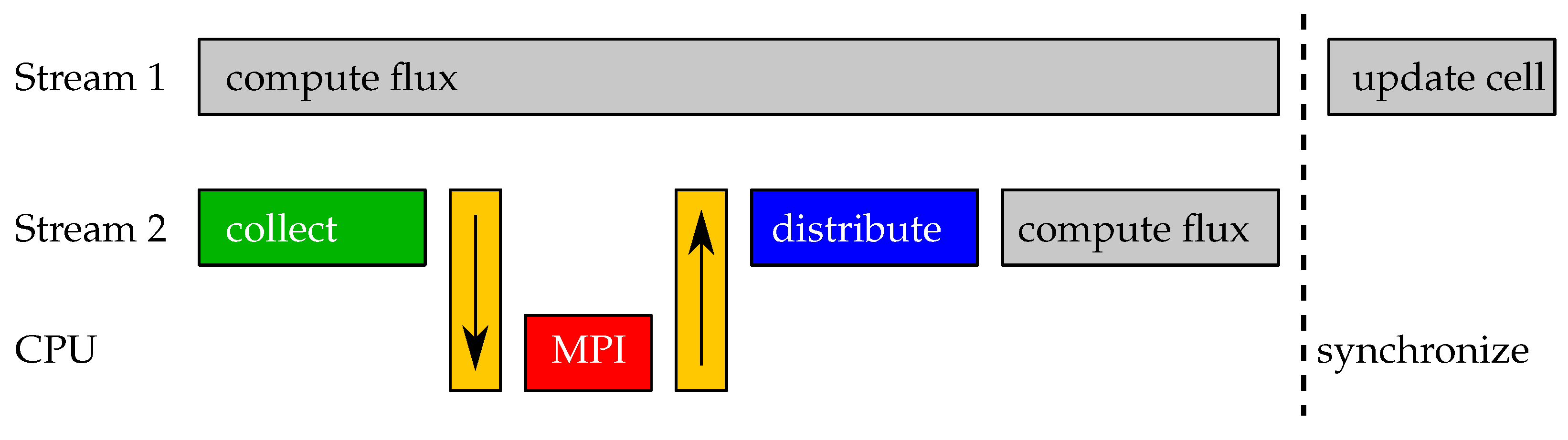
4. Multi-GPGPU Implementation
| Algorithm 1 Recursive nested time stepping for multi-GPU. |
|
5. Combustion Model
6. Validation
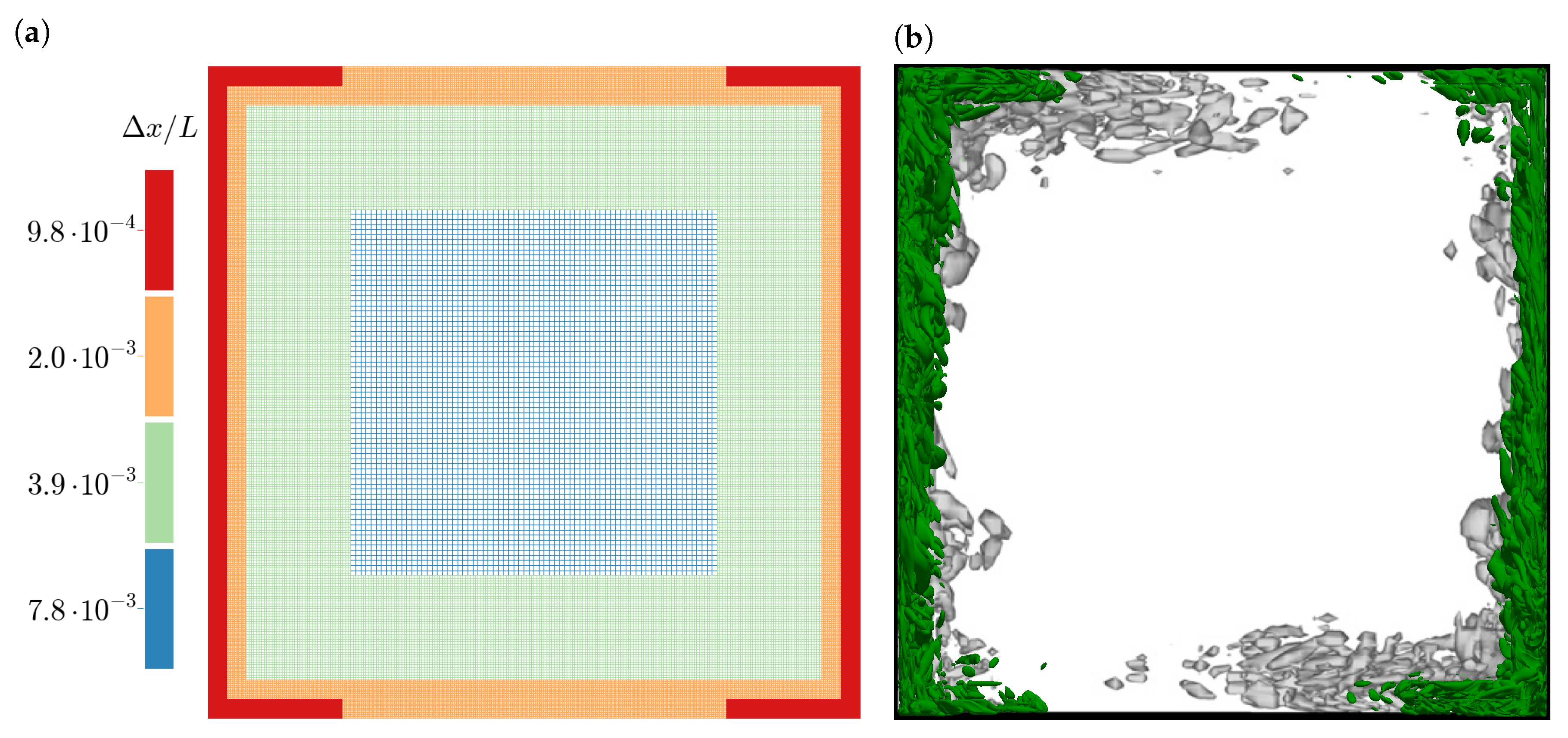
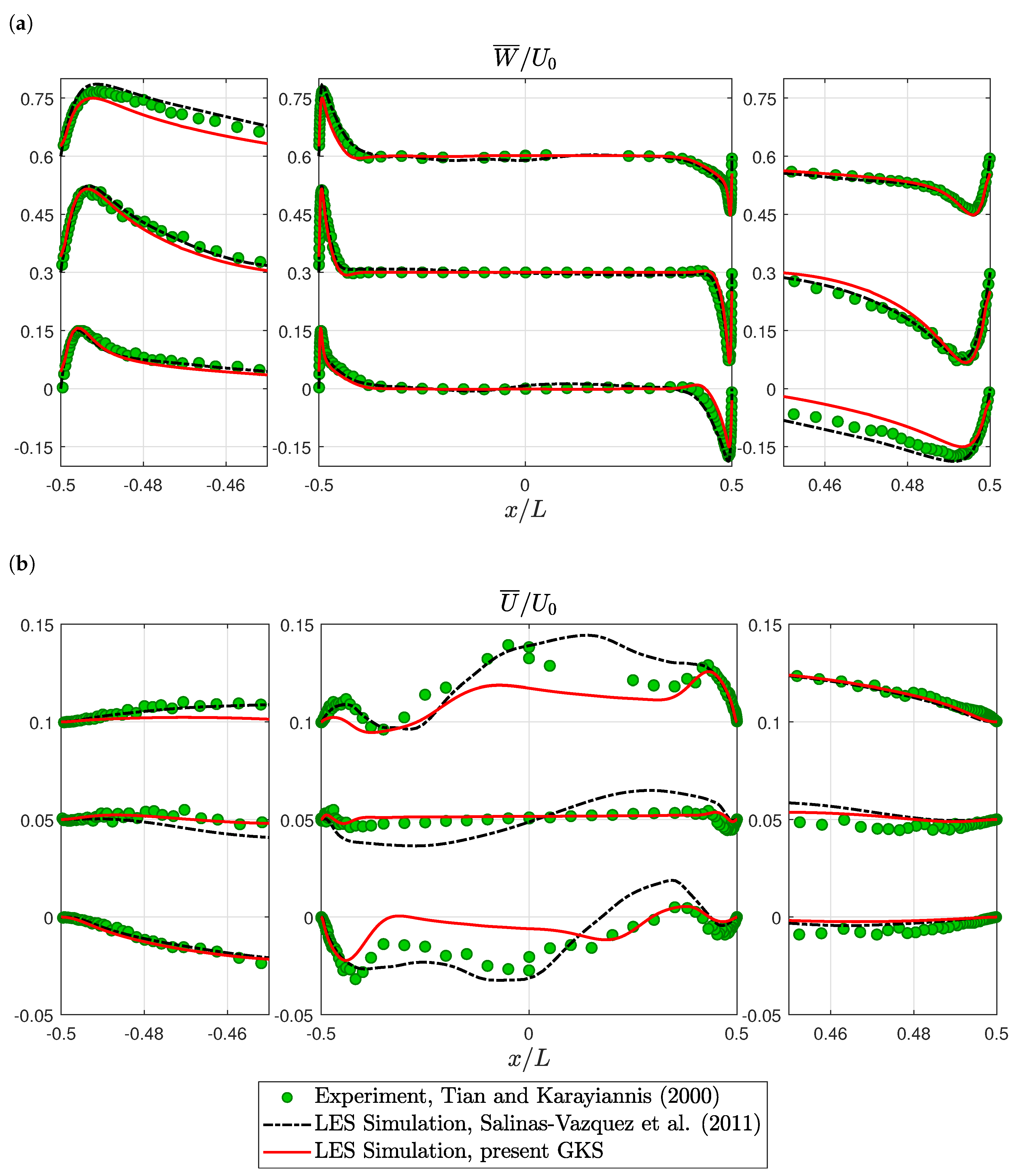
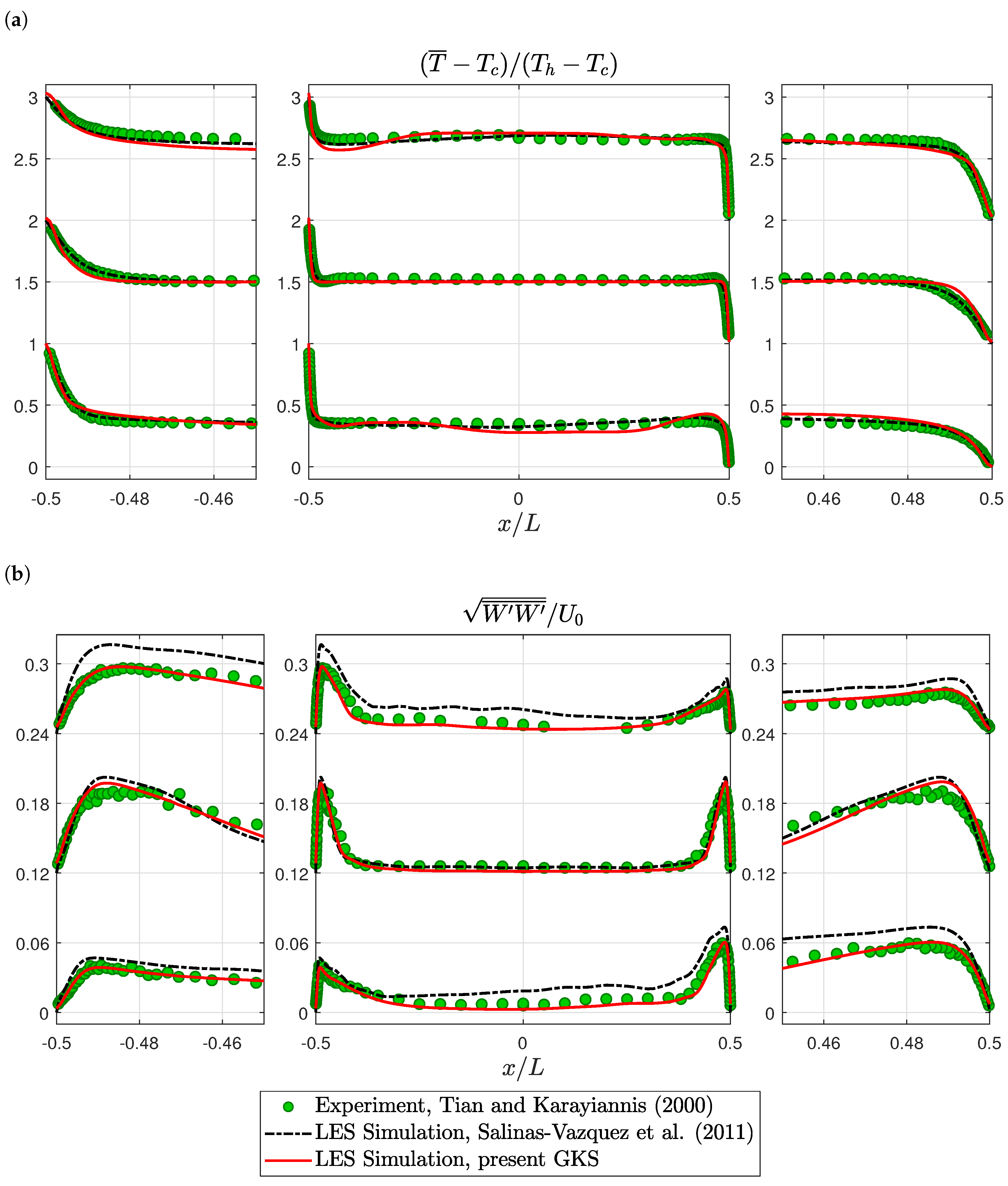
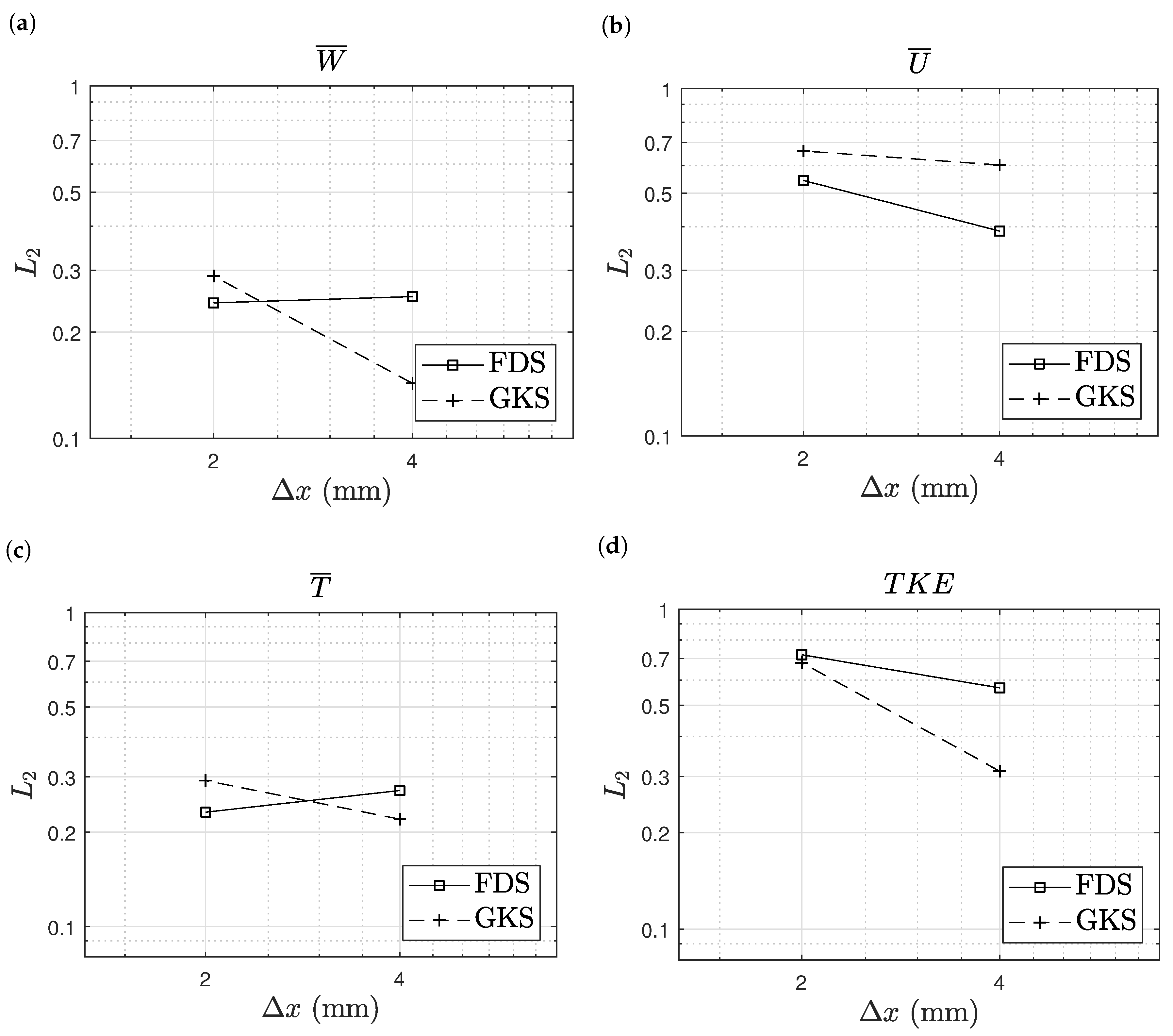
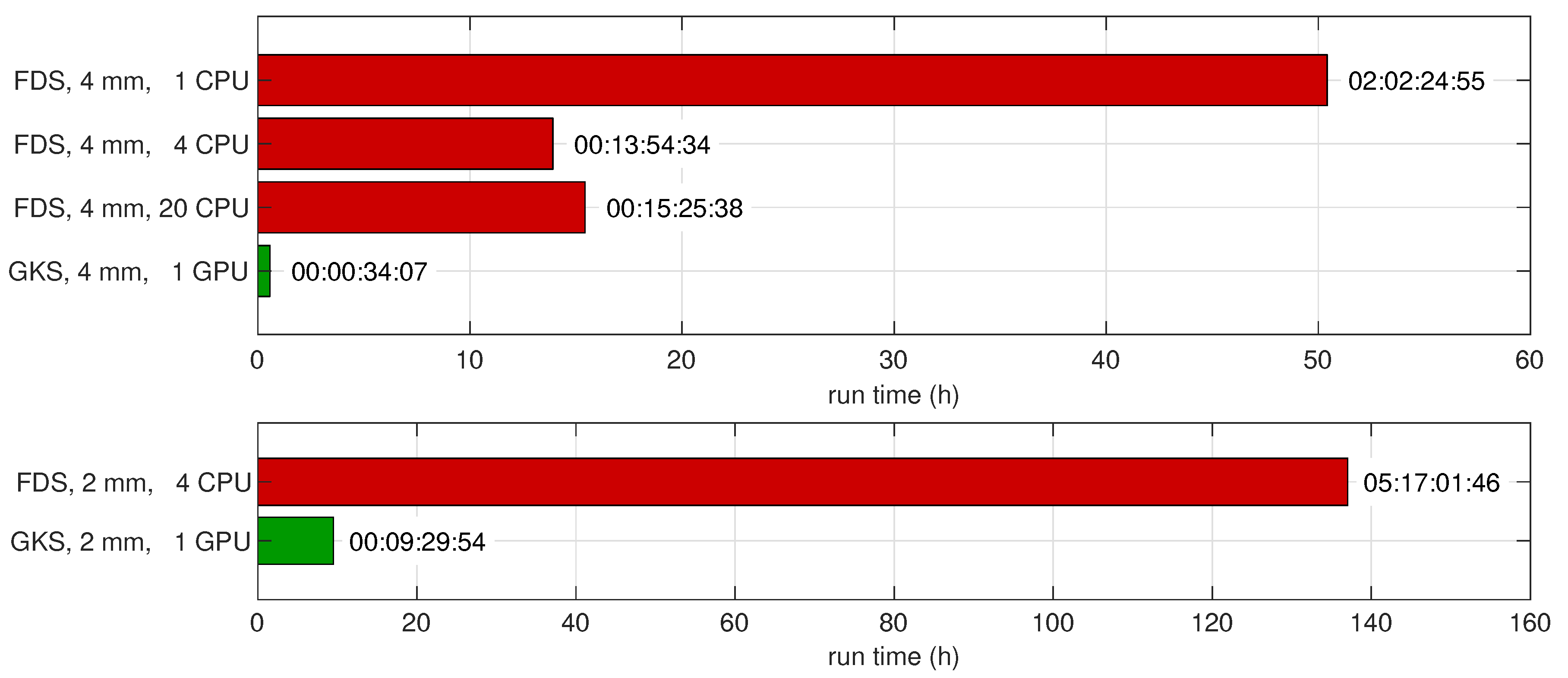
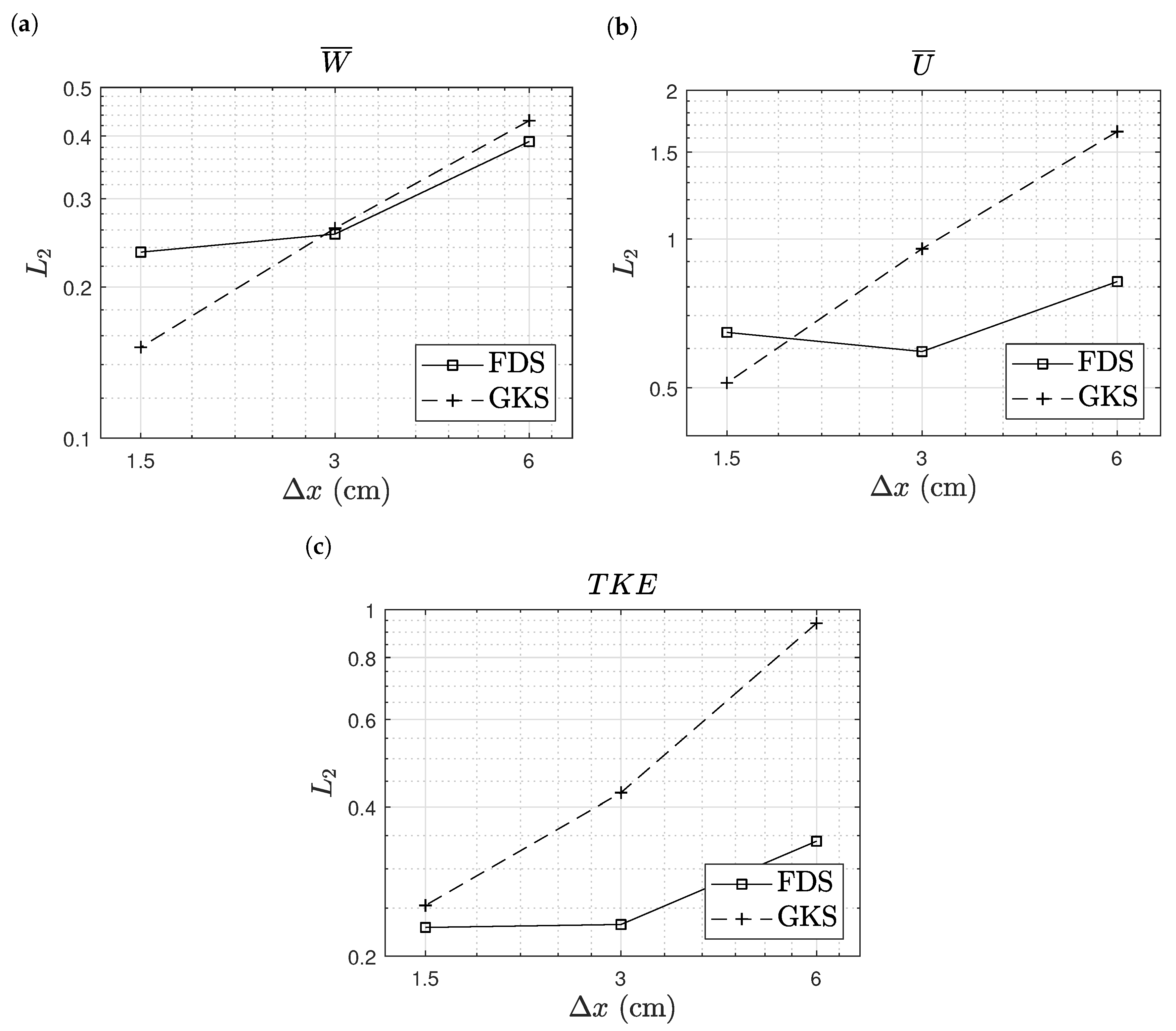
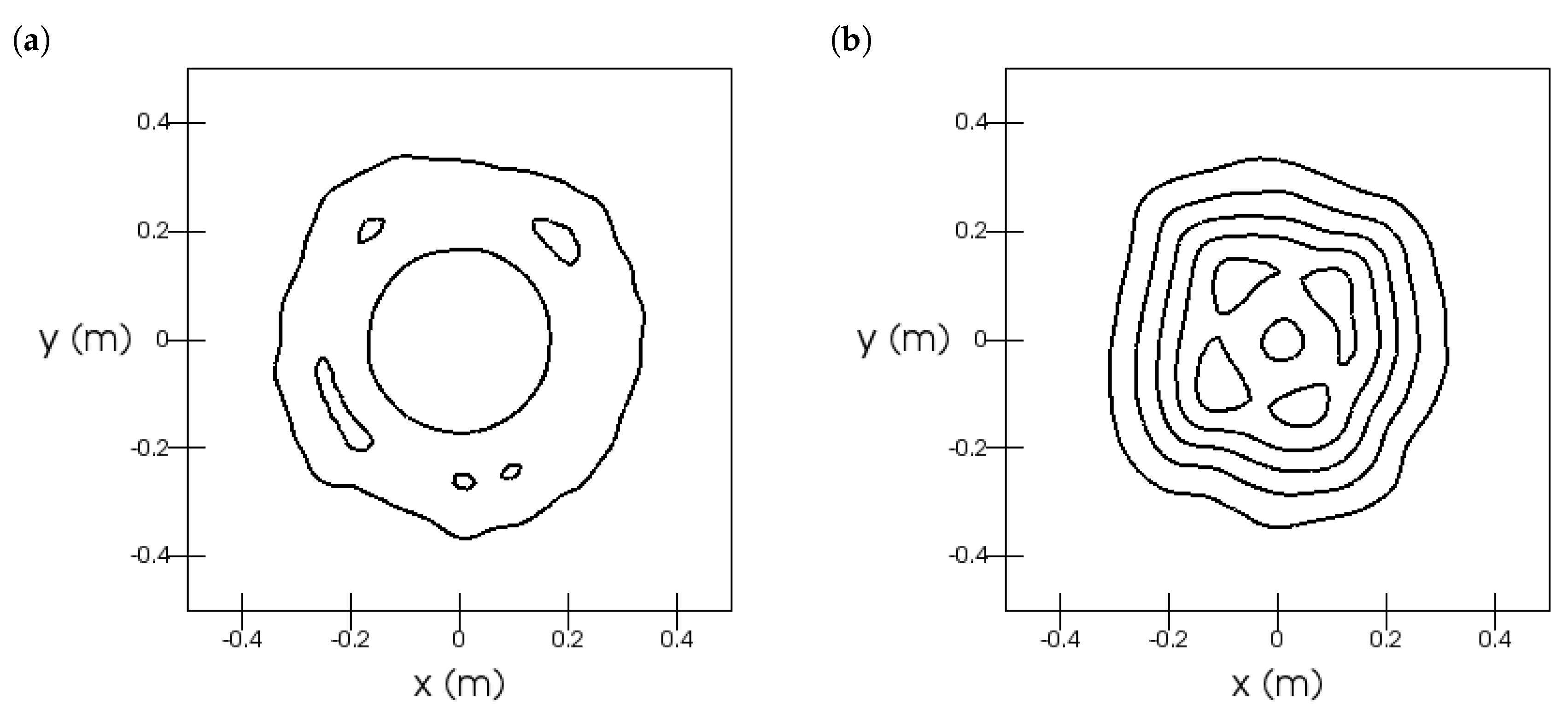
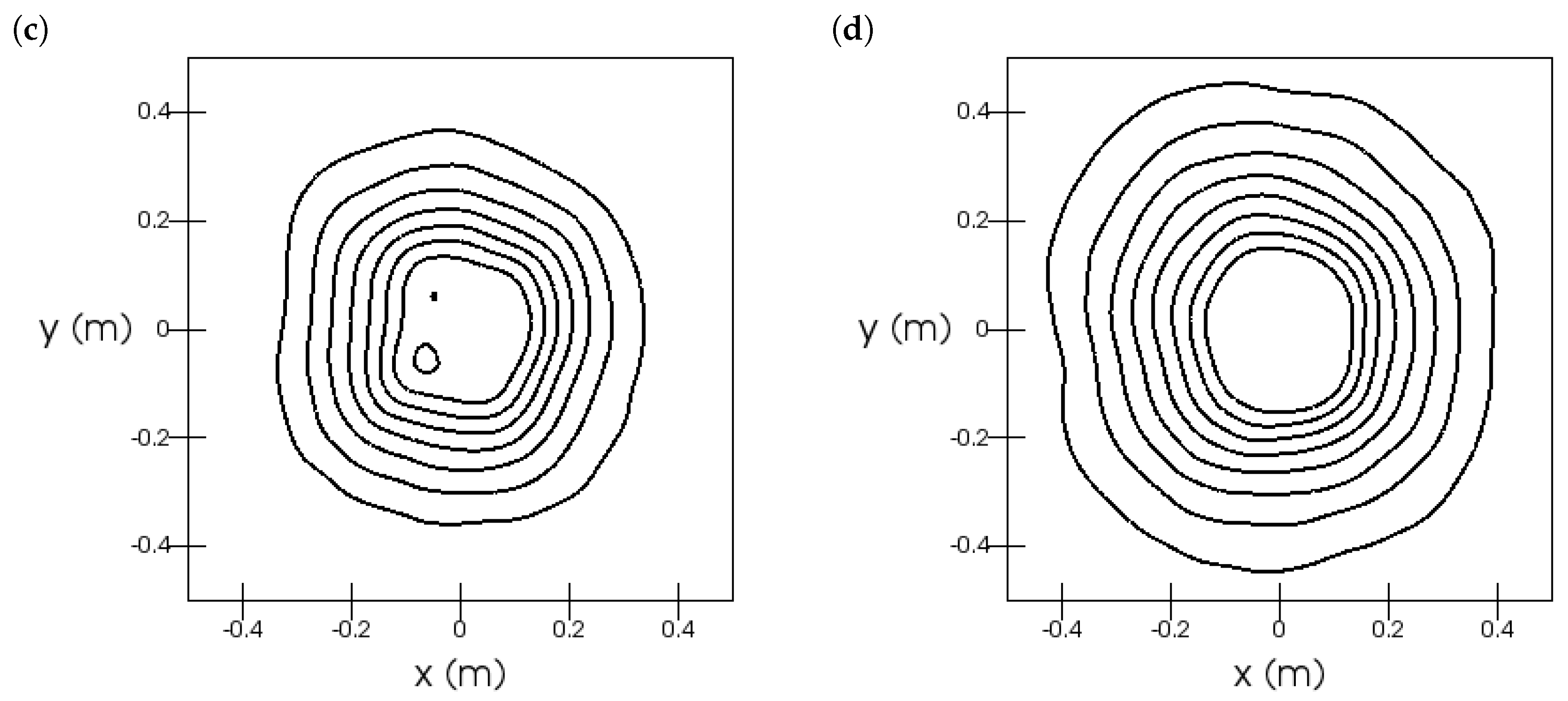
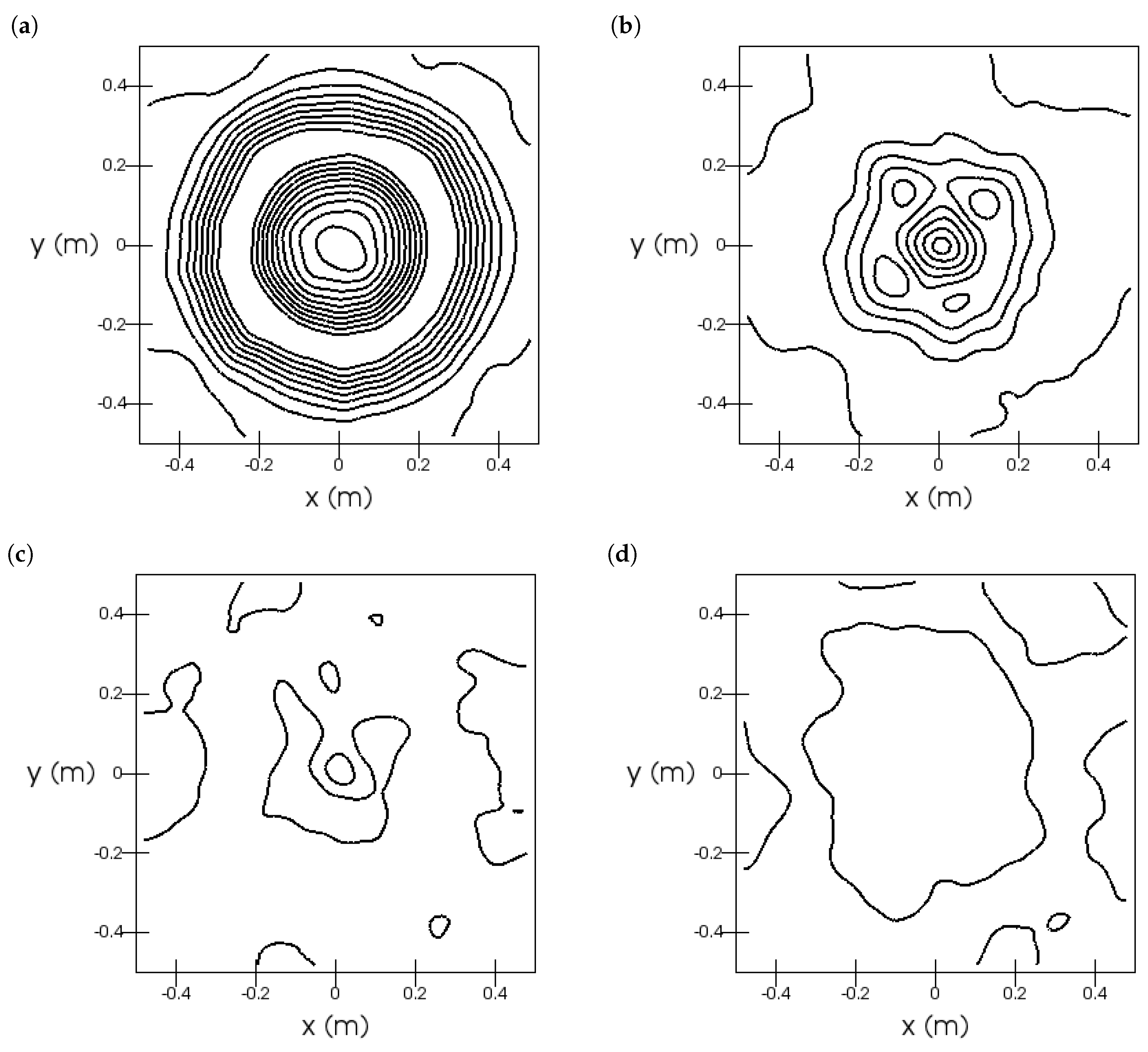
6.1. Turbulent Natural Convection
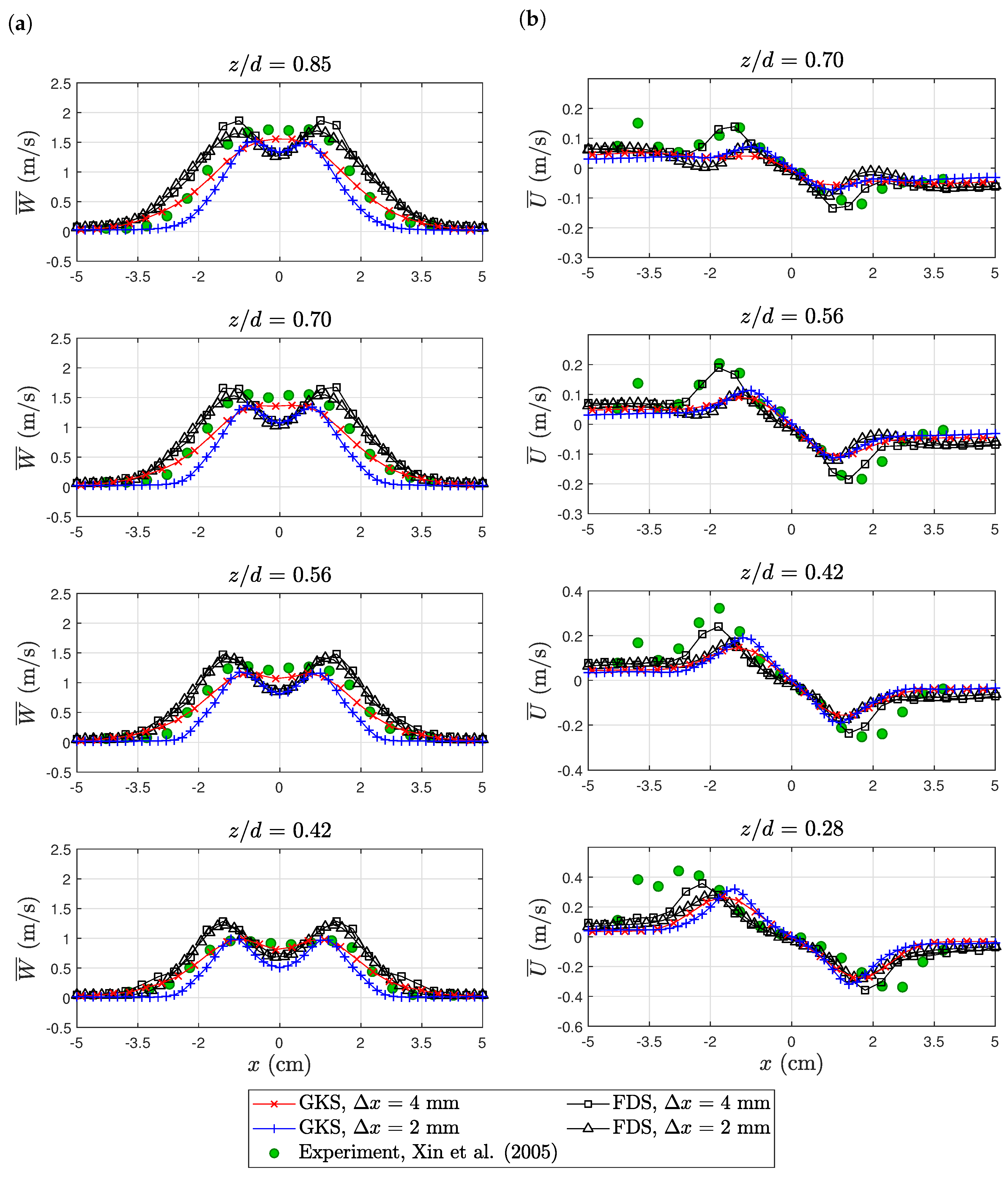
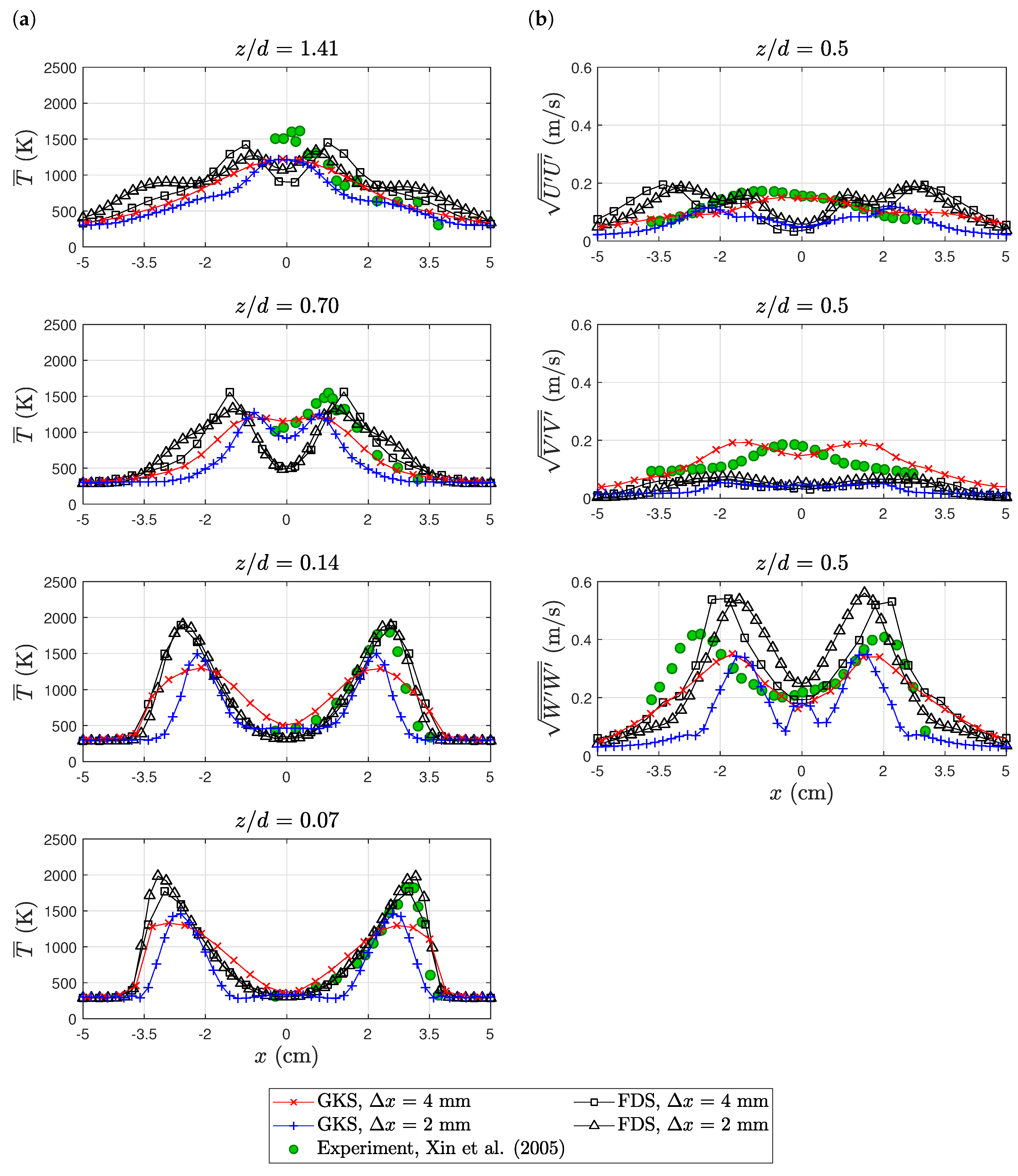
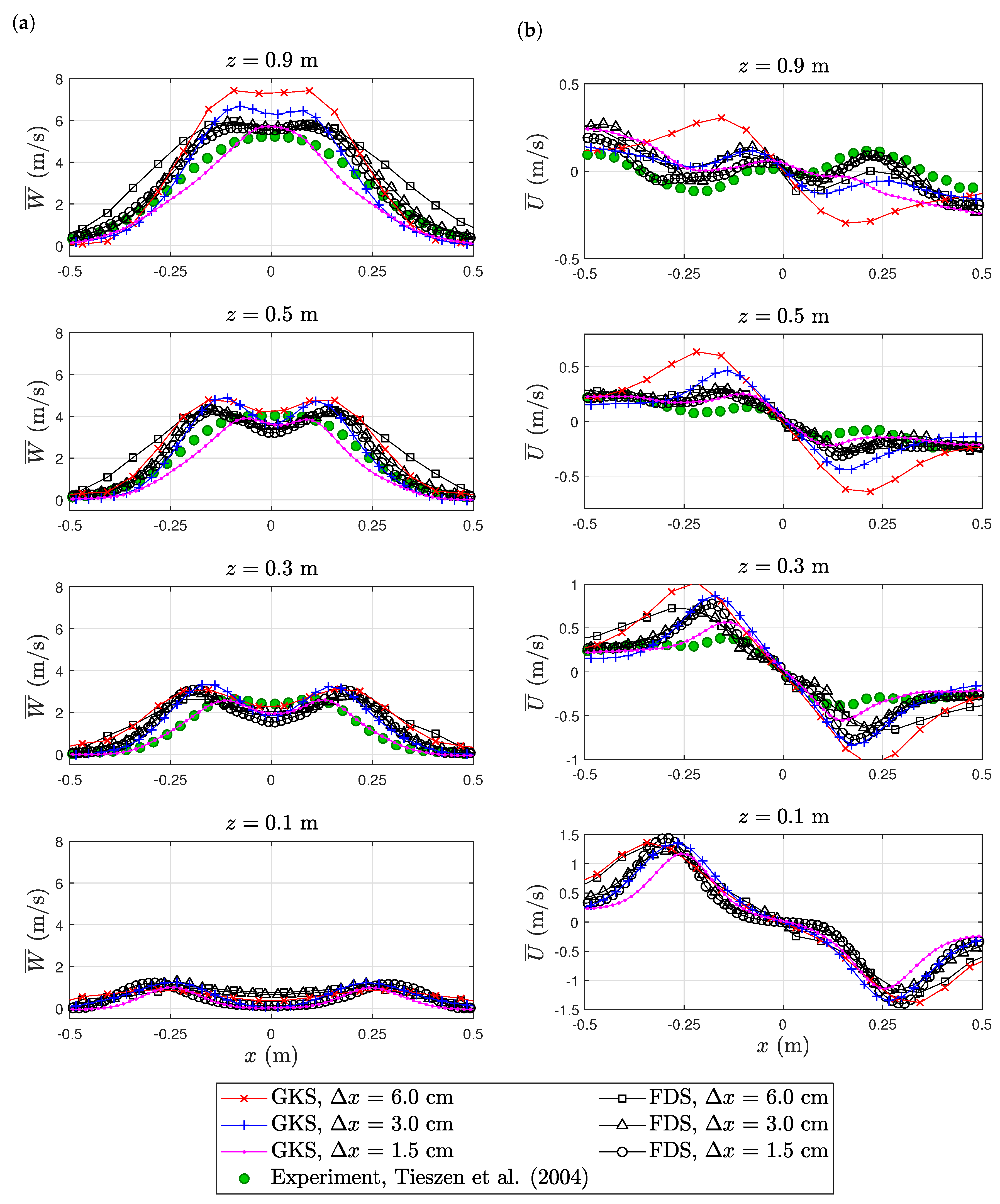
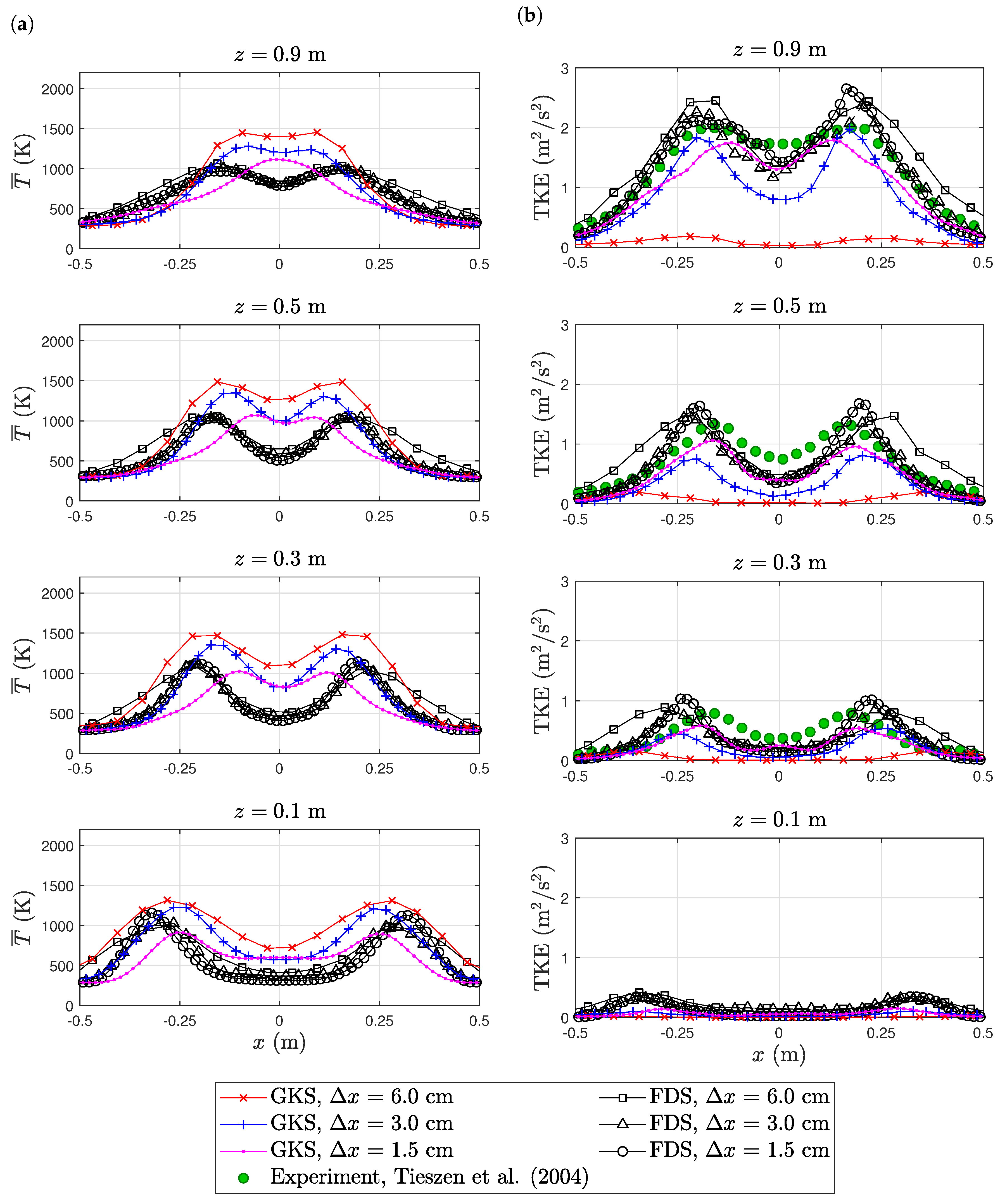
6.2. Purdue Flame
6.3. Sandia Flame
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BGK | Bhatnagar–Gross–Krook |
| FDS | Fire Dynamics Simulator |
| GKS | Gas Kinetic Scheme |
| GPGPU | General Purpose Graphics Processing Unit |
| HPC | High Performance Computing |
| LBM | Lattice Boltzmann Method |
| LES | Large Eddy Simulation |
| MPI | Message Passing Interface |
Appendix A. Relations between Mass and Mole Fractions
References
- Quintiere, J.G. Principles of Fire Behavior, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar] [CrossRef]
- Berna, F.; Goldberg, P.; Horwitz, L.K.; Brink, J.; Holt, S.; Bamford, M.; Chazan, M. Microstratigraphic evidence of in situ fire in the Acheulean strata of Wonderwerk Cave, Northern Cape province, South Africa. Proc. Natl. Acad. Sci. USA 2012, 109, E1215–E1220. [Google Scholar] [CrossRef] [PubMed]
- Moore-Bick, M. Grenfell Tower Inquiry: Phase 1 Report. 2019, Volume 4. Available online: https://www.grenfelltowerinquiry.org.uk/phase-1-report (accessed on 17 May 2020).
- Gawad, A.F.A.; Ghulman, H.A. Prediction of Smoke Propagation in a Big Multi-Story Building Using Fire Dynamics Simulator (FDS). Am. J. Energy Eng. 2015, 3, 23. [Google Scholar] [CrossRef]
- Long, X.; Zhang, X.; Lou, B. Numerical simulation of dormitory building fire and personnel escape based on Pyrosim and Pathfinder. J. Chin. Inst. Eng. 2017, 40, 257–266. [Google Scholar] [CrossRef]
- Khan, E.; Ahmed, M.A.; Khan, E.; Majumder, S. Fire Emergency Evacuation Simulation of a shopping mall using Fire Dynamic Simulator (FDS). J. Chem. Eng. 2017, 30, 32–36. [Google Scholar] [CrossRef][Green Version]
- Guillaume, E.; Dréan, V.; Girardin, B.; Benameur, F.; Koohkan, M.; Fateh, T. Reconstruction of Grenfell Tower fire. Part 3—Numerical simulation of the Grenfell Tower disaster: Contribution to the understanding of the fire propagation and behaviour during the vertical fire spread. Fire Mater. 2019, 46, 605. [Google Scholar] [CrossRef]
- Grosshandler, W.L.; Bryner, N.P.; Madrzykowski, D.M.; Kuntz, K. Report of the Technical Investigation of The Station Nightclub Fire; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2005. [Google Scholar]
- McGrattan, K.B.; Bouldin, C.E.; Forney, G.P. Computer Simulation of the Fires in the World Trade Center Towers, Federal Building and Fire Safety Investigation of the World Trade Center Disaster (NCSTAR 1-5F); Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2005. [Google Scholar]
- Barowy, A.M.; Madrzykowski, D.M. Simulation of the Dynamics of a Wind-Driven Fire in a Ranch-Style House—Texas; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2012. [Google Scholar]
- Chi, J.H. Using FDS program and an evacuation test to develop hotel fire safety strategy. J. Chin. Inst. Eng. 2014, 37, 288–299. [Google Scholar] [CrossRef]
- McGrattan, K.B.; Hostikka, S.; Floyd, J.; McDermott, R.; Vanella, M. Fire Dynamics Simulator User’s Guide, 6th ed.; NIST Special Publication, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2006. [Google Scholar]
- McGrattan, K.B.; Hostikka, S.; Floyd, J.; McDermott, R.; Vanella, M. Fire Dynamics Simulator Technical Reference Guide: Volume 1: Mathematical Model, 6th ed.; NIST Special Publication, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2006. [Google Scholar]
- McGrattan, K.B.; Hostikka, S.; Floyd, J.; McDermott, R.; Vanella, M. Fire Dynamics Simulator Technical Reference Guide: Volume 2: Verification, 6th ed.; NIST Special Publication, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2006. [Google Scholar]
- McGrattan, K.B.; Hostikka, S.; Floyd, J.; McDermott, R.; Vanella, M. Fire Dynamics Simulator Technical Reference Guide: Volume 3: Validation, 6th ed.; NIST Special Publication, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2006. [Google Scholar]
- Weller, H.G.; Tabor, G.; Jasak, H.; Fureby, C. A tensorial approach to computational continuum mechanics using object-oriented techniques. Comput. Phys. 1998, 12, 620. [Google Scholar] [CrossRef]
- Husted, B.; Li, Y.Z.; Huang, C.; Anderson, J.; Svensson, R.; Ingason, H.; Runefors, M.; Wahlqvist, J. Verification, Validation and Evaluation of FireFOAM as a Tool for Performance Based Design. 2017. Available online: https://www.brandskyddsforeningen.se/globalassets/brandforsk/rapporter-2017/brandforsk_rapport_309_131_firefoam_new.pdf (accessed on 24 October 2019).
- Wickström, U. Temperature Calculation in Fire Safety Engineering; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Peacock, R.D.; Reneke, P.A.; Forney, G.P. CFAST—Consolidated Model of Fire Growth and Smoke Transport (Version 7) Volume 2: User’s Guide; NIST Technical Note 1889v2; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2015. [Google Scholar] [CrossRef]
- Benzi, R.; Succi, S.; Vergassola, M. The lattice Boltzmann equation: Theory and applications. Phys. Rep. 1992, 222, 145–197. [Google Scholar] [CrossRef]
- Chen, S.; Doolen, G.D. Lattice boltzmann method for fluid flows. Annu. Rev. Fluid Mech. 1998, 30, 329–364. [Google Scholar] [CrossRef]
- D’Humières, D.; Ginzburg, I.; Krafczyk, M.; Lallemand, P.; Luo, L.S. Multiple–relaxation–time lattice Boltzmann models in three dimensions. Philos. Trans. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 2002, 360, 437–451. [Google Scholar] [CrossRef]
- Geier, M.; Schönherr, M.; Pasquali, A.; Krafczyk, M. The cumulant lattice Boltzmann equation in three dimensions: Theory and validation. Comput. Math. Appl. 2015, 70, 507–547. [Google Scholar] [CrossRef]
- Godenschwager, C.; Schornbaum, F.; Bauer, M.; Köstler, H.; Rüde, U. A framework for hybrid parallel flow simulations with a trillion cells in complex geometries. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 17–21 November 2013; pp. 1–12. [Google Scholar] [CrossRef]
- Kutscher, K.; Geier, M.; Krafczyk, M. Multiscale simulation of turbulent flow interacting with porous media based on a massively parallel implementation of the cumulant lattice Boltzmann method. Comput. Fluids 2018, 193, 103733. [Google Scholar] [CrossRef]
- Onodera, N.; Idomura, Y. Acceleration of Wind Simulation Using Locally Mesh-Refined Lattice Boltzmann Method on GPU-Rich Supercomputers. In Supercomputing Frontiers; Yokota, R., Wu, W., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 128–145. [Google Scholar]
- Xu, K. A Gas-Kinetic BGK Scheme for the Navier–Stokes Equations and Its Connection with Artificial Dissipation and Godunov Method. J. Comput. Phys. 2001, 171, 289–335. [Google Scholar] [CrossRef]
- Xu, K.; Mao, M.; Tang, L. A multidimensional gas-kinetic BGK scheme for hypersonic viscous flow. J. Comput. Phys. 2005, 203, 405–421. [Google Scholar] [CrossRef]
- May, G.; Srinivasan, B.; Jameson, A. An improved gas-kinetic BGK finite-volume method for three-dimensional transonic flow. J. Comput. Phys. 2007, 220, 856–878. [Google Scholar] [CrossRef]
- Ni, G.; Jiang, S.; Xu, K. Efficient kinetic schemes for steady and unsteady flow simulations on unstructured meshes. J. Comput. Phys. 2008, 227, 3015–3031. [Google Scholar] [CrossRef]
- Xiong, S.; Zhong, C.; Zhuo, C.; Li, K.; Chen, X.; Cao, J. Numerical simulation of compressible turbulent flow via improved gas-kinetic BGK scheme. Int. J. Numer. Methods Fluids 2011, 67, 1833–1847. [Google Scholar] [CrossRef]
- Li, W.; Kaneda, M.; Suga, K. An implicit gas kinetic BGK scheme for high temperature equilibrium gas flows on unstructured meshes. Comput. Fluids 2014, 93, 100–106. [Google Scholar] [CrossRef]
- Pan, D.; Zhong, C.; Li, J.; Zhuo, C. A gas-kinetic scheme for the simulation of turbulent flows on unstructured meshes. Int. J. Numer. Methods Fluids 2016, 82, 748–769. [Google Scholar] [CrossRef]
- Pan, L.; Xu, K.; Li, Q.; Li, J. An efficient and accurate two-stage fourth-order gas-kinetic scheme for the Euler and Navier–Stokes equations. J. Comput. Phys. 2016, 326, 197–221. [Google Scholar] [CrossRef]
- Pan, L.; Xu, K. Two-stage fourth-order gas-kinetic scheme for three-dimensional Euler and Navier–Stokes solutions. Int. J. Comput. Fluid Dyn. 2018, 32, 395–411. [Google Scholar] [CrossRef]
- Ji, X.; Zhao, F.; Shyy, W.; Xu, K. A family of high-order gas-kinetic schemes and its comparison with Riemann solver based high-order methods. J. Comput. Phys. 2018, 356, 150–173. [Google Scholar] [CrossRef]
- Cao, G.; Su, H.; Xu, J.; Xu, K. Implicit high-order gas kinetic scheme for turbulence simulation. Aerosp. Sci. Technol. 2019, 92, 958–971. [Google Scholar] [CrossRef]
- Zhao, F.; Ji, X.; Shyy, W.; Xu, K. Compact higher-order gas-kinetic schemes with spectral-like resolution for compressible flow simulations. Adv. Aerodyn. 2019, 1, 63. [Google Scholar] [CrossRef]
- Su, M.; Xu, K.; Ghidaoui, M. Low-Speed Flow Simulation by the Gas-Kinetic Scheme. J. Comput. Phys. 1999, 150, 17–39. [Google Scholar] [CrossRef][Green Version]
- Liao, W.; Peng, Y.; Luo, L.S. Gas-kinetic schemes for direct numerical simulations of compressible homogeneous turbulence. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2009, 80, 046702. [Google Scholar] [CrossRef]
- Jin, C.; Xu, K.; Chen, S. A Three Dimensional Gas-Kinetic Scheme with Moving Mesh for Low-Speed Viscous Flow Computations. Adv. Appl. Math. Mech. 2010, 2, 746–762. [Google Scholar] [CrossRef]
- Chen, S.; Jin, C.; Li, C.; Cai, Q. Gas-kinetic scheme with discontinuous derivative for low speed flow computation. J. Comput. Phys. 2011, 230, 2045–2059. [Google Scholar] [CrossRef]
- Wang, P.; Guo, Z. A semi-implicit gas-kinetic scheme for smooth flows. Comput. Phys. Commun. 2016, 205, 22–31. [Google Scholar] [CrossRef]
- Zhou, D.; Lu, Z.; Guo, T. A Gas-Kinetic BGK Scheme for Natural Convection in a Rotating Annulus. Appl. Sci. 2018, 8, 733. [Google Scholar] [CrossRef]
- Lenz, S.; Krafczyk, M.; Geier, M.; Chen, S.; Guo, Z. Validation of a two-dimensional gas-kinetic scheme for compressible natural convection on structured and unstructured meshes. Int. J. Therm. Sci. 2019, 136, 299–315. [Google Scholar] [CrossRef]
- Lenz, S.; Geier, M.; Krafczyk, M. An explicit gas kinetic scheme algorithm on non-uniform Cartesian meshes for GPGPU architectures. Comput. Fluids 2019, 186, 58–73. [Google Scholar] [CrossRef]
- Xu, K.; Huang, J.C. A unified gas-kinetic scheme for continuum and rarefied flows. J. Comput. Phys. 2010, 229, 7747–7764. [Google Scholar] [CrossRef]
- Xu, K.; Huang, J.C. An improved unified gas-kinetic scheme and the study of shock structures. IMA J. Appl. Math. 2011, 76, 698–711. [Google Scholar] [CrossRef]
- Huang, J.C.; Xu, K.; Yu, P. A Unified Gas-Kinetic Scheme for Continuum and Rarefied Flows II: Multi-Dimensional Cases. Commun. Comput. Phys. 2012, 12, 662–690. [Google Scholar] [CrossRef]
- Huang, J.C.; Xu, K.; Yu, P. A Unified Gas-Kinetic Scheme for Continuum and Rarefied Flows III: Microflow Simulations. Commun. Comput. Phys. 2013, 14, 1147–1173. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhong, C.; Xu, K. Unified gas-kinetic scheme with multigrid convergence for rarefied flow study. Phys. Fluids 2017, 29, 096102. [Google Scholar] [CrossRef]
- Guo, Z.; Xu, K.; Wang, R. Discrete unified gas kinetic scheme for all Knudsen number flows: Low-speed isothermal case. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2013, 88, 033305. [Google Scholar] [CrossRef]
- Guo, Z.; Wang, R.; Xu, K. Discrete unified gas kinetic scheme for all Knudsen number flows. II. Thermal compressible case. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2015, 91, 033313. [Google Scholar] [CrossRef]
- Zhu, L.; Guo, Z.; Xu, K. Discrete unified gas kinetic scheme on unstructured meshes. Comput. Fluids 2016, 127, 211–225. [Google Scholar] [CrossRef]
- Bo, Y.; Wang, P.; Guo, Z.; Wang, L.P. DUGKS simulations of three-dimensional Taylor–Green vortex flow and turbulent channel flow. Comput. Fluids 2017, 155, 9–21. [Google Scholar] [CrossRef]
- Tao, S.; Zhang, H.; Guo, Z.; Wang, L.P. A combined immersed boundary and discrete unified gas kinetic scheme for particle–fluid flows. J. Comput. Phys. 2018, 375, 498–518. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, K.; Guo, Z. A discrete unified gas-kinetic scheme for immiscible two-phase flows. Int. J. Heat Mass Transf. 2018, 126, 1326–1336. [Google Scholar] [CrossRef]
- Bhatnagar, P.L.; Gross, E.P.; Krook, M. A Model for Collision Processes in Gases. I. Small Amplitude Processes in Charged and Neutral One-Component Systems. Phys. Rev. 1954, 94, 511–525. [Google Scholar] [CrossRef]
- NVIDIA. CUDA C Programming Guide; NVIDIA: Santa Clara, CA, USA, 2018. [Google Scholar]
- Sanders, J.; Kandrot, E. CUDA by Example: An Introduction to General-Purpose GPU Programming, 3rd ed.; Addison-Wesley: Upper Saddle River, NJ, USA, 2011. [Google Scholar]
- Smagorinsky, J. General circulation experiments with the primitive equations. Mon. Weather Rev. 1963, 91, 99–164. [Google Scholar] [CrossRef]
- iRMB. VirtualFluids. Available online: https://www.tu-braunschweig.de/irmb/forschung/virtualfluids (accessed on 17 May 2020).
- Deakin, T.; Price, J.; Martineau, M.; McIntosh-Smith, S. GPU-STREAM v2.0: Benchmarking the Achievable Memory Bandwidth of Many-Core Processors Across Diverse Parallel Programming Models. In High Performance Computing; Taufer, M., Mohr, B., Kunkel, J.M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9945, pp. 489–507. [Google Scholar]
- Obrecht, C.; Kuznik, F.; Tourancheau, B.; Roux, J.J. Multi-GPU implementation of the lattice Boltzmann method. Comput. Math. Appl. 2013, 65, 252–261. [Google Scholar] [CrossRef]
- Calore, E.; Marchi, D.; Schifano, S.F.; Tripiccione, R. Optimizing communications in multi-GPU Lattice Boltzmann simulations. In Proceedings of the 2015 International Conference on High Performance Computing Simulation (HPCS), Amsterdam, The Netherlands, 20–24 July 2015; pp. 55–62. [Google Scholar] [CrossRef]
- Robertsén, F.; Westerholm, J.; Mattila, K. Lattice Boltzmann Simulations at Petascale on Multi-GPU Systems with Asynchronous Data Transfer and Strictly Enforced Memory Read Alignment. In Proceedings of the 2015 23rd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, Turku, Finland, 4–6 March 2015; pp. 604–609. [Google Scholar] [CrossRef]
- Lian, Y.S.; Xu, K. A Gas-Kinetic Scheme for Multimaterial Flows and Its Application in Chemical Reactions. J. Comput. Phys. 2000, 163, 349–375. [Google Scholar] [CrossRef]
- Li, Q.; Fu, S.; Xu, K. A compressible Navier–Stokes flow solver with scalar transport. J. Comput. Phys. 2005, 204, 692–714. [Google Scholar] [CrossRef]
- McGrattan, K.; Hostikka, S.; Floyd, J.; Baum, H.; Rehm, R. Fire Dynamics Simulator (Version 5): Technical Reference Guide; NIST Special Publication, National Institute of Standards and Technology NIST: Gaithersburg, MD, USA, 2007. [Google Scholar]
- Tian, Y.S.; Karayiannis, T.G. Low turbulence natural convection in an air filled square cavity: Part I: The thermal and fluid flow fields. Int. J. Heat Mass Transf. 2000, 43, 849–866. [Google Scholar] [CrossRef]
- Tian, Y.S.; Karayiannis, T.G. Low turbulence natural convection in an air filled square cavity: Part II: The turbulence quantities. Int. J. Heat Mass Transf. 2000, 43, 867–884. [Google Scholar] [CrossRef]
- Salinas-Vázquez, M.; Vicente, W.; Martínez, E.; Barrios, E. Large eddy simulation of a confined square cavity with natural convection based on compressible flow equations. Int. J. Heat Fluid Flow 2011, 32, 876–888. [Google Scholar] [CrossRef]
- De Vahl Davis, G. Natural convection of air in a square cavity: A bench mark numerical solution. Int. J. Numer. Methods Fluids 1983, 3, 249–264. [Google Scholar] [CrossRef]
- Vierendeels, J.; Merci, B.; Dick, E. Benchmark solutions for the natural convective heat transfer problem in a square cavity with large horizontal temperature differences. Int. J. Numer. Methods Heat Fluid Flow 2003, 13, 1057–1078. [Google Scholar] [CrossRef]
- Vierendeels, J.; Merci, B.; Dick, E. Numerical study of natural convective heat transfer with large temperature differences. Int. J. Numer. Methods Heat Fluid Flow 2001, 11, 329–341. [Google Scholar] [CrossRef]
- Tian, C.T.; Xu, K.; Chan, K.L.; Deng, L.C. A three-dimensional multidimensional gas-kinetic scheme for the Navier–Stokes equations under gravitational fields. J. Comput. Phys. 2007, 226, 2003–2027. [Google Scholar] [CrossRef]
- Hunt, J.; Wray, A.; Moin, P. Eddies, Streams, and Convergence Zones in Turbulent Flow; Center for Turbulence Research Proceedings of the Summer Program: Stanford, CA, USA, 1988. [Google Scholar]
- Xin, Y.; Gore, J.; McGrattan, K.; Rehm, R.; Baum, H. Fire dynamics simulation of a turbulent buoyant flame using a mixture-fraction-based combustion model. Combust. Flame 2005, 141, 329–335. [Google Scholar] [CrossRef]
- Fire Dynamics Simulator–GitHub. Available online: https://github.com/firemodels/fds (accessed on 28 January 2020).
- Deardorff, J.W. Stratocumulus-capped mixed layers derived from a three-dimensional model. Bound. Lay. Meteorol. 1980, 18, 495–527. [Google Scholar] [CrossRef]
- Tieszen, S.R.; O’Hern, T.J.; Schefer, R.W.; Weckman, E.J.; Blanchat, T.K. Experimental study of the flow field in and around a one meter diameter methane fire. Combust. Flame 2002, 129, 378–391. [Google Scholar] [CrossRef]
- Tieszen, S.R.; O’Hern, T.J.; Weckman, E.J.; Schefer, R.W. Experimental study of the effect of fuel mass flux on a 1-m-diameter methane fire and comparison with a hydrogen fire. Combust. Flame 2004, 139, 126–141. [Google Scholar] [CrossRef]
- Orloff, L.; de Ris, J. Froude modeling of pool fires. Symp. Int. Combust. 1982, 19, 885–895. [Google Scholar] [CrossRef]


















© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lenz, S.; Geier, M.; Krafczyk, M. Simulation of Fire with a Gas Kinetic Scheme on Distributed GPGPU Architectures. Computation 2020, 8, 50. https://doi.org/10.3390/computation8020050
Lenz S, Geier M, Krafczyk M. Simulation of Fire with a Gas Kinetic Scheme on Distributed GPGPU Architectures. Computation. 2020; 8(2):50. https://doi.org/10.3390/computation8020050
Chicago/Turabian StyleLenz, Stephan, Martin Geier, and Manfred Krafczyk. 2020. "Simulation of Fire with a Gas Kinetic Scheme on Distributed GPGPU Architectures" Computation 8, no. 2: 50. https://doi.org/10.3390/computation8020050
APA StyleLenz, S., Geier, M., & Krafczyk, M. (2020). Simulation of Fire with a Gas Kinetic Scheme on Distributed GPGPU Architectures. Computation, 8(2), 50. https://doi.org/10.3390/computation8020050