
The MLDAR Model: Machine Learning-Based Denoising of Structural Response Signals Generated by Ambient Vibration



Abstract
1. Introduction
2. Structural Response Due to Ambient Vibration and SDOF Models
2.1. Structural Response Generated by Ambient Vibration
2.2. Models Used for Calibrating the NN
3. Machine Learning-Based Models: Architecture and Calibration
3.1. Convolutional Neural Networks
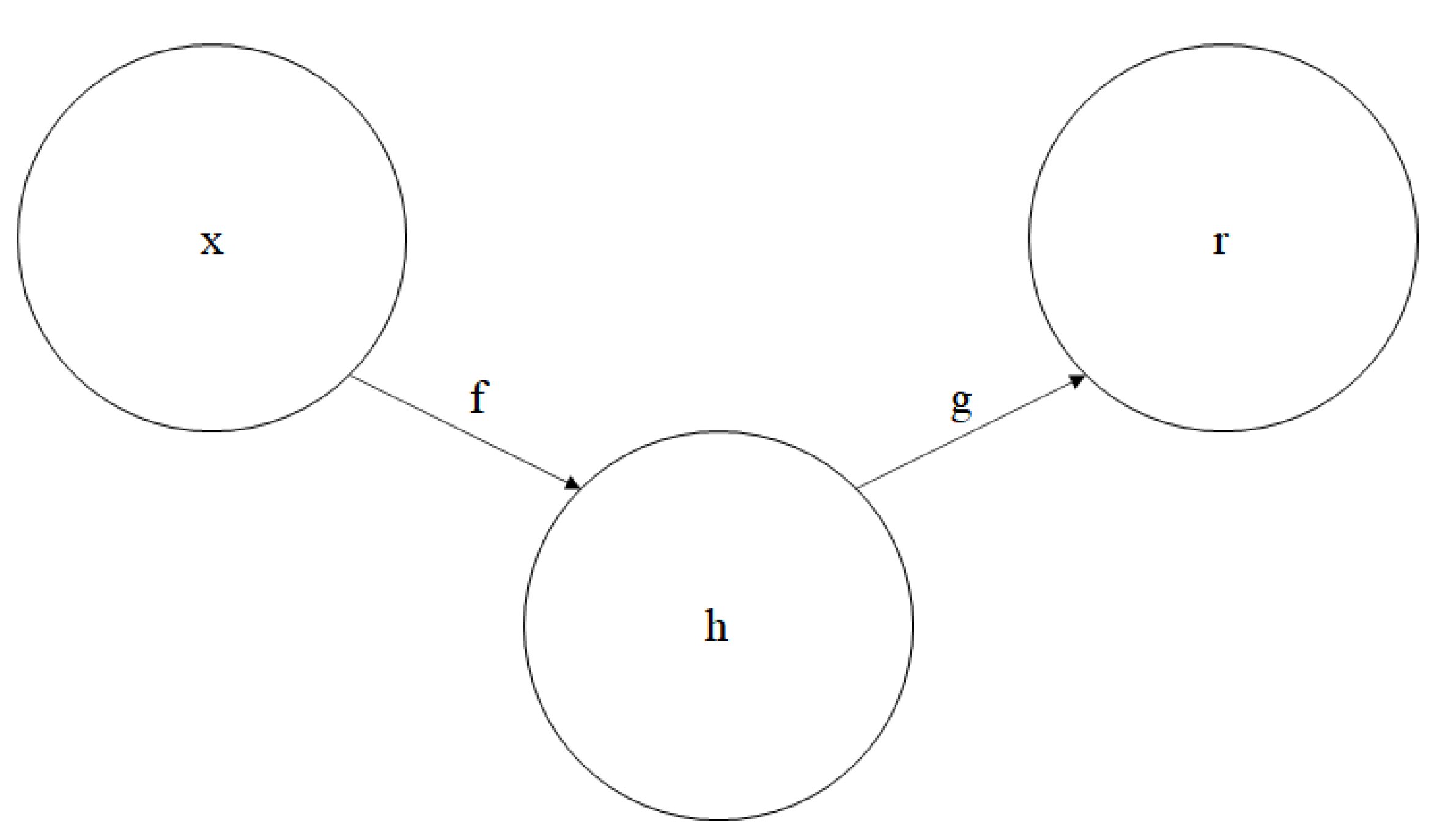
3.2. The Autoencoders
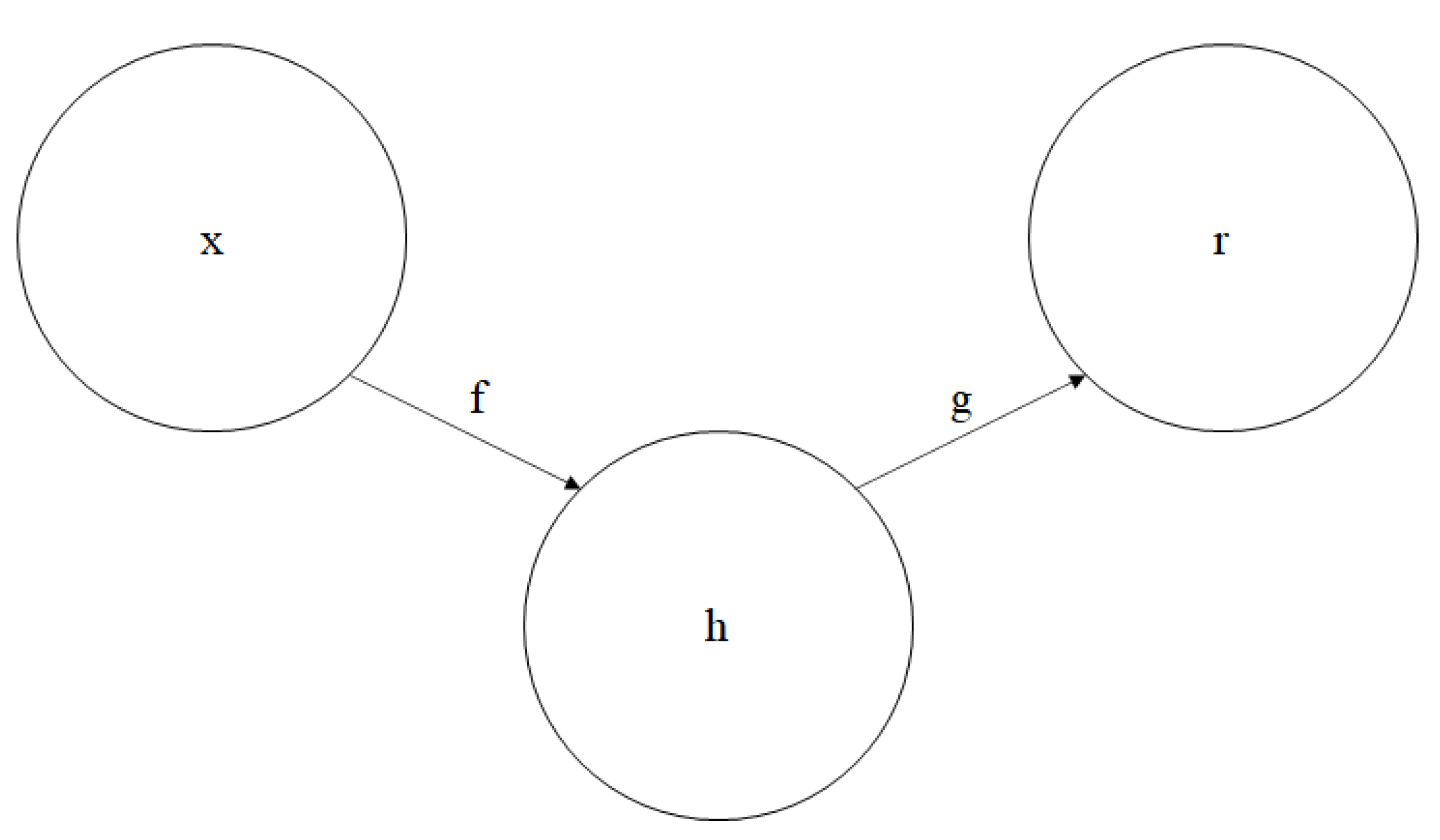
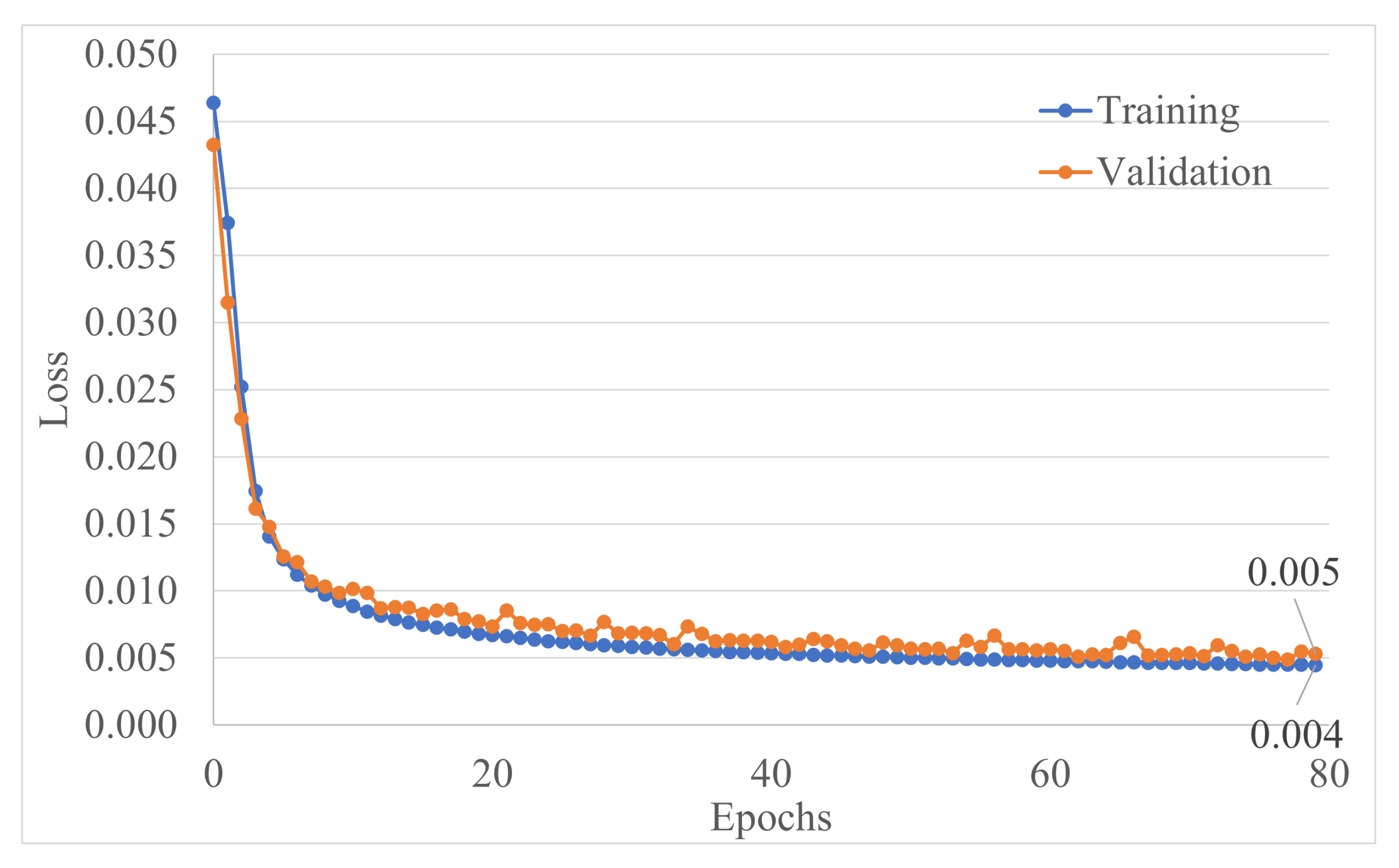
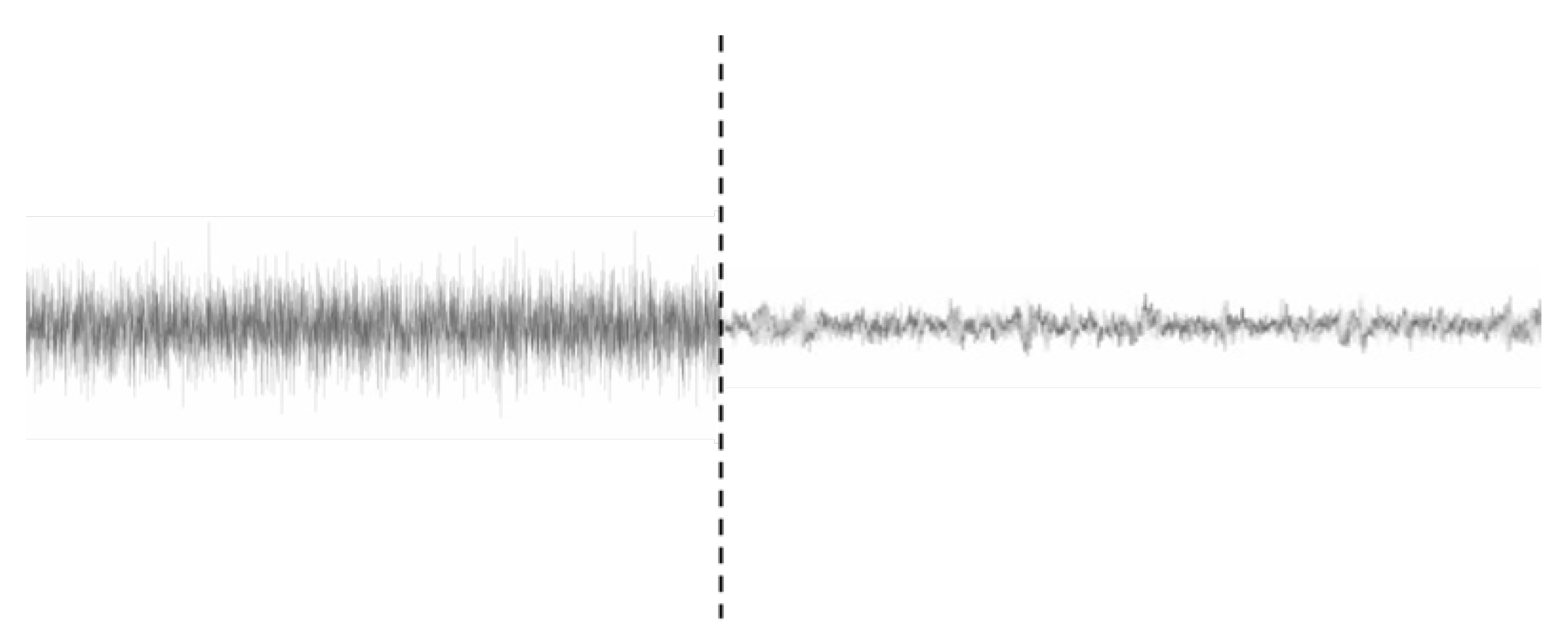
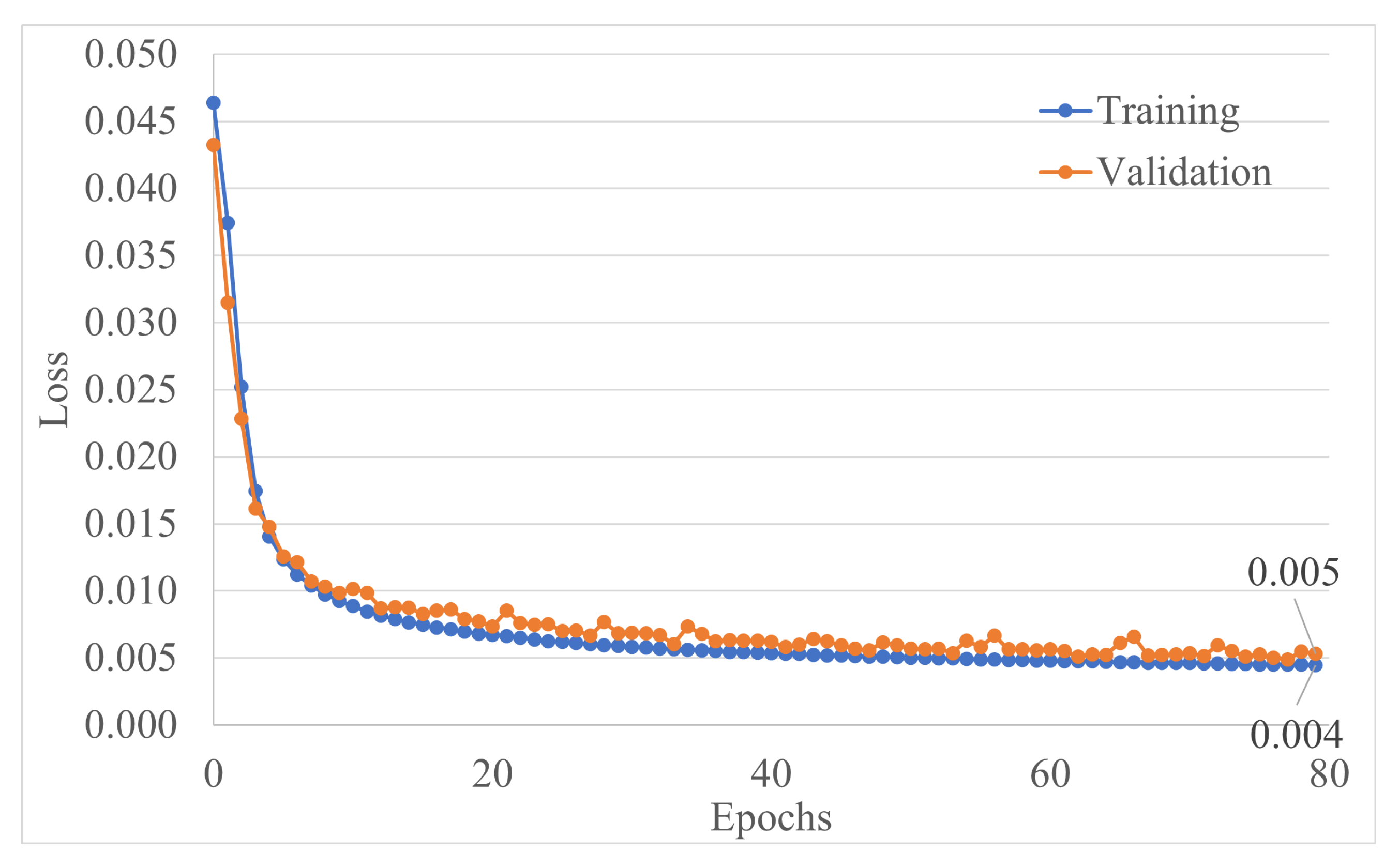
3.3. MLDAR: A Machine Learning-Based Model for Denoising the Ambient Structural Response
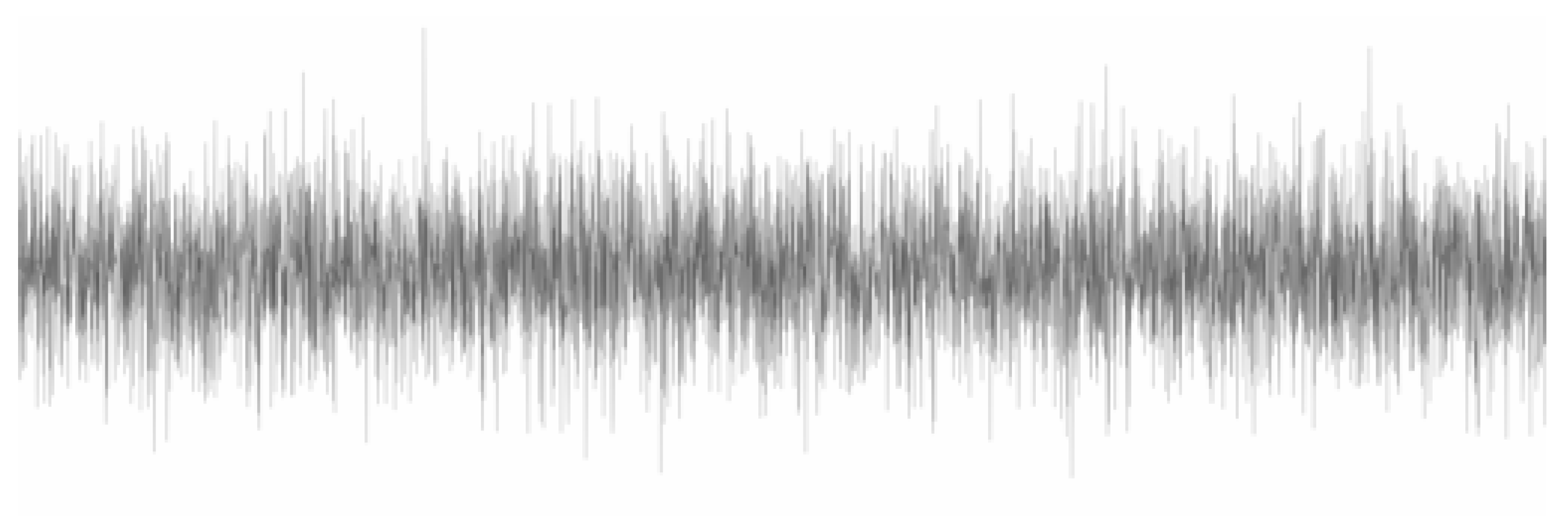
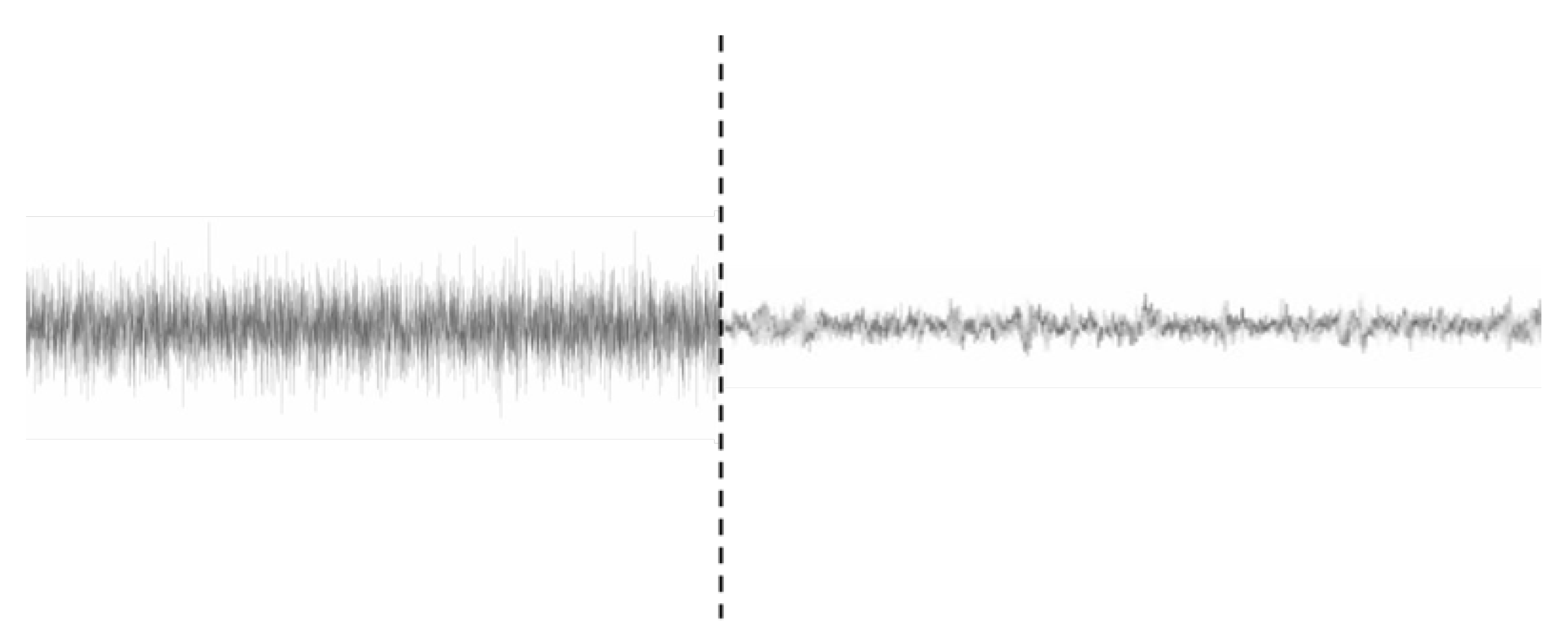
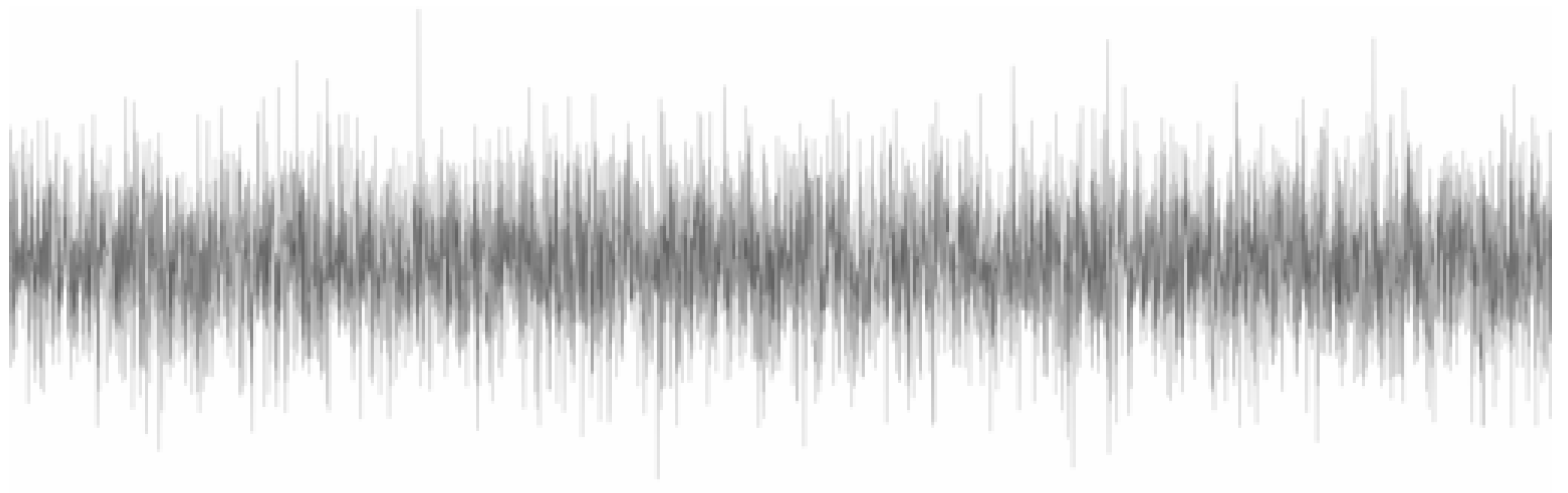
- Input images (noisy response): minimum value of −0.000442 g, maximum value of 0.000437 g;
- Output images (no-noise response): minimum value of −0.000074 g, maximum value of 0.000072 g.
4. Frequency Spectrum Comparison: Qualitative and Quantitative Results
4.1. Qualitative Comparison: Sample of Low-Frequency Signals
4.2. Qualitative Comparison: Sample of Medium-Frequency Signal
4.3. Qualitative Comparison: Sample of High-Frequency Signal
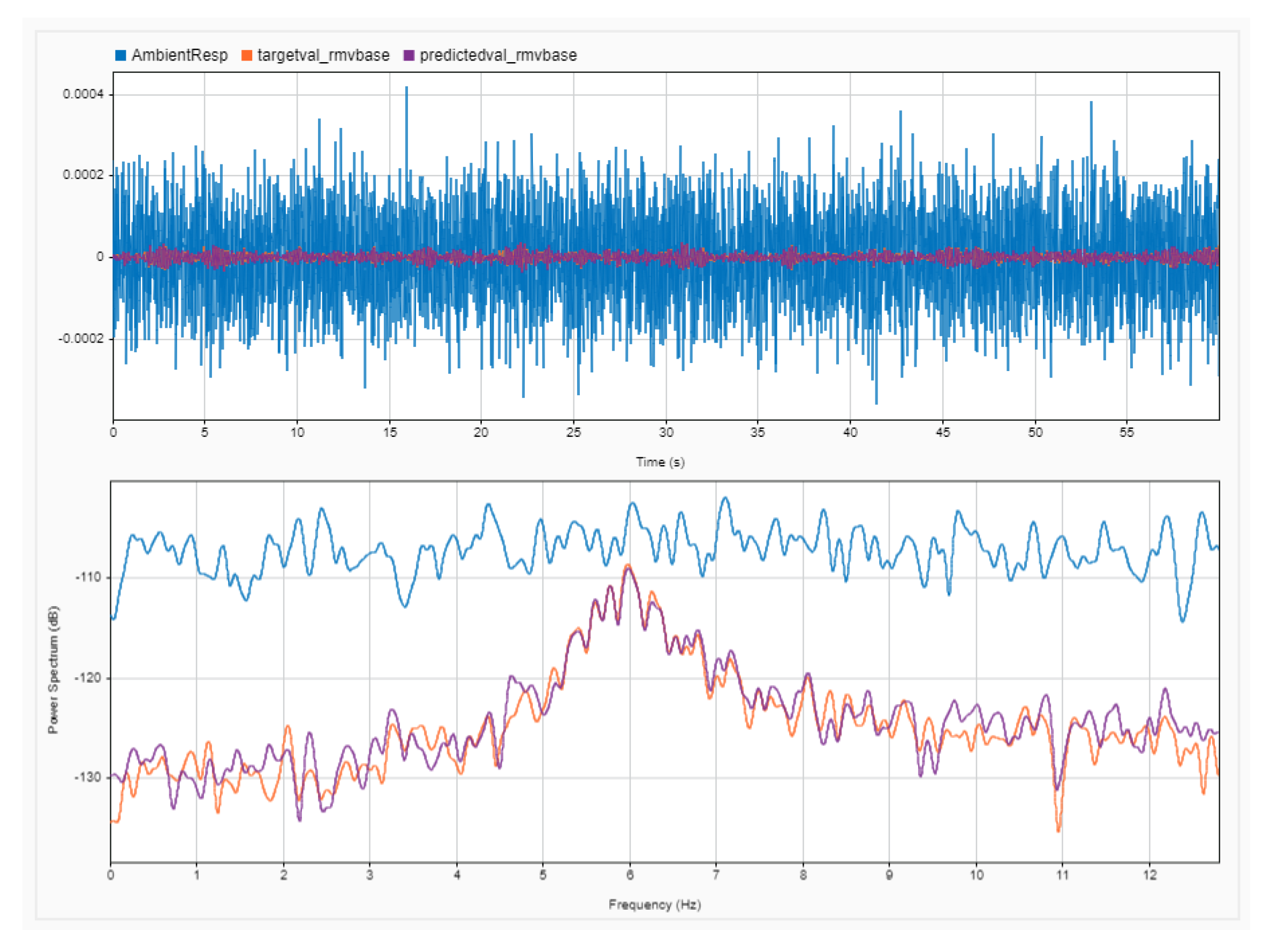
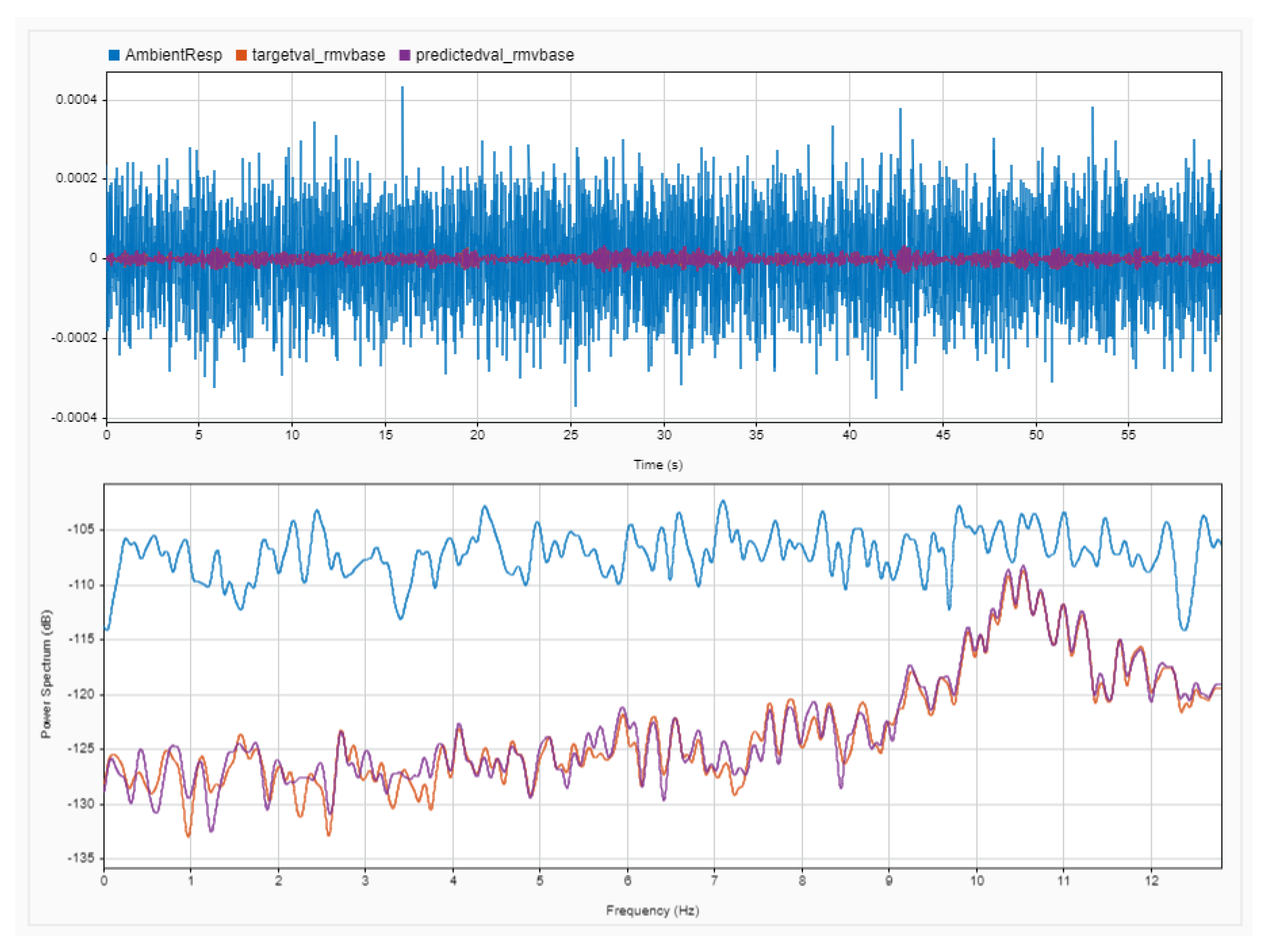
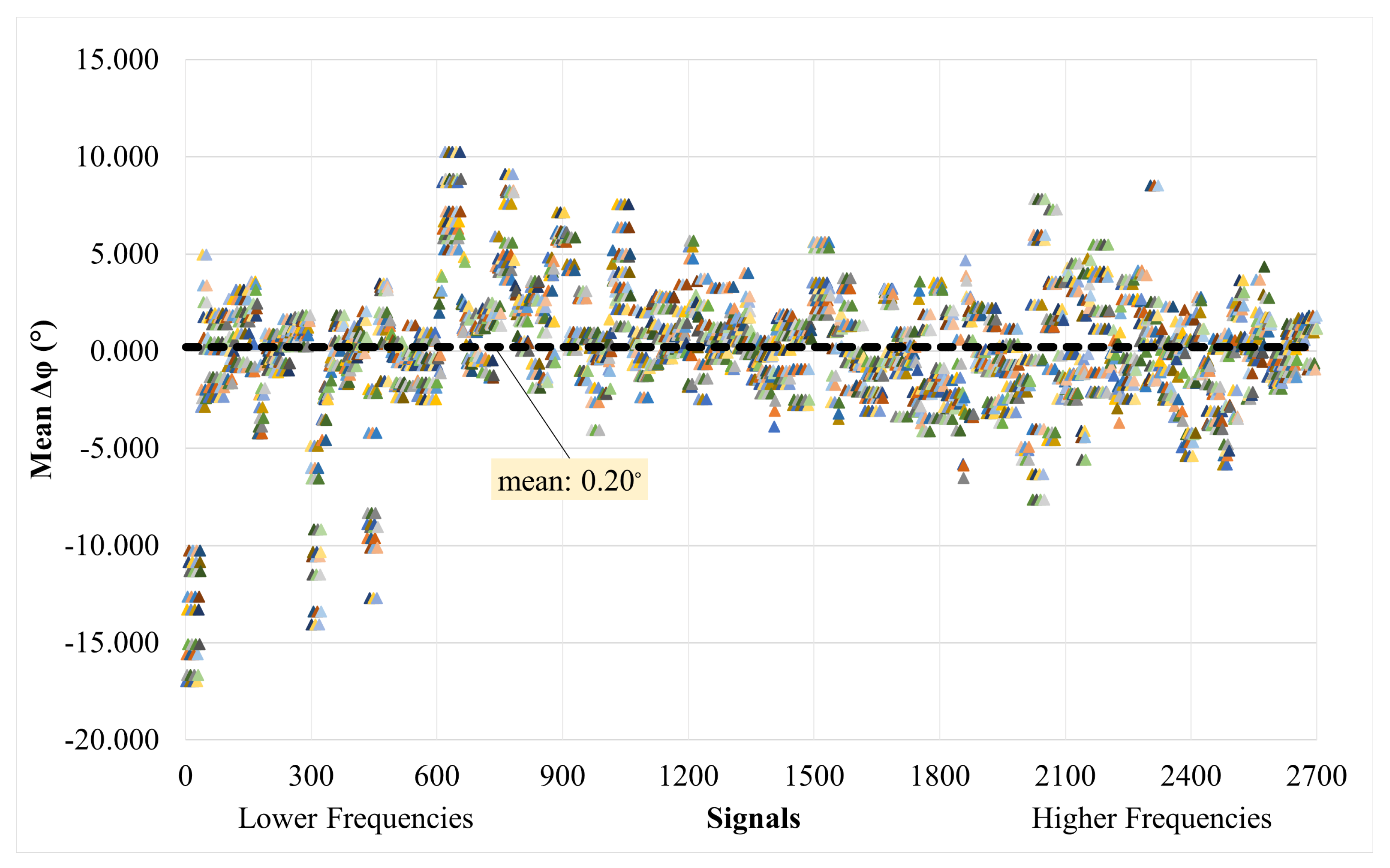
4.4. Quantitative Results: Comparing Frequency Spectra of Prediction and Target for the Whole Dataset through Magnitude-Squared Coherence
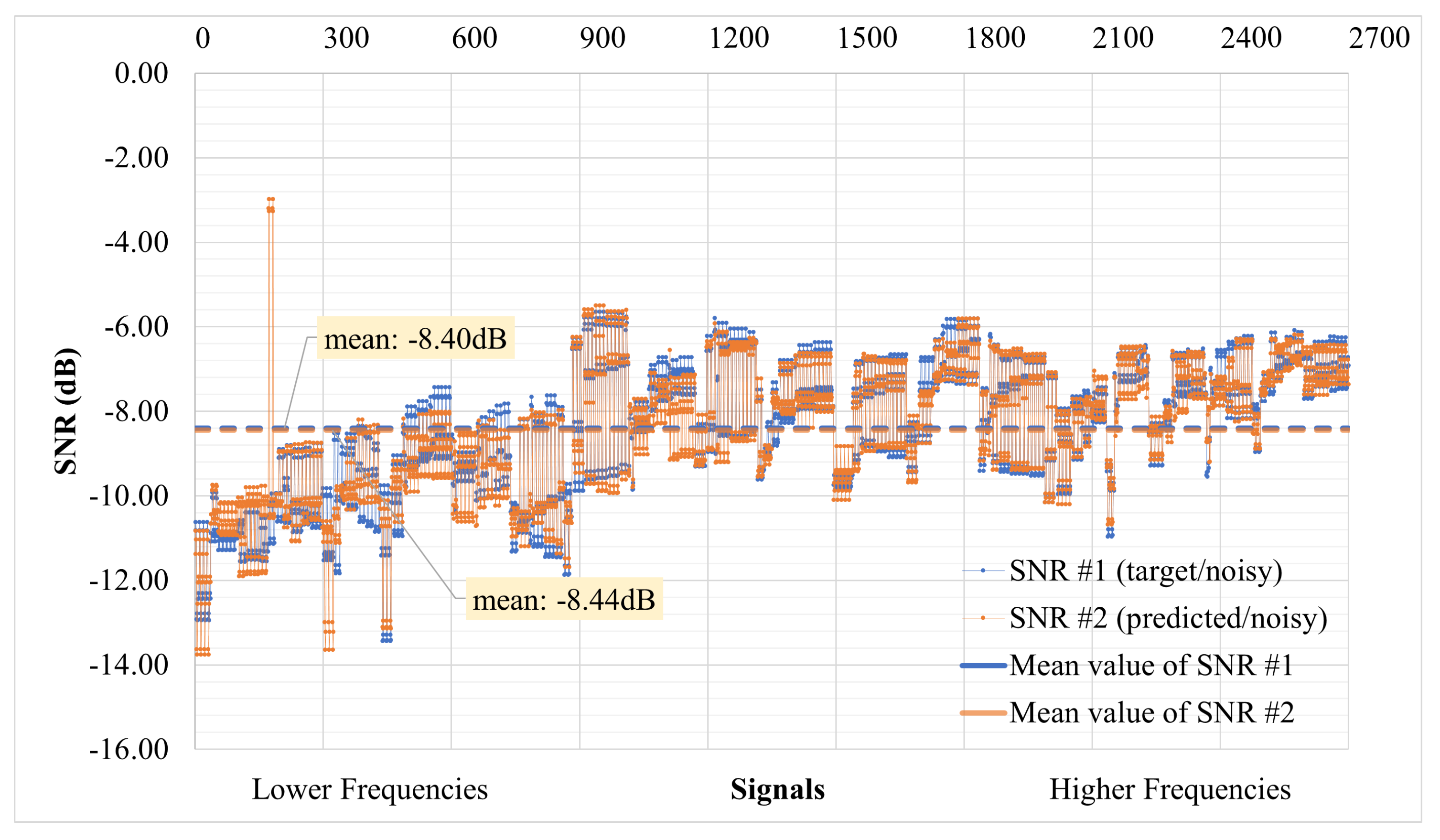
4.5. Quantitative Results: Evaluating Denoising Performance through SNR Levels
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANNs | Artificial neural networks |
| AV | Ambient vibration |
| CNN | Convolutional neural network |
| ML | Machine learning |
| MLDAR | Machine Learning-based Denoising of Ambient Response |
| MEMs | Micro-Electromechanical Systems |
| NN | Neural network |
| NPUs | Neural Processing Units |
| RNN | Recurrent Neural Network |
| SDOF | Single Degree of Freedom |
| SHM | Structural Health Monitoring |
| SNR | Signal-to-Noise Ratio |
References
- Zhang, C.; Mousavi, A.A.; Masri, S.F.; Gholipour, G.; Yan, K.; Li, X. Vibration feature extraction using signal processing techniques for structural health monitoring: A review. Mech. Syst. Signal Process. 2022, 177, 109175. [Google Scholar] [CrossRef]
- Zinno, R.; Shaffiee Haghshenas, S.; Guido, G.; Vitale, A. Artificial Intelligence and Structural Health Monitoring of Bridges: A Review of the State-of-the-Art. IEEE Access 2022, 10, 88058–88078. [Google Scholar] [CrossRef]
- Nadkarni, R.R.; Puthuvayi, B. A comprehensive literature review of Multi-Criteria Decision Making methods in heritage buildings. J. Build. Eng. 2020, 32, 101814. [Google Scholar] [CrossRef]
- Mishra, M. Machine learning techniques for structural health monitoring of heritage buildings: A state-of-the-art review and case studies. J. Cult. Herit. 2021, 47, 227–245. [Google Scholar] [CrossRef]
- Sony, S.; Dunphy, K.; Sadhu, A.; Capretz, M. A systematic review of convolutional neural network-based structural condition assessment techniques. Eng. Struct. 2021, 226, 111347. [Google Scholar] [CrossRef]
- Xu, R.; Wu, R.; Ishiwaka, Y.; Vondrick, C.; Zheng, C. Listening to Sounds of Silence for Speech Denoising. arXiv 2020, arXiv:2010.12013. [Google Scholar]
- Elad, M.; Kawar, B.; Vaksman, G. Image Denoising: The Deep Learning Revolution and Beyond—A Survey Paper. SIAM J. Imaging Sci. 2023, 16, 1594–1654. [Google Scholar] [CrossRef]
- Izadi, S.; Sutton, D.; Hamarneh, G. Image denoising in the deep learning era. Artif. Intell. Rev. 2023, 56, 5929–5974. [Google Scholar] [CrossRef]
- Damikoukas, S.; Lagaros, N.D. MLPER: A Machine Learning-Based Prediction Model for Building Earthquake Response Using Ambient Vibration Measurements. Appl. Sci. 2023, 13, 10622. [Google Scholar] [CrossRef]
- Xiang, P.; Zhang, P.; Zhao, H.; Shao, Z.; Jiang, L. Seismic response prediction of a train-bridge coupled system based on a LSTM neural network. Mech. Based Des. Struct. Mach. 2023, 1–23. [Google Scholar] [CrossRef]
- Demertzis, K.; Kostinakis, K.; Morfidis, K.; Iliadis, L. An interpretable machine learning method for the prediction of R/C buildings’ seismic response. J. Build. Eng. 2023, 63, 105493. [Google Scholar] [CrossRef]
- Kohler, M.D.; Hao, S.; Mishra, N.; Govinda, R.; Nigbor, R.L. ShakeNet: A Portable Wireless Sensor Network for Instrumenting Large Civil Structures; US Geological Survey: Reston, VA, USA, 2015.
- Sabato, A.; Feng, M.Q.; Fukuda, Y.; Carní, D.L.; Fortino, G. A Novel Wireless Accelerometer Board for Measuring Low-Frequency and Low-Amplitude Structural Vibration. IEEE Sens. J. 2016, 16, 2942–2949. [Google Scholar] [CrossRef]
- Sabato, A.; Niezrecki, C.; Fortino, G. Wireless MEMS-Based Accelerometer Sensor Boards for Structural Vibration Monitoring: A Review. IEEE Sens. J. 2017, 17, 226–235. [Google Scholar] [CrossRef]
- Zhu, L.; Fu, Y.; Chow, R.; Spencer, B.F.; Park, J.W.; Mechitov, K. Development of a High-Sensitivity Wireless Accelerometer for Structural Health Monitoring. Sensors 2018, 18, 262. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Yan, G.; Wang, L.; Ou, J. Review of Benchmark Studies and Guidelines for Structural Health Monitoring. Adv. Struct. Eng. 2013, 16, 1187–1206. [Google Scholar] [CrossRef]
- Yang, Y.; Li, Q.; Yan, B. Specifications and applications of the technical code for monitoring of building and bridge structures in China. Adv. Mech. Eng. 2017, 9, 1687814016684272. [Google Scholar] [CrossRef]
- Moreu, F.; Li, X.; Li, S.; Zhang, D. Technical Specifications of Structural Health Monitoring for Highway Bridges: New Chinese Structural Health Monitoring Code. Front. Built Environ. 2018, 4, 10. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, Y.; Tan, X. Review on Vibration-Based Structural Health Monitoring Techniques and Technical Codes. Symmetry 2021, 13, 1998. [Google Scholar] [CrossRef]
- Dunand, F.; Gueguen, P.; Bard, P.Y.; Rodgers, J. Comparison of the dynamic parameters extracted from weak, moderate and strong building motion. In Proceedings of the 1st European Conference of Earthquake Engineering and Seismology, Geneva, Switzerland, 3–8 September 2006. [Google Scholar]
- Damikoukas, S.; Chatzieleftheriou, S.; Lagaros, N.D. First Level Pre- and Post-Earthquake Building Seismic Assessment Protocol Based on Dynamic Characteristics Extracted In Situ. Infrastructures 2022, 7, 115. [Google Scholar] [CrossRef]
- ADINA, version: 9.2.1; ADINA R&D Inc.: Watertown, MA, USA, 2016. Available online: http://www.adina.com/ (accessed on 19 September 2022).
- FEMA. Hazus—MH 2.1: Technical Manual; Department of Homeland Security, Federal Emergency Management Agency, Mitigation Division: Washington, DC, USA, 2013. [Google Scholar]
- MATLAB, version 9.11.0 (R2021b); The MathWorks Inc.: Natick, MA, USA, 2021.
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Shabani, A.; Feyzabadi, M.; Kioumarsi, M. Model updating of a masonry tower based on operational modal analysis: The role of soil-structure interaction. Case Stud. Constr. Mater. 2022, 16, e00957. [Google Scholar] [CrossRef]
- Unquake. Unquake Accelerograph-Accelerometer Specifications. Available online: https://unquake.co (accessed on 19 September 2022).
- Chatzieleftheriou, S.; Damikoukas, S. Optimal Sensor Installation to Extract the Mode Shapes of a Building—Rotational DOFs, Torsional Modes and Spurious Modes Detection. Technical Report. Unquake (Structures & Sensors P.C.). 2021. Available online: https://www.researchgate.net/institution/Unquake/post/6130bc2ca1abfe50c1559a26_Download_White_Paper_Optimal_sensor_installation_to_extract_the_mode_shapes_of_a_building-Rotational_DOFs_torsional_modes_and_spurious_modes_detection (accessed on 19 September 2022).
- Welch, P. The use of fast Fourier transform for the estimation of power spectra: A method based on time averaging over short, modified periodograms. IEEE Trans. Audio Electroacoust. 1967, 15, 70–73. [Google Scholar] [CrossRef]
- Rabiner, L.R.; Gold, B. Theory and Application of Digital Signal Processing; Prentice-Hall: Englewood Cliffs, NJ, USA, 1975. [Google Scholar]
- Kay, S. Spectral Estimation. In Advanced Topics in Signal Processing; Prentice-Hall, Inc.: Englewood Cliffs, NJ, USA, 1987; pp. 58–122. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Geometry | |
| Plan | 10.00 × 7.00 (m2) |
| Stories | 1 to 7 |
| Story height | 3.50 (m) |
| Slab thickness | 0.25 (m) |
| Columns | 0.50 × 0.50 (m2) |
| Beams | 0.40 × 0.70 (m2) |
| Loads | |
| Dead | 806.75 (kN) |
| Live | 806.75 (kN) |
| Safety factor | 1 1 |
| Dynamic characteristics | |
| Mass (per story) | 110.78 (tons) |
| Damping ratio | 5% |
| Eigenfrequency | 1 to 10 Hz with step of 0.5 |
| Material | |
| Reinforced concrete | |
| Bilinear material | Figure 2 |
| Yield point | 0.0105 m 2 |
| Post-yield stiffness | 50% of geometric one 3 |
| Encoder | ||||
|---|---|---|---|---|
| C1 1 | C2 1 | C3 1 | C4 1 | |
| Filters: | 128 | 64 | 64 | 64 |
| Kernel size: | (2,2) | (2,2) | (2,2) | (2,2) |
| Dilation: | (1,1) | (2,2) | (4,4) | (6,6) |
| Stride: | (1,1) | (1,1) | (1,1) | (1,1) |
| Padding: | Valid | Valid | Valid | Valid |
| Decoder | Upscaling | |||||
|---|---|---|---|---|---|---|
| TC1 1 | TC2 1 | TC3 1 | TC4 1 | TC5 1 | C5 2 | |
| Filters: | 64 | 64 | 64 | 128 | 128 | 1 |
| Kernel size: | (2,2) | (2,2) | (2,2) | (2,2) | (4,4) | (3,2) |
| Dilation: | (6,6) | (4,4) | (2,2) | (1,1) | (1,1) | (1,1) |
| Stride: | (1,1) | (1,1) | (1,1) | (1,1) | (3,3) | (1,1) |
| Padding: | Valid | Valid | Valid | Valid | Valid | Valid |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Damikoukas, S.; Lagaros, N.D. The MLDAR Model: Machine Learning-Based Denoising of Structural Response Signals Generated by Ambient Vibration. Computation 2024, 12, 31. https://doi.org/10.3390/computation12020031
Damikoukas S, Lagaros ND. The MLDAR Model: Machine Learning-Based Denoising of Structural Response Signals Generated by Ambient Vibration. Computation. 2024; 12(2):31. https://doi.org/10.3390/computation12020031
Chicago/Turabian StyleDamikoukas, Spyros, and Nikos D. Lagaros. 2024. "The MLDAR Model: Machine Learning-Based Denoising of Structural Response Signals Generated by Ambient Vibration" Computation 12, no. 2: 31. https://doi.org/10.3390/computation12020031
APA StyleDamikoukas, S., & Lagaros, N. D. (2024). The MLDAR Model: Machine Learning-Based Denoising of Structural Response Signals Generated by Ambient Vibration. Computation, 12(2), 31. https://doi.org/10.3390/computation12020031