
Data Augmentation for Regression Machine Learning Problems in High Dimensions

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Methodology
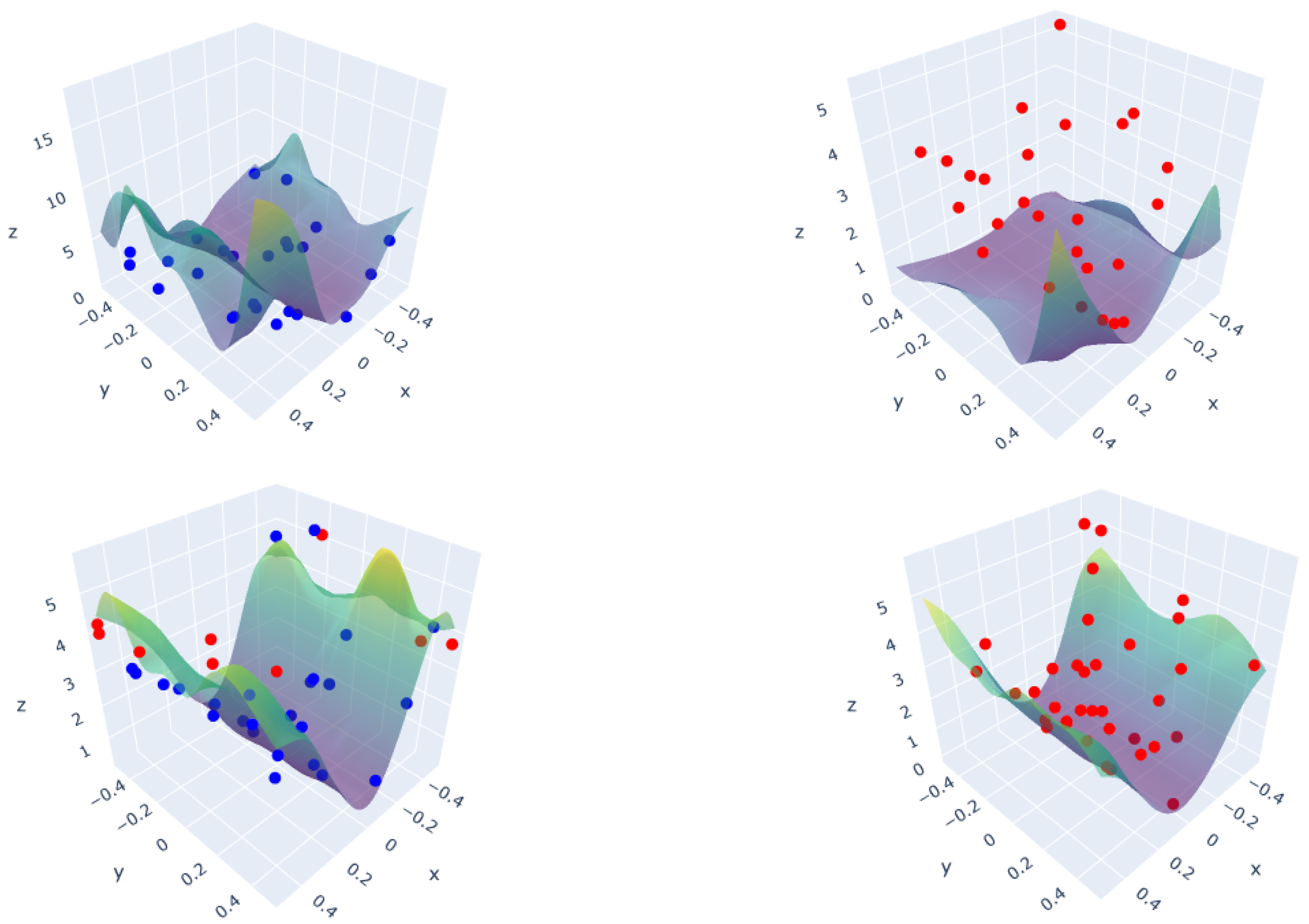
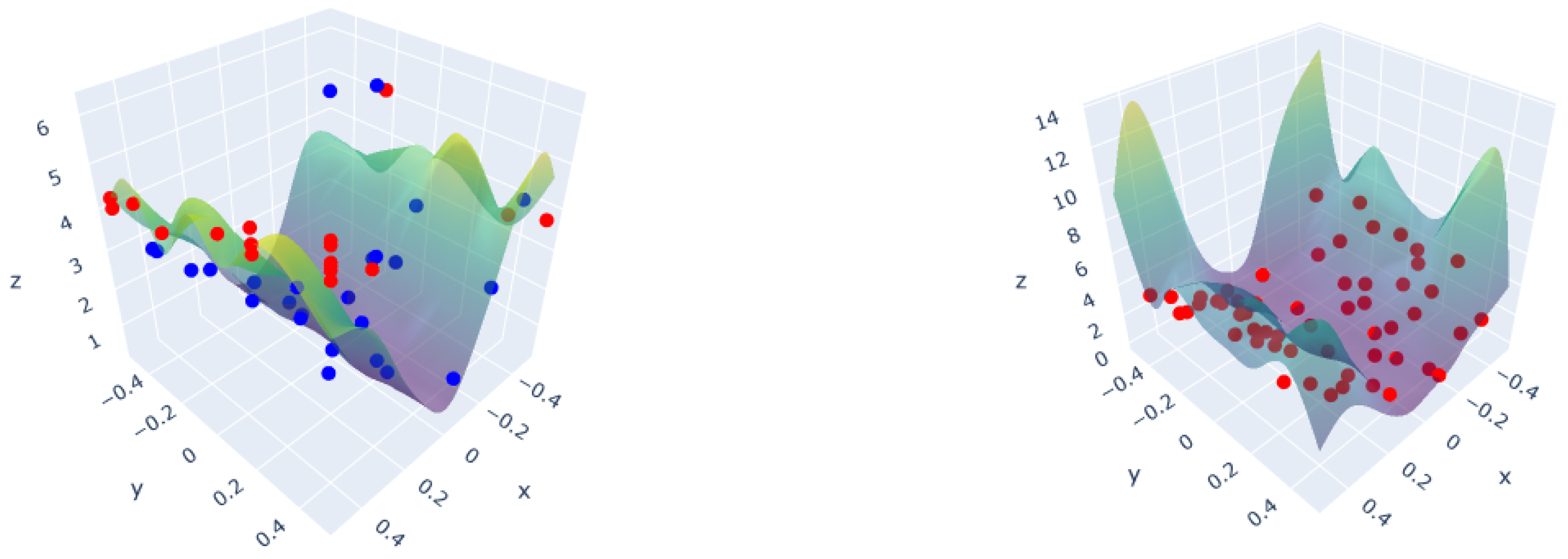
2.1. Active Learning
2.1.1. Scenarios
- (i)
- Membership query synthesis [12]: here, the model can ask for any sample in the input space, and it can also ask for queries generated de novo rather than for those sampled from an underlying natural distribution. This method has been particularly effective for problems confined to a finite domain [13]. Initially developed for classification models, it can also be extended to regression models [14]. However, this method may leave too much freedom to the algorithm, which can be led to request samples without any physical meaning.
- (ii)
- Stream-based selective sampling [15]: here, the initial assumption is that it is not expensive to add a sample. Therefore, the model decides for each possible sample whether to add it as training data. This approach is also sometimes called stream-based or sequential active learning because all the samples are considered one by one and the model chooses for each one whether to keep it or not.
- (iii)
- Pool-based sampling [16]: here, a small set, L, of labeled data and a large set, denoted U, of unlabeled available data are considered. The query is then made according to the information criterion, which evaluates the relevance of a sample from the basis U in comparison with the others. The best sample according to this criterion is then chosen and added to the training set. The difference with the previous scenario is that the decision regarding a sample is taken individually. In pool-based sampling, the other samples still available are taken into account. This last method is the most used in real applications.
2.1.2. Query Strategies
- Uncertainty Sampling:
- Query by Committee:A committee of models trained on different hypothesis on the base L is defined as . Then, a vote is carried out and the sample that generates the most disagreement is selected and added [20]. There are different ways to measure the level of disagreement and make the final vote. The two most used are the vote entropy, described in [21], and the Kullback–Leibler (KL) divergence in [22].
- Expected model change:For a given model and a given sample, the impact of the sample if added to the training database, L, is estimated through a gradient calculation. The sample that induces the biggest change is here the most relevant and is added to the training set [23,24]:where is the gradient of the objective function, l, respectively, to the parameters, , applied to the tuple .
- Variance reduction:The most informative sample that will be added to the training set is the one minimizing the output variance (i.e., minimizing the generalization error) [25]:where is the estimated mean output variance across the input distribution after the model has been re-trained on the query, x, and its corresponding label.
2.2. s-PGD Equations
2.3. Fisher Matrix
2.4. Computation of a New Information Criterion
| Algorithm 1 Active Learning: Matrix criterion |
|
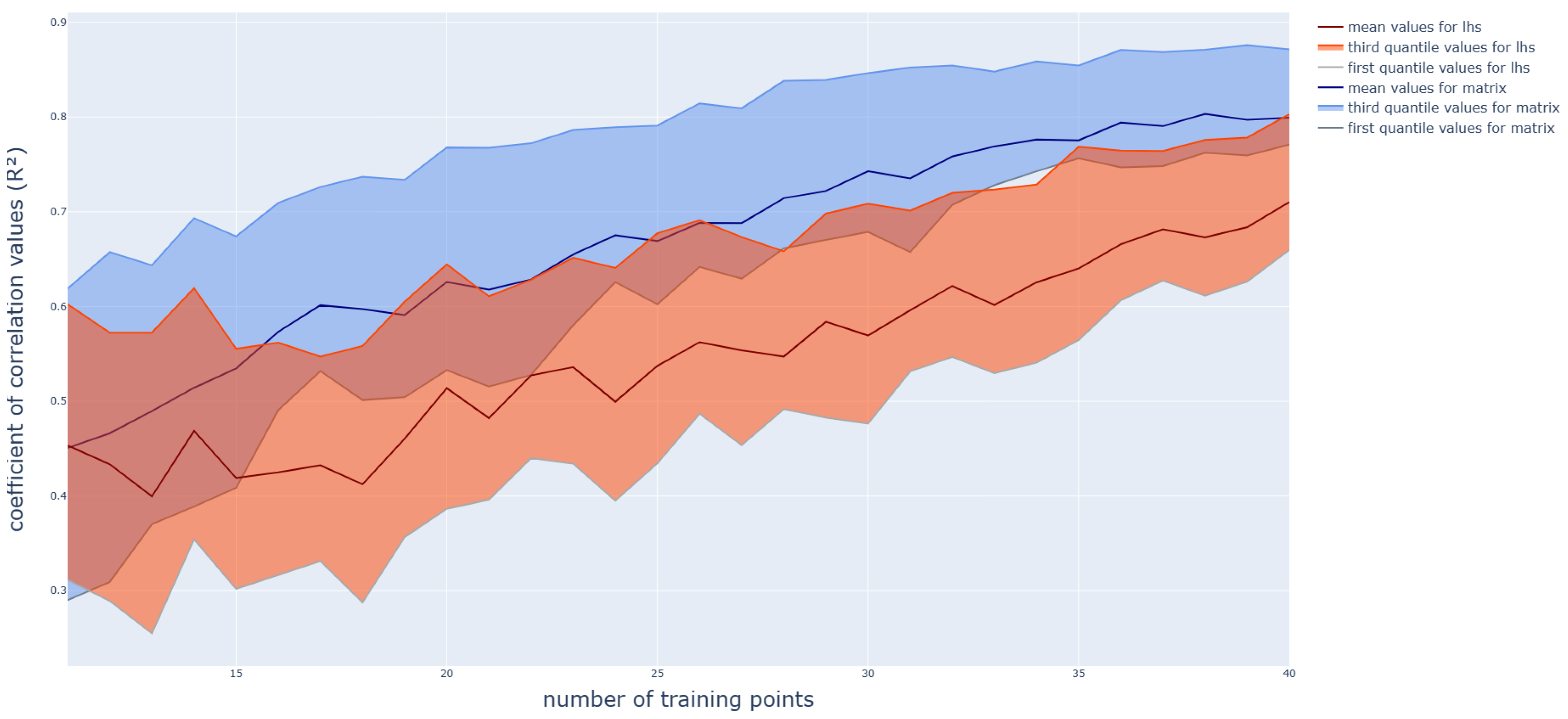
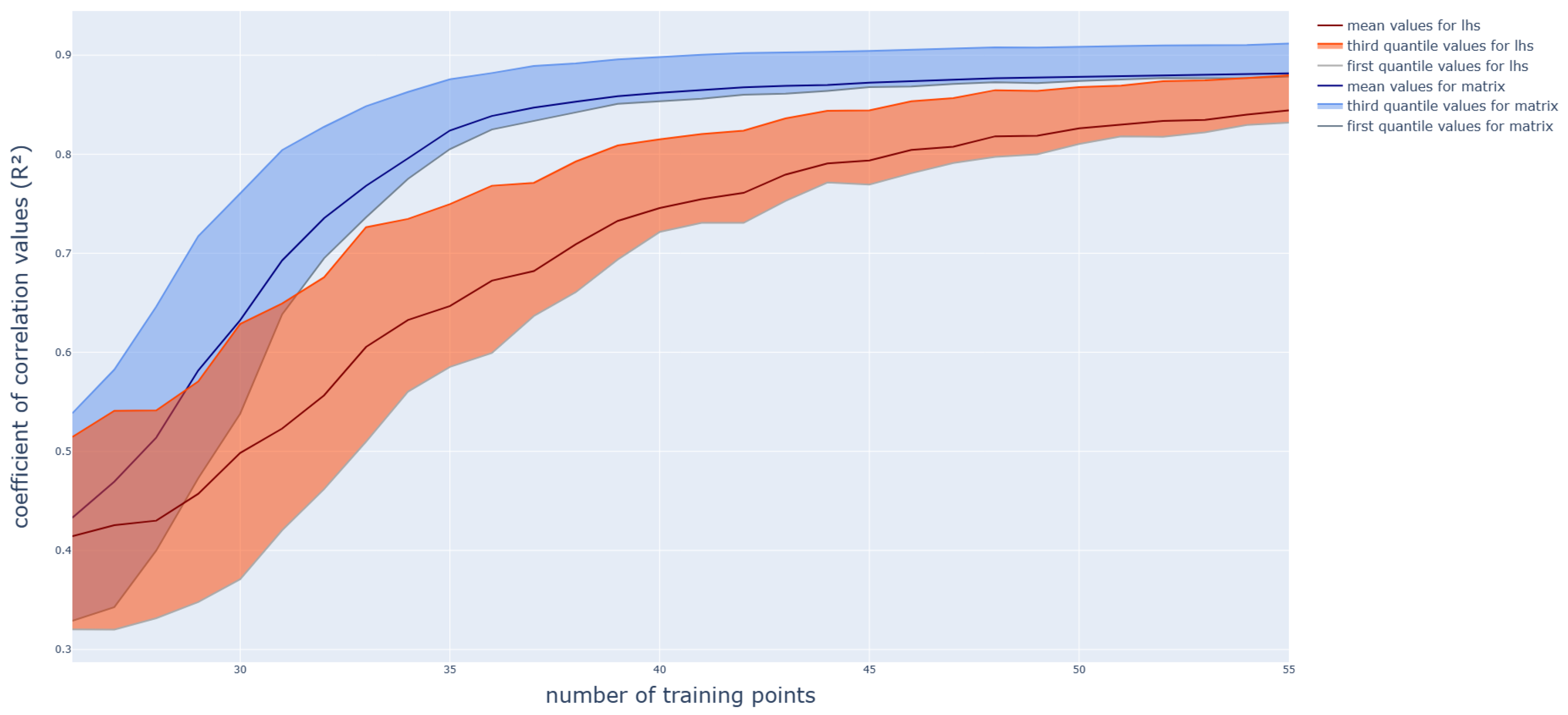
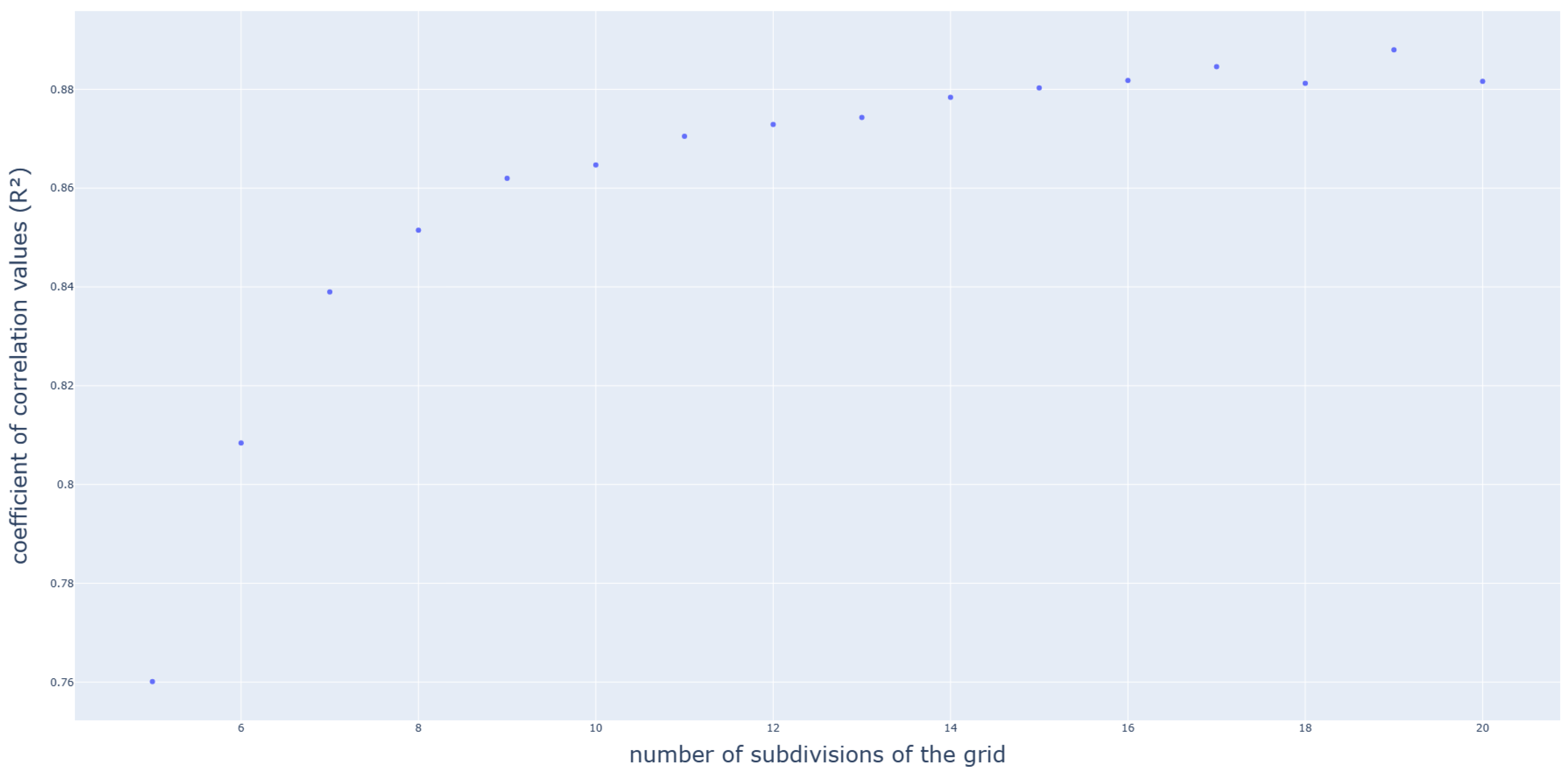
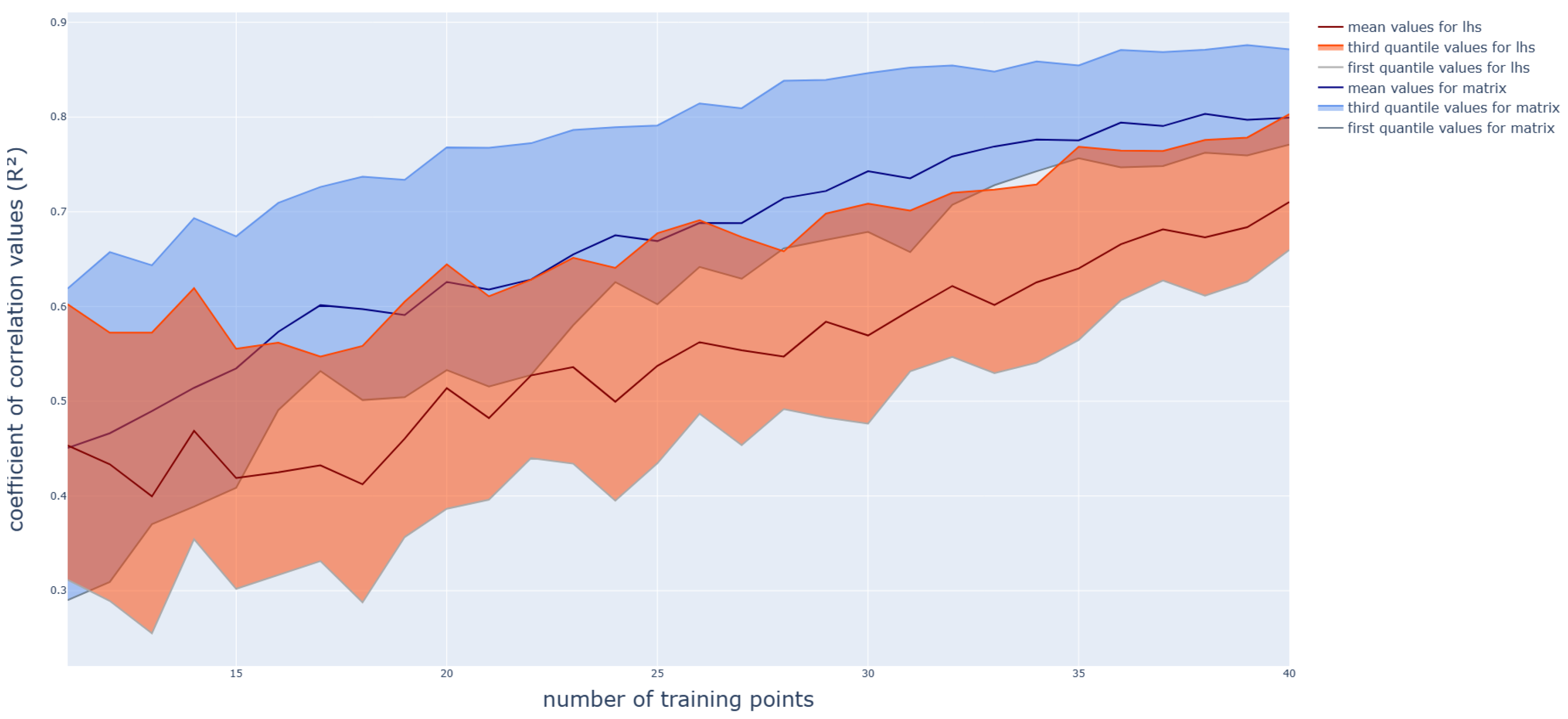
3. Tests and Results
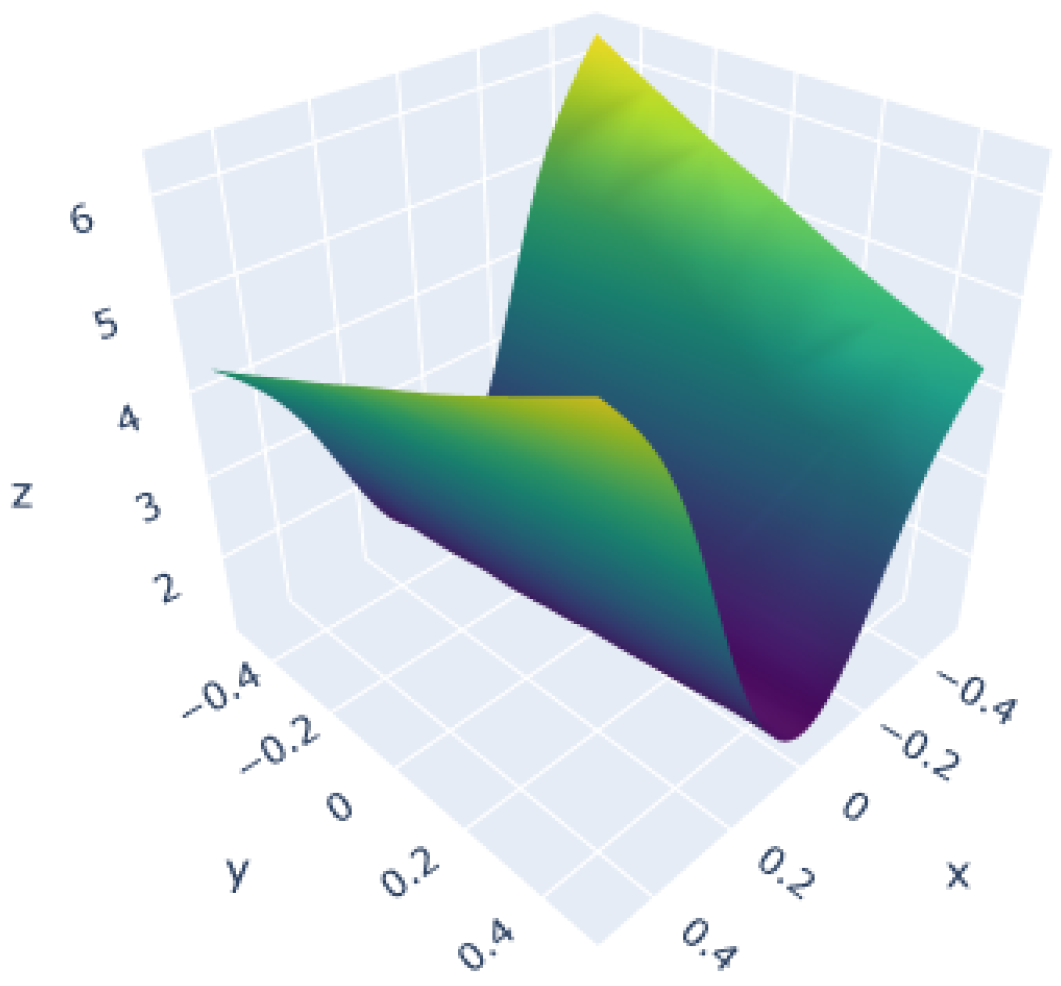
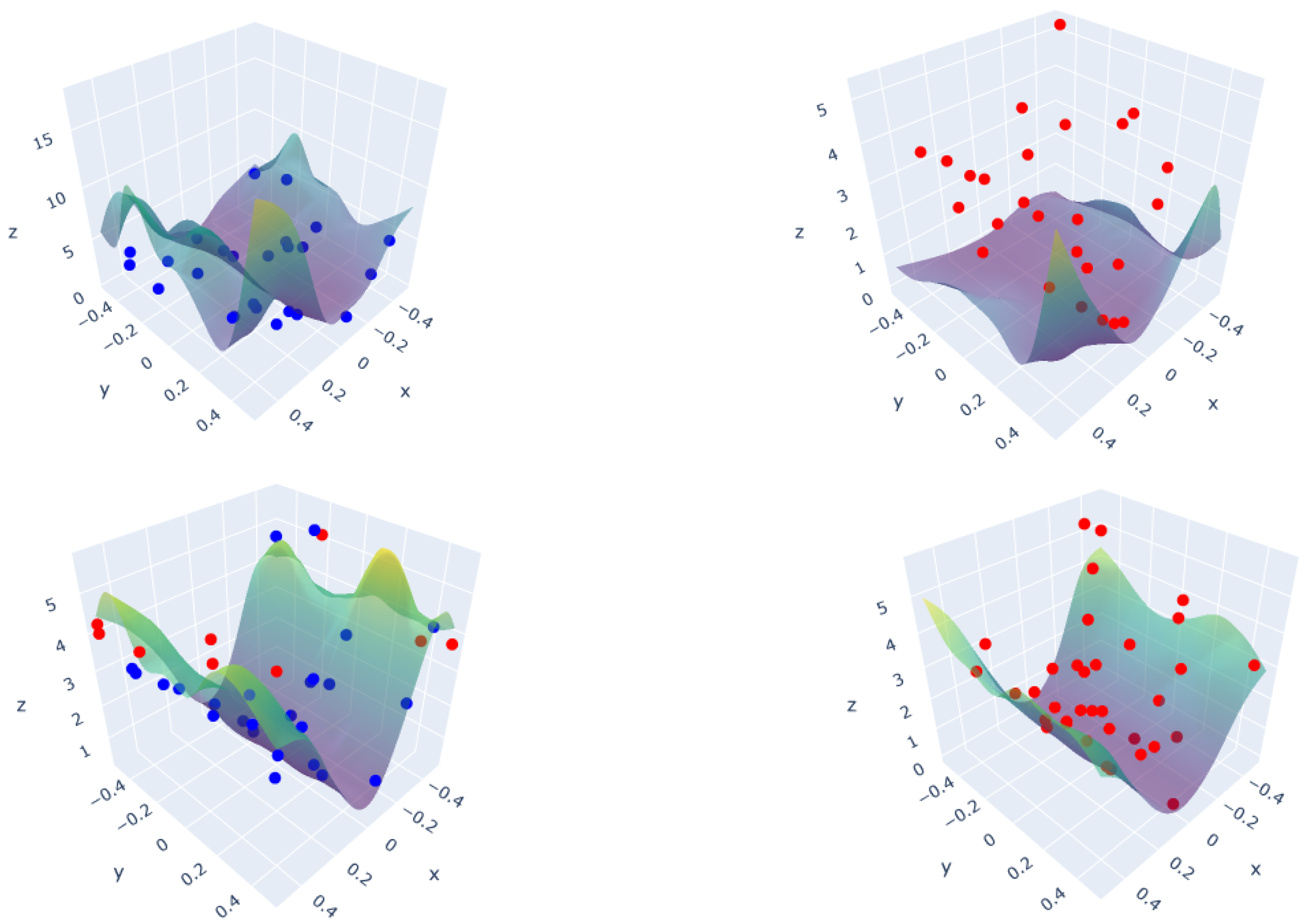
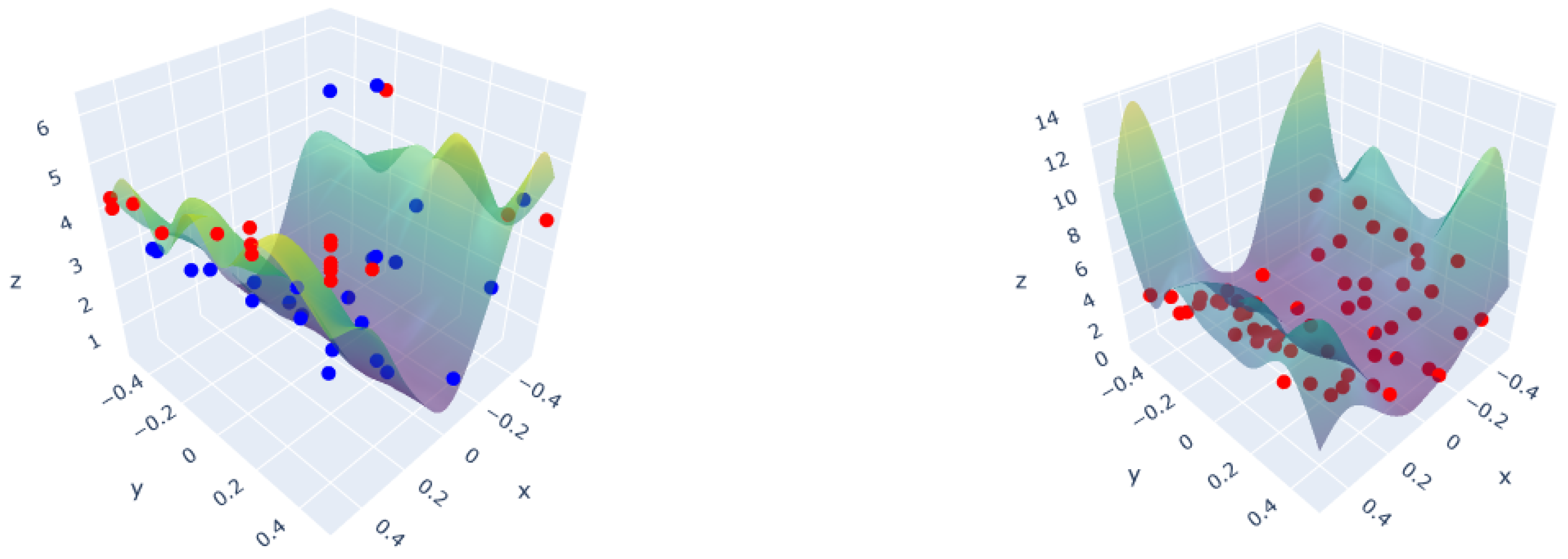
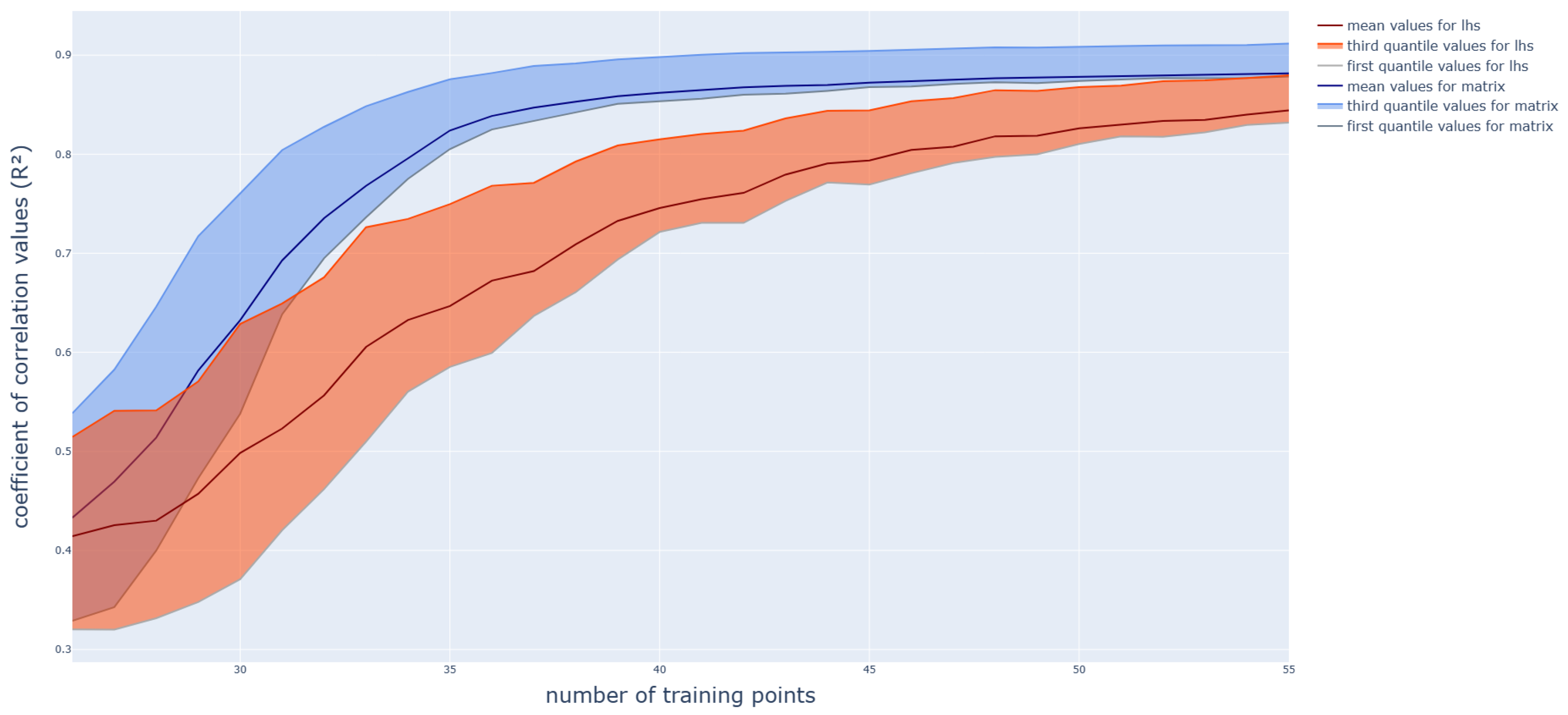
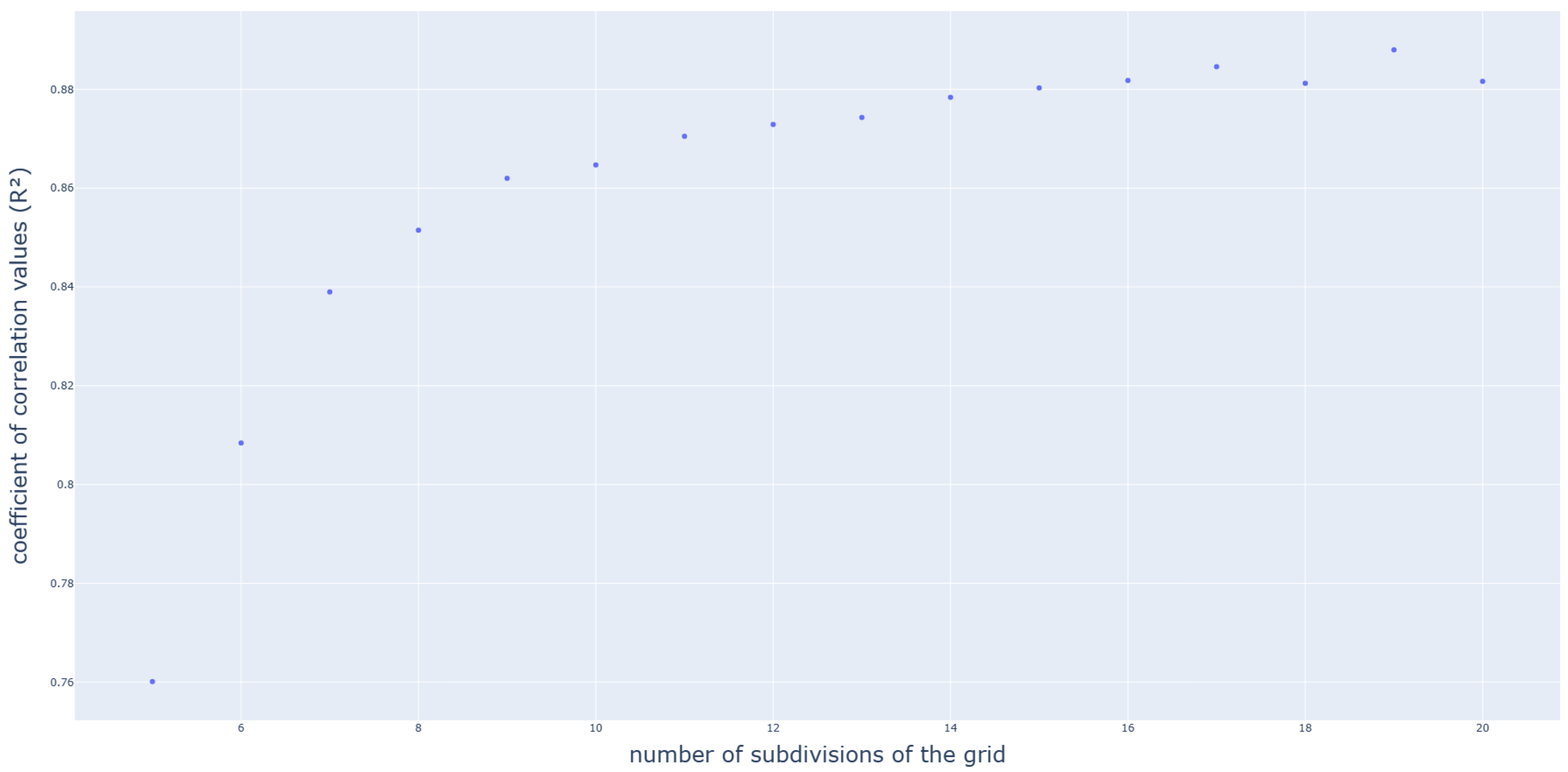
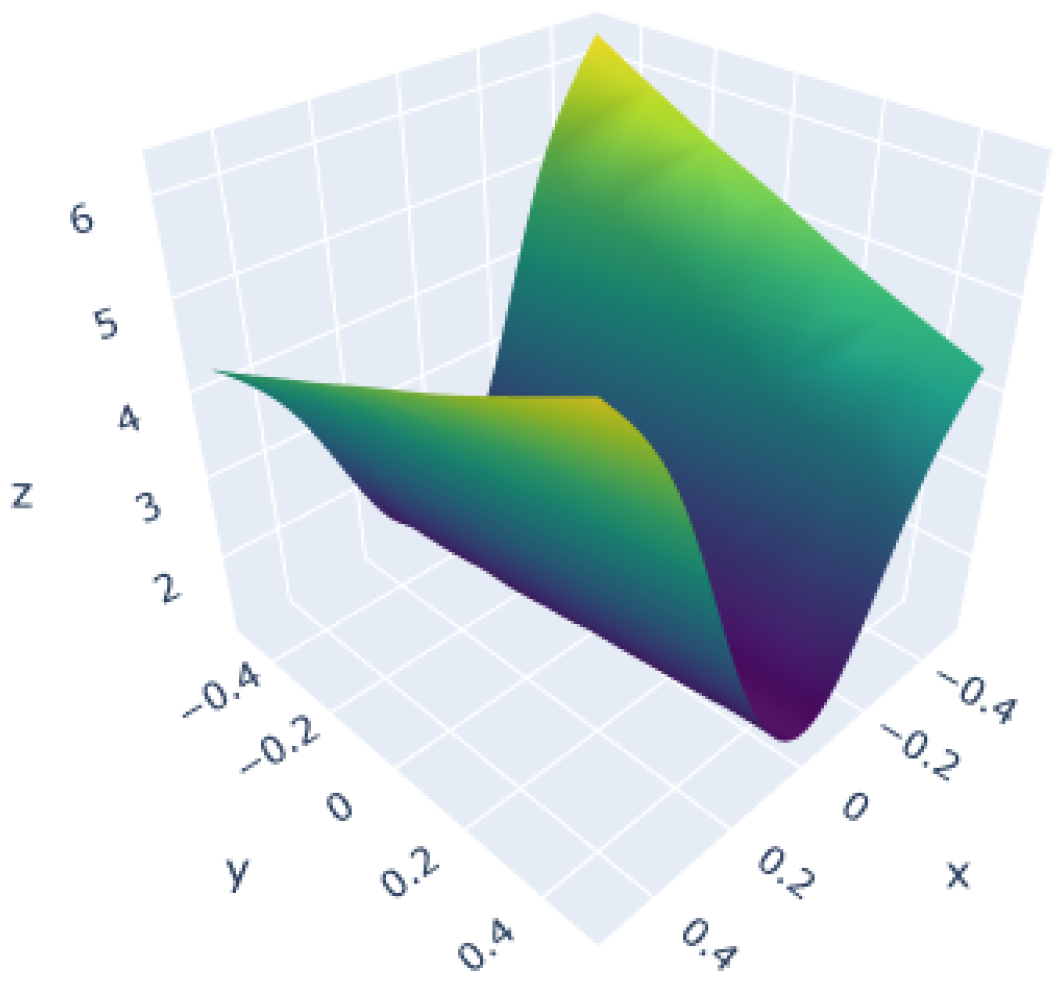
3.1. Polynomial Function
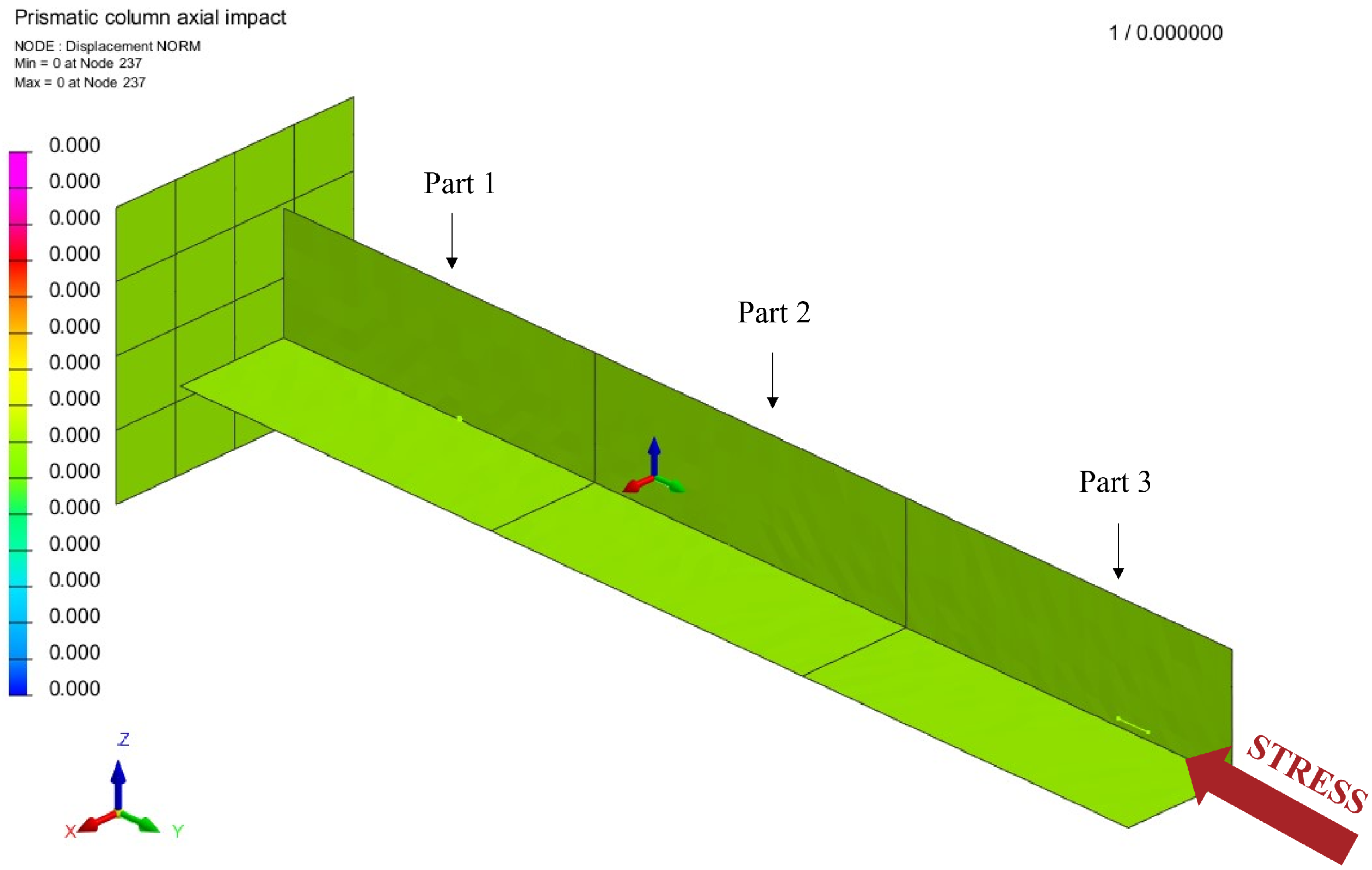
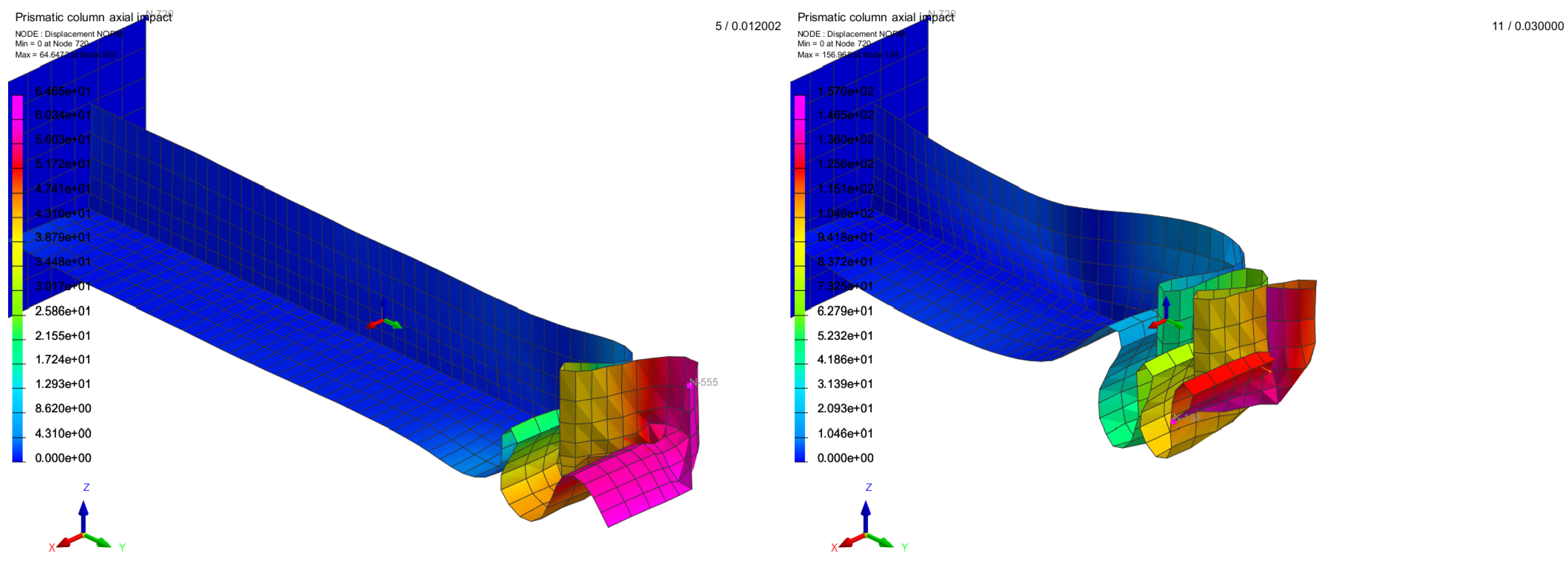
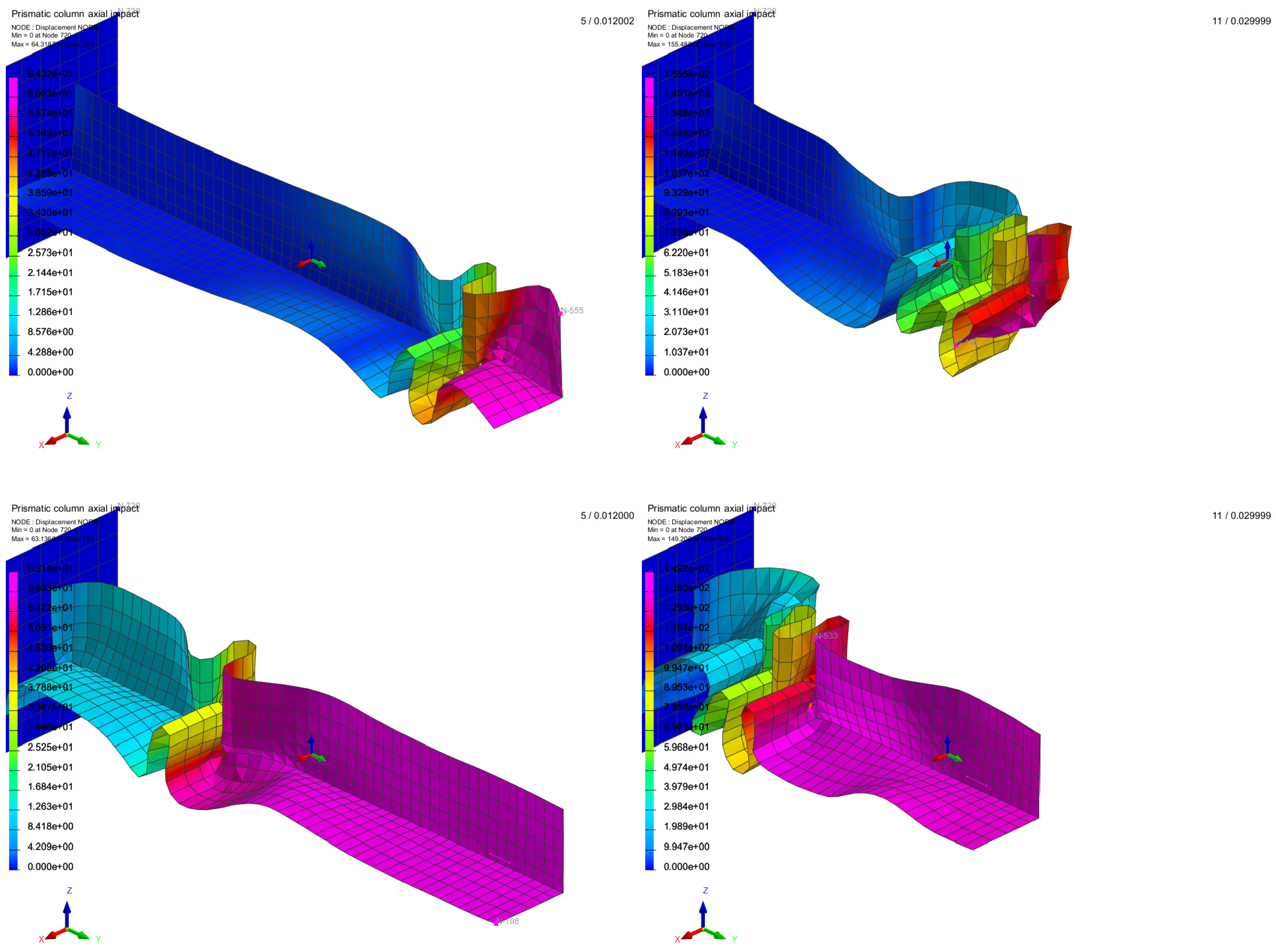
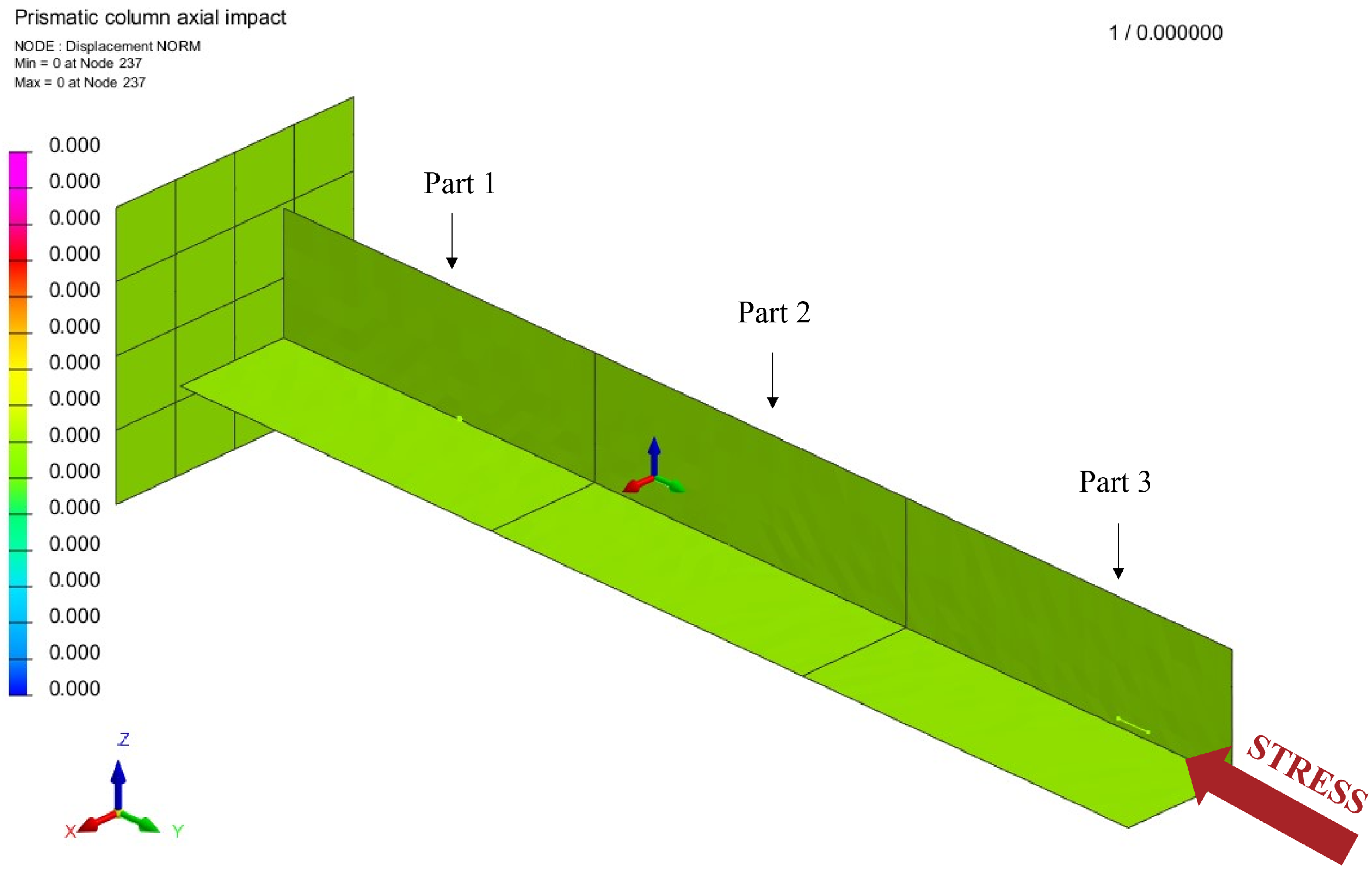
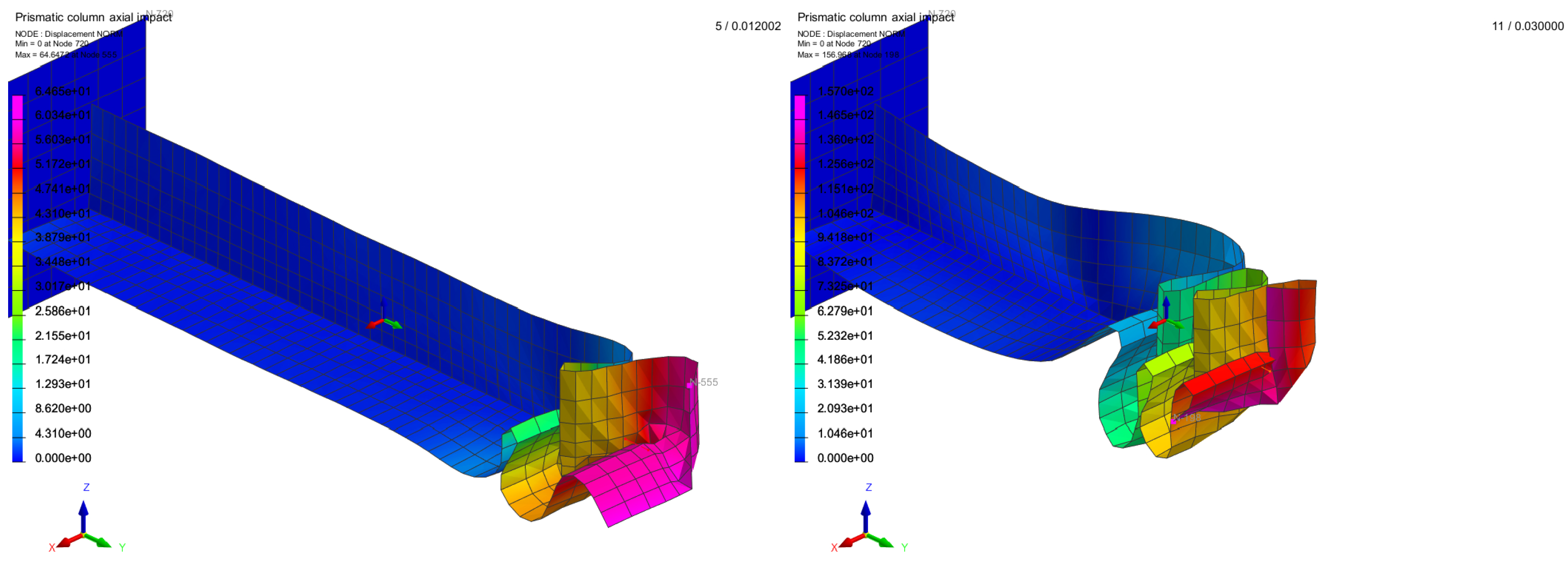
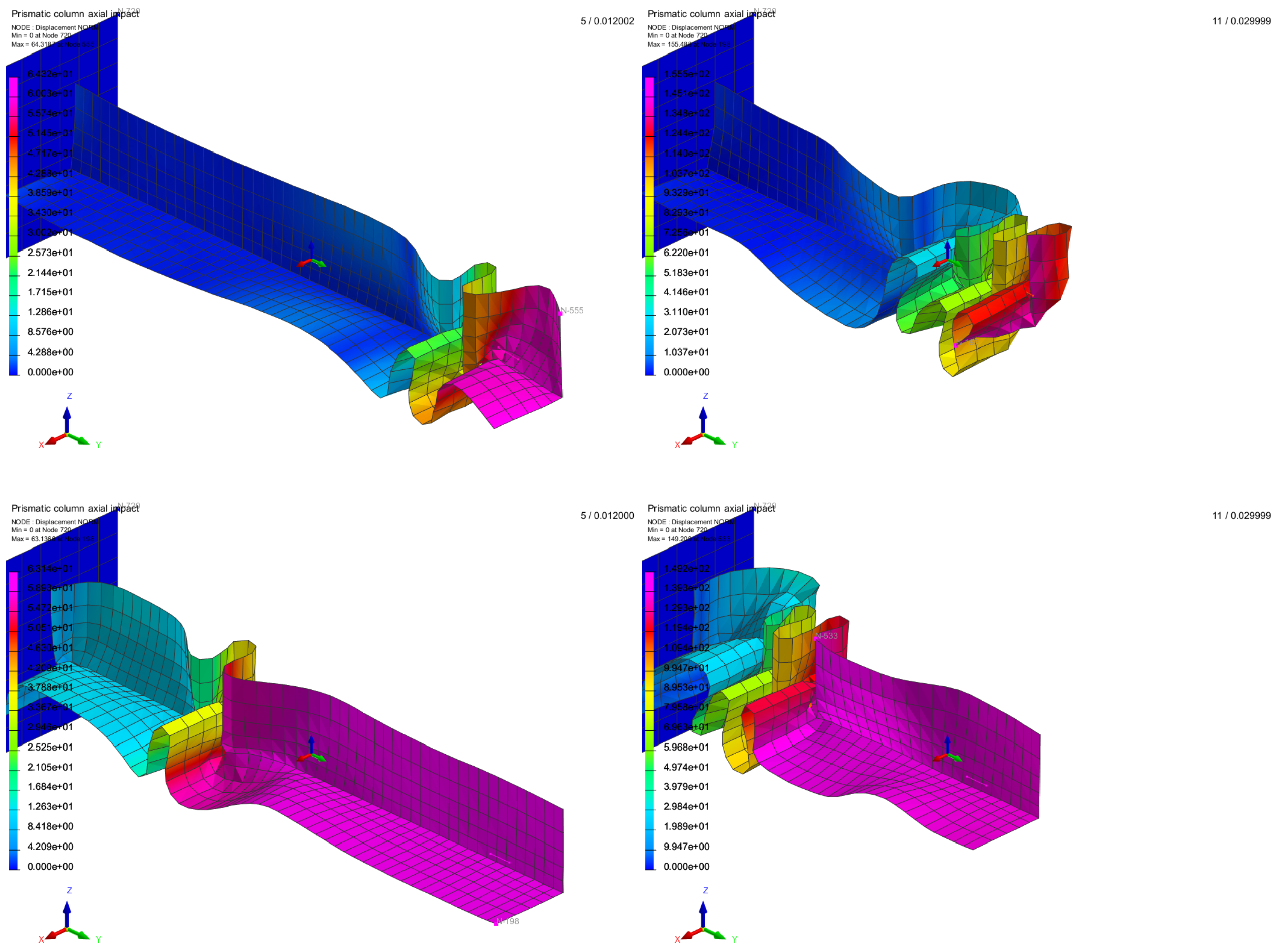
3.2. Application on a Box-Beam Crash Absorber
4. Conclusions and Future Works
- First, the samples in this study, are added one by one, but it could be interesting to add them by group. Indeed, it seems that the algorithm needs to select some points in the same area to estimate it before moving to others. This behavior can be explained by the fact that the information criterion used aims to minimize the global output variance. Adding points by group could be an interesting way to solve this issue. In further studies, studying how many points to add would be relevant. Moreover, when the real output value (given by the “oracle”) comes from experiments, it is more pertinent to add more than one point simultaneously to have better organization.
- Another point that could be optimized is the search for the criterion optimum value. As for now, a simple search along a refined grid is used. Using an optimized method to find the optimum (such as a gradient descent for example) or using another model for the criterion could be an option. This is also interesting for the purpose of reducing the computational cost of the algorithm. Indeed, finding the optimal value without generating a huge grid would be a good improvement and should be optimized.
- In terms of practical use, developing an algorithm to determine and maybe adapt the s-PGD parameter (number of modes, function degrees) during the whole active learning process would also improve the speed of convergence.
- Finally, the mix of the criterion with a more specific cost function is also considered to improve the results, as was studied in the preliminary step of the method development.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Matrix Method Criterion Detailed Definition
References
- Mitchell, T. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Laughlin, R.B.; Pines, D. The theory of everything. Proc. Natl. Acad. Sci. USA 2000, 97, 28–31. [Google Scholar] [CrossRef] [PubMed]
- Goupy, J.; Creighton, L. Introduction to Design of Experiments; Dunod/L’Usine nouvelle: Paris, France, 2006. [Google Scholar]
- Settles, B. Active Learning Literature Survey; Computer Sciences Technical Report; University of Wisconsin-Madison: Madison, WI, USA, 2009. [Google Scholar]
- Frieden, B.R.; Gatenby, A.R. Principle of maximum Fisher information from Hardy’s axioms applied to statistical systems. Comput. Sci. Tech. Rep. E 2013, 88, 042144. [Google Scholar] [CrossRef]
- Ibáñez, R.; Abisset-Chavanne, E. A Multidimensional Data-Driven Sparse Identification Technique: The Sparse Proper Generalized Decomposition; Hindawi: London, UK, 2018. [Google Scholar]
- Fisher, R. The Arrangement of Field Experiments. J. Minist. Agric. Great Br. 1926, 33, 503–515. [Google Scholar]
- Box, G.E.; Hunter, W.G.H. Statistics for Experimenters: Design, Innovation, and Discovery; Wiley: Hoboken, NJ, USA, 2005. [Google Scholar]
- Plackett, R.L.; Burman, J.P. The Design of Optimum Multifactorial Experiments. Biometrika 1946, 33, 305–325. [Google Scholar] [CrossRef]
- McKay, M.D.; Beckman, R.J.; Conover, W.J. A Comparison of Three Methods for Selecting Values of Input Variables in the Analysis of Output from a Computer Code. Technometrics Am. Stat. Assoc. 1979, 42, 55–61. [Google Scholar]
- Nguyen, N.K. A new class of orthogonal Latin hypercubes. In Statistics and Applications, Volume 6, Nos.1 & 2, (New Series); Society of Statistics, Computer and Applications: New Delhi, India, 2008; pp. 119–123. [Google Scholar]
- Angluin, D. Queries Concept Learning. Mach.-Mediat. Learn. 1988, 2, 319–342. [Google Scholar] [CrossRef]
- Angluin, D. Queries Revisited; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Cohn, Z.G.D.; Jordan, M. Active learning with statistical models. J. Artif. Intell. Res. 1996, 4, 129–145. [Google Scholar] [CrossRef]
- Atlas, L.; Cohn, D.; Ladner, R.; El-Sharkawi, M.A.; Marks, R.J. Training connection networks with queries and selective sampling. In Advances in Neural Information Processing Systems 2; Morgan Kaufmann Publishers, Inc.: San Francisco, CA, USA, 1990; pp. 566–573. [Google Scholar]
- Lewis, D.; Gale, W. A sequential algorithm for training text classifiers. In Proceedings of the ACM SIGIR Conference on Research and Development Information Retrieval, Dublin, Ireland, 3–6 July 1994. [Google Scholar]
- Lewis, D.; Catlett, J. Heterogeneous uncertainty sampling for supervised learning. In Proceedings of the International Conference on Machine Learning (ICML), New Brunswick, NJ, USA, 10–13 July 1994. [Google Scholar]
- Scheffer, T.; Decomain, C.; Wrobel, S. Active hidden Markov models for information extraction. In Proceedings of the International Conference on Advancesin Intelligent Data Analysis (CAIDA), Cascais, Portugal, 13–15 September 2001. [Google Scholar]
- Shannon, C. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Seung, H.S.M.O.; Sompolinsky, H. Query by committee. In Proceedings of the ACM Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992. [Google Scholar]
- Dagan, I.; Engelson, S. Committee-based sampling for training probabilistic classifiers. In Proceedings of the International Conference on Machine Learning (ICML), Tahoe City, CA, USA, 9–12 July 1995. [Google Scholar]
- McCallum, A.; Nigam, K. Employing EM in pool-based active learning for text classification. In Proceedings of the International Conference on Machine Learning (ICML), Madison, WI, USA, 24–27 July 1998. [Google Scholar]
- Seung, H.S.M.O.; Sompolins, H. Multiple-instance active learning. Adv. Neural Inf. Process. Syst. 20 (Nips) 2007, 1289–1296. [Google Scholar]
- Settles, B.; Craven, M.; Friedland, L. Active learning with real annotation costs. In Proceedings of the NIPS Workshop on Cost-Sensitive Learning, Whistler, BC, Canada, 12 December 2008. [Google Scholar]
- MacKay, D. Information-based objective functions for active data selection. Neural Comput. 1992, 4, 590–604. [Google Scholar] [CrossRef]
- Gal, Y.; Riashat Islam, Z.G. Deep Bayesian Active Learning with Image Data. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Qu, T.; Guan, S.; Feng, Y.T.; Ma, G.; Zhou, W.; Zhao, J. Deep active learning for constitutive modelling of granular materials: From representative volume elements to implicit finite element modelling. Int. J. Plast. 2023, 164, 103576. [Google Scholar] [CrossRef]
- Deng, W.; Liu, Q.; Zhao, F.; Pham, D.T.; Hu, J.; Wang, Y.; Zhou, Z. Learning by doing: A dual-loop implementation architecture of deep active learning and human-machine collaboration for smart robot vision. Robot. Comuted Integr. Manuf. 2024, 86, 102673. [Google Scholar] [CrossRef]
- Martins, V.E.; Cano, A.; Junior, S.B. Meta-learning for dynamic tuning of active learning on stream classification. Pattern Recognit. 2023, 138, 109359. [Google Scholar] [CrossRef]
- Ren, M.; Triantafillou, E.; Ravi, S.; Snell, J.; Swersky, K.; Tenenbaum, J.B.; Larochelle, H.; Zemel, R.S. Meta-Learning for Semi-Supervised Few-Shot Classification. Conference paper at ICLR arXiv 2018, arXiv:1803.00676. [Google Scholar]
- Sousa, A.F.; Prudêncio, R.B.; Ludermir, T.B.; Soares, C. Active learning and data manipulation techniques for generating training examples in meta-learning. Neurocomputing 2016, 194, 45–55. [Google Scholar] [CrossRef]
- Wu, X.; Xiao, L.; Sun, Y.; Zhang, J.; Ma, T.; He, L. A survey of human-in-the-loop for machine learning. Future Gener. Comput. Syst. 2022, 135, 364–381. [Google Scholar] [CrossRef]
- Atkinson, A.; Donev, A.; Tobias, R. Optimum experimental designsock. In SAS; OUP: Oxford, UK, 2007; Volume 34. [Google Scholar]
- Mitchell, T.J. An algorithm for the construction of “D-optimal” experimental designs. Technometrics 2000, 42, 48–54. [Google Scholar]
- Wilmut, M.; Zhou, J. D-optimal minimax design criterion for two-level fractional factorial designs. J. Stat. Plan. Inference 2011, 141, 576–587. [Google Scholar] [CrossRef]
- Zhang, Q.Z.; Dai, H.S.; Liu, M.Q.; Wang, Y. A method for augmenting supersaturated designs. J. Stat. Plan. Inference 2019, 199, 207–218. [Google Scholar] [CrossRef]
- Lu, L.; Anderson-Cook, C.M. Input-response space-filling designs. Qual. Reliab. Eng. Int. 2021, 37, 3529–3551. [Google Scholar] [CrossRef]
- Chinesta, F.; Huerta, A.; Rozza, G.; Willcox, K. Encyclopedia of Computational Mechanics; Volume Model Order Reduction; John Wiley and Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Sancarlos, A.; Victor Champaney, J.L.D.; Chinesta, F. PGD-based Advanced Nonlinear Multiparametric Regression for Constructing Metamodels at the scarce data limit. arXiv 2021, arXiv:2103.05358. [Google Scholar]
- Ibanez, R. Advanced Physics-Based and Data-Driven Strategies. Ph.D. Thesis, Universitat Politècnica de Catalunya · Barcelona Tech—UPC, Barcelona, Spain, 2019. [Google Scholar]
- Sancarlos, A.; Cueto, E.; Chinesta, F.; Duval, J.L. A novel sparse reduced order formulation for modeling electromagnetic forces in electric motors. SN Appl. Sci. 2021, 3, 355. [Google Scholar] [CrossRef]
- Sancarlos, A.; Cameron, M.; Abel, A.; Cueto, E.; Duval, J.-L.; Chinesta, F. From ROM of electrochemistry to ai-based battery digital and hybrid twin. Arch. Comput. Methods Eng. 2020, 28, 979–1015. [Google Scholar] [CrossRef]
- Argerich, C. Study and Development of New Acoustic Technologies for Nacelle Products. Ph.D. Thesis, Universitat Politecnica de Catalunya, Barcelona, Spain, 2020. [Google Scholar]
- RA, F. On the mathematical foundations of theoretical statistics. A Contain. Pap. Math. Phys. Character 1922, 222, 309–368. [Google Scholar]
- Kiefer, J.; Wolfowitz, J. The equivalence of two extremum problems. Can. J. Math. 1960, 12, 363–366. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guilhaumon, C.; Hascoët, N.; Chinesta, F.; Lavarde, M.; Daim, F. Data Augmentation for Regression Machine Learning Problems in High Dimensions. Computation 2024, 12, 24. https://doi.org/10.3390/computation12020024
Guilhaumon C, Hascoët N, Chinesta F, Lavarde M, Daim F. Data Augmentation for Regression Machine Learning Problems in High Dimensions. Computation. 2024; 12(2):24. https://doi.org/10.3390/computation12020024
Chicago/Turabian StyleGuilhaumon, Clara, Nicolas Hascoët, Francisco Chinesta, Marc Lavarde, and Fatima Daim. 2024. "Data Augmentation for Regression Machine Learning Problems in High Dimensions" Computation 12, no. 2: 24. https://doi.org/10.3390/computation12020024
APA StyleGuilhaumon, C., Hascoët, N., Chinesta, F., Lavarde, M., & Daim, F. (2024). Data Augmentation for Regression Machine Learning Problems in High Dimensions. Computation, 12(2), 24. https://doi.org/10.3390/computation12020024