
Modeling of Nonlinear Dynamic Processes of Human Movement in Virtual Reality Based on Digital Shadows


Abstract
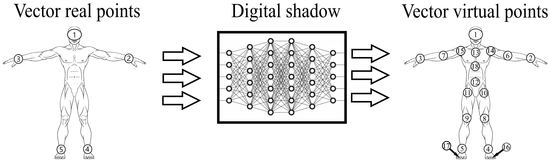
1. Introduction
1.1. Study of the Processes of Human Body Movement and Tracking
1.1.1. Direct Kinematics
1.1.2. Inverse Kinematics
1.1.3. Comparison of Approaches to Human Movements Tracking
- -
- Tracking the trajectories of human movements using a motion capture suit (for example, Perception Neuron—a system based on inertial sensors [10]), which allows for tracking a change in the position of 59 segments of the human body relative to the base (reference) point. The disadvantage of this approach is the lack of information about the absolute person’s position value in a three-dimensional space and the high probability of data distortion when located close to a source of electromagnetic interference;
- -
- High-precision tracking of a person’s key points using trackers and virtual reality controllers with low measurement error in the visibility zone of base stations (up to 9 × 9 m) [11]. In the case of leaving the visibility zone of base stations or their overlapping, signal loss from sensors is possible, which leads to incorrect data; the size and weight of trackers limit the possible number of sensors attached to a person;
- -
- The application of computer vision technologies based on a single camera, stereo cameras, or a system of several synchronized cameras to obtain corrected and more accurate data about a person’s position in a three-dimensional space by recognizing key points of the human body, including fingers and face [12]. When using this technology, there are problems with recognizing key fragments of a person’s silhouette when the object is moving quickly or in low-light conditions.
1.2. Approaches to Solving the Problem of Inverse Kinematics
1.2.1. Digital Model
1.2.2. Digital Twin
1.2.3. Digital Shadow
1.3. Machine Learning Technologies for Solving the Task
1.3.1. Overview of Machine Learning Algorithms
1.3.2. Overview of Metrics for Assessing the Quality of Human Movements Reconstruction
1.4. Aim of This Study
- -
- To simplify the motion capture system, it is necessary to use an approach based on inverse kinematics;
- -
- The development of a mathematical model that fully describes all the patterns of human limb movement is a non-trivial task, as well as the implementation of a digital twin of the body movement process. In conditions when not all points of the body can be tracked or in the absence of a number of key points when using inverse kinematics, this task may be unsolvable due to its high complexity;
- -
- As the main method for solving the problem, the concept of digital shadows is proposed, which is based on the generalization of a large amount of data on various typical scenarios of human movements;
- -
- Machine learning algorithms will be used to approximate the regression dependency between a limited number of KTPs and a fully reconstructed human body model.
2. Materials and Methods
- -
- Collecting data on KTP from one or more sources—motion capture systems (motion capture suits, VR trackers, IMU sensors, computer vision, and so on), as well as from a person’s virtual avatar;
- -
- Formalization of nonlinear dynamic motion processes in the form of a certain model adapted for subsequent software implementation of the digital shadow;
- -
- Optimization of the model to ensure effective operation in conditions of insufficient data on the person’s position;
- -
- Software implementation of a digital shadow, which allows modeling nonlinear dynamic motion processes in virtual reality under conditions of insufficient information, based on machine learning methods.
2.1. Modeling of Nonlinear Dynamic Processes of Human Movement Based on Digital Shadow
- -
- The lengths are the same (when ), then if the condition of the KTP location relative to the VKTP placement scheme is met, all KTPs are used to build a virtual avatar;
- -
- If the number of real KTPs is less than the number of VKTPs (for ), including the situation when part of the KTP is discarded due to incorrect placement, there is a lack of initial data for constructing a virtual avatar, and it is required to implement algorithms for reconstructing the missing VKTPs based on incomplete input data;
- -
- If the number of real KTPs is greater than the number of VKTPs (when ), then the KTPs closest to the VKTPs are used to build a virtual avatar, the rest of the KTPs can be discarded.
- Let there be some motion capture system that does not allow for a complete reconstruction of the person’s digital representation (insufficient number of sensors, interference, poor conditions for body recognition), that is, .
- The selected motion capture system transfers to the virtual environment a certain set of KTP values in the form of an vector.
- Each KTP is assigned the VKTP closest to it in position. Denote a subset of VKTPa as . Then, a relation is formed between two vectors: .
- The machine learning algorithm, , is selected, aimed at solving the regression problem of the following form:
- 5.
- After successful training of the algorithm, , the vector of real KTP is fed to its input, and the reconstruction of the virtual avatar is carried out: .
2.2. Formation of Sets of Key Human Tracking Points
3. Results
3.1. Experiment Scheme
3.2. Description of the Dataset of Human Movements
3.3. Determining the Optimal Layout of Tracking Points
- 3 KTPs: head (1) and left (2) and right (3) hand;
- 5 KTPs: 3 KTPs with the addition of the left (4) and right (5) foot (heel area);
- 7 KTPs: 5 KTPs with the addition of the left (6) and right (7) elbows;
- 9 KTPs: 7 KTPs with the addition of the left (8) and right (9) knee;
- 11 KTPs: 9 KTPs with the addition of the left (10) and right (11) hip joint;
- 13 KTPs: 11 KTPs with the addition of the lower (12) and upper (13) points of the back.
3.4. Description of Used Machine Learning Models
3.5. Analysis of Experimental Data
4. Discussion
- -
- : an option for simplified motion capture systems that do not require foot tracking and precise hand positioning;
- -
- : the optimal solution for most virtual reality systems due to the ability to accurately position all the user’s limbs;
- -
- : a solution for systems that require high accuracy in the positioning of the upper limbs, providing a reconstruction error comparable to more complex models.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Al-Jundi, H.A.; Tanbour, E.Y. A framework for fidelity evaluation of immersive virtual reality systems. Virtual Real. 2022, 26, 1103–1122. [Google Scholar] [CrossRef]
- Obukhov, A.D.; Volkov, A.A.; Vekhteva, N.A.; Teselkin, D.V.; Arkhipov, A.E. Human motion capture algorithm for creating digital shadows of the movement process. J. Phys. Conf. Ser. 2022, 2388, 012033. [Google Scholar] [CrossRef]
- Oudah, M.; Al-Naji, A.; Chahl, J. Hand Gesture Recognition Based on Computer Vision: A Review of Techniques. J. Imaging 2020, 6, 73. [Google Scholar] [CrossRef] [PubMed]
- Nie, J.Z.; Nie, J.W.; Hung, N.T.; Cotton, R.J.; Slutzky, M.W. Portable, open-source solutions for estimating wrist position during reaching in people with stroke. Sci. Rep. 2021, 11, 22491. [Google Scholar] [CrossRef] [PubMed]
- Hindle, B.R.; Keogh, J.W.L.; Lorimer, A.V. Inertial-Based Human Motion Capture: A Technical Summary of Current Processing Methodologies for Spatiotemporal and Kinematic Measures. Appl. Bionics Biomech. 2021, 2021, 6628320. [Google Scholar] [CrossRef]
- Filippeschi, A.; Schmitz, N.; Miezal, M.; Bleser, G.; Ruffaldi, E.; Stricker, D. Survey of Motion Tracking Methods Based on Inertial Sensors: A Focus on Upper Limb Human Motion. Sensors 2017, 17, 1257. [Google Scholar] [CrossRef]
- Gonzalez-Islas, J.-C.; Dominguez-Ramirez, O.-A.; Lopez-Ortega, O.; Peña-Ramirez, J.; Ordaz-Oliver, J.-P.; Marroquin-Gutierrez, F. Crouch Gait Analysis and Visualization Based on Gait Forward and Inverse Kinematics. Appl. Sci. 2022, 12, 10197. [Google Scholar] [CrossRef]
- Parger, M.; Mueller, J.H.; Schmalstieg, D.; Steinberger, M. Human upper-body inverse kinematics for increased embodiment in consumer-grade virtual reality. In Proceedings of the 24th ACM Symposium on Virtual Reality Software and Technology, Tokyo, Japan, 28 November 2018; pp. 1–10. [Google Scholar] [CrossRef]
- Van Emmerik, R.E.; Rosenstein, M.T.; McDermott, W.J.; Hamill, J. A Nonlinear Dynamics Approach to Human Movement. J. Appl. Biomech. 2004, 20, 396–420. [Google Scholar] [CrossRef]
- Wu, Y.; Tao, K.; Chen, Q.; Tian, Y.; Sun, L. A Comprehensive Analysis of the Validity and Reliability of the Perception Neuron Studio for Upper-Body Motion Capture. Sensors 2022, 22, 6954. [Google Scholar] [CrossRef]
- Ikbal, M.S.; Ramadoss, V.; Zoppi, M. Dynamic Pose Tracking Performance Evaluation of HTC Vive Virtual Reality System. IEEE Access 2020, 9, 3798–3815. [Google Scholar] [CrossRef]
- Hellsten, T.; Karlsson, J.; Shamsuzzaman, M.; Pulkkis, G. The Potential of Computer Vision-Based Marker-Less Human Motion Analysis for Rehabilitation. Rehabil. Process Outcome 2021, 10, 11795727211022330. [Google Scholar] [CrossRef]
- Chen, W.; Yu, C.; Tu, C.; Lyu, Z.; Tang, J.; Ou, S.; Fu, Y.; Xue, Z. A Survey on Hand Pose Estimation with Wearable Sensors and Computer-Vision-Based Methods. Sensors 2020, 20, 1074. [Google Scholar] [CrossRef]
- Degen, R.; Tauber, A.; Nüßgen, A.; Irmer, M.; Klein, F.; Schyr, C.; Leijon, M.; Ruschitzka, M. Methodical Approach to Integrate Human Movement Diversity in Real-Time into a Virtual Test Field for Highly Automated Vehicle Systems. J. Transp. Technol. 2022, 12, 296–309. [Google Scholar] [CrossRef]
- Caserman, P.; Garcia-Agundez, A.; Konrad, R.; Göbel, S.; Steinmetz, R. Real-time body tracking in virtual reality using a Vive tracker. Virtual Real. 2019, 23, 155–168. [Google Scholar] [CrossRef]
- Feigl, T.; Gruner, L.; Mutschler, C.; Roth, D. Real-time gait reconstruction for virtual reality using a single sensor. In Proceedings of the 2020 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Recife, Brazil, 9–13 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 84–89. [Google Scholar]
- Liu, H.; Zhang, Z.; Xie, X.; Zhu, Y.; Liu, Y.; Wang, Y.; Zhu, S.-C. High-Fidelity Grasping in Virtual Reality using a Glove-based System. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 5180–5186. [Google Scholar]
- Li, J.; Xu, C.; Chen, Z.; Bian, S.; Yang, L.; Lu, C. HybrIK: A Hybrid Analytical-Neural Inverse Kinematics Solution for 3D Human Pose and Shape Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3383–3393. [Google Scholar]
- Oyama, E.; Agah, A.; MacDorman, K.F.; Maeda, T.; Tachi, S. A modular neural network architecture for inverse kinematics model learning. Neurocomputing 2001, 38, 797–805. [Google Scholar] [CrossRef]
- Bai, Y.; Luo, M.; Pang, F. An Algorithm for Solving Robot Inverse Kinematics Based on FOA Optimized BP Neural Network. Appl. Sci. 2021, 11, 7129. [Google Scholar] [CrossRef]
- Kratzer, P.; Toussaint, M.; Mainprice, J. Prediction of Human Full-Body Movements with Motion Optimization and Recurrent Neural Networks. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1792–1798. [Google Scholar] [CrossRef]
- Bataineh, M.; Marler, T.; Abdel-Malek, K.; Arora, J. Neural network for dynamic human motion prediction. Expert Syst. Appl. 2016, 48, 26–34. [Google Scholar] [CrossRef]
- Cui, Q.; Sun, H.; Li, Y.; Kong, Y. Efficient human motion recovery using bidirectional attention network. Neural Comput. Appl. 2020, 32, 10127–10142. [Google Scholar] [CrossRef]
- Kritzinger, W.; Karner, M.; Traar, G.; Henjes, J.; Sihn, W. Digital Twin in manufacturing: A categorical literature review and classification. IFAC-PapersOnLine 2018, 51, 1016–1022. [Google Scholar] [CrossRef]
- Grieves, M. Origins of the Digital Twin Concept. 2016. Available online: https://www.researchgate.net/publication/307509727 (accessed on 11 April 2023).
- Krüger, J.; Wang, L.; Verl, A.; Bauernhansl, T.; Carpanzano, E.; Makris, S.; Fleischer, J.; Reinhart, G.; Franke, J.; Pellegrinelli, S. Innovative control of assembly systems and lines. CIRP Ann. 2017, 66, 707–730. [Google Scholar] [CrossRef]
- Ribeiro, P.M.S.; Matos, A.C.; Santos, P.H.; Cardoso, J.S. Machine Learning Improvements to Human Motion Tracking with IMUs. Sensors 2020, 20, 6383. [Google Scholar] [CrossRef]
- Stančić, I.; Musić, J.; Grujić, T.; Vasić, M.K.; Bonković, M. Comparison and Evaluation of Machine Learning-Based Classification of Hand Gestures Captured by Inertial Sensors. Computation 2022, 10, 159. [Google Scholar] [CrossRef]
- Yacchirema, D.; de Puga, J.S.; Palau, C.; Esteve, M. Fall detection system for elderly people using IoT and ensemble machine learning algorithm. Pers. Ubiquitous Comput. 2019, 23, 801–817. [Google Scholar] [CrossRef]
- Halilaj, E.; Rajagopal, A.; Fiterau, M.; Hicks, J.L.; Hastie, T.J.; Delp, S.L. Machine learning in human movement biomechanics: Best practices, common pitfalls, and new opportunities. J. Biomech. 2018, 81, 1–11. [Google Scholar] [CrossRef]
- Bartol, K.; Bojanić, D.; Petković, T.; Peharec, S.; Pribanić, T. Linear regression vs. deep learning: A simple yet effective baseline for human body measurement. Sensors 2022, 22, 1885. [Google Scholar] [CrossRef] [PubMed]
- Turgeon, S.; Lanovaz, M.J. Tutorial: Applying Machine Learning in Behavioral Research. Perspect. Behav. Sci. 2020, 43, 697–723. [Google Scholar] [CrossRef]
- Pavllo, D.; Feichtenhofer, C.; Auli, M.; Grangier, D. Modeling Human Motion with Quaternion-Based Neural Networks. Int. J. Comput. Vis. 2020, 128, 855–872. [Google Scholar] [CrossRef]
- Almeida, R.O.; Munis, R.A.; Camargo, D.A.; da Silva, T.; Sasso Júnior, V.A.; Simões, D. Prediction of Road Transport of Wood in Uruguay: Approach with Machine Learning. Forests 2022, 13, 1737. [Google Scholar] [CrossRef]
- Li, B.; Bai, B.; Han, C. Upper body motion recognition based on key frame and random forest regression. Multimedia Tools Appl. 2020, 79, 5197–5212. [Google Scholar] [CrossRef]
- Sipper, M.; Moore, J.H. AddGBoost: A gradient boosting-style algorithm based on strong learners. Mach. Learn. Appl. 2022, 7, 100243. [Google Scholar] [CrossRef]
- Kanko, R.M.; Laende, E.K.; Davis, E.M.; Selbie, W.S.; Deluzio, K.J. Concurrent assessment of gait kinematics using marker-based and markerless motion capture. J. Biomech. 2021, 127, 110665. [Google Scholar] [CrossRef]
- Choo, C.Z.Y.; Chow, J.Y.; Komar, J. Validation of the Perception Neuron system for full-body motion capture. PLoS ONE 2022, 17, e0262730. [Google Scholar] [CrossRef]
- Al-Faris, M.; Chiverton, J.; Ndzi, D.; Ahmed, A.I. A Review on Computer Vision-Based Methods for Human Action Recognition. J. Imaging 2020, 6, 46. [Google Scholar] [CrossRef]
- Zheng, B.; Sun, G.; Meng, Z.; Nan, R. Vegetable Size Measurement Based on Stereo Camera and Keypoints Detection. Sensors 2022, 22, 1617. [Google Scholar] [CrossRef] [PubMed]
- Sers, R.; Forrester, S.; Moss, E.; Ward, S.; Ma, J.; Zecca, M. Validity of the Perception Neuron inertial motion capture system for upper body motion analysis. Meas. J. Int. Meas. Confed. 2020, 149, 107024. [Google Scholar] [CrossRef]
- The Daz-Friendly Bvh Release of Cmu Motion Capture Database. Available online: https://www.sites.google.com/a/cgspeed.com/cgspeed/motion-capture/the-daz-friendly-bvh-release-of-cmus-motion-capture-database (accessed on 22 March 2023).
- Demir, S. Comparison of Normality Tests in Terms of Sample Sizes under Different Skewness and Kurtosis Coefficients. Int. J. Assess. Tools Educ. 2022, 9, 397–409. [Google Scholar] [CrossRef]
- Zeng, Q.; Zheng, G.; Liu, Q. PE-DLS: A novel method for performing real-time full-body motion reconstruction in VR based on Vive trackers. Virtual Real. 2022, 26, 1391–1407. [Google Scholar] [CrossRef]
- Yi, X.; Zhou, Y.; Xu, F. Transpose: Real-time 3D human translation and pose estimation with six inertial sensors. ACM Trans. Graph. 2021, 40, 1–13. [Google Scholar] [CrossRef]
- Obukhov, A.; Volkov, A.A.; Nazarova, A.O. Microservice Architecture of Virtual Training Complexes. Inform. Autom. 2022, 21, 1265–1289. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Number of KTP | Accuracy | Measurement Sample Rate | Tracking Area |
|---|---|---|---|---|
| Motion capture suit | 12 … 32 | ±1 mm | Up to 250 Hz | Radius up to 150 m |
| VR trackers | 1 … 68 | ±0.7 mm | 60 … 120 Hz | From 1.5 × 2 m to 9 × 9 m |
| Computer vision | 17 … 33 | From ±5 mm to ±40 mm | 15 … 120 Hz | Limited by camera field of view |
| Our method | Unlimited | Up to ±10−6 mm (using “float”), up to ±10−13 mm (using “double”) | Up to 600 Hz | Unlimited |
| Points | Mean ± SD | [Min; Max] | ||||
|---|---|---|---|---|---|---|
| # | X | Y | Z | X | Y | Z |
| 1 | 0.01 ± 0.1 | 1.425 ± 0.226 | 0.007 ± 0.089 | [−0.526; 0.544] | [−1.002; 1.622] | [−0.52; 0.724] |
| 2 | −0.004 ± 0.052 | 0.976 ± 0.192 | −0.003 ± 0.049 | [−0.25; 0.248] | [−1.072; 1.26] | [−0.28; 0.497] |
| 3 | 0.002 ± 0.031 | 1.116 ± 0.197 | 0.001 ± 0.028 | [−0.197; 0.274] | [−0.92; 1.28] | [−0.201; 0.594] |
| 4 | 0.005 ± 0.07 | 1.336 ± 0.214 | 0.004 ± 0.062 | [−0.422; 0.443] | [−0.937; 1.516] | [−0.426; 0.677] |
| 5 | 0.012 ± 0.105 | 1.29 ± 0.21 | −0.007 ± 0.102 | [−0.41; 0.436] | [−0.939; 1.471] | [−0.421; 0.566] |
| 6 | 0.02 ± 0.171 | 1.109 ± 0.215 | −0.014 ± 0.173 | [−0.654; 0.63] | [−1.046; 1.64] | [−0.593; 0.624] |
| 7 | 0.028 ± 0.224 | 1.045 ± 0.277 | −0.005 ± 0.222 | [−0.877; 0.827] | [−1.155; 1.858] | [−0.774; 0.806] |
| 8 | −0.003 ± 0.106 | 1.292 ± 0.211 | 0.014 ± 0.107 | [−0.42; 0.415] | [−0.879; 1.476] | [−0.412; 0.751] |
| 9 | −0.01 ± 0.169 | 1.104 ± 0.212 | 0.023 ± 0.173 | [−0.666; 0.645] | [−1.037; 1.65] | [−0.598; 0.774] |
| 10 | 0.001 ± 0.22 | 1.035 ± 0.27 | 0.025 ± 0.216 | [−0.871; 0.84] | [−1.133; 1.864] | [−0.778; 0.944] |
| 11 | −0.003 ± 0.088 | 0.849 ± 0.19 | −0.012 ± 0.086 | [−0.322; 0.343] | [−1.224; 1.31] | [−0.332; 0.394] |
| 12 | 0.006 ± 0.13 | 0.502 ± 0.199 | −0.008 ± 0.13 | [−0.615; 0.605] | [−1.46; 1.616] | [−0.614; 0.607] |
| 13 | 0.001 ± 0.187 | 0.129 ± 0.225 | −0.02 ± 0.186 | [−0.999; 1.017] | [−1.809; 2.032] | [−1.015; 0.98] |
| 14 | 0.014 ± 0.211 | 0.049 ± 0.227 | −0.016 ± 0.211 | [−1.125; 1.154] | [−1.885; 2.177] | [−1.148; 1.057] |
| 15 | −0.012 ± 0.09 | 0.846 ± 0.19 | 0.0 ± 0.086 | [−0.331; 0.331] | [−1.215; 1.31] | [−0.346; 0.513] |
| 16 | −0.009 ± 0.128 | 0.498 ± 0.199 | 0.012 ± 0.126 | [−0.591; 0.605] | [−1.479; 1.624] | [−0.598; 0.789] |
| 17 | −0.022 ± 0.186 | 0.123 ± 0.223 | 0.006 ± 0.179 | [−1.003; 1.001] | [−1.85; 2.046] | [−0.968; 1.013] |
| 18 | −0.011 ± 0.205 | 0.041 ± 0.226 | 0.015 ± 0.2 | [−1.144; 1.048] | [−1.936; 2.156] | [−1.117; 1.122] |
| Q | Used KTPs | Q | Used KTPs | ± SD | |
|---|---|---|---|---|---|
| 1 | 2 | 0.444 ± 0.141 | 2 | 1,15 | 0.431 ± 0.147 |
| 3 | 0.448 ± 0.133 | 1,7 | 0.437 ± 0.143 | ||
| 6 | 0.449 ± 0.130 | 1,3 | 0.438 ± 0.148 | ||
| 7 | 0.452 ± 0.133 | 1,2 | 0.441 ± 0.154 | ||
| 14 | 0.469 ± 0.150 | 1,6 | 0.442 ± 0.141 | ||
| 3 | 1,3,17 | 0.381 ± 0.142 | 4 | 1,2,3,17 | 0.332 ± 0.149 |
| 1,3,5 | 0.388 ± 0.142 | 1,3,16,17 | 0.333 ± 0.119 | ||
| 1,2,17 | 0.389 ± 0.144 | 1,2,16,17 | 0.335 ± 0.125 | ||
| 1,7,17 | 0.389 ± 0.145 | 1,3,6,17 | 0.336 ± 0.146 | ||
| 1,3,9 | 0.393 ± 0.154 | 1,3,5,16 | 0.338 ± 0.122 | ||
| 5 | 1–3,16,17 | 0.248 ± 0.09 | 6 | 1–3,9,16,17 | 0.243 ± 0.109 |
| 1–3,5,16 | 0.254 ± 0.100 | 1–3,8,16,17 | 0.245 ± 0.110 | ||
| 1,3,6,16,17 | 0.256 ± 0.099 | 1–3,5,9,16 | 0.246 ± 0.111 | ||
| 1–3,4,17 | 0.256 ± 0.101 | 1–4,8,17 | 0.248 ± 0.098 | ||
| 1,2,7,16,17 | 0.258 ± 0.099 | 1–3,7,16,17 | 0.249 ± 0.098 | ||
| 7 | 1–4,9,16,17 | 0.241 ± 0.111 | 8 | 1–3,7,9,10,16,17 | 0.233 ± 0.104 |
| 1–3,6,9,16,17 | 0.241 ± 0.109 | 1–4,9,16–18 | 0.236 ± 0.109 | ||
| 1–3,5,9,16,17 | 0.242 ± 0.109 | 1–4,6,9,16,17 | 0.239 ± 0.112 | ||
| 1–5,9,16 | 0.243 ± 0.111 | 1–3,5,6,9,16,17 | 0.240 ± 0.113 | ||
| 1–3,5,8,16,17 | 0.244 ± 0.114 | 1–3,6–8,16,17 | 0.241 ± 0.111 | ||
| 9 | 1–5,7–9,13 | 0.220 ± 0.122 | 10 | 1–3,7–9,11,14,16,17 | 0.195 ± 0.06 |
| 1–4,6,9,16–18 | 0.229 ± 0.114 | 1–8,9,13 | 0.196 ± 0.08 | ||
| 1–4,7,9,16–18 | 0.230 ± 0.120 | 1–3,5,7–9,11,14,16 | 0.197 ± 0.07 | ||
| 1–3,6,7,9,10,16,17 | 0.231 ± 0.108 | 1–4,7–9,11,14,17 | 0.198 ± 0.07 | ||
| 1–4,8,9,13,15,17 | 0.231 ± 0.115 | 1–5,7–9,11,14 | 0.200 ± 0.08 | ||
| 11 | 1–9,13,17 | 0.182 ± 0.06 | 12 | 1–11,18 | 0.163 ± 0.049 |
| 1–9,13,16 | 0.184 ± 0.066 | 1–10,15,18 | 0.169 ± 0.031 | ||
| 1–4,6–9,13,16,17 | 0.191 ± 0.077 | 1–9,11,14,18 | 0.170 ± 0.037 | ||
| 1–3,6–11,16,17 | 0.193 ± 0.085 | 1–9,13,16,17 | 0.179 ± 0.064 | ||
| 1–5,7–9,11,14,18 | 0.193 ± 0.062 | 1–3,5–11,16,18 | 0.180 ± 0.101 | ||
| 13 | 1–11,17,18 | 0.162 ± 0.048 | 14 | 1–11,16–18 | 0.161 ± 0.038 |
| 1–11,16,18 | 0.163 ± 0.049 | 1–11,13,17,18 | 0.165 ± 0.039 | ||
| 1–11,13,18 | 0.166 ± 0.049 | 1–11,13,16,18 | 0.166 ± 0.041 | ||
| 1–9,11,14,17,18 | 0.169 ± 0.036 | 1–9,11,14,16–18 | 0.168 ± 0.026 | ||
| 1–9,11,14,16,18 | 0.169 ± 0.037 | 1–10,15–18 | 0.170 ± 0.025 | ||
| 15 | 1–11,13,16–18 | 0.164 ± 0.048 | 16 | 1–11,13,14,16–18 | 0.176 ± 0.053 |
| 1–9,11,13,14,16–18 | 0.173 ± 0.043 | 1–11,13,15–18 | 0.178 ± 0.053 | ||
| 1–10,13,15,16–18 | 0.174 ± 0.042 | 1–11,13–17 | 0.182 ± 0.011 | ||
| 1–11,14,16–18 | 0.175 ± 0.052 | 1–13,16–18 | 0.184 ± 0.017 | ||
| 1–11,15–18 | 0.176 ± 0.051 | 1–11,14–18 | 0.191 ± 0.012 | ||
| 17 | 1–11,13–18 | 0.192 ± 0.013 | 18 | 1–18 | 1 × 10−5 ± 0.0 |
| 1–9,11–18 | 0.279 ± 0.094 | ||||
| 1–14,16–18 | 0.317 ± 0.021 | ||||
| 1–13,15–18 | 0.317 ± 0.021 | ||||
| 1–7,9–18 | 0.743 ± 0.318 |
| Model | Description |
|---|---|
| LinearRegression (LR) | Ordinary least squares linear regression with default parameters. |
| SGDRegressor (SGDR) | Standard linear model fitted with stochastic gradient descent with loss = “squared_loss” passed to MultiOutputRegressor. |
| Simple neural network (NN (S)) | Multilayer neural network with input of 9–39 neurons, 3 hidden dense layers of 100 neurons with ReLU activation function, 2 dropout layers (20% dropout rate), output—54 neurons. |
| Multiple neural network (NN (M)) | Multilayer neural network with two inputs (9–39 neurons and 54), 3 hidden dense layers of 100 neurons, 2 dropout layers (20% dropout rate), output—54 neurons. |
| KNeighborsRegressor (KNN) | Standard regression based on k-nearest neighbors algorithm = “ball_tree”. |
| DecisionTreeRegressor (DTR) | Standard decision tree regressor with max_depth = 5. |
| RandomForestRegressor (RFR) | Standard random forest with n_estimators = 10, max_depth = 5. |
| AdaBoostRegressor (ADA) | Standard AdaBoost regressor based on DecisionTreeRegressor with n_estimators = 100, max_depth = 10. |
| Q | Method | ± SD | ± SD | ± SD | MSE | T, ms |
|---|---|---|---|---|---|---|
| 3 | LR | 0.153 ± 0.052 | 0.4 ± 0.17 | 2.757 ± 0.945 | 0.014 | <0.001 |
| SGDR | 0.153 ± 0.052 | 0.4 ± 0.169 | 2.756 ± 0.944 | 0.014 | 0.112 | |
| NN (S) | 0.173 ± 0.064 | 0.423 ± 0.198 | 3.114 ± 1.159 | 0.017 | 1.273 | |
| NN (M) | 0.17 ± 0.063 | 0.409 ± 0.19 | 3.051 ± 1.133 | 0.016 | 1.548 | |
| KNR | 0.183 ± 0.071 | 0.437 ± 0.218 | 3.288 ± 1.278 | 0.019 | 1.228 | |
| DTR | 0.221 ± 0.069 | 0.463 ± 0.144 | 3.977 ± 1.244 | 0.022 | 0.001 | |
| RFR | 0.216 ± 0.066 | 0.443 ± 0.139 | 3.894 ± 1.18 | 0.021 | 0.001 | |
| ADA | 0.173 ± 0.048 | 0.451 ± 0.172 | 3.119 ± 0.858 | 0.018 | 0.300 | |
| 5 | LR | 0.102 ± 0.035 | 0.26 ± 0.102 | 1.835 ± 0.638 | 0.007 | <0.001 |
| SGDR | 0.102 ± 0.035 | 0.26 ± 0.1 | 1.841 ± 0.638 | 0.007 | 0.008 | |
| NN (S) | 0.141 ± 0.038 | 0.26 ± 0.073 | 2.544 ± 0.684 | 0.008 | 1.214 | |
| NN (M) | 0.128 ± 0.044 | 0.255 ± 0.066 | 2.311 ± 0.789 | 0.008 | 1.542 | |
| KNR | 0.147 ± 0.052 | 0.282 ± 0.083 | 2.65 ± 0.94 | 0.010 | 12.463 | |
| DTR | 0.243 ± 0.07 | 0.499 ± 0.144 | 4.381 ± 1.253 | 0.027 | <0.001 | |
| RFR | 0.236 ± 0.067 | 0.484 ± 0.141 | 4.252 ± 1.204 | 0.025 | 0.001 | |
| ADA | 0.095± 0.028 | 0.246 ± 0.076 | 1.718 ± 0.509 | 0.006 | 0.316 | |
| 7 | LR | 0.089 ± 0.032 | 0.256 ± 0.101 | 1.6 ± 0.578 | 0.006 | <0.001 |
| SGDR | 0.09 ± 0.032 | 0.255 ± 0.099 | 1.617 ± 0.576 | 0.006 | 0.011 | |
| NN (S) | 0.142 ± 0.041 | 0.257 ± 0.084 | 2.559 ± 0.742 | 0.009 | 1.221 | |
| NN (M) | 0.134 ± 0.046 | 0.258 ± 0.073 | 2.411 ± 0.823 | 0.008 | 1.553 | |
| KNR | 0.145 ± 0.052 | 0.276 ± 0.086 | 2.604 ± 0.94 | 0.009 | 15.877 | |
| DTR | 0.23 ± 0.071 | 0.477 ± 0.145 | 4.141 ± 1.274 | 0.024 | <0.001 | |
| RFR | 0.23 ± 0.071 | 0.477 ± 0.145 | 4.139 ± 1.272 | 0.024 | 0.001 | |
| ADA | 0.08 ± 0.027 | 0.24 ± 0.08 | 1.441 ± 0.479 | 0.005 | 0.335 | |
| 9 | LR | 0.072 ± 0.036 | 0.251 ± 0.127 | 1.297 ± 0.644 | 0.005 | <0.001 |
| SGDR | 0.075 ± 0.036 | 0.247 ± 0.123 | 1.351 ± 0.65 | 0.005 | 0.013 | |
| NN (S) | 0.125 ± 0.034 | 0.232 ± 0.088 | 2.253 ± 0.611 | 0.007 | 1.211 | |
| NN (M) | 0.131 ± 0.039 | 0.234 ± 0.065 | 2.354 ± 0.697 | 0.007 | 1.563 | |
| KNR | 0.139 ± 0.048 | 0.254 ± 0.072 | 2.501 ± 0.87 | 0.009 | 20.011 | |
| DTR | 0.23 ± 0.071 | 0.477 ± 0.145 | 4.141 ± 1.276 | 0.024 | <0.001 | |
| RFR | 0.23 ± 0.071 | 0.477 ± 0.145 | 4.142 ± 1.275 | 0.024 | 0.001 | |
| ADA | 0.058 ± 0.022 | 0.207 ± 0.076 | 1.041 ± 0.39 | 0.003 | 0.353 | |
| 11 | LR | 0.039 ± 0.023 | 0.192 ± 0.073 | 0.708 ± 0.414 | 0.002 | <0.001 |
| SGDR | 0.059 ± 0.034 | 0.195 ± 0.062 | 1.055 ± 0.609 | 0.003 | 0.012 | |
| NN (S) | 0.133 ± 0.036 | 0.242 ± 0.062 | 2.4 ± 0.65 | 0.007 | 1.22 | |
| NN (M) | 0.133 ± 0.043 | 0.252 ± 0.065 | 2.398 ± 0.768 | 0.008 | 1.56 | |
| KNR | 0.138 ± 0.048 | 0.252 ± 0.075 | 2.476 ± 0.856 | 0.008 | 29.341 | |
| DTR | 0.23 ± 0.071 | 0.477 ± 0.145 | 4.141 ± 1.278 | 0.024 | <0.001 | |
| RFR | 0.23 ± 0.071 | 0.477 ± 0.145 | 4.14 ± 1.277 | 0.024 | 0.002 | |
| ADA | 0.034 ± 0.01 | 0.18 ± 0.043 | 0.621 ± 0.185 | 0.001 | 0.427 | |
| 13 | LR | 0.028 ± 0.005 | 0.186 ± 0.018 | 0.507 ± 0.082 | 0.001 | <0.001 |
| SGDR | 0.056 ± 0.032 | 0.148 ± 0.062 | 1.014 ± 0.58 | 0.002 | 0.054 | |
| NN (S) | 0.128 ± 0.037 | 0.239 ± 0.064 | 2.307 ± 0.666 | 0.007 | 1.212 | |
| NN (M) | 0.129 ± 0.043 | 0.229 ± 0.058 | 2.33 ± 0.774 | 0.007 | 1.572 | |
| KNR | 0.137 ± 0.047 | 0.251 ± 0.075 | 2.474 ± 0.846 | 0.008 | 37.614 | |
| DTR | 0.23 ± 0.071 | 0.477 ± 0.145 | 4.141 ± 1.278 | 0.024 | <0.001 | |
| RFR | 0.23 ± 0.071 | 0.477 ± 0.145 | 4.14 ± 1.278 | 0.024 | 0.001 | |
| ADA | 0.03 ± 0.005 | 0.184 ± 0.018 | 0.537 ± 0.09 | 0.001 | 0.418 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Obukhov, A.; Dedov, D.; Volkov, A.; Teselkin, D. Modeling of Nonlinear Dynamic Processes of Human Movement in Virtual Reality Based on Digital Shadows. Computation 2023, 11, 85. https://doi.org/10.3390/computation11050085
Obukhov A, Dedov D, Volkov A, Teselkin D. Modeling of Nonlinear Dynamic Processes of Human Movement in Virtual Reality Based on Digital Shadows. Computation. 2023; 11(5):85. https://doi.org/10.3390/computation11050085
Chicago/Turabian StyleObukhov, Artem, Denis Dedov, Andrey Volkov, and Daniil Teselkin. 2023. "Modeling of Nonlinear Dynamic Processes of Human Movement in Virtual Reality Based on Digital Shadows" Computation 11, no. 5: 85. https://doi.org/10.3390/computation11050085
APA StyleObukhov, A., Dedov, D., Volkov, A., & Teselkin, D. (2023). Modeling of Nonlinear Dynamic Processes of Human Movement in Virtual Reality Based on Digital Shadows. Computation, 11(5), 85. https://doi.org/10.3390/computation11050085