Fault-Tolerant Anomaly Detection Method in Wireless Sensor Networks

Abstract
:1. Introduction
- (i)
- In temporal correlation of sensor network, we propose the PCM and interval methods;
- (ii)
- In spatial correlation we divide the sensor network into fault neighborhood, event and fault mixed neighborhood, event boundary neighborhood, and other regions for anomaly detection, respectively, to achieve fault tolerance.
- (iii)
- We conduct extensive simulations to evaluate the performance of the proposed algorithms. The results demonstrate the effectiveness of the proposed algorithms.
2. Related Work
3. Symbols and Network Model
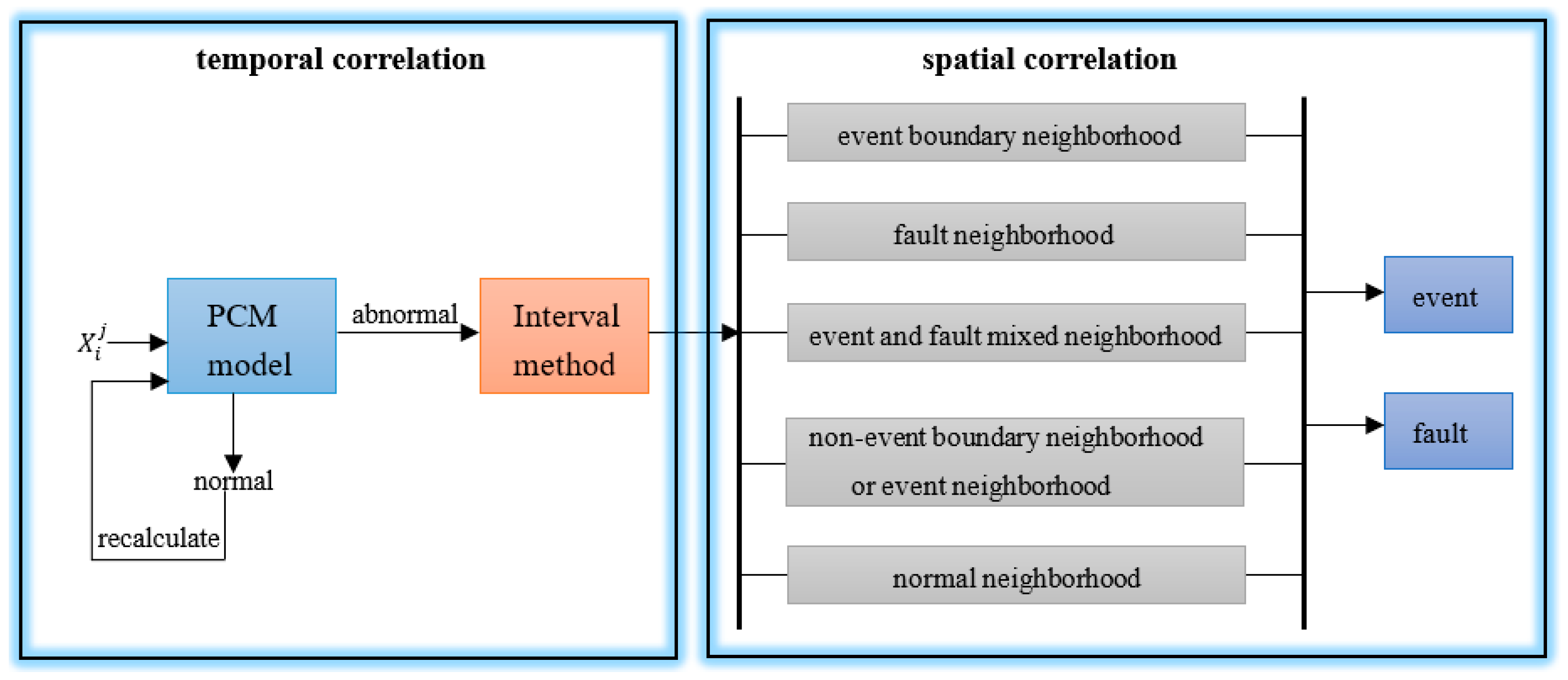
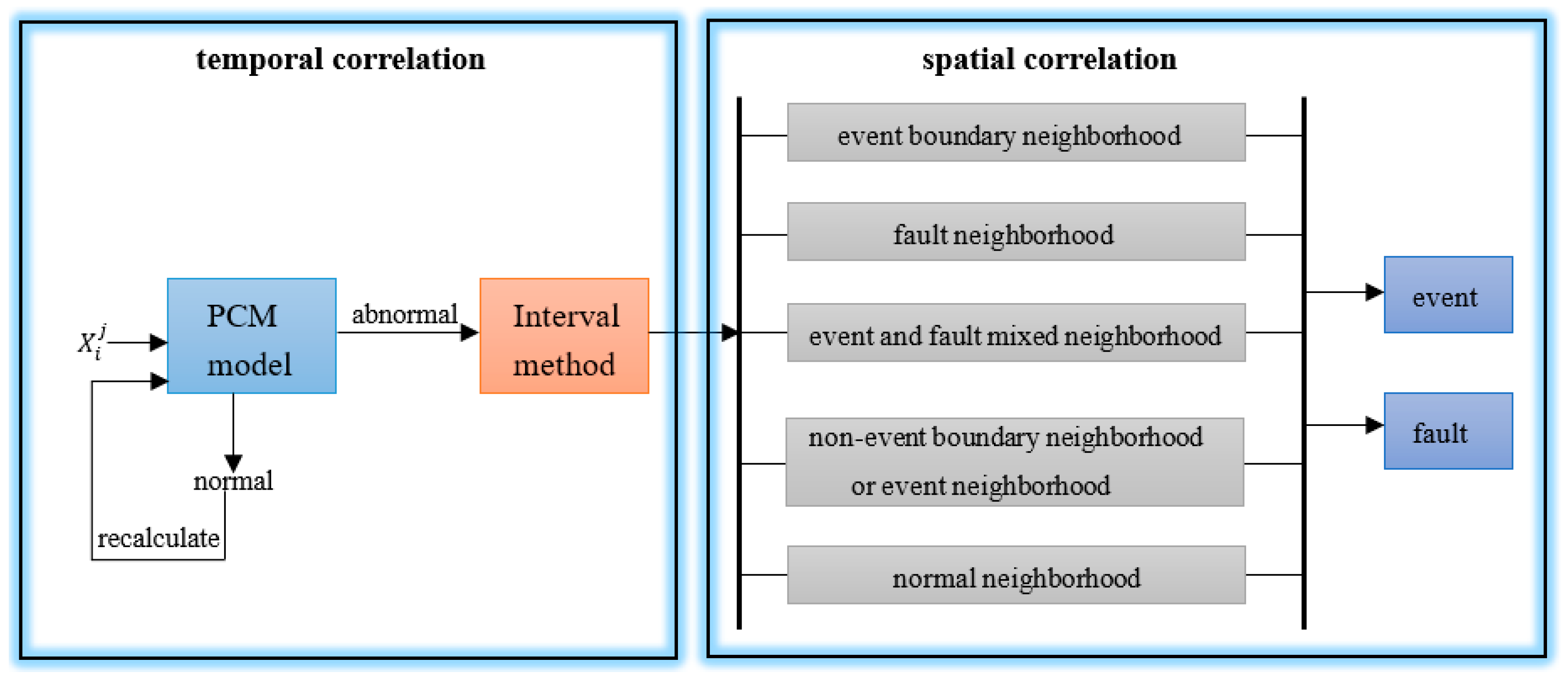
4. Fault Tolerance Detection Method
4.1. Temporal Correlation of Fault Tolerance Anomaly Detection Methods
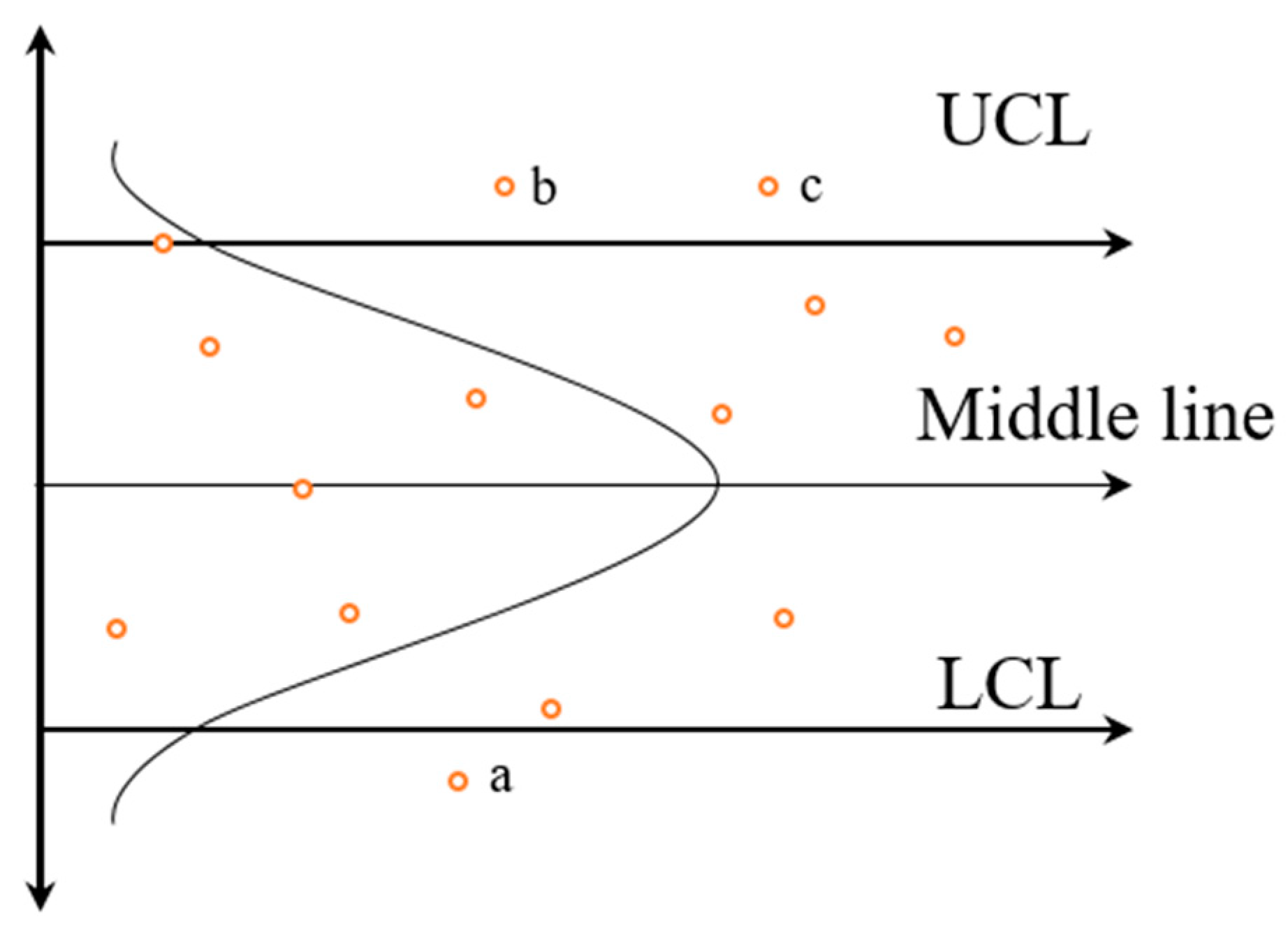
Pauta Criterion Method, PCM, and Interval Method
| Algorithm 1. Temporal correlation. |
| 1://Calculate interval for each sensor node 2: for each do 3: Data sets collected during the T time period 4: Calculate using R 5: end for 6://Detect if a sensor abnormal occurred. 7: if then 8: status = 9: Recalculate 10: else 11: calculate and 12: if then 13: increase 14: end if 15: if then 16: increase 17: end if 18: end if 19: if then 20: status = 21: else 22: status = 23: end if 24: broadcasting status and to all neighbors… |
4.2. Spatial Correlation of Fault Tolerance Anomaly Detection Methods
| Algorithm 2. Spatial correlation. |
| 1: receiving statuses and from neighbors… 2: if status = then 3: continue 4: else 5: if in then 6: final status equal last status 7: end if 8: if in then 9: if status is same most of neighbors then 10: final status is fault 11: else 12: final status is event 13: end if 14: if in then 15: Compare and 16: end if 17: if in or in then 18: if status is same most of neighbors then 19: final status is event 20: else 21: final status is fault 22: end if 23: if in then 24: if status is most same of neighbors then 25: final status is normal 26: else 27: final status is fault 28: end if 29: end if |
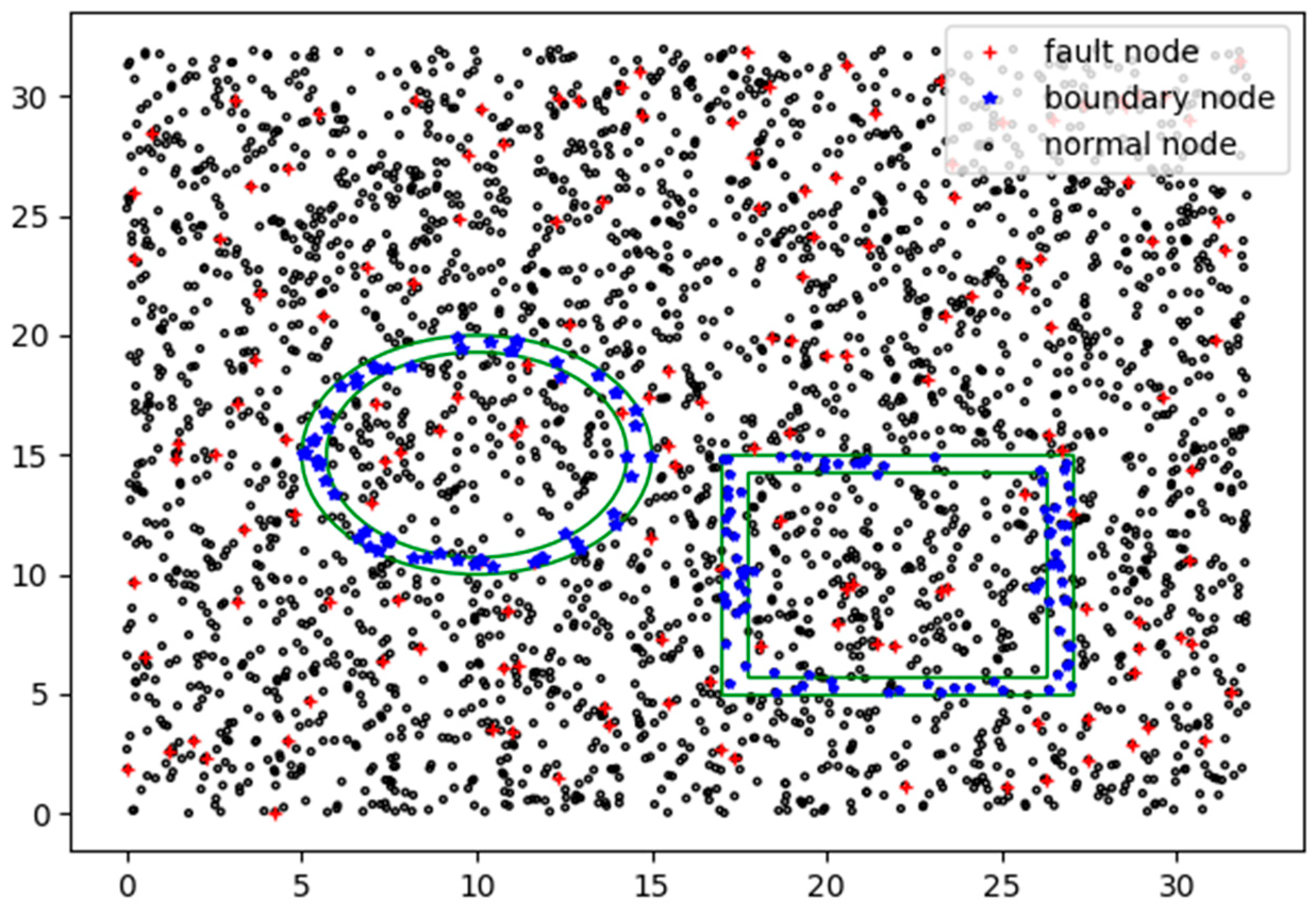
5. Experimental Results and Analysis
5.1. Experimental Design
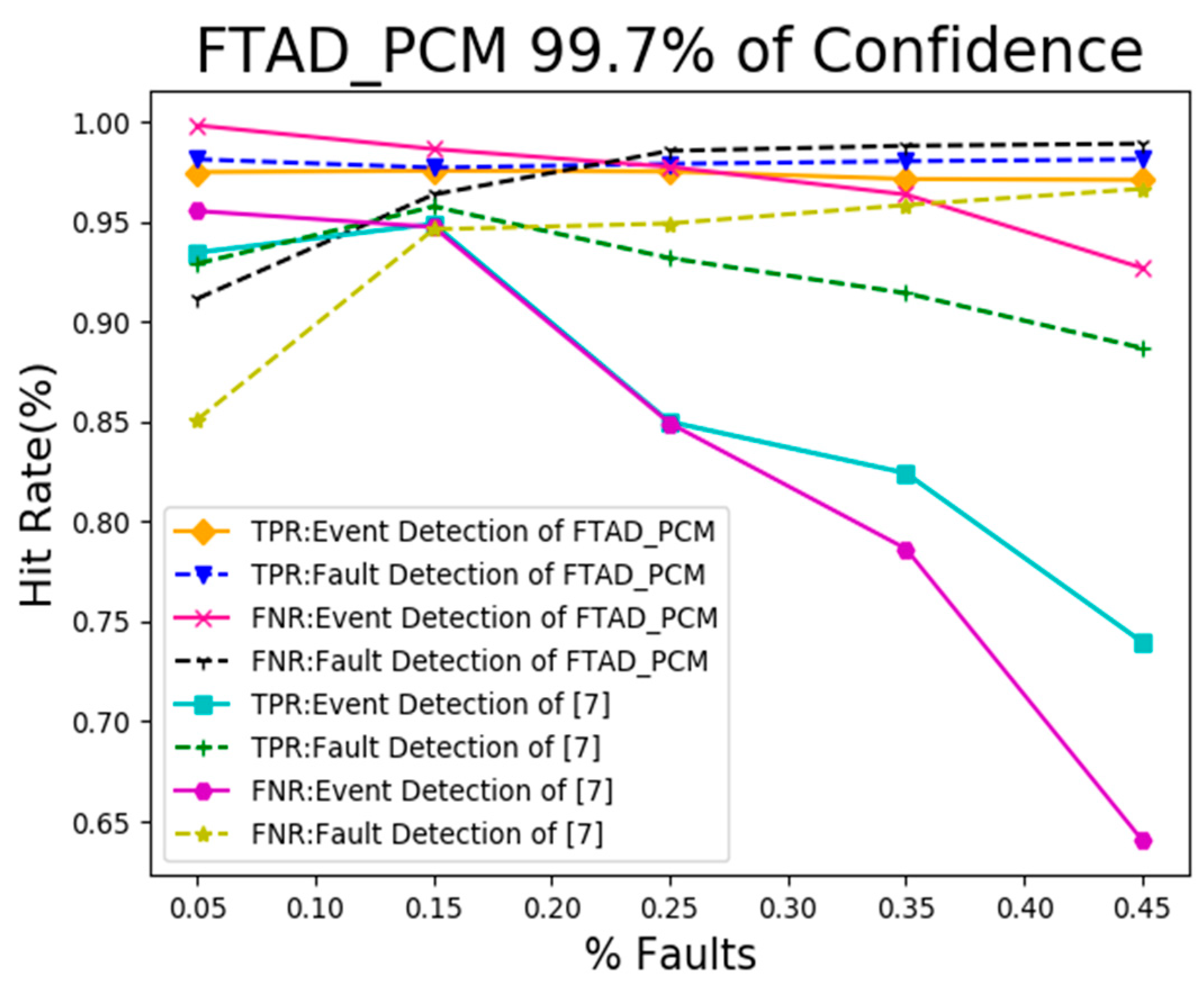
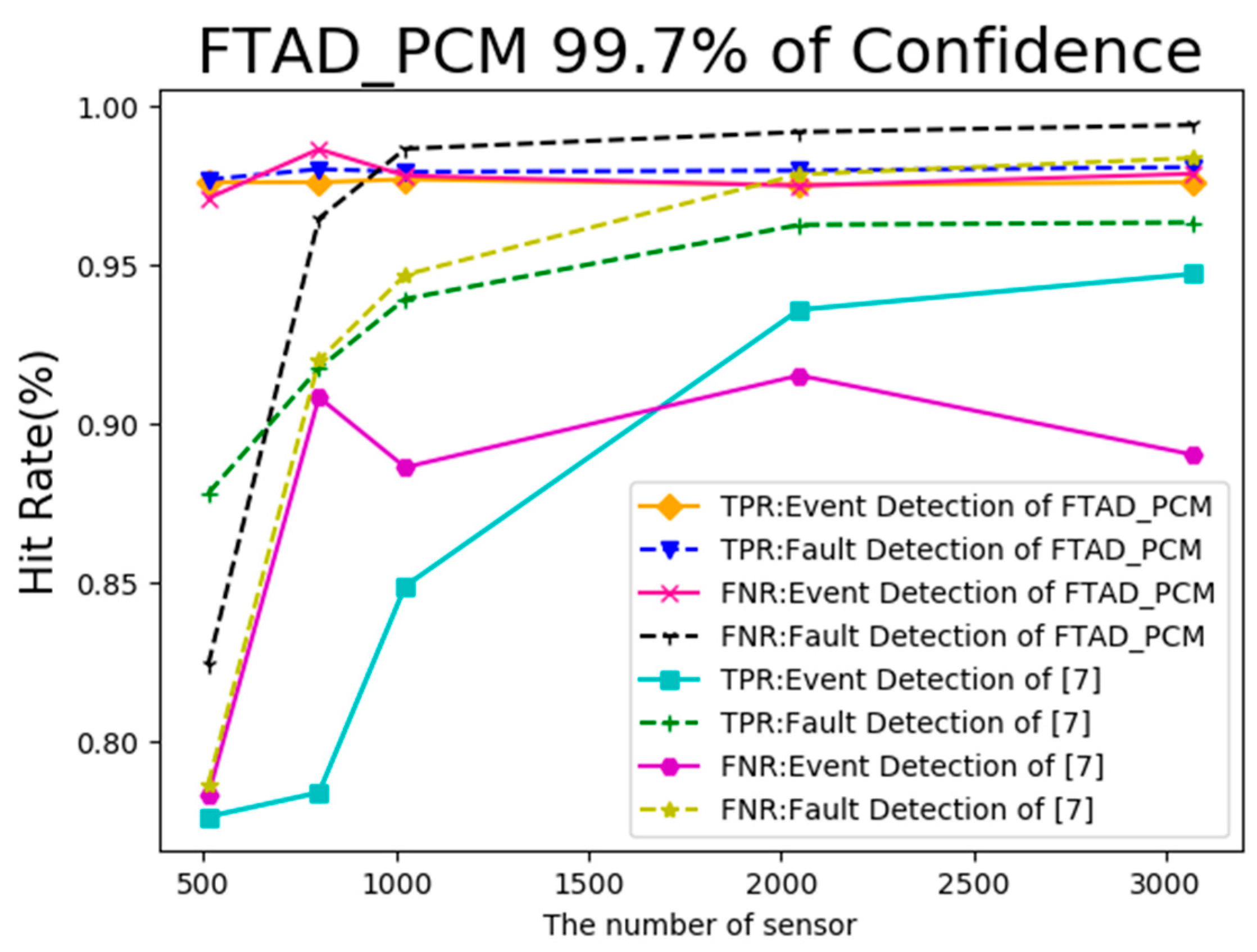
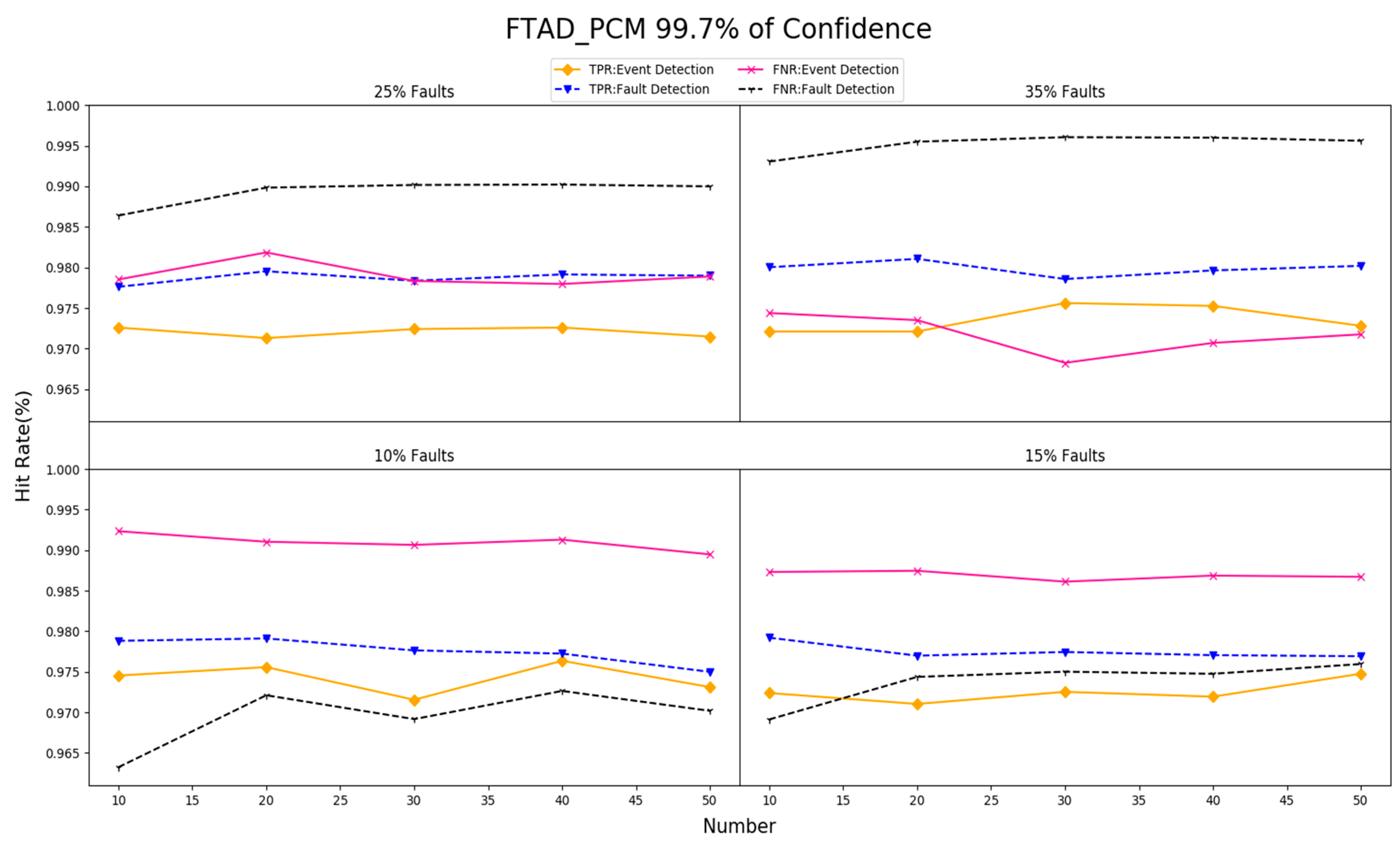
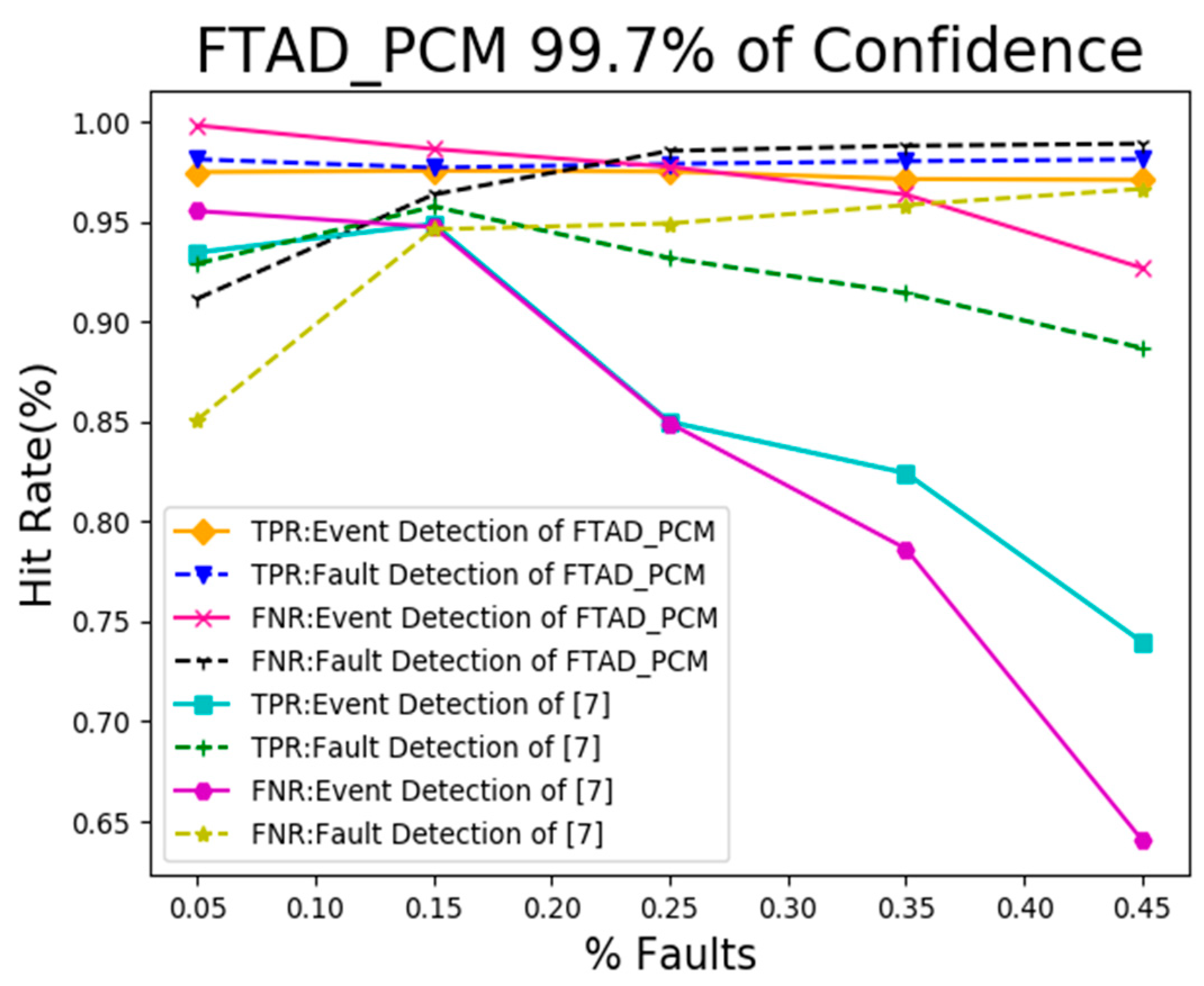
5.2. Result Analysis of Event and Fault Detection
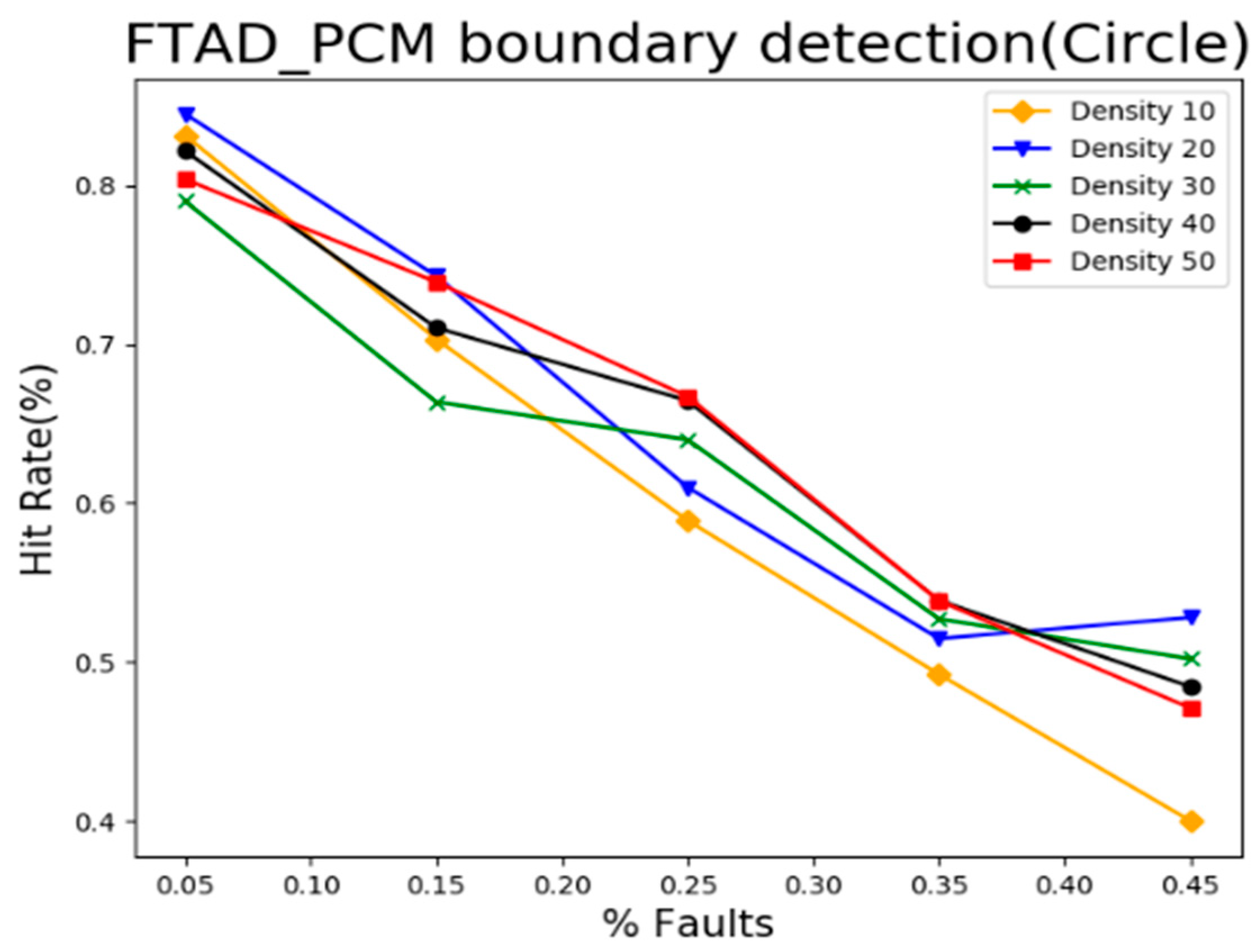
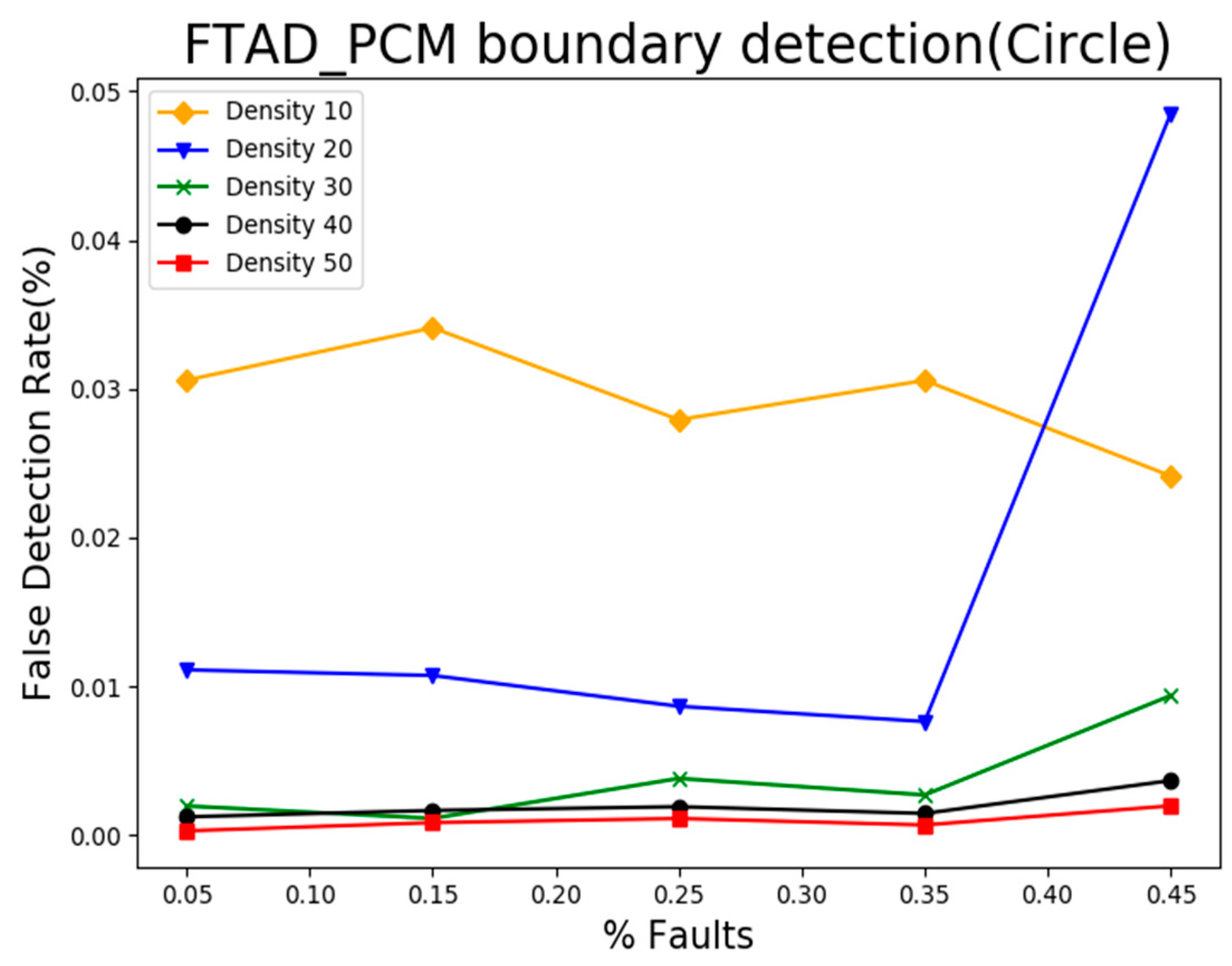
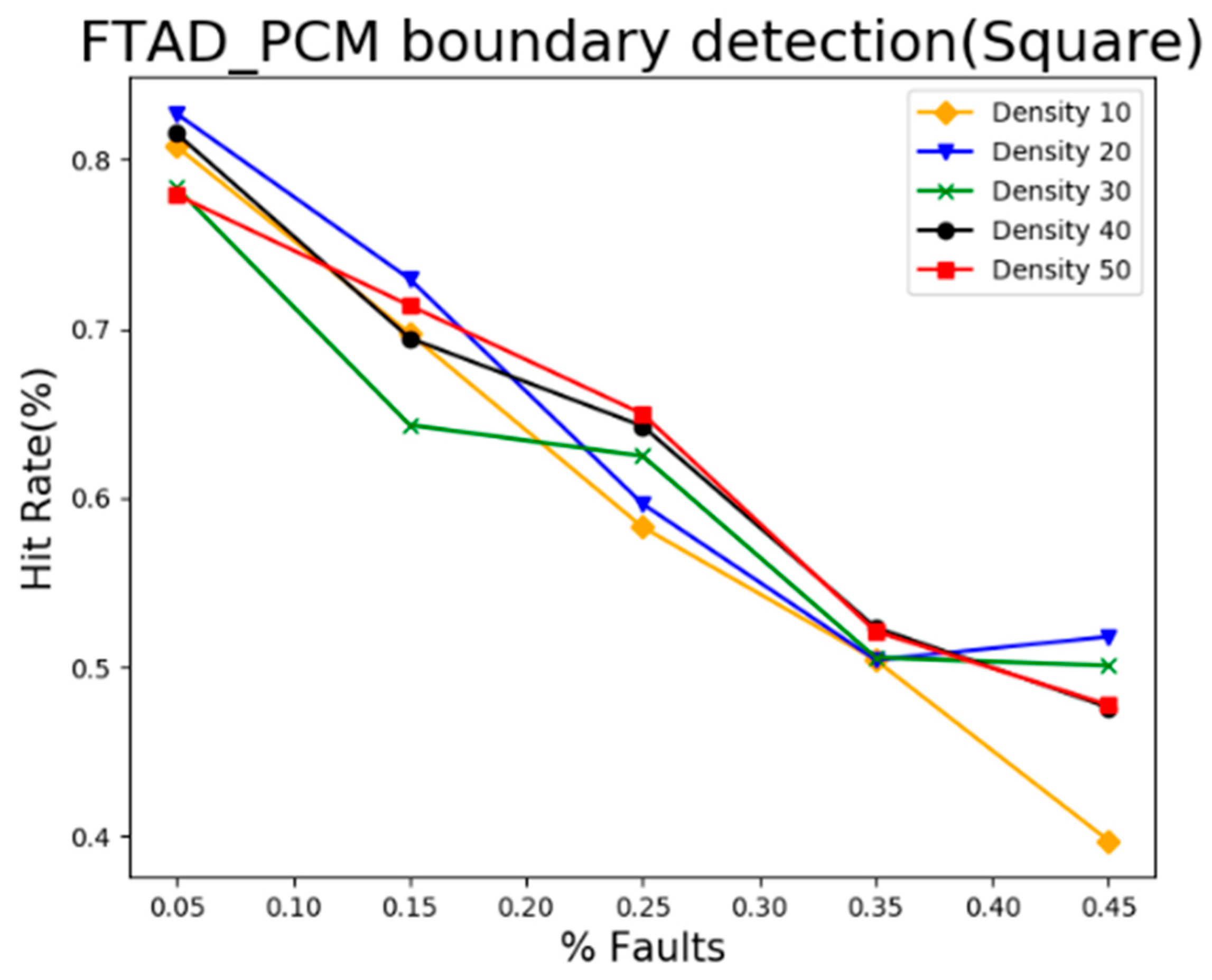
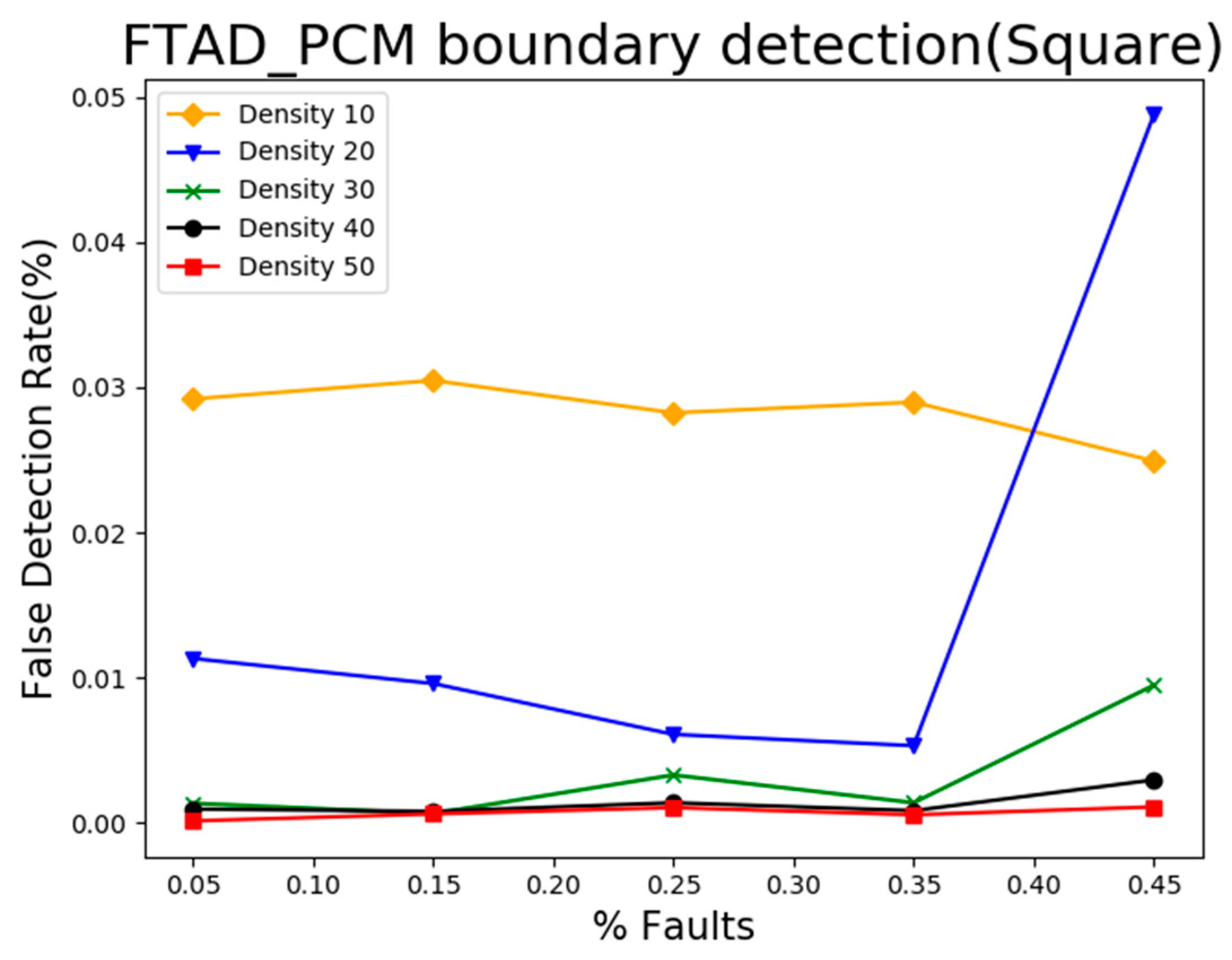
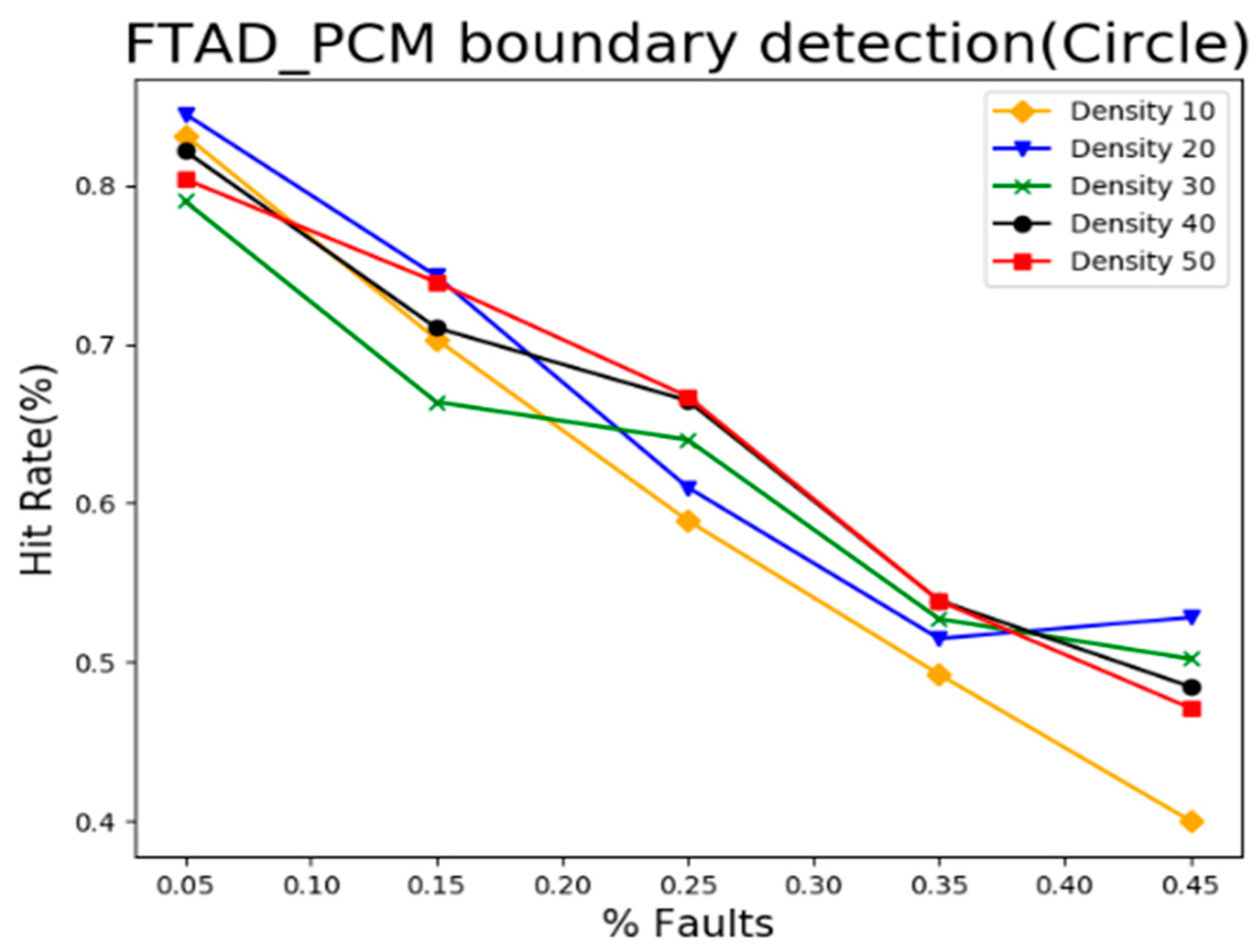
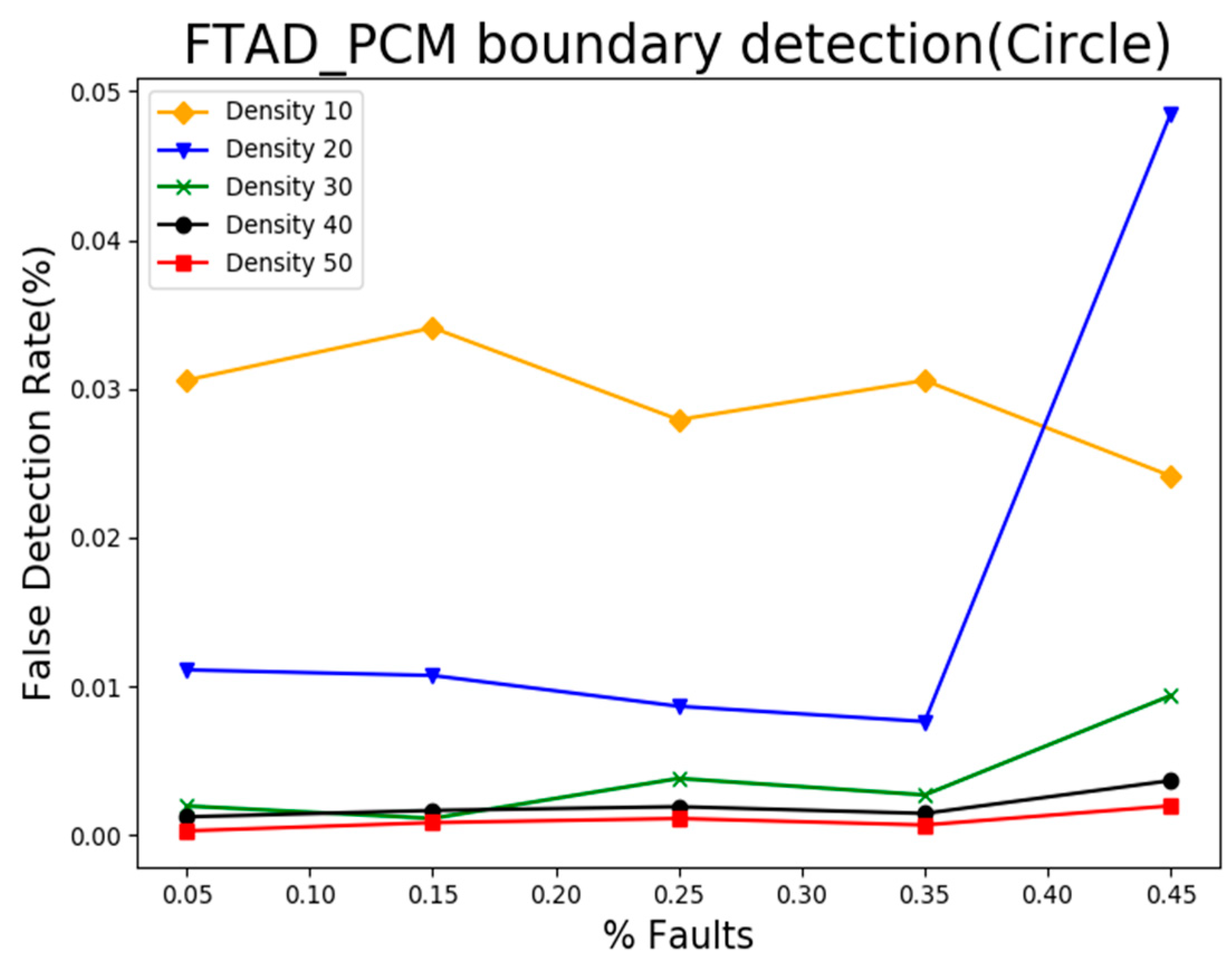
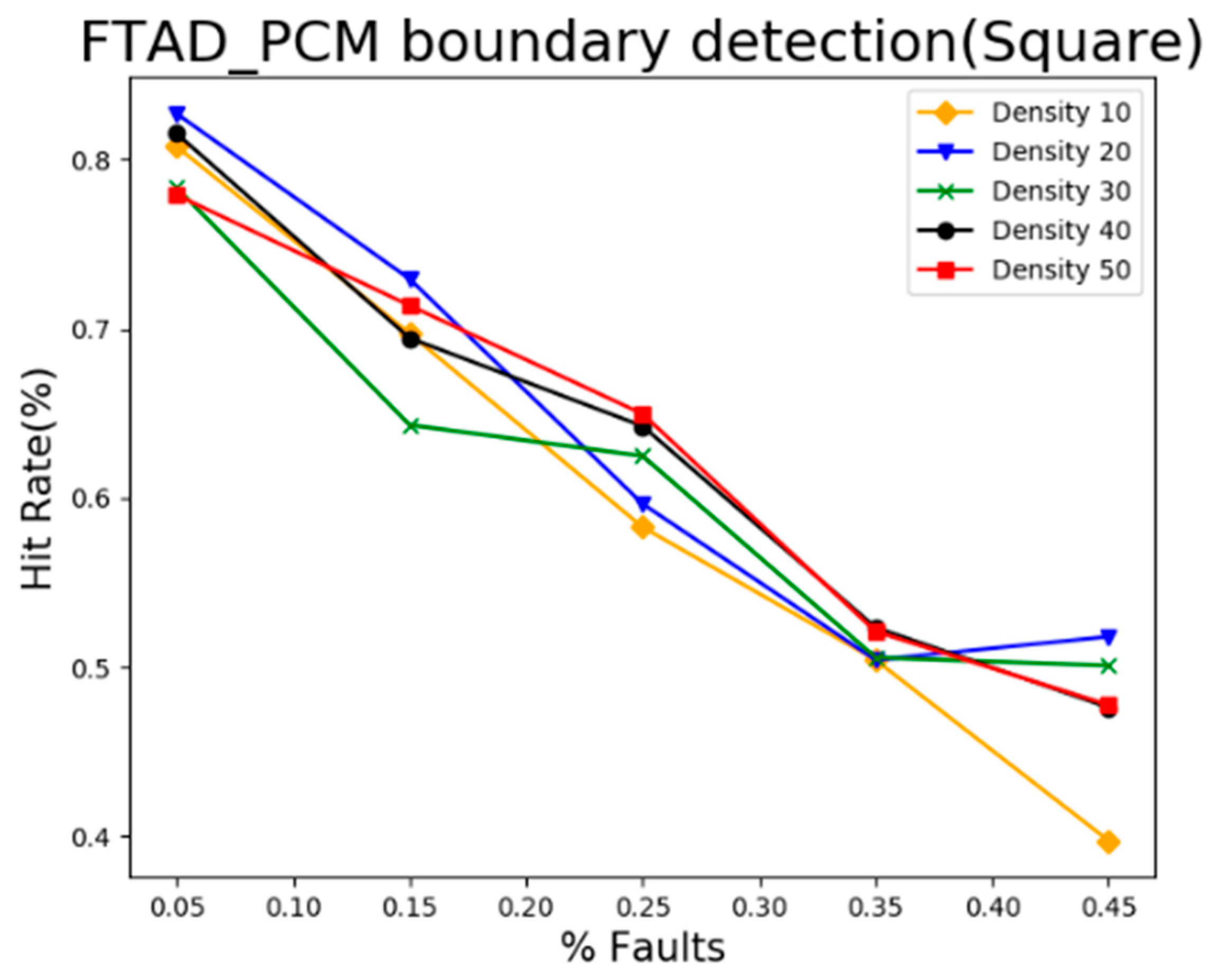
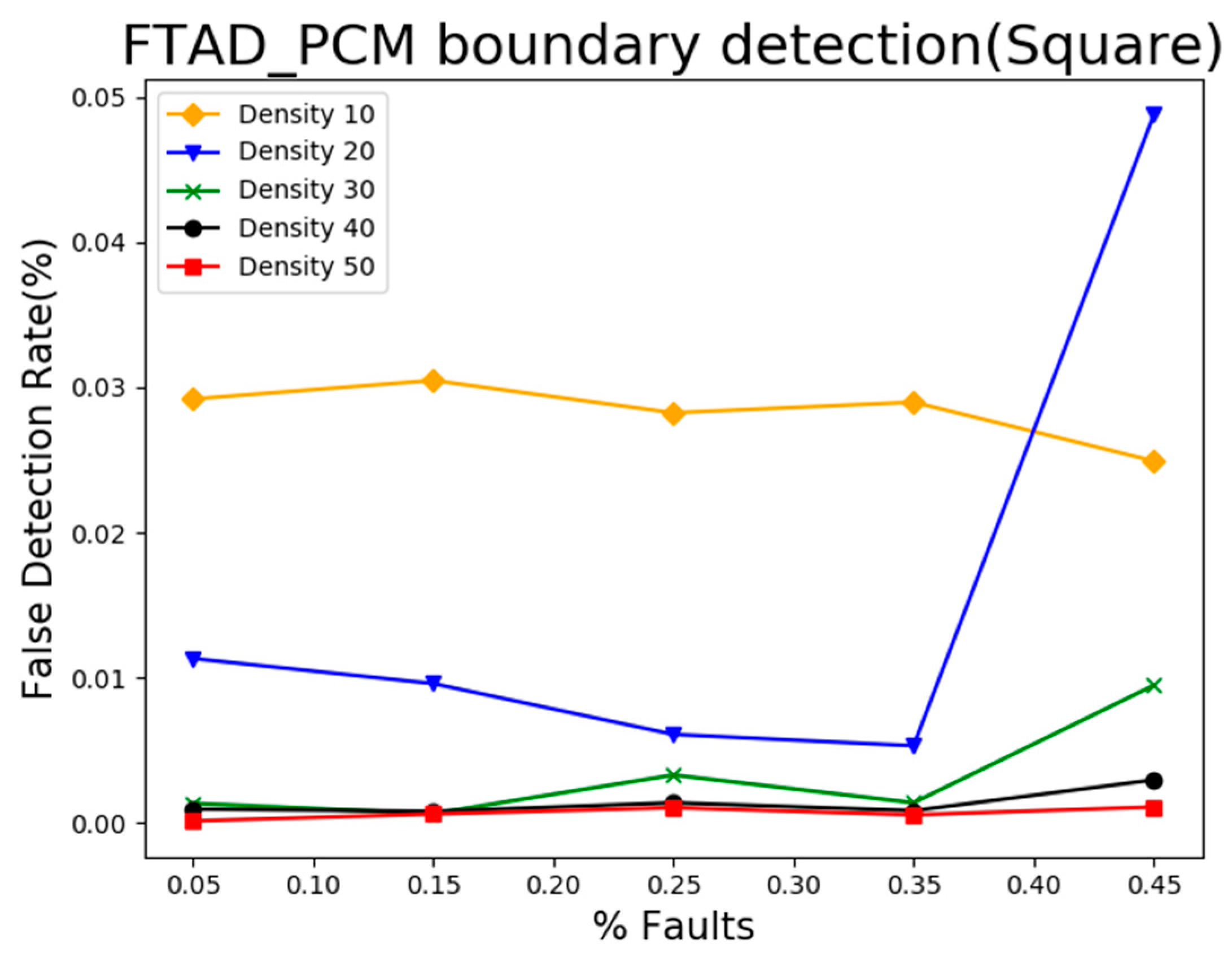
5.3. Result Analysis of Event Boundary Neighborhood Detection
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bai, X.; Liu, L.; Cao, M.; Panneerselvam, J.; Sun, Q.; Wang, H. Collaborative Actuation of Wireless Sensor and Actuator Networks for the Agriculture Industry. IEEE Access 2017, 5, 13286–13296. [Google Scholar] [CrossRef]
- Qiu, T.; Zhao, A.; Xia, F.; Si, W.; Wu, D.O. ROSE: Robustness Strategy for Scale-Free Wireless Sensor Networks. IEEE/ACM Trans. Netw. 2017, 25, 2944–2959. [Google Scholar] [CrossRef]
- Liu, K.; Zhuang, Y.; Liang, J.; Ma, J. Spatiotemporal Correlation Based Fault-Tolerant Event Detection in Wireless Sensor Networks. Int. J. Distrib. Sens. Netw. 2015, 2015, 7. [Google Scholar] [CrossRef]
- Alippi, C.; Ntalampiras, S.; Roveri, M. A Cognitive Fault Diagnosis System for Distributed Sensor Networks. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1213–1226. [Google Scholar] [CrossRef] [PubMed]
- Osanaiye, O.; Alfa, A.S.; Hancke, G.P. A Statistical Approach to Detect Jamming Attacks in Wireless Sensor Networks. Sensors 2018, 18, 1691. [Google Scholar] [CrossRef] [PubMed]
- Sousa, L.D.D.; Frery, A.C.; Nakamura, E.F.; Loureiro, A.A.F. Event detection framework for wireless sensor networks considering data anomaly. In Proceedings of the 2012 IEEE Computers and Communications, Cappadocia, Turkey, 1–4 July 2012; pp. 500–507. [Google Scholar]
- Cao, D.L. A Fault-Tolerant Algorithm for Event Region Detection in Wireless Sensor Networks. Chin. J. Comput. 2007, 30, 1770–1776. [Google Scholar]
- Lo, C.; Lynch, J.P.; Liu, M. Distributed model-based nonlinear sensor fault diagnosis in wireless sensor networks. Mech. Syst. Signal Process. 2016, 66, 470–484. [Google Scholar] [CrossRef] [Green Version]
- Ntalampiras, S. Fault Identification in Distributed Sensor Networks Based on Universal Probabilistic Modeling. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 1939–1949. [Google Scholar] [CrossRef] [PubMed]
- Tang, P.; Chow, T.W.S. Wireless Sensor-Networks Conditions Monitoring and Fault Diagnosis Using Neighborhood Hidden Conditional Random Field. IEEE Trans. Ind. Inform. 2016, 12, 933–940. [Google Scholar] [CrossRef]
- Su, J.; Long, Y.; Qiu, X.; Li, S.; Liu, D. Anomaly Detection of Single Sensors Using OCSVM_KNN. In Proceedings of the International Conference on Big Data Computing and Communications, Taiyuan, China, 1–3 August 2015; Springer: Cham, Germany, 2015; pp. 217–230. [Google Scholar]
- Rashid, S.; Akram, U.; Qaisar, S.; Khan, S.H.; Felemban, E. Wireless Sensor Network for Distributed Event Detection Based on Machine Learning. In Proceedings of the 2014 IEEE International Conference on Internet of Things (iThings), and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom), Taipei, Taiwan, 1–3 September 2014; pp. 540–545. [Google Scholar]
- Miao, X.; Liu, Y.; Zhao, H.; Li, C. Distributed Online One-Class Support Vector Machine for Anomaly Detection over Networks. IEEE Trans. Cybern. 2018, 99, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Deng, T.; Sui, R. An Adaptive Weighted One-Class SVM for Robust Outlier Detection. In Proceedings of the 2015 Chinese Intelligent Systems Conference; Springer: Berlin/Heidelberg, Germany; 2016. [Google Scholar]
- Swain, R.R.; Khilar, P.M. A fuzzy MLP approach for fault diagnosis in wireless sensor networks. In Proceedings of the 2016 IEEE Region 10 Conference, Singapore, 22–25 November 2016; pp. 3183–3188. [Google Scholar]
- Zhao, M.; Tian, Z.; Chow, T.W.S. Fault diagnosis on wireless sensor network using the neighborhood kernel density estimation. Neural Comput. Appl. 2018, 15, 1–12. [Google Scholar] [CrossRef]
- Ghorbel, O.; Abid, M.; Snoussi, H. Improved KPCA for outlier detection in Wireless Sensor Networks. In Proceedings of the 2014 1st International Conference on Advanced Technologies for Signal and Image Processing, Sousse, Tunisia, 17–19 March 2014; pp. 507–511. [Google Scholar]
- Ding, M.; Chen, D.; Xing, K.; Cheng, X. Localized fault-tolerant event boundary detection in sensor networks. In Proceedings of the IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; Volume 2, pp. 902–913. [Google Scholar]
- Ali, K.; Ali, S.B.; Naqvi, I.H.; Lodhi, M.A. Distributed Event Identification for WSNs in Non-Stationary Environments. In Proceedings of the IEEE Global Communications Conference, San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar]
- Bezdek, J.C.; Havens, T.C.; Keller, J.M.; Leckie, C.; Park, L.; Palaniswami, M.; Rajasegarar, S. Clustering elliptical anomalies in sensor networks. In Proceedings of the IEEE International Conference on Fuzzy Systems, Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Ali, K.; Naqvi, I.H. EveTrack: An event localization and tracking scheme for WSNs in dynamic environments. In Proceedings of the 2016 IEEE Wireless Communications and Networking Conference, Doha, Qatar, 3–6 April 2016. [Google Scholar]
- Oakland, J. Statistical Process Control; Elsevier: New York, NY, USA, 2008. [Google Scholar]
- Krishnamachari, B.; Iyengar, S.S. Efficient and Fault-Tolerant Feature Extraction in Wireless Sensor Networks. In Information Processing in Sensor Networks; Springer: Berlin/Heidelberg, Germany, 2003; pp. 488–501. [Google Scholar]
- Ren, K.; Zeng, K.; Lou, W. Secure and Fault-Tolerant Event Boundary Detection in Wireless Sensor Networks. IEEE Trans. Wirel. Commun. 2008, 7, 354–363. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| The total number of sensor nodes in the sensor network | |
| Event characteristic duration | |
| Sensor node adjacent sampling interval | |
| Times of the sensor node sampled in . | |
| Sampled readings of sensor node at time | |
| The threshold function of sensor reading, in order to determine whether the event occurred | |
| The expected value of the event | |
| Sample size | |
| Confidence | |
| The upper limit (maximum value of normal interval, change with environment) | |
| The lower limit (minimum value of normal interval, change with environment) | |
| Sensor node is in the normal condition | |
| Sensor node is in the event state | |
| Sensor node is in the fault state | |
| A fault has occurred on the sensor node | |
| The sensor node detected the event |
| Parameter | Value | |
|---|---|---|
| 1 | Sensing area | |
| 2 | Measurement value of the sensor in the event area | Normal distribution |
| 3 | Measurement value of the sensor out of the event area | Uniform distribution |
| 4 | Faulty measurement value of the sensor | Uniform distribution |
| 5 | Communication radius |
| Result | TPR | FNR | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | 5% | 15% | 25% | 35% | 5% | 15% | 25% | 35% | |
| FTAD | 98.1% | 98.0% | 98.0% | 97.9% | 91.2% | 96.0% | 98.3% | 98.3% | |
| KPCA | 95.0% | 92.5% | 89.4% | 85.0% | 94.0% | 93.8% | 91.0% | 90.0% | |
| FDS | 97.5% | 95.3% | 92.0% | 88.9% | 96.5% | 94.5% | 92.8% | 91.1% | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, N.; Zhang, W.; Ling, H.; Zhang, Y.; Zheng, L. Fault-Tolerant Anomaly Detection Method in Wireless Sensor Networks. Information 2018, 9, 236. https://doi.org/10.3390/info9090236
Peng N, Zhang W, Ling H, Zhang Y, Zheng L. Fault-Tolerant Anomaly Detection Method in Wireless Sensor Networks. Information. 2018; 9(9):236. https://doi.org/10.3390/info9090236
Chicago/Turabian StylePeng, Nengsong, Weiwei Zhang, Hongfei Ling, Yuzhao Zhang, and Lixin Zheng. 2018. "Fault-Tolerant Anomaly Detection Method in Wireless Sensor Networks" Information 9, no. 9: 236. https://doi.org/10.3390/info9090236
APA StylePeng, N., Zhang, W., Ling, H., Zhang, Y., & Zheng, L. (2018). Fault-Tolerant Anomaly Detection Method in Wireless Sensor Networks. Information, 9(9), 236. https://doi.org/10.3390/info9090236