Semantic Modelling and Publishing of Traditional Data Collection Questionnaires and Answers †



Abstract
1. Introduction
- Providing a semantic model for generic and domain-specific traditional data collections and analysis together with an ontology that provides the required semantics to interpret the content consistently.
- Providing a semantic mapping to uplift the existing data to an LOD platform. We provide an R2RML mapping which will be used to transform the collection to an LOD following the W3C recommendations.
- Providing an implementation and validation of the proposed approach that supports user requirements. To support this, we use common navigation paths that are extracted from the daily information requirements of existing users.
- Additionally, capturing methods of integrating domain experts in the semantic modelling process and improved handling of changes during the semantic modelling and uplifting process.
2. Background
3. The Approach and Development of a Semantic Model
3.1. User Requirements
- The model should formally represent the semantics of the core entities and their attributes as well as the relationships between these entities. This process includes:
- Identification of the major entities in the collections;
- Identification of useful and relevant attributes of the entities; and
- Identification of the major relationships that link those entities.
- The model should be suitable to annotate the existing content semantically. The semantic uplift process should be able to generate LOD and be amenable to future changes and updates.
- The model should support a structured query to allow users to construct queries based on their information requirements. It should further allow computer agents to access the data via APIs.
- The model should reuse existing ontologies and vocabularies to supply rich semantics and interlinking.
- It is preferable to provide multilingual support in English and German languages (with possible extension to other languages) with names of entities and their description appearing in both languages to support a wide range of users.
3.2. Modelling the Domain
3.2.1. Domain Analysis of Questionnaires
3.2.2. Domain Analysis of Paper Slips
3.3. Schema Analysis
4. The Semantic Model: OLDCAN
4.1. Concepts and Taxonomical Hierarchies
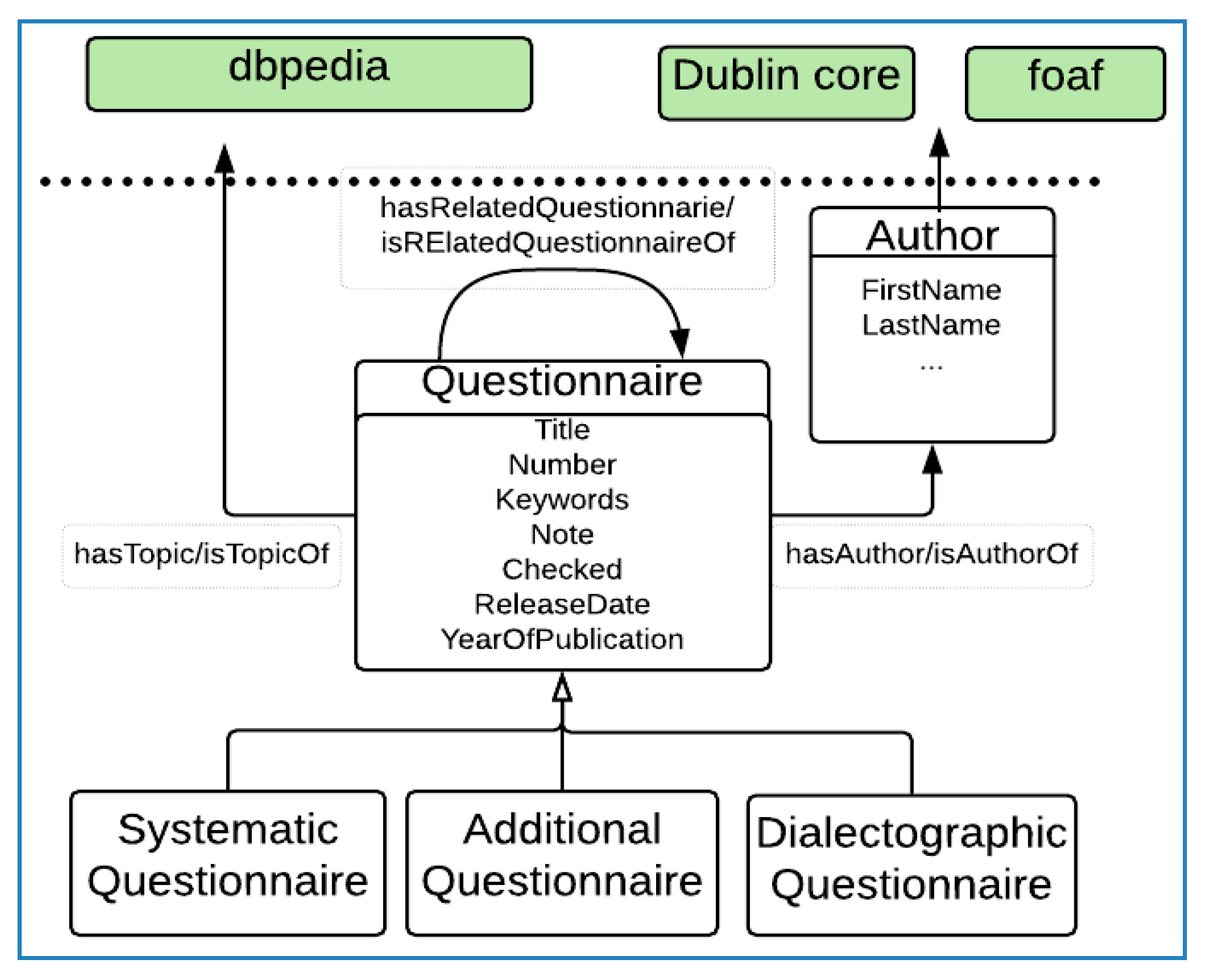
4.1.1. Questionnaire
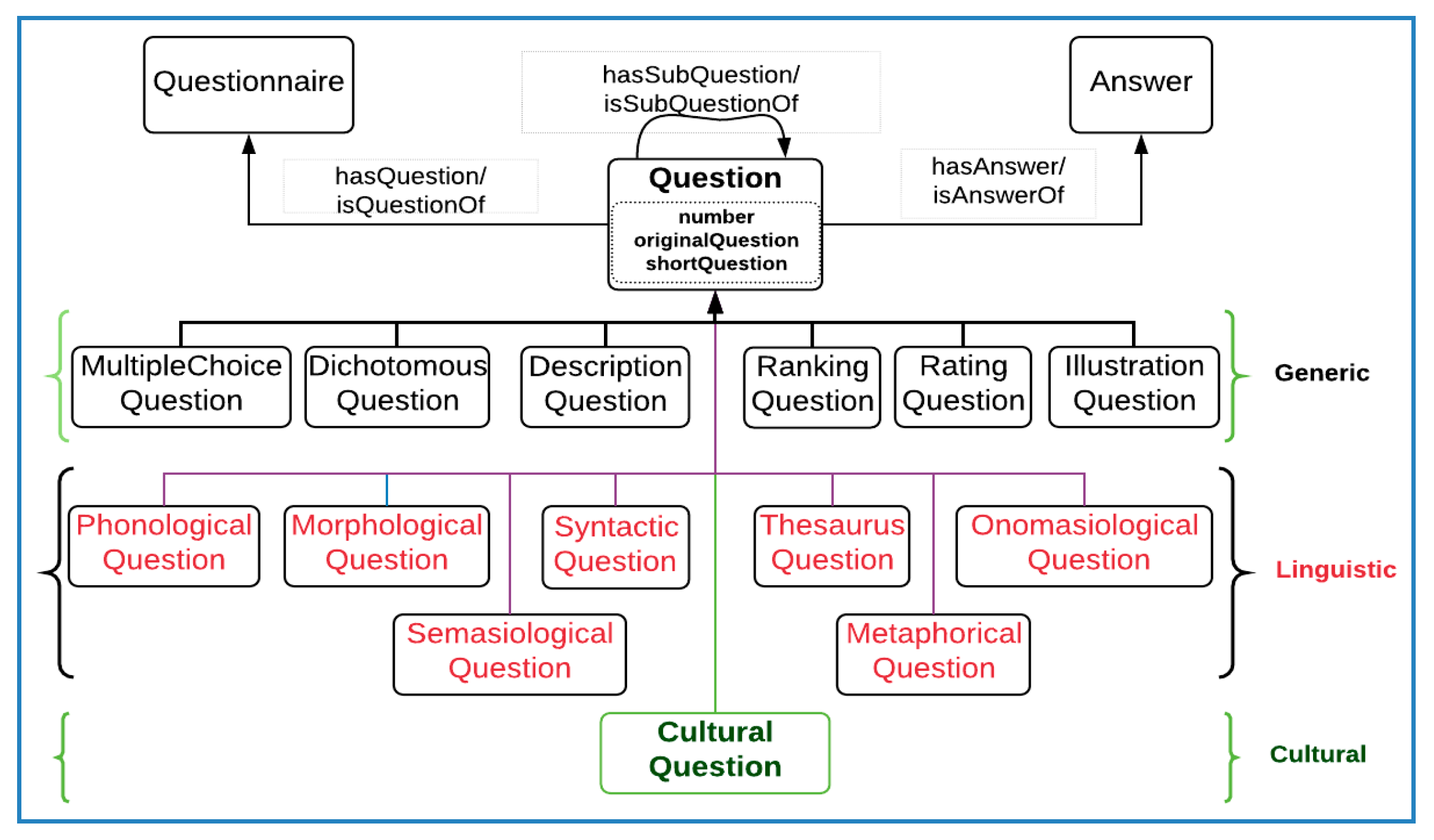
4.1.2. Questions
4.1.3. Answer
4.1.4. Paper Slips
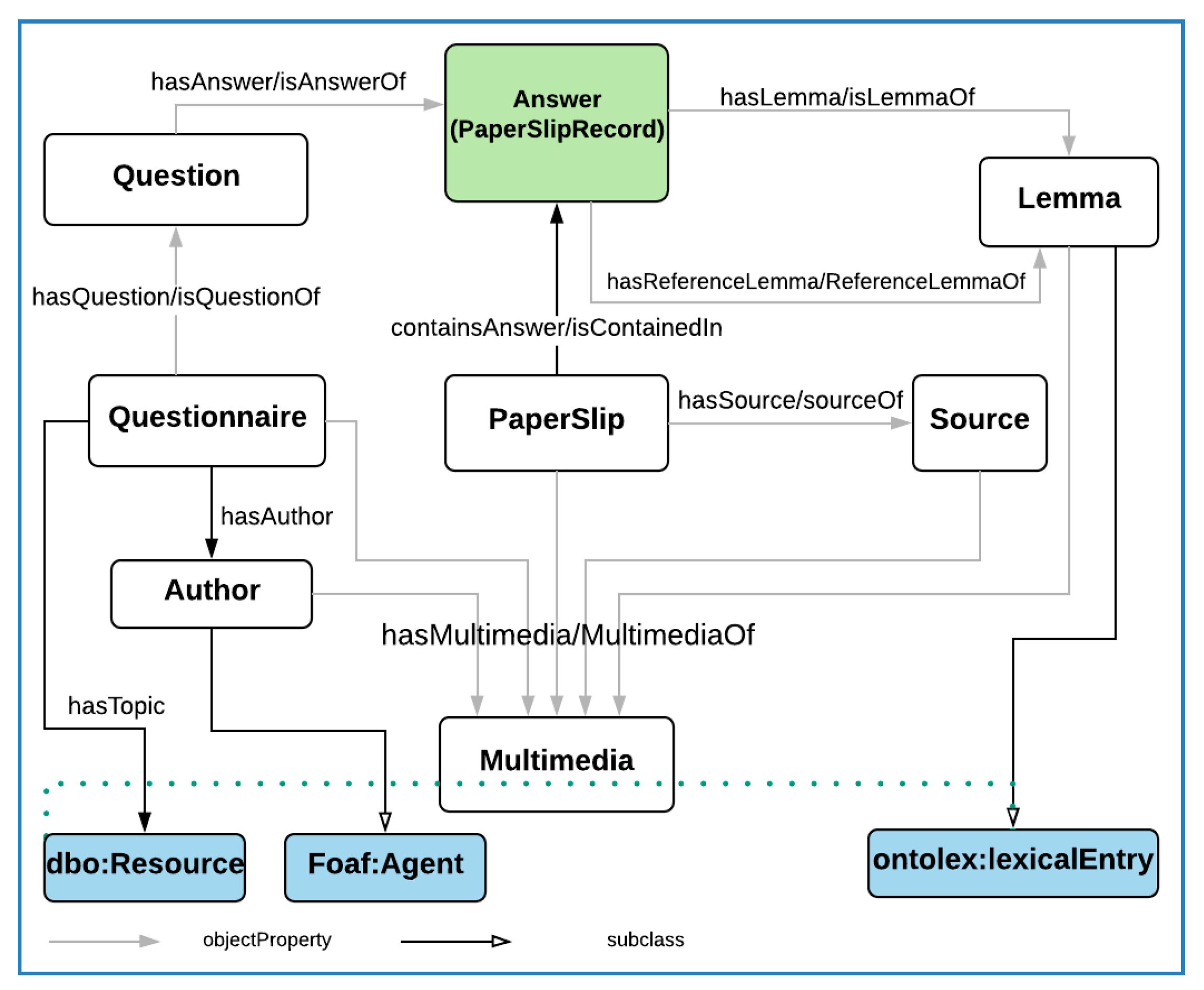
4.1.5. Lemma, Multimedia, Source and Author
5. Semantic Uplift of Historical Resources at Exploreat
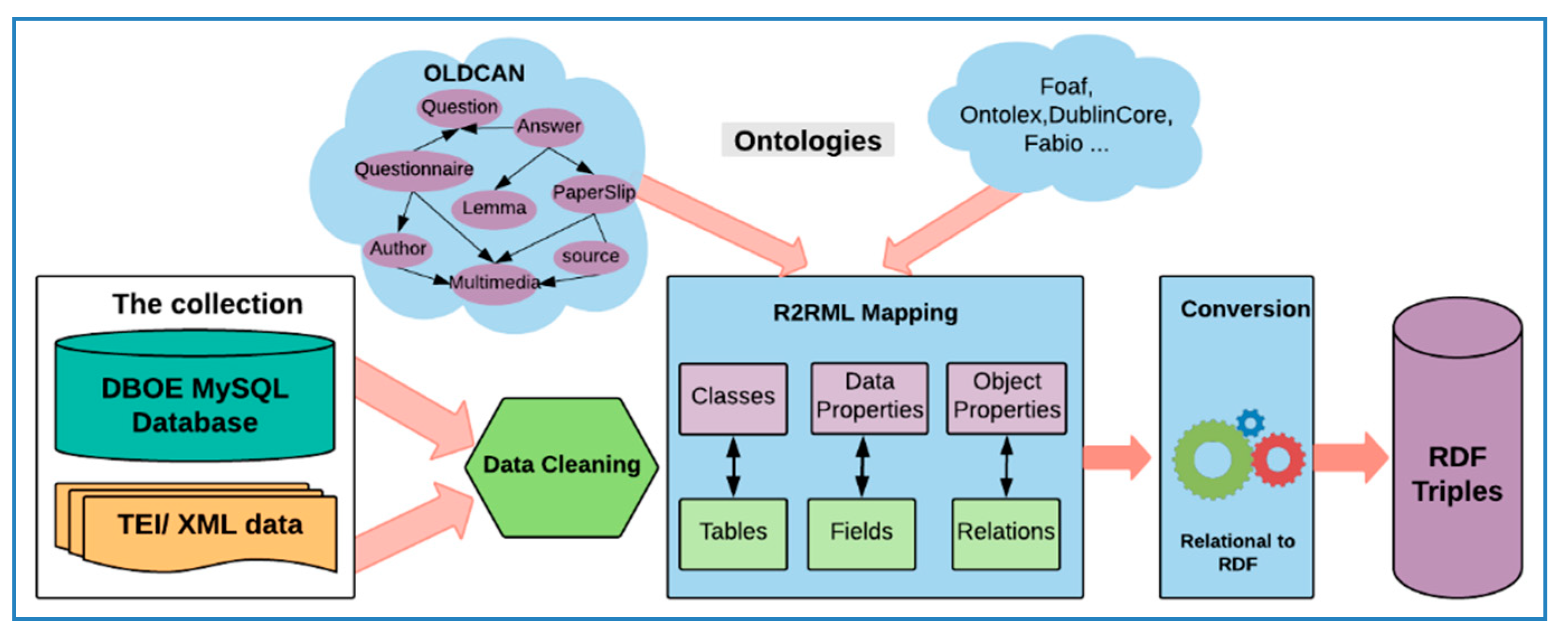
5.1. The Semantic Uplift Process
5.1.1. Data Cleaning
5.1.2. R2RML Mapping
- Converting the major tables into classes;
- Mapping object property relationships;
- Mapping data property relationships; and
- Enriching the data with additional semantics.
5.2. Linked Open Data (LOD) Generation
6. Implementation and Validation
6.1. Exploration Paths
6.2. Qualitative Evaluation of the Ontology Model
6.3. Qualitative Evaluation of the Mapping
7. Related Work
8. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Doerr, M. Ontologies for Cultural Heritage. In Handbook on Ontologies; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Kansa, E.C.; Kansa, S.W.; Burton, M.M.; Stankowski, C. Googling the Grey: Open Data, Web Services, and Semantics. Archaeologies 2010, 6, 301–326. [Google Scholar] [CrossRef]
- Beretta, F.; Ferhod, D.; Gedzelman, S.; Vernus, P. The SyMoGIH project: Publishing and sharing historical data on the semantic web. In Proceedings of the Digital Humanities 2014, Lausanne, Switzerland, 7–12 July 2014; pp. 469–470. [Google Scholar]
- Meroño-Peñuela, A.; Ashkpour, A.; Van Erp, M.; Mandemakers, K.; Breure, L.; Scharnhorst, A.; Schlobach, S.; Van Harmelen, F. Semantic Technologies for Historical Research: A Survey. Semant. Web 2015, 6, 539–564. [Google Scholar] [CrossRef]
- Lampron, P.; Mixter, J.; Han, M.J.K. Challenges of mapping digital collections metadata to Schema.org: Working with CONTENTdm. In Proceedings of the 10th International Research Conference on Metadata and Semantics Research, Göttingen, Germany, 22–25 November 2016; pp. 181–186. [Google Scholar]
- Wandl-Vogt, E.; Kieslinger, B.; O´Connor, A.; Theron, R. exploreAT! Perspektiven einer Transformation am Beispiel eines lexikographischen Jahrhundertprojekts. Available online: http://docplayer.org/16597238-Exploreat-perspektiven-einer-transformation-am-beispiel-eines-lexikographischen-jahrhundertprojekts.html (accessed on 22 November 2018).
- Wandl-Vogt, E. Datenbank der bairischen Mundarten in Österreich electronically mapped (dbo@ema). Available online: https://wboe.oeaw.ac.at/projekt/beschreibung/ (accessed on 22 November 2018).
- Dominque, J.; Fensel, D.; Hendler, J.A. Handbook of Semantic Web Technologies; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Nevalainen, T.; Raumolin-Brunberg, H. Historical Sociolinguistics: Origins, Motivations, and Paradigms. In The Handbook of Historical Sociolinguistics; Wiley-Blackwell: Hoboken, NJ, USA, 2012; pp. 22–40. [Google Scholar]
- Kramsch, C.; Widdowson, H. Language and Culture; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Chiarcos, C.; Cimiano, P.; Declerck, T.; McCrae, J.P. Linguistic Linked Open Data (LLOD)—Introduction and Overview. In Proceedings of the 2nd Workshop on Linked Data in Linguistics (LDL-2013): Representing and Linking Lexicons, Terminologies and Other Language Data, Pisa, Italy, 23 September 2013. [Google Scholar]
- Burnard, L. What Is the Text Encoding Initiative? How to Add Intelligent Markup to Digital Resources; OpenEdition Press: Marseille, France, 2014. [Google Scholar]
- McCrae, J.P.; Bosque-Gil, J.; Gracia, J.; Buitelaar, P.; Cimiano, P. The OntoLex-Lemon Model: Development and applications. In Proceedings of the the 5th Biennial Conference on Electronic Lexicography (eLex 2017), Leiden, The Netherlands, 19–21 September 2017; pp. 587–597. [Google Scholar]
- Pedersen, B.; McCrae, J.; Tiberius, C.; Krek, S. ELEXIS—A European infrastructure fostering cooperation and information exchange among lexicographical research communities. In Proceedings of the 9th Global WordNet Conference, Singapore, 8–12 January 2018. [Google Scholar]
- Wandl-Vogt, E. Wie man ein Jahrhundertprojekt zeitgemäß hält: Datenbankgestützte Dialektlexikografie am Institut für Österreichische Dialekt- und Namenlexika (I Dinamlex) (mit 10 Abbildungen). In Bausteine zur Wissenschaftsgeschichte von Dialektologie / Germanistischer Sprachwissenschaft im 19. und 20. Jahrhundert. Beiträge zum 2. Kongress der Internationalen Gesellschaft für Dialektologie des Deutschen; Praesens: Vienna, Austria, 2008; pp. 93–112. [Google Scholar]
- Arbeitsplan. Arbeitsplan und Geschäftsordnung für das bayerisch-österreichische Wörterbuch. 16. Juli 1912. Karton 1. In Arbeitsplan-a-h Bayerisch-Österreichisches Wörterbuch; Archive of the Austrian Academy of Sciences: Vienna, Austria, 1912. [Google Scholar]
- WBÖ. Wörterbuch der bairischen Mundarten in Österreich (1970–2015). In Bayerisches Wörterbuch: I. Österreich, 5 vols. Ed.; Verlag der Österreichischen Akademie der Wissenschaften: Vienna, Austria.
- Barabas, B.; Hareter-Kroiss, C.; Hofstetter, B.; Mayer, L.; Piringer, B.; Schwaiger, S. Digitalisierung handschriftlicher Mundartbelege. Herausforderungen einer Datenbank. In Fokus Dialekt. Analysieren-Dokumentieren-Kommunizieren; Olms Verlag: Hildesheim, Germany, 2010; pp. 47–64. [Google Scholar]
- Schopper, D.; Bowers, J.; Wandl-Vogt, E. dboe@TEI: Remodelling a data-base of dialects into a rich LOD resource. In Proceedings of the 9th International Conference on Tangible, Embedded, and Embodied Interaction (TEI 2015), Stanford, CA, USA, 15–19 January 2015. [Google Scholar]
- De Wilde, M.; Hengchen, S. Semantic Enrichment of a Multilingual Archive with Linked Open Data. Digit. Hum. Q. 2017, 11, 1938–4122. [Google Scholar]
- Strok, L.; Weber, A.; Miracle, G.G.; Verbeek, F.; Plaat, A.; Herik, J.V.D.; Wolstencroft, K. Semantic annotation of natural history collections. Web Semant. Sci. Serv. Agents World Wide Web 2018, in press. [Google Scholar] [CrossRef]
- Hrastnig, E. A Linked Data Approach for Digital Humanities. Prototypical Storage of a Dialect Data Set in a Triplestore. Master’s Thesis, Graz University of Technology, Graz, Austria, January 2017. [Google Scholar]
- Peroni, S. Automating Semantic Publishing. Data Sci. 2017, 1, 155–173. [Google Scholar] [CrossRef]
- Scholz, J.; Lampoltshammer, T.J.; Bartelme, N.; Wandl-Vogt, E. Spatial-temporal Modeling of Linguistic Regions and Processes with Combined Indeterminate and Crisp Boundaries. In Progress in Cartography: EuroCarto 2015; Gartner, G., Jobst, M., Huang, H., Eds.; Springer: Cham, Switzerland, 2016; pp. 133–151. [Google Scholar]
- Scholz, J.; Hrastnig, E.; Wandl-Vogt, E. A Spatio-Temporal Linked Data Representation for Modeling Spatio-Temporal Dialect Data. In Proceedings of the Workshops and Posters at the 13th International Conference on Spatial Information Theory (COSIT 2017), L’Aquila, Italy, 4–8 September 2017; pp. 275–282. [Google Scholar]
- Boyce, S.; Pahl, C. Developing Domain Ontologies for Course Content. Educ. Technol. Soc. 2007, 10, 275–288. [Google Scholar]
- Noy, N.F.; Mcguinness, D.L. Ontology Development 101: A Guide to Creating Your First Ontology. Available online: http://www.corais.org/sites/default/files/ontology_development_101_aguide_to_creating_your_first_ontology.pdf (accessed on 22 November 2018).
- Gura, C.; Piringer, B.; Wandl-Vogt, E. Nation Building durch Großlandschaftswörterbücher. Das Wörterbuch der bairischen Mundarten in Österreich (WBÖ) als identitätsstiftender Faktor des österreichischen Bewusstseins. Status (unpublished).
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked Data—The Story So Far. Int. J. Semant. Web Inf. Syst. 2009, 5, 1–22. [Google Scholar] [CrossRef]
- Hogan, A.; Umbrich, J.; Harth, A.; Cyganiak, R.; Polleres, A.; Decker, S. An empirical survey of linked data conformance. Web Semant. Sci. Serv. Agents World Wide Web 2012, 14, 14–44. [Google Scholar] [CrossRef]
- Uschold, M.; Gruninger, M. Ontologies: Principles, methods, and applications. Knowl. Eng. Rev. 1996, 11, 93–155. [Google Scholar] [CrossRef]
- Edgar, S.M.; Alexei, S.A. Ontology for knowledge management in software maintenance. Int. J. Inf. Manag. 2014, 34, 704–710. [Google Scholar]
- Brickley, D.; Miller, L. FOAF Vocabulary Specification 0.99, 2014. Namespace Document. Available online: http://xmlns.com/foaf/spec/ (accessed on 23 November 2018).
- Board, DCMI Usage. DCMI Metadata Terms, 2014. Dublin Core Metadata Initiative. Available online: http://dublincore.org/documents/dcmi-terms/ (accessed on 23 November 2018).
- Mendes, P.N.; Jakob, M.; García-Silva, A.; Bizer, C. DBpedia spotlight. In Proceedings of the 7th International Conference on Semantic Systems, Graz, Austria, 7–9 September 2011; pp. 1–8. [Google Scholar]
- Abgaz, Y.; Dorn, A.; Piringer, B.; Wandl-Vogt, E.; Way, A. A Semantic Model for Traditional Data Collection Questionnaires Enabling Cultural Analysis. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; pp. 21–29. [Google Scholar]
- Shotton, D.; Peroni, S. FaBiO, the FRBR-aligned Bibliographic Ontology, 2018. Available online: https://sparontologies.github.io/fabio/current/fabio.html (accessed on 23 November 2018).
- Heath, T.; Bizer, C. Semantic Annotation and Retrieval: Web of Data. In Handbook of Semantic Web Technologies; Domingue, J., Fensel, D., Hendler, J.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Ferdinand, M.; Christian, Z.; David, T. Lifting XML Schema to OWL. In Proceedings of the Web Engineering—4th International Conference (ICWE 2004), Munich, Germany, 26–30 July 2004; pp. 354–358. [Google Scholar]
- Battle, S. Gloze: XML to RDF and back again. In Proceedings of the First Jena User Conference, Bristol, UK, 10–11 May 2006. [Google Scholar]
- Deursen, D.V.; Poppe, C.; Martens, G.; Mannens, E.; Walle, R.V.d. XML to RDF Conversion: A Generic Approach. In Proceedings of the 2008 International Conference on Automated Solutions for Cross Media Content and Multi-Channel Distribution, Florence, Italy, 17–19 November 2008; pp. 138–144. [Google Scholar]
- Simpson, J.; Brown, S. From XML to RDF in the Orlando Project. In Proceedings of the International Conference on Culture and Computing. Culture and Computing, Kyoto, Japan, 16-18 September 2013; pp. 194–195. [Google Scholar]
- Gueta, T.; Carmel, Y. Quantifying the value of user-level data cleaning for big data: A case study using mammal distribution models. Ecol. Inform. 2016, 34, 139–145. [Google Scholar] [CrossRef]
- Prud’hommeaux, E.; Labra Gayo, J.E.; Solbrig, H. Shape Expressions: An RDF Validation and Transformation Language. In Proceedings of the 10th International Conference on Semantic Systems (Sem2014), Leipzig, Germany, 14 July 2014; pp. 32–40. [Google Scholar] [CrossRef]
- Berners-Lee, T. Relational Databases on the Semantic Web. In Design Issues for the World Wide Web. Available online: https://www.w3.org/DesignIssues/RDB-RDF.html (accessed on 22 November 2018).
- Michel, F.; Montagnat, J.; Faron, Z.C. A Survey of RDB to RDF Translation Approaches and Tools. Available online: https://hal.archives-ouvertes.fr/hal-00903568v1 (accessed on 22 November 2018).
- Das, S.; Sundara, S.; Cyganiak, R. R2RML: RDB to RDF Mapping Language. W3C RDB2RDF Working Group. Available online: https://www.w3.org/TR/r2rml/ (accessed on 23 November 2018).
- Debruyne, C.; O’Sullivan, D. R2RML-F: Towards Sharing and Executing Domain Logic in R2RML Mappings. In Proceedings of the Workshop on Linked Data on the Web, LDOW 2016, co-located with the 25th International World Wide Web Conference (WWW 2016), Montreal, QC, Canada, 12 April 2016. [Google Scholar]
- Dorn, A.; Wandl-Vogt, E.; Abgaz, Y.; Benito Santos, A.; Therón, R. Unlocking Cultural Knowledge in Indigenous Language Resources: Collaborative Computing Methodologies. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Raad, J.; Cruz, C. A Survey on Ontology Evaluation Methods. In Proceedings of the International Conference on Knowledge Engineering and Ontology Development, part of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Lisbon, Portugal, 12–14 November 2015; pp. 179–186. [Google Scholar]
- Tsarkov, D.; Horrocks, I. FaCT Description Logic Reasoner: System Description. In Proceedings of the International Joint Conference on Automated Reasoning, Seattle, WA, USA, 17–20 August 2006; pp. 292–297. [Google Scholar]
- Glimm, B.; Horrocks, I.; Motik, B.; Stoilos, G.; Wang, Z. HermiT: An OWL 2 Reasoner. J. Autom. Reason. 2014, 53, 245–269. [Google Scholar] [CrossRef]
- Jean-Baptiste, M.; Yuan, K.S.; Aviva, P.A.; Adrian, V.; Matthew, K.G.; Team, T.G.B.; Joseph, P.P.; Dale, H.; Dan, C.; Peter, N.; et al. Quantitative Analysis of Culture Using Millions of Digitized Books. Science 2011, 331, 176–182. [Google Scholar]
- Guus, S.; Alia, A.; Lora, A.; Mark, v.A.; Victor, d.B.; Lynda, H.; Michiel, H.; Borys, O.; Jacco, v.O.; Anna, T.; et al. Semantic annotation and search of cultural-heritage collections: The MultimediaN E-Culture demonstrator. Web Semant. Sci. Serv. Agents World Wide Web 2008, 6, 243–249. [Google Scholar]
- Declerck, T. Towards a Linked Lexical Data Cloud based on OntoLex-Lemon. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Tittel, S.; Bermúdez-Sabel, H.; Chiarcos, C. Using RDFa to Link Text and Dictionary Data for Medieval French. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Book of Questionnaires | |||
|---|---|---|---|
| Entity @en | Description @en | Entity @de | Description @de |
| Questionnaire | A questionnaire represents a set of questions that are related to each other. A questionnaire contains metadata such as questionnaire identifiers, titles, agents and publication-related information. | Fragebogen | Ein Fragebogen stellt eine Reihe von Fragen dar, die miteinander in Beziehung stehen. Ein Fragebogen enthält Metadaten wie Fragebogenbezeichner, Titel, Agenten und Informationen zur Veröffentlichung. |
| Authors | Authors are agents or persons who prepare the questionnaires and the questions contained in them. | Autoren | Autoren sind Agenten oder Personen, die die Fragebögen und die darin enthaltenen Fragen vorbereiten. |
| Collectors | Collectors are defined in friend of a friend (FOAF) ontology, and we will reuse the definition provided in FOAF agent classes. | Kollektor | Die Sammler sind in der FOAF-Ontologie definiert und wir werden die in den FOAF-Agenten-Klassen enthaltene Definition übernehmen. |
| Questions | A question represents an expression used to request information. A question can be asked in various forms and seeks different kinds of answers. Based on this, a question is further divided into subclasses. | Frage | Eine Frage ist eine Äußerung, die eine Antwort zur Beseitigung einer Wissens- oder Verständnislücke herausfordert. Eine Frage kann in verschiedenen Formen gestellt werden und sucht nach verschiedenen Arten von Antworten. Basierend darauf wird eine Frage weiter in Unterklassen unterteilt. |
| Topics | A topic represents the main subject of a questionnaire or a question. A questionnaire may focus on a general topic such as “Food” and a question may cover subtopics such as “Traditional Food”. | Thema | Ein Thema ist das Hauptthema eines Fragebogens oder einer Frage. Ein Fragebogen kann sich auf ein allgemeines Thema wie “Essen“ konzentrieren und eine Frage kann Unterthemen wie “Traditionelles Essen“ abdecken. |
| Catalogue of Paper Slips | |||
|---|---|---|---|
| Entity @en | Description @en | Entity @de | Description @de |
| Paper Slip | A paper slip represents the information contained on individually printed paper slips. A paper slip contains original answers to the questions in the distributed questionnaires and could further contain additional comments. | Belegzettel | Ein Papierzettel repräsentiert die Informationen auf einzelnen gedruckten Papierbelegen. Ein Zettel enthält originale Antworten auf die Fragen in den verteilten Fragebögen und kann zusätzliche Kommentare des Sammlers oder des Bearbeiters enthalten. |
| Source | A source is anything that is used as a source of information. A source could be a person, a document or any other thing. | Quelle | Eine Quelle ist alles, was als Informationsquelle dient. Eine Quelle kann eine Person, ein Dokument oder eine andere Sache sein. |
| Lemma | A lemma is a word which is used as a headword in a dictionary. Lemma in our context refers to the headwords that are used in (WBÖ) and (DBÖ/dbo@ema). | Lemma | Ein Lemma ist ein Wort, das als Stichwort in einem Wörterbuch verwendet wird. Lemma bezieht sich in unserem Zusammenhang auf die Stichwörter, die im WBÖ und in der DBÖ/dbo@ema verwendet werden. |
| Answer | An answer represents a written, spoken or illustrated response to a question. | Antworten | Eine Antwort repräsentiert eine schriftliche, gesprochene oder illustrierte Antwort auf eine Frage. |
| Question | ||
| attribute@en | attribute@de | Description |
| number | nummer | “Number” of the single question (but without their respective questionnaire numbers), compiled like it is listed in the book of questionnaires |
| originalQuestion | originalfrage | Question in the entire length, edited by linguists |
| shortQuestion | kurzfrage | Shortened question (limited to one line); thus, usually strongly edited; (originally) to be displayed after the question number in the entries of the TUSTEP/xml-files of the DBÖ/dbo@ema; with an indication of more text in the original, if available (asterisk at the end) |
| originalData | originaldaten | Question in the entire length, edited by linguists before 2007—text based on the TUSTEP database entry |
| Questionnaire | ||
| number | nummer | Number of the questionnaire like it is indicated in the headings of the questionnaires |
| title | titel | Title, heading of the questionnaire like it is indicated in the questionnaires |
| keyword | schlagwoerter | Thematic keywords matching the topic of the questionnaire |
| yearOfPublication | erscheinungsJahr | The year, when the questionnaire was finally sent out to the collectors. |
| authorId | autorenId | The creator(s) of the questionnaire |
| originalData | originaldaten | A questionnaire in its entire length |
| note | anmerkung | Fields for possible notes; currently the label of the person who entered the (unedited) |
| release | freigabe | Release of entry (by the data scientists) for further processing by the linguists |
| checked | checked | This means: review and additional processing (e.g., adding the correct lemma) by linguists is completed |
| wordToolbar | wordleiste | Entry to be considered in the MS Word bar (which was established for compiling WBÖ entries ~2005-2007) |
| druck | Entry is checked and can be considered for printing | |
| online | online | This entry is released online (it will be visible on the dbo@ema website) |
| published | publiziert | This entry is already processed for the printed version of the WBÖ |
| Level | Question Types | Description |
|---|---|---|
| Level-1: Generic | Multiple Choice | Asks for a selection of one item from a list of three or more potential answers. |
| Dichotomous | Asks for a selection of answers from a binary option. It includes yes/no or agree/disagree types of answers to stated questions. | |
| Description | Asks for a written representation of a given entity, e.g., “What would be the function of x?”. | |
| Ranking | Requires the respondent to compare entities and rank them in a given order. | |
| Rating | Asks the respondent to assign a rating (degree of excellence) to a given entity based on a predefined range | |
| Illustration | Asks for a pictorial or diagrammatic representation of a given entity, e.g., “What does x look like?”. | |
| Level-2: Linguistic | Phonological | Asks for the pronunciation or phonetic representation of words. |
| Morphological | Asks about the structure and the formation of words and parts of words. Based on the structure, morphological questions can take various forms. | |
| Thesaurus | Asks for a list of words or expressions that are used as synonyms (sometimes, antonyms) or contrasts of a given entity. | |
| Syntactic | Demands the construction of phrases or sentences using a given word or a given idiom, e.g., “Provide a phrase/sentence for/using a word/idiom x”. | |
| Onomasiological | Asks for the name of a given entity, e.g., “how do you call x?” where x stands for an entity. | |
| Semasiological | Seeks the meaning of a given entity, e.g., “what does x mean?”. | |
| Metaphorical | Asks for some conveyed meanings given a word or an expression. Metaphorical questions are related to semasiological questions, but they ask for an additional interpretation of the expression beyond its apparent meaning. | |
| Level-3: Cultural | Cultural | Asks for a belief of societies, procedures on how to prepare things, and how to play games, contents of cultural songs or poems used for celebrations. |
| Questionnaire | Question |
|---|---|
| <#QuestionnaireTriplesMap> a rr:TriplesMap; rr:logicalTable [ rr:sqlQuery “““ SELECT Fragebogen.*, (CASE fragebogen_typ_id WHEN ‘1′ THEN ‘SystematicQuestionnaire’ WHEN ‘2′ THEN ‘AdditionalQuestionnaire’ WHEN ‘3′ THEN ‘DialectographicQuestionnaire’ END) QUESTIONNAIRETYPE FROM Fragebogen “““ ]; rr:subjectMap [ rr:template “http://exploreat.adaptcentre.ie/Questionnaire/{id}” ; rr:class oldcan:Questionnaire ; rr:graph <http://exploreat.adaptcentre.ie/Questionnaire_graph> ;]; rr:predicateObjectMap [ rr:predicate oldcan:title ; rr:predicate rdfs:label; rr:objectMap [ rr:column “titel” ; rr:language “de”;] ; rr:graph <http://exploreat.adaptcentre.ie/Questionnaire_graph> ;] ; rr:predicateObjectMap [ rr:predicate oldcan:publicationYear ; rr:objectMap [ rr:column “erscheinungsjahr” ] ; rr:graph <http://exploreat.adaptcentre.ie/Questionnaire_graph> ;]; rr:predicateObjectMap [ rr:predicate oldcan:note ; rr:objectMap [ rr:column “anmerkung”; rr:language “de”]; rr:graph <http://exploreat.adaptcentre.ie/Questionnaire_graph> ;]; rr:predicateObjectMap [ rr:predicate rdf:type ; rr:objectMap [ rr:template “https://explorations4u.acdh.oeaw.ac.at/ontology/oldcan#{QUESTIONNAIRETYPE}”; rr:graph <http://exploreat.adaptcentre.ie/Questionnaire_graph> ;] ;]; rr:predicateObjectMap [ rr:predicate oldcan:hasAuthor ; rr:predicate dct:creator; rr:graph <http://exploreat.adaptcentre.ie/Questionnaire_graph> ; rr:objectMap [ rr:parentTriplesMap <#PersonTripleMap> ; rr:joinCondition [ rr:child “person_id” ; rr:parent “id” ;]]] ;. | <#QuestionTripleMap> a rr:TriplesMap; rr:logicalTable [ rr:sqlQuery “““SELECT Frage.* FROM Frage”““ ]; rr:subjectMap [ rr:template “http://exploreat.adaptcentre.ie/Question/{id}” ; rr:class oldcan:Question ; rr:graph <http://exploreat.adaptcentre.ie/Question_graph> ;]; rr:predicateObjectMap [ rr:predicate oldcan:combinedID ; rr:objectMap [ rr:template“http://exploreat.adaptcentre.ie/Question/{fragebogen_id}-{nummer}”]; rr:graph <http://exploreat.adaptcentre.ie/Question_graph> ;]; rr:predicateObjectMap [ rr:predicate oldcan:number ; rr:objectMap [ rr:column “nummer” ] ; rr:graph <http://exploreat.adaptcentre.ie/Question_graph> ;]; rr:predicateObjectMap [ rr:predicate oldcan:originalQuestion ; rr:predicate rdfs:label; rr:objectMap [ rr:column “originalfrage” ; rr:language “de”;] ; rr:graph <http://exploreat.adaptcentre.ie/Question_graph> ;]; rr:predicateObjectMap [ rr:predicate oldcan:shortQuestion ; rr:objectMap [ rr:column “kurzfrage” ; rr:language “de”;] ; rr:graph <http://exploreat.adaptcentre.ie/Question_graph> ;]; rr:predicateObjectMap [ rr:predicate oldcan:isQuestionOf ; rr:graph <http://exploreat.adaptcentre.ie/Question_graph> ; rr:objectMap [ rr:parentTriplesMap <#QuestionnaireTriplesMap> ; rr:joinCondition [ rr:child “fragebogen_id” ; rr:parent “id” ; ]]] ;. |
| Generated Triples for Questionnaire 1 |
|---|
| (http://exploreat.adaptcentre.ie/Questionnaire/1 rdfs:type oldcan:Questionnaire) (http://exploreat.adaptcentre.ie/Questionnaire/1 rdfs:type oldcan:SystematicQuestionnaire) (http://exploreat.adaptcentre.ie/Questionnaire/1 oldcan:publicationYear 1920) (http://exploreat.adaptcentre.ie/Questionnaire/1 oldcan:title “Kopf”) (http://exploreat.adaptcentre.ie/Questionnaire/1 oldcan:hasAuthor “http://exploreat.adaptcentre.ie/Person/22192“ |
| Named Graph | Unique Entities | Triples | Named Graph | Unique Entities | Triples |
|---|---|---|---|---|---|
| Questionnaire_graph | 762 | 2969 | Source_graph | 16839 | 231537 |
| Question_graph | 24382 | 163705 | Agents_graph | 11163 | 123438 |
| Paperslip_graph | 65839 | 539749 | Multimedia_graph | 8218 | 63741 |
| Papersliprecord_graph | 140509 | 824925 | Lemma_graph | 61878 | 921261 |
| Query | Description | Purpose |
|---|---|---|
| Q1 | All the questionnaires that deal with a topic T | Conceptualisation and topic discovery |
| Q2 | All the questionnaires whose author has a gender G (male, female, unknown) | Biographical and prosopographical analysis |
| Q3 | All the paper slips that contain answers to question X | Generic, historical and cultural |
| Q4 | Number of questions authored by a female author | Statistical analysis |
| Q5 | All the questions that are related to a lemma x | Lexical and lexicographic analysis |
| Q6 | All answers that are collected for questionnaire X | Generic, historical and cultural inquiry |
 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abgaz, Y.; Dorn, A.; Piringer, B.; Wandl-Vogt, E.; Way, A. Semantic Modelling and Publishing of Traditional Data Collection Questionnaires and Answers. Information 2018, 9, 297. https://doi.org/10.3390/info9120297
Abgaz Y, Dorn A, Piringer B, Wandl-Vogt E, Way A. Semantic Modelling and Publishing of Traditional Data Collection Questionnaires and Answers. Information. 2018; 9(12):297. https://doi.org/10.3390/info9120297
Chicago/Turabian StyleAbgaz, Yalemisew, Amelie Dorn, Barbara Piringer, Eveline Wandl-Vogt, and Andy Way. 2018. "Semantic Modelling and Publishing of Traditional Data Collection Questionnaires and Answers" Information 9, no. 12: 297. https://doi.org/10.3390/info9120297
APA StyleAbgaz, Y., Dorn, A., Piringer, B., Wandl-Vogt, E., & Way, A. (2018). Semantic Modelling and Publishing of Traditional Data Collection Questionnaires and Answers. Information, 9(12), 297. https://doi.org/10.3390/info9120297