Towards the Representation of Etymological Data on the Semantic Web


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Etymologies—A Little Bit of Background
2.1. What Are Etymologies?
In principle, anything can be studied etymologically simply by asking the question “where did that come from?”. The items investigated may be a phoneme or an entire text, and thus the question might be considered part of different disciplines, not even linguistic ones in the case of texts [...] As a result, it seems unproblematic to extend the notion of linguistic etymology and etymological research beyond words and word histories to anything that can be linguistically described.
2.2. Example Etymologies
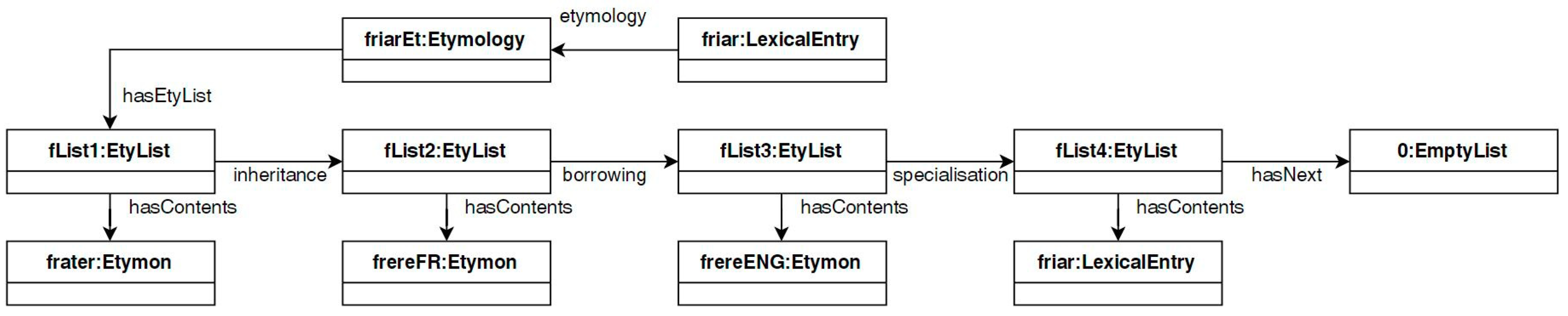
Latin frāter brother < Old French frere brother, also member of a religious order of “brothers” < Middle English frere, friar < modern English friar.
GIRL, a female child, young woman. (E.) ME. gerle, girle, gyrle, formerly used of either sex, and signifying either a boy or girl. In Chaucer, C.T. 3767 (A 3769) girl is a young woman; but in C.T. 666 (A 664), the pl. girles means young people of both sexes. In Will. of Palerne, 816, and King Alisander, 2802, it means ‘young women’; in P. Plowman, B. i.33, it means ‘boys;’ cf. B. x. 175. Answering to an AS. form *gyr-el-, Teut. *gur-wil-, a dimin. form from Teut. base *gur-. Cf. NFries. gör, a girl; Pomeran. goer, a child; O. Low G. gör, a child; see Bremen Wörtebuch, ii. 528. Cf. Swiss gurre, gurrli, a depreciatory term for a girl; Sanders, G. Dict. i. 609, 641; also Norw. gorre, a small child (Aasen); Swed. dial. gårrä, guerre (the same). Root uncertain. Der. girl-ish, girl-ish-ly, girl-ish-ness, girl-hood.
girl, whence girlish, derives from ME girle, varr gerle, gurle: o.o.o.: perh of C origin: cf Ga and Ir caile, EIr cale, a girl; with Anglo-Ir girleen (dim -een), a (young) girl, cf Ga-Ir cailin (dim -in), a girl. However, far more prob, girl is of Gmc origin: Whitehall postulates the OE etymon *gyrela or *gyrele and adduces Southern E dial girls, primrose blossoms, and grlopp, a lout, and tentatively LG goere, a young p/erson (either sex). Ult, perh, related to L puer, puella, with basic idea ‘(young) growing thing’.
2.3. Where Are Etymologies Found?
Etymological research naturally is fundamental to the historical investigations of a language. Etymologies permit generalizations about historical developments, for instance the formulation of sound laws or about a particular synchronically attested phenomenon, such as the occurrence of a particular type of stem formation. Moreover, etymologies are also used as arguments to answer questions about historical relationships among languages.”..[E]tymology can be regarded as something like a fundamental auxiliary discipline of historical linguistics
Titles of Honour, such as are Duke, Count, Marquis, and Baron, are honourable; as signifying the value set upon them by the Soveraigne Power of the Common-wealth: Which Titles, were in old time titles of Office, and Command, derived some from the Romans, some from the Germans and French. Dukes, in Latine Duces, being generals in war; Counts, Comites, such as bare the general company out of friendship; and were left to govern and defend places conquered, and pacified; Marquises, Marchiones, were Counts that governed the Marches, or bounds of the Empire. Which titles of Duke, Count, and Marquis came into the Empire about the time of Constantine the Great, from the customs of the German Militia. However, Baron seems to have been a title of the Gaules, and signifies a Great man; such as were the Kings or Princes men, whom they employed in war about their persons; and seems to be derived from Vir, to Ber, and Bar, that signified the same in the language of the Gaules, that Vir in Latin; and thence to Bero, and Baro: so that such men were called Berones, and after Barones; and (in Spanish) Varones.
3. Representing Etymologies on the Semantic Web
3.1. Advantages (and Some Drawbacks) of Publishing Etymological Data as Linked Data
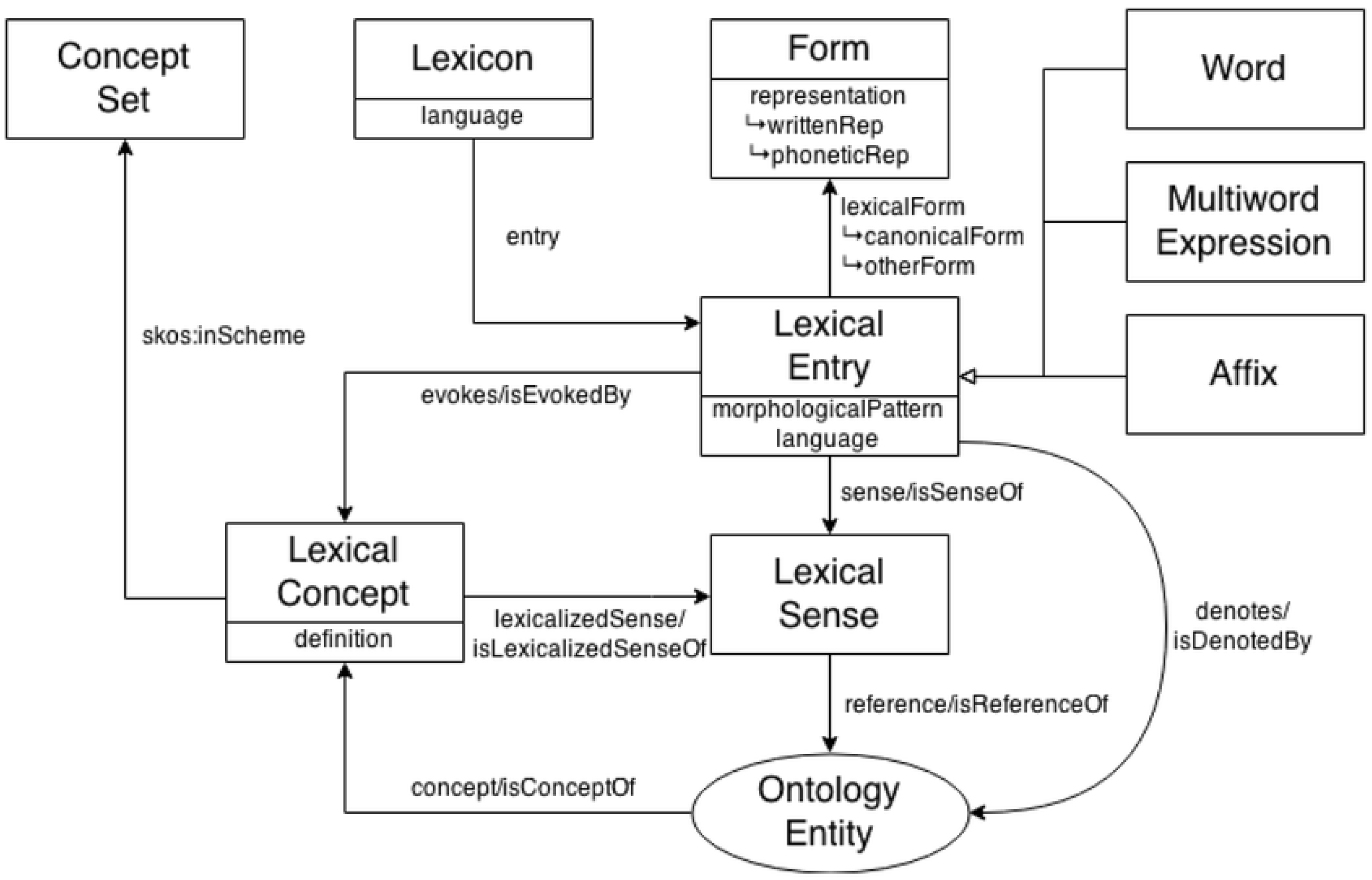
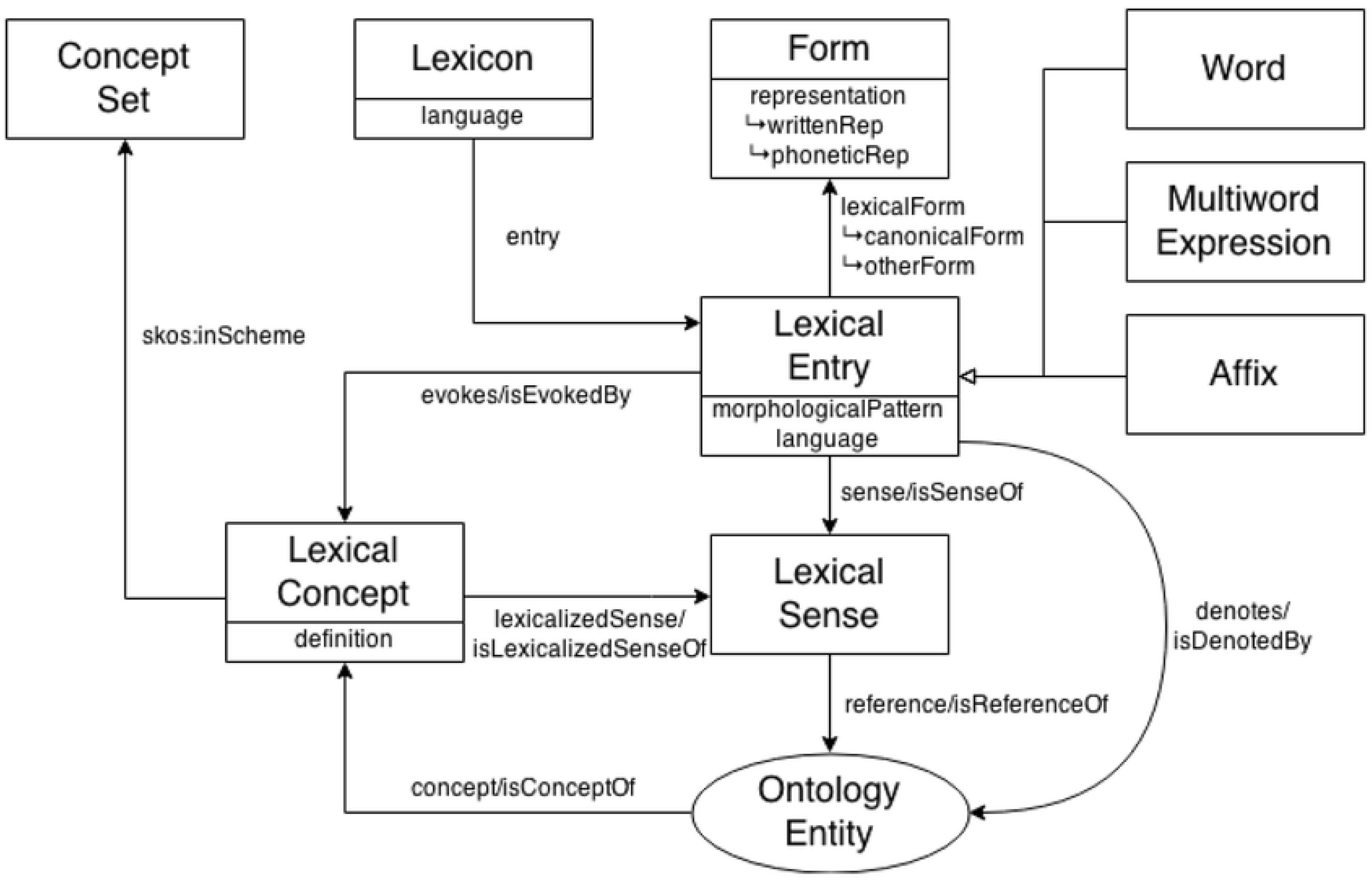
3.2. The Ontolex-Lemon Model
3.3. Related Work
4. A First Proposal for a Linked Data Vocabaulary for Etymology
4.1. Etymology and Etymon
4.2. Building up Etymologies
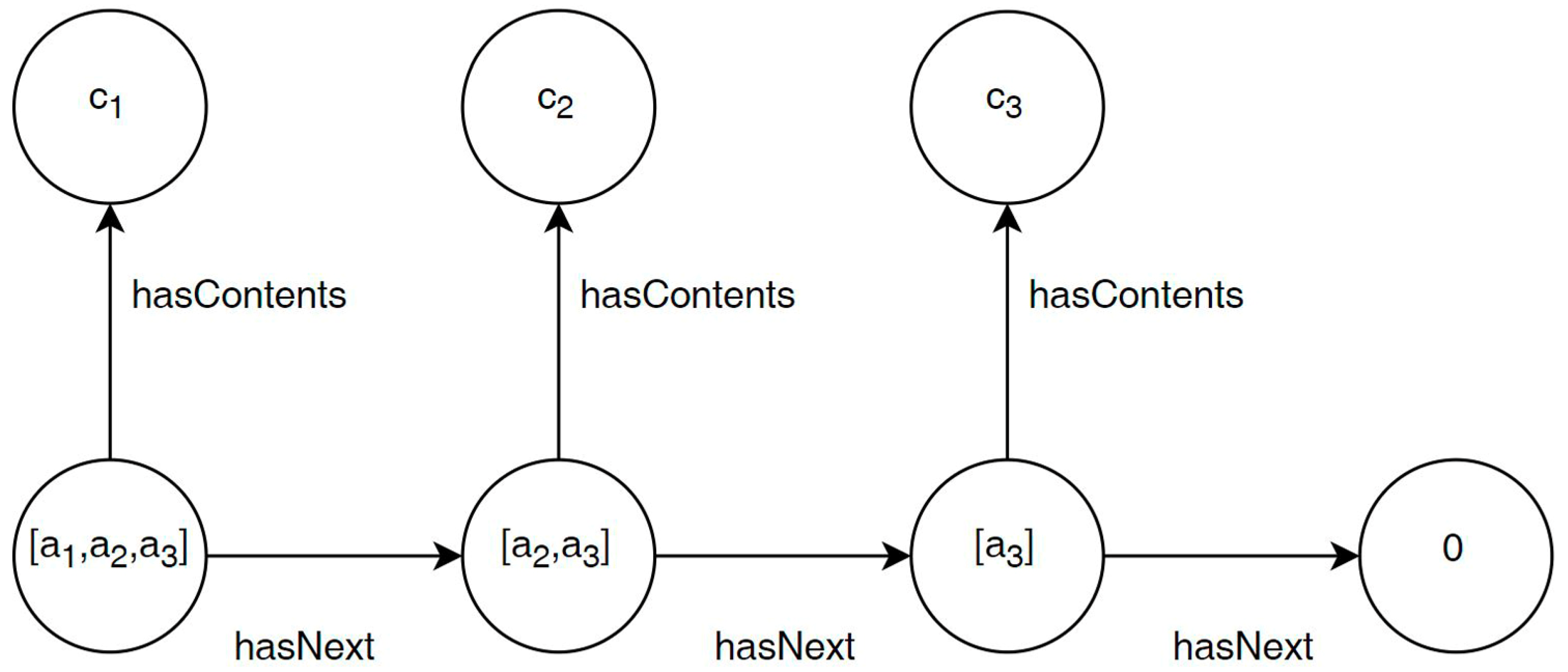
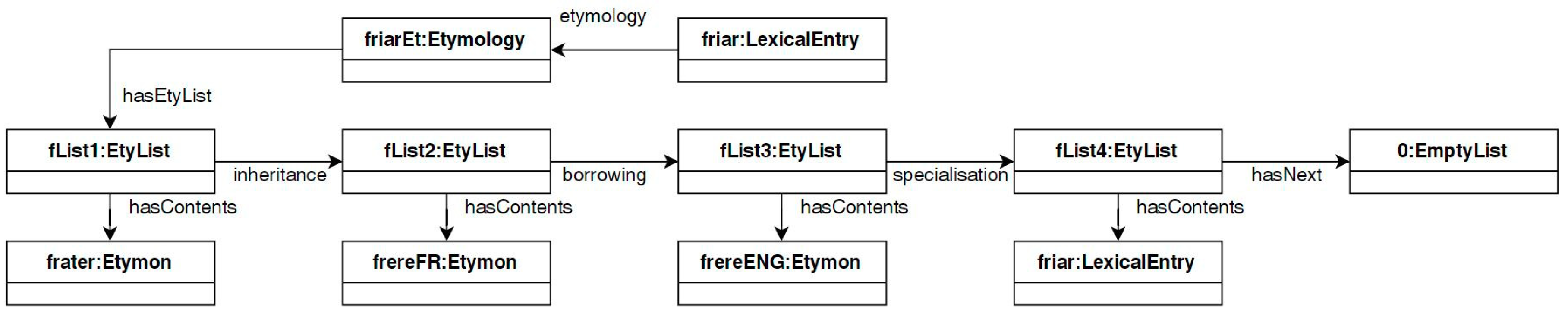
4.2.1. Etymological List
- The object property hasLink is a generic etymological relationship between two elements in an EtyList; it is a subproperty of hasNext and its domain and range are both EtyList;
- The object property borrowingLink is used to link two cells , together when we want to specify a relationship of borrowing between and ; it is a subproperty of hasLink;
- The object property inheritanceLink is used to link two cells , together when we want to specify an inheritance relationship between and ; it is also a subproperty of hasLink.
- :fList1
- a lemonety:EtyList ;lemonety:inheritance :fList2 ;<https://w3id.org/list#hasContents> :frater .
- :fList2
- a lemonety:EtyList ;lemonety:borrowing :fList3 ;<https://w3id.org/list#hasContents> :frereFR .
- :fList3
- a lemonety:EtyList ;:inheritance :fList4 ;<https://w3id.org/list#hasContents> :frere .
- :fList4
- a lemonety:EtyList ;<https://w3id.org/list#hasContents> :friarENG ;<https://w3id.org/list#hasNext> :empT .
- :empT
- a <https://w3id.org/list#EmptyList> .
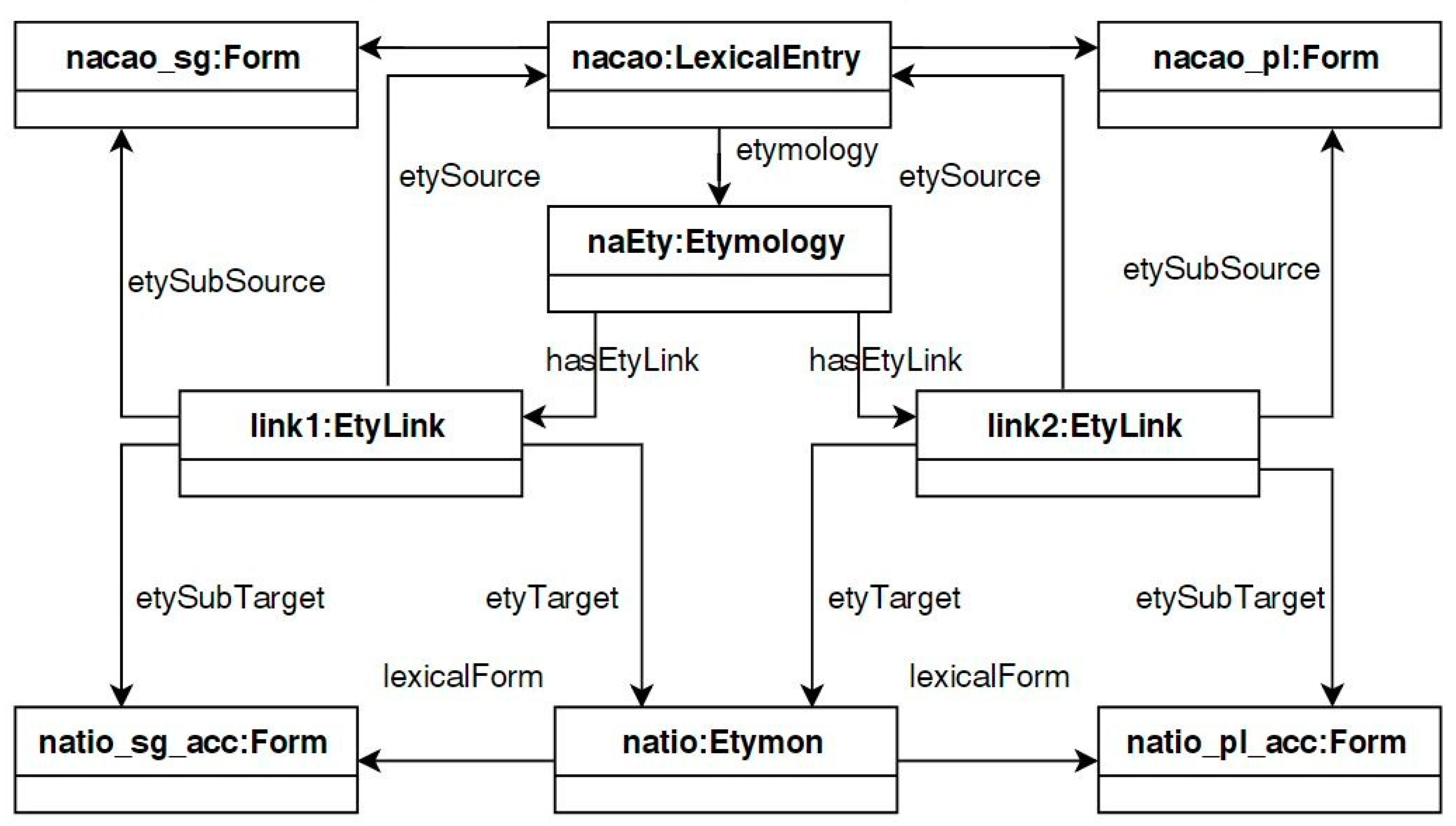
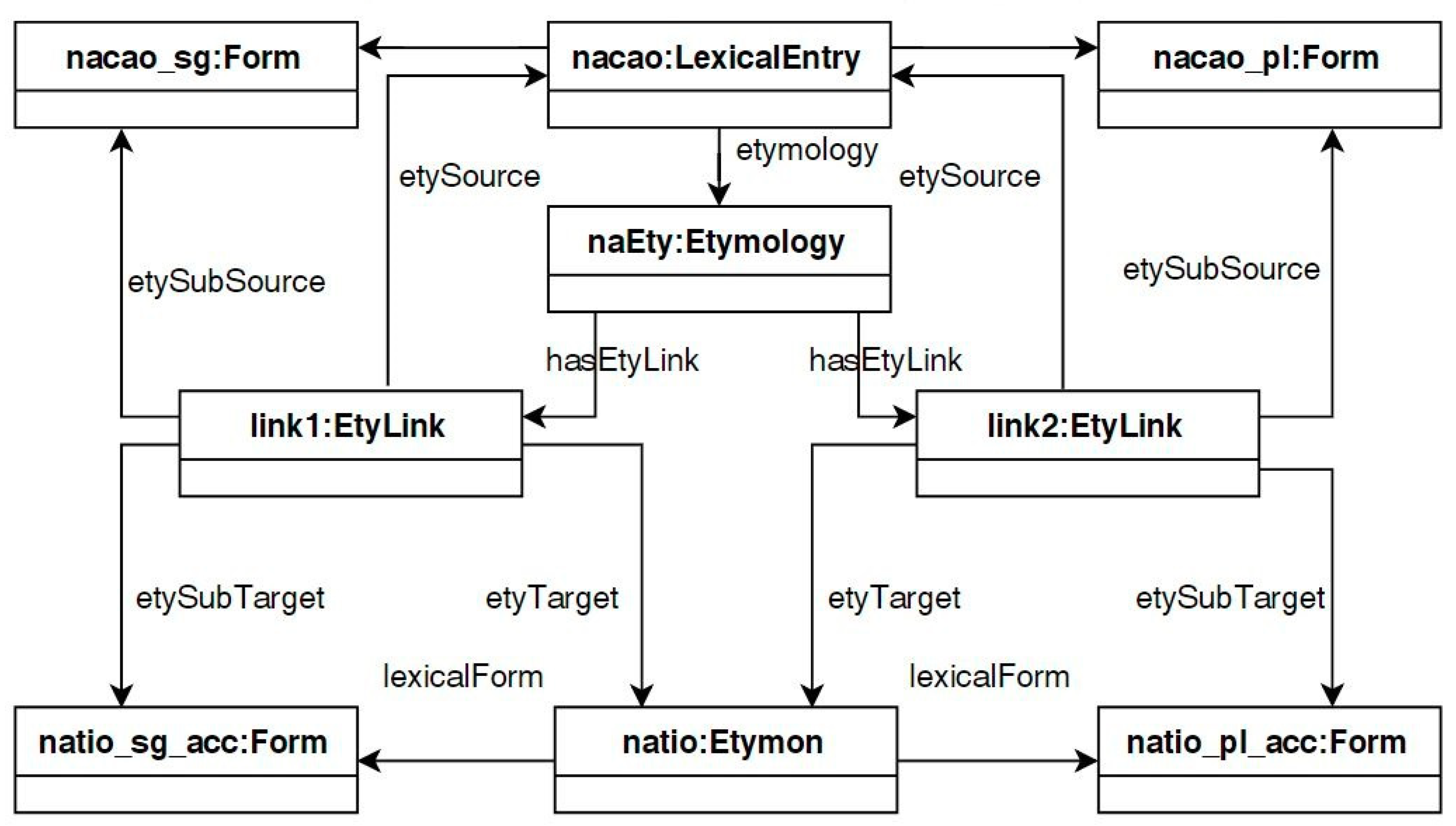
4.2.2. Graph-Based Etymologies and the Etymological Link Class
- The object property hasEtyLink has Etymology as its domain and EtyLink as its range, it therefore links an etymology together with its etymological links.
- The object property etySource links etymological links with their source etymons/lexical entries, its domain is EtyLink and its range is LexicalEntry; similarly for the object property etyTarget which links etymological links with their targets.
- The object properties etySubSource and etySubTarget allows us to deal with cases such as that of nação and frere where we would like to create additional links between lexical elements such as word senses and forms and etymons and lexical entries in order to add to the explanatory value of an etymology
- The datatype property type describes the type of an etymological link as a string value; type has the domain EtyLink.
- The datatype property justification allows us to associate a justification with an etymological link.
4.3. There Is No “One Size Fits All” Approach
Lexical Domain
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Bohbot, H.; Frontini, F.; Luxardo, G.; Khemakhem, M.; Romary, L. Presenting the Nénufar Project: A Diachronic Digital Edition of the Petit Larousse Illustré. In Proceedings of the GLOBALEX Workshop at LREC 2018, Miyazaki, Japan, 8 May 2018. [Google Scholar]
- Bellandi, A.; Giovannetti, E.; Weingart, A. Multilingual and Multiword Phenomena in a lemon Old Occitan Medico-Botanical Lexicon. Information 2018, 9, 52. [Google Scholar] [CrossRef]
- Khan, F. Towards the Representation of Etymological and Diachronic Lexical Data on the Semantic Web. In Proceedings of the 6th Workshop on Linked Data in Linguistics, Miyazaki, Japan, 12 May 2018. [Google Scholar]
- ten Hacken, P. On the Interpretation of Etymologies in Dictionaries. In Proceedings of the XVIII EURALEX International Congress: Lexicography in Global Contexts, Ljubljana, Slovenia, 17–21 July 2018; p. 144. [Google Scholar]
- Mailhammer, R. Lexical and Structural Etymology: Beyond Word Histories; Walter de Gruyter: Berlin, Germany, 2013; Volume 11. [Google Scholar]
- Durkin, P. The Oxford Guide to Etymology; Oxford University Press: Oxford, UK, 2009. [Google Scholar]
- Skeat, W.W. An Etymological Dictionary of the English Language/Rev. Walter W. Skeat, 4th revised, enlarged and reset. ed.; Oxford University Press: London, UK, 1910; 780p. [Google Scholar]
- Hollmann, W. Semantic Change. In English Language: Description, Variation and Context; Palgrave: London, UK, 2009. [Google Scholar]
- Partridge, E. Origins: A Short Etymological Dictionary of Modern English, 4th ed.; With Numerous Revisions and Some Substantial Additions; Routledge and Kegan Paul: London, UK, 1966; 972p. [Google Scholar]
- Khan, A.F.; Boschetti, F. Towards a Representation of Citations in Linked Data Lexical Resources. In Proceedings of the XVIII EURALEX International Congress, Ljubljana, Slovenia, 17–21 July 2018; p. 144. [Google Scholar]
- Bronkhorst, J. Etymology and magic: Yāska’s Nirukta, Plato’s Cratylus, and the riddle of semantic etymologies. Numen 2001, 48, 147–203. [Google Scholar] [CrossRef]
- McCrae, J.; Bosque-Gil, J.; Gracia, J.; Buitelaar, P.; Cimiano, P. The Ontolex-Lemon model: development and applications. In Proceedings of the eLex 2017 Conference, Leiden, The Netherlands, 19–21 September 2017; pp. 19–21. [Google Scholar]
- Francopoulo, G.; George, M.; Calzolari, N.; Monachini, M.; Bel, N.; Pet, M.; Soria, C. Lexical markup framework (LMF). In Proceedings of the International Conference on Language Resources and Evaluation-LREC 2006, Genoa, Italy, 22–28 May 2006. [Google Scholar]
- Salmon-Alt, S. Data structures for etymology: Towards an etymological lexical network. Bull. Linguist. Appl. Génér. 2006, 31, 1–12. [Google Scholar]
- Bowers, J.; Romary, L. Deep encoding of etymological information in TEI. arXiv, 2016; arXiv:1611.10122. [Google Scholar]
- Sagot, B. Extracting an Etymological Database from Wiktionary. In Proceedings of the Electronic Lexicography in the 21st century (eLex 2017), Leiden, The Netherlands, 19–21 September 2017; pp. 716–728. [Google Scholar]
- De Melo, G. Etymological Wordnet: Tracing The History of Words. In Proceedings of the LREC 2014, Reykjavik, Iceland, 26–31 May 2014; pp. 1148–1154. [Google Scholar]
- Moran, S.; Bruemmer, M. Lemon-aid: Using Lemon to aid quantitative historical linguistic analysis. In Proceedings of the 2nd Workshop on Linked Data in Linguistics (LDL-2013): Representing and Linking Lexicons, Terminologies and Other Language Data, Pisa, Italy, 23 September 2013; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 28–33. [Google Scholar]
- Chiarcos, C.; Abromeit, F.; Fäth, C.; Ionov, M. Etymology Meets Linked Data. A Case Study In Turkic. In Proceedings of the Digital Humanities 2016, Krakow, Poland, 11–16 July 2016. [Google Scholar]
- Drummond, N.; Rector, A.L.; Stevens, R.; Moulton, G.; Horridge, M.; Wang, H.; Seidenberg, J. Putting OWL in Order: Patterns for Sequences in OWL. In Proceedings of the OWLED, Athens, GA, USA, 10–11 November 2006. [Google Scholar]


© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, A.F. Towards the Representation of Etymological Data on the Semantic Web. Information 2018, 9, 304. https://doi.org/10.3390/info9120304
Khan AF. Towards the Representation of Etymological Data on the Semantic Web. Information. 2018; 9(12):304. https://doi.org/10.3390/info9120304
Chicago/Turabian StyleKhan, Anas Fahad. 2018. "Towards the Representation of Etymological Data on the Semantic Web" Information 9, no. 12: 304. https://doi.org/10.3390/info9120304
APA StyleKhan, A. F. (2018). Towards the Representation of Etymological Data on the Semantic Web. Information, 9(12), 304. https://doi.org/10.3390/info9120304