
Information and Phylogenetic Systematic Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Statement of Purpose
1.2. Consistent Cladograms
1.3. Information Theory and Cladistic Analysis
1.4. Apomorphic Density Format
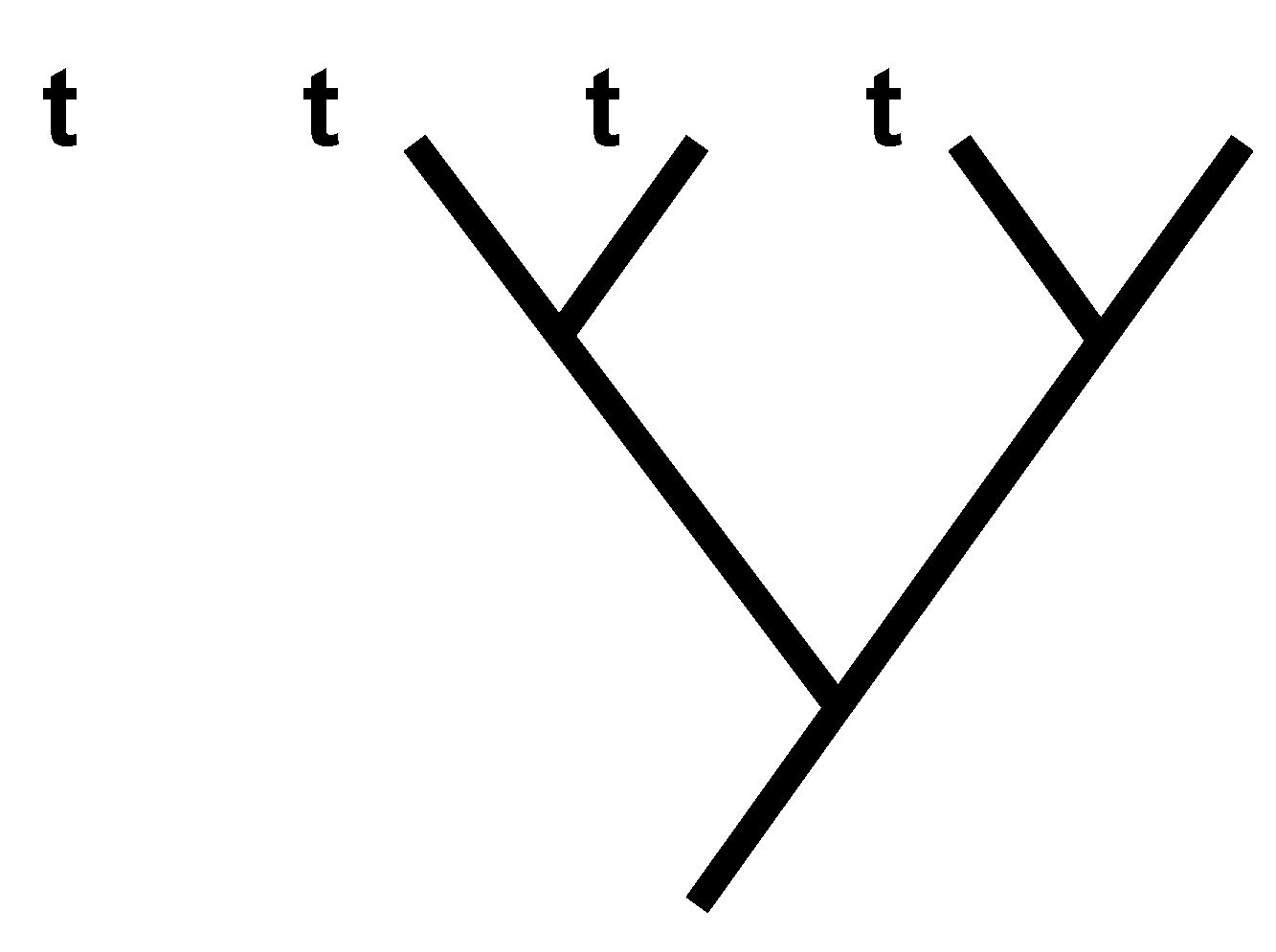
1.5. A General Expression Quantifying I
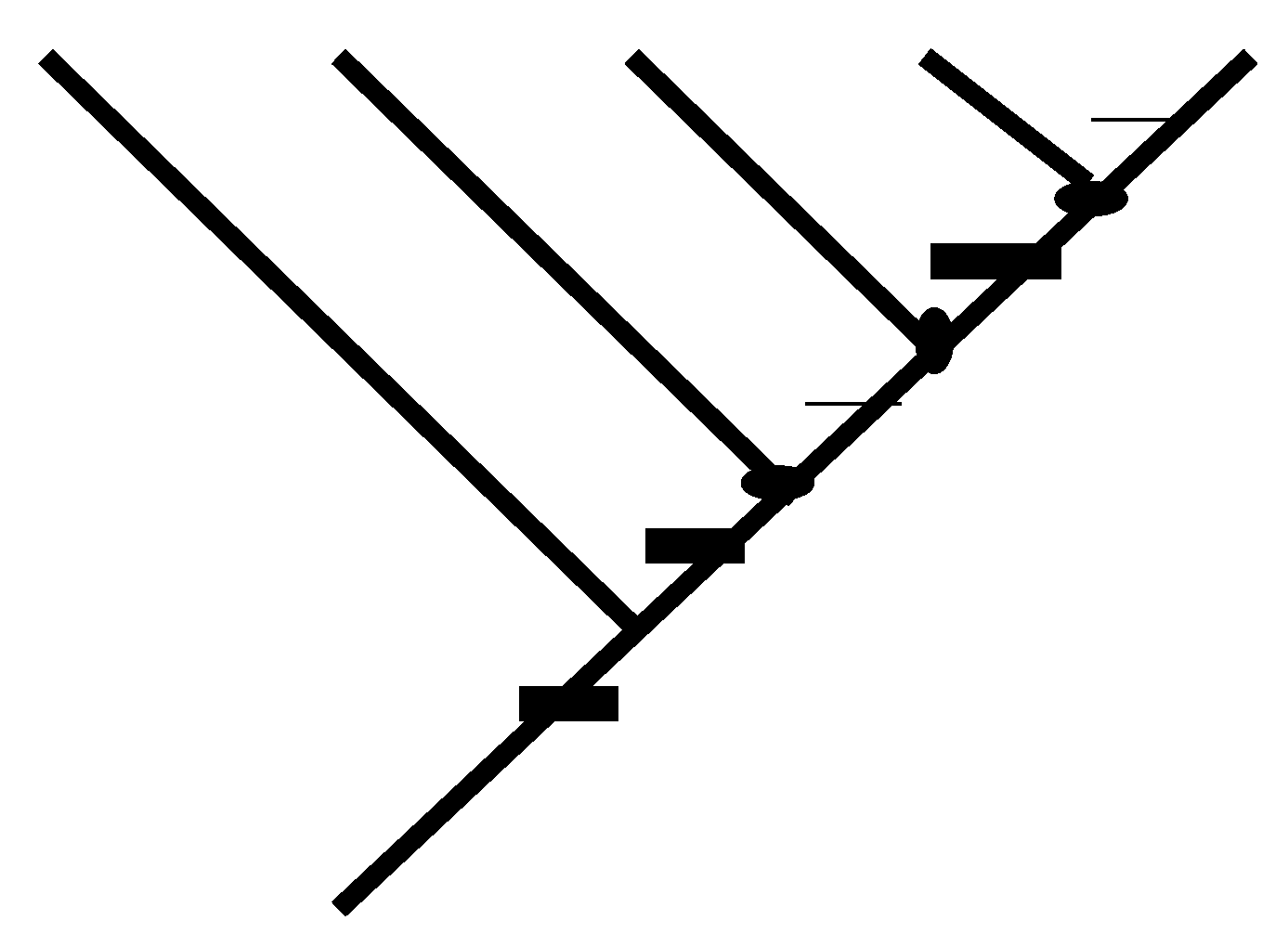
1.6. Consistent Basal Matrices and Conventions
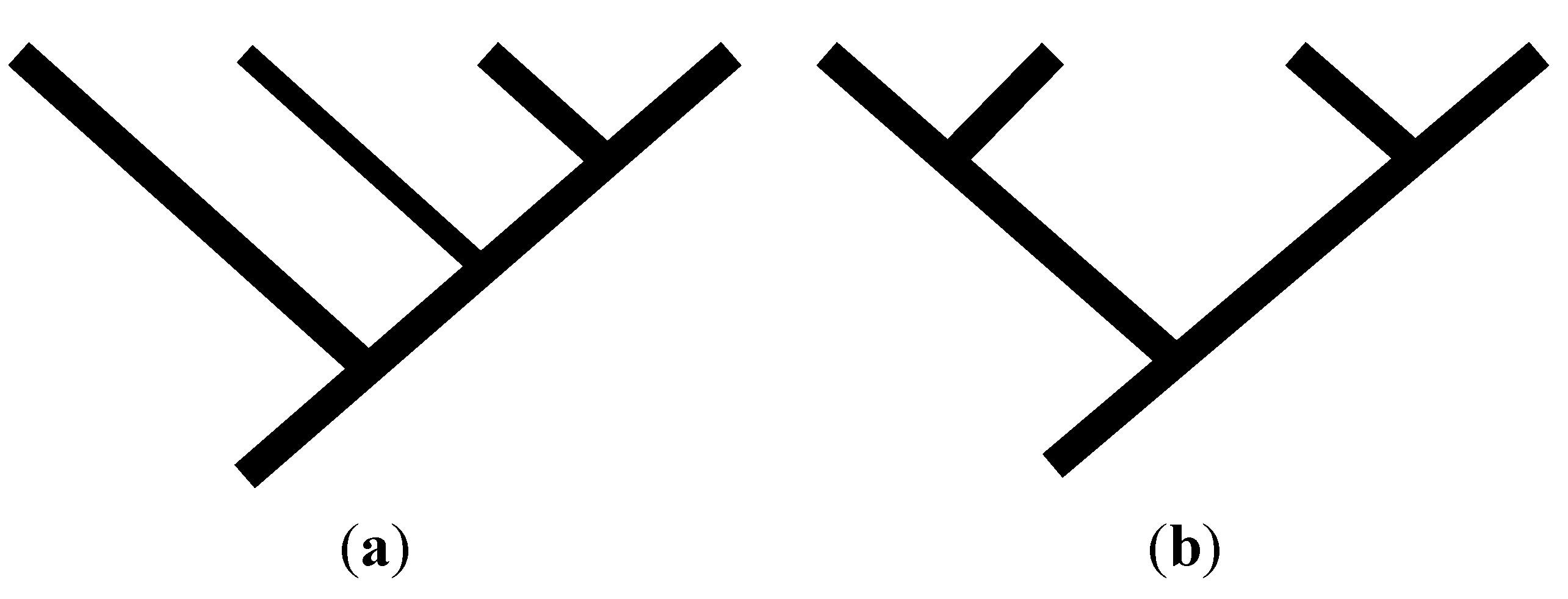
1.7. Adding Character Vectors to Consistent Basal Matrices
2. Results and Discussion
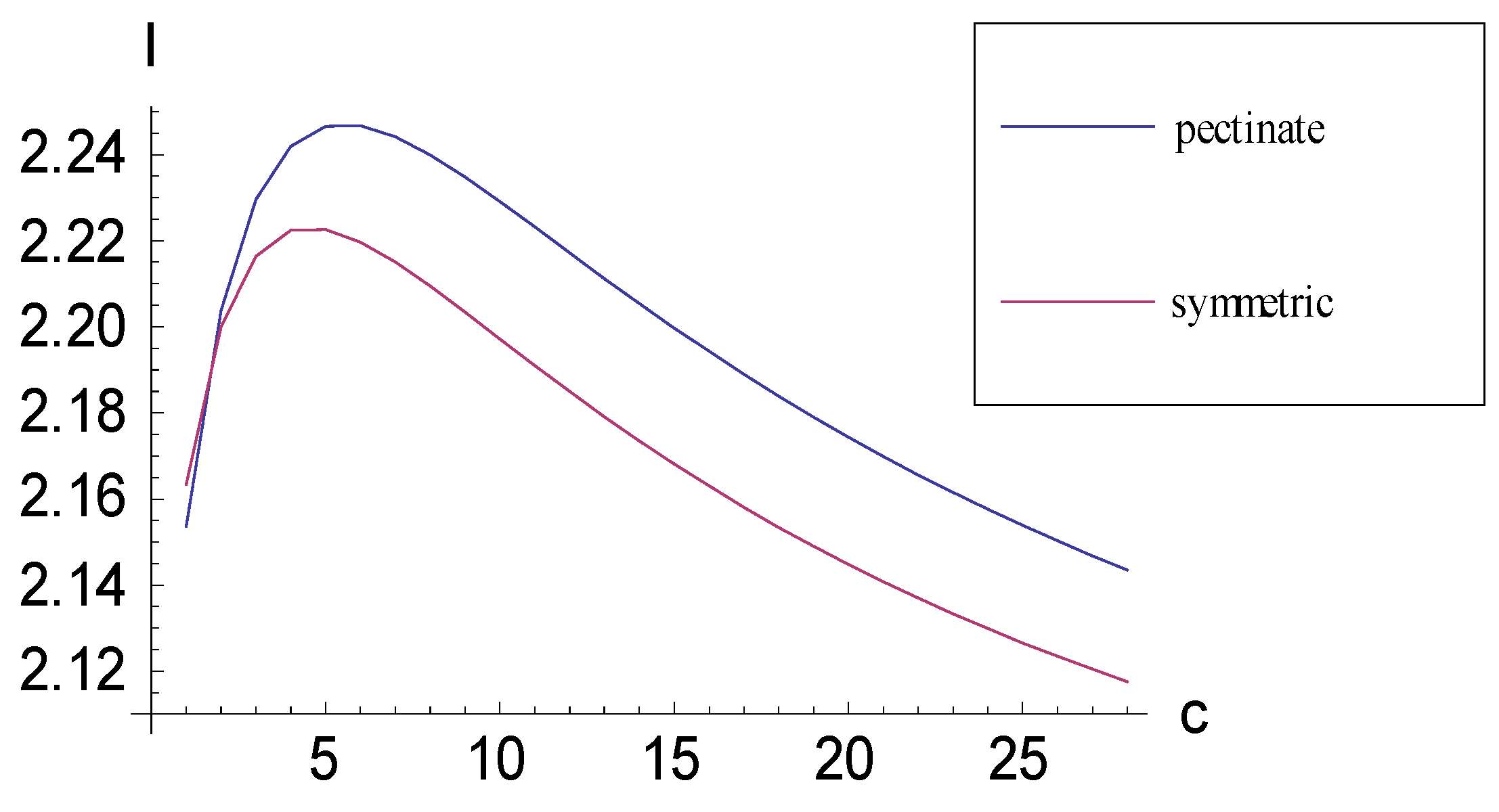
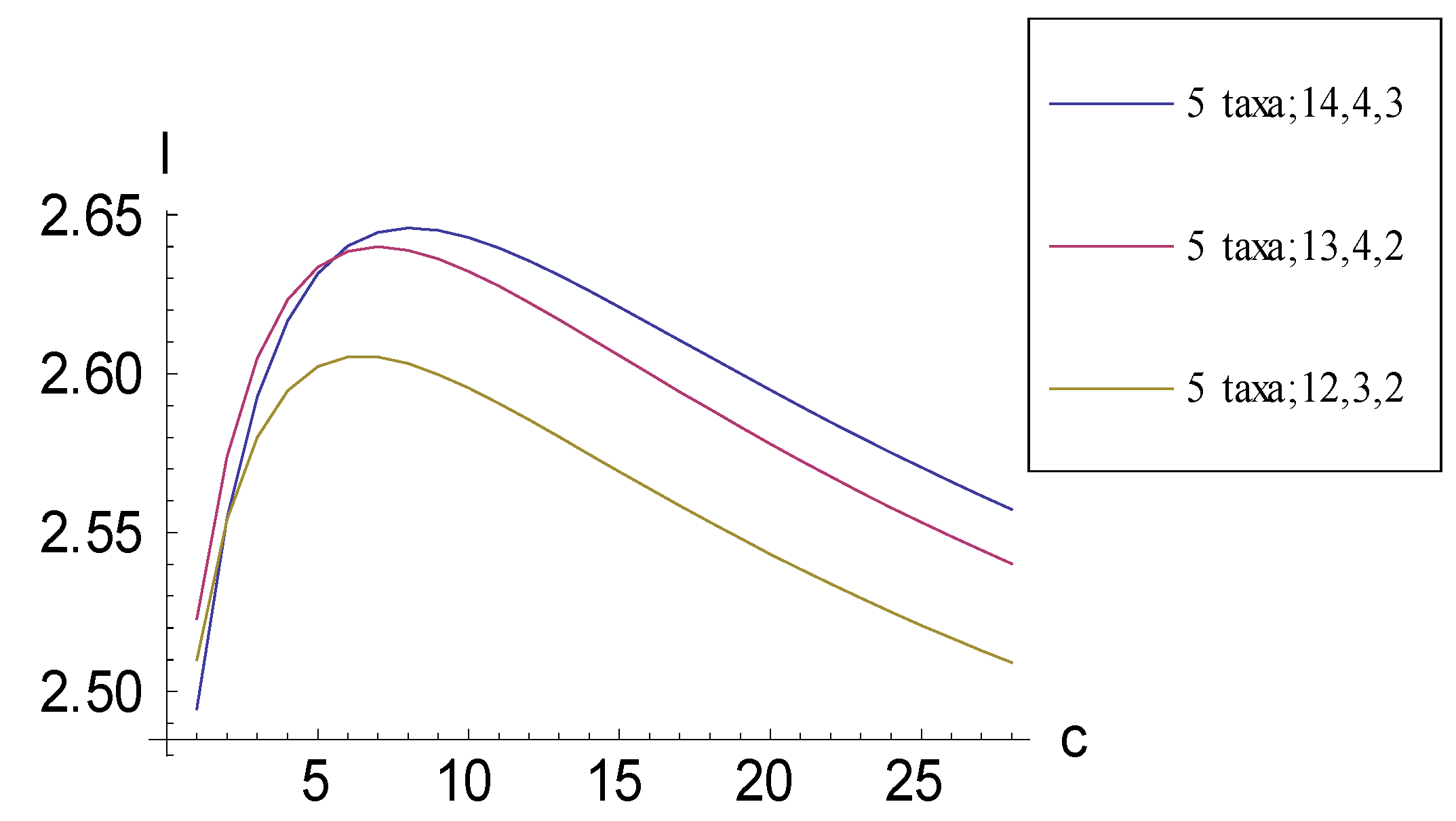
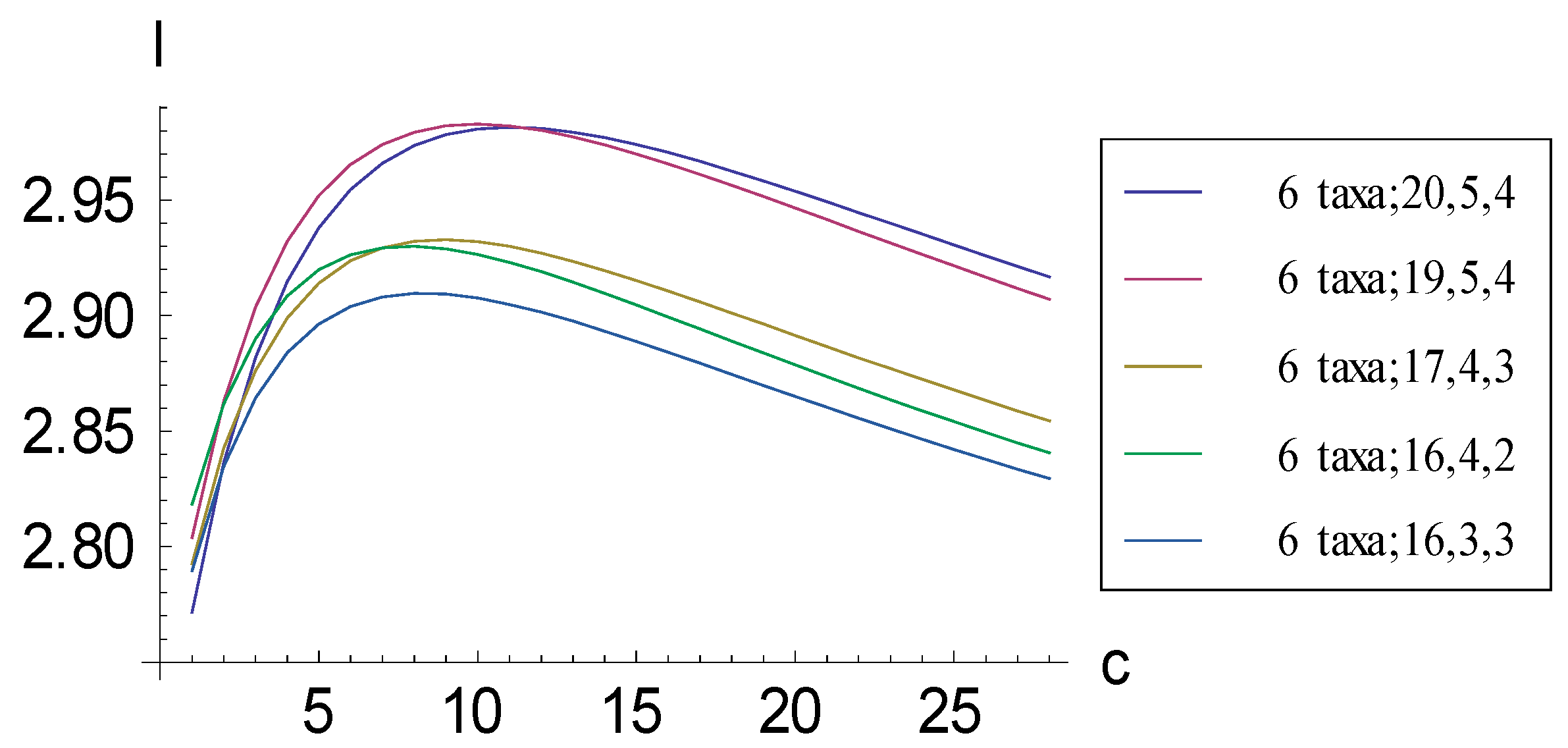
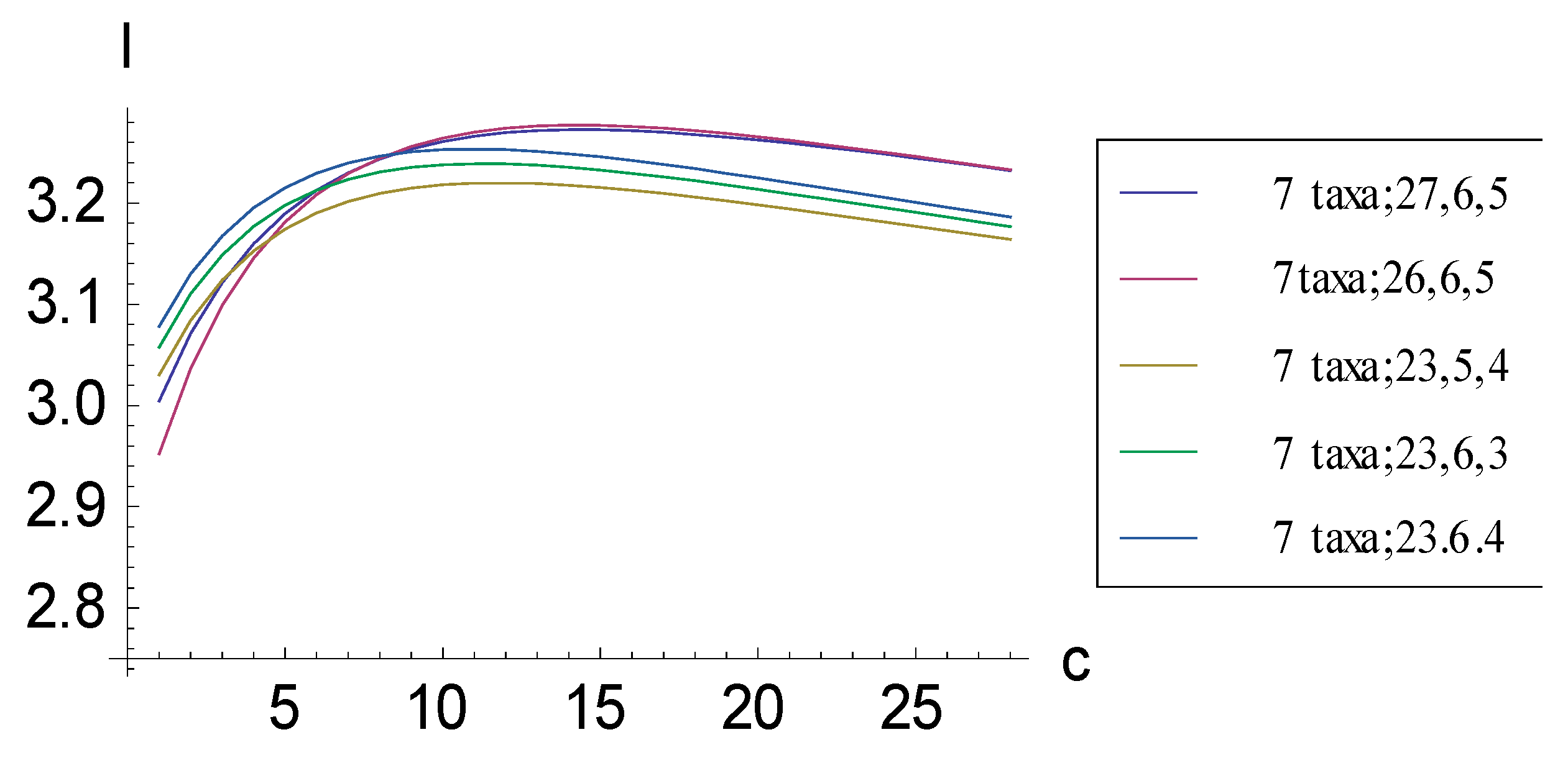
2.1. Achieving Maximum I as Autapomorphic Character Vectors are Added to Consistent Basal Matrices
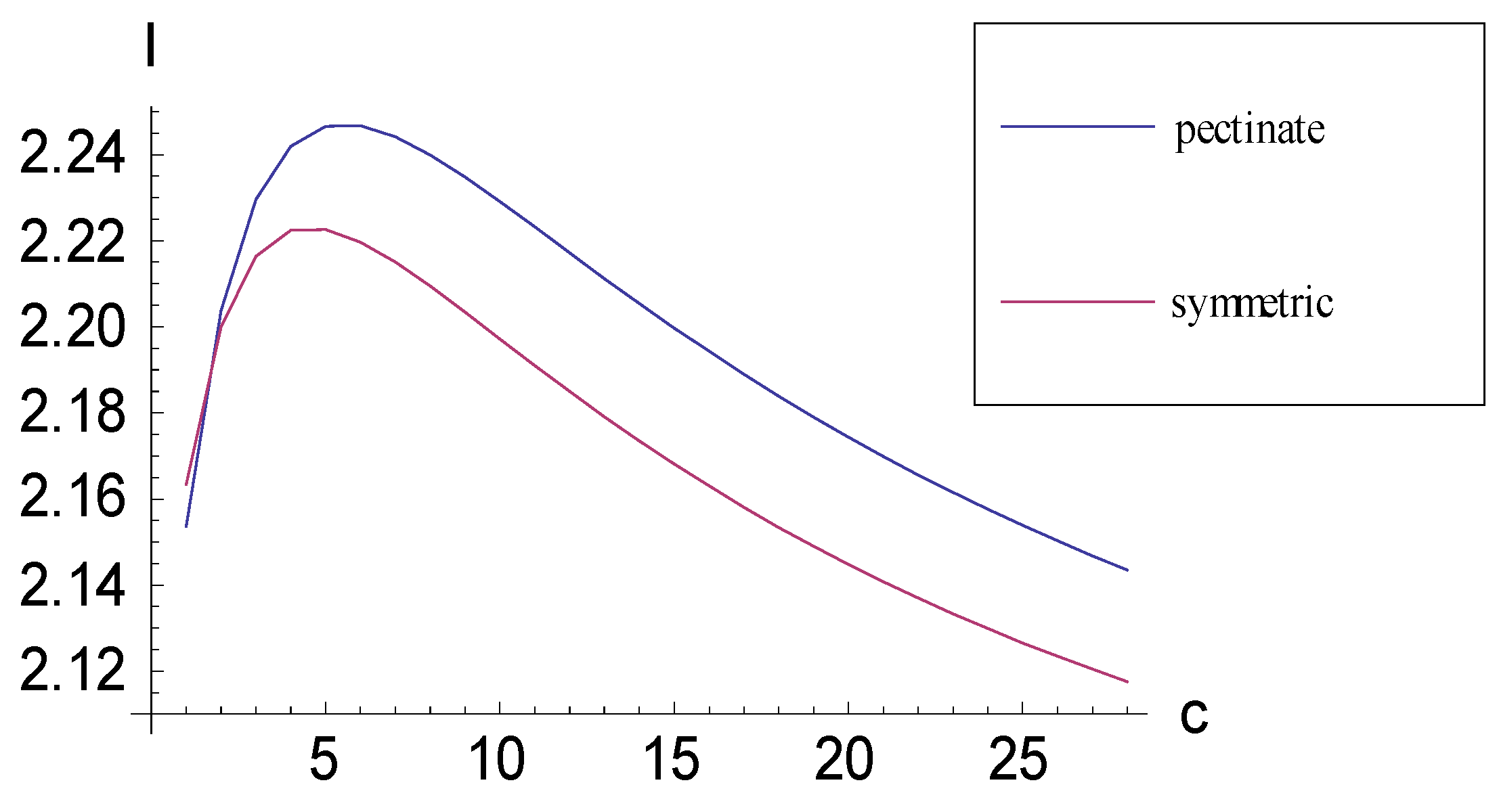
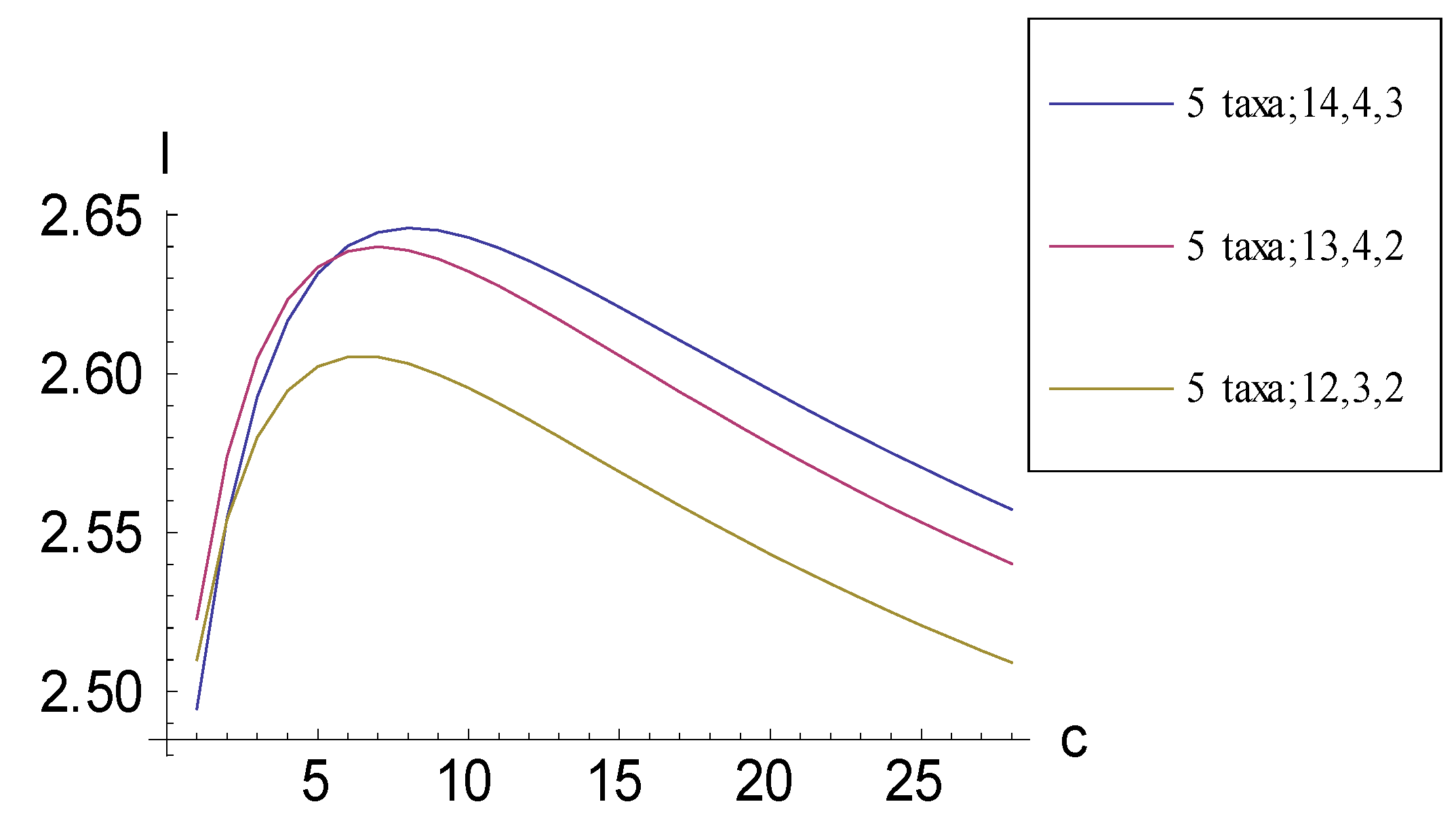
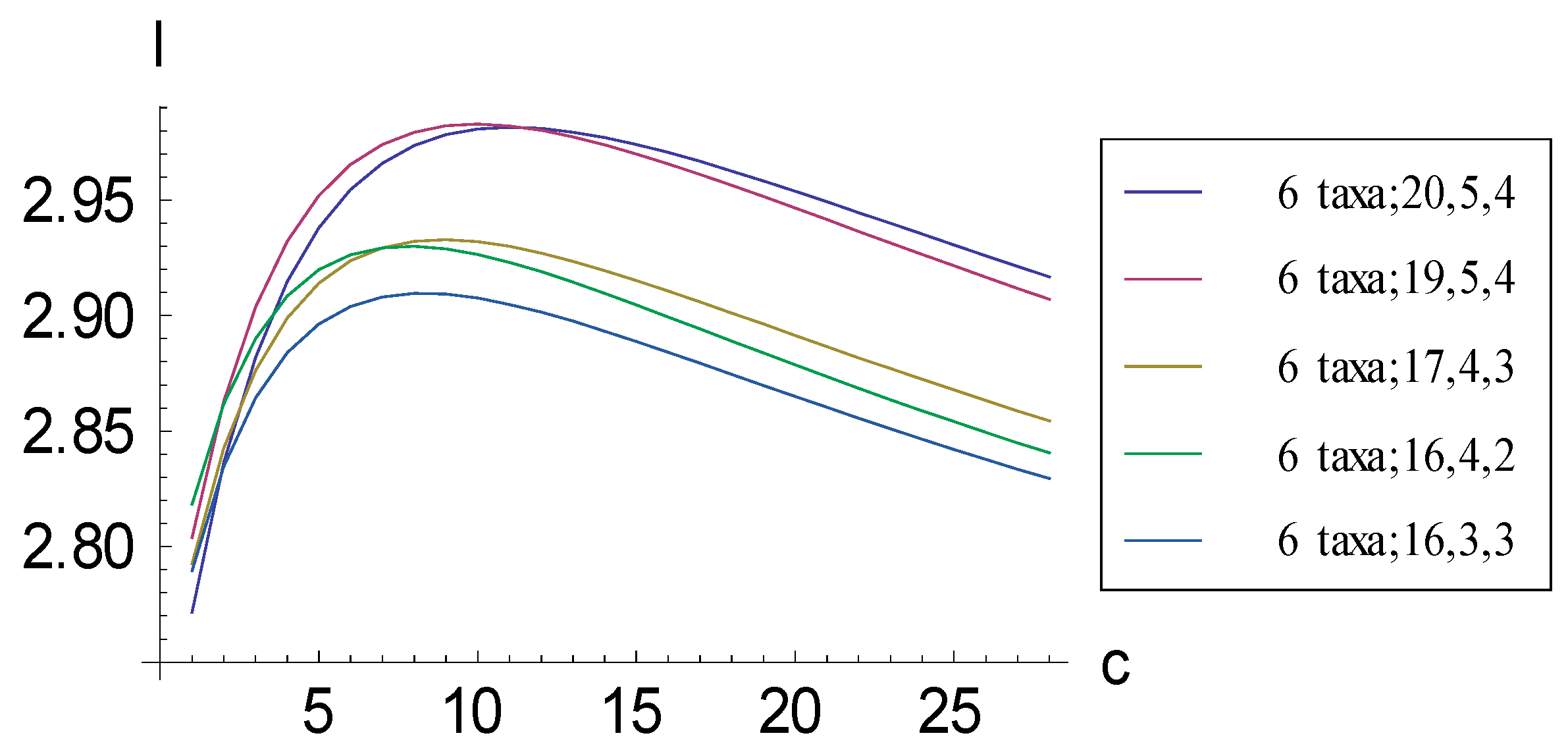
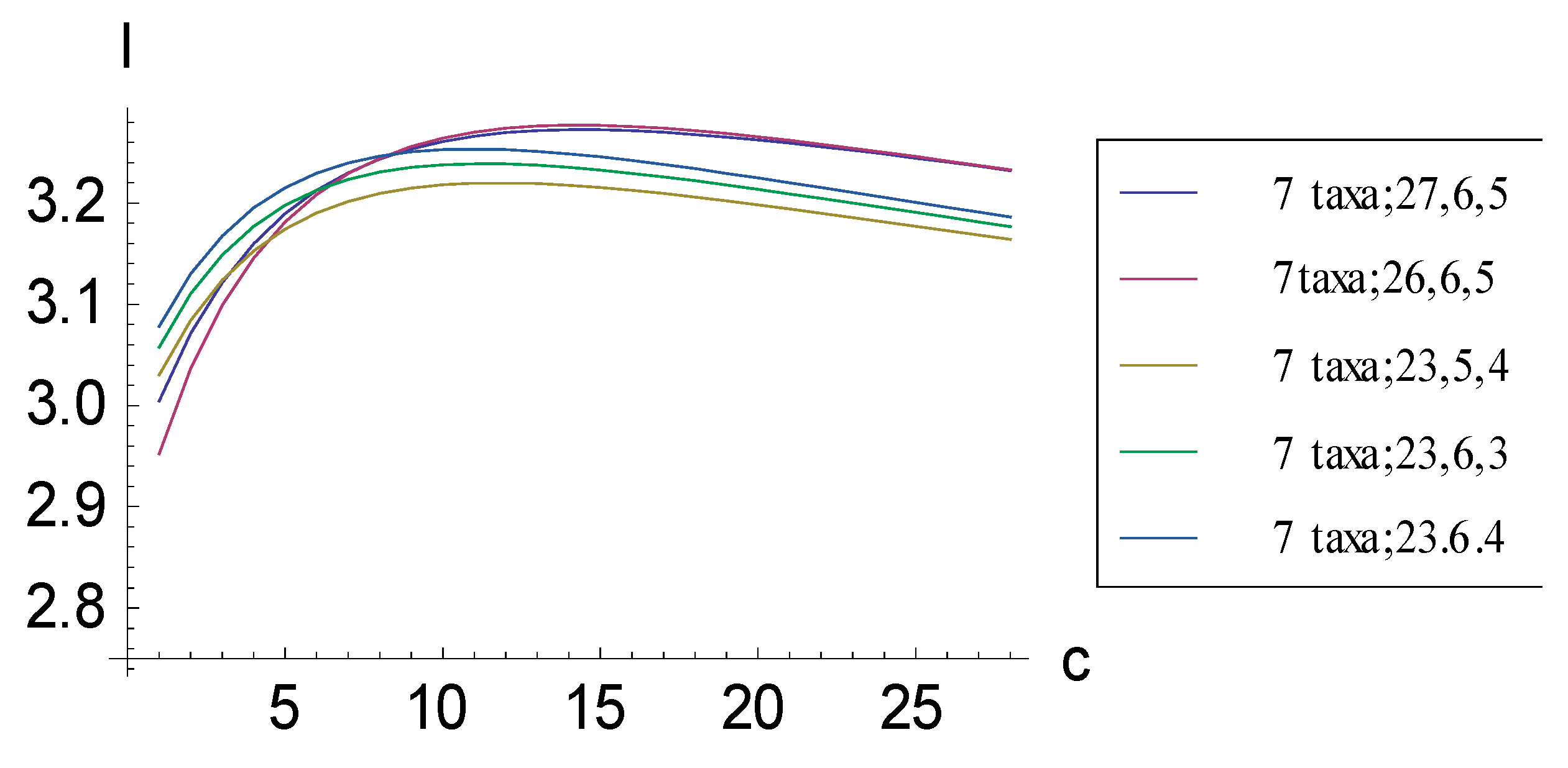
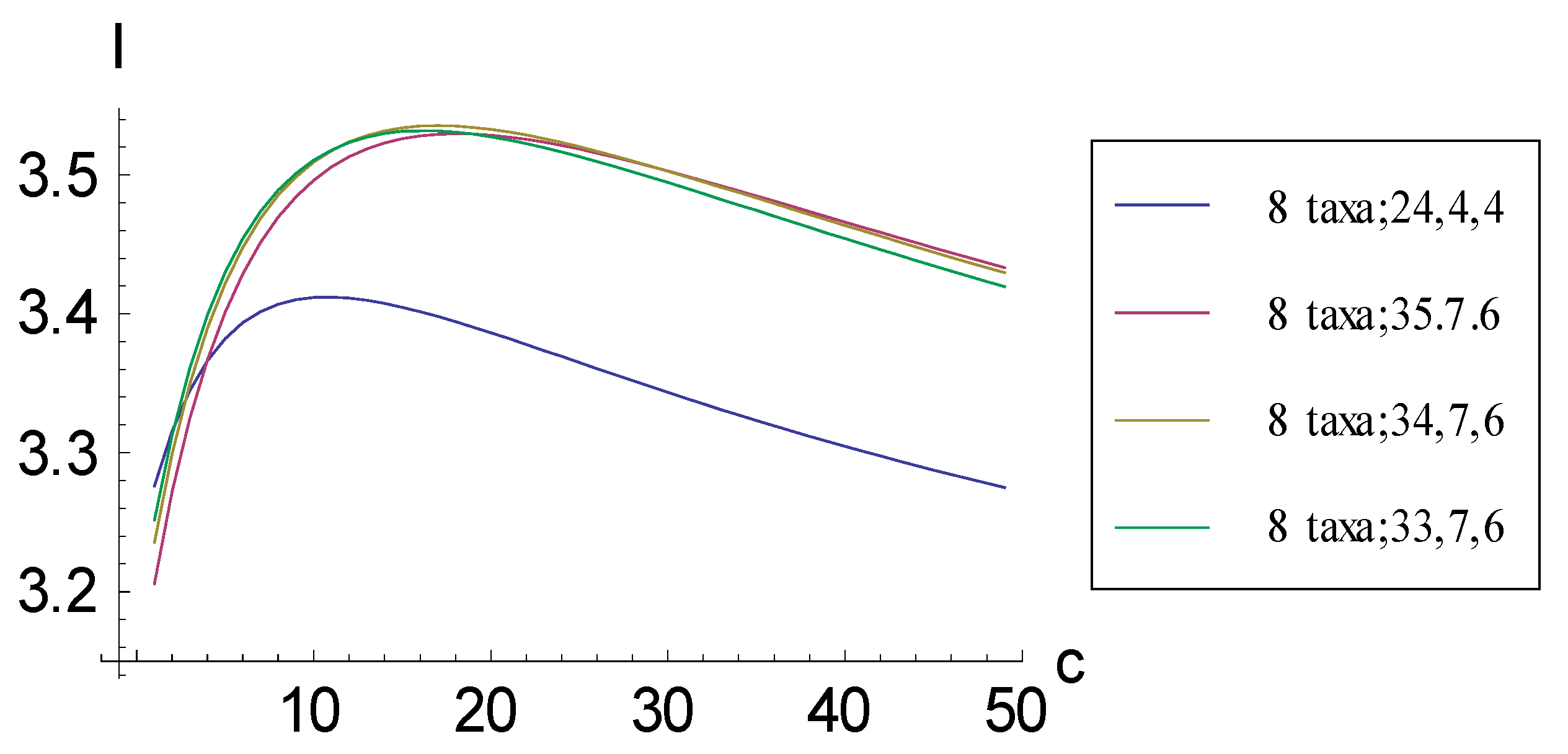
2.2. Achieving Maximum I as Synapomorphic Character Vectors are Added to Consistent Basal Matrices


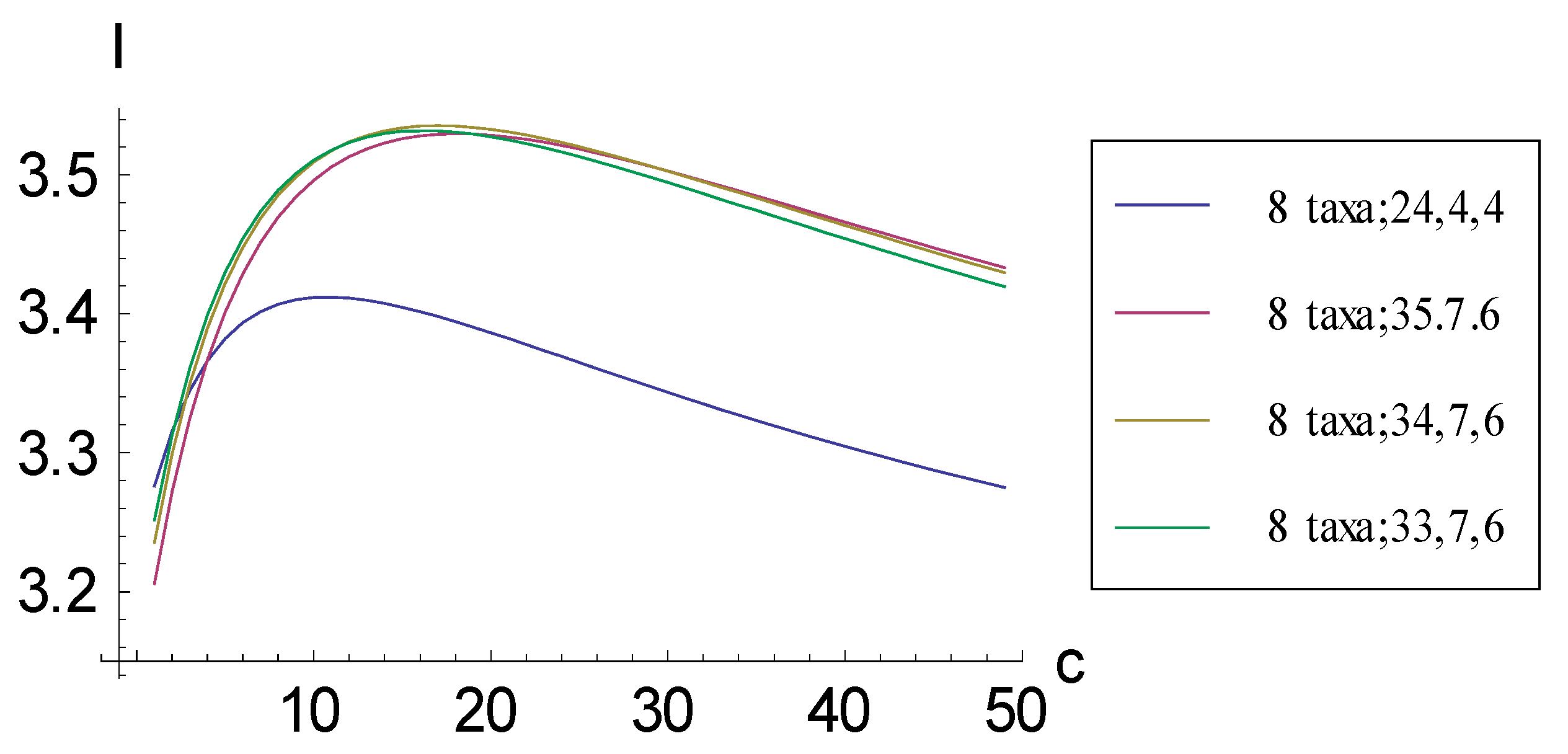
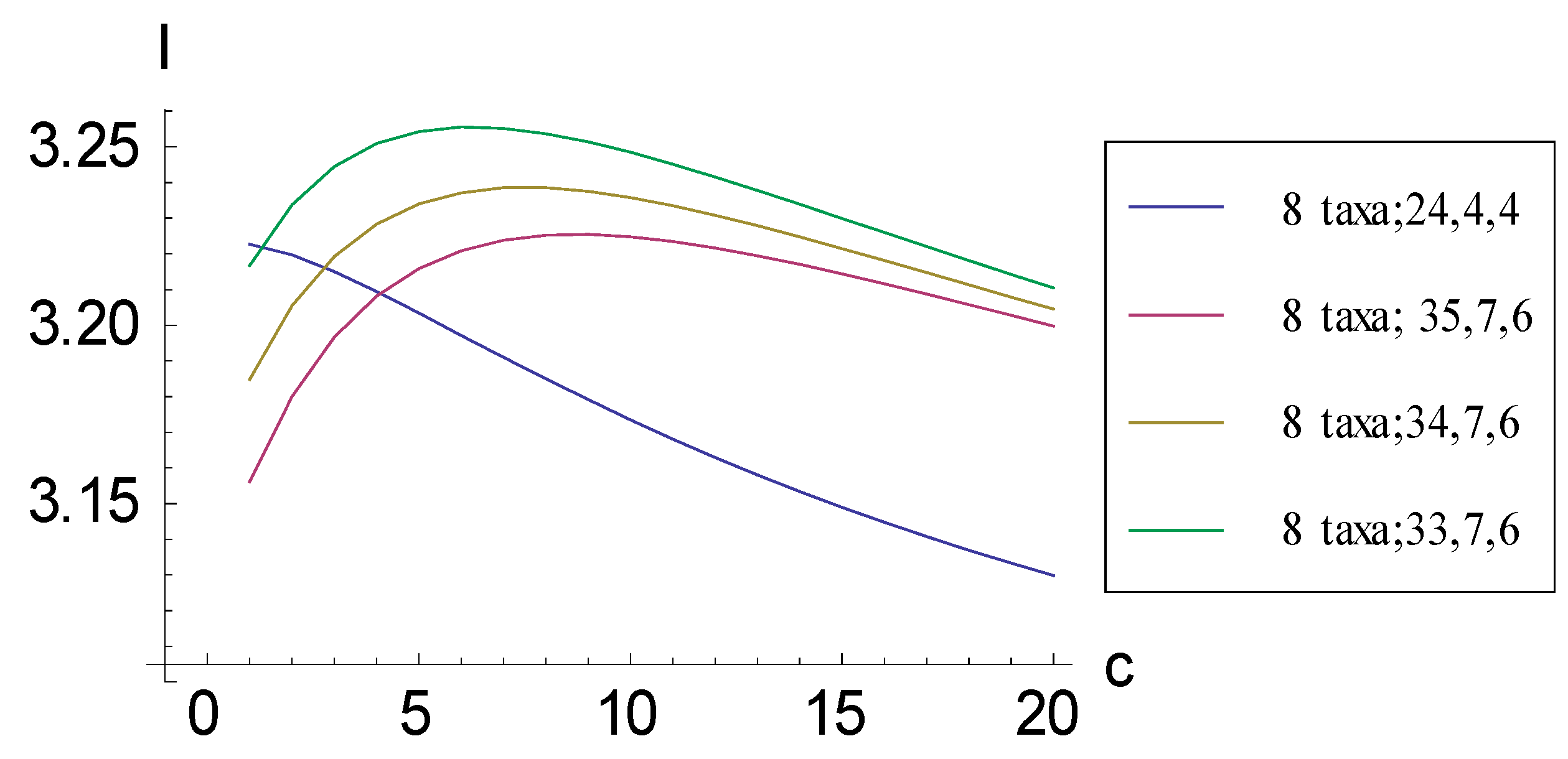
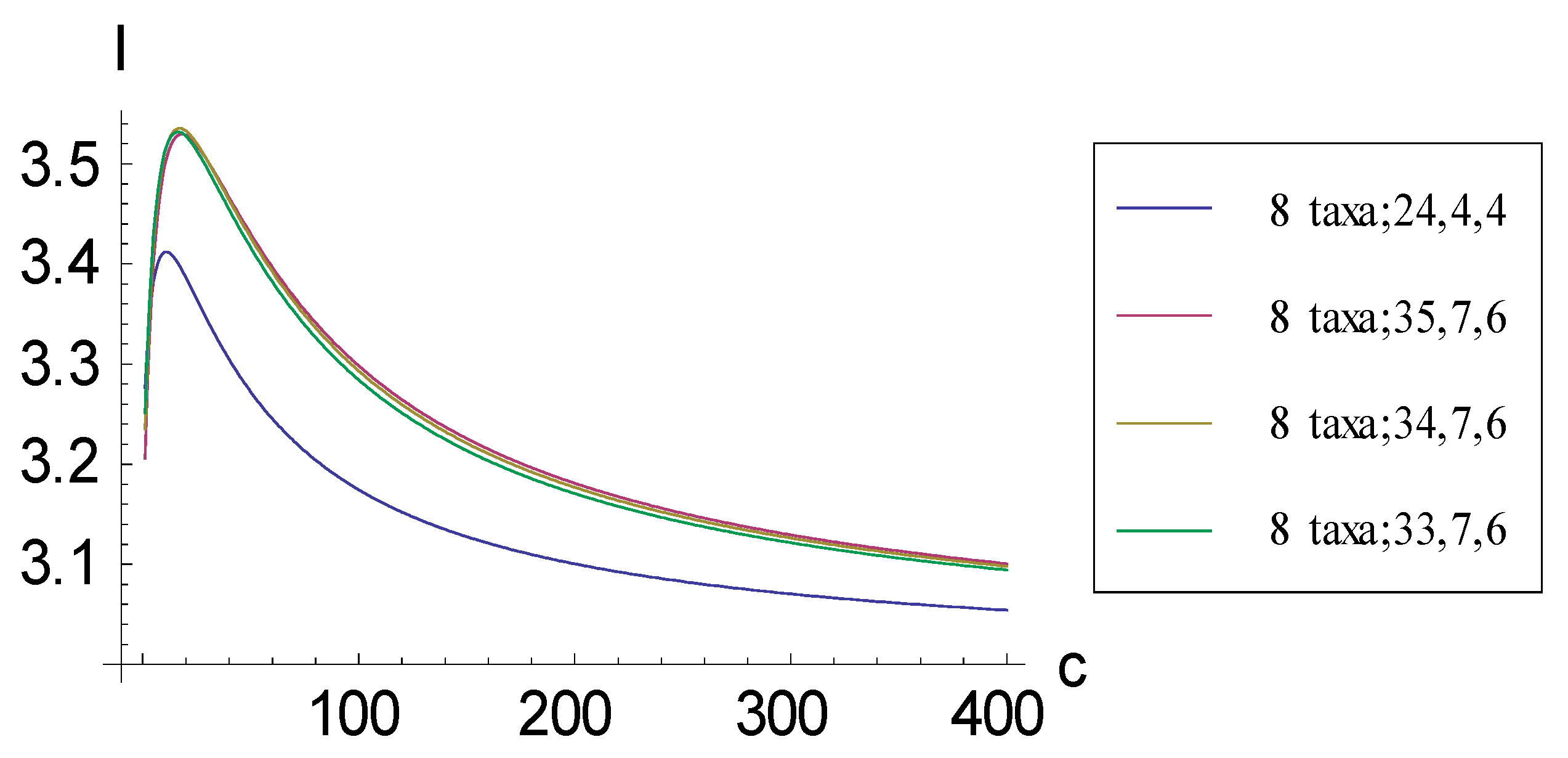
2.3. Minima for I
2.4. Information and Phylogenetic Systematic Analyses
2.5. Information as a Quantitative Metric
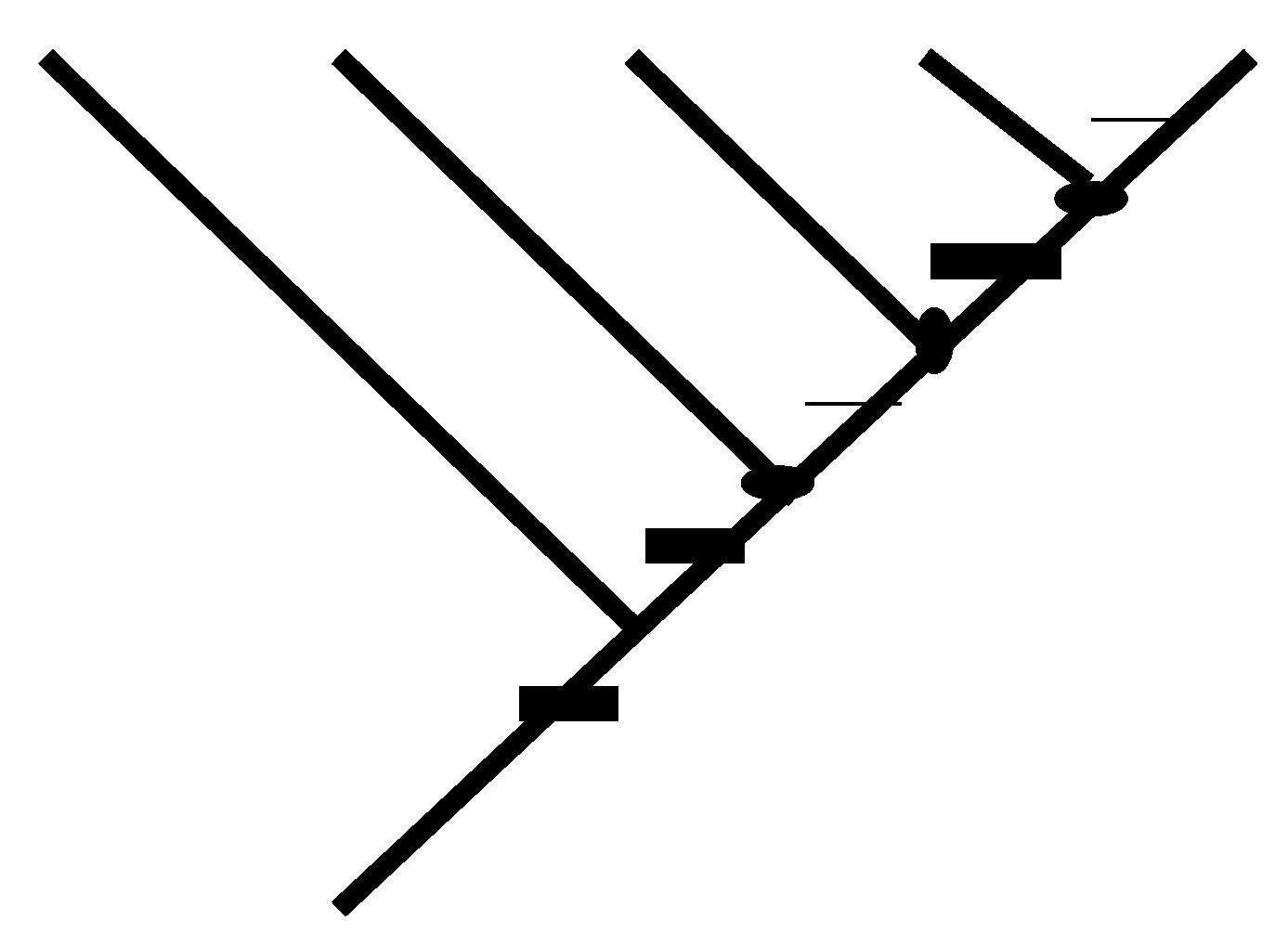
2.6. Information as a Means for Considering Evolution in Thermodynamic Terms
2.7. Information as a Criterion for Choosing among Competing Systematic Classifications
2.8. Information as a Guiding Variable in Constructing Supertrees
2.9. Information as a Parameter for Measuring Diversity
2.10. Information as a Basis for Comparing Data Types
3. Conclusions
3.1. Interpretation
3.2. Information as a Quantitative Metric
3.3. Information as a Means for Considering Evolution in Thermodynamic Terms
3.4. Information as a Criterion for Choosing among Competing Systematic Classifications
3.5. Information as a Guiding Variable in Constructing Supertrees
3.6. Information as a Parameter for Measuring Diversity
3.7. Information as a Basis for Comparing Data Types
3.8. Prospectus
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix
Deriving Equation (8)
Demonstrating the Limit for Equation (16)
Theorem
Proof
References
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 279–423, 623–656. [Google Scholar] [CrossRef]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: Urbana, IL, USA, 1949. [Google Scholar]
- Brillouin, L. Science and Information Theory; Academic Press: New York, NY, USA, 1962. [Google Scholar]
- Johnson, J.A. Information theory in biology after 18 years. Science 1970, 168, 1545–1550. [Google Scholar] [CrossRef] [PubMed]
- Atlan, H. L’Organisation Biologique et la Theorie de L’Information; Hermann Press: Paris, France, 1972. (In French) [Google Scholar]
- Gatlin, L.L. Information Theory and the Living System; Columbia University Press: New York, NY, USA, 1972. [Google Scholar]
- Prigogine, I.; Nicolis, G.; Babloyantz, A. Thermodynamics of evolution. Phys. Today 1972, 25, 23–28, 38–44. [Google Scholar] [CrossRef]
- Saunders, P.T.; Ho, M.W. On the increase in complexity in evolution. J. Theor. Biol. 1976, 63, 375–384. [Google Scholar] [CrossRef]
- Saunders, P.T.; Ho, M.W. On the increase in complexity in evolution II. The relativity of complexity and the principle of minimum increase. J. Theor. Biol. 1981, 90, 515–530. [Google Scholar] [CrossRef]
- Wicken, J.S. The generation of complexity in evolution: A thermodynamic and information-theoretical discussion. J. Theor. Biol. 1979, 77, 349–365. [Google Scholar] [CrossRef]
- Wicken, J.S. A thermodynamic theory of evolution. J. Theor. Biol. 1979, 87, 9–23. [Google Scholar] [CrossRef]
- Maynard Smith, J. The concept of information in biology. Philos. Sci. 2000, 67, 177–194. [Google Scholar] [CrossRef]
- Sterelny, K. The “genetic program” program: A commentary on Maynard Smith on information in biology. Philos. Sci. 2000, 67, 195–201. [Google Scholar] [CrossRef]
- Godfrey-Smith, P. Information, arbitrariness, and selection: Comments on Maynard Smith. Philos. Sci. 2000, 67, 202–207. [Google Scholar] [CrossRef]
- Sarkar, S. Information in genetics and developmental biology: Comments on Maynard Smith. Philos. Sci. 2000, 67, 208–213. [Google Scholar] [CrossRef]
- Kauffman, S.; Logan, R.K.; Este, R.; Goebel, R.; Hobill, D.; Shmulevich, I. Propagating organization: An enquiry. Biol. Philos. 2007, 23, 27–45. [Google Scholar] [CrossRef]
- Logan, R.K. What is information? Why is it relativistic and what is its relationship to materiality, meaning and organization? Information 2012, 3, 68–91. [Google Scholar] [CrossRef]
- Hawksworth, F.G.; Estabrook, G.F.; Rogers, D.F. Application of an information theory model for character analysis in the genus Arceuthobium (Viscaceae). Taxon 1968, 17, 605–619. [Google Scholar] [CrossRef]
- Rohlf, F.J.; Sokal, R.R. Comparing numerical taxonomic studies. Syst. Zool. 1982, 30, 459–490. [Google Scholar] [CrossRef]
- Rohlf, F.J.; Coless, D.H.; Hart, G. Taxonomic congruence reexamined. Syst. Zool. 1983, 32, 144–158. [Google Scholar] [CrossRef]
- Schuh, R.T.; Farris, J.S. Methods for investigating taxonomic congruence and their application to the Leptopodomorpha. Syst. Zool. 1981, 30, 331–351. [Google Scholar] [CrossRef]
- Nelson, G. Cladistic analysis and synthesis: Principles and definitions, with a historical note on Adanson’s Families des Plantes (1763–1764). Syst. Zool. 1979, 28, 1–21. [Google Scholar] [CrossRef]
- Mickevich, M.F.; Platnick, N.I. On the information content of classifications. Cladistics 1989, 5, 33–47. [Google Scholar] [CrossRef]
- Page, R.D.M. Comments on the information content of classifications. Cladistics 1992, 8, 87–95. [Google Scholar] [CrossRef]
- Wiley, E.O.; Brooks, D.R. Victims of history—A nonequilibrium approach to evolution. Syst. Zool. 1982, 31, 1–24. [Google Scholar] [CrossRef]
- Wiley, E.O.; Brooks, D.R. Nonequilibrium thermodynamics and evolution: A response to Løvtrup. Syst. Zool. 1983, 32, 209–219. [Google Scholar] [CrossRef]
- Løvtrup, S. Victims of ambition: Comments on the Wiley and Brooks approach to evolution. Syst. Zool. 1983, 32, 90–96. [Google Scholar] [CrossRef]
- Duncan, T.; Estabrook, G.F. An operational method for evaluating classifications. Syst. Bot. 1976, 1, 373–382. [Google Scholar] [CrossRef]
- Carpenter, K.E. Optimal cladistic and quantitative evolutionary classifications as illustrated by fusilier fishes (Teleostei: Caesionidae). Syst. Biol. 1993, 42, 142–154. [Google Scholar] [CrossRef]
- Brooks, D.R.; Wiley, E.O. Evolution as Entropy; University of Chicago Press: Chicago, IL, USA, 1988. [Google Scholar]
- Brooks, D.R.; O’Grady, R.T.; Wiley, E.O. A measure of the information content of phylogenetic trees, and its use as an optimality criterion. Syst. Zool. 1986, 35, 571–581. [Google Scholar] [CrossRef]
- Purvis, A. A modification to Baum and Ragan’s method for combining phylogenetic trees. Mol. Phylogenet. Evol. 1995, 1, 53–58. [Google Scholar]
- Ronquist, F. Matrix representation of trees, redundancy, and weighting. Syst. Biol. 1996, 45, 247–253. [Google Scholar] [CrossRef]
- Thorley, J.L.; Wilkinson, M.; Charleston, M. The Information Content of Consensus Trees. In Advances in Data Science and Classification: Studies in Classification, Data Analysis and Knowledge Organisation; Rizzi, A., Vichi, M., Bock, H.-H., Eds.; Springer: Berlin, Germany, 1998; pp. 91–98. [Google Scholar]
- Wilkinson, M.; Cotton, J.A.; Thorley, J.L. The information content of trees and their matrix representation. Syst. Biol. 2004, 53, 989–1001. [Google Scholar] [CrossRef] [PubMed]
- Stone, J.R. Information obtained in cladistic analysis. Biosystems 2001, 61, 33–39. [Google Scholar] [CrossRef]
- Cotton, J.A.; Wilkinson, M. Quantifying the potential utility of phylogenetic characters. Taxon 2008, 57, 131–136. [Google Scholar]
- Levine, R.D.; Bernstein, R.B. Molecular Reaction Dynamics; Clarendon Press: Oxford, UK, 1974. [Google Scholar]
- Baum, B.R. Combining trees as a way of combining data sets for phylogenetic inference, and the desirability for combining gene trees. Taxon 1992, 41, 1–10. [Google Scholar] [CrossRef]
- Ragan, M.A. Phylogenetic inference based on matrix representations of trees. Mol. Phylogenet. Evol. 1992, 1, 538–558. [Google Scholar] [CrossRef]
- Carter, M.; Hendy, M.D.; Penny, D.; Székely, L.A.; Wormald, N.C. On the distribution of lengths of evolutionary trees. SIAM J. Discret. Math. 1990, 3, 38–47. [Google Scholar] [CrossRef]
- Goldman, N. Phylogenetic information and experimental design in molecular systematics. Proc. R. Soc. Lond. B 1998, 265, 1779–1786. [Google Scholar] [CrossRef] [PubMed]
- Massingham, T.; Goldman, N. EDIBLE: Experimental design and information calculations in phylogenetics. Bioinformatics 2000, 16, 294–295. [Google Scholar] [CrossRef] [PubMed]
- Posada, D.; Buckley, T.R. Model selection and model averaging in phylogenetics: Advantages of Akaike information criterion and Bayesian approaches over likelihood ratio tests. Syst. Biol. 2004, 53, 793–808. [Google Scholar] [CrossRef] [PubMed]
- Fuhrman, S.; Cunningham, M.J.; Wen, X.; Zweiger, G.; Seilhamer, J.J.; Somogyi, R. The application of Shannon entropy in the identification of putative drug targets. Biosystems 2000, 55, 5–14. [Google Scholar] [CrossRef]
- Robson, B. Clinical and pharmacogenomic data mining: 3. zeta theory as a general tactic for clinical bioinformatics. J. Proteom. Res. 2004, 4, 445–455. [Google Scholar] [CrossRef] [PubMed]
- Mossel, E.; Steel, M. How Much Can Evolved Characters Tell Us about the Tree That Generated Them? In Mathematics of Evolution and Phylogeny; Gascuel, O., Ed.; Oxford University Press: New York, NY, USA, 2005; pp. 384–412. [Google Scholar]
- Chen, H.-D.; Chang, C.-H.; Hsieh, L.-C.; Lee, H.-C. Divergence and Shannon information in genomes. Phys. Rev. Lett. 2005, 94, 178103. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Craig, W.; Stone, J. Information and Phylogenetic Systematic Analysis. Information 2015, 6, 811-832. https://doi.org/10.3390/info6040811
Craig W, Stone J. Information and Phylogenetic Systematic Analysis. Information. 2015; 6(4):811-832. https://doi.org/10.3390/info6040811
Chicago/Turabian StyleCraig, Walter, and Jonathon Stone. 2015. "Information and Phylogenetic Systematic Analysis" Information 6, no. 4: 811-832. https://doi.org/10.3390/info6040811
APA StyleCraig, W., & Stone, J. (2015). Information and Phylogenetic Systematic Analysis. Information, 6(4), 811-832. https://doi.org/10.3390/info6040811