

Adaptive Multi-Hop P2P Video Communication: A Super Node-Based Architecture for Conversation-Aware Streaming


Abstract
1. Introduction
Our Contribution
2. WebRTC Overview
3. Related Work
3.1. WebRTC-Based Conferencing Systems
3.2. Performance Evaluation and Quality Enhancement of WebRTC
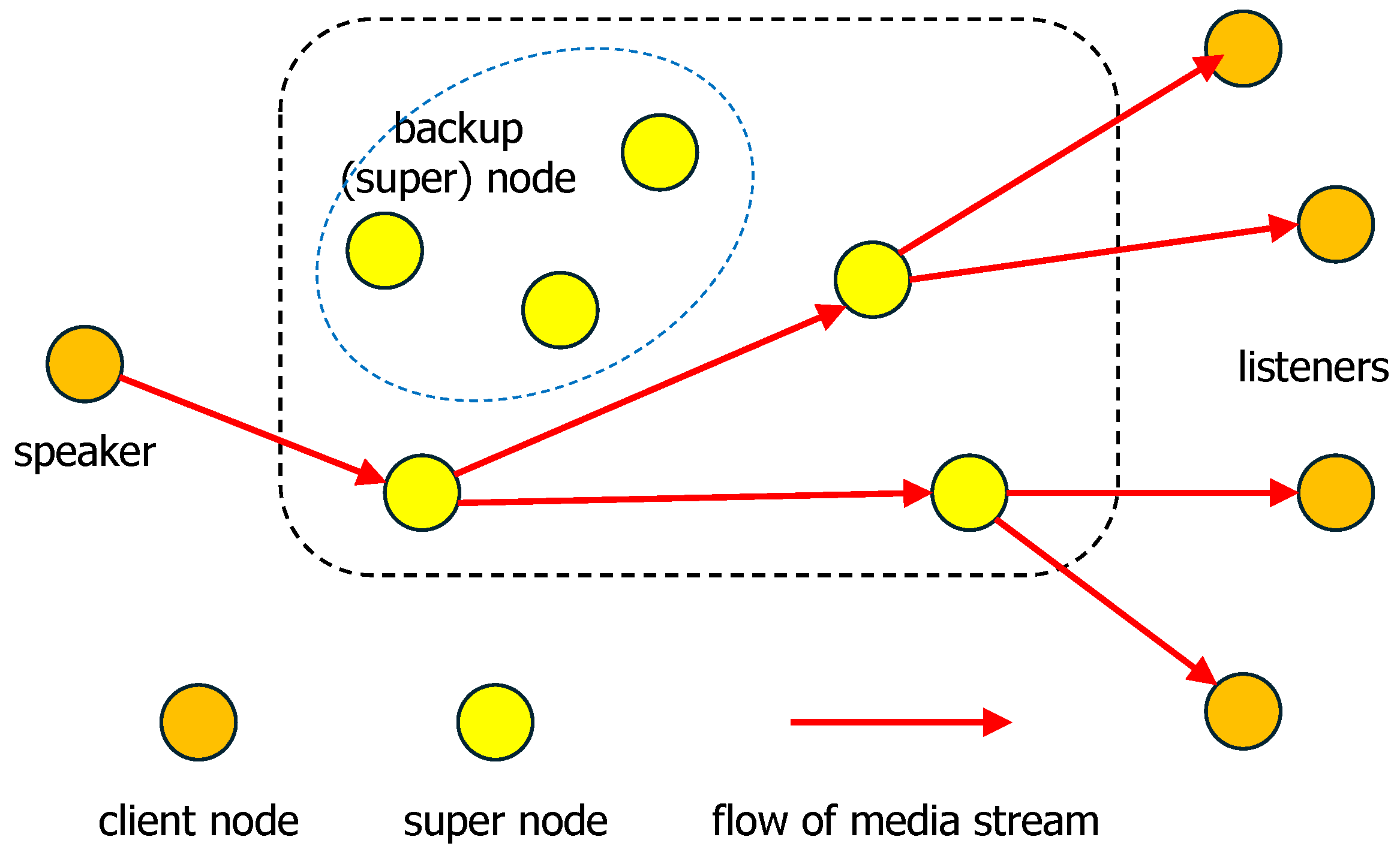
4. Multi-Hop Distributed Streaming Model
4.1. Overview
- The first hop, where the speaker transmits media to the nearest super node.
- The intermediate hop, where super nodes relay streams between each other.
- The final hop, where listeners receive media from their respective super nodes.
- In the first hop, the speaker establishes a WebRTC connection with the nearest super node (Mediasoup SFU). Once the connection is established, the super node receives the incoming audio and video streams and performs initial bandwidth optimizations, such as bitrate adjustments.
- In the intermediate hop, super nodes exchange signaling information via WebRTC DataChannel or WebSockets and optimize media forwarding. The system dynamically selects the optimal relay path to minimize transmission latency.
- In the final hop, the end users (receivers) retrieve media streams from their respective super nodes, ensuring efficient and scalable content delivery.
4.2. Optimized Media Transmission via RTP and RTCP Integration
- Dynamic Stream Rerouting: When high packet loss, jitter, or latency is detected, a super node dynamically reroutes the affected stream through an alternative super node. This proactive mechanism enhances transmission stability, mitigates network disruptions, and ensures continuous media playback.
- Adaptive Bitrate Adjustment: In response to network congestion or fluctuating network conditions, super nodes dynamically regulate media stream bitrates. This adaptive control maintains smooth playback while preventing excessive network load, optimizing both performance and resource utilization.
- Aggregated RTCP Feedback for Network Optimization: Super nodes collect RTCP feedback from multiple participants, aggregating data to generate a holistic view of network conditions, including packet loss, delay, and jitter. By analyzing this aggregated feedback, the system enables intelligent, centralized decision-making to refine media distribution strategies, optimize transmission routes, dynamically adjust codec settings, and effectively balance network load.
4.3. Interconnecting Super Nodes via Mediasoup PipeTransport
4.4. Control of the Configuration of the Super Node Network
5. Efficient Support for Changes in Chat Groups and Speaker Rotation
5.1. Role Distribution of Super Nodes
- Participating Nodes: These are individual end-user devices connected to the WebRTC network. Each participating node establishes a direct media connection with its designated super node, which acts as its gateway to the larger system.
- Super Nodes: Functioning as the primary SFUs in the multi-hop hierarchy, super nodes are responsible for routing, forwarding, and aggregating media streams from multiple participating nodes. They also handle key system operations such as congestion control and load balancing. In the proposed system, super nodes can relay media not only to participating nodes but also to other super nodes positioned at different levels of the hierarchy, forming a multi-hop transmission path.
- Backup Super Nodes: These are pre-initialized super nodes that remain in standby mode under normal conditions. They continuously synchronize with active super nodes to maintain consistent session states. When an active super node becomes overloaded or fails, a backup super node can be dynamically activated to assume its responsibilities, thereby supporting seamless failover and enhancing system robustness.
5.2. Procedure for Joining a Conversation Group
- Evaluation of Capacity in Active Super Nodes:The system first examines the currently active super nodes to determine whether any have sufficient capacity to accommodate the new participant.Action:
- If a suitable super node is found, the new user establishes a connection and immediately begins receiving media streams through it.
Benefit: Leveraging already-operational resources minimizes system overhead and reduces connection latency. - Activation of Unused Super Nodes:If all active super nodes are operating at full capacity, the system searches for unused but pre-initialized super nodes.Action:
- An unused super node is activated and assigned to handle the new participant’s connection and media delivery.
Benefit: Efficient load balancing is achieved without impacting the performance of existing active nodes. - Promotion of Backup Super Nodes:If no unused super nodes are available, the system promotes a backup super node from the standby pool. Backup super nodes continuously maintain synchronized session states, enabling rapid activation when needed.Action:
- A backup super node is activated and designated to manage the new participant’s session.
Benefit: This ensures fault tolerance and continuous service availability, even during periods of high load or unexpected node failures. - Denial of Participation Request:If no suitable super node is available at any level, the system denies the user’s request to join the conversation.Action:
- A rejection message is sent to the user, informing them that participation is currently unavailable.
Benefit: Protects system stability and preserves the quality of service for existing participants by preventing resource exhaustion.
5.3. Procedure for Leaving a Conversation Group
- Termination of Participant Connection:The system first identifies the super node associated with the departing participant and terminates the participant’s active media stream connection.Action:
- Cease the participant’s media sessions and release the resources allocated to the corresponding super node.
Benefit: Immediate resource recovery reduces bandwidth consumption and computational load, thereby enhancing overall system efficiency. - Assessment of Super Node Occupancy:Following the termination, the system evaluates whether the departure has rendered the super node vacant. If all active super nodes remain at full capacity, the system also checks for unused but pre-initialized super nodes to maintain operational flexibility.Action:
- If other participants remain connected, the super node updates its internal connection registry without further intervention.
- If no active participants remain, the system proceeds to optimize resource usage in the next step.
Benefit: This selective response minimizes unnecessary processing overhead and maintains efficient operation. - Super Node Role Adjustment and Resource Management:If a super node is found to be vacant, the system determines the appropriate course of action based on the node’s operational role.Action:
- For active super nodes: Downgrade the node to a backup role, preserving synchronized state information for rapid reactivation if needed.
- For backup super nodes: Fully release associated resources and transition the node into a shutdown state.
Benefit: Role-based management preserves critical standby nodes while optimizing resource allocation and improving energy efficiency. - Reconfiguration of Media Stream Routing:To maintain communication integrity and adaptability, the system autonomously reconfigures media stream forwarding and signaling paths in response to the participant’s departure.Action:
- Recalculate the media transmission topology among the remaining participants.
- Reconstruct media stream routing paths and broadcast updated connection states to all affected nodes to ensure network consistency and synchronization.
Benefit: This mechanism enables continuous and stable media delivery even under dynamic network conditions, preventing communication interruptions and quality degradation, thereby ensuring a seamless user experience.
5.4. Procedure for Switching Speakers Within the Same Conversation Group
- Speaker Identification and Node State Update:The system first identifies the participant designated as the new active speaker and broadcasts signaling messages to all associated super nodes and backup nodes to coordinate the transition.Action:
- The signaling control module broadcasts a speaker-change notification, specifying both the new and previous speakers.
- Upon receiving the notification, each super node updates its internal state to prioritize media streams originating from the new speaker node.
Benefit: Rapid synchronization of node states minimizes coordination delays, enabling swift and smooth speaker transitions across the system. - Real-time Dynamic Resource Allocation:Following the speaker update, the system dynamically reallocates network and computational resources to meet the new speaker’s media transmission requirements.Action:
- Bandwidth and computational resources are automatically reallocated among super nodes and backup nodes to prioritize the new speaker’s media stream.
- Based on current load conditions, backup nodes are selectively activated to maintain balanced resource utilization across the network.
Benefit: Precise resource management prevents node overload, improves system performance, and ensures continuous high-quality media delivery. - Transition Confirmation and Logging:After completing the reconfiguration of media streams and the reallocation of resources, the system verifies the success of the transition.Action:
- Each super node and backup node reports the successful completion of the speaker-switching process to the central signaling server.
- The system logs detailed records of the transition events and any corresponding changes in node load conditions.
Benefit: Enhanced system observability and maintainability facilitates ongoing optimization and troubleshooting, improving overall system robustness.
6. Experiments
6.1. Setup
6.1.1. Test Tool Preparation
- Simulated interactions for signaling processes typical of user behavior, including room creation, room joining, and room leaving, as well as SDP exchange.
- Establishment and termination of media sessions.
- Parallel simulation of multiple concurrent users to emulate realistic load conditions.
- Create Room: This operation represents the complete process initiated when a user creates a new session. It includes WebRTC signaling exchanges, server-side resource allocation, and session state initialization. The corresponding response time reflects the system’s efficiency in initializing new communication sessions.
- Join Call: This refers to the sequence of events triggered when a user attempts to join an active session. It involves hierarchical node allocation strategies, super node selection based on real-time conditions, relay path construction, and synchronization of session state between nodes.
- Leave Call: This operation captures the process executed when a user leaves an ongoing session, including the deallocation of routing resources, updates to the overlay network topology, and activation of backup nodes if necessary to maintain session continuity.
6.1.2. Evaluation Metrics
- Response Time: The latency between a user’s operation and the system’s corresponding response.
- Throughput: The number of requests processed per unit time, used to measure the system’s processing capacity.
- Packet Loss Rate: The proportion of audio and video packets lost during media streaming sessions.
- System Resource Utilization: Node-level load indicators such as CPU usage, memory consumption, and network bandwidth utilization.
6.2. Basic Test Scenarios
- Thread Count (Concurrent Virtual Users): 10, 20, 50, and 100. Each configuration represents a distinct concurrency level used to evaluate the system’s resource usage, responsiveness, and bandwidth efficiency.
- Test Structure: Each test run simulates a single session unit representing a complete interaction lifecycle: Create Room →Users Join One by One→Stable Interaction→ Users Leave One by One.
- Session Duration: Each session unit spans a total of 20 s, divided into four distinct behavioral phases to reflect realistic interaction dynamics. Although the total number of users per test remains fixed, the number of active participants changes over time to simulate various stages of the session lifecycle.
- Ramp-Up Period: 1 s. All threads (i.e., virtual users) are launched linearly during this period. For example, in the 10-user case, threads start at 0.1-s intervals; for 20 users, at 0.05-s intervals, and so on.
- Loop Count: Infinite. Each thread repeatedly performs its designated operations throughout the 20-s session duration to maintain continuous system load.
- Thread Lifetime Control: Enabled via the “Specify Thread Duration” option. This ensures that each thread remains active for a defined time span, rather than a fixed number of iterations, thereby simulating more realistic user behavior.
- 0–1 s: Threads start linearly and execute the room creation operation once. Users then begin joining the room gradually.
- 2–19 s: Thread count remains constant, simulating a stable period of interaction among users.
- 19–20 s: Threads terminate linearly, representing users leaving the call one by one.
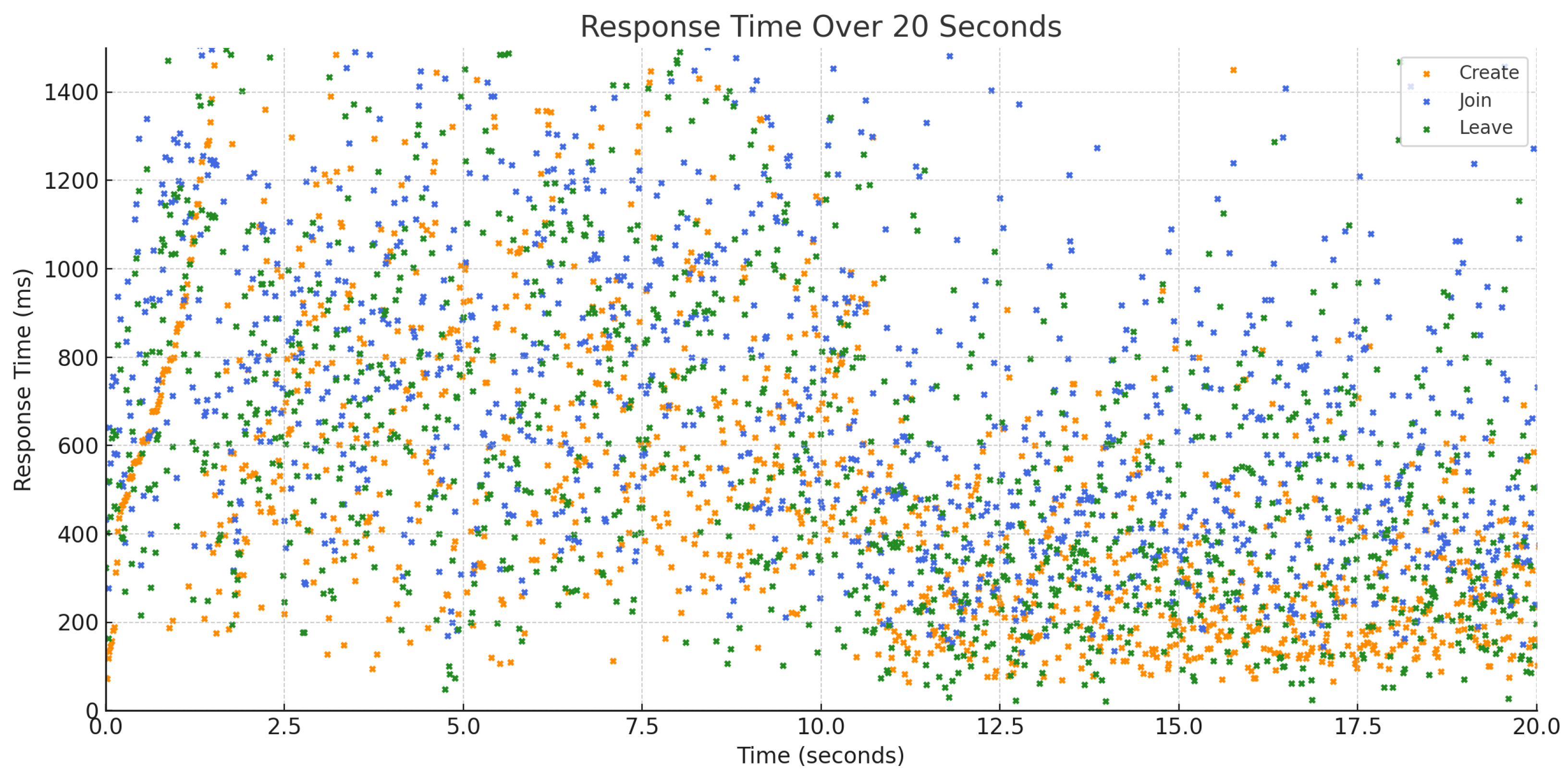
Results
- Received bandwidth: approximately 186–190 KB/s.
- Sent bandwidth: approximately 56–59 KB/s.
- Create Room: Remains nearly constant across all user loads. This is likely because room creation is only triggered during the ramp-up phase and involves minimal contention.
- Join Call: Increases from 87 ms (10 users) to 739 ms (100 users).
- Leave Call: Increases from 85 ms to 647 ms over the same range.
- Join Call involves multi-step coordination, including layered node selection and session state replication, resulting in the highest latency and variability.
- Leave Call entails resource cleanup and topology updates, leading to moderate latency.
- Create Room is a lightweight initialization process with the lowest latency and least variability.
6.3. CPU Usage Under Varying User Loads
6.3.1. Setup
6.3.2. Results
6.4. Dynamic Load Mutation Scenario
6.4.1. Setup
- Test Configuration Parameters:
- Number of Threads (Concurrent Virtual Users): 100 dropping to 50.All 100 threads are initiated simultaneously at time 0. At exactly 10 s, 50 threads are terminated instantly to simulate an abrupt decrease in system load.
- Ramp-Up Period: 0 s.All threads are launched simultaneously without any ramp-up delay.
- Loop Count: Infinite.Each thread continues to execute the defined operations until the total test duration elapses. The full duration of the test is 20 s.
- Thread Lifetime Control: Enabled (“Specify thread duration”).Each thread is configured to run for a set duration rather than a fixed number of iterations. This method offers higher fidelity in simulating real-time load transitions and usage patterns.
- Thread Count Variation Over Time:
- 0–10 s: 100 threads are maintained.
- At 10 s: Thread count drops abruptly from 100 to 50.
- 11–20 s: 50 threads are maintained.
6.4.2. Results
6.5. Observations
6.5.1. Overall Response Time Trends
6.5.2. Impact of Backup Nodes on Response Time
6.6. Comparison with Existing Methods
6.6.1. Performance Evaluation with a Single SFU Server
- Create Room: Max 1903 ms, Min 273 ms, Avg 699.33 ms, Std Dev 214.48 ms.
- Join Call: Max 2871 ms, Min 364 ms, Avg 1425 ms, Std Dev 400.75 ms.
- Leave Call: Max 2655 ms, Min 281 ms, Avg 1247 ms, Std Dev 374.20 ms.
- Create Room: Max 1588 ms, Min 132 ms, Avg 393.58 ms, Std Dev 146.42 ms.
- Join Call: Max 2171 ms, Min 259 ms, Avg 847 ms, Std Dev 295.44 ms.
- Leave Call: Max 1850 ms, Min 253 ms, Avg 682 ms, Std Dev 269.75 ms.
6.6.2. Comparison with Multi-Node Setup (No Backup Nodes)
- Create Room: Max 1783 ms, Min 72 ms, Avg 547 ms, Std Dev 166.30 ms.
- Join Call: Max 1943 ms, Min 271 ms, Avg 987 ms, Std Dev 327.53 ms.
- Leave Call: Max 1802 ms, Min 255 ms, Avg 804 ms, Std Dev 296.40 ms.
- Create Room: Max 709 ms, Min 114 ms, Avg 379 ms, Std Dev 133.20 ms.
- Join Call: Max 1439 ms, Min 183 ms, Avg 726 ms, Std Dev 287.51 ms.
- Leave Call: Max 1452 ms, Min 89 ms, Avg 517 ms, Std Dev 271.44 ms.
6.7. Evaluation of the Efficiency of Turn Taking
6.7.1. Setup
- —The time at which the server receives the speaker-switch request.
- —The time at which the speaker-switch operation completes and the updated speaker state is broadcast to all session participants.
6.7.2. Results
7. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aristotle, U. The politics. In Democracy: A Reader; Columbia University Press: New York, NY, USA, 2016; pp. 200–202. [Google Scholar]
- Hook, D.; Franks, B.; Bauer, M. (Eds.) The Social Psychology of Communication; Palgrave Macmillan: London, UK, 2016. [Google Scholar]
- Sidnell, J.; Stivers, T. (Eds.) The Handbook of Conversation Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Vangelisti, A.L. Communication in personal relationships. In APA Handbook of Personality and Social Psychology, Vol. 3. Interpersonal Relations; Mikulincer, M., Shaver, P.R., Simpson, J.A., Dovidio, J.F., Eds.; American Psychological Association: Washington, DC, USA, 2015; pp. 371–392. [Google Scholar]
- Lin, Y.; Zheng, Y.; Zeng, M.; Shi, W. Predicting Turn-Taking and Backchannel in Human-Machine Conversations Using Linguistic, Acoustic, and Visual Signals. arXiv 2025, arXiv:2505.12654. [Google Scholar]
- Skantze, G. Turn-taking in conversational systems and human-robot interaction: A review. Comput. Speech Lang. 2021, 67, 101178. [Google Scholar] [CrossRef]
- Ter Bekke, M.; Drijvers, L.; Holler, J. Hand gestures have predictive potential during conversation: An investigation of the timing of gestures in relation to speech. Cogn. Sci. 2024, 48, e13407. [Google Scholar] [CrossRef] [PubMed]
- Arora, N.; Suomalainen, M.; Pouke, M.; Center, E.G.; Mimnaugh, K.J.; Chambers, A.P.; Pouke, S.; LaValle, S.M. Augmenting immersive telepresence experience with a virtual body. IEEE Trans. Vis. Comput. Graph. 2022, 28, 2135–2145. [Google Scholar] [CrossRef] [PubMed]
- Irlitti, A.; Latifoglu, M.; Hoang, T.; Syiem, B.V.; Vetere, F. Volumetric hybrid workspaces: Interactions with objects in remote and co-located telepresence. In Proceedings of the CHI ’24: CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; pp. 1–16. [Google Scholar]
- Hu, E.; Grønbæk, J.E.S.; Houck, A.; Heo, S. Openmic: Utilizing proxemic metaphors for conversational floor transitions in multiparty video meetings. In Proceedings of the CHI ’23: CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–17. [Google Scholar]
- Tosato, L.; Fortier, V.; Bloch, I.; Pelachaud, C. Exploiting temporal information to detect conversational groups in videos and predict the next speaker. Pattern Recognit. Lett. 2024, 177, 164–168. [Google Scholar] [CrossRef]
- Wang, P.; Han, E.; Queiroz, A.; DeVeaux, C.; Bailenson, J.N. Predicting and Understanding Turn-Taking Behavior in Open-Ended Group Activities in Virtual Reality. arXiv 2024, arXiv:2407.02896. [Google Scholar]
- Kushwaha, R.; Bhattacharyya, R.; Singh, Y.N. ReputeStream: Mitigating Free-Riding through Reputation-Based Multi-Layer P2P Live Streaming. arXiv 2024, arXiv:2411.18971. [Google Scholar]
- Ma, Y.; Fujita, S. Decentralized incentive scheme for peer-to-peer video streaming using solana blockchain. IEICE Trans. Inf. Syst. 2023, E106.D, 1686–1693. [Google Scholar] [CrossRef]
- Wei, D.; Zhang, J.; Li, H.; Xue, Z.; Peng, Y.; Pang, X.; Han, R.; Ma, Y.; Li, J. Swarm: Cost-Efficient Video Content Distribution with a Peer-to-Peer System. arXiv 2024, arXiv:2401.15839. [Google Scholar]
- Edan, N.M.; Al-Sherbaz, A.; Turner, S. WebNSM: A novel WebRTC signalling mechanism for one-to-many bi-directional video conferencing. In Proceedings of the 2018 SAI Computing Conference, London, UK, 10–12 July 2018; pp. 1–6. [Google Scholar]
- Elleuch, W. Models for multimedia conference between browsers based on WebRTC. In Proceedings of the 2013 IEEE 9th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Lyon, France, 7–9 October 2013; pp. 279–284. [Google Scholar]
- Suciu, G.; Stefanescu, S.; Beceanu, C.; Ceaparu, M. WebRTC role in real-time communication and video conferencing. In Proceedings of the 2020 Global Internet of Things Summit (GIoTS), Dublin, Ireland, 3–5 June 2020; pp. 1–6. [Google Scholar]
- Jawad, A.M. Using JavaScript on 5G networks to improve real-time communication through WebRTC. Al-Rafidain J. Eng. Sci. 2023, 1, 9–23. [Google Scholar] [CrossRef]
- Hu, Y.-H.; Ito, K.; Igarashi, A. Improving real-time communication for educational metaverse by alternative WebRTC SFU and delegating transmission of avatar transform. In Proceedings of the 2023 International Conference on Consumer Electronics—Taiwan (ICCE-Taiwan), PingTung, Taiwan, 17–19 July 2023; pp. 201–202. [Google Scholar]
- Singh, V.; Lozano, A.A.; Ott, J. Performance analysis of receive-side real-time congestion control for WebRTC. In Proceedings of the 2013 20th International Packet Video Workshop (PV), San Jose, CA, USA, 12–13 December 2013; pp. 1–8. [Google Scholar]
- Jansen, B.; Goodwin, T.; Gupta, V.; Kuipers, F.; Zussman, G. Performance evaluation of WebRTC-based video conferencing. ACM Sigmetrics Perform. Eval. Rev. 2018, 45, 56–68. [Google Scholar] [CrossRef]
- Lee, I.; Kim, S.; Sathyanarayana, S.; Bin, K.; Chong, S.; Lee, K.; Grunwald, D.; Ha, S. R-fec: Rl-based fec adjustment for better qoe in webrtc. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 2948–2956. [Google Scholar]
- Sathyanarayana, S.D.; Lee, K.; Grunwald, D.; Ha, S. Converge: Qoe-driven multipath video conferencing over WebRTC. In Proceedings of the ACM SIGCOMM ’23: ACM SIGCOMM 2023 Conference, New York, NY, USA, 10–14 September 2023; pp. 637–653. [Google Scholar]
- Schneider, L.; Goffman, E. Behavior in public places. Am. Sociol. Rev. 2008, 29, 427. [Google Scholar] [CrossRef]
- Sacks, H.; Schegloff, E.A.; Jefferson, G. A simplest systematics for the organization of turn-taking for conversation. Language 1974, 50, 696–735. [Google Scholar] [CrossRef]
- Ishii, R.; Otsuka, K.; Kumano, S.; Yamato, J. Prediction of who will be the next speaker and when using gaze behavior in multiparty meetings. ACM Trans. Interact. Intell. Syst. 2016, 6, 4. [Google Scholar] [CrossRef]
- Kawahara, T.; Iwatate, T.; Takanashi, K. Prediction of Turn-Taking by Combining Prosodic and Eye-Gaze Information in Poster Conversations. In Proceedings of the Interspeech 2012, Portland, OR, USA, 9–13 September 2012; pp. 727–730. [Google Scholar]
- Russell, S.O.C.; Harte, N. Visual cues enhance predictive turn-taking for two-party human interaction. arXiv 2025, arXiv:2505.21043. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # of Users | Label | Samples | Avg [ms] | Min [ms] | Max [ms] | Recv [KB/s] | Sent [KB/s] |
|---|---|---|---|---|---|---|---|
| 10 | Create room | 10 | 46.0 | 42 | 51 | 190.24 | 59.44 |
| 10 | Join call | 100 | 87.4 | 74 | 113 | 190.29 | 58.71 |
| 10 | Leave call | 100 | 84.9 | 66 | 107 | 189.80 | 58.44 |
| 20 | Create room | 10 | 45.4 | 41 | 52 | 187.59 | 58.70 |
| 20 | Join call | 200 | 148.5 | 72 | 183 | 188.45 | 59.52 |
| 20 | Leave call | 200 | 169.5 | 69 | 157 | 188.57 | 59.91 |
| 50 | Create room | 10 | 48.4 | 42 | 52 | 187.42 | 58.28 |
| 50 | Join call | 500 | 337.5 | 81 | 474 | 188.47 | 57.96 |
| 50 | Leave call | 500 | 301.8 | 74 | 429 | 186.53 | 59.44 |
| 100 | Create room | 10 | 46.4 | 40 | 51 | 187.33 | 56.37 |
| 100 | Join call | 1000 | 739.4 | 76 | 1124 | 188.49 | 58.86 |
| 100 | Leave call | 1000 | 648.2 | 73 | 947 | 186.74 | 56.12 |
| # of Users | A | B | C | D (Back Up) |
|---|---|---|---|---|
| 10 | 0.1633 | 0.1589 | 0.1598 | 0.0000 |
| 20 | 0.2479 | 0.2253 | 0.2392 | 0.0000 |
| 50 | 0.6933 | 0.6049 | 0.5831 | 0.0000 |
| 100 | 0.8824 | 0.8279 | 0.7942 | 0.6461 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Fujita, S. Adaptive Multi-Hop P2P Video Communication: A Super Node-Based Architecture for Conversation-Aware Streaming. Information 2025, 16, 643. https://doi.org/10.3390/info16080643
Chen J, Fujita S. Adaptive Multi-Hop P2P Video Communication: A Super Node-Based Architecture for Conversation-Aware Streaming. Information. 2025; 16(8):643. https://doi.org/10.3390/info16080643
Chicago/Turabian StyleChen, Jiajing, and Satoshi Fujita. 2025. "Adaptive Multi-Hop P2P Video Communication: A Super Node-Based Architecture for Conversation-Aware Streaming" Information 16, no. 8: 643. https://doi.org/10.3390/info16080643
APA StyleChen, J., & Fujita, S. (2025). Adaptive Multi-Hop P2P Video Communication: A Super Node-Based Architecture for Conversation-Aware Streaming. Information, 16(8), 643. https://doi.org/10.3390/info16080643