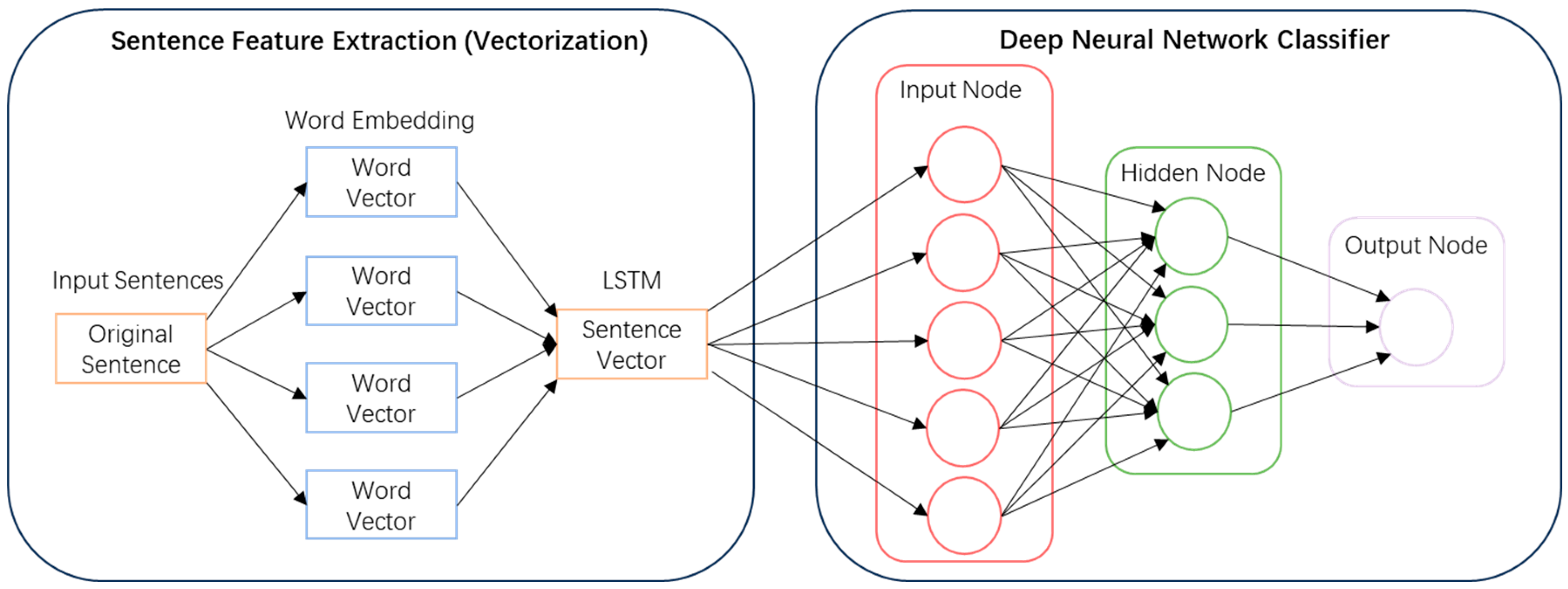
4.1. Nodal Identification of Brand Product Reviews
In this study, we collected 19,875 consumer reviews across 11 smartphone product series of a specific brand through web crawling on the JD.com platform. Following text segmentation processing, the top 100 keywords were extracted through the combined implementation of TF-IDF weighting and TextRank graph-based ranking algorithms. The results are presented in
Table 5.
By analyzing the extraction results of the TF-IDF and TextRank algorithms, we were able to identify key user concerns regarding the selected brand’s smartphone offerings. Under the TF-IDF algorithm, the top ten keywords are ranked as follows: phone, speed, screen, photography, operation, appearance, effect, sound effect, shape, and like. Under the TextRank algorithm, the top ten keywords are ranked as follows: screen, phone, photography, sound effect, appearance, standby time, speed, very, operation, and battery. A comparison reveals that, although there is a certain degree of overlap between the keywords extracted using the two algorithms—such as “phone”, “screen”, “photography”, “appearance”, and “operation”—there are differences in the importance ranking of the keywords. For example, “speed” is ranked higher using TF-IDF but is ranked relatively lower using TextRank; conversely, “sound effect” ranks higher using TextRank but is not ranked higher when using TF-IDF. This indicates that different algorithms have different assessments of the importance of words in text, possibly due to the different factors they consider when calculating word weights. Based on this, we can regard the keywords extracted using the two algorithms as network nodes and construct edges based on co-occurrence relationships, thereby determining the intralayer connections of TF-IDF and TextRank, respectively. Interlayer connections are made based on the principle of node name identity, ultimately constructing a multilayer network model comprising the TF-IDF layer, TextRank layer, and repeated node layer.
On e-commerce platforms like JD.com, consumers can review purchased products, and these reviews form the main content of online evaluations. As the primary medium of information dissemination, review content serves as a conduit for transmitting actionable market intelligence—including consumer preferences and product performance metrics—to stakeholders such as prospective buyers, retailers, and brand custodians. To deeply explore consumer sentiment and product feature information embedded in review data, this section builds a multilayer network model based on brand product reviews, keyword extraction algorithms, and feature associations. In this model, the association rules between nodes are as follows:
(1) TF-IDF network layer: the nodes represent TF-IDF-derived keywords, with the edges constructed based on co-occurrence relationships within individual smartphone reviews.
(2) TextRank network layer: the nodes correspond to TextRank-generated keywords, with the edges defined by lexical co-occurrence within singular review instances.
(3) Shared node network layer: the nodes consist of intersectional keywords identified by both TF-IDF and TextRank, with the edges reflecting cross-product lexical associations within the brand’s review corpus.
Within multilayer network architectures, node influence is determined by three interdependent factors: the aggregated degree centrality of both focal nodes and their intralayer counterparts, the betweenness centrality quantified by path traversal frequency, and the systemic dominance of specific node types within heterogeneous networks proportional to their population density. Intralayer node interactions and interlayer connectivity collectively characterize the heterogeneous attributes of nodes within multilayered network frameworks. In sentiment–feature co-analysis, the lexical–semantic overlap of multi-domain keywords within consumer reviews induces cross-layer semantic bridging, thereby dynamically constructing interlayer edges in multi-modal network architectures. Intralayer nodes across distinct network strata are interconnected via three primary mechanisms—review co-occurrence patterns, feature keyword co-occurrence distributions, and sentiment affinity metrics—which are synthetically integrated into a multilayered analytical framework for brand sentiment intelligence mining. This model yields granular insights into consumer sentiment polarity and domain-specific attention allocation patterns toward the brand’s mobile devices, which serve as actionable data assets to inform evidence-based strategic decision-making in competitive market positioning.
4.2. Multilayer Network Analysis of BKMN
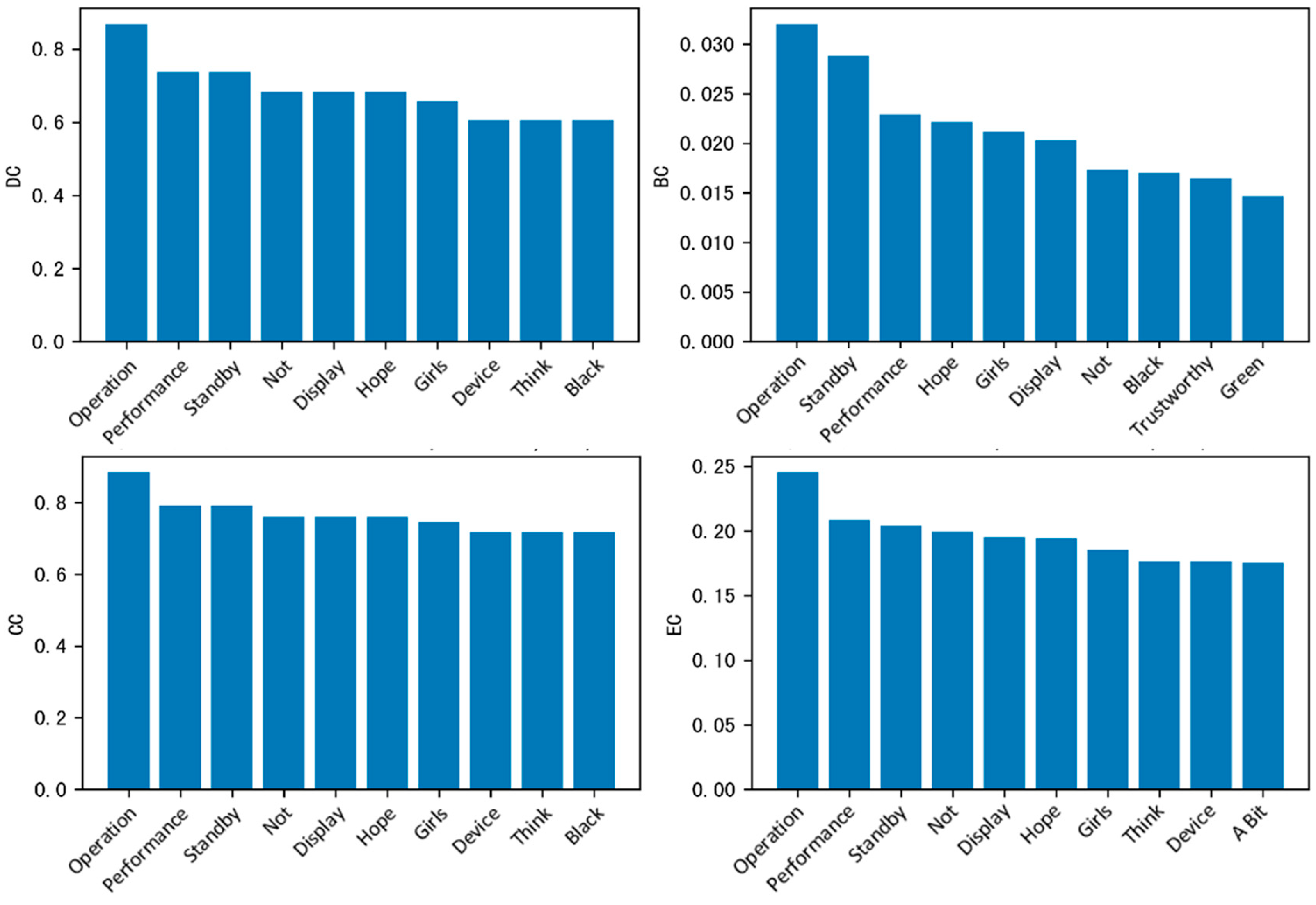
Firstly, according to the identified keyword nodes in
Section 4.1, among the keywords extracted by the TFIDF algorithm from the review data of a cell phone in Jingdong, the duplicated keyword nodes extracted by the TFIDF and TextRank algorithms are removed, and based on the centrality computation method in
Section 3.2.3, used to compute the four centrality scores of the remaining lower nodes, DC, BC, CC and EC, which are ranked. After that, the histograms of different centrality methods are plotted separately, as shown in
Figure 3.
From the four kinds of centrality in the figure, we can see that “operation”, “performance” and “standby” are at the top of both degree centrality and proximity centrality, indicating that these three keywords co-occur most frequently with other words and can be quickly associated with other topics, and are the core functional attributes discussed by users; the meso-centrality of “operation” stands out, indicating that it is the link between “performance” and “system”. This indicates that these three keywords have the highest frequency of co-occurrence with other words and can be quickly associated with other topics, which are the core functional attributes discussed by users; the meso-centrality of “operation” stands out, indicating that it is the key mediator connecting different functional topics such as “performance” “system” is a key mediator connecting different functional topics such as “performance” and “system”; the eigenvector centrality of “operation” and “performance” is high, as they are often associated with other high-impact nodes such as “speed”, further reinforcing their importance. The feature vectors of “operation” and “performance” have higher centrality because they are often associated with other high-influence nodes such as “speed”, which further strengthens their centrality at the statistical feature level. In addition, the colors of cell phones that consumers pay attention to are concentrated in black and green, the keyword “girls” reflects the high influence of the brand on girls, and the keyword “hope” reflects the expectation of consumers for the brand. Overall, this reflects the high frequency of users’ attention to the hardcore indicators of cell phones.
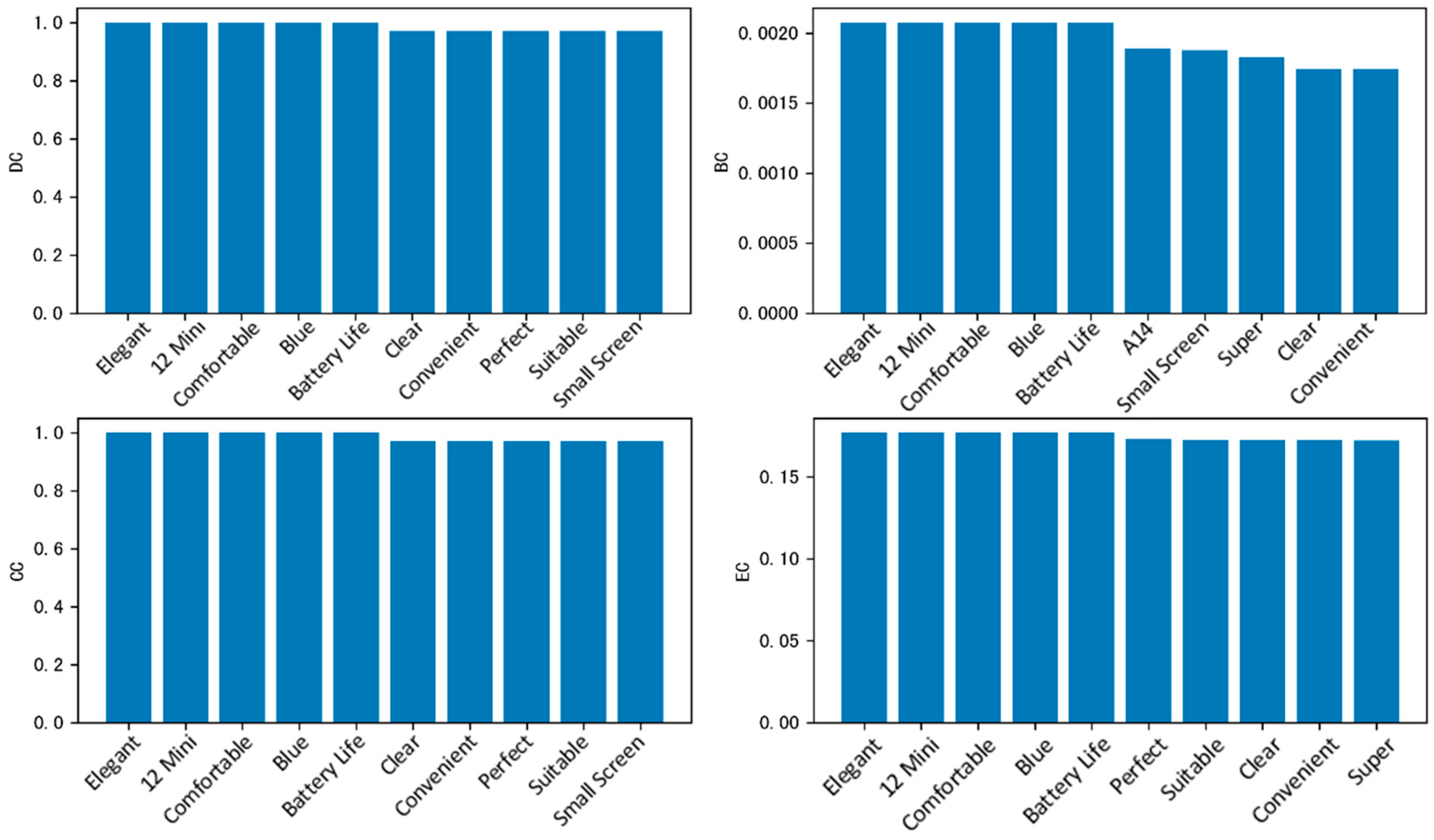
Next, using the same method, based on the keyword nodes identified in
Section 4.1, among the keywords extracted by TextRank algorithm from the review data of a cell phone in Jingdong, the duplicated keyword nodes extracted by the TFIDF and TextRank algorithms are removed, and based on the centrality computation method in
Section 3.2.3, the remaining nodes’ four centrality scores, namely, DC, BC, CC, and EC, are calculated and ranked. These are then sorted and plotted as bar charts for different centrality methods, respectively, as shown in
Figure 4.
As can be seen from the four centrality of the graph, the centrality of the top-ranked nodes is of the same size, indicating that in the keywords extracted by this algorithm to build into the network layer, the top-ranked nodes have the same influence, and the probability of consumers mentioning them in their comments is the same. The degree centrality and feature vector centrality of “delicate”, “comfortable” and “clear” are in the front, reflecting the fact that these descriptive words are in the semantic context with “appearance”, “feel” and other important nodes that are closely related, which is the core expression of the user’s subjective experience, indicating that consumers have a better sense of the brand’s goods; the meso-centrality of “12mini” is significant as a link between “small-screen” and “clear”. The centrality of “12mini” is significant, as an intermediary connecting topics such as “small screen” and “battery life”, and becoming a hub for the discussion of specific models, indicating that consumers are more concerned about the 12mini series of cell phones, and are also more concerned about the size and usage time of the cell phones under the brand; close to the centrality of high “clear” can be quickly associated with visual related topics such as “screen” and “photo”. Overall, it reflects users’ semantic focus on usage experience and segmented models, and forms a complementary perspective of function and experience with the TF-IDF layer.
Secondly, using the TFIDF and TextRank algorithms to extract repetitive keywords from Jingdong Apple cell phone review data, we were able to construct a repetitive node network hierarchy. The results show that the centrality of the first ten keyword nodes is the same; this indicates that the two algorithms have the same influence and control in sorting the top ten nodes in the network, reflecting strong control over the network information flow. In using the two keyword extraction algorithms, combined with centrality, it can be concluded that the photo effect, running speed, screen, appearance, shape, and sound effects comprise the central focus in consumer reviews.
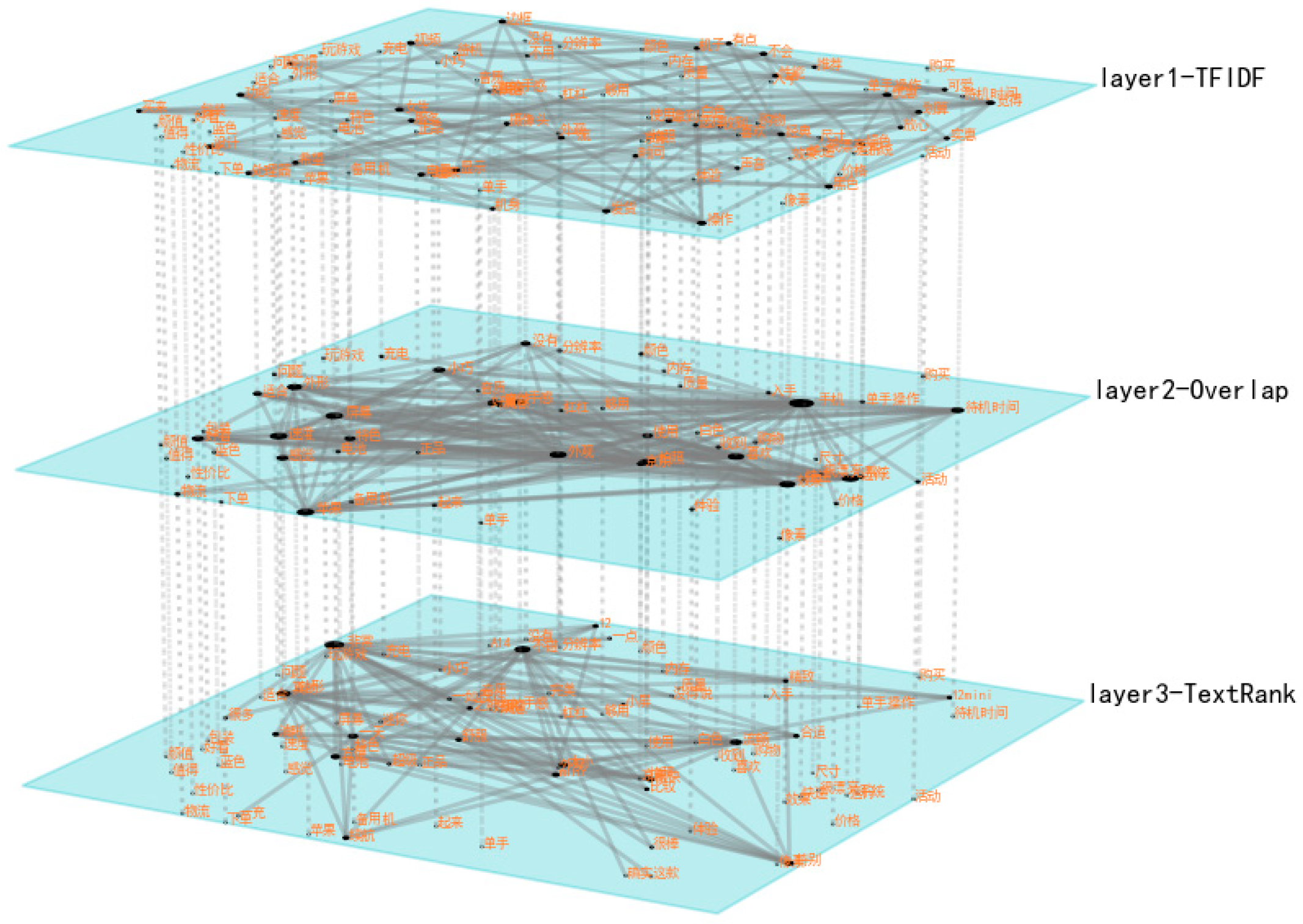
Finally, the multilevel network is constructed using a TFIDF layer, a TextRank layer, and an overlap layer (overlapping keywords layer); these layers improve the visual effect of the network. The edges with lower weights at the connected edges in the network layer are deleted, with focus on the nodes that are more closely connected. The sizes of the nodes are related to the degree of the multilevel network—the larger the degree, the larger the nodes. These data were plotted using Python 3.13.5 programming and toolkits such as pymnet, matplotlib, networkx, and pandas; the plotted multilevel network is shown in
Figure 5. This network is used to show the connections between the keywords at different network levels, with different weighted connected edges and nodes. Since the network is based on Chinese corpus analysis, the nodes in the graph are Chinese words.
In the BKMN network, the overlap layer exhibits the highest node degrees, followed by the TextRank layer, with the TF-IDF layer showing the lowest node degrees. The key consumer concerns across the layers focus on “photography”, “performance”, “speed”, “audio quality”, “design”, and “battery life”. Among consumers who recently purchased and reviewed a mobile phone, there is a relatively high level of attention paid towards the iPhone12 mini.
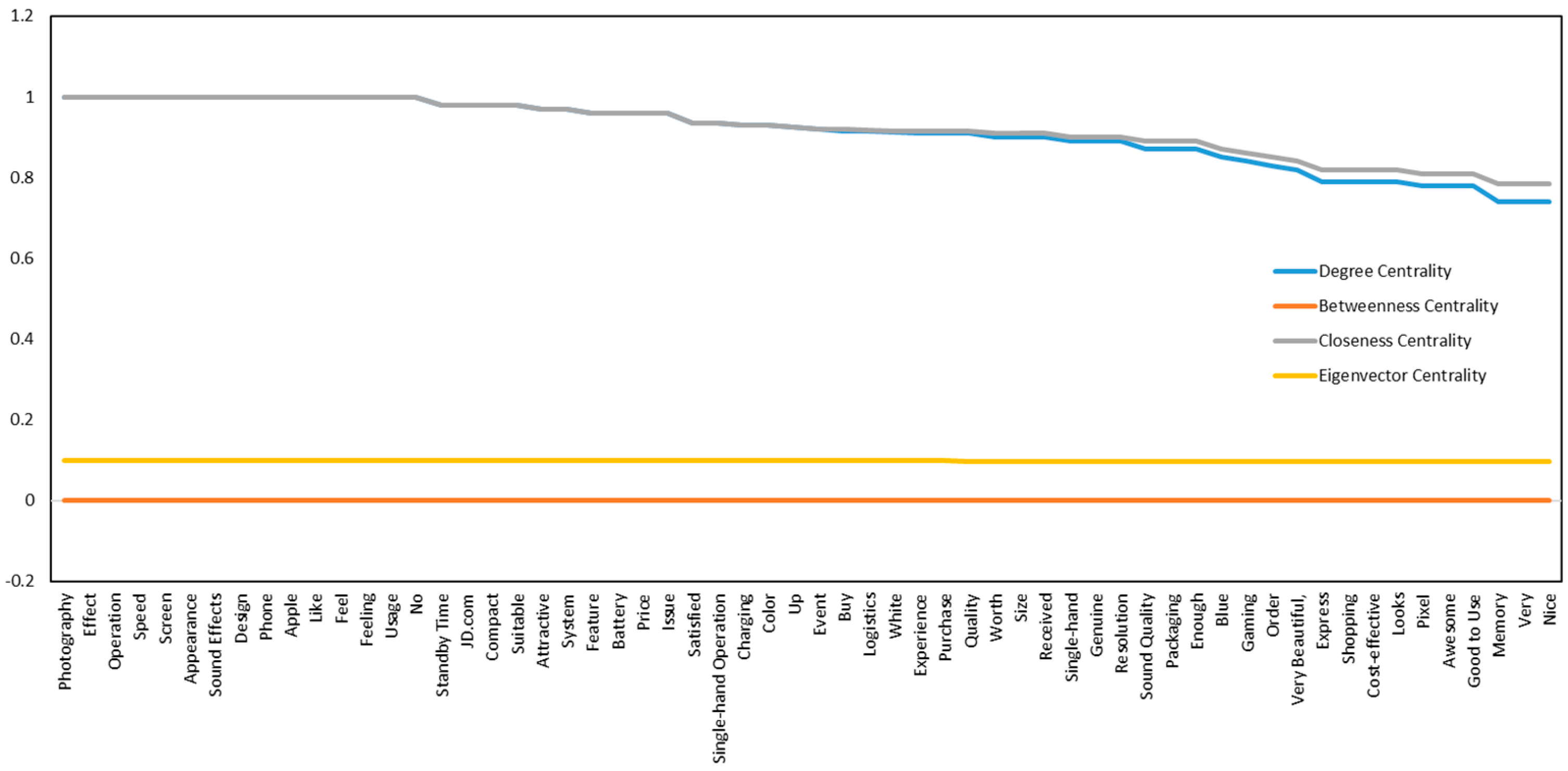
To ensure that the plotted keywords do not overlap, and to enable us to consider the number of overlapping keyword nodes among the two algorithms, 60 keyword nodes were selected according to their degree of centrality and sorted in order to plot the four centrality trends, as shown in
Figure 6.
This selection reveals that the first 15 keywords in the BKMN multilevel network are the focal points of consumer attention in brand reviews. The degree centrality curve shows a pattern similar to that of betweenness centrality, whereas the curves for closeness and eigenvector centralities exhibit relatively minor fluctuations.
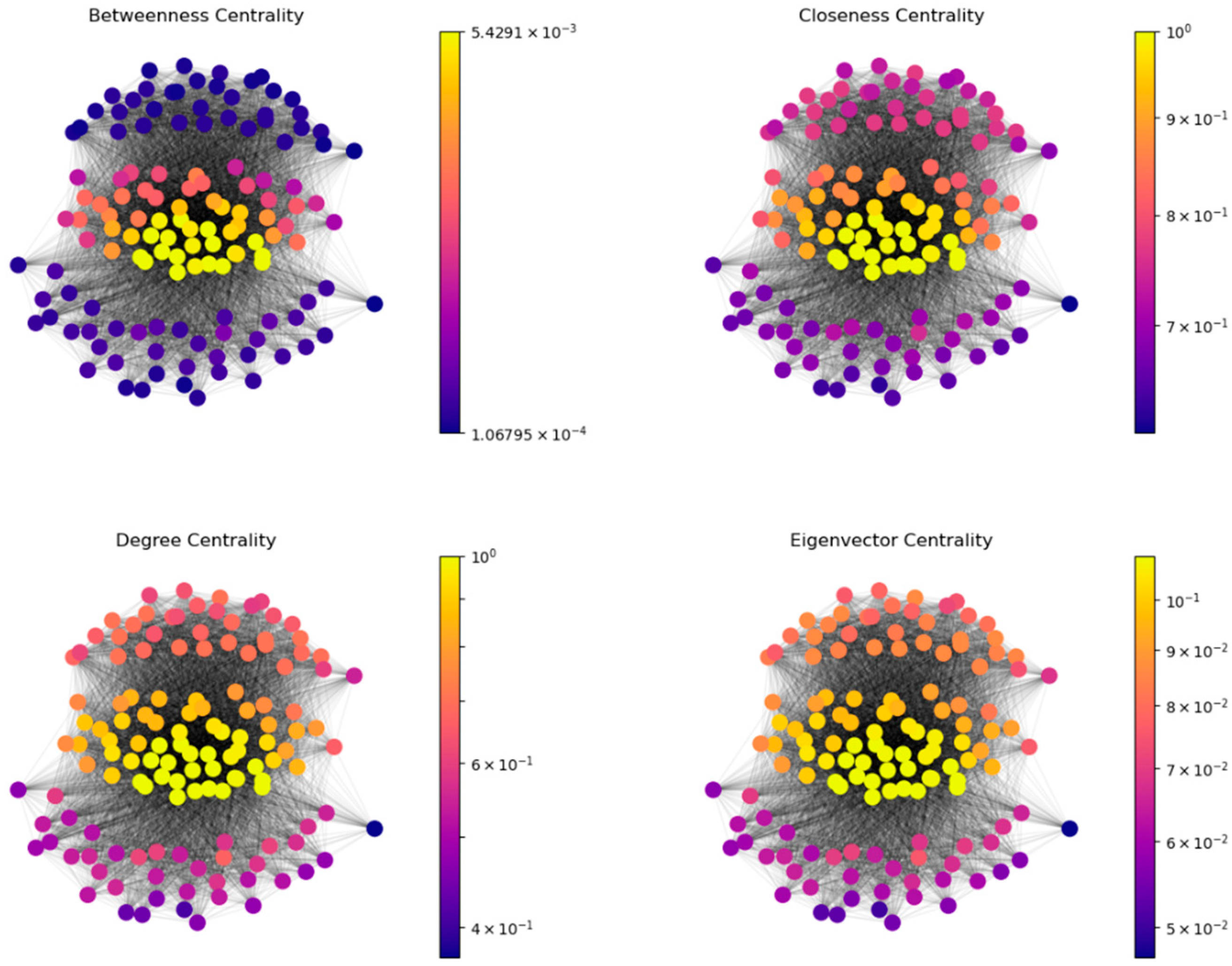
A heatmap, integrated with the FR force-directed algorithm for node layout, unveils an overall three-layer network structure, as depicted in
Figure 7.
The color distribution within the BKMN multilayer network illustrates node distribution under different centralities. Most nodes exhibit low betweenness centrality, yet they possess high degree, closeness, and eigenvector centralities. Few nodes with high betweenness centrality exist in the network, indicating that only a small number of keywords act as the shortest-path nodes in branded product reviews. These nodes perform a vital “mediating” function in information transmission and semantic expression.
The characteristics of the multilayer network facilitate a more comprehensive and in-depth understanding of the network structure and the relationships between nodes. By analyzing the network topology features of each individual layer as well as the overall multilayer network, the results presented in
Table 6 were obtained.
The structural hierarchy analysis reveals that 60 intersectional nodes were co-identified by both the TF-IDF and TextRank algorithms. These nodes exhibit cross-algorithmic dominance in multilayered network architectures, signifying consensus-driven consumer focus points within brand-related review ecosystems.
A comparative analysis of the average degree centrality metrics indicates that the network layer derived from TextRank surpasses its TF-IDF counterpart in edge density. However, the shared node subgraph shows reduced connectivity. The BKMN multiplex network demonstrates the highest global degree centrality, reflecting a high level of node interconnectivity across hierarchical layers. This structural pattern suggests that TextRank prioritizes semantically cohesive keyword clusters, while the heterogeneity in degree distributions across algorithms arises from differential weighting mechanisms.
An analysis of the network diameter indicates that both the individual layers and the overall multilevel network have a diameter of 2. This signifies that the maximum distance between any two keyword nodes is at most two steps, reflecting the close proximity of consumer attention points. Additionally, the average path length within each network layer remains below 2, suggesting that the multilevel network exhibits small-world properties. This facilitates the more effective observation of node propagation and influence.
An analysis of the normalized clustering coefficient reveals that the average clustering coefficient of the multilevel network exceeds 0.8, with each layer also exhibiting values above 0.8. This indicates that, despite variations in the co-occurrence levels of keywords extracted from product reviews across different algorithms, the keywords consistently co-occur with high frequency and exhibit strong interconnections. Consequently, consumer attention within the mobile phone product category of a given brand appears to be tightly clustered.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}