
Brain Tumour Segmentation Using Choquet Integrals and Coalition Game

 ,
, 
 , and
, and 
Abstract
1. Introduction
- 1.
- Channel shuffling: Intermixes encoder and decoder feature maps to improve hierarchical feature processing and spatial detail capture;
- 2.
- Width shuffling: Shuffles feature map widths to enhance spatial resolution, particularly for high-dimensional 3D data.
- Novel channel and width shuffling techniques to enhance U-Net-based architectures;
- A method for fuzzy measure calculation using coalition game theory and the Lambda fuzzy approximation;
- Application of the Choquet integral to aggregate predictions, enabling robust tumour segmentation.
2. Related Work
2.1. Standalone Models for Brain Tumour Segmentation
2.2. Ensemble-Based Approaches
2.3. Methods Leveraging Recent Deep Architectures
- A and B are two sets of points (e.g., boundary points of two segmentations).
- : A point from set A.
- : A point from set B.
- : The Euclidean distance between points a and b.
- : The shortest distance from a point a in A to any point in B.
- : The shortest distance from a point b in B to any point in A.
- ∪: The union operator, combining the distances calculated in both directions.
- : The 95th percentile value of the combined set of minimum distances, making the metric robust to outliers.
3. Methodology
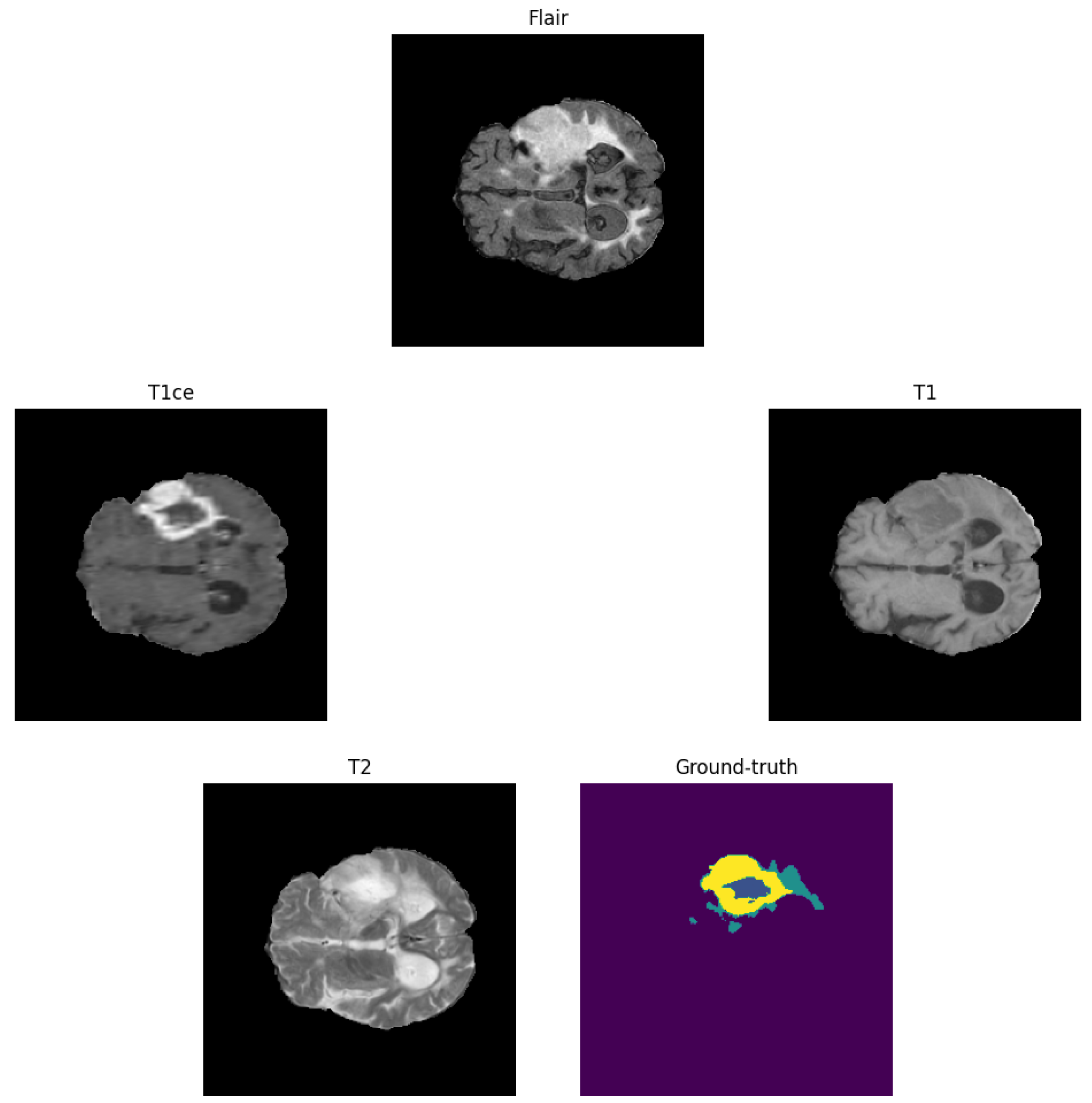
3.1. Image Pre-Processing
3.2. Data Augmentation
- 1.
- Input channel rescaling: Voxel values are multiplied by a factor with a probability of 70–80%, as follows:
- 2.
- Input channel intensity shift: A constant is added to each voxel with a probability of 5–10%, as follows:
- 3.
- Additive Gaussian noise: Noise is added to each voxel, as follows:
- 4.
- Input channel dropping: A randomly selected input channel is set to zero with a probability of 12–16%.
- 5.
- Random flipping: Inputs are flipped along spatial axes with a probability of 70–80%.
3.3. Proposed Brain Tumour Segmentation
- Deep Models: Train multiple U-Net variants.
- Ensemble Aggregation: Aggregate predictions using the Choquet integral with fuzzy measures.
- Post-Processing: Refine segmentation masks.
3.3.1. Neural Network Architectures
3.3.2. Ensemble Method for Brain Tumour Segmentation
- 1.
- Shapley Values: The Shapley value , represented by Equation (6), represents the average contribution of classifier i to all possible coalitions.where n is the total number of classifiers, S is a subset of classifiers excluding i, is the cardinality of S, is the characteristic function indicating the value of coalition S, and is the value with classifier i included. is the marginal contribution of classifier i on coalition S. It is calculated by Equation (7).where is the conditional mutual information between the predictions of classifier and the ground truth labels, based on the outputs of classifiers in the set L, and is the mutual information between L’s classifiers and the true labels.Based on the values of and , classifiers can be as follows:
- Redundant:
- Independent:
- Interdependent:
- 2.
- Lambda Fuzzy Approximation: Computational tractability is enhanced using a parameter , which facilitates the estimation of fuzzy measures for all subsets X, as follows:Here, N is the number of classifiers, and refers to individual classifiers. is used to compute fuzzy measures for larger subsets by leveraging those of individual classifiers. The fuzzy measure of the union of two classifiers and can be calculated by Equation (12), given that , as follows:A heuristic based on mutual information is utilized (Equation (13)), as follows:L is the current set of selected classifiers with cardinality l, and is the mutual information between and . This heuristic estimates the marginal contribution of a classifier by taking into account its relevance and redundancy.
Weighting Schemes
- 1.
- Weighting Scheme 1:and are respectively the validation accuracies of and . This approach assigns lower weights to classifiers with superior validation accuracy.
- 2.
- Weighting Scheme 2:Here, the reciprocal of validation accuracy is used, such that higher accuracy corresponds to lower weight.
- 3.
- Weighting Scheme 3:This scheme utilizes the negative logarithm of validation accuracies, similarly reducing the weight for more accurate classifiers.
Choquet Integral
4. Fuzzy Measures
- 1.
- Boundary Condition: The measure of the empty set is zero, and the measure of the entire universe of discourse X is one, as follows:
- 2.
- Monotonicity: This refers to the requirement that fuzzy measures respect the natural inclusion relationship between subsets. Specifically, for , if , then .
- 3.
- Continuity: If you have a sequence of sets that are either increasing or decreasing, the measure of the limit of these sets should equal the limit of their measures, as follows: or , then .
- 4.
- Super-additivity and Sub-additivity: These concepts refer to how the measure of the union of sets relates to the measures of the individual sets. Super-additivity means that the measure of the union is at least as large as the sum of the measures of the individual sets, while sub-additivity means that it is at most that sum.
5. Experimental Setup
5.1. Configuration Setup
5.2. Evaluation Metrics
- Dice Similarity Coefficient (DSC): Measures overlap between predicted and ground truth segmentations.
- Sensitivity: Measures the ability to detect positive instances.
- Specificity: Measures the ability to detect negative instances.
- Dice Loss: Used to train the network.
- 1.
- Learning Rate Schedule: Initial learning rate of 0.0001 reduced using cosine decay after 100 epochs.
- 2.
- Stochastic Weight Averaging: Applied after 250 epochs.
- 3.
- Optimiser: Ranger optimiser for primary training, Adam optimiser during Stochastic Weight Averaging.
- 4.
- Model Selection: The two best-performing models were selected based on validation loss.
- 1.
- Predicted Masks: Each model generated binary masks for ET, TC, and WT.
- 2.
- Pixel-Wise Aggregation: Predictions were combined using the Choquet integral.
- 3.
- Final Labelmap Reconstruction: Tumour sub-regions were combined to construct a 3-channel labelmap.
6. Results and Discussion
6.1. Performance Analysis of the Proposed Approach
- Individual Model Performance: Dice scores for TC ranged from 0.82436 to 0.83919, WT ranged from 0.87065 to 0.88439, and ET ranged from 0.76689 to 0.78964. Specifically, Model 2 achieved a Dice score of 0.82436 for TC, while Model 5 reached 0.83919. For WT, Model 1 scored 0.87065, and Model 6 achieved 0.88439. ET segmentation showed the highest variability, with scores between 0.76689 (Model 6) and 0.78964 (Model 3). Sensitivity values for ET were highest for Model 1 (0.81825) and lowest for Model 6 (0.78967). WT sensitivity showed excellent performance across all models, with values exceeding 0.918, whereas TC sensitivity varied, with Model 3 performing the worst (0.8306) and Model 2 performing the best (0.85453). Specificity was consistently high across all models for all tumour sub-regions, with values close to 0.999. The Hausdorff distance (95%) for ET was lowest for Model 3 (20.71231), reflecting better boundary prediction, while Model 6 had the highest (32.78875), indicating less accurate boundary delineation. For WT and TC, the Hausdorff distances were generally low, with the best values for Models 6 and 5, respectively.
- Weighted Ensembles: Weighted ensemble techniques optimised model performance, especially for WT segmentation. Weight1 achieved strong results for WT segmentation (Dice = 0.89318) and specificity (0.99976 for TC), while Hausdorff distances showed improvements, particularly for WT (6.02998). Weight2 performed comparably with the highest Dice score for ET (0.77724) and slightly better TC segmentation than Weight1 (Dice = 0.82411). WT sensitivity also improved (0.92054), demonstrating that the ensemble effectively integrated complementary strengths of the models. Weight3 had slightly lower performance overall but maintained competitive metrics for specificity (0.99977 for ET and TC) and WT segmentation. A simple average ensemble yielded stronger results for TC and ET but lagged in WT performance. The simple average approach outperformed the weighted techniques for Dice scores in TC (0.84869) and ET (0.79047), but it did not achieve the same level of performance in WT segmentation (Dice = 0.88571). It demonstrated good sensitivity for all sub-regions, particularly TC (0.84953) and WT (0.94181). The Hausdorff distance for TC (6.62945) was notably the best among all approaches, while ET and WT distances remained competitive. The weighted ensembles (Weight1, Weight2, and Weight3) provided consistent performance improvements for WT segmentation compared with individual models, highlighting the ensemble’s ability to leverage diverse model outputs effectively. The Dice scores and Hausdorff distances suggest that the ensembles prioritize overall stability, particularly for WT segmentation, where the weights focus on integrating the strengths of all models. However, for the more challenging ET region, none of the ensembles managed to outperform the simple average, indicating that additional refinement or ET-specific weighting strategies may be required to address the small size and variability of this tumour sub-region.
6.2. Comparison with State-of-the-Art Methods
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yahiaoui, M.E.; Derdour, M.; Abdulghafor, R.; Turaev, S.; Gasmi, M.; Bennour, A.; Aborujilah, A.; Sarem, M.A. Federated Learning with Privacy Preserving for Multi- Institutional Three-Dimensional Brain Tumor Segmentation. Diagnostics 2024, 14, 2891. [Google Scholar] [CrossRef]
- Sulaiman, A.; Anand, V.; Gupta, S.; Al Reshan, M.; Alshahrani, H.; Shaikh, A.; Elmagzoub, M. An intelligent LinkNet-34 model with EfficientNetB7 encoder for semantic segmentation of brain tumor. Sci. Rep. 2024, 14, 1345. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Elbachir, Y.M.; Makhlouf, D.; Mohamed, G.; Bouhamed, M.M.; Abdellah, K. Federated Learning for Multi-institutional on 3D Brain Tumor Segmentation. In Proceedings of the 2024 6th International Conference on Pattern Analysis and Intelligent Systems (PAIS), El Oued, Algeria, 24–25 April 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Bhowal, P.; Sen, S.; Yoon, J.; Geem, Z.W.; Sarkar, R. Choquet Integral and Coalition Game-based Ensemble of Deep Learning Models for COVID-19 Screening from Chest X-ray Images. IEEE J. Biomed. Health Inform. 2021, 25, 4328–4339. [Google Scholar] [CrossRef]
- Lee, K.M.; Leekwang, H. Identification of λ-fuzzy measure by genetic algorithms. Fuzzy Sets Syst. 1995, 75, 301–309. [Google Scholar] [CrossRef]
- Qin, J.; Xu, D.; Zhang, H.; Xiong, Z.; Yuan, Y.; He, K. BTSegDiff: Brain tumor segmentation based on multimodal MRI Dynamically guided diffusion probability model. Comput. Biol. Med. 2025, 186, 109694. [Google Scholar] [CrossRef]
- Habchi, Y.; Kheddar, H.; Himeur, Y.; Ghanem, M.C. Machine learning and vision transformers for thyroid carcinoma diagnosis: A review. arXiv 2024, arXiv:2403.13843. [Google Scholar] [CrossRef]
- Sun, J.; Li, Y.; Wu, X.; Tang, C.; Wang, S.; Zhang, Y. HAD-Net: An attention U-based network with hyper-scale shifted aggregating and max-diagonal sampling for medical image segmentation. Comput. Vis. Image Underst. 2024, 249, 104151. [Google Scholar] [CrossRef]
- Ma, B.; Sun, Q.; Ma, Z.; Li, B.; Cao, Q.; Wang, Y.; Yu, G. DTASUnet: A local and global dual transformer with the attention supervision U-network for brain tumor segmentation. Sci. Rep. 2024, 14, 28379. [Google Scholar] [CrossRef]
- S, C.; Clement, J.C. Enhancing brain tumor segmentation in MRI images using the IC-net algorithm framework. Sci. Rep. 2024, 14, 15660. [Google Scholar] [CrossRef]
- Habchi, Y.; Kheddar, H.; Himeur, Y.; Ghanem, M.C.; Boukabou, A.; Al-Ahmad, H. Deep transfer learning for kidney cancer diagnosis. arXiv 2024, arXiv:2408.04318. [Google Scholar]
- Zhang, M.; Liu, D.; Sun, Q.; Han, Y.; Liu, B.; Zhang, J.; Zhang, M. Augmented Transformer network for MRI brain tumor segmentation. J. King Saud Univ. Comput. Inf. Sci. 2024, 36, 101917. [Google Scholar] [CrossRef]
- Guan, X.; Yang, G.; Ye, J.; Yang, W.; Xu, X.; Jiang, W.; Lai, X. 3D AGSE-VNet: An automatic brain tumor MRI data segmentation framework. BMC Med. Imaging 2022, 22, 6. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, Y.; Liu, H.; Song, E.; Hung, C.C. A 3D Cross-Modality Feature Interaction Network With Volumetric Feature Alignment for Brain Tumor and Tissue Segmentation. IEEE J. Biomed. Health Inform. 2023, 27, 75–86. [Google Scholar] [CrossRef]
- Ahmad, P.; Jin, H.; Alroobaea, R.; Qamar, S.; Zheng, R.; Alnajjar, F.; Aboudi, F. MH UNet: A multi-scale hierarchical based architecture for medical image segmentation. IEEE Access 2021, 9, 148384–148408. [Google Scholar] [CrossRef]
- Xu, W.; Yang, H.; Zhang, M.; Cao, Z.; Pan, X.; Liu, W. Brain tumor segmentation with corner attention and high-dimensional perceptual loss. Biomed. Signal Process. Control 2022, 73, 103438. [Google Scholar] [CrossRef]
- Liu, Z. Innovative multi-class segmentation for brain tumor MRI using noise diffusion probability models and enhancing tumor boundary recognition. Sci. Rep. 2024, 14, 29576. [Google Scholar] [CrossRef]
- Rajput, S.; Kapdi, R.; Roy, M.; Raval, M. A triplanar ensemble model for brain tumor segmentation with volumetric multiparametric magnetic resonance images. Healthc. Anal. 2024, 5, 100307. [Google Scholar] [CrossRef]
- Henry, T.; Carré, A.; Lerousseau, M.; Estienne, T.; Robert, C.; Paragios, N.; Deutsch, E. Brain tumor segmentation with self-ensembled, deeply-supervised 3D U-net neural networks: A BraTS 2020 challenge solution. In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries; Proceedings of the 6th International Workshop, BrainLes 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, 4 October 2020; Revised Selected Papers, Part I 6; Springer: Cham, Switzerland, 2021; pp. 327–339. [Google Scholar]
- Nguyen, H.T.; Le, T.T.; Nguyen, T.V.; Nguyen, N.T. Enhancing MRI brain tumor segmentation with an additional classification network. In Proceedings of the International MICCAI Brainlesion Workshop, Lima, Peru, 4 October 2020; Springer: Cham, Switzerland, 2020; pp. 503–513. [Google Scholar]
- Zhao, J.; Xing, Z.; Chen, Z.; Wan, L.; Han, T.; Fu, H.; Zhu, L. Uncertainty-Aware Multi-Dimensional Mutual Learning for Brain and Brain Tumor Segmentation. IEEE J. Biomed. Health Inform. 2023, 27, 4362–4372. [Google Scholar] [CrossRef]
- Wen, L.; Sun, H.; Liang, G.; Yu, Y. A deep ensemble learning framework for glioma segmentation and grading prediction. Sci. Rep. 2025, 15, 4448. [Google Scholar] [CrossRef]
- Akbar, A.S.; Fatichah, C.; Suciati, N. Single level UNet3D with multipath residual attention block for brain tumor segmentation. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 3247–3258. [Google Scholar] [CrossRef]
- Liu, H.; Huo, G.; Li, Q.; Guan, X.; Tseng, M.L. Multiscale lightweight 3D segmentation algorithm with attention mechanism: Brain tumor image segmentation. Expert Syst. Appl. 2023, 214, 119166. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, J.; Guan, Y.; Ahmad, F.; Mahmood, T.; Rehman, A. MSegNet: A Multi-View Coupled Cross-Modal Attention Model for Enhanced MRI Brain Tumor Segmentation. Int. J. Comput. Intell. Syst. 2025, 18, 63. [Google Scholar] [CrossRef]
- Silva, C.A.; Pinto, A.; Pereira, S.; Lopes, A. Multi-stage Deep Layer Aggregation for Brain Tumor Segmentation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2021; Volume 12659, pp. 179–188. [Google Scholar] [CrossRef]
- Fidon, L.; Ourselin, S.; Vercauteren, T. Generalized wasserstein dice score, distributionally robust deep learning, and ranger for brain tumor segmentation: BraTS 2020 challenge. In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries; Proceedings of the 6th International Workshop, BrainLes 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, 4 October 2020; Revised Selected Papers, Part II 6; Springer: Cham, Switzerland, 2021; pp. 200–214. [Google Scholar]
- Rastogi, D.; Johri, P.; Donelli, M.; Kadry, S.; Khan, A.; Espa, G.; Feraco, P.; Kim, J. Deep learning-integrated MRI brain tumor analysis: Feature extraction, segmentation, and Survival Prediction using Replicator and volumetric networks. Sci. Rep. 2025, 15, 1437. [Google Scholar] [CrossRef] [PubMed]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-net: Learning dense volumetric segmentation from sparse annotation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2016; Volume 9901, pp. 424–432. [Google Scholar] [CrossRef]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.S.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Advancing The Cancer Genome Atlas glioma MRI collections with expert segmentation labels and radiomic features. Sci. Data 2017, 4, 170117. [Google Scholar] [CrossRef]
- Bakas, S.; Reyes, M.; Jakab, A.; Bauer, S.; Rempfler, M.; Crimi, A.; Shinohara, R.T.; Berger, C.; Ha, S.M.; Rozycki, M.; et al. Identifying the Best Machine Learning Algorithms for Brain Tumor Segmentation, Progression Assessment, and Overall Survival Prediction in the BRATS Challenge. arXiv 2018, arXiv:1811.02629. [Google Scholar] [CrossRef]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.; Freymann, J.; Farahani, K.; Davatzikos, C. Segmentation labels and radiomic features for the pre-operative scans of the TCGA-LGG collection. Cancer Imaging Arch. 2017, 286. [Google Scholar] [CrossRef]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.; Freymann, J.; Farahani, K.; Davatzikos, C. Segmentation labels and radiomic features for the pre-operative scans of the TCGA-GBM collection. Cancer Imaging Arch. 2017, 9. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 834–848. [Google Scholar] [CrossRef]
- Murofushi, T.; Sugeno, M. An interpretation of fuzzy measures and the Choquet integral as an integral with respect to a fuzzy measure. Fuzzy Sets Syst. 1989, 29, 201–227. [Google Scholar] [CrossRef]
- Beliakov, G.; James, S.; Wu, J.Z. Discrete Fuzzy Measures: Computational Aspects, 1st ed.; Springer Publishing Company, Incorporated: New York, NY, USA, 2019. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work Reference | Methods | Dataset | Results |
|---|---|---|---|
| [3] | Modality-pairing learning; parallel modality-specific branches | BraTS-2018 | Dice: 89.1%, 84.2%, 81.6% |
| [28] | Wasserstein Dice loss; distributionally robust optimization; Ranger optimizer | BraTS-2020, BraTS-2021 | Dice: 88.9%, 84.1%, 81.4%; HD95: 6.4, 19.4, 15.8 |
| [21] | DCNN with classification branch to aid segmentation | BraTS-2020 | Dice: 78.43%, 89.99%, 84.22% |
| [14] | AGSE-VNet using SE and AG modules | BraTS-2020 | Dice: 68%, 85% (enhanced tumour) |
| [16] | Dense + residual-inception blocks for gradient/contextual flow | BraTS-2018, BraTS-2019, BraTS-2020 | Dice: Not reported |
| [17] | U-Net with Corner Attention Module (CAM) and HDPL | BraTS-2018, BraTS-2019, BraTS-2020 | Dice: 89.6%, 85.1%, 79.2% |
| Category | Details |
|---|---|
| Hardware |
|
| Software |
|
| Aspect | Details |
|---|---|
| Models | 3D U-Net variants (related pooling, channel/width shuffle, 3D MaxPool) |
| Parameters | 19,167,819 per model |
| Epochs | 500 total |
| Training Time | ∼41.75 h (500 epochs, A100 40 GB GPU) |
| Per Epoch Time | Training: 254 s; validation: 70 s (134 s with swa) |
| Ensemble | Choquet integral, 63 subsets, Shapley values, 3 weighting schemes |
| Ensemble Time | T4: 21 h; L4: 18 h; A100: 160–178 s/patient, 18.22 h total |
| Methods | Dice | Sensitivity | Specificity | Hausdorff95 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ET | WT | TC | ET | WT | TC | ET | WT | TC | ET | WT | TC | |
| W276 | 0.787 | 0.870 | 0.833 | 0.818 | 0.941 | 0.846 | 0.999 | 0.998 | 0.999 | 21.09 | 8.06 | 6.98 |
| W288 | 0.784 | 0.873 | 0.824 | 0.808 | 0.932 | 0.854 | 0.999 | 0.998 | 0.999 | 21.58 | 8.78 | 10.32 |
| C402swa | 0.789 | 0.872 | 0.832 | 0.817 | 0.945 | 0.830 | 0.999 | 0.998 | 0.999 | 20.71 | 8.74 | 8.25 |
| C387 | 0.784 | 0.877 | 0.833 | 0.815 | 0.942 | 0.847 | 0.999 | 0.998 | 0.999 | 20.95 | 10.15 | 8.76 |
| r445 | 0.783 | 0.877 | 0.839 | 0.799 | 0.931 | 0.843 | 0.999 | 0.998 | 0.999 | 29.30 | 7.40 | 7.40 |
| r401 | 0.766 | 0.884 | 0.835 | 0.789 | 0.918 | 0.827 | 0.999 | 0.998 | 0.999 | 32.78 | 6.63 | 7.88 |
| Choquet Integral (WS-1) | 0.775 | 0.893 | 0.817 | 0.768 | 0.902 | 0.775 | 0.999 | 0.999 | 0.999 | 29.50 | 6.02 | 9.11 |
| Choquet Integral (WS-2) | 0.777 | 0.892 | 0.824 | 0.772 | 0.920 | 0.787 | 0.999 | 0.998 | 0.999 | 29.49 | 6.25 | 8.98 |
| Choquet Integral (WS-3) | 0.774 | 0.892 | 0.813 | 0.764 | 0.893 | 0.768 | 0.999 | 0.999 | 0.999 | 29.54 | 6.02 | 9.18 |
| 6 models simple avg | 0.790 | 0.885 | 0.848 | 0.812 | 0.941 | 0.849 | 0.999 | 0.998 | 0.999 | 23.74 | 6.89 | 6.62 |
| Subset | Tumour | SV (WS-1) | SV (WS-2) | SV (WS-3) |
|---|---|---|---|---|
| W276 | ET, WT, TC | 0.011256, 0.036154, 0.019697 | 0.026734, 0.103931, 0.051548 | −0.003341, −0.010863, −0.003477 |
| W288 | ET, WT, TC | 0.011129, 0.038152, 0.016595 | 0.026717, 0.106726, 0.047071 | −0.003527, −0.009044, −0.005739 |
| C402_swa | ET, WT, TC | 0.0115, 0.03664, 0.019509 | 0.026931, 0.103906, 0.051083 | −0.00323, −0.00992, −0.003161 |
| C387 | ET, WT, TC | 0.010704, 0.039278, 0.017495 | 0.026101, 0.107952, 0.048416 | −0.003864, −0.008584, −0.005179 |
| r445 | ET, WT, TC | 0.009916, 0.038467, 0.020848 | 0.025075, 0.106737, 0.05255 | −0.004238, −0.008989, −0.001954 |
| r401 | ET, WT, TC | 0.009628, 0.039894, 0.020227 | 0.024291, 0.10801, 0.051912 | −0.004343, −0.006779, −0.002642 |
| Subset | Tumour | SV (WS-1-20) | SV (WS-2-20) | SV (WS-1-17) | SV (WS-2-17) |
|---|---|---|---|---|---|
| W276 | ET, WT, TC | 0.203293, 0.036154, 0.196238 | 0.206182, 0.103931, 0.203742 | 0.175549, −0.010863, 0.172221 | 0.171537, 0.048112, 0.170193 |
| W288 | ET, WT, TC | 0.200709, 0.038152, 0.165327 | 0.20605, 0.106726, 0.186044 | 0.173318, −0.009044, 0.145093 | 0.171427, 0.049405, 0.15541 |
| C402_swa | ET, WT, TC | 0.2077, 0.03664, 0.194358 | 0.2077, 0.103906, 0.201904 | 0.179355, −0.00992, 0.170571 | 0.1728, 0.0481, 0.168659 |
| C387 | ET, WT, TC | 0.193323, 0.039278, 0.174298 | 0.201301, 0.107952, 0.191362 | 0.16694, −0.008584, 0.152966 | 0.167476, 0.049973, 0.159853 |
| r445 | ET, WT, TC | 0.179092, 0.038467, 0.2077 | 0.193383, 0.106737, 0.2077 | 0.154651, −0.008989, 0.18228 | 0.160889, 0.049411, 0.1735 |
| r401 | ET, WT, TC | 0.17389, 0.039894, 0.201511 | 0.187343, 0.10801, 0.20518 | 0.150159, −0.006779, 0.176849 | 0.155863, 0.05, 0.171395 |
| Method | Tumour | Dice | Sensitivity | Specificity | Hausdorff95 |
|---|---|---|---|---|---|
| 6 models simple average | ET, WT, TC | 0.79047, 0.88571, 0.84869 | 0.81294, 0.94181, 0.84953 | 0.99966, 0.99858, 0.99954 | 23.74679, 6.89449, 6.62945 |
| Choquet ensemble | ET, WT, TC | 0.79227, 0.89602, 0.85051 | 0.81833, 0.91051, 0.85677 | 0.99965, 0.99909, 0.99952 | 20.74244, 5.9681, 6.65144 |
| Methods | Dice | Sensitivity | Hausdorff95 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ET | WT | TC | ET | WT | TC | ET | WT | TC | |
| [3] | 0.787 | 0.908 | 0.856 | 0.786 | 0.905 | 0.822 | 35.01 | 4.71 | 5.70 |
| [28] | 0.776 | 0.910 | 0.844 | - | - | - | 26.80 | 5.80 | 4.40 |
| [21] | 0.784 | 0.899 | 0.842 | - | - | - | 24.02 | 5.68 | 9.56 |
| [17] | 0.780 | 0.900 | 0.820 | - | - | - | 26.58 | 4.43 | 12.35 |
| [14] | 0.680 | 0.850 | 0.690 | 0.680 | 0.830 | 0.650 | 47.40 | 8.44 | 31.60 |
| [16] | 0.782 | 0.906 | 0.836 | - | - | - | 32.20 | 4.16 | 9.80 |
| Proposed Approach | 0.792 | 0.896 | 0.851 | 0.818 | 0.910 | 0.856 | 20.74 | 5.96 | 6.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Derdour, M.; Yahiaoui, M.E.B.; Kahil, M.S.; Gasmi, M.; Ghanem, M.C. Brain Tumour Segmentation Using Choquet Integrals and Coalition Game. Information 2025, 16, 615. https://doi.org/10.3390/info16070615
Derdour M, Yahiaoui MEB, Kahil MS, Gasmi M, Ghanem MC. Brain Tumour Segmentation Using Choquet Integrals and Coalition Game. Information. 2025; 16(7):615. https://doi.org/10.3390/info16070615
Chicago/Turabian StyleDerdour, Makhlouf, Mohammed El Bachir Yahiaoui, Moustafa Sadek Kahil, Mohamed Gasmi, and Mohamed Chahine Ghanem. 2025. "Brain Tumour Segmentation Using Choquet Integrals and Coalition Game" Information 16, no. 7: 615. https://doi.org/10.3390/info16070615
APA StyleDerdour, M., Yahiaoui, M. E. B., Kahil, M. S., Gasmi, M., & Ghanem, M. C. (2025). Brain Tumour Segmentation Using Choquet Integrals and Coalition Game. Information, 16(7), 615. https://doi.org/10.3390/info16070615