1. Introduction
Community-based Question-Answering platforms including Yahoo! Answers (An archived link can be found at
https://archive.fo/agAtD, since it was shut down in 2021), Reddit (
https://www.reddit.com/), and Stack Exchange (
https://stackexchange.com/), as well as Quora (
https://www.quora.com/), are visited by millions of users worldwide on a daily basis. The goal of these internauts is browsing and asking complex, subjective, and/or context-dependent questions. One of the key factors in their success relies on community fellows providing timely responses tailored to specific real-world situations. These types of answers are unlikely to be discovered via querying web search engines. Hence quickly matching community peers that are suitable and willing to help is crucial to continue the vibrancy of this sort of network.
For the sake of establishing constructive connections, cQA systems exploit frontier information technologies to harness the collective intelligence of the whole online social platform [
1,
2]. In so doing, demographic profiling of community members has shown to be instrumental. For instance, automatically identifying geographic locations is vital to reduce delays in obtaining the first acceptable answers, genders to reward users, and generational cohorts to receive suitable answers [
3,
4,
5,
6,
7,
8,
9]. In achieving this, recent advances in machine learning, especially deep neural networks, have played a pivotal role in enhancing user experience across cQA sites.
In fact, the eruption of pre-trained models (PTMs) such as BERT during the last five years has drastically changed the field by making it much easier for any individual to develop innovative and cost-efficient solutions for knotty problems. In this framework, a PTM is trained on massive amounts of corpora and adapted to a particular task afterwards. They are used as a starting point for developing other machine learning-oriented solutions since they offer a set of initial weights and biases that any person can adjust to a specific downstream task later. In the realm of cQAs, this sort of approach has produced auspicious results in many tasks including the automatic identification of demographic variables, namely age and gender [
10,
11].
In brief, this piece of research explores a novel criterion to calibrate these weights and biases based on their semantic contribution instead of using global frequencies only. Simply put, we aim to determine what occurrences of a particular term are convenient to consider when both fine-tuning and classifying new contexts. We hypothesize that sometimes a word should be taken into account and sometimes it should not, even though this might be a highly frequent term across the domain collection. To determine its semantic contribution to a specific context, we look at its depth in its corresponding lexicalized dependency tree. Therefore, by trimming dependency trees at different levels (depths), we can automatically generate several abstractions for a given text in consonance with their semantic granularity.
Hence, the novelty of this paper lies in quantifying the variation in the performance of a handful of state-of-the-art PTMs when systematically increasing the amount of details within their textual inputs. With this in mind, our contributions to this body of knowledge are summarized as follows:
By systematically varying the granularity of input contexts when fine-tuning PTMs, we aim to find out the point at which it turns detrimental or inefficient to add more detailed information.
Our test beds include two classification tasks (i.e., age and gender recognition) and three cQA collections of radically distinctive nature and size, more specifically Reddit, Yahoo! Answers, and Stack Exchange. Furthermore, our empirical configurations additionally target four combinations of input signals such as question titles and bodies, answers, and self-descriptions.
By zooming into our experimental results, we determine the types of syntactics and semantics that marginally contribute to enhancing performance.
We also analyzed whether our discoveries are consistent across both downstream tasks and whether their respective best models are strongly correlated or not.
In short, our empirical figures support the use of cost-efficient technologies that exploit distilled frontier deep architectures and coarse-grained semantic information (i.e., terms contained in the first three levels of the respective lexicalized dependency tree). The roadmap of this work is as follows. First,
Section 2 fleshes out the works of our forerunners; subsequently,
Section 3 delineates our research questions. Next,
Section 4 and
Section 5 deal at length with our methodology and experimental results, respectively. Eventually,
Section 6 and
Section 7 set forth our key findings, and the limitations of our approach, and outline some future research directions.
4. Methodology
In the first place, ten different linguistically motivated textual abstractions were produced for each community peer by processing his/her questions, answers/comments, and short bio. For this purpose, we took into account the level of granularity (information details) carried by each word across all these texts. In the same spirit of [
47,
48] (see also [
49]), we profited from Natural Language Processing (NLP) to generate these abstractions, specifically from lexicalized dependency trees computed by CoreNLP (
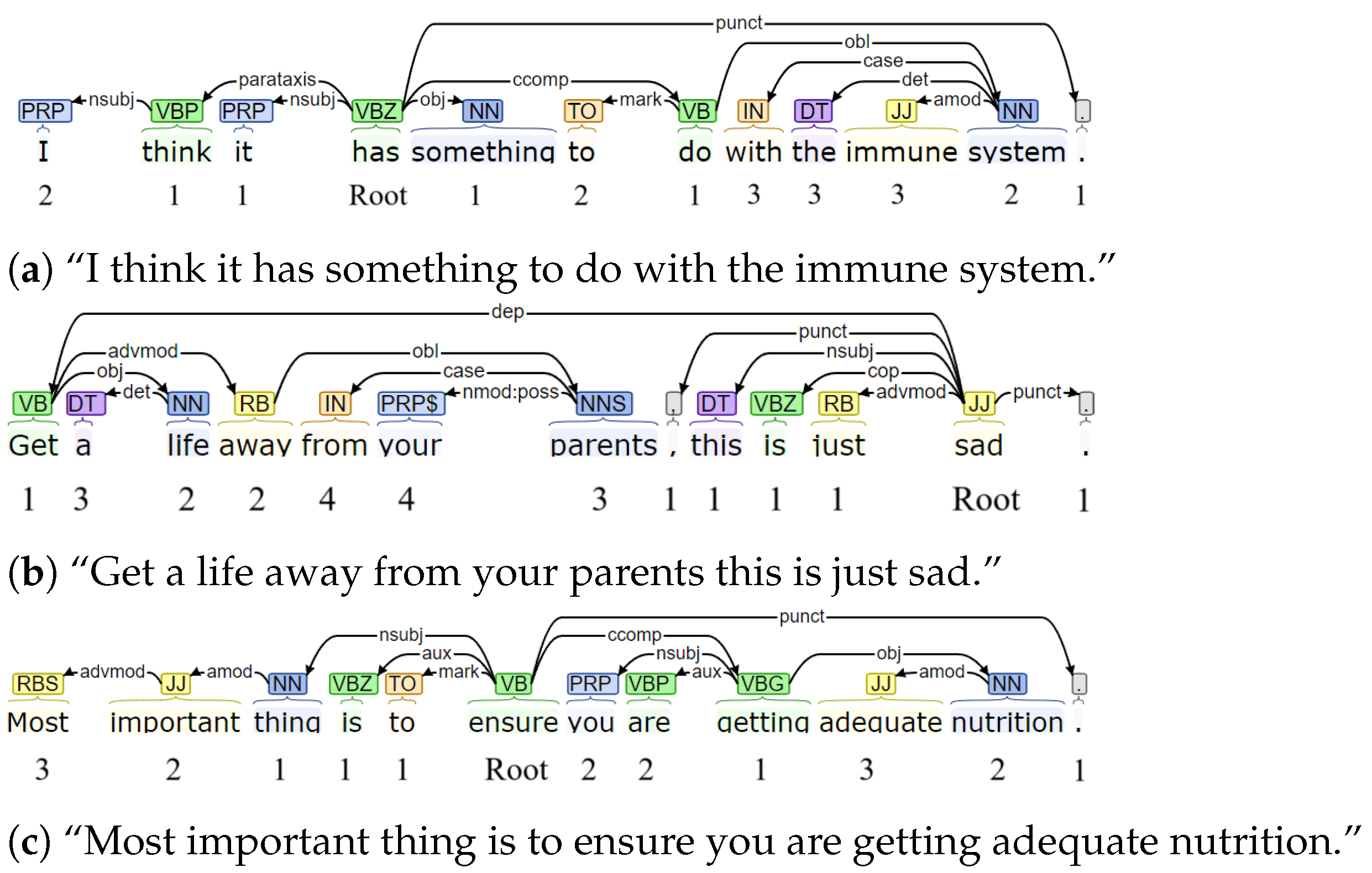
https://corenlp.run/). Essentially, the level of granularity of a term in a sentence conforms to its corresponding depth in its respective lexicalized tree, and thus the level of abstraction of a given text can be controlled by trimming dependency trees at different depths (see illustrative samples in
Figure 1). It is worth underlining here that word depth is defined as the number of edges needed to traverse in order to reach that particular term from the root node. In dependency trees, words in the topmost levels bear the largest amount of semantics, whereas terms at the nethermost are more likely to provide the details.
Figure 2 serves as an illustrative example of this transformation according to four different depths for a given user. Lastly, note that stop-words and punctuation were also removed from the processed corpora, but we kept both in
Figure 2 for the sake of readability and clarity. In our empirical settings, we considered ten distinct abstraction levels by pruning dependency trees at depths from zero (i.e., root nodes only) to nine.
Secondly, as a way of assessing the appropriateness of each of these abstractions for classifying age and gender, we utilized six well-known frontier pre-trained neural networks. The first one is the widely used BERT (Bidirectional Encoder Representations from Transformers) (cf. [
33,
34]). This architecture encompasses a multi-layer bidirectional transformer trained on clean plain text for masked words and next sentence prediction [
31,
34]. It predicates upon the old principle that words are, to at least a great extent, defined by other terms within the same context [
50]. BERT is composed of twelve transformer blocks and twelve self-attention heads with a hidden state of 768. Our experimental configurations made allowances for five additional state-of-the-art BERT-inspired architectures: ALBERT (A Lite BERT), DistilBERT, DistilRoBERTa, ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately), and RoBERTa [
51,
52,
53,
54]. Take, for instance, ELECTRA building a discriminator (transformer) that determines whether every token is an original or a replacement, instead of only masking a fraction of tokens within the input [
53]. A generator, another neural network, masks and substitutes tokens to generate corrupted samples. This architecture is more efficient than BERT since it demands significantly less computation while achieving competitive accuracy on several downstream tasks.
Thirdly, these six PTMs were adjusted to two different downstream tasks, i.e., name and gender recognition. Roughly speaking, the main investigative question of this work is determining the point (abstraction level) where it is better to count on semantic contributions than on global term frequencies computed from the target collection when fine-tuning. It is worth recalling here that it is standard practice to preserve only terms with a frequency higher than a minimum threshold during model adjustment. By and large, and also in this work, this parameter is set to five. This entails that new model fits rely on inferences embodied in pre-trained weights every time an unseen or an eliminated low-frequent word shows up in new contexts. Put differently, we hypothesize that global frequencies are just one important factor. We conjecture that another key aspect is the amount of semantics that each term carries within the context being analyzed. That is to say, there are some words in some contexts that are irrelevant or detrimental to their classification despite the correct deduction of their meanings due to being highly recurrent across the target task domain. This might happen because the most prominent meanings of some very common terms have nothing to do with their particular usage within specific contexts, and thus these words might introduce some noise when categorizing. For this reason, we claim that words must also be picked as features according to their semantic contribution to the particular context instead of using only a filter in consonance with a given threshold. To put it in another way, we keep the traditional minimum frequency threshold but we additionally remove words from each context in conformity to their semantic contribution to that specific text. In contrast to the conventional threshold, our filter is context-dependent.
Lastly, with regard to fine-tuning, we capitalized on the implementations provided by Hugging Face (
https://huggingface.co/). By and large, we chose default parameter settings to level the grounds and reduce the experimental workload. At all times, two epochs were set during model adjustment, and hence the time for fine-tuning was restricted to five days in the case of the most computationally demanding models. It is worth noting here that going beyond one epoch did not show any significant extra refinement, but we intentionally gave all encoders enough time to converge. The maximum sequence length was equal to 512. As for the batch size, this was set to make sure that the corresponding GPU memory usage reached its limit, namely eight; this way, it always allowed convergence. In our experiments, we used sixteen NVIDIA A16 (16gb) Tesla GPU cards. On a final note, it is worth pointing out that we employed half precision (fp16) format when working with all models but ELECTRA.
5. Experiments
This study made allowances for three fundamentally distinct collections, which belong to three cQA websites that serve different purposes and demographics, i.e., Reddit, Stack Exchange, and Yahoo! Answers. Accordingly, these corpora are described below as follows (see
Table 1):
Yahoo! Answers (from now on referred to as YA) is a collection composed of 53 million question–answer pages in addition to twelve million member profiles. This corpus was gathered by [
6,
18,
55] in an effort to perform a gender and age analysis on this cQA site. These profiles contain the respective questions, answers, nicknames, and short bios. From previous studies [
10,
11,
17,
24,
56], this collection also identifies a total of 548,375 community peers with both their age and gender.
Stack Exchange (SE, for short) regularly publishes its data dumps on the Internet for public use (
https://archive.org/download/stackexchange/). More concretely, we profited from the version published on 6 September 2021. Each record includes the corresponding questions, answers (called comments), nicknames, and self-descriptions. As a means of tagging members with their age and gender, we employed a strategy similar to previous works by taking into account all its 173 sub-communities (cf. [
6,
24,
56]). On the whole, we obtained 525 elements as a working corpus. It is worth noting here that age could be automatically recognized for about eight thousand members only.
Reddit makes its repository accessible to everyone via Project Arctic Shift (
https://github.com/ArthurHeitmann/arctic_shift?tab=readme-ov-file, accessed on 9 July 2025). Since decompressing this collection requires “seemingly infinite disk space”, we capitalized on the dumps offered by Pushshift (
https://files.pushshift.io/reddit/, accessed on 9 July 2025), which encompasses more than 1.3 billion questions (called submissions) posted before July 2021 and almost 350 billion answers (referred to as comments) [
57]. Likewise, we identified age and gender across a random subset of this dataset by means of the same automatic processing utilized for YA and SE. Overall, this resulted in 68,717 profiles labeled with both demographic variables. Unlike both previous repositories, these records provide submissions, comments, and aliases, but not short bios.
Table 1.
Datasets descriptions.
| Dataset | No. Samples | Male/Female | Gen Z/Gen Y/Olders |
|---|
| YA | 548,375 | 37.33%/62.67% | 49.07%/41.87%/9.05% |
| Reddit | 68,717 | 60.74%/39.26% | 40.84%/45.48%/13.68% |
| SE | 525 | 80.57%/19.43% | 40.57%/32.38%/27.05% |
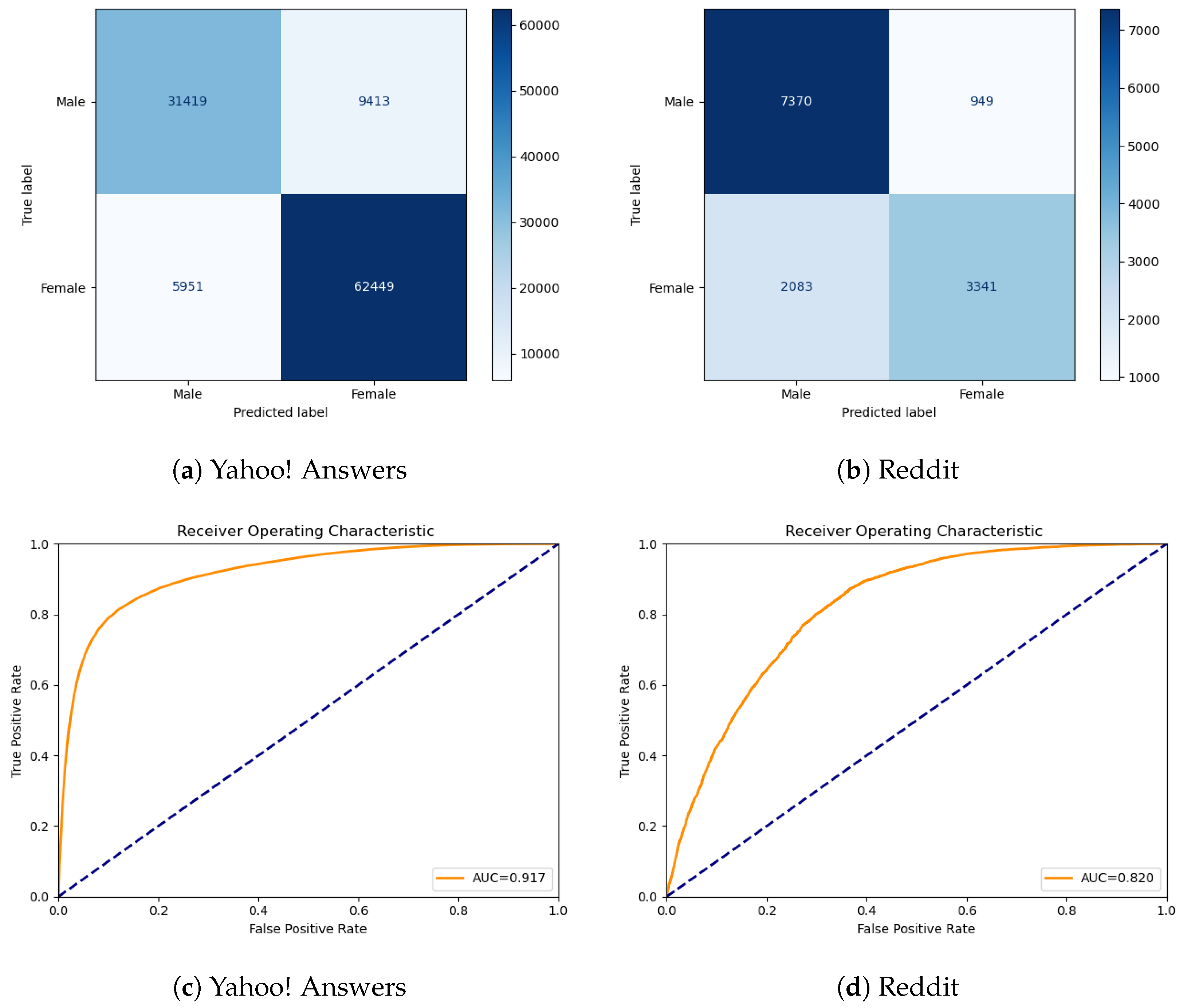
It is worth underlining here that we chose these three cQA datasets not only because of their inherent differences but also to carry out experiments on collections of strikingly different sizes. For all empirical purposes, working datasets were randomly divided into training (60%), evaluation (20%), and testing (20%) as well. Accordingly, held-out evaluations were carried out by keeping these three splits fixed, and the test material was used only for yielding unbiased assessments of final model fits on the training/evaluation folders. With regard to metrics, accuracy was employed in assessing gender (two-sided) models, whereas Macro F1-Score was employed in evaluating age, since this is a three-generation task, specifically Gen Z, Gen Y, and older peers (cf. [
11,
18]).
Four empirical scenarios were considered in order to study the impact of abstraction levels (aside from analyzing both demographic factors independently). These scenarios are signaled by the following abbreviations:
T (question/submission titles only).
TB (questions/submission titles plus their bodies).
TBA (full questions/submissions coupled with answers/comments).
TBAD (full questions/submissions, answers/comments, and short bios).
Table 2,
Table 3 and
Table 4 and
Table 5 and
Table 6 highlight the outcomes accomplished by different combinations of encoders and configurations as they relate to both age and gender identification, respectively. A bird’s eye view of the results points towards the substantial impact of the collection size on the classification rate. In a statement, our figures show that the larger the better. Broadly speaking, there was not an overwhelmingly dominant encoder in the case of SE (see
Table 4), while it is reasonably clear that DistillRoBERTa outclassed its rivals on YA and Reddit. Further, the results seem to be somehow random when it comes to SE. For instance, both T and TBAD appear to have a competitive model, but on average, T outperforms TBDA by 11.40%. These dissonant figures signify ineffective learning, which confirms some recent discoveries about fine-tuning transformers regarding their bad performance when adjusted to downstream tasks via datasets distilled from “non-standard”, especially small, collections [
58,
59,
60]. We recall here that pre-trained models are built largely upon clean corpora including books, Wikipedia, and news articles (cf. [
10]), whereas Stack Overflow, a programming community inside SE, takes the lion’s share of the SE corpus. This entails that this material is markedly biased towards texts like coding snippets, which can hardly be found across clean “standard” training corpora. Overall, our figures point towards at least ca. 70,000 samples as the desirable amount to achieve some good prediction rates for both tasks, especially via DistillRoBERTa. On a side note, the results for gender prediction on SE were not reported here since differences in classification rates across distinct empirical settings were negligible due to an additional third factor: class imbalance. To be more concrete, SE is a community strongly biased towards men [
7], and in our collection, only 19.43% of the instances belong to the women category. Hence, for the sake of reliability, from now on, we performed an in-depth analysis of the results obtained when working on YA and Reddit only.
Another general conclusion regards self-descriptions. Their contribution was shown to be unpredictable. Although they turned out to be slightly detrimental to the best models, other competitive configurations were marginally enhanced by incorporating these training signals. This unpredictability might be due to their sparseness since about solely 7% of the profiles yield bios [
10]. This suggests that these profile descriptions might be discarded without significantly compromising performance. On the flip side, this puts forward the idea that it is still plausible to obtain better classification rates by exploiting additional (probably multi-modal) training sources, such as images and activity patterns. This is particularly insightful for platforms like Reddit, where short bios are unavailable.
5.1. Age Prediction
Table 2 and
Table 3 display the figures obtained for identifying age. In light of these outcomes, we can draw the following conclusions:
Essentially, taking into account terms embodied deeper than the third level resulted in relatively small improvements. This means that most of the semantic cues necessary for guessing age can be found at the highest levels of the dependency trees. Although there are some refinements until level seven in most cases, the performance tends to converge asymptotically.
Interestingly enough, despite the overall supremacy of DistillRoBERTa, RoBERTa finished with the best model every time the Reddit collection was targeted, while in the event of YA, this happened in two out of four cases only. Some key facts about the relationship between these two models are the following: (a) the former was distilled from the base version of the latter; (b) DistillRoBERTa follows the same training procedure as DistilBERT [
52,
61]; (c) DistillRoBERTa consists of 6 layers, 768 dimensions, and 12 heads, totalizing 82 million parameters (compared to 125 million parameters utilized by RoBERTa-base); and (d) DistilRoBERTa is twice as fast as RoBERTa-base on average.
It is worth recalling here that knowledge distillation is a compression technique in which a compact model (the student) is built to reproduce the behavior of a larger model (the teacher) via a loss function over the soft target probabilities of the bigger model [
62]. Note that empirical results show that distillation retains ca. 97% of the language understanding capabilities of the larger model while having about 60% of its parameters. Analogously, trimming lexicalized dependency trees reduced the size of the training vocabulary and contexts, or alternatively, one can fit more relevant information in the same context window while achieving competitive classification rates.
The previous finding entails that not every word, and not all instances of a particular term, significantly contribute to deducing/refining its meanings or the distribution over its potential usages during fine-tuning. Chiefly, relatively medium-high frequency words do not need their occurrences, where they do not significantly contribute to their corresponding contexts (i.e., deep in the dependency tree), to yield a clearer understanding of their own sets of meanings.
To be more concrete, the reduction in vocabulary size from depth nine to three is around 88–89% for TBAD (YA) and TBA (Reddit) models. Despite this subtraction, most of the performance is preserved (see
Table 2 and
Table 3).
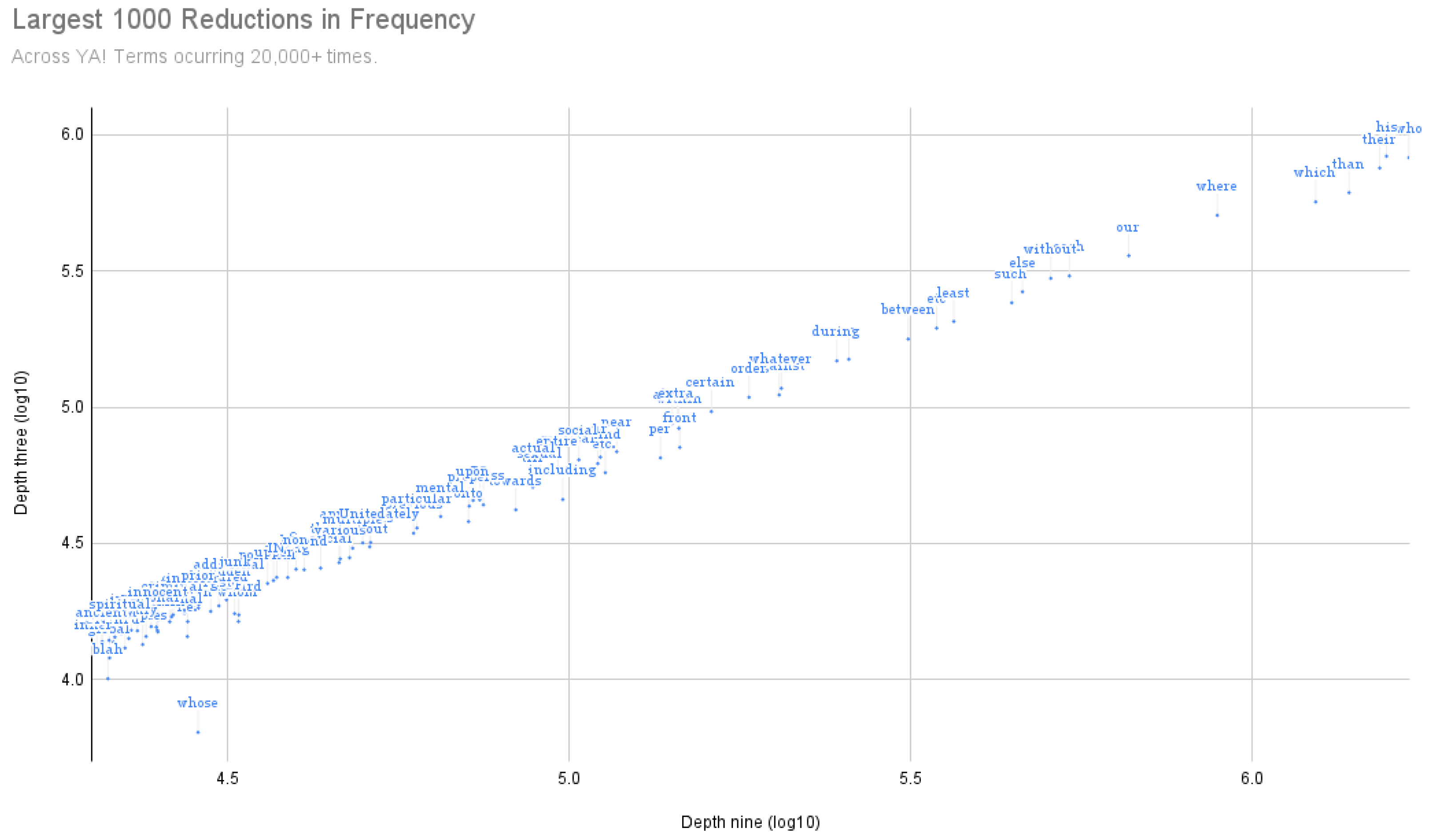
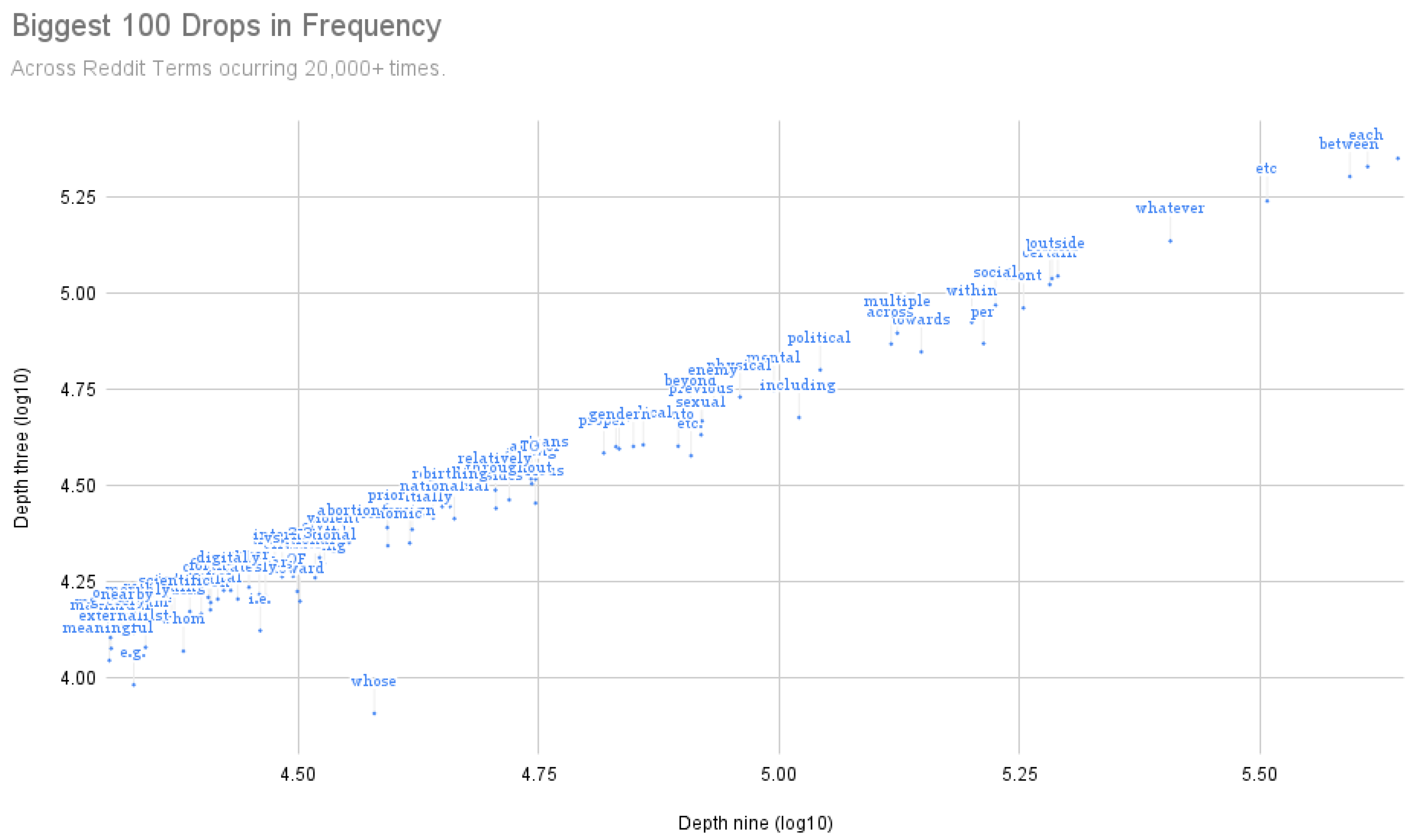
Figure 3 and
Figure 4 depict the largest decrements in frequency across the twenty thousand most recurrent terms across both the YA and Reddit corpus, respectively. Interestingly enough, discourse markers such as “whose”, “whom”, and “which” suffered from significant frequency decreases together with prepositions such as “including” and “such as” that denote parts of a whole already mentioned in the context. Furthermore, we also found variations of words like “etc.,” “i.e.,” and “e.g.,” which all signal that very specific information has been given or is going to be mentioned. All in all, these terms do not need these instances to specify their meanings, as they are just serving a syntactic function at this level.
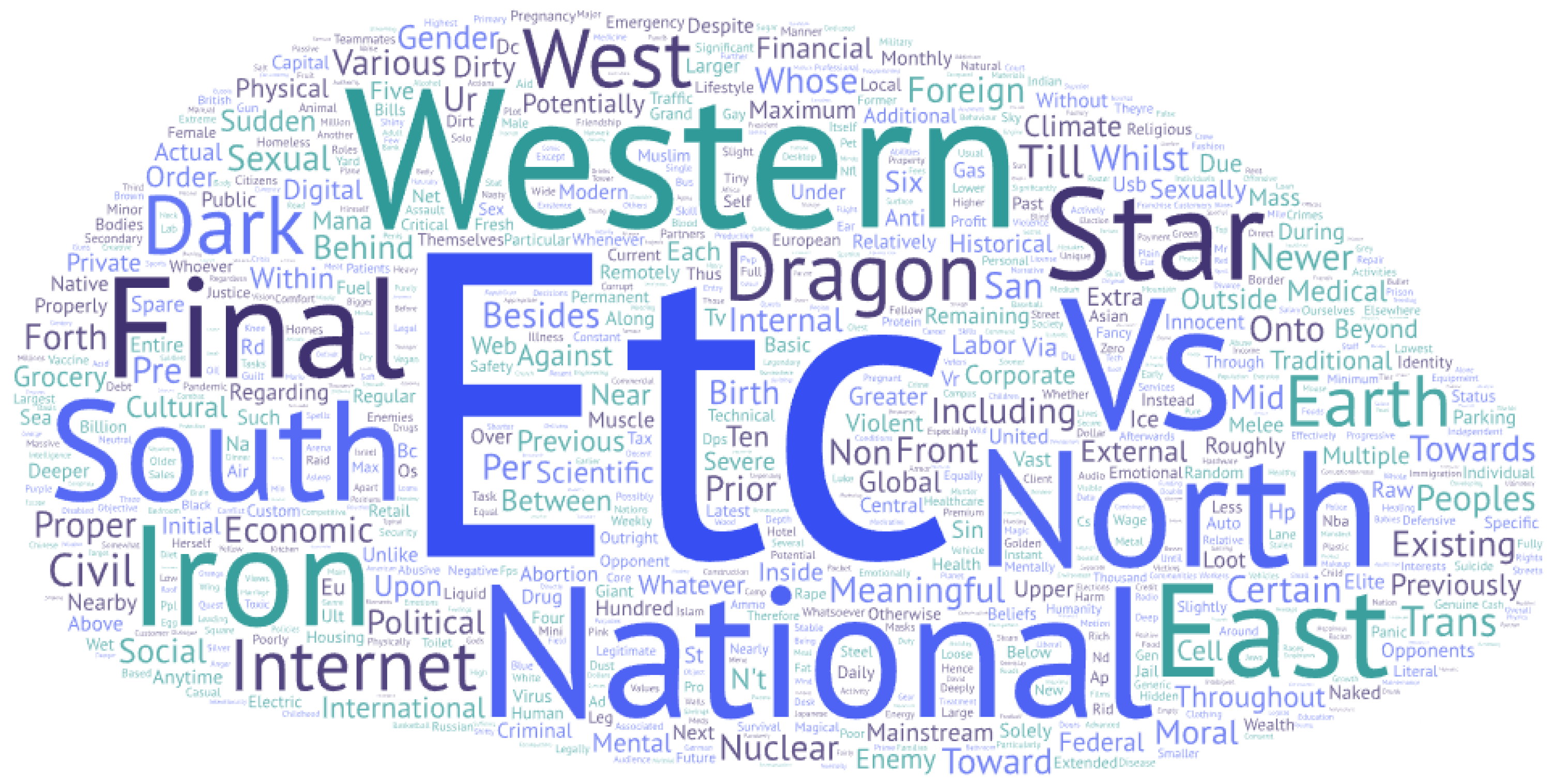
In order to have a more concrete idea of the semantics conveyed by these prepositional/relative clauses,
Figure 5 and
Figure 6 highlight the word clouds generated from the sharpest one thousand drops in frequency within the twenty thousand most recurrent terms for both YA and Reddit, respectively. In both cases, locations such as cardinal points and the Internet obtained the lion’s share. Another common topic involves intimacy, relationships, and emotions (e.g., “abusive”, “adult”, “divorce”, “happiness”, “marriage”, “separate”, “feelings”, “sexual”, and “violent”). As for the Internet, we discovered words such as “traffic”, “web”, “security”, and “network”. Distinct from these topics, we can also identify terms related to finance, namely “dollars”, “funds”, “tax”, “federal”, and “interests”. Basically, any of these subjects is very likely to be the main talking point of several submissions. In fact, there is a plethora of community fellows that share these sorts of interests. Hence it is not far-fetched to think that these “deeper” instances do not greatly contribute during fine-tuning to adjust their meanings or the distribution of their meanings. Furthermore, our outcomes suggest that these “deeper” occurrences are less helpful at testing time also, as a result of users over-elaborating their contexts or as a consequence of topic redundancy across all their posts.
In summary, our qualitative results point towards cost-efficient models that make inferences by looking at the most abstract semantic information within sentences (first three levels). Our results also reveal that distilled encoders play a pivotal role in building this type of solution. But for applications that need to walk the extra mile, that is to say, where any small gain in classification rate is vital, fine-tuning undistilled models coupled with terms embodied in the first seven levels seems to be a better recipe for success. Instead of accounting for fine-grained details, our figures suggest that extra semantically coarse-grained samples are more likely to bring about some significant additional growth in the classification rate.
In quantitative terms, BERT finished with the best model most of the time when operating solely on question titles, especially for the YA collection. To be more precise, BERT reaped a Macro F1-Score of 0.5965 and 0.4619 for YA and Reddit, respectively. Curiously enough, terms embodied in the deepest levels of the dependency trees did not bring about improvements in the classification rate. One reason for this is that question titles seldom over-elaborate, and therefore trees are not typically that deep, contrary to answer and question bodies, which are normally long-winded.
In the event of responses and question contents, the best achieved Macro F1-Score was 0.7325 (YA) and 0.6156 (Reddit). These outcomes support the conclusion that a wider variety of contexts is more instrumental than fine-grained details since adding more contexts (i.e., bodies and answers) brings about more significant improvements. Note that the classification rate grew by 15.43% (0.0874 Macro F1 points) when accounting for question bodies, and on top of that, by 6.93% (0.0474 Macro F1 points) when considering answers as well, and a total of 22.80% (0.136 Macro F1 points) with regard to the best model for title-only (YA). Similarly, a rise of 19.74% (0.0912 points) via making allowances for question content, and on top of that, 11.30% (0.0625 Macro F1 points) by considering answers too. On the whole, a 33.28% (0.1537 Macro F1 points) increase was achieved with regard to the title-only best model for Reddit. Consequently, we can draw the conclusion that a wider diversity of coarse-grained contexts is preferred to more detailed information.
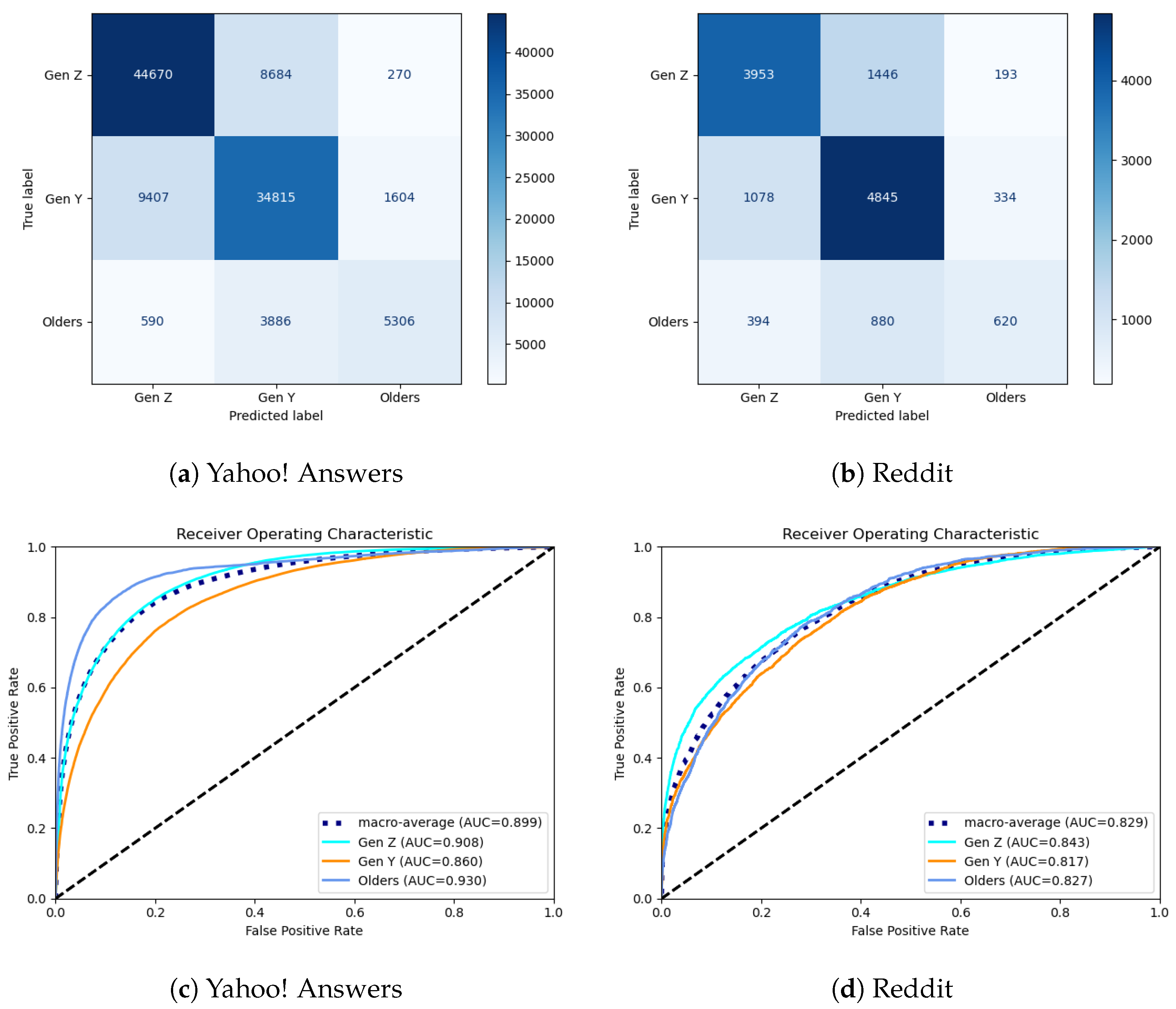
As aforementioned, the best models for YA and Reddit accomplished Macro F1-Scores of 0.7325 and 0.6156, respectively.
Figure 7 underlines the corresponding Confusion Matrices and ROC (Receiver Operating Characteristic) curves for both approaches. Like previous studies [
6,
11,
17,
18], errors were shown to be more prominent between contiguous generations: older peers–GEN Y and GEN Y–GEN Z. In terms of AUC (Area under the Curve), a very similar performance was obtained for every class in the event of Reddit, whereas a markedly better score was accomplished for older peers and a considerably worse score for Gen Y.
To sum this up, our quantitative results indicate that fewer details, and thus more coarse-grained semantics, together with a larger diversity of contexts, enhance age recognition.
6. Limitations and Future Research
Aside from the two previously discussed considerations regarding the objects of this study: the sparseness/lack of self-descriptions and the insufficiency of the SE corpus, there are a few extra aspects that we need to emphasize.
First off, the strong bias towards coding, and especially male programmers, inherent in the SE collection made it impossible to effectively fine-tune models. One way of tackling this head-on might be devising new automatic approaches (heuristics) to manually label the age and gender of a larger fraction of its members. However, SE fellows are very unlikely to explicitly tell their age when interacting on the website. Providing this kind of information is something unusual when talking about stuff related to coding. It is much more common to express the years of experience you have in the field instead. Nonetheless, it is conceivable that this experience might also be exploited for roughly estimating age cohorts in future works.
Secondly, the computed dependency trees are subject to errors since we capitalized on the standard CoreNLP models for dependency parsing. These tools are built upon cleaner corpora, and thus errors are expected when employed on user-generated content. In the same vein, these parsing models are designed to cope with English, and in the case of cQA texts, code-switching can happen in a single post or sentence, especially across language-related topics. This alternation between two or more languages affects the output of the parser, and many times, it also goes unnoticed by language detectors.
In fact, our limitations on computational power prevented us from testing larger transformers. In addition, these cutting-edge architectures could also be pre-trained on a large amount of user-generated cQA texts if the necessary infrastructure is available. In so doing, one could be in a position to infer more refined meanings for frequent community jargon, spellings, aliases, entities, and acronyms, for instance.
Additionally, our results suggest that pre-training title-only models would be beneficial for several reasons: (a) their grammar is sharply different from what we can find across question bodies and answers; (b) they encompass smaller succinct contexts that can be readily contained within traditional pre-training token windows; and (c) one could conjecture that the semantic range of words is comparatively limited since their usage is restricted to the syntax of relatively short questions. Hence, this leads us to believe that pre-training models solely on a massive amount of titles could aid in producing cost-efficient approaches to some downstream tasks.
Lastly, we also envision that exploiting multi-lingual encoders and texts written in different languages can assist in enhancing the classification rate on both tasks, especially across community peers linked to very few questions/answers published in English.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}