1. Introduction
Keyword extraction (KE), also known as keyphrase or key term extraction, is an information extraction task that aims to identify a number of words/phrases that best summarise the nature or the context of a piece of text. It has several applications in information retrieval (IR) and natural language processing (NLP), including text summarisation, topic analysis, and document indexing [
1,
2]. Considering the vast amount of text-based documents online in today’s digital society, it is very useful to be able to extract keywords from online documents automatically to support large-scale textual analysis. Therefore, for many years, the research community has been investigating automatic keyword extraction (AKE) methods, especially with the recent advancements in artificial intelligence (AI) and NLP. Despite these efforts, however, AKE has been shown to be a challenging task, and AKE methods with very high performance are still to be found [
3]. Two main challenges are the lack of a precise definition of the AKE task and the lack of consistent performance evaluation metrics and benchmarks [
1]. Since there is no consensus on the definition and characteristics of a
keyword, KE datasets created by researchers have different characteristics. Examples include the minimum/average/maximum numbers of keywords, if absent keywords (human-labelled keywords that do not appear in the text) are allowed, and what part-of-speech (PoS) tags, such as verbs, are accepted as valid keywords. This makes performance evaluation and comparison of AKE methods more difficult.
Based on whether a labelled training set is used, AKE methods reported in the literature can be grouped into unsupervised and supervised methods. Unsupervised methods include statistical, graph-based, embedding-based and/or language model-based methods, while supervised ones use either traditional or deep machine learning models [
3]. Surprisingly, for most AKE methods, semantic information has not been considered or only insufficiently considered to align the returned keywords with the semantic context of the input document [
4].
In this work, to fill the above-mentioned gap on the lack of or insufficient use of semantic information in the state-of-the-art (SOTA) AKE methods, we propose a universal performance improvement approach for any AKE methods. This approach serves as a post-processor that can consider semantic information more explicitly, with the support of PoS tagging. To start with, we conducted an analysis of human-annotated ‘gold standard’ keywords in 17 KE datasets to better understand some relevant characteristics of such keywords. Particularly, this analysis focuses on PoS tag patterns, n-gram sizes, and the possible consideration of semantic information by human labellers when extracting keywords.
Our proposed approach is demonstrated using the following three post-processing steps that can be freely combined: (1) keeping candidate keywords with a desired PoS tag only; (2) matching candidate keywords with one or more context-specific thesauri containing more semantically relevant terms; and (3) prioritising candidate keywords that appear as a valid Wikipedia named entity. We applied different combinations of the above three post-processing steps to five SOTA AKE methods, YAKE! [
5], KP-Miner [
6], RaKUn [
7], LexRank [
8], and SIFRank+ [
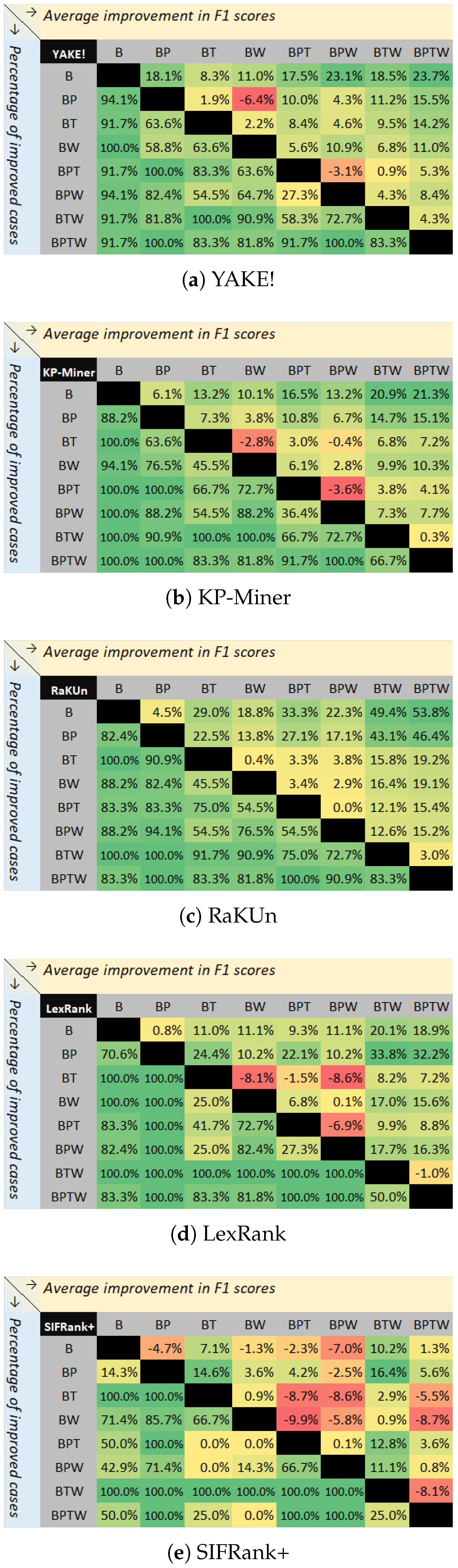
9], and compared the performances of the original methods with those of the enhanced versions. The experimental results with the 17 KE datasets showed that our proposed post-processing steps helped improve the performances of all the five SOTA AKE methods both
consistently (up to 100% in terms of improved cases) and
significantly (between 10.2% and 53.8%, with an average of 25.8%, in terms of F1-score and across all five methods), particularly when all the three steps are combined. Our work validates the possibility of using easy-to-use post-processing steps to enhance the semantic awareness of AKE methods and to improve their performance in real-world applications, a fact that has not been reported before (to the best of our knowledge). The main contributions of this paper are as follows:
We propose a modular and universal post-processing pipeline that enhances existing AKE methods using part-of-speech filtering and external knowledge sources.
We provide a comprehensive analysis of 17 AKE datasets to empirically justify our design choices.
We conduct extensive experiments to demonstrate that the proposed pipeline improves the performance of multiple state-of-the-art AKE methods across diverse evaluation settings.
The rest of the paper is organised as follows.
Section 2 briefly surveys AKE methods in the literature. The analysis of the human-annotated keywords in 17 KE datasets is given in
Section 3. In
Section 4, we present the methodology of our study.
Section 5 explains the experimental setup for evaluation as well as the results. Finally, the paper is concluded with some further discussions in
Section 6, and an overall summary in
Section 7.
6. Further Discussions
The proposed post-processing steps in this study were applied to five representative SOTA AKE methods, showing their universality to improve the performance of many different AKE methods. The universality of the post-processing steps is rooted in the fact that they rely on access to the list of candidate keywords and their scores, which are the standard output for most (if not all) AKE methods. The performance improvements can be explained by two main reasons: (i) utilising PoS tagging avoids AKE methods, especially those less benefiting from linguistic features, to generate keywords that are less likely to be meaningful keywords, such as conjunctions, determiners, and adverbs; and (ii) thesauri and Wikipedia-based enhancements allow prioritisation of more domain-specific and context-specific keywords to be returned by AKE methods.
Although PoS tagging can be easily integrated into AKE methods to implement a filtering mechanism, it should be separately considered for each dataset since AKE datasets lack linguistic standards for golden keywords. This can significantly increase the accuracy of the AKE methods, benefiting from PoS tagging. Thesaurus and Wikipedia integration can also be applied to AKE methods without much effort. Considering that a text document can cover multiple contexts, the results we reported can be further improved by integrating multiple contexts. This can be achieved by utilising a multi-label classifier. Since one-vs-rest classifiers can be used for multi-label classification, our classifier can be refined to cover multiple contexts. In addition, more advanced models, such as BERT, can be utilised to develop a more accurate classifier. It is also worth noting that two of the proposed post-processing steps in this study were selected as representative examples of semantic elements. Other semantic elements can also be used to further improve the performance of AKE methods.
Although our experiments on the proposed post-processing steps are based on English NLP tools and datasets, they can also be applied to multilingual AKE methods, e.g., YAKE!, for any language. The language of input documents can be identified automatically with a language identifier, which can achieve high accuracy for many languages [
64]. Then, the corresponding PoS tagger and Wikipedia data can be utilised, although the set of acceptable PoS tag patterns will need updating according to the identified language. Nevertheless, utilising a context-aware thesaurus could be tricky for some languages, especially small ones, as there might be no thesaurus relevant to the context of the document in the identified language.
This study has a number of limitations that can be addressed in future work. Firstly, the selected baseline AKE methods are just examples of SOTA methods, so they may not be sufficiently representative. As our focus was improving AKE methods in general, we did not aim to achieve the best scores among the studies on AKE. As a result, this study is limited to open-source, unsupervised, and general-purpose AKE methods. In addition, this study leveraged multiple elements of the English language and used English datasets for evaluation. Therefore, it disregarded non-English settings, which are needed especially for multilingual AKE methods, such as YAKE!. The proposed mechanisms have been applied separately throughout the experiments. Therefore, the results could be improved further if different mechanisms benefit from each other (e.g., applying PoS tag-based filtering to the Wikipedia integration mechanism to disregard the Wikipedia named entities that cannot be keywords). Finally, a better matching strategy considering word ambiguities can be developed for checking if a candidate keyword appears in a thesaurus or Wikipedia, with the help of techniques such as word sense disambiguation.
Furthermore, while the proposed post-processing approaches are designed to be applicable across a wide range of AKE methods, their effectiveness inherently depends on the availability and quality of external knowledge sources. Specifically, the performance of the pipeline relies on the following: (1) accurate part-of-speech (PoS) tagging, (2) comprehensive and context-relevant thesauri, and (3) sufficient coverage in Wikipedia. These dependencies introduce certain robustness constraints. For example, in low-resource or emerging domains where structured thesauri are not available, or in informal text genres such as social media that include many novel or slang expressions not covered by Wikipedia, the performance gains from our approach may be limited. Similarly, PoS tagging tools may be less reliable on noisy or non-standard input. While our modular design allows selective activation of individual steps depending on the context, future work can explore adaptive strategies and fallback mechanisms to improve robustness under such conditions.
Author Contributions
Conceptualization, E.A. and S.L.; methodology, E.A., J.R.C.N. and S.L.; software, E.A.; validation, E.A., Y.X. and J.G.; formal analysis, E.A.; investigation, E.A.; writing—original draft preparation, E.A.; writing—review and editing, J.R.C.N. and S.L.; supervision, J.R.C.N. and S.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
We would like to thank Ricardo Campos for clarification and additional information about the YAKE! algorithm. The first author E. Altuncu was supported by funding from the Ministry of National Education, Republic of Türkiye, under grant number MoNE-YLSY-2018.
Conflicts of Interest
The authors declare no competing interest.
References
- Merrouni, Z.A.; Frikh, B.; Ouhbi, B. Automatic Keyphrase Extraction: A Survey and Trends. J. Intell. Inf. Syst. 2020, 54, 391–424. [Google Scholar] [CrossRef]
- Gavrilescu, M.; Leon, F.; Minea, A.A. Techniques for Transversal Skill Classification and Relevant Keyword Extraction from Job Advertisements. Information 2025, 16, 167. [Google Scholar] [CrossRef]
- Papagiannopoulou, E.; Tsoumakas, G. A review of keyphrase extraction. WIREs Data Min. Knowl. Discov. 2020, 10, e1339. [Google Scholar] [CrossRef]
- Firoozeh, N.; Nazarenko, A.; Alizon, F.; Daille, B. Keyword extraction: Issues and methods. Nat. Lang. Eng. 2020, 26, 259–291. [Google Scholar] [CrossRef]
- Campos, R.; Mangaravite, V.; Pasquali, A.; Jorge, A.; Nunes, C.; Jatowt, A. YAKE! Keyword extraction from single documents using multiple local features. Inf. Sci. 2020, 509, 257–289. [Google Scholar] [CrossRef]
- El-Beltagy, S.R.; Rafea, A. KP-Miner: A keyphrase extraction system for English and Arabic documents. Inf. Syst. 2009, 34, 132–144. [Google Scholar] [CrossRef]
- Škrlj, B.; Repar, A.; Pollak, S. RaKUn: Rank-based Keyword Extraction via Unsupervised Learning and Meta Vertex Aggregation. In Proceedings of the 7th International Conference on Statistical Language and Speech Processing (SLSP’19), Ljubljana, Slovenia, 14–16 October 2019; Volume 11816, pp. 311–323. [Google Scholar] [CrossRef]
- Ushio, A.; Liberatore, F.; Camacho-Collados, J. Back to the Basics: A Quantitative Analysis of Statistical and Graph-Based Term Weighting Schemes for Keyword Extraction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP ’21), Online, 7–11 November 2021; pp. 8089–8103. [Google Scholar] [CrossRef]
- Sun, Y.; Qiu, H.; Zheng, Y.; Wang, Z.; Zhang, C. SIFRank: A New Baseline for Unsupervised Keyphrase Extraction Based on Pre-Trained Language Model. IEEE Access 2020, 8, 10896–10906. [Google Scholar] [CrossRef]
- Jones, K.S. A Statistical Interpretation of Term Specificity and Its Application in Retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Brin, S.; Page, L. The Anatomy of a Large-Scale Hypertextual Web Search Engine. In Proceedings of the Seventh International World Wide Web Conference (WWW ’98), Brisbane, Australia, 14–18 April 1998; Volume 30, pp. 107–117. [Google Scholar] [CrossRef]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Wan, X.; Xiao, J. Single Document Keyphrase Extraction Using Neighborhood Knowledge. In Proceedings of the 23rd National Conference on Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008; Volume 2, pp. 855–860. [Google Scholar]
- Rose, S.; Engel, D.; Cramer, N.; Cowley, W. Automatic Keyword Extraction from Individual Documents. In Text Mining: Applications and Theory; Wiley: Hoboken, NJ, USA, 2010; Chapter 1; pp. 1–20. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP ’14), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Bennani-Smires, K.; Musat, C.; Hossmann, A.; Baeriswyl, M.; Jaggi, M. Simple Unsupervised Keyphrase Extraction using Sentence Embeddings. In Proceedings of the 22nd Conference on Computational Natural Language Learning (CoNLL’18), Brussels, Belgium, 31 October–1 November 2018; pp. 221–229. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, Q.; Wang, W.; Deng, C.; Zhang, S.; Li, B.; Wang, W.; Cao, X. MDERank: A Masked Document Embedding Rank Approach for Unsupervised Keyphrase Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 396–409. [Google Scholar] [CrossRef]
- Rabby, G.; Azad, S.; Mahmud, M.; Zamli, K.Z.; Rahman, M.M. TeKET: A Tree-based Unsupervised Keyphrase Extraction Technique. Cogn. Comput. 2020, 12, 811–833. [Google Scholar] [CrossRef]
- Liu, Z.; Li, P.; Zheng, Y.; Sun, M. Clustering to Find Exemplar Terms for Keyphrase Extraction. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing (EMNLP’09), Singapore, 6–7 August 2009; pp. 257–266. [Google Scholar]
- Witten, I.H.; Paynter, G.W.; Frank, E.; Gutwin, C.; Nevill-Manning, C.G. KEA: Practical Automated Keyphrase Extraction. In Design and Usability of Digital Libraries: Case Studies in the Asia Pacific; IGI Global: Hershey, PA, USA, 2005; pp. 129–152. [Google Scholar] [CrossRef]
- Basaldella, M.; Antolli, E.; Serra, G.; Tasso, C. Bidirectional LSTM Recurrent Neural Network for Keyphrase Extraction. In Proceedings of the Digital Libraries and Multimedia Archives, Udine, Italy, 25–26 January 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 180–187. [Google Scholar] [CrossRef]
- Martinc, M.; Škrlj, B.; Pollak, S. TNT-KID: Transformer-based neural tagger for keyword identification. Nat. Lang. Eng. 2022, 28, 409–448. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Q.; Qin, C.; Xu, T.; Wang, Y.; Chen, E.; Xiong, H. Exploiting Topic-Based Adversarial Neural Network for Cross-Domain Keyphrase Extraction. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM’18), Singapore, 17–20 November 2018; pp. 597–606. [Google Scholar] [CrossRef]
- Bordoloi, M.; Chatterjee, P.C.; Biswas, S.K.; Purkayastha, B. Keyword extraction using supervised cumulative TextRank. Multimed. Tools Appl. 2020, 79, 31467–31496. [Google Scholar] [CrossRef]
- Hulth, A. Improved Automatic Keyword Extraction Given More Linguistic Knowledge. In Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, Sapporo, Japan, 11–12 July 2003; pp. 216–223. [Google Scholar]
- Pay, T. Totally automated keyword extraction. In Proceedings of the 2016 IEEE International Conference on Big Data, Washington, DC, USA, 5–8 December 2016; pp. 3859–3863. [Google Scholar] [CrossRef]
- Zervanou, K. UvT: The UvT Term Extraction System in the Keyphrase Extraction task. In Proceedings of the 5th International Workshop on Semantic Evaluation (SemEval-2010), Uppsala, Sweden, 15–16 July 2010; pp. 194–197. [Google Scholar]
- Li, G.; Wang, H. Improved Automatic Keyword Extraction Based on TextRank Using Domain Knowledge. In Proceedings of the Third CCF International Conference on Natural Language Processing and Chinese Computing (NLPCC’14), Shenzhen, China, 5–9 December 2014; Volume 496, pp. 403–413. [Google Scholar] [CrossRef]
- Gazendam, L.; Wartena, C.; Brussee, R. Thesaurus Based Term Ranking for Keyword Extraction. In Proceedings of the 2010 Workshops on Database and Expert Systems Applications, Bilbao, Spain, 30 August–3 September 2010; pp. 49–53. [Google Scholar] [CrossRef]
- Hulth, A.; Karlgren, J.; Jonsson, A.; Boström, H.; Asker, L. Automatic Keyword Extraction Using Domain Knowledge. In Proceedings of the Computational Linguistics and Intelligent Text Processing: Procedings of the Second International Conference on Intelligent Text Processing and Computational Linguistics (CICLing’01), Hanoi, Vietnam, 18–24 March 2001; Volume 2004, pp. 472–482. [Google Scholar] [CrossRef]
- Medelyan, O.; Witten, I.H. Thesaurus Based Automatic Keyphrase Indexing. In Proceedings of the 6th ACM/IEEE-CS Joint Conference on Digital Libraries, Chapel Hill, NC, USA, 11–15 June 2006; pp. 296–297. [Google Scholar] [CrossRef]
- Sheoran, A.; Jadhav, G.V.; Sarkar, A. SubModRank: Monotone Submodularity for Opinionated Key-phrase Extraction. In Proceedings of the IEEE 16th International Conference on Semantic Computing (ICSC’22), Laguna Hills, CA, USA, 26–28 January 2022; pp. 159–166. [Google Scholar] [CrossRef]
- Shi, T.; Jiao, S.; Hou, J.; Li, M. Improving Keyphrase Extraction Using Wikipedia Semantics. In Proceedings of the 2nd International Symposium on Intelligent Information Technology Application, Shanghai, China, 21–22 December 2008; Volume 2, pp. 42–46. [Google Scholar] [CrossRef]
- Yu, Y.; Ng, V. WikiRank: Improving Unsupervised Keyphrase Extraction using Background Knowledge. In Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC’18), Miyazaki, Japan, 7–12 May 2018; pp. 3723–3727. [Google Scholar]
- Ferragina, P.; Scaiella, U. TAGME: On-the-Fly Annotation of Short Text Fragments (by Wikipedia Entities). In Proceedings of the 19th ACM International Conference on Information and Knowledge Management (CIKM’10), Toronto, ON, Canada, 26–30 October 2010; pp. 1625–1628. [Google Scholar] [CrossRef]
- Papagiannopoulou, E.; Tsoumakas, G. Local Word Vectors Guiding Keyphrase Extraction. Inf. Process. Manag. 2018, 54, 888–902. [Google Scholar] [CrossRef]
- Zesch, T.; Gurevych, I. Approximate Matching for Evaluating Keyphrase Extraction. In Proceedings of the International Conference RANLP-2009, Borovets, Bulgaria, 14–16 September 2009; pp. 484–489. [Google Scholar]
- Marujo, L.; Gershman, A.; Carbonell, J.; Frederking, R.; Neto, J.P. Supervised Topical Key Phrase Extraction of News Stories using Crowdsourcing, Light Filtering and Co-reference Normalization. arXiv 2013. [Google Scholar] [CrossRef]
- Medelyan, O.; Frank, E.; Witten, I.H. Human-Competitive Tagging Using Automatic Keyphrase Extraction. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing (EMNLP’09), Singapore, 6–7 August 2009; pp. 1318–1327. [Google Scholar]
- Medelyan, O.; Witten, I.H. Domain-Independent Automatic Keyphrase Indexing with Small Training Sets. J. Am. Soc. Inf. Sci. Technol. 2008, 59, 1026–1040. [Google Scholar] [CrossRef]
- Das Gollapalli, S.; Caragea, C. Extracting Keyphrases from Research Papers Using Citation Networks. Proc. AAAI Conf. Artif. Intell. 2014, 28, 1629–1635. [Google Scholar] [CrossRef]
- Gallina, Y.; Boudin, F.; Daille, B. KPTimes: A Large-Scale Dataset for Keyphrase Generation on News Documents. In Proceedings of the 12th International Conference on Natural Language Generation (INLG’19), Tokyo, Japan, 29 October–1 November 2019; pp. 130–135. [Google Scholar] [CrossRef]
- Krapivin, M.; Autaeu, A.; Marchese, M. Large Dataset for Keyphrases Extraction; Departmental Technical Report DISI-09-055; University of Trento: Trento, Italy, 2009. [Google Scholar]
- Nguyen, T.D.; Kan, M.Y. Keyphrase Extraction in Scientific Publications. In Proceedings of the Asian Digital Libraries. Looking Back 10 Years and Forging New Frontiers: Proceedings of the 10th International Conference on Asian Digital Libraries (ICADL’07), Hanoi, Vietnam, 10–13 December 2007; Volume 4822, pp. 317–326. [Google Scholar] [CrossRef]
- Gay, C.W.; Kayaalp, M.; Aronson, A.R. Semi-Automatic Indexing of Full Text Biomedical Articles. In Proceedings of the 2005 AMIA Symposium. American Medical Informatics Association (AMIA), Washington, DC, USA, 22–26 October 2005; pp. 271–275. [Google Scholar]
- Schutz, A.T. Keyphrase Extraction from Single Documents in the Open Domain Exploiting Linguistic and Statistical Methods. Master’s Thesis, National University of Ireland, Galway, Ireland, 2008. [Google Scholar]
- Kim, S.N.; Medelyan, O.; Kan, M.Y.; Baldwin, T. SemEval-2010 Task 5: Automatic Keyphrase Extraction from Scientific Articles. In Proceedings of the 5th International Workshop on Semantic Evaluation (SemEval-2010), Los Angeles, CA, USA, 15–16 July 2010; pp. 21–26. [Google Scholar]
- Augenstein, I.; Das, M.; Riedel, S.; Vikraman, L.; McCallum, A. SemEval 2017 Task 10: ScienceIE-Extracting Keyphrases and Relations from Scientific Publications. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 546–555. [Google Scholar] [CrossRef]
- Medelyan, O.; Witten, I.H.; Milne, D. Topic Indexing with Wikipedia. In Proceedings of the 2008 AAAI Workshop on Wikipedia and Artificial Intelligence: An Evolving Synergy, Chicago, IL, USA, 13 July 2008; pp. 19–24. [Google Scholar]
- Smadja, F. Retrieving Collocations from Text: Xtract. Comput. Linguist. 1993, 19, 143–178. [Google Scholar]
- Justeson, J.S.; Katz, S.M. Technical Terminology: Some Linguistic Properties and an Algorithm for Identification in Text. Nat. Lang. Eng. 1995, 1, 9–27. [Google Scholar] [CrossRef]
- Ajallouda, L.; Fagroud, F.Z.; Zellou, A.; Benlahmar, E.H. A Systematic Literature Review of Keyphrases Extraction Approaches. Int. J. Interact. Mob. Technol. (iJIM) 2022, 16, 31–58. [Google Scholar] [CrossRef]
- Bird, S. NLTK: The Natural Language Toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions, Sydney, Australia, 17–18 July 2006; pp. 69–72. [Google Scholar] [CrossRef]
- Choueka, Y. Looking for Needles in a Haystack or Locating Interesting Collocational Expressions in Large Textual Databases. In Proceedings of the RIAO Conference on User-Oriented Content-Based Text and Image Handling, Cambridge, MA, USA, 21–24 March 1988; pp. 609–623. [Google Scholar]
- Boudin, F. PKE: An Open Source Python-Based Keyphrase Extraction Toolkit. In Proceedings of the 26th International Conference on Computational Linguistics: System Demonstrations (COLING’16), Osaka, Japan, 13–16 December 2016; pp. 69–73. [Google Scholar]
- Caracciolo, C.; Stellato, A.; Morshed, A.; Johannsen, G.; Rajbhandari, S.; Jaques, Y.; Keizer, J. The AGROVOC Linked Dataset. Semant. Web 2013, 4, 341–348. [Google Scholar] [CrossRef]
- Lipscomb, C.E. Medical Subject Headings (MeSH). Bull. Med. Libr. Assoc. 2000, 88, 265–266. [Google Scholar] [PubMed]
- Salatino, A.A.; Thanapalasingam, T.; Mannocci, A.; Osborne, F.; Motta, E. The Computer Science Ontology: A Large-Scale Taxonomy of Research Areas. In Proceedings of the Semantic Web: Proceedings of the 17th International Semantic Web Conference (ISWC’18), Part II, Monterey, CA, USA, 8–12 October 2018; Volume 11137, pp. 187–205. [Google Scholar] [CrossRef]
- Osborne, F.; Motta, E. Klink-2: Integrating Multiple Web Sources to Generate Semantic Topic Networks. In Proceedings of the Semantic Web: Proceedings of the 14th International Semantic Web Conference (ISWC’15), Part I, Bethlehem, PA, USA, 11–15 October 2015; Volume 9366, pp. 408–424. [Google Scholar] [CrossRef]
- Kempf, A.O.; Neubert, J. The Role of Thesauri in an Open Web: A Case Study of the STW Thesaurus for Economics. Knowl. Organ. 2016, 43, 160–173. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Arora, S.; Liang, Y.; Ma, T. A Simple but Tough-to-Beat Baseline for Sentence Embeddings. In Proceedings of the 2017 International Conference on Learning Representations (ICLR ’17), Toulon, France, 24–26 April 2017; pp. 1–16. [Google Scholar]
- Jauhiainen, T.; Lui, M.; Zampieri, M.; Baldwin, T.; Lindén, K. Automatic Language Identification in Texts: A Survey. J. Artif. Intell. Res. 2019, 65, 675–782. [Google Scholar] [CrossRef]
Figure 1.
The overview of the proposed post-processing approach.
Figure 2.
Average improvements in F1 scores across all the datasets (upper side), and percentages of the improved cases across all the datasets (bottom side), for different AKE methods. (B: Baseline, P: PoS tagging, T: Thesaurus integration, W: Wikipedia integration).
Table 1.
Basic information about the 17 datasets.
| Dataset | Content | Context | Size | Avg. # (Keys) | Abs. Keys | Annotators 1 |
|---|
| KPCrowd [39] | News | Misc. | 500 | 48.92 | 13.5% | Readers |
| citeulike180 [40] | Paper | Misc. | 183 | 18.42 | 32.2% | Readers |
| DUC-2001 [13] | News | Misc. | 308 | 8.1 | 3.7% | Readers |
| fao30 [41] | Paper | Agr. | 30 | 33.23 | 41.7% | Experts |
| fao780 [41] | Paper | Agr. | 779 | 8.97 | 36.1% | Experts |
| Inspec [26] | Abstract | CS | 2000 | 14.62 | 37.7% | Experts |
| KDD [42] | Abstract | CS | 755 | 5.07 | 53.2% | Authors |
| KPTimes (test) [43] | News | Misc. | 20,000 | 5.0 | 54.7% | Editors |
| Krapivin2009 [44] | Paper | CS | 2304 | 6.34 | 15.3% | Authors |
| Nguyen2007 [45] | Paper | CS | 209 | 11.33 | 17.8% | Authors & Readers |
| PubMed [46] | Paper | Health | 500 | 15.24 | 60.2% | Authors |
| Schutz2008 [47] | Paper | Health | 1231 | 44.69 | 13.6% | Authors |
| SemEval2010 [48] | Paper | CS | 243 | 16.47 | 11.3% | Authors & Readers |
| SemEval2017 [49] | Paragr | Misc. | 493 | 18.19 | 0.0% | Experts & Readers |
| theses100 2 | Thesis | Misc. | 100 | 7.67 | 47.6% | Unknown |
| wiki20 [50] | Report | CS | 20 | 36.50 | 51.2% | Readers |
| WWW [42] | Abstracts | CS | 1330 | 5.80 | 55.0% | Authors |
Table 2.
Percentages of top 10 PoS tag patterns across 17 datasets. PoS tags: NN—noun (singular), NNS—noun (plural), JJ—adjective, VBG—verb gerund.
| Dataset | NN | NN NN | JJ NN | NNS | JJ | JJ NNS | NN NNS | JJ NN NN | VBG | NN NN NN |
|---|
| KPCrowd | 31.38 | 2.18 | 3.29 | 11.65 | 10.13 | 0.95 | 0.95 | 0.26 | 5.27 | 0.17 |
| citeulike180 | 48.71 | 7.03 | 4.78 | 12.93 | 12.74 | 1.61 | 1.56 | 0.15 | 1.95 | 0.05 |
| DUC-2001 | 19.13 | 15.90 | 15.28 | 10.49 | 1.80 | 8.73 | 10.16 | 3.65 | 0.28 | 1.52 |
| fao30 | 32.60 | 14.68 | 7.92 | 15.84 | 5.06 | 6.62 | 9.35 | 0.00 | 0.78 | 0.26 |
| fao780 | 29.56 | 14.11 | 9.11 | 15.18 | 3.78 | 6.02 | 10.88 | 0.06 | 1.21 | 0.04 |
| Inspec | 19.05 | 12.57 | 12.49 | 6.64 | 3.85 | 8.11 | 5.95 | 4.35 | 1.11 | 2.50 |
| KDD | 27.93 | 13.49 | 9.06 | 5.89 | 9.25 | 5.13 | 3.55 | 2.22 | 4.81 | 0.76 |
| KPTimes | 15.32 | 16.65 | 15.67 | 4.27 | 2.83 | 8.62 | 6.26 | 2.92 | 1.76 | 1.51 |
| Krapivin2009 | 35.15 | 4.70 | 4.06 | 14.14 | 5.67 | 2.17 | 1.47 | 0.27 | 0.95 | 0.17 |
| Nguyen2007 | 20.85 | 19.83 | 11.31 | 4.84 | 2.53 | 4.79 | 3.37 | 3.06 | 1.51 | 2.66 |
| PubMed | 30.88 | 9.23 | 3.87 | 15.43 | 12.01 | 3.51 | 5.50 | 0.77 | 0.56 | 2.03 |
| Schutz2008 | 30.15 | 6.20 | 10.61 | 18.63 | 10.91 | 5.04 | 3.19 | 1.61 | 0.31 | 0.66 |
| SemEval2010 | 19.45 | 21.74 | 21.54 | 0.08 | 3.20 | 0.17 | 0.06 | 6.40 | 0.42 | 3.15 |
| SemEval2017 | 14.57 | 8.73 | 9.00 | 7.23 | 2.12 | 5.95 | 4.46 | 3.31 | 0.66 | 1.62 |
| theses100 | 27.88 | 8.55 | 5.39 | 9.48 | 15.24 | 6.13 | 4.28 | 0.00 | 1.30 | 0.19 |
| wiki20 | 41.91 | 18.65 | 11.06 | 1.49 | 6.60 | 0.50 | 1.82 | 2.81 | 2.81 | 0.99 |
| WWW | 32.33 | 13.44 | 8.98 | 5.41 | 8.74 | 3.88 | 3.88 | 1.63 | 2.86 | 1.05 |
| Average (%) | 28.05 | 12.22 | 9.61 | 9.39 | 6.85 | 4.59 | 4.51 | 1.97 | 1.68 | 1.13 |
Table 3.
n-gram distributions of the 17 datasets. Bold values indicate the proportion of the most frequently observed n-gram length in the corresponding dataset.
| Dataset | | | | | | |
|---|
| KPCrowd | 73.78 | 18.47 | 4.90 | 2.83 | 92.25 | 97.15 |
| citeulike180 | 77.10 | 19.98 | 2.79 | 0.09 | 97.08 | 99.87 |
| DUC-2001 | 17.32 | 61.29 | 17.73 | 3.66 | 78.61 | 96.34 |
| fao30 | 43.02 | 52.74 | 3.41 | 0.83 | 95.76 | 99.17 |
| fao780 | 42.32 | 53.72 | 3.62 | 0.34 | 96.04 | 99.66 |
| Inspec | 16.44 | 53.68 | 23.05 | 6.84 | 70.12 | 93.17 |
| KDD | 25.48 | 56.32 | 13.97 | 4.24 | 81.80 | 95.77 |
| KPTimes | 46.68 | 34.39 | 12.55 | 6.38 | 81.07 | 93.62 |
| Krapivin2009 | 18.95 | 61.61 | 15.74 | 3.70 | 80.56 | 96.30 |
| Nguyen2007 | 27.53 | 49.96 | 15.42 | 6.97 | 77.49 | 92.91 |
| PubMed | 35.79 | 43.74 | 15.90 | 4.58 | 79.53 | 95.43 |
| Schutz2008 | 57.83 | 30.22 | 8.15 | 1.67 | 88.05 | 96.20 |
| SemEval2010 | 20.05 | 52.97 | 20.66 | 6.31 | 73.02 | 93.68 |
| SemEval2017 | 25.23 | 33.74 | 17.19 | 23.84 | 58.97 | 76.16 |
| theses100 | 31.63 | 50.37 | 11.09 | 6.90 | 82.00 | 93.09 |
| wiki20 | 26.20 | 53.52 | 18.17 | 2.11 | 79.72 | 97.89 |
| WWW | 34.36 | 47.71 | 12.15 | 5.78 | 82.07 | 94.22 |
| Average (%) | 36.45 | 45.55 | 12.73 | 5.12 | 82.01 | 94.74 |
Table 4.
The percentages of golden keywords covered by Wikipedia.
| Dataset | % | Dataset | % |
|---|
| KPCrowd | 71.77 | Nguyen2007 | 52.19 |
| citeulike180 | 83.78 | PubMed | 81.28 |
| DUC-2001 | 51.05 | Schutz2008 | 67.43 |
| fao30 | 80.97 | SemEval2010 | 41.27 |
| fao780 | 79.00 | SemEval2017 | 31.02 |
| Inspec | 39.08 | theses100 | 68.82 |
| KDD | 62.92 | wiki20 | 89.01 |
| KPTimes | 79.09 | WWW | 63.83 |
| Krapivin2009 | 52.12 | | |
Table 5.
An overview of some existing open-source unsupervised AKE methods, showing a number of key characteristics.
| Method | Easy to | PoS Tagging | Thesaurus | Wikipedia |
|---|
| | Reconfigure | | | |
|---|
| Statistical Methods | | | | |
| KP-Miner [6] | ✓ | – | – | – |
| YAKE! [5] | ✓ | – | – | – |
| LexSpec [8] | ✓ | ✓ | – | – |
| Graph-based Methods | | | | |
| TextRank [12] | ✓ | ✓ | – | – |
| SingleRank [13] | ✓ | ✓ | – | – |
| RAKE [14] | ✓ | – | – | – |
| RaKUn [7] | ✓ | – | – | – |
| LexRank [8] | ✓ | ✓ | – | – |
| TFIDFRank [8] | ✓ | ✓ | – | – |
| Embeddings-based Methods | | | | |
| EmbedRank [17] | ✓ | ✓ | – | ✓ |
| SIFRank [9] | ✓ | ✓ | – | ✓ |
| SIFRank+ [9] | ✓ | ✓ | – | ✓ |
| MDERank [18] | – | ✓ | – | ✓ |
Table 6.
Comparison of the precision, recall, and F1 score of the original YAKE! and the one utilising PoS tagging, at 10 extracted keywords. Bold values indicate the best scores obtained for each dataset.
| Dataset | YAKE! | YAKE!+PoS |
|---|
| P% | R% | F1% | P% | R% | F1% |
|---|
| KPCrowd | 24.20 | 4.92 | 8.17 | 33.98 | 6.90 | 11.47 |
| citeulike180 | 23.11 | 13.27 | 16.86 | 25.68 | 14.74 | 18.73 |
| DUC-2001 | 12.01 | 14.87 | 13.29 | 17.44 | 21.58 | 19.29 |
| fao30 | 22.00 | 6.83 | 10.42 | 25.33 | 7.86 | 12.00 |
| fao780 | 11.93 | 14.95 | 13.27 | 13.18 | 16.52 | 14.67 |
| Inspec | 19.82 | 14.05 | 16.44 | 24.57 | 17.41 | 20.38 |
| KDD | 6.01 | 14.68 | 8.53 | 5.83 | 14.23 | 8.27 |
| KPTimes | 7.97 | 15.83 | 10.61 | 11.37 | 22.58 | 15.12 |
| Krapivin2009 | 9.54 | 17.88 | 12.44 | 9.93 | 18.61 | 12.95 |
| Nguyen2007 | 19.00 | 15.82 | 17.26 | 19.19 | 15.98 | 17.43 |
| PubMed | 7.28 | 5.11 | 6.01 | 8.66 | 6.08 | 7.15 |
| Schutz2008 | 37.29 | 8.06 | 13.26 | 47.63 | 10.30 | 16.93 |
| SemEval2010 | 20.37 | 13.08 | 15.93 | 20.82 | 13.37 | 16.28 |
| SemEval2017 | 20.61 | 11.91 | 15.10 | 29.41 | 17.00 | 21.55 |
| theses100 | 9.40 | 14.09 | 11.28 | 10.50 | 15.74 | 12.60 |
| wiki20 | 19.50 | 5.49 | 8.57 | 22.00 | 6.20 | 9.67 |
| WWW | 6.49 | 13.47 | 8.76 | 6.58 | 13.66 | 8.88 |
| Avg. Score (%) | 16.27 | 12.02 | 12.13 | 19.54 | 14.04 | 14.32 |
| Improvement (%) | | | | 20.10
| 16.81 | 18.05 |
Table 7.
Comparison of the precision, recall, and F1 score of the original SIFRank+ and the one utilising PoS tagging, at 10 extracted keywords. Bold values indicate the best scores obtained for each dataset.
| Dataset | SIFRank+ | SIFRank+ + PoS |
|---|
| P% | R% | F1% | P% | R% | F1% |
|---|
| KPCrowd | 26.08 | 5.30 | 8.81 | 26.20 | 5.32 | 8.85 |
| DUC-2001 | 28.34 | 35.09 | 31.36 | 27.86 | 34.49 | 30.82 |
| Inspec | 35.68 | 25.29 | 29.60 | 35.10 | 24.88 | 29.12 |
| KDD | 5.68 | 13.87 | 8.06 | 4.42 | 10.80 | 6.28 |
| KPTimes | 7.92 | 15.74 | 10.54 | 7.74 | 15.37 | 10.30 |
| SemEval2017 | 41.66 | 24.08 | 30.52 | 40.16 | 23.21 | 29.42 |
| WWW | 6.59 | 13.69 | 8.90 | 5.26 | 10.93 | 7.10 |
| Avg. Score (%) | 21.71 | 19.01 | 18.26 | 20.96 | 17.86 | 17.41 |
| Improvement (%) | | | | −3.45 | −6.05 | −4.65 |
Table 8.
Comparison of the precision, recall, and F1 score of YAKE! when the original (PoS) and the tailored (PoS*) filtering approaches are used, at 10 extracted keywords. Bold values indicate the best scores obtained for each dataset.
| Dataset | YAKE! + PoS | YAKE! + PoS* |
|---|
| P% | R% | F1% | P% | R% | F1% |
|---|
| PubMed | 8.66 | 6.08 | 7.15 | 8.70 | 6.11 | 7.18 |
| Schutz2008 | 47.63 | 10.30 | 16.93 | 47.80 | 10.34 | 17.00 |
| Avg. Score (%) | 28.15 | 8.19 | 12.04 | 28.25 | 8.23 | 12.09 |
| Improvement (%) | | | | 0.36
| 0.49 | 0.42 |
Table 9.
Comparison of precision, recall, and F1 score of the original LexRank and its enhanced versions with manual (M) and automatic (A) thesaurus integration, at 10 extracted keywords. Bold values indicate the best scores obtained for each dataset.
| Dataset | Context | LexRank | LexRank + T (M) | LexRank + T (A) |
|---|
| P% | R% | F1% | P% | R% | F1% | P% | R% | F1% |
|---|
| fao30 | Agr. | 20.33 | 6.31 | 9.63 | 30.33 | 9.41 | 14.36 | — | — | — |
| fao780 | Agr. | 8.55 | 10.72 | 9.51 | 13.04 | 16.35 | 14.51 | — | — | — |
| Inspec | CS | 30.49 | 21.61 | 25.29 | 31.10 | 22.04 | 25.79 | 30.97 | 21.95 | 25.69 |
| KDD | CS | 6.07 | 14.81 | 8.61 | 6.23 | 15.20 | 8.83 | 6.25 | 15.26 | 8.87 |
| Krapivin2009 | CS | 7.01 | 13.14 | 9.15 | 8.79 | 16.48 | 11.47 | 8.74 | 16.37 | 11.39 |
| Nguyen2007 | CS | 13.25 | 11.04 | 12.04 | 15.69 | 13.07 | 14.26 | 15.45 | 12.87 | 14.04 |
| SemEval2010 | CS | 13.13 | 8.43 | 10.27 | 15.10 | 9.70 | 11.81 | 15.10 | 9.70 | 11.81 |
| wiki20 | CS | 14.00 | 3.94 | 6.15 | 23.00 | 6.48 | 10.11 | 23.00 | 6.48 | 10.11 |
| WWW | CS | 6.66 | 13.83 | 8.99 | 6.95 | 14.43 | 9.38 | 6.93 | 14.40 | 9.36 |
| PubMed | Health | 4.22 | 2.96 | 3.48 | 8.98 | 6.31 | 7.41 | 8.92 | 6.26 | 7.36 |
| Schutz2008 | Health | 28.32 | 6.12 | 10.07 | 34.35 | 7.43 | 12.21 | 34.00 | 7.35 | 12.09 |
| KPTimes-Econ | Econ. | 3.27 | 7.03 | 4.46 | 4.09 | 8.80 | 5.59 | 4.09 | 8.79 | 5.58 |
| Avg. Score (%) | | 12.94 | 9.99 | 9.80 | 16.47 | 12.14 | 12.14 | 15.35 | 11.94 | 11.63 |
| Improvement (%) | | | | | 27.28 | 21.52 | 23.88 | 21.44 | 16.03 | 18.07 |
Table 10.
Comparison of precision, recall, and F1 score of the original SIFRank+ and its enhanced versions with manual (M) and automatic (A) thesaurus integration, at 10 extracted keywords. Bold values indicate the best scores obtained for each dataset.
| Dataset | Context | SIFRank+ | SIFRank+ + T (M) | SIFRank+ + T (A) |
|---|
| P% | R% | F1% | P% | R% | F1% | P% | R% | F1% |
|---|
| Inspec | CS | 35.68 | 25.29 | 29.60 | 36.62 | 25.95 | 30.37 | 36.03 | 25.53 | 29.88 |
| KDD | CS | 5.68 | 13.87 | 8.06 | 5.97 | 14.58 | 8.48 | 5.95 | 14.52 | 8.44 |
| WWW | CS | 6.59 | 13.69 | 8.90 | 7.32 | 15.19 | 9.88 | 7.27 | 15.10 | 9.81 |
| KPTimes-Econ | Econ. | 3.49 | 7.50 | 4.76 | 4.56 | 9.81 | 6.23 | 4.56 | 9.81 | 6.23 |
| Avg. Score (%) | | 12.86 | 15.09 | 12.83 | 13.62 | 16.38 | 13.74 | 13.45 | 16.24 | 13.59 |
| Improvement (%) | | | | | 5.91 | 8.55 | 7.09 | 4.59 | 7.62 | 5.92 |
Table 11.
Comparison of precision, recall, and F1 score of the original RaKUn and its enhanced versions with Wikipedia, at 10 extracted keywords. Bold values indicate the best scores obtained for each dataset.
| Dataset | RaKUn | RaKUn+Wiki |
|---|
| P% | R% | F1% | P% | R% | F1% |
|---|
| KPCrowd | 42.52 | 8.64 | 14.36 | 42.64 | 8.66 | 14.40 |
| citeulike180 | 16.56 | 9.50 | 12.08 | 17.92 | 10.29 | 13.07 |
| DUC-2001 | 5.68 | 7.03 | 6.29 | 6.17 | 7.64 | 6.82 |
| fao30 | 15.00 | 4.65 | 7.10 | 18.67 | 5.79 | 8.84 |
| fao780 | 6.50 | 8.14 | 7.23 | 7.64 | 9.57 | 8.50 |
| Inspec | 6.54 | 4.64 | 5.43 | 6.74 | 4.77 | 5.59 |
| KDD | 3.66 | 8.92 | 5.19 | 3.63 | 8.86 | 5.15 |
| KPTimes | 8.07 | 16.03 | 10.74 | 8.15 | 16.18 | 10.84 |
| Krapivin2009 | 2.77 | 5.20 | 3.62 | 4.94 | 9.26 | 6.44 |
| Nguyen2007 | 6.79 | 5.66 | 6.17 | 9.67 | 8.05 | 8.78 |
| PubMed | 4.30 | 3.02 | 3.55 | 6.58 | 4.62 | 5.43 |
| Schutz2008 | 33.14 | 7.16 | 11.78 | 40.09 | 8.67 | 14.25 |
| SemEval2010 | 6.75 | 4.33 | 5.28 | 10.04 | 6.45 | 7.85 |
| SemEval2017 | 11.42 | 6.60 | 8.37 | 11.74 | 6.79 | 8.60 |
| theses100 | 3.90 | 5.85 | 4.68 | 4.80 | 7.20 | 5.76 |
| wiki20 | 9.50 | 2.68 | 4.18 | 19.50 | 5.49 | 8.57 |
| WWW | 4.32 | 8.98 | 5.84 | 4.39 | 9.12 | 5.93 |
| Avg. Score (%) | 11.02 | 6.88 | 7.17 | 13.14 | 8.08 | 8.52 |
| Improvement (%) | | | | 19.24 | 17.44 | 18.83 |
Table 12.
Comparison of the precision, recall, and F1 score of the original SIFRank+ and the one utilising Wikipedia named entities, at 10 extracted keywords. Bold values indicate the best scores obtained for each dataset.
| Dataset | SIFRank+ | SIFRank+ + Wiki |
|---|
| P% | R% | F1% | P% | R% | F1% |
|---|
| KPCrowd | 26.08 | 5.30 | 8.81 | 27.46 | 5.58 | 9.27 |
| DUC-2001 | 28.34 | 35.09 | 31.36 | 22.82 | 28.26 | 25.25 |
| Inspec | 35.68 | 25.29 | 29.60 | 36.60 | 25.94 | 30.36 |
| KDD | 5.68 | 13.87 | 8.06 | 6.11 | 14.90 | 8.66 |
| KPTimes | 7.92 | 15.74 | 10.54 | 9.22 | 18.31 | 12.26 |
| SemEval2017 | 41.66 | 24.08 | 30.52 | 41.34 | 23.89 | 30.28 |
| WWW | 6.59 | 13.69 | 8.90 | 7.50 | 15.57 | 10.12 |
| Avg. Score (%) | 21.71 | 19.01 | 18.26 | 21.58 | 18.92 | 18.03 |
| Improvement (%) | | | | −0.60 | −0.47 | −1.26 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}