1. Introduction
The metaverse has emerged as a transformative paradigm, redefining digital interaction across many fields by integrating extended reality (XR), immersive virtual environments, and artificial intelligence (AI) [
1]. Its accelerated development has been driven by technological advancements and an increasing demand for virtual engagement, particularly in response to global disruptions such as the COVID-19 pandemic [
2]. Extensive research has explored the metaverse’s evolution, economic impact, and technological potential, emphasizing its role in shaping future digital ecosystems [
1,
3,
4]. However, realizing its full potential requires a comprehensive strategy encompassing technological innovation, regulatory frameworks, cross-industry integration, and ethical considerations [
1].
A key advantage of the metaverse is its ability to merge physical and virtual realities, enabling immersive and interactive experiences [
5,
6]. Successful implementation of metaverse technologies follows four key phases: design, model training, operation, and evaluation [
7]. However, significant challenges remain, particularly in the areas of user interaction and personalization. Ensuring realistic and adaptive interactions between users and virtual agents—such as non-player characters (NPCs)—is critical for enhancing immersion and engagement. Despite advancements in AI-driven personalization, most NPCs rely on pre-scripted interactions, limiting their ability to adapt dynamically to user input, behaviors, and context in real time [
8,
9].
Current VR applications often fail to provide believable, context-aware interactions, as they primarily depend on static dialogue options and constrained NPC responses. This hinders user immersion and limits engagement, particularly in scenarios requiring dynamic, real-time adaptation [
6]. Communication and collaboration within virtual teams also pose challenges, as the absence of non-verbal cues and natural conversational flow can reduce shared understanding [
10].
In this context, virtual reality, conversational generative AI, and speech processing can contribute to enhancing user engagement and interaction within virtual spaces. However, integrating these technologies to create cohesive and responsive non-player characters (NPCs) remains a challenge. This work proposes an AI-driven augmented reality framework to enhance intelligent tutoring through real-time, personalized NPC interactions. By integrating large language models (LLMs) with speech-to-speech (SST), text-to-speech (TTS), and lip-sync technologies, the framework aims to develop context-aware AI tutors capable of dynamic and realistic engagement, bridging the gap between scripted virtual agents and fully adaptive NPCs for a more interactive and personalized learning experience in the metaverse.
Our proposed solution enhances natural language interactions between users and NPCs in VR by integrating AI-driven speech processing and natural language understanding. The system enables real-time, context-aware conversations, allowing NPCs to generate dynamic responses while synchronizing speech with facial animations for a natural and immersive experience. When a VR user interacts with an NPC, the system captures speech, transcribes it via STT, processes it using an LLM, and converts the response back to speech via TTS. This audio is then synchronized with the NPC’s lip movements and facial expressions, ensuring seamless and realistic interactions. By combining speech recognition, language processing, and animation synchronization, this framework enhances NPC engagement and interactivity, significantly improving immersion and realism in virtual environments. This work contributes to the fields of virtual reality, artificial intelligence, and immersive learning by enhancing NPC interactivity through real-time adaptivity and personalization.
The remainder of this paper is organized as follows.
Section 2 reviews related works, discussing existing approaches to AI-driven virtual interactions and NPC engagement in immersive environments.
Section 3 presents the proposed system, detailing the architecture, core components, and workflow for integrating natural language processing, speech synthesis, and animation synchronization in the VR space.
Section 4 provides an analysis of the first results, evaluating system performance, user interaction quality, and the effectiveness of AI-driven NPC responses. Finally,
Section 5 concludes this paper by summarizing the key findings and outlining potential directions for future research and improvements.
3. Proposed Architecture
Our proposed system focuses on enhancing natural language interactions between users and NPCs within an immersive VR environment. Using AI-driven speech processing and natural language understanding, the system enables seamless and contextually aware conversations between users and NPCs. A key feature of this architecture is its real-time adaptability, allowing NPCs to generate dynamically relevant responses while synchronizing their animations with the corresponding speech output. This integration ensures that interactions are natural, engaging, and immersive, thereby significantly improving the realism of virtual environments.
To help contextualize the technical architecture that follows, we briefly describe the interaction from a learner’s perspective. A user enters the VR classroom, is represented by an avatar, and engages with an NPC tutor. The user communicates naturally, and the system responds in real time by interpreting the input, generating a relevant reply, and delivering it through synchronized facial expressions and speech. This conversational loop feels natural and adaptive, supporting a fluid and personalized learning experience.
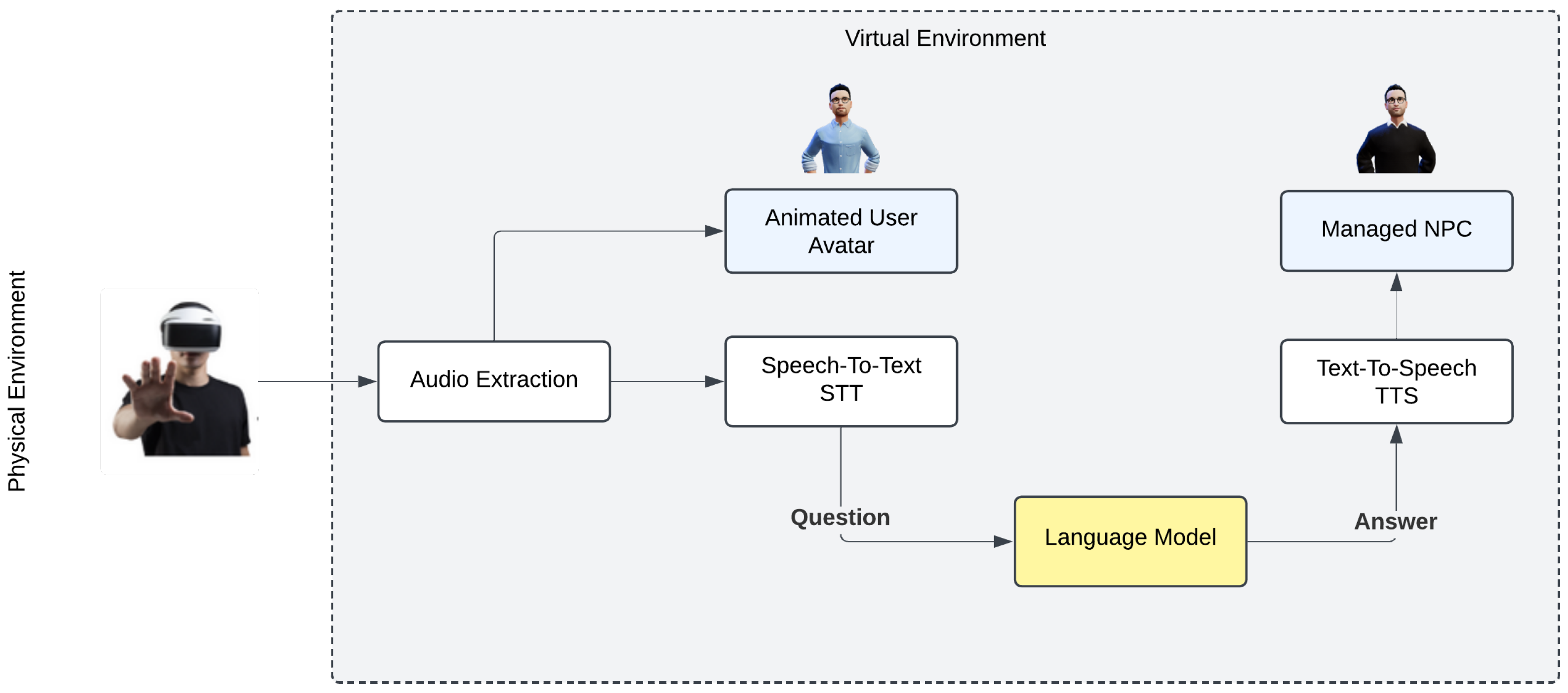
The proposed system architecture, as illustrated in
Figure 2, consists of interconnected components designed to support virtual interactive experiences driven by AI. When a user wearing a VR headset initiates interaction with an NPC, the system captures and processes the spoken input through a structured pipeline. This process begins with audio extraction, where the user’s speech is recorded and stored as an audio clip. The captured audio is transcribed into text by an STT module, enabling further processing by the system’s natural language model. The transcribed text serves as input for an LLM, which analyzes the query and generates an appropriate textual response.
To create a coherent and interactive virtual experience, the system employs TTS conversion to transform the LLM-generated text into synthesized speech. This synthesized response is synchronized with the NPC’s lip movements and facial animations, ensuring that the visual representation aligns naturally with the spoken dialogue. This multi-step process enhances realism, immersion, and user engagement by enabling NPCs to respond dynamically in real time, adapting to contextual changes within the virtual environment. By integrating speech recognition, language processing, and animation synchronization, this system establishes a highly interactive and responsive framework for AI-driven conversational agents in VR environments.
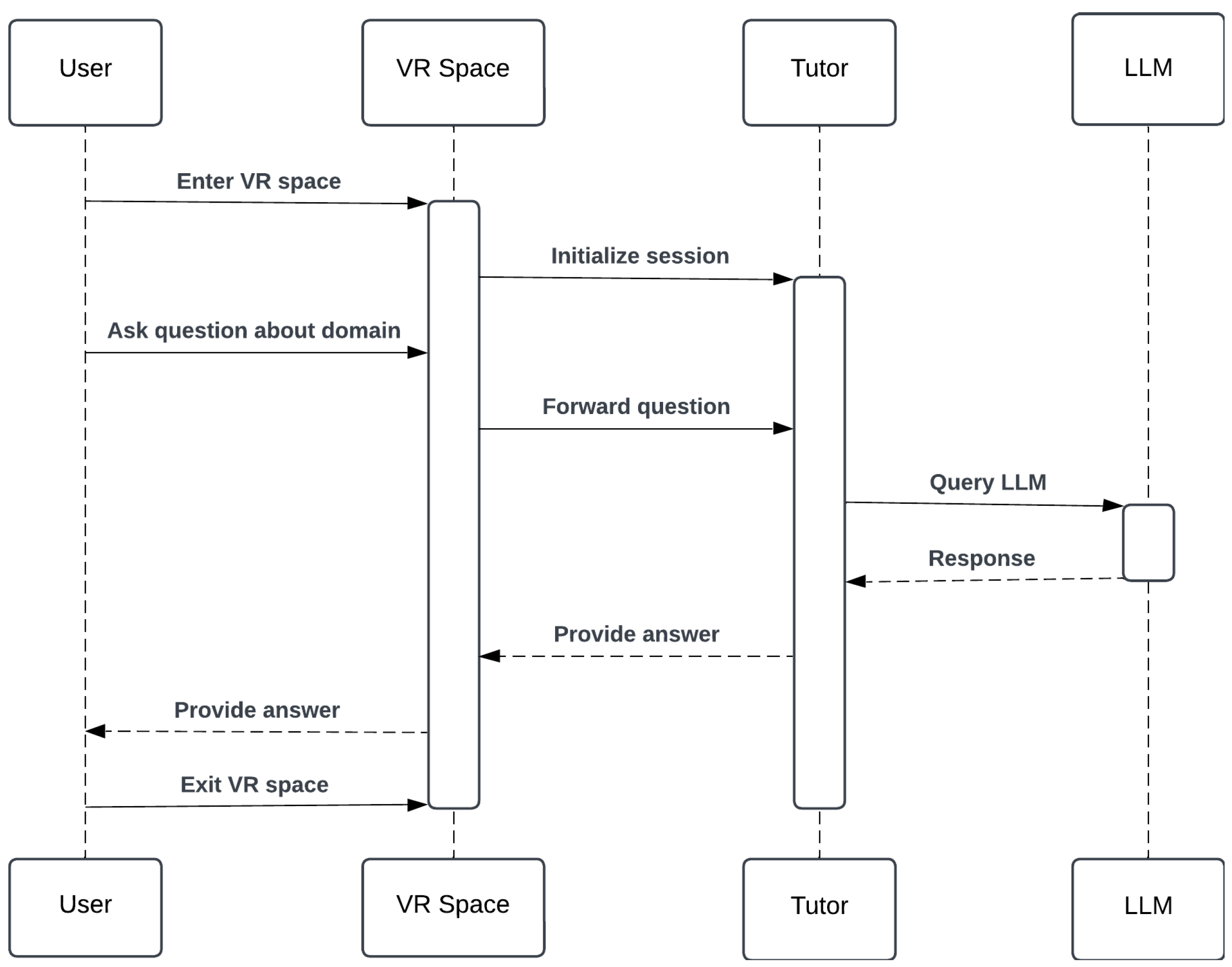
Figure 3 depicts a sequence diagram of the proposed chat completion process, illustrating the interaction between the user, VR space, tutor, and LLM. The sequence begins when the user enters the VR space and initiates a session with the NPC tutor. The user then asks a question related to a specific domain, triggering the chat-processing workflow. The tutor queries the LLM, which processes the request and returns a contextually appropriate response. This response is delivered back to the user within the VR environment, enabling a seamless tutoring interaction.
3.4. Design Trade-Offs and Technical Choices
The architecture presented in the previous sections reflects deliberate design decisions aimed at balancing system performance, realism, accessibility, and pedagogical coherence within a VR-based educational setting. In this subsection, we outline the key technical trade-offs that guided our implementation.
Language Model Selection: As discussed in the adaptive LLM deployment section, we adopted a dual-model strategy to support scalability across various hardware profiles. Lightweight models such as llama3.2:3b-text-q8_0 were chosen for deployment on devices with limited processing capacity, while larger models like deepseek-r1:14b-qwen-distill-q4_K_M were reserved for higher-performance configurations. This trade-off allowed us to maintain acceptable response latency and preserve conversational depth while enabling fully offline operation, which is essential for privacy and deployment in bandwidth-limited environments.
Rendering Engine and Avatar Design: We selected Unity’s Universal Render Pipeline (URP) to optimize visual fidelity and runtime performance in immersive environments. Although alternatives like Unreal Engine or Unity HDRP offer more advanced rendering features, they demand significantly higher computational resources. The URP provided the necessary balance, enabling smooth performance on Meta Quest 3 headsets and desktop setups. For avatar creation, ReadyPlayerMe offers cross-platform compatibility and expressive, stylized models, aligning with our goal of maintaining immersion without overloading system resources.
Speech Pipeline: For speech-to-text (STT), we used the OpenAI Whisper model locally due to its robust transcription performance, even in noisy environments. For text-to-speech (TTS), we used the Kokoro model, which was selected for its lightweight architecture, compatibility with real-time synthesis, and ability to produce natural, intelligible speech on local devices. Although more advanced cloud-based TTS systems offer greater expressiveness, Kokoro provides a favorable trade-off between performance, speed, and privacy, which is essential for educational use cases requiring offline operation. The TTS output is assigned as the NPC audio source and is synchronized with facial animation using viseme mapping through Oculus Lipsync to preserve immersion and realism.
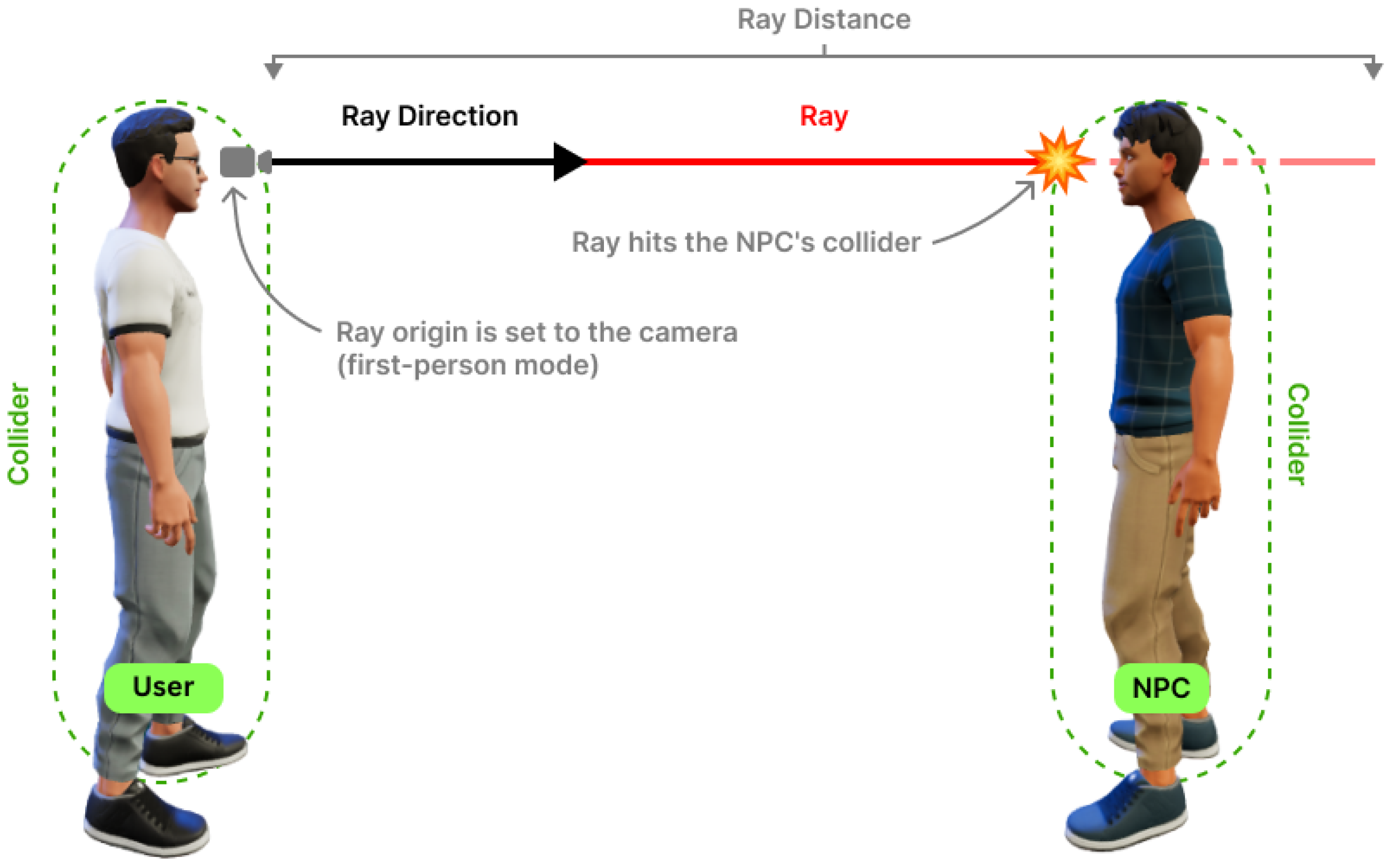
Multimodal Input Support: For user–NPC interactions, we implemented a raycasting system that emits a virtual ray from the user’s camera to detect collisions with the NPC avatar. This mechanism enables lightweight and highly responsive interaction triggers without requiring external sensors or advanced hardware. The avatars were instantiated using the ReadyPlayerMe platform, with a custom loader script that manages parameters such as animation control, posture (sitting/standing), and initialization logic. This approach ensures compatibility across platforms while preserving a sense of embodiment and control within the virtual environment.
Together, these design choices represent a larger design approach that aims to develop an immersive and adaptable tutoring system that is responsive, ensures user privacy, and is accessible on a variety of devices and in a variety of learning environments.
4. Results
4.4. Evaluation Metrics and System Performance
To assess the effectiveness and efficiency of the proposed architecture, we evaluated key performance indicators across multiple dimensions, including system timing, user configuration choices, prompting efficiency, and error analysis. The evaluation was conducted in both desktop simulation mode and virtual reality (VR) mode on the Meta Quest 3, ensuring a comprehensive assessment of system behavior across different environments.
System timing metrics were assessed to evaluate the startup time, interaction latency, scene loading duration, and response delays. The system demonstrated stable performance across both the desktop and VR configurations. In desktop simulation mode, the system achieved an average loading time of 21.58 s. In contrast, direct deployment to the Meta Quest 3 VR headset resulted in a slightly improved average loading time of 20.36 s. This difference suggests that running the system natively in VR reduces initialization overhead.
Speech and audio processing latency also played a critical role in interaction fluidity. The text-to-speech (TTS) system required approximately 10 s to generate spoken responses from text input, while speech-to-text (STT) transcription took 2 s to process user speech.
Interaction delays were observed at two key moments: a 2 s freeze at the beginning of the recording phase and a 10 s delay during TTS conversion, temporarily disrupting the real-time flow of interaction.
Another factor affecting performance was prompting efficiency, which depended on the LLM model chosen for chatbot responses. The selected model affected both the coherence and adaptability of the system’s responses. The efficiency of each model varied based on its computational demands and linguistic structuring capabilities.
To ensure an engaging and pedagogically effective interaction, the LLM-driven NPC’s response quality was analyzed in terms of contextual alignment and instructional relevance. Two distinct models were evaluated for prompting efficiency: LLaMA 3.2:3b, which is optimized for rapid text generation, producing structured and concise responses, and Deepseek-r1:14b, which is designed for in-depth explanations, delivering more detailed responses at the cost of higher computational complexity and increased latency. The choice of the LLM model played a significant role in balancing speed and depth, impacting how well the chatbot could adapt to user queries.
To identify system limitations, a comprehensive error analysis was conducted, focusing on audio processing, system stability, and speech recognition accuracy.
In terms of audio processing, the TTS module performed without errors, as the Kokoro model had been extensively trained on a large dataset, ensuring high-quality speech synthesis.
However, STT transcription exhibited minor errors due to the limitations of the local Whisper model, which lacked sufficient parameters for perfect transcription. Despite this limitation, the system was able to recognize the majority of speech inputs with acceptable accuracy.
Table 3 summarizes the system performance metrics across both VR and desktop modes.
Through this performance evaluation, we identified system bottlenecks and optimization possibilities, ensuring that the LLM-based NPC could provide an engaging, real-time learning experience with minimal issues.
4.5. Findings and Observations
The evaluation results indicate that the system effectively delivers immersive and interactive learning experiences while maintaining stable performance across different modalities. The VR version demonstrated strong potential for enhanced engagement, as its natural voice and gesture-based interactions are inherently more intuitive compared to traditional text-based input. This aligns with findings from [
54], who reported that VR training enhances learning efficacy and provides a heightened sense of presence in mechanical assembly tasks. A recent study has also confirmed that VR-based environments promote increased user engagement, as they offer more immersive experiences that foster active learning [
20].
However, the increased complexity of rendering and audio processing introduced minor latency issues and higher system load, which were observed during performance testing. These challenges are consistent with prior research highlighting the need for continuous optimization in VR-based educational platforms [
55]. The desktop version, while lacking the full immersion of VR, provides a stable and reliable alternative with efficient interaction capabilities through text input and traditional navigation methods. This observation is supported by [
45], who introduced VREd, a virtual reality-based classroom using Unity3D WebGL, highlighting that, while VR offers immersive experiences, desktop platforms remain practical and accessible for online education.
The prompting efficiency analysis demonstrated that the LLM-based NPC effectively generates context-aware responses, ensuring adaptive and dynamic interactions. However, the absence of direct user testing means that further validation is required to assess real-world engagement levels and usability. Additionally, audio-related challenges in VR suggest the need for future improvements in speech recognition accuracy and system optimization to reduce potential errors.
From a technical perspective, VR’s customizable avatars, immersive learning spaces, and spatial interactions contribute to an improved educational experience. While the desktop version is a stable and accessible alternative, its capabilities remain limited compared to VR’s rich and immersive interactions. This is supported by a study on VR- and AR-assisted STEM (Science, Technology, Engineering, and Mathematics) learning, which highlighted the unique benefits of immersive technologies in engaging students and improving learning outcomes [
56].
Overall, the findings suggest that VR-based learning environments offer transformative educational experiences by bridging the gap between digital and physical interactions. While the desktop version remains a functional alternative, the immersive nature of VR fosters deeper learning engagement, natural interaction, and a more effective simulation of real-world educational scenarios. Future work will focus on further optimizing VR performance, improving speech recognition accuracy, and enhancing avatar interactivity to advance the capabilities of next-generation immersive learning environments.
Future research will focus on enhancing the performance of the system to support more natural and effective interactions in immersive learning environments. A central objective will be to deploy the system in authentic educational settings to assess its practical effectiveness and evaluate its impact on learning outcomes and user engagement through empirical studies. Technical refinements will include improving speech recognition accuracy to facilitate more precise and responsive communication, thereby enhancing the overall user experience. In parallel, efforts will be directed toward optimizing system performance by mitigating latency and reducing computational overhead to ensure smoother performance. Additionally, innovative strategies will be investigated to advance avatar interactivity, with the objective of creating more adaptive and responsive virtual agents capable of accommodating a wider range of user behaviors and inputs. Furthermore, future work will explore the scalability of the system for multi-user classroom settings and its adaptability to lower-end hardware, with the aim of supporting deployment in underserved educational environments.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}