
Trustworthy Load Prediction for Cantilever Roadheader Robot Without Imputation


Abstract
1. Introduction
- We propose a load-trustworthy-boosting (LTB) framework that integrates safety constraints and missing data handling into a boosting-based load prediction model for underground tunneling.
- We develop a Trust MIP Tree as the base learner, combining MIA-based splitting with mixed-integer programming to directly encode cutting safety constraints during tree construction.
- We validate the proposed method using real-world underground multi-sensor datasets, demonstrating superior accuracy and robustness over classical models, even with 3% missing data.
2. Collection and Analysis of Key Sensor Data for Cutting Load
2.1. Data Acquisition Scheme
2.2. Data Analysis
2.3. Impact of Missing Data on Cutting Load Prediction
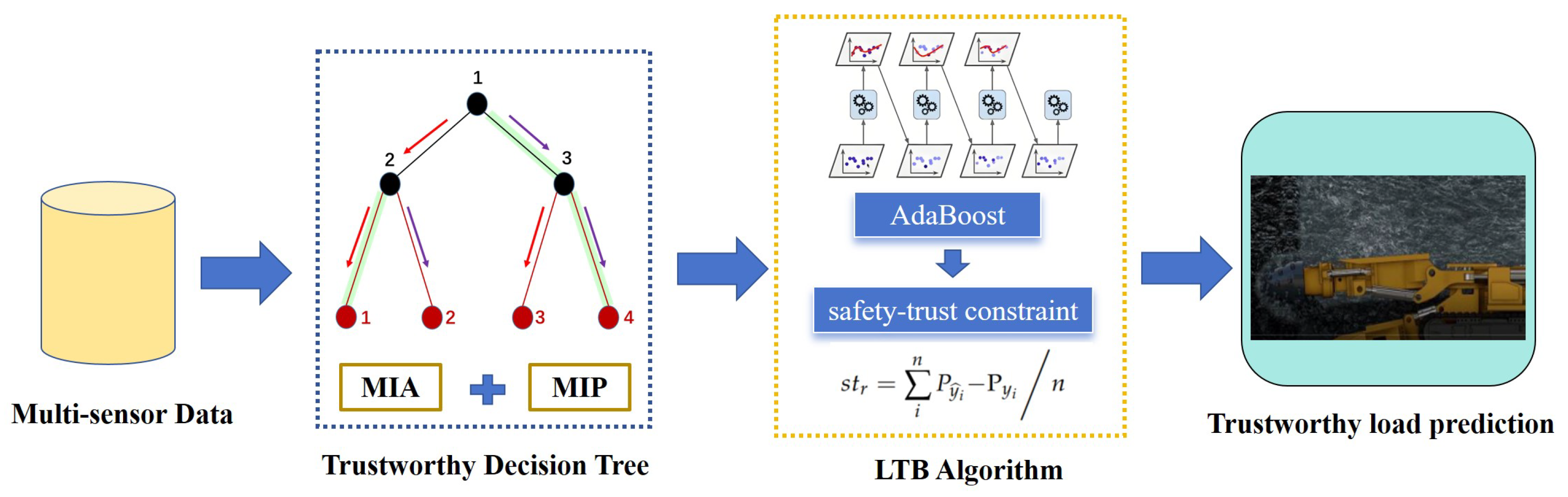
3. Design of Load Prediction Algorithm
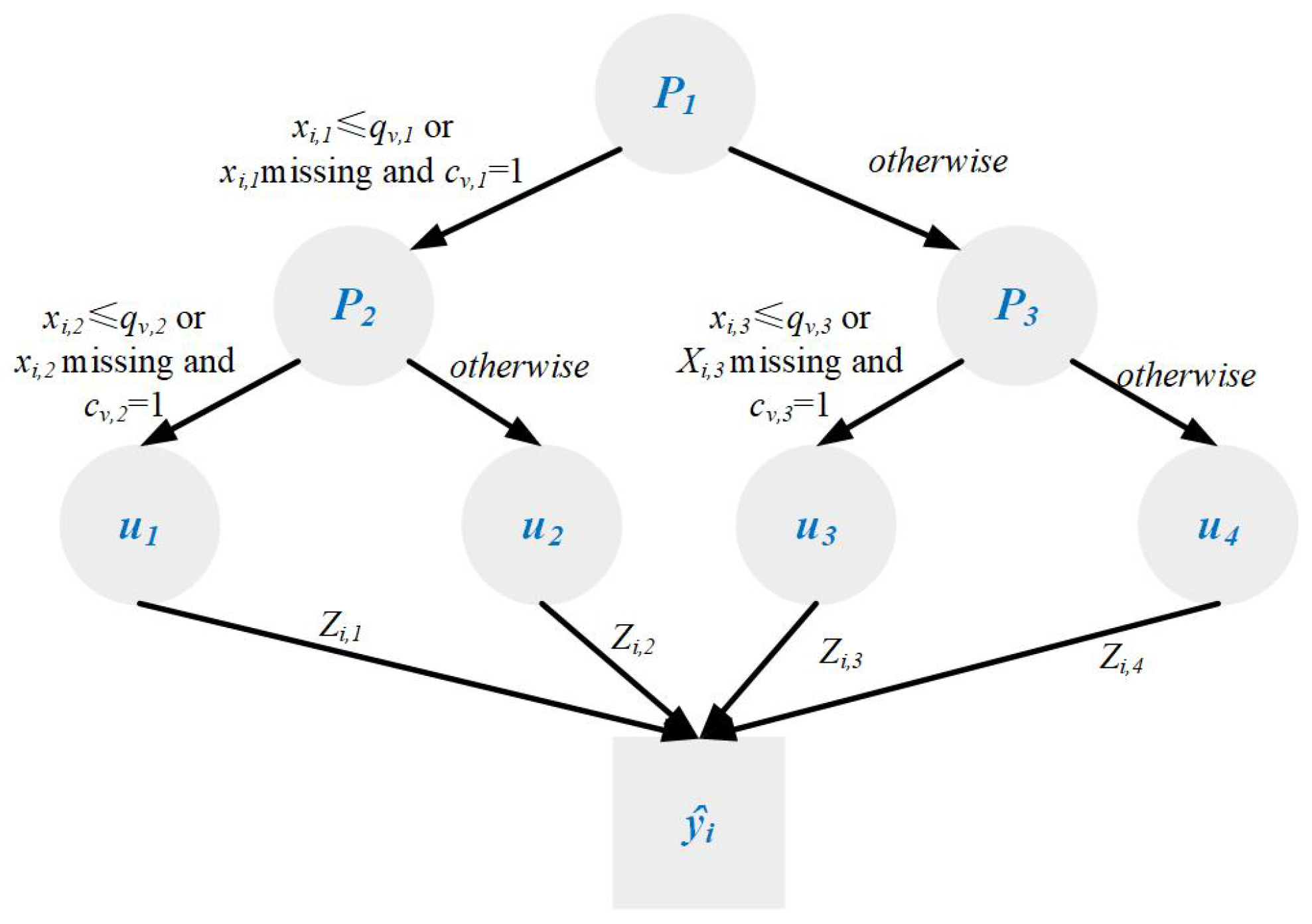
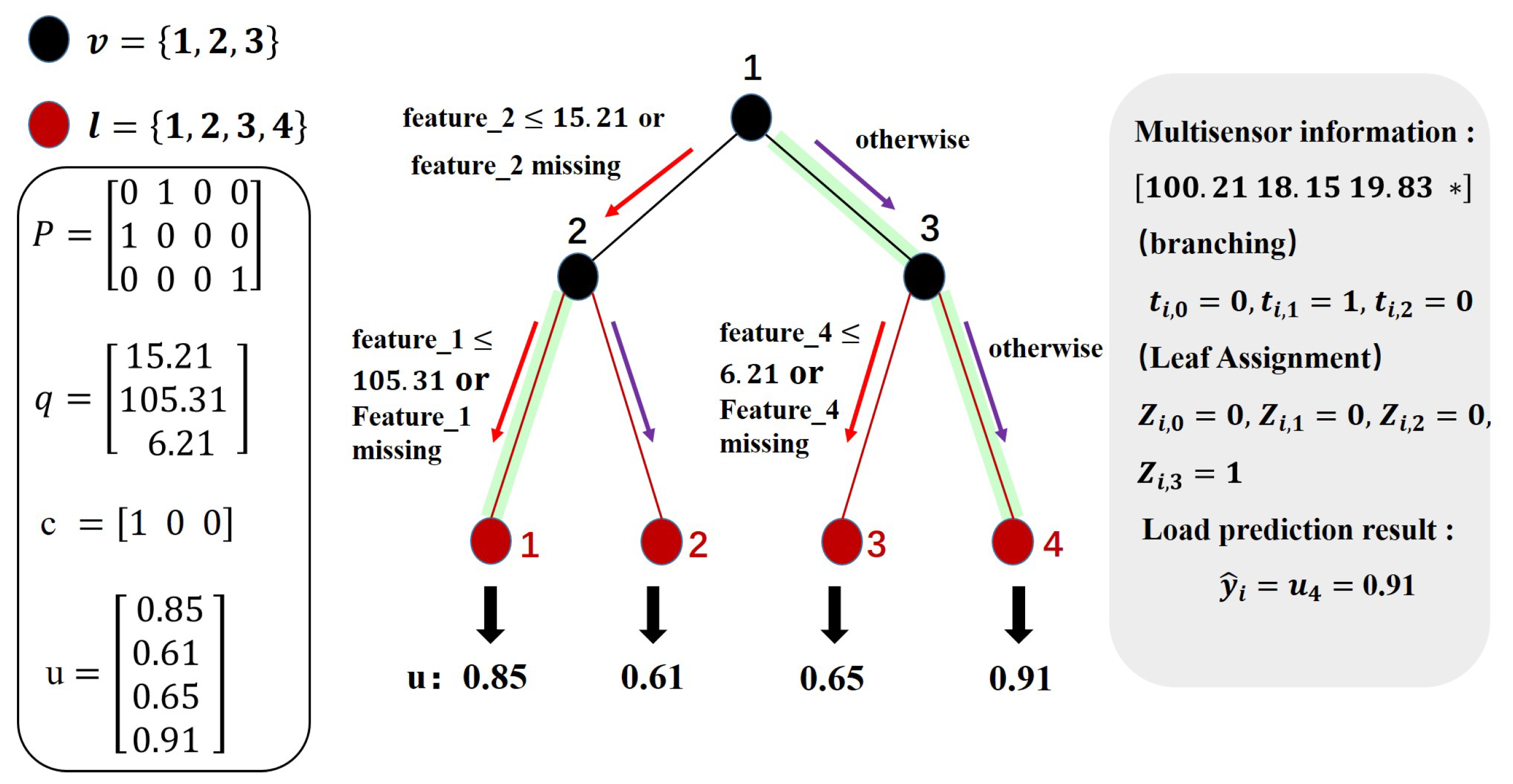
3.1. Trustworthy Decision Tree as a Base Predictor
- Multi-Path Information Aggregation (MIA): This mechanism allows the model to split samples with missing values along multiple valid paths, thereby preserving decision diversity and avoiding data discards.
- Trust-Aware Multi-Instance Prediction (MIP): In cases where multiple candidate paths are taken, MIP uses trust-weighted aggregation to generate a robust final prediction. This trust score reflects data completeness and consistency.
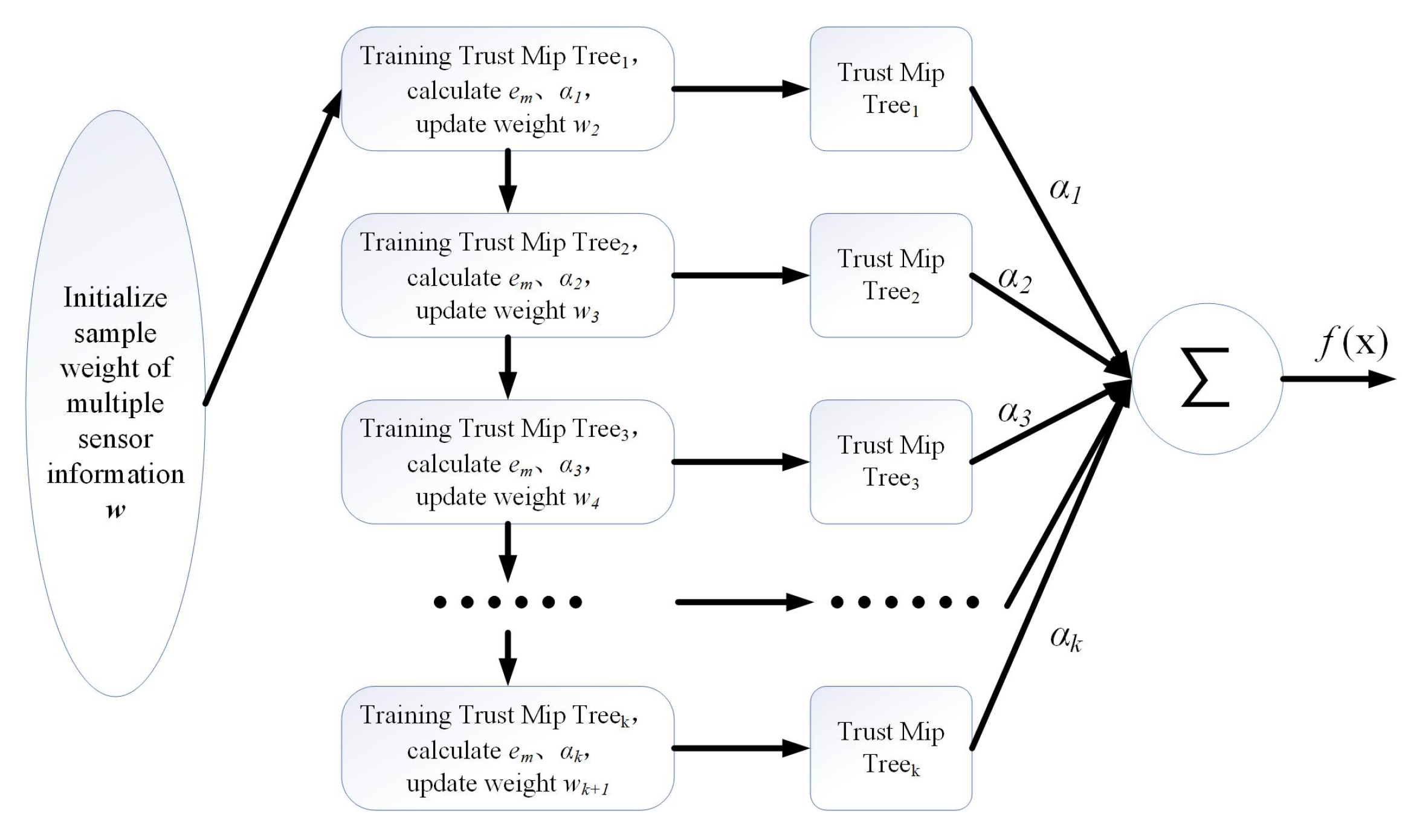
3.2. Load-Trustworthy-Boosting Algorithm (LTB)
| Algorithm 1 The detailed implementation of the LTB algorithm. |
| LTB Algorithm Input: Dataset ; ; base predictor ; Number of iterations K. Process: 1: Initialize weight 2: for do 3: Train predictor based on weight Add safety-trust constraint to calculate total error rate 4: Update weight coefficient 5: Update sample distribution weights: 6: end for Output: |
3.3. Convergence Analysis of LTB Algorithm
4. Validation Experiment
4.1. Experimental Settings and Parameter Selection
- MICE relies on iterative modeling and assumes conditional independence between variables, which may not hold in sensor streams with strong temporal correlation. It is also computationally expensive.
- RFI uses ensemble trees to predict missing values but requires intensive parameter tuning and significant memory resources, especially in large-scale or real-time environments.
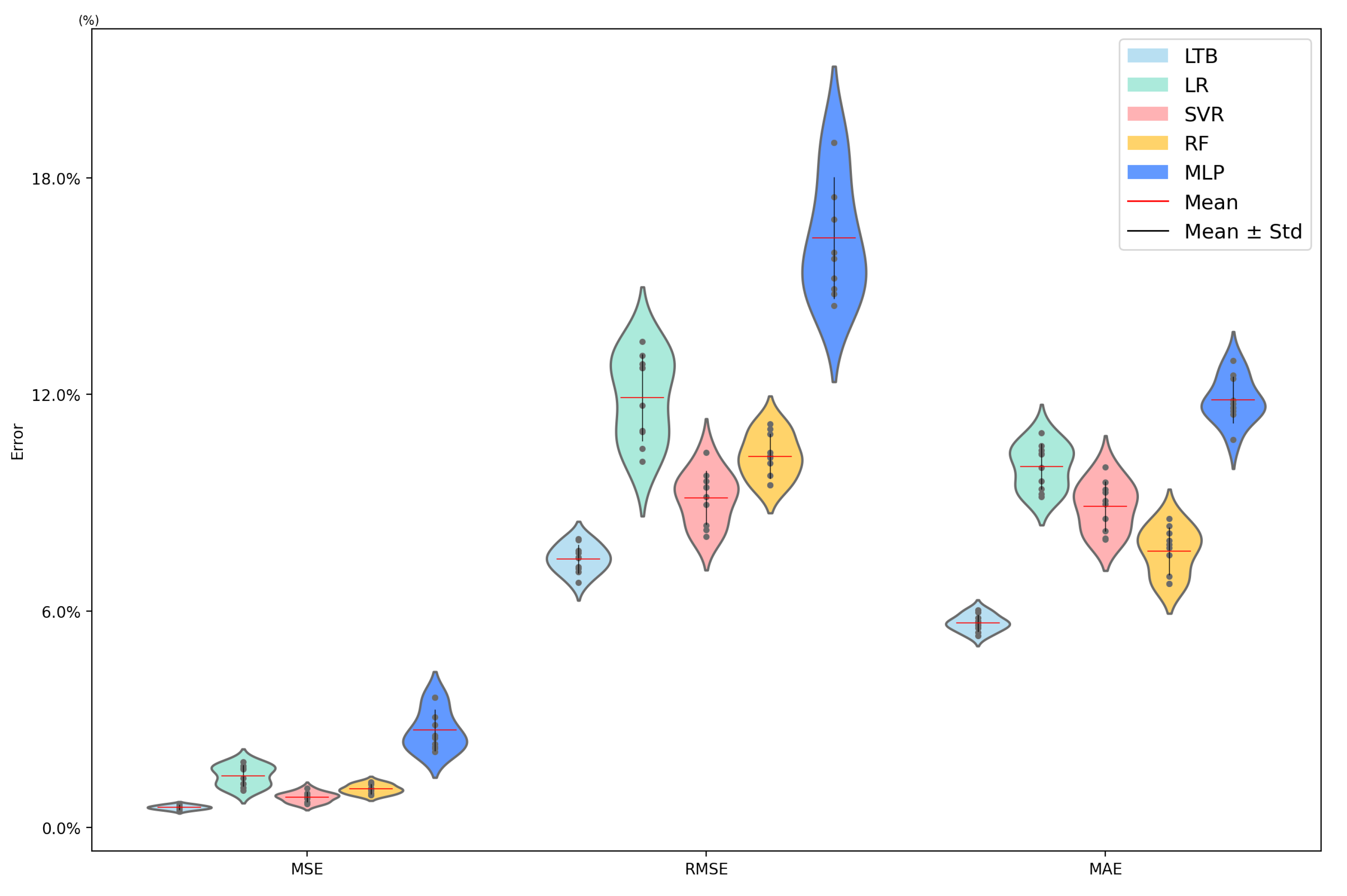
4.2. Load Prediction Results Without Considering Missing Data
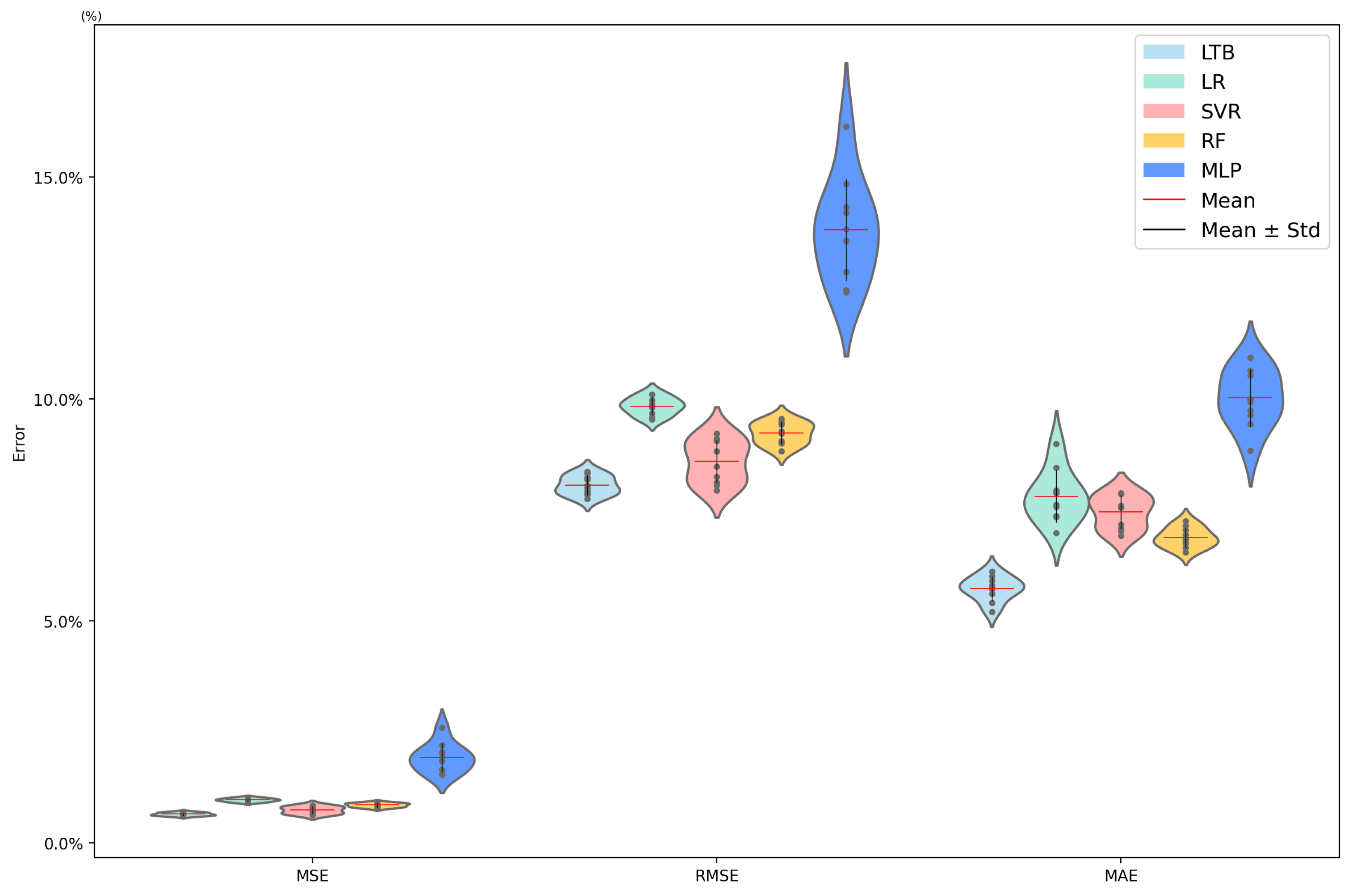
4.3. Load Prediction Results Considering Missing Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, D.; Song, Z.; Liu, N.; Xu, T.; Wang, X.; Zhang, Y.; Su, W.; Cheng, Y. Performance study of hard rock cantilever roadheader based on PCA and DBN. Rock Mech. Rock Eng. 2024, 57, 2605–2623. [Google Scholar] [CrossRef]
- Cheng, J.; Jiang, H.; Wang, D.; Zheng, W.; Shen, Y.; Wu, M. Analysis of position measurement accuracy of boom-type roadheader based on binocular vision. IEEE Trans. Instrum. Meas. 2024, 73, 5016712. [Google Scholar] [CrossRef]
- Zhang, J.; Wan, C.; Wang, J.; Chen, C.; Wang, T.; Zhang, R.; Guo, H. Research on the “shape-performance-control” integrated digital twin system for boom-type roadheaders. Sci. Rep. 2024, 14, 5780. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Zhang, L.; Li, S.; Li, S.; Feng, Y.; Meng, L.; Nan, B.; Du, M.; Fu, Z.; Li, R. Progress in the theory and technology development of unmanned intelligent coal mining systems. J. China Coal Soc. 2023, 48, 34–53. [Google Scholar]
- Ge, S.; Hu, E.; Li, Y. New advances and new directions in coal mine robot technology. J. China Coal Soc. 2023, 48, 54–73. [Google Scholar]
- Zhang, J.; Tu, S.; Cao, Y.; Tan, Y.; Xin, H.; Pang, J. Intelligent separation and filling technology of coal gangue in underground coal mines and its engineering application. J. China Univ. Min. Technol. 2021, 50, 14. [Google Scholar]
- Ding, Z. Current status and development trend of coal roadway excavation equipment in China. Ind. Mine Autom. 2014, 40, 5. [Google Scholar]
- Xu, X.; Peng, S.; Ma, Z.; Zhu, P.; Wang, Y. Principle and key technologies of dynamic detection of coal-rock interface in mines based on air-coupled radar. J. China Coal Soc. 2022, 47, 47. [Google Scholar]
- Miao, S.; Shao, D.; Liu, Z.; Fan, Q.; Li, S.; Ding, E. Study on coal-rock identification method based on terahertz time-domain spectroscopy technology. Spectrosc. Spectr. Anal. 2022, 42, 1806–1812. [Google Scholar]
- Chen, G.; Fan, Y.; Li, Q. A study of coalbed methane (CBM) reservoir boundary detection based on azimuth electromagnetic waves. J. Pet. Sci. Eng. 2019, 179, 432–443. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, C.; Zheng, Z.; Guo, L.; Ma, Z.; Han, Z. Intelligent vehicle positioning method based on multi-sensor information fusion. J. Automot. Eng. 2021, 11, 10. [Google Scholar]
- Ding, X. Research on encryption control of multi-sensor information for intelligent robots based on blockchain. Comput. Meas. Control 2021, 196, 103245. [Google Scholar]
- Xu, A. Research on mobile robot positioning based on fuzzy PID Kalman filter multi-sensor information fusion. J. Chongqing Univ. Sci. Technol. (Nat. Sci. Ed.) 2014, 16, 4. [Google Scholar]
- Li, J.; Zhang, S.; Gong, Z.; Guo, Q. Fire early warning method for conveyorbelt transport tunnels based on multi-sensor information fusion. Coal Mine Mach. 2017, 38, 4. [Google Scholar]
- Xie, H.; Tan, F.; Sun, Z. Research and implementation of warehouse alarm system based on multi-sensor fusion and GSM. Sens. World 2008, 31, 38–40. [Google Scholar]
- Deng, Z.; Li, H. Review of automatic navigation technology for mobile robots. Sci. Technol. Inf. 2016, 33, 142–144. [Google Scholar]
- Wang, H.; Huang, M.; Gao, X.; Lu, S.; Zhang, Q. Coal-rock interface perception and identification based on multi-sensor information fusion considering cutter wear. J. China Coal Soc. 2021, 46, 14. [Google Scholar]
- Yang, J.; Fu, S.; Jiang, H.; Zhao, X.; Wu, M. Identification of cutting hardness of coal-rock based on fuzzy criteria. J. China Coal Soc. 2015, 40, 6. [Google Scholar]
- Ebrahimabadi, A.; Azimipour, M.; Bahreini, A. Prediction of roadheader performance using artificial neural network approaches (MLP and KOSFM). J. Rock Mech. Geotech. Eng. 2015, 7, 573–583. [Google Scholar] [CrossRef]
- Wang, P.; Mu-Qin, T.; Lin, Y.; Hua, Y.; Na, Z.; Hong, L. Dynamic load identification method of rock roadheader using multi-neural network and evidence theory. Coal Technol. 2018, 1238–1243. [Google Scholar] [CrossRef]
- Wang, P.; Yang, Y.; Wang, D.; Ji, X.; Shen, Y.; Chen, S.; Li, X.; Wu, M. Intelligent cutting control system and method for cantilever-type roadheader in coal gangue. J. China Coal Soc. 2021, 46, 11. [Google Scholar]
- Wang, P.; Shen, Y.; Li, R.; Zong, K.; Fu, S.; Wu, M. Multisensor informationbased adaptive control method for cutting head speed of roadheader. Proc. Inst. Mech. Eng. C 2021, 235, 1941–1955. [Google Scholar] [CrossRef]
- Newman, D.A. Missing data: Five practical guidelines. Organ. Res. Methods 2014, 17, 372–411. [Google Scholar] [CrossRef]
- Twala, B.; Jones, M.; Hand, D. Good methods for coping with missing data in decision trees. Pattern Recognit. Lett. 2008, 29, 950–956. [Google Scholar] [CrossRef]
- Jeong, H.; Wang, H.; Calmon, F. Fairness without imputation: A decision tree approach for fair prediction with missing values. In Proceedings of the IEEE International Conference on Big Data, Orlando, FL, USA, 15–18 December 2021. [Google Scholar]
- Wang, P.; Shen, Y.; Ji, X.; Zong, K.; Zheng, W.; Wang, D.; Wu, M. Multiparameter control strategy and method for cutting arm of roadheader. Shock Vib. 2021, 2021, 9918988. [Google Scholar] [CrossRef]
- Sobota, P.; Dolipski, M.; Cheluszka, P. Investigating the simulated control of the rotational speed of roadheader cutting heads in relation to the reduction of energy consumption during the cutting process. J. Min. Sci. 2015, 51, 298–308. [Google Scholar]
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data. Technometrics 2002, 45, 364–365. [Google Scholar]
- Schafer, J.L.; Graham, J.W. Missing data: Our view of the state of the art. Psychol. Methods 2002, 7, 147–177. [Google Scholar] [CrossRef]
- van Buuren, S.; Groothuis-Oudshoorn, K. MICE: Multivariate Imputation by Chained Equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef]
- Royston, P. Multiple imputation of missing values: Update. Stata J. 2005, 5, 227–241. [Google Scholar] [CrossRef]
- Tang, F.; Ishwaran, H. Random forest missing data algorithms. Stat. Anal. Data Min. 2017, 10, 363–377. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z. Missing data imputation: Focusing on single imputation. Ann. Transl. Med. 2016, 4, 9. [Google Scholar] [PubMed]
- Bertsimas, D.; Pawlowski, C.; Zhuo, Y.D. From predictive methods to missing data imputation: An optimization approach. J. Mach. Learn. Res. 2018, 18, 1–39. [Google Scholar]
- Wulff, J.N.; Ejlskov, L. Multiple imputation by chained equations in praxis: Guidelines and review. Electron. J. Bus. Res. Methods 2017, 15, 2017–2058. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Sequence Number | Cutting Motor Current I/A | Rotary Cylinder Pressure MPa | Lifting Cylinder Pressure MPa | Vibration Acceleration of Cutting Arm Acc/m·s−2 |
|---|---|---|---|---|
| 1 | 100.21 | 18.15 | 19.83 | 4.53 |
| 2 | 26.03 | 6.13 | 6.54 | 0.81 |
| 3 | 53.24 | 6.68 | 7.12 | 0.92 |
| 4 | 82.12 | 14.95 | 16.15 | 3.05 |
| 5 | 114.16 | 18.32 | 20.15 | 6.13 |
| Method | Load Prediction Result | ||
|---|---|---|---|
| MSE | RMSE | MAE | |
| LTB | 0.0055 | 0.0743 | 0.0566 |
| LR | 0.0143 | 0.1191 | 0.1000 |
| SVR | 0.0084 | 0.0914 | 0.0890 |
| RF | 0.0106 | 0.1029 | 0.0766 |
| MLP | 0.0269 | 0.1633 | 0.1185 |
| Method | Load Prediction Result | ||
|---|---|---|---|
| MSE | RMSE | MAE | |
| LTB | 0.0065 | 0.0806 | 0.0572 |
| LR | 0.0097 | 0.0983 | 0.0781 |
| SVR | 0.0074 | 0.0859 | 0.0745 |
| RF | 0.0085 | 0.0923 | 0.0688 |
| MLP | 0.0192 | 0.1382 | 0.1003 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, P.; Li, Y.; Li, Y.; Shen, Y.; Zheng, W.; Fu, S. Trustworthy Load Prediction for Cantilever Roadheader Robot Without Imputation. Information 2025, 16, 548. https://doi.org/10.3390/info16070548
Wang P, Li Y, Li Y, Shen Y, Zheng W, Fu S. Trustworthy Load Prediction for Cantilever Roadheader Robot Without Imputation. Information. 2025; 16(7):548. https://doi.org/10.3390/info16070548
Chicago/Turabian StyleWang, Pengjiang, Yuxin Li, Yunwang Li, Yang Shen, Weixiong Zheng, and Shigen Fu. 2025. "Trustworthy Load Prediction for Cantilever Roadheader Robot Without Imputation" Information 16, no. 7: 548. https://doi.org/10.3390/info16070548
APA StyleWang, P., Li, Y., Li, Y., Shen, Y., Zheng, W., & Fu, S. (2025). Trustworthy Load Prediction for Cantilever Roadheader Robot Without Imputation. Information, 16(7), 548. https://doi.org/10.3390/info16070548