1. Introduction
An overdose occurs when someone takes an excessive amount of opioids, surpassing their body’s safe limit, which can lead to life-threatening symptoms. Early detection of an opioid overdose is crucial for quick medical intervention and can help save a person’s life. The misuse of opioids has escalated into a significant health crisis in the United States over the last ten years [
1]. People with poor mental health and chronic pain are often at risk of suicide. Since the beginning of the 21st century, nearly 400,000 Americans have lost their lives due to opioid overdose [
2], and more than 115 people die daily from opioid overdoses [
3]. Furthermore, it is estimated that over 2 million Americans are afflicted with substance use disorders stemming from prescription opioid pain relievers [
4].
The patterns of risk [
5] and associated behaviors among individuals who misuse opioids are not uniform. A better understanding of each individual’s specific risks and needs could help customize efforts to effectively address opioid crises [
6]. Nevertheless, reaching illicit drug users, particularly those not receiving treatment, can be a challenge for research engagement. Social media offers a potential avenue for reaching these elusive populations [
7]. However, the use of social media is a new strategy, with only a limited number of studies using it to target individuals who misuse opioids [
8]. Recently, there has been a rapid epidemiological transition in overdose deaths in the U.S., shifting from those involving prescription opioids to heroin and now to potent synthetic opioids [
9]. Illicitly manufactured synthetic opioids, particularly fentanyl and its analogs, are currently the most common class of drugs implicated in overdose deaths in the U.S. [
10]. In the past, fentanyl was primarily used as a prescription medication in the form of patches or oral lozenges to manage persistent pain and as an injectable for pain relief during surgical operations [
11,
12,
13]. Compared to other prescription opioids, it had notably lower rates of misuse [
14] and did not significantly contribute to overall deaths from overdose. However, since 2013, there has been a significant and rapid increase in the presence of illicitly manufactured fentanyl in the U.S. illicit drug market. This surge has coincided with a sharp rise in overdose deaths involving synthetic opioids, particularly fentanyl [
15,
16,
17].
Social media provide access to observational data sources that are potentially different from the data streams currently employed in public health surveillance. The pseudo-anonymous nature of these platforms can also encourage users to discuss stigmatized behaviors [
18]. Another advantage of social media data is that many individuals are using these platforms to discuss their health and health-related issues [
19].
One prominent platform for such discussions is Reddit, a social media platform where people can discuss a wide variety of topics. Each topic has its own subreddit for topic-specific content identified by a leading ‘r/’, where they can discuss various issues including sensitive issues, mental health [
20], weight loss [
21], gender issues [
22], and substance abuse [
23,
24]. For example, ‘r/addiction’ is a subreddit where members support each other in battling addiction. Moreover, utilizing social media data that include geo-tagged information can be valuable in understanding the variations in opioid overdoses and deaths across different regions. Moreover, these data are free from expert bias, often reflecting first-hand user reports.
Most studies on opioid use and social media have focused on Twitter [
25,
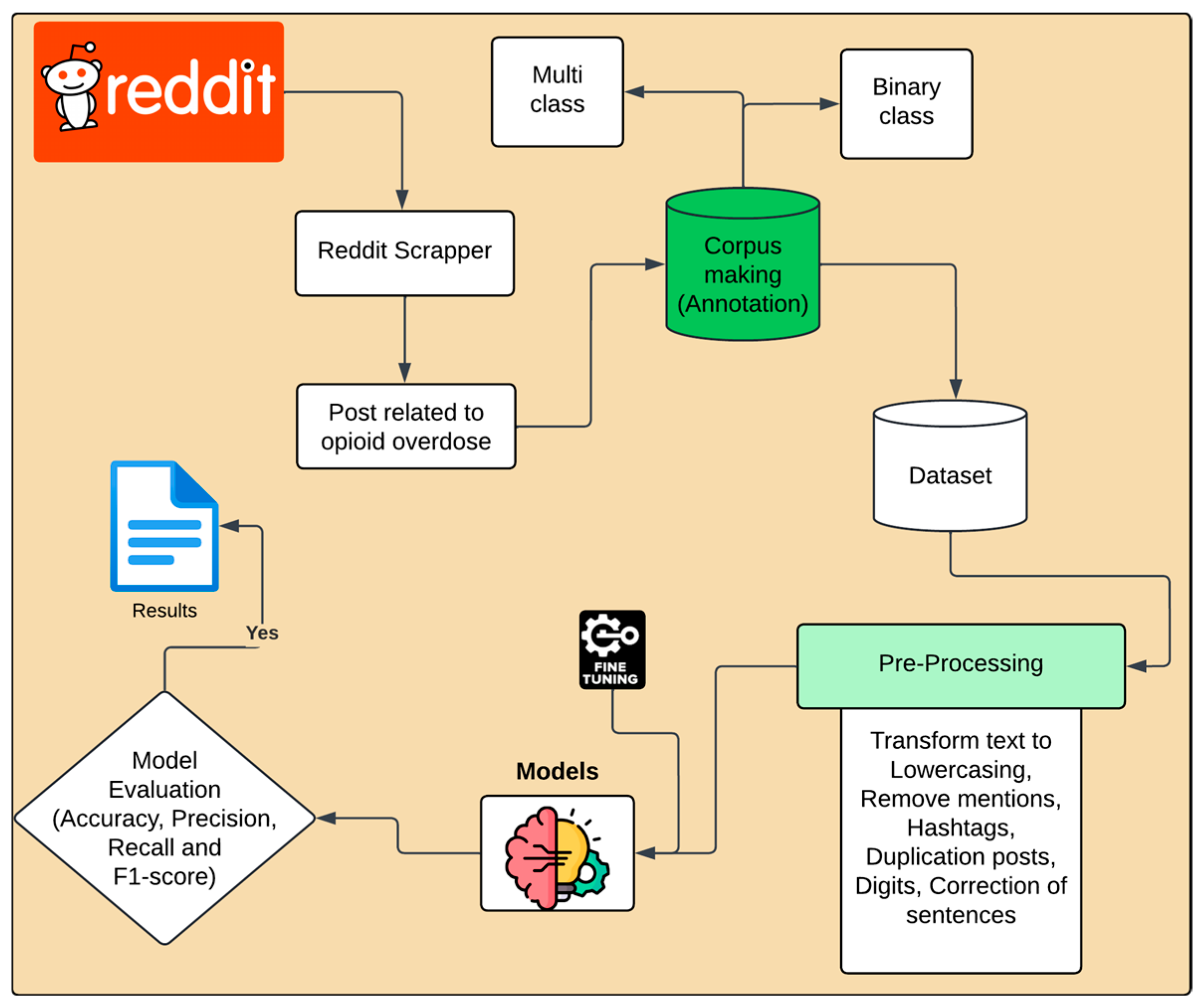
26]. However, the platform supports only 280 characters. This limit can restrict users from sharing information in a single post, which may make it difficult to express opioid overdose-related issues. In contrast, in this study, we developed a methodology utilizing a manually annotated dataset sourced from Reddit, which is the fifth most visited site in the U.S. and provides enough space for the user to express their self-reported experience related to a specific topic with a character limit of 40,000 for a text post. Thus, this dataset serves as a foundation for analyzing patterns of substance use and understanding user behaviors related to opioid consumption. To achieve this, the methodology encompasses the application of advanced natural language processing techniques and machine learning and deep learning models to extract meaningful insights from the textual data. Furthermore, the route of drug administration plays a significant role in determining health outcomes for users. It affects the likelihood of dependence and vulnerability to infections and can lead to health issues that may pose life-threatening risks. For example, smoking facilitates rapid absorption, leading to immediate effects on the lungs, and significantly increasing the risk of respiratory depression and potential death. Oral ingestion typically results in a slower onset, which can cause individuals to consume higher doses, ultimately leading to an overdose and severe liver damage. Intranasal also allows for quick absorption but can lead to nasal tissue damage, complicating further use and increasing the risk of overdose. Lastly, intravenous injection provides immediate effects but complicates dosage accuracy and is associated with severe risks, including life-threatening infections, such as HIV and hepatitis C. Therefore, to mitigate the risks associated with various routes of opioid administration, this study examines the efficacy of an automated tool leveraging natural language processing models, such as RoBERTa, to analyze patterns of substance use. By systematically examining these patterns, the model contributes to public health surveillance efforts, facilitating the identification of at-risk populations and informing the development of targeted interventions. Ultimately, this approach aims to enhance prevention and treatment strategies for opioid misuse through data-driven insights.
This study makes the following contributions:
- ✓
We applied the schema to develop a comprehensive opioid overdose dataset for healthcare professionals, accurately annotated with high-quality labels able to identify high-risk behaviors and develop targeted interventions.
- ✓
We propose, implement, and evaluate a transfer learning model designed to optimize the analysis of opioid overdose incidents based on social media data related to the opioid crisis, enhancing diagnostic accuracy and efficiency in identifying routes of administration, improving response strategies, and reducing reliance on human intervention through automated classification systems.
- ✓
The tool was trained and tested using a comprehensive dataset of Reddit posts related to opioid overdose incidents, with binary classification indicating overdose (yes or no) and multi-class classification assessing the route of administration such as oral, intravenous, intranasal, smoking, and other classes.
- ✓
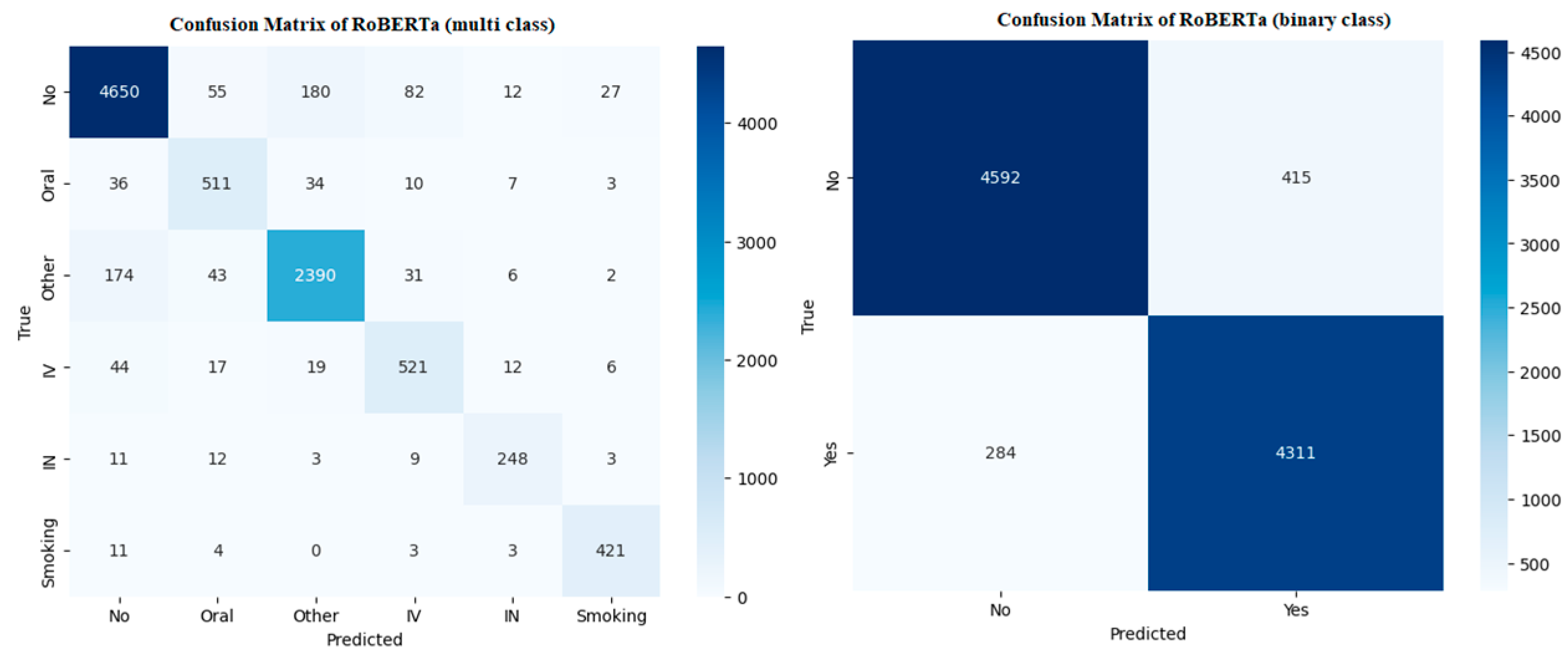
The proposed model (RoBERTa) achieved a 93% cross-validation score in binary classification and a 91% cross-validation score in multi-class classification, resulting in improvements of 9.41% and 10.98%, respectively, compared to traditional machine learning models.
Task Description
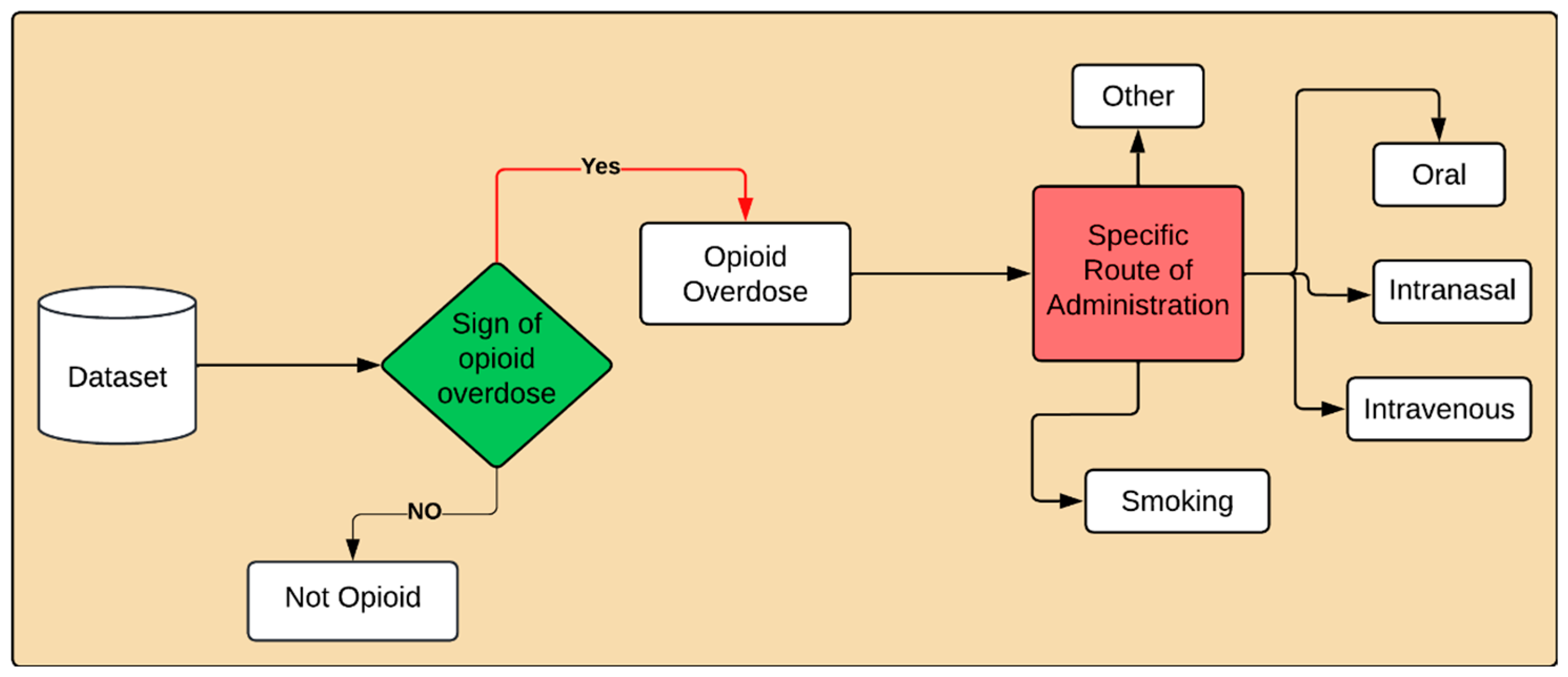
Task A—Binary Opioid Overdose Detection: In the binary classification task, each user post will be identified as either “Opioid overdose” or “Not Opioid overdose”.
Task B—Multi Class Opioid Overdose Detection: In this task, each user post will be classified into fine-grained opioid overdose categories: “Oral”, “Smoking”, “Intravenous”, “Intranasal”, and “other”, along with the Not opioid overdose class. We introduce an “Other” class for instances where the route of administration is not disclosed or is unknown. This class is designed to capture cases of opioid overdose where the specific method of substance use is not specified by the user.
The rest of the paper is organized as follows.
Section 2 provides an overview of the related work.
Section 3 discusses the proposed methodology.
Section 4 covers the experimental setup. Finally,
Section 5 concludes the paper and discusses the future work.
4. Results and Analysis
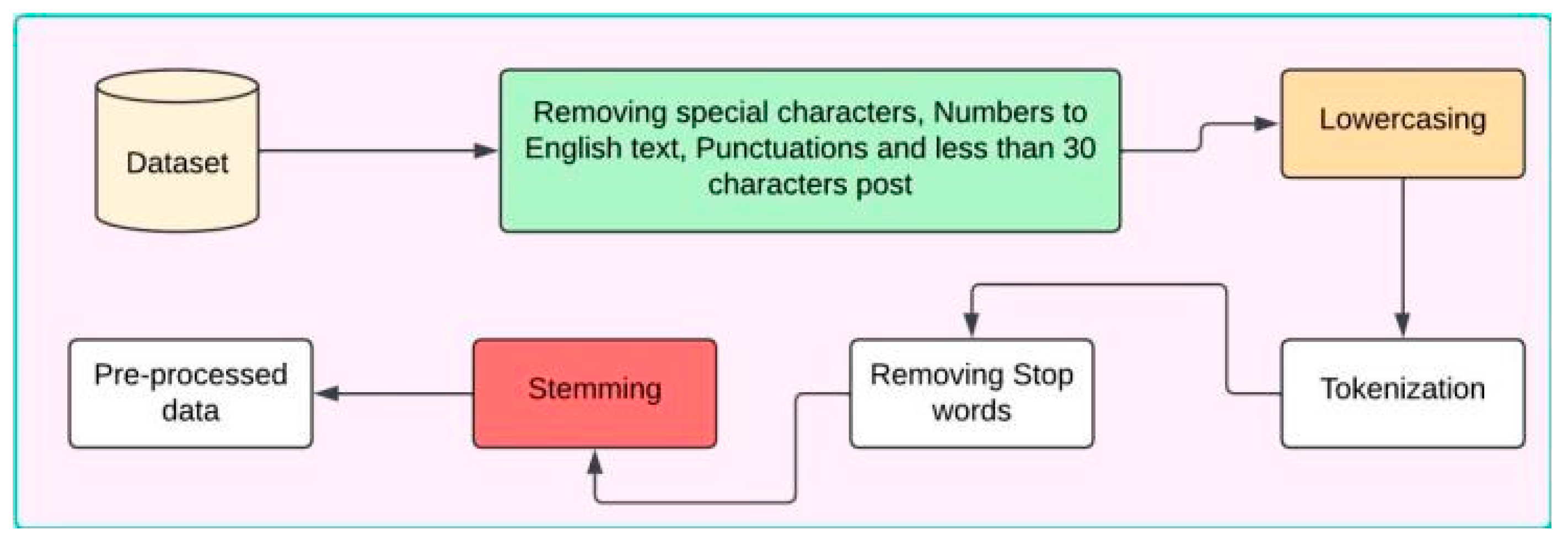
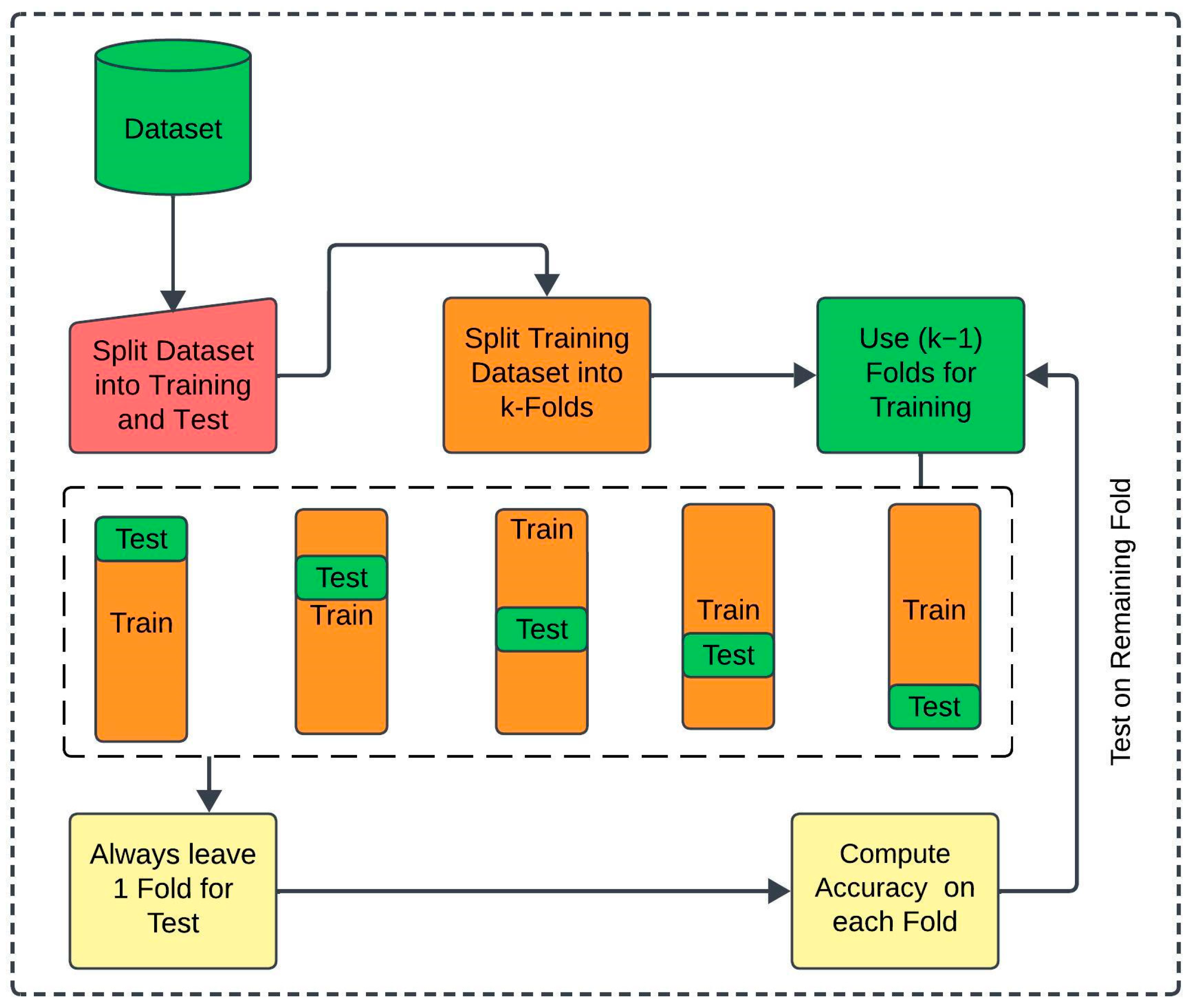
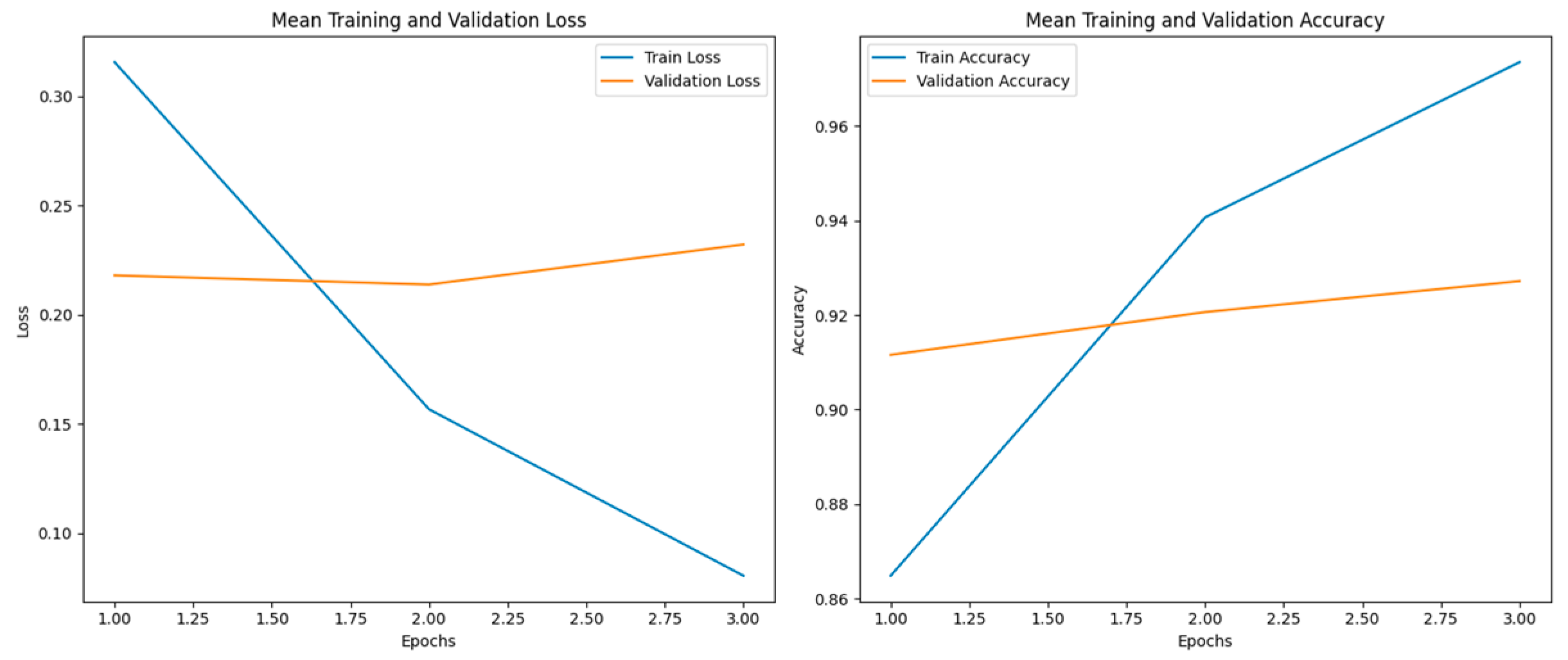
In this section, we discuss the results based on the methodology, implementation, and experiments presented in the previous sections. For machine learning models, we optimized hyperparameters using GridSearchCV, exploring parameters like regularization parameters (C, gamma) for SVM, penalty terms for LR, boosting parameters such as the learning rate, number of estimators, and maximum depth for XGB, and weights and neighbors for KNN. For deep learning models, we varied epochs, batch sizes, and learning rates to adapt BiLSTM and CNN to achieve the best results for our dataset. For transfer learning models, we fine-tuned pre-trained weights by adjusting learning rates, sequence lengths, and transformer-specific parameters to optimize BERT, Electra, RoBERTa, and XLNet for our dataset. To ensure optimal performance across all models, we systematically analyzed and fine-tuned their parameters, maximizing the specific contributions of each model and its hyperparameters. The detailed hyperparameters and corresponding search grids for the proposed methodology are presented in Table 6.
Author Contributions
Conceptualization, G.S., M.A. (Muhammad Ahmad), and I.B.; methodology, M.A. (Muhammad Ahmad) and I.B.; software, M.A. (Muhammad Ahmad); validation, G.S. and M.A. (Maaz Amjad); formal analysis, M.A. (Maaz Amjad); investigation, I.B.; resources, G.S. and I.B.; data curation, M.A. (Muhammad Ahmad); writing—original draft preparation, M.A. (Muhammad Ahmad) and I.B.; writing—review and editing, M.A. (Muhammad Ahmad) and I.A.; visualization, G.S. and I.A.; supervision, I.B.; project administration, I.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be made available upon request.
Acknowledgments
This work was performed with partial support from the Mexican Government through the grant A1-S-47854 of CONACYT, Mexico, and grants 20241816, 20241819, and 20240951 of the Secretaría de Investigación y Posgrado of the Instituto Politécnico Nacional, Mexico. The authors thank CONACYT for the computing resources brought to them through the Plataforma de Aprendizaje Profundo para Tecnologías del Lenguaje of the Laboratorio de Supercómputo of the INAOE, Mexico and acknowledge support of Microsoft through the Microsoft Latin America PhD.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Compton, W.M.; Jones, C.M.; Baldwin, G.T. Relationship between nonmedical prescription-opioid use and heroin use. N. Engl. J. Med. 2016, 374, 154–163. [Google Scholar] [CrossRef] [PubMed]
- Scholl, L. Drug and opioid-involved overdose deaths—United States, 2013–2017. MMWR Morb. Mortal. Wkly. Rep. 2019, 67, 1419–1427. [Google Scholar] [CrossRef] [PubMed]
- National Center for Health Statistics. National Vital Statistics System; Centers for Disease Control and Prevention: Atlanta, GA, USA, 2018. Available online: https://www.cdc.gov/nchs/nvss/deaths.htm (accessed on 22 September 2015).
- Substance Abuse and Mental Health Services Administration (SAMHSA). 2017 National Survey on Drug Use and Health: Detailed Tables; Center for Behavioral Health Statistics and Quality: Rockville, MD, USA, 2018. Available online: https://www.samhsa.gov/data (accessed on 6 November 2024).
- Kalichman, S.C.; Rompa, D. Sexual sensation seeking and sexual compulsivity scales: Validity, and predicting HIV risk behavior. J. Personal. Assess. 1995, 65, 586–601. [Google Scholar] [CrossRef] [PubMed]
- Malow, R.M.; Dévieux, J.G.; Jennings, T.; Lucenko, B.A.; Kalichman, S.C. Substance-abusing adolescents at varying levels of HIV risk: Psychosocial characteristics, drug use, and sexual behavior. J. Subst. Abus. 2001, 13, 103–117. [Google Scholar] [CrossRef]
- Miller, P.G.; Sønderlund, A.L. Using the internet to research hidden populations of illicit drug users: A review. Addiction 2010, 105, 1557–1567. [Google Scholar] [CrossRef]
- Yuan, Y.; Kasson, E.; Taylor, J.; Cavazos-Rehg, P.; De Choudhury, M.; Aledavood, T. Examining the Gateway Hypothesis and Mapping Substance Use Pathways on Social Media: Machine Learning Approach. JMIR Form. Res. 2024, 8, e54433. [Google Scholar] [CrossRef]
- Jalal, H.; Buchanich, J.M.; Roberts, M.S.; Balmert, L.C.; Zhang, K.; Burke, D.S. Changing dynamics of the drug overdose epidemic in the United States from 1979 through 2016. Science 2018, 361, eaau1184. [Google Scholar] [CrossRef]
- Wilson, N. Drug and opioid-involved overdose deaths—United States, 2017–2018. MMWR Morb. Mortal. Wkly. Rep. 2020, 69, 290–297. [Google Scholar] [CrossRef]
- Food and Drug Administration. Duragesic Prescribing Information. 2019. Available online: https://www.accessdata.fda.gov/drugsatfda_docs/label/2019/019813s079lbl.pdf (accessed on 6 November 2024).
- Food and Drug Administration. Fentora Prescribing Information. 2019. Available online: https://www.accessdata.fda.gov/drugsatfda_docs/label/2019/021947s029lbl.pdf (accessed on 6 November 2024).
- Food and Drug Administration. Fentanyl Citrate Prescribing Information. 2019. Available online: https://www.accessdata.fda.gov/drugsatfda_docs/label/2019/019115s033lbl.pdf (accessed on 6 November 2024).
- Butler, S.F.; Black, R.A.; Cassidy, T.A.; Dailey, T.M.; Budman, S.H. Abuse risks and routes of administration of different prescription opioid compounds and formulations. Harm Reduct. J. 2011, 8, 29. [Google Scholar] [CrossRef]
- Spencer, M.R.; Warner, M.; Bastian, B.A.; Trinidad, J.P.; Hedegaard, H. Drug Overdose Deaths Involving Fentanyl, 2011–2016; National Vital Statistics Reports: From the Centers for Disease Control and Prevention, National Center for Health Statistics, National Vital Statistics System; CDC: Atlanta, GA, USA, 2019; Volume 68, pp. 1–19.
- Drug Enforcement Administration. NFLIS Drug Brief: Fentanyl; U.S. Department of Justice. Available online: https://www.nflis.deadiversion.usdoj.gov/nflisdata/docs/15431NFLISDrugBriefFentanyl.pdf (accessed on 6 November 2024).
- O’Donnell, J.K. Trends in deaths involving heroin and synthetic opioids excluding methadone, and law enforcement drug product reports, by census region—United States, 2006–2015. MMWR Morb. Mortal. Wkly. Rep. 2017, 66, 897–903. [Google Scholar] [CrossRef]
- Hanson, C.L.; Cannon, B.; Burton, S.; Giraud-Carrier, C. An exploration of social circles and prescription drug abuse through Twitter. J. Med. Internet Res. 2013, 15, e189. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, F.; Newell, R.; Babu, G.R.; Chatterjee, T.; Sandhu, N.K.; Gupta, L. The social media Infodemic of health-related misinformation and technical solutions. Health Policy Technol. 2024, 13, 100846. [Google Scholar] [CrossRef]
- De Choudhury, M.; De, S. Mental health discourse on reddit: Self-disclosure, social support, and anonymity. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 71–80. [Google Scholar]
- Enes, K.B.; Brum, P.P.V.; Cunha, T.O.; Murai, F.; da Silva, A.P.C.; Pappa, G.L. Reddit weight loss communities: Do they have what it takes for effective health interventions? In Proceedings of the 2018 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Santiago, Chile, 3–6 December 2018; pp. 508–513. [Google Scholar]
- Saha, K.; Kim, S.C.; Reddy, M.D.; Carter, A.J.; Sharma, E.; Haimson, O.L.; De Choudhury, M. The language of LGBTQ+ minority stress experiences on social media. Proc. ACM Hum.-Comput. Interact. 2019, 3, 89. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Sridhar, S.; Pandey, R.; Hasan, M.A.; Mohler, G. Redditors in recovery: Text mining reddit to investigate transitions into drug addiction. arXiv 2019, arXiv:1903.04081. [Google Scholar]
- Chancellor, S.; Nitzburg, G.; Hu, A.; Zampieri, F.; De Choudhury, M. Discovering alternative treatments for opioid use recovery using social media. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–15. [Google Scholar]
- Mackey, T.K.; Kalyanam, J.; Katsuki, T.; Lanckriet, G. Twitter-based detection of illegal online sale of prescription opioid. Am. J. Public Health 2017, 107, 1910–1915. [Google Scholar] [CrossRef]
- Kalyanam, J.; Katsuki, T.; Lanckriet, G.R.; Mackey, T.K. Exploring trends of nonmedical use of prescription drugs and polydrug abuse in the Twittersphere using unsupervised machine learning. Addict. Behav. 2017, 65, 289–295. [Google Scholar] [CrossRef]
- Blackley, S.V.; MacPhaul, E.; Martin, B.; Song, W.; Suzuki, J.; Zhou, L. Using natural language processing and machine learning to identify hospitalized patients with opioid use disorder. In Proceedings of the AMIA Annual Symposium, San Diego, CA, USA, 30 October–3 November 2021; Volume 2020, p. 233. [Google Scholar]
- Sarker, A.; Nataraj, N.; Siu, W.; Li, S.; Jones, C.M.; Sumner, S.A. Concerns among people who use opioids during the COVID-19 pandemic: A natural language processing analysis of social media posts. Subst. Abus. Treat. Prev. Policy 2022, 17, 16. [Google Scholar] [CrossRef]
- Wright, A.P.; Jones, C.M.; Chau, D.H.; Gladden, R.M.; Sumner, S.A. Detection of emerging drugs involved in overdose via diachronic word embeddings of substances discussed on social media. J. Biomed. Inform. 2021, 119, 103824. [Google Scholar] [CrossRef]
- Green, C.A.; Perrin, N.A.; Hazlehurst, B.; Janoff, S.L.; DeVeaugh-Geiss, A.; Carrell, D.S.; Coplan, P.M. Identifying and classifying opioid-related overdoses: A validation study. Pharmacoepidemiol. Drug Saf. 2019, 28, 1127–1137. [Google Scholar] [CrossRef]
- Schell, R.C.; Allen, B.; Goedel, W.C.; Hallowell, B.D.; Scagos, R.; Li, Y.; Krieger, M.S.; Neill, D.B.; Marshall, B.D.L.; Cerda, M.; et al. Identifying predictors of opioid overdose death at a neighborhood level with machine learning. Am. J. Epidemiol. 2022, 191, 526–533. [Google Scholar] [CrossRef]
- Neill, D.B.; Herlands, W. Machine learning for drug overdose surveillance. J. Technol. Hum. Serv. 2018, 36, 8–14. [Google Scholar] [CrossRef]
- Dong, X.; Deng, J.; Hou, W.; Rashidian, S.; Rosenthal, R.N.; Saltz, M.; Wang, F. Predicting opioid overdose risk of patients with opioid prescriptions using electronic health records based on temporal deep learning. J. Biomed. Inform. 2021, 116, 103725. [Google Scholar] [CrossRef] [PubMed]
- Anderson, T.S.; Wang, B.X.; Lindenberg, J.H.; Herzig, S.J.; Berens, D.M.; Schonberg, M.A. Older Adult and Primary Care Practitioner Perspectives on Using, Prescribing, and Deprescribing Opioids for Chronic Pain. JAMA Netw. Open 2024, 7, e241342. [Google Scholar] [CrossRef] [PubMed]
- Goudman, L.; Moens, M.; Pilitsis, J.G. Incidence and Prevalence of Pain Medication Prescriptions in Pathologies with a Potential for Chronic Pain. Anesthesiology 2024, 140, 524–537. [Google Scholar] [CrossRef] [PubMed]
- Graham, S.S.; Shifflet, S.; Amjad, M.; Claborn, K. An interpretable machine learning framework for opioid overdose surveillance from emergency medical services records. PLoS ONE 2024, 19, e0292170. [Google Scholar] [CrossRef]
- Abuse, S.; Mental Health Services Administration. Results from the 2013 National Survey on Drug Use and Health: Mental Health Findings; NSDUH Series H-49; Substance Abuse and Mental Health Services Administration: Rockville, MD, USA, 2014; Volume 2, pp. 55–68.
- Paulozzi, L.J.; Jones, C.M.; Mack, K.A.; Rudd, R.A. Vital Signs: Overdoses of Prescription Opioid Pain Relievers--United States, 1999–2008. MMWR Morb. Mortal. Wkly. Rep. 2011, 60, 1487. [Google Scholar]
- Warner, M.; Chen, L.H.; Makuc, D.M.; Anderson, R.N.; Minino, A.M. Drug poisoning deaths in the United States, 1980–2008. NCHS Data Brief 2011, 81, 1–8. [Google Scholar]
- May, A.L.; Freedman, D.; Sherry, B.; Blanck, H.M.; Centers for Disease Control and Prevention (CDC). Obesity—United States, 1999–2010. MMWR Surveill. Summ. 2013, 62 (Suppl. S3), 120–128. [Google Scholar]
- Rudd, R.A.; Aleshire, N.; Zibbell, J.E.; Gladden, R.M. Increases in drug and opioid overdose deaths—United States, 2000–2014. Am. J. Transplant. 2016, 16, 1323–1327. [Google Scholar] [CrossRef]
- Zimmerman, M.S. Health information-seeking behavior in the time of COVID-19: Information horizons methodology to decipher source path during a global pandemic. J. Doc. 2021, 77, 1248–1264. [Google Scholar] [CrossRef]
- Brown University. Cold weather increases the risk of fatal opioid overdoses, study finds. News from Brown. 17 June 2019. Available online: https://www.brown.edu/news/2019-06-17/cold-overdoses (accessed on 6 November 2024).
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Falotico, R.; Quatto, P. Fleiss’ kappa statistic without paradoxes. Qual. Quant. 2015, 49, 463–470. [Google Scholar] [CrossRef]
- Pedregosa, F. Scikit-learn: Machine learning in python Fabian. J. Mach. Learn. Res. 2011, 12, 2825. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Zheng, X. {TensorFlow}: A system for {Large-Scale} machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}