
Human vs. AI: Assessing the Quality of Weight Loss Dietary Information Published on the Web

 , , ,
, , ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Design
2.2. Retrieval of Webpages to Be Assessed
2.3. Existing Methods Used for Quality Information Assessment
2.4. A Method Developed by ChatGPT-4.5 for Quality Information Assessment
2.5. Human Operated Assessments
2.6. AI Operated Assessments
Prompt Preparation
2.7. Data Processing
2.8. Statistical Analysis
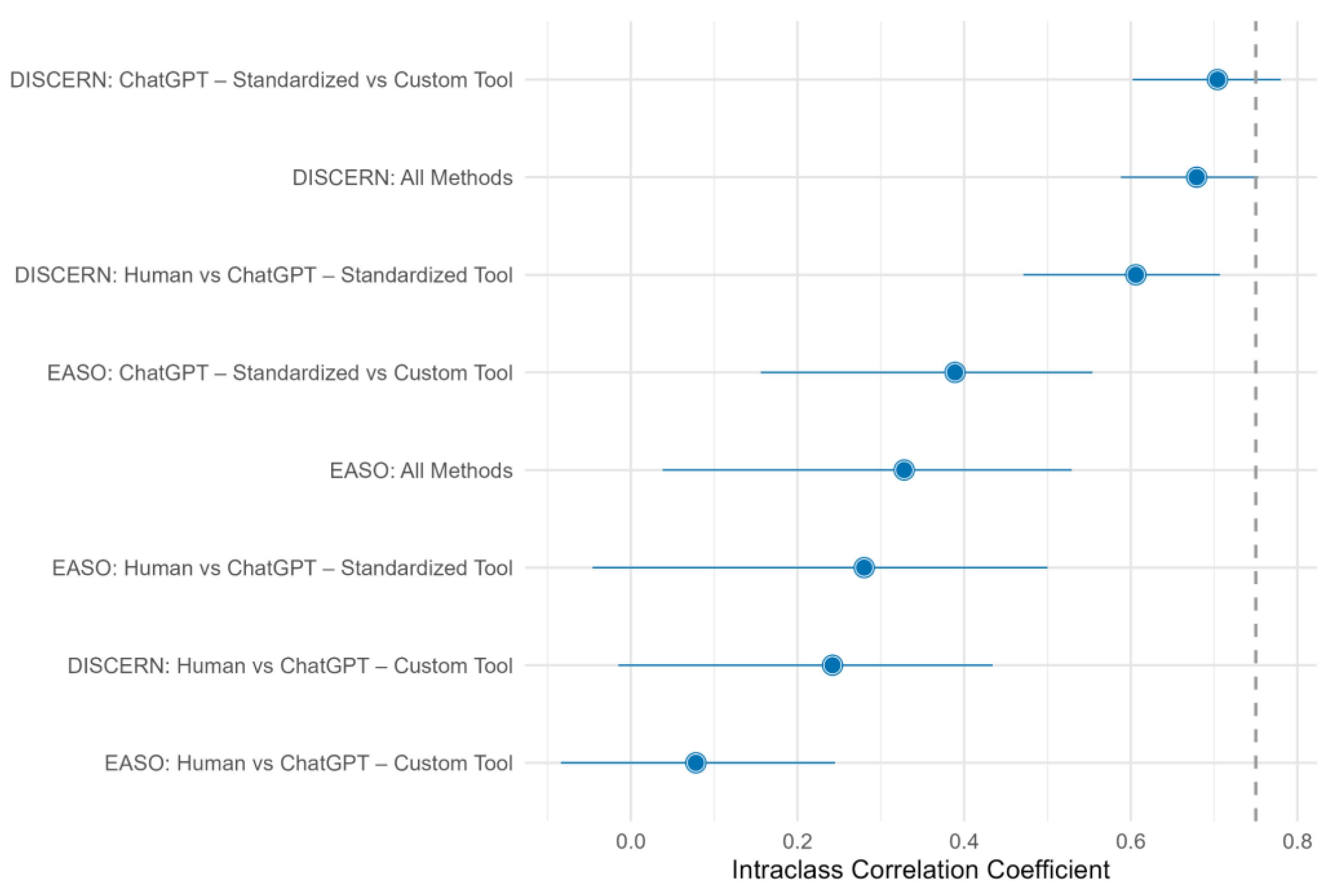
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ChatGPT | Chat Generative Pre-trained Transformer |
| EQIP | Ensuring Quality Information for Patients |
| JAMA | Journal of American Medical Association |
| QUEST | Quality Evaluation Scoring Tool |
| LLM | Large Language Model |
| SERP | Search Engine Result Page |
| Portable Document Format | |
| EASO | European Association for the Study of Obesity |
| WHO | World Health Organization |
| CDC | Centers for Disease Control |
| EFSA | European Food Safety Authority |
| HONcode | Health On the Net Foundation code of conduct |
| ICC | Intraclass Correlation Coefficient |
| SPSS | Statistical Package for the Social Sciences |
| IQR | Interquartile Range |
| n/a | Not Applicable |
| URL | Uniform Resource Locator |
References
- Baqraf, Y.K.A.; Keikhosrokiani, P.; Al-Rawashdeh, M. Evaluating Online Health Information Quality Using Machine Learning and Deep Learning: A Systematic Literature Review. Digit. Health 2023, 9, 20552076231212296. [Google Scholar] [CrossRef]
- Tan, S.S.L.; Goonawardene, N. Internet Health Information Seeking and the Patient-Physician Relationship: A Systematic Review. J. Med. Internet Res. 2017, 19, e9. [Google Scholar] [CrossRef] [PubMed]
- Eurostat Individuals Using the Internet for Seeking Health-Related Information. Available online: https://ec.europa.eu/eurostat/databrowser/view/tin00101/default/bar?lang=en (accessed on 10 April 2025).
- Jia, X.; Pang, Y.; Liu, L.S. Online Health Information Seeking Behavior: A Systematic Review. Healthcare 2021, 9, 1740. [Google Scholar] [CrossRef] [PubMed]
- Daraz, L.; Morrow, A.S.; Ponce, O.J.; Beuschel, B.; Farah, M.H.; Katabi, A.; Alsawas, M.; Majzoub, A.M.; Benkhadra, R.; Seisa, M.O.; et al. Can Patients Trust Online Health Information? A Meta-Narrative Systematic Review Addressing the Quality of Health Information on the Internet. J. Gen. Intern. Med. 2019, 34, 1884–1891. [Google Scholar] [CrossRef]
- Zhang, Y.; Kim, Y. Consumers’ Evaluation of Web-Based Health Information Quality: Meta-Analysis. J. Med. Internet Res. 2022, 24, e36463. [Google Scholar] [CrossRef]
- Denniss, E.; Lindberg, R.; McNaughton, S. Quality and Accuracy of Online Nutrition-Related Information: A Systematic Review of Content Analysis Studies. Public Health Nutr. 2023, 26, 1345–1357. [Google Scholar] [CrossRef]
- Fappa, E.; Micheli, M. Content Accuracy and Readability of Dietary Advice Available on Webpages: A Systematic Review of the Evidence. J. Hum. Nutr. Diet. 2025, 38, e13395. [Google Scholar] [CrossRef]
- Charnock, D.; Shepperd, S.; Needham, G.; Gann, R. DISCERN: An Instrument for Judging the Quality of Written Consumer Health Information on Treatment Choices. J. Epidemiol. Community Health 1999, 53, 105–111. [Google Scholar] [CrossRef]
- Moult, B.; Franck, L.S.; Brady, H. Ensuring Quality Information for Patients: Development and Preliminary Validation of a New Instrument to Improve the Quality of Written Health Care Information. Health Expect. 2004, 7, 165–175. [Google Scholar] [CrossRef]
- Silberg, W.M.; Lundberg, G.D.; Musacchio, R.A. Assessing, Controlling, and Assuring the Quality of Medical Information on the Internet: Caveant Lector et Viewor—Let the Reader and Viewer Beware. JAMA 1997, 277, 1244–1245. [Google Scholar] [CrossRef]
- Robillard, J.M.; Jun, J.H.; Lai, J.A.; Feng, T.L. The QUEST for Quality Online Health Information: Validation of a Short Quantitative Tool. BMC Med. Inform. Decis. Mak. 2018, 18, 87. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Sun, Y.; Xie, B. Quality of Health Information for Consumers on the Web: A Systematic Review of Indicators, Criteria, Tools, and Evaluation Results. J. Assoc. Inf. Sci. Technol. 2015, 66, 2071–2084. [Google Scholar] [CrossRef]
- Gkouskou, K.; Markaki, A.; Vasilaki, M.; Roidis, A.; Vlastos, I. Quality of Nutritional Information on the Internet in Health and Disease. Hippokratia 2011, 15, 304–307. [Google Scholar]
- Keaver, L.; Huggins, M.D.; Chonaill, D.N.; O’Callaghan, N. Online Nutrition Information for Cancer Survivors. J. Hum. Nutr. Diet. 2022, 36, 415–433. [Google Scholar] [CrossRef] [PubMed]
- Guardiola-Wanden-Berghe, R.; Gil-Pérez, J.D.; Sanz-Valero, J.; Wanden-Berghe, C. Evaluating the Quality of Websites Relating to Diet and Eating Disorders. Health Inf. Libr. J. 2011, 28, 294–301. [Google Scholar] [CrossRef]
- Golan, R.; Ripps, S.J.; Reddy, R.; Loloi, J.; Bernstein, A.P.; Connelly, Z.M.; Golan, N.S.; Ramasamy, R. ChatGPT’s Ability to Assess Quality and Readability of Online Medical Information: Evidence From a Cross-Sectional Study. Cureus 2023, 15, e42214. [Google Scholar] [CrossRef]
- Rose, L.; Bewley, S.; Payne, M.; Colquhoun, D.; Perry, S. Using Artificial Intelligence (AI) to Assess the Prevalence of False or Misleading Health-Related Claims. R. Soc. Open Sci. 2024, 11, 240698. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Proceedings of the 34th International Conference on Neural Information Processing System, Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A Survey of Large Language Models. arXiv 2023, arXiv:2303.18223. [Google Scholar] [CrossRef]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the Opportunities and Risks of Foundation Models. Arxiv Learn. 2021, 10, 1–46. [Google Scholar] [CrossRef]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-Assisted Medical Education Using Large Language Models. PLOS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef]
- van Dis, E.A.M.; Bollen, J.; Zuidema, W.; van Rooij, R.; Bockting, C.L. ChatGPT: Five Priorities for Research. Nature 2023, 614, 224–226. [Google Scholar] [CrossRef] [PubMed]
- Phelps, N.H.; Singleton, R.K.; Zhou, B.; Heap, R.A.; Mishra, A.; Bennett, J.E.; Paciorek, C.J.; Lhoste, V.P.; Carrillo-Larco, R.M.; Stevens, G.A.; et al. Worldwide Trends in Underweight and Obesity from 1990 to 2022: A Pooled Analysis of 3663 Population-Representative Studies with 222 Million Children, Adolescents, and Adults. Lancet 2024, 403, 1027–1050. [Google Scholar] [CrossRef] [PubMed]
- Fassier, P.; Chhim, A.S.; Andreeva, V.A.; Hercberg, S.; Latino-Martel, P.; Pouchieu, C.; Touvier, M. Seeking Health- and Nutrition-Related Information on the Internet in a Large Population of French Adults: Results of the NutriNet-Santé Study. Br. J. Nutr. 2016, 115, 2039–2046. [Google Scholar] [CrossRef]
- Modave, F.; Shokar, N.K.; Peñaranda, E.; Nguyen, N. Analysis of the Accuracy of Weight Loss Information Search Engine Results on the Internet. Am. J. Public Health 2014, 104, 1971–1978. [Google Scholar] [CrossRef] [PubMed]
- Cardel, M.I.; Chavez, S.; Bian, J.; Peñaranda, E.; Miller, D.R.; Huo, T.; Modave, F. Accuracy of Weight Loss Information in Spanish Search Engine Results on the Internet. Obesity 2016, 24, 2422–2434. [Google Scholar] [CrossRef]
- Meyer, S.; Elsweiler, D.; Ludwig, B. Assessing the Quality of Weight Loss Information on the German Language Web. Mov. Nutr. Health Dis. 2020, 4, 39–52. [Google Scholar] [CrossRef]
- StatCounter Search Engine Market Share in Greece-January 2024–2025. Available online: https://gs.statcounter.com/search-engine-market-share/desktop/greece (accessed on 13 March 2025).
- StatCounter Browser Market Share in Greece-January 2024–2025. Available online: https://gs.statcounter.com/browser-market-share/all/greece (accessed on 13 March 2025).
- Zhang, Y. Consumer Health Information Searching Process in Real Life Settings. Proc. Am. Soc. Inf. Sci. Technol. 2012, 49, 1–10. [Google Scholar] [CrossRef]
- Cai, H.C.; King, L.E.; Dwyer, J.T. Using the GoogleTM Search Engine for Health Information: Is There a Problem? Case Study: Supplements for Cancer. Curr. Dev. Nutr. 2021, 5, nzab002. [Google Scholar] [CrossRef]
- Alfaro-Cruz, L.; Kaul, I.; Zhang, Y.; Shulman, R.J.; Chumpitazi, B.P. Assessment of Quality and Readability of Internet Dietary Information on Irritable Bowel Syndrome. Clin. Gastroenterol. Hepatol. 2019, 17, 566–567. [Google Scholar] [CrossRef]
- Lee, J.; Nguyen, J.; O’leary, F. Content, Quality and Accuracy of Online Nutrition Resources for the Prevention and Treatment of Dementia: A Review of Online Content. Dietetics 2022, 1, 148–163. [Google Scholar] [CrossRef]
- El Jassar, O.G.; El Jassar, I.N.; Kritsotakis, E.I. Assessment of Quality of Information Available over the Internet about Vegan Diet. Nutr. Food Sci. 2019, 49, 1142–1152. [Google Scholar] [CrossRef]
- Charnock, D. The DISCERN Handbook; Radcliffe Medical Press: London, UK, 1998; ISBN 1857753100. [Google Scholar]
- San Giorgi, M.R.M.; de Groot, O.S.D.; Dikkers, F.G. Quality and Readability Assessment of Websites Related to Recurrent Respiratory Papillomatosis. Laryngoscope 2017, 127, 2293–2297. [Google Scholar] [CrossRef] [PubMed]
- Hassapidou, M.; Vlassopoulos, A.; Kalliostra, M.; Govers, E.; Mulrooney, H.; Ells, L.; Salas, X.R.; Muscogiuri, G.; Darleska, T.H.; Busetto, L.; et al. European Association for the Study of Obesity Position Statement on Medical Nutrition Therapy for the Management of Overweight and Obesity in Adults Developed in Collaboration with the European Federation of the Associations of Dietitians. Obes. Facts 2023, 16, 11–28. [Google Scholar] [CrossRef] [PubMed]
- Ambra, R.; Canali, R.; Pastore, G.; Natella, F. COVID-19 and Diet: An Evaluation of Information Available on Internet in Italy. Acta Biomed. 2021, 92, e2021077. [Google Scholar] [CrossRef]
- Cannon, S.; Lastella, M.; Vincze, L.; Vandelanotte, C.; Hayman, M. A Review of Pregnancy Information on Nutrition, Physical Activity and Sleep Websites. Women Birth 2020, 33, 35–40. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann: Waltham, MA, USA, 2012; ISBN 9780123814791. [Google Scholar]
- Koo, T.K.; Li, M.Y. A Guideline of Selecting and Reporting Intraclass Correlation Coefficients for Reliability Research. J. Chiropr. Med. 2016, 15, 155–163. [Google Scholar] [CrossRef]
- Meng, X.; Yan, X.; Zhang, K.; Liu, D.; Cui, X.; Yang, Y.; Zhang, M.; Cao, C.; Wang, J.; Wang, X.; et al. The Application of Large Language Models in Medicine: A Scoping Review. iScience 2024, 27, 109713. [Google Scholar] [CrossRef]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large Language Models in Medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef]
- Heiberg Engel, P.J. Tacit Knowledge and Visual Expertise in Medical Diagnostic Reasoning: Implications for Medical Education. Med. Teach. 2008, 30, e184–e188. [Google Scholar] [CrossRef]
- Meskó, B.; Topol, E.J. The Imperative for Regulatory Oversight of Large Language Models (or Generative AI) in Healthcare. NPJ Digit. Med. 2023, 6, 120. [Google Scholar] [CrossRef]
- World Health Organization. Ethics and Governance of Artificial Intelligence for Health: WHO Guidance; World Health Organization: Geneva, Switzerland, 2021. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Kreft, M.; Smith, B.; Hopwood, D.; Blaauw, R. The Use of Social Media as a Source of Nutrition Information. S. Afr. J. Clin. Nutr. 2023, 36, 162–168. [Google Scholar] [CrossRef]
- Weiß, K.; König, L.M. Does the Medium Matter? Comparing the Effectiveness of Videos, Podcasts and Online Articles in Nutrition Communication. Appl. Psychol. Health Well Being 2023, 15, 669–685. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
| Scoring System | ||||
|---|---|---|---|---|
| Scoring Section | Scoring Criteria | Criterion Fully Met (5 Marks) | Criterion Partially Met (3 Marks) | Criterion Not Met (1 Mark) |
| 1. Source Credibility | 1.1 Author Qualifications | |||
| 1.2 Presence of Scientific Backing | ||||
| 1.3 Website Reliability | ||||
| 1.4 HONcode Certification | ||||
| 2. Accuracy and Scientific Validity | 2.1 Accuracy of Nutritional Claims | |||
| 2.2 Absence of Misinformation | ||||
| 2.3 Clear Explanation of Concepts | ||||
| 2.4 Balanced Presentation | ||||
| 3. Completeness and Depth | 3.1 Coverage of Key Nutritional Aspects | |||
| 3.2 Inclusion of Practical Recommendations | ||||
| 3.3 Use of Supporting Data | ||||
| 3.4 Consideration of Individual Differences | ||||
| 4. Objectivity and Absence of Bias | 4.1 Advertisement Acknowledgment | |||
| 4.2 Lack of Product Promotion | ||||
| 4.3 Avoidance of Sensationalism | ||||
| 4.4 Ethical Considerations | ||||
| 5. Usability and Readability | 5.1 Readability and Language Clarity | |||
| 5.2 Logical Organization and Structure | ||||
| 5.3 Engagement and User-Friendliness | ||||
| 5.4 Up-to-Date Information | ||||
| Information Quality Score | Media (IQR) | p |
| DISCERN applied by human (overall score) | 42.2 (36.7–52.3) | 0.528 |
| DISCERN applied by ChatGPT-4.5 (overall score) | 53.1 (32.8–64.1) | |
| ChatGPT’s custom scoring system (overall score) | 48.8 (36.3–57.5) | |
| Content Accuracy Score | Median (IQR) | |
| EASO guidelines checklist applied by human (overall score) | 16.7 (11.1–27.8) | <0.001 |
| EASO guidelines checklist applied by ChatGPT-4.5 (overall score) | 50.0 (5.6–88.9) | |
| ChatGPT’s custom scoring system (accuracy item score) | 75.0 (50.0–75.0) | |
| Post hoc Content Accuracy Score | ||
| EASO guidelines checklist applied by human vs. EASO guidelines checklist applied by ChatGPT-4.5 | <0.001 | |
| EASO guidelines checklist applied by human vs. ChatGPT’s custom scoring system (accuracy item score) | <0.001 | |
| EASO guidelines checklist applied by ChatGPT-4.5 vs. ChatGPT’s custom scoring system (accuracy item score) | <0.001 | |
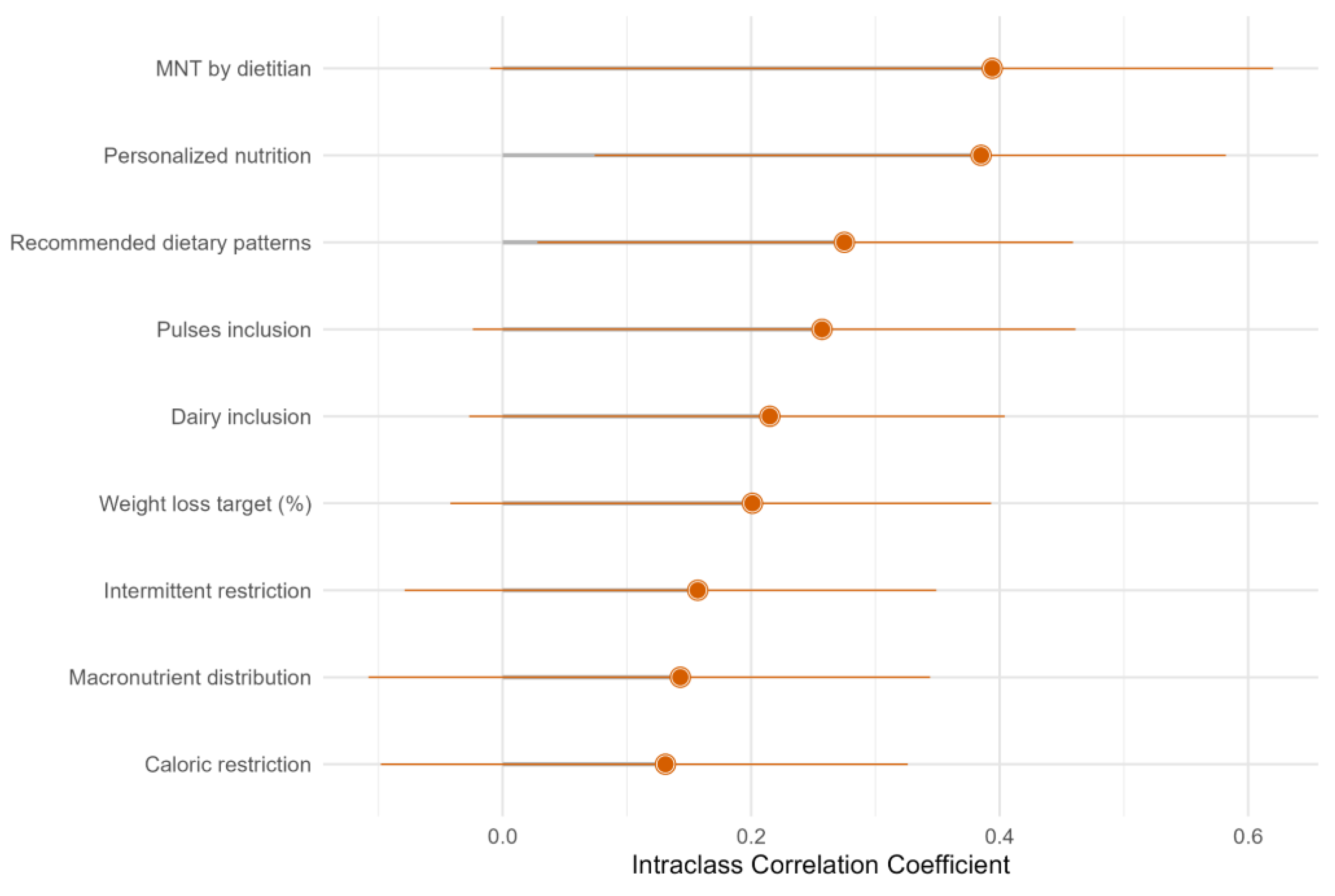
| Possible Explanation for Discrepancies Observed in Marking Between ChatGPT-4.5 and Humans | ||
|---|---|---|
| EASO Based Dietary Guideline | ChatGPT-4.5 | Human Raters |
| MNT by dietitian | ChatGPT-4.5 provided greater scores when the webpage was written by a dietitian. | Human raters provided lower scores when the webpage did not clearly propose to consult a dietitian for MNT. |
| Personalized nutrition | ChatGPT-4.5 provided greater scores when the dietary advice was more general (i.e., “try to eat breakfast”) and not specific (i.e., “try to eat this or that breakfast”) or when different guidance was provided to women than men (i.e., different portions of recommended water intake). | Human raters provided lower scores when the webpage did not clearly support personalized nutrition. |
| Recommended dietary patterns | ChatGPT-4.5 provided greater scores when the dietary advice written on the webpage conformed with a dietary pattern (i.e., it was written “eat a lot of vegetables, fruits and whole grains, low fat dairy and less meat” instead of “follow a Mediterranean Dietary pattern”). | Human raters provided lower scores when none of the recommended dietary patterns (Mediterranean, vegetarian, DASH, etc.) was clearly proposed. |
| Pulses inclusion | ChatGPT-4.5 provided greater scores when there was dietary advice written on the webpage proposing the consumption of food variety. | Human raters provided lower scores when the recommendation to include some kind of pulses in the diet was not clearly stated. |
| Dairy inclusion | ChatGPT-4.5 provided greater scores when there was dietary advice implying to consume dairy (i.e., “prefer a bowl with cereals for breakfast”; note: cereals are usually consumed with milk in a bowl for breakfast). | Human raters provided lower scores when the recommendation to include consuming dairy as part of the diet was not clearly stated. |
| Weight loss target (%) | ChatGPT-4.5 provided greater scores when the webpage promoted a slow weight loss rate (i.e., “do not hurry to lose weight”, “a healthy weight loss is 0.5 to 1.0 kg per week”). | Human raters provided lower scores when the recommendation “5–7% weight loss in 6–12 months” was not presented. |
| Intermittent or continuous calorie restriction is recommended to achieve body weight reduction | ChatGPT-4.5 provided greater scores when the dietary advice found on the webpage complied with the recommendation. | Human raters provided lower scores when there was not a clear statement of or a way to apply this recommendation. |
| Macronutrient distribution | ChatGPT-4.5 provided greater scores when the dietary advice found on the webpage contained no specific guidance regarding macronutrients intake but implied partial compliance with the recommendation of “variable macronutrient distribution ranges are recommended to achieve body weight loss”. | Human raters provided lower scores when there was not any information on macronutrient (proteins, carbohydrates, fats) distribution variety. |
| Caloric restriction | ChatGPT-4.5 provided greater scores when the dietary advice on the webpage promoted caloric restriction (i.e., “leave food on your plate when you are feeling full”, “eat more fruit and vegetables”, “avoid sodas and juices containing added sugar” | Human raters provided lower scores when the recommendation that a caloric restriction is needed for weight loss was not clearly stated. |
| DISCERN–Human N (%) | DISCERN–ChatGPT-4.5 N (%) | ChatGPT’s Custom Scoring System | p * | |
|---|---|---|---|---|
| Very Poor | 0 (0%) | 26 (14.7%) | n/a | <0.001 |
| Poor | 35 (19.9%) | 48 (27.1%) | 45 (25.4%) | |
| Fair | 102 (58.0%) | 30 (16.9%) | 111 (62.7%) | |
| Good | 34 (19.3%) | 34 (19.2%) | 19 (10.7%) | |
| Excellent | 5 (2.8%) | 39 (22.0%) | 2 (1.1%) | |
| Post hoc pairwise comparisons | ||||
| DISCERN instrument applied by human vs. applied by ChatGPT-4.5 | <0.001 | |||
| DISCERN instrument applied by human vs. ChatGPT’s custom scoring system | 0.002 | |||
| DISCERN instrument applied by ChatGPT-4.5 vs. ChatGPT’s custom scoring system | <0.001 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fappa, E.; Micheli, M.; Panaretos, D.; Skordis, M.; Tsirpanli, P.; Panoutsopoulos, G.I. Human vs. AI: Assessing the Quality of Weight Loss Dietary Information Published on the Web. Information 2025, 16, 526. https://doi.org/10.3390/info16070526
Fappa E, Micheli M, Panaretos D, Skordis M, Tsirpanli P, Panoutsopoulos GI. Human vs. AI: Assessing the Quality of Weight Loss Dietary Information Published on the Web. Information. 2025; 16(7):526. https://doi.org/10.3390/info16070526
Chicago/Turabian StyleFappa, Evaggelia, Mary Micheli, Dimitris Panaretos, Marios Skordis, Petroula Tsirpanli, and George I. Panoutsopoulos. 2025. "Human vs. AI: Assessing the Quality of Weight Loss Dietary Information Published on the Web" Information 16, no. 7: 526. https://doi.org/10.3390/info16070526
APA StyleFappa, E., Micheli, M., Panaretos, D., Skordis, M., Tsirpanli, P., & Panoutsopoulos, G. I. (2025). Human vs. AI: Assessing the Quality of Weight Loss Dietary Information Published on the Web. Information, 16(7), 526. https://doi.org/10.3390/info16070526