2. Materials and Methods
As mentioned earlier, this paper presents a new methodology for generating jazz chord sequences using a statistical approach. This section is divided into three main parts: (1) the first part introduces the corpus used to train our model, a comprehensive dataset containing the harmonic structures of over one thousand jazz standards; (2) the second part presents the statistical calculations; and (3) the third and final part presents a detailed explanation of the new method for generating chord sequences.
2.1. The Jazz Standards Corpus
Next to classical music, jazz is perhaps one of the most prolific music genres. Born from the confluence of African rhythms, European harmonies, and American blues, jazz emerged in the late 19th and early 20th centuries as a musical form unlike any other.
At its inception, jazz was an oral tradition, passed down through generations of musicians via jam sessions, performances, and late-night collaborations. However, as jazz became increasingly complex and sophisticated, a need arose for a standardized method of sharing its repertoire.
A lead sheet is a simplified musical score commonly used in jazz. It typically consists of two main elements: melody notation and chord symbols, which indicate the underlying harmonic structure of the music. Lead sheets are prized for their simplicity and versatility, making them ideal for improvisation and spontaneous collaboration among musicians.
In the early 1970s, a group of musicians in Boston compiled a collection of lead sheets of jazz standards and originals. These clandestine collections, often referred to as “fake books,” became essential tools for jazz musicians, providing a common language through which to interpret and perform the vast repertoire of the genre. The Real Book was first published in 1975 and became an indispensable companion for jazz musicians around the world.
More recently, iReal Pro (version 2025.2), a mobile app and software program designed for musicians, particularly those who play jazz and other improvisational styles, was launched. The app and its associated forums serve as a collaborative platform for musicians to publicly share, among other things, the harmonic structure of jazz standards in a format similar to a lead sheet. The corpus of 1382 standards used in this work can be found at iReal (
https://irealb.com/forums/ (accessed on 14 June 2025)).
2.2. Probabilistic Analysis: Training the Model
The probabilistic analysis and training of our model constitute a fundamental aspect of our generative approach to chord sequence generation. This section presents in detail all the aspects that have been the subject of analysis, namely,
The probabilities of the 24 possible central tonal keys of the song (12 major keys and 12 minor keys).
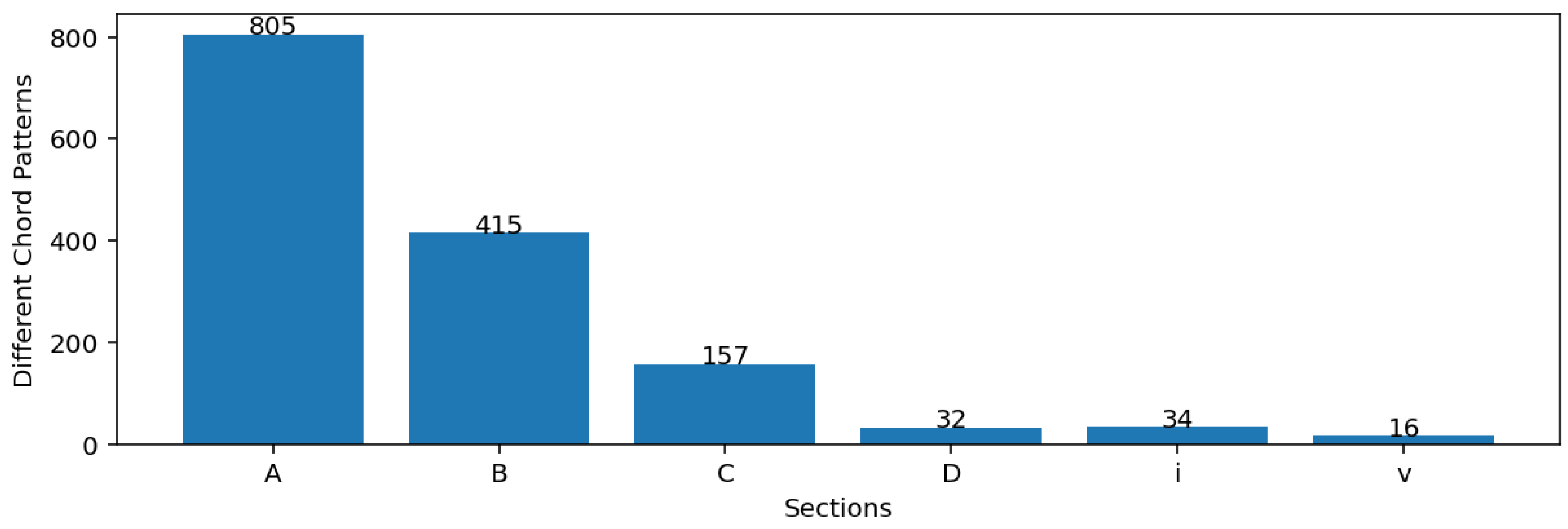
The probabilities of all existing section structure forms in the corpus.
The probabilities of all existing section chord patterns in the corpus.
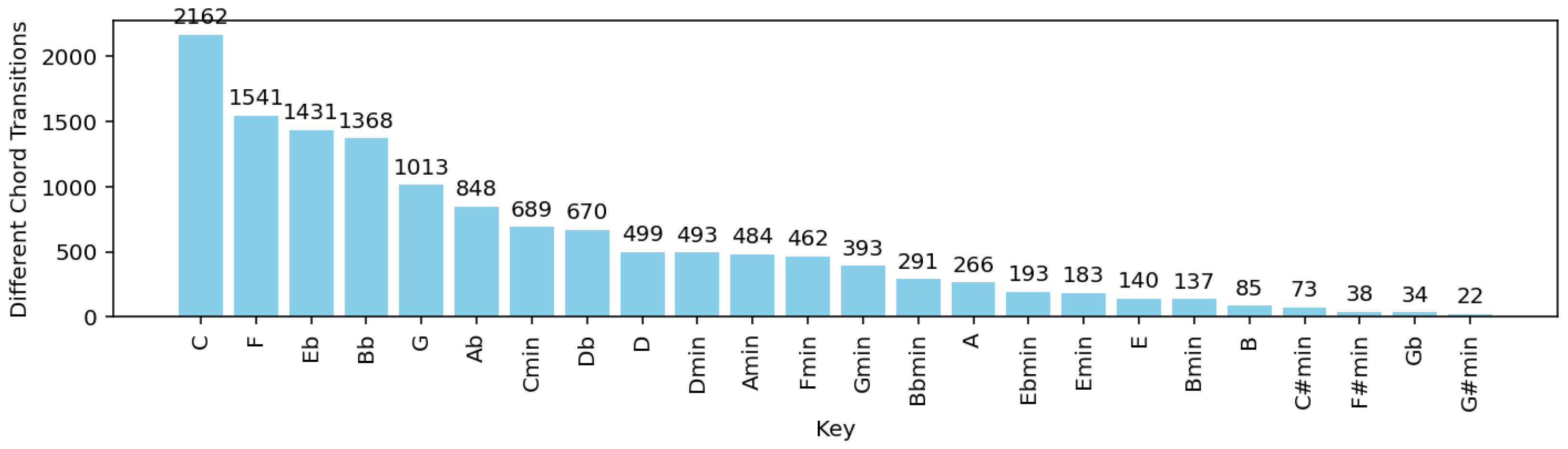
The probabilities of all chord transitions in each of the 24 tonal keys.
The data resulting from this probabilistic analysis will be instrumental for the implementation of the core chord sequence generation method.
2.2.6. Modulation Between Sections
The corpus we worked with provides only the global key of each song, without any annotation of the key used in individual sections. This limitation prevented us from adopting a corpus-informed statistical approach to model key modulations between sections, such as estimating transition probabilities from observed section-level modulations.
Knowing that modulations to the dominant, subdominant, or relative key are common in tonal music due to their closeness to the original key in the circle of fifths, we adopted a key proximity-based approach, assigning higher modulation probabilities to keys that are closer to the original key. While this approach is not directly derived from corpus data, it provides a realistic and musically grounded strategy for generating plausible modulations.
Let
be a mapping of each of the 12 major and 12 minor keys to consecutive positions around the circle of fifths as presented in
Table 6.
We define the distance between a candidate key
k and the current key
as follows:
This ensures that always reflects the minimal number of steps between two keys on the circle of fifths, regardless of direction (clockwise or counterclockwise).
Based on this distance, we model the probability of modulating to key
k using an exponential decay function:
To ensure a valid probability distribution over all candidate keys, we normalize the function:
where the sum is taken over all possible modulation targets
. This formulation gives higher probabilities to modulations toward keys closer to the current key, effectively favoring common modulations like to the dominant, subdominant, or relative, while still allowing for rarer modulations with lower probability, leaving room for exploratory compositions.
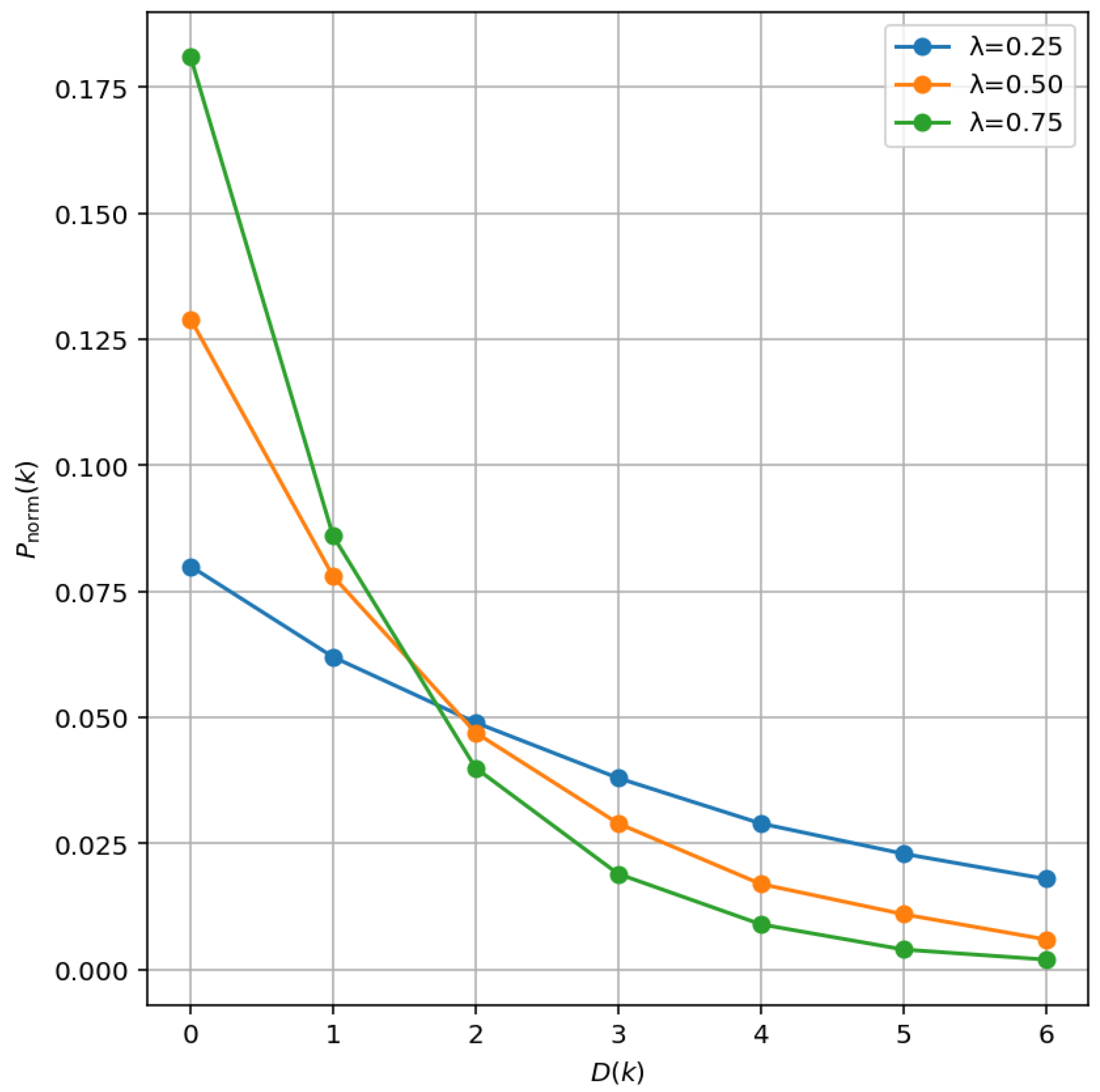
Figure 4 illustrates how the decay function behaves for different values of
, while
Figure 5 presents an example centered on
C major as the current key. In this example, the model appropriately favors modulation to
Amin (the relative minor),
G (the dominant), and
F (the subdominant). The same pattern applies to any other key, with the modulation probabilities centered accordingly.
Selecting a value of between 0.25 and 0.75 effectively emphasizes the most harmonically plausible modulations, while still allowing for transitions to more distant keys—even those at the maximal circle-of-fifths distance . This balance enables the system to prioritize musically related modulations without being overly restrictive, thereby preserving modulation diversity.
2.3. Generate the Chord Progression
While it is entirely possible to generate independent chord sequences outside the context of a song, this section introduces a straightforward methodology for generating chord sequences for a structured, full-length song. After training our generative model as described in
Section 2.2, we present the core algorithm of our generative methodology in Algorithm 1.
It is important to distinguish between chord transitions (i.e., bigrams) and chord progressions (i.e., full sequences). Our generative method employs a first-order Markov model to sample chord-to-chord transitions based on empirical probabilities derived from the dataset. While these bigrams are observed in the training corpus, the complete chord sequences generated by our model are not directly sampled from the data. Instead, they are constructed by stochastically chaining transitions, enabling the system to explore novel combinations of known elements. With this approach, even though all transitions are grounded in the dataset, it is both possible—and very likely—for chord progressions to emerge that do not exist in the original corpus, which is precisely our goal. This effect is not limited to short sequences; if it occurs with shorter progressions, it naturally propagates and becomes increasingly likely in longer progressions, where the combinatorial possibilities expand significantly.
The algorithm works equally well for both randomly chosen and explicitly chosen keys and song structures (see lines 1 to 6 of Algorithm 1). After that, the algorithm begins by iterating over S, which represents the song structure, and for each section label section in S, it generates a chord pattern P and the first chord of the section using the key k. The first chord of the section is then added to the array of chords C. Subsequently, the algorithm iterates over the string representing the chord pattern P and, taking into account the origin chords and the key, generates new chords that are added to the final array of chords C.
Algorithm 1 was developed to generate the entire harmony for a full song with several sections, including potential key changes between sections. However, the algorithm can be adapted and simplified to generate a single chord sequence in a given key (random or not). To achieve this, the section processing can be omitted, following only lines 9 to 19 of the algorithm.
The time complexity of Algorithm 1 can be analyzed as , where represents the number of sections in the structure S, is the average size of the patterns generated for each section, and N is the average number of iterations in the innermost loop, determined by the pattern values. The algorithm iterates through sections, and for each section, it processes a pattern of size . For each element in the pattern, the innermost loop iterates N times to generate chords. Thus, the overall time complexity reflects the combined contribution of these nested iterations.
The space complexity is dominated by the storage requirements for the chord progression array
C, which grows proportionally to the total number of chords generated. This depends on
,
, and
N, leading to a space complexity of
. Temporary variables and probabilistic data structures used for chord generation contribute only a constant
space overhead. As a result, both the time and space complexities are proportional to the total number of chords generated by the algorithm.
| Algorithm 1 Generating the chord progression of a structured song |
- Require:
A key k and a structure S - Ensure:
An array of chords C - 1:
if k is null then - 2:
- 3:
end if - 4:
if S is null then - 5:
- 6:
end if - 7:
for to do - 8:
- 9:
- 10:
- 11:
Add to C - 12:
for to do - 13:
- 14:
for to n do - 15:
- 16:
Add to C - 17:
- 18:
end for - 19:
end for - 20:
- 21:
end for - 22:
return C
|
- 1
The starting key is stochastically picked following the probabilities presented in
Table 1.
- 2
The section structure of the song is generated based on the probabilities presented in
Table 2.
- 3
The chord patterns can be randomly generated using the probabilistic analysis in
Table 3.
- 4
The first chord of each section is chosen randomly based on the probabilistic analysis presented in
Section 2.2.4.
- 5
The destination chord is chosen randomly based on the probabilities presented in
Section 2.2.5.
- 6
The stochastic key modulation between sections is presented in
Section 2.2.6.
3. Results and Discussion
Evaluating a generative method is a critical step in validating its ability to replicate or innovate within the constraints of the domain it seeks to emulate. In the context of music, and particularly generative music systems, this evaluation becomes even more essential due to the inherently subjective nature of artistic and aesthetic judgments. Unlike purely objective domains, the quality of music is often assessed through individual or cultural preferences, making it difficult to establish universal benchmarks for evaluation. To mitigate this subjectivity, statistical evaluation provides a robust, quantitative framework for comparing generated outputs to known datasets, enabling a more rigorous and replicable assessment of a model’s performance.
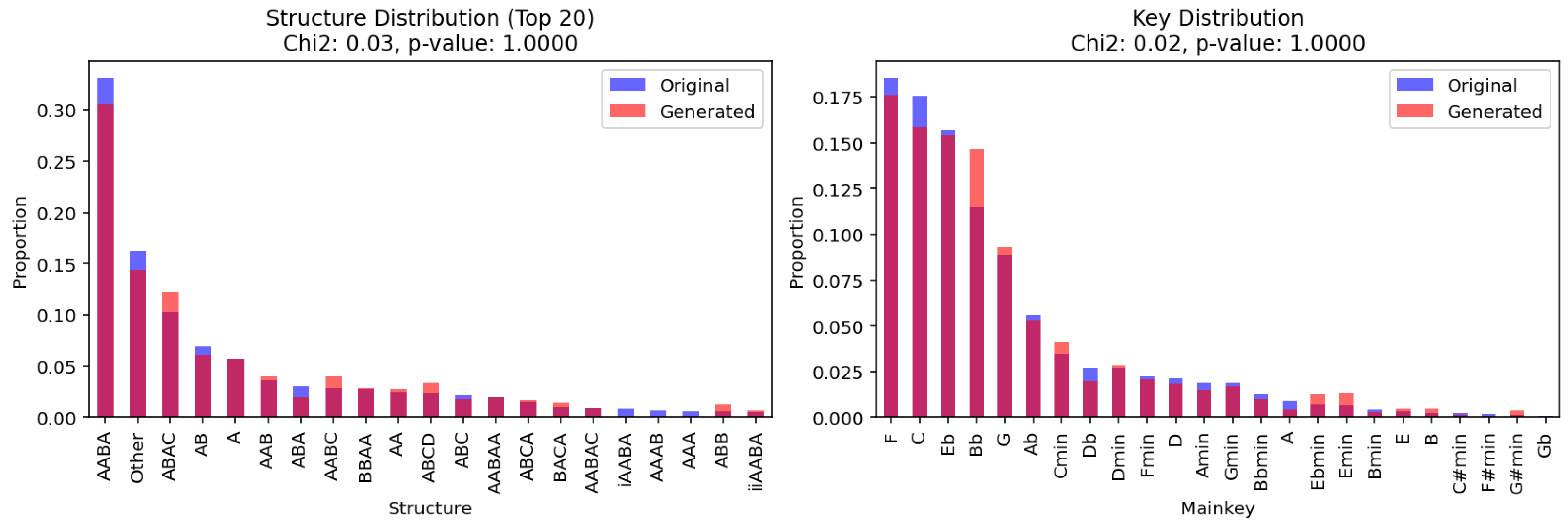
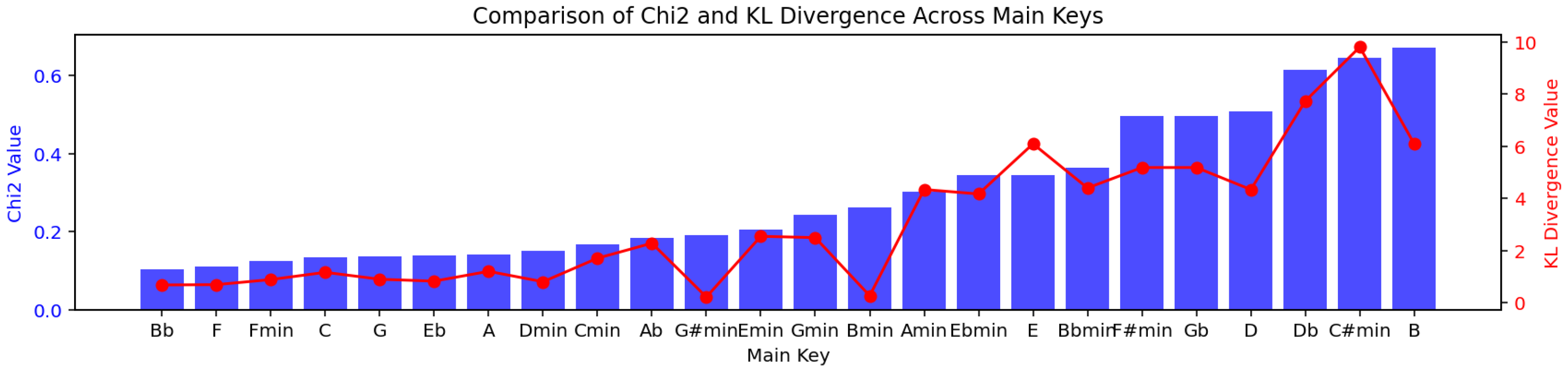
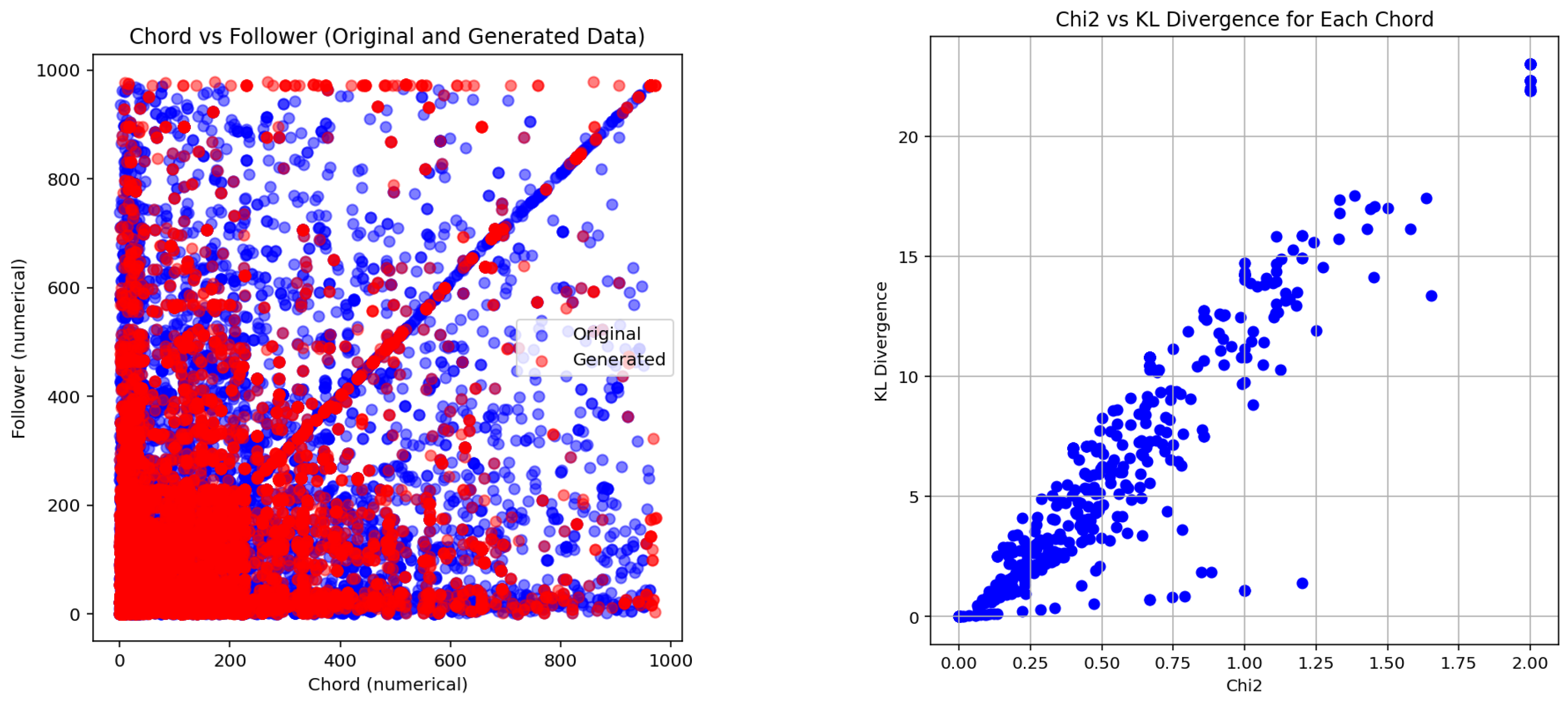
In this study, the generative method was evaluated using a dataset comprising 1382 harmonies from jazz standards, serving as the “original” dataset. This was compared against a corresponding “generated” dataset containing 1382 harmonies synthesized by our model. The synthesized dataset took less than 7 s to generate on an Intel i7 consumer laptop.
To facilitate a meaningful comparison, both datasets were decomposed into bigrams of chord–follower pairs, capturing the fundamental transitions between chords. These bigrams allowed for a granular analysis of the relationships and dependencies between chords, providing insights into the model’s ability to replicate the structure and stylistic nuances of the original dataset. The statistical evaluation, performed through metrics such as Chi-squared and Kullback–Leibler divergence, ensured that the generative method was assessed not only for surface-level similarity but also for its deeper alignment with the probabilistic and structural patterns of the original data. This approach bridges the gap between the subjective appreciation of generated music and the objective criteria needed for scientific validation.
One of the key challenges in evaluating our proposed method is the lack of directly comparable existing work. To the best of our knowledge, previous studies on harmony generation primarily focus on melody harmonization, where a given melody is harmonized with appropriate chord progressions. In contrast, our approach generates chord progressions independently, without requiring a predefined melody, making it particularly suitable for applications such as improvisation and exploratory composition. Due to this fundamental difference, there is no established benchmark or prior work that directly addresses the same problem formulation. As a result, we propose our method as a first benchmark for this specific task, paving the way for future research in this direction.
4. Conclusions
This paper presents a novel statistical approach to generating jazz chord sequences that extends beyond traditional jazz progressions. By leveraging a comprehensive corpus of 1382 jazz standards, the proposed method integrates key information, song structure, and chord sequences to produce harmonically rich and contextually coherent progressions. This approach not only ensures alignment with the stylistic essence of jazz but also introduces a degree of unpredictability, fostering the creation of innovative and inspiring harmonic pathways.
The primary advantages of this method include its ability to generate stylistically authentic yet novel harmonic progressions, striking a balance between adherence to established jazz conventions and creative exploration. The approach offers a systematic and scalable means of analyzing and synthesizing jazz harmony, making it a valuable tool for both music analysis and generative composition. Additionally, it facilitates the discovery of new harmonic structures that could inspire composers, improvisers, and educators alike.
While our method incorporates well-known statistical tools such as first-order Markov models, we emphasize that the overall generative framework introduced in this work is novel. This includes not only the use of a section chord pattern—a structural representation that defines the number of chords per bar over a fixed-length segment—but also the combination of structural modeling, harmonic transition probabilities, and stylistic constraints to guide the generation of full chord progressions. To the best of our knowledge, this probabilistic integrated approach to jazz chord progression generation has not been previously proposed.
The evaluation of the generated dataset highlights the method’s ability to closely align with the statistical characteristics of the original corpus across multiple analytical parameters. This suggests that the approach successfully balances adherence to established jazz conventions while enabling the exploration of novel harmonic possibilities. While the generated results demonstrate significant promise, the findings also reveal opportunities for further refinement, particularly in enhancing the diversity and complexity of harmonic structures.
Despite these advantages, the proposed method has certain limitations. While the statistical framework ensures coherence with established jazz conventions, it does not explicitly model voice leading, instrumentation, or phrasing—crucial elements of jazz performance. Thus, while quantitative evaluation confirms statistical alignment with the corpus, a more comprehensive qualitative assessment involving expert musicians is needed to fully understand the aesthetic and practical implications of the generated progressions.
Future work could focus on expanding the generative framework to incorporate temporal dynamics, inter-sectional relationships, and real-time adaptability, further enriching the creative potential of the system. Additionally, qualitative evaluations involving expert musicians and listeners could provide deeper insights into the aesthetic and practical applications of the generated progressions in modern jazz compositions. This research lays the groundwork for a broader exploration of statistical methods in music generation, opening new avenues for creativity in jazz and beyond.







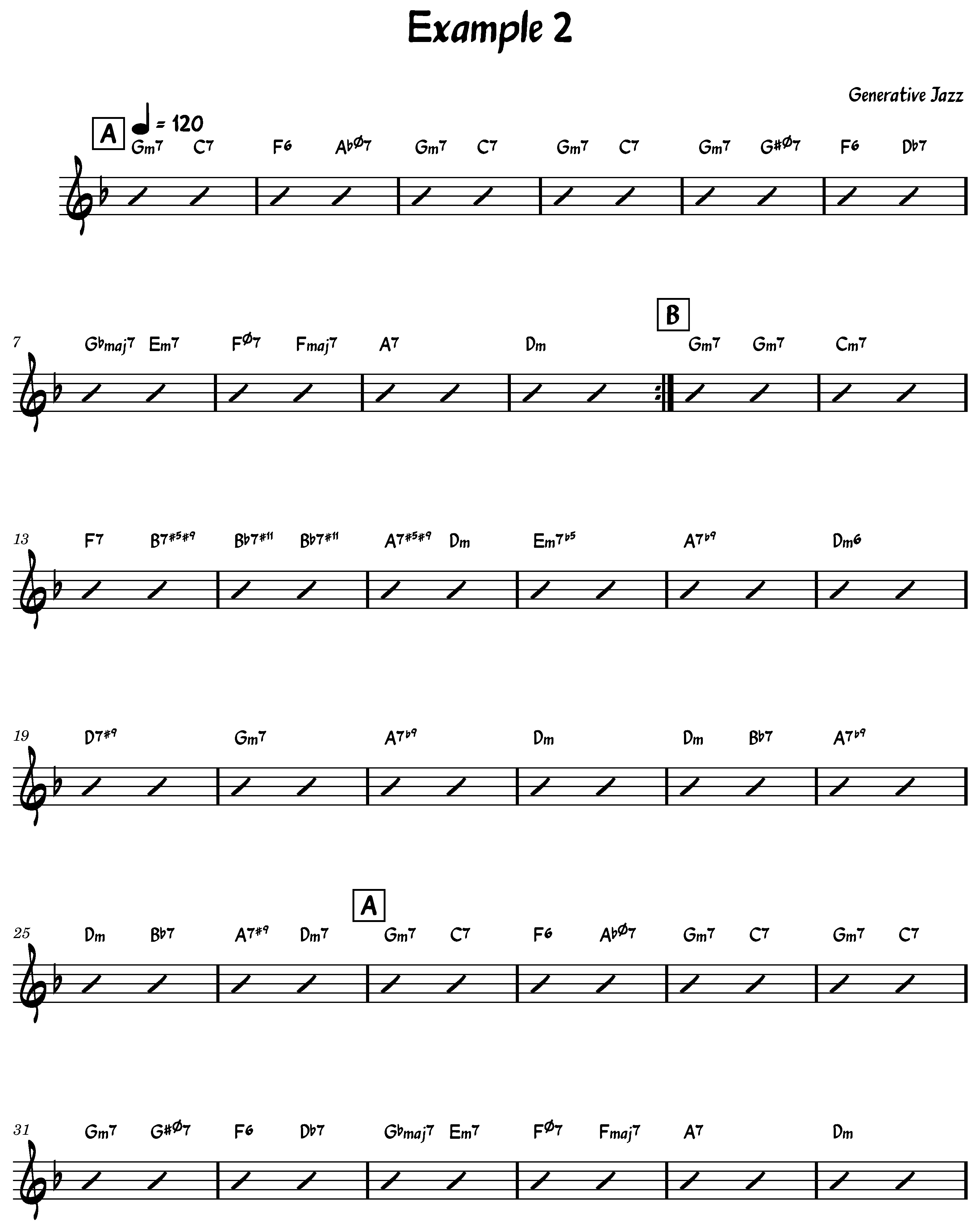
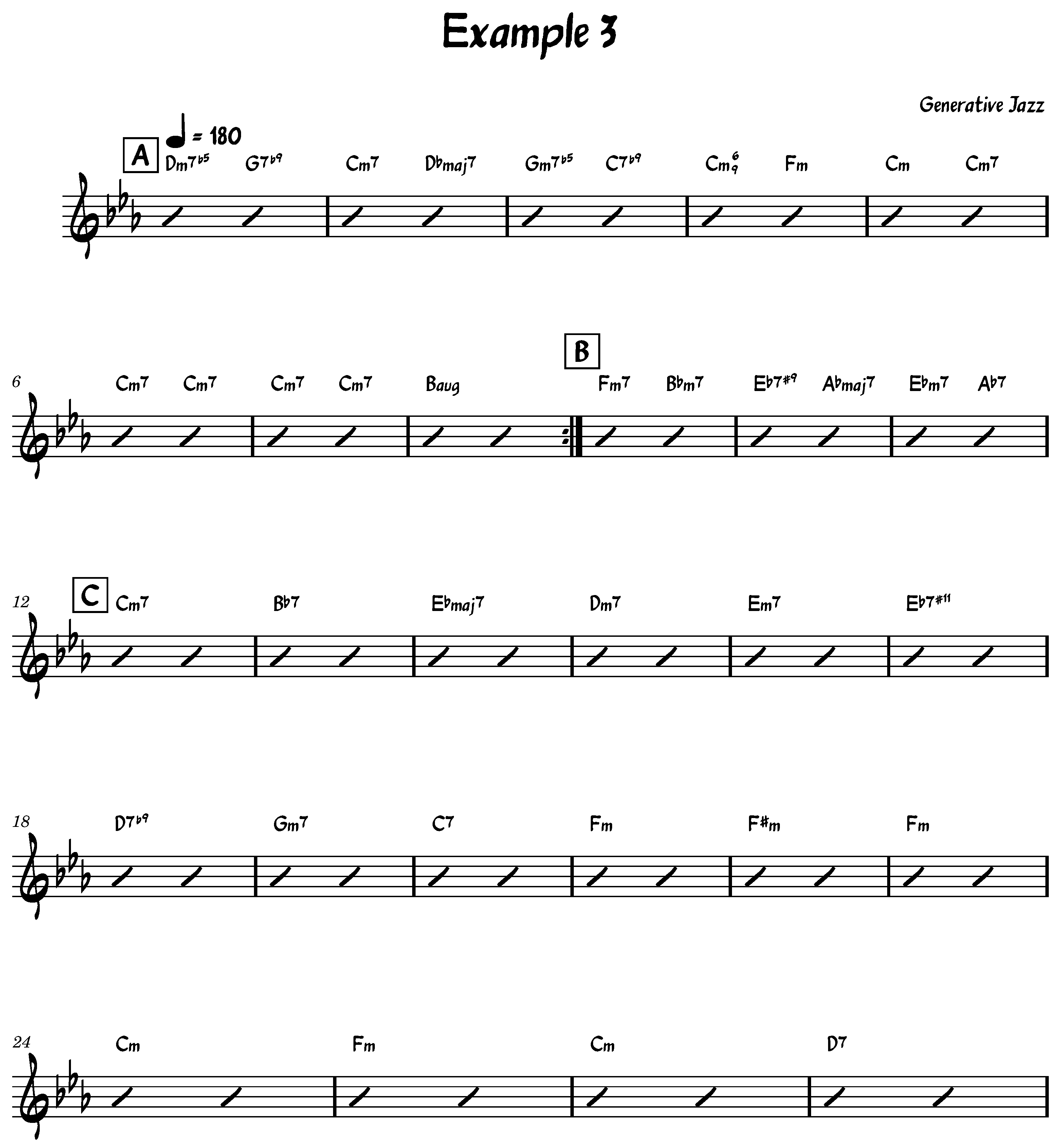
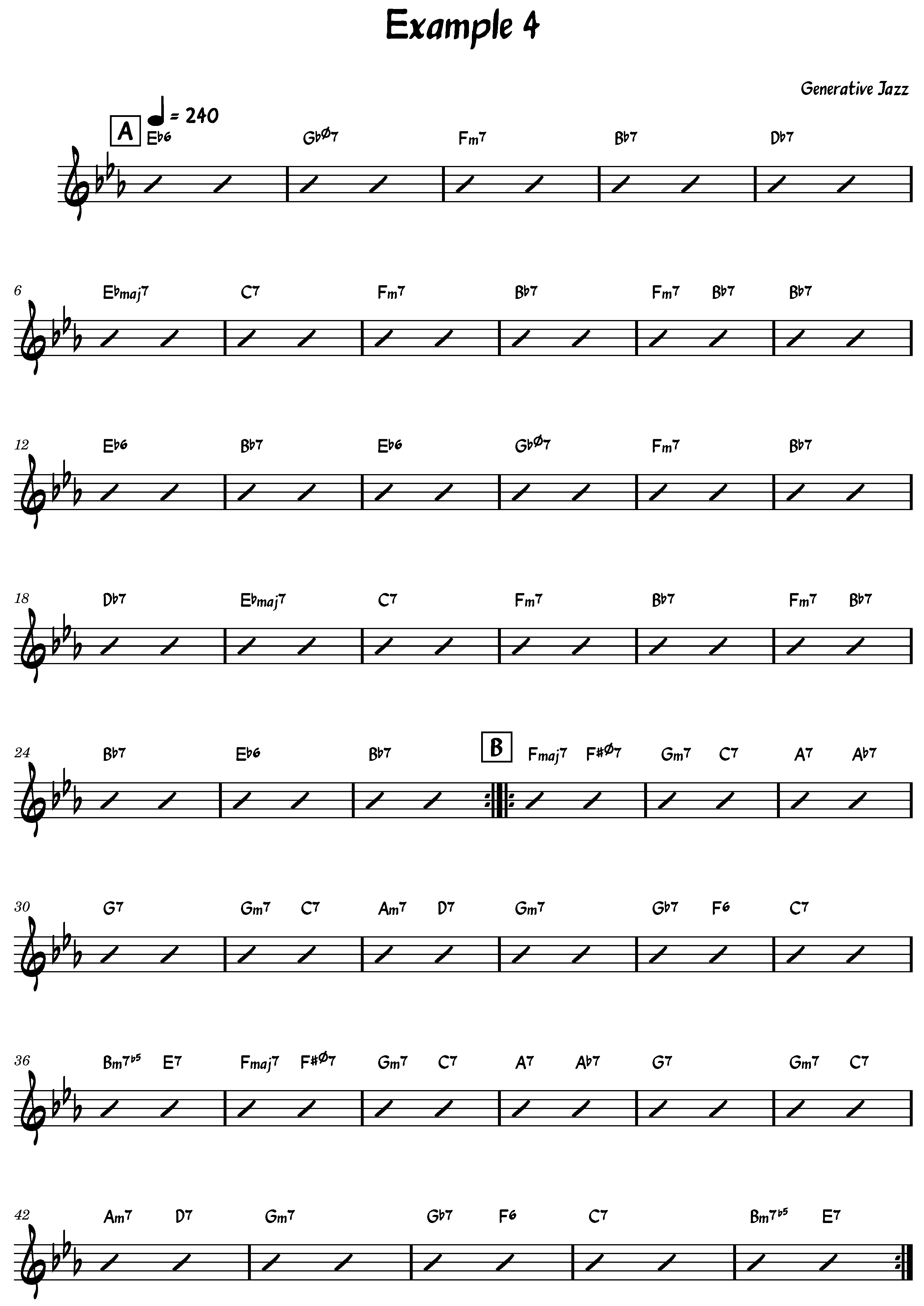
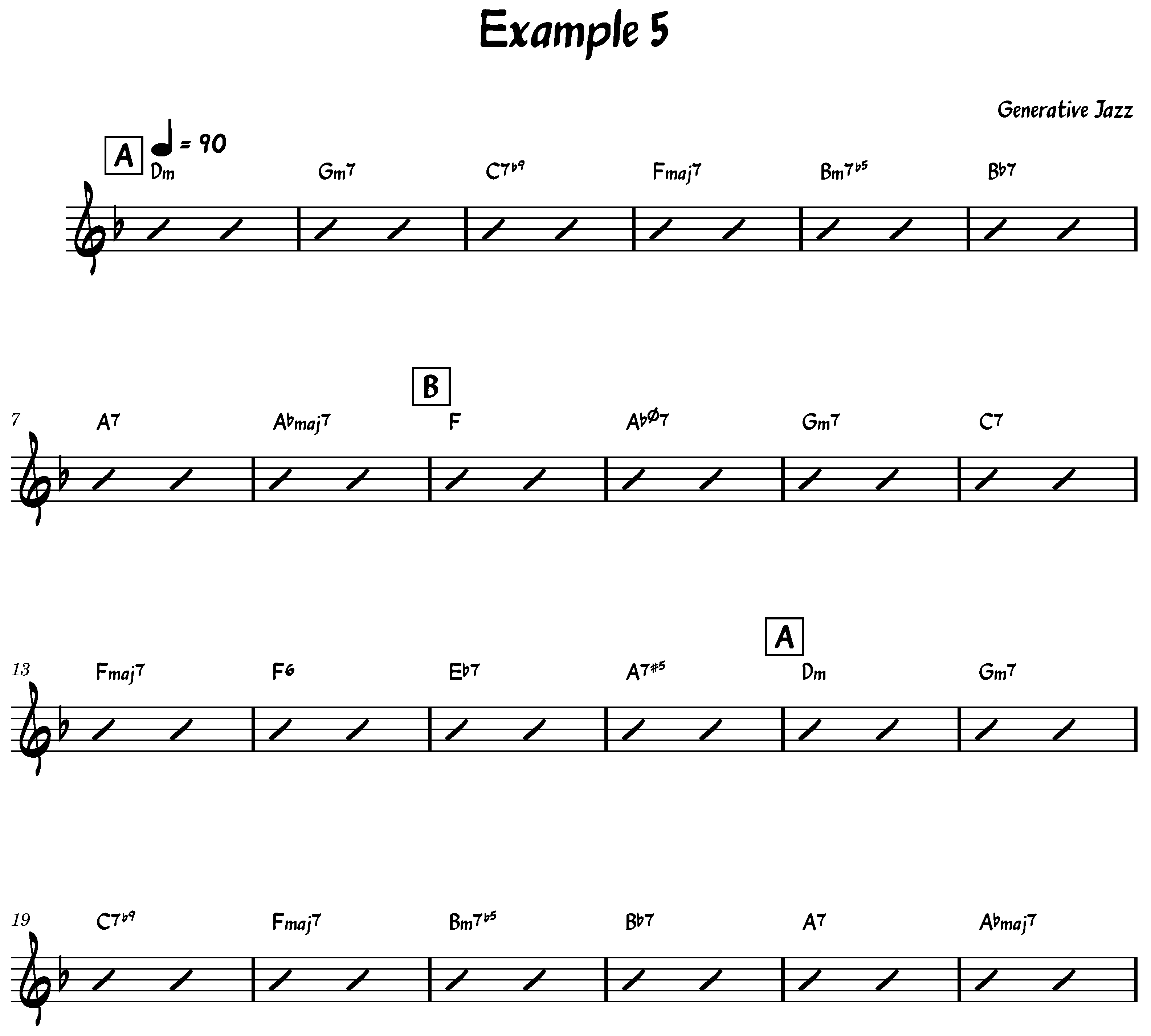




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}