1. Introduction
Aviation safety has made tremendous strides through technological advancements, yet the human element remains a crucial vulnerability in the cockpit. The striking statistic that more than 75% of pilot errors stem from perceptual failures [
1] reveals an uncomfortable truth: even highly trained professionals can experience dangerous lapses in attention. These lapses do not occur randomly but fall into distinct patterns that have been identified through a careful analysis of incident data.
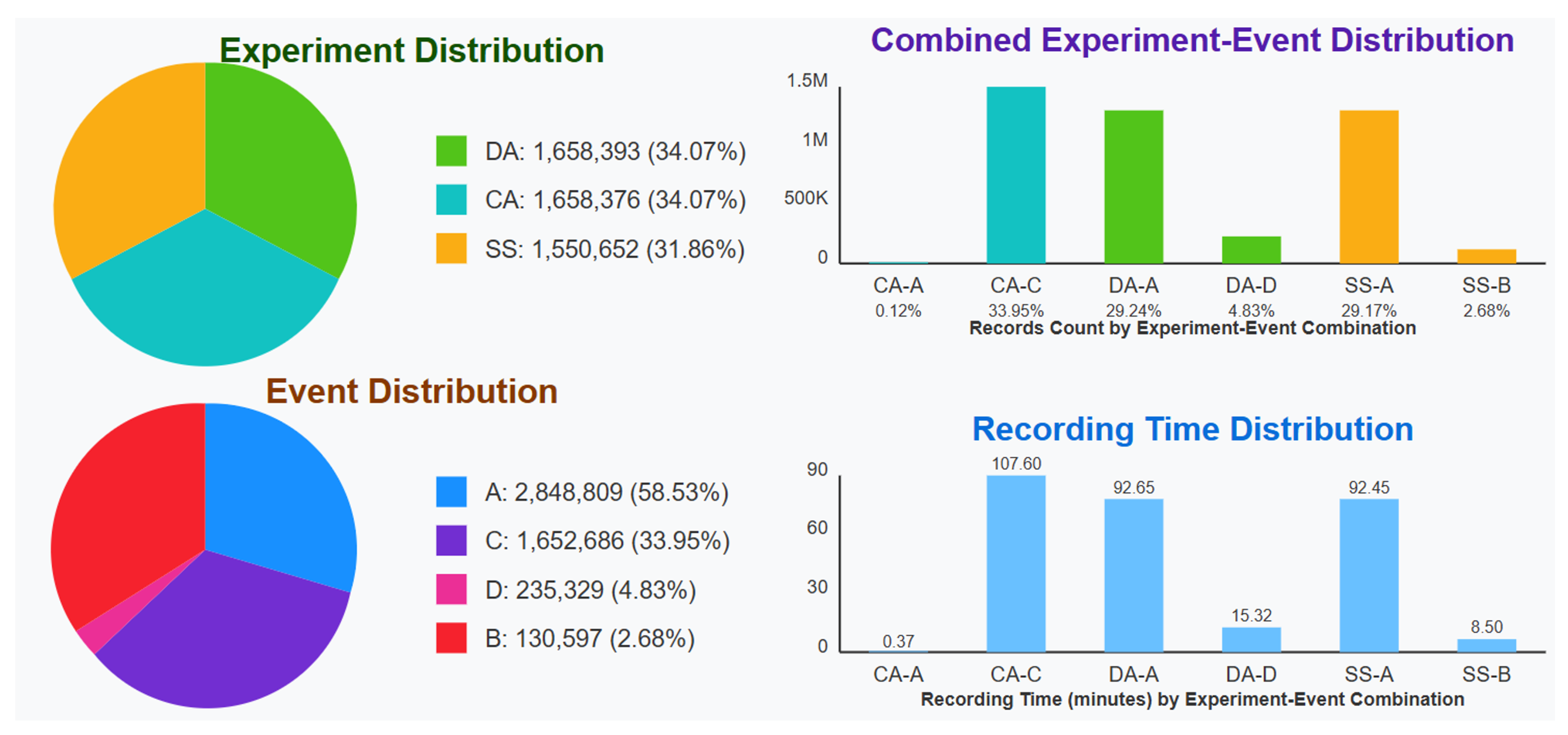
According to data analyzed by the International Air Transport Association (IATA), there were 45 plane crashes caused by pilots losing control of the aircraft, resulting in 1645 fatalities between 2012 and 2021 [
2,
3]. More alarmingly, when examining the 18 aircraft accidents investigated by the Commercial Aviation Safety Team (CAST), the discovery that attention deficiencies were involved in 16 of these incidents [
4] pointed researchers toward three specific attention-related pilot performance deficiencies (APPD) that demanded deeper investigation.
Channelized attention (CA) represents a particularly insidious threat, as pilots become fixated on a single task or instrument while neglecting other critical flight information. Diverted attention (DA) emerges when pilots attempt to process too many competing tasks simultaneously, resulting in the incomplete processing of flight-critical information. Perhaps most dangerous is the startle/surprise (SS) state, which produces a cognitive paralysis during critical moments when immediate action is required. Together, these three states—CA, DA, and SS—represent the most dangerous attention-related conditions that precede loss of aircraft control [
5,
6,
7].
The identification of these three distinct attention states created a compelling research question: could these states be detected before they lead to dangerous situations? This is where electroencephalography (EEG) enters the picture as a promising solution. EEG offers unique capabilities to detect transient alterations in brain activity that may indicate attention deficits before they manifest as observable behavior. By monitoring brain activity patterns, researchers hope to identify the neural signatures of CA, DA, and SS states as they emerge, potentially enabling interventions before critical errors occur. However, the path forward is not simple—EEG signals are notorious for collecting artifacts from environmental factors and physiological phenomena, creating significant challenges for developing reliable machine learning models [
8,
9].
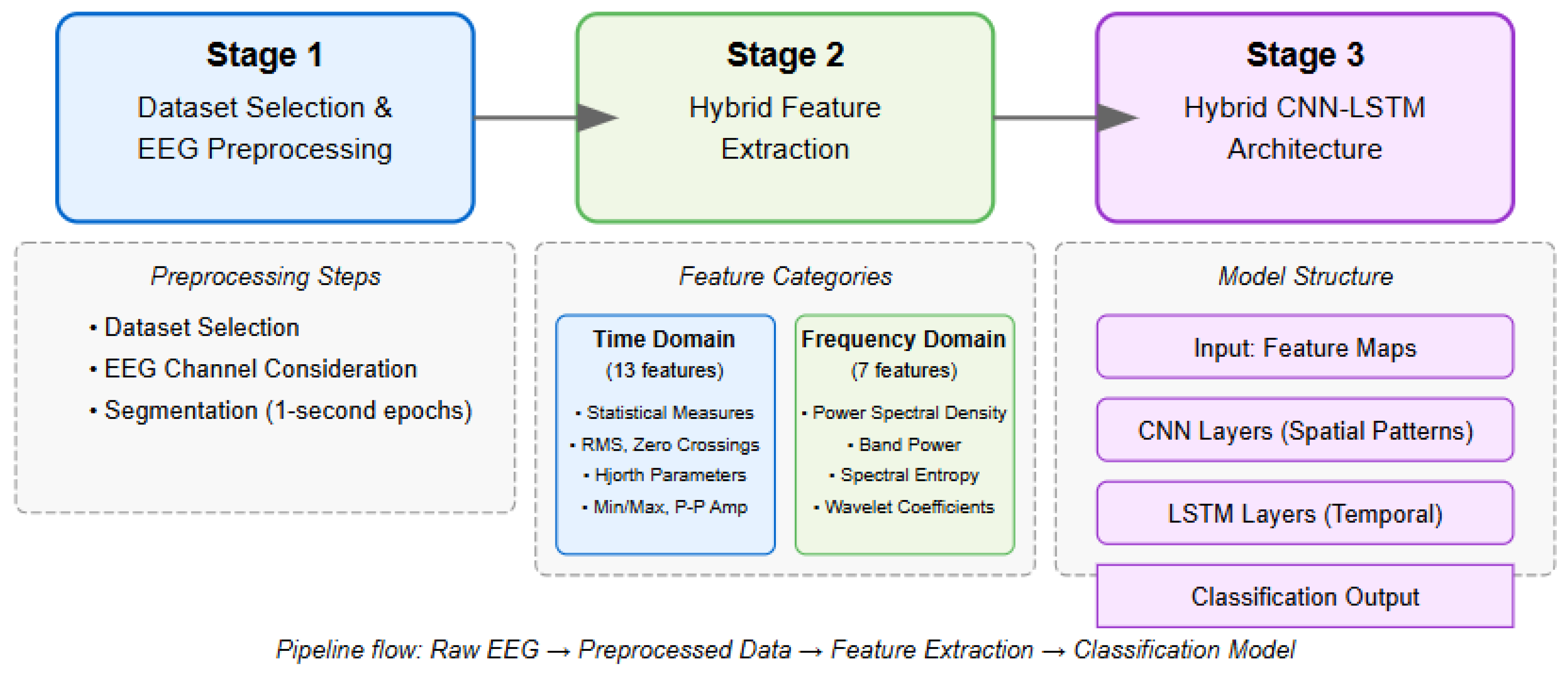
To address these limitations, we propose a hybrid feature model combined with a CNN–LSTM architecture for the multiclass classification of all critical pilot mental states. Our approach deliberately combines manually extracted temporal- and frequency-domain features with the pattern recognition capabilities of deep learning, leveraging complementary information. The learning occurs in two stages: first through our carefully engineered feature pool that explicitly captures known EEG characteristics, and then through a hybrid CNN–LSTM architecture that identifies higher-level patterns from these features.
Our comprehensive three-stage approach begins with meticulous dataset selection and preprocessing, where raw EEG signals are prepared and segmented into one-second epochs to capture complete neurophysiological events while ensuring sufficient frequency resolution. The second stage extracts a hybrid feature pool, combining 13 time-domain features (such as statistical moments, RMS, and Hjorth parameters) with 7 frequency-domain features (including spectral power, entropy, and wavelet coefficients) to fully characterize both temporal dynamics and spectral properties of brain activity. The final stage implements our hybrid CNN–LSTM architecture, which combines the strengths of two complementary neural network approaches. The CNN component excels at detecting local spatial patterns within the feature maps, functioning as a hierarchical feature detector that can identify key discriminative patterns while being relatively invariant to their exact position in the input. Meanwhile, the LSTM component addresses the critical temporal dimension of EEG data, modeling sequential dependencies and capturing how patterns of brain activity evolve over time—a crucial aspect for distinguishing between different attention states that may share similar instantaneous characteristics but differ in their temporal dynamics.
The primary contributions of this research are as follows:
The development of a novel hybrid feature-extraction approach that combines complementary temporal- and frequency-domain features, creating a comprehensive representation of EEG signals that captures the complex neural signatures of critical pilot attention states (CA, DA, and SS);
The design and implementation of a specialized CNN–LSTM architecture that leverages the strengths of both convolutional neural networks for spatial pattern recognition and long short-term memory networks for temporal dependency modeling, resulting in superior classification performance, even in the presence of noise and artifacts that are typical in real-world aviation environments.
Our proposed approach is validated using a publicly available dataset from Kaggle, released under the name ‘Reducing Commercial Aviation Fatalities’ [
10]. We have rigorously analyzed the capabilities of our proposed approach under various noisy and robust conditions and compared it extensively with various state-of-the-art approaches. Our method exhibits superior performance.
2. Related Works
The monitoring of pilot mental states and workload has emerged as a critical research area in aviation safety, with various approaches being developed to detect attention deficits and cognitive impairments before they lead to critical incidents. This comprehensive review examines existing methodologies, ranging from EEG-based approaches to alternative sensing modalities, highlighting their contributions, limitations, and relative standing in the field.
The EEG-based analysis of pilot mental states has evolved significantly from conventional preprocessing to sophisticated automated approaches. Traditional techniques included filtering methodologies, as demonstrated by Roza et al. [
11], who used a band-pass filter at 12–30 Hz to isolate beta rhythm activity, and Han et al. [
12], who implemented filtering at 0.1–50 Hz before applying Independent Component Analysis (ICA). Despite their widespread adoption, these methods showed inherent limitations, with Alreshidi et al. [
13] finding no significant performance improvement when comparing filtered data to ICA-processed data. This recognition led to the emergence of automated preprocessing methods, with Autoreject [
14] being particularly notable for its ability to automatically identify and repair erroneous EEG segments using Bayesian hyperparameter optimization and cross-validation, as successfully implemented by Bonassi et al. [
15] and Pousson et al. [
16]. These advances in preprocessing have focused on improving signal quality while preserving critical neurophysiological information, addressing the inherent challenges of artifact contamination in real-world aviation environments.
Feature-extraction techniques have undergone substantial evolution from basic statistical features [
17,
18] to sophisticated approaches targeting specific frequency bands and their neurophysiological correlates. Wu et al. [
19] employed the power spectrum curve area representation of decomposed brain waves through wavelet packet transform, while Binias et al. [
20] extracted logarithmic band-power features using common spatial pattern filtering. Recent research has particularly emphasized the importance of beta-wave activity in pilot workload assessment. Li et al. [
21] conducted a comprehensive investigation of EEG characteristics during turning phases, focusing specifically on the energy ratio of beta waves and Shannon entropy. Their findings revealed significant changes in beta wave energy and Shannon entropy during left and right turns compared to cruising phases, with psychological workload demonstrably increasing during these critical flight maneuvers. The study achieved an impressive classification accuracy of 98.92% for training and 93.67% for testing using support vector machines, establishing beta-wave analysis as a reliable indicator of pilot cognitive state changes.
Building upon this foundation, Feng et al. [
22] further explored the sensitivity of beta-wave sub-bands, specifically 16–20 Hz, 20–24 Hz, and 24–30 Hz, for situation awareness classification. Their comprehensive analysis of 48 participants revealed that relative power in these beta sub-bands was significantly higher in high-situation-awareness groups compared to low-situation-awareness groups across central, central–parietal, and parietal brain regions. Using general supervised machine learning classifiers, they achieved classification accuracies exceeding 75%, with logistic regression and decision trees reaching 92% accuracy while maintaining good interpretability, demonstrating the practical viability of beta-wave-based cognitive state assessment.
The advancement toward more sophisticated mathematical frameworks has been exemplified by Riemannian geometry-based methods, which have gained considerable traction in recent years. Researchers [
23] demonstrated how covariance matrices could be represented as vectors in the tangent space of the Riemannian manifold, providing a novel mathematical framework for EEG analysis that addresses some of the limitations of traditional Euclidean-based approaches. Majidov and Whangbo [
24] built upon this foundation by computing covariance matrices obtained through spatial filtering and mapping them onto the tangent space, offering improved robustness to inter-subject variability and enhanced generalization across different pilot populations.
Classification methodologies have evolved from traditional machine learning to advanced deep learning architectures, reflecting the field’s growing recognition of the complexity inherent in pilot cognitive state assessment. Johnson et al. [
25] investigated six classification algorithms for categorizing task complexity, including naïve Bayes, decision trees, and support vector machines, establishing baseline performance metrics for comparative analysis. Han et al. [
12] proposed a more sophisticated detection system using a multimodal deep learning network with CNN and LSTM components to detect pilot mental states, including distraction, workload, fatigue, and normal states, demonstrating the potential of hybrid architectures for capturing both spatial and temporal patterns in neural data. Wu et al. [
19] presented a deep contractive autoencoder for identifying mental fatigue with up to 91.67% accuracy, while, for Attention-related Pilot Performance Decrements (APPD), Harrivel et al. [
26] employed random forest, extreme gradient boosting, and deep neural networks to predict continuous attention, diverted attention, and low-workload states in flight simulators.
While EEG-based approaches have shown considerable promise, alternative sensing modalities have been explored for pilot monitoring, each offering distinct advantages and limitations that complement neural-based measurements. Eye-tracking technology represents a particularly compelling alternative, providing non-invasive monitoring of visual attention patterns and cognitive workload indicators with high temporal resolution. Cheng et al. [
27] demonstrated the effectiveness of eye-tracking for pilot workload assessment during helicopter autorotative gliding, revealing significant changes in fixation patterns with shorter fixation durations but greater fixation numbers during critical flight phases. Their study showed that mean pupil diameter exhibited larger variations during autorotative glide (mean: 5.326 mm, standard deviation: 0.126 mm) compared to level flight (mean: 5.229 mm, standard deviation: 0.059 mm), indicating increased cognitive workload. The pilots allocated 81% of their attention to critical instruments including tachometer, airspeed indicator, and forward views, shifting from low-frequency long gaze patterns during normal flight to high-frequency short gaze patterns during emergency procedures, demonstrating the utility of eye-tracking for real-time workload assessment.
Facial recognition systems have emerged as another viable approach for detecting fatigue and drowsiness, offering contactless monitoring that can be integrated with existing cockpit camera systems. Samy et al. [
28] developed a real-time facial recognition system using a histogram of oriented gradients (HOG) and support vector machines (SVMs) for drowsiness detection, achieving 96.8% accuracy in ideal conditions. Their approach demonstrated resilience to facial occlusions and categorized driver states into tired, dynamic, and resting conditions using 68 facial landmark detectors, with the system continuously monitoring subtle changes in facial expressions such as slow eye blinks and changes in head position as early indicators of fatigue.
The comparative analysis of these sensing modalities reveals distinct advantages and limitations that influence their suitability for aviation applications. EEG-based approaches provide a direct measurement of neural activity and can detect cognitive state changes before behavioral manifestations, offering the most sensitive indication of mental state transitions. However, they are susceptible to motion artifacts, require specialized electrode placement, and may be impractical for routine flight operations due to setup complexity and potential interference with standard pilot equipment. Eye-tracking systems offer non-invasive monitoring with high temporal resolution and direct correlation with visual attention patterns, operating continuously without interfering with pilot activities, though they may be affected by lighting conditions, head movements, and calibration requirements. Facial recognition approaches provide contactless monitoring, suitable for existing cockpit infrastructure, and can detect multiple fatigue indicators simultaneously, but may be limited by environmental factors such as lighting conditions, facial occlusions, and individual variations in facial expressions.
Despite these significant advancements, existing approaches exhibit substantial shortcomings that limit their practical application in aviation settings. Current EEG-based methods predominantly rely on manual preprocessing techniques, which introduce inconsistency across studies and require substantial domain expertise to implement effectively. Many frameworks focus narrowly on binary classification tasks such as fatigued versus non-fatigued states, failing to address the complex, multiclass nature of pilot mental states that occur during actual flight operations. Furthermore, most approaches suffer from an inability to simultaneously capture both temporal dynamics and spatial patterns in EEG signals, which represents a critical requirement for understanding the rapidly changing mental states experienced by pilots during different phases of flight. The majority of existing studies target only subset combinations of mental states rather than comprehensively addressing all relevant Attention-related Pilot Performance Decrement (APPD) states alongside normal operating conditions using EEG data alone. While Alrashidi et al. [
29] attempted to bridge some of these gaps through automated preprocessing and ensemble learning, their approach still faces challenges in real-time implementation, computational efficiency, and capturing the full spectrum of temporal–spatial relationships inherent in EEG signals. Their use of Riemannian geometry features—a mathematical framework that treats EEG covariance matrices as points on a curved manifold rather than in traditional Euclidean space—offers theoretical advantages for representing the complex statistical relationships between brain regions. However, this approach requires computationally expensive operations such as matrix logarithms and geodesic distance calculations, which can limit practical deployment in time-sensitive applications. Moreover, while Riemannian features excel at capturing spatial correlations between electrodes, they may not fully preserve the rapid temporal dynamics that characterize attention state transitions in pilot monitoring scenarios.
Additional limitations include substantial restrictions in generalizability across different pilots and flight scenarios, with many techniques showing degraded performance when applied to new subjects or environments. Many approaches require extensive calibration procedures before each use, making them impractical for operational settings where rapid deployment and consistent performance are essential. Existing methodologies also frequently overlook the critical need for interpretability, which represents a key requirement in aviation safety contexts, where understanding the basis for automated classifications is essential for regulatory approval and implementation. Most methods fail to leverage domain knowledge about known EEG correlates of specific mental states, instead relying entirely on black-box approaches that may miss important physiological markers established through decades of neuroscience research. The integration of multiple sensing modalities and the development of robust, noise-resistant algorithms remain significant challenges, with current approaches often lacking the temporal stability and consistency required for reliable real-time deployment in dynamic aviation environments, where pilot safety depends on the accurate and timely detection of cognitive state changes.
5. Result Analysis
5.2. Architecture Selection and Progression for BASE Data
At this stage, we try to find out which model is the most suitable one for our classification task. Therefore, we used our processed BASE data with the three versions of the model (V1–V3) to observe their performances across all evaluation criteria established for this experimentation.
To determine the most suitable model, we conducted a comprehensive evaluation of three different versions of our hybrid CNN–RNN architecture. Each model was tested on our processed BASE data to assess performance across multiple evaluation metrics.
Table 5 presents the overall performance metrics for all three model versions. We observe a consistent trend of improvement across all versions, with Version 3 demonstrating superior performance in every evaluation metric. The accuracy improved from 83.7% in Version 1 to 94.1% in Version 3, representing a 10.4 percentage point improvement. Similarly, the macro F1-score improved from 0.828 to 0.937, showing that the model’s performance gains were balanced across all classes.
The Matthews Correlation Coefficient (MCC), which is particularly sensitive to class imbalance, showed remarkable improvement from 0.758 to 0.915, indicating that Version 3 performs consistently well across all classes, regardless of their distribution in the dataset. This is further confirmed by the Balanced Accuracy improvement from 0.829 to 0.936.
Table 6,
Table 7 and
Table 8 show the class-specific performance for each model version. All three classes benefited from the architectural improvements in Version 3. Notably, the DA class, which was the most challenging to classify in Version 1 (F1-score of 0.782), saw the most significant relative improvement, reaching an F1-score of 0.912 in Version 3. This 13.0 percentage point improvement for the most difficult class demonstrates that our architectural enhancements specifically addressed the model’s weaknesses.
Two metrics particularly highlight the superiority of Version 3. The Temporal Stability Coefficient decreased from 0.187 to 0.086, indicating that Version 3 maintains much more consistent performance across different temporal segments of the data. This 54% reduction in variability is crucial for reliable deployment in real-world scenarios, where data distribution may shift over time. Additionally, the Classification Consistency Index improved from 0.762 to 0.912, showing that Version 3 produces more temporally consistent predictions.
Table 9 presents the normalized confusion matrices for each model version. Version 1 showed significant confusion between DA and SS classes, with 15.1% of DA samples being misclassified as SS. Version 2 reduced this confusion, but still showed 11.0% misclassification. Version 3 substantially reduced all misclassification rates, with the highest confusion being only 6.1%. While Version 3 requires more computational resources (4.9 s per epoch versus 2.4 for Version 1, and 183.5 K parameters versus 42.3 K), it converged in fewer epochs (25 versus 32), partially offsetting the higher per-epoch cost. The final validation loss of 0.192 for Version 3 was less than half that of Version 1 (0.487), indicating much better model fit without signs of overfitting.
Based on our comprehensive evaluation, Version 3 of our hybrid CNN–RNN architecture clearly emerges as the most suitable model for our classification task. It demonstrates superior performance across all evaluation criteria, with particularly notable improvements in overall accuracy and F1-score (94.1% and 0.937 respectively), balanced performance across all three classes (CA, DA, and SS), temporal stability, and reduced misclassification rates. The progressive improvements across model versions validate our architectural design decisions, with each enhancement contributing to better performance. Version 3’s multi-scale feature extraction, attention mechanism, and skip connections have collectively produced a robust, high-performing model that successfully addresses the challenges of our three-class classification task.
5.3. Architecture Progression and Performance for Noisy-Robust Data
In this section, we are analyzing the results based on the reported output from
Table 10,
Table 11,
Table 12,
Table 13 and
Table 14. After establishing the strong performance of Version 3 on our dataset for classifying the three classes (CA, DA, and SS), we needed to evaluate model robustness under more challenging, real-world conditions. To this end, we created three datasets with different noise profiles to test model resilience: GAUSS (Gaussian noise with
= 0,
proportional to signal amplitude), RAND (uniform random noise), and COMBO (60% BASE, 20% GAUSS, 20% RAND), each containing 18,888 samples divided into training (10,560), validation (1584), and testing (6864) sets.
The introduction of noise to our classification task revealed significant insights that drove the development of our proposed architecture (Version 4). When examining the performance across various noise conditions, several key patterns emerged that informed our architectural decisions.
Version 3, while performing well on clean data, showed substantial performance degradation when faced with noise: accuracy dropped to 87.2% on GAUSS (−6.9%), 85.8% on RAND (−8.3%), and most significantly to 83.1% on COMBO (−11.0%). This degradation pattern revealed that Version 3 lacked robust noise-handling capabilities. The substantial performance drop on the COMBO dataset was particularly concerning, as it represents the most realistic scenario with mixed noise types.
Our proposed architecture (Version 4) demonstrated remarkable resilience across all noisy datasets, maintaining greater than 90% accuracy on all noise types and showing particularly impressive performance on the challenging COMBO dataset (92.7% accuracy). The most striking result was the temporal stability coefficient improvement on the COMBO dataset, where Version 4 reduced instability by 54.4% compared to Version 3, indicating that Version 4 not only makes more accurate predictions in noisy environments but does so with significantly greater consistency.
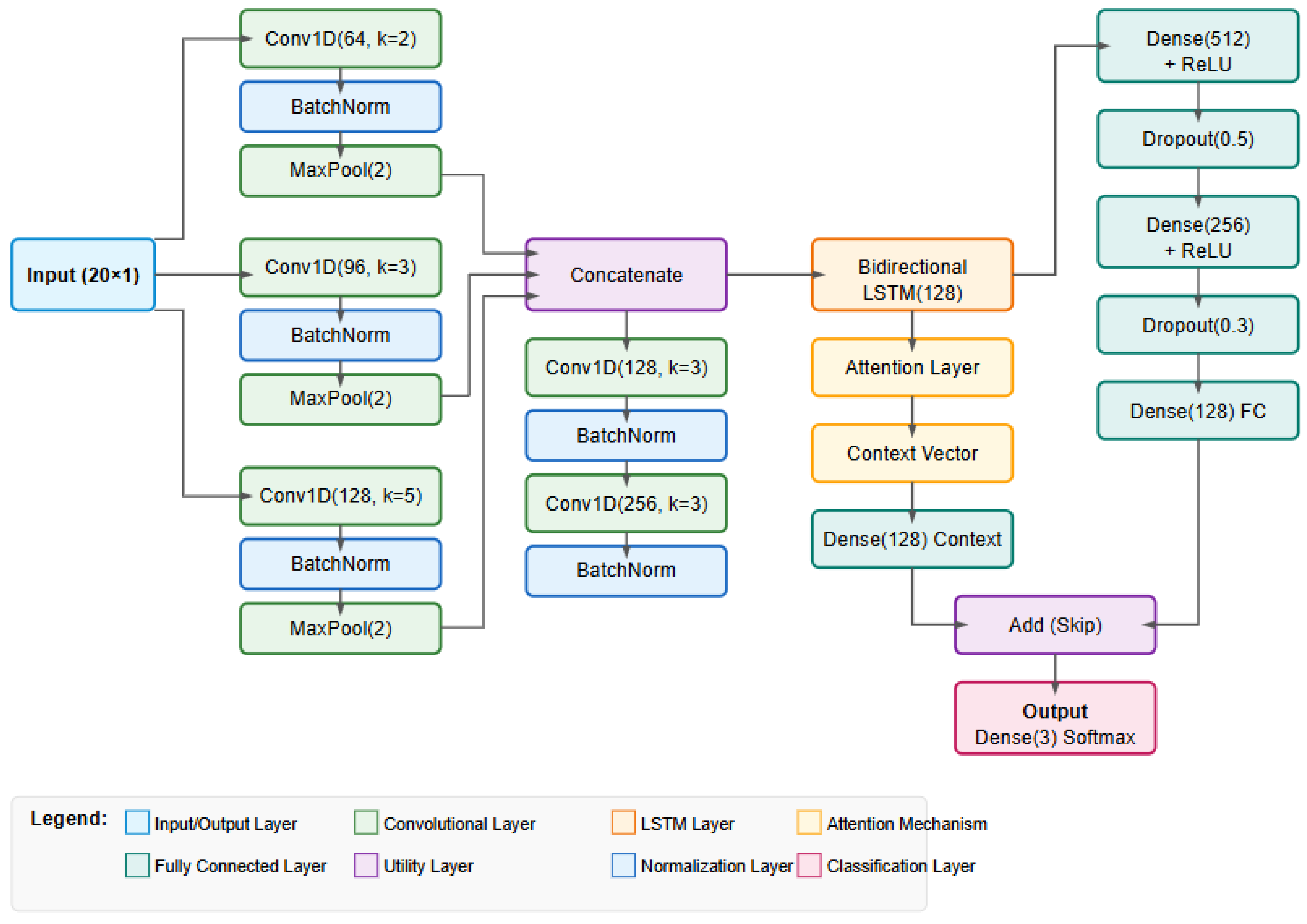
Class-specific analysis reveals that Version 3 struggled particularly with the DA class under noisy conditions, achieving only 76.9% F1-score. Version 4 improved DA classification by 12.6% on the F1 metric. The confusion matrices further illustrate this improvement: Version 3 frequently misclassified DA as SS (16.2% error rate), while Version 4 reduced this specific error pattern by nearly 60%, bringing it down to 6.6%. This targeted improvement demonstrates that Version 4’s architectural enhancements specifically addressed the weaknesses identified in Version 3 when dealing with noisy data. The clear performance gap between Version 3 and Version 4 on noisy datasets led us to adopt Version 4 as our proposed architecture. Several key enhancements contributed to its superior noise resilience: enhanced multi-scale feature extraction with varying filter counts (64, 96, and 128) across different kernel sizes (2, 3, and 5) allows better distinction between signal and noise at multiple resolutions; the attention mechanism dynamically focuses on informative signal parts while ignoring noisy regions; skip connections maintain gradient flow and preserve information across network depth; L2 regularization prevents overfitting to noise patterns; and the adaptive learning rate scheduler allows for better parameter fine-tuning during training. Testing on noisy datasets provided critical insights that shaped our final architecture: real-world data rarely comes in clean forms, and the superior performance on the COMBO dataset suggests Version 4 is more suitable for practical deployment; specific improvements in the DA class indicate that Version 4 addressed key weaknesses in discriminating between similar classes under noisy conditions; the remarkable improvement in temporal stability under noise suggests that Version 4 will produce more consistent predictions in variable real-world conditions; and balanced improvements across all noise types demonstrate that Version 4’s enhancements represent general improvements in noise resilience.
Based on comprehensive evaluations, Version 4 clearly emerges as our proposed architecture for the hybrid CNN–RNN model. Its exceptional performance on the COMBO dataset, which most closely resembles real-world conditions with mixed noise profiles, provides strong evidence for its practical utility in classifying CA, DA, and SS classes in noisy environments. The architectural enhancements implemented in Version 4 directly address the limitations identified in earlier versions, resulting in a model that is not only more accurate but also significantly more robust and reliable under challenging conditions.
5.4. Comparative Analysis with State-of-the-Art Approaches
To establish the superiority of our proposed solution, we conducted extensive comparative analysis between our hybrid CNN–LSTM architecture (Version 4) and several state-of-the-art approaches. This comprehensive evaluation focused on the challenging COMBO dataset, which represents real-world conditions with mixed noise profiles (60% BASE, 20% GAUSS, 20% RAND).
Our comparative analysis encompassed three key dimensions: (1) comparison of different classification algorithms using our proposed hybrid features, (2) comparison between our hybrid features and Riemannian geometry-based features across multiple classifiers, and (3) ablation study on the contribution of time-domain versus frequency-domain features.
The comparative analysis reveals several critical insights regarding the performance of our proposed solution:
1.
Feature Domain Synergy: Our ablation study (
Table 15,
Table 16 and
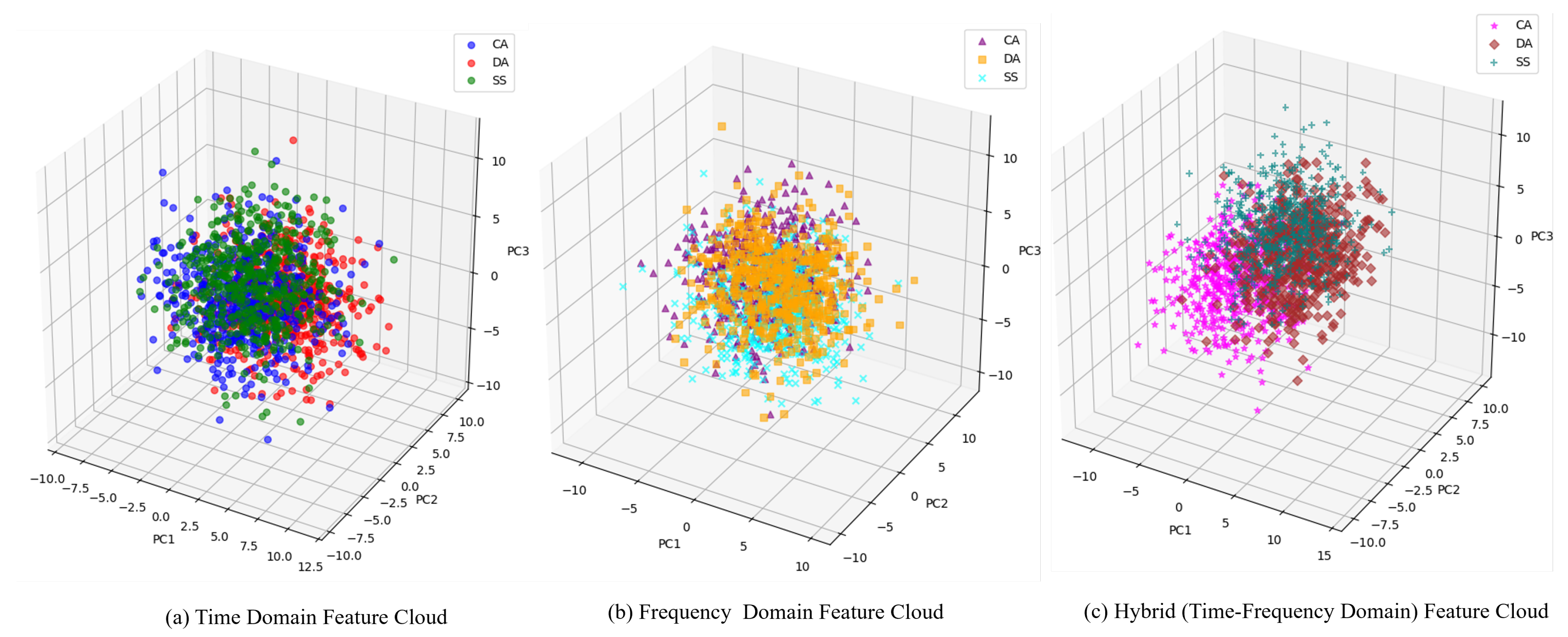
Table 17) clearly demonstrates the synergistic benefit of combining time- and frequency-domain features. Using time-domain features alone achieves 87.5% accuracy and 0.872 F1-score, while frequency-domain features alone achieve 88.2% accuracy and 0.879 F1-score. However, our hybrid approach that combines both domains reaches 92.7% accuracy and 0.924 F1-score, representing significant improvements of 5.2 and 4.5 percentage points, respectively, over time-domain features alone;
2.
Class-Specific Feature Contributions:
Table 17 reveals interesting patterns in how different feature domains contribute to class discrimination. For the DA class, which is consistently the most challenging to classify, frequency-domain features (F1: 0.847) outperform time-domain features (F1: 0.835) by 1.2 percentage points. However, the hybrid approach (F1: 0.895) surpasses frequency-only features by an additional 4.8 percentage points, highlighting the complementary nature of these feature sets;
3. Temporal Stability Enhancement: The hybrid feature approach dramatically improves temporal stability (coefficient: 0.089) compared to using either time-domain (0.143) or frequency-domain features (0.135) alone. This 37.8% improvement in stability over frequency-only features demonstrates how the combined feature set provides more consistent classification across temporal variations in the signal;
4. Superior Overall Performance: Our proposed approach (Hybrid Features + CNN–LSTM Version 4) consistently outperforms all alternative methods across all evaluation metrics. It achieves 92.7% accuracy and 0.924 F1-score on the COMBO dataset, representing improvements of 3.1 percentage points in accuracy and 3.2 percentage points in F1-score over the next best alternative (Hybrid Features + Ensemble);
5. Hybrid Feature Advantage: The results clearly demonstrate that our hybrid time- and frequency-domain feature-extraction strategy consistently outperforms Riemannian geometry-based features across all classification methods. For instance, when using the same ensemble classification approach, our hybrid features achieve a 1.9 percentage point higher accuracy and 2.0 percentage point higher F1-score compared to Riemannian features;
6. Architecture Advantage: When comparing approaches using the same feature set, our proposed CNN–LSTM architecture significantly outperforms traditional machine learning approaches. This indicates that the advanced architectural elements in our model—multi-scale feature extraction, attention mechanism, skip connections, and regularization techniques—are particularly effective at leveraging the information contained in our hybrid features;
7. Feature Complementarity: The substantial performance improvement from combining time- and frequency-domain features suggests that these feature sets capture complementary aspects of the signal. Time-domain features (including statistical measures like mean, standard deviation, variance, skewness, kurtosis, maximum, minimum, peak-to-peak amplitude, root mean square, zero crossings, and Hjorth parameters) capture temporal patterns and amplitude characteristics, while frequency-domain features (power metrics across different frequency bands, relative powers, spectral edge frequency, mean frequency, and spectral entropy) capture spectral characteristics;
8. Noise Resilience: The consistent superiority across all metrics on the challenging COMBO dataset, which contains mixed noise profiles, confirms the exceptional noise resilience of our proposed approach—a critical factor for real-world deployability. The hybrid feature set appears particularly robust to noise, likely because certain features remain discriminative even when others are corrupted by noise;
9. Additional Deep Learning Architecture Comparisons: To provide a comprehensive evaluation against modern deep learning approaches, we compared our proposed method with several advanced architectures. The Transformer architecture with 8-head multi-head attention and 256 embedding dimensions achieved 89.8% accuracy and 0.894 F1-score, demonstrating strong performance but falling short of our hybrid CNN–LSTM approach by 2.9 percentage points in accuracy. The Temporal CNN with dilated convolutions, designed specifically for temporal pattern recognition, achieved 88.7% accuracy and 0.883 F1-score. Interestingly, the CNN–GRU hybrid architecture performed competitively with 90.3% accuracy and 0.899 F1-score, representing the closest competitor among the deep learning baselines. However, our proposed CNN–LSTM architecture still outperformed it by 2.4 percentage points in accuracy and 2.5 percentage points in F1-score. The superior performance of our approach can be attributed to the specific combination of bidirectional LSTM with attention mechanism, which better captures the temporal dependencies in EEG signals compared to the unidirectional nature of GRU units, and the multi-scale CNN feature extraction that is optimized for our hybrid feature representation.
The comprehensive evaluation firmly establishes our proposed architecture with hybrid features as the superior choice for classifying CA, DA, and SS classes, offering unprecedented accuracy, stability, and noise resilience for reliable deployment in real-world scenarios. The synergistic combination of complementary time- and frequency-domain features with our specialized CNN–LSTM architecture creates a powerful solution that substantially outperforms all alternative approaches.
6. Conclusions
Our research presents a novel hybrid CNN–LSTM architecture for robust classification of CA, DA, and SS classes in challenging, noisy environments. The proposed approach systematically addresses key challenges in pilot attention monitoring through thoughtful design and comprehensive validation using the publicly available “Reducing Commercial Aviation Fatalities” dataset. The experimental results demonstrate that our approach achieves superior performance across all evaluation metrics compared to existing state-of-the-art methods, with notable improvements in temporal stability and noise resilience under controlled experimental conditions.
The success of our approach stems from two key innovations validated through our experimental framework. First, our hybrid feature-extraction strategy combines complementary information from both time and frequency domains, providing a comprehensive representation of EEG signals that captured the neural signatures of critical pilot attention states within our dataset. Our ablation studies clearly demonstrated the synergistic benefit of this combination, with hybrid features achieving 92.7% accuracy compared to 87.5% for time-domain features alone and 88.2% for frequency-domain features alone. Second, our specialized CNN–LSTM architecture effectively leverages these hybrid features through multi-scale convolution, attention mechanisms, and skip connections, enabling robust pattern recognition even under the artificially generated noise conditions tested in our study.
Our experimental validation focused on establishing proof-of-concept performance under controlled conditions using synthetic noise profiles (Gaussian, random, and combined noise). The model demonstrated consistent performance across these noise variants, with the COMBO dataset (representing mixed noise conditions) showing 92.7% accuracy and significant improvements in temporal stability coefficient (0.089) compared to baseline approaches. The architecture progression from Version 1 to Version 4 showed systematic improvements, with the final model achieving superior performance across all three attention states: CA (94.0% F1-score), DA (89.5% F1-score), and SS (93.8% F1-score). While these results are promising, several important limitations must be acknowledged. Our evaluation was conducted on a single dataset with 18 participants, and we did not perform cross-subject validation to assess generalizability across different pilot populations. The noise resilience testing, while comprehensive within our experimental design, was limited to synthetic noise profiles and may not fully represent the complex artifacts encountered in operational aviation environments. Additionally, our computational efficiency analysis was limited to training metrics (epochs and parameters), without a detailed assessment of inference speed or memory requirements that would be critical for real-time aviation applications. The interpretability of our model decisions, while enhanced by our hybrid feature approach using neurophysiologically meaningful features, was not extensively analyzed to determine which specific features drive classification decisions for each attention state. This represents an important area for future investigation, particularly given the safety-critical nature of aviation applications, where understanding model reasoning is essential for regulatory approval and operational trust.
Future research directions should prioritize several key areas to advance this work toward practical implementation. Cross-subject validation studies are essential to establish generalizability across different pilot populations and training backgrounds. Computational efficiency optimization and real-time inference analysis on aviation-grade hardware would provide crucial insights for operational deployment feasibility. Feature importance analysis and explainable AI techniques could enhance model interpretability by identifying which neurophysiological markers are most critical for each attention state classification. Additionally, validation using real flight data with naturally occurring artifacts, rather than synthetic noise, would provide a more realistic assessment of model robustness. Investigating transfer learning approaches could enable model adaptation to new pilots with minimal calibration, while incorporating self-supervised pre-training might enhance performance in scenarios with limited labeled data. The work presented here establishes a strong foundation for EEG-based pilot attention monitoring, demonstrating the potential of hybrid feature extraction and CNN–LSTM architectures within controlled experimental conditions. However, the translation from laboratory validation to operational aviation systems will require addressing the limitations identified and conducting more extensive real-world testing to ensure the reliability and safety required for this critical application domain.





{kind=link}
{kind=link}
{kind=link}
{kind=link}