Abstract
Machine learning has brought about a revolutionary transformation in healthcare. It has traditionally been employed to create predictive models through training on locally available data. However, privacy concerns can sometimes impede the collection and integration of data from diverse sources. Conversely, a lack of sufficient data may hinder the construction of accurate models, thereby limiting the ability to produce meaningful outcomes. Especially in the field of healthcare, collecting datasets centrally is challenging due to privacy concerns. Indeed, federated learning (FL) emerges as a sophisticated distributed machine learning approach that comes to the rescue in such scenarios. It allows multiple devices hosted at different institutions, like hospitals, to collaboratively train a global model without sharing raw data. In addition, each device retains its data securely on locally, addressing the challenges of time-consuming annotation and privacy concerns. In this paper, we conducted a comprehensive literature review aimed at identifying the most advanced federated learning applications in cancer research and clinical oncology analysis. Our main goal was to present a comprehensive overview of the development of federated learning in the field of oncology. Additionally, we discuss the challenges and future research directions.
1. Introduction
Data have played an essential role in our daily lives in recent decades. The collected data across various sectors are increasing due to rapid technological advancements. As they are growing extremely fast, there are fundamental needs to extract valuable information [1]. With our greater understanding of the data, productivity and usability could be enhanced within each sector across the globe. Consequently, Machine Learning (ML) algorithms were developed to grasp hidden patterns and critical points from the captured data [2,3]. As a subset of Artificial Intelligence, ML is a data analysis method that enables model deployments for different data types. Various kinds of ML have been developed, but there are two main techniques, supervised and unsupervised learning, which attempt to predict or identify the unseen parts of the collected data.
ML has been deployed into various sectors, including finance [4], agriculture [5], and transportation [6]. Healthcare is also one of the most relevant areas of ML, given the large amount of collected data in this domain [7]. ML techniques can be applied using critical data collected from hospitals or Internet of Things (IoT) devices. Wearable IoT devices are one of the primary sources for collecting data from users to be processed by ML algorithms [8]. Moreover, Electronic Medical Records (EMR) are another data source for analysis [9]. Medical institutions are the central source for maintaining the data, whether structured or unstructured. ML models yield more accurate results with structured data. However, most EMR datasets are unstructured and require preprocessing before being fed into the ML models [10]. Medical imaging is one critical type of data within healthcare, which can assist in detecting various types of diseases, especially cancer [11]. ML has been widely developed across cancer institutions to assist physicians by giving a second opinion on each patient. It has been applied effectively to various cancers, such as breast, lung, and prostate cancer, delivering significant improvements [12,13].
While ML has significantly advanced cancer detection and treatment, a major concern remains: data privacy. The use of patient data in ML models raises ethical and legal challenges regarding confidentiality and security. To address privacy concerns, federated learning (FL), a decentralized data analysis method introduced by McMahan et al. in 2015 [14], allows institutions to train models locally without sharing data centrally. The central concept of this type of learning is that it trains the model remotely in a decentralized/distributed format. The backbone of this technique is to avoid sharing the collected data from medical institutions with the central model. Instead, each institution will train its own local model, and all the local models will be shared with a global model at each iteration. In this case, data privacy across medical institutions will be preserved better than in ML models. Consequently, FL has been deployed within healthcare, especially for cancer diagnosis and prediction.
Contributions of This Paper
This paper aims to provide a comprehensive analysis of FL in cancer detection and oncology by reviewing the latest advancements, identifying challenges, and outlining future research directions. The key contributions of this study are as follows:
- Comprehensive Literature Review: We present a systematic review of FL applications in oncology, summarizing key methodologies, datasets, and advancements in cancer detection using FL.
- Benchmark Datasets and Challenges: We provide an in-depth discussion of publicly available cancer datasets commonly used in FL research, explicitly outlining their challenges, such as data distribution issues and privacy concerns.
- Critical Analysis of FL Challenges: We discuss key challenges associated with FL in medical applications, including data heterogeneity, privacy risks, communication bottlenecks, and regulatory constraints.
- Future Research Directions: We propose a research direction for advancing FL in oncology, emphasizing improvements in privacy-preserving techniques, model optimization, and federated architectures tailored to medical applications.
The remainder of this paper is structured as follows: Section 2 reviews publicly available cancer datasets and highlights their challenges in FL applications. Section 3 discusses the foundations of FL in healthcare, including aggregation techniques, privacy, and personalization strategies. Section 4 provides an overview of ML in clinical decisions. Section 5 explores current applications of FL in oncology, reviewing recent studies. Section 6 provides a comparative analysis of FL approaches in oncology. Section 7 presents key challenges and limitations of FL in healthcare. Section 8 provides some future research directions. Section 9 presents the concluding remarks.
2. Benchmark Datasets
In this section, we provide a description of datasets that have been widely used to conduct experiments, analyze data, and compare state-of-the-art techniques for cancer detection and classification in FL.
2.1. BRATS 2018 Dataset
BRATS 2018 (https://www.kaggle.com/datasets/sanglequang/brats2018/data (accessed on 24 March 2025)) is a dataset that is collected from 19 institutions and widely used in healthcare. It provides multimodal 3D brain MRI scans, and all ground-truth brain tumor segmentations have been verified by neuroradiologist experts. The dataset includes three tumor sub-structures: the enhanced tumor, the peritumoral edema, and the necrotic and non-enhancing tumor core. The total sets are 476, including 285 training and 191 testing sets [15]. In [16], the authors proposed an FL system for brain tumor segmentation on the BRATS 2018 dataset. The results show that the proposed FL achieved comparable segmentation while protecting patient privacy. A significant challenge for federated learning in this case is the non-IID nature of the data, where the data distributions differ between institutions, which can impair model performance. FL systems must also handle the heterogeneity in the image quality, which can affect segmentation results.
2.2. HAM10000 Dataset
HAM10000 (https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/DBW86T (accessed on 24 March 2025)) (Human Against Machine with 10,000 training images) [17] is a collection of dermatoscopic images of pigmented skin lesions collected from multiple sources. It provides 10,015 dermatoscopic images of common pigmented skin lesions. The dataset includes 7 different types of skin cancer: Nevus, Melanoma, Pigmented Bowen’s, Basal Cell Carcinoma, Pigmented Benign Keratoses, Vascular, and Dermatofibroma. Zhang et al. [18] proposed an FL scheme for skin cancer detection in an Internet of Things-based healthcare system. The results show that, compared with existing schemes, the proposed scheme detects skin cancer types with an accuracy of more than 76.9%. However, a major challenge when applying federated learning to this dataset is the privacy concern, particularly with image-based datasets, where sensitive patient data are involved. In federated learning, ensuring data privacy while enabling collaboration across institutions with diverse datasets is crucial.
2.3. WBCD Dataset
Wisconsin Breast Cancer dataset (https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic) (accessed on 24 March 2025)) consists of 699 records taken from Fine Needle Aspirates (FNA) of human breast tissue. The database contains nine attributes for each record. In addition, it contains 16 instances with missing values, with the remaining 683 samples being used for analysis. There are, therefore, 444 benign samples in the dataset (65.0%) and 239 malignant samples (35.0%) [19]. In [20], the authors proposed an FL scheme for cancer detection using the WBCD dataset. According to the results of the experiments, the proposed method is able to detect cancer problems with a high level of accuracy of 93.83%. This dataset poses challenges for federated learning primarily due to missing data (16 instances have missing values) and the imbalance between benign and malignant samples. In a federated setting, data missingness could cause issues when aggregating local models, leading to potential biases in the final model. Additionally, the class imbalance could impact model performance.
2.4. BreakHis Dataset
Breast Cancer Histopathological Image database (BreakHis) (https://web.inf.ufpr.br/vri/databases/breast-cancer-histopathological-database-breakhis/ (accessed on 24 March 2025)) contains 9109 microscopic images of breast tumor tissue collected from 82 patients using different magnifying factors (40×, 100×, 200×, and 400×). This dataset consists of 2480 benign and 5429 malignant samples (700 by 460 pixels, RGB, 8 bits depth in each channel, PNG format) [21]. Li et al. [22] proposed an FL framework based on aggregating model parameters for efficient medical image diagnosis. They used the BreakHis dataset in the proposed FL model for breast cancer detection. The experimental results show that the proposed model is an effective way to solve data silos and protect data privacy in the knowledge fusion process in the intelligent medical field. This dataset presents the challenge of multimodal data and varying image quality due to different magnification factors used across the samples. The diversity in image acquisition procedures can lead to non-IID data distribution, which can reduce the performance of federated learning models that rely on IID assumptions.
2.5. DDSM Dataset
Regarding Digital Database Screening, the mammography dataset contains 2620 scanned film mammographies. Since it provides a large collection of mammograms in digital format, it is an invaluable resource for digital mammography research [23]. The database contains normal, benign, and malignant cases, along with pathology data that has been verified. Based on the FL framework, the paper in [24] used the FedAvg-CNN in a federated prediction model to develop breast cancer classification using mammography data. The accuracy of the Digital Database for Screening Mammography (DDSM) dataset reaches more than 98%. The result demonstrates that FedAvg-CNN leads to much higher classification performance and ensures customer privacy and personal security in AI healthcare applications. One of the primary challenges in applying federated learning to this dataset is communication efficiency. The large size of mammography data can lead to high communication overhead during model updates.
3. Federated Learning in Healthcare
FL attempts to deploy an ML model across multiple clients or medical institutions. Briefly, FL aims to train medical data using ML models in two individual processes, including training on sites and model inference. Training on sites includes only exchanging data to build a local model. Once the local models are trained with the accessible data, they will be aggregated as one global model to be deployed for model inference. Since the training is local and performed at medical institutions or devices, data privacy is protected, and confidential information will not be revealed to the global model. This approach is called the client–server model, where the server is responsible for aggregating the weights of the local models that the institutions or devices send [14]. After building a global model, it sends the initial global model to the institutions or devices. This could be a repetitive procedure until the desired outcome is achieved. In addition to its privacy-preserving benefits, this approach helps reduce communication costs by leaving the actual data at the institutions. Moreover, these communications between the server and clients could be encrypted using other techniques, such as homomorphic encryption, to prevent data leakage [25,26]. Another FL architecture could be peer-to-peer, where institutions communicate directly, like a collaborative learning system. Although this system provides a higher level of security compared to the client–server method, it could increase the computation costs for encrypting the information in the network. FL could be divided into three different categories, including vertical federated learning (VFL), horizontal federated learning (HFL), and Transfer Federated Learning (TFL), based on the types of data partitioning across clients. As every set of data could consist of features and samples, they may have various settings based on the strategy of collection by the data owners. HFL involves the methodology, when the data owners, as local clients participating in the FL training, could have features that overlap but with different samples. This method is also known as sample-partitioned FL [25]. Another method, VFL, refers to the case when local clients, e.g., medical devices or institutions, could have samples overlapping with different features. VFL is also known as feature-partitioned FL. Federated Transfer Learning is the third model with no overlapping between features and samples.
An example of HFL in the medical context could be when the medical oncology departments in two hospitals maintain data on their patients. At the same time, those collected data have main similarities in the data features based on the cancer types. In this case, both hospitals could collaboratively share their findings to fight cancer. This involves ML modeling and training at each site based on the FL setting. In the VFL, an example could be when a hospital collaborates with an Information Technology company that is responsible for tracking data from medical devices. In this case, they both maintain a different set of features but the same samples, including users’ information. This is the area for cooperation to create an efficient VFL setting that benefits both institutions. The third approach, called Transfer Learning, enables the effective building of machine learning models when data are heterogeneous and could be hard to partition with vertical or horizontal learning. Transfer Learning can be divided into three methods: instance, feature, and model transfer. This approach could be effectively helpful when dealing with image datasets facing high heterogeneity [27]. To better understand the impact of federated learning in oncology, it is essential to explore its foundational principles, particularly the evolution of FL frameworks and aggregation techniques that play a crucial role in mitigating the challenges discussed above.
3.1. Federated Learning Foundations and Aggregation Techniques
Federated learning (FL) was first introduced by McMahan et al. (2017) in their seminal work on Federated Averaging (FedAvg), a decentralized learning approach that enables model training across multiple devices while keeping raw data localized [14]. FedAvg aggregates model updates from distributed clients and averages them to update the global model. While FedAvg has been widely adopted due to its simplicity and efficiency, it suffers from challenges such as convergence issues in heterogeneous data environments, slow training speeds, and high communication costs. These limitations have led to the development of various optimization and aggregation techniques to enhance FL performance, particularly in healthcare settings.
To address the drawbacks of FedAvg, researchers have proposed alternative aggregation strategies tailored for non-IID data and resource-constrained environments. For example, FedProx [28] introduces a proximal term in the local objective function to mitigate client drift and stabilize training in heterogeneous datasets. SCAFFOLD [29] further refines aggregation by using variance reduction techniques to correct local updates, thereby improving convergence. Additionally, FedNova [30] normalizes client updates to balance differences in local training epochs, while FedOpt [31] leverages adaptive optimization techniques, such as Adam and Yogi, to improve FL efficiency. These advancements have significantly improved FL’s robustness in real-world applications, particularly in medical imaging and oncology.
3.2. Recent Advances in FL for Privacy and Personalization
Beyond aggregation improvements, privacy-preserving enhancements have also been a focus in FL research. Google’s work on differential privacy in FL [32] ensures individual client data remains protected while contributing to model training. Techniques such as Secure Aggregation (Bonawitz et al., 2017) and Homomorphic Encryption have further strengthened FL’s applicability in privacy-sensitive domains, including healthcare [33]. Moreover, recent studies have explored personalized FL, allowing clients to fine-tune global models to their specific data distributions, which is particularly relevant for oncology applications where patient data varies significantly across institutions [34].
3.3. Comparative Summary of FL Aggregation Techniques
To provide a structured comparison of different FL aggregation methods, Table 1 summarizes key attributes, advantages, and limitations of the most relevant approaches in FL for healthcare applications.

Table 1.
Comparative summary of FL aggregation techniques.
4. Machine Learning in Cancer
In the past few years, cancer has continued to be one of the leading causes of death across the globe. According to the World Health Organization, around 10 million people died due to various cancer types worldwide, proving the critical need for early diagnosis and prognosis of cancers [35]. However, research has been growing on this matter for decades and is still ongoing. The application of ML has helped advance the findings toward better clinical decisions for patients dealing with cancer [36]. This includes identifying the types of cancer and assessing their stages, which are critical for planning appropriate treatments. Also, ML has an improved prognosis when defining the appropriate treatments after the diagnosis. Some of the main ML techniques that have been effectively deployed to fight against cancer are Artificial Neural Networks (ANN), Support Vector Machines (SVM), Bayesian Networks (BN), and Decision Trees (DT) [12].
Although these techniques have improved our knowledge of cancer detection and progression, their actual clinical application is still limited and is an ongoing process among scientists. A major reason is the confidential data collected from patients across each medical institution. One of ML scientists’ restrictions on accessing data are the Health Insurance Portability and Accountability Act of 1996 (HIPAA) law, which limits data accessibility to protect patients’ privacy [37]. Consequently, real-time ML applications could be nearly impossible since accessibility is not privileged to scientists. In the next section, FL will be considered as it has different settings and data partitioning techniques.
5. Federated Learning Applications in Cancer
The literature review of the existing FL applications in cancer studies demonstrates that scientists attempt to validate various FL settings with ML-centralized approaches. Dealing with current challenges and performance in cancer research has been the main goal for deploying these techniques, as they utilize various cancer datasets to conduct the research. Since FL is a novel research area, one primary approach among scientists has been setting up new environments and validating them with a specific dataset to demonstrate their performance.
5.1. Breast Cancer
Breast cancer occurs when the cells of the breast are damaged and is considered to be the most common form of cancer among women in the world after skin cancer. Breast cancer can affect both men and women, but it is significantly more common in women as compared to men due to breast density [38]. Several FL approaches are applied to breast cancer datasets for training and testing features that distinguish malignant from benign objects. In the following, we will review some of them.
As the research mentioned in [39,40], breast density plays an important role in estimating the patient’s risk of developing breast cancer, which means women with a high breast density have a higher risk of breast cancer compared to those with a lower breast density. Researchers have recently been attracted to the idea of detecting and classifying breast cancer using deep learning approaches and advancements in medical image analysis. However, it is well known that all of the models have to be constructed on the basis of large amounts of data to become more robust and accurate. Also, due to the data privacy and ethical concerns associated with data sharing in healthcare, centralized data becomes more challenging for deep learning models.
In [41], the authors investigate whether AI models can be trained without centralizing data that differs substantially from multiple resources. They proposed real-world implementations of an FL-based model for breast density classification. Finally, the experimental results indicate that the models trained using FL outperform those trained on a local dataset alone by an average of 6.3%. In addition to that, the presented FL-based model also shows a 45.8% relative improvement in the models’ generalizability tested on the experimental data. Although the proposed model achieves similar or better performance compared to models trained on local datasets, it does not account for the effects of different data domains, nor do the authors apply techniques to harmonize non-IID data or explore domain adaptation with the FL model. In addition, they also do not take into account the issues of data size heterogeneity and data imbalance in their work.
Despite the fact that FL is proposed to train ML models using diverse datasets from various sources to enhance privacy by avoiding data collection and improve model accuracy through access to broader data. However, the main idea of FL is to share the trained parameters, which are obtained in the local steps and then integrated into one common model, which can cause privacy breaches. To enhance FL’s security, Differential Privacy was introduced to provide strong privacy protections. DP seeks to share certain data from a dataset while safeguarding the privacy of individuals within it. During the process of training FL models, Differential Privacy Stochastic Gradient Descent is the most commonly used mechanism.
In [42], the authors proposed differentially private FL methods for Cancer Prediction to secure the privacy and sensitivity of data during the process of training ML models in the area of FL. The proposed model is called DP-SGD with Cyclic Federated Learning. Since in DP-SGD, it is not easy to maintain privacy with duplicate samples, the authors propose that they will not modify the training datasets to ensure the accuracy of the evaluation of privacy. In their algorithm, the initial client sets the model parameters randomly. During each federated round, this client updates the model using its local dataset for a fixed number of steps before transferring the refined parameters to the next client. Similarly, the second client trains the model on its own local dataset for an equivalent number of steps. After that, the second client will send the new parameters back to the first client. After performing several federated rounds, they will obtain the final aggregated ML model and preserve the sensitivity and privacy of datasets. The experimental results show that the proposed DP model obtains better performance than the logistic regression model. However, implementing training protocols to prevent the leakage of sensitive data has affected the allocation of the privacy budget.
In addition to differential privacy, federated learning (FL) employs various techniques to safeguard intermediate data during transfer, such as homomorphic encryption, which balances security with practical usability. However, the complex computations and large data operands introduce considerable computational overhead to FL systems. Achieving both high accuracy and robust security efficiently remains a central challenge in FL. In [43], the authors present a hardware-accelerated solution by developing an FPGA-based framework for homomorphic encryption to enhance the efficiency of the FL training phase. Their approach implements the Paillier homomorphic cryptosystem using high-level synthesis to ensure flexibility and portability, with targeted optimizations for modular multiplication to improve processing speed, resource efficiency, and clock frequency. Evaluated on the Breast Cancer Wisconsin Dataset, their framework achieves near-optimal execution cycles, surpassing existing designs in DSP efficiency and reducing encryption time by up to 71% across various FL model training processes.
Although federated learning (FL) enables collaborative model training across large, distributed datasets, its reliance on unstable network connections poses challenges. Several FL methods employ (k,n)-threshold secret sharing schemes, assuming semi-honest clients, to support secure multiparty computation for exchanging local model updates, addressing random client dropouts at the expense of increased data volume. However, these approaches remain susceptible to malicious clients. To address this, in [44], proposed a blockchain-based, privacy-preserving FL framework that ensures reliability and accountability. By leveraging the decentralized trust and immutability of blockchain, this framework tracks the provenance of model updates. Integrating blockchain into the privacy-preserving FL (PPFL) process mitigates random client dropouts by asynchronously recording local updates on the blockchain. Additionally, the global ledger’s immutability and provenance features enable the detection and exclusion of malicious client updates. The framework was evaluated using the Breast Cancer Dataset from the UCI Machine Learning Repository. Experimental results demonstrate that this blockchain-based PPFL approach supports fully decentralized model training, enhancing transparency and verifiability while safeguarding data privacy.
Also, FL helps break data islands and achieve privacy protection. In addition, FL allows models to be trained locally and send encrypted information to the global server, and the local clients can update the parameters by themselves using GD, SGD, and Mini-Batch SGD methods. However, these approaches are all first-order accuracy, which also will bring various problems. In [45], the authors proposed Vertical FL. They presented this method for applying the quasi-Newton method, which included DFP and BFGS, in the logistic regression algorithm of Vertical FL, which is capable of managing heterogeneous federated environments to ensure privacy security. After the evaluation on the Breast Cancer dataset, the results demonstrate that the BDFL model can achieve better performance with less communication time than existing traditional methods.
Recent studies suggest that the sequence and frequency of local model updates significantly affect the performance of the global model in federated learning (FL). So, in [46], the authors introduce a memory-aware curriculum learning strategy tailored for federated breast cancer classification, which strategically orders training samples by prioritizing those forgotten after the global model’s aggregation. Their methodology addresses three key challenges: system and statistical heterogeneity, privacy preservation, and distributed optimization, as illustrated in Figure 1.
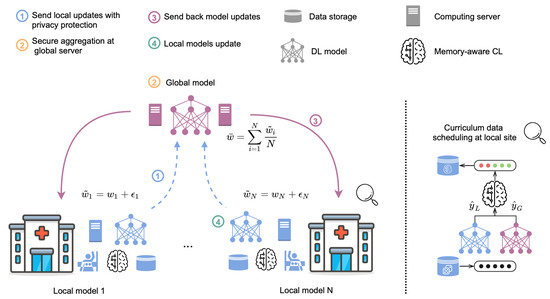
Figure 1.
Memory-Aware Curriculum-Based Federated Learning Framework with privacy preservation [46]. (1) Local models transmit their weights after applying Gaussian noise to enhance privacy (indicated by dashed blue arrows). (2) The central server aggregates the weights from the local models to produce a global model. (3) The averaged global model is distributed to each participating site (denoted by purple arrows). (4) Local models are updated with the global model’s parameters. A curriculum-based data scheduler reorders training samples, prioritizing those forgotten following the global model’s deployment to improve learning efficiency.
As we discussed before, FL will help in training ML models from different datasets to protect privacy. Given that various system vendors generate images with markedly different intensity distributions, the authors propose an Unsupervised Domain Adaptation (UDA) approach to address the challenges posed by non-independent and identically distributed (non-IID) data. For the second challenge, they leverage Differential Privacy, which helps perturb the parameters of each local model by purposefully adding noise before uploading them to the aggregation server. To our best knowledge, FL comprises individual models that train on different datasets in various locations and a central server that integrates these updated models into a common model. Typically, local models transmit their updates to the central server a fixed number of times per epoch.
To mitigate the impact of varying local update frequencies, the authors introduce an innovative curriculum learning strategy that establishes a purposeful sequence for training samples. One data scheduler is embedded in this approach to establish prioritization for the training samples. Through the data scheduler, greater priority is given to training samples that are overlooked following the global model’s deployment on the central server. Finally, the experimental findings demonstrate that the data scheduler, by strategically sequencing training samples, enhances the performance of federated learning (FL) and improves domain alignment across domain pairs.
In contrast to [41], which presents a federated learning (FL) framework for breast density classification without addressing domain misalignment, their approach tackles the more complex challenge of breast cancer classification.
On the basis of the discussion above, FL is an advanced method that is used to train machine learning models over distributed resources limited by data privacy and ethical concerns. However, the multi-centric data heterogeneity in the healthcare domain is always challenging for FL. In [47], the authors propose one creative FL strategy, denoted as SiloBN, which introduces the local-statistic batch normalization layers, leading to collaboratively trained models. Evaluations on real-world multi-center datasets demonstrate that the proposed framework achieves comparable or superior intra-center generalization performance compared to existing federated learning (FL) models. Additionally, it not only achieves strong performance and stability, but crucially, it also protects data privacy by not sharing local activation statistics.
Federated learning (FL) is classified into three types: horizontal FL, vertical FL, and federated transfer learning. Current vertical FL approaches face challenges, including constrained neural network architectures, slow convergence, and limited capability to utilize data with non-matching identifiers. In [48], the authors introduce a novel self-taught federated learning (STFL) framework to address these issues, leveraging unsupervised feature extraction for distributed supervised deep learning tasks. Privacy is maintained by transmitting only latent variables to other parties for model training while keeping activation data, weights, and biases stored locally. They evaluate STFL with multiple datasets, including the Breast Cancer Wisconsin Diagnostic Dataset, and the experimental results show that their FL model could help reduce the required training speed and simultaneously maintain one similar level of performance with existing methods. However, the STFL still has problems that need to be improved, such as how to balance privacy protection and learning efficiency.
Computational pathology has been achieving more accurate results with the exceptional performance of ML approaches. Using more diverse data could potentially enhance both the results and accuracy of these models. Moreover, the analysis of whole slide images (WSIs) for pathology purposes essentially faces a heterogeneity issue. Also, using various institutions to adopt a centralized approach could help deploy a better model. However, data centralization endangers the security and privacy of data being transmitted among the institutions [49]. Other disadvantages of these WSIs could be the high cost of transmission and the need for large data storage [50]. In [51], the authors have proposed the application of federated learning to solve the current challenges in the use of WSIs for histopathologic diagnosis [51]. They conducted the first FL approach on computational pathology, where large amounts of WSIs are utilized from multiple institutions. Two main classification problems, including binary and multi-class, are addressed using histopathology breast cancer and kidney real datasets.
Discussion: As we discussed above, many studies have applied federated learning (FL) in breast cancer detection. For instance, Ref. [41] was the first to explore training AI models without centralizing data from multiple breast cancer sources. However, this study did not address issues such as data protection and privacy. Compared to this study, in [42], the authors indicated that the Stochastic Gradient Descent method could help bound the sensitivity of batch-gradient calculation. So, they added the SGD in the DP approach together with one cyclic FL strategy to better preserve the sensitivity and privacy of data. As we know, as the methods of updating parameters, SGD is mainly used for first-order accuracy. In [45], they proposed to use quasi-Newton methods, DFP and BFGS, which are higher-order accuracy methods to improve the communication efficiency and non-iid data in FL. As shown in Table 2, we briefly compare these works in the area of breast cancer.
Table 2.
Comparison of current strategies of federated learning Strategies on breast cancer detection.
5.2. Brain Tumor
A brain tumor refers to an abnormal collection of cells, categorized into four degrees. Tumors classified as Grade 1 and 2 are generally slow-growing and more benign, while those falling under Grade 3 and 4 are malignant cancerous tumors that grow rapidly and present greater challenges for treatment [52]. There are some machine learning techniques for brain tumor segmentation, such as fuzzy C-means, k-means clustering, and Otsu threshold methods. However, these methods raise privacy concerns in the healthcare domain. In the following, we will review federated learning techniques for brain tumor segmentation, considering health data privacy.
Li et al., in [16], proposed an FL-based method for brain tumor segmentation and preserved the privacy of data by bringing models to the data owners and only sharing the intermediate parameters. The authors investigate the feasibility of safeguarding data against leakage by employing differential privacy techniques. By evaluating the FL models on the brain tumor dataset named BraTS, the experimental results show that there must exist some trade-offs between model performance and data privacy protection. Besides that, the models trained with FL approaches can achieve comparable performance compared to models trained with centralized datasets. However, the differences compared to the [42], the authors do not apply SGD, which could help better protect the training examples leaking within the DP approach.
Federated learning (FL) facilitates collaborative training of machine learning models across multiple sources without sharing local data, yet handling non-independent and identically distributed (non-IID) data remains a challenge. In [53], the authors introduce Federated Disentanglement (FedDis) for unsupervised brain pathology segmentation, which separates model parameters into shape and appearance components, sharing only the shape parameters with clients. The core concept of FedDis involves modeling the distribution of healthy brain anatomy by efficiently compressing and encoding scans from multiple institutions, followed by reconstructing the data to closely match the original input. Experimental findings demonstrate that FedDis effectively utilizes scans from diverse sites and databases while preserving privacy.
In [54], the authors present an initial application of federated learning to facilitate collaboration across multiple institutions, allowing deep learning models to be trained without centralizing or exchanging patient data, specifically for brain tumor segmentation tasks. Their quantitative analysis shows that federated semantic segmentation models achieve comparable performance to models trained with fully shared datasets on multimodal brain imaging. However, in this study, they only apply the FL to the ML models without considering domain adaption, data imbalance, and non-IID data.
In [55], the authors demonstrate one efficient federated learning model, SU-Net, for brain tumor segmentation, based on the encoder–decoder infrastructure of U-Net [56]. The SU-Net architecture incorporates inception modules and dense layers to enhance both the width and depth of the network. Inception modules enable the extraction of features at multiple receptive field sizes, contributing to improved classification accuracy. To increase network depth, dense blocks use short connections via feature map concatenation, which promotes feature reuse across layers. Additionally, dropout layers are replaced with batch normalization to further enhance performance. To assess the effectiveness of SU-Net, experiments were performed on the Low-Grade Glioma Segmentation Dataset (“Brain MRI Segmentation”). The model was benchmarked against DeepLabv3+, a cutting-edge segmentation approach, and the conventional U-Net model commonly used in medical image segmentation. Results demonstrate that SU-Net outperforms the compared methods, achieving an AUC of 99.7% and DSC of 78.5%.
Discussion: Federated learning has also been explored in brain tumor detection. Ref. [54] was the first to implement FL for multi-institutional collaboration, training deep learning models on decentralized datasets. However, it overlooked domain adaptation and data imbalance issues. Ref. [16] addressed data privacy concerns by incorporating Differential Privacy to prevent leaks during model training. They explored the use of the Differential Privacy approach to handle the data privacy leaking and the experimental results showed that their model performed very well with trade-offs between performance and privacy protection. In addition, Ref. [53] proposed a completely novel approach named FedDis, which captures the distribution of healthy anatomical structures by learning to compress and encode healthy brain scans from multiple institutions, aiming to reconstruct them as accurately as possible to their original form. As shown in Table 3, we have briefly compared these studies in the area of brain cancer.
Table 3.
Current framework of federated learning, dataset, and result for brain cancer detection.
5.3. Pancreas Cancer
Pancreatic cancer is one of the deadliest forms of cancer, with a high mortality rate due to its late detection and limited treatment options. Deep learning (DL) methods have shown significant potential in medical image detection tasks, particularly in automating segmentation and diagnosis tasks. However, the application of these methods in pancreatic cancer research faces several barriers, including the challenges of obtaining large centralized datasets due to privacy regulations and ethical considerations. Federated learning is proposed to handle these challenges by enabling collaborative model training across multiple institutions while preserving data privacy. For example, in [57], the authors collaboratively generate and evaluate the FL model for pancreatic cancer segmentation, emphasizing data privacy throughout the process. In their study, the authors employ a coarse-to-fine network architecture search framework, enhanced with a variational auto-encoder (VAE) branch attached to the end of the encoder. Experimental findings show that this federated learning approach significantly boosts model generalization on both the server and client sides across the two datasets. This study also marked the first application of FL in pancreatic cancer segmentation, paving the way for the broader adoption of privacy-preserving collaborative models in oncology research.
In [58], the author investigates the application of federated learning (FL) in medical image segmentation, with a focus on segmenting the pancreas and pancreatic tumors from abdominal CT scans. The study highlights the challenges of data heterogeneity, where datasets from different institutions may vary significantly in content—for instance, some datasets include only healthy pancreases, while others contain both healthy and tumor-labeled data. To address these challenges, the authors propose two novel optimization methods adapted from multi-task learning: Dynamic Task Prioritization (DTP) and Dynamic Weight Averaging (DWA). The authors evaluated their methods using three pancreas datasets to simulate three heterogeneous clients. Experimental results revealed that FL global models significantly outperformed standalone models trained locally on each dataset. Among the proposed methods, DWA demonstrated superior performance, particularly for smaller datasets like Synapse, and outperformed standard FL algorithms such as FedAvg and FedProx. DTP also improved segmentation by focusing on harder tasks but required extensive hyperparameter tuning to achieve optimal results.
Discussion: Ref. [57] used FL with a coarse-to-fine network and variational auto-encoder (VAE) to improve generalizability across datasets. Ref. [58] introduced Dynamic Task Prioritization (DTP) and Dynamic Weight Averaging (DWA) to address data heterogeneity and enhance model aggregation, achieving better performance with unequal client data. Both studies highlight FL’s ability to overcome challenges such as limited annotated data, varying imaging protocols, and the computational cost of centralized training. However, FL’s success relies on careful model configuration and hyperparameter tuning.
5.4. Skin Cancer
As we know, skin cancer has been regarded as one of the most dangerous cancers all over the world. The advancement of deep learning has surpassed traditional methods in image detection tasks, contributing to early diagnosis and ultimately lowering mortality rates associated with skin cancer. However, due to privacy and ethical issues, it is difficult to collect large amounts of data from multiple institutions. Federated learning enables the training of machine learning models in a distributed, privacy-aware fashion but typically relies on annotated data from clients—an often scarce and costly resource. To address this challenge, Ref. [59] introduces FedPerl, a semi-supervised federated learning approach that draws on peer learning concepts from social sciences and integrates ensemble averaging from committee machines. This strategy forms learning communities where participants collaboratively generate higher-quality pseudo labels. Moreover, FedPerl incorporates a peer anonymization (PA) mechanism designed to preserve user privacy, cut down communication overhead, and sustain performance without introducing extra complexity. Experimental results on four public datasets reveal that FedPerl outperforms baseline models and existing semi-supervised federated learning (SSFL) techniques by margins of 15.8% and 1.8%, respectively. The method also demonstrates increased robustness to noisy clients.
Al-Rakhami et al. [60] propose a federated deep convolutional neural network (DCNN) architecture for skin cancer diagnosis. This architecture combined convolutional and pooling layers to extract relevant features from skin lesion images, achieving high diagnostic accuracy while ensuring data privacy. The study emphasized the effectiveness of FL in developing robust diagnostic models without the need for centralized data storage. In [61], the authors propose a privacy-preserving approach to skin cancer detection using asynchronous federated learning integrated with convolutional neural networks (CNNs). Their strategy enhances communication efficiency by separating CNN layers into shallow and deep components, updating the shallow layers more frequently. The approach demonstrated improved accuracy and communication efficiency in skin cancer diagnosis, highlighting the potential of FL in resource-constrained healthcare settings.
Discussion: The integration of federated learning into skin cancer detection frameworks presents a promising result for enhancing diagnostic accuracy while addressing critical concerns related to data privacy and security. The reviewed studies demonstrate that FL achieves performance similar to centralized models. However, challenges such as heterogeneous data distributions and the complexity of asynchronous updates may impact model performance. Ensuring communication efficiency and robustness across diverse datasets remains a critical consideration.
5.5. Cancer Study in Histology
To the best of our knowledge, histopathology remains the definitive standard for diagnosing various cancers, such as breast cancer, brain cancer, and others. However, AI-assisted histopathology analysis approaches still require improvement in several areas. For example, datasets from multiple institutions characterized by privacy regulations need robust, privacy-preserving collaborative training.
Nowadays, even though AI methods have achieved ideal performance in the area of analysis of histopathology detection, they still heavily rely on domain experts’ prior knowledge to select reference templates. Since the Generative Adversarial Networks can largely enable an end-to-end learning-based normalization and then convert normalization into one style-transfer problem and the FL has been proved that it could help implement robust data-private collaborative training from multiple data centers, so in [62], they propose a novel generative adversarial network with one orchestrating generator with FL together to further preserve data privacy and security. Evaluations confirm that the proposed model outperforms various color normalization techniques, enhancing histopathology detection performance. In [63], the authors integrate federated learning (FL) and Generative Adversarial Networks (GANs) to enhance AI-assisted histopathology analysis while preserving data privacy. They introduce a federated deep learning approach for tumor detection in colon histopathology images, demonstrating improved accuracy without compromising patient confidentiality. Howard et al. [64] developed a generative adversarial network, HistoXGAN, capable of reconstructing representative histology images from various cancer types. They evaluated HistoXGAN across 29 cancer subtypes, demonstrating that the reconstructed images effectively preserve critical information about tumor grade, histologic subtype, and gene expression patterns. This approach facilitates the generation of high-quality synthetic data, aiding in training robust diagnostic models.
Discussion: The combination of FL and GANs in histopathology advances AI-assisted cancer diagnostics by leveraging decentralized learning across institutions and generating synthetic histopathology images. Ref. [64] facilitated the creation of synthetic images for training, particularly when annotated data are scarce. While FL’s decentralization improves model robustness, the quality of GAN-generated images must be ensured to prevent negative impacts on model performance. Future work should focus on enhancing FL protocols, improving synthetic image fidelity, and integrating these technologies into clinical workflows.
5.6. Lung Cancer
People tend to have lung nodules, which are usually cancerous. However, such nodules could be malignant, causing lung cancer. As a result, it is important to efficiently detect and diagnose them. Basically, these nodules maintain a quite small size, which could be conflicted with any biological structures with respect to size and shape. Moreover, lung nodules could be mistakenly identified as tuberculosis. This requires practitioners to conduct further tests to ensure the object is a lung nodule. In case the nodule is malignant, this could be very dangerous to the patient due to the delay in detecting lung cancer, resulting in a decrease in the survival rate of the patient by 67% [65]. Previously, different traditional ML models have been deployed for detecting these nodules. However, achieving high accuracy requires large dataset training, which is not compatible with the patients’ privacy. To address this problem, Baheti et al. [66] developed two imaging algorithms within a federated learning setup to detect lung nodules. FL itself enables training the data in a decentralized manner, which preserves the privacy of patients. Basically, the first model was developed using Vnet 3D in order to detect the nodules. The second model was deployed for its confirmation using Resnet architecture. Overall, a classification of images was conducted based on being nodular or non-nodular. The models presented acceptable results with rounded accuracy of 91% and 98% for the first and second models, respectively.
Moreover, one of the main challenges in developing ML models is that the data are heterogeneous and especially limited in amount. Training at various institutions containing larger datasets could be a great solution to this particular need. However, training such data at different institutions could result in a high cost of network usage. With respect to these challenges and the importance of patient data protection, the authors in [67] proposed an FL implementation based on single and cyclical weight training. To securely work with the data, the authors deployed various security toolkits from Microsoft. Moreover, two datasets related to the tobacco and radon metrics are utilized for evaluating the FL models within those two medical institutions. The chances of lung cancer could be increased by these metrics. As a result, the model was basically evaluated based on predicting or diagnosing lung cancer or chronic obstructive pulmonary disease (COPD) [67].
In addition to the lung nodules, tobacco and radon are two other metrics that could enhance the chance of lung cancer. The authors in [67] proposed an FL implementation based on two medical institutions. The main approach considered two types of simulated and real-time environments using the Microsoft Azure cloud-based platform. The FL setup was based on two ML models, including ANN and Logistic Regression.
Discussion: FL has the potential to revolutionize lung cancer detection, especially for distinguishing small and similar nodules. Recent research [66,67] has shown that federated learning (FL) enables model training on distributed datasets while mitigating privacy risks. Nevertheless, issues such as data heterogeneity, computational overhead, and optimization challenges persist. Future research could explore adaptive FL strategies and advanced model designs to improve robustness and generalization.
5.7. Thyroid Cancer
Federated learning (FL) is a decentralized machine learning paradigm that addresses medical data privacy regulations while enhancing the generalization of deep learning models. By sharing only model parameters during training, FL reduces systemic privacy risks, eliminating the need to transfer existing medical datasets. In [68], an ultrasound image analysis was conducted using federated learning (FL) to classify thyroid nodules as benign or malignant. The primary objective was to compare FL’s performance against conventional deep learning. A dataset of 8457 ultrasound images from six institutions was utilized for both FL and conventional deep learning, employing five neural network architectures: VGG19, ResNet50, ResNext50, SE-ResNet50, and SE-ResNext50. For internal validation, 20% of the images (1075 malignant, 616 benign) were selected via stratified random sampling. External validation was performed using 100 ultrasound images (50 malignant, 50 benign) from a separate institution [68].
Xiang et al. [69] introduce the MAUNet network, a federated learning-based model incorporating multi-attention guided techniques to improve segmentation accuracy and generalization. MAUNet employs UNet as its backbone, integrating a Multi-Scale Contextual Attention (MSCA) module to address data variations across centers and a Dual Attention (DA) module to enhance feature extraction through the Sobel operator and hybrid dilated convolutions. Experimental results on datasets from 17 hospitals demonstrate that MAUNet outperforms existing methods in segmentation accuracy, robustness, and adaptability to noisy and heterogeneous data.
Discussion: FL’s application to thyroid cancer diagnosis ensures privacy-preserving collaboration among institutions. While MAUNet [69] highlighted its success, issues like noise sensitivity and basic aggregation methods like FedAvg suggest room for improvement. Future research should explore adaptive optimization techniques and integrate advanced attention mechanisms, such as self-attention, to enhance robustness and scalability.
5.8. Cervical Cancer
As FL attempts to enhance data protection, multiple parties should participate in collaborating with others by only sending parameters of models or encrypted data. Three main types of FL are Horizontal FL(HFL), Vertical FL (VFL), and Federated Transfer Learning techniques, which are basically focused on the parties’ and models’ participation. The authors in [70] deployed HFL and VFL to calculate the collaboration of different parties. For HFL, each party participated in performing a part of the training. In addition to that, a detection method for capturing the instance effectiveness among all the parties was developed. Moreover, VFL was deployed along with Shapely Values [71] to efficiently consider the feature importance. Moreover, a credit allocation for each party was achieved toward deploying a more efficient model. The authors adopted the Support Vector Machine (SVM) to train and evaluate their algorithm based on a classification task, which is predicting the possibility of cervical cancer among women. Finally, it is claimed that this model could be deployed in various domains as an FL tool. Joynab et al. [72] propose CNN-based FL architecture to demonstrate the effectiveness of integrating federated learning (FL) with deep learning algorithms. The proposed CNN-based FL architecture significantly outperformed classical ML models, highlighting the potential of FL in the classification of cervical cancer cells. The proposed model achieved test accuracies of 94.36% and 78.43% in IID and non-IID settings.
Discussion: FL offers an effective solution for enhancing data privacy in cervical cancer diagnosis. The studies [70,72] demonstrated that FL outperforms traditional ML methods. However, they also highlighted challenges such as data privacy and optimization. Future work should investigate techniques like differential privacy and secure multi-party computation to further strengthen data confidentiality. Incorporating diverse datasets and pre-trained models could also improve FL’s applicability and robustness.
5.9. Prostate Cancer
Deep Learning techniques in the context of healthcare are limited to training large datasets. This enhances the essential need for distributed learning techniques, which aim to provide better performance compared to traditional models. Federated learning, one of the main distributed learning techniques, attempts to transfer the learned weights (not data) from institution to institution and improves privacy. With respect to the massive amount of available data among medical institutions, there is a critical need for developing such models to prevent using or creating pooled datasets. As a result, Sarma et al. deployed a practical FL to efficiently train data from radiological institutions under a decentralized model [73]. They have demonstrated the great benefits of FL for securely training data at three academic institutions. The authors evaluated their model using private and public datasets containing MRI images from three specific institutions. The research was conducted to perform a diagnosis of prostate cancer based on whole image segmentation. In addition to FL, private deep learning models were also deployed to demonstrate the effectiveness of the FL model on the private and public datasets [73].
In a related study, Ref. [74] introduced a variation-aware federated learning (VAFL) framework to reduce client-specific variations by mapping images from all clients into a unified image space. Initially, a client with the least complex data are chosen to establish the target image space, and a privacy-preserving generative adversarial network (PPWGAN-GP) generates a set of synthetic images. A subset of these images, which accurately represent the raw images’ features while remaining distinct from them, is selected for sharing across clients. Each client then employs a tailored CycleGAN to transform its raw images into the target image space defined by the shared synthetic images, thereby mitigating cross-client variability while preserving privacy. The framework was applied to the automated classification of clinically significant prostate cancer using decentralized multi-source apparent diffusion coefficient (ADC) image data. Experimental results show that the VAFL framework consistently surpasses the performance of existing horizontal federated learning approaches [74].
Discussion: FL is particularly valuable for diagnosing prostate cancer using decentralized datasets, as demonstrated by [73]. By leveraging private and public datasets, FL maintains privacy while training models across multiple institutions. However, the potential for model inversion attacks remains, and future work should explore privacy-enhancing techniques to address this vulnerability. Despite this, FL represents a significant improvement over traditional centralized data-sharing methods.
5.10. Colorectal Cancer
Colorectal cancer ranks as the fourth leading cause of cancer-related mortality. Classifying colorectal cancer poses a significant challenge for pathologists, with colorectal polyps frequently mistaken for malignant tumors. In [75], the authors propose a federated neural style transfer (FNST) algorithm based on federated learning to synthesize data to address the problem of highly imbalanced datasets and complete the task of image classification of colorectal cancer. They used the publicly available Chaoyang CRC imaging dataset to obtain the result. In the experiment, the performance improvement of synthesized images was observed by comparing the use of FNST-synthesized images with original image data in federated learning (FL). Three experimental architectures were introduced: Single Learning (SL), Centralized Learning (CL), and federated learning (FL). In SL, each participating collaborator trains a model solely on its local data without inter-collaborator communication. In CL, all collaborator data are aggregated on a single system, where a deep learning (DL) model is trained on the combined dataset, typically yielding the highest performance. The experimental results show that the performance of the enhanced data model synthesized using FNST has been improved, and the performance of FNST-synthesized data based on the FL architecture far surpasses the other two architectures.
In [76], the authors develop a federated learning (FL)-based model for classifying histopathological images to efficiently detect colorectal cancer while ensuring high prediction accuracy. FL addresses the challenge of maintaining data privacy by leveraging vast and heterogeneous datasets from multiple healthcare facilities without requiring data centralization. Recognizing the critical role of large-scale patient data in improving system accuracy, the experiment utilized an extensive dataset comprising cancerous and non-cancerous colorectal tissue images. Additionally, FL reduces costs associated with traditional machine learning (ML) approaches by enabling decentralized training. They implement various convolutional neural network (CNN) models, including VGG, InceptionV3, ResNet, and ResNeXt were evaluated for precision. ResNeXt50 achieved the highest accuracy of 99.53% on centralized data. When integrated with FL, ResNeXt50 maintained robust performance, achieving an accuracy of 96.045% and an F1 score of 0.96, demonstrating its effectiveness in decentralized and privacy-preserving settings.
Discussion: FL has proven effective in classifying colorectal cancer histopathological images [75,76]. However, challenges such as computational variability and throughput limitations persist in real-world deployments. Future improvements, such as incorporating blockchain technology, could enhance security, data traceability, and scalability, facilitating broader integration into clinical workflows for more accurate colorectal cancer diagnostics.
6. Comparative Analysis of Federated Learning Approaches in Oncology
Federated learning (FL) has gained traction in oncology research as a privacy-preserving alternative to centralized machine learning models. Various FL methodologies have been proposed to address challenges in data heterogeneity, security, and performance. Table 4 provides a comparative analysis of different FL approaches applied to oncology, highlighting their architecture, privacy-preserving mechanisms, performance, and challenges.
Table 4.
Comparative analysis of FL approaches in oncology.
In terms of FL architecture, centralized approaches like FedAvg and FedProx are widely used due to their simplicity and efficiency in aggregating models. However, they face scalability challenges and struggle with non-IID (Independent and Identically Distributed) data, which can degrade model performance when data distributions vary across institutions. Decentralized and hybrid architectures, such as Blockchain-based FL and Transfer Learning in FL, enhance security and adaptability by reducing reliance on a central aggregator. However, these methods introduce higher communication and computational overhead due to increased synchronization and consensus mechanisms.
Regarding privacy-preserving techniques, Differential Privacy (DP) enhances data protection by adding controlled noise to gradients or model updates during training, reducing the risk of data leakage. However, this introduces a trade-off between privacy and model accuracy, as excessive noise can impact learning efficiency. Homomorphic Encryption (HE) ensures data remains encrypted throughout computations, offering strong cryptographic security, but its high computational cost limits practicality for real-time FL applications. Blockchain-based FL strengthens model integrity and tamper resistance by maintaining immutable logs of updates, yet it demands significant computational resources and energy, raising concerns about feasibility in resource-constrained environments.
To better illustrate the trade-offs of different FL approaches, Table 5 provides a comparative analysis highlighting their advantages and limitations:
Table 5.
FL approaches: advantages and limitations.
In terms of performance and challenges, FedAvg, despite its widespread adoption, struggles with non-IID data, leading to slow convergence and suboptimal results in heterogeneous medical datasets. Techniques like FedProx help mitigate this by incorporating regularization terms to stabilize training. Personalized FL addresses client heterogeneity by tailoring models to individual institutions, improving adaptability but increasing computational complexity. Transfer Learning in FL improves generalization across datasets by leveraging pre-trained models, but its success depends on effective domain adaptation methods, such as adversarial training or feature alignment.
The selection of the most suitable FL approach in oncology research depends on the specific requirements of the application. When privacy is the primary concern, Homomorphic Encryption-based FL or DP-based FL may be preferred despite their higher computational costs. For scalable solutions, FedProx or Personalized FL offers better adaptability to heterogeneous cancer datasets. If auditability and security are critical, Blockchain-based FL provides transparency and tamper-resistant model updates across institutions.
Future research should focus on developing hybrid FL models that balance privacy, computational efficiency, and robustness to non-IID data. Additionally, enhancing model interpretability through explainable AI techniques and ensuring regulatory compliance (e.g., HIPAA, GDPR) will be crucial for the broader adoption of FL in clinical oncology.
7. Challenges
There are multiple challenges associated with FL’s deployment in a real-world healthcare setting. The main challenges of FL are data heterogeneity, label deficiency, domain shifts, data privacy, and communication costs. We will describe each of these challenges in this section.
7.1. Data Heterogeneity
One of the key challenges in the federated learning (FL) environment that limits its application to real-world scenarios is data heterogeneity. This issue arises when data are produced by different collaborators or users on diverse devices, scanners, or protocols, leading to variations in statistical distributions. As a result, these differences can introduce a drift in the FL learning process, causing non-independent and identically distributed (non-iid) data, which can ultimately affect the performance and accuracy of FL models [29].
Several approaches have been proposed to address this challenge in the healthcare domain. For example, the authors in [82] introduced the HarmoFL model to mitigate both local and global drifts in FL when working with heterogeneous medical image data. Their approach focuses on harmonizing the feature space across local clients and reducing local update drift. To achieve this, they developed a client weight perturbation strategy, which helps to converge toward a flat optimum. This, in turn, improves the optimization of the global model by aggregating local optima effectively.
However, despite the progress made with methods like HarmoFL, challenges persist in achieving consistent model performance across highly heterogeneous datasets in real-world healthcare applications. The methods for harmonizing client data remain limited, particularly when scaling to larger datasets that vary significantly across medical institutions, devices, or patient populations. Moreover, harmonization techniques such as those used in HarmoFL may not fully address the complexities introduced by extreme heterogeneity, including variations in imaging protocols or data missingness.
7.2. Label Deficiency
A decentralized approach like FL suffers from label deficiencies, which result in performance degradation. Especially in real-world medical image datasets, label deficiency is a prominent problem. Label deficiency can occur when some sites do not have the bandwidth or incentives to complete labor-intensive data labeling, so only a small percentage of available images are labeled. In the healthcare domain, a variety of approaches have been proposed to address this issue. The problem with many of these methods is that they assume that the data are centralized, whereas label deficiency is a more significant issue at the edge than in a centralized system [83]. Traditional centralized approaches may not effectively address the unique complexities of FL, where clients may have sparse or incomplete labels. There have been many strategies proposed for addressing label deficiencies in federated learning within the healthcare industry. Yan et al. [84] have proposed a robust training self-supervised FL model to address label deficiency for medical imaging. The framework facilitates collaborative training of models on decentralized data, employing masked image modeling as the self-supervised task. Also, it shows significant resilience to non-IID data distribution among clients. Despite the progress made by methods like Yan et al.’s, the issue of label deficiency in FL for healthcare remains underexplored. The challenge lies in the fact that most existing solutions are limited to certain data types or assume ideal conditions of data availability.
7.3. Non-IID (Non-Independent and Identically Distributed)
In federated learning (FL), data distributed across different clients are often heterogeneous and non-IID (non-independent and identically distributed). This means that the data distributions can vary significantly from one client to another, which is particularly evident in applications like oncology, where each medical institution may have distinct patient populations, diagnostic tools, and disease prevalence. The heterogeneity in data distribution can negatively affect the performance of the global model, as traditional aggregation techniques in FL typically assume IID data. When the underlying data distributions differ, the model may struggle to generalize, leading to suboptimal performance and inaccurate predictions.
Traditional FL algorithms assume IID (independent and identically distributed) data, where each client contributes equally to the learning process. However, in real-world medical applications, such an assumption does not hold. For instance, some hospitals may specialize in certain types of cancer, while others may primarily treat patients from specific age groups or geographic regions. Consequently, model drift occurs, where the global model becomes biased toward institutions with dominant data distributions, leading to suboptimal performance for underrepresented hospitals.
To address the challenges posed by non-IID data, several recent advancements have been proposed. One approach is personalized federated learning, which focuses on customizing the global model for each client to better handle the unique characteristics of their local data. This strategy allows for a more tailored model, improving performance for individual clients without compromising the privacy of their data. Another promising approach is hierarchical federated learning, where clients are organized into groups based on similarities in their data. This clustering facilitates more effective aggregation strategies, as clients within the same group tend to have more similar data distributions. Finally, domain adaptation techniques aim to adapt the global model to the various data distributions across clients, ensuring that the model can generalize better across different domains. These strategies are particularly relevant for healthcare applications, where data distributions are often diverse due to varying clinical practices and patient demographics. By incorporating a detailed discussion of these techniques, particularly in the context of oncology, the challenges associated with non-IID data in FL can be better understood and addressed, thus improving the robustness and applicability of federated learning in this field.
Despite these advancements, there is no single solution that fully resolves the challenges associated with non-IID data in FL for oncology. Balancing personalization, generalization, and computational efficiency remains an ongoing research challenge, highlighting the need for further innovation in this field.
7.4. Domain Shift
It is important to note that medical data are generated by a variety of institutions using multiple technologies for a variety of patients with complex diseases, which may lead to differences in the distribution of training and testing data in clinical practice, resulting in the problem of domain shift when deploying algorithms trained in a single domain [46]. Some researchers have proposed federated domain adaptation approaches that extend domain adaptation to federated setting constraints to address domain shifts more effectively [85]. Lu et al. [86] proposed a FedAP framework to tackle domain shifts. FedAP is a weighted, personalized federated transfer learning algorithm designed for healthcare applications, leveraging batch normalization to derive tailored models for individual clients. It captures client similarities by analyzing batch normalization layer statistics while maintaining client-specific characteristics through distinct local batch normalization. Evaluations across five healthcare benchmarks demonstrate that FedAP outperforms conventional federated learning (FL) methods in accuracy and convergence speed. This approach presents a promising solution to domain shift issues in healthcare FL. However, while FedAP offers impressive performance, it is crucial to consider whether this approach can be scaled across a broader range of medical datasets or adapted to more complex medical conditions.
7.5. Data Protection
The privacy of data is one of the most significant concerns in federated learning applications. Federated learning (FL) represents an initial approach to safeguarding device-generated data by exchanging model updates, such as gradients, rather than transmitting raw data stored on individual devices. However, in some circumstances the attacker can steal sensitive data throughout the training process [32]. One notable threat is gradient inversion attacks, where attackers exploit shared gradients to reconstruct sensitive data. Although these gradients are aggregated and anonymized, sophisticated attacks can still infer diagnostic information or even patient identities. To mitigate such risks, methods like differential privacy can be employed, adding noise to gradients to obscure sensitive information. Another risk is membership inference attacks, in which adversaries attempt to determine whether a specific patient’s data were included in the training process. This is particularly concerning in oncology, where patient records contain highly sensitive medical details. These attacks are made possible by exposing model parameters or gradients and can be mitigated using differential privacy or federated averaging with noise to reduce the accuracy of attackers’ inferences.
Additionally, model poisoning attacks present a serious challenge in FL systems. In these attacks, malicious participants deliberately submit faulty updates to the model, which can degrade its performance or introduce biases. This occurs when attackers manipulate gradients during the training process, potentially affecting the global model’s reliability. For example, if an attacker skews the model toward misdiagnosing certain demographic groups, it could lead to inequities in cancer detection and treatment. To counter this, techniques like secure aggregation can be used to aggregate model updates without revealing individual contributions, preventing direct manipulation. Robust aggregation strategies can also weigh updates based on trustworthiness, minimizing the impact of poisoned updates. While federated learning offers enhanced privacy, these potential vulnerabilities underscore the importance of employing strong privacy-preserving techniques and balancing privacy with model performance and security.
Privacy-preserving techniques are essential in mitigating the risks associated with federated learning, particularly when balancing privacy with model performance. Recent methods such as Homomorphic Encryption (HE) [18] or Differential Privacy (DP) [87] aim to enhance data privacy in federated learning. Differential Privacy (DP) is a technique that involves adding noise to gradients or model updates to prevent attackers from inferring sensitive information about individual data points. While DP offers strong privacy protection, it often comes with a trade-off in model accuracy. The degree of privacy is governed by the privacy parameter (), where lower values enhance privacy but may lead to a larger drop in accuracy. Different noise mechanisms, such as Gaussian or Laplacian noise, can be applied depending on the dataset and model characteristics. However, the noise introduced by DP can hinder the model’s ability to capture subtle patterns, especially in complex, high-dimensional datasets, affecting overall performance.
Homomorphic Encryption (HE), which allows computations on encrypted data without requiring decryption. This ensures that sensitive information remains private during model training, enabling secure aggregation of model updates in federated learning. However, while HE provides robust privacy guarantees, it also comes with significant computational challenges. Fully homomorphic encryption (FHE) is computationally intensive and may not be practical in resource-constrained environments. On the other hand, partially homomorphic encryption (PHE), which supports only specific operations, may provide a middle ground between privacy and efficiency. The main trade-off with HE is the high computational overhead, which can lead to delays in training and increased communication costs, particularly in federated learning applications where devices with limited resources must perform computations in real time. The author in [18] proposed a novel privacy-preserving federated learning mechanism for skin cancer detection. They applied a masking scheme based on homomorphic encryption and secure multi-party computation to protect private medical data against inference attacks in a federated learning system.
Despite these advancements in privacy-preserving techniques, ensuring robust security while maintaining model accuracy and efficiency remains a major challenge. Oncology applications require a delicate balance between privacy protection, computational feasibility, and model performance, highlighting the importance of continued research in secure federated learning frameworks.
It is important to acknowledge that this paper is a review of existing privacy-preserving techniques in federated learning, with a particular focus on oncology applications. Due to the nature of this work, we do not provide empirical validation or comparative benchmarks with traditional machine learning methods. Instead, we offer a comprehensive discussion of potential attacks, privacy-preserving techniques, and their trade-offs. Evaluating these techniques against traditional machine learning methods remains an open research area that warrants further investigation. Future studies should focus on empirical comparisons to establish clear benchmarks for performance, privacy, and security in federated learning frameworks.
7.6. Communication Cost
Communication costs are a major concern in federated learning (FL) networks, particularly due to the high number of connected devices and the necessity of frequent model updates across decentralized systems [88]. Unlike traditional centralized learning approaches, where data are transferred to a central server for training, FL requires model updates to be exchanged between clients and servers while keeping raw data stored locally. This decentralized approach is essential for preserving privacy but introduces significant communication overhead. A federated network typically consists of a vast number of smartphones, medical devices, and Internet of Things (IoT) devices, all of which have limited computational resources, including bandwidth, energy, and power [89]. As a result, communication within the network can become a bottleneck, making it challenging to implement large-scale FL models efficiently. Addressing this issue is critical to ensuring that FL remains practical for real-world applications, especially in resource-constrained environments such as healthcare, where timely model updates can directly impact patient outcomes. To tackle this challenge, researchers have proposed various communication-efficient FL methods that aim to optimize the trade-off between model performance and resource consumption. One such approach is presented in [90], where the authors developed a privacy-preserving FL framework specifically designed for the Internet of Medical Things (IoMT) devices. Their method leverages local fog nodes to enhance data privacy while simultaneously minimizing energy consumption. Evaluations showed that the proposed framework achieved a 41% reduction in energy usage, underscoring the efficacy of communication-efficient federated learning (FL) approaches for medical applications.
While these advancements are promising, further research is needed to develop more adaptive and scalable solutions that optimize communication efficiency without compromising model accuracy.
8. Future Directions
After a critical review of several challenges in the previous sections, future directions are provided for some of them. There are some possible future work directions that are worth exploring in order to solve the challenges mentioned previously.
8.1. Solving Medical Data Heterogeneity Issues of FL Systems
To address the challenge of medical data heterogeneity in federated learning, future research should focus on developing adaptive optimization techniques that can dynamically adjust to the varying data distributions across clients. There are several key directions to handle the issue, such as asynchronous communication and active device sampling [91]. The asynchronous communication technique parallelizes iterative optimization algorithms, which allow for parallelization and optimization under non-IID conditions. A well-defined research agenda could focus on developing algorithms that dynamically adapt communication protocols in response to data heterogeneity, thereby minimizing reliance on centralized coordination [92]. In order to solve heterogeneity issues, the FL active device sampling or participant selection method is becoming increasingly popular. In this technique, the devices are chosen to actively participate in each training round to ensure maximum update aggregation [93]. An experimental comparison of various aggregation strategies tailored for healthcare data could provide valuable insights into their effectiveness across different client configurations.
8.2. Privacy Protection Model Based on Device-Specific Restrictions
Additionally, due to the heterogeneity of various devices within the network, their privacy restrictions have varying characteristics, so it is necessary to define the privacy restrictions of batch devices in a more detailed manner to ensure a strong level of privacy protection for specific samples. Therefore, it is an open research issue that future work could focus on developing privacy protection methods based on device privacy restrictions [94].
Given the varying privacy restrictions across devices in a federated learning network, future work should focus on the development of device-specific privacy protection frameworks. This could involve integrating existing privacy-preserving techniques, such as differential privacy or homomorphic encryption, with new strategies that account for device capabilities. A potential research direction is to design dynamic privacy models that adjust the level of privacy protection based on the device’s hardware and data sensitivity. For example, more powerful devices could provide stronger privacy guarantees without compromising performance, while devices with limited resources could adapt to a more lightweight privacy model. This research agenda could include designing algorithms that provide both fine-grained control over privacy settings and quantifiable performance trade-offs, ensuring that privacy is maintained without significant loss of model utility.
8.3. Addressing Label Scarcity with Novel Semi-Supervised and Unsupervised Learning Approaches
The majority of federated learning frameworks focus on a label-sufficiency scenario, where each client is provided with fully labeled data before they begin learning. In fact, most of the federated learning research relies heavily on supervised or semi-supervised methods [95]. However, in real-world scenarios, clients may not have sufficient labels or lack interaction between users to provide interactive labels due to the lack of expertise and motivation of the clients to label their own data. Therefore, the label scarcity problem makes federated learning impractical in many scenarios. The idea of keeping private data on the device is fantastic; however, taking label deficiencies into consideration is critical in a realistic situation [96]. A specific research direction could involve the integration of self-supervised learning techniques into federated learning, allowing clients to leverage unlabeled data to pre-train models and then fine-tune them with a small set of labeled data. Additionally, active learning methods could be employed to intelligently select which data points need labeling, thus reducing the overall need for labeled data. A clear agenda could include testing these approaches in medical domains, comparing them against traditional fully supervised FL methods, and quantifying the trade-off between model performance and labeling effort.
8.4. Managing Domain Shift
Digital Imaging and Communications in Medicine (DICOM) and Picture Archiving and Communication System (PACS) are standardized frameworks for managing and storing medical imaging data. However, differences in imaging protocols and equipment across institutions can introduce variability [97]. Also, different healthcare institutions may use different image acquisition processes and hardware, which can affect FL models’ performance [98]. For instance, stain heterogeneity in cancer image analysis can be an issue as various institutions use a variety of staining methods. To address this issue, future research should focus on the development of domain adaptation techniques, such as adversarial training or deep domain confusion, to enhance the ability of FL models to handle the increasing complexity and variability of healthcare data across institutions. A specific research agenda could involve testing unsupervised domain adaptation algorithms that adapt a global model trained on one set of data to another institution’s domain without requiring access to sensitive data. This could be complemented by domain-invariant feature learning methods that ensure robustness to shifts in medical data characteristics, such as variations in imaging modalities or staining techniques. Such methods could be tested on large-scale datasets from different healthcare institutions, with a clear focus on improving model performance across diverse domains.
It is, therefore, possible to consider histopathological images as a more promising direction for the future [99].
8.5. Optimizing Communication in Federated Learning Systems
Federated architectures often suffer from high communication overhead due to the transmission of large model parameters. For instance, communication bottlenecks in FL networks can arise when numerous clients, such as smartwatches and health gadgets, are involved in the training process [100]. These bottlenecks occur because devices need to download models from the server during downlink communication, and FL clients must upload their model parameters to the central server after training during uplink communication. Given the inherent communication challenges in FL, especially in medical applications, future research should focus on developing communication-efficient FL protocols that reduce both the volume of transmitted data and the number of communication rounds. A promising research agenda could involve exploring model compression techniques such as federated pruning and quantization, which can significantly reduce model size while maintaining accuracy. Additionally, investigating multi-level communication strategies that combine local model updates with aggregated global models could optimize the trade-off between communication overhead and model accuracy. Furthermore, benchmarking frameworks could be developed to assess the impact of these communication strategies on model performance and scalability, particularly in scenarios involving large numbers of clients or high-dimensional medical data. One potential avenue for research is optimizing communication bandwidth by reducing the number of uplink communication rounds [101].
9. Conclusions
The field of federated learning is continuously expanding, and in privacy-preserving scenarios where direct access to medical data is not possible, FL has gained prominence as a decentralized learning approach for medical applications. This study provides a comprehensive review of contemporary FL methods applied to the diagnosis of various cancers in the human body. The article comprehensively reviews, analyzes, and categorizes the methodologies used for different types of cancer diagnoses while also identifying and discussing existing limitations in these approaches. The review presented nine types of cancer, which are breast cancer, brain tumor, pancreas cancer, skin cancer, lung cancer, thyroid cancer, cervical cancer, prostate cancer, and colorectal cancer. We also define some challenges and future research directions.
Author Contributions
Conceptualization, M.N., S.P. and F.M.; methodology, M.N., S.P., R.M.P., M.H., F.M., Y.X., L.L. and D.M.B.; investigation, M.N.; writing—original draft preparation, M.N.; writing—review and editing, M.N., S.P., R.M.P., M.H., F.M., Y.X., L.L. and D.M.B.; supervision, S.P. and D.M.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research is part of the INCT of the Future Internet for Smart Cities funded by CNPq proc. 465446/2014-0, Coordenação de Aperfeiçoamento de Pessoal de Nível Superior—Brasil (CAPES)—Finance Code 001, FAPESP proc. 14/50937-1 and proc. 15/24485-9. It is also part of the FAPESP proc. 21/06995-0. This research was additionally funded by the National Key Research and DevelopmentProgram of China under Grant No.2023YFB2704400.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Elgendy, N.; Elragal, A. Big data analytics: A literature review paper. In Proceedings of the Industrial Conference on Data Mining, St. Petersburg, Russia, 16–20 July 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 214–227. [Google Scholar]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Harrington, P. Machine Learning in Action; Simon and Schuster: New York, NY, USA, 2012. [Google Scholar]
- Ghoddusi, H.; Creamer, G.G.; Rafizadeh, N. Machine learning in energy economics and finance: A review. Energy Econ. 2019, 81, 709–727. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef]
- Zantalis, F.; Koulouras, G.; Karabetsos, S.; Kandris, D. A review of machine learning and IoT in smart transportation. Future Internet 2019, 11, 94. [Google Scholar] [CrossRef]
- Wiens, J.; Shenoy, E.S. Machine learning for healthcare: On the verge of a major shift in healthcare epidemiology. Clin. Infect. Dis. 2018, 66, 149–153. [Google Scholar] [CrossRef] [PubMed]
- Mahdavinejad, M.S.; Rezvan, M.; Barekatain, M.; Adibi, P.; Barnaghi, P.; Sheth, A.P. Machine learning for Internet of Things data analysis: A survey. Digit. Commun. Netw. 2018, 4, 161–175. [Google Scholar] [CrossRef]
- Sun, W.; Cai, Z.; Li, Y.; Liu, F.; Fang, S.; Wang, G. Data processing and text mining technologies on electronic medical records: A review. J. Healthc. Eng. 2018, 2018, 4302425. [Google Scholar] [CrossRef]
- Bhardwaj, R.; Nambiar, A.R.; Dutta, D. A study of machine learning in healthcare. In Proceedings of the 2017 IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), Turin, Italy, 4–8 July 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 2, pp. 236–241. [Google Scholar]
- Erickson, B.J.; Korfiatis, P.; Akkus, Z.; Kline, T.L. Machine learning for medical imaging. Radiographics 2017, 37, 505–515. [Google Scholar] [CrossRef]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef]
- Wong, D.; Yip, S. Machine learning classifies cancer. Nature 2018, 22, 446–447. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Bakas, S.; Reyes, M.; Jakab, A.; Bauer, S.; Rempfler, M.; Crimi, A.; Shinohara, R.T.; Berger, C.; Ha, S.M.; Rozycki, M.; et al. Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge. arXiv 2018, arXiv:1811.02629. [Google Scholar]
- Li, W.; Milletarì, F.; Xu, D.; Rieke, N.; Hancox, J.; Zhu, W.; Baust, M.; Cheng, Y.; Ourselin, S.; Cardoso, M.J.; et al. Privacy-Preserving Federated Brain Tumour Segmentation. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Shenzhen, China, 13 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 133–141. [Google Scholar]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2018, 5, 180161. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Xu, J.; Vijayakumar, P.; Sharma, P.K.; Ghosh, U. Homomorphic Encryption-based Privacy-preserving Federated Learning in IoT-enabled Healthcare System. IEEE Trans. Netw. Sci. Eng. 2022, 10, 2864–2880. [Google Scholar] [CrossRef]
- Newman, C.L.; Blake, D.J. UCI Repository of Machine Learning Databases. 1998. Available online: http://www.ics.uci.edu/~mlearn/MLRepository.html (accessed on 21 February 2025).
- Salmeron, J.L.; Arévalo, I. A privacy-preserving, distributed and cooperative FCM-based learning approach for cancer research. In Proceedings of the Rough Sets: International Joint Conference, IJCRS 2020, Havana, Cuba, 29 June–3 July 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 477–487. [Google Scholar]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. A dataset for breast cancer histopathological image classification. IEEE Trans. Biomed. Eng. 2015, 63, 1455–1462. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Xie, N.; Yuan, S. A Federated Learning Framework for Breast Cancer Histopathological Image Classification. Electronics 2022, 11, 3767. [Google Scholar] [CrossRef]
- Heath, M.; Bowyer, K.; Kopans, D.; Kegelmeyer, P.; Moore, R.; Chang, K.; Munishkumaran, S. Current status of the digital database for screening mammography. In Digital Mammography: Nijmegen; Springer: Berlin/Heidelberg, Germany, 1998; pp. 457–460. [Google Scholar]
- Tan, Y.N.; Tinh, V.P.; Lam, P.D.; Nam, N.H.; Khoa, T.A. A Transfer Learning Approach to Breast Cancer Classification in a Federated Learning Framework. IEEE Access 2023, 11, 27462–27476. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 12. [Google Scholar] [CrossRef]
- Liu, Y.; Kang, Y.; Xing, C.; Chen, T.; Yang, Q. A secure federated transfer learning framework. IEEE Intell. Syst. 2020, 35, 70–82. [Google Scholar] [CrossRef]
- Nasajpour, M.; Karakaya, M.; Pouriyeh, S.; Parizi, R.M. Federated Transfer Learning For Diabetic Retinopathy Detection Using CNN Architectures. In Proceedings of the SoutheastCon 2022, Mobile, AL, USA, 26 March–3 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 655–660. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for federated learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 5132–5143. [Google Scholar]
- Wang, J.; Liu, Q.; Liang, H.; Joshi, G.; Poor, H.V. Tackling the objective inconsistency problem in heterogeneous federated optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 7611–7623. [Google Scholar]
- Reddi, S.; Charles, Z.; Zaheer, M.; Garrett, Z.; Rush, K.; Konečnỳ, J.; Kumar, S.; McMahan, H.B. Adaptive federated optimization. arXiv 2020, arXiv:2003.00295. [Google Scholar]
- McMahan, H.B.; Ramage, D.; Talwar, K.; Zhang, L. Learning differentially private recurrent language models. arXiv 2017, arXiv:1710.06963. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Fallah, A.; Mokhtari, A.; Ozdaglar, A. Personalized federated learning: A meta-learning approach. arXiv 2020, arXiv:2002.07948. [Google Scholar]
- Ferlay, J.; Ervik, M.; Lam, F.; Colombet, M.; Mery, L.; Piñeros, M.; Znaor, A.; Soerjomataram, I.; Bray, F. Global Cancer Observatory: Cancer Today; International Agency for Research on Cancer: Lyon, France, 2020. [Google Scholar]
- Mccarthy, J.F.; Marx, K.A.; Hoffman, P.E.; Gee, A.G.; O’neil, P.; Ujwal, M.L.; Hotchkiss, J. Applications of machine learning and high-dimensional visualization in cancer detection, diagnosis, and management. Ann. N. Y. Acad. Sci. 2004, 1020, 239–262. [Google Scholar] [CrossRef] [PubMed]
- Annas, G.J. HIPAA regulations: A new era of medical-record privacy? N. Engl. J. Med. 2003, 348, 1486. [Google Scholar] [CrossRef]
- Sadad, T.; Munir, A.; Saba, T.; Hussain, A. Fuzzy C-means and region growing based classification of tumor from mammograms using hybrid texture feature. J. Comput. Sci. 2018, 29, 34–45. [Google Scholar] [CrossRef]
- Boyd, N.F.; Byng, J.; Jong, R.; Fishell, E.; Little, L.; Miller, A.; Lockwood, G.; Tritchler, D.; Yaffe, M.J. Quantitative classification of mammographic densities and breast cancer risk: Results from the Canadian National Breast Screening Study. JNCI J. Natl. Cancer Inst. 1995, 87, 670–675. [Google Scholar] [CrossRef]
- Razzaghi, H.; Troester, M.A.; Gierach, G.L.; Olshan, A.F.; Yankaskas, B.C.; Millikan, R.C. Mammographic density and breast cancer risk in White and African American Women. Breast Cancer Res. Treat. 2012, 135, 571–580. [Google Scholar] [CrossRef]
- Roth, H.R.; Chang, K.; Singh, P.; Neumark, N.; Li, W.; Gupta, V.; Gupta, S.; Qu, L.; Ihsani, A.; Bizzo, B.C.; et al. Federated learning for breast density classification: A real-world implementation. In Domain Adaptation and Representation Transfer, and Distributed and Collaborative Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 181–191. [Google Scholar]
- Beguier, C.; Terrail, J.O.d.; Meah, I.; Andreux, M.; Tramel, E.W. Differentially Private Federated Learning for Cancer Prediction. arXiv 2021, arXiv:2101.02997. [Google Scholar]
- Yang, Z.; Hu, S.; Chen, K. FPGA-Based Hardware Accelerator of Homomorphic Encryption for Efficient Federated Learning. arXiv 2020, arXiv:2007.10560. [Google Scholar]
- Awan, S.; Li, F.; Luo, B.; Liu, M. Poster: A Reliable and Accountable Privacy-Preserving Federated Learning Framework using the Blockchain. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019. [Google Scholar]
- WenJie, S.; Xuan, S. Vertical federated learning based on DFP and BFGS. arXiv 2021, arXiv:2101.09428. [Google Scholar]
- Jiménez-Sánchez, A.; Tardy, M.; Ballester, M.A.G.; Mateus, D.; Piella, G. Memory-aware curriculum federated learning for breast cancer classification. arXiv 2021, arXiv:2107.02504. [Google Scholar] [CrossRef]
- Andreux, M.; du Terrail, J.O.; Beguier, C.; Tramel, E.W. Siloed federated learning for multi-centric histopathology datasets. In Domain Adaptation and Representation Transfer, and Distributed and Collaborative Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 129–139. [Google Scholar]
- Chu, K.F.; Zhang, L. Privacy-Preserving Self-Taught Federated Learning for Heterogeneous Data. arXiv 2021, arXiv:2102.05883. [Google Scholar]
- Scheibner, J.; Ienca, M.; Kechagia, S.; Troncoso-Pastoriza, J.R.; Raisaro, J.L.; Hubaux, J.P.; Fellay, J.; Vayena, E. Data protection and ethics requirements for multisite research with health data: A comparative examination of legislative governance frameworks and the role of data protection technologies. J. Law Biosci. 2020, 7, lsaa010. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Lu, M.Y.; Kong, D.; Lipkova, J.; Chen, R.J.; Singh, R.; Williamson, D.F.; Chen, T.Y.; Mahmood, F. Federated learning for computational pathology on gigapixel whole slide images. arXiv 2020, arXiv:2009.10190. [Google Scholar] [CrossRef] [PubMed]
- Nazir, M.; Khan, M.A.; Saba, T.; Rehman, A. Brain tumor detection from MRI images using multi-level wavelets. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 3–4 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Bercea, C.I.; Wiestler, B.; Rueckert, D.; Albarqouni, S. FedDis: Disentangled Federated Learning for Unsupervised Brain Pathology Segmentation. arXiv 2021, arXiv:2103.03705. [Google Scholar]
- Sheller, M.J.; Reina, G.A.; Edwards, B.; Martin, J.; Bakas, S. Multi-institutional deep learning modeling without sharing patient data: A feasibility study on brain tumor segmentation. In Proceedings of the International MICCAI Brainlesion Workshop, Granada, Spain, 16 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 92–104. [Google Scholar]
- Yi, L.; Zhang, J.; Zhang, R.; Shi, J.; Wang, G.; Liu, X. SU-Net: An Efficient Encoder-Decoder Model of Federated Learning for Brain Tumor Segmentation; Springer: Cham, Switzerland, 2020; pp. 761–773. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Wang, P.; Shen, C.; Roth, H.R.; Yang, D.; Xu, D.; Oda, M.; Misawa, K.; Chen, P.T.; Liu, K.L.; Liao, W.C.; et al. Automated pancreas segmentation using multi-institutional collaborative deep learning. In Domain Adaptation and Representation Transfer, and Distributed and Collaborative Learning; Springer: Cham, Switzerland, 2020; pp. 192–200. [Google Scholar]
- Shen, C.; Wang, P.; Roth, H.R.; Yang, D.; Xu, D.; Oda, M.; Wang, W.; Fuh, C.S.; Chen, P.T.; Liu, K.L.; et al. Multi-task federated learning for heterogeneous pancreas segmentation. In Proceedings of the Clinical Image-Based Procedures, Distributed and Collaborative Learning, Artificial Intelligence for Combating COVID-19 and Secure and Privacy-Preserving Machine Learning: 10th Workshop, CLIP 2021, Second Workshop, DCL 2021, First Workshop, LL-COVID19 2021, and First Workshop and Tutorial, PPML 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, 27 September–1 October 2021; Proceedings 2. Springer: Berlin/Heidelberg, Germany, 2021; pp. 101–110. [Google Scholar]
- Bdair, T.; Navab, N.; Albarqouni, S. Peer Learning for Skin Lesion Classification. arXiv 2021, arXiv:2103.03703. [Google Scholar]
- Al-Rakhami, M.S.; AlQahtani, S.A.; Alawwad, A. Effective Skin Cancer Diagnosis Through Federated Learning and Deep Convolutional Neural Networks. Appl. Artif. Intell. 2024, 38, 2364145. [Google Scholar] [CrossRef]
- Yaqoob, M.M.; Alsulami, M.; Khan, M.A.; Alsadie, D.; Saudagar, A.K.J.; AlKhathami, M. Federated machine learning for skin lesion diagnosis: An asynchronous and weighted approach. Diagnostics 2023, 13, 1964. [Google Scholar] [CrossRef]
- Ke, J.; Shen, Y.; Lu, Y. Style Normalization in Histology with Federated Learning. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 953–956. [Google Scholar]
- Gunesli, G.N.; Bilal, M.; Raza, S.E.A.; Rajpoot, N.M. A Federated Learning Approach to Tumor Detection in Colon Histology Images. J. Med. Syst. 2023, 47, 99. [Google Scholar] [CrossRef]
- Howard, F.M.; Hieromnimon, H.M.; Ramesh, S.; Dolezal, J.; Kochanny, S.; Zhang, Q.; Feiger, B.; Peterson, J.; Fan, C.; Perou, C.M.; et al. Generative adversarial networks accurately reconstruct pan-cancer histology from pathologic, genomic, and radiographic latent features. Sci. Adv. 2024, 10, eadq0856. [Google Scholar] [CrossRef] [PubMed]
- Sivakumar, S.; Chandrasekar, C. Lung nodule detection using fuzzy clustering and support vector machines. Int. J. Eng. Technol. 2013, 5, 179–185. [Google Scholar]
- Baheti, P.; Sikka, M.; Arya, K.; Rajesh, R. Federated Learning on Distributed Medical Records for Detection of Lung Nodules. In Proceedings of the VISIGRAPP (4: VISAPP), 15th International Conference on Computer Vision Theory and Applications, Valletta, Malta, 27–29 February 2020; pp. 445–451. [Google Scholar]
- Rajendran, S.; Obeid, J.S.; Binol, H.; Foley, K.; Zhang, W.; Austin, P.; Brakefield, J.; Gurcan, M.N.; Topaloglu, U. Cloud-based federated learning implementation across medical centers. JCO Clin. Cancer Inform. 2021, 5, 1–11. [Google Scholar] [CrossRef]
- Lee, H.; Chai, Y.J.; Joo, H.; Lee, K.; Hwang, J.Y.; Kim, S.M.; Kim, K.; Nam, I.C.; Choi, J.Y.; Yu, H.W.; et al. Federated Learning for Thyroid Ultrasound Image Analysis to Protect Personal Information: Validation Study in a Real Health Care Environment. JMIR Med. Inform. 2021, 9, e25869. [Google Scholar] [CrossRef]
- Xiang, Z.; Tian, X.; Liu, Y.; Chen, M.; Zhao, C.; Tang, L.N.; Xue, E.S.; Zhou, Q.; Shen, B.; Li, F.; et al. Federated learning via multi-attention guided UNET for thyroid nodule segmentation of ultrasound images. Neural Netw. 2025, 181, 106754. [Google Scholar] [CrossRef]
- Wang, G.; Dang, C.X.; Zhou, Z. Measure contribution of participants in federated learning. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2597–2604. [Google Scholar]
- Wang, G. Interpret federated learning with shapley values. arXiv 2019, arXiv:1905.04519. [Google Scholar]
- Joynab, N.S.; Islam, M.N.; Aliya, R.R.; Hasan, A.R.; Khan, N.I.; Sarker, I.H. A federated learning aided system for classifying cervical cancer using PAP-SMEAR images. Inform. Med. Unlocked 2024, 47, 101496. [Google Scholar] [CrossRef]
- Sarma, K.V.; Harmon, S.; Sanford, T.; Roth, H.R.; Xu, Z.; Tetreault, J.; Xu, D.; Flores, M.G.; Raman, A.G.; Kulkarni, R.; et al. Federated learning improves site performance in multicenter deep learning without data sharing. J. Am. Med. Inform. Assoc. 2021, 28, 1259–1264. [Google Scholar] [CrossRef]
- Yan, Z.; Wicaksana, J.; Wang, Z.; Yang, X.; Cheng, K.T. Variation-Aware federated learning with multi-source decentralized medical image data. IEEE J. Biomed. Health Inform. 2021, 25, 2615–2628. [Google Scholar] [CrossRef]
- Nergiz, M. Collaborative Colorectal Cancer Classification on Highly Class Imbalanced Data Setting via Federated Neural Style Transfer Based Data Augmentation. Int. Inf. Eng. Technol. Assoc. 2022, 39, 2077. [Google Scholar] [CrossRef]
- Arthi, N.T.; Mubin, K.E.; Rahman, J.; Rafi, G.; Sheja, T.T.; Reza, M.T.; Alam, M.A. Decentralized federated learning and deep learning leveraging xai-based approach to classify colorectal cancer. In Proceedings of the 2022 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), Gold Coast, Australia, 18–20 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Geyer, R.C.; Klein, T.; Nabi, M. Differentially Private Federated Learning: A Client Level Perspective. arXiv 2017, arXiv:1712.07557. [Google Scholar]
- Aono, Y.; Hayashi, T.; Trieu, N.; Wang, L. Privacy-Preserving Deep Learning via Additively Homomorphic Encryption. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1333–1345. [Google Scholar]
- Attya, S.M.; Jumaa, D.A.; Hwezy, N.N.K.; Sajid, W.A.; Khaleefah, A.M.; Zhyrov, G.; Ali, H. Harnessing Federated Learning for Secure Data Sharing in Healthcare Systems. In Proceedings of the 2024 36th Conference of Open Innovations Association (FRUCT), Tampere, Finland, 24–26 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 390–399. [Google Scholar]
- Smith, V.; Chiang, C.K.; Sanjabi, M.; Talwalkar, A. Federated Multi-Task Learning. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Mandal, P.K. Vertical federated alzheimer’s detection on multimodal data. arXiv 2023, arXiv:2312.10237v2. [Google Scholar]
- Jiang, M.; Wang, Z.; Dou, Q. Harmofl: Harmonizing local and global drifts in federated learning on heterogeneous medical images. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 1087–1095. [Google Scholar]
- He, C.; Yang, Z.; Mushtaq, E.; Lee, S.; Soltanolkotabi, M.; Avestimehr, S. Ssfl: Tackling label deficiency in federated learning via personalized self-supervision. arXiv 2021, arXiv:2110.02470. [Google Scholar]
- Yan, R.; Qu, L.; Wei, Q.; Huang, S.C.; Shen, L.; Rubin, D.; Xing, L.; Zhou, Y. Label-efficient self-supervised federated learning for tackling data heterogeneity in medical imaging. IEEE Trans. Med. Imaging 2023, 42, 1932–1943. [Google Scholar]
- Li, X.; Gu, Y.; Dvornek, N.; Staib, L.H.; Ventola, P.; Duncan, J.S. Multi-site fMRI analysis using privacy-preserving federated learning and domain adaptation: ABIDE results. Med. Image Anal. 2020, 65, 101765. [Google Scholar]
- Lu, W.; Wang, J.; Chen, Y.; Qin, X.; Xu, R.; Dimitriadis, D.; Qin, T. Personalized federated learning with adaptive batchnorm for healthcare. IEEE Trans. Big Data 2022, 10, 915–925. [Google Scholar]
- Islam, T.U.; Ghasemi, R.; Mohammed, N. Privacy-Preserving Federated Learning Model for Healthcare Data. In Proceedings of the IEEE 12th CCWC, Las Vegas, NA, USA, 26–29 January 2022; pp. 0281–0287. [Google Scholar] [CrossRef]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečnỳ, J.; Mazzocchi, S.; McMahan, B.; et al. Towards federated learning at scale: System design. Proc. Mach. Learn. Syst. 2019, 1, 374–388. [Google Scholar]
- Van Berkel, C. Multi-core for mobile phones. In Proceedings of the 2009 Design, Automation & Test in Europe Conference & Exhibition, Nice, France, 20–24 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1260–1265. [Google Scholar]
- Lakhan, A.; Mohammed, M.A.; Nedoma, J.; Martinek, R.; Tiwari, P.; Vidyarthi, A.; Alkhayyat, A.; Wang, W. Federated-Learning Based Privacy Preservation and Fraud-Enabled Blockchain IoMT System for Healthcare. IEEE J. Biomed. Health Inform. 2022, 27, 664–672. [Google Scholar]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar]
- Stripelis, D.; Ambite, J.L.; Lam, P.; Thompson, P. Scaling neuroscience research using federated learning. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1191–1195. [Google Scholar]
- Fu, L.; Zhang, H.; Gao, G.; Wang, H.; Zhang, M.; Liu, X. Client Selection in Federated Learning: Principles, Challenges, and Opportunities. arXiv 2022, arXiv:2211.01549. [Google Scholar]
- Rauniyar, A.; Hagos, D.H.; Jha, D.; Håkegård, J.E.; Bagci, U.; Rawat, D.B.; Vlassov, V. Federated learning for medical applications: A taxonomy, current trends, challenges, and future research directions. arXiv 2022, arXiv:2208.03392. [Google Scholar]
- Shi, J.; Wan, W.; Hu, S.; Lu, J.; Zhang, L.Y. Challenges and approaches for mitigating byzantine attacks in federated learning. In Proceedings of the 2022 IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Wuhan, China, 9–11 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 139–146. [Google Scholar]
- Ji, S.; Saravirta, T.; Pan, S.; Long, G.; Walid, A. Emerging trends in federated learning: From model fusion to federated x learning. arXiv 2021, arXiv:2102.12920. [Google Scholar]
- Nazir, S.; Kaleem, M. Federated Learning for Medical Image Analysis with Deep Neural Networks. Diagnostics 2023, 13, 1532. [Google Scholar] [CrossRef] [PubMed]
- Guan, H.; Liu, M. Federated Learning for Medical Image Analysis: A Survey. arXiv 2023, arXiv:2306.05980. [Google Scholar]
- Shen, Y.; Sowmya, A.; Luo, Y.; Liang, X.; Shen, D.; Ke, J. A federated learning system for histopathology image analysis with an orchestral stain-normalization gan. IEEE Trans. Med. Imaging 2022, 42, 1969–1981. [Google Scholar]
- Agrawal, S.; Sarkar, S.; Aouedi, O.; Yenduri, G.; Piamrat, K.; Alazab, M.; Bhattacharya, S.; Maddikunta, P.K.R.; Gadekallu, T.R. Federated learning for intrusion detection system: Concepts, challenges and future directions. Comput. Commun. 2022, 195, 346–361. [Google Scholar]
- Gadekallu, T.R.; Pham, Q.V.; Huynh-The, T.; Bhattacharya, S.; Maddikunta, P.K.R.; Liyanage, M. Federated learning for big data: A survey on opportunities, applications, and future directions. arXiv 2021, arXiv:2110.04160. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).