
A Transductive Zero-Shot Learning Framework for Ransomware Detection Using Malware Knowledge Graphs


Abstract
1. Introduction
- This research presents a ZSL model based on the VQ-VAE framework that is specifically designed for malware classification. By enabling the detection and classification of previously unseen ransomware variants, the proposed approach addresses a significant limitation in traditional machine learning techniques, which typically rely on large volumes of labeled data.
- The proposed TZSL model based on VQ-VAE achieves an F1-score of 93.5% in detecting novel or variant ransomware samples. This significantly improves detection accuracy during the early download or infection phase, while also reducing false positive rates.
- In contrast, traditional CNN-based models—including LeNet-5, ResNet-50, VGG-16, and AlexNet—achieve a lower F1-score of 65.6%, 71.8%, 74.3%, and 65.3%, respectively, when classifying ransomware variants. These results highlight the superior generalization capability of the proposed TZSL model in handling previously unseen threats.
- The remainder of this paper is organized as follows: Section 2 provides an overview of the Zero-Shot Learning (ZSL) approach and introduces the proposed ZSL-based model for recognizing previously unseen malware. Section 3 details the architecture of the proposed ZSL malware detection framework, including the integration of a similarity-based analysis for constructing the malware knowledge graph. Section 4 presents and discusses the experimental results, highlighting model performance across various evaluation metrics. Finally, Section 5 concludes this paper and outlines directions for future work.
2. Overview of Deep Learning Techniques and Their Applications in Malware Detection
2.1. Misclassification Analysis in Machine Learning Models
- A.
- Addressing Misclassification in Deep Learning-Based Malware Detection
- B.
- Deep Learning-based Misclassification for Malware Classification
2.2. Zero-Shot Learning Model for Malware Detection
System Architecture
- Operational Steps for Zero-Shot Learning (ZSL) [15]
- Dataset Construction:A dataset comprising training categories and their corresponding attribute descriptions is first prepared. This dataset includes labeled images from seen classes along with textual descriptions representing each category’s semantic characteristics.
- Attribute Description Extraction:For each known category, attribute descriptions are extracted in textual form. These descriptions typically include human-interpretable features and behavioral characteristics, serving as the foundation for semantic reasoning.
- Feature Extraction:Visual features are extracted from training images using deep learning models (e.g., CNNs or VQ-VAE). These features are used to construct a visual embedding space that encodes the appearance or structure of malware samples.
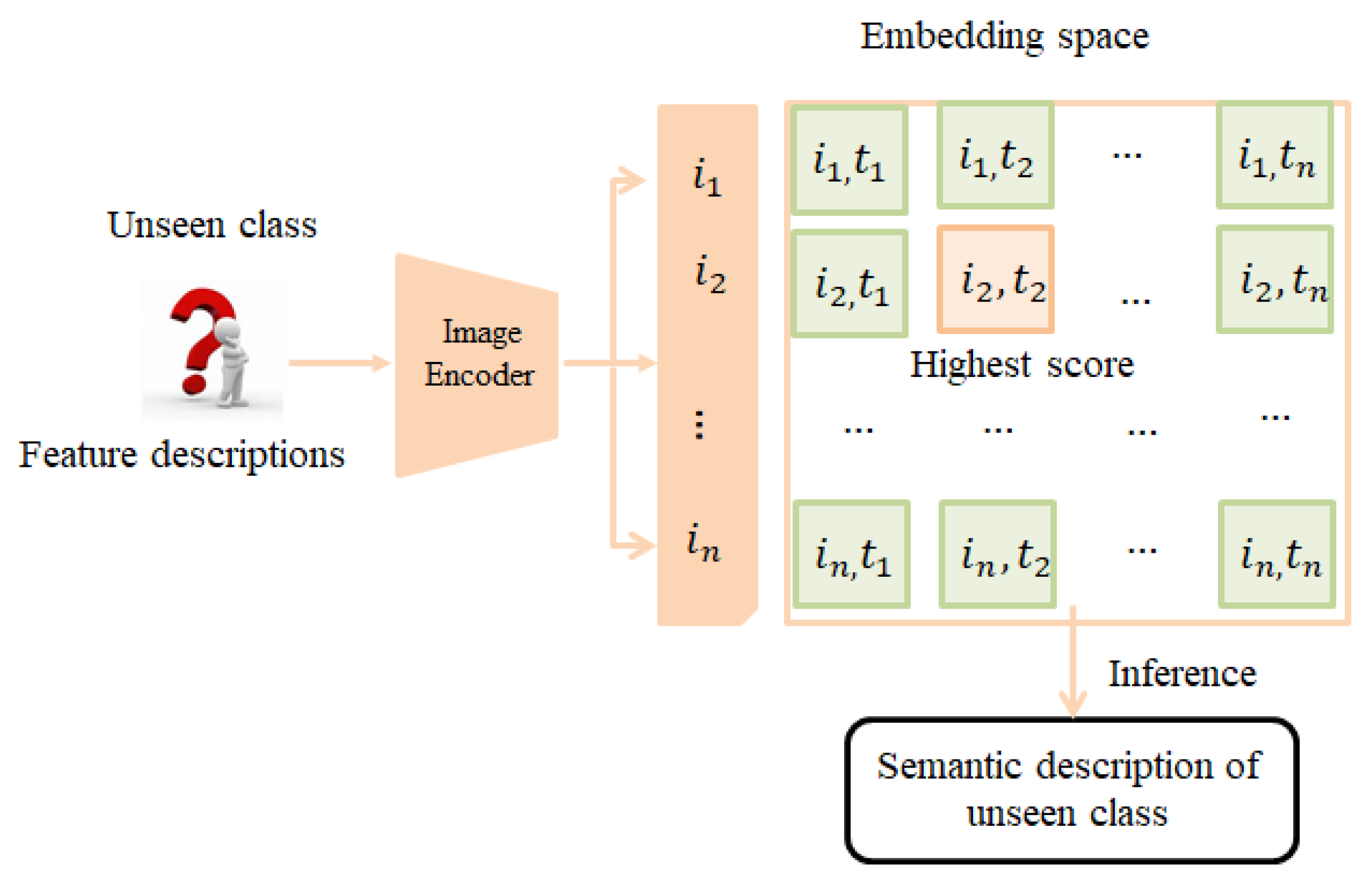
- Semantic Embedding and Alignment:The extracted attribute descriptions are converted into semantic vectors (see Note 1), which map words or phrases into a high-dimensional semantic space. A contrastive pre-training model is then employed to jointly embed both semantic and visual features into a shared embedding space (as illustrated in Figure 1), enabling effective comparison and alignment across modalities.
- Prediction and Classification:During inference, the trained model projects the features of unseen malware samples into the shared embedding space. Based on similarity to known semantic vectors, the model predicts the most likely category for the previously unseen instance (see Figure 2).
- Performance Evaluation:The trained model is evaluated using a test dataset containing samples from unseen categories. Metrics such as classification accuracy, precision, recall, and H-mean are used to assess the model’s generalization ability under the GZSL setting.
- Note 1:
- Variable Definitions
- Feature Extraction
- For each training sample x∈X, extract its feature vector f (x).
- Loss Function
- A loss function is typically used to optimize the mapping function f, such as cross-entropy loss.
- Mapping Learning
- Class Prediction
2.3. Vector Quantized Variational Autoencoder Model
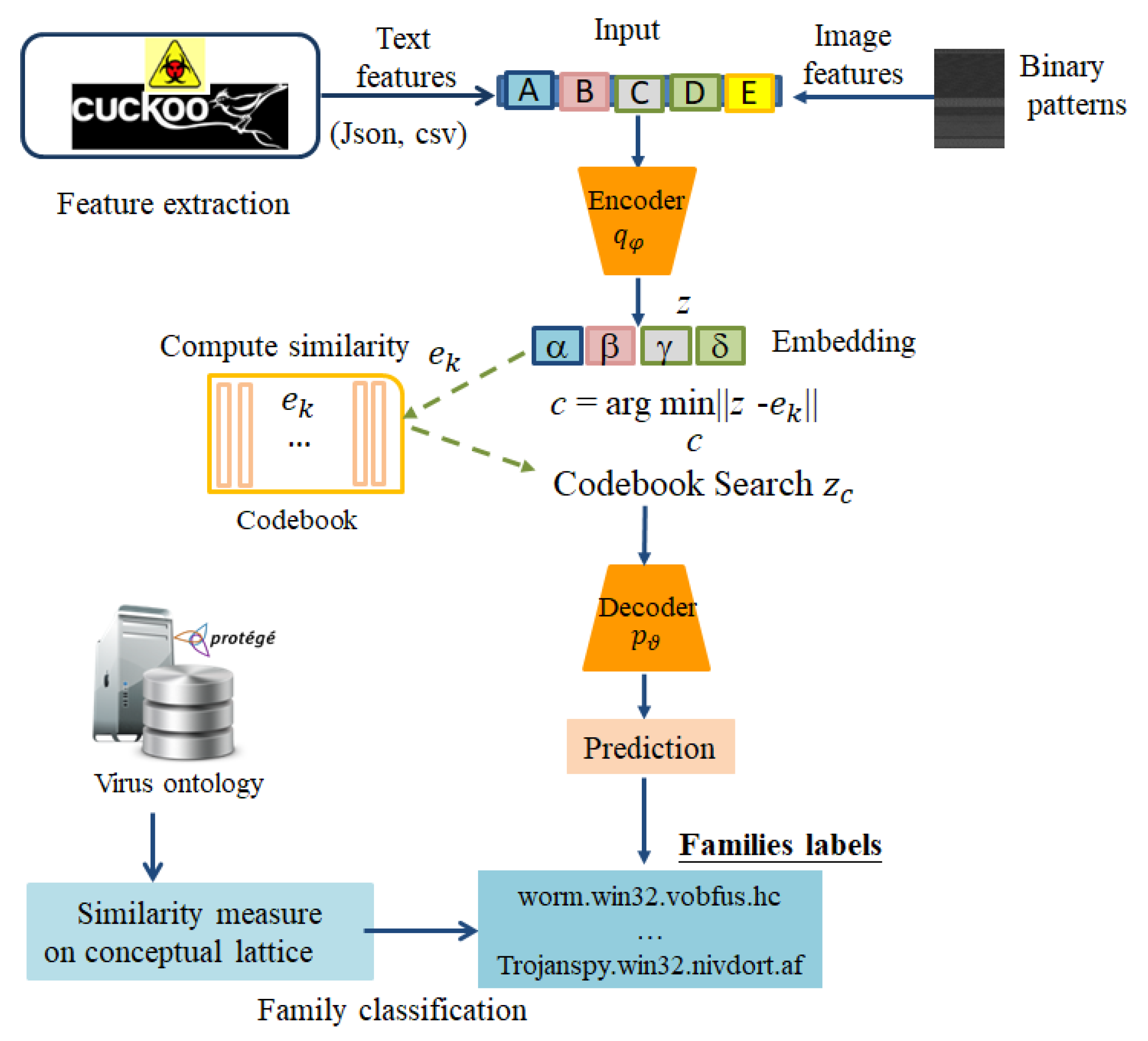
- Encoder: The input vector x is processed by the encoder to produce a latent vector .
- Codebook Search: The model searches a learned codebook, which represents the discrete latent space, to find the latent vector that is closest to . This is achieved by identifying the code vector with the minimum Euclidean distance to .
- Decoder: The selected latent vector is then fed into the decoder to reconstruct the input data, denoted as .
- Loss Function: The reconstruction error is measured using a loss function, such as entropy, between the original input x and its reconstructed version .
3. A ZSL-Based Classification Model for Malware Detection
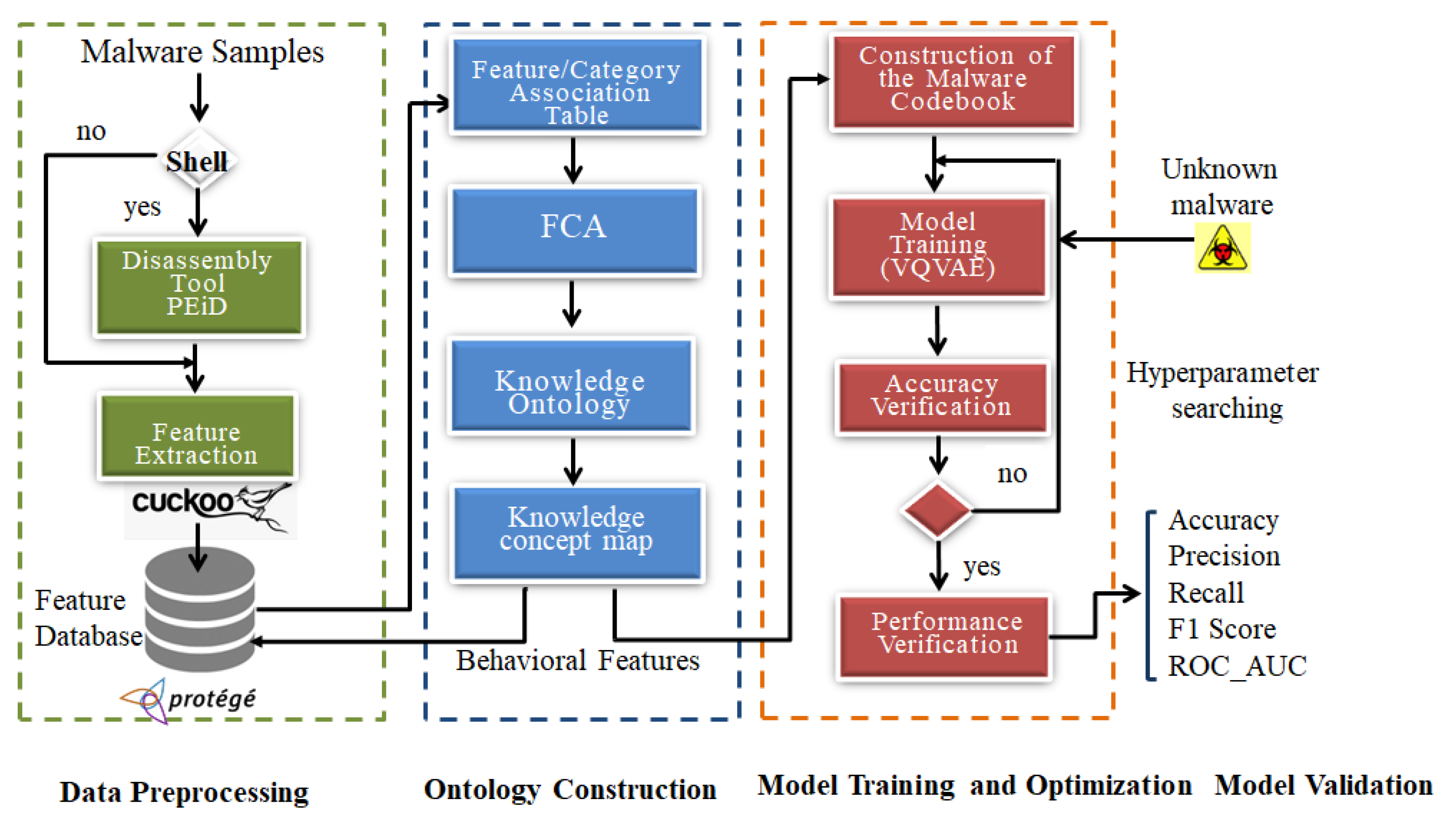
3.1. Architecture Design for ZSL Models in Malware Identification
- (i)
- Data preprocessing;
- (ii)
- Ontology construction;
- (iii)
- Semantic knowledge concept mapping;
- (iv)
- Model training and optimization;
- (v)
- Model validation.
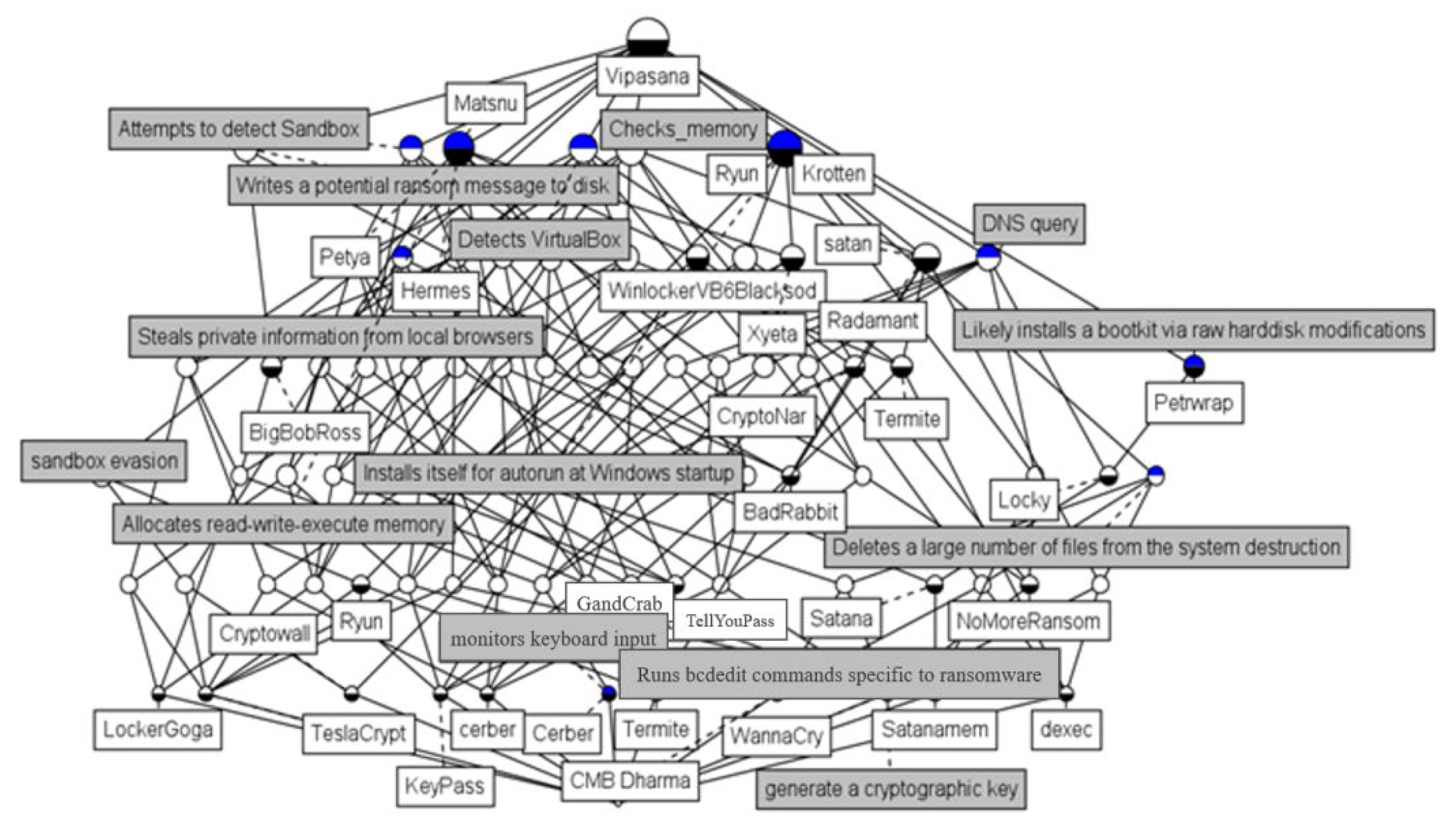
3.2. Knowledge Graph Construction and Inference on the Evolution of Ransomware Threats
- # Assume nodes is a list of semantic vectors representing ransomware families or attributes
- # threshold is the minimum similarity value to create an edge
- for i in range (len (nodes)):
- for j in range (i + 1, len (nodes)):
- similarity = Jaccard_similarity (nodes [i], node s [j])
- if similarity >= threshold:
- create_edge (node i, node j, weight = similarity)
A Knowledge Graph for Inferring the Evolution of Ransomware Threats
3.3. Mathematical Model of TZSL for Malware Classification
- Feature space representation. Malware samples x are represented as a feature vector , where n is the number of features extracted from the malware using sandbox (e.g., API calls, opcode sequences, or static analysis features). The training set consists of labeled instances from known classes (seen classes), while the test set includes instances from unknown classes (unseen classes). Let Cs denote the set of seen classes and Cu denote the set of unseen classes.
- Attribute-based representation. Each class can be described by a set of attributes. For instance, malware families can be characterized by attributes such as encrypted files, spread through e-mail, or disguised as legitimate software. These attributes form a semantic space A, where each class c∈C is associated with a vector of attributes ac∈Rn
- Learning mechanism. The model learns to predict attributes for unseen classes based on their feature representations. This can be expressed as follows:
- D.
- Classification decision. The predicted class for an unseen instance is determined by selecting the class with the highest similarity score:
- E.
- Training and evaluation. The model can be trained using a loss function that minimizes the difference between predicted and actual attributes for seen classes, often using cross-entropy loss:
- F.
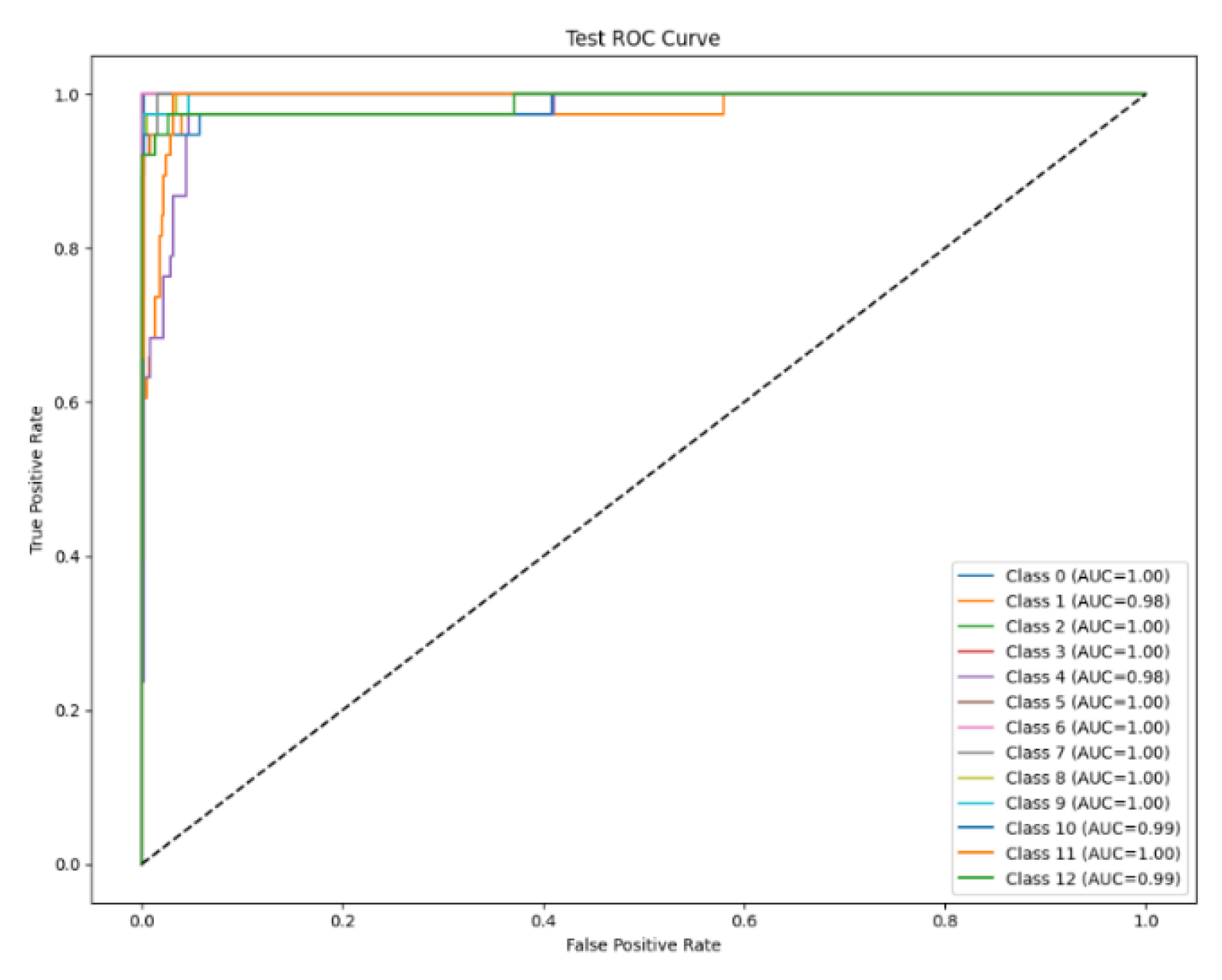
- Evaluation Metrics. The performance of the ZSL model can be evaluated using metrics such as accuracy, precision, recall, F1-score, and ROC curve analysis.
3.4. Generalized Zero-Shot Learning Model
- Semantic space embedding: Each class (seen or unseen) is represented by a semantic vector, such as an attribute vector, word embedding, or ontology-based descriptor.
- Visual-semantic mapping: A mapping function is trained to project input features (e.g., images, behavior logs) into the semantic space.
- Inference: During testing, a sample is mapped to the semantic space and classified into the class whose semantic representation is most similar.
4. Experimental Results
4.1. Case Studies
- Step 1. Data preprocessing
- Resampling Strategy
- A.
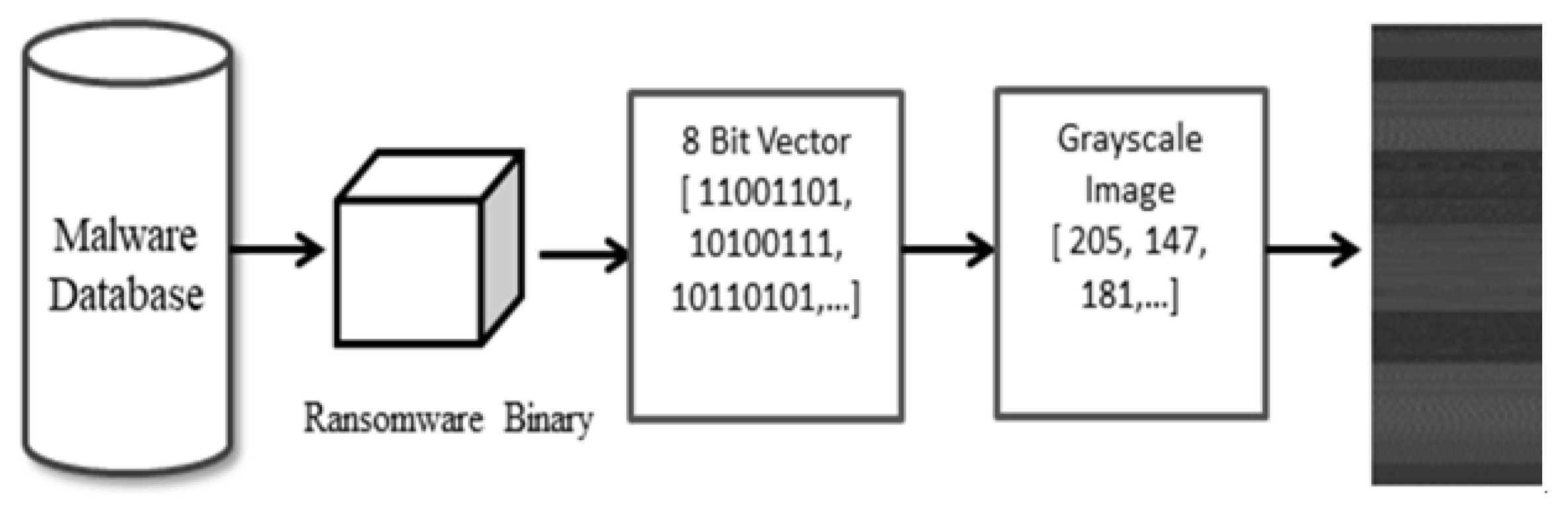
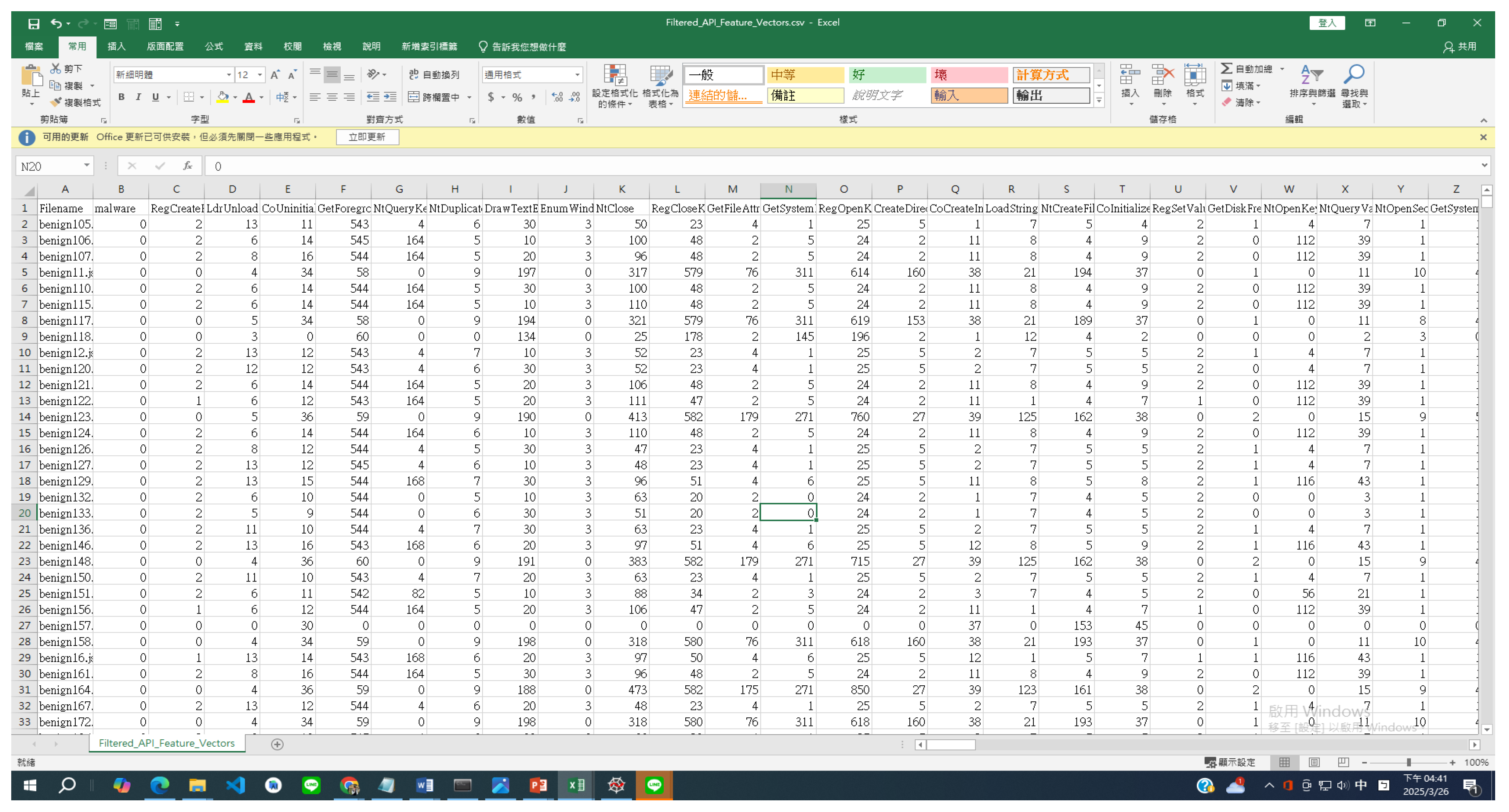
- Feature image
- B.
- Auxiliary information: semantic descriptions
- Step 2. Ontology construction
- Data Visualization
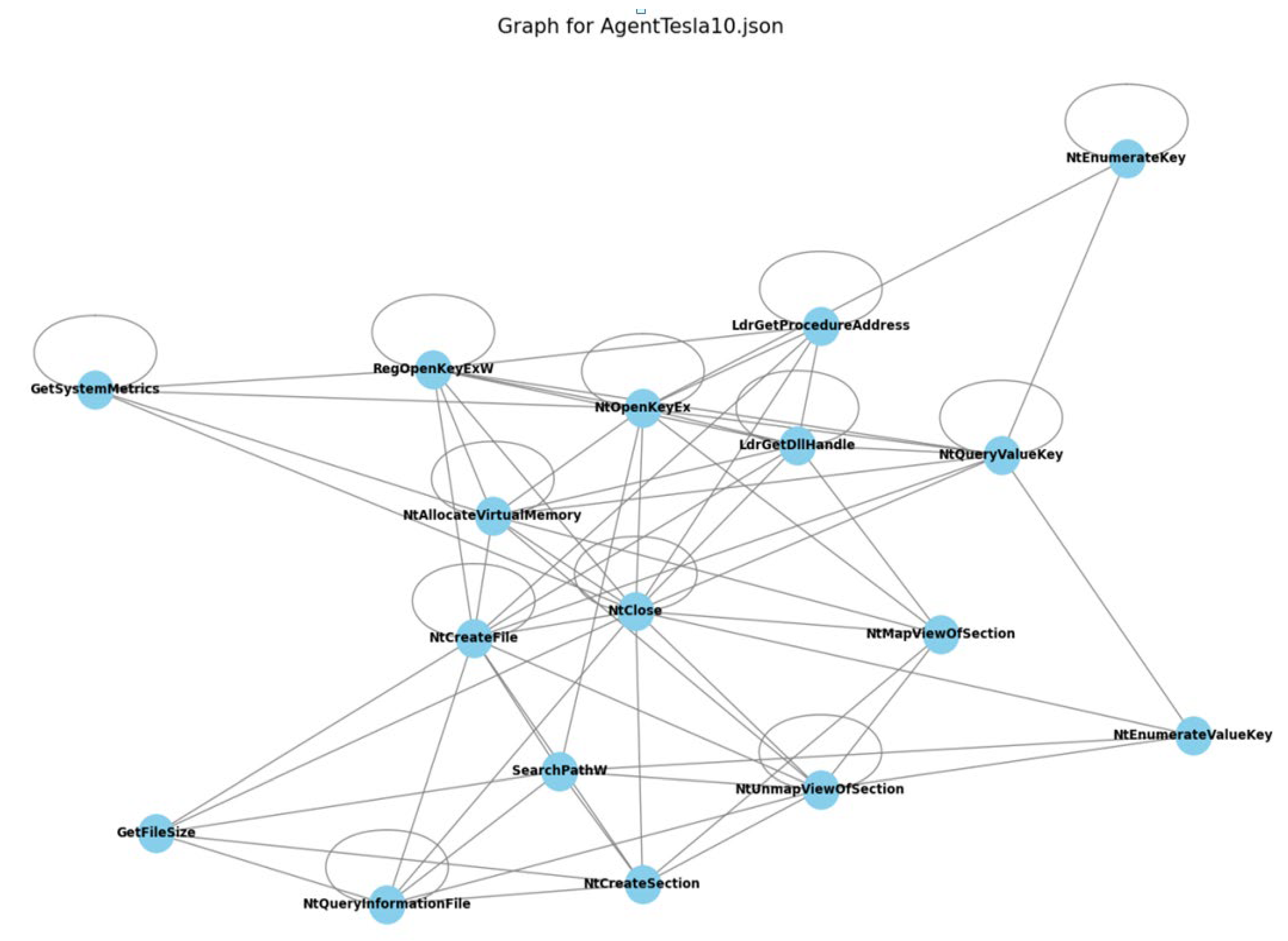
- Step 3. Knowledge Concept Map
- Step 4: Construction of the Malware Codebook
- Step 5. Model training and optimization
- Step 6. Model Validation
- Case I: Conventional Machine Learning Classification Experiment
- Binary classification
4.2. Performance Comparison
4.3. Generalized Zero-Shot Learning Experiment
4.4. Practical Deployment Considerations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Montalbano, E. Hit with ‘Severe’ LockerGoga Ransomware Attack, Norsk Hydro Press, 19 March 2019. Available online: https://securityledger.com/2019/03/norsk-hydro-hit-with-severe-lockergoga-ransomware-attack/ (accessed on 15 May 2024).
- Wallix. What Happened in the Colonial Pipeline Ransomware Attack. Available online: https://www.wallix.com/what-happened-in-the-colonial-pipeline-ransomware-attack-2/ (accessed on 5 February 2025).
- Abrams, L. Chemical Distributor Pays $4.4 Million to DarkSide Ransomware. Available online: https://www.bleepingcomputer.com/news/security/chemical-distributor-pays-44-million-to-darkside-ransomware/ (accessed on 7 February 2025).
- Reuters. Toyota Suspends Domestic Factory Operations After Suspected Cyber Attack. 1 March 2022. Available online: https://www.reuters.com/business/autos-transportation/toyota-suspends-all-domestic-factory-operations-after-suspected-cyber-attack-2022-02-28/ (accessed on 7 February 2025).
- Trend Micro. Ransomware Review: First Half of 2024. Available online: https://unit42.paloaltonetworks.com/unit-42-ransomware-leak-site-data-analysis/ (accessed on 10 September 2024).
- Check Point Research, Global Cyber Attack Statistics for Q3, 12 November 2024. 2024. Available online: https://www.informationsecurity.com.tw/article/article_detail.aspx?aid=11374 (accessed on 5 March 2025).
- Olaimat, M.N.; Aizaini Maarof, M.; Al-rimy, B.A.S. Ransomware Anti-Analysis and Evasion Techniques: A Survey and Research Directions. In Proceedings of the 2021 3rd International Cyber Resilience Conference (CRC), Langkawi Island, Malaysia, 29–31 January 2021; pp. 1–6. [Google Scholar]
- Beaman, C.; Barkworth, A.; Akande, T.D.; Hakak, S.; Khan, M.K. Ransomware: Recent advances, analysis, challenges and future research directions. Comput. Secur. 2021, 111, 102490. [Google Scholar] [CrossRef] [PubMed]
- Gyamfi, N.K.; Goranin, N.; Ceponis, D.; Čenys, H.A. Automated System-Level Malware Detection Using Machine Learning: A Comprehensive Review. Appl. Sci. 2023, 13, 11908. [Google Scholar] [CrossRef]
- Fidelis Security. Breaking Down Signature-Based Detection: A Practical Guide. Available online: https://fidelissecurity.com/threatgeek/network-security/signature-based-detection/ (accessed on 2 March 2025).
- Chaudhary, S.; Garg, A.A. Machine Learning Technique to Detect Behavior Based Malware. In Proceedings of the 2020 10th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 29–31 January 2020; pp. 655–659. [Google Scholar]
- Reddy, V.J.; Jyoshna, R.; Jyothi, B.; Poojari, R.J.; Kartheek, N.; Karthik, G.B.; Karthik, R. Behaviour Based Malware Detection using Machine Learning. Int. J. Res. Appl. Sci. Eng. Technol. 2023, 11, 706–7111. [Google Scholar] [CrossRef]
- Bensaoud, A.; Kalita, J. A Survey of Malware Detection Using Deep Learning. arXiv 2024, arXiv:2407.19153v1. [Google Scholar] [CrossRef]
- Wang, P.; Lin, H.C.; Chen, J.H.; Lin, W.H.; Li, H.C. Improving Cyber Defense Against Ransomware: A Generative Adversarial Networks-Based Adversarial Training Approach for Long Short-Term Memory Network Classifier. Electronics 2025, 14, 810. [Google Scholar] [CrossRef]
- Wang, W.; Duan, L.; En, Q.; Zhang, B. Context-sensitive Zero-shot Semantic Segmentation Model based on Meta-learning. Neurocomputing 2021, 465, 465–475. [Google Scholar] [CrossRef]
- Li, X.; Fang, M.; Feng, D.; Li, H.; Wu, J. Prototype Adjustment for Zero Shot Classification. Signal Process. Image Commun. 2019, 74, 242–252. [Google Scholar] [CrossRef]
- Wan, Z.; Chen, D.; Li, Y.; Yan, X.; Zhang, J.; Yu, Y.; Liao, J. Transductive Zero-Shot Learning with Visual Structure Constraint. arXiv 2019, arXiv:1901.01570. [Google Scholar] [CrossRef]
- Palatucci, M.; Pomerleau, D.; Hinton, G.; Mitchell, T.M. Zero-shot Learning with Semantic Output Codes. In Proceedings of the 22nd International Conference on Neural Information Processing Systems (NIPS’09), Vancouver, BC, Canada, 7–10 December 2009; pp. 1410–1418. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, F.; Wan, L.; Wang, Z. Intelligent Fault Diagnostic Model for Industrial Equipment Based on Multimodal Knowledge Graph. IEEE Sens. J. 2023, 23, 26269–26278. [Google Scholar] [CrossRef]
- Han, H.; Wang, J.; Wang, X.; Chen, S. Construction and Evolution of Fault Diagnosis Knowledge Graph in Industrial Process. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Peng, C.; Xia, F.; Naseriparsa, M.; Osborne, F. Knowledge Graphs: Opportunities and Challenges. Artif. Intell. Rev. 2023, 56, 13071–13102. [Google Scholar] [CrossRef] [PubMed]
- Haffar, R.; Domingo-Ferrer, J.; Sánchez, D. Explaining Misclassification and Attacks in Deep Learning via Random Forests. In Modeling Decisions for Artificial Intelligence (MDAI 2020); Torra, V., Narukawa, Y., Nin, J., Agell, N., Eds.; Lecture Notes in Computer Science 12256; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Dunmore, A.; Jang-Jaccard, J.; Sabrina, F.; Kwak, J.A. Comprehensive Survey of Generative Adversarial Networks (GANs) in Cybersecurity Intrusion Detection. IEEE Access 2023, 11, 76071–76094. [Google Scholar] [CrossRef]
- Abusnaina, A.; Abuhamad, M.; Alasmary, H.; Anwar, A.; Jang, R.; Salem, S.; Nyang, D.; Muheisin, D. A Deep Learning-based Fine-grained Hierarchical Learning Approach for Robust Malware Classification. arXiv 2020, arXiv:2005.07145. [Google Scholar] [CrossRef]
- Alam, M.; Akram, A.; Saeed, T.; Arshad, S. DeepMalware: A Deep Learning based Malware Images Classification. In Proceedings of the 2021 International Conference on Cyber Warfare and Security (ICCWS), Islamabad, Pakistan, 23–25 November 2021; pp. 93–99. [Google Scholar]
- Aslan, O.; Yılmaz, A.A. A New Malware Classification Framework Based on Deep Learning Algorithm. IEEE Access 2021, 9, 87936–87951. [Google Scholar] [CrossRef]
- Card, Q.; Aryal, K.; Gupta, M. Explainability-Informed Targeted Malware Misclassification. arXiv 2024, arXiv:2405.04010. [Google Scholar]
- Tiu, E. Understanding Zero-Shot Learning—Making ML More Human. Available online: https://www.linkedin.com/pulse/understanding-zero-shot-learning-making-ml-more-human-chittibabu/ (accessed on 10 September 2024).
- Barros, P.H.; Chagas, E.T.C.; Oliveira, L.B.; Queiroz, F.; Ramos, H.S. Malware-SMELL: A zero-shot learning strategy for detecting zero-day vulnerabilities. Comput. Secur. 2022, 120, 102785. [Google Scholar] [CrossRef]
- Sawadogo, Z.; Dembele, J.M.; Mendy, G.; Ouya, S. Zero-Vuln: Using deep learning and zero-shot learning techniques to detect zero-day Android malware. In Proceedings of the 2023 3rd International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), Tenerife, Canary Islands, Spain, 19–21 July 2023. [Google Scholar]
- Chao, W.L.; Changpinyo, S.; Gong, B.; Sha, F. An Empirical Study and Analysis of Generalized Zero-Shot Learning for Object Recognition in the Wild. In Proceedings of the Computer Vision–ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Zhang, C.; Li, Z. Generalized zero-shot learning via discriminative and transferable disentangled representations. Neural Netw. 2025, 183, 106964. [Google Scholar] [CrossRef]
- Intezer. Intezer Analyze. Available online: https://analyze.intezer.com/ (accessed on 5 September 2024).
- Malware Bazaar. Malware Bazaar Database. Available online: https://bazaar.abuse.ch/browse/ (accessed on 5 September 2024).
- Tan, X.; Su, S.; Huang, Z.; Guo, X.; Zuo, Z.; Sun, Z.; Li, L. Wireless sensor networks intrusion detection based on SMOTE and the random forest algorithm. Sensors 2019, 19, 203. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowye, K.W.; Hal, R.L.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Anderson, S.H.; Roth, P. EMBER: An Open Dataset for Training Static PE Malware, Machine Learning Models. arXiv 2018, arXiv:1804.04637v2. [Google Scholar]
- Imdea Software Institute, Academia. Available online: https://software.imdea.org/~juanca/bibtex.html#driving (accessed on 17 May 2025).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Limitations | ||
|---|---|---|---|
| Basic Theory | Function | ||
| Signature-based detection [10] | Relies on known static patterns of malware retrieved from the sandbox offline to identify threats. | Fast and efficient for known threats; low false positive rate when signatures are accurate. | Ineffective against new or mutated malware that lacks signatures. |
| Behavioral analysis [11] | Dynamically analyzes malware behavior online via an SDN (software-defined network) controller. | This approach effectively detects and prevents infections from unknown malware through the analysis of predefined behavioral patterns configured in the SDN controller, assuming that the malware variants share behavioral features with known threats. | Relies on pattern update frequencies in SDN controllers; may be vulnerable to stealthy malware. |
| Machine learning [9,12] | Utilizes algorithms such as CNNs, RNNs, LSTMs, and GRUs to classify malware based on features extracted from collected binary files. | Can adapt to new threats through training; improves detection accuracy over time with sufficient labeled malware samples. | Requires large labeled datasets for training; may struggle with zero-day threats. |
| Features | Advantages | Limitations | |
|---|---|---|---|
| Increase model algorithm complexity [15,16,17,18,19] | -Increases model algorithm complexity, e.g., using semantic embedding techniques. | -Improves classification accuracy; enhances generalization ability. | -Increased computational cost; requires more auxiliary information. |
| Use diverse training data [23] | -Ensures training data covers various types of samples; uses sample augmentation algorithms. | -Improves model robustness; reduces overfitting. | -Increased data collection cost; may introduce noise. |
| Adversarial attack training [24] | -Researches adversarial attacks and defense strategies to enhance the model’s recognition ability. | -Improves model security; enhances generalization ability. | -Increased computational cost; requires additional data. |
| Symbol | Definition |
|---|---|
| x | A malware instance (sample) in the dataset. |
| Feature vector representation of malware sample xxx, where n is the feature dimension. | |
| Cs | The set of seen classes (i.e., malware families available during training). |
| Cu | The set of unseen classes (i.e., malware families not present during training). |
| ac∈Rn | Attribute vector representing semantic features of class c. |
| A | Semantic space is composed of class attribute vectors. |
| f(⋅) | Mapping function from feature space to semantic attribute space. |
| Predicted attribute vector output by model for input x. | |
| True attribute vector associated with an unseen class c∈Cu. | |
| Cosine similarity between predicted and true attribute vectors. | |
| Predicted class label for an unseen instance. | |
| Classification error at feature dimension iii, i.e., = (i) − (i). | |
| L | Loss function (cross-entropy) used during model training. |
| Item | Hardware/Software Installed |
|---|---|
| Host | CPU: Intel i7-6700 3.4 Ghz RAM: 32 G, NVIDIA GTX-2080 TI x2 |
| Disassembly tools | 1. PETools; 2. Exeinfo PE; and 3. Pestudio on Ubuntu v16.04 |
| Feature library | Protégé v3.1.1 |
| Sandbox | Cuckoo v2.0.7 |
| Library Package | Python 3.12.4, Tensorflow 2.10.0, Pytorch 1.13.1, abslpy 0.7.1, Opencv, numpy 1.16.3, Pandas 1.3.5, scikit-learn 1.0.2, and Matplotlib 3.5.3. |
| Family | Date of First Detection | Download Date | # of Samples | Feature |
|---|---|---|---|---|
| Benign | N/A | 02/2024 | 299 | Clean software used for control comparison |
| Lokibot | 06/2016 | 02/2023 | 215 | Info-stealer with ransomware component; email phishing vector |
| Dharma | 08/2016 | 02/2023 | 74 | Uses RDP for infection vector; strong file encryption |
| Cerber | 09/2016 | 06/2023 | 55 | Offline encryption; voice ransom note; uses RSA + RC4 |
| AgentTesla | 06/2017 | 06/2023 | 107 | .NET-based keylogger and info-stealer; spreads via malicious attachments |
| RaccoonStealer | 04/2019 | 02/2024 | 94 | Malware-as-a-Service; targets browser credentials, crypto wallets |
| Conti | 12/2020 | 02/2024 | 37 | Ransomware-as-a-Service; rapid file encryption and data exfiltration |
| Chaos | 08/2021 | 02/2024 | 100 | Fake ransomware; destroys files instead of encrypting them |
| Lockbit | 01/2021 | 02/2024 | 67 | Autonomous spreading via the Active Directory; fast encryption |
| TrickBot | 10/2016 | 02/2025 | 242 | Modular banking Trojan; used for later ransomware delivery (e.g., Ryuk, Conti) |
| Emotet | 03/2017 | 02/2025 | 83 | Email-based Trojan dropper; often delivers TrickBot or Ryuk |
| WannaCry 2.0 | 05/2017 | 02/2025 | 32 | Encrypts files via EternalBlue exploit and demands Bitcoin; spreads via SMB protocol |
| RedLineStealer | 03/2020 | 03/2025 | 377 | Steals passwords, cookies, and cryptocurrency wallets; spreads via cracked software ads |
| Object | Form | Meanings |
|---|---|---|
| An implicit object | A blank circle | Symbolizing an abstract concept that may encompass further attributes. |
| The concept of common features | A circle shaded in blue and white | A concept that shares common features; the text inside each cell describes these shared features. |
| A real object | A white and black circle  | A real object within the entire concept lattice. |
| A real object and common attributes | A blue and black circle  | A real object within the entire concept lattice that simultaneously exhibits common attributes shared with others. |
| Hyperparameters | Value |
|---|---|
| Codebook size | 512 |
| Embedding dimension | 64 |
| Regularization coefficient α | 0.01 |
| Batch size | 64 |
| Number of layers (encoder/decoder) | 3 |
| Optimizer | Adam |
| Latent vector update frequency | Each mini-batch |
| Dense (Softmax) | 12 (normal:1 + ransomware:12) |
| Loss function | Categorical entropy |
| The maximum number of epochs | 20 |
| Comparison Aspect | Generalized ZSL Experiment | Traditional Machine Learning Classification Experiment |
|---|---|---|
| Training data | Uses only a subset of malware families and a portion of goodware samples | Includes all malware families and all goodware samples |
| Testing data | Includes both seen and unseen malware families | Contains only samples from the same families seen during training |
| Objective | Evaluates the model’s ability to infer previously unseen malware families | Evaluates the model’s classification performance on previously seen families |
| Applicable scenario | Zero-day attacks; dynamic threat environments | Static, fully labeled environments |
| Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | |
|---|---|---|---|---|
| Training | 98.0 | 98.0 | 99.0 | 99.0 |
| Validation | 97.0 | 98.0 | 99.0 | 98.0 |
| Testing | 95.0 | 92.0 | 100.0 | 96.0 |
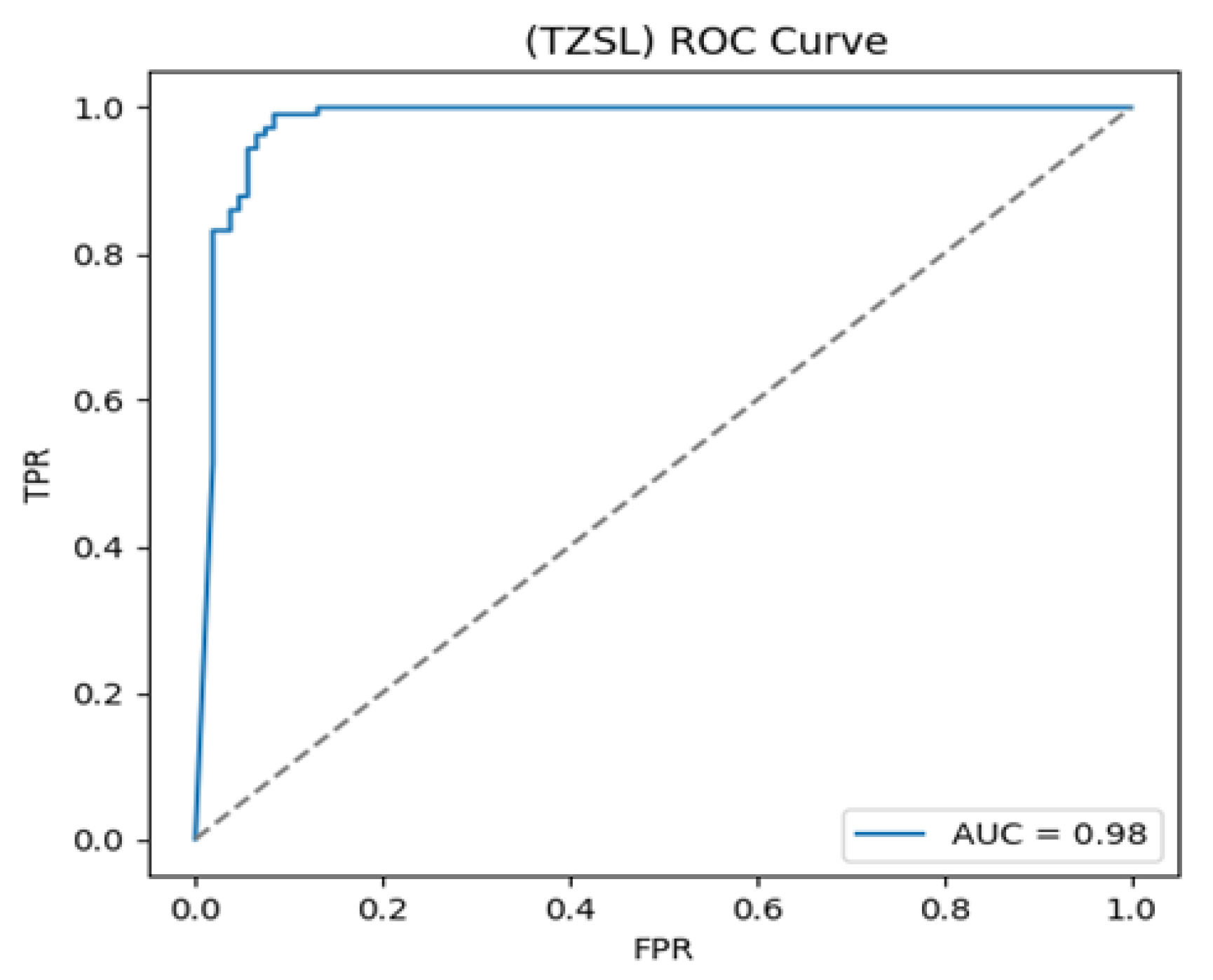
| Family | AUC |
|---|---|
| Benign | 0.999 |
| Loki | 0.978 |
| Dharma | 1.000 |
| Lockbit | 1.000 |
| AgentTesla | 0.978 |
| Conti | 1.000 |
| Chaos | 1.000 |
| Cerber | 0.998 |
| RaccoonStealer | 0.999 |
| WannaCry 2.0 | 0.999 |
| TrickBot | 0.988 |
| Emotet | 0.998 |
| RedLineStealer | 0.989 |
| Micro-averaged | 0.996 |
| Macro-averaged | 0.995 |
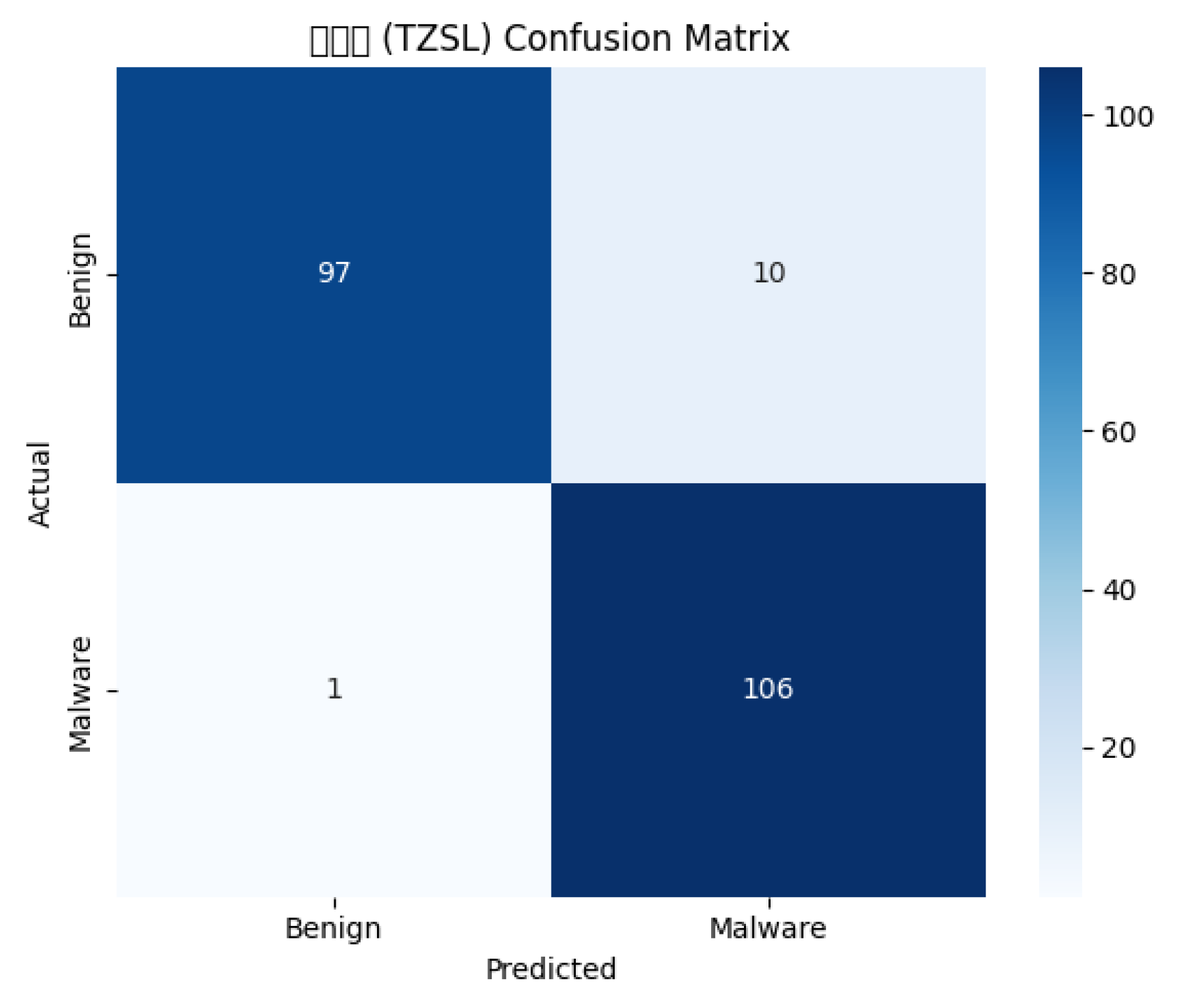
| Family | Accuracy (Per_Family) (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| Benign | 100 | 84.4 | 100.0 | 91.6 |
| Loki | 0.86.8 | 75.0 | 86.8 | 80.5 |
| Dharma | 100.0 | 100.0 | 100.0 | 100.0 |
| Lockbit | 100.0 | 100.0 | 100.0 | 100.0 |
| AgentTesla | 71.1 | 87.1 | 71.1 | 78.4 |
| Conti | 100.0 | 100.0 | 100.0 | 100 |
| Chaos | 100.0 | 100.0 | 100.0 | 100 |
| Cerber | 94.7 | 92.3 | 94.7 | 93.5 |
| RaccoonStealer | 97.4 | 92.5 | 97.4 | 94.9 |
| WannaCry 2.0 | 92.1 | 97.2 | 92.1 | 94.6 |
| TrickBot | 94.7 | 97.3 | 94.7 | 96.0 |
| Emotet | 92.1 | 94.6 | 92.1 | 93.3 |
| RedLineStealer | 86.8 | 100.0 | 86.8 | 93.0 |
| Average value | 93.5 | 93.9 | 93.5 | 93.5 |
| Micro-averaged | - | - | - | 99.6 |
| Macro-averaged | - | - | - | 99.5 |
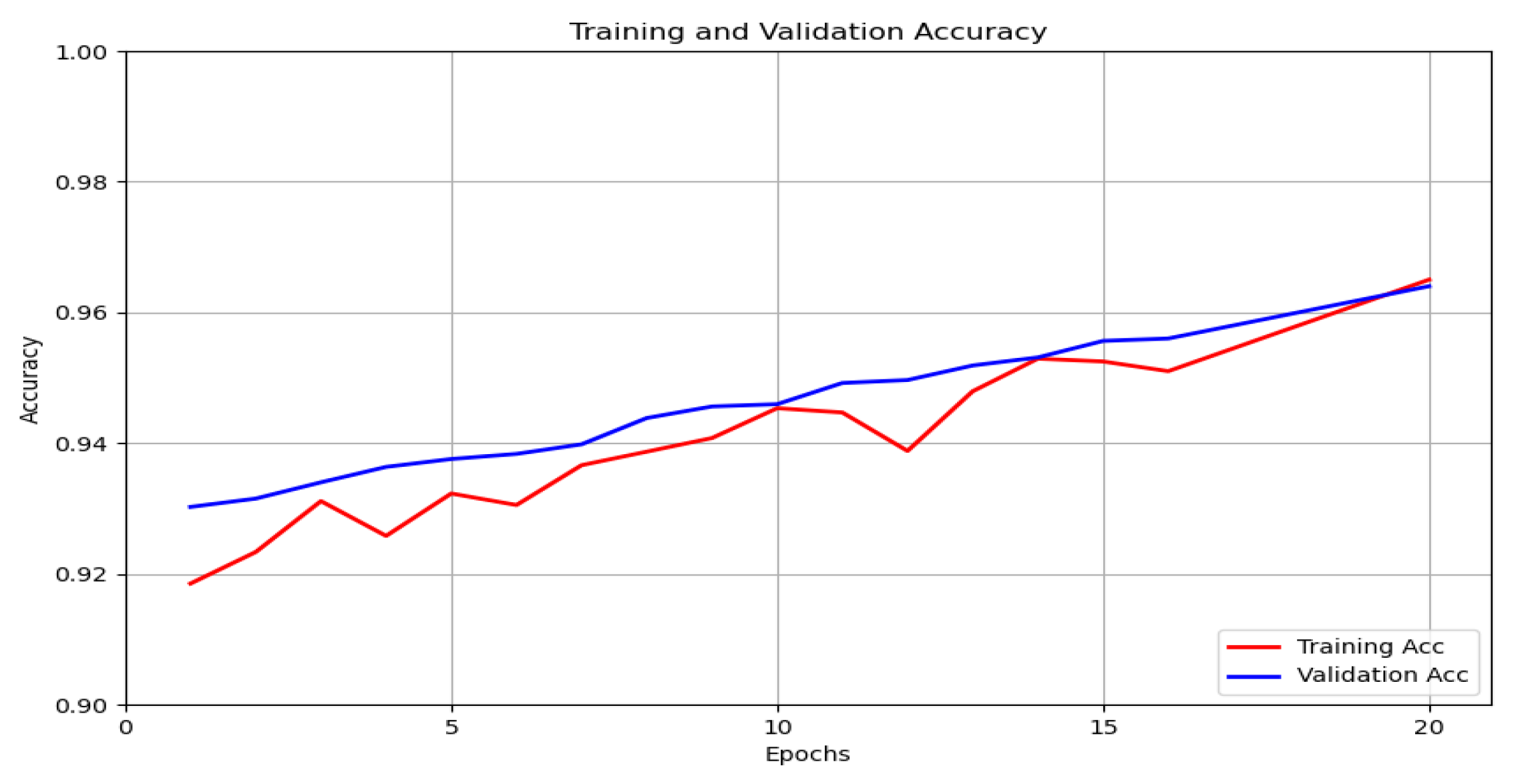
| Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | |
|---|---|---|---|---|
| Training | 94.9 | 95.2 | 94.9 | 94.9 |
| Validation | 93.5 | 94.3 | 93.5 | 93.6 |
| Testing | 93.5 | 93.9 | 93.5 | 93.5 |
| Family | Accuracy (Per_Family) (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) |
|---|---|---|---|---|---|
| Benign | 82.6 | 86.4 | 82.6 | 84.4 | 96.6 |
| Loki | 84.4 | 96.4 | 84.4 | 90.0 | 98.6 |
| Dharma | 81.4 | 88.0 | 81.5 | 84.6 | 98.4 |
| Lockbit | 100.0 | 53.8 | 100.0 | 70.0 | 99.8 |
| AgentTesla | 81.8 | 90.0 | 81.8 | 85.7 | 98.0 |
| Conti | 90.0 | 90.0 | 90.0 | 90.0 | 99.8 |
| Chaos | 100.0 | 90.0 | 100.0 | 94.7 | 99.9 |
| Cerber | 71.5 | 50.0 | 71.4 | 58.8 | 96.6 |
| RaccoonStealer | 57.1 | 80.0 | 57.1 | 66.7 | 93.7 |
| WannaCry 2.0 | 8.3 | 33.3 | 8.30 | 13.3 | 97.2 |
| TrickBot | 66.7 | 14.3 | 66.7 | 23.5 | 93.2 |
| Emotet | 85.7 | 75.0 | 85.7 | 80.0 | 96.4 |
| RedLineStealer | 50.0 | 100.0 | 50.0 | 66.7 | 93.5 |
| Average value | 72.8 | 73.8 | 69.9 | 97.1 | 97.1 |
| Micro-averaged | - | - | - | - | 97.8 |
| Macro-averaged | - | - | - | - | 97.1 |
| Model | Accuracy (Per_Family) (%) | Precision (%) | Recall (%) | F1-Score (%) | Macro-Averaged | Micro-Averaged | Execution Time (Sec) |
|---|---|---|---|---|---|---|---|
| VQ-VAE | 93.5 | 93.9 | 93.5 | 93.5 | 99.5 | 99.6 | 3.85 |
| LetNet5 | 63.3 | 73.2 | 63.3 | 65.6 | 95.1 | 97.4 | 3.93 |
| ResNet-50 | 72.8 | 73.8 | 69.9 | 71.8 | 97.1 | 97.8 | 10.39 |
| VGG16 | 82.3 | 74.5 | 74.1 | 74.3 | 96.5 | 94.4 | 13.01 |
| AlexNet | 67.5 | 63.3 | 67.5 | 65.3 | 97.6 | 98.8 | 6.55 |
| Family | Accuracy (Per_Family) (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) |
|---|---|---|---|---|---|
| Benign(seen) | 98.86 | 78.38 | 98.86 | 87.44 | 98.8636 |
| Loki(seen) | 65.91 | 96.67 | 65.91 | 78.38 | 65.91 |
| Dharma(seen) | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Lockbit(seen) | 92.78 | 99.19 | 92.78 | 95.87 | 92.78 |
| AgentTesla(seen) | 86.36 | 78.89 | 86.36 | 82.46 | 86.36 |
| Conti(seen) | 98.48 | 96.65 | 98.48 | 97.56 | 98.48 |
| Chaos(seen) | 98.86 | 48.69 | 98.86 | 65.24 | 98.86 |
| Cerber(seen) | 94.74 | 92.31 | 94.748 | 93.51 | 94.74 |
| RaccoonStealer(seen) | 92.42 | 97.60 | 92.42 | 94.94 | 92.42 |
| Average (Seen) | 91.40 | 87.70 | 91.63 | 88.38 | 92.05 |
| WannaCry 2.0 (unseen) | 43.0 | 56.0 | 54.0 | 55.0 | 58.0 |
| TrickBot(unseen) | 81.0 | 79.0 | 83.0 | 81.0 | 83.0 |
| Emotet(unseen) | 40.0 | 51.0 | 46.0 | 48.0 | 49.0 |
| RedLineStealer(unseen) | 73.0 | 74.0 | 76.0 | 75.0 | 76.0 |
| Average (Unseen) | 59.25 | 65 | 64.75 | 64.75 | 66.5 |
| Evaluation Metric | Value (%) |
|---|---|
| Seen class accuracy | 91.40 |
| Unseen class accuracy | 59.25 |
| Harmonic mean (H-mean) | 71.89 |
| Metric | Details |
|---|---|
| Average inference time | 75–85 ms per sample (with image + semantic input) |
| Hardware used | Intel Core i7-6700 CPU, 32 GB RAM, NVIDIA GTX 1080 GPU (3–3.5 GB) |
| Minimum hardware requirements | Intel Core i5 CPU, 8 GB RAM, 4 GB GPU VRAM |
| Edge deployment feasibility | Supported (under development using TensorRT/ONNX compression) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, P.; Li, H.-C.; Lin, H.-C.; Lin, W.-H.; Xie, N.-Z. A Transductive Zero-Shot Learning Framework for Ransomware Detection Using Malware Knowledge Graphs. Information 2025, 16, 458. https://doi.org/10.3390/info16060458
Wang P, Li H-C, Lin H-C, Lin W-H, Xie N-Z. A Transductive Zero-Shot Learning Framework for Ransomware Detection Using Malware Knowledge Graphs. Information. 2025; 16(6):458. https://doi.org/10.3390/info16060458
Chicago/Turabian StyleWang, Ping, Hao-Cyuan Li, Hsiao-Chung Lin, Wen-Hui Lin, and Nian-Zu Xie. 2025. "A Transductive Zero-Shot Learning Framework for Ransomware Detection Using Malware Knowledge Graphs" Information 16, no. 6: 458. https://doi.org/10.3390/info16060458
APA StyleWang, P., Li, H.-C., Lin, H.-C., Lin, W.-H., & Xie, N.-Z. (2025). A Transductive Zero-Shot Learning Framework for Ransomware Detection Using Malware Knowledge Graphs. Information, 16(6), 458. https://doi.org/10.3390/info16060458