
Desentiment: A New Method to Control Sentimental Tendency During Summary Generation

Abstract
1. Introduction
- We formulate the fusion of sentiment analysis and text summarization as a task of sentimental-supervised summarization (S3T), aiming to produce summaries with specific sentimental orientations for textual content.
- We balance the sentiment requirement and semantic requirement of S3T by weighting the sentimental loss and semantic loss.
- To guide the model to generate summaries with the intended sentimental tendency, we define the intended sentimental tendency as the prompt for predicting and the sentimental tendency of the ground truth summary as the prompt for training.
2. Method
2.1. Sentiment Prompter
2.2. Summary Calibrator
2.3. Sentiment Calibrator
2.4. Loss Function
2.4.1. Sentiment Loss
2.4.2. Semantic Loss
2.4.3. Total Loss
3. Experiments
3.1. Experimental Settings
3.1.1. Datasets
3.1.2. Baselines
3.1.3. Evaluation Metrics
3.1.4. Parameters
3.2. Comparison with SOTA Models
3.2.1. Senti-Req Comparison
3.2.2. Seman-Req Comparison
4. Ablation Study
4.1. Effectiveness of Sentiment Prompter
4.1.1. Senti-Req Comparison
4.1.2. Seman-Req Comparison
4.2. Effectiveness of Sentiment Calibrator

{kind=link}
{kind=link}
| Model | R-1 | T-3 | T-4 |
|---|---|---|---|
| CNN/DM | |||
| Desentiment | 44.42 | −28.74 | 19.33 |
| Desentiment-c | 45.94 | −29.39 | 18.04 |
| XSum | |||
| Desentiment | 47.10 | −29.51 | 3.87 |
| Desentiment-c | 48.22 | −29.80 | 1.79 |
4.2.1. Senti-Req Comparison
4.2.2. Seman-Req Comparison
5. Analysis of Sentiment Mismatch
5.1. Sentiment Experiments
5.2. Semantic Experiments
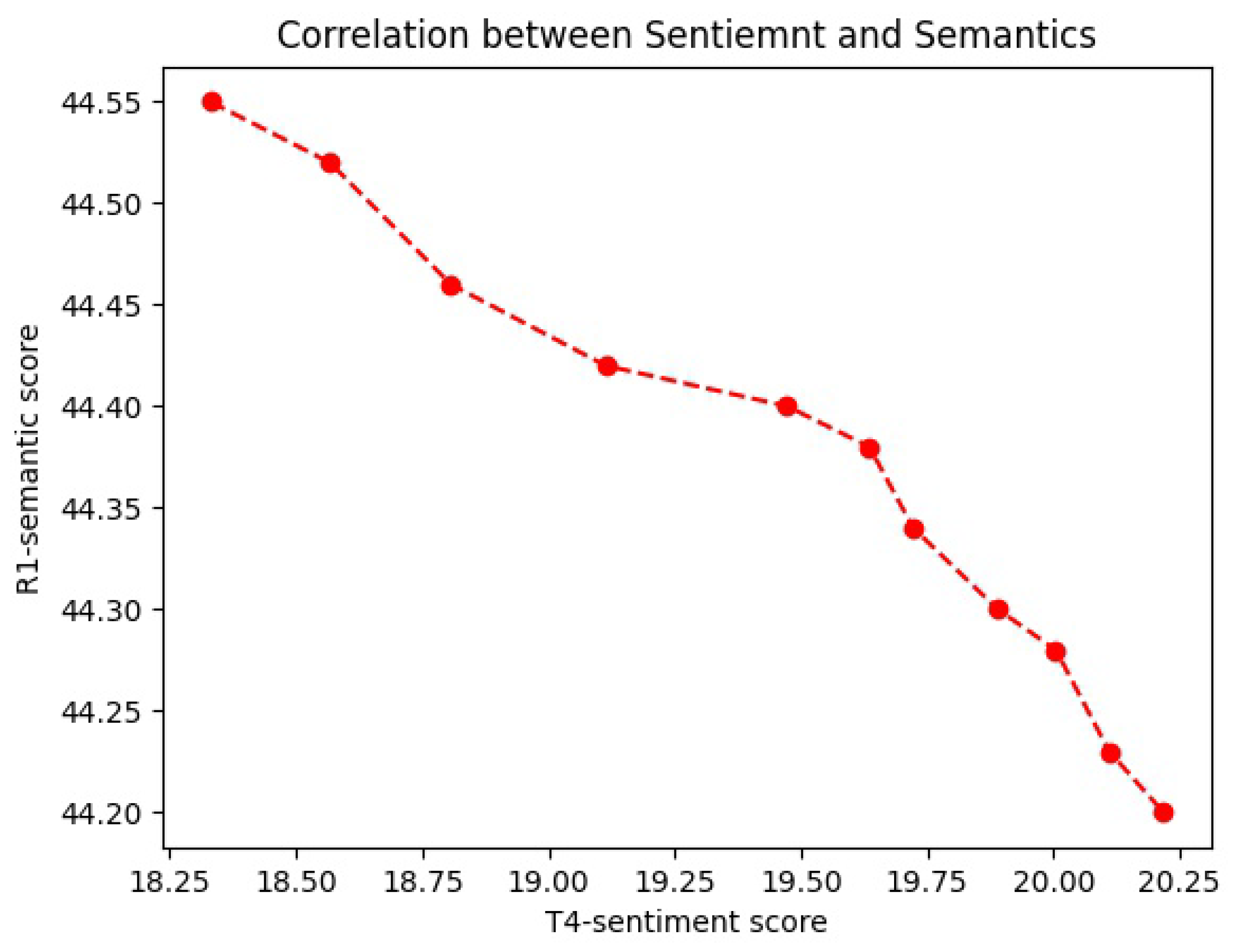
6. Study of Correlation Between Sentiment and Semantics
7. Human Evaluation
7.1. Experiment Settings
7.1.1. Data Preparation
7.1.2. Data Collection
7.1.3. Evaluation
7.2. Result
8. Comparison with LLM
8.1. Experiment Setting
8.2. Result and Analysis
9. Discussion and Limitation
10. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, X.; Wu, P.; Zou, C.; Xie, H.; Wang, F.L. Sentiment lossless summarization. Knowl. Based Syst. 2021, 227, 107170. [Google Scholar] [CrossRef]
- Calvo, R.A.; Kim, S.M. Emotions in text: Dimensional and categorical models. Comput. Intell. 2013, 29, 527–543. [Google Scholar] [CrossRef]
- Li, C.; Xu, W.; Li, S.; Gao, S. Guiding generation for abstractive text summarization based on key information guide network. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 2 (Short Papers). Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 55–60. [Google Scholar] [CrossRef]
- Amplayo, R.K.; Angelidis, S.; Lapata, M. Aspect-controllable opinion summarization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing; Online and Punta Cana, Dominican Republic. Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 6578–6593. [Google Scholar] [CrossRef]
- Dou, Z.-Y.; Liu, P.; Hayashi, H.; Jiang, Z.; Neubig, G. GSum: A general framework for guided neural abstractive summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4830–4842. [Google Scholar] [CrossRef]
- Cao, S.; Wang, L. Inference time style control for summarization. arXiv 2021, arXiv:2104.01724. [Google Scholar] [CrossRef]
- Zhong, M.; Liu, Y.; Ge, S.; Mao, Y.; Jiao, Y.; Zhang, X.; Xu, Y.; Zhu, C.; Zeng, M.; Han, J. Unsupervised multi-granularity summarization. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 4980–4995. [Google Scholar] [CrossRef]
- Urlana, A.; Mishra, P.; Roy, T.; Mishra, R. Controllable Text Summarization: Unraveling Challenges, Approaches, and Prospects—A Survey. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 11–16 August 2024; Ku, L.-W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 1603–1623. [Google Scholar] [CrossRef]
- Wen, Z.; Cao, C.; Yang, R.; Wang, S. Decode with template: Content preserving sentiment transfer. In Proceedings of the Language Resources and Evaluation, Language Resources and Evaluation, Marseille, France, 11–16 May 2020. [Google Scholar]
- Xie, Y.; Xu, J.; Qiao, L.; Liu, Y.; Huang, F.; Li, C. Generative sentiment transfer via adaptive masking. arXiv 2023, arXiv:2302.12045. [Google Scholar] [CrossRef]
- Liu, G.; Feng, Z.; Gao, Y.; Yang, Z.; Liang, X.; Bao, J.; He, X.; Cui, S.; Li, Z.; Hu, Z. Composable text controls in latent space with ODEs. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 16543–16570. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, P.; Radev, D.; Neubig, G. Brio: Bringing order to abstractive summarization. arXiv 2022, arXiv:2203.16804. [Google Scholar]
- Constantin, D.; Mihăescu, M.C.; Heras, S.; Jordán, J.; Palanca, J.; Julián, V. Using Data Augmentation for Improving Text Summarization. In Proceedings of the Intelligent Data Engineering and Automated Learning–IDEAL 2024: 25th International Conference, Valencia, Spain, 20–22 November 2024; Proceedings, Part II. Springer: Berlin/Heidelberg, Germany, 2024; pp. 132–144, ISBN 978-3-031-77737-0. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, X.; Wang, X.; Chen, S.; Wei, F. Latent prompt tuning for text summarization. arXiv 2022, arXiv:2211.01837. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Yang, Z.; Fang, Y.; Chen, Y.; Radev, D.; Zhu, C.; Zeng, M.; Zhang, R. Macsum: Controllable summarization with mixed attributes. arXiv 2023, arXiv:2211.05041. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. arXiv 2005, arXiv:cs/0506075. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2019. [Google Scholar]
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P.J. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. arXiv 2020, arXiv:1912.08777. [Google Scholar] [CrossRef]
- Nallapati, R.; Zhou, B.; santos, C.N.d.; Gulcehre, C.; Xiang, B. Abstractive text summarization using sequence-to-sequence rnns and beyond. arXiv 2016, arXiv:1602.06023. [Google Scholar] [CrossRef]
- Narayan, S.; Cohen, S.B.; Lapata, M. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Luo, F.; Li, P.; Yang, P.; Zhou, J.; Tan, Y.; Chang, B.; Sui, Z.; Sun, X. Towards fine-grained text sentiment transfer. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 2013–2022. [Google Scholar] [CrossRef]
- Lin, C.-Y. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 74–81. Available online: https://aclanthology.org/W04-1013/ (accessed on 20 May 2025).
- Zeng, A.; Liu, X.; Du, Z.; Wang, Z.; Lai, H.; Ding, M.; Yang, Z.; Xu, Y.; Zheng, W.; Xia, X.; et al. Glm-130b: An open bilingual pre-trained model. arXiv 2023, arXiv:2210.02414. [Google Scholar] [CrossRef]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar] [CrossRef]

| System | R-1 | R-2 | R-L | T-1 | T-2 | T-3 | T-4 |
|---|---|---|---|---|---|---|---|
| CNN/DM | |||||||
| BART | 44.16 | 21.28 | 40.90 | 38.46 | −31.21 | −29.71 | 16.50 |
| BRIO-ctr | 47.28 | 22.93 | 44.15 | 38.84 | −29.95 | −29.58 | 17.52 |
| BRIO + FGST | 15.64 | 4.79 | 13.68 | 67.58 * | 25.65 * | 20.37 * | 34.98 * |
| Desentiment (Ours) | 44.42 | 21.13 | 41.47 | 40.41 | −28.18 | −28.74 | 19.33 |
| XSum | |||||||
| PEGASUS | 47.46 | 24.69 | 39.53 | 48.51 | −15.61 | −30.02 | 1.13 |
| BRIO-ctr | 48.13 | 25.13 | 39.84 | 47.72 | −14.48 | −29.84 | 1.63 |
| BRIO + FGST | 14.28 | 5.74 | 12.97 | 69.61 * | 27.48 * | 22.76 * | 20.59 * |
| Desentiment (Ours) | 47.10 | 24.73 | 39.37 | 46.79 | −10.40 | −29.51 | 3.87 |
| Model | R-1 | T-3 | T-4 |
|---|---|---|---|
| CNN/DM | |||
| Desentiment | 44.42 | −28.74 | 19.33 |
| Desentiment-p | 45.03 | −28.67 | 18.33 |
| XSum | |||
| Desentiment | 47.10 | −29.51 | 3.87 |
| Desentiment-p | 47.10 | −29.79 | 2.56 |
| 0.25 | 0.5 | 0.75 | 1.0 | ||
|---|---|---|---|---|---|
| 0.25 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.5 | −1.77 | −1.03 | −0.61 | −4.23 | |
| 0.75 | 8.68 | 6.36 | −2.49 | −4.17 | |
| 1.0 | 12.67 | 8.53 | 13.48 | −0.35 | |
| 0.25 | 0.5 | 0.75 | 1.0 | ||
|---|---|---|---|---|---|
| 0.25 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 0.5 | −0.08 | −2.03 | −0.78 | −5.11 | |
| 0.75 | 13.33 | 29.75 | 21.59 | 36.13 | |
| 1.0 | 21.96 | 23.37 | 20.90 | 25.60 | |
| 0.25 | 0.5 | 0.75 | 1.0 | ||
|---|---|---|---|---|---|
| 0.25 | 48.34 | 47.96 | 46.87 | 51.23 | |
| 0.5 | 44.48 | 46.40 | 46.68 | 49.60 | |
| 0.75 | 45.09 | 47.62 | 46.12 | 51.23 | |
| 1.0 | 47.56 | 49.54 | 50.66 | 49.58 | |
| 0.25 | 0.5 | 0.75 | 1.0 | ||
|---|---|---|---|---|---|
| 0.25 | 46.03 | 45.57 | 46.92 | 49.67 | |
| 0.5 | 43.48 | 44.63 | 45.13 | 47.75 | |
| 0.75 | 42.72 | 47.23 | 49.04 | 47.77 | |
| 1.0 | 42.88 | 47.98 | 47.30 | 51.54 | |
| Dataset | ||
|---|---|---|
| CNN/DM | 0.81 | 0.79 |
| XSum | 0.77 | 0.75 |
| System | R-1 | R-2 | R-L | T-1 | T-2 | T-3 | T-4 |
|---|---|---|---|---|---|---|---|
| CNN/DM | |||||||
| llama2-7B | 18.25 | 6.56 | 14.57 | 22.41 | −14.41 | −17.53 | 14.73 |
| chatglm3-6B | 16.75 | 6.34 | 14.85 | 32.82 | −7.46 | −25.82 | 11.35 |
| Desentiment (Ours) | 44.42 | 21.13 | 41.47 | 40.41 | −28.18 | −28.74 | 19.33 |
| XSum | |||||||
| llama2-7B | 18.72 | 6.59 | 16.02 | 29.76 | −6.21 | −11.56 | 3.65 |
| chatglm3-6B | 16.54 | 6.43 | 14.42 | 44.21 | 3.85 | −33.84 | 0.29 |
| Desentiment (Ours) | 47.10 | 24.73 | 39.37 | 46.79 | −10.40 | −29.51 | 3.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, H.; Li, J. Desentiment: A New Method to Control Sentimental Tendency During Summary Generation. Information 2025, 16, 453. https://doi.org/10.3390/info16060453
Cao H, Li J. Desentiment: A New Method to Control Sentimental Tendency During Summary Generation. Information. 2025; 16(6):453. https://doi.org/10.3390/info16060453
Chicago/Turabian StyleCao, Hongyu, and Jinlong Li. 2025. "Desentiment: A New Method to Control Sentimental Tendency During Summary Generation" Information 16, no. 6: 453. https://doi.org/10.3390/info16060453
APA StyleCao, H., & Li, J. (2025). Desentiment: A New Method to Control Sentimental Tendency During Summary Generation. Information, 16(6), 453. https://doi.org/10.3390/info16060453