1. Introduction
Object detection, which aims to jointly predict the categories and bounding boxes of foreground objects in images, is a fundamental task in the field of computer vision. Effective training of object detection models heavily depends on the availability of large-scale annotated datasets. However, in many practical applications, such training data may not be readily available due to constraints in cost, time, and other factors. In such cases, a common strategy is to train the model on publicly available datasets and then deploy it in specific application scenarios. Consequently, the model’s performance may suffer a significant degradation due to the discrepancy between the training data and the application environment, commonly referred to as the domain shift [
1,
2].
To address this issue, researchers have explored unsupervised domain adaptation (UDA) detection [
3], aiming to transfer knowledge learned from an annotated source domain to an unlabeled target domain. Specifically, UDA methods extract valuable information from unlabeled target domain samples and integrate it into the training process to improve model generalization. Beyond object detection, UDA has also been extensively studied in other vision tasks such as classification [
4] and segmentation [
5]. Although the performance and generalization capabilities of large visual models, such as SAM [
6] or Grounding DINO [
7], have significantly improved in recent years, these models often require substantial computational resources. As a result, UDA-based detection models remain a preferred choice for practical engineering applications where efficiency and adaptability are critical.
Existing UDA methods can be generally categorized into six main classes [
8]: domain-invariant feature learning [
9,
10], pseudo-label-based self-training [
11], image-to-image translation [
12], domain randomization [
13], mean-teacher training [
14], and graph reasoning [
15]. Each of these approaches offers distinct advantages, which has motivated researchers to combine multiple strategies to improve performance. A particularly effective strategy involves employing the teacher–student framework to generate pseudo-labels for target domain samples and utilizing these labels for pseudo-supervised training [
16,
17,
18,
19].
In previous works, the student network typically employs a single detection head for both the source and target domains, while the teacher network inherits the student model’s weights via the exponential moving average (EMA) algorithm. However, when the positive and negative samples are imbalanced, which is common in domain adaptation, the resulting pseudo-labels tend to be unreliable. In two-stage detection models, most of those pseudo-labels are filtered out during proposal generation, which helps mitigate their negative impact. In contrast, in one-stage detection models, pseudo-labels may lead the model to overfit the source domain, thereby neglecting critical information specific to the target domain.
To address the challenges outlined above, we propose a novel domain-specific teacher–student framework with FCOS [
20] as the baseline detector. The proposed approach involves two primary modifications.
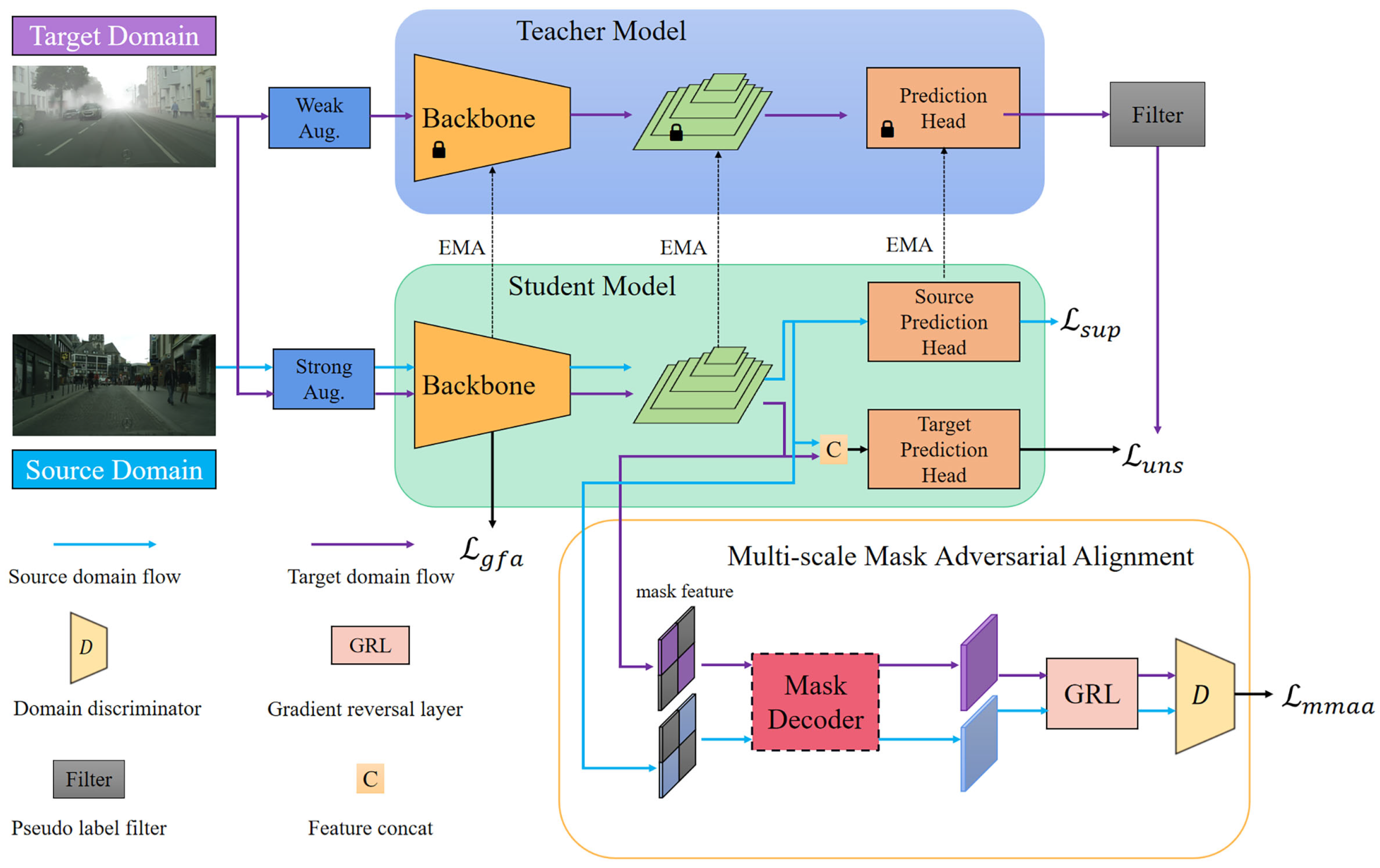
First, a target-domain-specific detection head is incorporated into the student model and is independently optimized using target-domain samples. As shown in
Figure 1, the dual domain-specific heads (DSHs) facilitate more effective extraction of latent domain-specific features and mitigates the negative impact of unreliable pseudo-labels. This design fully exploits the unique information specific to the target domain.
Second, we introduce an auxiliary reconstruction task into the teacher–student framework, referred to as the multi-scale mask adversarial alignment (MMAA) module. This module enhances the student model’s semantic representation capability, thereby enabling the generation of more reliable pseudo-labels. In particular, multi-scale sparse features are extracted through random masking and subsequently reconstructed by a dedicated decoder. The auxiliary task is trained under an adversarial paradigm to encourage the backbone to learn domain-invariant feature representations.
The rest of this paper is organized as follows:
Section 2 provides an overview of related work.
Section 3 defines the problem and introduces the self-training framework.
Section 4 describes the core methodology in detail.
Section 5 presents the experimental results. Finally,
Section 6 concludes the study.
Author Contributions
Conceptualization and methodology, S.D.; software and validation, K.D.; writing—original draft preparation, S.D.; writing—review and editing, K.Z.; visualization, K.D.; supervision, K.Z.; project administration, K.Z.; funding acquisition, S.D. and K.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by National Natural Science Foundation of China grant numbers 62002053 and 62271130, Natural Science Foundation of Guangdong Province grant number 2023A1515010066, Key Area Special Fund of Guangdong Provincial Department of Education grant number 2022ZDZX3042, and Social Public Welfare and Basic Research Project of Zhongshan City grant number 2024B2021.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the IEEE/CVF International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- VS, V.; Oza, P.; Patel, V.M. Towards online domain adaptive object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 478–488. [Google Scholar]
- Chen, L.; Chen, H.; Wei, Z.; Jin, X.; Tan, X.; Jin, Y.; Chen, E. Reusing the task-specific classifier as a discriminator: Discriminator-free adversarial domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7181–7190. [Google Scholar]
- Chen, M.; Zheng, Z.; Yang, Y.; Chua, T.S. Pipa: Pixel-and patch-wise self-supervised learning for domain adaptative semantic segmentation. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 1905–1914. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 3992–4003. [Google Scholar]
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Jiang, Q.; Li, C.; Yang, J.; Su, H. Grounding DINO: Marrying DINO with grounded pre-training for open-Set object detection. In Proceedings of the European Conference on Computer Vision, Paris, France, 26–27 March 2025; pp. 38–55. [Google Scholar]
- Guan, D.; Huang, J.; Xiao, A.; Lu, S.; Cao, Y. Uncertainty-aware unsupervised domain adaptation in object detection. IEEE Trans. Multimed. 2022, 24, 2502–2514. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Gool, L.V. Domain adaptive faster R-CNN for object detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3339–3348. [Google Scholar]
- Vibashan, V.S.; Oza, P.; Sindagi, V.A.; Gupta, V.; Patel, V.M. MeGA-CDA: Memory guided attention for category-aware unsupervised domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4514–4524. [Google Scholar]
- Zhou, H.; Ge, Z.; Liu, S.; Mao, W.; Li, Z.; Yu, H.; Sun, J. Dense teacher: Dense pseudo-labels for semi-supervised object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 35–50. [Google Scholar]
- Xie, X.; Chen, J.; Li, Y.; Shen, L.; Ma, K.; Zheng, Y. Self-supervised CycleGAN for object-preserving image-to-image domain adaptation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 498–513. [Google Scholar]
- Zakharov, S.; Kehl, W.; Ilic, S. Deceptionnet: Network-driven domain randomization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 532–541. [Google Scholar]
- Deng, J.; Li, W.; Chen, Y.; Duan, L. Unbiased mean teacher for cross-domain object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4089–4099. [Google Scholar]
- Li, W.; Liu, X.; Yuan, Y. Sigma: Semantic-complete graph matching for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5291–5300. [Google Scholar]
- Zhao, Z.; Wei, S.; Chen, Q.; Li, D.; Yang, Y.; Peng, Y.; Liu, Y. Masked retraining teacher-student framework for domain adaptive object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 19039–19049. [Google Scholar] [CrossRef]
- Li, Y.J.; Dai, X.; Ma, C.Y.; Liu, Y.C.; Chen, K.; Wu, B.; He, Z.; Kitani, K.; Vajda, P. Cross-domain adaptive teacher for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7581–7590. [Google Scholar]
- Cao, S.; Joshi, D.; Gui, L.Y.; Wang, Y.X. Contrastive mean teacher for domain adaptive object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 23839–23848. [Google Scholar]
- Deng, J.; Xu, D.; Li, W.; Duan, L. Harmonious teacher for cross-domain object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 23829–23838. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: A simple and strong anchor-free object detector. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1922–1933. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multi-box detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 9626–9635. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv 2021, arXiv:2010.04159. [Google Scholar]
- Zong, Z.; Song, G.; Liu, Y. DETRs with collaborative hybrid assignments training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 6748–6758. [Google Scholar]
- Goodfellow, I.; Abadie, J.P.; Mirza, M.; Xu, B.; Farley, D.W.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661v1. [Google Scholar]
- Xu, M.; Wang, H.; Ni, B.; Tian, Q.; Zhang, W. Cross-domain detection via graph-induced prototype alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12355–12364. [Google Scholar]
- Li, C.; Du, D.; Zhang, L.; Wen, L.; Luo, T.; Wu, Y.; Zhu, P. Spatial attention pyramid network for unsupervised domain Adaptation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 481–497. [Google Scholar]
- Kim, T.; Jeong, M.; Kim, S.; Choi, S.; Kim, C. Diversify and match: A domain adaptive representation learning paradigm for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12448–12475. [Google Scholar]
- Hsu, H.K.; Yao, C.H.; Tsai, Y.H.; Hung, W.C.; Tseng, H.Y.; Singh, M.; Yang, M.H. Progressive Domain Adaptation for Object Detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 738–746. [Google Scholar]
- Hsu, C.C.; Tsai, Y.H.; Lin, Y.Y.; Yang, M.H. Every pixel matters: Center-aware feature alignment for domain adaptive object detector. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 733–748. [Google Scholar]
- Su, P.; Wang, K.; Zeng, X.; Tang, S.; Wang, X. Adapting object detectors with conditional domain normalization. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 403–419. [Google Scholar]
- Xu, C.D.; Zhao, X.R.; Jin, X.; Wei, X.S. Exploring categorical regularization for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11721–11730. [Google Scholar]
- Zhao, L.; Wang, L. Task-specific inconsistency alignment for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14197–14206. [Google Scholar] [CrossRef]
- Jiang, J.; Chen, B.; Wang, J.; Long, M. Decoupled adaptation for cross-domain object detection. arXiv 2021, arXiv:2110.02578. [Google Scholar]
- Zhou, W.; Du, D.; Zhang, L.; Luo, T.; Wu, Y. Multi-granularity alignment domain adaptation for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9571–9580. [Google Scholar]
- Zhang, S.; Tuo, H.; Hu, J.; Jing, Z. Domain adaptive Yolo for one-stage cross-domain detection. In Proceedings of the Asian Conference on Machine Learning, Online, 17–19 November 2021; pp. 785–797. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, L.; Wang, W.; Chen, A.; Sun, M.; Kuo, C.H.; Todorovic, S. Bidirectional alignment for domain adaptive detection with transformers. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 18729–18739. [Google Scholar] [CrossRef]
- Weng, W.; Yuan, C. Mean teacher DETR with masked feature alignment: A robust domain adaptive detection transformer framework. Proc. AAAI Conf. Artif. Intell. 2024, 38, 5912–5920. [Google Scholar] [CrossRef]
- Li, H.; Zhang, R.; Yao, H.; Song, X.; Hao, Y.; Zhao, Y.; Li, L.; Chen, Y. Learning domain-aware detection head with prompt tuning. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; pp. 4248–4262. [Google Scholar]
- Chen, Z.; Cheng, J.; Xia, Z.; Hu, Y.; Li, X.; Dong, Z.; Tashi, N. Focusing on feature-level domain alignment with text semantic for weakly-supervised domain adaptive object detection. Neurocomputing 2025, 622, 129435. [Google Scholar] [CrossRef]
- Feng, Y.; Liu, Y.; Yang, S.; Cai, W.; Zhang, J.; Zhan, Q.; Huang, Z.; Yan, H.; Wan, Q.; Liu, C. Vision-language model for object detection and segmentation: A review and evaluation. arXiv 2025, arXiv:2504.09480. [Google Scholar]
- Chen, J.; Liu, L.; Deng, W.; Liu, Z.; Liu, Y.; Wei, Y.; Liu, Y. Refining pseudo labeling via multi-granularity confidence alignment for unsupervised cross domain object detection. IEEE Trans. Image Process. 2025, 34, 279–294. [Google Scholar] [CrossRef]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. arXiv 2017, arXiv:1703.01780. [Google Scholar]
- Chen, M.; Chen, W.; Yang, S.; Song, J.; Wang, X.; Zhang, L.; Yan, Y.; Qi, D.; Zhuang, Y.; Xie, D.; et al. Learning domain adaptive object detection with probabilistic teacher. arXiv 2022, arXiv:2206.06293. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhang, Y.F.; Wang, J.; Liang, J.; Zhang, Z.; Yu, B.; Wang, L.; Tao, D.; Xie, X. Domain-specific risk minimization for domain generalization. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 3409–3421. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. arXiv 2020, arXiv:2006.04388. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. ConvNeXt v2: Co-designing and scaling Convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Sakaridis, C.; Dai, D.; Gool, L.V. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef]
- Johnson-Roberson, M.; Barto, C.; Mehta, R.; Sridhar, S.N.; Rosaen, K.; Vasudevan, R. Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks? arXiv 2016, arXiv:1610.01983. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The Kitti vision benchmark suite. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Inoue, N.; Furuta, R.; Yamasaki, T.; Aizawa, K. Cross-domain weakly-supervised object detection through progressive domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5001–5009. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. 2017. Available online: https://openreview.net/pdf?id=BJJsrmfCZ (accessed on 23 May 2025).
- Liu, D.; Zhang, C.; Song, Y.; Huang, H.; Wang, C.; Barnett, M.; Cai, W. Decompose to adapt: Cross-domain object detection via feature disentanglement. IEEE Trans. Multimed. 2022, 25, 1333–1344. [Google Scholar] [CrossRef]
- Yoo, J.; Chung, I.; Kwak, N. Unsupervised domain adaptation for one-stage object detector using offsets to bounding box. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 691–708. [Google Scholar]
- Liu, Y.; Wang, J.; Huang, C.; Wang, Y.; Xu, Y. CIGAR: Cross-modality graph reasoning for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 23776–23786. [Google Scholar] [CrossRef]
- Liu, F.; Zhang, X.; Wan, F.; Ji, X.; Ye, Q. Domain contrast for domain adaptive object detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8227–8237. [Google Scholar] [CrossRef]
- Wang, H.; Jia, S.; Zeng, T.; Zhang, G.; Li, Z. Triple feature disentanglement for one-stage adaptive object detection. AAAI Conf. Artif. Intell. 2024, 38, 5401–5409. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, H.; Xu, X.; Hu, X.; Xu, Y.; Dai, L.; Choi, K.S.; Heng, P.A. Representative feature alignment for adaptive object detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 689–700. [Google Scholar] [CrossRef]
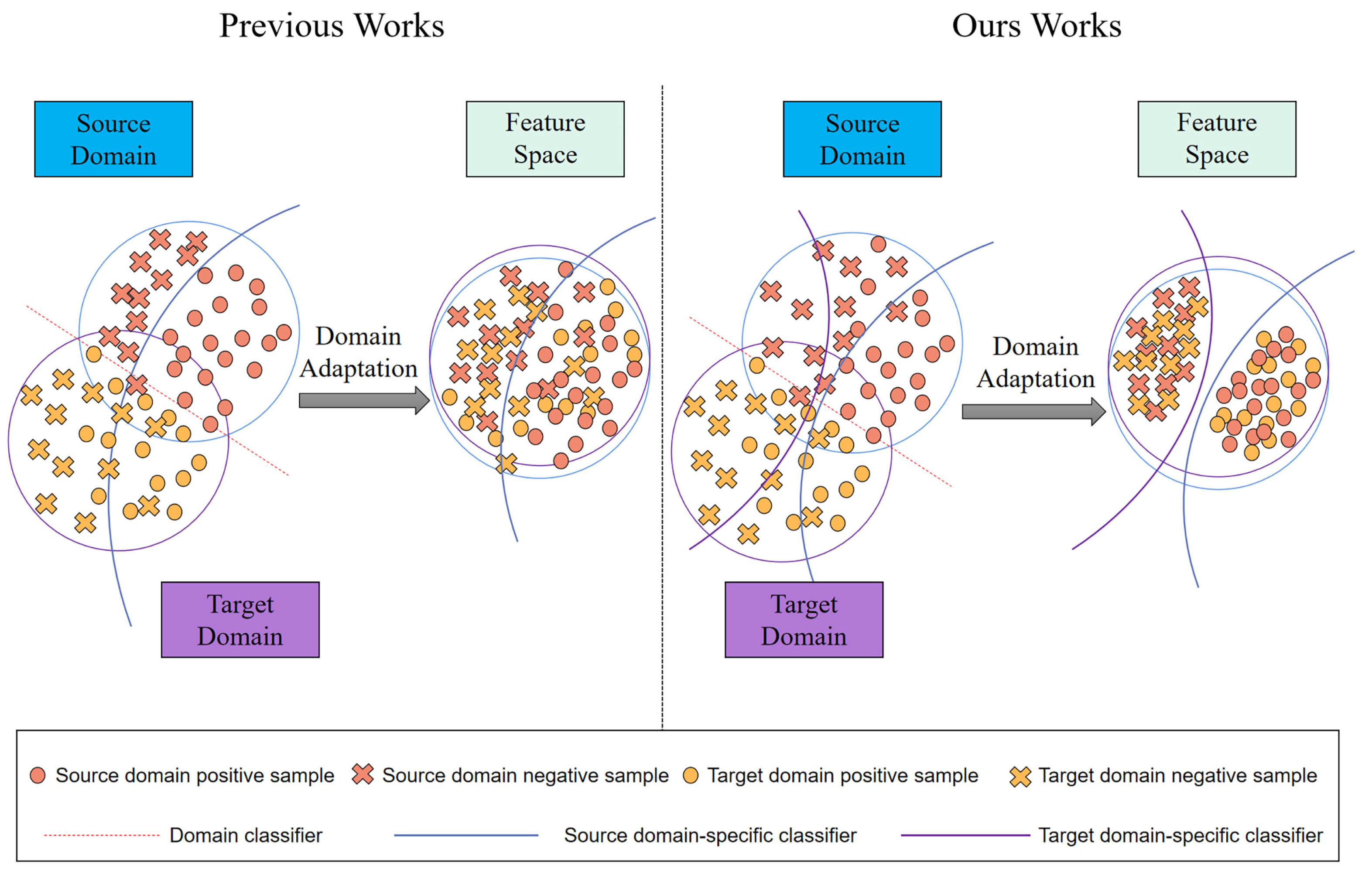
Figure 1.
Traditional adaptive teacher–student frameworks often suffer from suboptimal feature discrimination due to the shared detection head, which applies a shared decision boundary for both source and target domains. In contrast, our method introduces two independent detection heads tailored to each domain, enabling more accurate feature separation and reducing the interference caused by negative samples during adaptation.
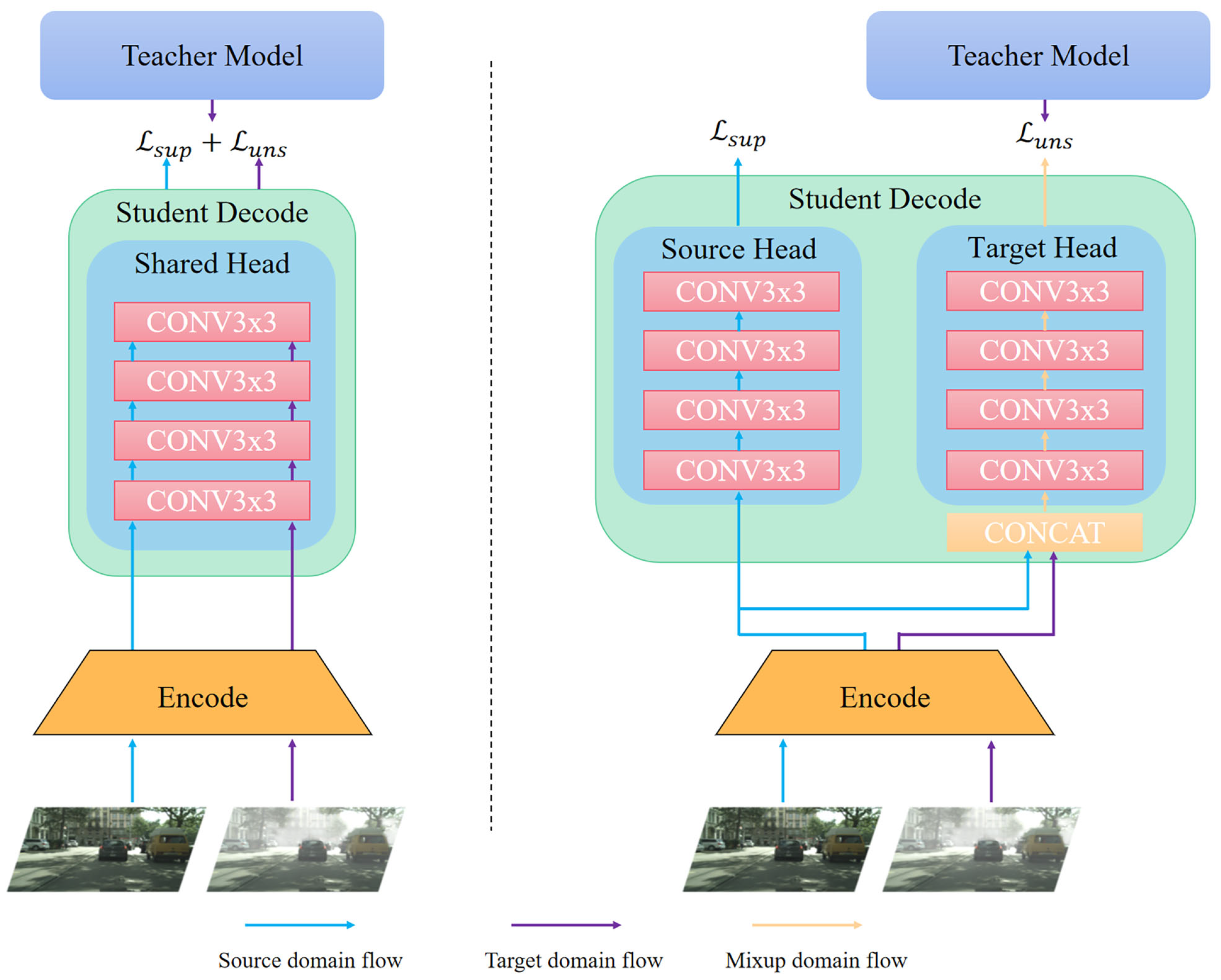
Figure 3.
A comparison of the structure of the detection head of the conventional adaptive teacher–student framework (left) and the domain-specific teacher–student framework proposed in this paper (right). The target domain samples and source domain samples of the previous adaptive teacher–student framework are encoded and fed into the weight-sharing detection head network for supervised loss optimization. On the contrary, our proposed framework splits the detection head network into two weight-independent detection heads corresponding to the decoding of source domain features and target domain features.
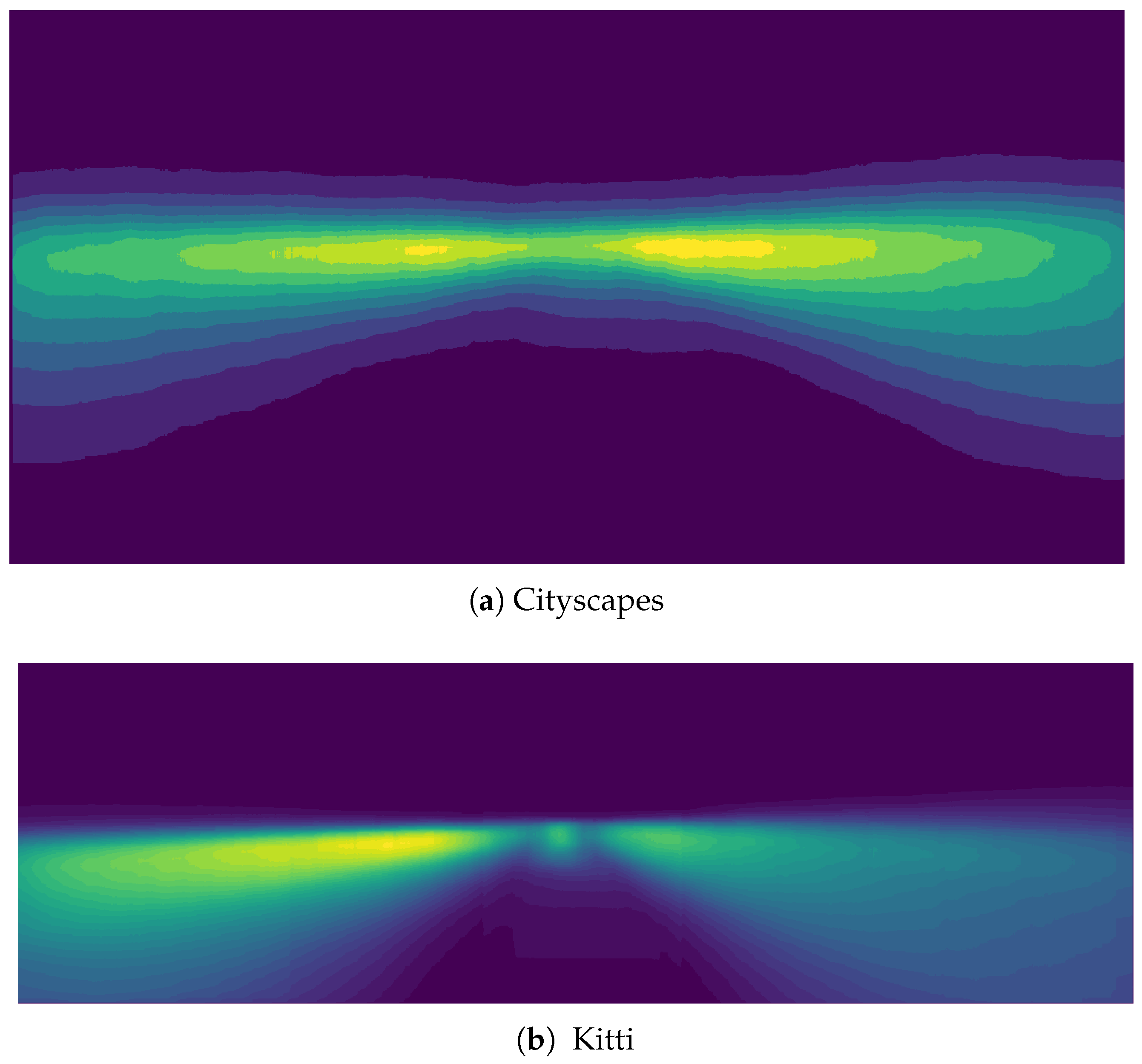
Figure 4.
Instance position distribution heatmaps: Cityscapes vs. KITTI. More instances in KITTI are near the boundaries and corners.
Figure 5.
The accuracy of the pseudo-labels produced during training is a key indicator of model performance.
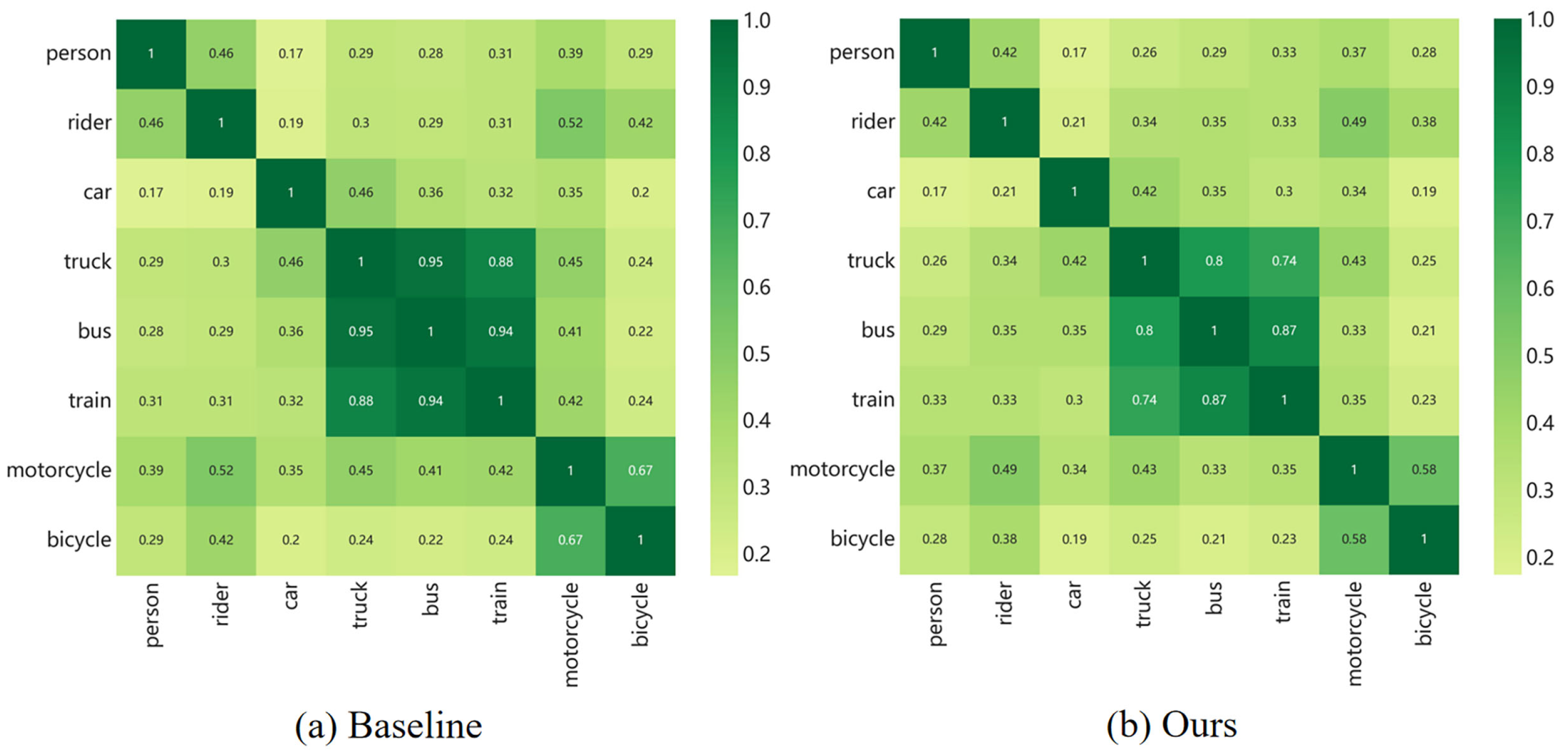
Figure 6.
Confusion matrix. The values in the matrix indicate the degree of similarity between the categories on the horizontal axis and the categories on the vertical axis.
Figure 7.
Visual results on three domain adaptation scenarios. From top to bottom: (a) Cityscapes→Foggy Cityscapes, (b) Sim10k→Cityscapes, (c) KITTI→Cityscapes.
Table 1.
Quantitative adaptation results from Cityscapes to Foggy Cityscapes. Our approach achieves the highest performance among all FCOS-based methods.
| Cityscapes→Foggy Cityscapes |
|---|
| Method
|
Venue
|
Detector
|
Person
|
Rider
|
Car
|
Truck
|
Bus
|
Train
|
Motor
|
Bicycle
| |
|---|
| DDF [66] | IEEE TMM 2022 | Faster R-CNN | 37.6 | 45.5 | 56.1 | 30.7 | 50.4 | 47.0 | 31.1 | 39.8 | 42.3 |
| PT [50] | ICML 2022 | Faster R-CNN | 43.2 | 52.4 | 63.4 | 33.4 | 56.6 | 37.8 | 41.3 | 48.7 | 47.1 |
| CMT [18] | CVPR 2023 | Faster R-CNN | 45.9 | 55.7 | 63.7 | 39.6 | 66.0 | 38.8 | 41.4 | 51.2 | 50.3 |
| BiADT [43] | ICCV 2023 | DETR | 52.2 | 58.9 | 69.2 | 31.7 | 55.0 | 45.1 | 42.6 | 51.3 | 50.8 |
| MRT [16] | ICCV 2023 | DETR | 52.8 | 51.7 | 68.7 | 35.9 | 58.1 | 54.5 | 41.0 | 47.1 | 51.2 |
| MTM [44] | AAAI 2024 | DETR | 51.0 | 53.4 | 67.2 | 37.2 | 54.4 | 41.6 | 38.4 | 47.7 | 48.9 |
| DA-Pro [45] | NeurIPS 2023 | RegionCLIP | 55.4 | 62.9 | 70.9 | 40.3 | 63.4 | 54.0 | 42.3 | 58.0 | 55.9 |
| MGCAMT [48] | IEEE TIP 2025 | RetinaNet | 60.2 | 66.6 | 76.5 | 33.2 | 60.1 | 43.2 | 49.8 | 57.9 | 55.9 |
| Source only | - | FCOS | 44.0 | 46.5 | 51.6 | 25.6 | 35.0 | 19.0 | 29.6 | 45.9 | 37.1 |
| Baseline | - | FCOS | 47.7 | 50.4 | 63.5 | 22.4 | 38.8 | 28.3 | 30.7 | 48.7 | 41.3 |
| EPM * [35] | ECCV 2020 | FCOS | 39.9 | 38.1 | 57.3 | 28.7 | 50.7 | 37.2 | 30.2 | 34.2 | 39.5 |
| OADA [67] | ECCV 2022 | FCOS | 47.8 | 46.5 | 62.9 | 32.1 | 48.5 | 50.9 | 34.3 | 39.8 | 45.4 |
| CIGAR [68] | CVPR2023 | FCOS | 46.1 | 47.3 | 62.1 | 27.8 | 56.6 | 44.3 | 33.7 | 41.3 | 44.9 |
| HT * [19] | CVPR 2023 | FCOS | 50.3 | 54.2 | 65.6 | 32.0 | 51.5 | 38.8 | 39.4 | 50.6 | 48.1 |
| Ours | - | FCOS | 51.4 | 54.3 | 68.4 | 37.8 | 54.6 | 40.2 | 42.4 | 51.8 | 50.1 |
| Oracle | - | FCOS | 52.5 | 52.1 | 70.3 | 30.9 | 50.2 | 36.1 | 41.6 | 51.8 | 48.2 |
Table 2.
Quantitative adaptation results from Sim10k to Cityscapes. Our approach achieves the highest performance among all FCOS-based methods.
| Sim10k→Cityscapes | |
|---|
|
Method
|
Venue
|
Detector
| |
|---|
| DDF [66] | IEEE TMM 2022 | Faster R-CNN | 44.3 |
| PT [50] | ICML 2022 | Faster R-CNN | 55.1 |
| BiADT [43] | ICCV 2023 | DETR | 56.6 |
| MRT [16] | ICCV 2023 | DETR | 62.0 |
| MTM [44] | AAAI 2024 | DETR | 58.1 |
| DA-Pro [45] | NeurIPS 2023 | RegionCLIP | 62.9 |
| MGCAMT [48] | IEEE TIP 2025 | RetinaNet | 67.5 |
| Source only | - | FCOS | 44.8 |
| Baseline | - | FCOS | 55.0 |
| EPM * [35] | ECCV 2020 | FCOS | 51.2 |
| OADA [67] | ECCV 2022 | FCOS | 59.2 |
| CIGAR [68] | VPR 2023 | FCOS | 58.5 |
| HT * [19] | CVPR 2023 | FCOS | 60.2 |
| Ours | - | FCOS | 60.4 |
| Oracle | - | FCOS | 74.9 |
Table 3.
Quantitative adaptation results from KITTI to Cityscapes. Our approach achieves the highest performance among all FCOS-based methods.
| KITTI→Cityscapes | |
|---|
|
Method
|
Venue
|
Detector
| |
|---|
| DDF [66] | IEEE TMM 2022 | Faster R-CNN | 46.0 |
| PT [50] | CIML 2022 | Faster R-CNN | 60.2 |
| DA-DETR [44] | CVPR 2023 | DETR | 58.1 |
| DA-Pro [45] | NeurIPS 2023 | RegionCLIP | 61.4 |
| MGCAMT [48] | IEEE TIP 2025 | RetinaNet | 62.2 |
| Source only | - | FCOS | 42.7 |
| Baseline | - | FCOS | 46.5 |
| EPM * [35] | ECCV 2020 | FCOS | 45.0 |
| OADA [67] | ECCV 2022 | FCOS | 47.8 |
| CIGAR [68] | CVPR 2023 | FCOS | 48.5 |
| HT * [19] | CVPR 2023 | FCOS | 50.3 |
| Ours | - | FCOS | 50.9 |
| Oracle | - | FCOS | 74.9 |
Table 4.
Quantitative adaptation results from Pascal VOC to Clipart. The performance of our method is on par with that of DC. Due to space constraints, the “Venue” and “Detector” columns are omitted; the corresponding information is provided in
Table 5 and
Table 6.
| Method | Aero | Bicycle | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | Table | Dog | Hrs | Bike | Prsn | Plnt | Sheep | Sofa | Train | Tv | mAP |
|---|
| DC [69] | 47.1 | 53.2 | 38.8 | 37.0 | 46.6 | 45.9 | 52.6 | 14.5 | 39.1 | 48.4 | 31.7 | 23.7 | 34.9 | 87.0 | 67.8 | 54.0 | 22.8 | 23.8 | 44.9 | 51.0 | 43.2 |
| CMT [18] | 31.9 | 66.9 | 33.9 | 30.2 | 26.3 | 65.2 | 43.6 | 12.6 | 44.5 | 46.3 | 47.9 | 19.3 | 29.9 | 53.1 | 63.3 | 40.5 | 17.1 | 41.2 | 49.6 | 43.9 | 40.4 |
| TFD [70] | 27.9 | 64.8 | 28.4 | 29.5 | 25.7 | 64.2 | 47.7 | 13.5 | 47.5 | 50.9 | 50.8 | 21.3 | 33.9 | 60.2 | 65.6 | 42.5 | 15.1 | 40.5 | 45.5 | 48.6 | 41.2 |
| DA-Pro [45] | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 46.9 |
| Source only | 27.3 | 60.4 | 17.5 | 16.0 | 14.5 | 43.7 | 32.0 | 10.2 | 38.6 | 15.3 | 24.5 | 16.0 | 18.4 | 49.5 | 30.7 | 30.0 | 2.3 | 23.0 | 35.1 | 29.9 | 26.7 |
| Baseline | 30.8 | 65.5 | 18.7 | 23.0 | 24.9 | 57.5 | 40.2 | 10.9 | 38.0 | 25.9 | 36.0 | 15.6 | 22.6 | 66.8 | 52.1 | 35.3 | 1.0 | 34.6 | 38.1 | 39.4 | 33.8 |
| Ours | 47.0 | 53.4 | 39.8 | 37.6 | 47.0 | 45.8 | 52.5 | 14.0 | 38.0 | 48.5 | 32.5 | 24.1 | 35.8 | 86.1 | 68.7 | 54.0 | 24.6 | 23.4 | 45.6 | 50.3 | 43.5 |
| Oracle | 30.1 | 51.4 | 47.2 | 42.5 | 30.7 | 55.7 | 59.4 | 25.1 | 47.4 | 52.5 | 37.8 | 43.3 | 42.6 | 61.6 | 73.3 | 41.9 | 44.3 | 25.5 | 59.0 | 51.3 | 46.1 |
Table 5.
Quantitative adaptation results from Pascal VOC to Watercolor. The performance of our method is on par with that of DC.
| Method | Venue | Detector | Bike | Bird | Car | Cat | Dog | Person | mAP |
|---|
| DC [69] | TCS 2022 | Faster R-CNN | 76.7 | 53.2 | 45.3 | 41.6 | 35.5 | 70.0 | 53.7 |
| CMT [18] | CVPR 2023 | Faster R-CNN | 87.1 | 48.7 | 50.2 | 37.1 | 31.5 | 66.3 | 53.5 |
| TFD [70] | AAAI 2024 | Faster R-CNN | 93.0 | 52.6 | 47.6 | 39.2 | 33.7 | 63.9 | 55.0 |
| RFA [71] | TCS 2023 | Faster R-CNN | 97.1 | 55.3 | 53.8 | 48.7 | 40.9 | 67.2 | 60.5 |
| DA-Pro [45] | NeurIPS 2023 | RegionCLIP | - | - | - | - | - | - | 58.1 |
| Source only | - | FCOS | 67.8 | 45.8 | 36.2 | 31.7 | 20.3 | 59.7 | 43.6 |
| Baseline | - | FCOS | 77.5 | 46.1 | 44.6 | 30.0 | 26.0 | 58.6 | 47.1 |
| Ours | - | FCOS | 54.6 | 55.5 | 31.8 | 35.2 | 69.1 | 76.2 | 53.8 |
| Oracle | - | FCOS | 83.5 | 55.7 | 44.9 | 50.3 | 51.4 | 74.5 | 60.1 |
Table 6.
Quantitative adaptation results from Pascal VOC to Comic. The performance of our method is on par with that of TFD.
| Method | Venue | Detector | Bike | Bird | Car | Cat | Dog | Person | mAP |
|---|
| DC [69] | TCS 2022 | Faster R-CNN | 51.9 | 23.9 | 36.7 | 27.1 | 31.5 | 61.0 | 38.7 |
| CMT [18] | CVPR 2023 | Faster R-CNN | 49.8 | 19.2 | 29.8 | 15.2 | 29.1 | 54.1 | 32.9 |
| TFD [70] | AAAI 2024 | Faster R-CNN | 53.4 | 19.2 | 35.0 | 16.1 | 33.2 | 49.2 | 34.4 |
| RFA [71] | TCS 2023 | Faster R-CNN | 46.6 | 24.2 | 33.3 | 21.7 | 29.0 | 61.2 | 36.0 |
| DA-Pro [45] | NeurIPS 2023 | RegionCLIP | - | - | - | - | - | - | 44.6 |
| Source only | - | FCOS | 43.3 | 9.4 | 23.6 | 9.8 | 10.9 | 34.2 | 21.9 |
| Baseline | - | FCOS | 50.5 | 15.9 | 27.2 | 11.4 | 18.4 | 46.1 | 28.3 |
| Ours | - | FCOS | 52.2 | 21.5 | 32.6 | 15.9 | 30.8 | 51.6 | 34.1 |
| Oracle | - | FCOS | 38.3 | 30.8 | 34.9 | 51.8 | 47.5 | 72.8 | 46.0 |
Table 7.
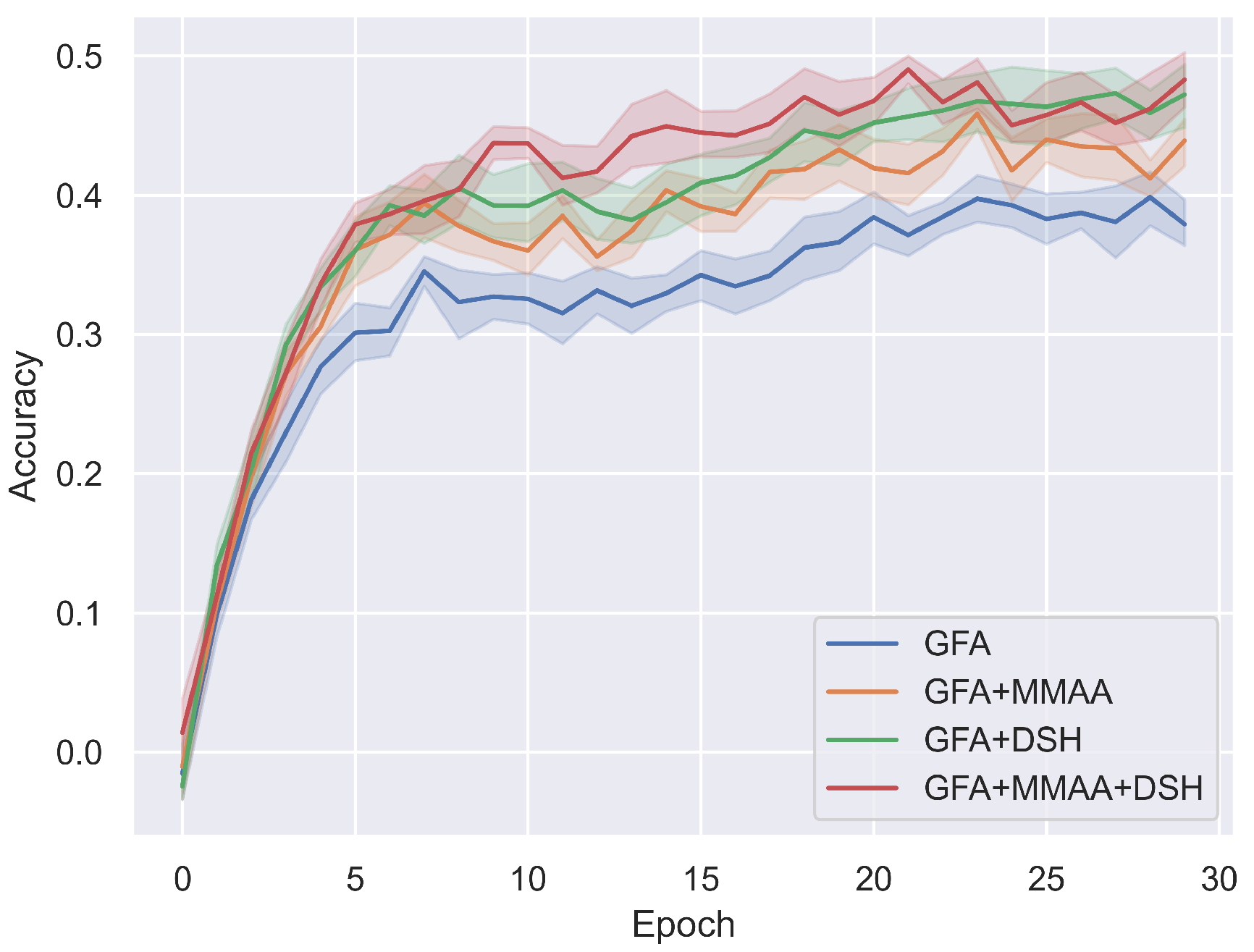
Ablation studies of our method on Cityscapes→Foggy Cityscapes using FCOS with a RestNet-50 backbone. GFA achieves 41.3% ; adding MMAA and DSH improves performance by 4.8% and 7.4%, respectively. Combining all components yields a total improvement of 8.8%, demonstrating their complementary benefits.
| Method | GFA | MMAA | DSH | |
|---|
| Baseline | ✔ | | | 41.3 |
| | ✔ | ✔ | | 46.1 (4.8 ↑) |
| ✔ | | ✔ | 48.7 (7.4 ↑) |
| | ✔ | ✔ | ✔ | 50.1 (8.8 ↑) |
Table 8.
Ablation study of the proposed multi-scale mask adversarial alignment module. In this study, we use different metrics to present results for different scale features.
| Mask Scale | | | | | | |
|---|
| without MMAA | 20.5 | 41.3 | 19.5 | 4.1 | 29.8 | 60.3 |
| 27.3 | 45.9 | 26.4 | 8.4 | 37.4 | 67.2 |
| 27.6 | 45.8 | 27.2 | 7.9 | 36.3 | 66.5 |
| 27.0 | 45.3 | 25.6 | 8.4 | 37.9 | 65.9 |
| 27.0 | 44.8 | 26.2 | 9.7 | 37.0 | 66.3 |
| 26.9 | 44.4 | 26.6 | 8.2 | 36.8 | 66.5 |
| 27.1 | 46.1 | 26.3 | 10.2 | 38.9 | 67.4 |
Table 9.
Performance comparison between the top strategy and the threshold strategy.
| Selection Strategy | Parameter | |
|---|
| threshold | | 44.4 |
| 45.7 |
| 45.8 |
| 45.1 |
| 43.9 |
| adaptive | 48.2 |
| top | | 49.1 |
| 50.1 |
| 49.4 |
| 47.6 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}