
Dynamic Algorithm for Mining Relevant Association Rules via Meta-Patterns and Refinement-Based Measures


Abstract

1. Introduction
- To formulate a scalable multi-step rule mining process that incorporates statistical, structural, and semantic constraints.
- To introduce adaptive thresholding mechanisms based on mutual information and dataset-specific variability.
- To define and validate a novel semantic Target Concentration Measure (TCM) that calculates the concentration of rule consequents.
- To empirically compare the proposed algorithm with standard and new methods on different datasets, determining its performance in terms of rule quality, interpretability, and computational efficiency.
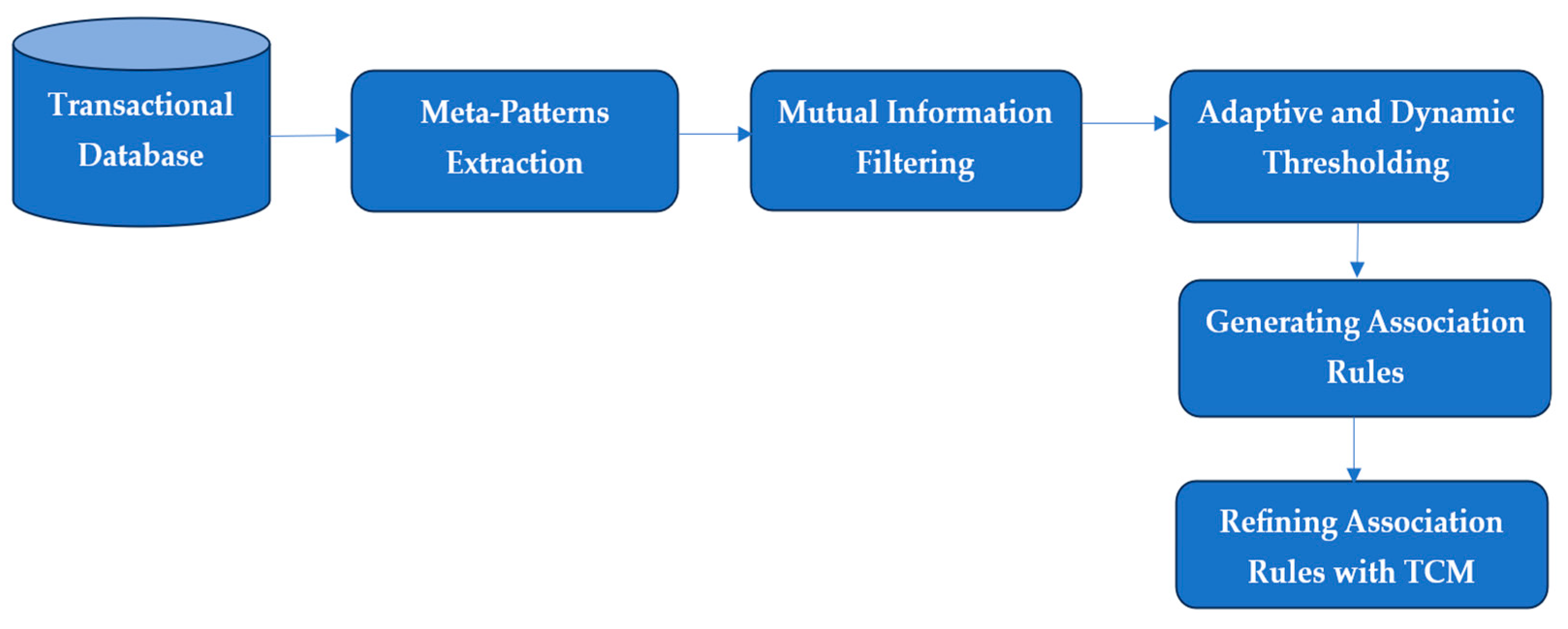
2. Methods
- Phase 1—Extraction of meta-patterns from a hierarchical transaction structure to group strongly co-occurring items and calculate stability score.
- Phase 2—Mutual information filtering, replacing purely frequency-based rating by finding statistically significant item associations.
- Phase 3—Adaptive and Dynamic Thresholding, where the decision criterion adapts to the distribution of mutual information, enhancing robustness.
- Phase 4—Generating Association Rules from validated meta-patterns, with confidence-based selection to retain the most valuable associations.
- Phase 5—Refining Association Rules through semantic coherence analysis among antecedents, ensuring clarity and reducing redundancy.
2.1. Extraction of Meta-Patterns
2.2. Mutual Information-Based Filtering
- When > 0, the items tend to appear together more frequently than would be expected under statistical independence, indicating a meaningful dependency.
- When ≈ 0, the items are essentially independent, regardless of how often they individually occur.
- When < 0, their joint presence is less likely than predicted by their individual frequencies—a case that is typically not exploited in association rule mining.
2.3. Adaptive and Dynamic Thresholding
2.4. Association Rule Generation
- Support [2]: Estimates the frequency of occurrence of the rule within the set of transactions as in Equation (6).
- Confidence [2]: Estimates the probability that Y will be visible when X is present by Equation (7).
2.5. Refining Association Rules
Formal Definition and Intuition of the Target Concentration Measure (TCM)
- The numerator Support(X ∪ ) measures the simultaneous frequency of the sets X and .
- The denominator represents the total frequency of X occurring with all its potential outcomes.
| Algorithm 1: DERAR (Dynamic Extracting of Relevant Association Rules). |
Input:
1.2 For each transaction t in DB: Insert into T by merging similar items. 1.3 Extract frequent meta-patterns X with support ≥ . 1.4 For each meta-pattern X:
2.3 Calculate a Dynamic Adaptive Threshold for each meta-pattern X:
3.2 For each meta-pattern X:
4.2 Define a Dynamic Adaptive Threshold to filter rules:
5.2 For each group of rules with the same antecedent X:
5.3 Build the list = {TCM(r) for all r ∈ R} 5.4 Compute μ = Average () and Compute σ =Deviation (). 5.5 Compute dynamic threshold θ = μ + λ × σ 5.6 = {r ∈ R | TCM(r) ≥ θ} Return |
3. Results
- Quantitative analysis of the resulting rules.
- Qualitative analysis of the resulting rules.
- Effect of TCM measurement on the logical integrity of rules.
- Computational efficiency: Execution time and memory consumption compared to other methods.
- Quantitative evaluation of λ-controlled dynamic Filtering: Impact analysis via precision, recall, and ROC metrics.
3.1. Dataset Overview
- Mushroom Dataset: The dense dataset contains descriptions of ~8124 mushroom samples, and ~119 various items. Categorical attributes were converted into transactions, and each feature is considered an item.
- Adult Dataset: Also called the “Census Income” dataset, this dense dataset contains ~48,842 instances with ~95 attributes and aims to predict whether a person’s annual income is above USD 50,000. The numerical attributes were discretized into discrete classes and then translated into transactions.
- Online Retail II Dataset: The sparse dataset includes all the transactions carried out between 1 December 2009, and 9 December 2011, by a United Kingdom-based online retailer. It has ~53,628 records with ~5305 attributes. It is typically used for sales pattern detection, customer segmentation, and market basket analysis.
- Retail Dataset: This sparse dataset, available at the SPMF website [41], contains ~88,162 retail transactions, widely used in frequent pattern mining and association rule mining, and ~16,470 items.
3.2. Analysis of Results
3.2.1. Quantitative Analysis of the Resulting Rules
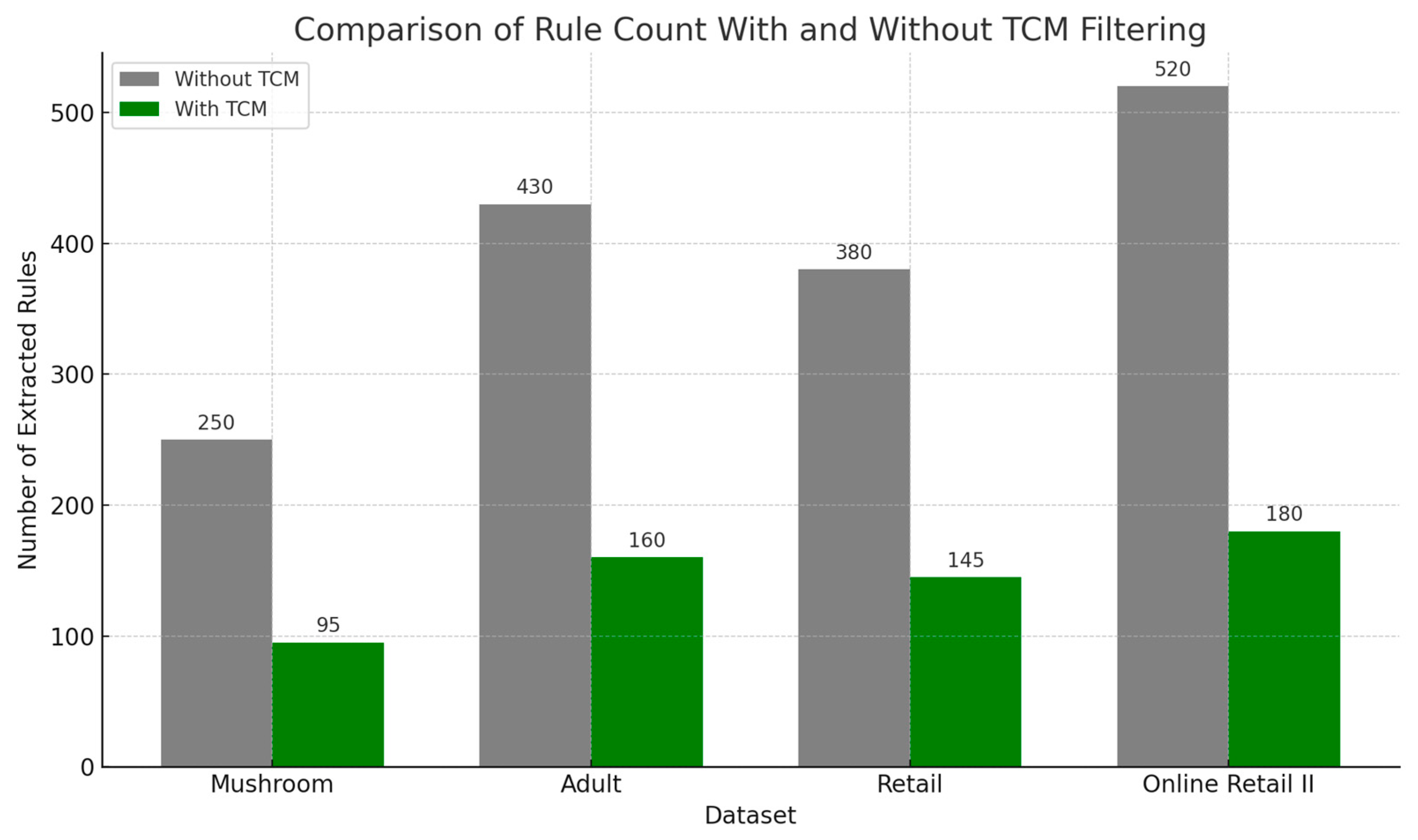
- Mushroom Dataset: consisting of structured and categorical data, normally generates a huge number of associations in classical algorithms. Apriori and FP-Growth both yield more than 4500 rules, whereas H-Apriori reduces this to 3120. In contrast, DERAR’s filtering mechanisms significantly minimize this quantity: from 2140 rules at λ = 0.5 to just 615 at λ = 1.5. This underscores the capacity of DERAR to remove redundant or weak statistical patterns while retaining important associations.
- Adult Dataset: with its socio-economic features and medium complexity, produces the largest rule counts of the datasets tested. Apriori and FP-Growth mine over 6300 rules. H-Apriori reduces this modestly to 4025. DERAR outperforms the three by a large margin by reducing the rule set to 2230 rules at λ = 1.0 and only 1072 rules at λ = 1.5. This result highlights the importance of both semantic and adaptive filtering for reducing cognitive overload in complex rule settings.
- Retail Dataset: This real-world dataset leads to over 3900 rules under Apriori and over 3700 with FP-Growth. H-Apriori improves output compactness to 1685. Yet DERAR offers even greater control: at λ = 1.5, only 410 rules remain, while still maintaining a high level of interpretability as previously demonstrated. This validates DERAR’s suitability for market basket analysis, where rule explosion is a common problem.
- Online Retail Dataset: Online Retail is the most sparse and high-dimensional dataset in this study. Classical algorithms suffer from a rule explosion, generating more than 5000 associations. H-Apriori cuts this by more than half (2090), but DERAR performs best with 1195 rules at λ = 1.0 and only 526 at λ = 1.5. These results show that DERAR handles data sparsity and dimensionality effectively by using dynamic thresholds and semantic structure to limit rule proliferation.
3.2.2. Qualitative Analysis of the Resulting Rules
3.2.3. Impact of the TCM Measure on the Logical Quality of the Rules
- High-TCM Rule: education = Bachelors → income = High. (Support: 4.2%, Confidence: 72%, TCM: 0.94). Interpretation: The rule identifies a strong correlation between the possession of a bachelor’s degree and achieving high-income levels. The high TCM value reveals a high level of correspondence between the antecedent and a particular consequence, thus being very useful for the prediction of income or classification of the workforce.
- Low-TCM Rule: age = Middle → income = {Low, Medium, High}. (Support: 15.1%, Confidence: 56%, TCM: 0.34). Interpretation: Though frequent, this rule has a very dispersed set of consequences. The low TCM shows the lack of semantic concentration. Hence, it is not very useful for decision-making.
- High-TCM Rule: product_category = Stationery → country = United Kingdom. (Support: 3.8%, Confidence: 83%, TCM: 0.91). Use case: Helps to establish core markets for product-specific demand, guiding location-based inventory deployment.
- Low-TCM Rule: basket_size = Small → country = {UK, Germany, Netherlands, Others}. (Support: 10.5%, Confidence: 41%, TCM: 0.29). Use case: The widespread use of the consequent reduces the interpretability for supply chain optimization or targeted marketing.
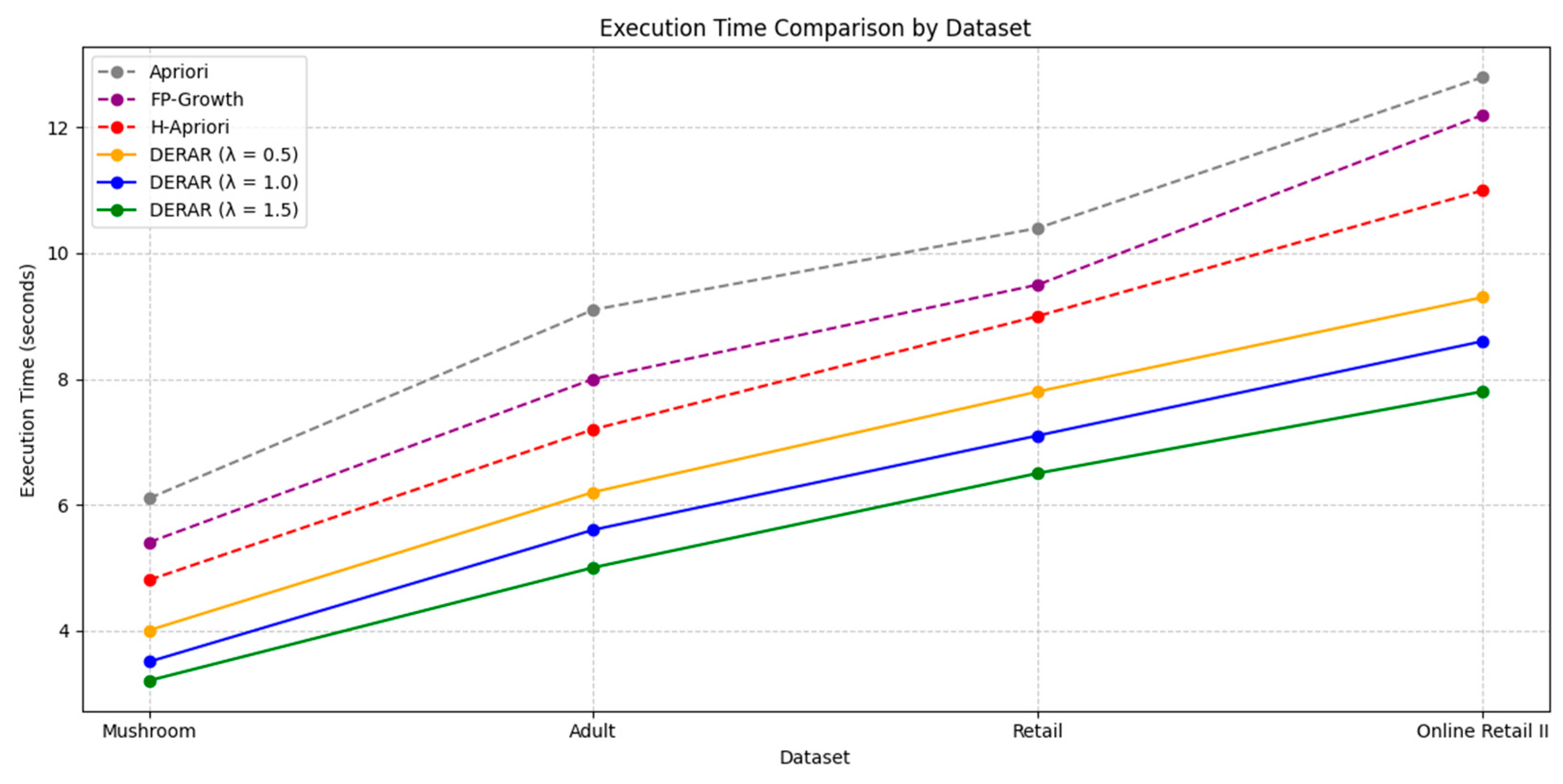
3.2.4. Execution Time
3.2.5. Quantitative Evaluation of λ-Controlled Dynamic Filtering
3.3. Computational Complexity of the DERAR Algorithm
- Meta-Pattern Extraction: this stage verifies all N transactions, with approximately I item per transaction, in order to categorize them into standardized pattern forms. The items of each transaction are set for uniform prefix alignment with a cost of O (I log I). Since this operation is performed for each transaction, the total cost becomes O (N × I × log I). This process is similar to preprocessing in FP-Growth and maintains scalability, even when run in parallel.
- Mutual Information-Based Filtering: Once meta-patterns are mined (P total), each is filtered based on mutual information to quantify the statistical dependence between items. Calculating MI is linear per pattern, and sorting the P values for ranking adds a log P term. Thus, the total cost is O (P × log P). This step eliminates noisy or weakly informative patterns prior to rule generation.
- Adaptive and Dynamic Thresholding of MI: Dynamic thresholding is applied to discard patterns with MI scores below an adaptive threshold. This threshold is determined from the distribution (average μ and standard deviation σ) of MI scores. As this process requires just one pass over the P-ranked patterns, this entails a linear complexity O(P). This process has minimal overhead but boosts selectivity.
- Association Rule Generation with Dynamic Filtering: The rule generation is performed only from the subset of selected meta-patterns, leading to a candidate set of R rules. Dynamic filtering of the rules is performed according to the λ parameter, which may involve sorting or indexing operations on support or confidence levels. The complexity is hence termed O (R × log R). This approach guarantees that the resulting rules are both targeted and computationally efficient.
- Semantic Refinement with TCM: Target Concentration Measure (TCM) is used to evaluate the logical focus of each rule. Since the TCM for each rule is computed separately from that rule’s support values, this step involves a single linear scan over all R rules. The complexity involved is therefore O(R). No sorting or recomputation is necessary at this stage.
3.4. Comparison with Related Algorithm
- Execution time: DERAR outperforms Apriori and FP-Growth on each dataset. Despite heuristic pruning in H-Apriori, it continues to calculate huge candidate spaces. DERAR employs early structural and semantic pruning via the λ parameter, thus leading to faster convergence and fewer rule sets for increasing λ.
- Scalability: DERAR is scalable to large and sparse data such as Retail and Online Retail II. It is scalable because it prunes low-value candidates early. Apriori and FP-Growth are not scalable due to their exhaustive pattern enumeration. H-Apriori performs better than them, but is still limited by its frequency-based heuristic.
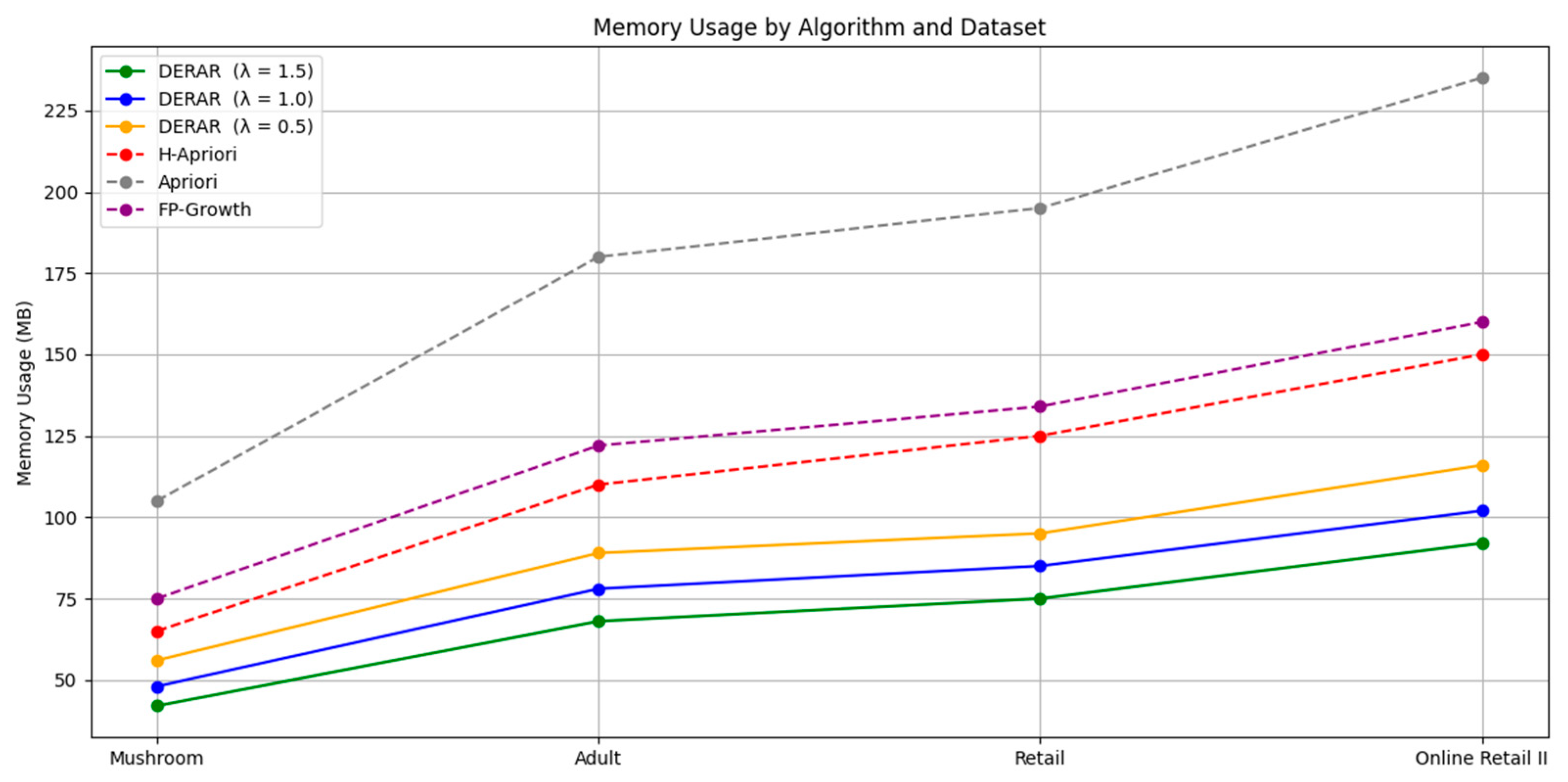
- Memory and Complexity: FP-Growth has linear memory growth with pattern frequencies, but Apriori’s exponential complexity limits its application. H-Apriori offers partial optimizations but no semantic filtering. DERAR’s meta-pattern compact structure and multi-layered filtering reduce memory usage and computational overhead.
- Logical quality of extracted rules: One significant benefit of DERAR is that it can generate rules of high logical quality. Through the use of the TCM measure, DERAR tends to support rules that link a single antecedent to a single consequent. This makes it possible to minimize broad rules and ambiguity. Apriori, FP-Growth, and H-Apriori, in contrast, due to the lack of semantic filtering, tend to generate numerous non-discriminative rules.
- Integrated semantic filtering: DERAR particularly incorporates an advanced filtering strategy in which the evaluation of rules is performed according to their structural form (meta-patterns), mutual information, contextual confidence, and logical density computed by TCM. Apriori, FP-Growth, and even H-Apriori only consider frequency thresholds alone and disregard the semantic context.
- Reduction of redundancy: Redundancy occurs frequently under the use of low thresholds in conventional algorithms. Although H-Apriori minimizes some redundancy through the utilization of heuristics, DERAR utilizes adaptive filtering combined with stability-based pattern selection to minimize redundancy greatly without compromising rule coverage.
- User control (dynamic λ): The introduction of the parameter λ in DERAR provides the user with a convenient way to dynamically adjust the level of selectivity. It is an effective method to manage the compromise between the number of rules and the targeted level of quality, an operation that is not possible with conventional techniques.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DERAR | Dynamic Extracting of Relevant Association Rules |
| FDs | Functional Dependencies |
| MI | Mutual Information |
| TCM | Target Concentration Measure |
| ARM | Association Rule Mining |
Appendix A
References
- Frawley, W.J.; Piatetsky-Shapiro, G.; Matheus, C.J. Knowledge discovery in databases: An overview. AI Mag. 1992, 13, 57–70. [Google Scholar]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 25–28 May 1993; pp. 207–216. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules in large databases. In Proceedings of the 20th International Conference on Very Large Data Bases (VLDB), Santiago de Chile, Chile, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Han, J.; Pei, J.; Yin, Y. Mining frequent patterns without candidate generation. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 1–12. [Google Scholar]
- Zaki, M.J. Fast Mining of Sequential Patterns in Very Large Databases; University of Rochester, Department of Computer Science: Rochester, NY, USA, 1997. [Google Scholar]
- Liu, Y.; Liao, W.K.; Choudhary, A. A two-phase algorithm for fast discovery of high utility itemsets. In Advances in Knowledge Discovery and Data Mining; Dai, H., Srikant, R., Zhang, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 689–695. [Google Scholar]
- Ahmed, C.F.; Tanbeer, S.K.; Jeong, B.S.; Lee, Y.K. Efficient tree structures for high utility pattern mining in incremental databases. IEEE Trans. Knowl. Data Eng. 2009, 21, 1708–1721. [Google Scholar] [CrossRef]
- Pamnani, H.K.; Raja, L.; Ives, T. Developing a Novel H-Apriori Algorithm Using Support-Leverage Matrix for Association Rule Mining. Int. J. Inf. Technol. 2024, 16, 5395–5405. [Google Scholar] [CrossRef]
- Tan, P.-N.; Kumar, V.; Srivastava, J. Selecting the right interestingness measure for association patterns. Inf. Syst. 2004, 29, 293–313. [Google Scholar] [CrossRef]
- Brin, S.; Motwani, R.; Ullman, J.D.; Tsur, S. Dynamic itemset counting and implication rules for market basket data. In Proceedings of the 1997 ACM SIGMOD International Conference on Management of Data, Tucson, AZ, USA, 13–15 May 1997; pp. 255–264. [Google Scholar]
- Geng, L.; Hamilton, H.J. Interestingness measures for data mining: A survey. ACM Comput. Surv. 2006, 38, 9–61. [Google Scholar] [CrossRef]
- Silberschatz, A.; Tuzhilin, A. What makes patterns interesting in knowledge discovery systems? IEEE Trans. Knowl. Data Eng. 1996, 8, 970–974. [Google Scholar] [CrossRef]
- Lavrač, N.; Flach, P.; Zupan, B. Rule evaluation measures: A unifying view. In Proceedings of the 9th International Workshop on Inductive Logic Programming (ILP 1999), Bled, Slovenia, 24–27 June 1999; Flach, P., Lavrač, N., Eds.; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1634, pp. 174–185. [Google Scholar]
- Hilderman, R.J.; Hamilton, H.J. Knowledge Discovery and Interestingness Measures: A Survey; University of Regina: Regina, SK, Canada, 2001. [Google Scholar]
- Lenca, P.; Meyer, P.; Vaillant, B.; Lallich, S. On selecting interestingness measures for association rules: User oriented description and multiple criteria decision aid. Eur. J. Oper. Res. 2008, 184, 610–626. [Google Scholar] [CrossRef]
- Mudumba, B.; Kabir, M.F. Mine-first association rule mining: An integration of independent frequent patterns in distributed environments. Decis. Anal. J. 2024, 10, 100434. [Google Scholar] [CrossRef]
- Pinheiro, C.; Guerreiro, S.; Mamede, H.S. A survey on association rule mining for enterprise architecture model discovery: State of the art. Bus. Inf. Syst. Eng. 2024, 66, 777–798. [Google Scholar] [CrossRef]
- Antonello, F.; Baraldi, P.; Zio, E.; Serio, L. A novel Measure to evaluate the association rules for identification of functional dependencies in complex technical infrastructures. Environ. Syst. Decis. 2022, 42, 436–449. [Google Scholar] [CrossRef]
- Alhindawi, N. Measures-based exploration and assessment of classification and association rule mining techniques: A comprehensive study. In Studies in Systems, Decision and Control; Springer: Cham, Switzerland, 2024; Volume 503, pp. 171–184. [Google Scholar]
- He, G.; Dai, L.; Yu, Z.; Chen, C.L.P. GAN-Based Temporal Association Rule Mining on Multivariate Time Series Data. IEEE Trans. Knowl. Data Eng. 2024, 36, 5168–5180. [Google Scholar] [CrossRef]
- Berteloot, T.; Khoury, R.; Durand, A. Association Rules Mining with Auto-Encoders. In IDEAL 2024; Pan, J.-S., Snášel, V., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2025; Volume 15346, pp. 52–62. [Google Scholar]
- Li, T.; Liu, F.; Chen, X.; Zhang, Y.; Xu, J.; Huang, W. Web Log Mining Techniques to Optimize Apriori Association Rule Algorithm in Sports Data Information Management. Sci. Rep. 2024, 14, 24099. [Google Scholar]
- Dehghani, M.; Yazdanparast, Z. Discovering the Symptom Patterns of COVID-19 from Recovered and Deceased Patients Using Apriori Association Rule Mining. Inf. Med. Unlocked. 2023, 42, 16–25. [Google Scholar] [CrossRef]
- Schoch, A.; Refflinghaus, R.; Schmitzberger, N.; Wolters, A. Association Rule Mining for Dynamic Error Classification in the Automotive Manufacturing Industry. Procedia CIRP 2024, 126, 1041–1046. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, J. Analysis and Research on Library User Behavior Based on Apriori Algorithm. Meas. Sens. 2023, 27, 458–463. [Google Scholar] [CrossRef]
- Fister, I., Jr.; Fister, D.; Fister, I.; Podgorelec, V.; Salcedo-Sanz, S. Time Series Numerical Association Rule Mining Variants in Smart Agriculture. J. Ambient Intell. Humaniz. Comput. 2023, 14, 16853–16866. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, H.; Wu, J. Discovery of Approximate Functional Dependencies Using Evolutionary Algorithms. Knowl.-Based Syst. 2021, 233, 107520. [Google Scholar]
- Song, W.; Chen, X. Discovering Relaxed Functional Dependencies with Genetic Algorithms. J. Intell. Inf. Syst. 2014, 42, 439–459. [Google Scholar]
- Li, Z.; Lin, X.; Zhang, Y. Mining Relaxed Functional Dependencies with Metaheuristic Optimization. Inf. Sci. 2020, 540, 367–386. [Google Scholar]
- Pasquier, N.; Bastide, Y.; Taouil, R.; Lakhal, L. Discovering frequent closed itemsets for association rules. In Proceedings of the 7th International Conference on Database Theory (ICDT), Jerusalem, Israel, 10–12 January 1999; pp. 398–416. [Google Scholar]
- Zaki, M.J. Scalable algorithms for association mining. IEEE Trans. Knowl. Data Eng. 2000, 12, 372–390. [Google Scholar] [CrossRef]
- García, S.; Luengo, J.; Herrera, F. Data Preprocessing in Data Mining; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Casella, G.; Berger, R.L. Statistical Inference, 2nd ed.; Duxbury Press: Pacific Grove, CA, USA, 2002. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning, 2nd ed.; Springer: Cham, Switzerland, 2009. [Google Scholar]
- Wackerly, D.D.; Mendenhall, W.; Scheaffer, R.L. Mathematical Statistics with Applications, 7th ed.; Cengage Learning: Boston, MA, USA, 2014. [Google Scholar]
- Freund, J.E.; Perles, B.M. Statistics: A First Course, 8th ed.; Pearson: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann: San Francisco, CA, USA, 2011. [Google Scholar]
- UCI Machine Learning Repository; University of California, Irvine, School of Information and Computer Sciences: Irvine, CA, USA, 2017; Available online: https://archive.ics.uci.edu/ (accessed on 10 April 2025).
- SPMF: A Java open-source pattern mining library. J. Mach. Learn. Res. 2016, 15, 3569–3573.
- Aggarwal, C.C.; Yu, P.S. A new framework for itemset generation. In Proceedings of the 20th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems (PODS 2001), Santa Barbara, CA, USA, 21–23 May 2001; pp. 18–24. [Google Scholar]
- Liu, B.; Hsu, W.; Ma, Y. Integrating classification and association rule mining. In Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining (KDD ′98), New York, NY, USA, 27–31 August 1998; pp. 80–86. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Meta-Patterns | Support(X) | Mutual Information | Threshold Dynamic | Obtained? |
|---|---|---|---|---|
| {B, C} | 4 | −0.039 | 0.1 | No |
| {B, E} | 4 | 0.175 | 0.1 | Yes |
| {A, C} | 3 | 0.131 | 0.1 | Yes |
| {B, C, E} | 3 | 0.292 | 0.1 | Yes |
| {C, E, A} | 1 | 0 | 0.1 | No |
| {B, C, E, A} | 1 | −0.078 | 0.1 | No |
| Measure | Advantages | Limits | What TCM Adds Additionally |
|---|---|---|---|
| Support | - Easy to calculate - Reflects the actual frequency - Robust to small datasets | - Favors frequent trivial rules - Ignores the distribution of consequences | TCM distinguishes whether this frequency is focused or dispersed |
| Confidence | - Intuitive probabilistic measure - Frequently used in practice | - Insensitive to the competition among several consequences - Can be high even if X is ambiguous | TCM completes the confidence by revealing the specificity of X→Y |
| TCM | - Evaluates the logical concentration of X - Normalized - Permits comparison between rules | - Depends on the availability of the rules X⇒Y - Not as well-known | Provides a structured, comparative, and standardized view on the consequences of X |
| Dataset | DERAR (λ = 0.5) | DERAR (λ = 1.0) | DERAR (λ = 1.5) | H-Apriori | FP-Growth | Apriori |
|---|---|---|---|---|---|---|
| Mushroom | 2140 | 1102 | 615 | 3120 | 4550 | 4690 |
| Adult | 3810 | 2230 | 1 072 | 4025 | 6324 | 6401 |
| Retail | 1965 | 982 | 410 | 1685 | 3723 | 3941 |
| Online Retail | 2540 | 1195 | 526 | 2090 | 5030 | 5197 |
| Dataset | DERAR (λ = 0.5) | DERAR (λ = 1.0) | DERAR (λ = 1.5) | H-Apriori | FP-Growth | Apriori |
|---|---|---|---|---|---|---|
| Mushroom | 66.67% | 83.78% | 96.00% | 81.50% | 69.80% | 65.00% |
| Adult | 57.95% | 81.16% | 95.83% | 83.60% | 71.30% | 66.40% |
| Retail | 48.20% | 83.17% | 95.83% | 76.50% | 68.20% | 62.30% |
| Online Retail | 46.40% | 82.42% | 93.85% | 74.20% | 65.00% | 59.10% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Essalmi, H.; El Affar, A. Dynamic Algorithm for Mining Relevant Association Rules via Meta-Patterns and Refinement-Based Measures. Information 2025, 16, 438. https://doi.org/10.3390/info16060438
Essalmi H, El Affar A. Dynamic Algorithm for Mining Relevant Association Rules via Meta-Patterns and Refinement-Based Measures. Information. 2025; 16(6):438. https://doi.org/10.3390/info16060438
Chicago/Turabian StyleEssalmi, Houda, and Anass El Affar. 2025. "Dynamic Algorithm for Mining Relevant Association Rules via Meta-Patterns and Refinement-Based Measures" Information 16, no. 6: 438. https://doi.org/10.3390/info16060438
APA StyleEssalmi, H., & El Affar, A. (2025). Dynamic Algorithm for Mining Relevant Association Rules via Meta-Patterns and Refinement-Based Measures. Information, 16(6), 438. https://doi.org/10.3390/info16060438