BiDFNet: A Bidirectional Feature Fusion Network for 3D Object Detection Based on Pseudo-LiDAR

Abstract
:1. Introduction
- We propose a bidirectional cross-sensor attention feature interaction module (BiCSAFIM), which significantly enhances the interaction between point cloud features and image features.
- A feature extraction module, termed SAF-Conv, is introduced for pseudo-point clouds. This module enlarges the receptive field, thereby improving the extraction of 2D features and concurrently reducing noise to a certain extent.
- Our method surpasses previous approaches, achieving state-of-the-art performance on the KITTI 3D object detection benchmark.
2. Related Work
2.1. LiDAR-Based 3D Object Detection
2.2. Fusion-Based 3D Object Detection
2.3. Pseudo-Point Cloud Methods
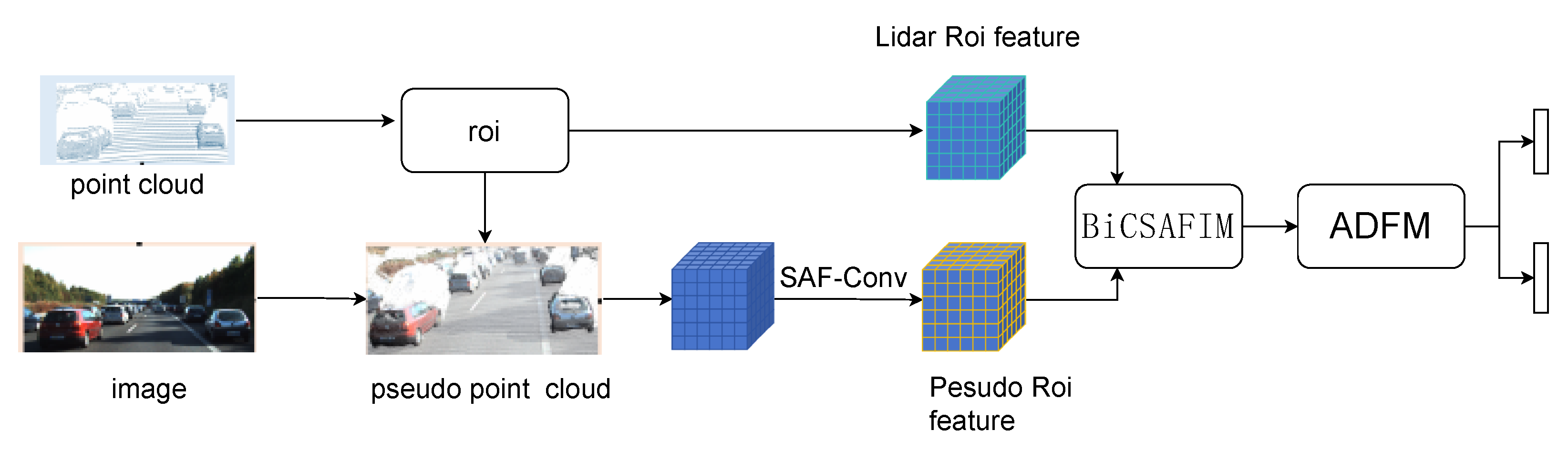
3. BiDFNet
3.1. Overall Architecture
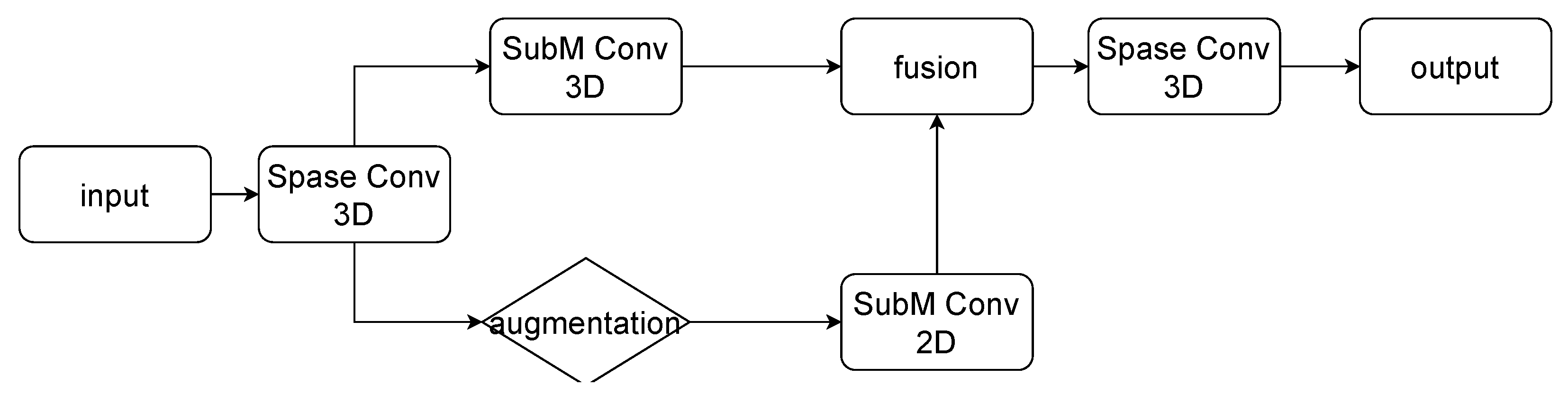
3.2. Pseudo-Point Cloud Feature Extraction
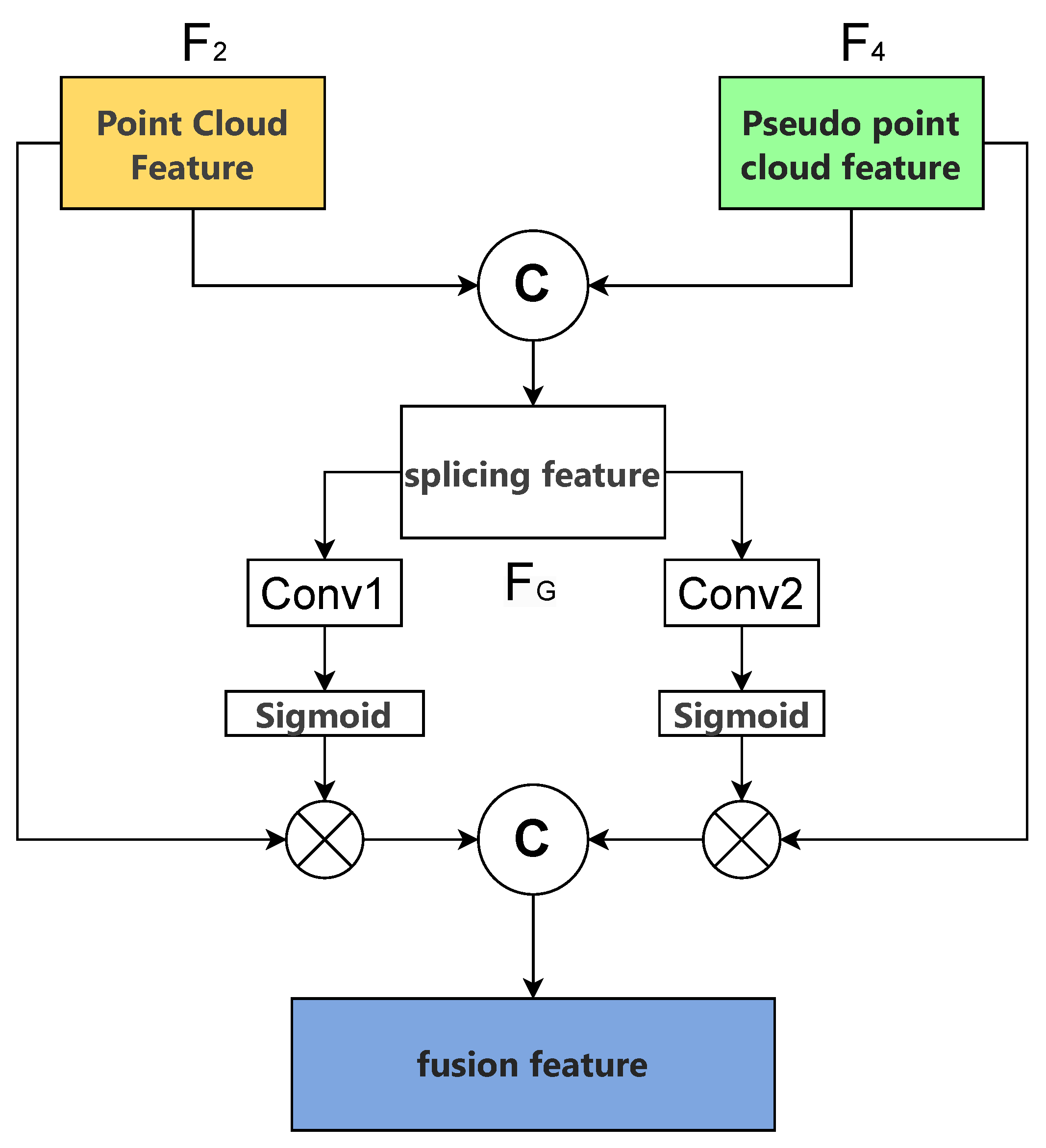
3.3. Interaction of Bidirectional Features
3.4. Attention-Driven ROI Fusion
4. Experiments
4.1. KITTI Dataset
4.2. Experimental Details
4.3. Loss and Data Augmentation
Training and Inference Details
4.4. Main Results
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection From Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3D object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1201–1209. [Google Scholar]
- Chen, Y.; Liu, J.; Zhang, X.; Qi, X.; Jia, J. Voxelnext: Fully sparse voxelnet for 3D object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21674–21683. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection From Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Shi, W.; Rajkumar, R. Point-gnn: Graph neural network for 3D object detection in a point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1711–1719. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3D object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3D bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 244–253. [Google Scholar]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3D object detection. In Proceedings, Part XV 16, Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 35–52. [Google Scholar]
- Liang, T.; Xie, H.; Yu, K.; Xia, Z.; Lin, Z.; Wang, Y.; Tang, T.; Wang, B.; Tang, Z. Bevfusion: A simple and robust lidar-camera fusion framework. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 10421–10434. [Google Scholar]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Lu, Y.; Zhou, D.; Le, Q.V.; et al. Deepfusion: Lidar-camera deep fusion for multi-modal 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17182–17191. [Google Scholar]
- Graham, B.; Van der Maaten, L. Submanifold sparse convolutional networks. arXiv 2017, arXiv:1706.01307. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–7 December 2017; Volume 30.
- Beltrán, J.; Guindel, C.; Moreno, F.M.; Cruzado, D.; Garcia, F.; De La Escalera, A. Birdnet: A 3D object detection framework from lidar information. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3517–3523. [Google Scholar]
- Huang, J.; Huang, G.; Zhu, Z.; Ye, Y.; Du, D. Bevdet: High-performance multi-camera 3D object detection in bird-eye-view. arXiv 2021, arXiv:2112.11790. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–7 December 2017; Volume 30. [Google Scholar]
- Zhao, T.; Ning, X.; Hong, K.; Qiu, Z.; Lu, P.; Zhao, Y.; Zhang, L.; Zhou, L.; Dai, G.; Yang, H.; et al. Ada3D: Exploiting the spatial redundancy with adaptive inference for efficient 3D object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 17–24 June 2023; pp. 17728–17738. [Google Scholar]
- Wang, Z.; Jia, K. Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3D object detection. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1742–1749. [Google Scholar]
- Nabati, R.; Qi, H. Centerfusion: Center-based radar and camera fusion for 3D object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–6 January 2021; pp. 1527–1536. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Yin, T.; Zhou, X.; Krähenbühl, P. Multimodal virtual point 3D detection. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 16494–16507. [Google Scholar]
- Wang, C.; Ma, C.; Zhu, M.; Yang, X. Pointaugmenting: Cross-modal augmentation for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11794–11803. [Google Scholar]
- Wu, X.; Peng, L.; Yang, H.; Xie, L.; Huang, C.; Deng, C.; Liu, H.; Cai, D. Sparse fuse dense: Towards high quality 3D detection with depth completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5418–5427. [Google Scholar]
- Li, Y.; Wang, Y.; Lu, Z.; Xiao, J. DepthGAN: GAN-based depth generation of indoor scenes from semantic layouts. arXiv 2022, arXiv:2203.11453. [Google Scholar]
- Mo, Y.; Wu, Y.; Zhao, J.; Hou, Z.; Huang, W.; Hu, Y.; Wang, J.; Yan, J. Sparse Query Dense: Enhancing 3D Object Detection with Pseudo points. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–November 2024; pp. 409–418. [Google Scholar]
- Wu, H.; Wen, C.; Shi, S.; Li, X.; Wang, C. Virtual sparse convolution for multimodal 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21653–21662. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Mao, J.; Niu, M.; Bai, H.; Liang, X.; Xu, H.; Xu, C. Pyramid r-cnn: Towards better performance and adaptability for 3D object detection. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 2723–2732. [Google Scholar]
- Zhao, X.; Su, L.; Zhang, X.; Yang, D.; Sun, M.; Wang, S.; Zhai, P.; Zhang, L. D-conformer: Deformable sparse transformer augmented convolution for voxel-based 3D object detection. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Shi, S.; Jiang, L.; Deng, J.; Wang, Z.; Guo, C.; Shi, J.; Wang, X.; Li, H. PV-RCNN++: Point-voxel feature set abstraction with local vector representation for 3D object detection. Int. J. Comput. Vis. 2023, 131, 531–551. [Google Scholar] [CrossRef]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3D-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3D object detection. In Proceedings, Part XXVII 16, Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 720–736. [Google Scholar]
- Wu, H.; Deng, J.; Wen, C.; Li, X.; Wang, C.; Li, J. CasA: A cascade attention network for 3-D object detection from LiDAR point clouds. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5704511. [Google Scholar] [CrossRef]
- Yang, H.; Liu, Z.; Wu, X.; Wang, W.; Qian, W.; He, X.; Cai, D. Graph r-cnn: Towards accurate 3D object detection with semantic-decorated local graph. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 662–679. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Reference | Car AP (R40) | Car AP (R11) | ||||
|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | ||
| Voxel-RCNN [4] | AAAI 2021 | 92.38 | 85.26 | 82.26 | 89.41 | 84.52 | 78.93 |
| Pyramid-PV [34] | ICCV 2021 | 92.26 | 85.23 | 82.94 | 89.37 | 84.38 | 78.84 |
| D-Conformer-TSD [35] | ICASSP 2023 | - | - | - | 89.69 | 85.36 | 79.53 |
| 3D-CVF [37] | ECCV 2020 | 89.67 | 79.88 | 78.47 | - | - | - |
| EPNet [12] | ECCV 2020 | 92.28 | 82.59 | 80.14 | - | - | - |
| SFD [27] | CVPR 2022 | 93.21 | 87.85 | 84.56 | 88.96 | 86.32 | 84.79 |
| VirConv-L [30] | CVPR 2023 | 93.36 | 88.71 | 85.83 | - | - | - |
| Ours | - | 93.47 | 88.79 | 86.41 | 89.71 | 86.81 | 85.70 |
| Method | Reference | Car AP (R40) | ||
|---|---|---|---|---|
| Easy | Mod. | Hard | ||
| Voxel-RCNN [4] | AAAI 2021 | 90.90 | 81.62 | 77.06 |
| Pyramid-PV [34] | ICCV 2021 | 88.39 | 82.08 | 77.49 |
| CasA [38] | TGRS 2022 | 91.58 | 83.06 | 80.08 |
| D-Conformer-TSD [35] | ICASSP 2023 | 89.13 | 82.18 | 79.75 |
| PV-RCNN++ [36] | IJCV 2023 | 90.53 | 81.60 | 77.07 |
| 3D-CVF [37] | ECCV 2020 | 89.20 | 80.85 | 73.11 |
| Graph-Vol [39] | ECCV 2022 | 91.89 | 83.27 | 77.78 |
| SFD [27] | CVPR 2022 | 91.73 | 84.76 | 77.92 |
| VirConv-L [30] | CVPR 2023 | 91.41 | 85.05 | 80.56 |
| Ada3D [21] | ICCV2023 | 87.46 | 79.41 | 75.63 |
| SQD [29] | ACM MM 2024 | 91.58 | 81.82 | 79.07 |
| Ours | - | 91.79 | 85.27 | 80.72 |
| Class | Method | 3D AP (R40) | ||
|---|---|---|---|---|
| Easy | Mod. | Hard | ||
| Pedestrian | Baseline | 70.55 | 62.92 | 57.35 |
| Pedestrian | Ours | 73.47 | 66.82 | 61.01 |
| Cyclist | Baseline | 89.86 | 71.13 | 66.67 |
| Cyclist | Ours | 90.13 | 73.87 | 69.15 |
| Pseudo | SAF-Conv | BiCSAFIM | ADFM | Car AP (R40) | Times (ms) | ||
|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | |||||
| 92.38 | 85.26 | 82.26 | 40 | ||||
| ✓ | 92.41 | 85.63 | 83.97 | 62 | |||
| ✓ | ✓ | 92.81 | 86.87 | 85.09 | 70 | ||
| ✓ | ✓ | 92.85 | 86.95 | 85.13 | 72 | ||
| ✓ | ✓ | 92.49 | 85.91 | 83.04 | 64 | ||
| ✓ | ✓ | ✓ | 93.20 | 88.34 | 86.10 | 80 | |
| ✓ | ✓ | ✓ | 92.97 | 87.63 | 85.41 | 76 | |
| ✓ | ✓ | ✓ | 93.02 | 87.54 | 85.51 | 74 | |
| ✓ | ✓ | ✓ | ✓ | 93.47 | 88.79 | 86.41 | 84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Q.; Wan, Y. BiDFNet: A Bidirectional Feature Fusion Network for 3D Object Detection Based on Pseudo-LiDAR. Information 2025, 16, 437. https://doi.org/10.3390/info16060437
Zhu Q, Wan Y. BiDFNet: A Bidirectional Feature Fusion Network for 3D Object Detection Based on Pseudo-LiDAR. Information. 2025; 16(6):437. https://doi.org/10.3390/info16060437
Chicago/Turabian StyleZhu, Qiang, and Yaping Wan. 2025. "BiDFNet: A Bidirectional Feature Fusion Network for 3D Object Detection Based on Pseudo-LiDAR" Information 16, no. 6: 437. https://doi.org/10.3390/info16060437
APA StyleZhu, Q., & Wan, Y. (2025). BiDFNet: A Bidirectional Feature Fusion Network for 3D Object Detection Based on Pseudo-LiDAR. Information, 16(6), 437. https://doi.org/10.3390/info16060437