
SemFedXAI: A Semantic Framework for Explainable Federated Learning in Healthcare



Abstract
1. Introduction
- Ontology-Enhanced Federated Learning: Integrates medical ontologies into the federated learning process to enrich models with domain knowledge.
- Semantic Aggregation Mechanism: Uses semantic technologies to improve the consistency and interpretability of federated models during the aggregation process.
- Knowledge Graph-Based Explanation: Provides contextualized explanations of model decisions based on knowledge graphs.
2. Related Work
2.1. Federated Learning in Healthcare
2.2. Explainable AI and Interpretable Models
2.3. Semantic Web and Knowledge Management in Healthcare
2.4. Integration of FL, XAI, and Semantic Technologies
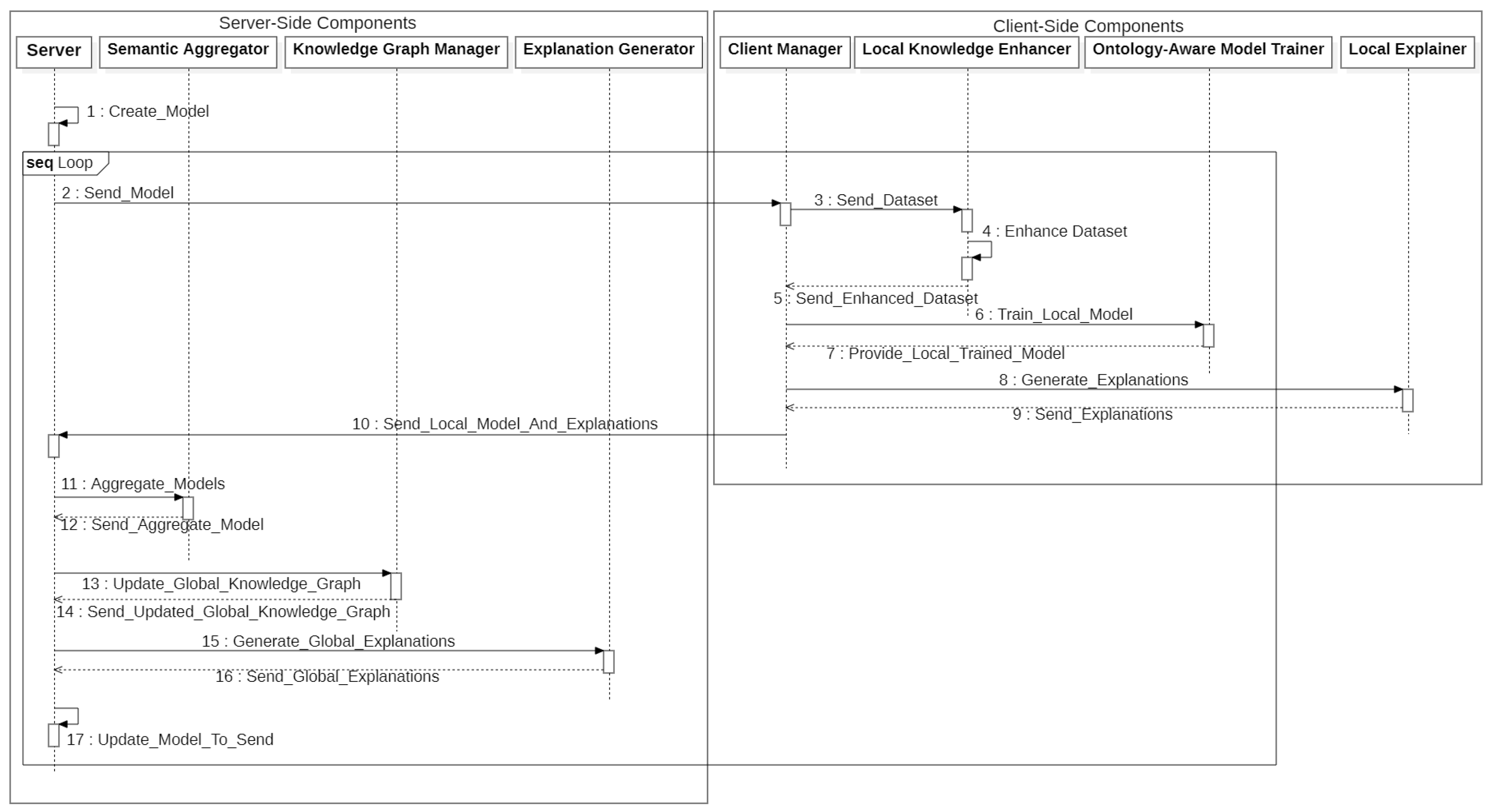
3. The SemFedXAI Framework
3.1. General Architecture
- The server creates the overall model and sends it to the clients;
- All the clients enrich their datasets using semantic knowledge through the Local Knowledge Enhancer;
- The Ontology-Aware Model Trainer is used by clients for training local models;
- Clients generate local explanations using the Local Explainer;
- Clients send local model parameters and explanations to the server;
- The server aggregates the local models using the Semantic Aggregator;
- The server updates the global knowledge graph with the new information using the Knowledge Graph Manager;
- The server generates global explanations using the Explanation Generator;
- The server sends the updated global model to the client;
- Steps 1–9 are repeated for a predefined number of rounds.
3.2. Ontology-Enhanced Federated Learning
3.3. Semantic Aggregation Mechanism
- is the original metric-based weight;
- is the semantic relevance of model i;
- is the domain knowledge consistency of model i;
- is the semantic diversity of model i;
- , , and are hyperparameters that control the influence of each factor.
3.4. Knowledge Graph-Based Explanation
3.5. Implementation
| Algorithm 1: Semantic aggregator for federated learning |
 |
4. Experiments and Results
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Medical Ontology
4.1.3. Models and Configuration
- FedAvg: The standard federated averaging algorithm [7], without any semantics or explainability components;
- FedXAI: A federated learning framework that includes post hoc interpretability using SHAP [19], but without semantic elements;
- SemFed: A federated learning framework integrating semantic aspects, namely, Ontology-Enhanced Federated Learning and Semantic Aggregation, with optional post hoc explainability but without explicit integration of semantic explanations;
- SemFedXAI: Our overall approach that captures all aspects presented in Section 3.
4.1.4. Evaluation Metrics
4.2. Results
4.2.1. Predictive Accuracy
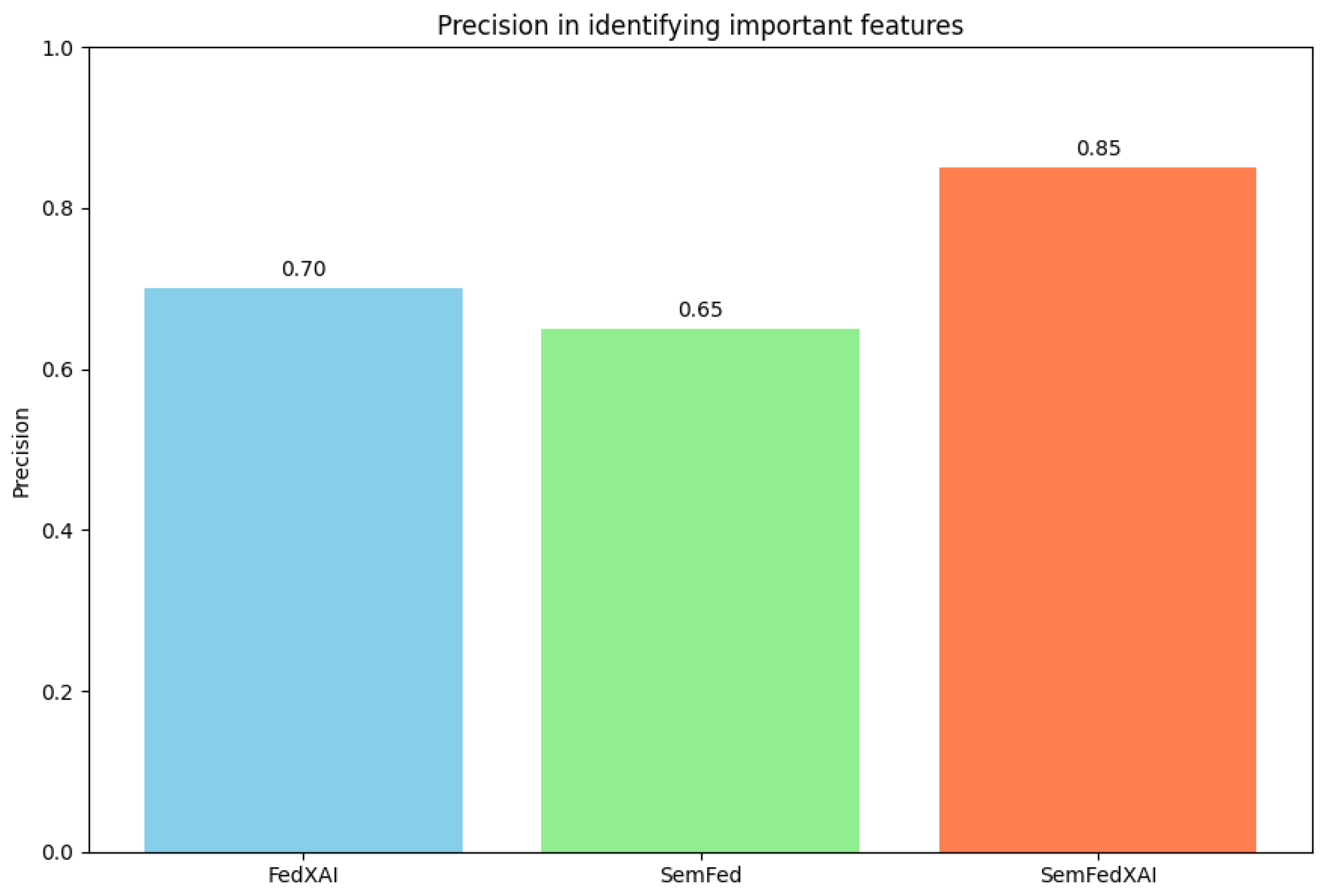
4.2.2. Explanation Quality
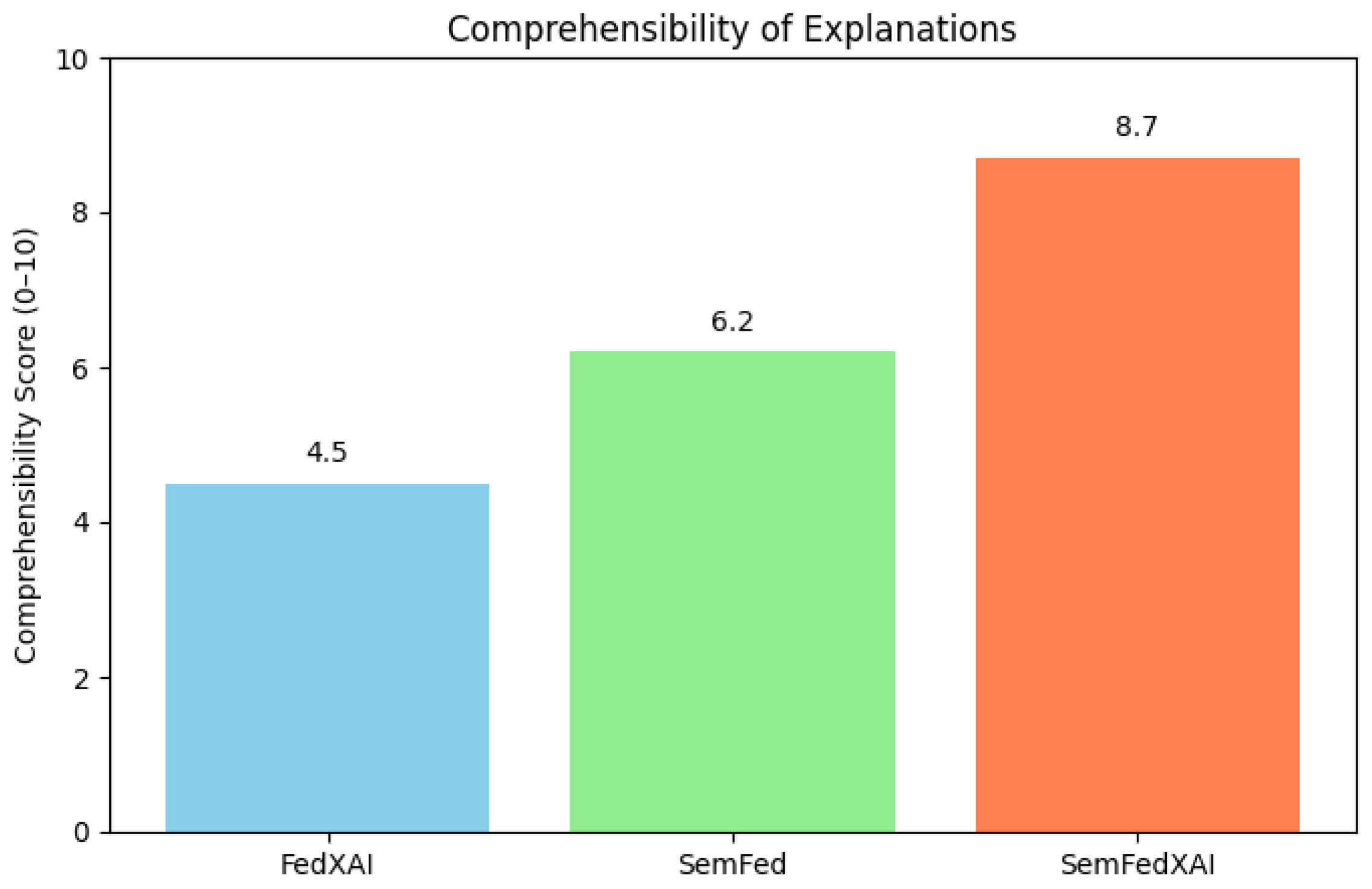
4.2.3. Explanation Comprehensibility
4.2.4. Computational Overhead
4.3. Qualitative Analysis of Explanations
5. Discussion
5.1. Implications
- Increased trust: Richer and more exhaustive explanations provide a means to build healthcare professionals’ trust in AI systems, thus ensuring increased adoption within clinical settings.
- Clinical decision-making support: Explanations based on knowledge graphs provide essential information to stakeholders that can enhance clinical decision-making by linking predictions made by the models to established medical knowledge.
- Compliance with regulations: The proposed approach can ensure compliance with regulations like GDPR that require protection of personal data to be combined with algorithmic explainability.
- Semantic interoperability: The use of standard ontologies can improve interoperability between heterogeneous AI systems within the healthcare sector, enabling more efficient integration and exchange of knowledge.
5.2. Limitations and Challenges
- Computational overhead: As outlined in Section 4.2.4, SemFedXAI demands significant computational resources. Algorithmic improvements and more efficient implementations could alleviate this cost.
- Scalability: The computational experiments carried out in this work were executed with a limited number of clients and features. The scalability of the presented methodology in settings with numerous clients or large features is a direction that deserves further investigation.
- Ontology quality: The fitness of SemFedXAI is largely dependent on the quality and completeness of the underlying medical ontology. Defective or incomplete ontologies can lead to interpretations that are incorrect.
- Evaluation with real users: Although we tested readability using quantitative metrics, experimental testing with real healthcare professionals is required to determine the real-world effectiveness of the produced explanations.
- Privacy of explanations: The explanations provided have an inherent risk of leaking personal information related to the training data. Further work aimed at preserving the privacy of such explanations is needed.
5.3. Comparison with Alternative Approaches
- Inherently interpretable models: An alternative approach includes the deployment of models based on intrinsic interpretability, such as fuzzy systems or decision trees, in a federated system [37]. Even with some level of transparency, such models tend to compromise prediction accuracy when faced with intricate datasets.
- Local vs. global explanations: SemFedXAI generates both local (client-level) and global (server-level) explanations. Alternative approaches could focus only on one of the two levels, sacrificing either local customization or global consistency of explanations.
- Neurosymbolic approaches: recent work on neurosymbolic models [33] offers an interesting alternative to integrate symbolic knowledge into deep learning models. However, their application in federated contexts remains largely unexplored.
6. Conclusions and Future Work
6.1. Conclusions
6.2. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Yurdem, B.; Kuzlu, M.; Gullu, M.K.; Catak, F.O.; Tabassum, M. Federated learning: Overview, strategies, applications, tools and future directions. Heliyon 2024, 10, e38137. [Google Scholar] [CrossRef] [PubMed]
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and explainability of artificial intelligence in medicine. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1312. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Branco, D. Fedbench: Federated Learning Clients/Server Desktop Implementation. GitHub Repository, 2023. Available online: https://github.com/vanvitellicode/fedbench (accessed on 6 April 2025).
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics, Palermo, Italy, 26–28 August 2020; pp. 2938–2948. [Google Scholar]
- Brisimi, T.S.; Chen, R.; Mela, T.; Olshevsky, A.; Paschalidis, I.C.; Shi, W. Federated learning of predictive models from federated electronic health records. Int. J. Med. Inform. 2018, 112, 59–67. [Google Scholar] [CrossRef]
- Liu, D.; Miller, T.; Sayeed, R.; Mandl, K.D. FADL: Federated-autonomous deep learning for distributed electronic health record. In Proceedings of the Machine Learning for Healthcare Conference, Virtual, 6–7 August 2021; pp. 811–837. [Google Scholar]
- Huang, L.; Shea, A.L.; Qian, H.; Masurkar, A.; Deng, H.; Liu, D. Patient clustering improves efficiency of federated machine learning to predict mortality and hospital stay time using distributed electronic medical records. J. Biomed. Inform. 2019, 99, 103291. [Google Scholar] [CrossRef]
- Rieke, N.; Hancox, J.; Li, W.; Milletarì, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The future of digital health with federated learning. NPJ Digit. Med. 2020, 3, 119. [Google Scholar] [CrossRef]
- Gunning, D.; Stefik, M.; Choi, J.; Miller, T.; Stumpf, S.; Yang, G.Z. XAI—Explainable artificial intelligence. Sci. Robot. 2019, 4, eaay7120. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning; Lulu.Com: Morrisville, NC, USA, 2020. [Google Scholar]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]
- Cai, C.J.; Winter, S.; Steiner, D.; Wilcox, L.; Terry, M. “Hello AI”: Uncovering the onboarding needs of medical practitioners for human-AI collaborative decision-making. Proc. ACM Hum. Comput. Interact. 2019, 3, 1–24. [Google Scholar] [CrossRef]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harv. J. Law Technol. 2017, 31, 841. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Tonekaboni, S.; Joshi, S.; McCradden, M.D.; Goldenberg, A. What clinicians want: Contextualizing explainable machine learning for clinical end use. In Proceedings of the Machine Learning for Healthcare Conference, Ann Arbor, MI, USA, 9–10 August 2019; pp. 359–380. [Google Scholar]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 34–43. [Google Scholar] [CrossRef]
- Donnelly, K. SNOMED-CT: The advanced terminology and coding system for eHealth. Stud. Health Technol. Inform. 2006, 121, 279. [Google Scholar]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef]
- World Health Organization. ICD-10: International Statistical Classification of Diseases and Related Health Problems: Tenth Revision; World Health Organization: Geneva, Switzerland, 2004. [Google Scholar]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; Melo, G.D.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S.; et al. Knowledge graphs. ACM Comput. Surv. 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Rotmensch, M.; Halpern, Y.; Tlimat, A.; Horng, S.; Sontag, D. Learning a health knowledge graph from electronic medical records. Sci. Rep. 2017, 7, 5994. [Google Scholar] [CrossRef]
- Celebi, R.; Uyar, H.; Yasar, E.; Gumus, O.; Dikenelli, O.; Dumontier, M. Evaluation of knowledge graph embedding approaches for drug-drug interaction prediction in realistic settings. BMC Bioinform. 2019, 20, 726. [Google Scholar] [CrossRef]
- Kamdar, M.R.; Musen, M.A. PhLeGrA: Graph analytics in pharmacology over the web of life sciences linked open data. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 321–329. [Google Scholar]
- Tiddi, I.; Schlobach, S. Knowledge graphs as tools for explainable machine learning: A survey. Artif. Intell. 2022, 302, 103627. [Google Scholar] [CrossRef]
- Garcez, A.D.A.; Lamb, L.C. Neurosymbolic AI: The 3rd Wave. arXiv 2020, arXiv:2012.05876. [Google Scholar] [CrossRef]
- Yang, J.; Xu, X.; Xiao, G.; Shen, Y. A Survey of Knowledge Enhanced Pre-trained Language Models. arXiv 2021, arXiv:2110.00269. [Google Scholar] [CrossRef]
- Peng, H.; Li, H.; Song, J.; Zheng, V.; Li, J. Differentially Private Federated Knowledge Graphs Embedding. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management (CIKM ’21), Gold Coast, Australia, 1–5 November 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1416–1425. [Google Scholar] [CrossRef]
- Xu, J.; Wang, F.; Tao, D. Federated learning for healthcare informatics. J. Healthc. Inform. Res. 2021, 5, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Ducange, P.; Marcelloni, F.; Renda, A.; Ruffini, F. Federated Learning of XAI Models in Healthcare: A Case Study on Parkinson’s Disease. Cogn. Comput. 2024, 16, 3051–3076. [Google Scholar] [CrossRef]
- Corcuera Bárcena, J.L.; Ducange, P.; Marcelloni, F.; Nardini, G.; Noferi, A.; Renda, A.; Ruffini, F.; Schiavo, A.; Stea, G.; Virdis, A. Enabling federated learning of explainable AI models within beyond-5G/6G networks. Comput. Commun. 2023, 211, 356–375. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Alpha | FedAvg | FedXAI | SemFed | SemFedXAI |
|---|---|---|---|---|
| 0.1 | 41.2 | 45.6 | 52.3 | 56.9 |
| 0.5 | 54.8 | 59.3 | 66.5 | 70.4 |
| 1.0 | 64.7 | 69.0 | 75.2 | 79.1 |
| 5.0 | 73.5 | 76.4 | 82.1 | 85.3 |
| 10.0 | 75.1 | 78.2 | 84.0 | 86.7 |
| Approach | Accuracy (%) |
|---|---|
| FedAvg | 73.5 |
| FedXAI | 76.4 |
| SemFed | 82.1 |
| SemFedXAI | 85.3 |
| Approach | Execution Time (s) | Memory Usage (MB) |
|---|---|---|
| FedAvg | 120 | 450 |
| FedXAI | 145 | 480 |
| SemFed | 150 | 520 |
| SemFedXAI | 162 | 575 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amato, A.; Branco, D. SemFedXAI: A Semantic Framework for Explainable Federated Learning in Healthcare. Information 2025, 16, 435. https://doi.org/10.3390/info16060435
Amato A, Branco D. SemFedXAI: A Semantic Framework for Explainable Federated Learning in Healthcare. Information. 2025; 16(6):435. https://doi.org/10.3390/info16060435
Chicago/Turabian StyleAmato, Alba, and Dario Branco. 2025. "SemFedXAI: A Semantic Framework for Explainable Federated Learning in Healthcare" Information 16, no. 6: 435. https://doi.org/10.3390/info16060435
APA StyleAmato, A., & Branco, D. (2025). SemFedXAI: A Semantic Framework for Explainable Federated Learning in Healthcare. Information, 16(6), 435. https://doi.org/10.3390/info16060435