Abstract
Existing smart contract honeypot detection approaches exhibit high false negatives and positives due to (i) their inability to generate transaction sequences triggering order-dependent traps and (ii) their limited code coverage from traditional fuzzing’s random mutations. In this paper, we propose a hybrid fuzzing framework for smart contract honeypot detection based on taint analysis, SCH-Hunter. SCH-Hunter conducts source-code-level feature analysis of smart contracts and extracts data dependency relationships between variables from the generated Control Flow Graph to construct specific transaction sequences for fuzzing. A symbolic execution module is also introduced to resolve complex conditional branches that fuzzing alone fails to penetrate, enabling constraint solving. Furthermore, real-time dynamic taint propagation monitoring is implemented using taint analysis techniques, leveraging taint flow information to optimize seed mutation processes, thereby directing mutation resources toward high-value code regions. Finally, by integrating EVM (Ethereum Virtual Machine) code instrumentation with taint information flow analysis, the framework effectively identifies and detects security-sensitive operations, ultimately generating a comprehensive detection report. Empirical results are as follows. (i) For code coverage, SCH-Hunter performs better than the state-of-art tool, HoneyBadger, achieving higher average code coverage rates on both datasets, surpassing it by 4.79% and 17.41%, respectively. (ii) For detection capabilities, SCH-Hunter is not only roughly on par with HoneyBadger in terms of precision and recall rate but also capable of detecting a wider variety of smart contract honeypot techniques. (iii) For the evaluation of components, we conducted three ablation studies to demonstrate that the proposed modules in SCH-Hunter significantly improve the framework’s detection capability, code coverage, and detection efficiency, respectively.
1. Introduction
In 2009, with the release of Satoshi Nakamoto’s Bitcoin [1], the concept of blockchain emerged in the public domain and has since undergone rapid development [2]. Unlike Bitcoin, Ethereum introduced support for the deployment of smart contracts, enabling a wide range of blockchain-based upper-layer applications [3]. Similar to traditional legal contracts, a smart contract defines a set of predefined rules and procedures that both parties in a transaction must follow [4]. Technically, a smart contract is implemented as a replicable and immutable piece of code deployed on the Ethereum blockchain, ensuring transparency, automation, and trustless execution.
To date, tens of millions of smart contracts have been deployed on the Ethereum blockchain, facilitating a wide range of applications across various domains, such as finance [5] and industry [6]. Given the substantial volume of digital assets managed by smart contracts, they have become prime targets for malicious blockchain attackers seeking to exploit vulnerabilities for illicit gains. Due to the structural similarities between smart contract code and traditional programming languages, attackers targeting smart contracts have frequently adopted vulnerability exploitation techniques from conventional software security. Specifically, they analyze the source code of smart contracts to identify and exploit security flaws, thereby extracting illegal profits. For instance, in 2016, the DAO smart contract suffered an attack due to two critical security vulnerabilities, leading to the theft of approximately USD 60 million worth of Ether and ultimately resulting in an Ethereum hard fork [7]. Similarly, the Cream.Finance contract was exploited through a reentrancy vulnerability, enabling attackers to steal over USD 130 million worth of digital assets [8]. With the deepening research into blockchain smart contract security, traditional smart contract code vulnerability detection techniques have developed into a multi-layered defense system, including static analysis tools, dynamic symbolic execution, formal verification, and machine-learning-based models for identification. The widespread adoption of these detection technologies and approaches has significantly reduced the success rate of exploiting traditional code vulnerabilities such as reentrancy attacks and integer overflow, from 34% in 2018 to 6% in 2022 (according to the ConsenSys Security Report). This shift has forced attackers to adopt alternative attack strategies, giving rise to the emergence of smart contract honeypots.
The essence of a smart contract honeypot lies in its proactive nature as an attack strategy. These types of contracts are designed to deceive victims into believing they contain obvious vulnerabilities, leading them to believe that exploiting these flaws will result in illicit profits. However, in reality, the victims not only fail to benefit but also suffer financial losses. The concept of smart contract honeypots emerged in 2018 [9], and by October of the same year, the economic losses attributed to the honeypot attacks had already reached approximately USD 90,000. By 2023, Ethereum mainnet detection revealed a 217% annual growth rate in smart contract honeypots, with asset losses surpassing USD 4.3 million.
The pollution and damage that smart contract honeypots inflict on the Ethereum blockchain ecosystem are substantial and cannot be overlooked. This new form of attack has not only transformed the security landscape of smart contracts but also underscores the complex interaction between human behavior and technical vulnerabilities in decentralized systems. As a result, to improve the security of data applications in blockchain technology, smart contract honeypot detection has become one of the key research directions in the broader field of smart contract code security.
Specifically, current research on smart contract honeypot detection still exhibits certain limitations, and existing detection approaches encounter several unresolved challenges, including the following.
- Currently, research on dynamic detection techniques remains relatively limited [10], with most proposed smart contract honeypot detection approaches confined to the domain of static analysis [9,11,12]. Although static detection techniques offer advantages such as rapid analysis and high code coverage, they still pose significant risks due to high false positive rates, extreme data imbalance, and the potential issue of symbolic path explosion. Moreover, when dealing with unknown types of smart contract honeypots, relying solely on static detection techniques to manually define detection rules is costly and inefficient.
- Traditional standalone fuzzing frameworks struggle to efficiently generate valid test cases for complex conditional statements within smart contracts, resulting in low code and branch coverage [13]. This limitation prevents comprehensive security assessments of smart contracts, as critical vulnerabilities may remain undetected due to inadequate exploration of execution paths.
- Traditional fuzzing methods typically generate test cases in a completely random manner and fail to adequately consider initial assignments and execution order when constructing transaction sequences [14]. As a result, they struggle to detect honeypot traps that require strict triggering conditions and specific execution sequences, leading to a high false negative rate.
- The completely random mutation approach in genetic algorithms lacks dynamic feedback guidance and optimization [15,16], making it difficult for fuzzing to efficiently navigate complex conditional statements in smart contracts. As a result, it struggles to identify optimal solutions within a short time, leading to significant resource waste and increased time consumption.
- The range of smart contract honeypot types that existing detection schemes can identify remains incomplete [9,11], indicating substantial potential for further optimization and enhancement.
In summary, due to the high false positive rates of pure static analysis tools like Mythril, which struggle to differentiate between real vulnerabilities and benign code patterns, as well as the path explosion issues that result in insufficient symbolic execution coverage for nested conditional statements and the inefficiencies in input space exploration of pure dynamic analysis tools like ContractFuzzer—where randomly generated transaction sequences fail to trigger honeypot techniques in deeper code spaces and face challenges in reproducing specific block timestamps/chain state combinations—we propose a taint-guided hybrid fuzzing framework for collaborative enhancement. By combining the strengths of both techniques, we avoid the disadvantages of relying on a single approach, effectively improving the framework’s detection capabilities while ensuring both high code coverage and detection efficiency.
To address these challenges, we propose SCH-Hunter, a taint-based hybrid fuzzing framework specifically designed for detecting smart contract honeypots in the Ethereum ecosystem. Specifically, SCH-Hunter consists of five key components: static analysis, adaptive construction of transaction sequences, hybrid fuzzing, taint-based seed optimization, and honeypot detection and reporting.
1.1. Static Analysis
The three types of smart contract honeypot techniques—Unexecuted Call, Map Key Encoding Trick, and Hidden Transfer—exhibit distinct honeypot characteristics at the source code level. However, these characteristics are highly likely to be lost when the source code is compiled into bytecode. As a result, during actual fuzzing, detection frameworks will face significant challenges in capturing these honeypot features.
Consequently, we have implemented a static analysis module that extracts static features from these three types of honeypot techniques to perform honeypot detection. Upon inputting the smart contract source code into this module, it performs a static check to determine if the contract belongs to any of these three honeypot categories. If not, the contract is passed to the fuzzing module for further examination.
1.2. Adaptive Construction of Transaction Sequences
Typically, a smart contract contains many functions. Traditional fuzzing frameworks usually construct test cases with random initial assignments and overlook the specific composition order of transaction sequences. This approach is likely to lead to directionless exploration of the code space, resulting in a waste of resources and becoming a bottleneck for fuzzing performance. Moreover, it can also become very challenging to find honeypot techniques that require the smart contract to be in a specific state, leading to low detection accuracy. However, smart contracts are highly sensitive to the initial assignments and composition order of transaction sequences during their execution. Changing the specific initial values of test cases or swapping the order of transactions within the sequences can lead to significant differences in execution outcomes. Therefore, understanding how to construct transaction sequences reasonably so that fuzzing can quickly and accurately find the vulnerabilities hidden in the deep space of smart contracts becomes very important.
We propose an adaptive strategy for initial test cases and constructing transaction sequences based on the RAW (Read-after-Write) principle, which consists of two parts: function relationship analysis and function call order generation. Specifically, we construct a data flow analyzer based on the RAW principle to capture the data dependency relationships between variables used by each function and also capture conditional statements that use these variables. Then, according to predefined rules, we determine the function call order that is most likely to trigger vulnerabilities. Subsequently, the initial value assignment range for each test case is specified according to the captured conditional statements and their prescribed condition ranges, which are then passed to the hybrid fuzzing module to generate the initial transaction sequence with the corresponding specific values.
1.3. Hybrid Fuzzing
On the one hand, the powerful constraint-solving capability of symbolic execution makes it adept at handling complex conditional statements in programs. However, it is prone to the path explosion problem and is unable to consider runtime information of the code during actual execution, resulting in a persistently high rate of false positives in vulnerability detection results. On the other hand, fuzzing, by actually executing the program under test and analyzing it based on the runtime information generated, can effectively reduce false positives. However, fuzzing also has defects, namely that randomly generated test cases struggle to pass through some complex conditional statements in smart contracts, leading to lower code coverage and a high rate of false negatives.
Therefore, in our framework, when a smart contract is sent to the fuzzing module, our framework will iteratively explore the code branches within the smart contract. During this process, when encountering complex conditional statements that are too challenging for the fuzzing module (i.e., code coverage has not shown any improvement after a certain period of time), it will pause and activate the symbolic execution module. In this module, the complex conditional statements will be input into the constraint solver as constraints, and the solver will find specific test cases that can pass through the complex conditional statements. Once the suitable test cases are found, they will be re-entered into the fuzzing module to continue exploring the code space and enhancing code coverage until a preset loop iteration threshold is reached or an exception is occurs.
1.4. Taint-Based Seed Optimization
The GA (Genetic Algorithm) used in the traditional fuzzing framework typically employs a complete random mutation method to mutate test cases. This means simply mutating the original input data randomly within the valid input domain. Therefore, it lacks optimization and guidance in the mutation process and possesses a high degree of randomness. This can lead to the generation of a large amount of useless data, resulting in slow speeds in finding local and global optimal solutions during fuzzing and low detection efficiency.
To address this issue, we propose a taint-based seed optimization strategy, which consists of three modules: taint marking, taint propagation and monitoring, and data categorization. Specifically, taint marking module marks the fuzzing input (e.g, the parameters contained in functions within the transaction sequence) as tainted data, which are then passed into the taint propagation and monitoring module. Subsequently, the taint propagation and monitoring module monitors the program execution process in real time to observe changes in the tainted flow. That is, when certain bytes of tainted data are used by predefined sensitive instructions or dangerous operations (i.e., sinks), these bytes will be marked with special identifiers and passed into the data categorization module. Finally, based on the analysis results of the taint propagation and monitoring module, the data categorization module classifies the bytes of the input transaction sequence. Bytes previously marked with special identifiers are classified as sensitive data, while the remaining bytes are marked as safe data. This classification result will be passed to the fuzzing module to provide mutation guidance for the genetic algorithm, allocating more resources to mutate sensitive data more frequently and reducing the mutation frequency for safe data, thereby reducing the waste of fuzzing resources and improving detection efficiency.
1.5. Honeypot Detection and Report
Given the diversity of smart contract honeypot techniques and various variants generated by them, it becomes crucial to formulate detection rules that are both accurate and capable of identifying as many honeypot types as possible.
Therefore, we propose a honeypot detection and report module based on code instrumentation. Specifically, we modify the EVM (Ethereum Virtual Machine) through code instrumentation, marking the EVM instructions commonly used in smart contract honeypot techniques as dangerous instructions. We construct detection functions for seven types of honeypot techniques. The principle of the honeypot detection functions is to evaluate the security of smart contracts by combining the collected taint propagation information (i.e., whether dangerous instructions were triggered) with predefined test oracles.
Our key contributions can be summarized as follows.
- To address the potential semantic loss during the bytecode compilation process, our framework introduces a static analysis engine at the source code level to detect the three types of smart contract honeypot techniques: Unexecuted Call, Map Key Encoding Trick, and Hidden Transfer. This module retains high-level semantic information and, in combination with relevant detection functions, it can effectively compensate for the limitations of traditional bytecode analysis in restoring code logic.
- To address the issue of generating transaction sequences with specific orders required to trigger certain smart contract honeypot techniques, our framework proposes a transaction sequence adaptive construction strategy based on the RAW (Read-after-Write) principle. By constructing control flow graphs and performing variable dependency analysis, the strategy will generate transaction sequences most likely to trigger honeypot techniques. This approach significantly enhances the framework’s ability to detect smart contract honeypots.
- To address the issue that traditional fuzz testing frameworks struggle to handle complex conditional branches, which hinders the improvement in code coverage, our framework introduces a hybrid fuzz testing engine. It employs a fuzz-testing–symbolic-execution dynamic switching architecture to overcome path exploration bottlenecks. Fuzzing is used as the primary approach, and when code coverage stagnates and remains below a set threshold for a specified period, the symbolic execution module is automatically activated. This module solves the path constraints of the current code and generates corresponding test cases, which are then reinjected into the fuzz testing queue, enabling targeted breakthroughs in complex conditional branches.
- To address the inefficiency and resource wastage caused by the purposeless seed mutation process in traditional genetic algorithms used in fuzzing, we propose a seed mutation optimization strategy guided by taint analysis. By taint-marking sensitive instructions closely related to smart contract honeypot techniques in the EVM virtual machine, the framework observes the taint propagation process of test cases and marks the byte positions of test cases flowing toward sensitive instructions. Based on the taint weights, the seed mutation probability is dynamically adjusted. High-frequency flipping and arithmetic mutations are applied to critical bytes, while low-energy random mutations are used for bytes in non-sensitive regions. This approach effectively reduces fuzz testing resource waste and improves detection efficiency.
- To address the issue of limited honeypot types detectable by current smart contract honeypot detection schemes, our framework proposes a smart contract honeypot detection method based on EVM runtime code instrumentation. By combining instruction-level real-time monitoring with taint flow analysis, it enables the implementation of ten common smart contract honeypot detection algorithms. This effectively increases the number of honeypot types that the framework can detect.
2. Related Work
2.1. Smart Contract Vulnerability Detection
The immutability of blockchain means that once a smart contract is deployed, it is endowed with the characteristic of being unmodifiable. When vulnerabilities are found in a smart contract, there is no way to rectify them other than through a blockchain hard fork. Therefore, conducting a thorough security check to ensure its safety before deploying becomes particularly important.
Currently, security auditing methods for smart contract code vulnerabilities are primarily categorized into three types: formal verification, symbolic execution, and fuzz testing.
In terms of formal verification, ref. [17] designed a verification model and used the Isabelle/HOL tool to verify the security of smart contracts. Further, refs. [18,19] define the formal semantics of smart contracts through the F* framework and K framework, respectively, and utilize these frameworks to detect vulnerabilities. Although these techniques provide solid formal verification support, their detection processes are still semi-automatic, leading to a high false positive rate.
In terms of symbolic execution, there are many smart contract security detection frameworks based on this technology, with notable examples including Oyente [20] and Slither [21]. Oyente [20] is one of the earliest detection frameworks for smart contracts, using symbolic execution to identify vulnerabilities and code errors within smart contracts and performing analysis based on expert-defined rules. Slither [21], on the other hand, converts smart contract source code into an intermediate representation (IR) and then uses symbolic execution for static analysis to detect code vulnerabilities. Although symbolic execution offers relatively fast detection speeds, it still faces key challenges such as path explosion and high false positive rates.
In terms of fuzzing, ContractFuzzer [22] is the first framework to apply fuzz testing technology to smart contract vulnerability detection. It monitors the runtime behavior of smart contracts during actual execution and identifies potential vulnerabilities through pre-defined detection rules. Harvey [23] and ReGuard [24], on the other hand, focus on generating a large number of test cases to cover as many code branches as possible that might trigger vulnerabilities. ILF [25] and sFuzz [26] propose feedback-based seed mutation strategies, ensuring that more fuzz testing resources are allocated to seeds that are likely to reveal interesting code segments. ItyFuzz [27] captures state snapshots and single transaction actions, utilizing a data flow path mechanism to identify and prioritize contract states with higher priority. Although fuzz testing technology is more feasible for practical applications compared to other methods and excels in vulnerability discovery and testing effectiveness, existing fuzz testing approaches still face significant challenges in terms of code coverage and detection efficiency. This, in turn, results in a high false negative rate.
2.2. Smart Contract Honeypot Detection
Currently, there are few studies that focus on smart contract honeypot detection, which are mainly categorized into three types: symbolic execution, heuristic feature matching, and machine-learning-based detection models.
In terms of symbolic execution, Torres et al. [9] designed the first smart contract honeypot detection tool in 2019, named HONEYBADGER, which utilizes symbolic execution for information gathering and the static analysis of eight types of contract honeypots. However, this tool employs symbolic execution and coarse-grained feature matching during static analysis, which may lead to false positives when facing certain conditions and susceptibility to path space explosion issues.
In terms of heuristic feature matching, [28] conducted fine-grained genetic feature mining around known honeypot families, constructed a honeypot genealogy, and designed a cross-family heterogeneity contract honeypot detection method. Nevertheless, its key part is still static feature matching, which will lead to false negatives in detecting new types of honeypot techniques.
In terms of machine learning, the study [11] extracted features from the source code, transaction history, and fund flows of honeypots, supporting the development of a smart contract honeypot detection model based on the XGBoost (eXtreme Gradient Boosting) algorithm. The study [29] designed a GRU network with an attention mechanism that learns from N-gram bytecode patterns to determine whether a smart contract is a honeypot or not. However, due to the high data imbalance between honeypot contracts and non-honeypot contracts, the detection performance of this model is highly unstable.
2.3. Grey Box Fuzzing
Fuzzing, a dynamic program analysis technique, is an efficient method used for discovering software vulnerabilities. Based on the level of understanding of the program under test before conducting fuzzing, fuzzing techniques can be categorized into three types: white-box fuzzing, black-box fuzzing, and grey-box fuzzing. In black-box fuzzing, the tester has no knowledge of the internal structure of the target program, whereas in white-box fuzzing, the tester has a comprehensive understanding of the internal architecture of the target program. Grey-box fuzz testing falls between black-box and white-box fuzz testing, where the tester has some degree of understanding of the internal structure of the target program but not complete knowledge.
Based on different fuzzing methods, grey-box fuzzing can be divided into two types. One type aims to cover as many code branches as possible to improve code coverage, known as coverage-guided grey-box fuzzing. For example, AFL, one of the most famous fuzzers, utilizes genetic algorithms to enhance code coverage. Additionally, some studies focus on carefully selecting and mutating test cases to generate as many test cases as possible to explore unexplored code branches, thus increasing code coverage. The other type continuously guides grey-box fuzz testing to a specific set of target locations in an attempt to discover vulnerabilities from these specific target locations. For instance, AFLGo utilizes the Control Flow Graph (CFG) of the program to calculate the distance between program entry points and code defect locations, thereby optimizing and guiding the mutation process of genetic algorithms.
2.4. Taint Analysis
Taint analysis is commonly used for information flow security, with its primary objective being to identify potential data flows from low-integrity sources (such as user inputs) to high-integrity sinks (such as database writes) [30]. Here, “sources” refer to data manipulable by users (i.e., user input data), while “sinks” denote sensitive security operations or APIs (e.g., deleting data in a database or using call.value() in smart contract code). Generally, if there is a data flow from source to sink during taint propagation, it may indicate security issues or vulnerabilities.
Taint analysis can be classified into two types: static and dynamic. Static taint analysis, although not highly accurate, it can cover all taint flows within the program, thus avoiding false negatives. In contrast, dynamic taint analysis is more accurate and less prone to false positives, but its coverage of taint flows within the program is limited by user-provided inputs, which leads to potential false negatives.
Currently, some smart contract security auditing approaches have adopted taint analysis methods. For instance, in reference [31], taint analysis techniques were utilized to discover and report gas-related vulnerabilities in smart contracts. However, this study relied entirely on static taint analysis for vulnerability detection, which entailed extensive modifications to the Ethereum Virtual Machine (EVM) code, consuming substantial human resources. Furthermore, the difficulty in accurately identifying and labeling taints limited its applicability to auditing specific types of vulnerabilities. This suggests that relying solely on taint analysis for security auditing has certain shortcomings. Considering the characteristics of taint analysis, we propose integrating it into the seed mutation process of the genetic algorithm to guide and optimize this process.
3. Threat Model
3.1. Example of Smart Contract Honeypot
Currently, there are ten common types of smart contract honeypot techniques. We categorize these techniques based on the levels of their effects and detail them in Table 1.

Table 1.
Ten types of smart contract honeypot techniques.
Listing 1 shows the simplified source code of the SMC (Straw Man Contract) honeypot. The honeypot consists of two main components: Bank and Log. Bank is an attacker-deployed smart contract (i.e., a smart contract honeypot) on the Ethereum blockchain, allowing contract visitors (i.e., victims) to deposit and withdraw funds through the Deposit and CashOut functions. The AddMessage function of the Log contract is intended to record transaction information. Although this contract does not actually serve any purpose (i.e., the main contract does not invoke this function), its name is similar to the contract called in the main contract, which confuses and misleads victims into making deposit operations.
| Listing 1. SMC (smart contract honeypot). |
 |
The attack process of the SMC honeypot can be described as follows:
- The victim initially discovers and analyzes the SMC honeypot through Etherscan or other blockchain explorers, identifying what appears to be a reentrancy vulnerability in the Bank contract. This analysis leads them to believe that the contract is poorly secured, making it an attractive target for exploitation. Under normal circumstances, users must first call the Deposit function to invest an amount equal to or greater than the required minimum deposit (MinDeposit). Once the deposit is made, they can then invoke the CashOut function to withdraw their funds. However, the CashOut function contains an insecure fund transfer API, which automatically triggers the fallback function in the victim’s contract when funds are sent. Believing they can exploit this vulnerability, victims set up a malicious contract with a fallback function that recursively calls CashOut, thereby executing a reentrancy attack. This allows them to continuously withdraw funds from the Bank contract before the balance updates, leading them to expect illicit profits from draining the contract’s funds.
- However, in reality, TransferLog is not an instance of the Log contract shown in Listing 1 but rather another contract with a different functionality under the same name.
- The attacker invokes the AddMessage function in another truly instantiated Log contract (as shown in Listing 2) to transfer funds from the Bank contract to the attacker’s account while leaving a balance of only 0.1 ether in the Bank contract.
- Eventually, the victims discover that they are unable to profit from the contract, and the funds they invested are frozen and transferred to the attacker’s account.
| Listing 2. Real Log() contract. |
 |
3.2. Smart Contract Honeypot Attack Model
Figure 1 illustrates the attack model of smart contract honeypots. The model summarizes the attack process in several steps: (1) construction of the smart contract honeypot, (2) compilation of the contract code, (3) contract deployment and propagation, (4) inducing transfers, (5) locking funds, (6) transferring funds into the attacker’s account.
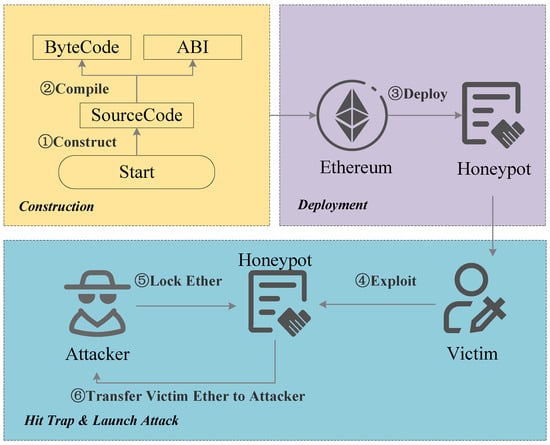
Figure 1.
Attack model of smart contract honeypot.
Specifically, the operations for each step are as follows:
- Attackers write contract source code with various smart contract honeypot techniques.
- The source code is compiled to generate bytecode and ABI (Application Binary Interface) files, making it deployable on the Ethereum blockchain.
- Attackers initiate a deployment transaction, submitting the compiled bytecode to Ethereum and requesting contract deployment, and then, the contract is indexed on platforms like Etherscan, allowing it to be discovered by unsuspecting victims. Attackers may also promote it in online communities to increase visibility.
- Victims analyze the contract, mistakenly believe they can exploit it for profit, and transfer funds into it, unknowingly falling into the trap.
- Attackers lock the funds transferred by the victims, preventing them from withdrawing funds.
- Attackers execute a concealed withdrawal mechanism, transferring the trapped funds to their own accounts, thereby profiting at the victim’s expense.
4. Method
4.1. Overview
The workflow of SCH-Hunter can be described as follows:
- The SCH-Hunter starts by taking the source code of the smart contract under test as input and feeding it into a static analysis engine. The engine generates an abstract syntax tree (AST) and sequentially applies source-level feature matching functions to detect three specific types of smart contract honeypot techniques. If any of these techniques are detected, a report is generated immediately, and no further analysis is performed. If no honeypot techniques are found, the smart contract is passed to the fuzz testing engine for further analysis.
- Once the contract enters the fuzz testing engine, it is first compiled into bytecode by the Ethereum Virtual Machine (EVM), and corresponding ABI files and Control Flow Graphs (CFGs) are generated. At this point, the adaptive transaction sequence generation strategy is triggered. This strategy analyzes the control flow graph to identify data dependencies between functions in the contract and determines the calling priority of each function based on the RAW (Read-After-Write) dependency principle. A specific function call sequence is then constructed. Furthermore, the strategy reads global variable conditions and, based on predefined rules, assigns more appropriate value ranges for the subsequent function parameters.
- Next, the hybrid fuzzing module is executed. It receives the analysis results from the adaptive transaction sequence generator and constructs transaction sequences with a specific order and concrete parameter assignments. These sequences are then subjected to the fuzz testing process. During fuzz testing, if the code coverage stagnates due to complex conditional statements, the system dynamically switches to the symbolic execution module. This module reads the current code path’s branching conditions and abstracts them into constraints for solving. Once the constraint is solved and specific parameter values are found, they are returned to the current test case and used to overwrite the original values, enabling further fuzz testing of the code path, thereby increasing code coverage.
- Simultaneously, the taint-based seed optimization strategy, guided by taint analysis and powered by a genetic algorithm, collects taint flow information during fuzz testing. Based on this information, tainted data are categorized, and mutation weights are dynamically assigned. This directs the mutation process toward high-value code areas, enhancing the contract’s honeypot detection capabilities while reducing overall resource consumption and improving detection efficiency.
- Finally, the honeypot detection module combines instruction-level real-time monitoring with taint flow analysis. Using code instrumentation techniques, this module detects potential honeypot techniques in the smart contract under test and generates a report accordingly.
The overall architecture of SCH-Hunter is outlined in Figure 2. Generally, SCH-Hunter consists of five key components:
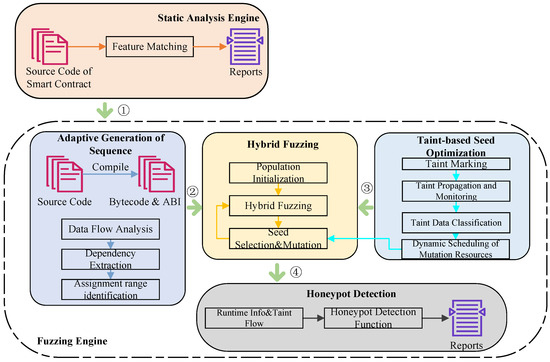
Figure 2.
A high-level overview of SCH-Hunter. SCH-Hunter has five main components, including (1) static analysis, (2) adaptive generation of the sequence, (3) hybrid fuzzing, (4) taint-based optimization, and (5) honeypot detection.
- Static Analysis: One major challenge in detecting smart contract honeypots is the semantic loss that occurs when source code is compiled into bytecode. Many honeypot techniques rely on subtle manipulations at the source code level, which may not be directly preserved in the compiled bytecode, making them difficult to detect through traditional bytecode-based fuzzing. To address this, we have designed a static analysis module specifically for detecting three types of smart contract honeypots by using AST (abstract syntax tree), thereby enhancing the detection capabilities of our framework.
- Adaptive Generation of Sequence: Note that a smart contract may contain many functions to explore their possible sequences order to improve the detection ability of framework, SCH-Hunter compile the inputtcontract source code to byte code and build CFG (Control–Flow–Graph) based on it. Then, it will analyze the data flow of smart contract based on the RAW principle and extract variables’ dependencies within functions. Finally, it will generate a ordered function invocation sequence (i.e., transaction sequence) along with assignment range of each parameter based on predefined rules, ensuring that generated transactions are meaningful and effective in triggering potential honeypot traps.
- Hybrid Fuzzing: To efficiently handle complex conditional statements encountered during fuzzing and enhance code coverage, SCH-Hunter adopts a hybrid fuzzing framework that combines fuzz testing and symbolic execution. This approach ensures that difficult-to-reach code branches are thoroughly explored. Specifically, when fuzzing encounters complex conditional statements that pose challenges for resolution (i.e., the code coverage has not shown any improvement over a specific period of time), the symbolic execution module is then automatically activated to perform constraint solving. Upon successful constraint solving, the obtained test case is returned to the location of the complex statement to resume fuzzing, thus exploring more undiscovered code branches.
- Taint-based Seed Optimization: To improve fuzzing efficiency and reduce ineffective mutations, SCH-Hunter employs taint analysis to guide the genetic algorithm-based seed mutation process. This ensures that computational resources are focused on high-impact mutations, rather than random, low-value changes. The taint analysis module labels each parameter in the input transaction sequence and monitors changes in the tainted-information flow during taint propagation. If certain bytes in the transaction sequence are used by predefined sensitive statements or functions, these bytes are recorded. Subsequent mutation processes will allocate more resources to mutate sensitive data and jump data more frequently and reducing the mutation frequency for safe data, thereby reducing the waste of fuzzing resources and improving detection efficiency.
- Honeypot Detection: To detect a greater number and variety of smart contract honeypots, SCH-Hunter performs code instrumentation on EVM instructions, which are commonly used in honeypot techniques. Subsequently, honeypot detection functions will be constructed based on the trigger principles of various smart contract honeypot techniques. Finally, the program information flow collected by code instrumentation and taint information are inputted into these honeypot detection functions for detection and analysis, and then it generates the corresponding detection report.
In what follows, we will elaborate on the details of these components one by one.
4.2. Static Analysis Engine
For the three types of smart contract honeypot techniques—Unexecuted Call, Map Key Encoding Trick, and Hidden Transfer—distinct honeypot characteristics are visible at the source code level. However, these characteristics are highly likely to be lost when the source code is compiled into bytecode. This makes it difficult for detection frameworks to capture these honeypot features during fuzzing. To address this issue, SCH-Hunter has designed effective feature matching functions for these three types of smart contract honeypots. The specific workflow of the static analysis engine is shown in Figure 3. Specifically, the static analysis engine receives the source code of the smart contract under test as input and sequentially activates three feature matching functions to determine whether the smart contract belongs to one of these three honeypot types. If the engine detects that the contract is a honeypot of a specific technique, it immediately generates a detection report and halts further operations. If the smart contract is not identified as a honeypot, the engine forwards it to the fuzzing engine module for subsequent testing and detection.
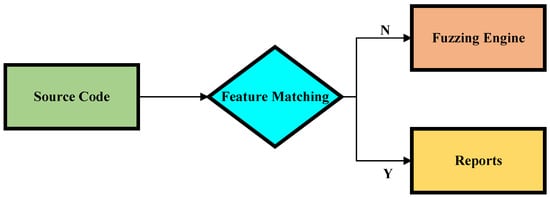
Figure 3.
Static analysis module.
4.2.1. Unexecuted Call
To detect the Unexecuted Call honeypot technique, we have designed a corresponding source-code-level feature matching detection function. The specific detection algorithm is shown in Algorithm 1. The core detection logic focuses on two aspects: conditional branch reachability analysis and high-risk operation identification. The detailed process is as follows:
- Parsing the Solidity Source Code: The Solidity source code is first parsed into a structured abstract syntax tree (AST), from which syntax units (such as function declarations and control flow statements) are extracted.
- Traversing the AST: All if nodes in the AST are traversed to identify conditional jump structures.
- Evaluating Constant Expressions: Constant expressions within the conditional branches are evaluated and simplified logically to deduce their boolean values (true or false).
- Unreachable Code Block Analysis: The analysis is divided into two situations: Conditionally Always True, where the condition is always true and thus the code block is reachable, and Conditionally Always False, where the condition is always false, making the corresponding code block unreachable.
- High-Risk Call Detection: In the unreachable code blocks, the detection algorithm looks for high-risk instructions based on the AST node type and function identifiers. These high-risk instructions include low-level calls (such as delegatecall, address.callvalue:…("")), asset transfer operations (selfdestruct, transfer), and permission changes (e.g., SSTORE modifications to contract owner addresses).
- Final Detection: If any unreachable code block contains high-risk calls, it is classified as an Unexecuted Call honeypot. If no high-risk calls are found in unreachable blocks, the contract is not identified as containing this honeypot technique.
| Algorithm 1 Detection of an Unexecuted Call |
Require:
Solidity source code for the contract under test Ensure:
Bool
|
4.2.2. Map Key Encoding Trick
To detect the Map Key Encoding Trick honeypot technique in smart contracts, we have designed a corresponding source-code-level feature matching detection function. The specific detection algorithm is shown in Algorithm 2. The core detection logic revolves around three aspects: non-standard key computation, key generation logic obfuscation, and storage–access asymmetry. The detailed process is as follows:
- Abstracting the Source Code: The source code of the smart contract under test is first abstracted into an abstract syntax tree (AST), from which all mapping declaration nodes are extracted, recording the mapping name, key type, and visibility modifiers.
- Identifying Mapping Assignments and Reads: The engine identifies all assignments (e.g., _balance[key] = value) and reads (e.g., value = _balance[key]) operations associated with the target mapping.
- Parsing Key Expressions: For each operation, the engine parses the key expressions to detect whether they include hashing functions, custom encoding schemes, or bit-wise operations. The engine also scans function comments to check if the key generation rules are explicitly defined.
- Comparing Storage and Access Operations: The key expressions involved in both storage and reading operations for the same mapping are extracted. Using the tree edit distance algorithm, the structural similarity of the abstract syntax tree (AST) is computed for these key expressions.
- Detection Criteria: If the hash value and the original input key show a significant difference in similarity, it is flagged as a Map Key Encoding Trick honeypot.
| Algorithm 2 Detection of the Map Key Encoding Trick |
Require:
Solidity source code for the contract under test Ensure:
Bool
|
4.2.3. Hidden Transfer
To detect the Hidden Transfer honeypot technique in smart contracts, we have designed a corresponding source-code-level feature matching detection function. The specific detection algorithm is shown in Algorithm 3. This detection function statically analyzes the abstract syntax tree (AST) of the tested smart contract to identify potential hidden transfer operations. The detailed process is as follows:
- Abstracting the Source Code: The source code of the smart contract is first parsed into an abstract syntax tree (AST), from which all function definitions and code block structures are extracted.
- Syntax Pattern Matching: The engine uses pattern matching to identify low-level calls such as transfer and explicit transfer functions such as call.value. These are typically involved in fund transfers in the contract and can be part of the hidden transfer mechanism.
- Symbolic Execution: Symbolic execution is employed to verify the reachability of the transfer paths, checking how conditions and proxy calls may hide the actual transfer path. It helps uncover situations where transfers are hidden behind complex condition checks or proxy methods that obscure the direct flow of funds.
- Event and Parameter Consistency Check: The algorithm checks whether transfer operations trigger legitimate events or if they trigger misleading events with inconsistent parameters. Hidden transfers may use misleading or false events to confuse attackers and hide the real transfer actions.
- Control Flow Graph (CFG) Analysis: The control flow graph (CFG) is analyzed to check whether the transfer instructions are located within unreachable code blocks. If transfer operations exist in code blocks that are unreachable or in situations where conditions are always false, these may point to a hidden transfer honeypot.
| Algorithm 3 Detection of Hidden Transfers |
Require:
Solidity source code for the contract under test Ensure:
Bool
|
4.3. Adaptive Generation of Sequence
Currently, smart contracts are typically composed of multiple functions, and most existing fuzzing approaches use a random selection of functions and randomly generated function parameter values to construct transaction sequences. However, research has shown that the final execution state (i.e., the outcome) of a smart contract is often influenced by the current states of the variables in the code, and even minor changes in variables can lead to significant differences in the execution results of the generated transaction sequences. Most existing fuzzing methods tend to ignore the variable dependencies between functions, which results in an inability to fully explore potential risks within the contract’s code space. For certain types of smart contract honeypot techniques, such as those that require the smart contract to be in a specific state to trigger the honeypot, blindly constructing transaction sequences can lead to these honeypot techniques being undetected and resources being wasted. Therefore, it is crucial to take the interdependencies between functions and variables into account when generating transaction sequences to effectively trigger the honeypot traps and identify potential vulnerabilities.
For example, in the source code of the Balance Disruption Honeypot smart contract shown in Listing 3, the analysis reveals that the success of the honeypot in capturing a victim depends on three essential conditions: the smart contract honeypot must contain a certain amount of contract balance to lure the victim; the victim must deposit funds into the smart contract; and the victim must then attempt to call the multiplicate function to withdraw the deposited funds and the contract’s balance. If the sequence of these function calls is altered, the honeypot trap will fail to trigger. For instance, if the victim directly calls the multiplicate function in an attempt to withdraw the contract balance without depositing any funds, the condition msg.value >= this.balance will not be satisfied, causing the function call to fail and the honeypot trap to be undetected. Thus, the transaction call chain required to trigger this honeypot trap is deposit() -> Command() -> multiplicate(). Any change in the sequence of these calls in the transaction chain could result in the honeypot trap not being triggered, making it difficult to detect effectively.
| Listing 3. Balance Disorder smart contract honeypot. |
 |
To address the issue described above, SCH-Hunter employs an adaptive transaction sequence construction module based on the RAW (Read-after-Write) principle, which consists of two main components: the data flow analyzer and the assignment range determination. Specifically, the process is as follows:
- Compilation and CFG Construction: First, the source code of the smart contract is compiled into bytecode, and the corresponding control flow graph (CFG) is constructed.
- Data Flow Analyzer: Using the data flow analyzer, the module extracts variable access types related to assignment and comparison operations from the CFG. It also captures the read–write dependencies of global variables between different functions in the smart contract, tracking how the state of these variables changes during the contract’s execution. Additionally, it extracts the conditional ranges of global variables involved in conditional statements.
- Determination of Execution Priority and Parameter Ranges: Based on the captured data dependencies, the module calculates the execution priority between functions to determine the order in which the transaction sequence should be composed. Furthermore, it uses the determined conditional ranges of the involved global variables to set the initial assignment ranges of the parameters in the transaction sequence.
- Fuzz Testing Integration: These determined parameters and transaction sequence order are then passed to the fuzz testing module, where optimized transaction sequence instances (i.e., test cases) are generated.
We use the Balance Disruption Honeypot smart contract source code shown in Listing 3 to illustrate the execution flow of this adaptive generation of sequence module.
4.3.1. Data Flow Analyzer
In smart contracts, functions that perform “write” operations on variables can modify the current state of the contract, while functions that only perform “read” operations do not impact the contract’s state. Therefore, functions that execute “write” operations on the same global variable should have a higher execution priority than those performing “read” operations on the same variable. This is the Read-after-Write (RAW) principle. SCH-Hunter designs a static data flow analyzer based on the RAW principle. Let the set of functions in the smart contract be denoted as , and the transaction sequence set as . If a global variable v is written to by and read by , then according to the RAW principle, a data dependency exists, and thus, the calling priority of is higher than that of . Consequently, the transaction sequence should be ordered as .
As observed from Listing 3, the global variable msg.value is used in both the Command and multiplicate functions. In the Command function, the msg.value variable undergoes an assignment operation, i.e., data are written to the storage slot represented by this variable in the EVM virtual machine, which can be referred to as a “write” operation. In contrast, in the multiplicate function, the msg.value variable is involved in a comparison operation, i.e., data are read from the storage slot corresponding to this variable in the EVM virtual machine, which can be termed as a “read” operation. Therefore, based on the Read-after-Write (RAW) principle, it can be inferred that the Command function should execute before the multiplicate function, meaning the function call sequence should be Command -> multiplicate. Thus, through the data dependency relationship, the normal function call order in the smart contract can be roughly deduced, which, to some extent, enhances the detection capability for specific types of smart contract honeypot techniques.
4.3.2. Assignment Range Determination
In Ethereum blockchain transactions, each transaction consists of two critical components: the function selector and the associated parameters. The function selector is a four-byte hash value derived by hashing the function signature. Additionally, the function parameters included in the transaction must be explicitly specified when initiating the transaction request. Therefore, we adopt two approaches to determine the value range of function parameters within the transaction sequence: constraint-based range determination and data-type-based range determination.
- Constraint-Based Range Determination: For global variables used within conditional statements inside a function, the corresponding value range is determined based on pre-captured constraint conditions (e.g., msg.value >= 100 ethers). This determined range is then passed to the fuzzing engine, which utilizes it as guidance, and then, the module assigns random values to the corresponding function parameters within the specified range and generates test instances accordingly.
- For other variables, specifically function parameters that do not reference global variables (e.g., various local variables), the value range is determined based on their corresponding data types. For integer-type variables, values are randomly selected within the valid integer range; for boolean-type variables, the value range is restricted to true or false. For instance, an variable will be randomly assigned a value from its valid domain, i.e., any number within the range to .
By integrating both assignment strategies, the fuzzing process can generate function parameter values more accurately and efficiently, ensuring that the constructed transaction sequences closely resemble real execution scenarios. This approach effectively reduces the number of seed mutations required to obtain a transaction sequence capable of truly triggering the honeypot trap, thereby enhancing SCH-Hunter’s detection capability and efficiency.
4.4. Hybrid Fuzzing
Even though fuzzing is highly effective in vulnerability detection, it exhibits significant weaknesses when handling complex conditional statements. For instance, consider a seemingly simple conditional statement that requires generating a test case where msg.value == 100 finney. In practice, however, the probability of a fuzzing-based approach randomly generating a test case that satisfies this condition can be extremely low, i.e., . This leads to prolonged stagnation in code coverage during the fuzzing process. On the other hand, symbolic execution possesses powerful constraint-solving capabilities that allow it to abstract complex conditional statements into constraints and leverage constraint solvers to determine concrete values that satisfy these conditions efficiently. However, relying solely on symbolic execution introduces the risk of path explosion, which becomes increasingly severe as the size of the smart contract code grows.
To address these challenges, SCH-Hunter employs a hybrid fuzzing module, integrating symbolic execution with fuzzing. This combination enables fuzz testing to explore deeper regions of the smart contract’s code space while effectively mitigating the path explosion problem associated with purely symbolic execution. Algorithm 4 provides an overview of the specific execution process of the hybrid fuzzing module in SCH-Hunter.
| Algorithm 4 Working process of the hybrid fuzzing module |
|
Specifically, the hybrid fuzzing module first utilizes the adaptive generation of the sequence module based on the RAW principle to guide test case generation. This process produces transaction sequences with concrete values and a predetermined function invocation order (Line 1), and then, the fuzzing process will be initiated (Line 3). As the fuzzing process progresses through continuous seed mutation, it explores deeper regions of the smart contract’s code space. When the fuzzing module encounters complex conditional statements that are difficult to resolve—indicated by a prolonged stagnation in code coverage within a threshold time—the symbolic execution module will be automatically triggered (Lines 4–6). This module abstractly interprets the constraints declared at the current code branch, formulates corresponding constraint conditions, and attempts to solve them. Once the symbolic execution successfully computes the solution to these constraints, the derived values are returned to the fuzzing module, which incorporates them into the original test cases and replaces the previous values. This enables the exploration of previously unreachable code branches, thereby improving code coverage. The hybrid fuzzing framework iterates through this process until a predefined threshold (e.g., iteration count) is reached or an exception occurs (Line 2). Due to its enhanced code branch exploration capabilities, this hybrid fuzzing framework outperforms traditional fuzzing approaches by improving the overall code coverage.
4.5. Taint-Based Seed Optimization
Traditional fuzzing methods employ genetic algorithms for seed mutation but typically rely on fully random mutation strategies without optimization. Specifically, mutations occur randomly within the valid range of data types, making the approach simple and convenient. However, this purely random mutation often leads to the generation of invalid or meaningless test cases, preventing the fuzzing process from quickly discovering optimal test cases. As a result, fuzzing resource waste will increase, and detection efficiency will decline. To address this issue, SCH-Hunter proposes a taint-based seed optimization module. This module aims to guide and optimize the seed mutation process in genetic algorithms, thereby reducing the number of ineffective mutations, minimizing resource waste, and enhancing the efficiency of the detection framework. The taint-based seed optimization module consists of four key components, which is shown in Figure 4: taint marking, taint propagation and monitoring, taint data classification, seed mutation resource scheduling.

Figure 4.
Taint-based seed optimization module.
Compared with traditional static taint analysis approaches, the taint-based seed optimization in SCH-Hunter adopts a dynamic taint analysis technique to guide and optimize the seed mutation process. This approach offers advantages such as real-time tracking at runtime and the ability to dynamically update propagation rules, thereby reducing the likelihood of false positives. Moreover, the primary purpose of employing dynamic taint analysis is to guide the scheduling of mutation resources, rather than directly using taint analysis for honeypot classification. By integrating dynamic taint analysis with runtime feedback information from smart contracts, SCH-Hunter is able to enhance its detection accuracy more effectively.
4.5.1. Sensitive Instruction Instrumentation in EVM
The Ethereum Virtual Machine (EVM) uses a stack-based architecture specifically optimized for the blockchain environment. This unique design fundamentally dictates that the EVM’s instruction set primarily performs operations by directly manipulating data in the EVM stack memory. Existing dynamic taint tracking schemes, which are designed for register-based or heap memory architectures, inherently face compatibility challenges with the EVM’s execution paradigm. This architectural difference necessitates the targeted reconstruction of taint propagation rules.
The EVM employs a non-register architecture design, completely discarding traditional operations related to registers in conventional computing systems. Instead, it uses three types of storage spaces for data exchange: memory, state storage, and stack. Memory is used to temporarily store function return values, complex data types, and intermediate data for cross-contract calls; state storage is responsible for persisting the global variables and state data of the smart contract, with its contents permanently recorded on the blockchain; and the stack serves as the main computational context, storing local variables and instruction operands, and supports arithmetic operations, logical comparisons, and control flow operations.
Given this structure, data storage locations are entirely deterministic in the EVM. Access to the blockchain state by smart contracts is strictly constrained to two channels. Data input: External data can only be accessed via transaction parameters (msg.data) or the contract’s storage state. Data output: The contract can only update the state storage or emit event logs to affect off-chain systems. Thus, it is entirely feasible to perform instruction instrumentation for taint analysis in the EVM. Specifically, taint analysis can be implemented by instrumenting the instructions related to memory, storage, and stack read/write operations, as well as control flow instructions (e.g., JUMPI, JUMPDEST). This enables the creation of cross-instruction taint propagation chains.
- SSTORE Instruction: When a write operation to storage occurs via the SSTORE instruction, the taint is propagated to the target storage slot.
- SLOAD Instruction: When a read operation from storage occurs via the SLOAD instruction, the loaded data inherit the taint label, thereby propagating the taint flow.
- Stack Operations: For stack manipulation instructions like DUP1 and SWAP3, the code is instrumented to enable dynamic taint propagation across stack operations.
4.5.2. Taint Marking
In the process of initiating a transaction in a smart contract, the input data (calldata) are composed of the function signature and the specific function parameters. Since the function signature does not change, the actual mutation process in fuzz testing involves changing the function parameters, meaning that the function parameters need to be taint-marked. We adopt an approach based on the ABI (Application Binary Interface) type parsing of the smart contract under test, generating a taint variable for each function’s parameter data type and assigning an independent taint label to each byte of the parameter.
4.5.3. Taint Propagation and Monitoring
By instrumenting the sensitive instructions and conditional jump instructions, the execution process of tainted test cases in the smart contract can be monitored in real time. Whenever certain byte streams from the test case flow into sensitive instructions or conditional jump instructions, the module will record the corresponding taint labels that were pre-assigned. The recorded content includes the input byte offset (byte_offset), the associated operation type (op_type), such as CALL or JUMPI, and the operand role (operand_role), such as the CALL.value or JUMPI.condition. These recorded results are then sent to the Taint Data Classification Module for further processing.
4.5.4. Taint Data Classification
After receiving the records from the taint propagation and monitoring module, the Taint Data Classification Module categorizes the tainted data based on the taint flow information. Specifically, the module classifies the tainted byte data into three types: sensitive data, jump data, and ordinary data.
- Sensitive data are the data used as parameters for instructions that are likely to trigger smart contract honeypot traps, such as transfer, SELFDESTRUCT, and CALL.
- Jump data are the data used in conditional checks that affect control flow instructions, such as JUMPI and JUMPDEST.
- Ordinary data are the tainted bytes that are not involved in either of the above two operations.
Among these, sensitive data pose the highest threat, followed by jump data, and finally, ordinary data. Based on these three data classification categories, the Taint Data Classification Module will label the corresponding bytes in the test case and send the classification results to the Seed Mutation Resource Scheduling Module. This will guide and optimize the seed mutation process, helping to refine the generation of test cases for a more effective and efficient fuzzing process.
4.5.5. Seed Mutation Resource Scheduling
Genetic algorithms (GAs) are a class of population-based optimization algorithms inspired by the theory of biological evolution. They iteratively optimize a set of candidate solutions by simulating natural selection, crossover, and mutation mechanisms. In fuzz testing, genetic algorithms are often used to generate high-quality test cases to maximize code coverage or vulnerability triggering probability in the target program.
When the Seed Mutation Resource Scheduling Module receives the tainted data classification results sent by the Taint Data Classification Module, it begins its process. By constructing a directed mutation strategy, the module prioritizes modifying high-value input areas, thereby improving the fuzz testing code coverage and honeypot trap triggering rate. Specifically, the module first assigns mutation probability weights to different categories of bytes based on the tainted data classification results, as shown in Equation (1). Sensitive data are assigned the highest weight of 0.6 because they have the highest likelihood of triggering a honeypot trap and require frequent mutation. Jump data are assigned a medium weight of 0.3, as mutating these can explore more new code paths and improve code coverage. Ordinary data are assigned the lowest weight of 0.1, as they do not provide immediate benefits, so reducing their mutation frequency helps minimize the overhead of ineffective mutations. Then, the module applies different mutation strategies based on the type of tainted data.
For the initial setting of the weight assignments (0.6, 0.3, 0.1), we conducted multiple rounds of experiments to evaluate how different parameter values affect SCH-Hunter’s detection capability, code coverage, and invalid mutation ratio. Based on the results, we determined that the configuration of (0.6, 0.3, 0.1) achieves the optimal balance between detection capability and code coverage, while keeping the invalid mutation ratio within an acceptable range. The experimental results are shown in Table 2.
Table 2.
Fuzzing performance comparison under different weight configurations.
- The sensitive byte mutation strategy is divided into two mutation approaches: semantic-preserving mutation, which introduces perturbations within the valid data value range, and boundary value testing, where extreme values (such as 0 and MAX_INT256) are inserted for numeric parameters (e.g., uint256).
- The jump-type byte mutation strategy also includes two mutation methods: conditional branch inversion, where the conditional parameters are modified to invert the jump logic (e.g., changing < to >=), and path-guided mutation, which utilizes the symbolic execution module in the hybrid fuzzing framework to solve constraints for newly generated code branch paths and produce test cases that satisfy the conditions.
- The ordinary byte mutation strategy only employs the random bit-flipping method, which introduces low-energy, low-intensity perturbations in a random manner to maintain population diversity.
Finally, based on the mutation effects (such as the improvement in code coverage and the number of honeytrap triggers), the weight ratio is dynamically updated in real time. The goal is to reward effective mutation-guided algorithms by concentrating resources on high-potential input areas and avoid the uncontrolled growth of weights, ensuring that weight changes are inversely proportional to the scale of testing. The dynamic weight adjustment formula is as shown in Equation (2).
represent the mutation weight for sensitive data in generation t. This value indicates the proportion of the total mutation probability assigned to sensitive data in the current iteration of the genetic algorithm mutation process. For example, if the total weight is 1 and = 0.6, this means that the mutation probability for sensitive byte data is 60%. represents the number of newly triggered honeytrap instances between generations t and . This metric shows the effectiveness of the mutation of sensitive bytes in discovering smart contract honeypot traps. Honeypots are typically triggered by sensitive operation instructions. A higher value of indicates that the generated test cases are more effective in triggering honeytrap traps. represents the total number of test cases generated in generation t. represents the updated mutation weight for sensitive data in generation , which is dynamically adjusted based on the mutation testing results from the previous generation. This allows the algorithm to focus more on the areas with higher potential for effective mutation.
4.6. Honeypot Detection
SCH-Hunter proposes a smart contract honeypot detection module based on code instrumentation. By leveraging code instrumentation, the module utilizes taint information to determine the type of honeypot when fuzzing test cases trigger a smart contract honeypot trap. We take a Balance–Disorder-type smart contract honeypot as an example to illustrate how the proposed detection module, based on EVM runtime code instrumentation, identifies corresponding smart contract honeypot techniques. The detection algorithms specifically designed for Balance–Disorder-type honeypots are presented in Algorithm 5.
Specifically, the detection process begins by leveraging EVM instruction instrumentation to mark taint pointers within the target smart contract bytecode. This enables real-time capture of execution contexts related to storage access (SLOAD, SSTORE), fund transfers (CALL), and control flow instructions (JUMPI). Next, the hybrid fuzzing framework generates diverse inputs, focusing on mutating parameters of balance inquiry and withdrawal functions to trigger potential anomalous execution paths. During this process, the module analyzes the consistency of storage access patterns—such as discrepancies between publicly exposed variables and actual storage slot values—and assesses the compliance of state updates following withdrawal operations to detect logic misdirection behaviors. Finally, based on key characteristics such as storage path divergence, mismatches between displayed balances and actual values, and abnormal control flow protections, the module determines whether the smart contract can be qualified as a Balance–Disorder-type honeypot. The classification criteria consist of three conditions, any one of which is sufficient to flag the contract as a Balance–Disorder-type honeypot:
- Display Inconsistency: The publicly queried balance value does not match the actual storage value.
- Implicit Tampering: After fund withdrawals, the storage slot fails to update as expected.
- Path Deception: Critical balance-related operations are consistently protected by always-false conditions (e.g., if (false)).
| Algorithm 5 Balance disorder detection algorithm for smart contract honeypots (Algorithms 3–5) |
Require:
Smart contract bytecode under test Ensure:
Boolean value
|
5. Experiments
In this section, we conduct a series experiments to evaluate the effectiveness and performance of SCH-Hunter by answering the following research questions:
- How effective is SCH-Hunter in detecting smart contract honeypot techniques? How does its detection performance compare to existing tool?
- How does SCH-Hunter perform in improving the code coverage of fuzz testing?
- Are the static analysis engine module, hybrid fuzzing module, and taint-based seed optimization module used in SCH-Hunter effective?
5.1. Environment and Set-Up
Regarding the SCH-Hunter hybrid fuzzing framework, since there is currently no widely recognized standard dataset for smart contract honeypots, we constructed a new smart contract honeypot dataset by integrating prior research literature [9,28] and verified smart contract honeypots from the Etherscan blockchain explorer. Additionally, we built a long smart contract dataset.
Specifically, the smart contract honeypot dataset (Dataset I) consists of three parts. First, we obtained and deduplicated publicly available smart contract honeypot datasets from [9,28] to ensure the dataset’s uniqueness and validity. Then, we retrieved smart contracts labeled as honeypots on Etherscan, scraped their source code, and incorporated them into the dataset. Based on these sources, we constructed a smart contract honeypot dataset comprising 631 honeypots spanning ten different honeypot types. The detailed composition of this dataset is presented in Table 3. In this dataset, the distribution of honeypots across different smart contract honeypot techniques is based on their frequency of occurrence in the real world. All samples meet two criteria: they have been labeled as “Honeypot” by Etherscan and have been manually verified as smart contract honeypots by at least two independent code auditors. It is worth noting that 86% of the contracts in this dataset are based on Solidity versions <=0.4.6, which may lead to an underestimation of specific attack patterns associated with contracts from later versions, such as Solidity 0.5.x.
Table 3.
Summary of honeypot techniques and their counts.
The long smart contract dataset (Dataset II), on the other hand, was built by crawling long smart contracts from the awesome-buggy-erc20-tokens [32] project and Etherscan. This dataset includes 1400 smart contracts, each containing no fewer than 3000 instructions after compilation.
The experimental environment is shown in Table 4.
Table 4.
Experimental Environment.
5.2. Effectiveness
To evaluate the detection capability of SCH-Hunter for smart contract honeypot techniques, we select the smart contract honeypot dataset(Dataset I) as the experimental dataset. SCH-Hunter is compared with HoneyBadger, a widely recognized and efficient smart contract honeypot detection tool based on symbolic execution, to assess its effectiveness in detecting smart contract honeypots.
Table 5 presents the types of smart contract honeypot techniques that both tools can detect. Table 6 displays the detection results of these two approaches for ten common smart contract honeypot types. Additionally, Figure 5 illustrates the number of detected smart contract honeypots for each honeypot technique category.
Table 5.
Tools and Detectors.
Table 6.
Comparative analysis of detection abilities across tools.
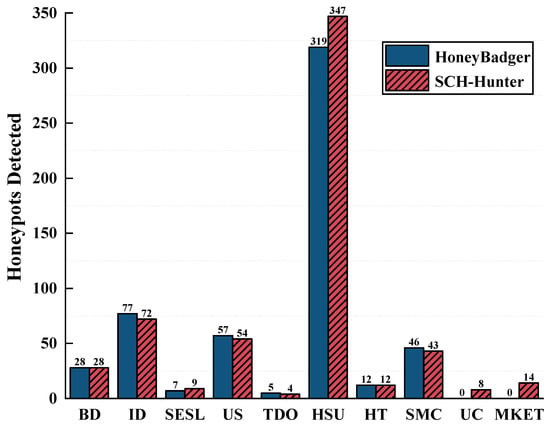
Figure 5.
Honeypot techniques detected by HoneyBadger and SCH-Hunter.
To evaluate the detection capability of these two detection approaches, this section employs three evaluation metrics: Precision, Recall, and F1-Score. Precision measures the proportion of detected honeypots that are actual smart contract honeypots; Recall assesses the proportion of actual smart contract honeypots that the detection approach successfully identifies; F1-Score is the harmonic mean of Precision and Recall, balancing the trade-off between the two metrics. The calculation methods for these three evaluation metrics are as follows:
As shown in the detection results presented in Table 6, when evaluating the eight types of smart contract honeypots that both tools can detect, the average precisions of HoneyBadger and SCH-Hunter are 95.35% and 95.04%, respectively, while their average recall rates are 93.07% and 92.21% and their average F1-scores are 0.9390 and 0.9339, respectively. Although HoneyBadger demonstrates a slight advantage across all three metrics, SCH-Hunter achieves nearly equivalent detection performance for these eight types of smart contract honeypots, indicating that its detection capability is highly reliable. Additionally, as illustrated in Figure 5, the detection performance of both tools is closely matched. The figure also reveals that the Hidden State Update type of smart contract honeypot has the highest occurrence, suggesting that this honeypot technique remains one of the most widely used honeypot technique in smart contracts.
The slightly lower performance of SCH-Hunter compared to HoneyBadger can be attributed to two main factors:
- Smart contract honeypots are typically displayed in source code form on blockchain explorers (such as Etherscan), which entices victims into traps. Some honeypot features are more prominent in the source code. However, once the smart contract honeypot’s source code is compiled into bytecode, certain semantics and features may be lost. This makes it difficult for dynamic detection techniques, such as fuzzing, to accurately capture the actual behavior of the contract, leading to potential false negatives.
- The smart contract honeypot detection module based on EVM runtime code instrumentation in SCH-Hunter still has room for optimization. There are certain specific features of some honeypot types that have not been fully considered, which results in both false positives and false negatives.
However, compared to HoneyBadger, SCH-Hunter demonstrated a 16.67% higher precision in detecting Type–Deduction–Overflow smart contract honeypots. This improvement is attributed to its ability to actually execute smart contracts and combine taint analysis to capture runtime information in real time, effectively identifying type deduction overflow issues that arise during the contract execution process. Additionally, SCH-Hunter can detect two extra smart contract honeypot techniques: Map Key Encoding Trick and Unexecute Call. When facing ten types of smart contract honeypots, SCH-Hunter achieved an average recall rate of 91.77%. It is worth noting that HoneyBadger is unable to detect the aforementioned two types of smart contract honeypot techniques primarily because it was originally designed to target eight commonly known honeypot patterns prevalent at the time of its development. In other words, HoneyBadger implements detection rules specifically tailored to these eight predefined categories mentioned in Table 4. However, the Unexecute–Call and Map-Key-Encoding-Trick techniques represent newer forms of smart contract honeypots that have emerged in recent years. Since HoneyBadger does not incorporate detection rules for these newly introduced techniques, it lacks the necessary capabilities to identify them effectively.
Certainly, as observed in Table 5, SCH-Hunter exhibits instances of both false negatives and false positives. For example, with regard to the Type–Deduction–Overflow honeypot technique, SCH-Hunter failed to detect one of the cases. An illustrative example of this missed detection can be found in one of the honeypot smart contracts, as shown in Listing 4. The reason for the false negative in detecting this honeypot smart contract is that, starting from Solidity version ≥0.8.0, overflow checks are enabled by default. However, the honeypot circumvents these checks by using an unchecked block. SCH-Hunter failed to identify the unchecked block and the potential overflow operation during the detection process. This indicates that SCH-Hunter still has certain compatibility limitations with newer versions of the Solidity compiler, which can lead to missed detections. Additionally, as shown in Table 5, SCH-Hunter exhibits relatively lower detection precision for the Hidden–State–Update honeypot technique compared to the other nine categories, resulting in false positives. To explain the cause of this misclassification, we take the honeypot smart contract shown in Listing 5 as a representative example. The false positive generated during the detection of this smart contract honeypot stems from the fact that legitimate smart contracts may rely on block.timestamp or block.number to implement standard functionalities such as time locks. However, SCH-Hunter, due to its stringent parameter sensitivity, flags all dependencies on block parameters as suspicious, failing to distinguish between malicious and legitimate usage. Moreover, it overlooks the directionality of temporal constraints. These oversights—namely, insufficient handling of timestamp and block number semantics and an overly conservative detection rule—contribute to the occurrence of false positives in such cases. Nevertheless, from an overall perspective, both the false positive rate and false negative rate of SCH-Hunter remain within acceptable limits, indicating that the framework still demonstrates strong and reliable detection capabilities.
In summary, SCH-Hunter not only demonstrates strong detection capabilities but also covers a wider range of smart contract honeypot types. This answers the first question raised in this section.
| Listing 4. The reason of false negative for Type–Deduction–Overflow. |
 |
| Listing 5. The reason of false positive for Type–Deduction–Overflow. |
 |
5.3. Code Coverage
To validate the code coverage capability of SCH-Hunter, we used the smart contract vulnerability dataset (Dataset I) and the long smart contract dataset (Dataset II) to observe and compare the average code coverage performance of SCH-Hunter and HoneyBadger when handling two types of smart contracts within the same amount of time. Figure 6 displays the average code coverage of SCH-Hunter and HoneyBadger when facing these two datasets.
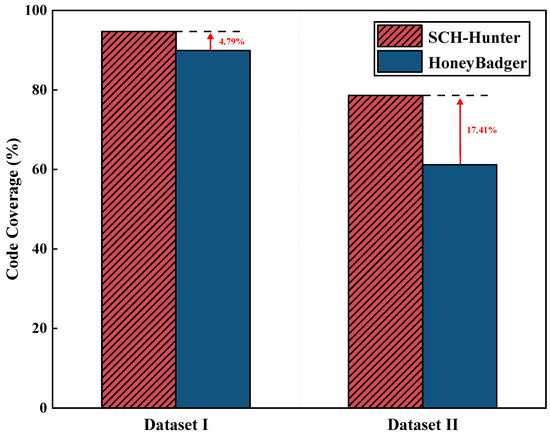
Figure 6.
Code coverage comparison between SCH-Hunter and HoneyBadger on different datasets.
By observing Figure 6, it can be concluded that, in the smart contract honeypot dataset, the average code coverage for the two detection tools is 94.71% and 89.92%, respectively. Both detection schemes exhibit excellent code coverage, mainly because the code of smart contract honeypots is typically shorter and simpler than that of normal benign smart contracts, the number of lines of code usually ranges between 100 to 200, and the code complexity is relatively low. Nevertheless, SCH-Hunter’s average code coverage is 4.79% higher than HoneyBadger, indicating a slight advantage for SCH-Hunter in this metric. In the long smart contract dataset, SCH-Hunter and HoneyBadger achieved average code coverage of 78.63% and 61.22%, respectively. SCH-Hunter outperforms HoneyBadger by 17.41% in terms of code coverage and the exploration of code branches. This difference can be attributed to the symbolic-execution-based design of HoneyBadger, which faces the issue of symbolic path explosion when dealing with larger smart contracts with more complex logic (e.g., those containing nested loops). This issue prevents further exploration of the code space, resulting in lower code coverage. In contrast, SCH-Hunter uses a hybrid fuzzing approach combined with a genetic algorithm seed mutation optimization strategy guided by taint analysis. By integrating the powerful test case generation capability of fuzzing with the symbolic execution advantages in solving complex constraints and using dynamic mutation weight allocation to prioritize jump-type data, SCH-Hunter explores deeper levels of the code space, significantly improving code coverage.
In conclusion, SCH-Hunter has a slight advantage over HoneyBadger in code coverage when dealing with smart contract honeypots. When facing more complex and larger smart contracts, SCH-Hunter demonstrates superior code coverage performance. Moreover, SCH-Hunter’s stronger code coverage capability gives it greater potential to detect longer and more complex smart contract honeypots in the future. This answers the second question posed in this section.
5.4. Component Evaluation
To evaluate the effectiveness of the static analysis engine module, the hybrid fuzzing testing module, and the taint-based seed optimization module in improving the performance of SCH-Hunter, we conducted ablation experiments to separately test the impact of each of these three modules.
The static analysis engine module is responsible for handling and identifying three specific types of smart contract honeypot techniques: Unexecuted Call, Map Key Encoding Trick, and Hidden Transfers. These three smart contract honeypot techniques manipulate the source code of smart contracts in particular ways to make them appear to have corresponding fund leakage vulnerabilities, thereby luring victims into traps. The reason for using the static analysis engine to identify these three types of smart contract honeypots is that, for example, the Unexecuted Call technique initiates a fund transfer request using an incorrect calling method (e.g., call.value(x)), but the call will not execute as expected and, in fact, will never execute. Therefore, after the smart contract is compiled, the Ethereum Virtual Machine (EVM) does not compile this line of code. This is a characteristic of the EVM, meaning that this honeypot trap does not reveal any features during fuzzing, thus making it undetectable without static analysis.
To demonstrate the impact of the static analysis engine module on SCH-Hunter’s ability to detect these three types of smart contract honeypots, we disable the static analysis engine module, referring to it as SCH-Hunter-NS, and compare its detection capability against the full version of SCH-Hunter when identifying these three specific honeypot techniques.
Table 7 presents the comparison results between SCH-Hunter-NS and SCH-Hunter. It can be observed that when the static analysis engine module is disabled, relying solely on the fuzzing engine module to detect these three types of smart contract honeypot techniques yields no detection results, i.e., a complete failure to detect them. This is because, during the actual execution of smart contracts, the features of these three smart contract honeypot techniques are completely erased from the bytecode by the Ethereum Virtual Machine (EVM). Therefore, although the fuzzing engine performs well, it remains ineffective when dealing with source-level features.
Table 7.
Specific smart contract honeypot techniques detected by SCH-Hunter-NS and SCH-Hunter.
From the above, it can be concluded that the static analysis engine module enhances the smart contract honeypot detection capability and scope of SCH-Hunter, enabling it to more accurately detect a wider range of smart contract honeypots. This demonstrates that the static analysis engine module proposed in this framework is effective. Also, it is important to note that, for the Unexecuted-Transfer-type smart contract honeypots, SCH-Hunter exhibits two false negatives. This is because the Solidity compiler version for these two smart contracts is 0.5x, which the current static analysis engine does not support, as it only supports Solidity compiler version 0.4x.
To verify the effectiveness of the hybrid fuzzing module and the taint-based seed optimization module in enhancing SCH-Hunter’s performance, we use code coverage as the evaluation metric, which both of these modules contribute positively to the improvement of code coverage. We compare SCH-Hunter with SCH-Hunter-NTS, which is a fuzzing framework using a genetic algorithm based solely on traditional random mutation, without the hybrid fuzzing or taint-guided mutation strategy. The experiment first uses the smart contract honeypot dataset as the test dataset. The comparison is made based on the improvement in average code coverage after the same number of fuzzing testing iterations. Figure 7 presents the comparison results of code coverage between SCH-Hunter and SCH-Hunter-NTS.
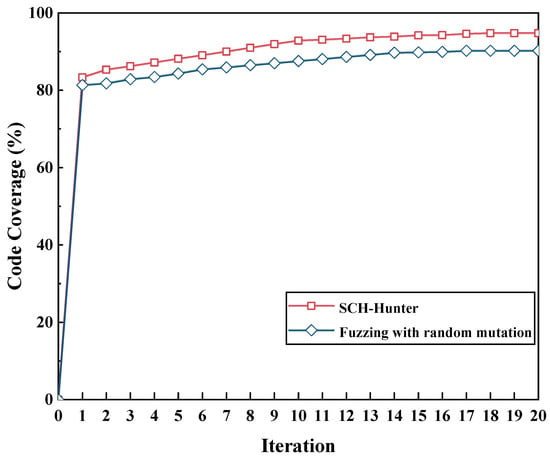
Figure 7.
Code coverage comparision between SCH-Hunter and SCH-Hunter-NTS on the Smart Contract Honeypot Dataset.
In Figure 7, the x-axis represents the number of iterations during the fuzzing process, while the y-axis shows the average code coverage. It can be observed that, when conducting fuzzing on the smart contract honeypot dataset, there is no significant difference in the code coverage or the speed of improvement between the two frameworks for the same number of iterations. This could be attributed to the fact that smart contract honeypots generally have small codebases with low complexity, allowing the fuzzing method based solely on a traditional fully random mutation genetic algorithm to quickly achieve good code coverage. The code coverage of SCH-Hunter stabilizes after the 11th iteration, while SCH-Hunter-NTS stabilizes after the 15th iteration. Thanks to the assistance of the symbolic execution module and the taint-based seed optimization module in the hybrid fuzzing framework, SCH-Hunter demonstrates superior performance in improving both code coverage and detection efficiency.
In addition, we also conducted comparative experiments on the long smart contract dataset, as observed in Figure 8. When dealing with smart contracts with higher code complexity and larger code sizes, SCH-Hunter’s hybrid fuzzing framework and taint-based seed optimization module show significant advantages in improving code coverage. By combining symbolic execution, SCH-Hunter can quickly activate the symbolic execution module when generating test cases that meet the conditions becomes challenging within a short time. It extracts complex conditions’ constraints and solves them, avoiding the symbolic path explosion issue that may arise from relying solely on symbolic execution. Moreover, by continuously monitoring the propagation of tainted data and taint flow information, SCH-Hunter can capture critical taint information, dynamically adjusting the mutation resource allocation weights, making the seed mutation process more focused on high-value code areas, such as vulnerable code paths and conditional branch paths, and continue to explore deeper. The synergy of these two methods ensures that even when dealing with smart contracts with high code complexity or large codebases, SCH-Hunter can still maintain excellent code coverage and high detection efficiency.
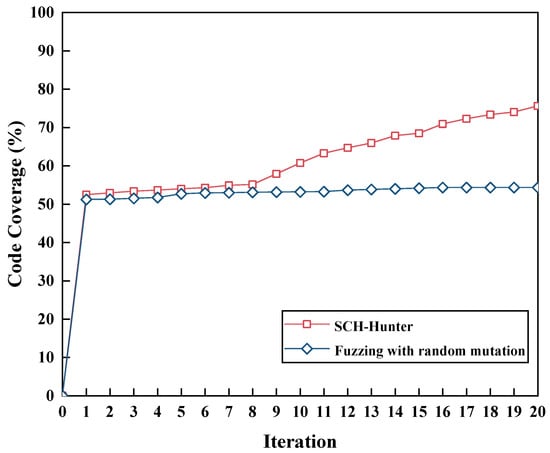
Figure 8.
Code coverage comparision between SCH-Hunter and SCH-Hunter-NTS on the Long Smart Contract Dataset.
To evaluate the effectiveness of the taint-based seed optimization in improving the detection efficiency of SCH-Hunter, we used average detection time as the primary metric. This is because the optimization module is designed to provide a positive feedback loop by reducing the time required for smart contract analysis.
We conducted a benchmark comparison between SCH-Hunter and its variant, SCH-Hunter-NTA, which employs a genetic algorithm with purely random mutations within the valid input domain without taint guidance. The evaluation was performed on Dataset II, which was composed of long smart contracts; we used this dataset because of its larger codebase and greater complexity, which make it more suitable for demonstrating the efficiency gains brought by this optimization module.
Figure 9 illustrates the comparison of average detection times between SCH-Hunter and SCH-Hunter-NTA. In the figure, the x-axis represents the number of iterations during the fuzzing process, while the y-axis indicates the corresponding average detection time.
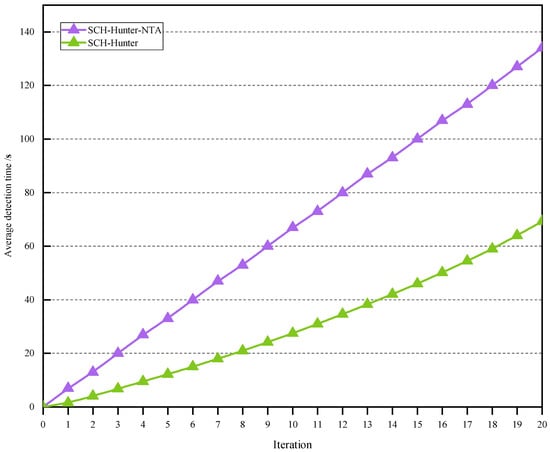
Figure 9.
Average detection time comparision between SCH-Hunter and SCH-Hunter-NTA on the Long Smart Contract Dataset.
As shown in Figure 9, SCH-Hunter is able to complete 20 iterations in approximately 70 s, whereas SCH-Hunter-NTA requires around 135 s to complete the same number of iterations. This result highlights that by continuously monitoring taint data propagation and taint flow information, SCH-Hunter can capture critical taint points and dynamically adjust the mutation resource allocation weights, allowing the mutation process to converge toward high-value code areas, such as vulnerable execution paths and conditional branches.
This strategy significantly reduces the number of ineffective mutations and resource consumption, resulting in faster detection times. Overall, the results demonstrate that SCH-Hunter achieves superior detection efficiency through its taint-guided optimization mechanism.
In conclusion, the modules proposed in this framework have a positive feedback effect on the detection framework itself, and they effectively improve both the code coverage and detection efficiency, which answers the third question of this section.
6. Conclusions
In this paper, we propose a novel hybrid fuzzing framework for smart contract honeypot detection based on taint analysis techniques, and implement a corresponding prototype tool called SCH-Hunter. SCH-Hunter provides solutions to the key technical challenges in smart contract honeypot detection: to address the issue of semantic loss in bytecode, a source-code-level static analysis engine is introduced to accurately identify three types of smart contract honeypots—Unexecuted Call, Map Key Encoding, and Hidden Transfers. An adaptive transaction sequence construction strategy based on the RAW principle is proposed, which generates transaction sequences with a high probability of triggering honeypot traps through control flow and data flow analysis, thereby enhancing the framework’s honeypot trap discovery capability. A hybrid fuzzing engine is developed, which dynamically switches between fuzzing and symbolic execution to overcome the path exploration bottleneck of complex conditional branches. A taint-analysis-guided genetic algorithm seed mutation optimization strategy is proposed, which dynamically optimizes mutation priorities based on the taint propagation weight of sensitive instructions, improving detection efficiency and code coverage. Additionally, a smart contract honeypot detection module based on real-time code instrumentation at the EVM runtime is designed and implemented, integrating ten types of honeypot detection algorithms, significantly expanding the types of smart contract honeypots that the framework can detect. By combining these multi-level methods, the framework achieves a synergistic optimization of detection accuracy, efficiency, and code coverage.
Author Contributions
Conceptualization, H.Z. and B.W.; methodology, H.Z.; data curation, H.Z.; validation, H.Z., B.W. and W.F.; review & editing, L.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data included in this study are available upon request by contact with the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CFG | Control Flow Graph |
| AST | Abstract Syntax Tree |
| GA | Genetic Algorithms |
References
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2008. Available online: https://ssrn.com/abstract=3440802 (accessed on 22 August 2019).
- Zou, W.; Lo, D.; Kochhar, P.S.; Le, X.B.D.; Xia, X.; Feng, Y.; Chen, Z.; Xu, B. Smart contract development: Challenges and opportunities. IEEE Trans. Softw. Eng. 2019, 47, 2084–2106. [Google Scholar] [CrossRef]
- Von Haller Gronbaek, M. Blockchain 2.0, smart contracts and challenges. Comput. Law SCL Mag. 2016, 1, 1–5. [Google Scholar]
- Szabo, N. Smart Contracts. 1994. Available online: http://www.fon.hum.uva.nl/rob/Courses/InformationInSpeech/CDROM/Literature/LOTwinterschool2006/szabo.best.vwh.net/smart.contracts.html (accessed on 22 August 2024).
- Treleaven, P.; Brown, R.G.; Yang, D. Blockchain technology in finance. Computer 2017, 50, 14–17. [Google Scholar] [CrossRef]
- Lin, S.Y.; Zhang, L.; Li, J.; Ji, L.l.; Sun, Y. A survey of application research based on blockchain smart contract. Wirel. Netw. 2022, 28, 635–690. [Google Scholar] [CrossRef]
- Mehar, M.I.; Shier, C.L.; Giambattista, A.; Gong, E.; Fletcher, G.; Sanayhie, R.; Kim, H.M.; Laskowski, M. Understanding a revolutionary and flawed grand experiment in blockchain: The DAO attack. J. Cases Inf. Technol. (JCIT) 2019, 21, 19–32. [Google Scholar] [CrossRef]
- He, Y.; Dong, H.; Wu, H.; Duan, Q. Formal analysis of reentrancy vulnerabilities in smart contract based on CPN. Electronics 2023, 12, 2152. [Google Scholar] [CrossRef]
- Torres, C.F.; Steichen, M.; State, R. The art of the scam: Demystifying honeypots in ethereum smart contracts. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 1591–1607. [Google Scholar]
- Chu, H.; Zhang, P.; Dong, H.; Xiao, Y.; Ji, S.; Li, W. A survey on smart contract vulnerabilities: Data sources, detection and repair. Inf. Softw. Technol. 2023, 159, 107221. [Google Scholar] [CrossRef]
- Camino, R.; Torres, C.F.; Baden, M.; State, R. A data science approach for honeypot detection in ethereum. arXiv 2019, arXiv:1910.01449. [Google Scholar]
- Chen, W.; Guo, X.; Chen, Z.; Zheng, Z.; Lu, Y.; Li, Y. Honeypot contract risk warning on ethereum smart contracts. In Proceedings of the 2020 IEEE International Conference on Joint Cloud Computing, Oxford, UK, 3–6 August 2020; pp. 1–8. [Google Scholar]
- Manes, V.J.; Han, H.; Han, C.; Cha, S.K.; Egele, M.; Schwartz, E.J.; Woo, M. Fuzzing: Art, science, and engineering. arXiv 2018, arXiv:1812.00140. [Google Scholar]
- Li, J.; Zhao, B.; Zhang, C. Fuzzing: A survey. Cybersecurity 2018, 1, 6. [Google Scholar] [CrossRef]
- Böhme, M.; Pham, V.T.; Nguyen, M.D.; Roychoudhury, A. Directed greybox fuzzing. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 2329–2344. [Google Scholar]
- Aschermann, C.; Schumilo, S.; Blazytko, T.; Gawlik, R.; Holz, T. REDQUEEN: Fuzzing with Input-to-State Correspondence. In Proceedings of the NDSS Symposium 2019, San Diego, CA, USA, 24–27 February 2019; Volume 19, pp. 1–15. [Google Scholar]
- Hirai, Y. Formal Verification of Deed Contract in Ethereum Name Service. November 2016. Available online: https://yoichihirai.com/deed.pdf (accessed on 22 August 2024).
- Bhargavan, K.; Delignat-Lavaud, A.; Fournet, C.; Gollamudi, A.; Gonthier, G.; Kobeissi, N.; Kulatova, N.; Rastogi, A.; Sibut-Pinote, T.; Swamy, N.; et al. Formal verification of smart contracts: Short paper. In Proceedings of the 2016 ACM Workshop on Programming Languages and Analysis for Security, Vienna, Austria, 24 October 2016; pp. 91–96. [Google Scholar]
- Hildenbrandt, E.; Saxena, M.; Rodrigues, N.; Zhu, X.; Daian, P.; Guth, D.; Moore, B.; Park, D.; Zhang, Y.; Stefanescu, A.; et al. Kevm: A complete formal semantics of the ethereum virtual machine. In Proceedings of the 2018 IEEE 31st Computer Security Foundations Symposium (CSF), Oxford, UK, 9–12 July 2018; pp. 204–217. [Google Scholar]
- Luu, L.; Chu, D.H.; Olickel, H.; Saxena, P.; Hobor, A. Making smart contracts smarter. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 254–269. [Google Scholar]
- Feist, J.; Grieco, G.; Groce, A. Slither: A static analysis framework for smart contracts. In Proceedings of the 2019 IEEE/ACM 2nd International Workshop on Emerging Trends in Software Engineering for Blockchain (WETSEB), Montreal, QC, Canada, 27 May 2019; pp. 8–15. [Google Scholar]
- Jiang, B.; Liu, Y.; Chan, W.K. Contractfuzzer: Fuzzing smart contracts for vulnerability detection. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 259–269. [Google Scholar]
- Wüstholz, V.; Christakis, M. Harvey: A greybox fuzzer for smart contracts. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, USA, 8–13 November 2020; pp. 1398–1409. [Google Scholar]
- Liu, C.; Liu, H.; Cao, Z.; Chen, Z.; Chen, B.; Roscoe, B. Reguard: Finding reentrancy bugs in smart contracts. In Proceedings of the 40th International Conference on Software Engineering: Companion, Gothenburg, Sweden, 27 May–3 June 2018; pp. 65–68. [Google Scholar]
- He, J.; Balunović, M.; Ambroladze, N.; Tsankov, P.; Vechev, M. Learning to fuzz from symbolic execution with application to smart contracts. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 531–548. [Google Scholar]
- Nguyen, T.D.; Pham, L.H.; Sun, J.; Lin, Y.; Minh, Q.T. sfuzz: An efficient adaptive fuzzer for solidity smart contracts. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, Seoul, Republic of Korea, 27 June–19 July 2020; pp. 778–788. [Google Scholar]
- Shou, C.; Tan, S.; Sen, K. Ityfuzz: Snapshot-based fuzzer for smart contract. In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, Seattle, WA, USA, 17–21 July 2023; pp. 322–333. [Google Scholar]
- Ji, T.; Fang, B.; Cui, X.; Wang, Z.; Liao, P.; Du, C.; Song, S. CADetector: Cross-family anisotropic contract honeypot detection method. Chin. J. Comput. 2022, 45, 877–895. [Google Scholar]
- Hu, H.; Bai, Q.; Xu, Y. Scsguard: Deep scam detection for ethereum smart contracts. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), New York, NY, USA, 2–5 May 2022; pp. 1–6. [Google Scholar]
- Sabelfeld, A.; Myers, A.C. Language-based information-flow security. IEEE J. Sel. Areas Commun. 2003, 21, 5–19. [Google Scholar] [CrossRef]
- Ghaleb, A.; Rubin, J.; Pattabiraman, K. eTainter: Detecting gas-related vulnerabilities in smart contracts. In Proceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual, Republic of Korea, 18–22 July 2022; pp. 728–739. [Google Scholar]
- Qin, S.J.; Liu, Z.; Ren, F.; Tan, C. Smart contract vulnerability detection based on critical combination path and deep learning. In Proceedings of the 2022 12th International Conference on Communication and Network Security, Beijing, China, 1–3 December 2022; pp. 219–226. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).