
Review and Mapping of Search-Based Approaches for Program Synthesis



Abstract
1. Introduction
2. Background and Related Work
2.1. Program Synthesis in Automated Code Generation
- Code template generation automates the creation of code by using predefined structures with customisable placeholders. These templates act as blueprints, where placeholders (such as class names, variables, or parameters) are dynamically replaced with actual values based on user input or configuration files. This method is widely used in frameworks and tools that generate boilerplate code, such as web application scaffolding, API endpoints, or database models. While it speeds up development by eliminating repetitive tasks, it lacks flexibility for highly customised logic, requiring manual adjustments if the templates do not fully match the desired output. Common tools include Jinja2, Yeoman, and IDE-based snippet generators.
- Code repair focuses on identifying and fixing errors, inefficiencies, or vulnerabilities in existing code. It relies on static analysis, machine learning, or rule-based systems to detect issues—such as syntax errors, security flaws, or performance bottlenecks—and then suggests or automatically applies corrections. This approach is particularly useful in debugging, refactoring, and maintaining software, as it reduces manual effort while improving code quality. However, automated fixes can sometimes introduce new bugs if the repair logic is flawed or if the system misinterprets the developer’s intent. Tools like GitHub Copilot (https://github.com/features/copilot), SonarQube (https://www.sonarsource.com/sem/products/sonarqube/), and linters with autofix capabilities (e.g., ESLint for JavaScript) employ this technique.
- Program synthesis generates executable code from high-level specifications, such as input–output examples, natural language descriptions, or formal constraints. Instead of relying on predefined templates, it uses techniques like symbolic reasoning, search algorithms, or machine learning to derive code that meets the given requirements. This method is powerful for creating complex logic from minimal instructions, making it useful for tasks like algorithm design. The nature of user specifications varies across different techniques, with search-based algorithms (e.g., evolutionary approaches) often leveraging input–output test cases and LLMs generating code based on prompts expressed in natural language. Emerging tools, including Microsoft PROSE and OpenAI Codex, demonstrate their potential, though program synthesis remains less mature than template-based or repair-based approaches.
2.2. Search-Based Program Synthesis
2.3. Reviews Related to Search-Based Program Synthesis
2.4. LLM-Based Program Synthesis
3. Methodology
3.1. Definition of Research Questions
- RQ1: What are the main techniques and trends in SBPS?
- RQ2: What are the guiding principles of SBPS algorithms?
- –
- RQ2.1: What type of user intent/input is used to guide the SBPS search process?
- –
- RQ2.2: What search space representation is used by SBPS algorithms?
- RQ3: What are the types of programming tasks targeted by each SBPS algorithm?
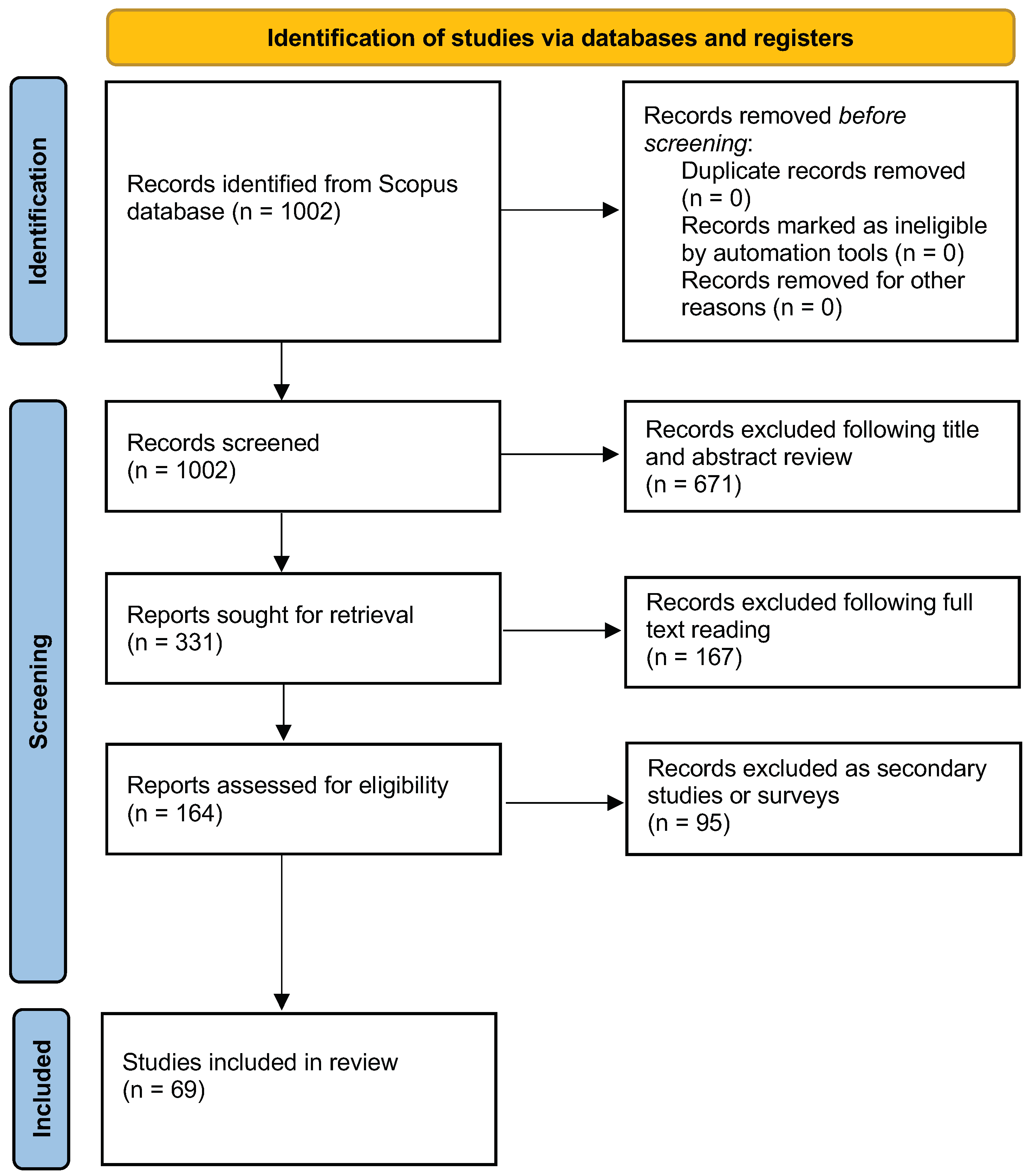
3.2. Search for Relevant Papers

3.3. Paper Screening and Selection
4. Analysis
4.1. Main SBPS Techniques and Trends (RQ1)
- Uninformed denotes an algorithmic approach that systematically explores a given search space in a predetermined order, devoid of any heuristic strategies or domain-specific knowledge. Such algorithms adhere to a straightforward exploration pattern, sequentially examining potential solutions without incorporating any informed guidance or optimisation criteria.
- Heuristic is an AI-based technique that is built for efficient search through large search spaces instead of using traditional exhaustive search methods. This type of algorithm often uses certain heuristics or rules to guide the search process towards the solution.
- Metaheuristic is a higher-level search strategy that is designed to find optimal solutions for a wider range of problems instead of focusing on one particular task. This type of algorithm is often inspired by natural phenomena or human behaviour to guide the search. Metaheuristics often guide the search process using an iterative process in an attempt to reach better solutions.
- Other encompasses search-based program synthesis algorithms that cannot be classified within the previously defined categories. For instance, our survey identified a subset of papers that employ a pre-built database search approach for iterative program synthesis. Notably, these algorithms do not adhere to standard search techniques, and we have grouped them under this distinct category.

4.2. Guiding Principles of SBPS Algorithms (RQ2)
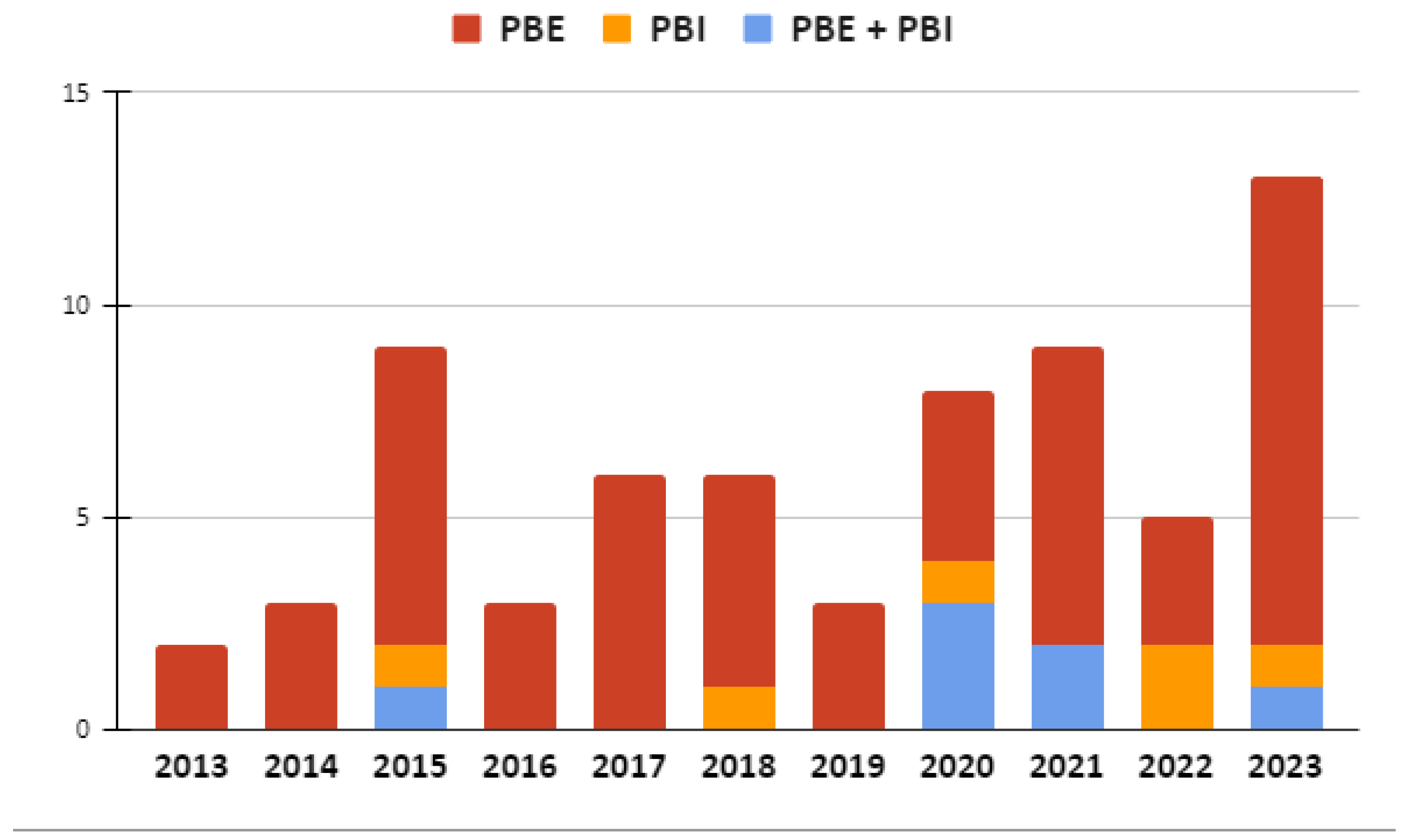
4.2.1. Analysis of SBPS Algorithm Input Type (RQ2.1)
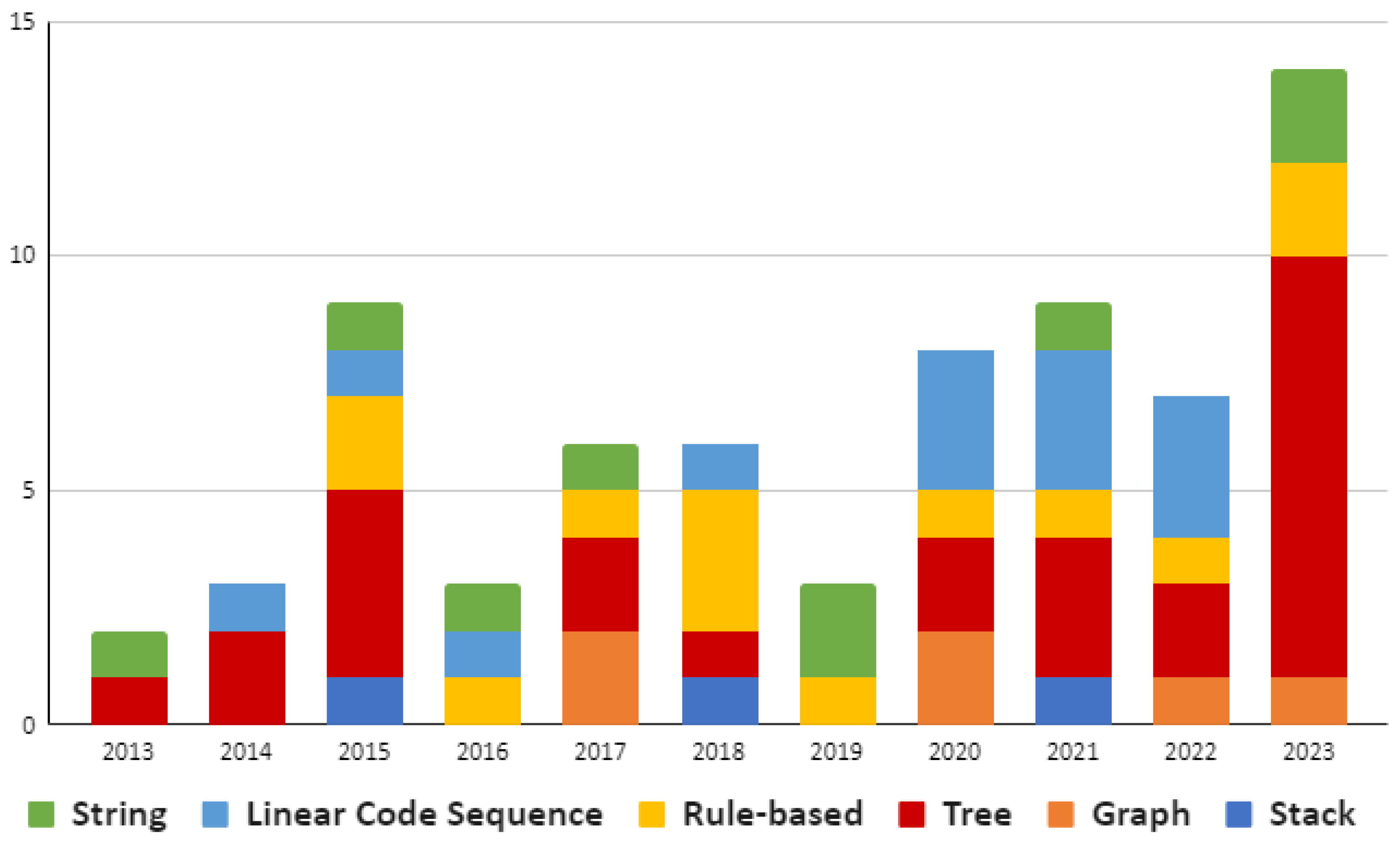
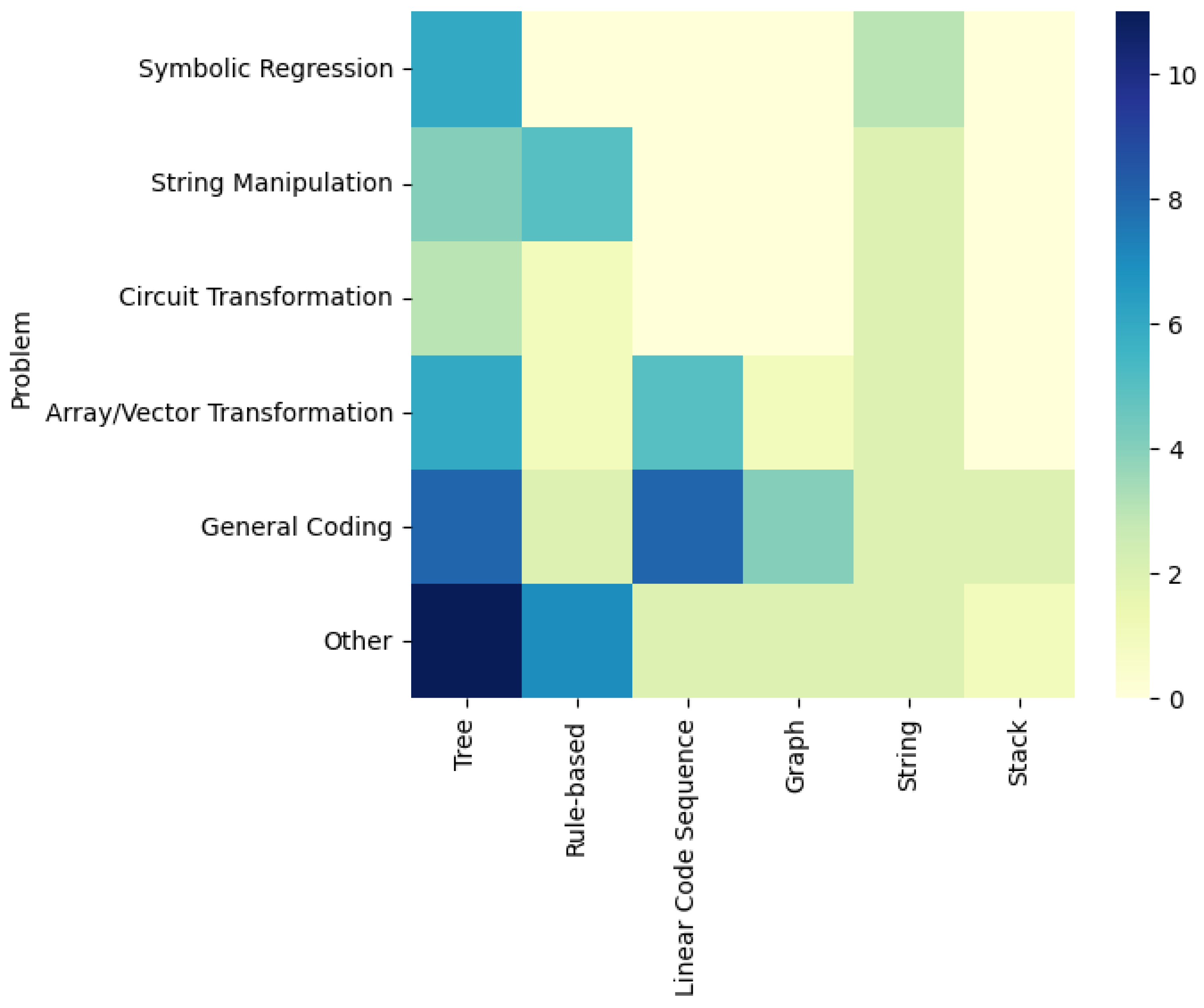
4.2.2. Representation of SBPS Search Space (RQ2.2)
- The most common approach for representing search space for the metaheuristic approaches is a tree representation, which was reported in 14 out of 33 publications.
- It is also the same for non-evolutionary metaheuristic approaches that tree representation is identified as the most used approach in this category.
- The representation type for heuristic algorithms are evenly distributed between trees, rule-based, linear code sequences and graphs. However, no selected paper reported a heuristic algorithm using string or stack representation.
- SBPS approaches using an uninformed search algorithm are more likely to use a tree- or rule-based representation. No paper has been reported using an uninformed search with graph, string, or stack representation.
- For the “Other” SBPS algorithms, linear code sequence is the only representation used to synthesise programs (all five studies in this category reported using linear code sequence as a representation method).
- Rule-based representation is mainly utilised in the uninformed search algorithms, while string and stack representations are utilised in the evolutionary metaheuristic approach.

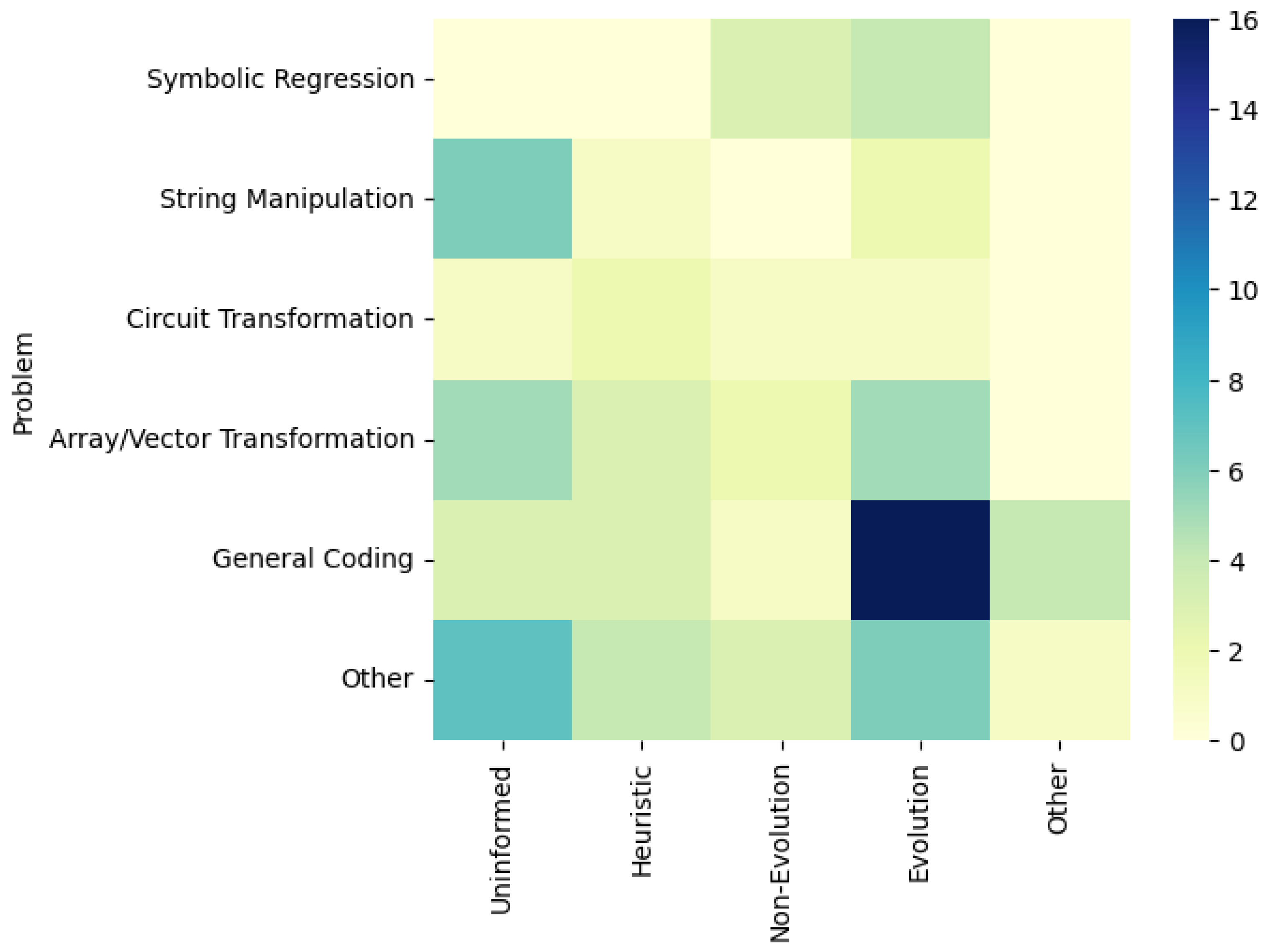
4.3. Type of Task Targeted by Each SBPS Algorithm (RQ3)
- Symbolic Regression: This type of problem aims to discover mathematical expressions or symbolic representations that model the relationship within a given dataset.
- String Manipulation: This involves the task of generating or transforming strings based on specific rules or requirements.
- Circuit Transformation: This problem type targets automatically modifying or optimising electronic circuits based on a digital specification of certain circuits.
- Array/Vector Transformation: Similar to other transformation tasks, this problem type aims to manipulate or transform elements within arrays or vectors.
- General Coding: This category of problem type generally aims to solve general coding tasks using high-level programming languages like Python, Java, etc.
- Others: In this problem type, we have collected relatively challenging real-world problems which cannot be included in previous categories.

5. Existing Challenge in SBPS
5.1. Bridging Theory and Practice
5.2. Advancing Algorithms: Tools, Strategies, and Evolution
5.3. Absence of a Common Benchmark
5.4. Computational Challenges in Search-Based Program Synthesis
6. Conclusions
- SBPS continues to attract an increasing and significant amount of novel work targeted various problems, from simple modification/manipulation problems to more challenging programming and real-world problems.
- Programming by example is the dominant way to guide the search of SBPS approaches, whereas Programming by Instruction has become popular recently.
- Approaches utilising evolutionary and uninformed search algorithms that leverage tree search spaces have been the most attractive in recent years, particularly the following:
- –
- Symbolic regression tasks are mostly tackled with metaheuristics, whereas string manipulation tasks are mostly tackled with uninformed algorithms. General coding tasks attracted a wide range of techniques; however, evolutionary methods are the most used.
- –
- Tree and string representations are utilised to tackle all kinds of problems, while linear code sequence and graph representations are utilised more for challenging problems.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hara, A.; Kushida, J.-i.; Tanabe, S.; Takahama, T. Parallel Ant Programming using genetic operators. In Proceedings of the 2013 IEEE 6th International Workshop on Computational Intelligence and Applications (IWCIA), Hiroshima, Japan, 13 July 2013; pp. 75–80. [Google Scholar]
- Nekoei, M.; Moghaddas, S.A.; Mohammadi Golafshani, E.; Gandomi, A.H. Introduction of ABCEP as an automatic programming method. Inf. Sci. 2021, 545, 575–594. [Google Scholar] [CrossRef]
- Hosseini Amini, S.M.H.; Abdollahi, M.; Amir Haeri, M. Rule-centred genetic programming (RCGP): An imperialist competitive approach. Appl. Intell. 2020, 50, 2589–2609. [Google Scholar] [CrossRef]
- Kim, H.T.; Kang, H.K.; Ahn, C.W. A Conditional Dependency Based Probabilistic Model Building Grammatical Evolution. IEICE Trans. Inf. Syst. 2016, E99.D, 1937–1940. [Google Scholar] [CrossRef]
- Mahanipour, A.; Nezamabadi-Pour, H. GSP: An automatic programming technique with gravitational search algorithm. Appl. Intell. 2019, 49, 1502–1516. [Google Scholar] [CrossRef]
- Lopes, R.L.; Costa, E. GEARNet: Grammatical Evolution with Artificial Regulatory Networks. In Proceedings of the 15th Annual Conference on Genetic and Evolutionary Computation, GECCO ’13, Kaohsiung, Taiwan, 6–8 October 2023; pp. 973–980. [Google Scholar]
- Bowers, M.; Olausson, T.X.; Wong, L.; Grand, G.; Tenenbaum, J.B.; Ellis, K.; Solar-Lezama, A. Top-Down Synthesis for Library Learning. Proc. ACM Program. Lang. 2023, 7, 1182–1213. [Google Scholar] [CrossRef]
- Lee, W.; Heo, K.; Alur, R.; Naik, M. Accelerating Search-Based Program Synthesis Using Learned Probabilistic Models. In Proceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2018, Philadelphia, PA, USA, 18–22 June 2018; pp. 436–449. [Google Scholar]
- Ameen, S.; Lelis, L.H. Program synthesis with best-first bottom-up search. J. Artif. Intell. Res. 2023, 77, 1275–1310. [Google Scholar] [CrossRef]
- Guria, S.N.; Foster, J.S.; Van Horn, D. Absynthe: Abstract Interpretation-Guided Synthesis. Proc. ACM Program. Lang. 2023, 7, 1584–1607. [Google Scholar] [CrossRef]
- Yuan, Y.; Banzhaf, W. Iterative genetic improvement: Scaling stochastic program synthesis. Artif. Intell. 2023, 322, 103962. [Google Scholar] [CrossRef]
- Miltner, A.; Fisher, K.; Pierce, B.C.; Walker, D.; Zdancewic, S. Synthesizing Bijective Lenses. Proc. ACM Program. Lang. 2017, 2, 1–30. [Google Scholar] [CrossRef]
- Valizadeh, M.; Berger, M. Search-Based Regular Expression Inference on a GPU. Proc. ACM Program. Lang. 2023, 7, 1317–1339. [Google Scholar] [CrossRef]
- Helmuth, T.; Frazier, J.G.; Shi, Y.; Abdelrehim, A.F. Human-Driven Genetic Programming for Program Synthesis: A Prototype. In Proceedings of the Companion Conference on Genetic and Evolutionary Computation, GECCO ’23 Companion, Lisbon, Portugal, 15–19 July 2023; pp. 1981–1989. [Google Scholar]
- Cropper, A.; Dumančić, S. Learning large logic programs by going beyond entailment. arXiv 2020, arXiv:2004.09855. [Google Scholar]
- Arcuri, A.; Yao, X. Co-evolutionary automatic programming for software development. Inf. Sci. 2014, 259, 412–432. [Google Scholar] [CrossRef]
- Botelho Guerra, H.; Ferreira, J.F.; Costa Seco, J. Hoogle: Constants and Lambda-abstractions in Petri-net-based Synthesis using Symbolic Execution. In Leibniz International Proceedings in Informatics (LIPIcs), Proceedings of the 37th European Conference on Object-Oriented Programming (ECOOP 2023), Seattle, WA, USA, 17–21 July 2023; Ali, K., Salvaneschi, G., Eds.; Dagstuhl: Wadern, Germany, 2023; Volume 263, pp. 4:1–4:28. [Google Scholar]
- Tao, N.; Ventresque, A.; Saber, T. Program synthesis with generative pre-trained transformers and grammar-guided genetic programming grammar. In Proceedings of the 2023 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Recife-Pe, Brazil, 29 October–1 November 2023; pp. 1–6. [Google Scholar]
- Tao, N.; Ventresque, A.; Saber, T. Assessing similarity-based grammar-guided genetic programming approaches for program synthesis. In Proceedings of the OLA, Syracuse, Italy, 18–20 July 2022; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Tao, N.; Ventresque, A.; Saber, T. Many-objective Grammar-guided Genetic Programming with Code Similarity Measurement for Program Synthesis. In Proceedings of the 2023 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Recife-Pe, Brazil, 29 October–1 November 2023. [Google Scholar]
- Tao, N.; Ventresque, A.; Saber, T. Multi-objective Grammar-guided Genetic Programming with Code Similarity Measurement for Program Synthesis. In Proceedings of the 2022 IEEE Congress on Evolutionary Computation (CEC), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Saha, R.K.; Ura, A.; Mahajan, S.; Zhu, C.; Li, L.; Hu, Y.; Yoshida, H.; Khurshid, S.; Prasad, M.R. SapientML: Synthesizing Machine Learning Pipelines by Learning from Human-Writen Solutions. In Proceedings of the 44th International Conference on Software Engineering, ICSE ’22, Pittsburgh, PA, USA, 25–27 May 2022; pp. 1932–1944. [Google Scholar]
- Poliansky, R.; Sipper, M.; Elyasaf, A. From Requirements to Source Code: Evolution of Behavioral Programs. Appl. Sci. 2022, 12, 1587. [Google Scholar] [CrossRef]
- Beltramelli, T. pix2code: Generating code from a graphical user interface screenshot. In Proceedings of the ACM SIGCHI Symposium on Engineering Interactive Computing Systems, Paris, France, 19–22 June 2018; pp. 1–6. [Google Scholar]
- Li, Y.; Choi, D.; Chung, J.; Kushman, N.; Schrittwieser, J.; Leblond, R.; Eccles, T.; Keeling, J.; Gimeno, F.; Dal Lago, A.; et al. Competition-Level Code Generation with AlphaCode. Science 2022, 378, 1092–1097. [Google Scholar] [CrossRef]
- Jesse, K.; Ahmed, T.; Devanbu, P.T.; Morgan, E. Large language models and simple, stupid bugs. In Proceedings of the 2023 IEEE/ACM 20th International Conference on Mining Software Repositories (MSR), Melbourne, Australia, 15–16 May 2023; pp. 563–575. [Google Scholar]
- Asare, O.; Nagappan, M.; Asokan, N. Is github’s copilot as bad as humans at introducing vulnerabilities in code? Empir. Softw. Eng. 2023, 28, 129. [Google Scholar] [CrossRef]
- Schuster, R.; Song, C.; Tromer, E.; Shmatikov, V. You autocomplete me: Poisoning vulnerabilities in neural code completion. In Proceedings of the USENIX Security 21, Virtual, 11–13 August 2021; pp. 1559–1575. [Google Scholar]
- Stechly, K.; Marquez, M.; Kambhampati, S. GPT-4 Doesn’t Know It’s Wrong: An Analysis of Iterative Prompting for Reasoning Problems. arXiv 2023, arXiv:2310.12397. [Google Scholar]
- Krishna, S.; Agarwal, C.; Lakkaraju, H. Understanding the Effects of Iterative Prompting on Truthfulness. arXiv 2024, arXiv:2402.06625. [Google Scholar]
- Pinna, G.; Ravalico, D.; Rovito, L.; Manzoni, L.; De Lorenzo, A. Enhancing Large Language Models-Based Code Generation by Leveraging Genetic Improvement. In Proceedings of the European Conference on Genetic Programming (Part of EvoStar), Aberystwyth, UK, 3–5 April 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 108–124. [Google Scholar]
- Hemberg, E.; Moskal, S.; O’Reilly, U.M. Evolving Code with A Large Language Model. arXiv 2024, arXiv:2401.07102. [Google Scholar] [CrossRef]
- Hemberg, E.; Jorgensen, S.; O’Reilly, U.M. Survey of Genetic Programming and Large Language Models. In Genetic Programming Theory and Practice XXI; Springer: Berlin/Heidelberg, Germany, 2025; pp. 67–86. [Google Scholar]
- Tao, N.; Ventresque, A.; Nallur, V.; Saber, T. Grammar-obeying program synthesis: A novel approach using large language models and many-objective genetic programming. Comput. Stand. Interfaces 2025, 92, 103938. [Google Scholar] [CrossRef]
- Tao, N.; Ventresque, A.; Nallur, V.; Saber, T. Enhancing Program Synthesis with Large Language Models Using Many-Objective Grammar-Guided Genetic Programming. Algorithms 2024, 17, 287. [Google Scholar] [CrossRef]
- Mittapalli, J.S.; Arthur, M.P. Survey on template engines in Java. ITM Web Conf. 2021, 37, 01007. [Google Scholar] [CrossRef]
- Monperrus, M. Automatic software repair: A bibliography. ACM Comput. Surv. (CSUR) 2018, 51, 1–24. [Google Scholar] [CrossRef]
- Sobania, D.; Schweim, D.; Rothlauf, F. A comprehensive survey on program synthesis with evolutionary algorithms. IEEE Trans. Evol. Comput. 2022, 27, 82–97. [Google Scholar] [CrossRef]
- Batouta, Z.I.; Dehbi, R.; Talea, M.; Hajoui, O. Automation in code generation: Tertiary and systematic mapping review. In Proceedings of the 2016 4th IEEE International Colloquium on Information Science and Technology (CiSt), Tangier, Morocco, 24–26 October 2016; pp. 200–205. [Google Scholar]
- Helmuth, T.; Spector, L. General program synthesis benchmark suite. In Proceedings of the GECCO 2015, Madrid, Spain, 11–15 July 2015. [Google Scholar]
- Olmo, J.L.; Romero, J.R.; Ventura, S. Swarm-based metaheuristics in automatic programming: A survey. WIREs Data Min. Knowl. Discov. 2014, 4, 445–469. [Google Scholar] [CrossRef]
- Bodík, R.; Jobstmann, B. Algorithmic program synthesis: Introduction. Int. J. Softw. Tools Technol. Transf. 2013, 15, 397–411. [Google Scholar] [CrossRef]
- Gulwani, S.; Polozov, O.; Singh, R. Program synthesis. Found. Trends® Program. Lang. 2017, 4, 1–119. [Google Scholar] [CrossRef]
- Alur, R.; Singh, R.; Fisman, D.; Solar-Lezama, A. Search-based program synthesis. Commun. ACM 2018, 61, 84–93. [Google Scholar] [CrossRef]
- Hou, X.; Zhao, Y.; Liu, Y.; Yang, Z.; Wang, K.; Li, L.; Luo, X.; Lo, D.; Grundy, J.; Wang, H. Large language models for software engineering: A systematic literature review. ACM Trans. Softw. Eng. Methodol. 2024, 33, 1–79. [Google Scholar] [CrossRef]
- Hemmat, A.; Sharbaf, M.; Kolahdouz-Rahimi, S.; Lano, K.; Tehrani, S.Y. Research directions for using LLM in software requirement engineering: A systematic review. Front. Comput. Sci. 2025, 7, 1519437. [Google Scholar] [CrossRef]
- Chen, L.; Guo, Q.; Jia, H.; Zeng, Z.; Wang, X.; Xu, Y.; Wu, J.; Wang, Y.; Gao, Q.; Wang, J.; et al. A survey on evaluating large language models in code generation tasks. arXiv 2024, arXiv:2408.16498. [Google Scholar]
- Zhang, Z.; Saber, T. Machine Learning Approaches to Code Similarity Measurement: A Systematic Review. IEEE Access 2025, 13, 51729–51764. [Google Scholar] [CrossRef]
- Zhang, Z.; Saber, T. Exploring the Boundaries Between LLM Code Clone Detection and Code Similarity Assessment on Human and AI-Generated Code. Big Data Cogn. Comput. 2025, 9, 41. [Google Scholar] [CrossRef]
- Austin, J.; Odena, A.; Nye, M.; Bosma, M.; Michalewski, H.; Dohan, D.; Jiang, E.; Cai, C.; Terry, M.; Le, Q.; et al. Program synthesis with large language models. arXiv 2021, arXiv:2108.07732. [Google Scholar]
- Nijkamp, E.; Pang, B.; Hayashi, H.; Tu, L.; Wang, H.; Zhou, Y.; Savarese, S.; Xiong, C. Codegen: An open large language model for code with multi-turn program synthesis. arXiv 2022, arXiv:2203.13474. [Google Scholar]
- Li, Y.; Parsert, J.; Polgreen, E. Guiding enumerative program synthesis with large language models. In Proceedings of the International Conference on Computer Aided Verification, Montreal, QC, Canada, 24–27 July 2024; pp. 280–301. [Google Scholar]
- Sobania, D.; Briesch, M.; Rothlauf, F. Choose your programming copilot: A comparison of the program synthesis performance of github copilot and genetic programming. In Proceedings of the GECCO 2022, Boston, MA, USA, 9–13 July 2022. [Google Scholar]
- Wang, B.; Wang, Z.; Wang, X.; Cao, Y.; A Saurous, R.; Kim, Y. Grammar prompting for domain-specific language generation with large language models. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar]
- Heule, S.; Sridharan, M.; Chandra, S. Mimic: Computing Models for Opaque Code. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, ESEC/FSE 2015, Bergamo, Italy, 30 August–4 September 2015; pp. 710–720. [Google Scholar]
- Polozov, O.; Gulwani, S. FlashMeta: A Framework for Inductive Program Synthesis. In Proceedings of the 2015 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications, OOPSLA 2015, Portland, OR, USA, 13–14 June 2015; pp. 107–126. [Google Scholar]
- Zhang, T.; Chen, Z.; Zhu, Y.; Vaithilingam, P.; Wang, X.; Glassman, E.L. Interpretable program synthesis. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Online, 8–13 May 2021; pp. 1–16. [Google Scholar]
- Feng, Y.; Martins, R.; Van Geffen, J.; Dillig, I.; Chaudhuri, S. Component-based synthesis of table consolidation and transformation tasks from examples. SIGPLAN Not. 2017, 52, 422–436. [Google Scholar] [CrossRef]
- Feser, J.K.; Chaudhuri, S.; Dillig, I. Synthesizing data structure transformations from input-output examples. SIGPLAN Not. 2015, 50, 229–239. [Google Scholar] [CrossRef]
- Polikarpova, N.; Kuraj, I.; Solar-Lezama, A. Program synthesis from polymorphic refinement types. SIGPLAN Not. 2016, 51, 522–538. [Google Scholar] [CrossRef]
- Chen, H.; Wu, C.; Zhao, A.; Raghothaman, M.; Naik, M.; Loo, B.T. Synthesizing Formal Network Specifications From Input-Output Examples. IEEE/ACM Trans. Netw. 2023, 31, 994–1009. [Google Scholar] [CrossRef]
- Ye, X.; Chen, Q.; Dillig, I.; Durrett, G. Optimal neural program synthesis from multimodal specifications. arXiv 2020, arXiv:2010.01678. [Google Scholar]
- Barke, S.; Peleg, H.; Polikarpova, N. Just-in-time learning for bottom-up enumerative synthesis. Proc. ACM Program. Lang. 2020, 4, 1–29. [Google Scholar] [CrossRef]
- Ren, H.; Mo, W.; Zhao, G.; Ren, D.; Liu, S. Breadth First Search Based COSINE Software Code Framework Automation Algorithm. In Proceedings of the ASME Power Conference, Baltimore, MD, USA, 28–31 July 2014; American Society of Mechanical Engineers: New York, NY, USA, 2015; Volume 56604, p. V001T07A003. [Google Scholar]
- Jin, Z.; Anderson, M.R.; Cafarella, M.; Jagadish, H.V. Foofah: Transforming Data By Example. In Proceedings of the SIGMOD ’17: 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 683–698. [Google Scholar]
- Jin, Z.; Anderson, M.R.; Cafarella, M.; Jagadish, H.V. Foofah: A Programming-By-Example System for Synthesizing Data Transformation Programs. In Proceedings of the SIGMOD ’17: 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 1607–1610. [Google Scholar]
- Liu, B.B.; Dong, W.; Liu, J.X.; Zhang, Y.T.; Wang, D.Y. Prosy: Api-based synthesis with probabilistic model. J. Comput. Sci. Technol. 2020, 35, 1234–1257. [Google Scholar] [CrossRef]
- Wong, C.; Ellis, K.M.; Tenenbaum, J.; Andreas, J. Leveraging language to learn program abstractions and search heuristics. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 11193–11204. [Google Scholar]
- Yoon, Y.; Lee, W.; Yi, K. Inductive program synthesis via iterative forward-backward abstract interpretation. Proc. ACM Program. Lang. 2023, 7, 1657–1681. [Google Scholar] [CrossRef]
- Cropper, A. Learning logic programs though divide, constrain, and conquer. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; pp. 6446–6453. [Google Scholar]
- Chen, H.; Wang, A.; Loo, B.T. Towards Example-Guided Network Synthesis. In Proceedings of the 2nd Asia-Pacific APNet ’18, Workshop on Networking, Beijing, China, 1–3 August 2018; pp. 65–71. [Google Scholar]
- Cui, G.; Zhu, H. Differentiable synthesis of program architectures. Adv. Neural Inf. Process. Syst. 2021, 34, 11123–11135. [Google Scholar]
- Hua, J.; Khurshid, S. EdSketch: Execution-Driven Sketching for Java. In Proceedings of the 24th ACM SIGSOFT International SPIN Symposium on Model Checking of Software, SPIN 2017, Santa Barbara, CA, USA, 13–14 July 2017; pp. 162–171. [Google Scholar]
- Yuan, Y.; Radhakrishna, A.; Samanta, R. Trace-Guided Inductive Synthesis of Recursive Functional Programs. Proc. ACM Program. Lang. 2023, 7, 860–883. [Google Scholar] [CrossRef]
- Herrmann, M.; Mayer, C.; Radig, B. Automatic generation of image analysis programs. Pattern Recognit. Image Anal. 2014, 24, 400–408. [Google Scholar] [CrossRef]
- Osera, P.M.; Zdancewic, S. Type-and-example-directed program synthesis. SIGPLAN Not. 2015, 50, 619–630. [Google Scholar] [CrossRef]
- Nguyen, S.; Zhang, M.; Johnston, M.; Tan, K.C. Automatic Programming via Iterated Local Search for Dynamic Job Shop Scheduling. IEEE Trans. Cybern. 2015, 45, 1–14. [Google Scholar] [CrossRef]
- Rosin, C.D. Stepping stones to inductive synthesis of low-level looping programs. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 2362–2370. [Google Scholar]
- Bornholt, J.; Torlak, E.; Grossman, D.; Ceze, L. Optimizing Synthesis with Metasketches. In Proceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL ’16, St. Petersburg, FL, USA, 20–22 January 2016; pp. 775–788. [Google Scholar]
- Feser, J.; Dillig, I.; Solar-Lezama, A. Inductive Program Synthesis Guided by Observational Program Similarity. Proc. ACM Program. Lang. 2023, 7. [Google Scholar] [CrossRef]
- Golafshani, E.M. Introduction of Biogeography-Based Programming as a new algorithm for solving problems. Appl. Math. Comput. 2015, 270, 1–12. [Google Scholar] [CrossRef]
- Ahmad, H.; Helmuth, T. A Comparison of Semantic-Based Initialization Methods for Genetic Programming. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, GECCO ’18, Kyoto, Japan, 15–19 July 2018; pp. 1878–1881. [Google Scholar]
- Helmuth, T.; Kelly, P. PSB2: The second program synthesis benchmark suite. In Proceedings of the Genetic and Evolutionary Computation Conference, Lille, France, 10–14 July 2021; pp. 785–794. [Google Scholar]
- Schweim, D.; Hemberg, E.; Sobania, D.; O’Reilly, U.M.; Rothlauf, F. Using Knowledge of Human-Generated Code to Bias the Search in Program Synthesis with Grammatical Evolution. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, GECCO ’21, Lille, France, 10–14 July 2021; pp. 331–332. [Google Scholar]
- Chennpati, G.; Azad, R.M.A.; Ryan, C. On the Automatic Generation of Efficient Parallel Iterative Sorting Algorithms. In Proceedings of the Companion Publication of the 2015 Annual Conference on Genetic and Evolutionary Computation, GECCO Companion ’15, Madrid, Spain, 11–15 July 2015; pp. 1369–1370. [Google Scholar]
- Pantridge, E.; Helmuth, T.; Spector, L. Functional Code Building Genetic Programming. In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’22, Boston, MA, USA, 9–13 July 2022; pp. 1000–1008. [Google Scholar]
- Pantridge, E.; Helmuth, T. Solving Novel Program Synthesis Problems with Genetic Programming using Parametric Polymorphism. In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’23, Lisbon, Portugal, 15–19 July 2023; pp. 1175–1183. [Google Scholar]
- Pantridge, E.; Spector, L. Code Building Genetic Programming. In Proceedings of the 2020 Genetic and Evolutionary Computation Conference, GECCO ’20, Cancún, Mexico, 8–12 July 2020; pp. 994–1002. [Google Scholar]
- Igwe, K.; Pillay, N. Automatic programming using genetic programming. In Proceedings of the 2013 Third World Congress on Information and Communication Technologies (WICT 2013), Hanoi, Vietnam, 15–18 December 2013; pp. 337–342. [Google Scholar]
- Xu, M.; Mei, Y.; Zhang, F.; Zhang, M. Genetic Programming with Lexicase Selection for Large-scale Dynamic Flexible Job Shop Scheduling. IEEE Trans. Evol. Comput. 2023, 28, 1235–1249. [Google Scholar] [CrossRef]
- Fernandes, M.C.; de França, F.O.; Francesquini, E. HOTGP–Higher-Order Typed Genetic Programming. arXiv 2023, arXiv:2304.03200. [Google Scholar]
- Islam, M.; Kharma, N.N.; Grogono, P. Expansion: A Novel Mutation Operator for Genetic Programming. In Proceedings of the IJCCI, Seville, Spain, 18–20 September 2018; pp. 55–66. [Google Scholar]
- Krawiec, K.; Blkadek, I.; Swan, J. Counterexample-Driven Genetic Programming. In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’17, Berlin, Germany, 15–19 July 2017; pp. 953–960. [Google Scholar]
- Serruto, W.F.; Alfaro, L. Many-Objective Cooperative Co-evolutionary Linear Genetic Programming Applied to the Automatic Microcontroller Program Generation. Int. J. Adv. Comput. Sci. Appl. 2019, 10. [Google Scholar] [CrossRef]
- Correia, A.; Iyoda, J.; Mota, A. A family of multi-concept program synthesisers in Alloy*. Sci. Comput. Program. 2021, 201, 102536. [Google Scholar] [CrossRef]
- Correia, A.; Iyoda, J.; Mota, A. Combining model finder and genetic programming into a general purpose automatic program synthesizer. Inf. Process. Lett. 2020, 154, 105866. [Google Scholar] [CrossRef]
- Virgolin, M.; Alderliesten, T.; Witteveen, C.; Bosman, P.A.N. Scalable Genetic Programming by Gene-Pool Optimal Mixing and Input-Space Entropy-Based Building-Block Learning. In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’17, Berlin, Germany, 15–19 July 2017; pp. 1041–1048. [Google Scholar]
- Liventsev, V.; Härmä, A.; Petković, M. Neurogenetic programming framework for explainable reinforcement learning. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Lille, France, 10–14 July 2021; pp. 329–330. [Google Scholar]
- Fix, S.; Probst, T.; Ruggli, O.; Hanne, T.; Christen, P. Automatic Programming As An Open-Ended Evolutionary System. Int. J. Comput. Inf. Syst. Ind. Manag. Appl. 2022, 14, 204–212. [Google Scholar]
- Shimonaka, K.; Higo, Y.; Matsumoto, J.; Naito, K.; Kusumoto, S. Towards automated generation of Java methods: A way of automated reuse-based programming. In Proceedings of the 2018 IEEE 12th International Workshop on Software Clones (IWSC), Campobasso, Italy, 20 March 2018; pp. 30–36. [Google Scholar]
- Liu, J.; Dong, W.; Liu, B. Boosting Component-Based Synthesis with API Usage Knowledge. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering, ASE ’20, Virtual, 21–25 December 2020; pp. 91–97. [Google Scholar]
- Liu, J.; Liu, B.; Dong, W.; Zhang, Y.; Wang, D. How Much Support Can API Recommendation Methods Provide for Component-Based Synthesis? In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; pp. 872–881. [Google Scholar]
- Ryan, C.; Collins, J.J.; Neill, M.O. Grammatical evolution: Evolving programs for an arbitrary language. In Proceedings of the Genetic Programming: First European Workshop, EuroGP’98, Paris, France, 14–15 April 1998; Proceedings 1. pp. 83–96. [Google Scholar]
- Spector, L.; Robinson, A. Genetic programming and autoconstructive evolution with the push programming language. Genet. Program. Evolvable Mach. 2002, 3, 7–40. [Google Scholar] [CrossRef]
- Pantridge, E.; Spector, L. PyshGP: PushGP in python. In Proceedings of the GECCO 2017, Berlin, Germany, 15–19 July 2017. [Google Scholar]
- Feng, Y.; Martins, R.; Wang, Y.; Dillig, I.; Reps, T.W. Component-based synthesis for complex APIs. In Proceedings of the 44th ACM SIGPLAN Symposium on Principles of Programming Languages, Paris, France, 15–21 January 2017; pp. 599–612. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Description |
|---|---|
| Inclusion (IC1) | The work focuses on program synthesis using a search-based algorithm. |
| Exclusion (EC1) | The work is not written in English. |
| Exclusion (EC2) | The work was published before January 2013. |
| Exclusion (EC3) | The work is a secondary study. |
| Exclusion (EC4) | The work is a minor incremental improvement of the approach. |
| Category | Subcategories | Papers | Count | ||
|---|---|---|---|---|---|
| Uninformed | Random search | [55] | 1 | 16 | |
| Enumerative search | [10,13,56,57,58,59,60] | 7 | |||
| Best-first search | [9,15,61] | 3 | |||
| Depth-first search | [17] | 1 | |||
| Top-down search | [7,62] | 2 | |||
| Bottom-up search | [63] | 1 | |||
| Breadth-first search | [64] | 1 | |||
| Heuristic | A* search | [8,65,66] | 3 | 14 | |
| Probability-based search | [67] | 1 | |||
| Neurally guided search | [68] | 1 | |||
| Bidirectional search | [69] | 1 | |||
| Divide and conquer search | [70,71] | 2 | |||
| Gradient-descent search | [72] | 1 | |||
| Backtracking search | [73] | 1 | |||
| Lenses with priority queue | [12] | 1 | |||
| Trace-guided search | [74] | 1 | |||
| Expert rule tree search | [75] | 1 | |||
| Proof search | [76] | 1 | |||
| Metaheuristic | Local search | [77,78,79,80] | 4 | 34 | |
| Gravitational search | [5] | 1 | |||
| Swarm intelligence | [1,2] | 2 | |||
| Biogeography-based programming | [81] | 1 | |||
| Evolution | Push GP | [40,82,83] | 3 | ||
| Grammatical Evolution | [4,6,84,85] | 4 | |||
| Code-building GP | [86,87,88] | 3 | |||
| Tree-based GP | [3,21,89,90,91,92] | 6 | |||
| Counterexample-guided GP | [14,93] | 2 | |||
| Linear GP | [11,94] | 2 | |||
| GP combined with other technique | [16,23,95,96,97,98] | 6 | |||
| Other | Database-based iterative search | [22,99,100] | 3 | 5 | |
| API search | [101,102] | 2 | |||
| Representation | Count | Papers |
|---|---|---|
| Tree | 26 | [1,2,3,7,9,11,16,17,21,23,57,58,62,63,64,69,74,76,77,80,81,89,90,91,92,93] |
| Rule-based | 13 | [8,10,12,15,23,56,59,60,61,71,72,73,78] |
| Linear code sequence | 12 | [22,55,68,70,75,79,95,96,98,100,101,102] |
| Graph | 6 | [65,66,67,86,87,88] |
| String | 9 | [4,5,6,13,14,84,85,94,97] |
| Stack | 3 | [40,82,83] |
| Representation | Uninformed | Heuristic | Metaheuristic | Other | |
|---|---|---|---|---|---|
| Non-Evolution | Evolution | ||||
| Tree | [7,9,17,57,58,62,63,64] | [69,76] | [1,2,77,80] | [3,11,16,21,23,89,90,91,92,93] | |
| Rule-based | [10,15,56,59,60,61] | [8,72,73] | [78] | [23] | |
| Linear code sequence | [55] | [70,75] | [79] | [95,96,98] | [22,99,100,101,102] |
| Graph | [65,66,67] | [86,87,88] | |||
| String | [5] | [4,6,14,84,85,94,97] | |||
| Stack | [40,82,83] | ||||
| Problem Type | Dataset | Count | Papers | |
|---|---|---|---|---|
| Symbolic Regression | Custom Benchmark | 9 | [1,2,3,4,5,6,7,92,97] | |
| String Manipulation | SyGuS | 10 | 5 | [8,9,10,11,63] |
| Custom Benchmark | 5 | [12,13,14,15,62] | ||
| Circuit Transformation | SyGuS | 6 | 3 | [8,63,69] |
| Custom Benchmark | 3 | [1,4,94] | ||
| Array/Vector Transformation | OpenAI Gym toolkit | 18 | 1 | [98] |
| Sorting | 2 | [16,85] | ||
| SyGuS | 9 | [8,9,11,63,69,79] | ||
| Custom Benchmark | 6 | [17,59,60,76,95,97] | ||
| General Coding | Apache dataset (JAVA) | 29 | 1 | [100] |
| SyPet (JAVA) | 3 | [67,101,102] | ||
| PSB1 | 7 | [21,40,78,82,86,88,91] | ||
| PSB2 | 1 | [83] | ||
| Algebra Calculation | 6 | [14,16,17,93,95,96] | ||
| Computer Vision | 1 | [75] | ||
| Array.prototype (Java Script) | 1 | [55] | ||
| java.util(Java) | 1 | [73] | ||
| Custom Benchmark | 8 | [7,14,70,74,84,87,89,102] | ||
| Other | ASCII Art | 21 | 1 | [15] |
| Path Finding | 2 | [6,15] | ||
| ML Pipeline | 1 | [22] | ||
| Custom Real-World Problem | 4 | [3,4,71,72] | ||
| Game of Tic-Tac-Toe | 1 | [23] | ||
| Data Transformation | 5 | [10,58,59,65,66] | ||
| Job Shop Scheduling | 2 | [77,90] | ||
| User Study | 1 | [57] | ||
| Feature Construction | 1 | [5] | ||
| Network Analysis | 1 | [61] | ||
| Inverse Constructive Solid Geometry | 1 | [80] | ||
| Nuclear Power Software Development | 1 | [64] | ||
| Problem | Uninformed | Heuristic | Metaheuristic | Other | |
|---|---|---|---|---|---|
| Non-Evolution | Evolution | ||||
| Symbolic Regression | [1,2,5] | [3,4,6,92] | |||
| String Manipulation | [7,9,10,15,62,63] | [8] | [11,14] | ||
| Circuit Transformation | [63] | [8,69] | [1] | [4] | |
| Array/Vector Transformation | [9,17,59,60,63] | [8,69,76] | [78,79] | [11,16,85,95,98] | |
| General Coding | [7,17,55] | [67,70,73] | [78] | [14,16,21,40,82,83,84,86,87,88,89,91,93,95,96,97] | [99,100,101,102] |
| Other | [10,15,57,58,59,61,64] | [65,66,72,75] | [5,77,80] | [3,4,6,23,90,94] | [22] |
| Problem | Tree | Rule-Based | Linear Code Sequence | Graph | String | Stack |
|---|---|---|---|---|---|---|
| Symbolic Regression | [1,2,3,5,69,92] | [4,5,6] | ||||
| String Manipulation | [7,9,62,63] | [8,10,11,12,15] | [13,14] | |||
| Circuit Transformation | [1,63,69] | [8] | [4,94] | |||
| Array/Vector Transformation | [9,11,16,17,63,76] | [59] | [8,60,79,95,98] | [79] | [85,97] | |
| General Coding | [7,16,17,21,74,89,91,93] | [73,78] | [55,70,75,95,96,100,101,102] | [67,86,87,88] | [14,84] | [40,83] |
| Other | [3,4,5,15,23,57,58,64,77,80,90] | [15,23,59,61,71,72,78] | [22,70] | [65,66] | [5,6] | [82] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saber, T.; Tao, N. Review and Mapping of Search-Based Approaches for Program Synthesis. Information 2025, 16, 401. https://doi.org/10.3390/info16050401
Saber T, Tao N. Review and Mapping of Search-Based Approaches for Program Synthesis. Information. 2025; 16(5):401. https://doi.org/10.3390/info16050401
Chicago/Turabian StyleSaber, Takfarinas, and Ning Tao. 2025. "Review and Mapping of Search-Based Approaches for Program Synthesis" Information 16, no. 5: 401. https://doi.org/10.3390/info16050401
APA StyleSaber, T., & Tao, N. (2025). Review and Mapping of Search-Based Approaches for Program Synthesis. Information, 16(5), 401. https://doi.org/10.3390/info16050401