1. Introduction
Databases are the backbone of modern information systems, enabling efficient storage, retrieval and management of data. A key phase for relational databases is the conceptual modeling, where the entity-relationship (ER) model is widely used to represent the data structure and constraints before translating them into a logical relational schema by means of translation rules (i.e., the generation of tables using SQL). An ER schema represents information through three key constructs: (i)
entities, classes of objects with independent existence; (ii)
relationships, logical associations between entities; and (iii)
attributes, properties of both entities and relationships. A proper conceptual model is crucial because it serves as the foundation for translating real-world requirements into a consistent database structure. By accurately representing the elements and constraints within a system, a well-designed conceptual model ensures data integrity, consistency, and scalability throughout the database lifecycle [
1,
2,
3,
4].
The ER data model plays an important role not only in the initial design of databases but also in their documentation and long-term maintenance. Although the ER data model is a simple and intuitive representation, textual documentation is an indispensable support to integrate the ER schema with descriptions of the information represented in the schema itself. In fact, a clear human-readable documentation of an ER schema—concerning the informative content of each construct—is essential for effective communication among database designers, developers, and business stakeholders.
In recent years, Large Language Models (LLMs) have shown remarkable capabilities in natural language understanding and generation, finding applications in various fields, including software development and database systems [
5,
6,
7]. Much of the existing research on LLMs in the database domain has focused on automating the query generation process to interact with databases using natural language, the definition of the final logical schema according to user requirements, and the textual explanation of tables, relationships, and constraints in an existing database [
8,
9].
LLMs also have the potential to serve as a powerful tool for automating the generation of natural language descriptions of ER schemas, improving the comprehensibility of database structures and information represented in the schema itself. They can provide detailed explanations of the schema, including the relationships between entities and their properties. As an example,
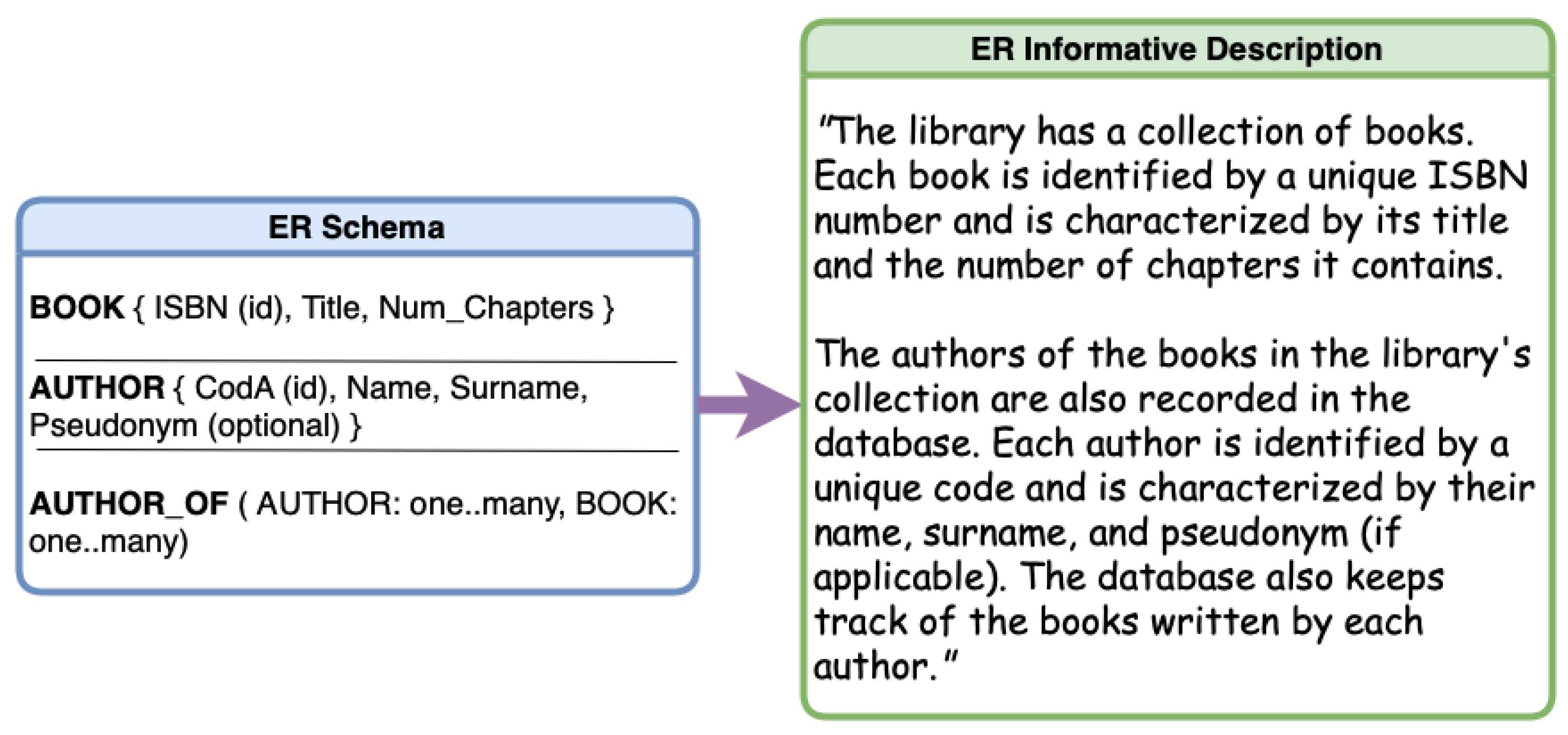
Figure 1 shows the portion of an initial ER schema for a database about a library loan system and the informative description corresponding to the ER obtained by employing an LLM. The text demonstrates how an LLM can understand the properties beyond the two entities (BOOK and AUTHOR) and the binary relationship linking them (AUTHOR_OF), and transform a structured schema into an accurate description. The obtained text is intuitively helpful for
communication with expert and non-expert users without the need to interpret (complex) ER schemas. By facilitating the deeper understanding of the database design, it serves as
documentation useful for knowledge transfer, reference, and future updates. It also supports the
validation of the schema to ensure that the requirements of the system are met.
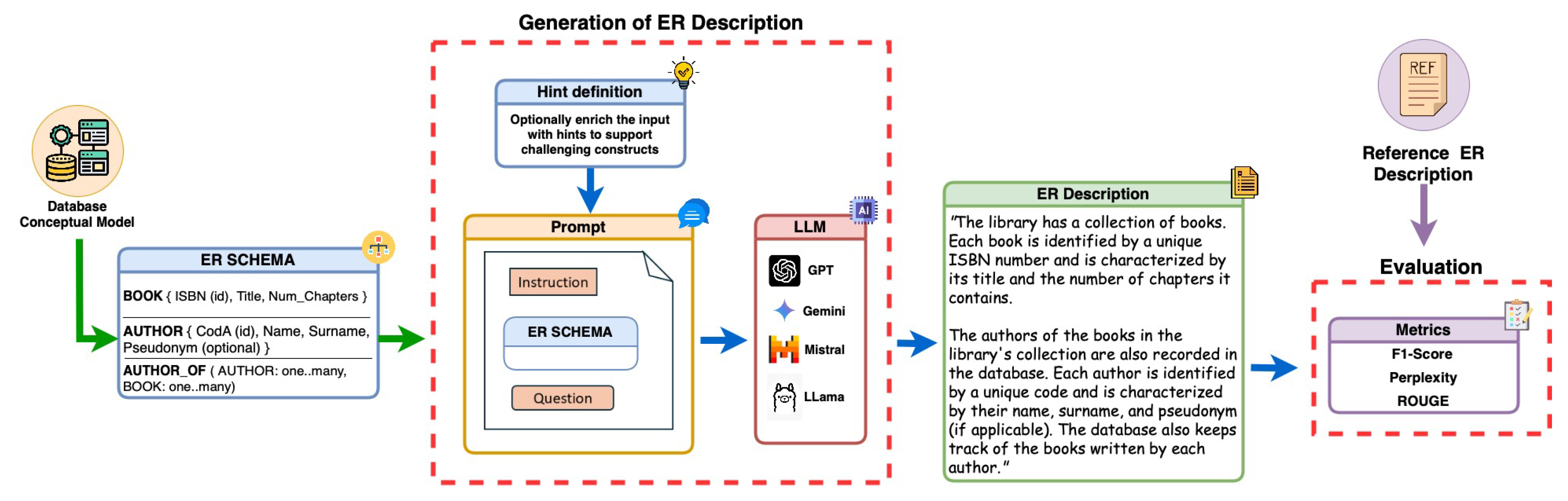
This paper explores the capabilities of LLMs in generating accurate, complete, and easily understandable textual descriptions of conceptual ER schemas. Our study involves testing various LLMs to identify the limitations of each model and assess their ability to understand and describe the main ER constructs with examples covering different levels of difficulty. Additionally, we explore strategies for enriching the conceptual schema with contextual-driven hints to guide LLMs in producing more precise and readable descriptions. The main contributions of this paper are as follows:
A comprehensive investigation into the performance of various LLMs (ChatGPT 3.5 and 4, LLama2, Gemini, Mistral 7B) in generating accurate and readable textual descriptions of ER schemas with varying complexity.
The exploration of effective enrichment strategies and techniques to improve the prompt and guiding LLMs to generate more precise descriptions of specific ER constructs.
The design of a framework for preprocessing the input ER schemas and postprocessing the generated textual descriptions, along with a comparison of LLM performance using evaluation metrics such as F1 score, ROUGE, and perplexity.
The release of a publicly available repository with test cases of ER schemas and the corresponding database requirements, supporting future research in this area.
Our investigation is guided by the following research questions (RQs):
Provide a quantitative assessment of LLMs’ ability to recognize and interpret the core constructs of an ER schema. We define a construct as properly “recognized” when the LLM provides an accurate description, identifying the type of construct and thoroughly detailing its properties (i.e., the characteristics of the information it represents). Our hypothesis is that an LLM that fails to correctly recognize a construct will struggle to generate a proper textual description of the construct or the whole ER schema. The goal is to qualitatively identify common issues, such as incompleteness or lack of understandability, that may arise during this process. These issues could be related to specific characteristics of the input schemas or inherent limitations of LLMs themselves. For example, we investigate which types of constructs are inaccurately or incompletely described, whether constructs are misrepresented or substituted, and the impact of these issues on the generated descriptions.
Evaluate the quality of the textual descriptions generated by LLMs when provided with an ER schema. We use quantitative measures (i.e., F1 score, ROUGE, and perplexity) to assess effectiveness and applicability in practical contexts.
Identify strategies for improving the quality of the textual descriptions generated by LLMs. We categorize these strategies into two main areas: (1) enriching the ER model with keywords or hints to guide the LLM in generating a more accurate description, and (2) adjusting LLM prompts to better align with the task of generating detailed and coherent textual descriptions. These actions seek to optimize the interaction between the ER model and the LLM to enhance the quality of the generated descriptions.
Author Contributions
Conceptualization, A.A., S.C. and A.F.; methodology, A.A., S.C. and A.T.; software, A.T.; validation, A.A. and A.T.; formal analysis, S.C. and A.F.; investigation, A.A. and A.T.; resources, A.T. and A.F.; data curation, A.T. and S.C.; writing—original draft preparation, A.A., S.C. and A.T.; writing—review and editing, A.A. and S.C.; supervision, S.C. and A.F.; project administration, S.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
This study was partially carried out within the FAIR—Future Artificial Intelligence Research—and received funding from the European Union Next-GenerationEU (PNRR MISSIONE 4 COMPONENTE 2, INVESTIMENTO 1.3 D.D. 1555 11/10/2022, PE00000013), as well as partially supported by the SmartData@PoliTO center on Big Data and Data Science. This paper reflects only the authors’ views and opinions, neither the European Union nor the European Commission can be considered responsible for them.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LLM | Large Language Model |
| ER | Entity-Relationship |
| SD | Standard Deviation |
| PPL | Perplexity Score |
References
- Atzeni, P.; Ceri, S.; Paraboschi, S.; Torlone, R. Database Systems—Concepts, Languages and Architectures; McGraw-Hill Book Company: New York, NY, USA, 1999. [Google Scholar]
- Ramakrishnan, R.; Gehrke, J. Database Management Systems, 3rd ed.; McGraw-Hill: New York, NY, USA, 2003. [Google Scholar]
- Silberschatz, A.; Korth, H.F.; Sudarshan, S. Database System Concepts, 6th ed.; McGraw-Hill: New York, NY, USA, 2010. [Google Scholar]
- Kimball, R.; Ross, M. The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling, 2nd ed.; Wiley: New York, NY, USA, 2002. [Google Scholar]
- Yu, W.; Zhu, C.; Li, Z.; Hu, Z.; Wang, Q.; Ji, H.; Jiang, M. A Survey of Knowledge-enhanced Text Generation. ACM Comput. Surv. 2022, 54, 1–38. [Google Scholar] [CrossRef]
- Chen, X.; Gao, C.; Chen, C.; Zhang, G.; Liu, Y. An Empirical Study on Challenges for LLM Application Developers. ACM Trans. Softw. Eng. Methodol. 2025. just accepted.. [Google Scholar] [CrossRef]
- Hou, X.; Zhao, Y.; Liu, Y.; Yang, Z.; Wang, K.; Li, L.; Luo, X.; Lo, D.; Grundy, J.; Wang, H. Large Language Models for Software Engineering: A Systematic Literature Review. ACM Trans. Softw. Eng. Methodol. 2024, 33, 1–79. [Google Scholar] [CrossRef]
- Katsogiannis-Meimarakis, G.; Koutrika, G. A Survey on Deep Learning Approaches for Text-to-SQL. VLDB J. 2023, 32, 905–936. [Google Scholar] [CrossRef]
- Guo, J.; Zhan, Z.; Gao, Y.; Xiao, Y.; Lou, J.G.; Liu, T.; Zhang, D. Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D., Màrquez, L., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4524–4535. [Google Scholar] [CrossRef]
- Lee, J.S.; Hsiang, J. Patent claim generation by fine-tuning OpenAI GPT-2. World Pat. Inf. 2020, 62, 101983. [Google Scholar] [CrossRef]
- Bień, M.; Gilski, M.; Maciejewska, M.; Taisner, W.; Wisniewski, D.; Lawrynowicz, A. RecipeNLG: A Cooking Recipes Dataset for Semi-Structured Text Generation. In Proceedings of the 13th International Conference on Natural Language Generation, Dublin, Ireland, 15–18 December 2020; Davis, B., Graham, Y., Kelleher, J., Sripada, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 22–28. [Google Scholar] [CrossRef]
- Avignone, A.; Fiori, A.; Chiusano, S.; Rizzo, G. Generation of Textual/Video Descriptions for Technological Products Based on Structured Data. In Proceedings of the 2023 IEEE 17th International Conference on Application of Information and Communication Technologies (AICT), Baku, Azerbaijan, 18–20 October 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Gong, H.; Sun, Y.; Feng, X.; Qin, B.; Bi, W.; Liu, X.; Liu, T. TableGPT: Few-shot Table-to-Text Generation with Table Structure Reconstruction and Content Matching. In Proceedings of the International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; Scott, D., Bel, N., Zong, C., Eds.; International Committee on Computational Linguistics: New York, NY, USA, 2020; pp. 1978–1988. [Google Scholar] [CrossRef]
- Ozkaya, I. Application of Large Language Models to Software Engineering Tasks: Opportunities, Risks, and Implications. IEEE Softw. 2023, 40, 4–8. [Google Scholar] [CrossRef]
- Zheng, Z.; Ning, K.; Zhong, Q.; Chen, J.; Chen, W.; Guo, L.; Wang, W.; Wang, Y. Towards an Understanding of Large Language Models in Software Engineering tasks. Empir. Softw. Engg. 2024, 30. [Google Scholar] [CrossRef]
- Marques, N.; Silva, R.R.; Bernardino, J. Using ChatGPT in Software Requirements Engineering: A Comprehensive Review. Future Internet 2024, 16, 180. [Google Scholar] [CrossRef]
- Cai, R.; Xu, B.; Zhang, Z.; Yang, X.; Li, Z.; Liang, Z. An Encoder-Decoder Framework translating Natural Language to Database Queries. In Proceedings of the IJCAI’18: International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; AAAI Press: Washington, DC, USA, 2018; pp. 3977–3983. [Google Scholar]
- Deng, N.; Chen, Y.; Zhang, Y. Recent Advances in Text-to-SQL: A Survey of What We Have and What We Expect. arXiv 2022. abs/2208.10099. [Google Scholar]
- Câmara, V.; Mendonca-Neto, R.; Silva, A.; Cordovil, L. A Large Language Model approach to SQL-to-Text Generation. In Proceedings of the 2024 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 5–8 January 2024; pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, X.; Yin, F.; Ma, G.; Ge, B.; Xiao, W. M-SQL: Multi-Task Representation Learning for Single-Table Text2sql Generation. IEEE Access 2020, 8, 43156–43167. [Google Scholar] [CrossRef]
- Li, Q.; You, T.; Chen, J.; Zhang, Y.; Du, C. LI-EMRSQL: Linking Information Enhanced Text2SQL Parsing on Complex Electronic Medical Records. IEEE Trans. Reliab. 2024, 73, 1280–1290. [Google Scholar] [CrossRef]
- Yu, T.; Li, Z.; Zhang, Z.; Zhang, R.; Radev, D. TypeSQL: Knowledge-Based Type-Aware Neural Text-to-SQL Generation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA; Walker, M., Ji, H., Stent, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 588–594. [Google Scholar] [CrossRef]
- Han, D.; Lim, S.; Roh, D.; Kim, S.; Kim, S.; Yi, M.Y. Leveraging LLM-Generated Schema Descriptions for Unanswerable Question Detection in Clinical Data. In Proceedings of the International Conference on Computational Linguistics, Abu Dhabi, United Arab Emirates, 19–24 January 2025; Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2025; pp. 10594–10601. [Google Scholar]
- Ferrari, A.; Abualhaija, S.; Arora, C. Model Generation with LLMs: From Requirements to UML Sequence Diagrams. In Proceedings of the 2024 IEEE 32nd International Requirements Engineering Conference Workshops (REW), Reykjavik, Iceland, 24–25 June 2024; pp. 291–300. [Google Scholar] [CrossRef]
- Wang, B.; Wang, C.; Liang, P.; Li, B.; Zeng, C. How LLMs Aid in UML Modeling: An Exploratory Study with Novice Analysts. In Proceedings of the 2024 IEEE International Conference on Software Services Engineering (SSE), Shenzhen, China, 7–13 July 2024; pp. 249–257. [Google Scholar] [CrossRef]
- Ardimento, P.; Bernardi, M.L.; Cimitile, M. Teaching UML using a RAG-based LLM. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-shot Learners. In Proceedings of the NIPS ’20: 34th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 6–12 December 2020. [Google Scholar]
- Sivarajkumar, S.; Kelley, M.; Samolyk-Mazzanti, A.; Visweswaran, S.; Wang, Y. An Empirical Evaluation of Prompting Strategies for Large Language Models in Zero-Shot Clinical Natural Language Processing. arXiv 2023. abs/2309.08008. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models are Zero-shot Reasoners. In Proceedings of the NIPS ’22: 36th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 28 November–9 December 2022. [Google Scholar]
- Reynolds, L.; McDonell, K. Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm. In Proceedings of the CHI EA ’21: Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 8–13 May 2021. [Google Scholar] [CrossRef]
- Min, S.; Lyu, X.; Holtzman, A.; Artetxe, M.; Lewis, M.; Hajishirzi, H.; Zettlemoyer, L. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? arXiv 2022. abs/2202.12837. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.H.; Le, Q.V.; Zhou, D. Chain-of-thought Prompting elicits reasoning in Large Language Models. In Proceedings of the NIPS ’22: 36th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 28 November–9 December 2022. [Google Scholar]
- Zhang, Z.; Zhang, A.; Li, M.; Smola, A. Automatic Chain of Thought Prompting in Large Language Models. arXiv 2022, arXiv:2210.03493. [Google Scholar]
- Jelinek, F.; Mercer, R.L.; Bahl, L.R.; Baker, J.K. Perplexity—A Measure of the Difficulty of Speech Recognition Tasks. J. Acoust. Soc. Am. 1977, 62, S63. [Google Scholar] [CrossRef]
- Colla, D.; Delsanto, M.; Agosto, M.; Vitiello, B.; Radicioni, D.P. Semantic Coherence Markers: The Contribution of Perplexity Metrics. Artif. Intell. Med. 2022, 134, 102393. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}